kafka学习笔记
kafka消息中间件精讲 - B站动力节点
JDK17在Windows安装及环境变量配置超详细的教程
Windows 多版本java 装多个版本jdk
Windows同时安装多个JDK
jdk17下载与安装教程(win10),超详细
jdk17-archive-downloads
如何在IDEA中配置指定JDK版本?轻松解决!!!
IDEA配置JDK
IDEA 2021.1.3下载和安装(解决IDEA过期问题)
Idea 2021.3 破解 window
IDEA2023隐藏.idea和.iml文件的实现步骤
IDEA为所有项目配置默认的MAVEN
kafka-ui
IDEA CTRL + 鼠标左键 查看引用的类和方法名 失效
Kafka 采用 RoundRobinPartitioner 时仅向偶数分区发送消息
【Kafka】Windows下安装Kafka(图文记录详细步骤)
kafka第一课-Kafka快速实战以及基本原理详解
Kafka第二课-代码实战、参数配置详解、设计原理详解
kafka第三课-可视化工具、生产环境问题总结以及性能优化
kafka官方文档
Kafka 采用 RoundRobinPartitioner 时仅向偶数分区发送消息 _
文章目录
- kafka介绍
- what is kafka
- 谁在使用Kafka
- Kafka的起源
- Kafka名字的由来
- Kafka的发展历程
- Kafka版本迭代演进
- kafka的安装&运行
- Kafka运行环境前置要求
- Kafka运行环境JDK17安装
- Kafka的下载和安装
- Kafka的目录
- 启动运行Kafka
- 使用内置的zookeeper
- 示例
- 使用独立的zookeeper
- Zookeeper的下载和安装
- Zookeeper的配置和启动
- 使用独立的Zookeeper启动Kafka
- 示例
- 使用kraft启动kafka
- 使用Docker启动运行Kafka
- 安装docker
- 使用Docker镜像启动
- kafka基本操作
- 创建主题Topic
- 主题和事件
- 主题的增删改查
- 在主题(Topic)中写入一些事件(Events)
- 从主题(Topic)中读取事件(Events)
- 外部环境连接Kafka
- ==修改kafka配置文件==
- Kafka图形界面连接工具
- Offset Explorer
- CMAK
- EFAK
- Spring Boot集成Kafka开发
- pom.xml
- application.yml
- EventProducer
- KafkaConsumer
- KafkaApplication
- KafkaApplicationTests
- 测试
- Kafka的几个概念
- springboot集成kafka读取最早的消息
- 使用一个新的消费者组ID
- 手动重置Kafka偏移量offset
- 消息消费时偏移量策略的配置
- spring-kafka生产者发送消息
- send(Message<?>)
- send(ProducerRecord<K,V>)
- send(String topic, Integer partition, Long timestamp, K key,V data)
- sendDefault(Integer partition, Long timestamp, K key, V data)
- kafkaTemplate.send(...) 和 kafkaTemplate.sendDefault(...) 的区别
- 获取生产者消息发送结果
- ==阻塞式获取生产者消息发送的结果==
- 非阻塞式获取生产者消息发送的结果
- 生产者发送对象消息
- Kafka的核心概念:Replica副本
- 指定topic的分区和副本
- 生产者发送消息的分区策略
- 默认分配策略测试
- 修改默认的分配策略
- 自定义分区策略
- 生产者发送消息的流程
- 生产者消息拦截器
- 接收生产者发送的消息
- @Payload&@Header&ConsumerRecord
- 接收对象消息
- 消息监听器手动确认消息
- 测试1
- 测试2
- Acknowledgment确认消息
- 测试3
- 测试4
- 指定topic-partition-offset消费消息
- 消费者批量消费消息
- 生产者
- pom.xml
- application.yml
- EventProducer
- User
- JSONUtils
- KafkaApplication
- KafkaApplicationTest
- 消费者
- EventConsumer
- 测试
- 消费消息拦截器
- KafkaConfig
- CustomConsumerInterceptor
- application.yml
- EventConsumer
- EventProducer
- KafkaAppTests
- 测试
- 消息转发
- EventConsumer
- 测试
- 消息消费的分区策略
- RangeAssignor
- KafkaConfig
- EventConsumer
- EventProducer
- KafkaAppTest
- application.yml
- 测试步骤
- RoundRobinAssignor
- KafkaConfig
- EventConsumer
- EventProducer
- application.yml
- 测试步骤
- StickyAssignor
- CooperativeStickyAssignor
- Kafka事件(消息、数据)的存储
- __consumer_offset主题
- Offset详解
- 1、生产者Offset
- 2、消费者Offset
- 测试
- kafka集群
- 基于Zookeeper的集群搭建方式
- 解压3个kafka
- 配置kafka集群
- 启动测试
- SpringBoot项目连接Kafka集群测试
- 基于kraft的集群搭建方式
- 服务器规划
- 步骤
- 解压3个kafka
- 配置config/kraft/server.properties文件
- 启动运行KRaft集群
- SpringBoot项目连接Kafka集群测试
- kafka集群架构分析
- Kafka的一些重要概念再梳理
- ISR副本
- LEO
- HW
- ISR&LEO&HW关系
kafka介绍
what is kafka
官网:https://kafka.apache.org/

超过80%的财富100强公司信任并使用Kafka;
Apache Kafka是一个开源分布式事件流平台,被数千家公司用于高性能数据管道、流分析、数据集成和关键任务应用程序;
谁在使用Kafka

Kafka的起源
kafka最初由LinkedIn(领英:全球最大的面向职场人士的社交网站)设计开发的,是为了解决LinkedIn的数据管道问题,用于LinkedIn网站的活动流数据和运营数据处理工具;
-
活动流数据:页面访问量、被查看页面内容方面的信息以及搜索情况等内容;
-
运营数据:服务器的性能数据(CPU、IO使用率、请求时间、服务日志等数据);
刚开始LinkedIn采用的是ActiveMQ来进行数据交换,大约在2010年前后,那时的ActiveMQ还远远无法满足LinkedIn对数据交换传输的要求,经常由于各种缺陷而导致消息阻塞或者服务无法正常访问,为了解决这个问题,LinkedIn决定研发自己的消息传递系统,当时LinkedIn的首席架构师 jay kreps 便开始组织团队进行消息传递系统的研发;
Kafka名字的由来
由于Kafka的架构师 jay kreps 非常喜欢franz kafka (弗兰茨·卡夫卡)(是奥匈帝国一位使用德语的小说家和短篇犹太人故事家,被评论家们认为是20世纪作家中最具影响力的一位),并且觉得Kafka这个名字很酷,因此把这一款消息传递系统取名为Kafka;
大师门取名字也是根据自己的喜好来取名,在我们看来有可能感觉很随意!
Kafka的发展历程
2010年底,Kafka在Github上开源,初始版本为0.7.0;
2011年7月,因为备受关注,被纳入Apache孵化器项目;
2012年10月,Kafka从Apache孵化器项目毕业,成为Apache顶级项目;
2014年,jay kreps离开LinkedIn,成立confluent公司,此后LinkedIn和confluent成为kafka的核心代码贡献组织,致力于Kafka的版本迭代升级和推广应用;
Kafka版本迭代演进
Kafka前期项目版本似乎有点凌乱,Kafka在1.x之前的版本,是采用4位版本号;
比如:0.8.2.2、0.9.0.1、0.10.0.0…等等;
在1.x之后,kafka 采用 Major.Minor.Patch 三位版本号;
- Major表示大版本,通常是一些重大改变,因此彼此之间功能可能会不兼容;
- Minor表示小版本,通常是一些新功能的增加;
- Patch表示修订版,主要为修复一些重点Bug而发布的版本;
比如:Kafka 2.1.3,大版本就是2,小版本是1,Patch版本为3,是为修复Bug发布的第3个版本;
Kafka总共发布了8个大版本,分别是0.7.x、0.8.x、0.9.x、0.10.x、0.11.x、1.x、2.x 及 3.x 版本,截止目前,最新版本是Kafka 3.7.0,也是最新稳定版本;
kafka的安装&运行
Kafka运行环境前置要求
Kafka是由Scala语言编写而成,Scala运行在Java虚拟机上,并兼容现有的Java程序,因此部署Kakfa的时候,需要先安装JDK环境;

Kafka源码: https://github.com/apache/kafka
Scala官网:https://www.scala-lang.org/
本地环境必须安装了Java 8+;(Java8、Java11、Java17、Java21都可以);
JDK长期支持版:https://www.oracle.com/java/technologies/java-se-support-roadmap.html
Kafka运行环境JDK17安装
1、下载JDK:https://www.oracle.com/java/technologies/downloads/#java17
2、解压缩:tar -zxvf jdk-17_linux-x64_bin.tar.gz -C /usr/local
3、配置JDK环境变量:
修改/etc/profile,添加如下内容。添加后,执行source /etc/profile
export JAVA_HOME=/usr/local/jdk-17.0.7
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/
Kafka的下载和安装
获取Kafka
- 下载最新版本的Kafka:https://kafka.apache.org/downloads
安装Kafka
tar -xzf kafka_2.13-3.7.0.tgz -C /usr/local/cd kafka_2.13-3.7.0
Kafka的目录
bin目录下包含了kafka启动脚本、zookeeper启动脚本;
conf目录下包含了zookeeper的配置文件和kafka的配置文件;
lib目录下包含了kafka所依赖的jar包和zookeeper的jar包;

启动运行Kafka
启动Kafka环境注意:
- 本地环境必须安装了Java 8+;
- Apache Kafka可以使用ZooKeeper或KRaft启动;但只能使用其中一种方式,不能同时使用;
- KRaft:Apache Kafka的内置共识机制,用于取代 Apache ZooKeeper;
Kafka启动使用Zookeeper
1、启动zookeeper:./zookeeper-server-start.sh ../config/zookeeper.properties &
2、启动kafka:./kafka-server-start.sh ../config/server.properties &
3、关闭Kafka:./kafka-server-stop.sh ../config/server.properties
4、关闭zookeeper: ./zookeeper-server-stop.sh ../config/zookeeper.properties
使用内置的zookeeper
启动kafka之前需要先启动zookeeper。
kafka的安装包解压之后,其中的lib包中,已经有了zookeeper的jar,所以可以使用内置的zookeeper的jar包启动kafka。
示例
1、使用如下命令启动zookeeper后,按enter
./zookeeper-server-start.sh ../config/zookeeper.properties &# ./zookeeper-server-start.sh ../config/zookeeper.properties > zk.log 2>&1 &

使用 ps -ef|grep zookeeper 和 netstat -tlnp查看是否启动成功

2、使用如下命令启动kafka,按enter
./kafka-server-start.sh ../config/server.properties &
# ./kafka-server-start.sh ../config/server.properties > kafka.log 2>&1 &

使用 ps -ef|grep kafka 和 netstat -tlnp查看是否启动成功

3、先关闭kafka,再关闭zookeeper,再使用ps -ef|grep zookeeper,ps -ef|grep kafka检查是否关闭成功
# 关闭kafka,按enter
./kafka-server-stop.sh ../config/server.properties# 关闭zookeeper
./zookeeper-server-stop.sh ../config/zookeeper.properties
如果需要连接到此kafka,需要修改kafka的server.properties文件,参考后面的修改kafka配置文件章节
使用独立的zookeeper
Zookeeper的下载和安装
获取Zookeeper
- 下载最新版本的Zookeeper:https://zookeeper.apache.org/
- 安装Zookeeper
tar -xzf apache-zookeeper-3.9.2-bin.tar.gz -C /usr/local/ cd apache-zookeeper-3.9.2-bin
Zookeeper的配置和启动
配置Zookeeper,在zookeeper的解压目录的conf目录下拷贝原来的zoo_sample.cfg文件,并修改名为zoo.cfg
-
cp zoo_sample.cfg zoo.cfg -
zoo.cfg 不需要修改,直接使用即可;
启动Zookeeper,在zookeeper的解压目录的bin目录下之执行
- 启动:
./zkServer.sh start - 关闭:
./zkServer.sh stop
(zookeeper启动默认会占用8080端口,这个可以通过修改配置文件,添加配置:admin.serverPort=9089解决)
使用独立的Zookeeper启动Kafka
1、启动Zookeeper
启动:./zkServer.sh start
2、启动Kafka
启动:./kafka-server-start.sh ../config/server.properties &
示例
1、解压缩apache-zookeeper-3.9.2-bin
tar -zxvf /usr/local/apache-zookeeper-3.9.2-bin.tar.gz -C /usr/local/



2、进入到/usr/local/apache-zookeeper-3.9.2-bin/conf/,将zoo_sample.cfg拷贝为zoo.cfg。如果8080端口被占用了,那么需要在zoo.cfg配置文件中加上admin.serverPort=9089这个配置解决
cp zoo_sample.cfg zoo.cfg
3、进入到/usr/local/apache-zookeeper-3.9.2-bin/bin/,使用如下命令启动zookeeper。
./zkServer.sh start

4、启动kafka
./kafka-server-start.sh ../config/server.properties &
查看下kafka的server.properties配置文件,可以看到kafka连接的zk是本机的2181端口。

使用kraft启动kafka
Kafka启动使用KRaft
1、生成Cluster UUID(集群UUID): ./kafka-storage.sh random-uuid
# 查看kafka-storage.sh的帮助信息
[root@zzhua bin]# ./kafka-storage.sh -h
usage: kafka-storage [-h] {info,format,random-uuid} ...The Kafka storage tool.positional arguments:{info,format,random-uuid}info Get information about the Kafka log directories on this node.format Format the Kafka log directories on this node.random-uuid Print a random UUID.optional arguments:-h, --help show this help message and exit# 生成集群uuid
[root@zzhua bin]# ./kafka-storage.sh random-uuid
NqK7IqvNSietIEznvJDxIg
2、格式化日志目录:./kafka-storage.sh format -t NqK7IqvNSietIEznvJDxIg -c ../config/kraft/server.properties
(这里的集群id是使用上面生成的。如果执行这个命令报错Invalid cluster.id,需要执行 rm -rf /tmp/kraft-combined-logs/*删除/tmp/kraft-combined-logs/下的所有文件,然后再生成集群id,再执行格式化日志目录的命令,并且集群id会写到/tmp/kraft-combined-logs/meta.properties中。)
# 查看./kafka-storage.sh format的帮助信息
# 其中 -t 就表示集群id,
# 其中 -c 就表示使用的配置文件
[root@zzhua bin]# ./kafka-storage.sh format -h
usage: kafka-storage format [-h] --config CONFIG --cluster-id CLUSTER_ID [--add-scram ADD_SCRAM] [--ignore-formatted][--release-version RELEASE_VERSION]optional arguments:-h, --help show this help message and exit--config CONFIG, -c CONFIGThe Kafka configuration file to use.--cluster-id CLUSTER_ID, -t CLUSTER_IDThe cluster ID to use.--add-scram ADD_SCRAM, -S ADD_SCRAMA SCRAM_CREDENTIAL to add to the __cluster_metadata log e.g.'SCRAM-SHA-256=[name=alice,password=alice-secret]''SCRAM-SHA-512=[name=alice,iterations=8192,salt="N3E=",saltedpassword="YCE="]'--ignore-formatted, -g--release-version RELEASE_VERSION, -r RELEASE_VERSIONA KRaft release version to use for the initial metadata version. The minimum is 3.0, the default is3.7-IV4# 查看kafka-storage.sh info命令的帮助信息
[root@zzhua bin]# ./kafka-storage.sh info --help
usage: kafka-storage info [-h] --config CONFIGoptional arguments:-h, --help show this help message and exit--config CONFIG, -c CONFIGThe Kafka configuration file to use.# 查看kafka的日志存储目录,
# 下面的metadata信息其实就是 /tmp/kafka-combined-logs/meta.properties中的内容
[root@zzhua bin]# ./kafka-storage.sh info -c ../config/kraft/server.properties
Found log directory:/tmp/kafka-logs
Found metadata: {broker.id=0, cluster.id=NqK7IqvNSietIEznvJDxIg, version=0}
3、启动Kafka:./kafka-server-start.sh ../config/kraft/server.properties &
# 启动之后,可以使用 netstat -tlnp 看到8857进程id所占用的端口:9092,9093,34645
[root@zzhua bin]# ./kafka-server-start.sh ../config/kraft/server.properties &
[1] 8857
[root@zzhua bin]# [2024-11-08 18:06:40,302] INFO Registered kafka:type=kafka.Log4jController MBean (kafka.utils.Log4jControllerRegistration$)
sh ...
4、关闭Kafka:./kafka-server-stop.sh ../config/kraft/server.properties
使用Docker启动运行Kafka
安装docker
Docker安装:
- 安装前查看系统是否已经安装了Docker:
- yum list installed | grep docker
- 卸载Docker:
- yum remove docker.x86_64 -y
- yum remove docker-client.x86_64 -y
- yum remove docker-common.x86_64 -y
- 安装Docker:
- yum install docker -y
注:这种方式安装的Docker版本比较旧;(查看版本:docker -v)
安装最新版的Docker:
1、yum install yum-utils -y
2、yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
3、yum install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin -y
查看是否安装成功:查看docker版本:docker --version(docker version,docker -v)
Docker启动:
启动:systemctl start docker 或者 service docker start
停止:systemctl stop docker 或者 service docker stop
重启:systemctl restart docker 或者 service docker restart
检查Docker进程的运行状态:systemctl status docker 或者 service docker status
查看docker进程:ps -ef | grep docker
查看docker系统信息:docker info
查看所有的帮助信息:docker --help
查看某个commond命令的帮助信息:docker commond --help
使用Docker镜像启动
1、拉取Kafka镜像:docker pull apache/kafka:3.7.0
2、启动Kafka容器:docker run -p 9092:9092 apache/kafka:3.7.0
查看已安装的镜像:docker images
删除镜像:docker rmi apache/kafka:3.7.0
kafka基本操作
创建主题Topic
主题和事件
使用Kafka之前,第一件事情是必须创建一个主题(Topic)
-
主题(Topic)类似于文件系统中的文件夹;
-
主题(Topic)用于存储
事件(Events)- 事件(Events)也称为记录或消息,比如支付交易、手机地理位置更新、运输订单、物联网设备或医疗设备的传感器测量数据等等都是事件(Events);
事件(Events)被组织和存储在主题(Topic)中- 简单来说,主题(Topic)类似于文件系统中的文件夹,事件(Events)是该文件夹中的文件;
主题的增删改查
创建主题使用:kafka-topics.sh 脚本;(必须要指定 --bootstrap-server 项)
1、不带任何参数会告知该脚本如何使用:./kafka-topics.sh
2、创建主题:./kafka-topics.sh --create --topic quickstart-events --bootstrap-server localhost:9092
3、列出所有的主题:./kafka-topics.sh --list --bootstrap-server localhost:9092
4、删除主题:./kafka-topics.sh --delete --topic quickstart-events --bootstrap-server localhost:9092
5、显示主题详细信息:./kafka-topics.sh --describe --topic quickstart-events --bootstrap-server localhost:9092
6、修改主题信息:./kafka-topics.sh --alter --topic quickstart-events --partitions 5 --bootstrap-server localhost:9092 修改主题的分区数
在主题(Topic)中写入一些事件(Events)
Kafka客户端通过网络与Kafka Brokers进行通信,可以写(或读)主题Topic中的事件Events;
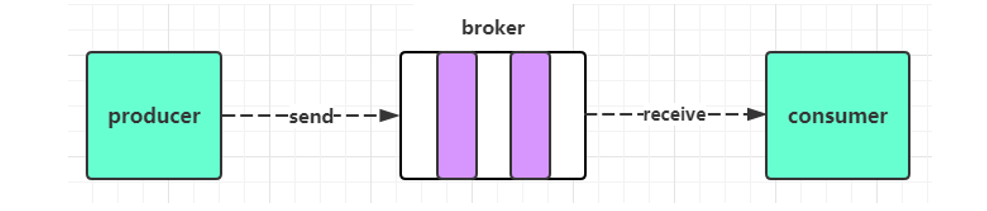
Kafka Brokers一旦收到事件Event,就会将事件Event以持久和容错的方式存储起来,可以永久地存储;
通过 kafka-console-producer.sh 脚本工具写入事件Events;
-
不带任何参数会告知该脚本如何使用:
./kafka-console-producer.sh -
./kafka-console-producer.sh --topic quickstart-events --bootstrap-server localhost:9092 -
每一次换行是一个事件Event;
-
使用Ctrl+C退出,停止发送事件Event到主题Topic;
从主题(Topic)中读取事件(Events)

使用kafka-console-consumer.sh消费者客户端读取之前写入的事件Event:
-
不带任何参数会告知该脚本如何使用:
./kafka-console-consumer.sh -
./kafka-console-consumer.sh --topic quickstart-events --from-beginning --bootstrap-server localhost:9092- –from-beginning 表示从kafka最早的消息开始消费(每次启动消费者都会从最初的那条消息开始消费)
- 不加–from-beginning 表示读取从现在开始发送的消息
-
使用Ctrl+C停止消费者客户端;
事件Events是持久存储在Kafka中的,所以它们可以被任意多次读取;
外部环境连接Kafka
1、启动Kafka容器:docker run -p 9092:9092 apache/kafka:3.7.0
2、安装外部连接工具;
3、外部连接工具连接Kafka;
修改kafka配置文件
我们使用的是官方容器镜像,找到官方镜像文档;https://hub.docker.com/
文档:https://github.com/apache/kafka/blob/trunk/docker/examples/README.md
Docker容器的Kafka有三种配置启动方式:
-
默认配置:使用Kafka容器的默认配置,外部是连不上的;
-
文件输入:提供一个本地kafka属性配置文件,替换docker容器中的默认配置文件;
-
环境变量:通过env变量定义Kafka属性,覆盖默认配置中定义对应该属性的值;
文件输入:提供一个本地kafka属性配置文件,替换docker容器中的默认配置文件;
# 运行镜像, 启动容器
docker run -d -p 9092:9092 --name mykafka apache/kafka:3.7.0# 查看容器
docker ps # 进入kafka容器
# 查看到/etc/kafka/docker/下有server.properties配置文件,还有其它的文件
# 查看到/mnt/shared/config/下没有任何文件或文件夹
docker exec -it mykafka /bin/bash # 把docker容器中的文件复制到linux中:
docker cp bf17abcf35f0:/etc/kafka/docker/server.properties /opt/kafka/## 或者如下面直接输出容器的文件到宿主机
docker run --rm --entrypoint=cat apache/kafka:3.7.0 /etc/kafka/docker/server.properties > /opt/kafka/server.properties
配置文件:server.properties中,Socket Server Settings配置下,作如下修改,允许远程连接
-
listeners=PLAINTEXT://0.0.0.0:9092,CONTROLLER://0.0.0.0:9093(加上0.0.0.0即可,否则会用java.net.InetAddress.getCanonicalHostName()获取主机名) -
advertised.listeners=PLAINTEXT://192.168.11.128:9092- advertise的含义表示宣称的、公布的,Kafka服务对外开放的IP和端口(这里就是linux服务器的ip);
文件映射:docker run -d --volume /opt/kafka/docker:/mnt/shared/config -p 9092:9092 apache/kafka:3.7.0
Kafka图形界面连接工具
Offset Explorer
Offset Explorer (以前叫 Kafka Tool),官网:https://www.kafkatool.com/


CMAK
CMAK(以前叫 Kafka Manager) 官网:https://github.com/yahoo/CMAK
一个web后台管理系统,可以管理kafka;
项目地址: https://github.com/yahoo/CMAK
注意该管控台运行需要JDK11版本的支持;

下载:https://github.com/yahoo/CMAK/releases下载下来是一个zip压缩包,
直接 unzip解压:unzip cmak-3.0.0.6.zip解压后即完成了安装;

基于zookeeper方式启动kafka才可以使用该web管理后台,否则不行;
1、CMAK配置:
修改conf目录下的application.conf配置文件:
-
kafka-manager.zkhosts="192.168.11.128:2181" -
cmak.zkhosts="192.168.11.128:2181"
2、CMAK启动:
切换到bin目录下执行:./cmak -Dconfig.file=../conf/application.conf -java-home /usr/local/jdk-11.0.22
- 其中-Dconfig.file是指定配置文件,-java-home是指定jdk11所在位置,如果机器上已经是jdk11,则不需要指定;
3、CMAK访问:
启动之后CMAK默认端口为9000,访问:http://192.168.11.128:9000/
EFAK
EFAK(以前叫 kafka-eagle) 官网:https://www.kafka-eagle.org/
EFAK一款优秀的开源免费的Kafka集群监控工具;(国人开发并开源)
官网:https://www.kafka-eagle.org/
Github:https://github.com/smartloli/EFAK
EFAK下载与安装:
下载:https://github.com/smartloli/kafka-eagle-bin/archive/v3.0.1.tar.gz
安装,需要解压两次:
1、tar -zxvf kafka-eagle-bin-3.0.1.tar.gz2、cd kafka-eagle-bin-3.0.13、tar -zxvf efak-web-3.0.1-bin.tar.gz4、cd efak-web-3.0.1
EFAK配置
1、安装数据库,需要MySQL,并创建数据库ke;
2、修改配置文件$KE_HOME/conf/system-config.properties
-
主要修改Zookeeper配置和MySQL数据库配置;
cluster1.zk.list=127.0.0.1:2181efak.driver=com.mysql.cj.jdbc.Driver efak.url=jdbc:mysql://127.0.0.1:3306/ke?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull efak.username=root efak.password=123456
3、在/etc/profile文件中配置环境变量KE_HOME,在profile文件的最后添加:
export KE_HOME=/usr/local/efak-web-3.0.1
export PATH=$KE_HOME/bin:$PATH
执行source让环境变量配置生效:source /etc/profile
启动EFAK
1、确保kafka采用zookeeper方式启动;
2、在EFAK安装目录的bin目录下执行:./ke.sh start (命令使用:ke.sh [start|status|stop|restart|stats])
访问EFAK
- http://192.168.11.128:8048/
- 登录账号:admin , 密码:123456

Spring Boot集成Kafka开发
pom.xml
引入依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>3.2.3</version><relativePath/> <!-- lookup parent from repository --></parent><groupId>com.zzhua</groupId><artifactId>kafka-demo-01</artifactId><version>0.0.1-SNAPSHOT</version><name>kafka-demo-01</name><properties><java.version>17</java.version></properties><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId></dependency><!--kafka的依赖,它这个不是starter依赖--><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-devtools</artifactId><scope>runtime</scope><optional>true</optional></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka-test</artifactId><scope>test</scope></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-json</artifactId></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><configuration><excludes><exclude><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></exclude></excludes></configuration></plugin></plugins></build>
</project>
application.yml
配置kafka连接地址
spring:application:#应用名称name: kafka-demo-01#kafka连接地址(ip+port)kafka:bootstrap-servers: 192.168.11.128:9092
EventProducer
@Component
public class EventProducer {// 加入了spring-kafka依赖 + .yml配置信息,// springboot就自动配置好了kafka,自动装配好了KafkaTemplate这个Bean@Resourceprivate KafkaTemplate<String, String> kafkaTemplate;public void sendEvent1(){/* 这里的topic不需要提前创建,这里发送时,如果不存在该主题,会自动创建 */kafkaTemplate.send("hello-topic", "hello kafka");}}
KafkaConsumer
@Component
public class KafkaConsumer {// 采用监听的方式接收事件(消息、数据)/* 必须指定 监听的主题 *//* 当使用@KafkaListener注解时,声明的topic如果不存在会自动创建,自动创建的topic只有1个分区,声明的消费者组也会在kafka中自动创建 */@KafkaListener(topics = {"hello-topic"}, groupId = "hello-group")public void receive(String msg){System.out.println("receive msg: " + msg);}
}
KafkaApplication
@SpringBootApplication
public class KafkaApplication {public static void main(String[] args) {SpringApplication.run(KafkaApplication.class, args);}}
KafkaApplicationTests
@SpringBootTest
public class KafkaApplicationTests {@Autowiredprivate EventProducer eventProducer;@Testvoid sendEvent1() {eventProducer.sendEvent1();}}
测试
使用内置的zookeeper的方式启动kafka(可以参考前面);
在启动kafka前,先修改kafka的server.properties配置文件
listeners=PLAINTEXT://0.0.0.0:9092
advertised.listeners=PLAINTEXT://192.168.134.3:9092
然后,依次启动虚拟机中的,zookeeper和kafka。
./zookeeper-server-start.sh ../config/zookeeper.properties &
./kafka-server-start.sh ../config/server.properties &
先启动KafkaApplication开启消费者,再启动KafkaApplicationTests调用生产者发送消息,可以看到消费者能够消费到生产者发送的这条消息。(在这里,消费者只能监听到消费者启动之后生产者发送的消息)
Kafka的几个概念
1、生产者Producer
2、消费者Consumer
3、主题Topic
4、分区Partition
5、偏移量Offset

1、Kafka中,每个topic可以有一个或多个partition;
2、当创建topic时,如果不指定该topic的partition数量,那么默认就是1个partition;
3、offset是标识每个分区中消息的唯一位置,从0开始;
springboot集成kafka读取最早的消息
默认情况下,当启动一个新的消费者组时,它会从每个分区的最新偏移量(即该分区中最后一条消息的下一个位置)开始消费(而不会消费到历史消息)。如果希望 从第一条消息开始消费,需要将消费者的auto.offset.reset设置为earliest;
-
注意: 如果之前已经用相同的消费者组ID消费过该主题,并且Kafka已经保存了该消费者组的偏移量,那么即使你设置了auto.offset.reset=earliest,该设置也不会生效,因为Kafka只会在找不到偏移量时使用这个配置。在这种情况下,你需要
手动重置偏移量或使用一个新的消费者组ID; -
情况说明:一个新的消费者组启动,这个新的消费者组不会消费到监听主题的历史消息,但是此时kafka也会记录了该消费者组的所监听的主题的消息的当前offset,此时再去设置auto.offset.reset=realiest,然后重启消费者,消费者不会从最早的消息开始消费。因为kafka在新的消费者组启动时已经记录了当前消费者组当前消费消息的offset了。
使用一个新的消费者组ID
1、修改配置文件
spring:application:name: kafka-demo-01kafka:bootstrap-servers: 192.168.134.3:9092consumer:# 添加此配置auto-offset-reset: earliest
2、修改kafkaConsumer
(因为kafka已经记录过了消费者组名hello-group消费的偏移量,所以这里修改为1个新的消费者组名,这样去消费消息的时候,这个消费者组在kafka中没有对应的偏移量,就会使用auto-offset-reset的配置从最早的消息开始消费了)
@Component
public class KafkaConsumer {// 将原来的消费者组名hello-group,改为hello-group-02@KafkaListener(topics = "hello-topic", groupId = "hello-group-02")public void receive(String msg){System.out.println("读取到事件: " + msg);}
}
3、测试

启动应用,此时收到了3条消息
读取到事件: hello kafka
读取到事件: hello kafka
读取到事件: hello kafka
手动重置Kafka偏移量offset
前面hello-group-02消费者组已经消费了3条消息,此时关闭应用,并再次启动应用,将不会从第一条消息开始消费,因为kafka会记录hello-group-02消费者组消费到了哪条消息的偏移量。这时,如果hello-group-02消费者组要从第一条消息开始消费,就要手动重置Kafka偏移量offset
使用方法如下:
# 格式(重置到最早的消息):
./kafka-consumer-groups.sh --bootstrap-server <your-kafka-bootstrap-servers> --group <your-consumer-group> --topic <your-topic> --reset-offsets --to-earliest --execute# 格式(重置到最后消息的下一个位置的消息):
./kafka-consumer-groups.sh --bootstrap-server <your-kafka-bootstrap-servers> --group <your-consumer-group> --topic <your-topic> --reset-offsets --to-latest --execute
首先执行重置命令
# 示例
# (注意,这个命令只能在消费者已关闭的情况下才能执行,否则会报错: Error: Assignments can only be reset if the group 'hello-group-02' is inactive, but the current state is Stable.)
[root@zzhua bin]./kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --group hello-group-02 --topic hello-topic --reset-offsets --to-earliest --executeGROUP TOPIC PARTITION NEW-OFFSET
hello-group-02 hello-topic 0 0
仍然使用修改后的kafkaConsumer代码,重新启动应用,此时hello-group-02消费者又收到了3条消息
读取到事件: hello kafka
读取到事件: hello kafka
读取到事件: hello kafka
消息消费时偏移量策略的配置
spring:application:name: kafka-demo-01kafka:bootstrap-servers: 192.168.134.3:9092consumer:# 可以取值: earliest、latest、noneauto-offset-reset: earliest
取值:earliest、latest、none、exception
earliest:自动将偏移量重置为最早的偏移量;
latest:自动将偏移量重置为最新偏移量;
none:如果没有为消费者组找到以前的偏移量,则向消费者抛出异常;
exception:向消费者抛出异常;(spring-kafka不支持)
spring-kafka生产者发送消息
spring-kafka生产者发送消息:(生产者客户端向kafka的主题topic中写入事件)

send(Message<?>)
@Component
public class EventProducer {@Resourceprivate KafkaTemplate<String, String> kafkaTemplate;public void sendEvent2(){// 通过构建器模式创建Message对象Message<String> message = MessageBuilder// 消息体.withPayload("hello kafka")// 指定topic, 该topic不需要提前创建.setHeader(KafkaHeaders.TOPIC, "test-topic-02").build();kafkaTemplate.send(message);}
}
@SpringBootTest
public class KafkaApplicationTests {@Autowiredprivate EventProducer eventProducer;@Testvoid sendEvent2() {eventProducer.sendEvent2();}}
执行测试后,查看到test-topic-02这个topic创建了,并且有了1个消息

send(ProducerRecord<K,V>)
@Component
public class EventProducer {@Resourceprivate KafkaTemplate<String, String> kafkaTemplate;public void sendEvent3(){// Headers里面是放一些信息(信息是key-value键值对),// 到时候消费者接收到该消息后,可以拿到这个Headers里面放的信息Headers headers = new RecordHeaders();headers.add("phone", "13709090909".getBytes(StandardCharsets.UTF_8));headers.add("orderId", "OD158932723742".getBytes(StandardCharsets.UTF_8));// String topic,// Integer partition,// Long timestamp,// K key,// V value,// Iterable<Header> headersProducerRecord<String, String> record = new ProducerRecord<>("test-topic-02",0,System.currentTimeMillis(),"k1","hello kafka",headers);kafkaTemplate.send(record);}
}
send(String topic, Integer partition, Long timestamp, K key,V data)
@Component
public class EventProducer {@Resourceprivate KafkaTemplate<String, String> kafkaTemplate;public void sendEvent4() {// String topic,// Integer partition, // Long timestamp, // K key, // V datakafkaTemplate.send("test-topic-02", 0, System.currentTimeMillis(), "k2", "hello kafka");}
}
sendDefault(Integer partition, Long timestamp, K key, V data)
配置模板默认的topic
spring:application:name: kafka-demo-01kafka:bootstrap-servers: 192.168.134.3:9092consumer:auto-offset-reset: latesttemplate:# 配置模板默认的主题topic名称default-topic: default-topic
@Component
public class EventProducer {@Resourceprivate KafkaTemplate<String, String> kafkaTemplate;// 在调用sendDefault方法前,需要配置模板默认的topic,否则会报错public void sendEvent5() {//Integer partition, Long timestamp, K key, V datakafkaTemplate.sendDefault(0, System.currentTimeMillis(), "k3", "hello kafka");}
}
kafkaTemplate.send(…) 和 kafkaTemplate.sendDefault(…) 的区别
主要区别是发送消息到Kafka时是否每次都需要指定主题topic;
1、kafkaTemplate.send(…) 该方法需要明确地指定要发送消息的目标主题topic;
2、kafkaTemplate.sendDefault() 该方法不需要指定要发送消息的目标主题topic,
-
kafkaTemplate.send(…) 方法适用于需要根据业务逻辑或外部输入动态确定消息目标topic的场景;
-
kafkaTemplate.sendDefault() 方法适用于总是需要将消息发送到特定默认topic的场景;
-
kafkaTemplate.sendDefault() 是一个便捷方法,它使用配置中指定的默认主题topic来发送消息,如果应用中所有消息都发送到同一个主题时采用该方法非常方便,可以减少代码的重复或满足特定的业务需求;
获取生产者消息发送结果
.send()方法和.sendDefault()方法都返回CompletableFuture<SendResult<K, V>>;
CompletableFuture 是Java 8中引入的一个类,用于异步编程,它表示一个异步计算的结果,这个特性使得调用者不必等待操作完成就能继续执行其他任务,从而提高了应用程序的响应速度和吞吐量;
因为调用 kafkaTemplate.send() 方法发送消息时,Kafka可能需要一些时间来处理该消息(例如:网络延迟、消息序列化、Kafka集群的负载等),如果 send() 方法是同步的,那么发送消息可能会阻塞调用线程,直到消息发送成功或发生错误,这会导致应用程序的性能下降,尤其是在高并发场景下;
使用 CompletableFuture,.send() 方法可以立即返回一个表示异步操作结果的未来对象,而不是等待操作完成,这样,调用线程可以继续执行其他任务,而不必等待消息发送完成。当消息发送完成时(无论是成功还是失败),CompletableFuture会相应地更新其状态,并允许我们通过回调、阻塞等方式来获取操作结果;
方式一:调用CompletableFuture的get()方法,同步阻塞等待发送结果;
方式二:使用 thenAccept(), thenApply(), thenRun() 等方法来注册回调函数,回调函数将在 CompletableFuture 完成时被执行;
阻塞式获取生产者消息发送的结果
@Component
public class EventProducer {@Resourceprivate KafkaTemplate<String, String> kafkaTemplate;public void sendEvent6() {// Integer partition,// Long timestamp,// K key,// V dataCompletableFuture<SendResult<String, String>> completableFuture= kafkaTemplate.sendDefault(0, System.currentTimeMillis(), "k3", "hello kafka");//怎么拿到结果,通过CompletableFuture这个类拿结果,这个类里面有很多方法try {//1、阻塞等待的方式拿结果// (SendResult中属性// ProducerRecord<K, V>// String topic;// Integer partition;// Headers headers;// K key;// V value;// Long timestamp;// RecordMetadata// long offset;// long timestamp;// int serializedKeySize;// int serializedValueSize;// TopicPartition topicPartition;// int hash = 0;// final int partition;// final String topic;// )SendResult<String, String> sendResult = completableFuture.get();// 该属性不为空,证明服务器收到了该消息if (sendResult.getRecordMetadata() != null) {//kafka服务器确认已经接收到了消息System.out.println("消息发送成功: " + sendResult.getRecordMetadata());}System.out.println("producerRecord: " + sendResult.getProducerRecord());} catch (Exception e) {throw new RuntimeException(e);}}
}
非阻塞式获取生产者消息发送的结果
@Component
public class EventProducer {@Resourceprivate KafkaTemplate<String, String> kafkaTemplate;public void sendEvent7() {// Integer partition,// Long timestamp, // K key, // V dataCompletableFuture<SendResult<String, String>> completableFuture= kafkaTemplate.sendDefault(0, System.currentTimeMillis(), "k3", "hello kafka");//怎么拿到结果,通过CompletableFuture这个类拿结果,这个类里面有很多方法try {//2、非阻塞的方式拿结果completableFuture.thenAccept((sendResult) -> {if (sendResult.getRecordMetadata() != null) {//kafka服务器确认已经接收到了消息System.out.println("消息发送成功: " + sendResult.getRecordMetadata());}System.out.println("producerRecord: " + sendResult.getProducerRecord());}).exceptionally((t) -> {t.printStackTrace();//做失败的处理return null;});} catch (Exception e) {throw new RuntimeException(e);}}
}
生产者发送对象消息
发送自定义消息类型,需要指定对应的序列化器
spring:application:name: kafka-demo-01kafka:bootstrap-servers: 192.168.134.3:9092producer:# 配置生产者默认的序列化器, 默认是StringSerializer.class序列化,value-serializer: org.springframework.kafka.support.serializer.JsonSerializer# key默认是StringSerializer.class序列化,key-serializer: org.apache.kafka.common.serialization.StringSerializerconsumer:auto-offset-reset: latesttemplate:# 配置模板默认的主题topic名称default-topic: default-topic
@Builder
@AllArgsConstructor
@NoArgsConstructor
@Data
public class User implements Serializable {private int id;private String phone;private Date birthDay;}
@Component
public class EventProducer {@Resourceprivate KafkaTemplate<String, String> kafkaTemplate;@Resourceprivate KafkaTemplate<String, Object> kafkaTemplate2;@Resourceprivate KafkaTemplate<Object, Object> kafkaTemplate3;public void sendEvent8() {User user = User.builder().id(1208).phone("13709090909").birthDay(new Date()).build();// 分区是null,让kafka自己去决定把消息发到哪个分区kafkaTemplate2.sendDefault(null, System.currentTimeMillis(), "k3", user);kafkaTemplate3.sendDefault(null, System.currentTimeMillis(), "k3", user);}}
Kafka的核心概念:Replica副本
Replica:副本,为实现备份功能,保证集群中的某个节点发生故障时,该节点上的partition数据不丢失,且 Kafka仍然能够继续工作,Kafka提供了副本机制,一个topic的每个分区都有1个或多个副本(其中,1个副本就是本身);
Replica副本分为Leader Replica和Follower Replica:
-
Leader:每个分区多个副本中的“主”副本,生产者发送数据以及消费者消费数据,都是来自leader副本;
-
Follower:每个分区多个副本中的“从”副本,实时从leader副本中同步数据,保持和leader副本数据的同步,leader副本发生故障时,某个follower副本会成为新的leader副本;
设置副本个数不能为0,也不能大于节点个数,否则将不能创建Topic;

指定topic的分区和副本
方式一:通过Kafka提供的命令行工具在创建topic时指定分区和副本;
# 因为当前是单节点部署kafka,所以副本数只能设置为1,不能大于节点个数
./kafka-topics.sh --create --topic myTopic --partitions 3 --replication-factor 1 --bootstrap-server 127.0.0.1:9092
方式二:执行代码时指定分区和副本
第1种:kafkaTemplate.send(“topic”, message);
- 直接使用send()方法发送消息时,kafka会帮我们自动完成topic的创建工作,但这种情况下创建的topic默认只有一个分区,分区有1个副本,也就是有它自己本身的副本,没有额外的副本备份;
第2种:我们可以在项目中新建一个配置类专门用来初始化topic;
当应用启动时,就会在kafka中创建1个名为heToic的主题
( 当应用再次启动时,对原来已存在的heTopic主题没有影响,如果原来的heTopic主题下的分区已有消息,也不会删除heTopic主题下的分区中的消息。)
@Configuration
public class KafkaConfig {@Beanpublic NewTopic newTopic() {// 创建一个名为heTopic的Topic并设置分区数为5,分区副本数为1// 因为我们当前是单节点部署,所以副本数不能超过1,又不能设置为0,所以这里副本数只能设置为1// 如果这里设置为2,会报错:InvalidReplicationFactorException: Replication factor: 2 larger than available brokers: 1.return new NewTopic("heTopic", 3, (short) 1);}
}
如果要修改分区数,只需修改配置值重启项目即可,修改分区数并不会导致数据的丢失,但是分区数只能增大不能减小
@Configuration
public class KafkaConfig {@Beanpublic NewTopic newTopic() {// 创建一个名为heTopic的Topic并设置分区数为5,分区副本数为1return new NewTopic("heTopic", 3, (short) 1);}// 如果要修改分区数,只需修改配置值重启项目即可,修改分区数并不会导致数据的丢失,但是分区数只能增大不能减小// 如果这里不是指定为2,项目启动也不会报错,heTopic主题的分区数也不会修改// 测试时,上面的newTopic可以不注释掉@Beanpublic NewTopic updateTopic() {return new NewTopic("heTopic", 10, (short) 1 );}}
生产者发送消息的分区策略
消息发到哪个分区中?是什么策略
生产者写入消息到topic,Kafka将依据不同的策略将数据分配到不同的分区中;
1、默认分配策略:BuiltInPartitioner
-
有指定消息的key时:Utils.toPositive(Utils.murmur2(serializedKey)) % numPartitions;
(只要key相同,并且该主题下的分区数不变,那么就会发送到该主题下的同一分区;即便key不同也是有可能发送到该主题下的同一分区)
-
没有指定消息的key时:是使用随机数 % numPartitions
2、轮询分配策略:RoundRobinPartitioner (接口:Partitioner)
3、自定义分配策略:我们自己定义;
了解下生产者发送消息的分区策略:
如果(producer)指定了分区,则使用指定的分区;
如果没有指定分区,但是使用了 key,则会基于 key 的 hash 选择一个分区;
如果没有指定分区也没有使用 key,选择当批处理满时改变的粘性分区(这里机翻了,大概意思就是会采用粘性分区策略),粘性分区策略详情查看 KIP-480: Sticky Partitioner
可参考:Kafka 采用 RoundRobinPartitioner 时仅向偶数分区发送消息 _
默认分配策略测试
当不指定分区时,并且始终使用同一key,即k3作为key时,多次执行该方法,发现都发送到了同一分区下。
(如果指定了分区,就直接发往该分区了)
@Component
public class EventProducer {@Resourceprivate KafkaTemplate<String, String> kafkaTemplate;@Resourceprivate KafkaTemplate<String, Object> kafkaTemplate2;@Resourceprivate KafkaTemplate<Object, Object> kafkaTemplate3;public void sendEvent9() {//String topic, Integer partition, Long timestamp, K key, V datakafkaTemplate.send("heTopic", null, System.currentTimeMillis(), "k3", "hello kafka");}}
修改默认的分配策略
@Configuration
public class KafkaConfig {@Resourceprivate KafkaProperties properties;@Beanpublic NewTopic newTopic() {// 创建一个名为heTopic的Topic并设置分区数为10,分区副本数为1return new NewTopic("heTopic", 10, (short) 1);}@Beanpublic DefaultKafkaProducerFactoryCustomizer customizer() {return producerFactory -> {HashMap<String, Object> configs = new HashMap<>();configs.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, RoundRobinPartitioner.class);producerFactory.updateConfigs(configs);};}
}
@Component
public class EventProducer {@Resourceprivate KafkaTemplate<String, String> kafkaTemplate;public void sendEvent8() {for (int i = 0; i < 10; i++) {//String topic, Integer partition, Long timestamp, K key, V datakafkaTemplate.send("heTopic", null, System.currentTimeMillis(), "k3", "hello kafka");}}}
heTopic主题下有10个分区,在这里连续发送10个消息到这个主题下,但是不指定分区,测试结果发现,只有1,3,5,7,9分区有收到数据,其它分区没有收到消息。
自定义分区策略
自定义分区策略实现,实现Partitioner接口
public class CustomerPartitioner implements Partitioner {private AtomicInteger nextPartition = new AtomicInteger(0);@Overridepublic int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);int numPartitions = partitions.size();if (key == null) {// 使用轮询方式选择分区int next = nextPartition.getAndIncrement();if (next >= numPartitions) {nextPartition.compareAndSet(next, 0);}System.out.println("分区值:" + next);return next;} else {// 如果key不为null,则使用默认的分区策略return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;}}@Overridepublic void close() {}@Overridepublic void configure(Map<String, ?> configs) {}
}
修改配置为自定义分区策略实现类
@Configuration
public class KafkaConfig {@Resourceprivate KafkaProperties properties;@Beanpublic NewTopic newTopic() {// 创建一个名为heTopic的Topic并设置分区数为10,分区副本数为1return new NewTopic("heTopic", 10, (short) 1);}@Beanpublic DefaultKafkaProducerFactoryCustomizer customizer() {return producerFactory -> {HashMap<String, Object> configs = new HashMap<>();configs.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, CustomerPartitioner.class);producerFactory.updateConfigs(configs);};}
}
也可以使用配置文件的方式来定义生产者发送消息的分区策略
spring:application:name: kafka-demo-01kafka:bootstrap-servers: 192.168.134.3:9092producer:# 配置生产者默认的序列化器, 默认是StringSerializer.class序列化,value-serializer: org.springframework.kafka.support.serializer.JsonSerializer# key默认是StringSerializer.class序列化,key-serializer: org.apache.kafka.common.serialization.StringSerializerproperties:'partitioner.class': com.zzhua.config.CustomerPartitionerconsumer:auto-offset-reset: latesttemplate:# 配置模板默认的主题topic名称default-topic: default-topic
生产者发送消息的流程

序列化器和分区器在前面已经介绍过了,这里看下拦截器
生产者消息拦截器
拦截器接口定义:
public interface ProducerInterceptor<K, V> extends Configurable, AutoCloseable {ProducerRecord<K, V> onSend(ProducerRecord<K, V> record);void onAcknowledgement(RecordMetadata metadata, Exception exception);void close();
}
在kafka的使用中,有2个地方涉及到拦截器,1个是KafkaTemplate中定义了ProducerInterceptor<K, V> producerInterceptor,另1个是KafkaProducer中定义了ProducerInterceptors<K, V> interceptors这个ProducerInterceptors就是ProducerInterceptor对象的集合。
public class CustomProducerInterceptor implements ProducerInterceptor<String, Object> {/*** 发送消息时,会先调用该方法,对消息进行拦截,可以在拦截中对消息做一些处理,记录日志等等操作*/@Overridepublic ProducerRecord<String, Object> onSend(ProducerRecord record) {System.out.println("拦截消息:" + record.toString());return record;}/*** 服务器收到消息后的一个确认*/@Overridepublic void onAcknowledgement(RecordMetadata metadata, Exception exception) {if (metadata != null) {System.out.println("服务器收到该消息:" + metadata.offset());} else {System.out.println("消息发送失败了,exception = " + exception.getMessage());}}@Overridepublic void close() {}@Overridepublic void configure(Map<String, ?> configs) {}
}
@Configuration
public class KafkaConfig {@Resourceprivate KafkaProperties properties;@Beanpublic NewTopic newTopic() {// 创建一个名为heTopic的Topic并设置分区数为5,分区副本数为1return new NewTopic("heTopic", 10, (short) 1);}@Beanpublic DefaultKafkaProducerFactoryCustomizer customizer() {return producerFactory -> {HashMap<String, Object> configs = new HashMap<>();configs.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,RoundRobinPartitioner.class);// 配置自定义的拦截器configs.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, CustomProducerInterceptor.class.getName());producerFactory.updateConfigs(configs);};}
}也可以如下这样配置生产者消息拦截器
spring:application:name: kafka-demo-01kafka:bootstrap-servers: 192.168.134.3:9092producer:# 配置生产者默认的序列化器, 默认是StringSerializer.class序列化,value-serializer: org.springframework.kafka.support.serializer.JsonSerializer# key默认是StringSerializer.class序列化,key-serializer: org.apache.kafka.common.serialization.StringSerializer# 配置自定义拦截器properties:'interceptor.classes': com.zzhua.config.CustomProducerInterceptorconsumer:auto-offset-reset: latesttemplate:# 配置模板默认的主题topic名称default-topic: default-topic
接收生产者发送的消息
@Payload&@Header&ConsumerRecord
@Payload : 标记该参数是消息体内容
@Header:标记该参数是消息头内容
配置如下
spring:application:name: kafka-demo-02kafka:bootstrap-servers: 192.168.134.3:9092
消息生产者
@Component
public class EventProducer {@Resourceprivate KafkaTemplate<String, String> kafkaTemplate;public void sendEvent() {kafkaTemplate.send("helloTopic", "hello kafka");kafkaTemplate.send("helloTopic", 0, System.currentTimeMillis(), "k1", "hello kafka again");}
}
消息消费者
@Slf4j
@Component
public class EventConsumer {/*1. @Payload接收消息内容2. @Header接收消息头3. @Header中不要写@Header(KafkaHeaders.TOPIC), 其中少了RECEIVED_4. @Header中如果没有对应的值, 需要将required设置为false, 否则接收到消息会因为缺少这个头而报错5. 可以使用ConsumerRecord接收消息所有内容,但是接收不到头信息*/@KafkaListener(topics = "helloTopic", groupId = "helloGroup")public void consumeEvent(@Payload String msg, // 这里也可以不使用@Payload@Header(KafkaHeaders.RECEIVED_TOPIC) String receivedTopic,@Header(KafkaHeaders.RECEIVED_PARTITION) String receivedPartition,@Header(KafkaHeaders.OFFSET) String offset,@Header(KafkaHeaders.RECEIVED_TIMESTAMP) String timestamp,@Header(name = KafkaHeaders.RECEIVED_KEY, required = false) String receivedKey,ConsumerRecord<String, String> consumerRecord) {log.info("---------------收到消息---------------");log.info("消息体: {}", msg);log.info("消息主题: {}", receivedTopic);log.info("消息分区: {}", receivedPartition);log.info("消息偏移量: {}", offset);log.info("消息时间戳: {}", timestamp);log.info("消息key: {}", receivedKey);log.info("消息对象: {}", consumerRecord);consumerRecord.headers().forEach(header -> log.info("消息头: {}", header));}}
先开启消费者应用,然后发送消息,测试结果
---------------收到消息---------------
消息体: hello kafka
消息主题: helloTopic
消息分区: 0
消息偏移量: 27
消息时间戳: 1731203524981
消息key: null
消息对象: ConsumerRecord(topic = helloTopic, partition = 0, leaderEpoch = 0, offset = 27, CreateTime = 1731203524981, serialized key size = -1, serialized value size = 11, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = hello kafka)
---------------收到消息---------------
消息体: hello kafka again
消息主题: helloTopic
消息分区: 0
消息偏移量: 28
消息时间戳: 1731203524995
消息key: k1
消息对象: ConsumerRecord(topic = helloTopic, partition = 0, leaderEpoch = 0, offset = 28, CreateTime = 1731203524995, serialized key size = 2, serialized value size = 17, headers = RecordHeaders(headers = [], isReadOnly = false), key = k1, value = hello kafka again)
接收对象消息
生产者发送对象类型的消息,消费者接收该对象类型的消息,此时需要配置序列化器和反序列化器,并且将对象所在包配置为受信任的包
spring:application:name: kafka-demo-02kafka:bootstrap-servers: 192.168.134.3:9092producer:value-serializer: org.springframework.kafka.support.serializer.JsonSerializerconsumer:value-deserializer: org.springframework.kafka.support.serializer.JsonDeserializerproperties:spring.json.trusted.packages: '*'
生产者
@Component
public class EventProducer {//加入了spring-kafka依赖 + .yml配置信息,springboot自动配置好了kafka,自动装配好了KafkaTemplate这个Bean@Resourceprivate KafkaTemplate<String, String> kafkaTemplate;@Resourceprivate KafkaTemplate<String, Object> kafkaTemplate2;public void sendEvent2() {User user = User.builder().id(1209).phone("13709090909").birthDay(new Date()).build();kafkaTemplate2.send("helloTopic2", user);}
}
消费者
@Slf4j
@Component
public class EventConsumer {@KafkaListener(topics = "helloTopic2", groupId = "helloGroup")public void consumeEvent2(@Payload User user,@Header(name = KafkaHeaders.RECEIVED_TOPIC) String receivedTopic,@Header(KafkaHeaders.RECEIVED_PARTITION) String receivedPartition,@Header(KafkaHeaders.OFFSET) String offset,@Header(KafkaHeaders.RECEIVED_TIMESTAMP) String timestamp,@Header(name = KafkaHeaders.RECEIVED_KEY, required = false) String receivedKey,ConsumerRecord<String, String> consumerRecord) {log.info("---------------收到消息2---------------");log.info("消息体: {}", user);log.info("消息主题: {}", receivedTopic);log.info("消息分区: {}", receivedPartition);log.info("消息偏移量: {}", offset);log.info("消息时间戳: {}", timestamp);log.info("消息key: {}", receivedKey);log.info("消息对象: {}", consumerRecord);}}
测试结果如下,消费者能够正常接收为User对象。
---------------收到消息2---------------
消息体: User(id=1209, phone=13709090909, birthDay=Sun Nov 10 10:19:53 CST 2024)
消息主题: helloTopic2
消息分区: 0
消息偏移量: 5
消息时间戳: 1731205193202
消息key: null
消息对象: ConsumerRecord(topic = helloTopic2, partition = 0, leaderEpoch = 0, offset = 5, CreateTime = 1731205193202, serialized key size = -1, serialized value size = 58, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = User(id=1209, phone=13709090909, birthDay=Sun Nov 10 10:19:53 CST 2024))
所以,最好是定义1个通用的消息对象,将消息封装到这个消息对象中,这样就可以通用了。
也可以在发送对象之前,使用JSONUtils将对象转为json字符串,然后再发过去,消费者接收到消息后,再使用JSONUtils将json字符串反序列化为对象。
public class JSONUtils {private static final ObjectMapper OBJECTMAPPER = new ObjectMapper();public static String toJSON(Object object) {try {return OBJECTMAPPER.writeValueAsString(object);} catch (JsonProcessingException e) {throw new RuntimeException(e);}}public static <T> T toBean(String json, Class<T> clazz) {try {return OBJECTMAPPER.readValue(json, clazz);} catch (JsonProcessingException e) {throw new RuntimeException(e);}}
}
消息监听器手动确认消息
默认情况下,Kafka消费者消费消息后会自动发送确认信息给Kafka服务器,表示消息已经被成功消费。
但在某些场景下,我们希望在消息处理成功后再发送确认,或者在消息处理失败时选择不发送确认,以便Kafka能够重新发送该消息;
测试1
配置文件如下
spring:application:name: kafka-demo-02kafka:bootstrap-servers: 192.168.134.3:9092
生产者
@Component
public class EventProducer {@Resourceprivate KafkaTemplate<String, String> kafkaTemplate;public void sendEvent3() {kafkaTemplate.send("helloTopic3", "halo kafka............");}}
消费者
@Slf4j
@Component
public class EventConsumer {@KafkaListener(topics = "helloTopic3", groupId = "helloGroup")public void consumeEvent2(String msg) {log.info("---------------收到消息2---------------");log.info("消息体: {}", msg);}}
先启动消费者,再启动生产者,这时,消费者能够收到1条消息。
测试2
配置文件如下
spring:application:name: kafka-demo-02kafka:bootstrap-servers: 192.168.134.3:9092
生产者
@Component
public class EventProducer {@Resourceprivate KafkaTemplate<String, String> kafkaTemplate;public void sendEvent4() {kafkaTemplate.send("helloTopic4", "halo kafka............");}}
消费者
@Slf4j
@Component
public class EventConsumer {@KafkaListener(topics = "helloTopic4", groupId = "helloGroup4")public void consumeEvent4(String msg) {log.info("---------------收到消息4---------------");log.info("消息体: {}", msg);// 模拟消费者处理消息发生异常的情况int i = 1/0;}}
先启动消费者,再启动生产者,这时,消费者收到了消息,发生了异常,消费者一共收到了10次消息。此时,关闭消费者,然后再次重启消费者,消费者这时没有再收到这条消息。
Acknowledgment确认消息
在消费者处理消息的方法中,如果要声明Acknowledgment类型参数,需要修改监听器的确认模式为手动spring.kafka.listener.ack-mode=manual,否则,声明Acknowledgment类型参数后,在接收到消息处理时会报错
测试3
配置文件如下
spring:application:name: kafka-demo-02kafka:bootstrap-servers: 192.168.134.3:9092listener:ack-mode: manual
生产者
@Component
public class EventProducer {@Resourceprivate KafkaTemplate<String, String> kafkaTemplate;public void sendEvent4() {int i = new Random().nextInt(500);System.out.println("发送消息:" + i);kafkaTemplate.send("helloTopic4", "halo kafka............" + i);}}
消费者
@Slf4j
@Component
public class EventConsumer {@KafkaListener(topics = "helloTopic4", groupId = "helloGroup4")public void consumeEvent2(String msg, Acknowledgment acknowledgment) {log.info("---------------收到消息4---------------");log.info("消息体: {}", msg);}}
先启动消费者,再启动生产者,这时,消费者收到了213消息,但是没有确认该213消息,然后又收到了该213消息。也就收到了2次,之后,就没有收到该消息了。
此时,关闭消费者,然后再次重启消费者,消费者这时又收到这条213消息。此时,再启动生产者发送1条新的105消息,观察到消费者收到了该105消息后,又由于没有确认该消息,就又收到了之前未确认的213消息和这条未确认的105消息。之后,就没有收到这2条消息了。
此时,再关闭消费者,再次重启消费者,再次收到了1次213消息和1次105消息
此时如下修改消费者,再次启动消费者,再次收到了1次213消息和1次105消息,再次重启消费者,没有再收到这2条消息了,说明这2条消息被确认过了。
@Slf4j
@Component
public class EventConsumer {@KafkaListener(topics = "helloTopic4", groupId = "helloGroup4")public void consumeEvent2(String msg, Acknowledgment acknowledgment) {log.info("---------------收到消息4---------------");log.info("消息体: {}", msg);acknowledgment.acknowledge();}}
上述的测试说明了如果消费者未对消息进行确认,那么kafka会默认再传1次消息过来,如果还未确认,则不会再发该消息了。等消费者重启后,又会把之前未确认的消息发送1次。并且每次接收到新消息时,也会把之前未确认的消息再发送1次。
测试4
配置文件如下
spring:application:name: kafka-demo-02kafka:bootstrap-servers: 192.168.134.3:9092listener:ack-mode: manual
生产者
@Component
public class EventProducer {@Resourceprivate KafkaTemplate<String, String> kafkaTemplate;public void sendEvent4() {int i = new Random().nextInt(500);System.out.println("发送消息:" + i);kafkaTemplate.send("helloTopic4", "halo kafka............" + i);}}
消费者
@Slf4j
@Component
public class EventConsumer {@KafkaListener(topics = "helloTopic4", groupId = "helloGroup4")public void consumeEvent2(String msg, Acknowledgment acknowledgment) {log.info("---------------收到消息4---------------");log.info("消息体: {}", msg);// 这里模拟异常, 所以不可能对这条消息进行确认int i = 1 / 0;acknowledgment.acknowledge();}}
先启动消费者,再启动生产者,消费者收到消息后,在处理消息时发生了异常,之后就一直收到该消息,一共收到了10次,然后就没有收到该消息了。
此时重启消费者,也没有收到该消息。此时,启动生产者再发送1条新消息,这时,消费者没有收到旧消息,而收到了该新消息,由于新消息每次都抛出异常,一共收到了10次新消息,然后就没收到该新消息了,
指定topic-partition-offset消费消息
配置文件
spring:application:name: kafka-demo-02kafka:bootstrap-servers: 192.168.134.3:9092listener:ack-mode: manual
配置类
@Configuration
public class KafkaConfig {@Beanpublic NewTopic newTopic() {return new NewTopic("helloTopic5",5,(short) 1);}}
消费者
@Slf4j
@Component
public class EventConsumer {@KafkaListener(groupId = "helloGroup5",topicPartitions = {// 监听topic的0、1、2号分区,// 同时监听topic的3号分区和4号分区里面offset从3开始的消息@TopicPartition(topic = "helloTopic5", // 6 4 6 6 3partitions = {"0", "1", "2"}, partitionOffsets = {@PartitionOffset(partition = "3", initialOffset = "3"),@PartitionOffset(partition = "4", initialOffset = "3")})})public void onEvent5(String userJSON,@Header(value = KafkaHeaders.RECEIVED_TOPIC) String topic,@Header(value = KafkaHeaders.RECEIVED_PARTITION) String partition,@Header(value = KafkaHeaders.OFFSET) String offset,@Payload ConsumerRecord<String, String> record,Acknowledgment ack) {try {// 收到消息后,处理业务User user = JSONUtils.toBean(userJSON, User.class);System.out.println("读取到的事件5:" + user+ ", topic : " + topic+ ", partition : " + partition+ ", offset: " + offset+ ", offset: " + record.offset());// 业务处理完成,给kafka服务器确认// 手动确认消息,就是告诉kafka服务器,该消息我已经收到了,默认情况下kafka是自动确认ack.acknowledge(); } catch (Exception e) {e.printStackTrace();}}}
生产者
@Component
public class EventProducer {@Resourceprivate KafkaTemplate<String, String> kafkaTemplate;public void sendEvent5() {for (int i = 0; i < 25; i++) { User user = User.builder().id(i).build();String userJSON = JSONUtils.toJSON(user);kafkaTemplate.send("helloTopic5", "k" + i, userJSON);}}}
测试类
@SpringBootTest(classes = KafkaApplication.class)
public class Kafka02ApplicationTests {@Resourceprivate EventProducer eventProducer;@Testvoid test05() {eventProducer.sendEvent5();}}
测试过程:
如果直接使用测试类发送消息,因为消费者正开着,所以刚发完就直接开始消费了,所以为了避免影响,所以先注释掉消费者的注解,先将消息发送到helloTopic5主题的下的5个分区,按分区号顺序依次是:6、4、6、6、3 的消息数量。
然后放开消费者的注释,启动应用,此时开始消费消息,观察到消费者收到了3条消息,如下所示。它们都是3号分区下的,因为默认情况下,对于0,1,2号分区来说,消费者是不会拿历史消息的,而对于4号分区的最大偏移量目前是2,所以不会拿到4号分区的消息。也应注意,其实kafka此时已经记录了helloGroup5消费者组对于0,1,2号分区的最大偏移量。
读取到的事件5:User(id=15), topic : helloTopic5, partition : 3, offset: 3, offset: 3
读取到的事件5:User(id=18), topic : helloTopic5, partition : 3, offset: 4, offset: 4
读取到的事件5:User(id=23), topic : helloTopic5, partition : 3, offset: 5, offset: 5
此时,关闭应用,然后再开启应用,仍然收到同样的消息,如下所示。这说明消息可以再次消费。
读取到的事件5:User(id=15), topic : helloTopic5, partition : 3, offset: 3, offset: 3
读取到的事件5:User(id=18), topic : helloTopic5, partition : 3, offset: 4, offset: 4
读取到的事件5:User(id=23), topic : helloTopic5, partition : 3, offset: 5, offset: 5
此时修改配置文件如下,将偏移量重置为earliest,然后再重启应用。
spring:application:name: kafka-demo-02kafka:bootstrap-servers: 192.168.134.3:9092consumer:auto-offset-reset: earliestlistener:ack-mode: manual
但由于kafka此前已经记录了helloGroup5消费者组对0,1,2号分区的偏移量,所以不会从0,1,2号分区中从最开始的消息拿,这个问题在<springboot集成kafka读取最早的消息>中有说过,所以这里,仍然只收到了同样的3条消息,如下所示:
读取到的事件5:User(id=15), topic : helloTopic5, partition : 3, offset: 3, offset: 3
读取到的事件5:User(id=18), topic : helloTopic5, partition : 3, offset: 4, offset: 4
读取到的事件5:User(id=23), topic : helloTopic5, partition : 3, offset: 5, offset: 5
这里再修改消费者组id为helloGroup55,
@Slf4j
@Component
public class EventConsumer {// 仅修改组id为 helloGroup55@KafkaListener(groupId = "helloGroup55",topicPartitions = {// 监听topic的0、1、2号分区,// 同时监听topic的3号分区和4号分区里面offset从3开始的消息@TopicPartition(topic = "helloTopic5", // 6 4 6 6 3partitions = {"0", "1", "2"}, partitionOffsets = {@PartitionOffset(partition = "3", initialOffset = "3"),@PartitionOffset(partition = "4", initialOffset = "3")})})public void onEvent5(String userJSON,@Header(value = KafkaHeaders.RECEIVED_TOPIC) String topic,@Header(value = KafkaHeaders.RECEIVED_PARTITION) String partition,@Header(value = KafkaHeaders.OFFSET) String offset,@Payload ConsumerRecord<String, String> record,Acknowledgment ack) {try {// 收到消息后,处理业务User user = JSONUtils.toBean(userJSON, User.class);System.out.println("读取到的事件5:" + user+ ", topic : " + topic+ ", partition : " + partition+ ", offset: " + offset+ ", offset: " + record.offset());// 业务处理完成,给kafka服务器确认// 手动确认消息,就是告诉kafka服务器,该消息我已经收到了,默认情况下kafka是自动确认ack.acknowledge(); } catch (Exception e) {e.printStackTrace();}}}
再次启动消费者,这时收到了19条消息,如下。0,1,2号分区 6 + 4 + 6 = 16,再加上3号分区偏移量3,4,5的消息3个,一共19个消息。
读取到的事件5:User(id=0), topic : helloTopic5, partition : 0, offset: 0, offset: 0
读取到的事件5:User(id=4), topic : helloTopic5, partition : 0, offset: 1, offset: 1
读取到的事件5:User(id=6), topic : helloTopic5, partition : 0, offset: 2, offset: 2
读取到的事件5:User(id=8), topic : helloTopic5, partition : 0, offset: 3, offset: 3
读取到的事件5:User(id=11), topic : helloTopic5, partition : 0, offset: 4, offset: 4
读取到的事件5:User(id=24), topic : helloTopic5, partition : 0, offset: 5, offset: 5
读取到的事件5:User(id=3), topic : helloTopic5, partition : 1, offset: 0, offset: 0
读取到的事件5:User(id=16), topic : helloTopic5, partition : 1, offset: 1, offset: 1
读取到的事件5:User(id=17), topic : helloTopic5, partition : 1, offset: 2, offset: 2
读取到的事件5:User(id=20), topic : helloTopic5, partition : 1, offset: 3, offset: 3
读取到的事件5:User(id=1), topic : helloTopic5, partition : 2, offset: 0, offset: 0
读取到的事件5:User(id=13), topic : helloTopic5, partition : 2, offset: 1, offset: 1
读取到的事件5:User(id=14), topic : helloTopic5, partition : 2, offset: 2, offset: 2
读取到的事件5:User(id=19), topic : helloTopic5, partition : 2, offset: 3, offset: 3
读取到的事件5:User(id=21), topic : helloTopic5, partition : 2, offset: 4, offset: 4
读取到的事件5:User(id=22), topic : helloTopic5, partition : 2, offset: 5, offset: 5
读取到的事件5:User(id=15), topic : helloTopic5, partition : 3, offset: 3, offset: 3
读取到的事件5:User(id=18), topic : helloTopic5, partition : 3, offset: 4, offset: 4
读取到的事件5:User(id=23), topic : helloTopic5, partition : 3, offset: 5, offset: 5
消费者批量消费消息
生产者
消息生产者先使用测试类发送125条消息。然后再启动应用开启消费者,按照application.yml中的配置,每次消费20条消息,一共消费了7次。注意把consumer.auto-offset-reset设置为earliest表示从最早的开始消费,并且该配置一定要先配置好了再启动应用开启消费者。否则:消费者会从最新的消息开始消费,以前的消息就收不到了,并且再次修改为这个配置也收不到之前的消息了,如果要收到以前的消息就要修改消费者组id了;
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>3.2.3</version><relativePath/> <!-- lookup parent from repository --></parent><groupId>org.example</groupId><artifactId>kafka-demo03</artifactId><version>1.0-SNAPSHOT</version><properties><maven.compiler.source>17</maven.compiler.source><maven.compiler.target>17</maven.compiler.target></properties><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId></dependency><!--kafka的依赖,它这个不是starter依赖--><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-devtools</artifactId><scope>runtime</scope><optional>true</optional></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka-test</artifactId><scope>test</scope></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-json</artifactId></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><configuration><excludes><exclude><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></exclude></excludes></configuration></plugin></plugins></build></project>
application.yml
spring:application:#应用名称name: kafkaApp#kafka连接地址(ip+port)kafka:bootstrap-servers: 192.168.134.3:9092#配置消息监听器listener:# 设置批量消费,默认是单个消息消费type: batchconsumer:# 批量消费每次最多消费多少条消息max-poll-records: 20auto-offset-reset: earliest
EventProducer
@Component
public class EventProducer {//加入了spring-kafka依赖 + .yml配置信息,springboot自动配置好了kafka,自动装配好了KafkaTemplate这个Bean@Resourceprivate KafkaTemplate<String, String> kafkaTemplate;public void sendEvent() {for (int i = 0; i < 125; i++) {User user = User.builder().id(i).phone("1370909090"+i).birthDay(new Date()).build();String userJSON = JSONUtils.toJSON(user);kafkaTemplate.send("batchTopic", "k" + i, userJSON);}}
}User
@Builder
@AllArgsConstructor
@NoArgsConstructor
@Data
public class User implements Serializable {private int id;private String phone;private Date birthDay;}
JSONUtils
public class JSONUtils {private static final ObjectMapper OBJECTMAPPER = new ObjectMapper();public static String toJSON(Object object) {try {return OBJECTMAPPER.writeValueAsString(object);} catch (JsonProcessingException e) {throw new RuntimeException(e);}}public static <T> T toBean(String json, Class<T> clazz) {try {return OBJECTMAPPER.readValue(json, clazz);} catch (JsonProcessingException e) {throw new RuntimeException(e);}}
}KafkaApplication
@SpringBootApplication
public class KafkaApplication {public static void main(String[] args) {SpringApplication.run(KafkaApplication.class, args);}}
KafkaApplicationTest
@SpringBootTest
class KafkaApplicationTest {@Resourceprivate EventProducer eventProducer;@Testvoid test01() {eventProducer.sendEvent();}
}
消费者
EventConsumer
@Component
public class EventConsumer {@KafkaListener(topics = {"batchTopic"}, groupId = "batchGroup2")public void onEvent(List<ConsumerRecord<String, String>> records) {System.out.println("批量消费,records.size() = " + records.size() + ",records = " + records);}
}
测试
测试结果如下,每次消费了20条,一共消费了7次。
批量消费,records.size() = 20,records = [ConsumerRecord(topic = batchTopic,
批量消费,records.size() = 20,records = [ConsumerRecord(topic = batchTopic,
批量消费,records.size() = 20,records = [ConsumerRecord(topic = batchTopic,
批量消费,records.size() = 20,records = [ConsumerRecord(topic = batchTopic,
批量消费,records.size() = 20,records = [ConsumerRecord(topic = batchTopic,
批量消费,records.size() = 20,records = [ConsumerRecord(topic = batchTopic,
批量消费,records.size() = 5,records = [ConsumerRecord(topic = batchTopic,
消费消息拦截器
启动应用,然后再使用测试类发送1条消息,当消费者指定listenerContainerFactory为自定义KafkaListenerContainerFactory时,才会走自定义的CustomConsumerInterceptor拦截器。
KafkaConfig
@Configuration
public class KafkaConfig {@Value("${spring.kafka.bootstrap-servers}")private String bootstrapServers;@Value("${spring.kafka.consumer.key-deserializer}")private String keyDeserializer;@Value("${spring.kafka.consumer.value-deserializer}")private String valueDeserializer;/*** 消费者相关配置** @return*/public Map<String, Object> producerConfigs() {Map<String, Object> props = new HashMap<>();props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, keyDeserializer);props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, valueDeserializer);//添加一个消费拦截器props.put(ConsumerConfig.INTERCEPTOR_CLASSES_CONFIG, CustomConsumerInterceptor.class.getName());return props;}/*** 消费者创建工厂** @return*/@Beanpublic ConsumerFactory<String, String> ourConsumerFactory() {return new DefaultKafkaConsumerFactory<>(producerConfigs());}/*** 创建监听器容器工厂** @param ourConsumerFactory* @return*/@Beanpublic KafkaListenerContainerFactory<?> ourKafkaListenerContainerFactory(ConsumerFactory<String, String> ourConsumerFactory) {ConcurrentKafkaListenerContainerFactory<String, String> listenerContainerFactory = new ConcurrentKafkaListenerContainerFactory<>();listenerContainerFactory.setConsumerFactory(ourConsumerFactory);return listenerContainerFactory;}
}CustomConsumerInterceptor
/*** 自定义的消费者拦截器**/
public class CustomConsumerInterceptor implements ConsumerInterceptor<String, String> {/*** 在消费消息之前执行** @param records records to be consumed by the client or records returned by the previous interceptors in the list.* @return*/@Overridepublic ConsumerRecords<String, String> onConsume(ConsumerRecords<String, String> records) {System.out.println("onConsumer方法执行:" + records);return records;}/*** 消息拿到之后,提交offset之前执行该方法** @param offsets A map of offsets by partition with associated metadata*/@Overridepublic void onCommit(Map<TopicPartition, OffsetAndMetadata> offsets) {System.out.println("onCommit方法执行:" + offsets);}@Overridepublic void close() {}@Overridepublic void configure(Map<String, ?> configs) {}
}application.yml
spring:application:#应用名称name: kafkaApp#kafka连接地址(ip+port)kafka:bootstrap-servers: 192.168.134.3:9092consumer:key-deserializer: org.apache.kafka.common.serialization.StringDeserializervalue-deserializer: org.apache.kafka.common.serialization.StringDeserializer
EventConsumer
@Component
public class EventConsumer {@KafkaListener(topics = {"intTopic"}, groupId = "intGroup", // 指定 消息监听器容器工厂 为自定义的containerFactory = "ourKafkaListenerContainerFactory")public void onEvent(ConsumerRecord<String, String> record) {System.out.println("消息消费,records = " + record);}
}
EventProducer
@Component
public class EventProducer {//加入了spring-kafka依赖 + .yml配置信息,springboot自动配置好了kafka,自动装配好了KafkaTemplate这个Bean@Resourceprivate KafkaTemplate<String, String> kafkaTemplate;public void sendEvent() {User user = User.builder().id(1028).phone("13709090901").birthDay(new Date()).build();String userJSON = JSONUtils.toJSON(user);kafkaTemplate.send("intTopic", "k", userJSON);}
}
KafkaAppTests
@SpringBootTest
class KafkaAppTests {@Resourceprivate EventProducer eventProducer;@Testvoid testContext() {eventProducer.sendEvent();}
}测试
onConsumer方法执行:org.apache.kafka.clients.consumer.ConsumerRecords@745838af
消息消费,records = ConsumerRecord(topic = intTopic, partition = 0, leaderEpoch = 0, offset = 0, CreateTime = 1732714699912, serialized key size = 1, serialized value size = 58, headers = RecordHeaders(headers = [], isReadOnly = false), key = k, value = {"id":1028,"phone":"13709090901","birthDay":1732714699716})
onCommit方法执行:{intTopic-0=OffsetAndMetadata{offset=1, leaderEpoch=null, metadata=''}}
消息转发
消息转发就是应用A从TopicA接收到消息,经过处理后转发到TopicB,再由应用B监听接收该消息,即一个应用处理完成后将该消息转发至其他应用处理,这在实际开发中,是可能存在这样的需求的;
启动应用,然后再使用测试类发送1条消息到topicA,其中onEventA收到消息处理后,将返回值作为消息发送到topicB,然后onEventB会收到这条消息
EventConsumer
@Component
public class EventConsumer {@KafkaListener(topics = {"topicA"}, groupId = "aGroup")@SendTo(value = "topicB")public String onEventA(ConsumerRecord<String, String> record) {System.out.println("消息A消费,records = " + record);return record.value() + "--forward message";}@KafkaListener(topics = {"topicB"}, groupId = "bGroup")public void onEventB(ConsumerRecord<String, String> record) {System.out.println("消息B消费,records = " + record);}
}测试
消息A消费,records = ConsumerRecord(topic = topicA, partition = 0, leaderEpoch = 0, offset = 0, CreateTime = 1732715783653, serialized key size = 1, serialized value size = 58, headers = RecordHeaders(headers = [], isReadOnly = false), key = k, value = {"id":1028,"phone":"13709090901","birthDay":1732715783556})
...
消息B消费,records = ConsumerRecord(topic = topicB, partition = 0, leaderEpoch = 0, offset = 0, CreateTime = 1732715783722, serialized key size = -1, serialized value size = 75, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = {"id":1028,"phone":"13709090901","birthDay":1732715783556}--forward message)
消息消费的分区策略
Kafka消费消息时的分区策略:是指Kafka主题topic中哪些分区应该由哪些消费者来消费;

Kafka有多种分区分配策略,默认的分区分配策略是RangeAssignor,除了RangeAssignor策略外,Kafka还有其他分区分配策略:RoundRobinAssignor、StickyAssignor、CooperativeStickyAssignor。
这些策略各有特点,可以根据实际的应用场景和需求来选择适合的分区分配策略;

RangeAssignor
Kafka默认的消费分区分配策略:RangeAssignor;
假设如下:
- 一个主题myTopic有10个分区(p0 - p9);
- 一个消费者组内有3个消费者:consumer1、consumer2、consumer3;
RangeAssignor消费分区策略:
1、计算每个消费者应得的分区数:分区总数(10)/ 消费者数量(3)= 3 … 余1;
-
每个消费者理论上应该得到3个分区,但由于有余数1,所以前1个消费者会多得到一个分区;
-
consumer1(作为第一个消费者)将得到 3 + 1 = 4 个分区;
-
consumer2 和 consumer3 将各得到 3 个分区;
2、具体分配:分区编号从0到9,按照编号顺序为消费者分配分区:
-
consumer1 将分配得到分区 0、1、2、3;
-
consumer2 将分配得到分区 4、5、6;
-
consumer3 将分配得到分区 7、8、9;
RangeAssignor策略是根据消费者组内的消费者数量和主题的分区数量,来均匀地为每个消费者分配分区。
下面用代码验证一遍。
KafkaConfig
@Configuration
public class KafkaConfig {@Beanpublic NewTopic newTopic() {return new NewTopic("myTopic", 10, (short)1);}
}EventConsumer
@Component
public class EventConsumer {@KafkaListener(topics = {"myTopic"}, groupId = "myGroup", concurrency = "3")public void onEvent(ConsumerRecord<String, String> record) {System.out.println(Thread.currentThread().getId() + " -->消息消费,records = " + record);}
}
EventProducer
@Component
public class EventProducer {//加入了spring-kafka依赖 + .yml配置信息,springboot自动配置好了kafka,自动装配好了KafkaTemplate这个Bean@Resourceprivate KafkaTemplate<String, String> kafkaTemplate;public void sendEvent() {for (int i = 0; i < 100; i++) {User user = User.builder().id(1028+i).phone("1370909090"+i).birthDay(new Date()).build();String userJSON = JSONUtils.toJSON(user);kafkaTemplate.send("myTopic", "k" + i, userJSON);}}}
KafkaAppTest
@SpringBootTest
class KafkaAppTest {@Resourceprivate EventProducer eventProducer;@Testvoid testContext() {eventProducer.sendEvent();}
}application.yml
spring:application:#应用名称name: kafkaApp#kafka连接地址(ip+port)kafka:bootstrap-servers: 192.168.134.3:9092consumer:key-deserializer: org.apache.kafka.common.serialization.StringDeserializervalue-deserializer: org.apache.kafka.common.serialization.StringDeserializerauto-offset-reset: earliest
测试步骤
修改消费者注解,设置concurrency为3
测试步骤:在代码中声明了myTopic主题,它有10个分区。先不开启消费者,先调用KafkaAppTest的测试方法发送100条消息到myTopic中。然后开启消费者,启动应用,查看这3个线程消费的消息的分区分配情况。
统计如下:
35(0,1,2,3)-41 /* 35号线程 消费了分区0,1,2,3 总共41条消息 */
37(4,5,6)-33 /* 37号线程 消费了分区4,5,6 总共33条消息 */
39(7,8,9)-26 /* 39号线程 消费了分区7,8,9 总共26条消息 */
结果如下:
39 -->消息消费,records = ConsumerRecord(topic = myTopic, partition = 7,
35 -->消息消费,records = ConsumerRecord(topic = myTopic, partition = 0,
37 -->消息消费,records = ConsumerRecord(topic = myTopic, partition = 4,
39 -->消息消费,records = ConsumerRecord(topic = myTopic, partition = 7,
35 -->消息消费,records = ConsumerRecord(topic = myTopic, partition = 0,
39 -->消息消费,records = ConsumerRecord(topic = myTopic, partition = 7,
37 -->消息消费,records = ConsumerRecord(topic = myTopic, partition = 4,
39 -->消息消费,records = ConsumerRecord(topic = myTopic, partition = 7,
...
...
35 -->消息消费,records = ConsumerRecord(topic = myTopic, partition = 2,
35 -->消息消费,records = ConsumerRecord(topic = myTopic, partition = 2,
35 -->消息消费,records = ConsumerRecord(topic = myTopic, partition = 2,
35 -->消息消费,records = ConsumerRecord(topic = myTopic, partition = 2,
接着,再发100条消息到myTopic,查看消费情况
统计如下
35(0,1,2,3)-41 /* 35号线程 消费了分区0,1,2,3 总共41条消息 */
37(4,5,6,7)-43 /* 37号线程 消费了分区4,5,6,7 总共43条消息 */
39(8,9)-26 /* 39号线程 消费了分区8,9 总共16条消息 */
RoundRobinAssignor
测试该分区策略。
KafkaConfig
@Configuration
public class KafkaConfig {@Value("${spring.kafka.bootstrap-servers}")private String bootstrapServers;@Value("${spring.kafka.consumer.key-deserializer}")private String keyDeserializer;@Value("${spring.kafka.consumer.value-deserializer}")private String valueDeserializer;@Value("${spring.kafka.consumer.auto-offset-reset}")private String autoOffsetReset;/*** 消费者相关配置** @return*/public Map<String, Object> producerConfigs() {Map<String, Object> props = new HashMap<>();props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, keyDeserializer);props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, valueDeserializer);props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, autoOffsetReset);//指定使用轮询的消息消费分区器props.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG, RoundRobinAssignor.class.getName());return props;}/*** 消费者创建工厂** @return*/@Beanpublic ConsumerFactory<String, String> ourConsumerFactory() {return new DefaultKafkaConsumerFactory<>(producerConfigs());}/*** 创建监听器容器工厂** @param ourConsumerFactory* @return*/@Beanpublic KafkaListenerContainerFactory<?> ourKafkaListenerContainerFactory(ConsumerFactory<String, String> ourConsumerFactory) {ConcurrentKafkaListenerContainerFactory<String, String> listenerContainerFactory = new ConcurrentKafkaListenerContainerFactory<>();listenerContainerFactory.setConsumerFactory(ourConsumerFactory);return listenerContainerFactory;}@Beanpublic NewTopic newTopic() {return new NewTopic("roundTopic", 10, (short) 1);}}EventConsumer
@Component
public class EventConsumer {@KafkaListener(topics = {"roundTopic"}, groupId = "roundGroup", concurrency = "3", containerFactory = "ourKafkaListenerContainerFactory")public void onEvent(ConsumerRecord<String, String> record) {System.out.println(Thread.currentThread().getId() + " -->消息消费,records = " + record);}
}EventProducer
@Component
public class EventProducer {//加入了spring-kafka依赖 + .yml配置信息,springboot自动配置好了kafka,自动装配好了KafkaTemplate这个Bean@Resourceprivate KafkaTemplate<String, String> kafkaTemplate;public void sendEvent() {for (int i = 0; i < 100; i++) {User user = User.builder().id(1028+i).phone("1370909090"+i).birthDay(new Date()).build();String userJSON = JSONUtils.toJSON(user);kafkaTemplate.send("roundTopic", "k" + i, userJSON);}}}
application.yml
spring:application:#应用名称name: kafkaApp#kafka连接地址(ip+port)kafka:bootstrap-servers: 192.168.134.3:9092consumer:key-deserializer: org.apache.kafka.common.serialization.StringDeserializervalue-deserializer: org.apache.kafka.common.serialization.StringDeserializerauto-offset-reset: earliest测试步骤
修改分区策略配置,注意还要在消费者的注解中指定为自定义的监听器容器工厂
在代码中声明了roundTopic主题,它有10个分区。先不开启消费者,先调用KafkaAppTest的测试方法发送100条消息到roundTopic中。然后开启消费者,启动应用,查看这3个线程消费的消息的分区分配情况。
统计如下:
35(0,3,6,9)-41 /* 35号线程 消费了分区0,1,2,3 总共41条消息 */
37(1,4,7)-29 /* 37号线程 消费了分区1,4,7 总共29条消息 */
42(2,5,8)-30 /* 42号线程 消费了分区2,5,8 总共30条消息 */
再发100条消息,测试如下
统计如下:
35(0,3,6,9)-41 /* 35号线程 消费了分区0,1,2,3 总共41条消息 */
37(1,4,7)-29 /* 37号线程 消费了分区1,4,7 总共29条消息 */
42(2,5,8)-30 /* 42号线程 消费了分区2,5,8 总共30条消息 */
StickyAssignor
-
尽可能保持消费者与分区之间的分配关系不变,即使消费组的消费者成员发生变化,减少不必要的分区重分配;
-
尽量保持现有的分区分配不变,仅对新加入的消费者或离开的消费者进行分区调整。这样,大多数消费者可以继续消费它们之前消费的分区,只有少数消费者需要处理额外的分区;所以叫“粘性”分配;
CooperativeStickyAssignor
- 与 StickyAssignor 类似,但增加了对协作式重新平衡的支持,即消费者可以在它离开消费者组之前通知协调器,以便协调器可以预先计划分区迁移,而不是在消费者突然离开时立即进行分区重分配;
Kafka事件(消息、数据)的存储
kafka的所有事件(消息、数据)都存储在/tmp/kafka-logs目录中,可通过server.properties配置文件中的log.dirs=/tmp/kafka-logs配置;
Kafka的所有事件(消息、数据)都是以日志文件的方式来保存;
Kafka一般都是海量的消息数据,为了避免日志文件过大,日志文件被存放在多个日志目录下,日志目录的命名规则为:<topic_name>-<partition_id>;

比如创建一个名为 firstTopic 的 topic,其中有 3 个 partition,那么在 kafka 的数据目录(/tmp/kafka-log)中就有 3 个目录,firstTopic-0、firstTopic-1、firstTopic-2;
- 00000000000000000000.index 消息索引文件(为了提高消息的查找效率)
- 00000000000000000000.log 消息数据文件
- 00000000000000000000.timeindex 消息的时间戳索引文件(根据时间戳提高消息的查找效率)
- 00000000000000000006.snapshot 快照文件,生产者发生故障或重启时能够恢复并继续之前的操作
- leader-epoch-checkpoint 记录每个分区当前领导者的epoch以及领导者开始写入消息时的起始偏移量
- partition.metadata 存储关于特定分区的元数据(metadata)信息
__consumer_offset主题
-
默认在/tmp/kafka-logs文件夹中,也有50个
__consumer_offset-<partition_id>文件夹,这些文件夹是kafka默认创建的主题,默认一共有50个分区; -
每次消费一个消息并且提交以后,会保存当前消费到的最近的一个offset;
-
在kafka中,有一个
__consumer_offsets的topic, 消费者消费提交的offset信息会写入到 该topic中,__consumer_offsets保存了每个consumer group某一时刻提交的offset信息,__consumer_offsets默认有50个分区; -
consumer_group 保存在哪个分区中的计算公式:
Math.abs("groupid".hashCode())%groupMetadataTopicPartitionCount;

Offset详解
1、生产者Offset
生产者发送一条消息到Kafka的broker的某个topic下某个partition中;
Kafka内部会为每条消息分配一个唯一的offset,该offset就是该消息在partition中的位置;

2、消费者Offset
消费者offset是消费者需要知道自己已经读取到哪个位置了,接下来需要从哪个位置开始继续读取消息;
每个消费者组(Consumer Group)中的消费者都会独立地维护自己的offset,当消费者从某个partition读取消息时,它会记录当前读取到的offset,这样,即使消费者崩溃或重启,它也可以从上次读取的位置继续读取,而不会重复读取或遗漏消息;(注意:消费者offset需要消费消息并提交后才记录offset)

1、每个消费者组启动开始监听消息,默认从消息的最新的位置开始监听消息,即把最新的位置作为消费者offset;
- 分区中还没有发送过消息,则最新的位置就是0;
- 分区中已经发送过消息,则最新的位置就是生产者offset的下一个位置;
2、消费者消费消息后,如果不提交确认(ack),则offset不更新,提交了才更新;
命令行命令:./kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --group osGroup --describe
结论:消费者从什么位置开始消费,就看消费者的offset是多少,消费者offset是多少,它启动后,可以通过上面的命令查看;
测试
消费者
@Component
public class EventConsumer {@KafkaListener(topics = {"osTopic"}, groupId = "osGroup")public void onEvent(ConsumerRecord<String, String> record) {System.out.println(Thread.currentThread().getId() + " -->消息消费,records = " + record);}
}
生产者
@Component
public class EventProducer {//加入了spring-kafka依赖 + .yml配置信息,springboot自动配置好了kafka,自动装配好了KafkaTemplate这个Bean@Resourceprivate KafkaTemplate<String, String> kafkaTemplate;public void sendEvent() {for (int i = 0; i < 2; i++) {User user = User.builder().id(1028+i).phone("1370909090"+i).birthDay(new Date()).build();String userJSON = JSONUtils.toJSON(user);kafkaTemplate.send("osTopic", "k" + i, userJSON);}}}
application.yml
spring:application:#应用名称name: kafkaApp#kafka连接地址(ip+port)kafka:bootstrap-servers: 192.168.134.3:9092consumer:key-deserializer: org.apache.kafka.common.serialization.StringDeserializervalue-deserializer: org.apache.kafka.common.serialization.StringDeserializerauto-offset-reset: earliest步骤
先不启用消费者,使用测试类,让生产者发送2条消息到osTopic。然后再启用消费者,启动应用。
使用命令查看,可以看到当前日志记录的LOG-END-OFFSET偏移量是2,消费者的偏移量CURRENT-OFFSET也是2,说明这2条消息被消费者消费了,并且记录了osGroup消费者组消费的偏移量。
./kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --group osGroup --describe

关闭应用,使用测试类,让生产者再发送2条消息到osTopic。使用命令查看,可以看到当前日志记录的LOG-END-OFFSET偏移量是4,消费者的偏移量CURRENT-OFFSET还是2,因为没有消费。并且LAG为2,表示2条消息等待osGroup消费。

kafka集群
基于Zookeeper的集群搭建方式
1、kafka是一个压缩包,直接解压即可使用,所以我们就解压三个kafka;
2、配置kafka集群:server.properties (参见后面的ppt配置)
3、集群启动并测试;
解压3个kafka
# 将kafka_2.13-3.7.0.tgz解压到/usr/local目录下;
tar -zxvf /root/kafka_2.13-3.7.0.tgz -C ./# 复制3份
cp -rf kafka_2.13-3.7.0 kafka-01
cp -rf kafka_2.13-3.7.0 kafka-02
cp -rf kafka_2.13-3.7.0 kafka-03
配置kafka集群
修改kafka配置文件:server.properties
(1)三台分别配置为:broker.id=1、broker.id=2、broker.id=3
该配置项是每个broker的唯一id,取值在0~255之间;
(2)三台分别配置listener=PAINTEXT:IP:PORT
listeners=PLAINTEXT://0.0.0.0:9091
listeners=PLAINTEXT://0.0.0.0:9092
listeners=PLAINTEXT://0.0.0.0:9093
三台分别配置advertised.listeners=PAINTEXT:IP:PORT
advertised.listeners=PLAINTEXT://192.168.134.3:9091
advertised.listeners=PLAINTEXT://192.168.134.3:9092
advertised.listeners=PLAINTEXT://192.168.134.3:9093
(3)配置日志目录
log.dirs=/tmp/kafka-logs-9091
log.dirs=/tmp/kafka-logs-9092
log.dirs=/tmp/kafka-logs-9093
这是极为重要的配置项,kafka所有数据就是写入这个目录下的磁盘文件中的;
(4)配置zookeeper连接地址:zookeeper.connect=localhost:2181
如果zookeeper是集群,则:zookeeper.connect=localhost:2181,localhost:2182,localhost:2183
按如下,分别依次修改/usr/local/kafka-0{x}/config/server.properties配置文件

zookeeper.connect默认就是localhost:2181,所以保持不动
启动测试
启动Zookeeper,切换到bin目录:./zkServer.sh start
启动三个Kafka,切换到bin目录:./kafka-server-start.sh ../config/server.properties
查看topic详情:./kafka-topics.sh --bootstrap-server 127.0.0.1:9091 --describe --topic clusterTopic(使用代码测试后,可查看topic详情)
启动zookeeper(独立安装的zookeeper)

启动kafka

声明topic后,查看指定topic主题下分区和副本详情

SpringBoot项目连接Kafka集群测试
@Configuration
public class KafkaConfig {@Beanpublic NewTopic newTopic() {//设置副本个数不能为0,也不能大于节点个数,否则将不能创建Topic;return new NewTopic("clusterTopic2", 2, (short)3);}
}
@Component
public class EventConsumer {//@KafkaListener(topics = {"clusterTopic"}, groupId = "clusterGroup2")public void onEvent(ConsumerRecord<String, String> record) {System.out.println(Thread.currentThread().getId() + " -->消息消费,records = " + record);}
}
@Component
public class EventProducer {//加入了spring-kafka依赖 + .yml配置信息,springboot自动配置好了kafka,自动装配好了KafkaTemplate这个Bean@Resourceprivate KafkaTemplate<String, String> kafkaTemplate;public void sendEvent() {for (int i = 0; i < 2; i++) {User user = User.builder().id(1028+i).phone("1370909090"+i).birthDay(new Date()).build();String userJSON = JSONUtils.toJSON(user);kafkaTemplate.send("clusterTopic", "k" + i, userJSON);}}
}
spring:application:#应用名称name: springKafka#kafka连接地址(ip+port)kafka:bootstrap-servers: 192.168.134.3:9091,192.168.134.3:9092,192.168.134.3:9093consumer:key-deserializer: org.apache.kafka.common.serialization.StringDeserializervalue-deserializer: org.apache.kafka.common.serialization.StringDeserializerauto-offset-reset: earliest
先调用生产者,发送消息到clusterTopic,此时查看:

然后,再开启消费者,启动应用,这两条消息被消费了,说明集群没有问题。
基于kraft的集群搭建方式

即:使用kraft方式下的kafka集群,有些节点既充当Controller节点,也充当broker节点,以替代zookeeper。
服务器规划

这里采用3台kafka节点都作为broker和controller节点,3台同时具备控制器和消息处理的功能
步骤
1、准备三个Kafka,Kafka是一个压缩包,直接解压即可使用,所以我们就解压三个Kafka;
2、配置kafka集群:config/kraft/server.properties
3、集群启动并测试
解压3个kafka
# 将kafka_2.13-3.7.0.tgz解压到/usr/local目录下;
tar -zxvf /root/kafka_2.13-3.7.0.tgz -C ./# 复制3份
cp -rf kafka_2.13-3.7.0 kafka-01
cp -rf kafka_2.13-3.7.0 kafka-02
cp -rf kafka_2.13-3.7.0 kafka-03
配置config/kraft/server.properties文件
(1) 三台分别配置各自:
broker.id=1
broker.id=2
broker.id=3
(2) 三台分别都配置节点角色:
process.roles=broker,controller
(3) 三台分别都配置参与投票的节点
controller.quorum.voters=1@192.168.134.3:9081,2@192.168.134.3:9082,3@192.168.134.3:9083
(其中,@前面的数字是brokerId)
(4) 三台配置各自监听本机的ip和端口
listeners=PLAINTEXT://0.0.0.0:9091,CONTROLLER://0.0.0.0:9081
listeners=PLAINTEXT://0.0.0.0:9092,CONTROLLER://0.0.0.0:9082
listeners=PLAINTEXT://0.0.0.0:9093,CONTROLLER://0.0.0.0:9083
(5) 三台配置各自对外开放访问的ip和端口
advertised.listeners=PLAINTEXT://192.168.134.3:9091
advertised.listeners=PLAINTEXT://192.168.134.3:9092
advertised.listeners=PLAINTEXT://192.168.134.3:9093
(6) 三台分别配置各自日志目录
log.dirs=/tmp/kraft-combined-logs-9091
log.dirs=/tmp/kraft-combined-logs-9092
log.dirs=/tmp/kraft-combined-logs-9093
启动运行KRaft集群
1、生成Cluster UUID(集群UUID): ./kafka-storage.sh random-uuid(在任一台kafka的bin目录中执行,得到集群id)
2、格式化日志目录:./kafka-storage.sh format -t L0WpFFvFTYmRurZt_X_6iA -c ../config/kraft/server.properties(3台kafka都要执行这条命令)
3、启动Kafka:./kafka-server-start.sh ../config/kraft/server.properties &(3台kafka都要执行这条命令)
4、关闭Kafka:./kafka-server-stop.sh ../config/kraft/server.properties
SpringBoot项目连接Kafka集群测试
与基于zooeeper的集群搭建方式中整合springboot完全一致。
kafka集群架构分析

图解:1个TopicA主题下有2个分区,每个分区有3个副本(1个主副本 + 2个从副本),其中副本个数不能超过节点个数,最少是1。
多副本的目的就是在主副本所在节点挂掉时,实现故障转移。

1、主副本究竟放在哪个broker中是由kafka内部机制决定的;
2、从副本和主副本不在同一个broker上;
Kafka的一些重要概念再梳理
- 服务器 broker
- 主题 topic
- 事件 Event (message、消息、数据)
- 生产者 producer
- 消费者 consumer
- 消费组 consumer group
- 分区 partition
- 偏移量offset (生产者偏移量,消费者偏移量)
- Replica副本: 分为 Leader Replica 和 Follower Replica;
- ISR副本: 在同步中的副本(ln-Sync Replicas)
- LEO: 日志未端偏移量(Log End Offset)
- HW: 高水位值(High Water mark)
ISR副本
ISR副本:在同步中的副本 (In-Sync Replicas),包含了Leader副本和所有与Leader副本保持同步的Follower副本;
写请求首先由 Leader 副本处理,之后 Follower 副本会从 Leader 上拉取写入的消息,这个过程会有一定的延迟,导致 Follower 副本中保存的消息略少于 Leader 副本,但是只要没有超出阈值都可以容忍,但是如果一个 Follower 副本出现异常,比如宕机、网络断开等原因长时间没有同步到消息,那这个时候,Leader就会把它踢出去,Kafka 通过ISR集合来维护一个“可用且消息量与Leader相差不多的副本集合,它是整个副本集合的一个子集”;
在Kafka中,一个副本要成为ISR(In-Sync Replicas)副本,需要满足一定条件:
1、Leader副本本身就是一个ISR副本;
2、Follower副本最后一条消息的offset与Leader副本的最后一条消息的offset之间的差值不能超过指定的阈值,超过阈值则该Follower副本将会从ISR列表中剔除;
- replica.lag.time.max.ms:默认是30秒;如果该Follower在此时间间隔内一直没有追上过Leader副本的所有消息,则该Follower副本就会被剔除ISR列表;
- replica.lag.max.messages:落后了多少条消息时,该Follower副本就会被剔除ISR列表,该配置参数现在在新版本的Kafka已经过时了;
LEO
LEO:日志末端偏移量 (Log End Offset),记录该副本消息日志(log)中下一条消息的偏移量,注意是下一条消息,也就是说,如果LEO=10,那么表示该副本只保存了偏移量值是[0, 9]的10条消息;
HW
HW:(High Watermark),即高水位值,它代表一个偏移量offset信息,表示消息的复制进度,也就是消息已经成功复制到哪个位置了?即在HW之前的所有消息都已经被成功写入副本中并且可以在所有的副本中找到,因此,消费者可以安全地消费这些已成功复制的消息。
对于同一个副本而言,小于等于HW值的所有消息都被认为是“已备份”的(replicated),消费者只能拉取到这个offset之前的消息,确保了数据的可靠性;

ISR&LEO&HW关系

相关文章:

kafka学习笔记
kafka消息中间件精讲 - B站动力节点 JDK17在Windows安装及环境变量配置超详细的教程 Windows 多版本java 装多个版本jdk Windows同时安装多个JDK jdk17下载与安装教程(win10),超详细 jdk17-archive-downloads 如何在IDEA中配置指定JDK版…...

【保姆级教程】基于OpenCV+Python的人脸识别上课签到系统
【保姆级教程】基于OpenCVPython的人脸识别上课签到系统 一、软件安装及环境配置1. 安装IDE:PyCharm2. 搭建Python的环境3. 新建项目、安装插件、库 二、源文件编写1. 采集人脸.py2. 训练模型.py3. 生成表格.py4. 识别签到.py5. 创建图形界面.py 三、相关函数分析1.…...

LVS能否实现两台服务器的负载均衡
LVS能否实现两台服务器的负载均衡 是的,LVS(Linux Virtual Server)可以实现两台服务器的负载均衡,并且它非常适合这种场景。 LVS(Linux Virtual Server)简介: LVS 是一种基于 Linux 的负载均…...

智能人体安全防护:3D 视觉技术原理、系统架构与代码实现剖析
随着工业化程度的提高,生产安全已成为企业关注的重点。尤其是在一些存在禁区的工业厂区和车间,人员误入或违规进入将带来严重的安全隐患。为了解决这一问题,迈尔微视推出了智能人体安全检测解决方案,为企业提供全方位的人员安全监…...

JAVA后端实现全国区县下拉选择--树形结构
设计图如图: 直接上代码 数据库中的格式: JAVA实体类: Data public class SysAreaZoningDO {private Long districtId;private Long parentId;private String districtName;private List<SysAreaZoningDO> children; } MapperSQL语句…...

DVWA及其他常见网络靶场
常见网络靶场 Metasploitable2 介绍: Metasploitable2 是一个用于安全培训和测试渗透测试工具的虚拟靶机。它故意配置了许多已知的安全漏洞,涵盖了操作系统、网络服务等多个方面。基于 Ubuntu Linux 操作系统构建,包含了如 Apache、MySQL、FT…...

API接口安全:电商数据保护的坚固防线
随着电子商务的蓬勃发展,电商平台的数据安全和隐私保护成为了至关重要的议题。API(应用程序编程接口)作为电商平台与外部系统交互的桥梁,其安全性直接关系到整个平台的数据保护能力。本文将从API接口安全的重要性、面临的安全威胁…...
_kaic)
springboot437校园悬赏任务平台(论文+源码)_kaic
摘 要 使用旧方法对校园悬赏任务平台的信息进行系统化管理已经不再让人们信赖了,把现在的网络信息技术运用在校园悬赏任务平台的管理上面可以解决许多信息管理上面的难题,比如处理数据时间很长,数据存在错误不能及时纠正等问题。这次开发的校…...

可视化报表如何制作?一文详解如何用报表工具开发可视化报表
在如今这个数据驱动的商业时代,众多企业正如火如荼地推进数字化转型,力求在激烈的市场竞争中占据先机。然而,随着业务规模的扩大和运营复杂度的提升,企业的数据量爆炸式增长,传统报表格式单一、信息呈现密集且不易解读…...

STM32 HAL库之SDIO例程 Micro SD卡 - 2
1、硬件图 2、示例代码 根据提示配置SDCLK为72/3 24MHz。 static void MX_SDIO_SD_Init(void) {/* USER CODE BEGIN SDIO_Init 0 */SD_InitTypeDef Init;Init.ClockEdge SDIO_CLOCK_EDGE_RISING;Init.ClockBypass SDIO_CLOCK_BYPASS_DISABLE;Init.ClockPo…...

架构实践02-高性能架构模式
零、文章目录 架构实践02-高性能架构模式 1、 高性能数据库集群:读写分离 (1)引言 背景:随着业务的发展和数据的增长,单个数据库服务器难以满足需求,必须考虑数据库集群。目的:介绍高性能数…...

leetcode-73.矩阵置零-day5
class Solution {public void setZeroes(int[][] mat) {int m mat.length, n mat[0].length;// 1. 扫描「首行」和「首列」记录「首行」和「首列」是否该被置零boolean r0 false, c0 false;for (int i 0; i < m; i) {if (mat[i][0] 0) {r0 true;break;}}for (int j …...

Docker与虚拟机:虚拟化技术的差异解析
在信息技术飞速发展的今天,虚拟化技术已成为现代IT架构不可或缺的一部分。而虚拟化从技术层面划分则分为以下几种: 完全虚拟化:虚拟机能够完全模拟底层硬件的特权指令的执行过程,客户操作系统无须进行修改。 硬件辅助虚拟化&#…...

数据结构——ST表
ST表的定义 ST表,又名稀疏表,是一种基于倍增思想,用于解决可重复贡献问题的数据结构 倍增思想 这里列举一个去寻找一个区间内的最大值的例子 因为每次会将将区间增大一倍,所以才被称之为倍增思想 ,这种思想十分好用…...

flutter命令行直接指定设备
> flutter driver Found 3 connected devices:sdk gphone16k x86 64 (mobile) • emulator-5554 • android-x64 • Android 15 (API 35) (emulator)Linux (desktop) • linux • linux-x64 • Ubuntu 22.04.5 LTS 6.8.0-49-genericChrome (…...

【STM32】RTT-Studio中HAL库开发教程九:FLASH中的OPT
文章目录 一、概要二、内部FLASH排布三、内部FLASH主要特色四、OTP函数介绍五、测试验证 一、概要 STM32系列是一款强大而灵活的微控制器,它的片内Flash存储器可以用来存储有关代码和数据,在实际应用中,我们也需要对这个存储器进行读写操作。…...
)
COLA学习之代码规范(二)
小伙伴们,你们好,我是老寇,上一节,我们学习了DDD相关术语,继续跟老寇学习COLA代码规范 代码规范 包命名 层次包名功能必选Adapter层web处理页面请求Controller否Adapter层wireless处理无线端适配否Adapter层wap处理…...
)
【优选算法】二分算法(在排序数组中查找元素的第一个和最后一个位置,寻找峰值,寻找排序数组中的最小值)
二分算法简介: 提到二分我们可能都会想起二分查找,二分查找要求待查找的数组是有序的,与我们今天讲的二分算法不同,并不是数组元素严格按照有序排列才可以使用二分算法,只要数组中有一个点可以将数组分为两个部分&…...
)
数据结构-排序(来自于王道)
排序的基本概念 插入排序 在这个算法中,除了输入的数组本身,没有使用额外的数据结构来存储数据,所有的操作都是在原数组上进行的。因此,无论输入数组的大小 n 是多少,算法执行过程中所占用的额外空间是固定的ÿ…...

用 Python 实现经典的 2048 游戏:一步步带你打造属于你的小游戏!
用 Python 实现经典的 2048 游戏:一步步带你打造属于你的小游戏!(结尾附完整代码) 简介 2048 是一个简单而又令人上瘾的数字拼图游戏。玩家通过滑动方块使相同数字的方块合并,目标是创造出数字 2048!在这篇…...

《C++:计算机视觉图像识别与目标检测算法优化的利器》
在当今科技飞速发展的时代,计算机视觉领域正经历着前所未有的变革与突破。图像识别和目标检测作为其中的核心技术,广泛应用于安防监控、自动驾驶、智能医疗等众多领域,其重要性不言而喻。而 C语言,凭借其卓越的性能、高效的资源控…...

医学分割数据集白内障严重程度分割数据集labelme格式719张3类别
数据集格式:labelme格式(不包含mask文件,仅仅包含jpg图片和对应的json文件) 图片数量(jpg文件个数):719 标注数量(json文件个数):719 标注类别数:3 标注类别名称:["normal","severe","mi…...
)
VirtIO实现原理之数据结构与数据传输演示(4)
接前一篇文章:VirtIO实现原理之数据结构与数据传输演示(3) 本文内容参考: VirtIO实现原理——vring数据结构-CSDN博客 VirtIO实现原理——数据传输演示-CSDN博客 特此致谢! 一、数据结构总览 2. 相关数据结构 前文书介绍了《Virtual I/O Device (VIRTIO) Version 1.3…...
)
C语言:详解指针最终篇(3)
一.字符指针变量 在指针的类型中我们知道有一种指针类型为字符指针char*。一般我们这样使用: 我们来看另一种使用方式: 这个常量字符串就相当于它本身首字符的地址,收地址加上方括号下标就可以访问该表达式中对应下标的元素。可以把该表达式…...

03篇--二值化与自适应二值化
二值化 定义 何为二值化?顾名思义,就是将图像中的像素值改为只有两种值,黑与白。此为二值化。 二值化操作的图像只能是灰度图,意思就是二值化也是一个二维数组,它与灰度图都属于单信道,仅能表示一种色调…...

Java 小抄|解析 JSON 并提取特定层级数据
文章目录 前言环境准备依赖库 示例代码JSON 数据Java 类定义解析 JSON 数据代码解释 结论 前言 在日常开发中,我们经常需要从 JSON 数据中提取特定的信息。本文将介绍如何使用 Java 和 Gson 库解析 JSON 数据,并通过流式处理提取特定层级的数据。我们将…...

qt 设置系统缩放为150%,导致的文字和界面的问题
1 当我们设置好布局后,在100%的设置里面都是正常的,但是当我们修改缩放为150%后,字体图标,界面大小就出现问题了,这就需要我们设置一些参数。 QCoreApplication::setAttribute(Qt::AA_EnableHighDpiScaling);QCoreAppl…...
)
【echarts】数据过多时可以左右滑动查看(可鼠标可滚动条)
1. 鼠标左右拖动 在和 series 同级的地方配置 dataZoom: dataZoom: [{type: inside, // inside 鼠标左右拖图表,滚轮缩放; slider 使用滑动条start: 0, // 左边的滑块位置,表示从 0 开始显示end: 60, // 右边的滑块位置…...
)
深度学习入门课程学习笔记(第25周)
摘要 本周报的目的在于汇报第25周的学习成果,本周主要聚焦于基于深度学习的目标检测领域算法的总体框架的学习。 在这本周的学习中,内容主要涵盖了目标检测算法的发展历程,包括发展历程和发展阶段,然后纤细说明了目标检测算法的…...

【Python】Matplotlib基本图表绘制
目录 Matplotlib基本图表绘制折线图更多外观外观类型颜色线条样式图例位置使用本地字体 散点图条形图横向条形图 直方图频率分布直方图 Matplotlib基本图表绘制 折线图 from matplotlib import pyplot as plt import matplotlib #字典类型的字体预设,键值对依次…...

【1211更新】腾讯混元Hunyuan3D-1文/图生3D模型云端镜像一键运行
目录 项目介绍 显存占用 11月21 新增纹理烘焙模块Dust3R 烘焙相关参数: AutoDL云端镜像 启动说明 标准模型下载 【1212更新】腾讯混元Hunyuan3D-1文图生3D模型云端镜像一键运行 项目介绍 https://github.com/Tencent/Hunyuan3D-1 腾讯混元 3D 生成模型,支持…...

工业大数据分析算法实战-day05
文章目录 day05分而治之中的MARS算法神经网络逼近能力解释 day05 今天是第5天,昨日从统计分析开始利用统计学的知识判断当前样本的分布以及估计总体的参数和假设检验的情况,以及介绍了线性回归算法的相关优化点,但是毕竟线性回归是线性划分的…...

Go 语言结构
Go 语言结构 Go 语言,也称为 Golang,是一种由 Google 开发和支持的静态类型、编译型编程语言。它于 2009 年首次发布,旨在提高多核处理器、网络资源和大型代码库的性能。Go 语言以其简洁的语法、并发支持和强大的标准库而闻名,特别适合构建高性能的网络服务和分布式系统。…...
)
【Python篇】PyQt5 超详细教程——由入门到精通(序篇)
文章目录 PyQt5 超详细入门级教程前言序篇:1-3部分:PyQt5基础与常用控件第1部分:初识 PyQt5 和安装1.1 什么是 PyQt5?1.2 在 PyCharm 中安装 PyQt51.3 在 PyCharm 中编写第一个 PyQt5 应用程序1.4 代码详细解释1.5 在 PyCharm 中运…...

9_less教程 --[CSS预处理]
LESS(Leaner Style Sheets)是一种CSS预处理器,它扩展了CSS语言,增加了变量、嵌套规则、混合(mixins)、函数等功能,使得样式表的编写更加灵活和易于维护。下面是一些LESS的基础教程内容ÿ…...

macOS:安装第三方软件
基于安全性考虑,Mac 系统通常不允许安装那些从网络上下载下来的第三方软件包。 比如,在打开镜像盘时,报错为“该镜像已损坏,请移至废纸篓”,或者打开软件时提示“XXX 已损坏,打不开。您应该将它移到废纸篓”…...

HTML+CSS+Vue3的静态网页,免费开源,可当作作业使用
拿走请吱一声,点个关注吧,代码如下,网页有移动端适配 HTML <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width…...

昇思25天学习打卡营第33天|共赴算力时代
文章目录 一、平台简介二、深度学习模型2.1 处理数据集2.2 模型训练2.3 加载模型 三、共赴算力时代 一、平台简介 昇思大模型平台,就像是AI学习者和开发者的超级基地,这里不仅提供丰富的项目、模型和大模型体验,还有一大堆经典数据集任你挑。…...

IAR环境下STM32静态库编译及使用
IAR环境下STM32静态库编译及使用 前言 最近了解到了STM32的静态库与动态库,在此记录一下STM32静态库的生成与使用。 静态库的作用主要是对代码进行封装及保护,使其他使用者只知其然而不知其所以然,因为封装后的静态库只有.h文件没有.c文件。…...

前端如何性能优化
前端性能优化是提高网页加载速度和响应速度的重要手段。优化前端性能不仅能提升用户体验,还能提高SEO排名,降低服务器负担,节省带宽等。下面是一些常见的前端性能优化方法: 1. 减少 HTTP 请求 每个页面资源(如图片、…...

【开源】为Stable Diffusion工作流程提供的一个更加灵活易用的Web界面
一个开源项目,旨在为Stable Diffusion工作流程提供一个更加灵活、易用的Web界面。这个项目特别适用于图像生成和编辑,具有以下几个显著特点: 分层和非破坏性编辑:OpenDream支持非破坏性编辑,允许用户在保留原始图像数据…...
)
安全见闻(1)
Target 开阔见闻,不做井底之蛙 Trial 建议 前期小白到中级红队:把python学好 C\C:偏向底层,适合逆向,不适合前期web渗透 编程语言 C语言: 一种通用的、面向过程的编程语言,广泛应用于系统软件和嵌入…...
)
基于32单片机的RS485综合土壤传感器检测土壤PH、氮磷钾的使用(超详细)
1-3为RS485综合土壤传感器的基本内容 4-5为基于STM32F103C8T6单片机使用RS485传感器检测土壤PH、氮磷钾并显示在OLED显示屏的相关配置内容 注意:本篇文件讲解使用的是PH、氮磷钾四合一RS485综合土壤传感器,但里面的讲解内容适配市面上的所有多合一的RS…...

SQL server学习03-创建和管理数据表
目录 一,SQL server的数据类型 1,基本数据类型 2,自定义数据类型 二,使用T-SQL创建表 1,数据完整性的分类 2,约束的类型 3,创建表时创建约束 4,任务 5,由任务编写…...

Windows 系统下 Python 环境安装
一、引言 Python 作为一种广泛应用的编程语言,在数据分析、人工智能等领域发挥着重要作用。本文将详细介绍在 Windows 系统上安装 Python 环境的步骤。 二、安装前准备 系统要求 Windows 7 及以上版本一般都能支持 Python。硬件方面,通常 2GB 内存、几…...

Redis 在Go项目中的集成和统一管理
本节我们在项目中安装和集成 go-redis,让项目能访问Redis,后面实战项目中的用户认证体系会依赖Redis来实现,像Token、Session这些都是在Redis中存储的。 本节大纲如下: Redis的使用场景有不少,不过有一点需要提醒的…...

Hive——HQL数据定义语言
文章目录 Hive HQL数据查询语言更多大数据资源持续更新中。。。学习目标一、HQL数据定义语言(DDL)概述1、DDL语法的作用2、Hive中DDL使用☆ 创建数据库☆ 查询数据库☆ 切换数据库☆ 修改数据库☆ 删除数据库 二、Hive DDL建表基础1、完整建表语法树2、H…...

Python机器视觉的学习
一、二值化 1.1 二值化图 二值化图:就是将图像中的像素改成只有两种值,其操作的图像必须是灰度图。 1.2 阈值法 阈值法(Thresholding)是一种图像分割技术,旨在根据像素的灰度值或颜色值将图像分成不同的区域。该方法…...

使用navicat新旧版本,连接PostgreSQL高版本报错问题图文解决办法
使用navicat新旧版本,连接PostgreSQL高版本报错问题图文解决办法 一、问题现象:二、出现原因三、解决方法:1、升级Navicat版本:2、使用低版本的postgreSQL:3、修改Navicat的dll二进制文件:navicat版本15nav…...

秒杀抢购场景下实战JVM级别锁与分布式锁
背景历史 在电商系统中,秒杀抢购活动是一种常见的营销手段。它通过设定极低的价格和有限的商品数量,吸引大量用户在特定时间点抢购,从而迅速增加销量、提升品牌曝光度和用户活跃度。然而,这种活动也对系统的性能和稳定性提出了极…...