第3周作业-1层隐藏层的神经网络分类二维数据
文章目录
- ***1层隐藏层的神经网络分类二维数据***¶
- 1. 导入包¶
- 2. 数据集¶
- 2.1 导入数据集¶
- 2.2 查看数据集图案¶
- 2.3 查看数据集维度¶
- 3. Logistic回归¶
- 3.1 Logistic回归简介¶
- 3.2 Logistic回归模型¶
- 3.3 绘制边界¶
- 4. 神经网络模型¶
- 4.1 神经网络简介¶
- 4.2 神经网络数学模型¶
- 4.3 建立神经网络方法¶
- 4.4 定义神经网络结构¶
- 4.5 初始化模型的参数¶
- 4.6 循环¶
- 4.6.1 前向传播¶
- 4.6.2 计算成本¶
- 4.6.3 后向传播¶
- 4.6.4 更新参数¶
- 4.7 整合¶
- 4.8 预测¶
- 5. 正式运行¶
- 5.1 构建训练模型¶
- 5.2 绘制决策边界¶
- 5.3 打印准确率¶
- 5.4 调节隐藏层节点数量¶
1层隐藏层的神经网络分类二维数据¶
1. 导入包¶
① numpy是Python科学计算的基本包。
② sklearn提供了用于数据挖掘和分析的简单有效的工具。
③ matplotlib是在Python中常用的绘制图形的库。
④ testCases提供了一些测试示例用以评估函数的正确性。
⑤ planar_utils提供了此作业中使用的各种函数。
In [2]:
import sys
import numpy
import matplotlib
import sklearn #安装 pip install scikit-learn
print(sys.version) # 打印 python 版本号
print(numpy.__version__) # 打印 numpy 包 版本号
print(matplotlib.__version__) # 打印 matplotlib 包 版本号
print(sklearn.__version__) # 打印 h5py 包 版本号3.12.4 (tags/v3.12.4:8e8a4ba, Jun 6 2024, 19:30:16) [MSC v.1940 64 bit (AMD64)]
2.2.3
3.10.1
1.6.1需要的文件
需要的testCases.py和planar_utils.py文件下载链接:
下载:https://wwyy.lanzouu.com/iekB72wste9a 密码:htp0
In [128]:
# Package imports
import numpy as np
import matplotlib.pyplot as plt
from testCases import *
import sklearn
import sklearn.datasets
import sklearn.linear_model
from planar_utils import plot_decision_boundary, sigmoid, load_planar_dataset, load_extra_datasets%matplotlib inline# 设置一个固定的随机种子,以保证接下来的步骤中我们的结果是一致的。
np.random.seed(1) 2. 数据集¶
2.1 导入数据集¶
① 首先,让我们获取要使用的数据集。
② 以下代码会将花的图案的2类数据集加载到变量X和Y中。
In [129]:
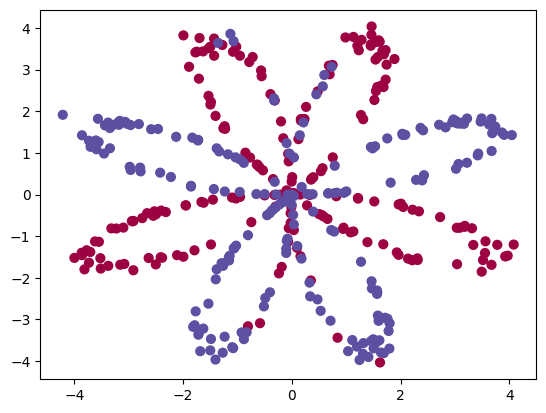
X, Y = load_planar_dataset() 2.2 查看数据集图案¶
① 把数据集加载完成了,然后使用matplotlib可视化数据集。
② 数据看起来像一朵由红色(y = 0)和蓝色(y = 1)的数据点组成的花朵图案。
③ 我们的目标是建立一个适合该数据的分类模型。
In [130]:
# 绘制散点图
plt.scatter(X[0, :], X[1, :], c=Y.reshape(X[0,:].shape), s=40, cmap=plt.cm.Spectral) Out[130]:
<matplotlib.collections.PathCollection at 0x24af4ea8ce0>
2.3 查看数据集维度¶
① 现在,我们已经有了以下的东西:
- X:一个numpy的矩阵,包含了这些数据点的数值
- Y:一个numpy的向量,对应着的是X的标签【0 | 1】(红色:0 , 蓝色 :1)
② 我们继续来仔细地看数据。
In [131]:
shape_X = X.shape
shape_Y = Y.shape
m = shape_X[1] # 训练集里面的数量print ('X的维度为: ' + str(shape_X))
print ('Y的维度为: ' + str(shape_Y))
print ("数据集里面的数据有:" + str(m) + " 个")X的维度为: (2, 400)
Y的维度为: (1, 400)
数据集里面的数据有:400 个3. Logistic回归¶
3.1 Logistic回归简介¶
① 在构建完整的神经网络之前,先让我们看看逻辑回归在这个问题上的表现如何。
② 我们可以使用sklearn的内置函数来做到这一点, 运行下面的代码来训练数据集上的逻辑回归分类器。
3.2 Logistic回归模型¶
In [133]:
# Train the logistic regression classifier
clf = sklearn.linear_model.LogisticRegressionCV();
# clf.fit(X.T, Y.T); #这个会报错
clf.fit(X.T, Y.T.ravel()); # 或 Y.T.flatten()代码解释:
sklearn.linear_model.LogisticRegressionCV()
- 这是 scikit-learn 库中用于逻辑回归的类,带有交叉验证功能。
- LogisticRegressionCV 是逻辑回归分类器的实现,它会通过交叉验证自动选择最佳的正则化参数(如 L1 或 L2 正则化)。
- clf 是这个分类器的实例。
clf.fit(X.T, Y.T.ravel())
- clf.fit 是逻辑回归分类器的训练方法,用于拟合模型。
- X.T 和 Y.T 是数据矩阵 X 和目标向量 Y 的转置。
- Y.T.ravel() 是对 Y.T 进行处理,将其从列向量(二维数组)转换为一维数组。
3.3 绘制边界¶
① 现在,你可以运行下面的代码以绘制此模型的决策边界:
相关知识
1. NumPy 的形状问题
- Y 和 LR_predictions 的形状必须是一致的,并且是一维数组(形状为 (n_samples,))。
- 如果 Y 是一个二维数组(形状为 (n_samples, 1)),需要将其转换为一维数组。
2. 计算准确性的公式
准确性公式是:
KaTeX parse error: Undefined control sequence: \* at position 35: …确预测的数量}{总样本数量} \̲*̲100\%
在代码中,np.dot(Y, LR_predictions) 和 np.dot(1 - Y, 1 - LR_predictions) 的结果应该是一个标量,表示正确预测的数量。
3. NumPy 的 np.dot
np.dot 用于计算两个数组的点积。
- 如果输入是一维数组,结果是一个标量。
- 如果输入是二维数组,结果是一个数组。
4. NumPy 的 np.mean
- np.mean 用于计算数组的均值。
- 可以用它来计算准确率,因为准确率本质上是正确预测的比例。
In [135]:
# Plot the decision boundary for logistic regression
# 绘制决策边界
plot_decision_boundary(lambda x: clf.predict(x), X, Y)
# 图标题
plt.title("Logistic Regression") # 打印准确性
LR_predictions = clf.predict(X.T)# LR_predictions = clf.predict(X.T).ravel() #展平为一维数组
Y = Y.ravel() #展平为一维数组
print ('逻辑回归的准确性:%d ' % float((np.dot(Y,LR_predictions) + np.dot(1-Y,1-LR_predictions))/float(Y.size)*100) +'% ' + "(正确标记的数据点所占的百分比)") 逻辑回归的准确性:47 % (正确标记的数据点所占的百分比)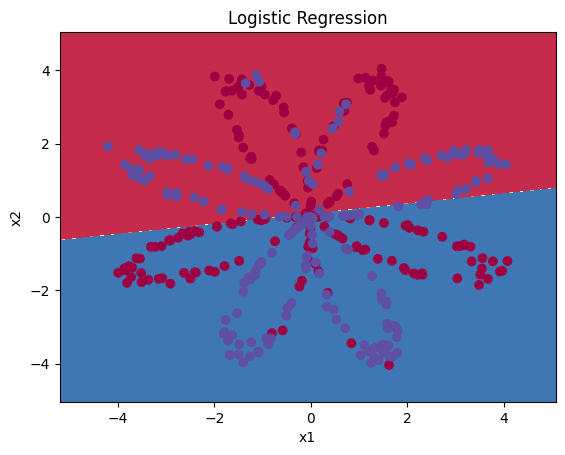
② 由于数据集不是线性可分类的,因此逻辑回归效果不佳。让我们试试是否神经网络会做得更好吧!
4. 神经网络模型¶
4.1 神经网络简介¶
① 从上面我们可以得知Logistic回归不适用于“flower数据集”。
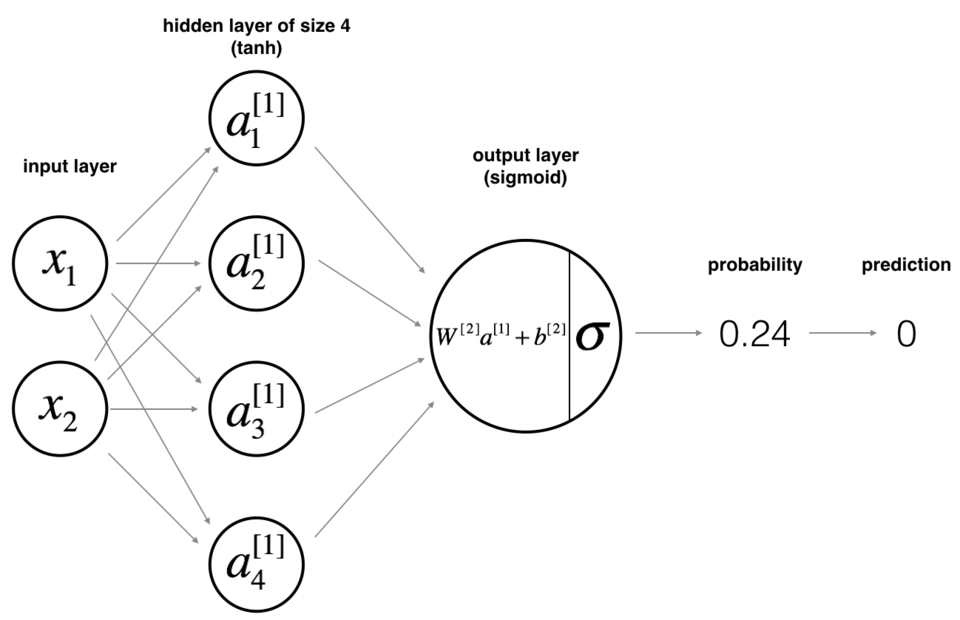
② 现在你将训练带有单个隐藏层的神经网络。
③ 这是我们的模型:
4.2 神经网络数学模型¶
① 数学原理:
例如对第 i i i个样本 x ( i ) x^{(i)} x(i),执行以下操作:
- KaTeX parse error: \tag works only in display equations
- KaTeX parse error: \tag works only in display equations
- KaTeX parse error: \tag works only in display equations
- KaTeX parse error: \tag works only in display equations
- KaTeX parse error: Undefined control sequence: \mbox at position 43: …gin{cases} 1 & \̲m̲b̲o̲x̲{if } a^{[2](i)…
② 根据所有的预测数据,你还可以如下计算损失J:
KaTeX parse error: \tag works only in display equations
4.3 建立神经网络方法¶
① 建立神经网络的一般方法是:
- 定义神经网络结构(输入单元数,隐藏单元数等)。
- 初始化模型的参数
- 循环:
- 3.1 实施前项传播
- 3.2 计算损失
- 3.3 实现后向传播
- 3.4 更新参数(梯度下降)
② 我们通常会构建辅助函数来计算第(1)-(3)步,然后将它们合并为nn_model()函数。
③ 一旦构建了 nn_model() 并学习了正确的参数,就可以对新数据进行预测。
4.4 定义神经网络结构¶
① 在构建神经网络之前,我们要先把神经网络的结构给定义好。
② 定义三个变量:
- n_x:输入层的大小
- n_h:隐藏层的大小(将其设置为4)
- n_y:输出层的大小
note:使用shape来找到n_x和n_y。 另外,将隐藏层大小硬编码为4。
In [136]:
def layer_sizes(X, Y):"""参数:X - 输入数据集,维度为(输入的数量,训练/测试的数量)Y - 标签,维度为(输出的数量,训练/测试数量)返回:n_x - 输入层的数量n_h - 隐藏层的数量n_y - 输出层的数量"""# 输入层大小n_x = X.shape[0] # 隐藏层大小n_h = 4# 输出层大小n_y = Y.shape[0] return (n_x, n_h, n_y)In [137]:
# 测试一下 layer_sizes 函数
print("=========================测试layer_sizes=========================")
X_assess, Y_assess = layer_sizes_test_case()
(n_x, n_h, n_y) = layer_sizes(X_assess, Y_assess)
print("The size of the input layer is: n_x = " + str(n_x))
print("The size of the hidden layer is: n_h = " + str(n_h))
print("The size of the output layer is: n_y = " + str(n_y))=========================测试layer_sizes=========================
The size of the input layer is: n_x = 5
The size of the hidden layer is: n_h = 4
The size of the output layer is: n_y = 24.5 初始化模型的参数¶
① 在这里,我们要实现函数initialize_parameters()。
② 我们要确保我们的参数大小合适。
③ 我们将会用随机值初始化权重矩阵。
- np.random.randn(a,b) * 0.01来随机初始化一个维度为(a,b)的矩阵。
- np.zeros((a,b))用零初始化矩阵(a,b)。将偏向量初始化为零。
In [138]:
def initialize_parameters(n_x, n_h, n_y):"""参数:n_x - 输入层节点的数量n_h - 隐藏层节点的数量n_y - 输出层节点的数量返回:parameters - 包含参数的字典:W1 - 权重矩阵,维度为(n_h,n_x)b1 - 偏向量,维度为(n_h,1)W2 - 权重矩阵,维度为(n_y,n_h)b2 - 偏向量,维度为(n_y,1)"""# 设置一个种子,这样你的输出与我们的匹配,尽管初始化是随机的。np.random.seed(2) W1 = np.random.randn(n_h,n_x) * 0.01b1 = np.zeros((n_h,1))W2 = np.random.randn(n_y,n_h) * 0.01b2 = np.zeros((n_y,1))# 使用断言确保我的数据格式是正确的assert(W1.shape == ( n_h , n_x ))assert(b1.shape == ( n_h , 1 ))assert(W2.shape == ( n_y , n_h ))assert(b2.shape == ( n_y , 1 ))parameters = {"W1": W1,"b1": b1,"W2": W2,"b2": b2}return parametersIn [139]:
#测试一下 initialize_parameters 函数
print("=========================测试initialize_parameters=========================")
n_x, n_h, n_y = initialize_parameters_test_case()
parameters = initialize_parameters(n_x, n_h, n_y)
print("W1 = " + str(parameters["W1"]))
print("b1 = " + str(parameters["b1"]))
print("W2 = " + str(parameters["W2"]))
print("b2 = " + str(parameters["b2"]))=========================测试initialize_parameters=========================
W1 = [[-0.00416758 -0.00056267][-0.02136196 0.01640271][-0.01793436 -0.00841747][ 0.00502881 -0.01245288]]
b1 = [[0.][0.][0.][0.]]
W2 = [[-0.01057952 -0.00909008 0.00551454 0.02292208]]
b2 = [[0.]]4.6 循环¶
4.6.1 前向传播¶
① 我们现在要实现前向传播函数forward_propagation()。
② 我们可以使用sigmoid()函数,也可以使用np.tanh()函数。
③ 步骤如下:
- 使用字典类型的parameters(它是initialize_parameters() 的输出)检索每个参数。
- 实现前向传播,计算 Z [ 1 ] , A [ 1 ] , Z [ 2 ] Z^{[1]}, A^{[1]}, Z^{[2]} Z[1],A[1],Z[2]和 A [ 2 ] A^{[2]} A[2](所有训练数据的预测结果向量)。
- 反向传播所需的值存储在cache中,cache将作为反向传播函数的输入。
步骤及相关解释
1. 前向传播(Forward Propagation)
前向传播是神经网络中从输入层到输出层的计算过程。它包括以下步骤:
- 输入层:接收输入数据。
- 隐藏层:对输入数据进行加权求和和非线性变换。
- 输出层:生成最终的预测结果。
在前向传播中,每个神经元的输出可以表示为:
Z = W ⋅ X + b Z = W \cdot X + b Z=W⋅X+b
A = g ( Z ) A = g(Z) A=g(Z)
其中:
- ( Z ) 是加权输入。
- ( W ) 是权重矩阵。
- ( X ) 是输入数据。
- ( b ) 是偏置项。
- ( g ) 是激活函数(如 Sigmoid、ReLU 等)。
- ( A ) 是激活后的输出。
2. 缓存(Cache)
在神经网络的实现中,cache 是一个字典,用于存储中间计算结果。这些结果在反向传播中会被用到。例如:
Z1:第一个隐藏层的加权输入。A1:第一个隐藏层的激活输出。Z2:输出层的加权输入。A2:输出层的激活输出。
3. 测试用例(Test Case)
forward_propagation_test_case() 是一个测试函数,用于生成测试数据:
X_assess:测试输入数据。parameters:测试模型的参数(包括权重和偏置)。
这些测试数据用于验证 forward_propagation 函数的正确性。
4. NumPy 的 np.mean
np.mean 用于计算数组的均值。在这段代码中,np.mean 被用来计算 cache 中各个变量的均值,以便验证输出是否与预期一致。
5. 打印结果
通过打印 cache 中各个变量的均值,可以直观地检查 forward_propagation 函数的输出是否正确。
In [171]:
def forward_propagation(X, parameters):"""参数:X - 维度为(n_x,m)的输入数据。parameters - 初始化函数(initialize_parameters)的输出返回:A2 - 使用sigmoid()函数计算的第二次激活后的数值cache - 包含“Z1”,“A1”,“Z2”和“A2”的字典类型变量"""# 从字典 “parameters” 中检索每个参数W1 = parameters["W1"]b1 = parameters["b1"]W2 = parameters["W2"]b2 = parameters["b2"]# 实现前向传播计算A2(概率)Z1 = np.dot(W1,X) + b1A1 = np.tanh(Z1)Z2 = np.dot(W2,A1) + b2A2 = sigmoid(Z2)# 确保 A2 的形状为 (1, n_samples)A2 = A2.reshape(1, -1)#使用断言确保我的数据格式是正确的assert(A2.shape == (1,X.shape[1]))cache = {"Z1": Z1,"A1": A1,"Z2": Z2,"A2": A2}return A2, cacheIn [141]:
# 测试一下 forward_propagation 函数
print("=========================测试forward_propagation=========================")
X_assess, parameters = forward_propagation_test_case()
A2, cache = forward_propagation(X_assess, parameters)
# 我们在这里使用均值只是为了确保你的输出与我们的输出匹配。
print(np.mean(cache['Z1']) ,np.mean(cache['A1']),np.mean(cache['Z2']),np.mean(cache['A2']))=========================测试forward_propagation=========================
-0.0004997557777419913 -0.000496963353231779 0.00043818745095914653 0.5001095468524314.6.2 计算成本¶
① 现在,我们已经计算了 A [ 2 ] A^{[2]} A[2]
② a [ 2 ] ( i ) a^{[2](i)} a[2](i)包含了训练集里每个数值,现在我们可以构建成本函数了。
③ 我们的成本选择交叉熵损失,计算成本的公式如下:
KaTeX parse error: \tag works only in display equations
In [142]:
def compute_cost(A2, Y, parameters):"""计算方程(7)中给出的交叉熵成本,参数:A2 - 使用sigmoid()函数计算的第二次激活后的数值Y - "True"标签向量,维度为(1,数量)parameters - 一个包含W1,B1,W2和B2的字典类型的变量返回:成本 - 交叉熵成本给出方程(7)"""# 样本数量m = Y.shape[1] # 计算交叉熵代价epsilon = 1e-5 # 一个非常小的值logprobs = Y * np.log(A2 + epsilon) + (1 - Y) * np.log(1 - A2 + epsilon) #防止为0# logprobs = Y*np.log(A2) + (1-Y)* np.log(1-A2)cost = -1/m * np.sum(logprobs)# 确保损失是我们期望的维度# 例如,turns [[17]] into 17 cost = np.squeeze(cost) assert(isinstance(cost, float))return costIn [143]:
# 测试一下 compute_cost 函数
print("=========================测试compute_cost=========================")
A2, Y_assess, parameters = compute_cost_test_case()print("cost = " + str(compute_cost(A2, Y_assess, parameters)))=========================测试compute_cost=========================
cost = 0.6928998985200261① 使用正向传播期间计算的cache,现在可以利用它实现反向传播。
② 现在我们要开始实现函数backward_propagation()。
4.6.3 后向传播¶
① 反向传播通常是深度学习中最难(数学意义)部分,为了帮助你,这里有反向传播讲座的幻灯片。
② 由于我们正在构建向量化实现,因此我们将需要使用这下面的六个方程:

③ 要计算 d z [ 1 ] dz^{[1]} dz[1],你首先需要计算 g [ 1 ] ′ ( Z [ 1 ] ) g^{[1]'}(Z^{[1]}) g[1]′(Z[1])。
④ g [ 1 ] ( . . . ) g^{[1]}(...) g[1](...) 是tanh激活函数,因此如果 a = g [ 1 ] ( z ) a = g^{[1]}(z) a=g[1](z)则 g [ 1 ] ′ ( z ) = 1 − a 2 g^{[1]'}(z) = 1-a^2 g[1]′(z)=1−a2。
⑤ 所以我们需要使用(1 - np.power(A1, 2))计算 g [ 1 ] ′ ( Z [ 1 ] ) g^{[1]'}(Z^{[1]}) g[1]′(Z[1])。
In [144]:
def backward_propagation(parameters, cache, X, Y):"""使用上述说明搭建反向传播函数。参数:parameters - 包含我们的参数的一个字典类型的变量。cache - 包含“Z1”,“A1”,“Z2”和“A2”的字典类型的变量。X - 输入数据,维度为(2,数量)Y - “True”标签,维度为(1,数量)返回:grads - 包含W和b的导数一个字典类型的变量。"""m = X.shape[1]# 首先,从字典“parameters”中检索W1和W2。W1 = parameters["W1"]W2 = parameters["W2"]# 还可以从字典“cache”中检索A1和A2。A1 = cache["A1"]A2 = cache["A2"]# 反向传播:计算 dW1、db1、dW2、db2。dZ2= A2 - YdW2 = 1 / m * np.dot(dZ2,A1.T)db2 = 1 / m * np.sum(dZ2,axis=1,keepdims=True)dZ1 = np.dot(W2.T,dZ2) * (1-np.power(A1,2))dW1 = 1 / m * np.dot(dZ1,X.T)db1 = 1 / m * np.sum(dZ1,axis=1,keepdims=True)grads = {"dW1": dW1,"db1": db1,"dW2": dW2,"db2": db2}return grads In [145]:
# 测试一下 backward_propagation 函数
print("=========================测试backward_propagation=========================")
parameters, cache, X_assess, Y_assess = backward_propagation_test_case()
grads = backward_propagation(parameters, cache, X_assess, Y_assess)
print ("dW1 = "+ str(grads["dW1"]))
print ("db1 = "+ str(grads["db1"]))
print ("dW2 = "+ str(grads["dW2"]))
print ("db2 = "+ str(grads["db2"])) =========================测试backward_propagation=========================
dW1 = [[ 0.01018708 -0.00708701][ 0.00873447 -0.0060768 ][-0.00530847 0.00369379][-0.02206365 0.01535126]]
db1 = [[-0.00069728][-0.00060606][ 0.000364 ][ 0.00151207]]
dW2 = [[ 0.00363613 0.03153604 0.01162914 -0.01318316]]
db2 = [[0.06589489]]⑥ 反向传播完成了,我们开始对参数进行更新。
4.6.4 更新参数¶
① 我们需要使用(dW1,db1,dW2,db2)更新(W1,b1,W2,b2)。
② 更新算法如下:
$ \theta = \theta - \alpha \frac{\partial J }{ \partial \theta }$
③ 其中:
- α \alpha α 代表学习率
- θ \theta θ 代表一个参数。
④ 我们需要选择一个良好的学习速率,我们可以看一下下面这两个图(图由Adam Harley提供)。
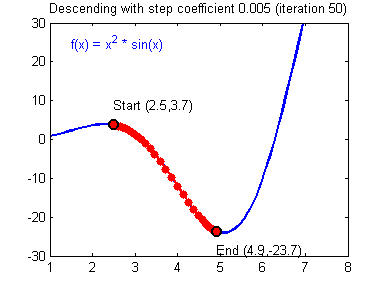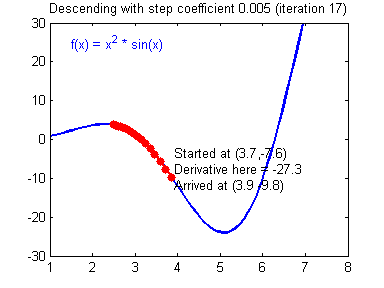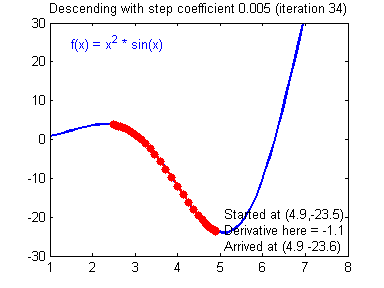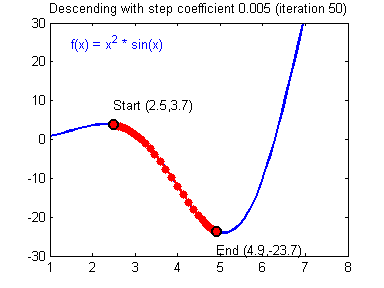
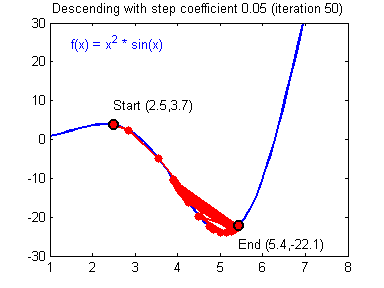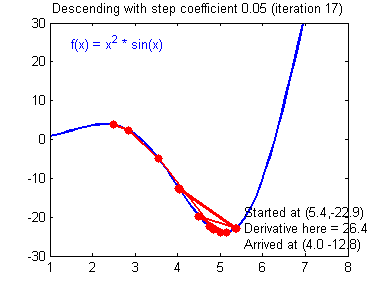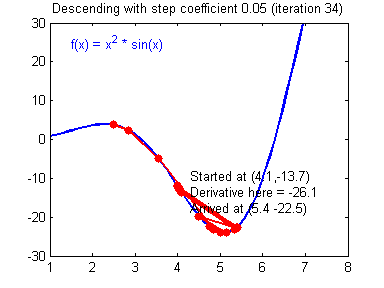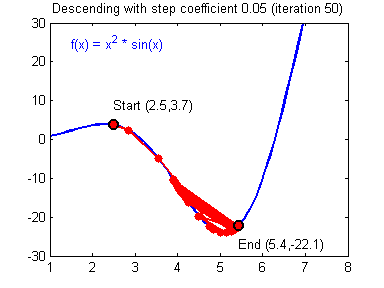
⑤ 上面两个图分别代表了具有良好学习速率(收敛)和不良学习速率(发散)的梯度下降算法。
In [146]:
def update_parameters(parameters, grads, learning_rate = 1.2):"""使用上面给出的梯度下降更新规则更新参数参数:parameters - 包含参数的字典类型的变量。grads - 包含导数值的字典类型的变量。learning_rate - 学习速率返回:parameters - 包含更新参数的字典类型的变量。"""# 从字典“parameters”中检索每个参数W1 = parameters["W1"]b1 = parameters["b1"]W2 = parameters["W2"]b2 = parameters["b2"]# 从字典“梯度”中检索每个梯度dW1 = grads["dW1"]db1 = grads["db1"]dW2 = grads["dW2"]db2 = grads["db2"]# 每个参数的更新规则W1 = W1 - learning_rate * dW1b1 = b1 - learning_rate * db1W2 = W2 - learning_rate * dW2b2 = b2 - learning_rate * db2parameters = {"W1": W1,"b1": b1,"W2": W2,"b2": b2}return parametersIn [147]:
# 测试一下 update_parameters 函数
print("=========================测试update_parameters=========================")
parameters, grads = update_parameters_test_case()
parameters = update_parameters(parameters, grads)print("W1 = " + str(parameters["W1"]))
print("b1 = " + str(parameters["b1"]))
print("W2 = " + str(parameters["W2"]))
print("b2 = " + str(parameters["b2"]))=========================测试update_parameters=========================
W1 = [[-0.00643025 0.01936718][-0.02410458 0.03978052][-0.01653973 -0.02096177][ 0.01046864 -0.05990141]]
b1 = [[-1.02420756e-06][ 1.27373948e-05][ 8.32996807e-07][-3.20136836e-06]]
W2 = [[-0.01041081 -0.04463285 0.01758031 0.04747113]]
b2 = [[0.00010457]]4.7 整合¶
① 我们现在把上面的东西整合到nn_model()中,神经网络模型必须以正确的顺序使用先前的功能。
In [208]:
def nn_model(X, Y, n_h, num_iterations = 10000, print_cost=False):"""参数:X - 数据集,维度为(2,示例数)Y - 标签,维度为(1,示例数)n_h - 隐藏层的数量num_iterations - 梯度下降循环中的迭代次数print_cost - 如果为True,则每1000次迭代打印一次成本数值返回:parameters - 模型学习的参数,它们可以用来进行预测。""" # 初始化参数,然后检索 W1, b1, W2, b2。输入:“n_x, n_h, n_y”。np.random.seed(3)n_x = layer_sizes(X, Y)[0]n_y = layer_sizes(X, Y)[2]# 初始化参数,然后检索 W1, b1, W2, b2。# 输入:“n_x, n_h, n_y”。输出=“W1, b1, W2, b2,参数”。parameters = initialize_parameters(n_x, n_h, n_y)W1 = parameters["W1"]b1 = parameters["b1"]W2 = parameters["W2"]b2 = parameters["b2"]# 循环(梯度下降)for i in range(0, num_iterations):# 前项传播A2, cache = forward_propagation(X, parameters)# 计算成本cost = compute_cost(A2, Y, parameters)# 反向传播grads = backward_propagation(parameters, cache, X, Y)# 更新参数parameters = update_parameters(parameters, grads)# 每1000次迭代打印成本if print_cost and i % 1000 == 0:print ("Cost after iteration %i: %f" %(i, cost))return parametersIn [210]:
# 测试一下 nn_model 函数
print("=========================测试nn_model=========================")
X_assess, Y_assess = nn_model_test_case()
parameters = nn_model(X_assess, Y_assess, 4, num_iterations=10000, print_cost=False)print("W1 = " + str(parameters["W1"]))
print("b1 = " + str(parameters["b1"]))
print("W2 = " + str(parameters["W2"]))
print("b2 = " + str(parameters["b2"]))=========================测试nn_model=========================C:\Users\86158\AppData\Local\Temp\ipykernel_10044\499126413.py:10: RuntimeWarning: divide by zero encountered in loglogprobs = np.multiply(np.log(A2), Y) + np.multiply(np.log(1 - A2), (1 - Y))
C:\Users\86158\AppData\Local\Temp\ipykernel_10044\499126413.py:6: RuntimeWarning: overflow encountered in expreturn 1/(1+np.exp(-z))W1 = [[-4.18501964 5.33203231][-7.53803638 1.20755888][-4.19301361 5.32615356][ 7.53798951 -1.2075854 ]]
b1 = [[ 2.32933188][ 3.81002159][ 2.33009153][-3.8101016 ]]
W2 = [[-6033.82354742 -6008.14298684 -6033.08777738 6008.07944581]]
b2 = [[-52.67924992]]4.8 预测¶
① 构建predict()来使用模型进行预测。
② 使用正向传播来预测结果。
note: y _ p r e d i c t i o n = 1 activation > 0.5 = { 1 if a c t i v a t i o n > 0.5 0 otherwise y\_{prediction} = \mathbb 1 \text{{activation > 0.5}} = \begin{cases} 1 & \text{if}\ activation > 0.5 \\ 0 & \text{otherwise} \end{cases} y_prediction=1activation > 0.5={10if activation>0.5otherwise
note:如果你想基于阈值将矩阵X设为0和1,则可以执行以下操作: X_new = (X > threshold)
In [151]:
def predict(parameters, X): """使用学习的参数,为X中的每个示例预测一个类参数:parameters - 包含参数的字典类型的变量。X - 输入数据(n_x,m)返回predictions - 我们模型预测的向量(红色:0 /蓝色:1)"""# 使用前向传播计算概率,并使用 0.5 作为阈值将其分类为 0/1。A2, cache = forward_propagation(X, parameters)predictions = np.round(A2)return predictions③ 现在运行模型以查看其如何在二维数据集上运行。
④ 运行以下代码以使用含有 n _ h n\_h n_h隐藏单元的单个隐藏层测试模型。
In [152]:
# 测试一下 predict 函数
print("=========================测试predict=========================")
parameters, X_assess = predict_test_case()predictions = predict(parameters, X_assess)
print("预测的平均值= " + str(np.mean(predictions)))=========================测试predict=========================
预测的平均值= 0.6666666666666666⑤ 现在我们把所有的东西基本都做完了,我们开始正式运行。
5. 正式运行¶
5.1 构建训练模型¶
In [216]:
# 用 n_h 维隐藏层构建一个模型
X, Y = load_planar_dataset()parameters = nn_model(X, Y, n_h = 4, num_iterations = 10000, print_cost=True)Cost after iteration 0: 0.693048
Cost after iteration 1000: 0.288083
Cost after iteration 2000: 0.254385
Cost after iteration 3000: 0.233864
Cost after iteration 4000: 0.226792
Cost after iteration 5000: 0.222644
Cost after iteration 6000: 0.219731
Cost after iteration 7000: 0.217504
Cost after iteration 8000: 0.219447
Cost after iteration 9000: 0.2186055.2 绘制决策边界¶
In [217]:
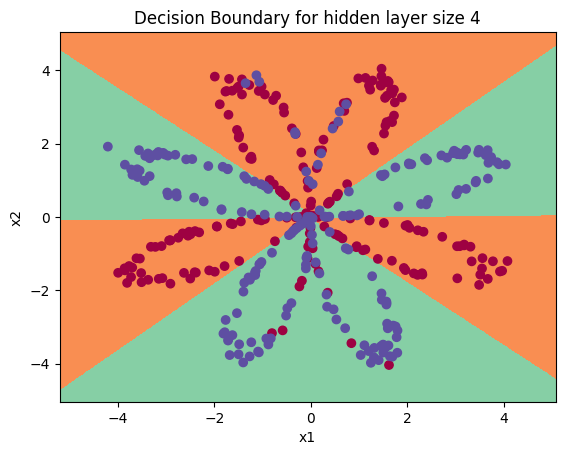
# 绘制决策边界
# Y = Y.ravel() #确保 Y为一维数组
plot_decision_boundary(lambda x: predict(parameters, x.T), X, Y)
plt.title("Decision Boundary for hidden layer size " + str(4))Out[217]:
Text(0.5, 1.0, 'Decision Boundary for hidden layer size 4')
5.3 打印准确率¶
In [221]:
# 打印准确率
predictions = predict(parameters, X)# print ('准确率: %d' % float((np.dot(Y, predictions.T) + np.dot(1 - Y, 1 - predictions.T)) / float(Y.size) * 100) + '%')
accuracy = np.mean(predictions == Y) * 100 #当前版本推荐的公式
print ("准确率: {} %".format(accuracy))准确率: 90.5 %① 与Logistic回归相比,准确性确实更高。
② 该模型学习了flower的叶子图案!与逻辑回归不同,神经网络甚至能够学习非线性的决策边界。
5.4 调节隐藏层节点数量¶
① 现在,让我们尝试几种不同的隐藏层大小。
② 调整隐藏层大小(可选练习)运行以下代码(可能需要1-2分钟),你将观察到不同大小隐藏层的模型的不同表现。
In [222]:
plt.figure(figsize=(16, 32))
hidden_layer_sizes = [1, 2, 3, 4, 5, 10, 20] # 隐藏层数量# X, Y = load_planar_dataset() #重新加入初识数据集即可解决报错问题
for i, n_h in enumerate(hidden_layer_sizes):plt.subplot(5, 2, i+1)plt.title('Hidden Layer of size %d' % n_h)parameters = nn_model(X, Y, n_h, num_iterations = 5000)plot_decision_boundary(lambda x: predict(parameters, x.T), X, Y)predictions = predict(parameters, X)# accuracy = float((np.dot(Y,predictions.T) + np.dot(1-Y,1-predictions.T))/float(Y.size)*100)accuracy = np.mean(predictions == Y) * 100 #当前版本推荐的公式print ("隐藏层的节点数量: {} ,准确率: {} %".format(n_h, accuracy))隐藏层的节点数量: 1 ,准确率: 67.5 %
隐藏层的节点数量: 2 ,准确率: 67.25 %
隐藏层的节点数量: 3 ,准确率: 90.75 %
隐藏层的节点数量: 4 ,准确率: 90.5 %
隐藏层的节点数量: 5 ,准确率: 91.25 %
隐藏层的节点数量: 10 ,准确率: 90.25 %
隐藏层的节点数量: 20 ,准确率: 90.5 %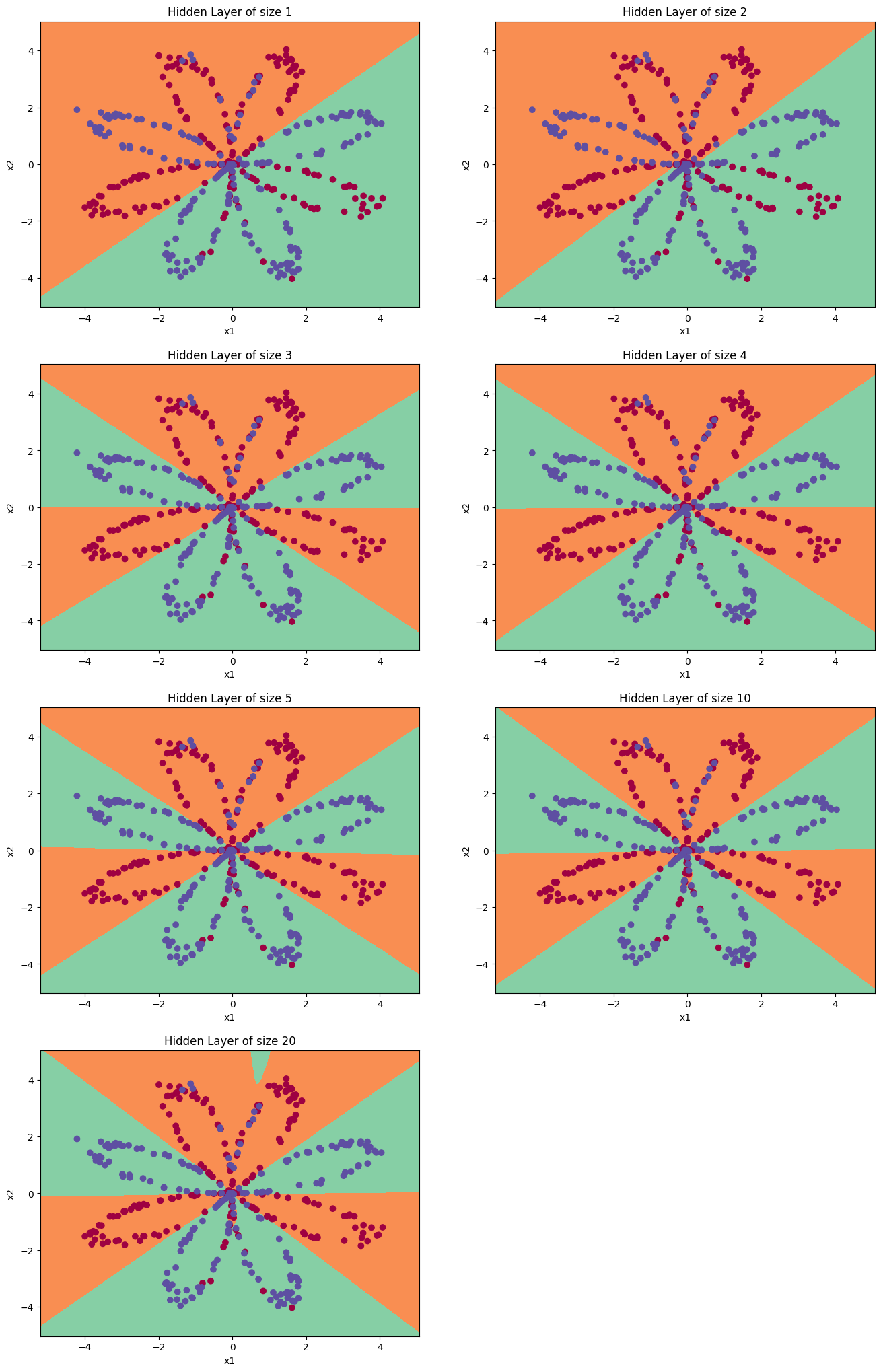
③ 较大的模型(具有更多隐藏单元)能够更好地适应训练集,直到最终的最大模型过度拟合数据。
④ 最好的隐藏层大小似乎在n_h = 5附近。实际上,这里的值似乎很适合数据,而且不会引起过度拟合。
⑤ 我们还将在后面学习有关正则化的知识,它允许我们使用非常大的模型(如n_h = 50),而不会出现太多过度拟合。
相关文章:

第3周作业-1层隐藏层的神经网络分类二维数据
文章目录 ***1层隐藏层的神经网络分类二维数据***1. 导入包2. 数据集2.1 导入数据集2.2 查看数据集图案2.3 查看数据集维度 3. Logistic回归3.1 Logistic回归简介3.2 Logistic回归模型3.3 绘制边界 4. 神经网络模型4.1 神经网络简介4.2 神经网络数学模型4.3 建立神经网络方法4.…...

中天智能装备科技有限公司:智能仓储领域的卓越之选
在仓储智能化转型的时代浪潮中,中天智能装备科技有限公司以深厚的技术积淀与创新实力,成为众多企业迈向高效仓储的理想合作伙伴。无论是自动化立体库的精准搭建,还是 AGV 系统的智能部署,中天都以专业姿态为行业树立标杆。 硬核…...
-内核实现)
Linux nbd 网络块设备(2)-内核实现
Linux nbd网络块设备(2)-内核实现 关注我,一起学习吧,后续持续更新内核相关 1. 概述: 内核linux/drivers/block/nbd.c 是nbd 网络设备的底层驱动实现逻辑。本文主要介绍nbd 设备注册及I/O请求的处理逻辑。 2. nbd 设备的初始化࿱…...

Python输出与输入
White graces:个人主页 🙉专栏推荐:Java入门知识🙉 🐹今日诗词:吟怀未许老重阳,霜雪无端入鬓长🐹 ⛳️点赞 ☀️收藏⭐️关注💬卑微小博主🙏 ⛳️点赞 ☀️收藏⭐️关注Ǵ…...

【C语言】复习~数组和指针
数组和指针 1.字符指针 char* 使用方法一: 使用方法二: 这里本质上是把常量字符串的首地址放到了指针变量pstr里面 看下面的面试题 str3和str4指向的是同一个常量字符串,c/c会把常量字符串存储到一个单独的内存区域, 当几…...

rocketmq优先级控制 + 并发度控制
背景 最近在做大模型的项目,算法部门提供的文档解析接口, 并发度为1, 业务这边需要在ai问答和上传文档时进行解析和向量化,文档解析只能单线程跑,问答的文档解析需要高优先级处理。 采用 rocketmq 做文档上传和解析的…...
)
从0开始学linux韦东山教程第四章问题小结(2)
本人从0开始学习linux,使用的是韦东山的教程,在跟着课程学习的情况下的所遇到的问题的总结,理论虽枯燥但是是基础。说实在的越看视频越感觉他讲的有点乱后续将以他的新版PDF手册为中心,视频作为辅助理解的工具。参考手册为嵌入式Linux应用开发…...

洛谷P1226 【模板】快速幂
题目来源 P1226 【模板】快速幂 - 洛谷 题目描述 给你三个整数 a,b,p,求 abmodp。 输入格式 输入只有一行三个整数,分别代表 a,b,p。 输出格式 输出一行一个字符串 a^b mod ps,其中 a,b,p 分别为题目给定的值, s 为运算结果…...

自动点焊机:在多类电池生产中筑牢质量与效率根基
在电池制造产业飞速发展的当下,焊接作为电池组装的关键环节,其质量与效率直接影响着电池的性能与安全性。自动点焊机凭借其高效、精准、稳定的特性,在电动工具电池、扭扭车电池、储能电池包、滑板车电池以及电动车电池等多个电池制造领域大放…...

信息系统项目管理师考前练习1
以下是结合《信息系统项目管理师教程》(第5版)核心考点和当前行业热点的20道选择题押题,涵盖重点知识和新兴趋势,供考前冲刺练习: 项目生命周期模型选择 在敏捷开发项目中,客户需求频繁变更,且团队希望快速交付最小可行产品(MVP),最适合采用的生命周期模型是: A. …...

C++ for QWidget:正则表达式和QRegExp
正则表达式 正则表达式,又称规则表达式,(Regular Expression,在代码中常简写为regex、regexp或RE),是计算机科学的一个概念。以下是对正则表达式的详细介绍: 一、定义与作用 正则表达式是一种文…...

day019-特殊符号、正则表达式与三剑客
文章目录 1. 磁盘空间不足-排查流程2. 李导推荐书籍2.1 大话存储2.2 性能之巅 3. 特殊符号3.1 引号系列(面试题)3.2 重定向符号3.2.1 cat与重定向3.2.2 tr命令:替换字符3.2.3 xargs:参数转换3.2.4 标准全量追加重定向 4. 正则表达…...
)
学习黑客了解5分钟了解中间人攻击(MITM)
5分钟了解中间人攻击(MITM)🕵️♂️ 什么是中间人攻击(Man-in-the-Middle, MITM)? 中间人攻击是一种网络攻击方式,攻击者悄无声息地“夹在”通信两端之间,偷偷读取、篡改、伪造或…...

亚马逊第四个机器人中心将如何降低30%配送成本?
近年来,亚马逊越来越依赖自动化技术来提升仓储效率和配送速度。2024年,亚马逊宣布其全球第四个机器人中心在美国正式投入运营,这一中心将成为改变供应链策略的新变量。据亚马逊官方消息,这一机器人中心有望帮助公司进一步削减运营…...

「AR智慧应急」新时代:当AR眼镜遇上智能监控,打造立体化应急指挥系统
引言:应急管理的未来已来 数字化浪潮正重塑应急管理领域。传统监控系统依赖固定屏幕、被动告警的短板,在复杂突发事件中暴露无遗。而AR眼镜视频监控管理平台应急应急管理平台的三维融合,正开启"上帝视角"指挥时代——通过虚实叠加…...

docker 启动一个python环境的项目
安装镜像 docker pull python:3.8-slim8902端口 启动容器 tail -f /dev/null 持续监听空文件,保持容器活跃 docker run -it \-p 8902:8902 \--name api_mock2 \-v /home/py/test:/app \-w /app \python:3.8-slim \tail -f /dev/null进入容器 docker exec -it api…...

Docker run命令-p参数详解
端口映射基础语法 docker run -p <宿主机端口>:<容器端口> 操作示例 docker run -d --restartalways --namespug -p 5000:80 registry.aliyuncs.com/openspug/spug参数解析 -d:后台运行容器--restartalways:设置容器自动重启--namespug&…...

vue3请求设置responseType: ‘blob‘,导致失败后获取不到返回信息
vue3请求设置responseType: ‘blob’,导致失败后获取不到返回信息 使用FileReader解决 dataCollect().downloadAll(data).then((res: any) > {if (res.type application/json) {const fileReader new FileReader();fileReader.readAsText(new Blob([res], { type: applica…...

在 Windows 系统部署对冲基金分析工具 ai-hedge-fund 的笔记
#工作记录 一、环境准备 在部署对冲基金分析工具ai-hedge-fund前,需提前安装好必备软件,为后续工作搭建好基础环境。 1. 安装 Anaconda Anaconda 集成了 Python 及众多科学计算库,是项目运行的重要基础。从Anaconda 官方网站下载适合 Win…...
—— 评估算法(一))
基于python的机器学习(八)—— 评估算法(一)
目录 一、机器学习评估的基本概念 1.1 评估的定义与目标 1.2 常见评估指标 1.3 训练集、验证集与测试集的划分 二、分离数据集 2.1 分离训练数据集和评估数据集 2.2 k折交叉验证分离 2.3 弃一交叉验证分离 2.4 重复随机评估和训练数据集分离 三、交叉验证技术 3.…...
—言语:语句排序题(听课后强化))
广东省省考备考(第十六天5.21)—言语:语句排序题(听课后强化)
错题 解析 对比选项,确定首句。①句介绍目前人类可以利用一些技术手段进入元宇宙,凭借网络重新定义自己,体验一种全新的生活,②句介绍对于多数人来说,首先要弄清楚什么是元宇宙,③句介绍元宇宙是指超越现实…...

什么是实时流数据?核心概念与应用场景解析
在当今数字经济时代,实时流数据正成为企业核心竞争力。金融机构需要实时风控系统在欺诈交易发生的瞬间进行拦截;电商平台需要根据用户实时行为提供个性化推荐;工业物联网需要监控设备状态预防故障。这些场景都要求系统能够“即时感知、即时分…...
)
计算机视觉与深度学习 | Python实现CEEMDAN-ABC-VMD-DBO-CNN-LSTM时间序列预测(完整源码和数据)
以下是一个结合CEEMDAN、ABC优化VMD、DBO优化CNN-LSTM的完整时间序列预测实现方案。该方案包含完整的数据生成、算法实现和模型构建代码。 完整实现代码 import numpy as np import pandas as pd from PyEMD import CEEMDAN from vmdpy import VMD from sklearn.preprocessing…...

每日Prompt:实物与手绘涂鸦创意广告
提示词 一则简约且富有创意的广告,设置在纯白背景上。 一个真实的 [真实物体] 与手绘黑色墨水涂鸦相结合,线条松散而俏皮。涂鸦描绘了:[涂鸦概念及交互:以巧妙、富有想象力的方式与物体互动]。在顶部或中部加入粗体黑色 [广告文案…...

期刊采编系统安装升级错误
我们以ojs系统为例: PHP Fatal error: Uncaught Error: Call to a member function getId() on null in /esci/data/html/classes/install/Upgrade.inc.php:1019 Stacktrace: #0 /esci/data/html/lib/pkp/classes/install/Installer.inc.php(415): Upgrade->con…...

【linux命令】git命令简单使用
git命令简单使用 1. 将代码下载到到本地2. 查看分支是否正确3. 将工作目录中的变更添加到暂存区,为下一次提交做准备4. 提交更改,添加提交信息5. 将本地的提交推送到远程仓库6.从远端仓库拉取分支代码7.查看修改日志8. 解决冲突 1. 将代码下载到到本地 …...

使用Tkinter写一个发送kafka消息的工具
文章目录 背景工具界面展示功能代码讲解运行环境创建GUI程序搭建前端样式编写功能实现代码 背景 公司是做AR实景产品的,近几年无人机特别的火,一来公司比较关注低空经济这个新型领域,二来很多政企、事业单位都采购了无人机用于日常工作。那么…...

【VS2017】cpp文件字符编码异常导致编译报错
这是一个 wav 转 pcm 的简单demo,但VS2017编译报错 #define _CRT_SECURE_NO_WARNINGS #include <stdio.h> #include <inttypes.h> #pragma pack(push, 1) struct TWavHead {int8_t riff[4]; /*!< (4)资源交换文件标志 RIFF */uint32_t file_si…...

Vue3 中 Route 与 Router 的区别
在 Vue Router 中,Route 和 Router 是两个相关但完全不同的概念: 1、Router (路由实例) 定义:Router 是路由器的实例,负责整个应用的路由管理 功能: 管理路由映射表(路由配置) 提供编程式导航…...

gcc还会有自己的头文件呢?
1. GCC自己的头文件目录 路径: .../lib/gcc/<target>/<version>/include 作用: 这里存放的是GCC编译器自身实现的一些头文件,比如 stdarg.h、float.h、limits.h、varargs.h 等。这些头文件是C/C标准规定必须有的,但…...

YOLO训练输入尺寸代表什么 --input_width 和 --input_height 参数
参数作用 硬件对齐要求 许多边缘计算芯片(如 K230)的 NPU 对输入尺寸有 内存对齐要求(例如 32 的倍数)。脚本会自动将你填写的输入尺寸向上对齐到最近的 32 倍数: input_width int(math.ceil(args.input_width / 32.0…...

缓存穿透、缓存击穿、缓存雪崩解决方案
在分布式系统中,缓存是提升性能的关键组件,但也可能面临 缓存穿透、缓存击穿、缓存雪崩 三大典型问题。以下是三者的核心概念、区别及解决方案: 一、缓存穿透(Cache Penetration) 概念 场景:客户端请求 不存在的数据(如恶意攻击的非法 Key),由于缓存和数...

前端面经-nginx/docker
1.如何查看 Linux 系统负载?如何判断负载是否过高? 使用 top、htop 或 uptime 查看系统负载。 负载值(Load Average)反映 CPU 繁忙程度,理想情况下应小于 CPU 核心数。例如,4 核 CPU 的负载持续超过 4 表示…...

权限控制相关实现
Spring Boot-Shiro-Vue: 这个项目可以满足基本的权限控制需求,前后端都有,开箱即用...

[论文精读]Ward: Provable RAG Dataset Inference via LLM Watermarks
Ward: Provable RAG Dataset Inference via LLM Watermarks [2410.03537] Ward: Provable RAG Dataset Inference via LLM Watermarks ICLR 2025 Rebuttal:Ward: 可证明的 RAG 数据集推理通过 LLM 水印 | OpenReview --- Ward: Provable RAG Dataset Inference v…...

第23天-Python Flet 开发指南
环境准备 pip install flet 示例1:基础计数器应用 import flet as ftdef main(page: ft.Page):page.title = "计数器"page.vertical_alignment = ft.MainAxisAlignment.CENTERtxt_number = ft.TextField(value="0", text_align=ft.TextAlign.RIGHT, wid…...
——自定义状态)
LangGraph(五)——自定义状态
目录 1. 向状态添加键2. 更新工具中的状态3. 构建状态图4. 提示聊天机器人5. 添加人工协助6. 手动更新状态参考 1. 向状态添加键 通过向状态添加name和birthday键来更新聊天机器人对实体生日的研究: from typing import Annotated from typing_extensions import T…...

fatload使用方式
Fatload是U-Boot中的一个命令,用于从FAT文件系统加载二进制文件到内存中。其基本用法如下: fatload <interface> <dev[:part]> <addr> <filename> <bytes>interface:所使用的接口,如MMC、…...

Pytorch基础操作
面试的时候,PhD看我简历上面写了”熟悉pytorch框架“,然后就猛猛提问了有关于tensor切片的问题…当然是没答上来,因此在这里整理一下pytorch的一些基础编程语法,常看常新 PyTorch基础操作全解 一、张量初始化 PyTorch的核心数据…...

Femap许可证安装与配置指南
在电磁仿真领域,Femap凭借其卓越的性能和广泛的应用场景,已成为许多工程师和科研人员的首选工具。为了确保您能够顺利安装和配置Femap许可证,本文将提供详细的安装和配置指南,帮助您快速完成设置,开启高效的仿真之旅。…...
)
家用和类似用途电器的安全 第1部分:通用要求 与2005版差异(7)
文未有本标准免费下载链接。 ——增加了“对峰值电压大于15kV的,其放电电能应不超过350mJ”的要求(见8.1.4) 1. GB/T4706.1-2024: 8.1.4 如果易触及部件为下述情况,则不认为其是带电的。 ——该部件由安全特低电压供电,且: 对…...

基于Browser Use + Playwright 实现AI Agent操作Web UI自动化
Browser Use是什么 Browser Use是一个开源项目官网:Browser Use - Enable AI to control your browser,专为大语言模型(LLM)设计的只能浏览器工具,能够让AI像人类一样自然的浏览和操作网页,支持多标签页管…...

【题解-洛谷】B4302 [蓝桥杯青少年组省赛 2024] 出现奇数次的数
题目:B4302 [蓝桥杯青少年组省赛 2024] 出现奇数次的数 题目描述 奇数:指不能被 2 2 2 整除的整数。 例如: 3 3...

Redis SETNX:分布式锁与原子性操作的核心
SETNX 是 Redis 中的一个经典命令,全称是 Set if Not eXists(当键不存在时设置值)。它的核心作用是原子性地完成 “检查并设置” 操作,常用于分布式锁、防止重复提交等需要 “独占性” 的场景。 一、基本语法与返回值 命令格式&…...

常见字符串相似度算法详解
目录 引言 一、Levenshtein距离(编辑距离) 1.1 算法原理 1.2 Java实现 1.3 springboot中实现 二、Jaro-Winkler相似度 2.1 算法特点 2.2 Java实现 三、余弦相似度(向量空间模型) 3.1 实现步骤 3.2 Java实现 3.3 简化版…...

红蓝对抗中的网络安全设备操作手册
目录 🔐 关键要点 设备操作与实战应用 📊 1. 防火墙 (Firewall) 蓝队(防御)用法 红队(攻击)用法 🔍 2. 入侵检测/防护系统 (IDS/IPS) 蓝队(防御)用法 红队&#…...

用python实现汉字转拼音工具
用python实现汉字转拼音工具 主要功能特点: 多种拼音风格选择(带声调符号、数字声调、无声调)输出模式:可以选择“普通模式”(仅拼音)或“拼音注音”(每个汉字的拼音显示在上方)可…...

spring中的Interceptor使用说明
一、Interceptor 的核心概念 Interceptor(拦截器) 是 Spring MVC 提供的一种机制,用于在请求处理的不同阶段插入自定义逻辑。其核心作用包括: • 预处理:在控制器方法执行前进行权限校验、日志记录等。 • 后处理&am…...
)
Wi-Fi(无线局域网技术)
Wi-Fi(Wireless Fidelity,无线保真)是通过无线电波传输数据的技术,它使设备能够通过无线连接方式访问网络、共享文件或连接互联网。Wi-Fi已经成为现代家庭、办公室以及公共场所中常见的无线通信方式,支持的设备包括手机…...
)
MySQL Host 被封锁解决方案(全版本适用 + Java 后端优化)
引言 MySQL 中 “Host is blocked because of many connection errors” 是生产环境常见问题,若处理不当会导致服务中断。本文结合 MySQL 官方文档(5.5/8.0)、Java 后端最佳实践及企业级经验,提供从 “快速解封” 到 “根源优化”…...