分类算法 Kmeans、KNN、Meanshift 实战
任务
1、采用 Kmeans 算法实现 2D 数据自动聚类,预测 V1=80,V2=60 数据类别;
2、计算预测准确率,完成结果矫正
3、采用 KNN、Meanshift 算法,重复步骤 1-2
代码工具:jupyter notebook
视频资料
无监督学习:15.17 无监督学习_哔哩哔哩_bilibili
Kmeans-KNN-Meanshift:16.18 Kmeans-KNN-Meanshift_哔哩哔哩_bilibili
Kmean 实战(1):17.20 Kmeans实战(1)_哔哩哔哩_bilibili
Kmean 实战(2):18.21 Kmeans实战(2)_哔哩哔哩_bilibili
KNN-meanshift:19.22 KNN-Meanshift_哔哩哔哩_bilibili
数据准备
数据集:kmeans_knn_meanshift_data.csv
链接: https://pan.baidu.com/s/1i0IxtE6rBKHIb-2kbX1NkA 提取码: 8497
#load the data
import pandas as pd
import numpy as np
data = pd.read_csv('kmeans_knn_meanshift_data.csv')
data.head()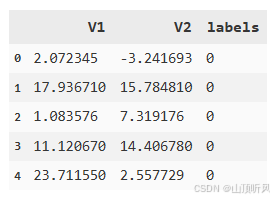
#看一下 labels 里面有多少类别
pd.value_counts(y) 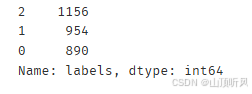
#数据可视化
%matplotlib inline
from matplotlib import pyplot as plt
fig1 = plt.figure()
plt.scatter(X.loc[:,'V1'], X.loc[:,'V2'])
plt.title("un-labled data")
plt.xlabel('V1')
plt.ylabel('V2')
plt.show()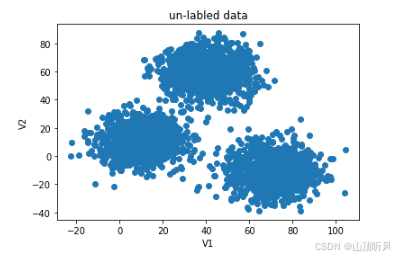
fig1 = plt.figure()
label0 = plt.scatter(X.loc[:,'V1'][y==0], X.loc[:,'V2'][y==0])
label1 = plt.scatter(X.loc[:,'V1'][y==1], X.loc[:,'V2'][y==1])
label2 = plt.scatter(X.loc[:,'V1'][y==2], X.loc[:,'V2'][y==2])plt.title("labeled data")
plt.xlabel('V1')
plt.ylabel('V2')
plt.legend((label0, label1, label2),('label0','label1','label2'))
plt.show()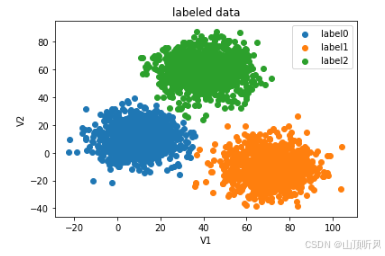
print(X.shape, y.shape) # (3000, 2) (3000,)Kmeans 算法(无监督)
创建模型并训练
# set the model
from sklearn.cluster import KMeans
KM = KMeans(n_clusters = 3, random_state = 0)
KM.fit(X)
原始数据可视化
centers = KM.cluster_centers_ # 三个中心点
fig3 = plt.figure()
#画原图
label0 = plt.scatter(X.loc[:,'V1'][y==0], X.loc[:,'V2'][y==0])
label1 = plt.scatter(X.loc[:,'V1'][y==1], X.loc[:,'V2'][y==1])
label2 = plt.scatter(X.loc[:,'V1'][y==2], X.loc[:,'V2'][y==2])plt.title("labeled data")
plt.xlabel('V1')
plt.ylabel('V2')
plt.legend((label0, label1, label2),('label0','label1','label2'))#展示中心点
plt.scatter(centers[:,0], centers[:,1])
plt.show()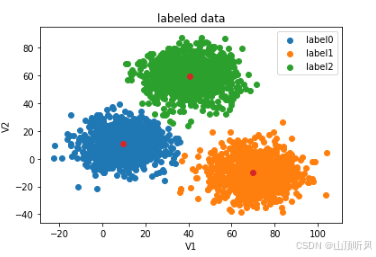
预测 V1=80,V2=60 数据类别
# test data :V1 = 80, V2 = 60
y_predict_test = KM.predict([[80,60]])
print(y_predict_test) # [1]#predict based on training data
y_predict = KM.predict(X)
# 打印出预测数据的分布
print(pd.value_counts(y_predict), pd.value_counts(y))
#发现与原始数据分布好像不太一样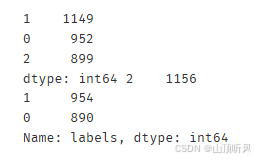
#看下准确率
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y, y_predict)
print(accuracy) # 0.0023333333333333335, 可以看出准确率很低预测数据与原数据一起展示
#数据画出来看看哪里的问题 fig4 = plt.subplot(121)# 一行两列,画第一列#画预测图================================================== label0 = plt.scatter(X.loc[:,'V1'][y_predict==0], X.loc[:,'V2'][y_predict==0]) label1 = plt.scatter(X.loc[:,'V1'][y_predict==1], X.loc[:,'V2'][y_predict==1]) label2 = plt.scatter(X.loc[:,'V1'][y_predict==2], X.loc[:,'V2'][y_predict==2]) plt.title("predicted data") plt.xlabel('V1') plt.ylabel('V2') plt.legend((label0, label1, label2),('label0','label1','label2')) #展示中心点 plt.scatter(centers[:,0], centers[:,1])#画原图================================================== fig5 = plt.subplot(122) label0 = plt.scatter(X.loc[:,'V1'][y==0], X.loc[:,'V2'][y==0]) label1 = plt.scatter(X.loc[:,'V1'][y==1], X.loc[:,'V2'][y==1]) label2 = plt.scatter(X.loc[:,'V1'][y==2], X.loc[:,'V2'][y==2]) plt.title("labled data") plt.xlabel('V1') plt.ylabel('V2') plt.legend((label0, label1, label2),('label0','label1','label2')) #展示中心点 plt.scatter(centers[:,0], centers[:,1])plt.show() # 从下图可以看到,类别是区分出来了,但是类别名称不对; # 这很正常,无监督式学习就是把类别区分出来至于取什么名称,那不一定 # 但是,如果已原数据的标签,可以将预结果的类别名称进行校正
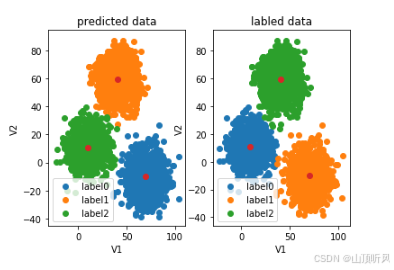
类别校正
# correct the results
y_corrected = []
for i in y_predict:if i == 0:y_corrected.append(1)elif i == 1:y_corrected.append(2)else:y_corrected.append(0)
print(pd.value_counts(y_corrected), pd.value_counts(y)) 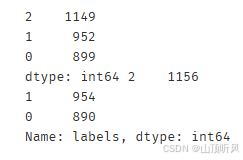
# 看下校正后的准确率是多少
print(accuracy_score(y, y_corrected)) # 0.997y_corrected = np.array(y_corrected)
print(type(y_corrected)) # <class 'numpy.ndarray'>校正后重新可视化
#画出校正后的图形,y_predict 换成 y_corrected
fig6 = plt.subplot(121)# 一行两列,画第一列#画预测图==================================================
label0 = plt.scatter(X.loc[:,'V1'][y_corrected==0], X.loc[:,'V2'][y_corrected==0])
label1 = plt.scatter(X.loc[:,'V1'][y_corrected==1], X.loc[:,'V2'][y_corrected==1])
label2 = plt.scatter(X.loc[:,'V1'][y_corrected==2], X.loc[:,'V2'][y_corrected==2])
plt.title("corrected data")
plt.xlabel('V1')
plt.ylabel('V2')
plt.legend((label0, label1, label2),('label0','label1','label2'))
#展示中心点
plt.scatter(centers[:,0], centers[:,1])#画原图==================================================
fig7 = plt.subplot(122)
label0 = plt.scatter(X.loc[:,'V1'][y==0], X.loc[:,'V2'][y==0])
label1 = plt.scatter(X.loc[:,'V1'][y==1], X.loc[:,'V2'][y==1])
label2 = plt.scatter(X.loc[:,'V1'][y==2], X.loc[:,'V2'][y==2])
plt.title("labeled data")
plt.xlabel('V1')
plt.ylabel('V2')
plt.legend((label0, label1, label2),('label0','label1','label2'))
#展示中心点
plt.scatter(centers[:,0], centers[:,1])plt.show() 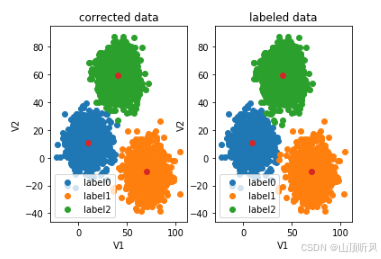
KNN 算法(有监督)
#3、采用 KNN、Meanshift 算法,重复步骤 1-2
X.head()
y.head()
创建模型并训练
#establish a KNN model(KNN 是 监督式)
from sklearn.neighbors import KNeighborsClassifier
KNN = KNeighborsClassifier(n_neighbors = 3)
KNN.fit(X, y)
进行预测
#predict based on the test data V1=80, V2=60
y_predict_knn_test = KNN.predict([[80,60]])
y_predict_knn = KNN.predict(X) # 训练数据使用 KNN的预测结果
print(y_predict_knn_test) # 结果:[2]
print('knn accureacy:', accuracy_score(y, y_predict_knn)) #knn accureacy: 1.0, 全部正确#打印出通过 KNN模型预测结果的分布,以及原来数据的分布
print(pd.value_counts(y_predict_knn), pd.value_counts(y)) # 可以看出完全一样
可视化
#画图 KNN
fig8 = plt.subplot(121)# 一行两列,画第一列#画预测图==================================================
label0 = plt.scatter(X.loc[:,'V1'][y_predict_knn==0], X.loc[:,'V2'][y_predict_knn==0])
label1 = plt.scatter(X.loc[:,'V1'][y_predict_knn==1], X.loc[:,'V2'][y_predict_knn==1])
label2 = plt.scatter(X.loc[:,'V1'][y_predict_knn==2], X.loc[:,'V2'][y_predict_knn==2])
plt.title("KNN results")
plt.xlabel('V1')
plt.ylabel('V2')
plt.legend((label0, label1, label2),('label0','label1','label2'))
#展示中心点
plt.scatter(centers[:,0], centers[:,1])#画原图==================================================
fig9 = plt.subplot(122)
label0 = plt.scatter(X.loc[:,'V1'][y==0], X.loc[:,'V2'][y==0])
label1 = plt.scatter(X.loc[:,'V1'][y==1], X.loc[:,'V2'][y==1])
label2 = plt.scatter(X.loc[:,'V1'][y==2], X.loc[:,'V2'][y==2])
plt.title("labeled data")
plt.xlabel('V1')
plt.ylabel('V2')
plt.legend((label0, label1, label2),('label0','label1','label2'))
#展示中心点
plt.scatter(centers[:,0], centers[:,1])plt.show() 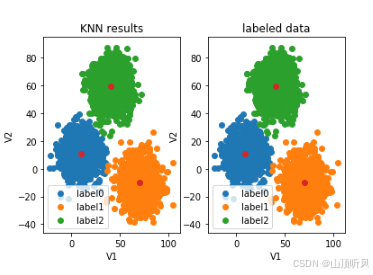
Meanshift 算法(无监督)
创建模型并训练
#try the meanshift model,当只有数据,不知道能分成几个类别的时候使用,可以自动聚类出类别
from sklearn.cluster import MeanShift, estimate_bandwidth
# obtain the bandwidth
bw = estimate_bandwidth(X, n_samples = 500) # n_samples :使用多少个样本点来估计带宽
print(bw) # 30.84663454820215, 带宽是 30
# 通过数据观察,横向X轴 150,纵向Y轴100,所以估出来 是 30 左右# establish the meanshift model( This is an un-supervised model.)
ms = MeanShift(bandwidth = bw)
ms.fit(X)
进行预测
y_predict_ms = ms.predict(X)
print(pd.value_counts(y_predict_ms), pd.value_counts(y))# 自动归成了三类
#通过与原始数据的对比可以看出,与原始数据的类别名称不同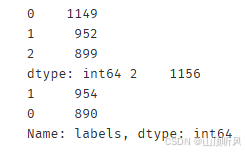
可视化
#画图,meanshift
fig9 = plt.subplot(121)# 一行两列,画第一列#画预测图==================================================
label0 = plt.scatter(X.loc[:,'V1'][y_predict_ms==0], X.loc[:,'V2'][y_predict_ms==0])
label1 = plt.scatter(X.loc[:,'V1'][y_predict_ms==1], X.loc[:,'V2'][y_predict_ms==1])
label2 = plt.scatter(X.loc[:,'V1'][y_predict_ms==2], X.loc[:,'V2'][y_predict_ms==2])
plt.title("ms results")
plt.xlabel('V1')
plt.ylabel('V2')
plt.legend((label0, label1, label2),('label0','label1','label2'))
#展示中心点
plt.scatter(centers[:,0], centers[:,1])#画原图==================================================
fig10 = plt.subplot(122)
label0 = plt.scatter(X.loc[:,'V1'][y==0], X.loc[:,'V2'][y==0])
label1 = plt.scatter(X.loc[:,'V1'][y==1], X.loc[:,'V2'][y==1])
label2 = plt.scatter(X.loc[:,'V1'][y==2], X.loc[:,'V2'][y==2])
plt.title("labeled data")
plt.xlabel('V1')
plt.ylabel('V2')
plt.legend((label0, label1, label2),('label0','label1','label2'))
#展示中心点
plt.scatter(centers[:,0], centers[:,1])plt.show()
#通过图形发现,橙色部分是一样的,另两种类别反了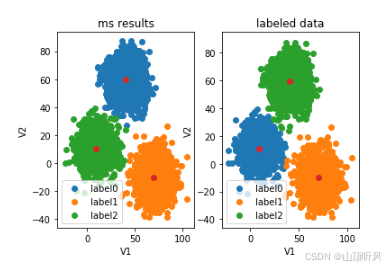
类别校正
# correct the results
y_corrected_ms = []
for i in y_predict_ms:if i == 0:y_corrected_ms.append(2)elif i == 1:y_corrected_ms.append(1)elif i == 2:y_corrected_ms.append(0)
print(pd.value_counts(y_corrected_ms), pd.value_counts(y))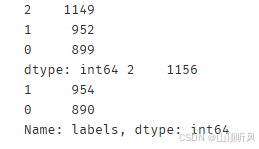
# convert the results to numpy array
y_corrected_ms = np.array(y_corrected_ms)
print(type(y_corrected_ms))# <class 'numpy.ndarray'>#画预测图==================================================
label0 = plt.scatter(X.loc[:,'V1'][y_corrected_ms==0], X.loc[:,'V2'][y_corrected_ms==0])
label1 = plt.scatter(X.loc[:,'V1'][y_corrected_ms==1], X.loc[:,'V2'][y_corrected_ms==1])
label2 = plt.scatter(X.loc[:,'V1'][y_corrected_ms==2], X.loc[:,'V2'][y_corrected_ms==2])
plt.title("ms corrected results")
plt.xlabel('V1')
plt.ylabel('V2')
plt.legend((label0, label1, label2),('label0','label1','label2'))
#展示中心点
plt.scatter(centers[:,0], centers[:,1])#画原图==================================================
fig12 = plt.subplot(122)
label0 = plt.scatter(X.loc[:,'V1'][y==0], X.loc[:,'V2'][y==0])
label1 = plt.scatter(X.loc[:,'V1'][y==1], X.loc[:,'V2'][y==1])
label2 = plt.scatter(X.loc[:,'V1'][y==2], X.loc[:,'V2'][y==2])
plt.title("labeled data")
plt.xlabel('V1')
plt.ylabel('V2')
plt.legend((label0, label1, label2),('label0','label1','label2'))
#展示中心点
plt.scatter(centers[:,0], centers[:,1])plt.show() 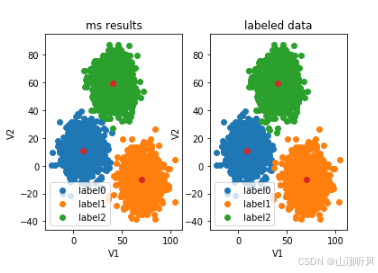
kmeans \ knn \ meanshift 总结
kmens \ meanshift: un-supervised, training data: X;
kmeans: need the category number;
meanshift:need to calculate the bandwidth;
knn: supervised: training data:X\y
相关文章:

分类算法 Kmeans、KNN、Meanshift 实战
任务 1、采用 Kmeans 算法实现 2D 数据自动聚类,预测 V180,V260 数据类别; 2、计算预测准确率,完成结果矫正 3、采用 KNN、Meanshift 算法,重复步骤 1-2 代码工具:jupyter notebook 视频资料 无监督学习ÿ…...

aws平台s3存储桶夸域问题处理
当我们收到开发反馈s3存在跨域问题 解决步骤: 配置 S3 存储桶的 CORS 设置: 登录到 AWS 管理控制台。转到 S3 服务。选择你存储文件的 存储桶。点击 权限 标签页。在 跨域资源共享(CORS)配置 部分,点击 编辑。 登陆…...

在Windows上安装Pygame 2.1.3:解决常见问题
在Windows系统上安装Pygame 2.1.3时,可能会遇到各种问题,例如网络问题或依赖安装失败。本文将详细介绍如何在Windows上成功安装Pygame 2.1.3,并解决常见的安装问题。 1. 前提条件 在开始安装之前,确保你的系统中已经安装了Pytho…...
,tomcat)
linux中安装jdk(Java环境),tomcat
安装时候选择 tomcat 软件版本要与程序开发使用的版本一致。jdk 版本要进行与 tomcat 保持一致。 1. 系统环境说明 [root@bogon ~]# getenforce Disabled [root@bogon ~]# systemctl status firewalld.service ● firewalld.service - firewalld - dynamic firewall daemon …...

DeepSeek源码解构:从MoE架构到MLA的工程化实现
文章目录 **一、代码结构全景:从模型定义到分布式训练****二、MoE架构:动态路由与稀疏激活的工程化实践****1. 专家路由机制(带负载均衡)****数学原理:负载均衡损失推导** **三、MLA注意力机制:低秩压缩与解…...
使用 PageOffice实现PDF文件加盖印章和签字功能)
国产linux系统(银河麒麟,统信uos)使用 PageOffice实现PDF文件加盖印章和签字功能
PageOffice 国产版 :支持信创系统,支持银河麒麟V10和统信UOS,支持X86(intel、兆芯、海光等)、ARM(飞腾、鲲鹏、麒麟等)、龙芯(Mips、LoogArch)芯片架构。 PageOffice支持…...
)
第四十三节:人脸检测与识别-人脸识别基础 (Eigenfaces, Fisherfaces, LBPH)
引言 人脸识别技术是计算机视觉领域最具应用价值的方向之一,广泛应用于安防监控、身份认证、人机交互等领域。本文将通过OpenCV框架,深入解析人脸检测与识别的核心算法(Eigenfaces/Fisherfaces/LBPH),并提供完整的代码实现。 第一部分:人脸检测基础 1.1 人脸检测原理 …...
)
面向恶劣条件的道路交通目标检测----大创自用(当然你也可以在里面学到很多东西)
全部内容梳理 目标检测的两个任务: 预测标签 边界框 语义分割 实力分割 一个是类别 一个是实例级别 分类任务把每个图像当作一张图片看待 所有解决方法是先生成候选区域 再进行分类 置信度: 包括对类别和边界框预测的自信程度 输出分类和IOU分数的…...

物联网相关词汇
物联网(英文:Internet of Things,缩写:IoT) specs 英[speks] 美[speks] 规格说明 topology 英[təpɒlədʒɪ] 拓扑结构 vertical 美 [ˈvɜrtɪk(ə)l] 英 [ˈvɜː(r)tɪk(ə)l] n.垂直线;垂直位…...
)
【net6】一文跑通前后端以及数据库,简单的天气系统管理(保姆入门)
一、前言 使用Vue3为前端,.net6为后端,连接postgreSQL数据库,连通前后端与数据库,实现最基础的天气管理系统的增删改查。 二、内容 目录 一、前言 二、内容 2.1 后端部分 2.1.1 在VS里面使用此模板创建项目 2.1.2 安装下列…...

宝塔安装的 MySQL 无法连接的情况及解决方案
宝塔安装的 MySQL 无法连接的情况及解决方案 宝塔面板是一款流行的服务器管理工具,其中集成的 MySQL 数据库有时会出现连接问题。本文详细介绍两种最常见的 MySQL 连接错误:“1130 - Host is not allowed to connect” 和 “1045 - Access denied”&…...

【iOS】分类、扩展、关联对象
分类、扩展、关联对象 前言分类扩展扩展和分类的区别关联对象key的几种用法流程 总结 前言 最近的学习中笔者发现自己对于分类、扩展相关知识并不是很熟悉,刚好看源码类的加载过程中发现有类扩展与关联对象详解。本篇我们来探索一下这部分相关知识,首先…...
—— OSI vs TCP/IP网络模型)
计算机网络学习(一)—— OSI vs TCP/IP网络模型
一、OSI模型(开放系统互联参考模型) OSI(Open Systems Interconnection)模型由ISO(国际标准化组织)在1984年提出,用于标准化网络通信,它将网络通信分为七个层次: 层级名…...

【MySQL成神之路】MySQL查询用法总结
MySQL查询语句全面指南 一、基础查询语句 MySQL中select的基本语法形式 select 属性列表 from 表名和视图列表 [where 条件表达式] [group by 属性名[having 条件表达式]] [order by 属性名[asc|desc]] [limit <offset>,row count] 说明: where子句&…...

攻防世界——Web题 fakebook
首先测试网站的功能,当我注册一个账号时,发现这里的链接: 点进去看到URL: 感觉no这个地方可以尝试一下sql注入 推测应该是数字型注入 发现果然可以进行sql注入, 最终测得列数应该是4列,但当我尝试sql注入…...

【Java微服务组件】异步通信P2—Kafka与消息
欢迎来到啾啾的博客🐱。 记录学习点滴。分享工作思考和实用技巧,偶尔也分享一些杂谈💬。 欢迎评论交流,感谢您的阅读😄。 目录 引言Kafka与消息生产者发送消息到Kafka批处理发送设计消息的幂等信息确保消息送达acks配置…...

AI数字人一体机和智慧屏方案:开启智能交互新纪元
在当今这个信息化飞速发展的时代,AI技术正以前所未有的速度改变着我们的生活方式和工作模式。特别是在人机交互领域,AI数字人的出现不仅极大地丰富了用户体验,也为各行各业提供了前所未有的创新解决方案。本文将重点介绍由广州深声科技有限公…...

10-码蹄集600题基础python篇
题目如上: 这题就是ASCII的转换,直接使用ord就可以 下面是代码: def main():#code here# a1,a2input().split(",")# print(f"The ASCII code of {a1} is {ord(a1)}")# print(f"The ASCII code of {a2} is {ord(a2…...

给几张图片和一段文字,怎么制作成带有语音的视频---php
想用PHP将图片和文字转换成带有语音的视频,想做自动化的视频生成,比如用于广告、演示或者其他需要多媒体处理的场景。 接下来考虑PHP本身的能力。PHP主要是用于服务器端的脚本语言,不太擅长处理多媒体内容,比如视频和语音合成。所…...

vue3中RouterView配合KeepAlive实现组件缓存
KeepAlive组件缓存 为什么需要组件缓存代码展示缓存效果为什么不用v-if 为什么需要组件缓存 业务需求:一般是列表页面通过路由跳转到详情页,跳转回来时,需要列表页面展示上次展示的内容 代码展示 App.vue入口 <script setup lang"…...

NIFI的处理器:ExecuteGroovyScript 2.4.0
ExecuteGroovyScript是常用的处理器之一,用于执行GroovyScript脚本。该脚本负责处理传入的流文件(例如传输到SUCCESS或删除)以及由该脚本创建的任何流文件。如果处理不完整或不正确,会话将被回滚。 属性值-失败处理策略 Failure …...

安全可控的AI底座:灯塔大模型应用开发平台全面实现国产信创兼容适配认证
国产信创产品兼容适配认证是为了支持和推动国产信息技术产品和服务的发展而设立的一种质量标准和管理体系。适配认证旨在确保相关产品在安全性、可靠性、兼容性等方面达到一定的标准,以满足政府和关键行业对信息安全和自主可控的需求。 北京中烟创新科技有限公司&a…...
)
.NET外挂系列:5. harmony 中补丁参数的有趣玩法(下)
一:背景 1. 讲故事 开局一张表,故事全靠编,为了能够承上启下,先把参数列表放出来。 参数名说明__instance访问非静态方法的实例(类似 this)。__result获取/修改返回值,要想修改用 ref。__res…...

Spring Boot 登录实现:JWT 与 Session 全面对比与实战讲解
Spring Boot 登录实现:JWT 与 Session 全面对比与实战讲解 2025.5.21-23:11今天在学习黑马点评时突然发现用的是与苍穹外卖jwt不一样的登录方式-Session,于是就想记录一下这两种方式有什么不同 在实际开发中,登录认证是后端最基础也是最重要…...

vscode离线安装组件工具vsix
1.外网下载vsix 网址为:Open VSX Registry 2.输入需要下载的组件 3.下载组件 4.安装 5.选择安装文件 6.安装完成...

Vue大数据量前端性能优化策略
文章目录 前言Vue大数据量前端性能优化策略1. 虚拟列表的使用方式及优势2. 列表和图表的懒加载技术3. Web Worker 在图表数据预处理中的应用4. 图表渲染优化技巧5. 分批渲染技术实现方法(如 requestIdleCallback)6. 其他可行的 Vue 层优化策略 前言 Vue…...

Hass-Panel - 开源智能家居控制面板
文章目录 ▎项目介绍:预览图▎主要特性安装部署Docker方式 正式版Home Assistant Addon方式详细安装方式1. Home Assistant 插件安装(推荐)2. Docker 安装命令功能说明 :3. Docker Compose 安装升级说明Docker Compose 版本升级 功…...

iPaaS集成平台技术选型关注哪些指标?
在数字化转型进程中,企业系统间的数据孤岛问题日益凸显。根据IDC调研,85%的IT决策者将“系统集成效率”列为业务创新的关键瓶颈。iPaaS(集成平台即服务)凭借其敏捷性、低代码特性和智能化能力,已成为企业构建数字生态的…...
:跨端JavaScript性能优化)
JavaScript性能优化实战(14):跨端JavaScript性能优化
在当今多端开发的时代,JavaScript已经突破了浏览器的界限,广泛应用于移动应用、桌面应用、小程序等各类环境。然而,不同平台的运行时环境存在差异,为JavaScript性能优化带来了新的挑战和思考维度。 目录 React Native性能优化最佳实践Electron应用性能优化策略混合应用中J…...

多通道经颅直流电刺激器产品及解决方案特色解析
前记 团队在多通道经颅直流电刺激这个技术方向,一路深耕。在服务了不少客户之后,为了方便后续的产品和方案推广。我们弄出来了产品和方案两种形态。标准产品是为了给用户演示以及一些常规的实验使用。方案则是为了满足不同方向的科研用户的需求。这两者相…...

Quasar 使用 Pinia 进行状态管理
官方文档:使用 Pinia 进行状态管理 |Quasar 框架 视频教程:quasar框架store-状态管理库pinia介绍_哔哩哔哩_bilibili 使用 Quasar CLI 创建一个新的store quasar new store date --format jsPinia存储模板详解解 基本结构解析 import { defineStore,…...
)
计算机网络--第一章(下)
1.计算机网络的分层结构 1.1 分层结构 网络体系结构描述的是,计算机网络有几层,有什么功能,用的什么协议。 水平方向的关系, 协议,说的是对等实体间通信需要遵守的规则。用于约束,这个约束的方向是水平的。…...

Veo 3 可以生成视频,并附带配乐
谷歌最新的视频生成 AI 模型 Veo 3 可以创建与其生成的剪辑相配的音频。 周二,在谷歌 I/O 2025 开发者大会上,谷歌发布了 Veo 3。该公司声称,这款产品可以生成音效、背景噪音,甚至对话,为其制作的视频增添配乐。谷歌表…...

数据结构核心知识总结:从基础到应用
数据结构核心知识总结:从基础到应用 数据结构是计算机科学中组织和存储数据的核心方式,直接影响程序的性能和资源利用率。本文系统梳理常见数据结构及其应用场景,帮助读者构建清晰的知识体系。 一、数据结构基础概念 数据结构是数据元素之间…...
)
Flannel后端为UDP模式下,分析数据包的发送方式(二)
发往 10.244.2.5 的数据包最终会经过物理网卡 enp0s3,尽管路由表直接指定通过 flannel.1 发出。以下以 Markdown 格式详细解释为什么会经过 enp0s3,结合 Kubernetes 和 Flannel UDP 模式的背景。 问题分析 在 Kubernetes 环境中,使用 Flanne…...

超低延迟音视频直播技术的未来发展与创新
引言 音视频直播技术正在深刻改变着我们的生活和工作方式,尤其是在教育、医疗、安防、娱乐等行业。无论是全球性的体育赛事、远程医疗、在线教育,还是智慧安防、智能家居等应用场景,都离不开音视频技术的支持。为了应对越来越高的需求&#x…...

改写视频生产流程!快手SketchVideo开源:通过线稿精准控制动态分镜的AI视频生成方案
Sketch Video 的核心特点 Sketch Video 通过手绘生成动画的形式,将复杂的信息以简洁、有趣的方式展现出来。其核心特点包括: 超强吸引力 Sketch Video 的手绘风格赋予了视频一种质朴而真实的质感,与常见的精致特效视频形成鲜明对比。这种独…...

Circle宣布Circle Payments Network主网上线
据 Circle 官方消息,Circle Payments Network 主网正式上线。该网络是一个基于区块链的支付协调协议,允许银行和支付服务提供商使用公共区块链上的 USDC 进行实时结算。 Circle Payments Network 支持企业对企业供应商支付、跨境汇款、资金管理、企业定期…...

【RabbitMQ】记录 InvalidDefinitionException: Java 8 date/time type
目录 1. 添加必要依赖 2. 配置全局序列化方案(推荐) 3. 配置RabbitMQ消息转换器 关键点说明 1. 添加必要依赖 首先确保项目中包含JSR-310支持模块: <dependency><groupId>com.fasterxml.jackson.datatype</groupId>&l…...
数据结构)
linux 学习之位图(bitmap)数据结构
bitmap 可以高效地表示大量的布尔值,并且在许多情况下可以提供快速的位操作。 1 定义 enum device_state{DOWN,DOEN_DONE,MAILBOX_READY,MAILBOX_PENDING,STATE_BUILD };DECLARE_BITMAP(state,STATE_BUILD);相当于》u32 state[BITS_TO_LONGS(4)] BIT…...

CNN手写数字识别/全套源码+注释可直接运行
数据集选择: MNIST数据集来自美国国家标准与技术研究所, National Institute of Standards and Technology (NIST)。训练集(training set)由来自250个不同人手写的数字构成,其中50%是高中学生,50%来自人口普查局&…...
)
基于springboot+vue网页系统的社区义工服务互动平台(源码+论文+讲解+部署+调试+售后)
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,我会一一回复,希望帮助更多的人。 系统背景 在社会文明程度不断提升、社区治理需求持续深化的大背景下,社区义工服务作为…...

MBSS-T1:基于模型的特定受试者自监督运动校正方法用于鲁棒心脏 T1 mapping|文献速递-深度学习医疗AI最新文献
Title 题目 MBSS-T1: Model-based subject-specific self-supervised motion correction forrobust cardiac T1 mapping MBSS-T1:基于模型的特定受试者自监督运动校正方法用于鲁棒心脏 T1 mapping 01 文献速递介绍 心脏T1定量成像(Quantitative Car…...
)
Google机器学习实践指南(迭代学习机制解析篇)
🔥 Google机器学习(5)-迭代学习机制解析 Google机器学习实战(5)-深入理解模型训练中的迭代优化过程 一、迭代学习概念 ▲ 核心定义: 在训练机器学习模型时,首先对权重和偏差进行初始猜测,然后反复调整这些猜测,直到…...

【时时三省】Python 语言----文件
目录 1,文件打开 2, 文件关闭 3, 文件写入 4, 文件读出 5, 文件定位 6, 文件重命名 7, 复制文件 山不在高,有仙则名。水不在深,有龙则灵。 ----CSDN 时时三省 1,文件打开 file = open(file, mode, buffering, encoding, errors, newline, closefd, opener) 2, 文…...

WPF···
设置启动页 默认最后一个窗口关闭,程序退出,可以设置 修改窗体的icon图标 修改项目exe图标 双击项目名会看到代码 其他 在A窗体点击按钮打开B窗体,在B窗体设置WindowStartupLocation=“CenterOwner” 在A窗体的代码设置 B.Owner = this; B.Show(); B窗体生成在A窗体中间…...

架构图 C4 规范简介
架构图 C4 规范简介 C4(Context, Containers, Components, Code)是一种用于软件架构可视化的分层建模方法,由 Simon Brown 提出。它通过四个不同层次的抽象来描述软件系统,适用于不同受众(如业务人员、架构师、开发人…...

运维Web服务器核心知识与实战指南
一、Web服务器基础概述 (一)核心定义与功能 Web服务器是互联网的基础设施,负责存储、处理和传输网页内容,通过HTTP/HTTPS协议与客户端交互。其核心功能包括: 请求处理:监听端口(默认80/443&a…...

免费建站系统是什么?如何选择免费建站系统?
如今,换互联网成为大家生活中必不可少的一部分。对于普通的个人、一些企业、包括一些事业单位,拥有一个高效实用的网站成为展示、宣传、产品介绍的重要途径。但是对于很多用户来说,对于一些没有建站基础的用户来说:建站是一项高门…...

React---day1
React 它允许我们只需要维护自己的状态,当状态改变时,React可以根据最新的状态去渲染我们的UI界面 开发React必须依赖三个库: eact:包含react所必须的核心代码react-dom:react渲染在不同平台所需要的核心代码babel&…...