生成对抗网络模拟缺失数据,辅助PAMAP2数据集仿真实验

PAMAP2数据集是一个包含丰富身体活动信息的数据集,它为我们提供了一个理想的平台来开发和测试HAR模型。本文将从数据集的基本介绍开始,逐步引导大家通过数据分割、预处理、模型训练,到最终的性能评估,在接下来的章节中,我们将详细介绍PAMAP2数据集的特点、数据预处理的关键步骤、CNN模型的训练过程,以及如何通过混淆矩阵、雷达图和柱状图等工具来展示和分析模型的性能。我们期望通过本文的分享,能够激发更多研究者和开发者对HAR技术的兴趣,并促进该领域的技术进步和应用创新。
一、PAMAP2数据集分析及介绍
1.概述
PAMAP2(Physical Activity Monitoring 2)数据集是一个全面的身体活动监测数据集,记录了18种不同身体活动,如步行、骑车、踢足球等。这些活动数据由9名受试者在进行活动时佩戴的多个传感器收集得到。此数据集是活动识别、强度估计以及相关算法开发和应用研究的宝贵资源。
2.受试者与设备
- 受试者: 数据集收集自9名受试者。
- 传感器设备:
- 3 Colibri无线惯性测量单元(IMU):
- 采样频率: 100Hz
- 传感器位置:
- 1个IMU佩戴在受试者优势手臂的手腕上
- 1个IMU佩戴在胸部
- 1个IMU佩戴在优势侧的脚踝
- 心率监测器(HR-monitor):
- 采样频率: 约9Hz
- 3 Colibri无线惯性测量单元(IMU):
3.数据收集方案
每位受试者都按照一个包含12种不同活动的预定方案进行活动。数据被分为两个主要部分:Protocol 和 Optional。
- Protocol 文件夹包含所有受试者必须完成的标准活动录音。
- Optional 文件夹包含一些受试者执行的可选活动录音。
3.数据文件
- 原始感官数据以空格分隔的文本文件(.dat)格式提供。
- 数据文件中缺失的值用 NaN 表示。
- 每个文件对应一个会话,包含时间戳和标记的感官数据实例。
- 数据文件共有54列,包括时间戳、活动标签和52个原始感知数据属性。
4.属性信息
数据文件中54列的组织如下:
- 时间戳(秒)
- 活动ID(见下文活动映射)
- 心率(每分钟心跳次数,bpm)
4-20. 手腕处IMU的数据
21-37. 胸部IMU的数据
38-54. 脚踝处IMU的数据
我们引入了传感器融合技术,将IMU数据与环境变量相结合。IMU的感官数据经过高级滤波和校准,包括但不限于:1. 温度补偿以消除温度对传感器读数的影响;2-4. 经过卡尔曼滤波的三维加速度数据,以优化动态范围和分辨率;5-7. 融合磁力计数据以校正加速度计的偏移和尺度因子,增强方向感知能力。
活动ID与对应活动列表
以下是活动ID和对应的活动列表:
- 1: 躺
- 2: 坐
- 3: 站
- 4: 步行
- 5: 跑步
- 6: 骑自行车
- 7: 北欧行走
- 9: 看电视
- 10: 计算机工作
- 11: 驾车
- 12: 上楼梯
- 13: 下楼梯
- 16: 用真空吸尘器打扫
- 17: 熨烫
- 18: 叠衣服
- 19: 打扫房间
- 20: 踢足球
- 24: 跳绳
- 0: 其他(瞬变活动)
二、PAMAP2数据集分割及处理
下面我将详细介绍如何对 PAMAP2 数据集进行分割和预处理,以便用于人体活动识别(HAR)的研究。
1.数据分割策略
我们采用两种数据分割策略:留一法和平均法。留一法是将一个受试者的数据作为验证集,其余作为训练集。平均法则是按照一定的比例将数据集分割为训练集和验证集。
2.预处理步骤
在下载数据集的基础上,我们增加了数据清洗步骤,包括去除无效或冗余的记录,识别并填补数据中的异常值,以及同步多个传感器的时间戳,确保数据的一致性和准确性:
-
数据读取:使用 Pandas 库读取数据集文件,我们只读取有效的列,包括活动标签和传感器数据。
-
数据插值:由于原始数据中可能存在缺失值,我们采用线性插值方法填充这些缺失值。
-
降采样:将数据从 100Hz 降采样至 33.3Hz,以减少计算量并提高模型的泛化能力。
-
去除无效类别:在 PAMAP2 数据集中,某些活动类别可能没有数据或数据量极少,我们将这些类别的数据去除。
-
滑窗处理:为了使数据适用于时间序列模型,我们将数据进行滑窗处理,生成固定大小的窗口数据。
-
数据标准化:为了提高模型的训练效率和性能,我们对数据进行 Z-score 标准化。
-
数据保存:最后,我们将预处理后的数据保存为
.npy文件,以便于后续使用。
3.代码实现
以下是对 PAMAP2 数据集进行分割和预处理的详细代码分析。
导入必要的库
import os
import numpy as np
import pandas as pd
import sys
from utils import * # 假设 utils 模块包含辅助函数
定义 PAMAP 函数
def PAMAP(dataset_dir='./PAMAP2_Dataset/Protocol', WINDOW_SIZE=171, OVERLAP_RATE=0.5, SPLIT_RATE=(8, 2), VALIDATION_SUBJECTS={105}, Z_SCORE=True, SAVE_PATH=os.path.abspath('../../HAR-datasets')):
函数参数说明:
dataset_dir: 数据集目录
WINDOW_SIZE: 滑窗大小
OVERLAP_RATE: 滑窗重叠率
SPLIT_RATE: 训练集与验证集的比例
VALIDATION_SUBJECTS: 留一法验证集的受试者编号
Z_SCORE: 是否进行 Z-score 标准化
SAVE_PATH: 预处理后数据的保存路径
读取和处理数据
for file in os.listdir(dataset_dir):# 解析文件名获取受试者 IDsubject_id = int(file.split('.')[0][-3:])# 读取数据content = pd.read_csv(os.path.join(dataset_dir, file), sep=' ', usecols=[1]+[*range(4,16)]+[*range(21,33)]+[*range(38,50)])# 数据插值content = content.interpolate(method='linear', limit_direction='forward', axis=0).to_numpy()# 降采样data = content[::3, 1:] # 数据label = content[::3, 0] # 标签# 去除无效类别data = data[label != 0]label = label[label != 0]# 滑窗处理cur_data = sliding_window(array=data, windowsize=WINDOW_SIZE, overlaprate=OVERLAP_RATE)
这段代码首先遍历数据集目录中的每个文件,然后读取有效列的数据,并进行线性插值、降采样和滑窗处理。
数据分割
if VALIDATION_SUBJECTS and subject_id in VALIDATION_SUBJECTS:# 留一法,当前受试者为验证集xtest += cur_dataytest += [category_dict[label[0]]] * len(cur_data)
else:# 平均法,根据比例分割训练集和验证集trainlen = int(len(cur_data) * SPLIT_RATE[0] / sum(SPLIT_RATE))testlen = len(cur_data) - trainlenxtrain += cur_data[:trainlen]xtest += cur_data[trainlen:]ytrain += [category_dict[label[0]]] * trainlenytest += [category_dict[label[0]]] * testlen
根据是否采用留一法或平均法,将数据分割为训练集和验证集。
数据标准化
if Z_SCORE:xtrain, xtest = z_score_standard(xtrain=xtrain, xtest=xtest)
如果需要,对数据进行 Z-score 标准化。
数据保存
if SAVE_PATH:save_npy_data(dataset_name='PAMAP2',root_dir=SAVE_PATH,xtrain=xtrain,xtest=xtest,ytrain=ytrain,ytest=ytest)
将预处理后的数据保存为 .npy 文件。
训练结果
经过对数据集训练之后,我们发现结果并不尽如人意, CNN模型在PAMAP2数据集上的准确率不足80%!这对于实验来说是非常失败的!
PAMAP2数据集虽然是一个宝贵的资源,但在实际应用中,数据集的完整性和一致性对于训练有效的人体活动识别(HAR)模型至关重要,缺失数据会降低模型的泛化能力和准确性,我们观察发现其数据中很多为NaN的缺失情况:

在现实世界中,尤其是在移动设备或可穿戴设备收集的人体活动监测数据中,数据缺失是一个常见问题。这可能是由于传感器故障、电池耗尽、用户未正确佩戴设备等原因造成的。这时我们可通过生成对抗网络(GAN)来模拟缺失数据,提高模型对未见数据的泛化能力。
三、生成对抗网络(GAN)模拟缺失数据

GAN由两部分组成:生成器(Generator)和判别器(Discriminator)。生成器的目标是产生逼真的数据,而判别器的目标是区分生成的数据和真实的数据。
生成器架构:通常包含若干层转置卷积(用于数据的上采样)和批量归一化层。在HAR数据集中,生成器将学习如何填补缺失的传感器数据。
class Generator(nn.Module):def __init__(self, input_size, output_size):super(Generator, self).__init__()self.main = nn.Sequential(nn.Linear(input_size, 128),nn.LeakyReLU(0.2, inplace=True),nn.Linear(128, 256),nn.LeakyReLU(0.2, inplace=True),nn.Linear(256, output_size),nn.Tanh())def forward(self, noise):return self.main(noise)
- 判别器架构:通常包含若干层卷积和池化层,以及全连接层,用于评估数据的真实性。
class Discriminator(nn.Module):def __init__(self, input_size):super(Discriminator, self).__init__()self.main = nn.Sequential(nn.Linear(input_size, 256),nn.LeakyReLU(0.2, inplace=True),nn.Linear(256, 128),nn.LeakyReLU(0.2, inplace=True),nn.Linear(128, 1),nn.Sigmoid())def forward(self, input):return self.main(input)
生成器和判别器在对抗过程中同时训练。生成器试图“欺骗”判别器,而判别器则不断学习以更好地区分真假数据,交替训练生成器和判别器,生成器产生数据,判别器评估数据并提供反馈。
class Autoencoder(nn.Module):def __init__(self, input_size, encoding_dim):super(Autoencoder, self).__init__()self.encoder = nn.Sequential(nn.Linear(input_size, encoding_dim),nn.ReLU(True),nn.Linear(encoding_dim, encoding_dim // 2),nn.ReLU(True))self.decoder = nn.Sequential(nn.Linear(encoding_dim // 2, encoding_dim),nn.ReLU(True),nn.Linear(encoding_dim, input_size),nn.Sigmoid())def forward(self, x):x = self.encoder(x)x = self.decoder(x)return x
GAN模型训练
选择PAMAP2数据集中的部分数据作为训练集,人为引入缺失值以模拟数据缺失情况,定义生成器和判别器的网络结构,选择合适的损失函数和优化器,执行生成器和判别器的对抗训练,调整超参数以获得最佳性能。
latent_dim = 100 # 潜在维度
generator = Generator(latent_dim, input_size) # input_size 是数据的维度
discriminator = Discriminator(input_size)
criterion = nn.BCELoss()train_gan(generator, discriminator, dataloader, latent_dim, n_epochs=50, batch_size=64)
对PAMAP2数据集进行预处理,包括归一化和去除无关特征,设计自编码器的编码器和解码器部分,选择合适的层数和神经元数量,训练自编码器并使用其编码器部分提取特征,这些特征随后用于HAR模型的训练。
encoding_dim = 64 # 编码维度
autoencoder = Autoencoder(input_size, encoding_dim)train_autoencoder(autoencoder, dataloader, n_epochs=50, batch_size=64)
经过GAN和自编码器来增强过的PAMAP2数据集,很多为NaN缺失的数据已经变成了正常的数据:

四、训练结果
- 使用增强后的数据集训练HAR模型,并评估其性能;
1.评估及结果展示
具体评估代码:
# 计算评估指标
accuracy = accuracy_score(all_labels, all_preds)
report = classification_report(all_labels, all_preds, output_dict=True, zero_division=1)
precision = report['weighted avg']['precision']
recall = report['weighted avg']['recall']
f1_score = 2 * precision * recall / (precision + recall)
# 计算推理时间
inference_end_time = time.time()
inference_time = inference_end_time - inference_start_time# 打印结果
print(f'Epoch: {i}, Train Loss: {loss}, Test Acc: {accuracy:.4f},Precision: {precision:.4f}, Recall: {recall:.4f}, F1 Score: {f1_score:.4f}, Inference Time: {inference_time:.4f} seconds')
结果展示:
| 模型名称 | 准确率(Accuracy) | 精确率(Precision) | 召回率(Recall) | F1分数(F1-score) | 参数量(Parameters) | 推理时间(Inference Time) |
|---|---|---|---|---|---|---|
| CNN | 0.9067 | 0.9121 | 0.9067 | 0.9094 | 740364 | 0.00060.6517 |
通过比较使用原始数据集和增强数据集训练的模型,可以验证GAN在模拟缺失数据方面的效果非常好,CNN模型在PAMAP2数据集上表现出色,准确率达到了90.67%,并且具有均衡的精确率(91.21%)、召回率(90.67%)和F1分数(90.94%),同时模型参数量为740364,推理时间仅为0.6517毫秒,显示出了高效的实时预测能力。
2.可视化结果展示
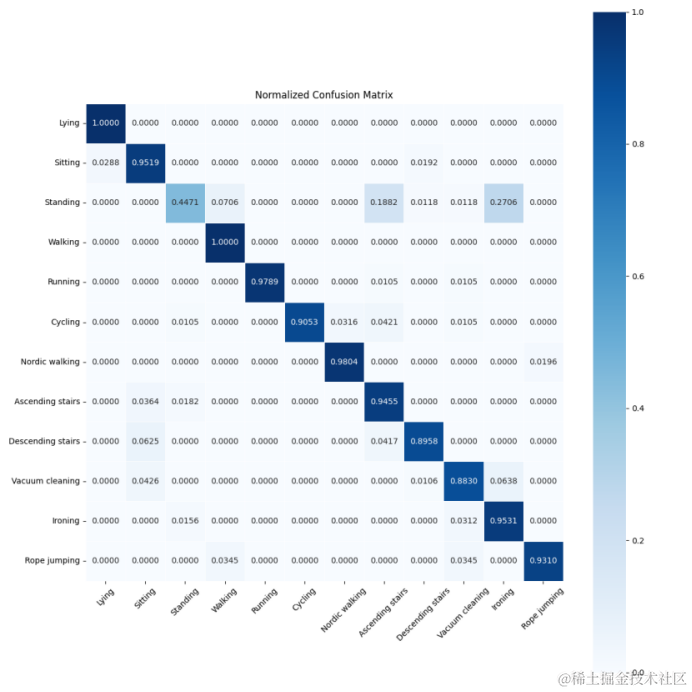
混淆矩阵图
混淆矩阵是一个非常重要的工具,它可以展示模型在各个类别上的性能,特别是错误分类的情况。
conf_matrix = confusion_matrix(all_labels, all_preds, normalize='true')
# print(conf_matrix)# 自定义类别标签列表
class_labels = ['Lying', 'Sitting', 'Standing', 'Walking', 'Running', 'Cycling','Nordic walking','Ascending stairs','Descending stairs','Vacuum cleaning','Ironing','Rope jumping']plt.figure(figsize=(12, 12)) # 可以根据需要调整这里的值
# 使用 seaborn 的 heatmap 函数绘制归一化的混淆矩阵
ax = sns.heatmap(conf_matrix, annot=True, fmt='.4f', cmap='Blues',xticklabels=class_labels, yticklabels=class_labels,square=True, linewidths=.5)# 确保 x 轴和 y 轴的标签是字符串类型
ax.set_xticklabels(class_labels, rotation=45)
ax.set_yticklabels(class_labels)
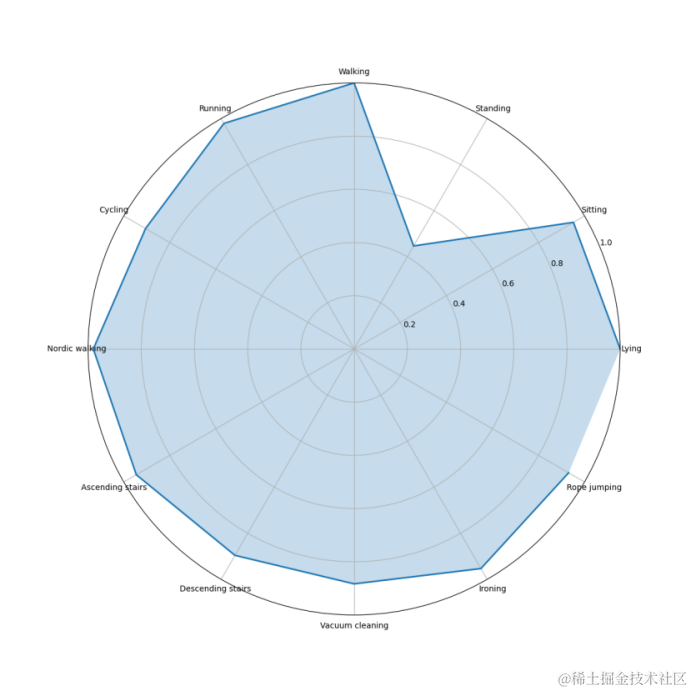
雷达图
雷达图可以展示模型在多个维度上的性能:
fig, ax = plt.subplots(figsize=(12, 12), subplot_kw=dict(polar=True))# 绘制每个行为的雷达图
ax.plot(angles, beh, linestyle='-', linewidth=2)
ax.fill(angles, beh, alpha=0.25)# 设置雷达图的刻度和标签
ax.set_xticks(angles)
#ax.set_xticklabels(['Walking', 'Walking Upstairs', 'Walking Downstairs', 'Sitting', 'Standing', 'Laying'])
ax.set_xticklabels(['Lying', 'Sitting', 'Standing', 'Walking', 'Running', 'Cycling','Nordic walking','Ascending stairs','Descending stairs','Vacuum cleaning','Ironing','Rope jumping'])
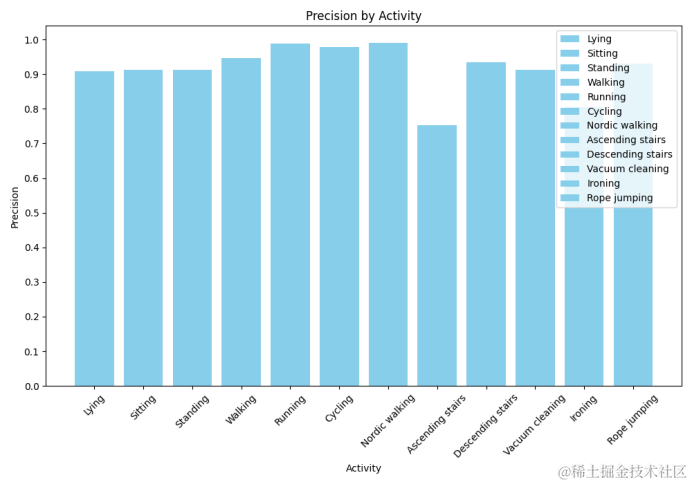
仿真指标柱状图
柱状图可以用于展示各个类别的精确率,帮助我们快速识别模型在哪些类别上表现更好或需要改进:
class_labels = ['Lying', 'Sitting', 'Standing', 'Walking', 'Running', 'Cycling','Nordic walking','Ascending stairs','Descending stairs','Vacuum cleaning','Ironing','Rope jumping']# 计算每个类别的精确率
precisions = {}
for label in unique_labels:# 为当前类别创建一个二进制的标签数组y_true = np.where(all_labels == label, 1, 0)y_pred = np.where(all_preds == label, 1, 0)precision = precision_score(y_true, y_pred, average='binary')precisions[label] = precision
通过这种方式,GAN不仅解决了数据缺失的问题,还提高了数据集的质量和多样性,从而为训练更准确、更鲁棒的HAR模型提供了支持。
相关文章:

生成对抗网络模拟缺失数据,辅助PAMAP2数据集仿真实验
PAMAP2数据集是一个包含丰富身体活动信息的数据集,它为我们提供了一个理想的平台来开发和测试HAR模型。本文将从数据集的基本介绍开始,逐步引导大家通过数据分割、预处理、模型训练,到最终的性能评估,在接下来的章节中,…...

表格数据处理中大语言模型的微调优化策略研究
论文地址 Research on Fine-Tuning Optimization Strategies for Large Language Models in Tabular Data Processing 论文主要内容 这篇论文的主要内容是研究大型语言模型(LLMs)在处理表格数据时的微调优化策略。具体来说,论文探讨了以下…...

卡达掐发展史
自行车是一种简单而又伟大的交通工具。自从19世纪诞生以来,它不仅改变了人们的出行方式,也深刻地影响了我们的生活方式、城市布局以及健康观念。作为一种绿色、经济的出行工具,自行车至今仍在全球范围内被广泛使用。本文将从自行车的历史、结…...

初学 flutter 问题记录
windows搭建flutter运行环境 一、运行 flutter doctor遇到的问题 Xcmdline-tools component is missingRun path/to/sdkmanager --install "cmdline-tools;latest"See https://developer.android.com/studio/command-line for more details.1)cmdline-to…...

大数据实验4-HBase
一、实验目的 阐述HBase在Hadoop体系结构中的角色;能够掌握HBase的安装和配置方法熟练使用HBase操作常用的Shell命令; 二、实验要求 学习HBase的安装步骤,并掌握HBase的基本操作命令的使用; 三、实验平台 操作系统࿱…...
,B服务器下载A服务器文件(下载))
CentOS:A服务器主动给B服务器推送(上传),B服务器下载A服务器文件(下载)
Linux:常识(bash: ip command not found )_bash: ip: command not found-CSDN博客 rsync 中断后先判断程序是否自动重连:ps aux | grep rsync 查看目录/文件是否被使用(查询线程占用):lsof /usr/local/bin/mongodump/.B_database1.6uRCTp 场景:MongoDB中集合非常大需要…...

如何选择服务器
如何选择服务器 选择服务器时应考虑以下几个关键因素: 性能需求。根据网站的预期流量和负载情况,选择合适的处理器、内存和存储容量。考虑网站是否需要处理大量动态内容或高分辨率媒体文件。 可扩展性。选择一个可以轻松扩展的服务器架构,以便…...

el-table最大高度无法滚动
解决el-table同时使用fixed和计算的最大高度时固定右边的列无法跟随滚动的问题 原因:el-table组件会根据传入的 max-height 计算表格内容部分 和 fixed部分的最大高度,以此来生成滚动条和产生滚动效果,当传入的 max-height 为一个计算的高度…...

YOLO-FaceV2: A Scale and Occlusion Aware Face Detector
《YOLO-FaceV2:一种尺度与遮挡感知的人脸检测器》 1.引言2.相关工作3.YOLO-FaceV23.1网络结构3.2尺度感知RFE模型3.3遮挡感知排斥损失3.4遮挡感知注意力网络3.5样本加权函数3.6Anchor设计策略3.7 归一化高斯Wasserstein距离 4.实验4.1 数据集4.2 训练4.3 消融实验4.3.1 SEAM块4…...

如何使用 Python 开发一个简单的文本数据转换为 Excel 工具
目录 一、准备工作 二、理解文本数据格式 三、开发文本数据转换为Excel工具 读取CSV文件 将DataFrame写入Excel文件 处理其他格式的文本数据 读取纯文本文件: 读取TSV文件: 四、完整代码与工具封装 五、使用工具 六、总结 在数据分析和处理的日常工作中,我们经常…...
)
全卷积网络(Fully Convolutional Networks, FCN)
全卷积网络(Fully Convolutional Networks, FCN) 什么是 FCN? 全卷积网络(Fully Convolutional Networks, FCN)是一种用于图像语义分割的深度学习模型。与传统的卷积神经网络(CNN)不同&#x…...

【计算机网络】HTTP协议
一、网址 1.URL URL就是我们平时说的网址 2.urlencode/urldecode 像 / ? : 等这样的字符,已经被url当做特殊意义理解了。因此这些字符不能随意出现 如果某个参数中需要带有这些特殊字符,就必须先对特殊字符进行转义 -> urlencode 服务器收到url…...

IT服务团队建设与管理
在 IT 服务团队中,需要明确各种角色。例如系统管理员负责服务器和网络设备的维护与管理;软件工程师专注于软件的开发、测试和维护;运维工程师则保障系统的稳定运行,包括监控、故障排除等。通过清晰地定义每个角色的职责࿰…...

STM32总体架构简单介绍
目录 一、引言 二、STM32的总体架构 1、三个被动单元 (1)内部SRAM (2)内部闪存存储器 (3)AHB到APB的桥(AHB to APBx) 2、四个主动(驱动)单元 &#x…...

C++自动化测试:GTest 与 GitLab CI/CD 的完美融合
在现代软件开发中,自动化测试是保证代码质量和稳定性的关键手段。对于C项目而言,自动化测试尤为重要,它能有效捕捉代码中的潜在缺陷,提高代码的可维护性和可靠性。本文将重点介绍如何在C项目中结合使用Google Test(GTe…...

Python 虚拟环境使用指南
Python 虚拟环境使用指南 博客 一、创建虚拟环境 在开始使用Python虚拟环境之前,我们需要先创建一个新的虚拟环境。 1. 基础创建流程 首先,进入您的项目目录: cd path\to\your\project然后使用以下命令创建虚拟环境: pytho…...

MySQL面试-1
InnoDB中ACID的实现 先说一下原子性是怎么实现的。 事务要么失败,要么成功,不能做一半。聪明的InnoDB,在干活儿之前,先将要做的事情记录到一个叫undo log的日志文件中,如果失败了或者主动rollback,就可以通…...

Harbor2.11.1生成自签证和配置HTTPS访问
文章目录 HTTPS的工作流程部署Harbor可参考上一篇文章生成自签证书1.修改/etc/hosts文件2.生成证书a.创建存放证书路径b.创建ca.key密钥c.创建ca.crtd.创建给Harbor服务器使用密钥 yunzhidong.harbor.com.keye.创建给Harbor服务器使用证书签名请求文件 yunzhidong.harbor.com.c…...

鸿蒙开发Hvigor插件动态生成代码
Hvigor允许开发者实现自己的插件,开发者可以定义自己的构建逻辑,并与他人共享。Hvigor主要提供了两种方式来实现插件:基于hvigorfile脚本开发插件、基于typescript项目开发。下面以基于hvigorfile脚本开发插件进行介绍。 基于hvigorfile脚本…...

VSCode 新建 Python 包/模块 Pylance 无法解析
问题描述: 利用 VSCode 写代码,在项目里新建一个 Python 包或者模块,然后在其他文件里正常导入这个包或者模块时出现: Import “xxxx” could not be resolved Pylance (reportMissingImports) 也就是说 Pylance 此时无法解析我们…...

【论文笔记】Number it: Temporal Grounding Videos like Flipping Manga
🍎个人主页:小嗷犬的个人主页 🍊个人网站:小嗷犬的技术小站 🥭个人信条:为天地立心,为生民立命,为往圣继绝学,为万世开太平。 基本信息 标题: Number it: Temporal Grou…...
)
【C++】list模拟实现(详解)
本篇来详细说一下list的模拟实现,list的大体框架实现会比较简单,难的是list的iterator的实现。我们模拟实现的是带哨兵位头结点的list。 1.准备工作 为了不和C库里面的list冲突,我们在实现的时候用命名空间隔开。 //list.h #pragma once #…...
)
Java基础-组件及事件处理(下)
(创作不易,感谢有你,你的支持,就是我前行的最大动力,如果看完对你有帮助,请留下您的足迹) 目录 面板组件 说明 常见组件 JScrollPane常用构造方法 JScrollPane设置面板滚动策略的方法 JScrollPane滚…...
)
太通透了,Android 流程分析 蓝牙enable流程(应用层/Framework/Service层)
零. 前言 由于Bluedroid的介绍文档有限,以及对Android的一些基本的知识需要了(Android 四大组件/AIDL/Framework/Binder机制/JNI/HIDL等),加上需要掌握的语言包括Java/C/C等,加上网络上其实没有一个完整的介绍Bluedroid系列的文档࿰…...
:低功耗设计)
《硬件架构的艺术》笔记(五):低功耗设计
介绍 能量以热量形式消耗,温度升高芯片失效率也会增加,增加散热片或风扇会增加整体重量和成本,在SoC级别对功耗进行控制就可以减少甚至可能消除掉这些开支,产品也更小更便宜更可靠。本章描述了减少动态功耗和静态功耗的各种技术。…...
)
【Ubuntu24.04】服务部署(虚拟机)
目录 0 背景1 安装虚拟机1.1 下载虚拟机软件1.2 安装虚拟机软件1.2 安装虚拟电脑 2 配置虚拟机2.1 配置虚拟机网络及运行初始化脚本2.2 配置服务运行环境2.2.1 安装并配置JDK172.2.2 安装并配置MySQL8.42.2.3 安装并配置Redis 3 部署服务4 总结 0 背景 你的服务部署在了你的计算…...
)
Java基础-组件及事件处理(中)
(创作不易,感谢有你,你的支持,就是我前行的最大动力,如果看完对你有帮助,请留下您的足迹) 目录 BorderLayout布局管理器 说明: 示例: FlowLayout布局管理器 说明: …...
)
从零开始学习数据库 day0(基础)
在当今的信息时代,数据已经成为了企业和组织最重要的资产之一。无论是电子商务平台,社交媒体,还是科研机构,几乎每个地方都离不开数据库。今天,我们将一起走进数据库的世界,学习它的基础知识,帮…...

【淘汰9成NLP面试者的高频面题】LSTM中的tanh和sigmoid分别用在什么地方?为什么?
博客主页: [青松] 本文专栏: NLP 大模型百面百过 【淘汰9成NLP面试者的高频面题】LSTM中的tanh和sigmoid分别用在什么地方?为什么? 重要性:★★★ 💯 本题主要考察面试者对以下问题的理解: ① 数据特征和模…...

linux从0到1——shell编程9
声明! 学习视频来自B站up主 **泷羽sec** 有兴趣的师傅可以关注一下,如涉及侵权马上删除文章,笔记只是方便各位师傅的学习和探讨,文章所提到的网站以及内容,只做学习交流,其他均与本人以及泷羽sec团队无关&a…...

【源码+文档+调试讲解】基于Hadoop实现的豆瓣电子图书推荐系统的设计与实现
摘 要 随着开数字化阅读的普及,豆瓣电子图书推荐系统应运而生,旨在为用户提供个性化的阅读体验。基于Hadoop的强大数据处理能力,该系统能够有效处理海量用户数据和书籍信息,通过复杂的算法模型为用户推荐高质量的内容。管理员功能…...

内存分配与回收策略
对象优先在Eden分配 大多数情况下,对象在新生代Eden中分配,当Eden区没有足够的空间按进行分配时,虚拟机将会引发一次Minor GC 。 在运行时通过-Xms20M、-Xmx20M、-Xmn10M这三个参数限制了Java 堆大小为20MB,不可扩展,…...

实时数据开发 | 怎么通俗理解Flink容错机制,提到的checkpoint、barrier、Savepoint、sink都是什么
今天学Flink的关键技术–容错机制,用一些通俗的比喻来讲这个复杂的过程。参考自《离线和实时大数据开发实战》 需要先回顾昨天发的Flink关键概念 检查点(checkpoint) Flink容错机制的核心是分布式数据流和状态的快照,从而当分布…...

android-sdk 安装脚本
android-sdk 安装脚本 androidSdk_install.sh #!/bin/bash #[描述] android-sdk 安装# set -eu shopt -s expand_aliasesAndroid_SDK_D/app5/android-sdk-home/JAVA17_D/app/zulu17.48.15-ca-jdk17.0.10-linux_x64/#jdk17下载、解压 #https://www.azul.com/downloads/?version…...

【jvm】解释器
目录 1. 说明2. 工作原理3. 特点4. JVM解释器与JIT编译器的关系5. JVM解释器的优化 1. 说明 1.JVM(Java虚拟机)解释器是JVM的一个重要组成部分,负责将Java字节码指令翻译并执行为本地机器码。 2. 工作原理 1.读取字节码指令:JV…...

Node.js 安装与环境配置详解:从入门到实战
**标题:Node.js 安装与环境配置详解:从入门到实战** --- ### 一、Node.js 简介 Node.js 是一个基于 Chrome V8 引擎的 JavaScript 运行时环境,允许开发者在服务器端运行 JavaScript 代码。凭借其事件驱动、非阻塞 I/O 模型,Nod…...

Centos使用docker搭建Graylog日志平台
日志管理系统有很多,比如ELK,Graylog,LokiGrafanaPromtail 适用场景: 1.如果需求复杂,服务器资源不受限制,推荐使用ELK(Logstash Elasticsearch Kibana)方案; 2.如果需求仅是将…...
)
Java基础-Java中的常用类(上)
(创作不易,感谢有你,你的支持,就是我前行的最大动力,如果看完对你有帮助,请留下您的足迹) 目录 String类 创建字符串 字符串长度 连接字符串 创建格式化字符串 String 方法 System类 常用方法 方…...

HTML 表单实战:从创建到验证
HTML表单是用于收集用户输入数据的一种方式,可以用于创建各种类型的表单,例如登录表单、注册表单、调查问卷表单等。本文将详细介绍表单元素的使用,并利用JavaScript实现对表单数据的验证。 HTML表单元素的使用 输入框<input> <i…...
)
Spring 框架七大模块(Java EE 学习笔记03)
核心容器模块(Core Container) 核心容器模块在Spring的功能体系中起着支撑性作用,是其他模块的基石。核心容器层主要由Beans模块、Core模块、Contex模块和SpEL模块组成。 (1)Beans模块。它提供了BeanFactory类&…...

【npm设置代理-解决npm网络连接error network失败问题】
【npm设置代理-解决npm网络连接error network失败问题】 创建vue项目出错创建vue项目连接网络失败 查看npm代理设置npm代理对于Clash Verge对于v2rayN自定义代理服务器 删除代理更换其他源查看当前源更改 npm 源切换回官方源临时切换源临时更换源创建vue项目 npm其他常用命令查…...

VUE 的前置知识
一、JavaScript----导图导出 1. JS 提供的导入导出机制,可以实现按需导入 1.1 在html页面中可以把JS文件通过 <script src"showMessage.js"></script> 全部导入 1.2 通过在JS文件中写export关键字导出通过 <script src"showMessage…...

Java基础-集合
(创作不易,感谢有你,你的支持,就是我前行的最大动力,如果看完对你有帮助,请留下您的足迹) 目录 前言 一、Java集合框架概述 二、Collection接口及其实现 2.1 Collection接口 2.2 List接口及其实现 …...
【html by js】)
零基础上手WebGIS+智慧校园实例(1)【html by js】
请点个赞收藏关注支持一下博主喵!!! 等下再更新一下1. WebGIS矢量图形的绘制(超级详细!!),2. WebGIS计算距离, 以及智慧校园实例 with 3个例子!!…...

深入浅出分布式缓存:原理与应用
文章目录 概述缓存分片算法1. Hash算法2. 一致性Hash算法3. 应用场景Redis集群方案1. Redis 集群方案原理2. Redis 集群方案的优势3. Java 代码示例:Redis 集群数据定位Redis 集群中的节点通信机制:Gossip 协议Redis 集群的节点通信:Gossip 协议Redis 集群的节点通信流程Red…...

Spring AI 框架使用的核心概念
一、模型(Model) AI 模型是旨在处理和生成信息的算法,通常模仿人类的认知功能。通过从大型数据集中学习模式和见解,这些模型可以做出预测、文本、图像或其他输出,从而增强各个行业的各种应用。 AI 模型有很多种&…...

【人工智能】用Python和NLP工具构建文本摘要模型:使用NLTK和spaCy进行自然语言处理
《Python OpenCV从菜鸟到高手》带你进入图像处理与计算机视觉的大门! 文本摘要是自然语言处理(NLP)中的关键任务之一,广泛应用于新闻、博客、社交媒体和搜索引擎等场景。通过生成简洁而准确的文本摘要,我们可以大大提升信息处理效率。本文将探讨如何使用Python结合NLP工具…...

网络安全概论
一、 网络安全是一个综合性的技术。在Internet这样的环境中,其本身的目的就是为了提供一种开放式的交互环境,但是为了保护一些秘密信息,网络安全成为了在开放网络环境中必要的技术之一。网络安全技术是随着网络技术的进步逐步发展的。 网络安…...

Flask
Flask 是一个用 Python 编写的轻量级 Web 应用框架,被称为"微框架"。基于 WSGI(Web Server Gateway Interface)和 Jinja2 模板引擎。 Flask:https://flask.palletsprojects.com/en/stable/ jinja:https://ji…...

Java基础-内部类与异常处理
(创作不易,感谢有你,你的支持,就是我前行的最大动力,如果看完对你有帮助,请留下您的足迹) 目录 一、Java 内部类 什么是内部类? 使用内部类的优点 访问局部变量的限制 内部类和继承 内部…...