逐行讲解大模型流式输出 streamer 源码
目录
- 简介
- TextStreamer 基础流式输出
- TextIterateStreamer 迭代器流式输出
- 本地代码模型加载并前端展示
- streamlit 输出显示
- gradio 输出显示
- vllm 部署模型并前端展示
- streamlit 输出显示
- gradio 输出显示
- 备注
简介
本文详细讲解了大模型流式输出的源码实现,包括TextStreamer 基础流式输出和TextIterateStreamer 迭代器流式输出。此外,还提供了两种主流Web框架(Streamlit和Gradio)的部署方案,设计前端界面进行大模型流式输出对话演示。模型提供了本地加载以及vllm部署两种方法,帮助读者快速应用部署大模型。
TextStreamer 基础流式输出
先定义一个基础版流式输出的加载模型并生成的代码
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer, Qwen2ForCausalLM
device = "cuda" # the device to load the model ontomodel_path = 'Qwen/Qwen2.5-1.5B-Instruct'
model: Qwen2ForCausalLM = AutoModelForCausalLM.from_pretrained(model_path, torch_dtype=torch.bfloat16, device_map="cuda")
tokenizer = AutoTokenizer.from_pretrained(model_path)
text = [{"role": "system", "content": "你是一个人工智能助手"},{"role": "user", "content": '写一个谜语'}
]
text = tokenizer.apply_chat_template(text, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer(text, return_tensors="pt").to(device)
# 定义基础版的流式输出
# skip_prompt参数决定是否将prompt打印出来
# skip_special_tokens是解码参数,决定tokenizer.decode解码时是否忽略特殊字符,例如<|im_end|>
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)generated_ids = model.generate(max_new_tokens=64,do_sample=True,streamer=streamer, # 传入model.generate**model_inputs,
)
generated_ids1 = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]response = tokenizer.batch_decode(generated_ids1, skip_special_tokens=True)[0]
print("最终结果:", response)
输出的结果如下,第一行是流式输出打印的结果,他是一个字一个字打印出来的。第二行是代码最后一行的print,打印最终的所有输出。
注意:这里第一行的打印除了传入streamer以外,没有其他的操作,也就是streamer内部自行一个字一个字打印了。

TextStreamer源码
在 transformers\generation\streamers.py文件中写了流式输出类的源码。
首先定义了一个BaseStreamer类,用于其他子类的继承。BaseStreamer类定义了put和end的抽象方法,表示子类在继承的时候必须重写这两个方法,否则这个类无法使用。
from queue import Queue
from typing import TYPE_CHECKING, Optionalif TYPE_CHECKING:from ..models.auto import AutoTokenizerclass BaseStreamer:def put(self, value):raise NotImplementedError()def end(self):raise NotImplementedError()
为什么必须实现这两个方法,我们来看transformers源码是在哪里调用它们的。
首先进入model.generate函数,也就是我们模型常用的生成函数,最开始先调用streamer.put将prompt传入进去,此时需要注意两点。
- 验证当前
batch是否为1,如果大于1会弹出异常,因为流式输出只能传入单个序列。 - 如果传入了
skip_prompt=True,则表示忽略打印prompt,否则在流式输出打印的时候会将prompt也打印出来。
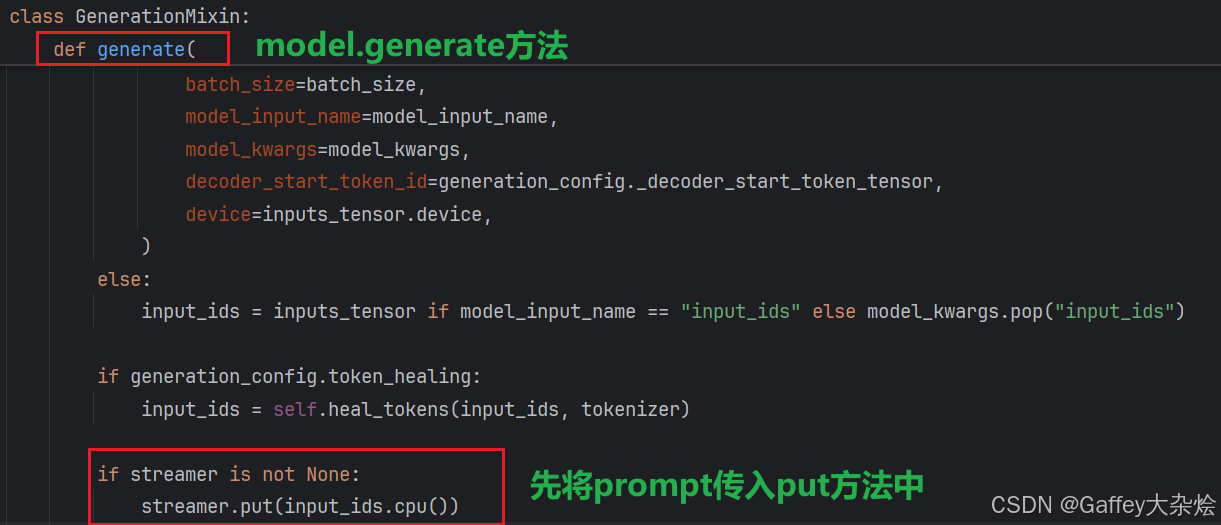
然后在实际采样的时候也会调用,在每个step预测下一个token的时候,会将该token_id传入streamer.put,在内部解码后打印出来。
在整个序列全部生成结束后,调用streamer.end方法,此时会打印剩下缓存中的所有字符。
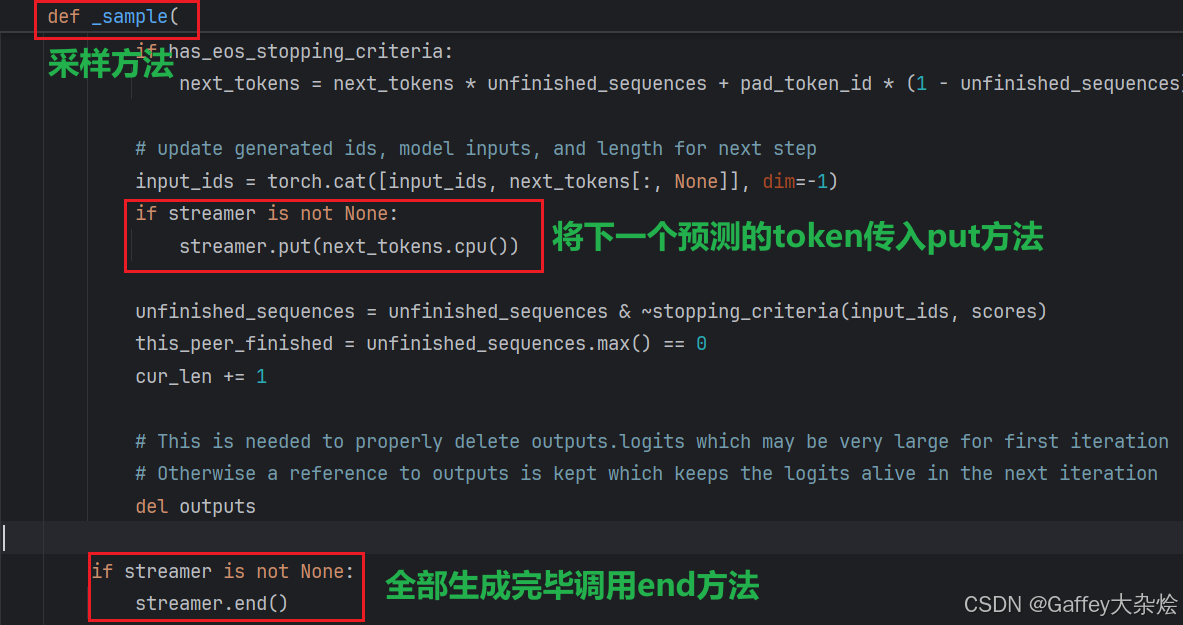
综上所述,.put()和.end()是TextStreamer的两个核心方法,所以子类必须重写。
下面为TextStreamer类的源码,.put方法接收开始的prompt和下一个预测的token,代码中有详细注释,总结起来的流程如下:
- 验证输入的
batch是否等于1,否则弹出异常 - 如果是第一次输入,则视为
prompt,用参数skip_prompt决定是否打印prompt,并直接返回 - 将下一个
token加入缓存序列中,使用tokenizer.decode解码序列,用4、5、6步决定如何打印 - 如果最后一个字符为换行符,则清空缓存序列,直接打印结尾字符
- 如果最后一个字符是中文,则直接打印
- 如果最后一个字符是英文,则解码出空格之后再打印空格前的字符
- 如果调用
end方法,则打印缓存中剩余的所有token
注:打印方法为print,直接将字符打印到标准输出上stdout
class TextStreamer(BaseStreamer):def __init__(self, tokenizer: "AutoTokenizer", skip_prompt: bool = False, **decode_kwargs):self.tokenizer = tokenizerself.skip_prompt = skip_prompt # 是否打印promptself.decode_kwargs = decode_kwargs # 解码参数# 用于记录流式输出过程中的变量self.token_cache = [] # 缓存tokenself.print_len = 0 # 记录上次打印位置self.next_tokens_are_prompt = True # 第一次为True,后续为False,记录当前调用put()时是否为promptdef put(self, value):"""传入token后解码,然后在他们形成一个完整的词时将其打印到标准输出stdout"""# 这个类只支持 batch_size=1# 第一次运行.put()时,value=input_id,此时检测batch大小,input_id.shape:(batch_size, seq_len)if len(value.shape) > 1 and value.shape[0] > 1:raise ValueError("TextStreamer only supports batch size 1")# 如果输入batch形式,但是batch_size=1,取第一个batch序列elif len(value.shape) > 1:value = value[0]# 第一次输入的视为prompt,用参数判断是否打印promptif self.skip_prompt and self.next_tokens_are_prompt:self.next_tokens_are_prompt = Falsereturn# 将新token添加到缓存,并解码整个tokenself.token_cache.extend(value.tolist())text = self.tokenizer.decode(self.token_cache, **self.decode_kwargs)# 如果token以换行符结尾,则清空缓存if text.endswith("\n"):printable_text = text[self.print_len :]self.token_cache = []self.print_len = 0# 如果最后一个token是中日韩越统一表意文字,则打印该字符elif len(text) > 0 and self._is_chinese_char(ord(text[-1])):printable_text = text[self.print_len :]self.print_len += len(printable_text)# 否则,打印直到最后一个空格字符(简单启发式,防止输出token是不完整的单词,在前一个词解码完毕后在打印)# text="Hello!",此时不打印。text="Hello! I",打印Hello!else:printable_text = text[self.print_len : text.rfind(" ") + 1]self.print_len += len(printable_text)self.on_finalized_text(printable_text)def end(self):"""清空缓存,并打印换行符到标准输出stdout"""# 如果缓存不为空,则解码缓存,并打印直到最后一个空格字符if len(self.token_cache) > 0:text = self.tokenizer.decode(self.token_cache, **self.decode_kwargs)printable_text = text[self.print_len :]self.token_cache = []self.print_len = 0else:printable_text = ""self.next_tokens_are_prompt = Trueself.on_finalized_text(printable_text, stream_end=True)def on_finalized_text(self, text: str, stream_end: bool = False):# flush=True,立即刷新缓冲区,实时显示,取消缓冲存在的延迟# 如果stream_end为True,则打印换行符print(text, flush=True, end="" if not stream_end else None)def _is_chinese_char(self, cp):"""检查CP是否是CJK字符"""# 这个定义了一个"chinese character"为CJK Unicode块中的任何内容:# https://en.wikipedia.org/wiki/CJK_Unified_Ideographs_(Unicode_block)# 我们使用Unicode块定义,因为这些字符是唯一的,并且它们是所有主要语言的常见字符。# 注意,CJK Unicode块不仅仅是日语和韩语字符,# 尽管它的名字如此,现代韩语的Hangul字母是另一个块,# 日语的Hiragana和Katakana也是另一个块,# 那些字母用于写space-separated words,所以它们不被特别处理,像其他语言一样处理if ((cp >= 0x4E00 and cp <= 0x9FFF)or (cp >= 0x3400 and cp <= 0x4DBF) #or (cp >= 0x20000 and cp <= 0x2A6DF) #or (cp >= 0x2A700 and cp <= 0x2B73F) #or (cp >= 0x2B740 and cp <= 0x2B81F) #or (cp >= 0x2B820 and cp <= 0x2CEAF) #or (cp >= 0xF900 and cp <= 0xFAFF)or (cp >= 0x2F800 and cp <= 0x2FA1F) #): return Truereturn False
TextIterateStreamer 迭代器流式输出
定义一个迭代器版流式输出的加载模型并生成的代码,与基础版的区别是需要单独启动一个线程调用,并且不会默认使用print打印到标准输出,需要将其视为迭代器循环取出字符。
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, TextIteratorStreamer, Qwen2ForCausalLM
device = "cuda" # the device to load the model ontomodel_path = 'Qwen/Qwen2.5-1.5B-Instruct'
model: Qwen2ForCausalLM = AutoModelForCausalLM.from_pretrained(model_path, torch_dtype=torch.bfloat16, device_map="cuda")
tokenizer = AutoTokenizer.from_pretrained(model_path)
text = [{"role": "system", "content": "你是一个人工智能助手"},{"role": "user", "content": '写一个谜语'}
]
text = tokenizer.apply_chat_template(text, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer(text, return_tensors="pt").to(device)
# 定义迭代版的流式输出,输入参数与基础版相同
# skip_prompt参数决定是否将prompt打印出来
# skip_special_tokens是解码参数,决定tokenizer.decode解码时是否忽略特殊字符,例如<|im_end|>
streamer = TextIteratorStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
generation_kwargs = dict(model_inputs, streamer=streamer, max_new_tokens=100)
# 在单独的线程中调用.generate()
thread = Thread(target=model.generate, kwargs=generation_kwargs)
thread.start()# 启动线程之后生成结果会阻塞,此时可以在任何地方调用streamer迭代器取出输出结果
# 当前将其取出后使用print打印,也可以自定义显示方法,例如下文使用gradio或streamlit显示
generated_text = ""
for new_text in streamer:print(new_text, end="", flush=True)
TextIteratorStreamer 源码
TextIteratorStreamer继承了TextStreamer类,也就是说复用了TextStreamer类中的.put()和.end()方法,只是在输出的时候重写了on_finalized_text()方法。
这意味着不再使用print将文本打印到标准输出,而是放到一个队列中。并且将对象本身也包装成了一个迭代器,每次调用时从队列中取出文本并返回,根据用户自己定义的方式去进行输出。
总结起来的流程如下(基于TextStreamer):
model.generate()中的put()方法依然使用TextStreamer中定义的,只不过在最后一行调用on_finalized_text()方法时,将该文本放入Queue队列中- 如果调用了
end()方法,将一个停止信号(设为None)也放入Queue队列中 - 定义
__iter__方法将自身包装成迭代器 - 每次循环调用迭代器,执行
__next__方法,从队列中取出一段文本返回
from queue import Queue
from typing import TYPE_CHECKING, Optionalclass TextIteratorStreamer(TextStreamer):"""将打印就绪的文本存储在队列中的流式处理器,可以被下游应用程序作为迭代器使用。这对于需要以非阻塞方式访问生成文本的应用程序很有用(例如在交互式 Gradio 演示中)。Parameters:tokenizer (`AutoTokenizer`):The tokenized used to decode the tokens.skip_prompt (`bool`, *optional*, defaults to `False`):Whether to skip the prompt to `.generate()` or not. Useful e.g. for chatbots.timeout (`float`, *optional*):文本队列的超时时间。如果为`None`,队列将无限期阻塞。当在单独的线程中调用`.generate()`时,这对于处理异常很有用。decode_kwargs (`dict`, *optional*):Additional keyword arguments to pass to the tokenizer's `decode` method."""def __init__(self, tokenizer: "AutoTokenizer", skip_prompt: bool = False, timeout: Optional[float] = None, **decode_kwargs):super().__init__(tokenizer, skip_prompt, **decode_kwargs)self.text_queue = Queue() # 文本队列self.stop_signal = None # 停止信号self.timeout = timeout # 队列超时时间def on_finalized_text(self, text: str, stream_end: bool = False):"""Put the new text in the queue. If the stream is ending, also put a stop signal in the queue."""# 将新文本放入队列self.text_queue.put(text, timeout=self.timeout)# 如果流结束,则将停止信号放入队列if stream_end:self.text_queue.put(self.stop_signal, timeout=self.timeout)# 调用自己,返回迭代器def __iter__(self):return selfdef __next__(self):# 调用一次迭代器,就从队列中获取一段文本,如果超时则抛出异常,默认self.timeout,表示不限时长value = self.text_queue.get(timeout=self.timeout)# 如果获取到停止信号,则抛出StopIteration异常表示迭代结束if value == self.stop_signal:raise StopIteration()# 否则返回获取到的文本else:return value
本地代码模型加载并前端展示
streamlit 输出显示
使用streamlit定义一个简单的对话界面,在streamlit程序中进行模型加载,并支持流式输出。
import streamlit as st
import random
import timeimport torch
from transformers import AutoModelForCausalLM, AutoTokenizer, TextIteratorStreamer, Qwen2ForCausalLM
from threading import Thread
device = "cuda" # the device to load the model ontost.title("大模型流式输出测试")if "messages" not in st.session_state:st.session_state.messages = [{"role": "system", "content": "你是一个人工智能助手"}]model_path = 'D:\learning\python\pretrain_checkpoint\Qwen2.5-1.5B-Instruct'st.session_state.model: Qwen2ForCausalLM = AutoModelForCausalLM.from_pretrained(model_path, torch_dtype=torch.bfloat16, device_map="cuda")st.session_state.tokenizer = AutoTokenizer.from_pretrained(model_path)for message in st.session_state.messages[1:]:with st.chat_message(message["role"]):st.markdown(message["content"])
if prompt := st.chat_input("请输入问题"):with st.chat_message("user"):st.markdown(prompt)st.session_state.messages.append({"role": "user", "content": prompt})text = st.session_state.tokenizer.apply_chat_template(st.session_state.messages, tokenize=False, add_generation_prompt=True)model_inputs = st.session_state.tokenizer(text, return_tensors="pt").to(device)streamer = TextIteratorStreamer(st.session_state.tokenizer, skip_prompt=True, skip_special_tokens=True)generation_kwargs = dict(model_inputs, streamer=streamer, max_new_tokens=1024)# 在单独的线程中调用.generate()thread = Thread(target=st.session_state.model.generate, kwargs=generation_kwargs)thread.start()with st.chat_message("assistant"):message_placeholder = st.empty()generated_text = ""for new_text in streamer:generated_text += new_textmessage_placeholder.markdown(generated_text)st.session_state.messages.append({"role": "assistant", "content": generated_text})if st.button("清空"):st.session_state.messages = [{"role": "system", "content": "你是一个人工智能助手"}]st.rerun()
下图为实际展示的界面,可以在下方输入框输入问题,大模型会流式输出回答。简单定义了一个清空历史消息的按钮,用于重新开启对话。

gradio 输出显示
使用gradio定义一个简单的对话界面,在gradio程序中进行模型加载,并支持流式输出。
import gradio as gr
from threading import Thread
from typing import List
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, TextIteratorStreamer, Qwen2ForCausalLM
device = "cuda" # the device to load the model ontomodel_path = 'D:\learning\python\pretrain_checkpoint\Qwen2.5-1.5B-Instruct'
model: Qwen2ForCausalLM = AutoModelForCausalLM.from_pretrained(model_path, torch_dtype=torch.bfloat16, device_map="cuda")
tokenizer = AutoTokenizer.from_pretrained(model_path)def chat(question, history):message = [{"role": "system", "content": "你是一个人工智能助手"}]if not history:message.append({"role": "user", "content": question})else:for i in history:message.append({"role": "user", "content": i[0]})message.append({"role": "assistant", "content": i[1]})message.append({"role": "user", "content": question})text = tokenizer.apply_chat_template(message, tokenize=False, add_generation_prompt=True)encoding = tokenizer(text, return_tensors="pt").to(device)streamer = TextIteratorStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)generation_kwargs = dict(encoding, streamer=streamer, max_new_tokens=1024)thread = Thread(target=model.generate, kwargs=generation_kwargs)thread.start()response = ""for text in streamer:response += textyield responsedemo = gr.ChatInterface(fn=chat,title="聊天机器人",description="输入问题开始对话"
)demo.queue().launch()
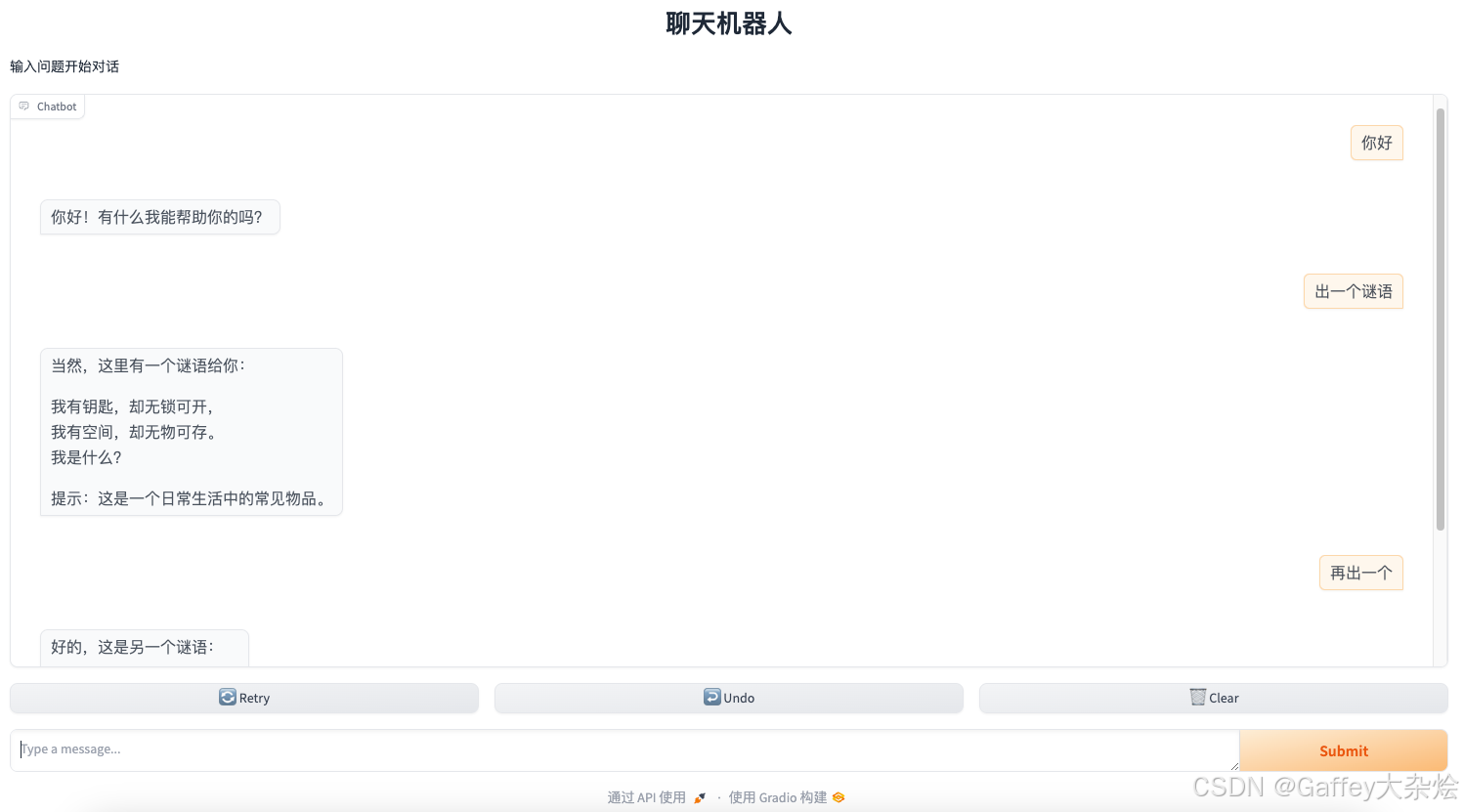
下图为实际展示的界面
vllm 部署模型并前端展示
使用如下命令启动部署一个模型,注意以下参数
CUDA_VISIBLE_DEVICES:指定GPU索引python:先conda进入你的环境,再启动--host 0.0.0.0 --port 5001:指定ip+端口--served-model-name:启动服务的名字,也就是下面调用client.chat.completions.create时输入的model名字--model:模型权重的存储位置--tensor_parallel_size:使用几个GPU加载模型,与前面CUDA_VISIBLE_DEVICES要对应上--gpu-memory-utilization:kv cache占用显存比例,使用默认0.9就好
CUDA_VISIBLE_DEVICES=0 python -m vllm.entrypoints.openai.api_server --host 0.0.0.0 --port 5001 --served-model-name qwen2.5 --model /data0/zejun7/model_checkpoint/Qwen2.5-1.5B-Instruct --tensor_parallel_size 1 --gpu-memory-utilization 0.9
streamlit 输出显示
使用streamlit定义一个简单的对话界面,在streamlit调用vllm部署的模型,并支持流式输出。
import streamlit as st
import random
import timeimport torch
from openai import OpenAIst.title("大模型流式输出测试")def get_response(message):openai_api_key = "EMPTY"openai_api_base = "http://0.0.0.0:5001/v1" # 换成自己的ip+端口client = OpenAI(api_key=openai_api_key,base_url=openai_api_base,)response = client.chat.completions.create(model="qwen2.5",messages=message,stream=True,)for chunk in response:if chunk.choices[0].delta.content is None:yield ""else:yield chunk.choices[0].delta.contentif "messages" not in st.session_state:st.session_state.messages = [{"role": "system", "content": "你是一个人工智能助手"}]for message in st.session_state.messages[1:]:with st.chat_message(message["role"]):st.markdown(message["content"])
if prompt := st.chat_input("请输入问题"):with st.chat_message("user"):st.markdown(prompt)st.session_state.messages.append({"role": "user", "content": prompt})with st.chat_message("assistant"):message_placeholder = st.empty()generated_text = ""for new_text in get_response(st.session_state.messages):generated_text += new_textmessage_placeholder.markdown(generated_text)st.session_state.messages.append({"role": "assistant", "content": generated_text})if st.button("清空"):st.session_state.messages = [{"role": "system", "content": "你是一个人工智能助手"}]st.rerun()

gradio 输出显示
使用gradio定义一个简单的对话界面,在gradio中调用vllm部署的模型,并支持流式输出。
import gradio as gr
from openai import OpenAIdef chat(question, history):message = [{"role": "system", "content": "你是一个人工智能助手"}]if not history:message.append({"role": "user", "content": question})else:for i in history:message.append({"role": "user", "content": i[0]})message.append({"role": "assistant", "content": i[1]})message.append({"role": "user", "content": question})openai_api_key = "EMPTY"openai_api_base = "http://0.0.0.0:5001/v1" # 换成自己的ip+端口client = OpenAI(api_key=openai_api_key,base_url=openai_api_base,)response = client.chat.completions.create(model="qwen2.5",messages=message,stream=True,)response_text = ""for chunk in response:if chunk.choices[0].delta.content is None:response_text += ""yield response_textelse:response_text += chunk.choices[0].delta.contentyield response_textdemo = gr.ChatInterface(fn=chat,title="聊天机器人",description="输入问题开始对话"
)demo.queue().launch(server_name="0.0.0.0", # 如果不好使,可以尝试换成localhost或自身真正的ip地址share=True,
)
下图为实际展示的界面

备注
如需使用此代码,注意替换中间的模型等参数,文中所有代码放置于github
相关文章:

逐行讲解大模型流式输出 streamer 源码
目录 简介TextStreamer 基础流式输出TextIterateStreamer 迭代器流式输出本地代码模型加载并前端展示streamlit 输出显示gradio 输出显示 vllm 部署模型并前端展示streamlit 输出显示gradio 输出显示 备注 简介 本文详细讲解了大模型流式输出的源码实现,包括TextSt…...
_kaic)
springboot533图书管理系统(论文+源码)_kaic
摘 要 传统信息的管理大部分依赖于管理人员的手工登记与管理,然而,随着近些年信息技术的迅猛发展,让许多比较老套的信息管理模式进行了更新迭代,图书信息因为其管理内容繁杂,管理数量繁多导致手工进行处理不能满足广…...

Dell服务器升级ubuntu 22.04失败解决
ubuntu系统原版本20.04,服务器dell T40. 执行apt update后,再执行apt upgrade。 apt update执行成功,但apt upgrade执行中断,提示如下: Checking package manager Reading package lists... Done Building dependen…...

sql列转行 行转列
列转行 在 SQL 中,转换数据以按列排列的值成为按行排列的值(即所谓的“列转行”或“列转行”)是常见的数据操作需求。这个操作在不同的数据库管理系统中可以通过不同的技术手段来实现。以下是几种常见的数据库系统中实现列转行的方法&#x…...

【在Python中生成随机字符串】
在Python中生成随机字符串,你可以使用random模块结合字符串操作来实现。以下是一个简单的例子,展示了如何生成一个指定长度的随机字符串,该字符串可以包含字母(大写和小写)以及数字: import random import…...
)
Qt解决可执行程序的图标问题(CMake)
通常情况下,我们编译生成的可执行程序的图标长这个样子: 可以看到他的图标非常丑陋。。。 要想改变图标,你需要通过以下方式: CMakeLists.txt : cmake_minimum_required(VERSION 3.10)project(CountCode VERSION 1.0 LANGUAGE…...
实践)
婴儿四维影像生成AI人脸照片-大模型 Agent(智能体)实践
婴儿四维影像生成AI人脸照片-大模型 Agent(智能体)实践 在当今科技飞速发展的时代,大模型 Agent(智能体)作为一种创新的技术范式,正逐渐崭露头角。它依托强大的大模型能力,通过可视化设计与流程编排,以无代码或低代码的方式,为开发者提供了构建各种功能性应用程序的便…...

XIAO Esp32 S3 网络摄像头——3音视频监控
1、介绍 之前分别介绍了音频和视频的接收,本文是整合了前2篇文章,实现了音视频的同时获取。 效果: 用xiao esp35 s3自制一个网络摄像头 2、适用场景广泛 家庭安防 无论是门前监控,还是室内安全,自制摄像头可以让你轻松把握每个角落,实时查看视频流,防止任何潜在风险。…...

【GIS教程】高程点制作DEM并使用ArcgisPro发布高程服务Elevation Layer
文章目录 应用场景数据源操作步骤1、数据加载2、创建TIN3、TIN转栅格4、发布高程服务 应用场景 我有高程点和等高线数据,我需要将其发布成高程服务,在 Portal 中直接使用,或者通过 Javascript API 进行调用。 数据源 数据源为dwg格式的地形…...
)
C++设计模式:状态模式(自动售货机)
什么是状态模式? 状态模式是一种行为型设计模式,它允许一个对象在其内部状态发生改变时,动态改变其行为。通过将状态相关的逻辑封装到独立的类中,状态模式能够将状态管理与行为解耦,从而让系统更加灵活和可维护。 通…...
)
智能工厂的设计软件 应用场景的一个例子:为AI聊天工具添加一个知识系统 之11 方案再探之2 项目文件(修改稿1)
(以下内容是第二次重建项目(“方案再探”)时的项目附件。) 为AI聊天工具添加一个知识系统 Part1 人性化&去中心化 前情提要 这一次我们暂时抛开前面对“智能工厂的软件设计”的考虑--其软件智能 产品就是 应用程序。直接将这些思维方式和方法论 运…...

Android 系统 Activity 系统层深度定制的方法、常见问题以及解决办法
Android 系统 Activity 系统层深度定制的方法、常见问题以及解决办法 目录 引言Activity 系统层概述Activity 系统架构图Activity 系统层深度定制的方法 4.1 自定义 Activity 生命周期4.2 自定义 Activity 启动流程4.3 自定义 Activity 转场动画4.4 自定义 Activity 窗口管理4…...

java并发之BlockingQueue
种类 类名特性ArrayBlockingQueue由数组结构组成的有界阻塞队列LinkedBlockingQueue由链表结构组成的有界的阻塞队列(有界,默认大小 Integer.MAX_VALUE,相当于无界)PriorityBlockingQueue支持优先级排序的无界阻塞队列DelayQueue…...

Python AI 教程之五: 强化学习
强化学习 强化学习:概述 强化学习 (RL) 是机器学习的一个分支,专注于在特定情况下做出决策以最大化累积奖励。与依赖具有预定义答案的训练数据集的监督学习不同,强化学习涉及通过经验进行学习。在强化学习中,代理通过执行操作并通过奖励或惩罚获得反馈来学习在不确定、可…...
)
uniapp——App下载文件,打开文档(一)
uniapp如何下载文件、打开文件 文章目录 uniapp如何下载文件、打开文件下载文件下载文件成功返回数据格式 打开文档处理 iOS 打开文件可能失败问题 相关API: uni.downloadFileuni.openDocument 注意: 只支持 GET 请求,需要 POST的ÿ…...
)
【信息系统项目管理师】高分论文:论信息系统项目的沟通管理(监控更新改造项目)
更多内容请见: 备考信息系统项目管理师-专栏介绍和目录 文章目录 论文1、制定沟通管理计划2、管理沟通3、监督沟通论文 2017年8月,我作为项目经理参加了某省委党校校园监控更新改造项目的建设,该项目投资共500万元人民币,建设工期为3个月,通过该项目的建设,实现了安全防…...
)
鸿蒙应用开发(1)
可能以为通过 鸿蒙应用开发启航计划(点我去看上一节) 的内容,就足够了,其实还没有。 可是我还是要告诉你,你还需要学习新的语言 -- ArkTS。 ,ArkTS是HUAWEI开发的程序语言。你需要学习这门语言。这会花费你…...

基于JavaWeb的汽车维修保养智能预约系统
作者简介:Java领域优质创作者、CSDN博客专家 、CSDN内容合伙人、掘金特邀作者、阿里云博客专家、51CTO特邀作者、多年架构师设计经验、多年校企合作经验,被多个学校常年聘为校外企业导师,指导学生毕业设计并参与学生毕业答辩指导,…...

CAN总线波形中最后一位电平偏高或ACK电平偏高问题分析
参考:https://zhuanlan.zhihu.com/p/689336144 有时候看到CAN总线H和L的差值波形的最后一位电平会变高很多,这是什么原因呢? 实际上这是正常的现象,最后一位是ACK位。问题描述为:CAN总线ACK电平偏高。 下面分析下原因…...

高等数学学习笔记 ☞ 无穷小与无穷大
1. 无穷小 1. 定义:若函数当或时的极限为零,那么称函数是当或时的无穷小。 备注: ①:无穷小描述的是自变量的变化过程中,函数值的变化趋势,绝不能认为无穷小是一个很小很小的数。 ②:说无穷小时…...

Docker Compose编排
什么是 Docker Compose? Docker Compose 是 Docker 官方推出的开源项目,用于快速编排和管理多个 Docker 容器的应用程序。它允许用户通过一个 YAML 格式的配置文件 docker-compose.yml 来定义和运行多个相关联的应用容器,从而实现对容器的统一管理和编…...

Node.js 处理 GeoPackage 数据的开源库:@ngageoint/geopackage介绍
使用 Node.js 处理 GeoPackage 数据的开源库:@ngageoint/geopackage 随着地理信息系统(GIS)和空间数据的广泛应用,OGC 的 GeoPackage 格式因其轻量、跨平台和高性能的特点,成为处理地理空间数据的重要工具。而对于 Node.js 开发者来说,@ngageoint/geopackage 是一个功能…...
(非强制登录版本完结)>)
21.<基于Spring图书管理系统②(图书列表+删除图书+更改图书)(非强制登录版本完结)>
PS: 开闭原则 定义和背景 开闭原则(Open-Closed Principle, OCP),也称为开放封闭原则,是面向对象设计中的一个基本原则。该原则强调软件中的模块、类或函数应该对扩展开放,对修改封闭。这意味着一个软件实体…...

MySQL日志体系的深度解析:功能与差异
优质博文:IT-BLOG-CN 一、binlog binlog记录数据库表结构和表数据变更,比如update/delete/insert/truncate/create,它不会记录select。存储着每条变更的SQL语句和XID事务Id等等。binlog日志文件如下: [root192.168.10.11]# mysq…...
商品下架同步更新ES索引库数据)
电商项目-数据同步解决方案(四)商品下架同步更新ES索引库数据
商品下架索引库删除数据 一、 需求分析和业务逻辑 商品下架后将商品从索引库中移除。 主要应用技术有: 消息队列-RabbitMQ ,分布式搜索引擎-ElasticSearch,Eureka,Canal,Feign远程调用 (1)在…...

Kafka
目录 一、什么是Kafka 核心组件 特性 使用场景 安装与配置 二、Kafka的使用 安装 ZooKeeper 和 Kafka 安装 ZooKeeper 安装 Kafka 配置 ZooKeeper 和 Kafka 配置 ZooKeeper 配置 Kafka 启动 ZooKeeper 和 Kafka 创建 Topic 编写生产者代码 编写消费者代码 运行…...

SAP SD学习笔记22 - VF04,VF06,VF24 等一括请求处理
上一篇学习了请求传票(发票)的拷贝管理。 SAP SD学习笔记21 - 请求传票的数据流(拷贝管理)-CSDN博客 本章继续学习 SAP SD的内容。 目录 1,VF04 - 一括请求处理(开票到期清单) 2,…...

JR-RLAA系20路模拟音频多功能编码器
JR-RLAA系20路模拟音频多功能编码器 产品特色 (1)工业级19英寸标准设备,内置双电源 (2)内嵌Web Server,支持远程Web页面登陆后的统一配置操作 (3)支持20路音频输入 (4)支持Dolby Digital(AC-3) ,MPEG-2,AAC-LC/HE-AAC&#x…...
)
数据结构复习 (二叉查找树,高度平衡树AVL)
1.二叉查找树: 为了更好的实现动态的查找(可以插入/删除),并且不超过logn的时间下达成目的 定义: 二叉查找树(亦称二叉搜索树、二叉排序树)是一棵二叉树,其各结点关键词互异,且中根序列按其关键词递增排列。 等价描述: 二叉查找…...

深入浅出梯度下降与反向传播
文章目录 1. 前言2. 基本概念2.1 一元函数的导数2.2 偏导数2.3 方向导数2.4 梯度2.5 均方误差 3. 梯度下降3.1 梯度下降的公式3.2 梯度下降的类型(优化器) 4. 反向传播4.1 反向传播的基本步骤4.2 反向传播的数学推导 5. 实战5.1 手动求导5.2 自动求导5.3…...
)
PLC(01)
一.职业规划 电路----------------->电工------------------>电气-------------------plc---------------------DCS--------------------> 机器人 二.交流电直流电的概念 1.交流电AC alternating current 大小方向随时间发生周期性变化 2.直流电 Direct current…...
)
如何通过本地部署的DIFY辅助学习算法(PS可以辅助帮你学习任何想学习的资料)
如何通过本地部署的DIFY辅助学习算法(PS可以辅助帮你学习任何想学习的资料 一 提升知识库的大小容量1.1 调大知识库的基础配置修改.env文件1.2 通过docker compose 重启加载最新配置1.3 重新上传知识库 二 搭建算法知识库的学习助手2.1 text embedding 模型对比2.1.1 如何选择合…...

深入探讨服务器虚拟化:架构、技术与应用
1. 引言 在现代IT基础设施中,服务器虚拟化已成为一种不可或缺的技术。它不仅提高了资源利用率,还增强了系统的灵活性和可管理性。随着企业对高效、灵活和可扩展IT环境的需求不断增加,服务器虚拟化技术的应用愈发广泛。本文将深入探讨服务器虚…...

C++笔记之尾后迭代器
C笔记之尾后迭代器 code review! 参考笔记 1.C笔记之尾后迭代器 2.C笔记之迭代器失效问题处理 在C中,尾后迭代器(通常称为 past-the-end iterator)是指指向容器中最后一个元素之后的位置的迭代器。它并不指向任何有效的元素,而是…...

2024年总结【第五年了】
2024年总结 北国绕院扫雪,南方围炉烹茶,且饮一杯无? 执笔温暖不曾起舞日子里的点点滴滴,誊写一段回忆,还以光阴一段副本。 那么你要听一支新故事吗?第五年总结的片碎。 衣单天寒,走趟流星孤骑…...
)
EasyExcel(环境搭建以及常用写入操作)
文章目录 EasyExcel环境搭建1.创建模块 easyexcel-demo2.引入依赖3.启动类创建 EasyExcel写1.最简单的写入1.模板2.方法3.结果 Write01.xlsx 2.指定字段不写入Excel1.模板2.方法3.结果 Write02.xlsx 3.指定字段写入excel1.模板2.方法3.结果 Write03.xlsx 4.按照index顺序写入ex…...

JVM类加载器
什么是类加载器 类加载器(ClassLoader)是Java虚拟机提供给应用程序去实现获取类和接口字节码数据的技术。 类加载器只参与加载过程中的字节码获取并加载到内存这一部分 类加载器的分类 类加载器分为两类,一类是Java代码中实现的࿰…...

druid连接池参数配置
最近发现生产环境经常有数据库连接超时的问题,排查发现是druid连接池参数设置不合理导致 总结问题如下: 为了防止僵尸连接,k8s ipvs做了连接超时限制,如果TCP连接闲置超过900s(15分钟),客户端再尝试通过这个连接去发起…...
)
【机器学习】Kaggle实战信用卡反欺诈预测(场景解析、数据预处理、特征工程、模型训练、模型评估与优化)
构建信用卡反欺诈预测模型 建模思路 本项目需解决的问题 本项目通过利用信用卡的历史交易数据,进行机器学习,构建信用卡反欺诈预测模型,提前发现客户信用卡被盗刷的事件。 项目背景 数据集包含由欧洲持卡人于2013年9月使用信用卡进行交的…...
下ESP-IDF下载与安装完整流程(2))
Linux(Ubuntu)下ESP-IDF下载与安装完整流程(2)
接前一篇文章:Linux(Ubuntu)下ESP-IDF下载与安装完整流程(1) 本文主要看参考官网说明,如下: 快速入门 - ESP32-S3 - — ESP-IDF 编程指南 latest 文档 Linux 和 macOS 平台工具链的标准设置 - ESP32-S3 - — ESP-IDF 编程指南 latest 文档 一、安装准备 1. Linux用...

SpringBoot3 快速启动框架
文章目录 1 SpringBoot3 介绍 1.1 SpringBoot3 简介1.2 快速入门1.3 入门总结 2 SpringBoot3 配置文件 2.1 统一配置管理概述2.2 属性配置文件使用2.3 YAML配置文件使用2.4 批量配置文件注入2.5 多环境配置和使用 3 SpringBoot 整合 springMVC 3.1 实现过程3.2 web相关配置3.3…...

Enum枚举类,静态常量类,静态类的区别
Enum枚举类,静态常量类,静态类的区别 Enum枚举类静态常量类静态类Enum枚举类,静态常量类,静态类的区别 Enum枚举类 Enum枚举类的结构组成和用法使用可以查阅 Enum枚举类与静态变量和静态数组的区别 静态常量类 public class St…...

解锁专利世界的钥匙 ——famiwei 网
在知识经济的时代,专利作为创新成果的重要体现,无论是对于企业、科研人员乃至整个社会的发展都具有举足轻重的意义。而在众多的专利网站中,famiwei 网为用户提供了一个全面、精准且高效的专利信息交流与服务的舞台。 一、卓越功能,开启专利探索之门 famiwei 网拥有一套强大的专…...

金融租赁系统的创新与发展推动行业效率提升
金融租赁系统的技术升级与创新 在当今快速发展的金融市场中,金融租赁系统的技术升级与创新充满了无限可能。想象一下,传统的租赁方式就像一位沉闷的老师,而新兴技术就如同一位活泼的学生,不断追求新鲜事物。通过自动化、人工智能…...

SQL-Server链接服务器访问Oracle数据
SQL Server 链接服务器访问 Oracle 离线安装 .NET Framework 3.5 方法一:使用 NetFx3.cab 文件 下载 NetFx3.cab 文件,并将其放置在 Windows 10 系统盘的 C:Windows 文件夹中。 以管理员身份运行命令提示符,输入以下命令并回车: …...

Sonic:开源Go语言开发的高性能博客平台
Sonic:一个用Go语言开发的高性能博客平台 简介 Sonic,一个以其速度如声速般快速而命名的博客平台,是一个用Go语言开发的高性能博客系统。正如其名字所暗示的,Sonic旨在提供一个简单而强大的博客解决方案。这个项目受到了Halo项目…...

【react】常见的性能优化 1
目录 常见的 React 性能优化手段 1. 使用 useMemo 和 useCallback 缓存数据和函数 2. 使用 React.memo 缓存组件 3. 组件懒加载 4. 合理使用 key 5. 在组件销毁时清除定时器/事件 6. 使用 Suspense 和 Lazy 拆分组件 7. 使用 Fragment 避免额外标记 8. 避免使用内联函…...

SpringCloud源码-openFeign
LoadBalancer默认只有nacos服务发现器 openFeign与springcloud loadbalancer的结合点...

QLabel添加点击处理
在QLabel中添加点击事件有三种方式,分别是 使用LinkActivated信号连接槽函数(有缺限)注册事件分发器eventFilter创建类重写鼠标事件 1. 使用LinkActivated信号 QLabel类中有LinkActivated信号,是当标签中的链接被点击的时候触发…...

Markdown表格的使用
Markdown表格的使用 前言语法详解定义表格设定表格列内容的对齐方式 使用场景及实例小结其他文章快来试试吧 Markdown表格的使用👈点击这里也可查看 前言 表格通常作为一种布局的形式,用于结构化的数据展示。 Markdown表格包含三个部分:表头…...