Scrapy数据解析+保存数据
Scrapy数据解析+保存数据
目录
1.数据解析
2.基于item存放数据并提交给管道
3.用txt文件来保存数据
今天我们需要爬取B站数据并保存到txt文件里面。
我们先打开B站, 然后点击热门, 进去之后再点击排行榜:
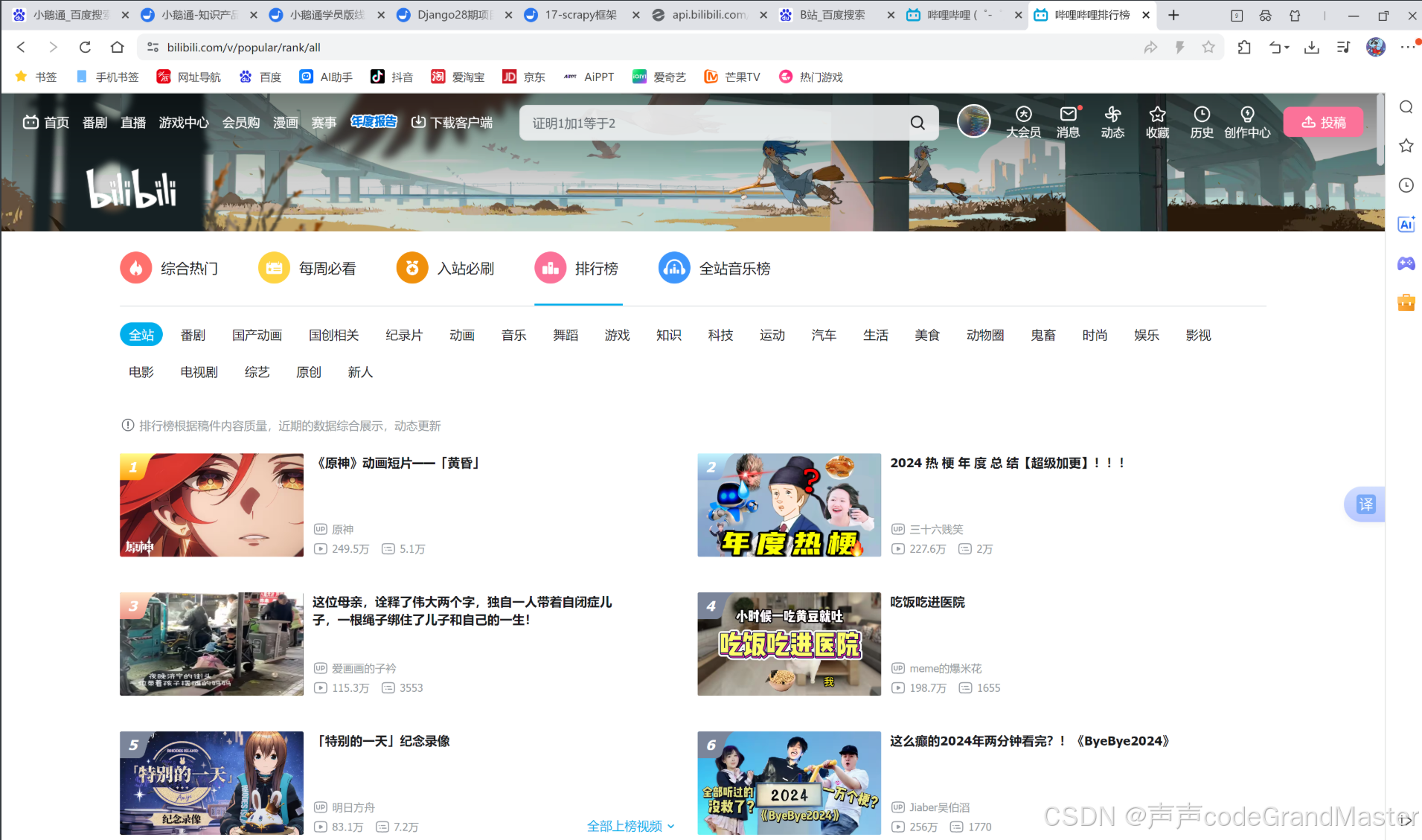
我们打开F12后, 可以看到, 我们想要的请求, 轻而易举的就可以拿到(通过搜索关键字功能)。
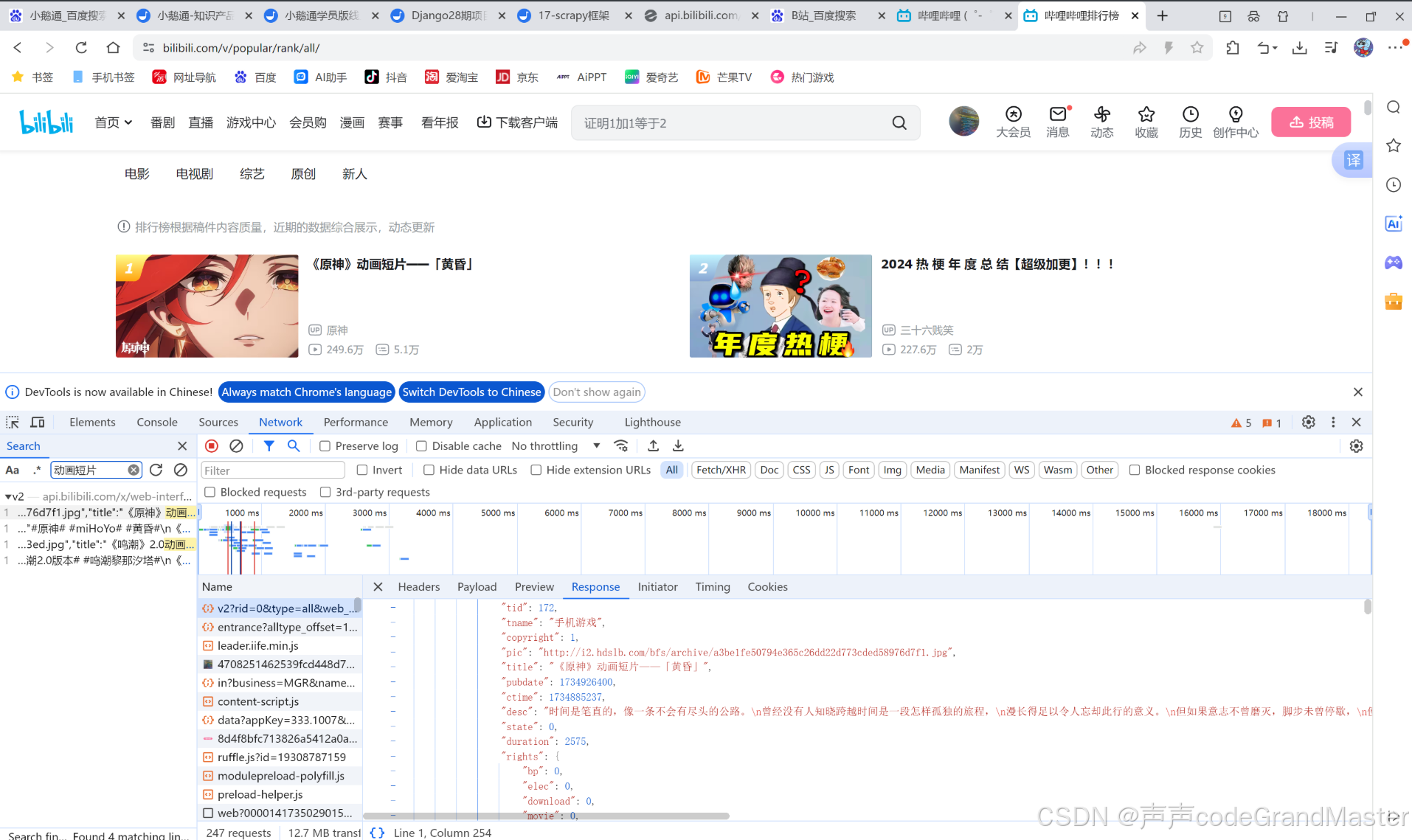
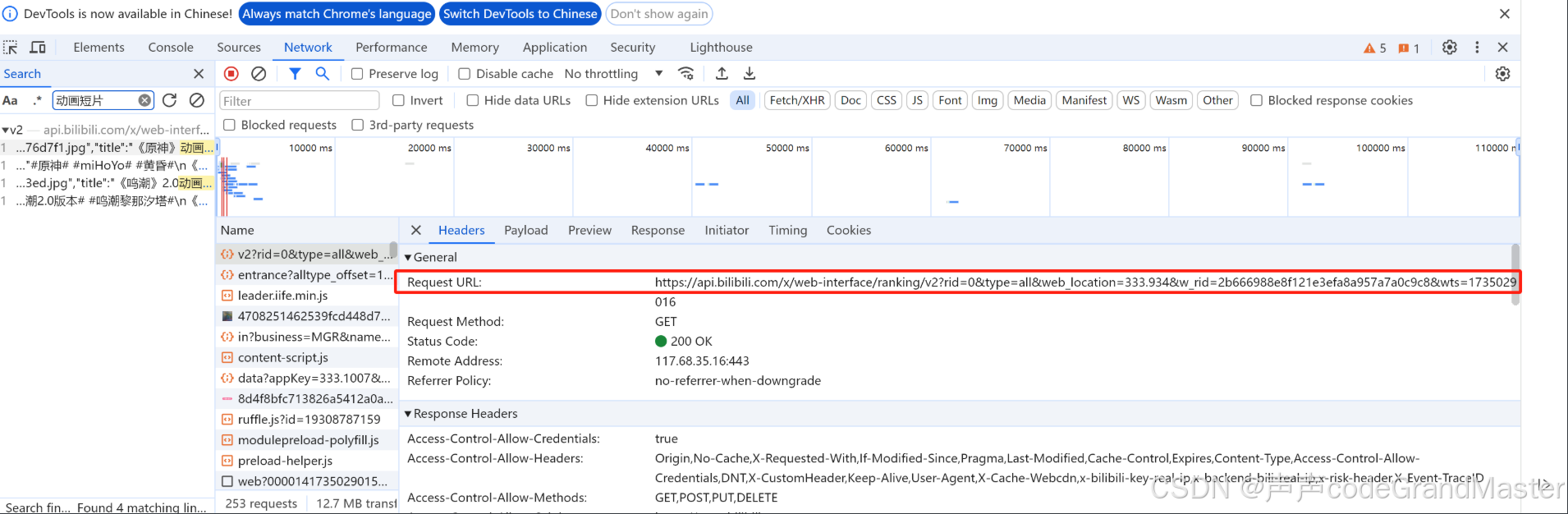
一、数据解析
首先, 我们需要把我们想要解析数据的请求, 放到start_urls里面:
start_urls = ["https://api.bilibili.com/x/web-interface/popular?ps=20&pn=1&web_location=333.934&w_rid=c78bd05ec31e04bcaa0689863761dd73&wts=1730296798"]
然后开始数据解析, 数据解析的方法, 之前爬虫文章已经讲到过, 并且还有大量的实战, 所以这里不再赘述, 直接上代码。
数据解析对应的代码:
def parse(self, response):data = response.json()for i in data['data']['list']:# 视频idbvid = i['bvid']# 视频作者name = i['owner']['name']# 视频标题title = i['title']# 视频描述desc = i['desc']# 播放数stat = i['stat']['view']print(bvid, name, title, desc, stat)
我们再parse里面写解析代码, 不过跟之前不一样的是, 不需要写url再发request请求之类的代码了, 因为我们用的是scrapy框架, 我们只需要直接用response.json()这样就可以解析json格式的数据, 而且response里面的数据, 就是我们在start_urls那个列表里面的请求出来的数据。
运行:
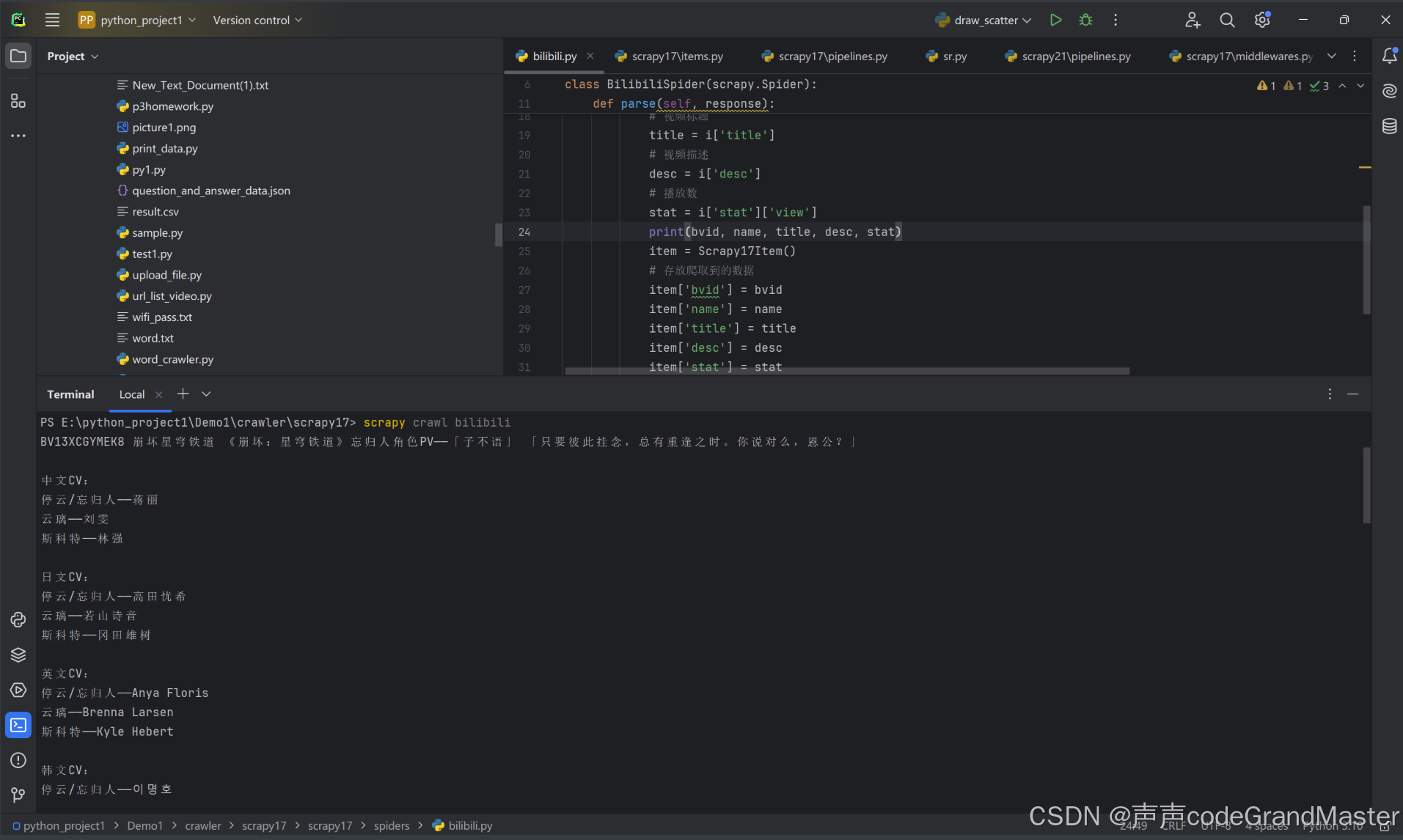
我们已经成功的爬到数据了。
二、基于item存放数据并提交给管道
我们需要编辑items.py
items.py:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.htmlimport scrapyclass Scrapy17Item(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()bvid = scrapy.Field()name = scrapy.Field()title = scrapy.Field()desc = scrapy.Field()stat = scrapy.Field()把我们所有要用到的字段, 全部写进来, 写法是变量名=scrapy.Field()
然后再parse函数里面在接着写代码:
import scrapyfrom scrapy17.items import Scrapy17Itemclass BilibiliSpider(scrapy.Spider):name = "bilibili"# allowed_domains = ["bilibili.com"]start_urls = ["https://api.bilibili.com/x/web-interface/popular?ps=20&pn=1&web_location=333.934&w_rid=c78bd05ec31e04bcaa0689863761dd73&wts=1730296798"]def parse(self, response):data = response.json()for i in data['data']['list']:# 视频idbvid = i['bvid']# 视频作者name = i['owner']['name']# 视频标题title = i['title']# 视频描述desc = i['desc']# 播放数stat = i['stat']['view']print(bvid, name, title, desc, stat)item = Scrapy17Item()# 存放爬取到的数据item['bvid'] = bviditem['name'] = nameitem['title'] = titleitem['desc'] = descitem['stat'] = stat# 提交itemyield item这里我们用刚才写好的Scrapy17Item, 把我们爬取到的数据先存到item里面, 这里用yield提交item数据, 为了之后保存数据做铺垫。
三、基于管道来保存数据
上面我们已经做好了铺垫, 那接下来我们就要对数据进行保存。
我们打开pipelines.py文件:
输入相应代码:
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html# useful for handling different item types with a single interface
from itemadapter import ItemAdapterclass Scrapy17Pipeline:def open_spider(self, spider):self.f = open("数据.txt", "a", encoding="utf-8")def process_item(self, item, spider):# print("管道内中的process_item执行了", item)self.f.write(str("视频id号:" + item['bvid'] + ",视频作者:" + item['name'] + ",视频描述:" + item['desc'] + ",播放数:" + str(item['stat']) + "\n"))return itemdef close_spider(self, spider):self.f.close()在pipe管道类里面有三个函数, 我们在open_spider函数里面创建文件, process_item里面的内容就是我们上面做好的铺垫拿到这里用, 把我们之前提交好的管道item写入, 在此函数里面使用item, 然后就可以用item[‘参数名’]这种方法给它获取我们之前爬虫获取的值, 最后不要忘记return item。最后我们在close_spider函数里面关闭文件资源。
运行结果:
打开txt文件:
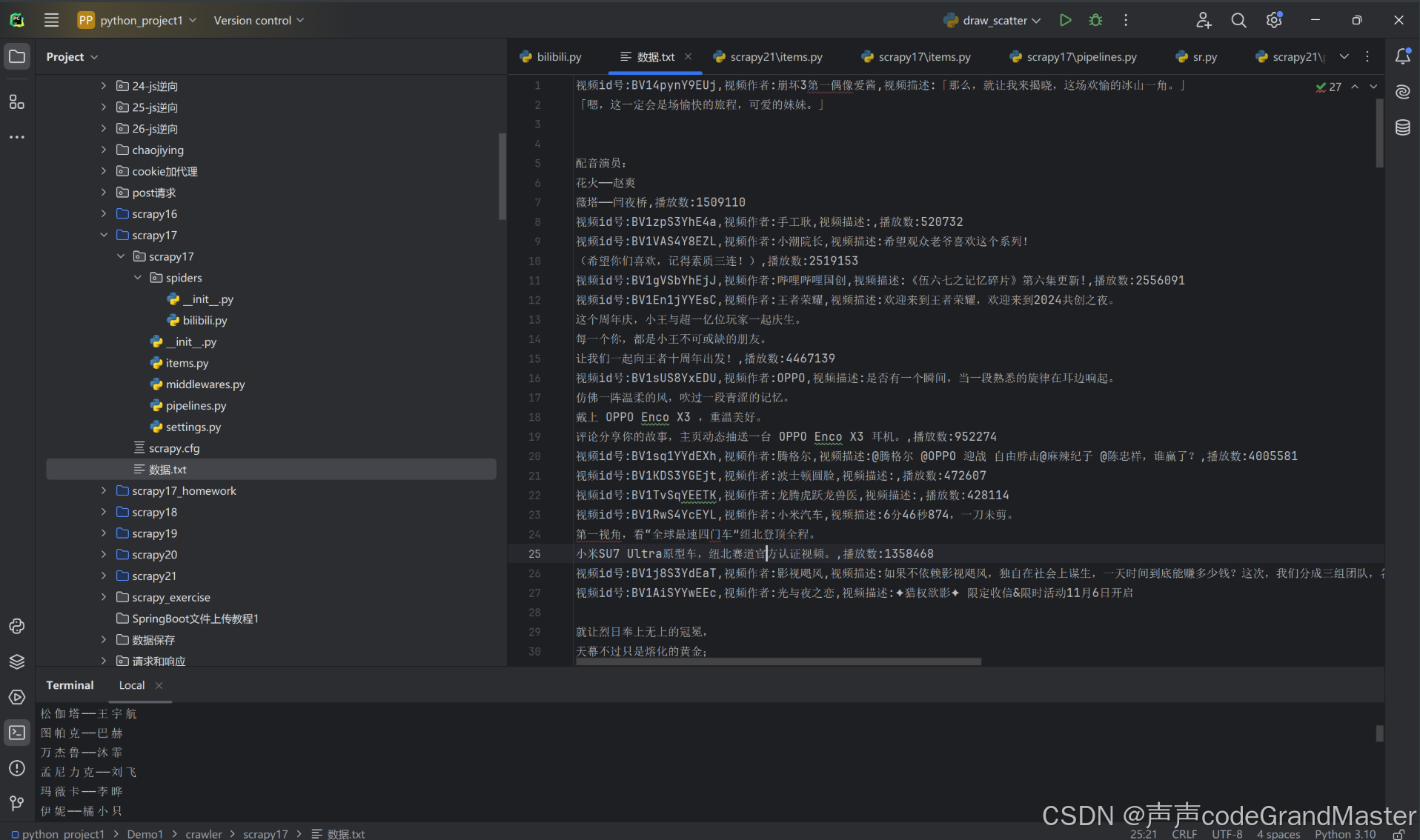
我们成功把B站的数据爬取并保存到txt文件。
创建scrapy和运行scrapy命令是上一篇文章所讲的, 如果大家对这个还不熟悉的话, 可以翻一翻上一篇文章的内容, 包括settings.py里面需要配置的细节内容, 也需要参考上一篇文章(如果settings.py配置文件里面的内容, 有新的东西要配置, 肯定会在文章中写出来, 如果文章中没有写关于settings.py配置的代码, 那就默认安装scrapy框架的第一篇文章里面的内容来配置)。
以上就是Scrapy数据解析+保存数据的所有内容了, 如果有哪里不懂的地方,可以把问题打在评论区, 欢迎大家在评论区交流!!!
如果我有写错的地方, 望大家指正, 也可以联系我, 让我们一起努力, 继续不断的进步.
学习是个漫长的过程, 需要我们不断的去学习并掌握消化知识点, 有不懂或概念模糊不理解的情况下,一定要赶紧的解决问题, 否则问题只会越来越多, 漏洞也就越来越大.
人生路漫漫, 白鹭常相伴!!!
相关文章:

Scrapy数据解析+保存数据
Scrapy数据解析保存数据 目录 1.数据解析 2.基于item存放数据并提交给管道 3.用txt文件来保存数据 今天我们需要爬取B站数据并保存到txt文件里面。 我们先打开B站, 然后点击热门, 进去之后再点击排行榜: 我们打开F12后, 可以看到, 我们想要的请求, 轻而易举的就可以拿到(…...
)
Redis--缓存穿透、击穿、雪崩以及预热问题(面试高频问题!)
缓存穿透、击穿、雪崩以及预热问题 如何解决缓存穿透?方案一:缓存空对象方案二:布隆过滤器什么是布隆过滤器?优缺点 方案三:接口限流 如何解决缓存击穿问题?方案一:分布式锁方案一改进成双重判定…...

【Python高级353】python实现多线程版本的TCP服务器
前面学了了套接字编程、tcp服务端客户端开发、面向对象版的服务端客户端、带有端口复用的服务端。 这里使用多线程开发多任务版的服务端 多任务版本的TCP服务器 来一个客户,就为其创建一个线程 import socket import threadingclass WebServer:# 3、定义一个__ini…...

【Pandas】pandas Series to_period
Pandas2.2 Series Conversion 方法描述Series.astype用于将Series对象的数据类型转换为指定类型的方法Series.convert_dtypes用于将 Series 对象的数据类型智能地转换为最佳可能的数据类型的方法Series.infer_objects用于尝试推断 Series 中对象(object࿰…...

深度学习领域车辆识别与跟踪
深度学习中车辆识别是一个广泛应用的领域,它涵盖了从车辆检测到车型识别的多个方面。以下是对深度学习中车辆识别与车辆相关内容的详细探讨: 一、车辆检测 车辆检测是车辆识别中的基础任务,其目标是在图像或视频中准确地定位出车辆的位置。…...
)
数学建模 绘图 图表 可视化(2)
文章目录 前言柱形图条形图克利夫兰点图系列坡度图南丁格尔玫瑰图径向柱图极坐标图词云图总结参考资料 前言 承接上期 数学建模 绘图 图表 可视化(1)的总体描述,这期我们继续跟随《Python 数据可视化之美 专业图表绘制指南》步伐来学习其中l…...
—— 生命周期)
vue源码分析(十)—— 生命周期
文章目录 前言一、关键方法 callHook二、详细的钩子函数说明1.beforeCreate和create2.beforeMount & mounted注意点组件(非根组件)的渲染节点(1)invokeInsertHook函数(2)insert方法(3&#…...

[创业之路-222]:波士顿矩阵与GE矩阵在业务组合选中作用、优缺点比较
目录 一、波士顿矩阵 1、基本原理 2、各象限产品的定义及战略对策 3、应用 4、优点与局限性 二、技术成熟度模型与产品生命周期模型的配对 1、技术成熟度模型 2、产品生命周期模型 3、技术成熟度模型与产品生命周期模型的配对 三、产品生命周期与产品类型的对应关系 …...

# 【超全面了解鸿蒙生命周期】-生命周期补充
【超全面了解鸿蒙生命周期】-生命周期补充 鸿蒙所有的生命周期函数梳理 文章目录 【超全面了解鸿蒙生命周期】-生命周期补充前言一、AbilityStage的生命周期二、ExtensionAbility卡片生命周期三、Web组件常用生命周期 前言 本文是继之前写的生命周期函数梳理的进一步补充&…...

sentinel-请求限流、线程隔离、本地回调、熔断
请求限流:控制QPS来达到限流的目的 线程隔离:控制线程数量来达到限流的目录 本地回调:当线程被限流、隔离、熔断之后、就不会发起远程调用、而是使用本地已经准备好的回调去提醒用户 熔断:熔断也叫断路器,当失败、或者…...

unplugin-vue-router 的基本使用
1. 前言 在Vue3开发过程中,每次创建新的页面都需要注册路由,需要在src/router.ts中新增页面的路径,并将URL路径映射到组件中,如下所示: import { createMemoryHistory, createRouter } from vue-routerimport HomePage…...

[Leetcode] 最大子数组和 [击败99%的解法]
解法1: 暴力解法 遍历每个元素,从它当前位置一直加到最后,然后用一个最大值来记录全局最大值。 代码如下: class Solution {public int maxSubArray(int[] nums) {long sum, max nums[len-1];for (int i0; i<nums.length;…...

SSRF服务端请求Gopher伪协议白盒测试
前言 是什么SSRF? 这个简单点说就是 服务端的请求伪造 就是这个如果是个 请求图片的网站 他的目的是请求外部其他网站的 图片 但是 SSRF指的是让他请求本地的图片 再展示出来 请求的是他的服务器上的图片 SSRF(Server-Side Request Forgery:服务器端请求伪造) …...

[2029].第6-06节:MyISAM引擎中的索引与 InnoDB引擎中的索引对比
所有博客大纲 后端学习大纲 MySQL学习大纲 1.MyISAM索引: 1.1.B树索引适用存储引擎: 1.B树索引适用存储引擎如下表所示: 2.即使多个存储引擎都支持同一种类型的B树索引,但它们的实现原理也是不同的 Innodb和MyISAM默认的索引是B…...
:(本地化校准)优化PCSE模型中的参数)
WOFOST作物模型(3):(本地化校准)优化PCSE模型中的参数
目录 一、准备自己的LAI观测数据二、优化参数三、损失函数四、NLOPT优化五、优化结果可视化一、准备自己的LAI观测数据 在进行田间实测后,得到自己的LAI观测数据 在程序这个地方输入自己的LAI采样日期和观测值 二、优化参数 这里主要选择了TDWI(Total Dry Weight at ger…...

如何修改pip全局缓存位置和全局安装包存放路径
使用场景: 在默认情况下,pip 会将安装的包存放在 Python 环境的 site-packages 目录下,会使用到系统盘的内存。 当遇到系统盘的内存很小的时候,需要修改pip的全局缓存位置和全局安装包存放路径,可以极大的节省系统盘内存 详细步骤ÿ…...

ZooKeeper注册中心实现
具体步骤 安装ZooKeeper(启动端口占用,2181:客户端,8080:管理端)引入客户端依赖实现注册中心接口SPI补充ZooKeeper注册中心 引入依赖 <!-- zookeeper --> <dependency><groupId>org.a…...

PyTorch快速入门教程【小土堆】之DataLoader的使用
视频地址DataLoader的使用_哔哩哔哩_bilibili dataset数据集,相当于一副扑克,dataloader数据加载器相当于我们的手,选择摸几张牌,怎么摸牌 import torchvision# 准备的测试数据集 from torch.utils.data import DataLoader from …...

khadas edge2安装ubuntu22.04与ubuntu20.04 docker镜像
khadas edge2安装ubuntu22.04与ubuntu20.04 docker镜像 一、资源准备1.1 镜像文件1.2 刷机工具1.3 ubuntu20.04 docker镜像(具备demon无人机所需各种驱动) 二、开始刷机(安装ubuntu22.04系统)2.1 进入刷机状态2.2 刷机 三、docker…...

大数据面试笔试宝典之Kafka面试
1.Kafka 如何实现高吞吐率 Kafka 如何实现高吞吐率? 参考答案: 1)顺序读写...

新手SEO入门指南如何有效提升网站排名
内容概要 在进行搜索引擎优化(SEO)时,了解基本概念与重要性是首要步骤。SEO不仅仅是提升网站在搜索引擎中排名的手段,它还关乎用户体验和网站内容的质量。随着互联网的发展,越来越多的人意识到优秀的SEO策略能带来持续…...

【Redis】:初识Redis
1.1 盛赞 Redis Redis 是⼀种基于键值对(key-value)的 NoSQL 数据库,与很多键值对数据库不同的是,Redis 中的值可以是由 string(字符串)、hash(哈希)、list(列表…...

C-5 B样条曲线
C-5 B样条曲线 N i , 0 ( u ) { 1 , u i ≤ u < u i 1 0 , o t h e r s N_{i,0}(u)\left\{\begin{matrix} 1 , \quad u_i\le u <u_{i1} \\0 ,\quad others \qquad \quad\end{matrix}\right. Ni,0(u){1,ui≤u<ui10,others N i , p ( u ) u − u i u i p −…...

python安装
python安装 1.下载2.安装3.验证安装成功 1.下载 (1)下载网址:https://www.python.org/downloads/windows/ 进入后稍等一会,比较慢 (2)选择版本 2.安装 (1)双击或者以管理员身份运…...

游戏引擎学习第65天
回顾我们在模拟区域更改方面的进展 目前我们正在进行游戏的架构调整,目标是建立一个引擎架构。我们正在实施的一个关键变化是引入模拟区域的概念,这样我们可以创建非常大的游戏世界,而这些世界的跨度不必受限于单个浮点变量。 通过这种方式…...

代码随想录算法训练营第十六天-二叉树-513.找树左下角的值
左下角不是以为的左下角,而最后一层最左侧的节点也是就是说一个右叶子节点,也可能是最左下角,当然是在其左侧再无其它同级节点看视频讲解使用的递归与回溯方法,自己是完全想不到的,对这道题解法完全是脑袋空空 #inclu…...

力扣第122题:买卖股票的最佳时机 II
力扣第122题:买卖股票的最佳时机 II - C语言解法 题目描述 给定一个数组 prices,其中 prices[i] 是一支股票第 i 天的价格。你可以多次买入和卖出股票,求能够获得的最大利润。 注意: 你不能同时参与多笔交易(即必须…...

【Spring MVC】第一站:Spring MVC介绍配置基本原理
目录 1.引入 2. Java web的发展史 Model I 和Model II 3. MVC模式 4. Spring MVC配置 5. SpringMVC原理 5.1 SpringMVC中心控制器 6. Maven配置 1.引入 $$ Spring与Spring MVC的区别 SSM 包含三部分: Spring MVCSpringMybatis SSM就是升级版的Servlet。 Servlet…...

密钥登录服务器
1. 生成 SSH 密钥对 如果您还没有生成密钥对,可以使用以下命令生成: ssh-keygen 在 root 用户的家目录中生成了一个 .ssh 的隐藏目录,内含两个密钥文件:id_rsa 为私钥,id_rsa.pub 为公钥。 在提示时,您可…...

Java中StopWatch的使用详解
stopWatch 是org.springframework.util 包下的一个工具类,使用它可直观的输出代码执行耗时,以及执行时间百分比。 在未使用这个工具类之前,如果我们需要统计某段代码的耗时,我们会这样写: public static void main(String[] args…...

安全运营 -- splunk restapi 最小权限
0x00 背景 最小化权限原则,为每个功能,每个账户分配最小的权限。 0x01 实践 只需要7个 capability: Youll need to add certain capabilities to that user or that userss role(s).[capability::rest_apps_management] * Lets a user edit settings …...

12. 日常算法
1. 主持人调度(一) 题目来源 class Solution { public:bool hostschedule(vector<vector<int>>& schedule) {// write code heresort(schedule.begin(), schedule.end());int start -1, end 0;for (auto & nums : schedule){end…...
)
运行Zr.Admin项目(后端)
1.下载Zr.Admin代码压缩包 https://codeload.github.com/izhaorui/Zr.Admin.NET/zip/refs/heads/main 2.打开项目 我这里装的是VS2022社区版 进入根目录,双击ZRAdmin.sln打开项目 3.安装.net7运行时 我当时下载的代码版本是.net7的 点击安装 点击安装࿰…...
:美化网页元素)
CSS(二):美化网页元素
目录 字体样式 文本样式 列表样式 背景图片 字体样式 字体相关的 CSS 属性: font-family:设置字体font-size:设置字体大小font-weight:设置字体的粗细(如 normal, bold, lighter 等)color:…...

如何不让场景UI受后处理影响
1)如何不让场景UI受后处理影响 2)Sprite打入SpriteAtlasv2依赖丢失 3)如何为Render Texture模式的videoPlayer生成封面 4)如何排查Shader变体的SRP Batcher兼容性 这是第415篇UWA技术知识分享的推送,精选了UWA社区的热…...

【教程】通过Docker运行AnythingLLM
转载请注明出处:小锋学长生活大爆炸[xfxuezhagn.cn] 如果本文帮助到了你,欢迎[点赞、收藏、关注]哦~ 官方教程:Local Docker Installation ~ AnythingLLM 1、先创建一个目录用于保存anythingllm的持久化文件: sudo mkdir /app su…...

2024/12/29 黄冈师范学院计算机学院网络工程《路由期末复习作业一》
一、选择题 1.某公司为其一些远程小站点预留了网段 172.29.100.0/26,每一个站点有10个IP设备接到网络,下面那个VLSM掩码能够为该需求提供最小数量的主机数目 ( ) A./27 B./28 C./29 D./30 -首先审题我们需要搞清楚站点与网…...
)
LeetCode-整数反转(007)
一.题目描述 给你一个 32 位的有符号整数 x ,返回将 x 中的数字部分反转后的结果。 如果反转后整数超过 32 位的有符号整数的范围 [−231, 231 − 1] ,就返回 0。 假设环境不允许存储 64 位整数(有符号或无符号)。 二.示例 …...

碰一碰发视频矩阵系统源码搭建,支持OEM
一、引言 随着短视频的火爆发展,碰一碰发视频的矩阵系统逐渐受到关注。这种系统能够实现用户通过碰一碰设备(如 NFC 标签)快速触发视频的发布,在营销推广、互动体验等领域有着广泛的应用前景。本文将详细介绍碰一碰发视频矩阵系统…...
)
Linux网络编程3——多线程编程(改良版)
一.多线程 1.什么是线程 要了解线程,首先需要知道进程。一个进程指的是一个正在执行的应用程序。线程对应的英文名称为“thread”,它的功能是执行应用程序中的某个具体任务,比如一段程序、一个函数等。 线程和进程之间的关系,类…...
数组)
LeetCode每日三题(六)数组
一、最大子数组和 自己答案: class Solution {public int maxSubArray(int[] nums) {int begin0;int end0;if(numsnull){//如果数组非空return 0;}else if(nums.length1){//如果数组只有一个元素return nums[0];}//初值选为数组的第一个值int resultnums[0];int i…...

安装了python,环境变量也设置了,但是输入python不报错也没反应是为什么?window的锅!
目录 问题 结论总结 衍生问题 1 第1步:小白python安装,不要埋头一直点下一步!!! 2 第2步:可以选择删了之前的,重新安装python 3 第3步:如果你不想或不能删了重装python&#…...

Vue.js组件开发-使用KeepAlive缓存特定组件
在Vue中,<keep-alive> 组件是一个非常有用的工具,可以用来缓存那些不希望每次切换时都重新渲染的组件。要缓存特定组件,可以使用 <keep-alive> 的 include 和 exclude 属性,这两个属性都接受字符串、正则表达式或数组…...

配置hive支持中文注释
hive元数据metastore默认的字符集是latin1,所以中文注释会乱码。但是不能将metastore库的字符集更改为utf-8,只能对特定表、特定列修改为utf-8。配置hive支持中文注释,主要在两个方面: 1、在Hive元数据存储的Mysql数据库中&#…...

Windows配置IE浏览器不自动跳转到Edge
一:使用 IE 浏览器自身设置(部分情况有效) 打开 IE 浏览器设置:启动 IE 浏览器,点击右上角的 “工具”(齿轮形状)图标,选择 “Internet 选项”。设置启动选项:在 “Inte…...

BGP特性实验
实验拓扑 实验需求及解法 本实验模拟大规模BGP网络部署,使用4字节AS号,传递IPv6路由。 预配说明: sysname R1 ospfv3 1router-id 1.1.1.1 # firewall zone Localpriority 15 # interface Serial1/0/0link-protocol pppipv6 enable ipv6 ad…...

【多模态】从零学习多模态——2024学习笔记总结
从零学习多模态——2024学习笔记总结 前言1. preliminary2. Transformer和NLP基础3. 多模态模型原理和架构学习4. 动手实验多模态模型第一步尝试Swift框架使用数据验证 5. 总结 前言 2024快结束啦,半年抽空学了学多模态还挺好玩的,学习和踩坑记录记一下&…...
:语义超越基于令牌的语言建模)
Meta AI 提出大型概念模型(LCMs):语义超越基于令牌的语言建模
在自然语言处理(Natural Language Processing, NLP)的领域,大型语言模型(Large Language Models, LLMs)已经取得了令人瞩目的成就,它们使得文本生成、摘要和问答等应用成为现实。但是,这些模型依…...
(C++))
【优先算法】滑动窗口 --(结合例题讲解解题思路)(C++)
目录 编辑 1.什么是滑动窗口? 2. 滑动窗口例题 2.1 例题1:长度最小的子数组 2.1.1 解题思路 2.1.2 方法一:暴力枚举出所有的子数组的和 2.1.3 方法二:使用 “同向双指针” 也就是滑动窗口来进行优化 2.2 例题2:无重…...

Linux下PostgreSQL-12.0安装部署详细步骤
一、安装环境 postgresql-12.0 CentOS-7.6 注意:确认linux系统可以正常连接网络,因为在后面需要添加依赖包。 二、pg数据库安装包下载 下载地址:PostgreSQL: File Browser 选择要安装的版本进行下载: 三、安装依赖包 在要安…...