第六十五周周报 UP2ME
文章目录
- week 65 UP2ME
- 摘要
- Abstract
- 1. 题目
- 2. Abstract
- 3. 文献解读
- 3.1 Introduction
- 3.2 创新点
- 4. 网络结构
- 4.1 单变量预训练
- 4.1.1 样例生成
- 4.1.2 掩码自动编码器预训练
- 4.1.3 即时反应模式
- 4.2 多元微调
- 4.2.1 稀疏依赖图构造
- 4.2.2 时域频道层
- 5. 实验结果
- 6. 结论
- 7. 部分关键代码
- 7.1 数据预处理
- 7.2 模型
week 65 UP2ME
摘要
本周阅读了题为UP2ME: Univariate Pre-training to Multivariate Fine-tuning as a General-purpose Framework for Multivariate Time Series Analysis的论文。该文提出了一种新的框架——UP2ME(从单变量预训练到多变量微调),其专为多变量时间序列(MTS)设计的框架,旨在改善预测、插补和异常检测等任务的表现。该框架采用“单变量预训练到多变量微调”的策略,先在不指定下游任务的情况下进行预训练,再根据具体任务需求进行微调。通过生成不同长度的单变量实例来消除跨通道依赖性,并利用预训练模型构建跨通道依赖关系图,增强了模型对时间序列中复杂依赖性的捕捉能力。实验证明,UP2ME在多个真实数据集上的预测和插补性能优异,接近特定任务的异常检测效果。
Abstract
This week’s weekly newspaper decodes the paper entitled UP2ME: Univariate Pre-training to Multivariate Fine-tuning as a General-purpose Framework for Multivariate Time Series Analysis. The paper proposes a new framework named UP2ME (Univariate Pre-training to Multivariate Fine-tuning), specifically designed for multivariate time series (MTS) to improve the performance of tasks such as prediction, imputation, and anomaly detection. This framework adopts a “univariate pre-training to multivariate fine-tuning” strategy, conducting pre-training without specifying downstream tasks and then fine-tuning according to specific task requirements. By generating univariate instances of varying lengths, it eliminates cross-channel dependencies and uses the pre-trained model to construct a cross-channel dependency graph, enhancing the model’s ability to capture complex dependencies in time series. Experiments show that UP2ME exhibits excellent performance in prediction and imputation on multiple real datasets, with results approaching those of task-specific anomaly detection.
1. 题目
标题:UP2ME: Univariate Pre-training to Multivariate Fine-tuning as a General-purpose Framework for Multivariate Time Series Analysis
作者:Yunhao Zhang 1 Minghao Liu 1 Shengyang Zhou 1 Junchi Yan 1
发布:Proceedings of the 41st International Conference on Machine Learning, PMLR 235:59358-59381, 2024.
- https://doi.org/10.1016/j.watres.2023.121092、
2. Abstract
尽管在文本和图像上的自我监督预训练取得了成功,但将其应用于多变量时间序列(MTS)上,却落后于预测、imputation和异常检测等任务的定制方法。提出了一个通用框架,命名为UP2ME(单变量预训练到多变量微调)。当下游任务未指定时,它进行任务不可知的预训练。一旦任务和设置(例如预测长度)确定,它就会用冻结的预训练参数给出合理的解决方案,这在以前是没有实现的。UP2ME通过微调进一步细化。设计了单变量-多变量范式来解决时间和跨通道依赖性的异质性。在单变量预训练中,生成不同长度的单变量实例用于掩码自动编码器(MAE)的预训练,消除了跨通道依赖性。预训练模型通过将下游任务表述为特定的掩模重建问题来处理下游任务。在多变量微调中,使用预训练的编码器构建通道间的依赖关系图,增强跨通道依赖捕获。在8个真实数据集上进行的实验表明,该方法在预测和imputation方面的性能接近于特定任务的异常检测性能。代码可在https://github.com/Thinklab-SJTU/UP2ME获得。
3. 文献解读
3.1 Introduction
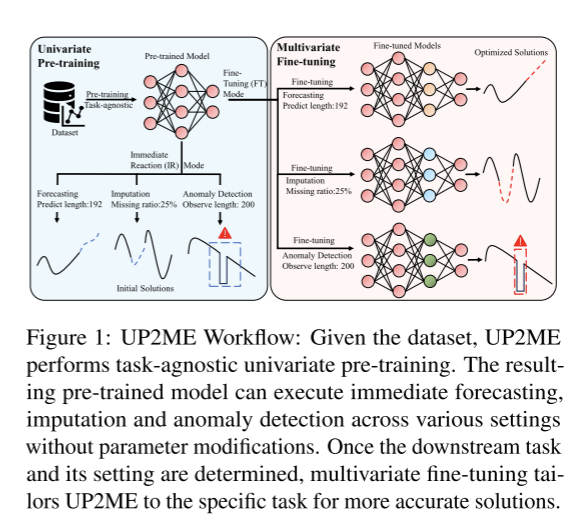
提出了一个统一的MTS分析框架,命名为UP2ME (Univariate Pre-training To Multivariate Fine-tuning)。如图1所示,当数据可用,但下游任务和设置不确定时,UP2ME执行任务不可知的预训练。预训练模型在不修改任何参数的情况下,为即时反应(IR)模式下的预测、归算和异常检测提供了初步合理的解决方案。一旦下游任务和设置确定,UP2ME进一步适应任务,并在微调(FT)模式下提供更准确的解决方案。
时间依赖捕获随时间变化的关系,而跨通道依赖捕获具有不同物理含义的数据之间的关系。由于潜在的物理动力学,后者保持相对稳定(Kipf et al., 2018)。受异质性的启发,开发了一个单变量到多变量的范式。UP2ME在单变量预训练期间忽略了跨通道依赖性,优先考虑了时间依赖性。随后在多变量微调期间合并通道依赖。具体来说,UP2ME使用可变窗口长度和信道解耦(参见第2.1.1节的详细信息)来生成具有不同长度的单变量实例,用于MAE预训练(He et al., 2022)。将预训练模型表述为特定的掩模重建任务,无需修改参数或架构,即可直接执行预测、imputation和异常检测。在微调期间冻结预训练的编码器和解码器,UP2ME引入可训练的时间通道(TC)层来捕获跨通道依赖性并进一步细化时间依赖性。TC层需要一个表示通道之间关系的依赖图,该图是使用预训练的冻结编码器构建的。
3.2 创新点
本研究的主要贡献如下:
- 受时间依赖性和跨通道依赖性异质性的启发,提出了一个通用的MTS框架UP2ME,其中单变量预训练集中于时间依赖性,跨通道依赖性纳入多变量微调。
- 在单变量预训练中,采用变窗长和信道解耦的方法生成MAE预训练实例。预训练模型通过将多个任务形成特定的掩模重建问题来处理多个任务。在多变量微调中,UP2ME细化了时间依赖性,并通过预训练的编码器在通道之间构建了一个图,以捕获跨通道依赖性。
- 在8个真实数据集上评估UP2ME,解决了三个下游任务:预测、imputation(下称补全)和异常检测。使用没有电感偏置架构的原始Transformer和Graph Transformer,具有冻结参数的预训练UP2ME(IR)在多个数据集上可与以前最先进的(SOTA)方法相比较。微调后的UP2ME(FT)在预测和imputation方面超越了所有以前的特定任务、通用和预训练方法,在异常检测方面接近特定任务的性能。
4. 网络结构
UP2ME在单变量设置中对给定数据集进行预训练,以捕获时间依赖性。预训练模型可以提供IR模式下的初始解。
UP2ME在多变量设置中进行了微调,以捕获跨通道依赖并细化时间依赖,以获得更准确的解决方案。
4.1 单变量预训练
4.1.1 样例生成
可变窗口长度。对于时间序列,在预训练期间是未知的,应该通过下游任务的设置来确定(例如,预测的过去和未来窗口长度)。为了满足对窗口长度的不确定性要求,在预训练时使窗口长度可变。具体来说,对于每个训练步骤,首先随机抽取一个窗口长度为L的样本,然后生成一批具有此长度的实例:
n ∼ ( N m i n , … , N m a x ) (1) n\sim (N_{min},\dots,N_{max})\tag{1} n∼(Nmin,…,Nmax)(1)
通道解耦。为了生成长度为L的实例,前面的工作采样一个时间戳t,得到多变量子序列 X t + 1 : t + L ∈ R L × C X_{t+1:t+L}\in \mathbb R_{L×C} Xt+1:t+L∈RL×C作为模型输入的实例。通过信道解耦,独立采样时间戳 t ∼ { 0 , … , T − L } t \sim\{0, \dots, T−L\} t∼{0,…,T−L}和通道索引 c ∼ { 1 , … , C } c \sim\{1,\dots,C\} c∼{1,…,C}。具有通道索引 ( X t 1 : t + L , c , c ) (X_{t_1: t+L,c}, c) (Xt1:t+L,c,c)的单变量子序列将被视为一个实例。
通道无关是一种处理多变量子序列的技术:将 x t + 1 : t + L x_{t+1: t+ L} xt+1:t+L拆分为C个单变量序列,并一起输入到模型中。虽然通道是独立处理的,但它们的共存在一定程度上反映了跨通道依赖性。通过信道解耦,完全放弃了跨信道依赖,在预训练中只关注时间依赖。
信道解耦的另一个优点是它对高维数据的效率。对于具有较大C的数据集,可以将B(B << C)解耦的单变量序列打包成一个mini-batch,而不是一次处理所有通道。有信道解耦和没有信道解耦的预训练开销的实验评估见附录C的图5(英伟达 Quadro RTX8000约等于rtx3090)。
4.1.2 掩码自动编码器预训练
使用上述两种实例生成技术,预训练过程类似于图像的MAE (He et al., 2022)。为方便起见,使用 ( x ( p t ) ) , c , x ( p t ) ∈ R L , c ∈ { 1 , … , C } (\mathbf x^{(pt)}), c, x^{(pt)}\in\mathbb R^L, c\in \{1, …, C\} (x(pt)),c,x(pt)∈RL,c∈{1,…,C}表示生成的实例。单变量序列 x ( p t ) x^{(pt)} x(pt)首先被分割成长度为P的不重叠的小块 P : { x 1 ( p a t c h ) , … , x N ( p a t c h ) } P:\{x^{(patch)}_1,\dots, x^{(patch)}_N\} P:{x1(patch),…,xN(patch)},其中 x i ( p a t c h ) ∈ R P , N = L / P x^{(patch)}_i\in \mathbb R^P,N = L/P xi(patch)∈RP,N=L/P。然后通过线性投影将每个patch嵌入到具有 d m o d e l d_{model} dmodel维度的token中,并添加可学习的位置嵌入和通道嵌入:
h i ( p a t c h ) = W ( e m b ) x i ( p a t c h ) + p i ( p o s ) + v c ( c h ) (2) \mathbf h^{(patch)}_i=\mathbf W^{(emb)}\mathbf x_i^{(patch)}+\mathbf p^{(pos)}_i+\mathbf v^{(ch)}_c\tag{2} hi(patch)=W(emb)xi(patch)+pi(pos)+vc(ch)(2)
随机抽取一个比例为α与掩码的patch子集,这里用em表示掩码patch的索引,U表示未掩码patch的索引。将未掩码补丁输入到编码器以捕获时间依赖性:
h i ( e n c ) = Encoder ( ∪ j ∈ U h j ( p a t c h ) ) i , ∀ i ∈ U (3) \mathbf h_i^{(enc)}=\text{Encoder}(\cup_{j\in\mathcal U}\mathbf\ h_j^{(patch)})_i,\forall\ i\in \mathcal U\tag{3} hi(enc)=Encoder(∪j∈U hj(patch))i,∀ i∈U(3)
这些编码后的非掩码补丁,连同指示掩码补丁的可学习标记,被输入到解码器中进行掩码补丁重建:
h i d e c − i n = { u ( m a s k ) + p i ( p o s ) + v c ( c h ) i ∈ M W ( p r o j ) h i ( e n c ) h ( d e c − o u t ) = D e c o d e r ( [ h 1 ( d e c − i n ) , … , h N ( d e c − i n ) ] ) x i ( r e c ) = W ( r e c ) h i ( d e c − o u t ) , ∀ i ∈ M (4) \begin{align} &\mathbf h^{dec-in}_i= \begin{cases} \mathbf u^{(mask)}+\mathbf p_i^{(pos)}+\mathbf v^{(ch)}_c\quad i\in \mathcal M\\ \mathbf W^{(proj)}\mathbf h_i^{(enc)} \end{cases}\\ &\mathbf h^{(dec-out)}=\text Decoder([\mathbf h_1^{(dec-in)},\dots,\mathbf h_N^{(dec-in)}])\\ & x_i^{(rec)}=\mathbf W^{(rec)}\mathbf h^{(dec-out)}_i, \forall i\in\mathcal M \end{align}\tag{4} hidec−in={u(mask)+pi(pos)+vc(ch)i∈MW(proj)hi(enc)h(dec−out)=Decoder([h1(dec−in),…,hN(dec−in)])xi(rec)=W(rec)hi(dec−out),∀i∈M(4)
编码器/解码器都由标准Transformer层组成。归一化技术RevIN (Kim et al., 2022)用于减少分布偏移。利用重建后的图像与ground truth mask patch之间的均方误差(Mean squared error, MSE)作为预训练损失:
L = 1 P ∣ M ∣ ∑ i ∈ M ∣ ∣ x i ( p a t c h ) − x i ( r e c ) ∣ ∣ 2 2 (5) \mathcal L=\frac{1}{P|\mathcal M|}\sum_{i\in \mathcal M}||\mathbf x_i^{(patch)}-x^{(rec)}_i||^2_2\tag{5} L=P∣M∣1i∈M∑∣∣xi(patch)−xi(rec)∣∣22(5)
4.1.3 即时反应模式
与原始图像的MAE在预训练后去除解码器不同,UP2ME保留了预训练的编码器和解码器,以用于潜在的下游任务。UP2ME将不同的下游任务作为特定的掩模重建问题,可以使用冻结的参数进行即时预测、异常检测和补全。由于即时反应 ( I R ) (IR) (IR)模式仅利用了时间依赖性,并且对每个通道的作用类似,因此在本节中仅描述单个通道的计算过程。
预测。为了根据过去的x(过去)∈RLp预测未来的时间序列x(未来)∈RLf,将过去的序列视为未掩码的补丁,将未来的序列视为掩码的补丁:
M f o r e c a s t = { i ∣ L p P < i ≤ L p + L f P } U f o r e c a s t = { i ∣ 1 ≤ i ≤ L p P } (6) \begin{align} \mathcal M^{forecast}=\{i|\frac{L_p}{P}<i\leq \frac{L_p+L_f}{P}\}\\ \mathcal U^{forecast}=\{i|1\leq i \leq \frac{L_p}{P}\} \end{align}\tag{6} Mforecast={i∣PLp<i≤PLp+Lf}Uforecast={i∣1≤i≤PLp}(6)
补全 。传统的插值方法可以很容易地处理逐点缺失。此外,现实世界中的缺失模式通常是结构化的,并且是连续出现的(Tashiro et al., 2021)。关注的是这种更具挑战性的场景,即连续的数据块丢失。给定观测数据 x ( i m p ) ∈ R L i m p x^{(imp)}\in \mathbb R^{L_{imp}} x(imp)∈RLimp和缺失位置的掩码 m ∈ [ 0 , 1 ] L i m p \mathbf m\in [0,1]^{L_{imp}} m∈[0,1]Limp(如果缺失第i个值 m i = 1 m_i = 1 mi=1),将m填补为 { m ( p a t c h ) 1 , … , m L i m p / P ( p a t c h ) \{\mathbf m^{(patch)}1,\dots ,\mathbf m^{(patch)}_{L_{imp}/P} {m(patch)1,…,mLimp/P(patch)对 x ( i m p ) x^{(imp)} x(imp)使用相同的补丁过程跛行。包含至少一个缺失点的补丁被视为遮罩补丁,完全观察到的补丁被视为未遮罩补丁:
M i m p u t a t e = { i ∣ ∣ ∣ m i ( p a t c h ) ∣ ∣ 0 ≥ 1 } U i m p u t a t e = { i ∣ ∣ ∣ m i ( p a t h c h ) ∣ ∣ 0 = 0 } (7) \begin{align} \mathcal M^{imputate}=\{i|\ ||\mathbf m_i^{(patch)}||_0\geq 1\}\\ \mathcal U^{imputate}=\{i|\ ||\mathbf m_i^{(pathch)}||_0=0\} \end{align}\tag{7} Mimputate={i∣ ∣∣mi(patch)∣∣0≥1}Uimputate={i∣ ∣∣mi(pathch)∣∣0=0}(7)
异常检测。由于异常的罕见性和不规则性,从序列的其他部分重建异常要比从正常点重建异常困难得多。在此基础上,为了检测观测序列x(det)∈RLdet中的异常,对每个patch进行迭代掩码,并使用其他未掩码的patch对其进行重构,重构序列与原始序列之间的MSE作为异常评分:
for i = 1 , … , L d e t P M i d e t e c t = { i } U i d e t e c t = { 1 , … , L d e t P } \ { i } x ~ d e t = [ x 1 ( r e c ) , … , x L d e t / P ( r e c ) ] AnomoalyScore ( t ) = ∣ x t ( d e t ) − x ~ t ( d e t ) ∣ 2 , 1 ≥ t ≥ L d e t (8) \begin{align} &\text{for}\ i=1,\dots,\frac{L_{det}}{P}\\ &\quad \mathcal M_i^{detect} =\{i\}\ \mathcal U^{detect}_i=\{1,\dots,\frac{L_{det}}{P}\}\backslash \{i\}\\ &\tilde {\mathbf x}^{det}=[\mathbf x_1^{(rec)},\dots,\mathbf x^{(rec)}_{L_{det}/P}]\\ &\text{AnomoalyScore}(t)=|x_t^{(det)}-\tilde x_t^{(det)}|^2,1\geq t\geq L_{det} \end{align}\tag{8} for i=1,…,PLdetMidetect={i} Uidetect={1,…,PLdet}\{i}x~det=[x1(rec),…,xLdet/P(rec)]AnomoalyScore(t)=∣xt(det)−x~t(det)∣2,1≥t≥Ldet(8)
在每次迭代中,使用 U i d e t e c t \mathcal U^{detect}_i Uidetect作为未掩码补丁重构 M i d e t e c t \mathcal M^{detect}_i Midetect,得到 x i ( r e c ) ∈ R P \mathbf x^{(rec)}_i\in \mathbb R^P xi(rec)∈RP。将这些重构的patch拼接到 x ~ ( d e t ) ∈ R L d e t \tilde {\mathbf x}^{(det)}\in \mathbb R^{L_{det}} x~(det)∈RLdet中计算异常评分。对于多变量数据,计算每个通道的异常分数,并使用跨通道的平均值作为最终异常分数。
4.2 多元微调
在微调中,给出了下游任务和相应的设置。UP2ME将一个多变量实例x(ft)∈RLft×C作为输入,并执行预测/检测/补全。具体来说,冻结了预训练的编码器和解码器的参数,同时在它们之间加入了可学习的时间通道(TC)层。TC层的主要功能是捕获通道之间的依赖关系,顺便调整时间依赖性,以减少预训练和下游任务之间的差距。
4.2.1 稀疏依赖图构造
捕获跨通道依赖关系的一种直接方法是跨C通道使用自关注,这对应于构造一个完全连接的依赖关系图。然而,O(C2)复杂性限制了其对潜在高维数据集的适用性(Zhang & Yan, 2023)。因此,有必要构建一个保留大多数依赖关系的稀疏图,以较少的边来指导跨通道依赖关系捕获。
由于编码器通过预训练获得了有意义的表示,利用它来构建稀疏图。首先对x(ft)的每个通道进行修补,然后独立输入到编码器,得到潜在令牌,记为 { ∪ i ∈ U c h i , c ( e n c ) } c = 1 c \{\cup_{i∈\mathcal U_c} \mathbf h^{(enc)}_{i,c}\}^c_{c=1} {∪i∈Uchi,c(enc)}c=1c,其中 U c \mathcal U_c Uc表示通道c中未被掩码的补丁, h i , c ( e n c ) \mathbf h^{(enc)}_{i,c} hi,c(enc)表示通道c中第i个编码的补丁。然后利用这些潜在令牌构建通道间的依赖图:
h c ( c h ) = Max_Pooling ( ∪ i ∈ U c h i , c ( e n c ) ) , ∀ c ∈ { 1 , … , C } A c , c ′ = ( h c ( c h ) , h c ′ ( c h ) ∣ ∣ h c ( c h ) ∣ ∣ 2 , ∀ c , c ′ ∈ { 1 , … , C } E = topK ( A , r C ) ∧ KNN ( A , r ) (9) \begin{align} &\mathbf h_c^{(ch)}=\text{Max\_Pooling}(\cup_{i\in\mathcal U_c}\mathbf h^{(enc)}_{i,c}),\forall c\in \{1,\dots, C\}\\ &A_{c,c'}=\frac{(\mathbf h_c^{(ch)},h^{(ch)}_{c'}}{||\mathbf h_c^{(ch)}||_2},\forall c,c'\in \{1,\dots,C\}\\ &\mathbf E=\text{topK}(\mathbf A,rC)\wedge\text{KNN}(\mathbf A,r) \end{align}\tag{9} hc(ch)=Max_Pooling(∪i∈Uchi,c(enc)),∀c∈{1,…,C}Ac,c′=∣∣hc(ch)∣∣2(hc(ch),hc′(ch),∀c,c′∈{1,…,C}E=topK(A,rC)∧KNN(A,r)(9)
相关矩阵a被定义为这些令牌的两两余弦相似性。每个通道的rC个最大元素与r个最近邻居的交集作为最终图E,其中r为常数超参数。
4.2.2 时域频道层
将编码的patch与表示未掩码patch的token (Eq. 4)连接起来,得到 H ( T C − i n ) ∈ R N ( d e c ) × C × d m o d e l \mathbf H^{(TC−in)}\in \mathbb R^{N^{(dec)}×C×d_{model}} H(TC−in)∈RN(dec)×C×dmodel,其中 N ( d e c ) N^{(dec)} N(dec)是每个信道中用于解码的patch的数量。在输入到解码器之前, H ( T C − i n ) \mathbf H^{(TC−in)} H(TC−in)和构建的依赖图E通过K≥1个时间通道(TC)层来捕获跨通道依赖并调整时间依赖。在几乎没有归纳偏差的情况下,TC层包含一个用于时间依赖性的标准Transformer层和一个用于跨通道依赖性的标准Graph Transformer层(Dwivedi & Bresson, 2021):
H ( c h , 0 ) = H ( T C − i n ) for k = 1 , … , K : H : , c ( t i m e , k ) = Transformer ( H : , c c h , k − 1 ) , ∀ c H i , : ( c h , k ) = Graph,Transformer ( H i , : ( t i m e , k ) , E ) , ∀ i H ( d e c − i n ) = H ( T C − o u t ) = H ( c h , K ) \begin{align} &\mathbf H^{(ch,0)}=\mathbf H^{(TC-in)}\\ &\text{for}\ k=1,\dots,K:\\ &\quad\mathbf H^{(time,k)}_{:,c}=\text{Transformer}(\mathbf H^{ch,k-1}_{:,c}),\forall c\\ &\quad \mathbf H^{(ch,k)}_{i,:}=\text{Graph,Transformer}(\mathbf H^{(time,k)}_{i,:},\mathbf E),\forall i\\ &\mathbf H^{(dec-in)}=\mathbf H^{(TC-out)}=\mathbf H^{(ch,K)} \end{align} H(ch,0)=H(TC−in)for k=1,…,K:H:,c(time,k)=Transformer(H:,cch,k−1),∀cHi,:(ch,k)=Graph,Transformer(Hi,:(time,k),E),∀iH(dec−in)=H(TC−out)=H(ch,K)
经过几个可学习的TC层,最终的 H ( d e c − i n ) ∈ R N ( d e c ) × C × d m o d e l \mathbf H^ {(dec−in)}\in \mathbb R^{N^{(dec)}×C×d_{model}} H(dec−in)∈RN(dec)×C×dmodel被输入到冻结的解码器中,得到下游任务的解。Graph Transformer层在功能上等同于标准Transformer层,使用图结构作为注意力权重掩模,但在稀疏图上更有效(Dwivedi & Bresson, 2021)。TC层的整体计算复杂度为 O ( C N 2 ) O ( r C N ) = O ( C N 2 ) O(CN^2) O(rCN) = O(CN^2) O(CN2)O(rCN)=O(CN2),由于构造的稀疏图是线性的w.r.t C,使得UP2ME可扩展到高维数据。
5. 实验结果
在八个真实世界的数据集上进行实验:1)ETTm1, 2)天气,3)电力,4)交通,5)SMD, 6)PSM, 7)SWaT, 8)GECCO。在每个数据集上,执行三个不同的下游任务:预测、imputation和异常检测3。改变任务的具体设置,例如预测的预测长度和imputation的缺失率等。为每个数据集预训练一个UP2ME作为基本模型,并对其进行微调以适应不同的下游任务和设置。报告了两种UP2ME模式的结果:1)UP2ME(IR):即时反应模式,直接提供预训练模型的初始解;2)UP2ME(FT):微调模式,适应特定的下游任务和设置。对于每个任务,比较了三类方法:1)任务特定方法;2)通用方法;3)预训练方法。详细的设置见附录A。
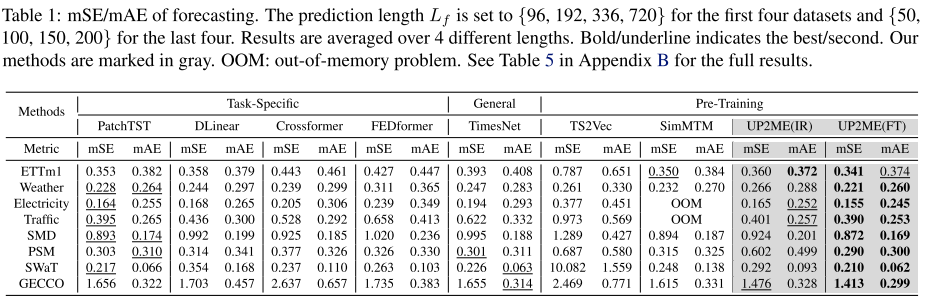
预测。选择PatchTST (Nie et al., 2023)、DLinear (Zeng et al., 2023)、Crossformer (Zhang & Yan, 2023)、FEDformer (Zhou et al., 2022)作为任务特定方法;TimesNet (Wu et al., 2023)作为通用方法;TS2Vec (Yue et al., 2022)和SimMTM (Dong et al., 2023)作为预训练方法。每种方法用不同的长度(Lf)预测未来的序列。评价指标为均方误差(mSE)和平均绝对误差(mAE) 4。
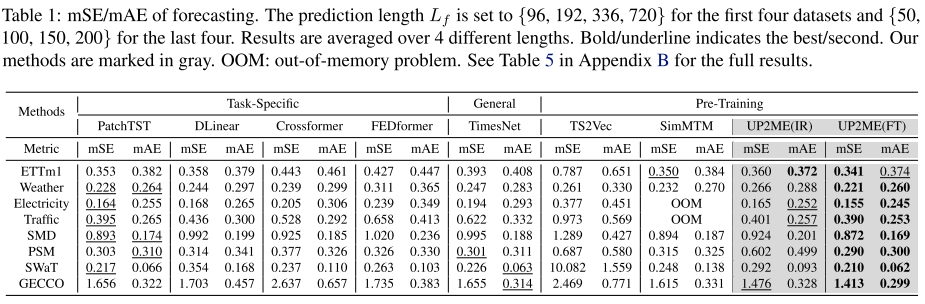
结果如表1所示。在不调整模型参数的情况下,UP2ME(IR)在ETTm1、Electricity、Traffic和GECCO数据集上与以前的SOTA方法相当。这表明实例生成技术使模型能够推广到下游任务,其中掩码分布和比例与预训练不同。经过微调后,UP2ME的预测更加准确,在所有数据集上都优于以前的sota。请注意,UP2ME只使用标准的Transformer和Graph Transformer层,没有电感偏置架构设计,例如扁平投影(PatchTST, TimesNet, SimMTM),趋势季节分解(DLinear, FEDformer),分层编码器-解码器(Crossformer)或频域增强(FEDformer, TimesNet)。
补全。选择SAITS (Du et al., 2023)、GRIN (Cini et al., 2022)、LI(线性插值)和SI(样条插值)作为任务特定方法;通用和预训练方法与预测方法相同。在不同的缺失率水平上评估性能,并使用mSE和mAE作为评
 估指标。
估指标。
表2显示了UP2ME(IR)在电力、交通、SMD和GECCO方面优于大多数以前的基线,并且在ETTm1和SWaT上也取得了可比的结果。值得一提的是,架构和参数与预测相同,显示了UP2ME处理多个任务的能力。在微调后配备了跨通道依赖性,UP2ME(FT)在8个数据集中的7个上优于所有其他方法。
异常检测。选择DCdetector (Yang et al., 2023)、AnomalyTrans (Xu et al., 2022)、ifforest (Liu et al., 2012)、OCSVM (Sch¨olkopf et al., 2001)作为任务特定方法,并使用与预测和imputation相同的通用和预训练方法。继Yang et al. (2023);Xu等人(2022),使用训练和验证集来选择一个阈值,并用它标记异常以进行f1分数评估。此外,为了减轻阈值选择对更全面比较的影响,还在每个可能的点上设置阈值来评估平均精度(AP) (Manning, 2009)。广泛使用的分段调整策略(Shen et al., 2020;Xu et al., 2022;Yang et al., 2023)用于f1评分和AP评估。
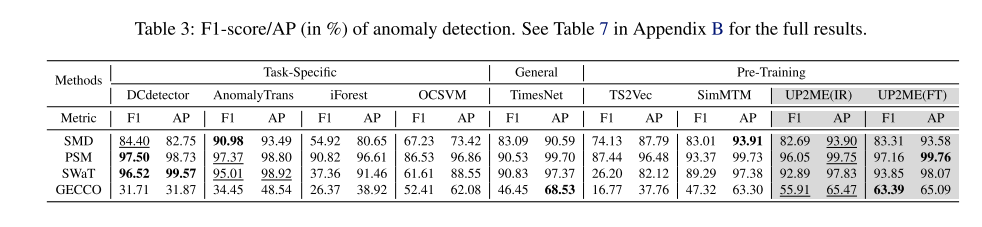
表3显示了两种特定任务的SOTA方法,DCdetector和AnomalyTrans,在前三个数据集上表现更好,但UP2ME仍然优于传统的特定任务、通用和预训练方法,并接近特定任务的方法。而在具有各种异常类型的更具挑战性的GECCO数据集上(Yang等人,2023),UP2ME在很大程度上优于特定于任务的方法,这表明单变量预训练优于多变量微调范式。
6. 结论
建议将UP2ME作为MTS分析的通用框架。从技术上讲,它利用单变量预训练到多变量微调范式,在预训练期间捕获时间依赖性,并在微调期间合并跨通道依赖性。在功能上,预训练的UP2ME在不修改参数的情况下,为预测、imputation和异常检测提供了初步的合理解决方案,这是以前从未实现过的。进一步的精度是通过微调实现的。
7. 部分关键代码
7.1 数据预处理
import os
import numpy as np
import pandas as pdfrom torch.utils.data import Dataset
from sklearn.preprocessing import StandardScaler#Forecasting dataset for data saved in csv format
class Forecast_Dataset_csv(Dataset):def __init__(self, root_path, data_path='ETTm1.csv', flag='train', size=None, data_split = [0.7, 0.1, 0.2], scale=True, scale_statistic=None):# size [past_len, pred_len]self.in_len = size[0]self.out_len = size[1]# initassert flag in ['train', 'test', 'val']type_map = {'train':0, 'val':1, 'test':2}self.set_type = type_map[flag]self.scale = scaleself.root_path = root_pathself.data_path = data_pathself.data_split = data_splitself.scale_statistic = scale_statisticself.__read_data__()def __read_data__(self):df_raw = pd.read_csv(os.path.join(self.root_path, self.data_path))#int split, e.g. [34560,11520,11520] for ETTm1if (self.data_split[0] > 1):train_num = self.data_split[0]; val_num = self.data_split[1]; test_num = self.data_split[2];#ratio split, e.g. [0.7, 0.1, 0.2] for Weatherelse:train_num = int(len(df_raw)*self.data_split[0]); test_num = int(len(df_raw)*self.data_split[2])val_num = len(df_raw) - train_num - test_num; border1s = [0, train_num - self.in_len, train_num + val_num - self.in_len]border2s = [train_num, train_num+val_num, train_num + val_num + test_num]border1 = border1s[self.set_type]border2 = border2s[self.set_type]cols_data = df_raw.columns[1:]df_data = df_raw[cols_data]if self.scale:if self.scale_statistic is None:self.scaler = StandardScaler()train_data = df_data[border1s[0]:border2s[0]]self.scaler.fit(train_data.values)else:self.scaler = StandardScaler(mean = self.scale_statistic['mean'], std = self.scale_statistic['std'])data = self.scaler.transform(df_data.values)else:data = df_data.valuesself.data_x = data[border1:border2]self.data_y = data[border1:border2]def __getitem__(self, index):past_begin = indexpast_end = past_begin + self.in_lenpred_begin = past_endpred_end = pred_begin + self.out_lenseq_x = self.data_x[past_begin:past_end].transpose() # [ts_d, ts_len]seq_y = self.data_y[pred_begin:pred_end].transpose()return seq_x, seq_ydef __len__(self):return len(self.data_x) - self.in_len - self.out_len + 1def inverse_transform(self, data):return self.scaler.inverse_transform(data)#Forecasting dataset for data saved in npy format
class Forecast_Dataset_npy(Dataset):'''For dataset stored in .npy files (originally for anomaly detection), which is usually saved in '*_train.npy', '*_test.npy' and '*_test_label.npy'We split the training set into training and validation setWe now use this dataset for forecasting task'''def __init__(self, root_path, data_name='SMD', flag="train", size=None, step=1,valid_prop=0.2, scale=True, scale_statistic=None, lead_in=1000):self.in_len = size[0]self.out_len = size[1]self.root_path = root_pathself.data_name = data_nameself.flag = flagself.step = step #like stride in convolution, we may skip multiple steps when using sliding window on large dataset (e.g. SMD has 566,724 timestamps)self.valid_prop = valid_propself.scale = scaleself.scale_statistic = scale_statistic'''the front part of the test series will be preserved for model input;to keep consistant with csv format where some steps in val set are input to the model to predict test set; With lead_in, if pred_len remain unchanged, varying input length will not change y in test set'''self.lead_in = lead_in self.__read_data__()def __read_data__(self):train_val_data = np.load(os.path.join(self.root_path, '{}_train.npy'.format(self.data_name)))test_data = np.load(os.path.join(self.root_path, '{}_test.npy'.format(self.data_name)))self.data_dim = train_val_data.shape[1]# we do not need anomaly label for forecastingtrain_num = int(len(train_val_data) * (1 - self.valid_prop))if self.scale:# use the mean and std of training setif self.scale_statistic is None:self.scaler = StandardScaler()train_data = train_val_data[:train_num]self.scaler.fit(train_data)else:self.scaler = StandardScaler(mean=self.scale_statistic['mean'], std=self.scale_statistic['std'])scale_train_val_data = self.scaler.transform(train_val_data)scale_test_data = self.scaler.transform(test_data)if self.flag == 'train':self.data_x = scale_train_val_data[:train_num]self.data_y = scale_train_val_data[:train_num]elif self.flag == 'val':self.data_x = scale_train_val_data[train_num - self.in_len:]self.data_y = scale_train_val_data[train_num - self.in_len:]elif self.flag == 'test':'''|------------------|------|----------------------------------------|^ ^| |lead_in-in_len lead_in'''self.data_x = scale_test_data[self.lead_in - self.in_len:] self.data_y = scale_test_data[self.lead_in - self.in_len:]else:if self.flag == 'train':self.data_x = train_val_data[:train_num]self.data_y = train_val_data[:train_num]elif self.flag == 'val':self.data_x = train_val_data[train_num - self.in_len:]self.data_y = train_val_data[train_num - self.in_len:]elif self.flag == 'test':self.data_x = test_data[self.lead_in - self.in_len:]self.data_y = test_data[self.lead_in - self.in_len:]def __len__(self):return (len(self.data_x) - self.in_len - self.out_len) // self.step + 1def __getitem__(self, index):index = index * self.steppast_begin = indexpast_end = past_begin + self.in_lenpred_begin = past_endpred_end = pred_begin + self.out_lenseq_x = self.data_x[past_begin:past_end].transpose() # [ts_d, ts_len]seq_y = self.data_y[pred_begin:pred_end].transpose()return seq_x, seq_y#Anomaly Detection dataset (all saved in npy format)
class Detection_Dataset_npy(Dataset):'''For dataset stored in .npy files, which is usually saved in '*_train.npy', '*_test.npy' and '*_test_label.npy'We split the original training set into training and validation set'''def __init__(self, root_path, data_name='SMD', flag="train", seg_len=100, step=None,valid_prop=0.2, scale=True, scale_statistic=None):self.root_path = root_pathself.data_name = data_nameself.flag = flagself.seg_len = seg_len # length of time-series segment, usually 100 for all anomaly detection experimentsself.step = step if step is not None else seg_len #use step to skip some steps when the set is too largeself.valid_prop = valid_propself.scale = scaleself.scale_statistic = scale_statisticself.__read_data__()def __read_data__(self):train_val_ts = np.load(os.path.join(self.root_path, '{}_train.npy'.format(self.data_name)))test_ts = np.load(os.path.join(self.root_path, '{}_test.npy'.format(self.data_name)))test_label = np.load(os.path.join(self.root_path, '{}_test_label.npy'.format(self.data_name)))self.data_dim = train_val_ts.shape[1]data_len = len(train_val_ts)train_ts = train_val_ts[0:int(data_len * (1 - self.valid_prop))]val_ts = train_val_ts[int(data_len * (1 - self.valid_prop)):]if self.scale:if self.scale_statistic is None:# use the mean and std of training setself.scaler = StandardScaler()self.scaler.fit(train_ts)else:self.scaler = StandardScaler(mean=self.scale_statistic['mean'], std=self.scale_statistic['std'])self.train_ts = self.scaler.transform(train_ts)self.val_ts = self.scaler.transform(val_ts)self.test_ts = self.scaler.transform(test_ts)else:self.train_ts = train_tsself.val_ts = val_tsself.test_ts = test_tsself.threshold_ts = np.concatenate([self.train_ts, self.val_ts], axis=0) #use both training and validation set to set thresholdself.test_label = test_labeldef __len__(self):# number of non-overlapping time-series segmentsif self.flag == "train":return (self.train_ts.shape[0] - self.seg_len) // self.step + 1elif (self.flag == 'val'):return (self.val_ts.shape[0] - self.seg_len) // self.step + 1elif (self.flag == 'test'):return (self.test_ts.shape[0] - self.seg_len) // self.step + 1elif (self.flag == 'threshold'):return (self.threshold_ts.shape[0] - self.seg_len) // self.step + 1def __getitem__(self, index):# select data by flagif self.flag == "train":ts = self.train_tselif (self.flag == 'val'):ts = self.val_tselif (self.flag == 'test'):ts = self.test_tselif (self.flag == 'threshold'):ts = self.threshold_tsindex = index * self.stepts_seg = ts[index:index + self.seg_len, :].transpose() # [ts_dim, seg_len]ts_label = np.zeros(self.seg_len)if self.flag == 'test':ts_label = self.test_label[index:index + self.seg_len]return ts_seg, ts_label
7.2 模型
模型的预训练部分(模型主体)
import torch
from torch import nn
from .embed import patch_embedding, learnable_position_embedding, RevIN
from .encoder_decoder import encoder, decoder
from einops import rearrange, repeat
from torch.nn.utils.rnn import pad_sequence
from loguru import loggerclass UP2ME_model(nn.Module):def __init__(self, data_dim, patch_size,d_model=256, d_ff=512, n_heads=4, e_layers=3, d_layers=1, dropout=0.0,mask_ratio=0.75, device=torch.device('cuda:0')):super(UP2ME_model, self).__init__()self.data_dim = data_dimself.patch_size = patch_sizeself.d_model = d_modelself.d_ff = d_ffself.n_heads = n_headsself.e_layers = e_layersself.d_layers = d_layersself.dropout = dropoutself.device = deviceself.RevIN = RevIN(data_dim, affine=True)self.patch_embedding = patch_embedding(patch_size, d_model)self.position_embedding = learnable_position_embedding(d_model)self.channel_embedding = nn.Embedding(data_dim, d_model)#encoderself.encoder = encoder(e_layers, d_model, n_heads, d_ff, dropout)#encoder-space to decoder-spaceself.enc_2_dec = nn.Linear(d_model, d_model)self.learnable_patch = nn.Parameter(torch.randn(d_model))#decoderself.decoder = decoder(patch_size, d_layers, d_model, n_heads, d_ff, dropout)def encode_uni_to_patch(self, ts, channel_idx, masked_patch_index=None, unmasked_patch_index=None, imputation_point_mask=None):'''Encode the unmaksed patches of unvariate time series to latent patches.Args:ts: time series with shape [batch_size, ts_length]channel_idx: channel index of time series with shape [batch_size]masked_patch_index: masked patch index with shape [batch_size, masked_patch_num]unmasked_patch_index: unmasked patch index with shape [batch_size, unmasked_patch_num]imputation_point_mask: point mask with shape [batch_size, ts_length], for imputation task.'''ts = self.RevIN(ts, channel_idx, mode='norm', mask=imputation_point_mask)patch_embed = self.patch_embedding.forward_uni(ts) # [batch_size, patch_size, d_model]position_embed = self.position_embedding(patch_embed.shape)channel_embed = self.channel_embedding(channel_idx) # [batch_size, d_model]patches = patch_embed + position_embed + channel_embed[:, None, :] # [batch_size, patch_size, d_model]imputation_patch_mask = Noneif masked_patch_index is not None and unmasked_patch_index is not None: # only encode the unmasked patchesencoder_input = patches.gather(1, unmasked_patch_index[:, :, None].expand(-1, -1, self.d_model))elif imputation_point_mask is not None:imputation_patch_mask = rearrange(imputation_point_mask, 'batch_size (patch_num patch_size) -> batch_size patch_num patch_size', patch_size=self.patch_size)imputation_patch_mask = imputation_patch_mask.sum(dim=-1) > 0 # [batch_size, patch_num]encoder_input = patcheselse:encoder_input = patchesencoded_patch_unmasked = self.encoder.forward_uni(encoder_input, imputation_patch_mask) # [batch_size, unmasked_patch_num, d_model]return encoded_patch_unmaskeddef patch_concatenate(self, encoded_patch_unmasked, channel_idx, masked_patch_index, unmasked_patch_index):'''concatenate encoded unmasked patches and tokens indicating masked patches, i.e. First line in Equation (4) except enc-to-decArgs:encoded_patch_unmasked: encoded patches without masking with shape [batch_size, unmasked_patch_num, d_model]channel_idx: channel index of time series with shape [batch_size]masked_patch_index: masked patch index with shape [batch_size, masked_patch_num]unmasked_patch_index: unmasked patch index with shape [batch_size, unmasked_patch_num] '''batch_size, unmasked_patch_num, _ = encoded_patch_unmasked.shapemasked_patch_num = masked_patch_index.shape[1]patch_embed_masked = self.learnable_patch[None, None, :].expand(batch_size, masked_patch_num, -1)position_embed_masked = self.position_embedding(patch_embed_masked.shape, masked_patch_index)channel_embed_masked = self.channel_embedding(channel_idx)patches_masked = patch_embed_masked + position_embed_masked + channel_embed_masked[:, None, :]patches_full = torch.cat([patches_masked, encoded_patch_unmasked], dim=1) #concate masked&unmasked patchespatch_index_full = torch.cat([masked_patch_index, unmasked_patch_index], dim=1)origin_patch_index = torch.argsort(patch_index_full, dim=1)origin_patch_index = origin_patch_index.to(encoded_patch_unmasked.device)patches_full_sorted = patches_full.gather(1, origin_patch_index[:, :, None].expand(-1, -1, self.d_model)) #rearrange to original orderreturn patches_full_sorteddef pretrain_decode(self, full_patches, channel_idx):'''Decoding process, passing decoder and perform final projectionArgs:concated_patches: masked & unmasked patches [batch_size, total_patch_num, d_model]channel_idx: channel index of time series with shape [batch_size]'''reconstructed_ts = self.decoder.forward_uni(full_patches)reconstructed_ts = self.RevIN(reconstructed_ts, channel_idx, mode='denorm')return reconstructed_ts#some functions for downstream tasksdef encode_multi_to_patch(self, multi_ts, masked_patch_index=None, unmasked_patch_index=None, imputation_point_mask=None):'''Encode the unmaksed patches of multivariate time series to latent patches.Args:multi_ts: time series with shape [batch_size, ts_d, ts_length]masked_patch_index: masked patch index with shape [batch_size, ts_d, masked_patch_num]unmasked_patch_index: unmasked patch index with shape [batch_size, ts_d, unmasked_patch_num]point_mask: point mask with shape [batch_size, ts_d, ts_length], for imputation task.'''batch_size, ts_d, ts_length = multi_ts.shapets_flatten = rearrange(multi_ts, 'batch_size ts_d ts_length -> (batch_size ts_d) ts_length')channel_idx = torch.arange(self.data_dim)[None, :].expand(batch_size, -1).to(multi_ts.device)channel_flatten = rearrange(channel_idx, 'batch_size ts_d -> (batch_size ts_d)')if masked_patch_index is not None and unmasked_patch_index is not None: # only encode the unmasked patchesmasked_patch_flatten = rearrange(masked_patch_index, 'batch_size ts_d masked_patch_num -> (batch_size ts_d) masked_patch_num')unmasked_patch_flatten = rearrange(unmasked_patch_index, 'batch_size ts_d unmasked_patch_num -> (batch_size ts_d) unmasked_patch_num')else:masked_patch_flatten, unmasked_patch_flatten = None, Noneif imputation_point_mask is not None:imputation_point_mask_flatten = rearrange(imputation_point_mask, 'batch_size ts_d ts_length -> (batch_size ts_d) ts_length')else:imputation_point_mask_flatten = Noneencoded_patch_flatten = self.encode_uni_to_patch(ts_flatten, channel_flatten, masked_patch_flatten, unmasked_patch_flatten, imputation_point_mask_flatten)encoded_patch = rearrange(encoded_patch_flatten, '(batch_size ts_d) patch_num d_model -> batch_size ts_d patch_num d_model', batch_size=batch_size)return encoded_patchdef decode_patch_to_multi(self, encoded_patch_unmasked, masked_patch_index, unmasked_patch_index):batch_size, ts_d, unmasked_patch_num, _ = encoded_patch_unmasked.shapeflatten_encoded_patch_unmasked = rearrange(encoded_patch_unmasked, 'batch_size ts_d unmasked_patch_num d_model -> (batch_size ts_d) unmasked_patch_num d_model')flatten_masked_patch_index = rearrange(masked_patch_index, 'batch_size ts_d masked_patch_num -> (batch_size ts_d) masked_patch_num')flatten_unmasked_patch_index = rearrange(unmasked_patch_index, 'batch_size ts_d unmasked_patch_num -> (batch_size ts_d) unmasked_patch_num')flatten_channel_idx = torch.arange(self.data_dim)[None, :].expand(batch_size, -1).reshape(batch_size * ts_d).to(encoded_patch_unmasked.device)flatten_encoded_patch_unmasked = self.enc_2_dec(flatten_encoded_patch_unmasked)flatten_full_patch = self.patch_concatenate(flatten_encoded_patch_unmasked, flatten_channel_idx, flatten_masked_patch_index, flatten_unmasked_patch_index)flatten_reconstructed_ts = self.pretrain_decode(flatten_full_patch, flatten_channel_idx)reconstructed_ts = rearrange(flatten_reconstructed_ts, '(batch_size ts_d) ts_len -> batch_size ts_d ts_len', batch_size=batch_size)return reconstructed_ts模型的编码器与解码器部分
from torch import nn
from torch.nn import TransformerEncoder, TransformerEncoderLayer
from einops import rearrange, repeatclass encoder(nn.Module):def __init__(self, n_layers=3, d_model=256, n_heads=4, d_ff=512, dropout=0.):super(encoder, self).__init__()#the encoder does not handle the patch staff, just encoded the given patchesself.n_layers = n_layersself.d_model = d_modelself.n_heads = n_headsself.d_ff = d_ffself.dropout = dropoutencoder_layer = TransformerEncoderLayer(d_model, n_heads, d_ff, dropout, batch_first = True)self.encoder_layers = TransformerEncoder(encoder_layer, n_layers)def forward_uni(self, patch, mask = None):batch_size, patch_num, _ = patch.shapeencoded_patch = self.encoder_layers(patch, src_key_padding_mask = mask)return encoded_patchclass decoder(nn.Module):def __init__(self, patch_size, n_layers=1, d_model=256, n_heads=4, d_ff=512, dropout=0.):super(decoder, self).__init__()#the decoder takes encoded tokens + indicating tokens as input, projects tokens to original spaceself.patch_size = patch_sizeself.n_layers = n_layersself.d_model = d_modelself.n_heads = n_headsself.d_ff = d_ffself.dropout = dropoutdecoder_layer = TransformerEncoderLayer(d_model, n_heads, d_ff, dropout, batch_first = True)self.decoder_layers = TransformerEncoder(decoder_layer, n_layers)self.output_layer = nn.Linear(d_model, patch_size)def forward_uni(self, patch):batch_size, patch_num, _ = patch.shapedecoded_patch = self.decoder_layers(patch)decoded_ts = self.output_layer(decoded_patch)decoded_ts = rearrange(decoded_ts, 'b patch_num patch_size -> b (patch_num patch_size)')return decoded_ts
模型的调整部分(预测)
import torch
import torch.nn as nn
from ..pretrain_model.UP2ME_model import UP2ME_model
from .temporal_channel_layer import Temporal_Channel_Layer
from ..pretrain_model.embed import learnable_position_embedding
from .graph_structure import graph_construct
from einops import rearrangeclass UP2ME_forecaster(nn.Module):def __init__(self, pretrained_model_path, pretrain_args, finetune_flag=False, finetune_layers=3, dropout=0.0):super(UP2ME_forecaster, self).__init__()self.pretrained_model_path = pretrained_model_pathself.pretrain_args = pretrain_argsself.data_dim = pretrain_args['data_dim']self.patch_size = pretrain_args['patch_size']self.finetune_flag = finetune_flagself.finetune_layers = finetune_layersself.dropout = dropout# load pre-trained modelself.pretrained_model = UP2ME_model(data_dim=pretrain_args['data_dim'], patch_size=pretrain_args['patch_size'],\d_model=pretrain_args['d_model'], d_ff = pretrain_args['d_ff'], n_heads=pretrain_args['n_heads'], \e_layers=pretrain_args['e_layers'], d_layers = pretrain_args['d_layers'], dropout=pretrain_args['dropout'])self.load_pre_trained_model()# if fine-tune, add new layersif self.finetune_flag:self.enc_2_dec = nn.Linear(pretrain_args['d_model'], pretrain_args['d_model'])self.learnable_patch = nn.Parameter(torch.randn(pretrain_args['d_model']))self.position_embedding = learnable_position_embedding(pretrain_args['d_model'])self.channel_embedding = nn.Embedding(pretrain_args['data_dim'], pretrain_args['d_model'])self.init_enc2dec_param()self.temporal_channel_layers = nn.ModuleList()for _ in range(finetune_layers):self.temporal_channel_layers.append(Temporal_Channel_Layer(d_model=pretrain_args['d_model'], n_heads=pretrain_args['n_heads'], d_ff=pretrain_args['d_ff'], dropout=dropout))def load_pre_trained_model(self):#load the pre-trained modelpretrained_model = torch.load(self.pretrained_model_path, map_location='cpu')self.pretrained_model.load_state_dict(pretrained_model)#freeze the encoder and decoder of pre-trained modelfor param in self.pretrained_model.parameters():param.requires_grad = False def init_enc2dec_param(self):self.position_embedding.load_state_dict(self.pretrained_model.position_embedding.state_dict())self.channel_embedding.load_state_dict(self.pretrained_model.channel_embedding.state_dict())self.learnable_patch.data.copy_(self.pretrained_model.learnable_patch.data)self.enc_2_dec.load_state_dict(self.pretrained_model.enc_2_dec.state_dict()) def train_mode(self):self.train()self.pretrained_model.eval()returndef eval_mode(self):self.eval()returndef immediate_forecast(self, multi_ts, pred_len):'''Immediate reaction mode, directly use the pretrained model to perform multi-variate forecasting without any parameter modificationArgs:multi_ts: [batch_size, ts_d, past_len]pred_len: [batch_size]'''batch_size, ts_d, past_len = multi_ts.shape# encode past patchesencoded_past_patch = self.pretrained_model.encode_multi_to_patch(multi_ts)#prepare masked and unmasked indicesfull_len = past_len + pred_lenfull_patch_num = full_len // self.patch_sizepast_patch_num = past_len // self.patch_sizefull_patch_idx = torch.arange(full_patch_num)[None, None, :].expand(batch_size, ts_d, -1).to(multi_ts.device)past_patch_idx = full_patch_idx[:, :, :past_patch_num]pred_patch_idx = full_patch_idx[:, :, past_patch_num:]reconstructed_full_ts = self.pretrained_model.decode_patch_to_multi(encoded_past_patch, pred_patch_idx, past_patch_idx)pred_ts = reconstructed_full_ts[:, :, past_len:]return pred_tsdef forward(self, past_ts, pred_patch_num, neighbor_num = 10):batch_size, ts_d, _ = past_ts.shapeencoded_patch_past = self.pretrained_model.encode_multi_to_patch(past_ts)#compute the graph structuregraph_adj = graph_construct(encoded_patch_past, k = neighbor_num)encoded_patch_past_transformed = self.enc_2_dec(encoded_patch_past) #[batch_size, ts_d, patch_num, d_model]#<----------------------------------concatenate past and future patches-------------------------------------------->_, _, past_patch_num, d_model = encoded_patch_past_transformed.shapechannel_idx = torch.arange(ts_d).to(past_ts.device)channel_embed = self.channel_embedding(channel_idx) #[ts_d, d_model]channel_embed_future = channel_embed[None, :, None, :].expand(batch_size, -1, pred_patch_num, -1) #[batch_size, ts_d, pred_patch_num, d_model]patch_embed_future = self.learnable_patch[None, None, None, :].expand(batch_size, ts_d, pred_patch_num, -1)future_patch_idx = torch.arange(past_patch_num, past_patch_num + pred_patch_num)[None, :].expand(batch_size, -1).to(past_ts.device)position_embed_future = self.position_embedding([batch_size, pred_patch_num, d_model], future_patch_idx) #[batch_size, pred_patch_num, d_model]position_embed_future = position_embed_future[:, None, :, :].expand(-1, ts_d, -1, -1) #[batch_size, ts_d, pred_patch_num, d_model]patches_future = patch_embed_future + position_embed_future + channel_embed_future #[batch_size, ts_d, pred_patch_num, d_model]patches_past = encoded_patch_past_transformedpatches_full = torch.cat((patches_past, patches_future), dim = -2) #[batch_size, ts_d, past_patch_num+pred_patch_num, d_model]#<----------------------------------------------------------------------------------------------------------------->#passing TC layersfor layer in self.temporal_channel_layers:patches_full = layer(patches_full, graph_adj)#passing pretrained decoderflatten_patches_full = rearrange(patches_full, 'batch_size ts_d seq_len d_model -> (batch_size ts_d) seq_len d_model')flatten_channel_index = channel_idx[None, :].expand(batch_size, -1).reshape(-1)flatten_full_ts = self.pretrained_model.pretrain_decode(flatten_patches_full, flatten_channel_index) # (batch_size*ts_d, past_len+pred_len)full_ts = rearrange(flatten_full_ts, '(batch_size ts_d) ts_len -> batch_size ts_d ts_len', batch_size = batch_size)pred_ts = full_ts[:, :, -pred_patch_num*self.pretrain_args['patch_size']:]return pred_ts
预测部分的代码
import argparse
import os
import torch
import json
import random
import numpy as npfrom exp.exp_forecast import UP2ME_exp_forecast
from utils.tools import string_splitparser = argparse.ArgumentParser(description='UP2ME for forecasting')parser.add_argument('--is_training', type=int, default=1, help='status')
parser.add_argument('--IR_mode', action='store_true', help='whether to use immediate reaction mode', default=False)parser.add_argument('--data_format', type=str, default='csv', help='data format')
parser.add_argument('--data_name', type=str, default='SMD', help='data name')
parser.add_argument('--root_path', type=str, default='./datasets/', help='root path of the data file')
parser.add_argument('--data_path', type=str, default='ETTh1.csv', help='data file')
parser.add_argument('--valid_prop', type=float, default=0.2, help='proportion of validation set, for numpy data only')
parser.add_argument('--data_split', type=str, default='0.7,0.1,0.2', help='train/val/test split, can be ratio or number')
parser.add_argument('--checkpoints', type=str, default='./checkpoints_forecast/', help='location to store model checkpoints')parser.add_argument('--pretrained_model_path', type=str, default='./checkpoints/U2M_ETTm1.csv_dim7_patch12_minPatch20_maxPatch200\_mask0.5_dm256_dff512_heads4_eLayer4_dLayer1_dropout0.0/epoch-80000.pth', help='location of the pretrained model')
parser.add_argument('--pretrain_args_path', type=str, default='./checkpoints/U2M_ETTm1.csv_dim7_patch12_minPatch20_maxPatch200\_mask0.5_dm256_dff512_heads4_eLayer4_dLayer1_dropout0.0/args.json', help='location of the pretrained model parameters')parser.add_argument('--in_len', type=int, default=720, help='input MTS length (T)')
parser.add_argument('--out_len', type=int, default=96, help='output MTS length (\tau)')parser.add_argument('--finetune_layers', type=int, default=1, help='forecast layers to finetune')
parser.add_argument('--dropout', type=float, default=0.0, help='dropout ratio for finetune layers')
parser.add_argument('--neighbor_num', type=int, default=10, help='number of neighbors for graph (for high dimensional data)')parser.add_argument('--num_workers', type=int, default=0, help='data loader num workers')
parser.add_argument('--batch_size', type=int, default=128, help='batch size of train input data')
parser.add_argument('--train_epochs', type=int, default=20, help='train epochs')
parser.add_argument('--learning_rate', type=float, default=1e-4, help='optimizer initial learning rate')
parser.add_argument('--lradj', type=str, default='none', help='adjust learning rate')
parser.add_argument('--tolerance', type=int, default=3, help='early stopping tolerance')
parser.add_argument('--itr', type=int, default=1, help='experiments times')
parser.add_argument('--slide_step', type=int, default=10, help='sliding steps for the sliding window of train and valid')parser.add_argument('--save_pred', action='store_true', help='whether to save the predicted future MTS', default=False)parser.add_argument('--use_gpu', type=bool, default=True, help='use gpu')
parser.add_argument('--gpu', type=int, default=0, help='gpu')
parser.add_argument('--use_multi_gpu', action='store_true', help='use multiple gpus', default=False)
parser.add_argument('--devices', type=str, default='0,1,2,3', help='device ids of multile gpus')parser.add_argument('--label', type=str, default='ft', help='labels to attach to setting')args = parser.parse_args()args.data_split = string_split(args.data_split)
args.use_gpu = True if torch.cuda.is_available() and args.use_gpu else Falseif args.use_gpu and args.use_multi_gpu:args.devices = args.devices.replace(' ', '')device_ids = args.devices.split(',')args.device_ids = [int(id_) for id_ in device_ids]args.gpu = args.device_ids[0]args.pretrain_args = json.load(open(args.pretrain_args_path))# fix random seed
torch.manual_seed(2023)
random.seed(2023)
np.random.seed(2023)
torch.cuda.manual_seed_all(2023)print('Args in experiment:')
print(args)for i in range(args.itr):setting = 'U2M_forecast_data{}_dim{}_patch{}_dm{}_dff{}_heads{}_eLayer{}_dLayer{}_IRmode{}_ftLayer{}_neighbor{}_inlen{}_outlen{}_itr{}'.format(args.data_name,args.pretrain_args['data_dim'], args.pretrain_args['patch_size'], args.pretrain_args['d_model'], args.pretrain_args['d_ff'],args.pretrain_args['n_heads'], args.pretrain_args['e_layers'], args.pretrain_args['d_layers'], args.IR_mode, args.finetune_layers, args.neighbor_num,args.in_len, args.out_len, i)exp = UP2ME_exp_forecast(args)if args.is_training:print('>>>>>>>start training : {}>>>>>>>>>>>>>>>>>>>>>>>>>>'.format(setting))exp.train(setting)print('>>>>>>>testing : {}<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<'.format(setting))exp.test(setting, args.save_pred)
相关文章:

第六十五周周报 UP2ME
文章目录 week 65 UP2ME摘要Abstract1. 题目2. Abstract3. 文献解读3.1 Introduction3.2 创新点 4. 网络结构4.1 单变量预训练4.1.1 样例生成4.1.2 掩码自动编码器预训练4.1.3 即时反应模式 4.2 多元微调4.2.1 稀疏依赖图构造4.2.2 时域频道层 5. 实验结果6. 结论7. 部分关键代…...
)
Unity 使用 Excel 进行配置管理(读Excel配置表、Excel转保存Txt 文本、读取保存的 Txt 文本配置内容)
Unity 使用 Excel 进行配置管理(读Excel配置表、Excel转保存Txt 文本、读取保存的 Txt 文本配置内容) 目录 Unity 使用 Excel 进行配置管理(读Excel配置表、Excel转保存Txt 文本、读取保存的 Txt 文本配置内容) 一、简单介绍 二、实现原理 三、注意事项 四、案例简单步…...

【STM32】MPU6050简介
文章目录 MPU6050简介MPU6050关键块带有16位ADC和信号调理的三轴MEMS陀螺仪具有16位ADC和信号调理的三轴MEMS加速度计I2C串行通信接口 MPU6050对应的数据手册:MPU6050 陀螺仪加速度计 链接: https://pan.baidu.com/s/13nwEhGvsfxx0euR2hMHsyw?pwdv2i6 提取码: v2i6…...
)
学习日记_20241123_聚类方法(MeanShift)
前言 提醒: 文章内容为方便作者自己后日复习与查阅而进行的书写与发布,其中引用内容都会使用链接表明出处(如有侵权问题,请及时联系)。 其中内容多为一次书写,缺少检查与订正,如有问题或其他拓展…...

Qt常用控件 按钮
文章目录 1. QAbstractButton 简介2. QPushButton2.1 例子1,设置按钮的图标2.2 例子2,设置按钮快捷键 3. QRadioButton3.1 介绍3.2 例子1,选择性别3.3 例子2,试试其他的信号3.3 例子3,分组 4. QCheckBox4.1 介绍4.2 例…...
)
医院信息化与智能化系统(22)
医院信息化与智能化系统(22) 这里只描述对应过程,和可能遇到的问题及解决办法以及对应的参考链接,并不会直接每一步详细配置 如果你想通过文字描述或代码画流程图,可以试试PlantUML,告诉GPT你的文件结构,让他给你对应…...
-稳定输出3.3V的太阳能电池-无限充放电)
嵌入式硬件实战基础篇(二)-稳定输出3.3V的太阳能电池-无限充放电
引言:本内容主要用作于学习巩固嵌入式硬件内容知识,用于想提升下述能力,针对学习稳压芯片和电容以及电池之间的运用,对于硬件PCB以及原理图的练习和前面硬件篇的实际运用;太阳能是一种清洁、可再生的能源,广…...

UE5材质篇5 简易水面
不得不说,UE5里搞一个水面实在是相比要自己写各种反射来说太友好了,就主要是开启一堆开关,lumen相关的,然后稍微连一些蓝图就几乎有了 这里要改一个shading model,要这个 然后要增加一个这个node 并且不需要连接base …...
)
Rollup配置实战:多产物与多入口的完美结合 (2)
常用配置 多产物配置 我们可以将 output 改造成一个数组,对外暴露出不同格式的产物供他人使用,不仅包括 ESM,也需要包括诸如CommonJS、UMD等格式,保证良好的兼容性 import { defineConfig } from rollupexport default defineC…...

iced源码分析
前言 iced是一个比较流行的UI库,设计思路还是挺有意思的,不过因为rust复杂的语法,这个库确实很难让一个不精通rust的开发者那么容易理解。这里记录下这几天的阅读源码心得。 正文 iced核心包括四个模块。 iced库,主要控制应用…...

Hadoop的MapReduce详解
文章目录 Hadoop的MapReduce详解一、引言二、MapReduce的核心概念1、Map阶段1.1、Map函数的实现 2、Reduce阶段2.1、Reduce函数的实现 三、MapReduce的执行流程四、MapReduce的使用实例Word Count示例1. Mapper类2. Reducer类3. 执行Word Count 五、总结 Hadoop的MapReduce详解…...

【Python系列】字典灵活的数据存储与操作
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

【MCU】微控制器的编程技术:ISP 与 IAP
在嵌入式领域中,将程序下载到内置 Flash 有两种技术 ISP (In-system programming) ISP 即在系统编程,是指一些可编程逻辑器件、微控制器、芯片组和其他嵌入式设备在安装到完整嵌入式系统后能够进行编程,而不需要在将芯片安装到系统中之前对…...
)
TCP/IP 协议:网络世界的基石(2/10)
一、引言 在当今数字化时代,互联网已经成为人们生活中不可或缺的一部分。而在互联网的背后,TCP/IP 协议扮演着至关重要的角色,堪称互联网的基石。 TCP/IP 协议是一组用于数据通信的协议集合,它的名字来源于其中最重要的两个协议…...

小R的二叉树探险 | 模拟
问题描述 在一个神奇的二叉树中,结构非常独特: 每层的节点值赋值方向是交替的,第一层从左到右,第二层从右到左,以此类推,且该二叉树有无穷多层。 小R对这个二叉树充满了好奇,她想知道…...

Redis ⽀持哪⼏种数据类型?适⽤场景,底层结构
目录 Redis 数据类型 一、String(字符串) 二、Hash(哈希) 三、List(列表) 四、Set(集合) 五、ZSet(sorted set:有序集合) 六、BitMap 七、HyperLogLog 八、GEO …...
、事件对象、事件流(事件捕获、事件冒泡、阻止冒泡和默认行为、事件委托))
十、事件类型(鼠标事件、焦点.. 、键盘.. 、文本.. 、滚动..)、事件对象、事件流(事件捕获、事件冒泡、阻止冒泡和默认行为、事件委托)
1. 事件类型 1.1 鼠标事件 1.1.1 click 鼠标点击 1.1.2 mouseenter 鼠标进入 1.1.3 mouseleave 鼠标离开 <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta name"viewport" content"widt…...

RabbitMQ学习-One
同步调用和异步调用 1.假设我们现在又两个服务,分别是修改商品服务和查询商品服务,每个服务都有自己的数据库; 2.左侧的流程假设我们总共需要耗时40ms; 3.因为不同服务数据库不一样,所以我们就要考虑修改了左边服务的…...

蓝队基础,网络七杀伤链详解
声明! 学习视频来自B站up主 泷羽sec 有兴趣的师傅可以关注一下,如涉及侵权马上删除文章,笔记只是方便各位师傅的学习和探讨,文章所提到的网站以及内容,只做学习交流,其他均与本人以及泷羽sec团队无关&#…...

机器学习实战:银行客户是否认购定期存款
项目结构与步骤 1. 项目概述 项目名称:葡萄牙银行电话营销活动分析与定期存款认购预测目标:通过分析银行的电话营销数据,构建模型预测客户是否会认购定期存款。数据来源:葡萄牙银行营销活动数据集关键挑战:数据不平衡…...

【一篇搞定配置】网络分析工具WireShark的安装与入门使用
🌈 个人主页:十二月的猫-CSDN博客 🔥 系列专栏: 🏀各种软件安装与配置_十二月的猫的博客-CSDN博客 💪🏻 十二月的寒冬阻挡不了春天的脚步,十二点的黑夜遮蔽不住黎明的曙光 目录 1.…...

气膜场馆照明设计:科技与环保的完美结合—轻空间
气膜场馆的照明设计,选用高效节能的400瓦LED灯具,结合现代节能技术,提供强大而均匀的光照。LED灯具在光效和寿命方面优势显著,不仅降低运营能耗,还有效减少碳排放,为绿色场馆建设贡献力量。 科学分布&…...

C语言程序编译和链接
编译环境和运行 编译环境也可以称为翻译环境,是将源代码转换为机器可以识别的二进制指令; 运行环境也可以称为执行环境,用于实际执行代码; 翻译环境 翻译环境由编译和链接两个部分组成,而编译又可以分解为&#x…...
)
springBoot整合 Tess4J实现OCR识别文字(图片+PDF)
1. 环境准备 JDK 8 或更高版本Maven 3.6 或更高版本Spring Boot 2.4 或更高版本Tesseract OCR 引擎Tess4J 库 2. 安装 Tesseract OCR 引擎 下载地址: Home UB-Mannheim/tesseract Wiki GitHub linux直接安装:sudo apt-get install tesseract-ocr 3.…...
:基于 Diffusion 直接生成视频的数字人方案)
阿里数字人工作 Emote Portrait Alive (EMO):基于 Diffusion 直接生成视频的数字人方案
TL;DR 2024 年 ECCV 阿里智能计算研究所的数字人工作,基于 diffusion 方法来直接的从音频到视频合成数字人,避免了中间的三维模型或面部 landmark 的需求,效果很好。 Paper name EMO: Emote Portrait Alive - Generating Expressive Portra…...

Java将PDF保存为图片
将 PDF 文件转换为图片是常见的需求之一,特别是在需要将 PDF 内容以图像形式展示或处理时。其中最常用的是 Apache PDFBox。 使用 Apache PDFBox Apache PDFBox 是一个开源的 Java 库,可以用来处理 PDF 文档。它提供了将 PDF 页面转换为图像的功能。 …...

医药企业的终端市场营销策略
近年来,随着医药行业的快速发展,终端市场逐渐成为企业竞争的关键领域。在政策趋严、市场环境变化以及数字化转型的大背景下,医药企业如何在终端市场中立于不败之地?本文结合我们在医药数字化领域的经验,为大家剖析终端…...

使用EFK收集k8s日志
首先我们使用EFK收集Kubernetes集群中的日志,本次实验讲解的是在Kubernetes集群中启动一个Elasticsearch集群,如果企业内已经有了Elasticsearch集群,可以直接将日志输出至已有的Elasticsearch集群。 文章目录 部署elasticsearch创建Kibana创建…...

Vue3 + TypeScript 项目搭建
Vue3 TypeScript 项目搭建 环境准备 首先确保你的开发环境满足以下要求: # 检查 Node.js 版本 (需要 14.0 或更高版本) node -v# 检查 npm 版本 npm -v# 安装或更新 Vue CLI npm install -g vue/cli创建项目 使用 Vue CLI 创建项目: # 创建项目 np…...
)
Python操作neo4j库py2neo使用(一)
Python操作neo4j库py2neo使用(一) 安装(只用于测试) docker-compose .yml 文件 version: 3.8 services:neo4j:image: neo4j:5.6.0-enterprise #商业版镜像hostname: neo4jcontainer_name: neo4jports:- "7474:7474"-…...
Android Studio新老界面UI切换及老版本下载地址)
(原创)Android Studio新老界面UI切换及老版本下载地址
前言 这两天下载了一个新版的Android Studio,发现整个界面都发生了很大改动: 新的界面的一些设置可参考一些博客: Android Studio新版UI常用设置 但是对于一些急着开发的小伙伴来说,没有时间去适应,那么怎么办呢&am…...

Linux——用户级缓存区及模拟实现fopen、fweite、fclose
linux基础io重定向-CSDN博客 文章目录 目录 文章目录 什么是缓冲区 为什么要有缓冲区 二、编写自己的fopen、fwrite、fclose 1.引入函数 2、引入FILE 3.模拟封装 1、fopen 2、fwrite 3、fclose 4、fflush 总结 前言 用快递站讲述缓冲区 收件区(类比输…...

CKA认证 | Day2 K8s内部监控与日志
第三章 Kubernetes监控与日志 1、查看集群资源状态 在 Kubernetes 集群中,查看集群资源状态和组件状态是非常重要的操作。以下是一些常用的命令和解释,帮助你更好地管理和监控 Kubernetes 集群。 1.1 查看master组件状态 Kubernetes 的 Master 组件包…...

大模型部署,运维,测试所需掌握的知识点
python环境部署: python3 -m site --user-base 返回用户级别的Python安装基础目录 sudo update-alternatives --install /usr/bin/python3 python3 /usr/bin/python3.8 1 将python3的默认路径/usr/bin/python3替…...

JDBC编程---Java
目录 一、数据库编程的前置 二、Java的数据库编程----JDBC 1.概念 2.JDBC编程的优点 三.导入MySQL驱动包 四、JDBC编程的实战 1.创造数据源,并设置数据库所在的位置,三条固定写法 2.建立和数据库服务器之间的连接,连接好了后ÿ…...
技术)
什么是沙箱(Sandbox)技术
沙箱技术是一种重要的计算机安全机制,主要用于隔离程序运行环境,以防止恶意代码或应用程序对系统和数据造成破坏。通过限制代码的访问权限和行为,沙箱为程序提供了一个受控且隔离的执行环境。 核心特点 隔离性沙箱运行的程序被限制在一个受控…...

TCP socket api详解
文章目录 netstat -nltpaccept简单客户端工具 telnet 指定服务连接connect异常处理version 1 单进程版version 2 多进程版version 3 -- 多线程版本version 4 ---- 线程池版本 创建套接字socket sockaddr_in结构体 bind 之后就和UDP不一样了。 因为TCP是一个面向连接的服务器&…...

Linux——环境变量
环境变量一般指的是在操作系统重用来指定操作系统运行环境的一些参数,这些参数会被bash使用,而bash是被我们用户使用的,也就是说,这些环境变量间接的也是被我们用户使用的。环境变量通常都有某些特殊的用途,它在系统重…...

Windows Pycharm 远程 Spark 开发 PySpark
一、环境版本 环境版本PyCharm2024.1.2 (Professional Edition)Ubuntu Kylin16.04Hadoop3.3.5Hive3.1.3Spark2.4.0 二、Pycharm远程开发 文件-远程-开发 选择 SSH连接,连接虚拟机,选择项目目录即可远程开发...

【es6进阶】vue3中的数据劫持的最新实现方案的proxy的详解
vuejs中实现数据的劫持,v2中使用的是Object.defineProperty()来实现的,在大版本v3中彻底重写了这部分,使用了proxy这个数据代理的方式,来修复了v2中对数组和对象的劫持的遗留问题。 proxy是什么 Proxy 用于修改某些操作的默认行为࿰…...

【Isaac Sim】加载自带模型或示例时报 Isaac Sim is not responding
Isaac Sim对电脑配置要求很高,开机第一次打开 Isaac Sim 时,直接就报 Isaac Sim is not responding 卡死了,这是由于第一次需要加载一些资源,耗时会导致 Isaac Sim 无响应,这里等一会会自动给回复。 加载自带模型或示…...
)
React (三)
文章目录 项目地址十二、性能优化12.1 使用useMemo避免不必要的计算12.2 使用memo缓存组件,防止过度渲染12.3 useCallBack缓存函数12.4 useCallBack里访问之前的状态(没懂)十三、Styled-Components13.1 安装13.2给普通html元素添加样式13.3 继承和覆盖样式13.4 给react组件添…...

C0031.在Clion中使用mingw编译器来编译opencv的配置方法
mingw编译器编译opencv库的配置方法...

多目标跟踪算法
文章目录 一、传统方法1. 基于卡尔曼滤波器的方法1.1 Kalman Filter(卡尔曼滤波器) 2. 基于数据关联的方法2.1 匈牙利算法 二、深度学习方法1. 基于检测的多目标跟踪1.1 SORT算法1.2 DeepSort1.3 BoT-SORT 2. 基于特征关联和增强的方法2.1 ByteTrack 3. 基于Transformer的方法3…...

【CSS in Depth 2 精译_059】9.2 把 CSS 模块组合成更大的结构
当前内容所在位置(可进入专栏查看其他译好的章节内容) 【第九章 CSS 的模块化与作用域】 ✔️ 9.1 模块的定义 9.1.1 模块和全局样式9.1.2 一个简单的 CSS 模块9.1.3 模块的变体9.1.4 多元素模块 9.2 将模块组合为更大的结构 ✔️ 9.2.1 模块中多个职责的…...

uniapp+vue3+ts H5端使用Quill富文本插件以及解决上传图片反显的问题
uniappvue3ts H5端使用Quill富文本插件以及解决上传图片反显的问题 1.在项目中安装Quill npm i quill1.3.72.需要显示富文本的页面完整代码 <template><view><div ref"quillEditor" style"height: 65vh"></div></view> &…...
)
shell(二)
声明! 学习视频来自B站up主 **泷羽sec** 有兴趣的师傅可以关注一下,如涉及侵权马上删除文章,笔记只是方便各位师傅的学习和探讨,文章所提到的网站以及内容,只做学习交流,其他均与本人以及泷羽sec团队无关&a…...

在使用PCA算法进行数据压缩降维时,如何确定最佳维度是一个关键问题?
一、PCA算法的基本原理 PCA算法的核心思想是通过正交变换,将一组可能相关的变量转换成一组线性不相关的变量,称为主成分。这组主成分能够以最小的信息损失来尽可能多地保留原始数据集的变异性。具体来说,PCA算法包括以下几个步骤:…...
)
学习嵩山版《Java 开发手册》:编程规约 - 命名风格(P1 ~ P2)
概述 《Java 开发手册》是阿里巴巴集团技术团队的集体智慧结晶和经验总结,他旨在提升开发效率和代码质量 《Java 开发手册》是一本极具价值的 Java 开发规范指南,对于提升开发者的综合素质和代码质量具有重要意义 学习《Java 开发手册》是一个提升 Jav…...

#渗透测试#红蓝攻防#HW#SRC漏洞挖掘01之静态页面渗透
免责声明 本教程仅为合法的教学目的而准备,严禁用于任何形式的违法犯罪活动及其他商业行为,在使用本教程前,您应确保该行为符合当地的法律法规,继续阅读即表示您需自行承担所有操作的后果,如有异议,请立即停…...