【深度学习】多目标融合算法(六):渐进式分层提取模型PLE(Progressive Layered Extraction)

目录
一、引言
二、PLE(Progressive Layered Extraction,渐进式分层提取模型)
2.1 技术原理
2.2 技术优缺点
2.3 业务代码实践
2.3.1 业务场景与建模
2.3.2 模型代码实现
2.3.3 模型训练与推理测试
2.3.4 打印模型结构
三、总结
一、引言
上一篇我们讲了PLE的前置模型CGC(Customized Gate Control)定制门控网络,核心思想是在MMoE基础上,为每一个任务tower定制独享专家,使用任务独享专家与共享专家共同决定任务Tower的输入,相比于MMoE仅用Gate门控表征任务Tower的方法,CGC引入独享专家,对任务表征更加全面,又通过共享专家保证关联性。
今天在CGC的基础上,重点讲解PLE(Progressive Layered Extraction)模型,可以理解PLE为CGC的多层堆叠,通过将独享专家、共享专家基于门控网络交叉学习,既能学习独有任务的特异性,又能学习共享信息。
二、PLE(Progressive Layered Extraction,渐进式分层提取模型)
2.1 技术原理
PLE(Progressive Layered Extraction)全称为渐进式分层提取模型,是一种改进的多任务学习模型,旨在解决多任务学习中的负迁移和跷跷板现象。PLE模型通过分层提取机制结合共享特征和任务特定特征,逐步优化多任务学习的性能。主要由多层CGC网络堆叠而成,每个CGC网络包含一组共享专家、若干组独立专家,通过对应的共享专家门控、独立专家门控对共享专家组、独立专家组内的多个MLP加权结果平均。
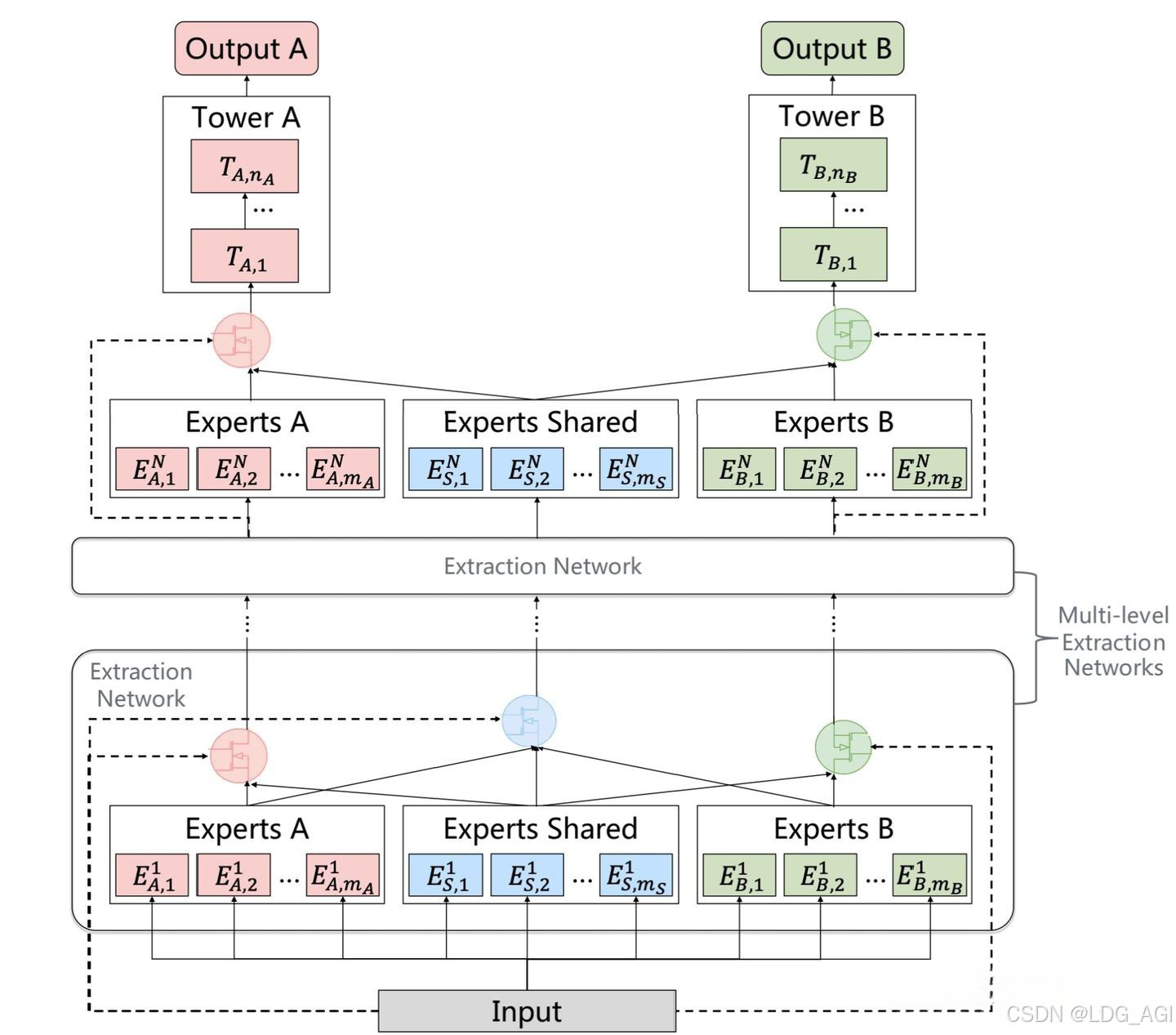
- 共享专家网络:样本数据分别输入num_shared_experts个专家网络进行推理,每个共享专家网络实际上是一个多层感知机(MLP),输入维度为x,输出维度为output_experts_dim。
- 独享专家网络:样本数据分别输入num_task_experts个专家网络进行推理,每个共享专家网络实际上是一个多层感知机(MLP),输入维度为x,输出维度为output_experts_dim。
- 门控网络:样本数据输出各自任务对应的门控网络,每个门控网络可以是一个多层感知机,也可以是一个双层的交叉,主要是为了输出专家网络的加权平均权重。
- 任务网络:对于每一个Task,将各自对应num_shared_experts个共享专家和num_task_experts个独立专家,基于对应gate门控网络的softmax加权平均,作为各自Task的输入,所有Task的输入统一维度均为output_experts_dim。
2.2 技术优缺点
相较于MMoE网络,CGC为每一个任务tower定制独享专家,实用任务独享专家与共享专家共同决定任务Tower的输入,相比于MMoE仅用Gate门控表征任务Tower的方法,CGC引入独享专家,对任务表征更加全面,又通过共享专家保证关联性。
优点:
- 分层提取结构:PLE通过多层提取机制逐步分离共享特征和任务特定特征,避免了传统多任务学习中的过度耦合问题。
- CGC(Customized Gate Control):每层包含共享专家和任务特定专家,通过门控机制动态分配特征,既保留了共享信息,又增强了任务特定性。
- 任务特定性增强:相比传统的多任务学习模型,PLE在每一层都为每个任务引入特定专家,增强了任务之间的解耦,提高了模型对不同任务的适应性。
- 多任务性能提升:通过分层结构和门控机制,PLE能在多任务场景中更好地平衡任务间冲突,提升整体性能。
缺点:
- 相较于DeepSeekMoE的路由方法,PLE专家组合不足。
2.3 业务代码实践
2.3.1 业务场景与建模
我们还是以小红书推荐场景为例,针对一个视频,用户可以点红心(互动),也可以点击视频进行播放(点击),针对互动和点击两个目标进行多目标建模

我们构建一个100维特征输入,2层CGC,第一层CGC包含1组共享专家网络(含2个共享专家),2组独享专家网络(各含2个独享专家),3个门控网络(1个共享门控,2个独立门控),第二层CGC包含1组共享专家网络(含2个共享专家),2组独享专家网络(各含2个独享专家),2个门控网络(2个独立门控),用于建模多目标学习问题,模型架构图如下:
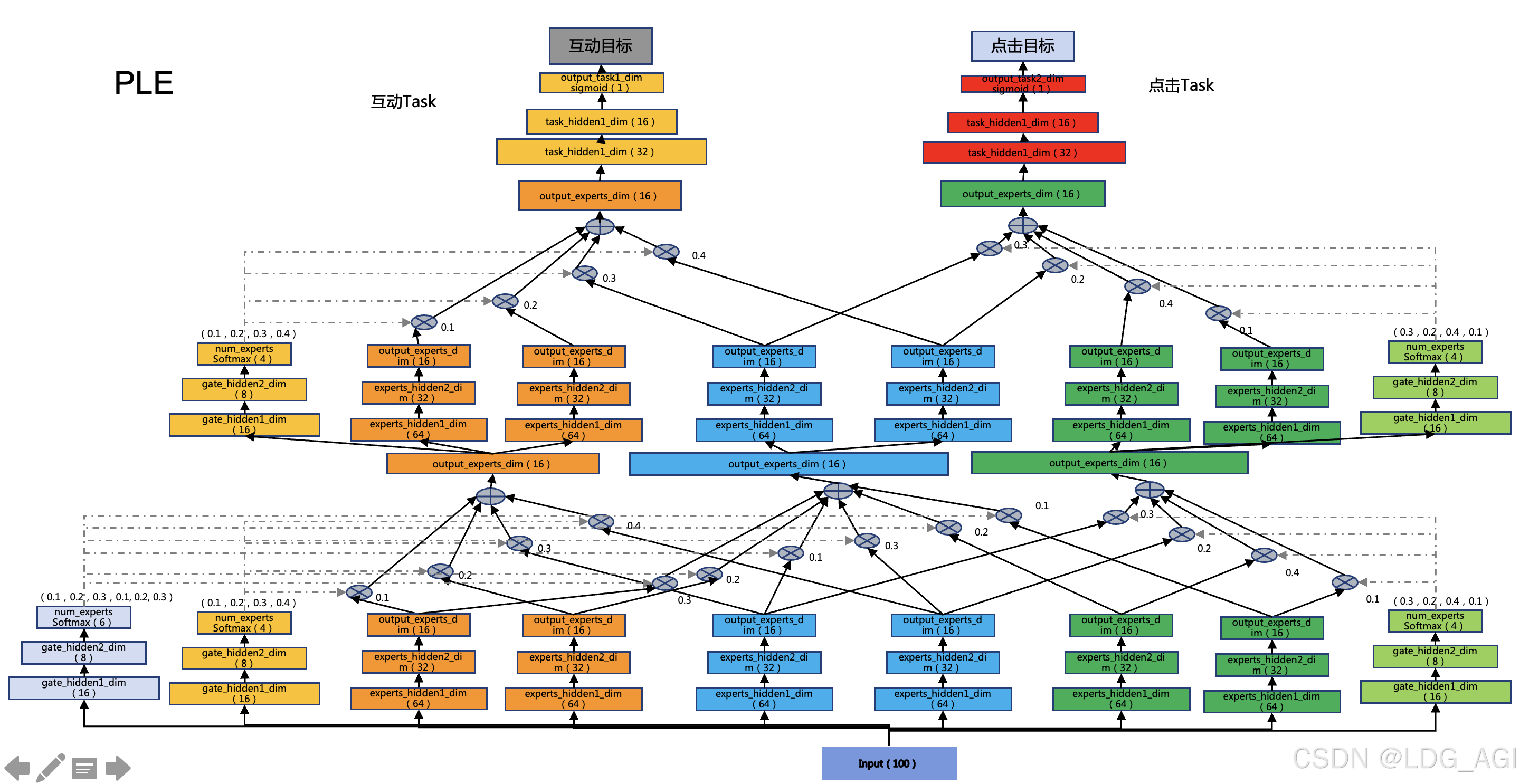
如架构图所示,其中有几个注意的点:
- num_shared_experts + num_task_experts:独立Gate的维度等于共享专家的维度(MLP个数,图中为2)加上任务独享专家的维度(MLP个数,图中为2)。
- num_shared_experts + num_task_experts + num_task_experts:共享Gate的维度等于共享专家的维度(MLP个数,图中为2)加上所有(图中为2组)任务独享专家的维度(MLP个数,图中为2)。
- output_experts_dim:共享专家、独享专家网络的输出维度和task网络的输入维度相同,task网络承接的是专家网络各维度的加权平均值,experts网络与task网络是直接对应关系。
- Softmax:Gate门控网络对共享专家和独享专家的偏好权重采用Softmax归一化,保证专家网络加权平均后值域相同
2.3.2 模型代码实现
基于pytorch,实现上述PLE网络架构,如下:
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDatasetclass PLEModel(nn.Module):def __init__(self, input_dim, experts_hidden1_dim, experts_hidden2_dim, output_experts_dim, task_hidden1_dim, task_hidden2_dim, output_task1_dim, output_task2_dim, gate_hidden1_dim, gate_hidden2_dim, num_shared_experts, num_task_experts):super(PLEModel, self).__init__()# 初始化函数外使用初始化变量需要赋值,否则默认使用全局变量# 初始化函数内使用初始化变量不需要赋值 self.num_shared_experts = num_shared_expertsself.num_task_experts = num_task_expertsself.output_experts_dim = output_experts_dim# 初始化1层共享专家self.shared_experts_1 = nn.ModuleList([nn.Sequential(nn.Linear(input_dim, experts_hidden1_dim),nn.ReLU(),nn.Linear(experts_hidden1_dim, experts_hidden2_dim),nn.ReLU(),nn.Linear(experts_hidden2_dim, output_experts_dim),nn.ReLU()) for _ in range(num_shared_experts)])# 初始化1层任务1专家self.task1_experts_1 = nn.ModuleList([nn.Sequential(nn.Linear(input_dim, experts_hidden1_dim),nn.ReLU(),nn.Linear(experts_hidden1_dim, experts_hidden2_dim),nn.ReLU(),nn.Linear(experts_hidden2_dim, output_experts_dim),nn.ReLU()) for _ in range(num_task_experts)])# 初始化1层任务2专家self.task2_experts_1 = nn.ModuleList([nn.Sequential(nn.Linear(input_dim, experts_hidden1_dim),nn.ReLU(),nn.Linear(experts_hidden1_dim, experts_hidden2_dim),nn.ReLU(),nn.Linear(experts_hidden2_dim, output_experts_dim),nn.ReLU()) for _ in range(num_task_experts)])# 初始化2层共享专家self.shared_experts_2 = nn.ModuleList([nn.Sequential(nn.Linear(output_experts_dim, experts_hidden1_dim),nn.ReLU(),nn.Linear(experts_hidden1_dim, experts_hidden2_dim),nn.ReLU(),nn.Linear(experts_hidden2_dim, output_experts_dim),nn.ReLU()) for _ in range(num_shared_experts)])# 初始化2层任务1专家self.task1_experts_2 = nn.ModuleList([nn.Sequential(nn.Linear(output_experts_dim, experts_hidden1_dim),nn.ReLU(),nn.Linear(experts_hidden1_dim, experts_hidden2_dim),nn.ReLU(),nn.Linear(experts_hidden2_dim, output_experts_dim),nn.ReLU()) for _ in range(num_task_experts)])# 初始化2层任务2专家self.task2_experts_2 = nn.ModuleList([nn.Sequential(nn.Linear(output_experts_dim, experts_hidden1_dim),nn.ReLU(),nn.Linear(experts_hidden1_dim, experts_hidden2_dim),nn.ReLU(),nn.Linear(experts_hidden2_dim, output_experts_dim),nn.ReLU()) for _ in range(num_task_experts)])# 初始化门控网络1层任务1self.gating1_network_1 = nn.Sequential(nn.Linear(input_dim, gate_hidden1_dim),nn.ReLU(),nn.Linear(gate_hidden1_dim, gate_hidden2_dim),nn.ReLU(),nn.Linear(gate_hidden2_dim, num_shared_experts+num_task_experts),nn.Softmax(dim=1))# 初始化门控网络1层任务2self.gating2_network_1 = nn.Sequential(nn.Linear(input_dim, gate_hidden1_dim),nn.ReLU(),nn.Linear(gate_hidden1_dim, gate_hidden2_dim),nn.ReLU(),nn.Linear(gate_hidden2_dim, num_shared_experts+num_task_experts),nn.Softmax(dim=1))# 初始化1层共享门控self.gating_shared_network_1 = nn.Sequential(nn.Linear(input_dim, gate_hidden1_dim),nn.ReLU(),nn.Linear(gate_hidden1_dim, gate_hidden2_dim),nn.ReLU(),nn.Linear(gate_hidden2_dim, num_shared_experts + num_task_experts + num_task_experts),nn.Softmax(dim=1))# 初始化门控网络2层任务1self.gating1_network_2 = nn.Sequential(nn.Linear(output_experts_dim, gate_hidden1_dim),nn.ReLU(),nn.Linear(gate_hidden1_dim, gate_hidden2_dim),nn.ReLU(),nn.Linear(gate_hidden2_dim, num_shared_experts+num_task_experts),nn.Softmax(dim=1))# 初始化门控网络2层任务2self.gating2_network_2 = nn.Sequential(nn.Linear(output_experts_dim, gate_hidden1_dim),nn.ReLU(),nn.Linear(gate_hidden1_dim, gate_hidden2_dim),nn.ReLU(),nn.Linear(gate_hidden2_dim, num_shared_experts+num_task_experts),nn.Softmax(dim=1))# 定义任务1的输出层self.task1_head = nn.Sequential(nn.Linear(output_experts_dim, task_hidden1_dim),nn.ReLU(),nn.Linear(task_hidden1_dim, task_hidden2_dim),nn.ReLU(),nn.Linear(task_hidden2_dim, output_task1_dim),nn.Sigmoid()) # 定义任务2的输出层self.task2_head = nn.Sequential(nn.Linear(output_experts_dim, task_hidden1_dim),nn.ReLU(),nn.Linear(task_hidden1_dim, task_hidden2_dim),nn.ReLU(),nn.Linear(task_hidden2_dim, output_task2_dim),nn.Sigmoid()) def forward(self, x):#处理第一层#第一层门控gates1 = self.gating1_network_1(x)gates2 = self.gating2_network_1(x)gates_shared = self.gating_shared_network_1(x)#定义第一层输出batch_size, _ = x.shapetask1_expert_inputs = torch.zeros(batch_size, self.output_experts_dim)task2_expert_inputs = torch.zeros(batch_size, self.output_experts_dim)shared_expert_inputs = torch.zeros(batch_size, self.output_experts_dim)#第一层task1、shared、task2专家网络输出task1_experts_1_output_0 = self.task1_experts_1[0](x)task1_experts_1_output_1 = self.task1_experts_1[1](x)shared_experts_1_output_0 = self.shared_experts_1[0](x)shared_experts_1_output_1 = self.shared_experts_1[1](x)task2_experts_1_output_0 = self.task2_experts_1[0](x)task2_experts_1_output_1 = self.task2_experts_1[1](x)#第一层共享专家网络输出shared_expert_inputs += task1_experts_1_output_0 * gates_shared[:, 0].unsqueeze(1)shared_expert_inputs += task1_experts_1_output_1 * gates_shared[:, 1].unsqueeze(1)shared_expert_inputs += shared_experts_1_output_0 * gates_shared[:, 2].unsqueeze(1)shared_expert_inputs += shared_experts_1_output_1 * gates_shared[:, 3].unsqueeze(1)shared_expert_inputs += task2_experts_1_output_0 * gates_shared[:, 4].unsqueeze(1)shared_expert_inputs += task2_experts_1_output_1 * gates_shared[:, 5].unsqueeze(1)#第一层任务1网络输出task1_expert_inputs += task1_experts_1_output_0 * gates1[:, 0].unsqueeze(1)task1_expert_inputs += task1_experts_1_output_1 * gates1[:, 1].unsqueeze(1)task1_expert_inputs += shared_experts_1_output_0 * gates1[:, 2].unsqueeze(1)task1_expert_inputs += shared_experts_1_output_1 * gates1[:, 3].unsqueeze(1)#第一层任务2网络输出task2_expert_inputs += shared_experts_1_output_0 * gates2[:, 0].unsqueeze(1)task2_expert_inputs += shared_experts_1_output_1 * gates2[:, 1].unsqueeze(1)task2_expert_inputs += task2_experts_1_output_0 * gates2[:, 2].unsqueeze(1)task2_expert_inputs += task2_experts_1_output_1 * gates2[:, 3].unsqueeze(1)#处理第二层gates1 = self.gating1_network_2(task1_expert_inputs)gates2 = self.gating2_network_2(task2_expert_inputs)#定义第二层输出task1_inputs = torch.zeros(batch_size, self.output_experts_dim)task2_inputs = torch.zeros(batch_size, self.output_experts_dim)#第二层task1、shared、task2专家网络输出task1_experts_2_output_0 = self.task1_experts_2[0](task1_expert_inputs)task1_experts_2_output_1 = self.task1_experts_2[1](task1_expert_inputs)shared_experts_2_output_0 = self.shared_experts_2[0](shared_expert_inputs)shared_experts_2_output_1 = self.shared_experts_2[1](shared_expert_inputs)task2_experts_2_output_0 = self.task2_experts_2[0](task2_expert_inputs)task2_experts_2_output_1 = self.task2_experts_2[1](task2_expert_inputs)#第二层任务1网络输出task1_inputs += task1_experts_2_output_0 * gates1[:, 0].unsqueeze(1)task1_inputs += task1_experts_2_output_1 * gates1[:, 1].unsqueeze(1)task1_inputs += shared_experts_2_output_0 * gates1[:, 2].unsqueeze(1)task1_inputs += shared_experts_2_output_1 * gates1[:, 3].unsqueeze(1)#第二层任务2网络输出task2_inputs += shared_experts_2_output_0 * gates2[:, 0].unsqueeze(1)task2_inputs += shared_experts_2_output_1 * gates2[:, 1].unsqueeze(1)task2_inputs += task2_experts_2_output_0 * gates2[:, 2].unsqueeze(1)task2_inputs += task2_experts_2_output_1 * gates2[:, 3].unsqueeze(1)task1_outputs = self.task1_head(task1_inputs)task2_outputs = self.task2_head(task2_inputs)return task1_outputs, task2_outputs# 实例化模型对象
experts_hidden1_dim = 64
experts_hidden2_dim = 32
output_experts_dim = 16
gate_hidden1_dim = 16
gate_hidden2_dim = 8
task_hidden1_dim = 32
task_hidden2_dim = 16
output_task1_dim = 1
output_task2_dim = 1
num_shared_experts = 2
num_task_experts = 2# 构造虚拟样本数据
torch.manual_seed(42) # 设置随机种子以保证结果可重复
input_dim = 100
num_samples = 1024
X_train = torch.randint(0, 2, (num_samples, input_dim)).float()
y_train_task1 = torch.rand(num_samples, output_task1_dim) # 假设任务1的输出维度为1
y_train_task2 = torch.rand(num_samples, output_task2_dim) # 假设任务2的输出维度为1# 创建数据加载器
train_dataset = TensorDataset(X_train, y_train_task1, y_train_task2)
train_loader = DataLoader(train_dataset, batch_size=128, shuffle=True)model = PLEModel(input_dim, experts_hidden1_dim, experts_hidden2_dim, output_experts_dim, task_hidden1_dim, task_hidden2_dim, output_task1_dim, output_task2_dim, gate_hidden1_dim, gate_hidden2_dim, num_shared_experts, num_task_experts)# 定义损失函数和优化器
criterion_task1 = nn.MSELoss()
criterion_task2 = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)# 训练循环
num_epochs = 100
for epoch in range(num_epochs):model.train()running_loss = 0.0for batch_idx, (X_batch, y_task1_batch, y_task2_batch) in enumerate(train_loader):# 前向传播: 获取预测值#print(batch_idx, X_batch )#print(f'Epoch [{epoch+1}/{num_epochs}-{batch_idx}], Loss: {running_loss/len(train_loader):.4f}')outputs_task1, outputs_task2 = model(X_batch)# 计算每个任务的损失loss_task1 = criterion_task1(outputs_task1, y_task1_batch)loss_task2 = criterion_task2(outputs_task2, y_task2_batch)total_loss = loss_task1 + loss_task2# 反向传播和优化optimizer.zero_grad()total_loss.backward()optimizer.step()running_loss += total_loss.item()if epoch % 10 == 0:print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {running_loss/len(train_loader):.4f}')print(model)
#for param_tensor in model.state_dict():
# print(param_tensor, "\t", model.state_dict()[param_tensor].size())
# 模型预测
model.eval()
with torch.no_grad():test_input = torch.randint(0, 2, (1, input_dim)).float() # 构造一个测试样本pred_task1, pred_task2 = model(test_input)print(f'互动目标预测结果: {pred_task1}')print(f'点击目标预测结果: {pred_task2}')相比于上一篇CGC中的代码,PLE代码更加复杂,其中有很多地方可以复用与简化。
2.3.3 模型训练与推理测试
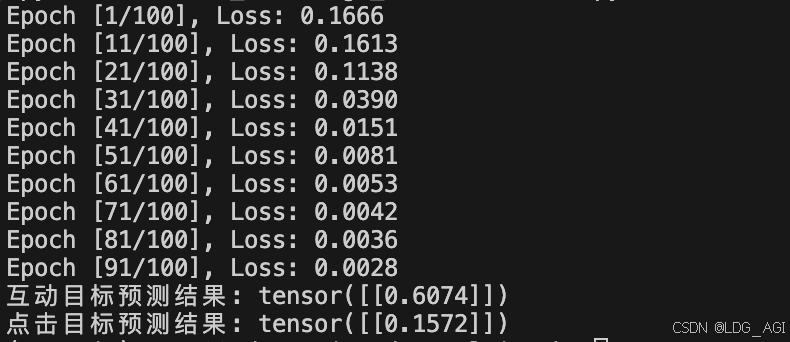
运行上述代码,模型启动训练,Loss逐渐收敛,测试结果如下:
2.3.4 打印模型结构
PLEModel((shared_experts_1): ModuleList((0-1): 2 x Sequential((0): Linear(in_features=100, out_features=64, bias=True)(1): ReLU()(2): Linear(in_features=64, out_features=32, bias=True)(3): ReLU()(4): Linear(in_features=32, out_features=16, bias=True)(5): ReLU()))(task1_experts_1): ModuleList((0-1): 2 x Sequential((0): Linear(in_features=100, out_features=64, bias=True)(1): ReLU()(2): Linear(in_features=64, out_features=32, bias=True)(3): ReLU()(4): Linear(in_features=32, out_features=16, bias=True)(5): ReLU()))(task2_experts_1): ModuleList((0-1): 2 x Sequential((0): Linear(in_features=100, out_features=64, bias=True)(1): ReLU()(2): Linear(in_features=64, out_features=32, bias=True)(3): ReLU()(4): Linear(in_features=32, out_features=16, bias=True)(5): ReLU()))(shared_experts_2): ModuleList((0-1): 2 x Sequential((0): Linear(in_features=16, out_features=64, bias=True)(1): ReLU()(2): Linear(in_features=64, out_features=32, bias=True)(3): ReLU()(4): Linear(in_features=32, out_features=16, bias=True)(5): ReLU()))(task1_experts_2): ModuleList((0-1): 2 x Sequential((0): Linear(in_features=16, out_features=64, bias=True)(1): ReLU()(2): Linear(in_features=64, out_features=32, bias=True)(3): ReLU()(4): Linear(in_features=32, out_features=16, bias=True)(5): ReLU()))(task2_experts_2): ModuleList((0-1): 2 x Sequential((0): Linear(in_features=16, out_features=64, bias=True)(1): ReLU()(2): Linear(in_features=64, out_features=32, bias=True)(3): ReLU()(4): Linear(in_features=32, out_features=16, bias=True)(5): ReLU()))(gating1_network_1): Sequential((0): Linear(in_features=100, out_features=16, bias=True)(1): ReLU()(2): Linear(in_features=16, out_features=8, bias=True)(3): ReLU()(4): Linear(in_features=8, out_features=4, bias=True)(5): Softmax(dim=1))(gating2_network_1): Sequential((0): Linear(in_features=100, out_features=16, bias=True)(1): ReLU()(2): Linear(in_features=16, out_features=8, bias=True)(3): ReLU()(4): Linear(in_features=8, out_features=4, bias=True)(5): Softmax(dim=1))(gating_shared_network_1): Sequential((0): Linear(in_features=100, out_features=16, bias=True)(1): ReLU()(2): Linear(in_features=16, out_features=8, bias=True)(3): ReLU()(4): Linear(in_features=8, out_features=6, bias=True)(5): Softmax(dim=1))(gating1_network_2): Sequential((0): Linear(in_features=16, out_features=16, bias=True)(1): ReLU()(2): Linear(in_features=16, out_features=8, bias=True)(3): ReLU()(4): Linear(in_features=8, out_features=4, bias=True)(5): Softmax(dim=1))(gating2_network_2): Sequential((0): Linear(in_features=16, out_features=16, bias=True)(1): ReLU()(2): Linear(in_features=16, out_features=8, bias=True)(3): ReLU()(4): Linear(in_features=8, out_features=4, bias=True)(5): Softmax(dim=1))(task1_head): Sequential((0): Linear(in_features=16, out_features=32, bias=True)(1): ReLU()(2): Linear(in_features=32, out_features=16, bias=True)(3): ReLU()(4): Linear(in_features=16, out_features=1, bias=True)(5): Sigmoid())(task2_head): Sequential((0): Linear(in_features=16, out_features=32, bias=True)(1): ReLU()(2): Linear(in_features=32, out_features=16, bias=True)(3): ReLU()(4): Linear(in_features=16, out_features=1, bias=True)(5): Sigmoid())
)三、总结
本文详细介绍了PLE多任务模型的算法原理、算法优势,并以小红书业务场景为例,构建PLE网络结构并使用pytorch代码实现对应的网络结构、训练流程。相比于CGC,PLE采用分层提取结构,每一层中采用共享门控、独享门控机制对共享专家组、独享专家组进行联合学习,增强了任务之间的解耦,提高了模型对不同任务的适应性,能在多任务场景中更好地平衡任务间冲突,提升多目标学习效果。
如果您还有时间,欢迎阅读本专栏的其他文章:
【深度学习】多目标融合算法(一):样本Loss加权(Sample Loss Reweight)
【深度学习】多目标融合算法(二):底部共享多任务模型(Shared-Bottom Multi-task Model)
【深度学习】多目标融合算法(三):混合专家网络MOE(Mixture-of-Experts)
【深度学习】多目标融合算法(四):多门混合专家网络MMOE(Multi-gate Mixture-of-Experts)
【深度学习】多目标融合算法(五):定制门控网络CGC(Customized Gate Control)
相关文章:
:渐进式分层提取模型PLE(Progressive Layered Extraction))
【深度学习】多目标融合算法(六):渐进式分层提取模型PLE(Progressive Layered Extraction)
目录 一、引言 二、PLE(Progressive Layered Extraction,渐进式分层提取模型) 2.1 技术原理 2.2 技术优缺点 2.3 业务代码实践 2.3.1 业务场景与建模 2.3.2 模型代码实现 2.3.3 模型训练与推理测试 2.3.4 打印模型结构 三、总结 一…...

ping、tcpping、psping、paping、hping的区别
ping、tcpping、psping、paping、hping的区别 这些工具都是用于网络测试的,但它们在功能和协议上有所不同,适用于不同的场景。 ping 基本功能: 发送ICMP echo请求包,并等待接收echo应答包,从而判断网络是否连通&…...

【Redis8】最新安装版与手动运行版
1. 下载 Redis 百度网盘 2. 解压后直接运行 redis-server.exe 3. 使用安装版 双击 install_redis_service.bat 输入安装路径(请提前创建好安装路径)后直接回车下一步直接回车即可,因为是使用配置模板文件为默认解压出来的,然后…...
学习笔记(CLASS 1):组件)
前端(小程序)学习笔记(CLASS 1):组件
1、小程序中组件的分类 小程序中的组件也是由宿主环境提供的,开发者可以基于组件快速搭建出漂亮的页面结构。官方把小程序的组件分为了9大类,分别是: * 视图容器,* 基础内容,* 表单组件,* 导航组件 媒体…...

Python MD5加密算法脚本
基本概念 MD5(Message Digest Algorithm 5)是一种常用的哈希函数,用于将任意长度的数据转换为固定长度的哈希值,通常为128位(16字节)。 特点 不可逆性:无法从哈希值还原出原始数据。无论原始…...

Python数据分析实战:Pandas高效处理Excel数据指南
目录 引言:为什么选择Pandas处理Excel? 一、环境搭建与数据读取 1.1 基础环境配置 1.2 数据高效载入技巧 二、数据清洗核心战术 三、数据加工实战案例 3.1 销售数据透视分析 3.2 异常值检测 3.3 跨表关联分析 四、性能优化秘籍 4.1 大文件处理…...

使用Starrocks制作拉链表
5月1日向ods_order_info插入3条数据: CREATE TABLE ods_order_info(dt string,id string COMMENT 订单编号,total_amount decimal(10,2) COMMENT 订单金额 ) PRIMARY KEY(dt, id) PARTITION BY (dt) DISTRIBUTED BY HASH(id) PROPERTIES ( "replication_num&q…...

【npm】npm命令大全
掌握 NPM:前端与 Node.js 开发者必备命令大全 NPM (Node Package Manager) 无疑是现代 JavaScript 开发的基石。无论是前端项目还是 Node.js 后端服务,NPM 都扮演着管理依赖、执行脚本、发布模块等关键角色。熟悉并熟练使用 NPM 命令,能够极…...

最新版Chrome浏览器调用ActiveX控件技术——alWebPlugin中间件V2.0.42版发布
allWebPlugin简介 allWebPlugin中间件是一款为用户提供安全、可靠、便捷的浏览器插件服务的中间件产品,致力于将浏览器插件重新应用到所有浏览器。它将现有ActiveX控件直接嵌入浏览器,实现插件加载、界面显示、接口调用、事件回调等。支持Chrome、Firefo…...

32核64G内存的物理机上,Netty理论能承载多少连接?
在 32核64G内存 的机器上,Netty 能承载的连接数取决于 业务场景、配置优化 和 操作系统调优。 以下是详细分析和实测数据参考: 1. 理论估算(基于资源限制) 资源影响内存每个连接占用 10KB~1MB(取决于业务࿰…...

对于final、finally和finalize不一样的理解
目录 1、final 1.1、不可变性(Immutability) 1.2、内存可见性(Visibility) 1.3、初始化安全(Initialization Safety) 1.4、禁止重排序(Reordering) 1、静态常量 2、实例常量 …...

Open CASCADE学习|刚体沿曲线运动实现方法
在三维几何建模中,刚体沿参数化曲线的运动模拟是机械运动仿真、机器人路径规划等领域的核心需求。本文基于Open Cascade几何内核,系统阐述刚体沿曲线运动的实现方法,重点解析标架构建、坐标变换及鲁棒性控制等关键技术。 一、基于标架的刚体运…...
?)
工作流引擎-03-聊一聊什么是流程引擎(Process Engine)?
前言 大家好,我是老马。 最近想设计一款审批系统,于是了解一下关于流程引擎的知识。 下面是一些的流程引擎相关资料。 工作流引擎系列 工作流引擎-00-流程引擎概览 工作流引擎-01-Activiti 是领先的轻量级、以 Java 为中心的开源 BPMN 引擎&#x…...

centos7 p8p1使用ip addr查看时有的时候有两个ip,有的时候只有一个ip,有一个ip快,有一个ip慢
在CentOS 7系统中,网络接口 p8p1 出现IP地址数量变化且访问速度不一致的问题,通常与以下原因相关。以下是逐步排查与解决方案: 1. 检查网络配置文件 可能原因:存在多个配置文件或重复配置(如静态IP与DHCP冲突…...

回溯算法——排列篇
目录 一、全排列 二、全排列II 一、全排列 46. 全排列 - 力扣(LeetCode) class Solution {List<List<Integer>> resultnew ArrayList<>();LinkedList<Integer> pathnew LinkedList<>();boolean[] used;public List<…...

Unity中SRP Batcher使用整理
SRP Batcher 是一种绘制调用优化,可显著提高使用 SRP 的应用程序的性能,SRP Batcher 减少了Unity为使用相同着色器变体的材质准备和调度绘制调用所需的CPU 时间。 工作原理: 传统优化方法通过减少绘制调用次数提升性能,而SRP Batcher的核心理念在于降低绘制调用间的渲染状…...

【JAVA学习】泛型
传统方法不能对加入到集合ArrayList中的数据类型进行约束,遍历的时候需要进行类型转换,如果集合中的数据量较大,对效率有影响。泛型又称参数化类型,是JDK5.0出现的新特性,解决数据类型的安全性问题,在类声明…...

实验分享|基于千眼狼sCMOS科学相机的流式细胞仪细胞核成像实验
实验背景 流式细胞仪与微流控技术,为细胞及细胞核成像提供新的路径。传统流式细胞仪在细胞核成像检测方面存在检测通量低,荧光信号微弱等局限,故某光学重点实验室开发一种基于高灵敏度sCMOS科学相机并集成在自组荧光显微镜的微流控细胞核成像…...

MySQL中的JSON_CONTAINS函数用法
MySQL中的JSON_CONTAINS函数用于检查一个JSON文档(目标)是否包含另一个JSON文档(搜索值)。以下是其详细用法: 函数语法 JSON_CONTAINS(target_json, search_json [, path]) target_json:要检查的目…...

如何在 Windows 11 或 10 上将 DNS 更改为 Cloudflare提供的 DNS 服务
域名解析服务(DNS)对于互联网来说至关重要,因为它使我们能够轻松地通过在浏览器中输入域名来访问网站。DNS 的作用是将域名解析为 IP 地址;你可以将其视为互联网上的电话簿。这是因为互联网上的计算机或服务器是通过 IPv4 或 IPv6(数字格式)来识别的,然而,要用户去记住…...
)
解除diffusers库的prompt长度限制(SDXL版)
2025-5-21 注:本文只提供思路,没有解决“权重识别”、“BREAK”问题。 要想实现与webui一样的绘图效果与无限prompt,可参考diffusers/examples/community/lpw_stable_diffusion_xl.py 1、上代码 from diffusers import StableDiffusionXLP…...

RISC-V 开发板 MUSE Pi Pro CSI测试,一把点亮ov5647摄像头
视频讲解: RISC-V 开发板 MUSE Pi Pro CSI测试,一把点亮ov5647摄像头 手上正好有一颗ov5674,看了下接口排线都是一致的,硬件条件满足的情况下,剩下的就是驱动软件的问题,直接接上CSI排线 https://bianbu-li…...

Word2Vec模型学习和Word2Vec提取相似文本体验
文章目录 说明Word2Vec模型核心思想两种经典模型关键技术和算法流程优点和局限应用场景 Word2Vec提取相似文本完整源码执行结果 说明 本文适用于初学者,体验Pytorch框架在自然语言处理中的使用。简单了解学习Word2Vec模型,体验其使用。 Word2Vec模型 …...

[测试_3] 生命周期 | Bug级别 | 测试流程 | 思考
目录 一、软件测试的生命周期(重点) 1、软件测试 & 软件开发生命周期 (1)需求分析 (2)测试计划 (3)测试设计与开发 (4)测试执行 (5&am…...

epoll_wait未触发的小Bug
上次看了一下epoll监听的原理,在Android Jni里使用epoll,来监听Gpio口的变化事件,具体代码如下: 打开 GPIO 文件描述符,因为该文件是内核虚拟出来的,不是实际文件,所以无法使用FileObserver来监…...

Unity异步加载image的材质后,未正确显示的问题
简述: 此问题涉及到Unity的UI刷新机制 问题描述: 如图所示,想要实现在打开新的界面时候,通过修改材质的方式,修改image的显示内容。 明明已经给image添加上材质了,可还是一片空白? 先看看代…...
)
Python----循环神经网络(Word2Vec)
一、Word2Vec Word2Vec是word to vector的简称,字面上理解就是把文字向量化,也就是词嵌入 的一种方式。 它的核心就是建立一个简单的神经网络实现词嵌入。 其模型仅仅包括输入层、隐藏层和输出层,模型框架根据输入输出的不同,主要…...

Oracle Enqueue Names
Oracle Enqueue Names Enqueue(排队锁)是Oracle数据库中用于协调多进程并发访问共享资源的锁机制。 This appendix lists Oracle enqueues. Enqueues are shared memory structures (locks) that serialize access to database resources. They can be…...
)
微服务中API网关作用(统一入口、路由转发、协议转换、认证授权、请求聚合、负载均衡、熔断限流、监控日志)
文章目录 在微服务架构中,API网关主要有以下作用1. 统一入口:作为所有客户端请求的单一入口点,隐藏后端服务的复杂性2. 路由转发:将客户端请求准确路由到适当的微服务(如图中的服务A、B、C)3. 协议转换&…...

Linux `cat` 命令深度解析与高阶应用指南
Linux `cat` 命令深度解析与高阶应用指南 一、核心功能解析1. 基本作用2. 与类似命令对比二、选项系统详解1. 常用选项矩阵2. 组合使用技巧三、高阶应用场景1. 数据流处理2. 系统维护操作3. 开发调试应用四、安全与权限管理1. 访问控制策略2. 二进制文件处理五、性能优化策略1.…...

融云 uni-app IMKit 上线,1 天集成,多端畅行
融云 uni-app IMKit 正式上线,支持一套代码同时运行在 iOS、Android、H5、小程序主流四端,集成仅需 1 天,并可确保多平台的一致性体验。 融云 uni-app IMKit 在 Vue 3 的高性能加持下开发实现,使用 Vue 3 Composition API&#x…...

VLA模型:自动驾驶与机器人行业的革命性跃迁,端到端智能如何重塑未来?
当AI开始操控方向盘和机械臂,人类正在见证一场静默的产业革命。 2023年7月,谷歌DeepMind抛出一枚技术核弹——全球首个视觉语言动作模型(VLA)RT-2横空出世。这个能将“把咖啡递给穿红衣服的阿姨”这类自然语言指令直接转化为机器人…...

IP地址详解
IP地址详解(技术向) 一、核心定义 IP地址(Internet Protocol Address)是 网络层逻辑地址,用于在网络中唯一标识设备。本质上是 32位(IPv4)或128位(IPv6)二进制数。 本机的地址为127.0.0.1,主机名:localhost192.168.0.0-192.168.255.255为私有地址,属于非注册地址,…...
-- GDB 调试 学习 笔记)
C++网络编程入门学习(四)-- GDB 调试 学习 笔记
GDB 调试 学习 笔记 GDB 调试 学习 笔记调试准备启动和退出gdbgdb中启动程序退出gdb查看代码断点调试命令继续运行gdb手动打印信息 自动打印信息单步调试step 可简写 snext 可简写成 nfinish 可简写成 finuntil 可简写成 u 设置变量值 GDB 调试 学习 笔记 学习地址:…...

C#面:Server.UrlEncode、HttpUtility.UrlDecode的区别
在C#编程中,Server.UrlEncode 和 HttpUtility.UrlDecode 是两个常用的方法,用于处理URL编码和解码操作。理解它们的区别对于确保数据在Web应用程序中的正确传输和解析至关重要。 Server.UrlEncode 和 HttpUtility.UrlDecode的区别 Server.UrlEncode 和…...

kafka配置SASL_PLAINTEXT简单认证
Kafka ZooKeeper 开启 SASL_PLAINTEXT 认证(PLAIN机制)最全实战教程 💡 本教程将手把手教你如何为 Kafka 配置基于 SASL_PLAINTEXT PLAIN 的用户名密码认证机制,包含 Kafka 与 ZooKeeper 的全部配置,适合入门。 &…...

Flink SQL 计算实时指标同比的实现方法
在 Flink SQL 中计算实时指标的同比(Year-on-Year),核心是通过时间窗口划分周期(如日、月、周),并关联当前周期与去年同期的指标值。以下是结合流数据处理特性的具体实现方法,包含数据准备、窗口聚合、历史数据关联等关键步骤。 一、同比的定义与场景 同比指当前周期指…...

Vue Router动态路由与导航守卫实战
在 Vue Router 中,动态路由与导航守卫的结合使用能够实现复杂的路由控制逻辑,例如权限验证、动态路由加载、数据预取等功能。以下是一个结合实战的详细说明: 一、动态路由基础 动态路由通过路径参数(:)实现动态匹配&a…...
实战:如何通过 HTML 报告识别潜在问题)
数据库健康监测器(BHM)实战:如何通过 HTML 报告识别潜在问题
在数据库运维中,健康监测是保障系统稳定性与性能的关键环节。通过 HTML 报告,开发者可以直观查看数据库的运行状态、资源使用情况与潜在风险。 本文将围绕 数据库健康监测器(Database Health Monitor, BHM) 的核心功能展开分析,结合 Prometheus + Grafana + MySQL Export…...
)
Oracle基础知识(二)
目录 1.聚合函数 2.COUNT(1)&COUNT(*)&COUNT(字段)区别(面试常问) 3.分组聚合——group by 4.去重:DISTINCT 、GROUP BY 5.聚合函数的过滤HAVING 6.oracle中having与where的区别 (面试常问) 7.ROUND与TRUNC函数 8.ROLLUP上卷…...

轻量化MEC终端 特点
MEC(多接入边缘计算)解决方案通过将计算能力下沉至网络边缘,结合5G网络特性,已在多个行业实现低延迟、高可靠、高安全的应用部署。以下从技术架构、核心优势及典型场景三方面进行总结: 一、技术架构 分层设计 MEC架…...

Git 提交大文件 this exceeds GitHub‘s file size limit of 100.00 MB
报错核心: File …/encoder-epoch-99-avg-1.int8.onnx is 173.47 MB File …/encoder-epoch-99-avg-1.onnx is 314.79 MB this exceeds GitHub’s file size limit of 100.00 MB 正确做法:使用 Git LFS 上传大文件 GitHub 对 单个文件最大限制是 100MB&…...

前后端的双精度浮点数精度不一致问题解决方案,自定义Spring的消息转换器处理JSON转换
在 Java 中,Long 是一个 64 位的长整型,通常用于表示很大的整数。在后端,Long 类型的数据没有问题,因为 Java 本身使用的是 64 位的整数,可以表示的范围非常大。 但是,在前端 JavaScript 中,Lo…...
)
C语言—Linux环境下CMake设置库(动态/静态)
1. Yesterday Once More 由于昨日我们在VSCode设置了如何使用CMake构建与编译c语言项目,如有疑问,请看以下链接,今日根据昨天的配置来进一步完成项目的构建。 c语言- 如何构建CMake项目(Linux/VSCode)-CSDN博客 2. 动态…...

C语言---内存函数
memcpy函数的使用及模拟实现 memcpy的功能和strcpy类似,都是用来拷贝数据的。与strcpy不同的是,memcpy的适用性更广并且是以字节为单位来拷贝的。 void * memcpy ( void * destination, const void * source, size_t num ) memcpy函数的作用就是拷贝从so…...
)
vue项目启动报错(node版本与Webpack)
一、问题 因为项目需要将node版本从v14.17.0升级到v20.9.1了,然后启动项目报错 报错有些多,直接省略部分 building 2/2 modules 0 activeError: error:0308010C:digital envelope routines::unsupported at new Hash (node:internal/crypto/hash:79:19) …...

Vite + Vue 工程中,为什么需要关注 `postcss.config.ts`?
📜 前言:当传统 CSS 遇见现代工程 在 Vue 项目开发中,CSS 管理一直是一个容易被忽视但极其重要的环节。传统的 CSS 编写方式(如手动处理浏览器兼容性、全局样式污染)已无法适应现代前端工程的需求。而 PostCSS 作为 C…...

LeetCode热题100:Java哈希表中等难度题目精解
49. 字母异位词分组 题目描述 给定一个字符串数组,要求将字母异位词组合在一起。可以按任意顺序返回结果列表。 字母异位词是由重新排列源单词的所有字母得到的一个新单词。 示例 示例 1: 输入: strs ["eat", "tea", "tan", &…...

设计模式1 ——单例模式
定义 在 C 里,单例模式是一种常用的设计模式,其目的是保证一个类仅存在一个实例,并且为该实例提供一个全局访问点。 实现 1 饿汉式 class Singleton { private:static Singleton instance;Singleton() default;~Singleton() default;Si…...
:のは ・ のが ・ のを)
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(26):のは ・ のが ・ のを
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(26):のは ・ のが ・ のを 1、前言(1)情况说明(2)工程师的信仰2、知识点(1)復習:(2)のは ・ のが ・ のを3、单词(1)日语(2)日语片假名单词4、相近词练习5、单词辨析记录6、总结1、前言 (1)情况说明…...