(6)python爬虫--selenium
文章目录
- 前言
- 一、初识selenium
- 二、安装selenium
- 2.1 查看chrome版本并禁止chrome自动更新
- 2.1.1 查看chrome版本
- 2.1.2 禁止chrome更新自动更新
- 2.2 安装对应版本的驱动程序
- 2.3安装selenium包
- 三、selenium关于浏览器的使用
- 3.1 创建浏览器、设置、打开
- 3.2 打开/关闭网页及浏览器
- 3.3 浏览器的最大/小化
- 3.4 浏览器打开位置、尺寸
- 3.5 浏览器截图、网页刷新
- 四、selenium关于元素的使用
- 4.1 元素定位
- 4.2 元素交互操作
- 4.3 元素八种定位方式
- 4.3.1 元素定位-ID
- 4.3.2 元素定位-NAME
- 4.3.3 元素定位-CLASS_NAME
- 4.3.4 元素定位-TAG_NAME
- 4.3.5 元素定位-LINK_TEXT
- 4.3.6 元素定位-PARTIAL_LINK_TEXT
- 4.3.7 元素定位-CSS_SELECTOR
- 4.3.8 元素定位-XPATH
- 4.4 元素定位的隐式等待
- 案例一: 获取表单元素并修改
- 案例二:重复填写表单
- 五、三种浏览器获取框(警告框、确认框、提示框)
- 5.1 警告框
- 5.2 确认框
- 5.3 提示框
- 六、 iframe嵌套网页内部元素获取
- 七、获取元素以及判断可见性
- 八、 网页前进、后退
- 总结
前言
在当今快速发展的互联网时代,自动化测试和网络爬虫技术已经成为开发者和测试工程师不可或缺的技能。Python 作为一门简洁、高效的编程语言,凭借其丰富的生态库和易用性,成为了自动化测试和爬虫开发的首选工具之一。而 Selenium,作为一款强大的浏览器自动化工具,不仅能够模拟用户操作,还能处理动态加载的网页内容,为开发者提供了极大的便利。
无论是进行 Web 应用的自动化测试,还是从复杂的网站中抓取数据,Selenium 都能胜任。它支持多种浏览器(如 Chrome、Firefox、Edge 等),并提供了灵活的 API,使得开发者可以轻松实现页面元素的定位、交互和验证。此外,结合 Python 的简洁语法,Selenium 让自动化任务的编写变得更加高效和直观。
本文将带你深入探索 Python 与 Selenium 的结合使用,从基础的环境搭建到高级的实战技巧,帮助你快速掌握这一强大工具。无论你是刚入门的新手,还是希望进一步提升技能的开发者,相信本文都能为你提供有价值的参考和启发。
一、初识selenium
- 自动化测试:快速完成重复性网页测试,提高效率
- 处理动态内容:完美支持JavaScript渲染的现代网页
- 跨浏览器支持:Chrome/Firefox/Edge等主流浏览器都兼容
- Python绝配:配合Requests/BeautifulSoup等库更强大
- 数据采集:解决普通爬虫无法处理的交互式网站
- 就业优势:Web自动化的必备技能,提升职场竞争力
简而言之:Selenium让网页自动化变得简单高效!
二、安装selenium
注意: 这里所有的举例都采用chrome浏览器。对于其他浏览器大致步骤一致。
2.1 查看chrome版本并禁止chrome自动更新
2.1.1 查看chrome版本
步骤: 设置 ➡ ➡ 关于chrome ➡ ➡ 查看版本

2.1.2 禁止chrome更新自动更新
chrome自动更新会导致chrome驱动出现失效问题,因而需要禁止自动更新。
详细步骤:
Win+ R 打开输入services.msc
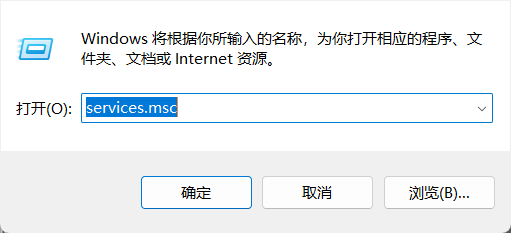
找到所有关于Google更新的相关程序,双击打开改为禁用即可

重新打开chrome 出现该效果即表示成功

2.2 安装对应版本的驱动程序
网址:
https://storage.googleapis.com/chrome-for-testing-public/你的版本号/win64/chromedriver-win64.zip
安装好对应的zip包之后,将其解压,复制一份chromedriver.exe程序

2.3安装selenium包
安装方式:通过之前安装(lxml,jsonpath等)操作来安装selenium,这里不再介绍。
三、selenium关于浏览器的使用
3.1 创建浏览器、设置、打开
注意:第一步先将复制的文件粘贴到对应的项目下面
测试:
# 用于操作浏览器
# from selenium import webdriver
# 用于设置谷歌浏览器
# from selenium.webdriver.chrome.options import Options
# 用于管理谷歌驱动
# from selenium.webdriver.chrome.service import Service# (1)导包
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service# 创建浏览器对象
options = Options()
# 禁用沙盒模式(增加兼容性)--- 如果没有出现秒闪退问题,可以不填入
options.add_argument('--no-sandbox')
# 保持浏览器打开状态(默认执行完之后会自动关闭)
options.add_experimental_option("detach", True)
# 创建并启动浏览器
browse = webdriver.Chrome(service=Service('chromedriver.exe'),options=options)
3.2 打开/关闭网页及浏览器
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
import time# 封装
def setup():options = Options()options.add_experimental_option("detach", True)browser = webdriver.Chrome(service=Service('chromedriver.exe'),options=options)return browserbrowser = setup()
# 打开指定的网址
browser.get('https://www.baidu.com')
# 打印源码
print(browser.page_source)
time.sleep(3)
# 关闭当前的标签页
browser.close()
# 退出浏览器并释放驱动
browser.quit()
3.3 浏览器的最大/小化
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Servicedef setup():options = Options()options.add_experimental_option("detach", True)browser = webdriver.Chrome(service=Service('chromedriver.exe'),options=options)return browserbrowser = setup()browser.get('https://www.baidu.com')
time.sleep(2)
# 浏览器最大化
browser.maximize_window()
time.sleep(2)
# 浏览器最小化
browser.minimize_window()
time.sleep(2)
# 重新返回最大化
browser.maximize_window()
time.sleep(2)
# 关闭浏览器
browser.quit()
3.4 浏览器打开位置、尺寸
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Servicedef setup():options = Options()options.add_experimental_option('detach', True)browser = webdriver.Chrome(service=Service('chromedriver.exe'), options=options)return browserbrowser = setup()# 单位均为像素
# 设置浏览器打开的位置(相对于左上角)
browser.set_window_position(100,100)
# 设置宽高px
browser.set_window_size(800,600)
# 关闭浏览器
browser.quit()
3.5 浏览器截图、网页刷新
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
import time
def setup():options = Options()options.add_experimental_option('detach', True)browser = webdriver.Chrome(service=Service('chromedriver.exe'), options=options)return browserbrowser = setup()
browser.get('https://www.baidu.com')
# 浏览器截图(尽量保存为png的格式)
browser.get_screenshot_as_file('baidu.png')
time.sleep(3)
# 刷新当前页
browser.refresh()
time.sleep(3)
# 关闭
browser.quit()
四、selenium关于元素的使用
4.1 元素定位
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import time
def setup():options = Options()options.add_experimental_option('detach', True)browser = webdriver.Chrome(service=Service('chromedriver.exe'), options=options)return browserbrowser = setup()
browser.get('https://www.baidu.com')
# 使用元素定位需要先导入对应的包
# from selenium.webdriver.common.by import By# 例如根据ID查找百度首页的输入框
# <input id="kw" name="wd"># find_element用来查找一个元素时使用
# 找不到时会直接报错
# 类似于根据id查找的,使用该方法即可,id是元素的唯一标识
input = browser.find_element(By.ID, 'kw')
# 获取class
print(input.get_attribute('class'))
# 获取标签名
print(input.tag_name)# find_elements用来查找多个元素时使用
# 返回的是列表,找不到时不会报错会返回一个空列表
inputs = browser.find_elements(By.ID, 'kw')
print(inputs)# 提示一下:也可以在浏览器的控制台输入
# document.getElementById('kw') 来先查找一下# 关闭浏览器
browser.quit()
4.2 元素交互操作
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import Bydef setup():options = Options()options.add_experimental_option('detach',True)browser = webdriver.Chrome(service=Service('chromedriver.exe'),options=options)return browserbrowser = setup()# 获取指定的网址
browser.get('https://www.baidu.com')
input = browser.find_element(By.ID,'kw')
# 元素输入
input.send_keys('fasgfagasgasg')
time.sleep(3)
# 元素清空
input.clear()
time.sleep(2)
# 元素再次输入
input.send_keys('古诗文')
time.sleep(2)
# 获取搜索按钮
button = browser.find_element(By.ID,'su')
# 调用按钮的点击方法
button.click()
time.sleep(2)
# 关闭浏览器
browser.quit()
4.3 元素八种定位方式
4.3.1 元素定位-ID
通过id定位元素结果基本上就是我们想要的元素,准确性比较高。
input = browser.find_element(By.ID, 'kw')
4.3.2 元素定位-NAME
通过name属性来获取元素,也是比较精准的。
input = browser.find_element(By.ID, 'kw')
4.3.3 元素定位-CLASS_NAME
使用class属性来查找元素,容易出现多个元素,因而往往需要用切片处理方式
注意:如果class属性值中包含空格是无法正常获取的
element = browser.find_element(By.CLASS_NAME, 'bg s_btn')
4.3.4 元素定位-TAG_NAME
通过tag标签来查找元素,缺点是获取的元素比较多,需要切片找到需要的元素
element = browser.find_element(By.TAG_NAME, 'input')
4.3.5 元素定位-LINK_TEXT
只标识a标签中的链接文字,根据链接文字查找元素
element = browser.find_element(By.LINK_TEXT, '新闻')
4.3.6 元素定位-PARTIAL_LINK_TEXT
与LINK_TEXT区别是,虽然都是通过链接文本获取元素,但是PARTIAL_LINK_TEXT是在LINK_TEXT的基础上增加了模糊匹配
element = browser.find_element(By.PARTIAL_LINK_TEXT, '地')
4.3.7 元素定位-CSS_SELECTOR
# 通过id等位
element = browser.find_element(By.CSS_SELECTOR, '#kw')
# 通过class定位
element = browser.find_element(By.CSS_SELECTOR, '.s_ipt')
# 不加修饰符(输入标签名)
element = browser.find_element(By.CSS_SELECTOR, 'input')
# 通过任意类型定位
# 精确匹配
element = browser.find_element(By.CSS_SELECTOR, '[value="百度一下"]')
# 模糊匹配
element = browser.find_element(By.CSS_SELECTOR, '[value*="百度"]')
# 匹配开头
element = browser.find_element(By.CSS_SELECTOR, '[value^="百"]')
# 匹配结尾
element = browser.find_element(By.CSS_SELECTOR, '[value$="一下"]')
以上都属于理论定位法,可以直接通过谷歌浏览器复制唯一的selector来确定元素
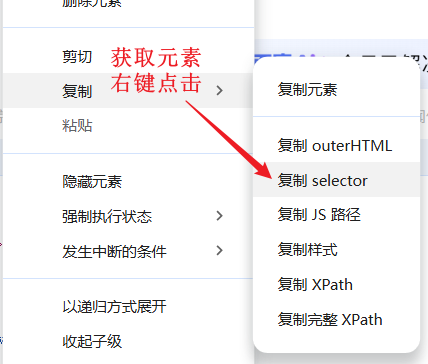
element = browser.find_element(By.CSS_SELECTOR, '#su')
4.3.8 元素定位-XPATH
打开谷歌浏览器,直接复制该元素的XPATH即可,与上述操作基本一致

当一个无法获取到指定元素的时候,采用第二个完整xpath写法
# Xpath
element = browser.find_element(By.XPATH, '//*[@id="su"]')
# 完成Xpath
element = browser.find_element(By.XPATH, '/html/body/div[1]/div[1]/div[5]/div/div/form/span[2]/input')
4.4 元素定位的隐式等待
隐式等待的作用是为了防止,当我们进入到一个页面时,该元素未第一时间加载出来,到底找不到元素而引发的报错。
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import Bydef setup():options = Options()options.add_experimental_option("detach", True)browser = webdriver.Chrome(service=Service('chromedriver.exe'),options=options)# 设置性代码,只要获取元素都会先等待10s 10s之后才会出现异常# 并且只需要设置一次即可browser.implicitly_wait(10)return browserbrowser = setup()browser.get(r'本地文件的绝对路径')
# time.sleep(4)
div = browser.find_element(By.CSS_SELECTOR,'#delayed-element')
print(div)
对应的html文件
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>隐式等待测试页面</title>
</head>
<body><h1>隐式等待测试</h1><div id="immediate-element">这个元素是立即存在的</div><script>// 5秒后动态添加一个元素setTimeout(function() {let newElement = document.createElement("div");newElement.id = "delayed-element";newElement.textContent = "这个元素是5秒后出现的";document.body.appendChild(newElement);}, 3000);</script>
</body>
</html>
案例一: 获取表单元素并修改
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import Bydef setup():options = Options()options.add_experimental_option("detach", True)browser = webdriver.Chrome(service=Service('chromedriver.exe'), options=options)# 设置性代码,只要获取元素都会先等待10s 10s之后才会出现异常# 并且只需要设置一次即可browser.implicitly_wait(10)return browserbrowser = setup()browser.get(r'HTML文件绝对路径')# 单选
browser.find_element(By.XPATH, '/html/body/form/div[1]/label[2]').click()# 多选
browser.find_element(By.XPATH, '/html/body/form/div[2]/label[1]').click()
browser.find_element(By.XPATH, '/html/body/form/div[2]/label[2]').click()
browser.find_element(By.XPATH, '/html/body/form/div[2]/label[3]').click()# 下拉
browser.find_element(By.XPATH, '/html/body/form/div[3]/select/option[2]').click()# 日期框
browser.find_element(By.XPATH, '/html/body/form/div[4]/div/input').send_keys('20210912')# 上传文件
browser.find_element(By.XPATH, '/html/body/form/div[5]/input').send_keys(r'D:\Python-learning\pythonProject\02-homework\12-test\baidu.png')# 提交
browser.find_element(By.XPATH, '/html/body/form/button').click()对应的HTML文件
test.html
<!DOCTYPE html>
<html lang="zh-CN">
<head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>表单示例</title><style>body {font-family: Arial, sans-serif;max-width: 600px;margin: 0 auto;padding: 20px;}.form-group {margin-bottom: 20px;padding: 15px;border: 1px solid #ddd;border-radius: 5px;}.form-group h3 {margin-top: 0;margin-bottom: 15px;}.rating {display: flex;flex-direction: column;gap: 10px;}.rating-item {display: flex;align-items: center;}.rating-label {width: 100px;}.date-input {display: flex;align-items: center;}.date-input input {width: 120px;margin-right: 10px;}.date-format {color: #666;}</style>
</head>
<body><form action="ok.html" method="post"><!-- 单选框 --><div class="form-group"><h3>单选框</h3><label><input type="radio" name="language" value="Python" checked> Python</label><br><label><input type="radio" name="language" value="Java"> Java</label><br><label><input type="radio" name="language" value="C++"> C++</label></div><!-- 多选框 --><div class="form-group"><h3>多选框</h3><label><input type="checkbox" name="device" value="手机"> 手机</label><br><label><input type="checkbox" name="device" value="电脑"> 电脑</label><br><label><input type="checkbox" name="device" value="网页"> 网页</label></div><!-- 下拉菜单 --><div class="form-group"><h3>下拉</h3><select name="city"><option value="北京" selected>北京</option><option value="上海">上海</option><option value="广州">广州</option></select></div><!-- 日期选择 --><div class="form-group"><h3>日期</h3><div class="date-input"><input type="text" id="dateInput" placeholder="输入年月日如20240521" maxlength="8"><span id="dateDisplay" class="date-format">年 / 月 / 日</span></div><input type="hidden" id="formattedDate" name="date"></div><!-- 附件上传 --><div class="form-group"><h3>附件</h3><input type="file" name="attachment"></div><!-- 提交按钮 --><button type="submit">提交</button></form><script>document.getElementById('dateInput').addEventListener('input', function(e) {let value = e.target.value.replace(/\D/g, ''); // 移除非数字字符if (value.length > 8) {value = value.substring(0, 8); // 限制最大长度为8}e.target.value = value; // 更新输入框值if (value.length === 8) {// 格式化为YYYY/MM/DDconst year = value.substring(0, 4);const month = value.substring(4, 6);const day = value.substring(6, 8);// 验证月份和日期是否有效const validMonth = parseInt(month) >= 1 && parseInt(month) <= 12;const validDay = parseInt(day) >= 1 && parseInt(day) <= 31;if (validMonth && validDay) {const formattedDate = `${year}/年${month}/月${day}日`;document.getElementById('dateDisplay').textContent = formattedDate;document.getElementById('formattedDate').value = formattedDate;} else {document.getElementById('dateDisplay').textContent = '日期无效';document.getElementById('formattedDate').value = '';}} else {document.getElementById('dateDisplay').textContent = '年 / 月 / 日';document.getElementById('formattedDate').value = '';}});</script>
</body>
</html>
ok.html
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>Title</title>
</head>
<body>
<h1>提交成功!!!</h1>
<a href="./test.html" target="_blank">跳转到填写页面</a>
</body>
</html>
案例二:重复填写表单
提示:需要使用到句柄
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import Bydef setup():options = Options()options.add_experimental_option("detach", True)browser = webdriver.Chrome(service=Service('chromedriver.exe'), options=options)# 设置性代码,只要获取元素都会先等待10s 10s之后才会出现异常# 并且只需要设置一次即可browser.implicitly_wait(10)return browserbrowser = setup()browser.get(r'HTML文件绝对路径')# 循环重复
for x in range(2):time.sleep(2)# 单选browser.find_element(By.XPATH, '/html/body/form/div[1]/label[2]').click()# 多选browser.find_element(By.XPATH, '/html/body/form/div[2]/label[1]').click()browser.find_element(By.XPATH, '/html/body/form/div[2]/label[2]').click()browser.find_element(By.XPATH, '/html/body/form/div[2]/label[3]').click()# 下拉browser.find_element(By.XPATH, '/html/body/form/div[3]/select/option[2]').click()# 日期框browser.find_element(By.XPATH, '/html/body/form/div[4]/div/input').send_keys('20210912')# 上传文件browser.find_element(By.XPATH, '/html/body/form/div[5]/input').send_keys(r'上传文件绝对路径')time.sleep(2)# 提交browser.find_element(By.XPATH, '/html/body/form/button').click()# 点击返回browser.find_element(By.XPATH, '/html/body/a').click()# 打开了新页面之后,我们要获取到全部的句柄(也就是所有的标签页)handles = browser.window_handles# print(handles)# 关闭之前的标签页browser.close()# 通过句柄切换到新的标签页browser.switch_to.window(handles[1])# 获取当前页句柄# print(browser.current_window_handle)
五、三种浏览器获取框(警告框、确认框、提示框)
➡➡➡测试网址
5.1 警告框
示例代码:
def setup():options = Options()options.add_experimental_option("detach", True)browser = webdriver.Chrome(service=Service('chromedriver.exe'), options=options)# 设置性代码,只要获取元素都会先等待10s 10s之后才会出现异常# 并且只需要设置一次即可browser.implicitly_wait(10)return browserbrowser = setup()browser.get('https://sahitest.com/demo/alertTest.htm')# 清空输入框的默认值
browser.find_element(By.XPATH,"/html/body/form/input[1]").clear()
time.sleep(2)# 修改输入框的值
browser.find_element(By.XPATH,"/html/body/form/input[1]").send_keys('大家一起学Python')# 点击按钮
browser.find_element(By.XPATH,"/html/body/form/input[2]").click()# 获取弹窗的内容
print(browser.switch_to.alert.text)time.sleep(2)
# 点击确认按钮
browser.switch_to.alert.accept()
5.2 确认框
➡➡➡测试网址
5.3 提示框
示例代码
def setup():options = Options()options.add_experimental_option("detach", True)browser = webdriver.Chrome(service=Service('chromedriver.exe'), options=options)# 设置性代码,只要获取元素都会先等待10s 10s之后才会出现异常# 并且只需要设置一次即可browser.implicitly_wait(10)return browserbrowser = setup()browser.get('https://sahitest.com/demo/confirmTest.htm')# 点击按钮browser.find_element(By.XPATH,'/html/body/form/input[1]').click()time.sleep(2)
# 点击确认按钮
# browser.switch_to.alert.accept()# 点击取消按钮
browser.switch_to.alert.dismiss()➡➡➡测试网址
示例代码:
def setup():options = Options()options.add_experimental_option("detach", True)browser = webdriver.Chrome(service=Service('chromedriver.exe'), options=options)# 设置性代码,只要获取元素都会先等待10s 10s之后才会出现异常# 并且只需要设置一次即可browser.implicitly_wait(10)return browserbrowser = setup()browser.get('https://sahitest.com/demo/promptTest.htm')# 点击按钮
browser.find_element(By.XPATH,'/html/body/form/input[1]').click()time.sleep(2)# 输入内容
browser.switch_to.alert.send_keys("123456")
time.sleep(2)# 点击确认按钮
browser.switch_to.alert.accept()六、 iframe嵌套网页内部元素获取
➡➡➡测试网址
示例代码:
def setup():options = Options()options.add_experimental_option("detach", True)browser = webdriver.Chrome(service=Service('chromedriver.exe'), options=options)# 设置性代码,只要获取元素都会先等待10s 10s之后才会出现异常# 并且只需要设置一次即可browser.implicitly_wait(10)return browserbrowser = setup()browser.get('https://sahitest.com/demo/iframesTest.htm')# iframe嵌套网页 里面的元素 不能够直接获取 因为不在同一个框架里面# 1. 获取iframe元素
iframe = browser.find_element(By.XPATH, '/html/body/iframe')# 2. 进入到iframe里面
browser.switch_to.frame(iframe)# 获取元素并点击
browser.find_element(By.XPATH, '/html/body/table/tbody/tr/td[1]/a[1]').click()
time.sleep(2)
# 此时如果想要获取原页面中的元素就必须退出iframe
browser.switch_to.default_content()time.sleep(2)
# 获取原页面元素
browser.find_element(By.XPATH, '/html/body/input[2]').click()
七、获取元素以及判断可见性
selenium提供了一些基础的爬虫方式。
示例代码:
def setup():options = Options()options.add_experimental_option("detach", True)browser = webdriver.Chrome(service=Service('chromedriver.exe'), options=options)# 设置性代码,只要获取元素都会先等待10s 10s之后才会出现异常# 并且只需要设置一次即可browser.implicitly_wait(10)return browserbrowser = setup()browser.get('https://content-static.cctvnews.cctv.com/snow-book/video.html?item_id=932400080038356852')# 获取元素内容 text
content = browser.find_element(By.XPATH,"/html/body/div/div/div/div[2]/div[1]/div[1]/div/div[5]/div/article/p[1]").text
print(content)# 获取元素可见性
# 简单来说 就是判断这个元素我们能否在页面上看见
flag = browser.find_element(By.XPATH,"/html/head/meta[2]").is_displayed()
print(flag)
八、 网页前进、后退
示例代码:
def setup():options = Options()options.add_experimental_option("detach", True)browser = webdriver.Chrome(service=Service('chromedriver.exe'), options=options)# 设置性代码,只要获取元素都会先等待10s 10s之后才会出现异常# 并且只需要设置一次即可browser.implicitly_wait(10)return browserbrowser = setup()browser.get('https://www.baidu.com')input = browser.find_element(By.ID, 'kw')
input.send_keys('selenium')button = browser.find_element(By.ID, 'su')
button.click()time.sleep(3)
# 网页后退
browser.back()
time.sleep(2)
# 网页前进
browser.forward()
time.sleep(2)
# 关闭
browser.quit()
总结
通过本文的学习,我们系统地了解了 Python 与 Selenium 的结合使用,涵盖了从基础配置到实际应用的多个方面。Selenium 不仅简化了 Web 自动化测试的流程,还为数据采集和动态网页交互提供了强大的支持。借助 Python 的灵活性和 Selenium 的丰富功能,开发者能够高效地完成复杂的任务,无论是自动化测试、爬虫开发,还是网页监控。
当然,Selenium 的强大功能也伴随着一定的学习曲线,尤其是在处理动态内容、反爬机制或复杂的页面结构时,可能需要更多的技巧和经验积累。但只要你掌握了核心的定位与交互方法,并学会利用等待机制、多窗口切换等高级功能,就能应对绝大多数场景的需求。
希望本文能为你打开 Selenium 世界的大门,让你在自动化测试或数据抓取的道路上更加得心应手。技术的进步永无止境,不断实践和探索,你将发现更多 Selenium 与 Python 结合的奇妙用法。继续加油,愿你在自动化的世界中创造更多可能!
相关文章:
python爬虫--selenium)
(6)python爬虫--selenium
文章目录 前言一、初识selenium二、安装selenium2.1 查看chrome版本并禁止chrome自动更新2.1.1 查看chrome版本2.1.2 禁止chrome更新自动更新 2.2 安装对应版本的驱动程序2.3安装selenium包 三、selenium关于浏览器的使用3.1 创建浏览器、设置、打开3.2 打开/关闭网页及浏览器3…...

MCU 上电不启动的常见原因分析与排查思路
在开发过程中,“MCU 上电不运行”是我们经常遇到的问题之一。但客户对此类问题的描述往往较为模糊,仅简单表示“产品不工作”或“怀疑 MCU 没有运行”,这给我们现场排查带来了较大的挑战。即便工程师到达现场,往往也无法迅速定位问…...

Spark Core 源码关键环节的深度解析
以下是对 Spark Core 源码关键环节的深度解析,包括核心组件启动与调度机制、Shuffle与调度系统、RDD高级机制。每个环节都细化到具体方法、逻辑、源码片段,附有流程图思路与速记口诀,便于记忆和理解。 一、核心组件启动与调度机制 1. RpcEnv…...

net Core》》包与库 LibMan、NPM
LibMan 资料 NPM 资料 在 Visual Studio 中使用 npm package.json 保存之后 vs会自动下载的。 注意:如果您没有看到 node_modules 文件夹,请确保在 Visual Studio 解决方案资源管理器中启用了“显示所有文件”选项 要卸载该库,您只需从 …...

数学建模,机器决策人建模
目录 数学建模 微分方程 动态系统建模 时间序列分析 概述 指数衰减 随机漂移 总结 曲线拟合 最优化方法 梯度下降法 概率建模(如贝叶斯建模、马尔可夫过程、MDP/POMDP) 等 贝叶斯建模 贝叶斯定理 优势 马尔可夫过程 马尔可夫过程的分类…...

FFmpeg中使用Android Content协议打开文件设备
引言 随着Android 10引入的Scoped Storage(分区存储)机制,传统的文件访问方式发生了重大变化。FFmpeg作为强大的多媒体处理工具,也在不断适应Android平台的演进。本文将介绍如何在FFmpeg 7.0版本中使用Android content协议直接访…...

SQL查询, 响应体临时字段报: Unknown column ‘data_json_map‘ in ‘field list‘
Overridepublic AjaxResult list(AgentPageReqVO pageReqVO, Integer pageNo, Integer pageSize) {// 1. 查询数据库获取代理列表List<AgentDO> list agentMapper.selectPage(pageReqVO).getList();// 如果结果为空,直接返回空分页结果if (CollectionUtils.i…...
——LBPH人脸识别)
OpenCv高阶(十四)——LBPH人脸识别
文章目录 前言一、LBPH原理1. LBP(局部二值模式)特征提取2. 图像分块处理3. 生成直方图4. 人脸识别(匹配阶段)5. LBPH的特点6. 变种与优化 二、LBPH人脸识别简单实现(一)LBPH人脸识别1、图像读取࿰…...

C#开发利器:SharpBoxesCore全解析
SharpBoxesCore 是一个基于 C# 的开源开发工具库,旨在为开发者提供一系列常用功能模块和辅助类,以提高开发效率、减少重复代码编写,并增强项目的可维护性和扩展性。该库集成了多种实用工具类和通用扩展方法,适用于桌面应用、Web 项…...

回表是数据库概念,还是mysql的概念?
主键索引没有列,根据耳机索引去查主键索引,又没有查表,为啥叫回表呢? “回表”这个词,其实算是数据库里的一个通用概念,不过它最常见的应用场景是在 MySQL 的 InnoDB 引擎里,所以很多人一提起回…...

49、c# 能⽤foreach 遍历访问的对象需满足什么条件?
在 C# 中,要使用 foreach 循环遍历一个对象,该对象必须满足以下条件之一: 1. 实现 IEnumerable 或 IEnumerable 接口 非泛型版本:System.Collections.IEnumerable public class MyCollection : IEnumerable {private int[] _da…...

DL00987-基于深度学习YOLOv11的红外鸟类目标检测含完整数据集
提升科研能力,精准识别红外鸟类目标! 完整代码数据集见文末 针对科研人员,尤其是研究生们,是否在鸟类目标检测中遇到过数据不够精准、处理困难等问题?现在,我们为你提供一款基于深度学习YOLOv11的红外鸟类…...

07 接口自动化-用例管理框架之pytest单元测试框架
文章目录 一、pytest用例管理框架(单元测试框架)二、pytest简介三、pytest的最基本的测试用例的规则四、运行方式1.主函数方式2.命令行方式3.通过pytest.ini的配置文件运行 五、pytest 默认执行测试用例的顺序六、跳过测试用例1.无条件跳过 pytest.mark.…...

Flutter 中 build 方法为何写在 StatefulWidget 的 State 类中
Flutter 中 build 方法为何写在 StatefulWidget 的 State 类中 在 Flutter 中,build 方法被设计在 StatefulWidget 的 State 类中而非 StatefulWidget 类本身,这种设计基于几个重要的架构原则和实际考量: 1. 核心设计原因 1.1 生命周期管理…...
)
多技术栈 iOS 项目的性能调试实战:从 Flutter 到 Unity(含 KeyMob 工具实测)
多技术栈 iOS 项目的性能调试实战:从 Flutter 到 Unity 随着移动端开发日趋多元化,iOS 项目中纯 Objective-C/Swift 已不再是唯一选择。越来越多团队采用 Flutter、React Native、Unity、WebView 混合等方案构建 App。这种“技术栈混合”带来灵活性的同…...

Base64加密解密
Base64 是一种基于 64 个可打印字符来表示二进制数据的编码方式,常用于需要通过文本协议传输二进制数据的场景(如 URL、邮件)。以下是不同场景下生成 Base64 编码的方法: 一、编程语言实现 Python import base64# 字符串转Base…...
)
程序设计基础----排序(2)
1、冒泡排序 #include <stdio.h>#define N 1000 int arr[N];/* 对长度为n的数组arr执行冒泡排序 */ void bubbleSort(int arr[], int n);/* 打印长度为n的数组arr */ void printArray(int arr[], int n);void swap(int *xp, int *yp) {int temp *xp;*xp *yp;*yp temp…...

C++:vector容器
vector容器与array容器相似,但vector容器是动态的,可以自动扩容。 使用方法和一些注意如下: #include<iostream> #include<vector> using namespace std;int main() {vector<char> vec { a,b,c,d };vec[4] e;//不能以此…...

十四、Hive 视图 Lateral View
作者:IvanCodes 日期:2025年5月20日 专栏:Hive教程 在Hive中,我们经常需要以不同于原始表结构的方式查看或处理数据。为了简化复杂查询、提供数据抽象,以及处理复杂数据类型(如数组或Map)&#…...

Frp Dockr Mysql内网映射
用 FRP 远程暴露 Mac mini 上的 Docker-MySQL(含 Ubuntu frps 安装和 macOS 客户端配置) 一、环境说明 服务器(公网):Ubuntu 22.04 frps内网设备:macOS (Mac mini) frpc Docker MySQL目标:…...
)
PHP 扇形的面积(Area of a Circular Sector)
圆形扇区或圆形扇区是圆盘上由两个半径和一个圆弧围成的部分,其中较小的区域称为小扇区,较大的区域称为大扇区。让我们看看这个图,试着找出扇区: 在该图中,绿色阴影部分是扇形,“r”是半径,“th…...

物业后勤小程序源码介绍
基于ThinkPHPFastAdminUniApp开发的物业后勤小程序源码,它为物业管理提供了高效便捷的解决方案。 该源码功能丰富,涵盖房屋认证、家人认证,保障社区居住安全;支持报事报修、装修申请,方便业主与物业沟通;还…...

git基础操作
当远程仓库迁移到一个新的组下面时,你需要在本地仓库中更新远程仓库的URL,以便与新的远程仓库关联。以下是详细步骤: 获取新的远程仓库URL: 首先,你需要从GitLab或相关平台获取新组下的仓库的新URL。通常,仓…...

鸿蒙HarmonyOS 【ArkTS组件】通用属性-背景设置
📑往期推文全新看点(附带最新鸿蒙全栈学习笔记) 嵌入式开发适不适合做鸿蒙南向开发?看完这篇你就了解了~ 鸿蒙岗位需求突增!移动端、PC端、IoT到底该怎么选? 分享一场鸿蒙开发面试经验记录(三面…...

java 在用redis 的时候,如何合理的处理分页问题? redis应当如何存储性能最佳
在 Java 中使用 Redis 处理用户表分页时,需结合其数据结构特性优化存储和查询 1. 数据结构设计 场景需求 用户表字段:id, name, age, register_time(注册时间)分页要求:按注册时间倒序分页展示,每页 10 条…...

分类预测 | Matlab实现PNN概率神经网络多特征分类预测
分类预测 | Matlab实现PNN概率神经网络多特征分类预测 目录 分类预测 | Matlab实现PNN概率神经网络多特征分类预测分类效果代码功能算法流程程序设计参考资料分类效果 代码功能 该代码实现了一个基于**概率神经网络(PNN)**的多分类任务,核心功能如下: 数据预处理 读取Exce…...

spring-retry
学习链接 【SpringBoot】spring-retry(重试机制) 【Spring】Spring Retry CSDN有点可恶啊,拿着别人的文章,要开VIP才能看...

RTMP协议解析【二】
文章目录 RTMP协议解析【二】RTMP消息消息的格式Basic HeaderMessage HeaderExtended Timestamp RTMP协议解析【二】 本专栏重点负责介绍RTMP协议的理论部分, 跳过定义,协议与其他协议的优缺点对比,协议的拓展与改进,协议的历史发…...

WebGL2混合与雾
混合技术 一、混合基本技术 混合技术就是将两个片元调和,主要通过各种测试将准备进入帧缓冲(源片元)与帧缓冲中原有片元(目标片元)按照设定的比例加权计算出最终片元的颜色值 。 两种常用 组合 : 源因子…...

Windows Docker笔记-扩展
docker扩展知识点 开放容器端口 背景,有一个docker Centos7镜像,运行容器后,想要通过22端口远程这个容器 创建容器时开放映射端口,将容器的22端口映射到本地的22端口 docker run -p <宿主机端口>:<容器端口> 镜像名…...

【C++ Primer 学习札记】智能指针
1)std::unique_ptr(独占所有权) 特点: 独占资源的所有权,同一时间只能有一个 unique_ptr 指向特定对象。 不可复制,但可以通过 std::move 转移所有权。 轻量级,几乎无额外开销(与…...
—— 政安晨:改造小智AI开发智能体硬件(案例:移植PowerManager后麦克风不工作))
【嵌入式人工智能产品开发实战】(二十二)—— 政安晨:改造小智AI开发智能体硬件(案例:移植PowerManager后麦克风不工作)
政安晨的个人主页:政安晨 欢迎 👍点赞✍评论⭐收藏 希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正! 目录 确定你硬件的关键点 案例分析 🔍 一、关键代码分析 ✅ 1. power_save_…...

Taro Error: chunk common [mini-css-extract-plugin]
目录 一、问题描述 二、解决方案 一、问题描述 taro项目编译时抛出一下异常: Error: chunk common [mini-css-extract-plugin] Conflicting order. Following module has been added: * css ./node_modules/css-loader/dist/cjs.js??ruleSet[1].rules[4].oneOf…...
:渐进式分层提取模型PLE(Progressive Layered Extraction))
【深度学习】多目标融合算法(六):渐进式分层提取模型PLE(Progressive Layered Extraction)
目录 一、引言 二、PLE(Progressive Layered Extraction,渐进式分层提取模型) 2.1 技术原理 2.2 技术优缺点 2.3 业务代码实践 2.3.1 业务场景与建模 2.3.2 模型代码实现 2.3.3 模型训练与推理测试 2.3.4 打印模型结构 三、总结 一…...

ping、tcpping、psping、paping、hping的区别
ping、tcpping、psping、paping、hping的区别 这些工具都是用于网络测试的,但它们在功能和协议上有所不同,适用于不同的场景。 ping 基本功能: 发送ICMP echo请求包,并等待接收echo应答包,从而判断网络是否连通&…...

【Redis8】最新安装版与手动运行版
1. 下载 Redis 百度网盘 2. 解压后直接运行 redis-server.exe 3. 使用安装版 双击 install_redis_service.bat 输入安装路径(请提前创建好安装路径)后直接回车下一步直接回车即可,因为是使用配置模板文件为默认解压出来的,然后…...
学习笔记(CLASS 1):组件)
前端(小程序)学习笔记(CLASS 1):组件
1、小程序中组件的分类 小程序中的组件也是由宿主环境提供的,开发者可以基于组件快速搭建出漂亮的页面结构。官方把小程序的组件分为了9大类,分别是: * 视图容器,* 基础内容,* 表单组件,* 导航组件 媒体…...

Python MD5加密算法脚本
基本概念 MD5(Message Digest Algorithm 5)是一种常用的哈希函数,用于将任意长度的数据转换为固定长度的哈希值,通常为128位(16字节)。 特点 不可逆性:无法从哈希值还原出原始数据。无论原始…...

Python数据分析实战:Pandas高效处理Excel数据指南
目录 引言:为什么选择Pandas处理Excel? 一、环境搭建与数据读取 1.1 基础环境配置 1.2 数据高效载入技巧 二、数据清洗核心战术 三、数据加工实战案例 3.1 销售数据透视分析 3.2 异常值检测 3.3 跨表关联分析 四、性能优化秘籍 4.1 大文件处理…...

使用Starrocks制作拉链表
5月1日向ods_order_info插入3条数据: CREATE TABLE ods_order_info(dt string,id string COMMENT 订单编号,total_amount decimal(10,2) COMMENT 订单金额 ) PRIMARY KEY(dt, id) PARTITION BY (dt) DISTRIBUTED BY HASH(id) PROPERTIES ( "replication_num&q…...

【npm】npm命令大全
掌握 NPM:前端与 Node.js 开发者必备命令大全 NPM (Node Package Manager) 无疑是现代 JavaScript 开发的基石。无论是前端项目还是 Node.js 后端服务,NPM 都扮演着管理依赖、执行脚本、发布模块等关键角色。熟悉并熟练使用 NPM 命令,能够极…...

最新版Chrome浏览器调用ActiveX控件技术——alWebPlugin中间件V2.0.42版发布
allWebPlugin简介 allWebPlugin中间件是一款为用户提供安全、可靠、便捷的浏览器插件服务的中间件产品,致力于将浏览器插件重新应用到所有浏览器。它将现有ActiveX控件直接嵌入浏览器,实现插件加载、界面显示、接口调用、事件回调等。支持Chrome、Firefo…...

32核64G内存的物理机上,Netty理论能承载多少连接?
在 32核64G内存 的机器上,Netty 能承载的连接数取决于 业务场景、配置优化 和 操作系统调优。 以下是详细分析和实测数据参考: 1. 理论估算(基于资源限制) 资源影响内存每个连接占用 10KB~1MB(取决于业务࿰…...

对于final、finally和finalize不一样的理解
目录 1、final 1.1、不可变性(Immutability) 1.2、内存可见性(Visibility) 1.3、初始化安全(Initialization Safety) 1.4、禁止重排序(Reordering) 1、静态常量 2、实例常量 …...

Open CASCADE学习|刚体沿曲线运动实现方法
在三维几何建模中,刚体沿参数化曲线的运动模拟是机械运动仿真、机器人路径规划等领域的核心需求。本文基于Open Cascade几何内核,系统阐述刚体沿曲线运动的实现方法,重点解析标架构建、坐标变换及鲁棒性控制等关键技术。 一、基于标架的刚体运…...
?)
工作流引擎-03-聊一聊什么是流程引擎(Process Engine)?
前言 大家好,我是老马。 最近想设计一款审批系统,于是了解一下关于流程引擎的知识。 下面是一些的流程引擎相关资料。 工作流引擎系列 工作流引擎-00-流程引擎概览 工作流引擎-01-Activiti 是领先的轻量级、以 Java 为中心的开源 BPMN 引擎&#x…...

centos7 p8p1使用ip addr查看时有的时候有两个ip,有的时候只有一个ip,有一个ip快,有一个ip慢
在CentOS 7系统中,网络接口 p8p1 出现IP地址数量变化且访问速度不一致的问题,通常与以下原因相关。以下是逐步排查与解决方案: 1. 检查网络配置文件 可能原因:存在多个配置文件或重复配置(如静态IP与DHCP冲突…...

回溯算法——排列篇
目录 一、全排列 二、全排列II 一、全排列 46. 全排列 - 力扣(LeetCode) class Solution {List<List<Integer>> resultnew ArrayList<>();LinkedList<Integer> pathnew LinkedList<>();boolean[] used;public List<…...

Unity中SRP Batcher使用整理
SRP Batcher 是一种绘制调用优化,可显著提高使用 SRP 的应用程序的性能,SRP Batcher 减少了Unity为使用相同着色器变体的材质准备和调度绘制调用所需的CPU 时间。 工作原理: 传统优化方法通过减少绘制调用次数提升性能,而SRP Batcher的核心理念在于降低绘制调用间的渲染状…...

【JAVA学习】泛型
传统方法不能对加入到集合ArrayList中的数据类型进行约束,遍历的时候需要进行类型转换,如果集合中的数据量较大,对效率有影响。泛型又称参数化类型,是JDK5.0出现的新特性,解决数据类型的安全性问题,在类声明…...