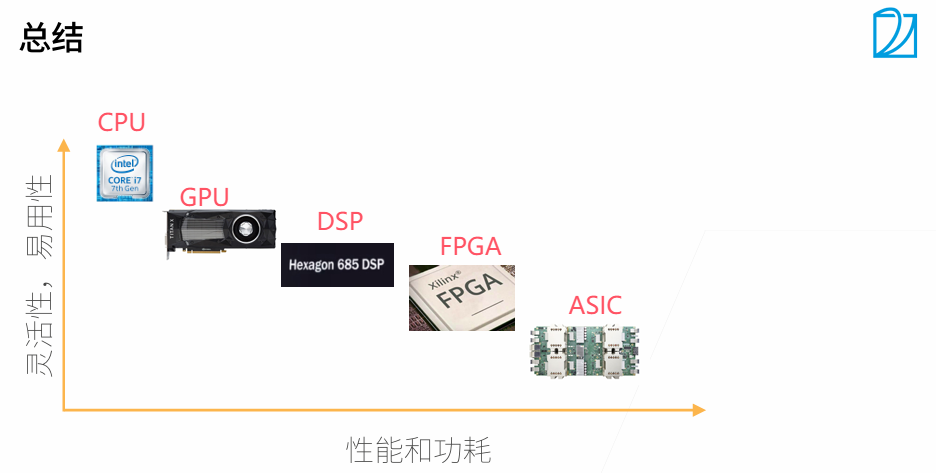
31-35【动手学深度学习】深度学习硬件
1. CPU和GPU
1.1 CPU
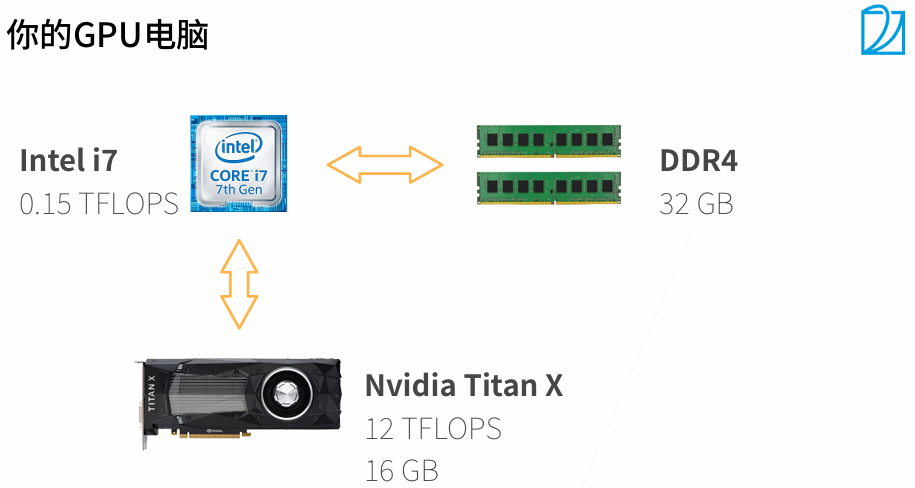
CPU每秒钟计算的浮点运算数为0.15,GPU为12。GPU的显存很低,16GB(可能32G封顶),CPU可以一直插内存。
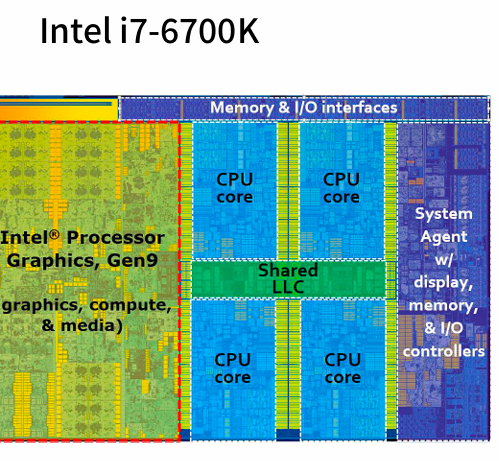
左边是GPU(只能做些很简单的游戏,视频处理),中间是CPU,右边是连接的通道,shared LLC第三级缓存(最后一级缓存)。

a和b都是向量,刚开始放在内存中,数据只有加载到寄存器中,才能参与运算,L3就是shared LLC。最快的是寄存器。


物理上直观上看有四个核(见上面的图),但是其实每个cpu有多个超线程(2个),所以有8个核,但是不一定提升性能,因为寄存器共用。

1.2 GPU
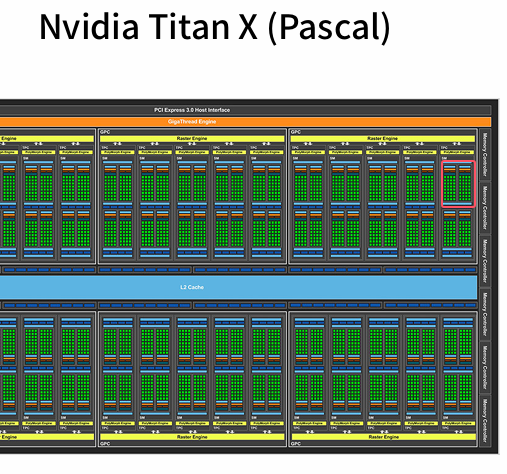
框红的就是一个核,十个(黄色线下)小核是一个大核,3060和3080的区别就是一个大核小,一个大核多。每个绿点是一个寄存单元,可以在一个绿点上开一个线程(上千个),(对于CPU来说,一个核算一个值,但是GPU是一个绿点算一个值)。就算一个绿点比GPU的一个核计算能力弱,但是GPU胜在绿点多。

/斜杠两侧分别是低端和高端CPU,GPU。GPU的显存很贵,所以内存很小。CPU的可能一半都是在做逻辑控制,所以控制流更强,(因为CPU不经常计算一个矩阵,但是可能渲染一个html网页)。



AMD的GPU游戏性能好,但是对高性能计算支持不算好。Intel有集成显卡,ARM的CPU和GPU在嵌入式端(手机)常用。



1.3 QA
①固定其他,增加数据(高质量数据)是提高泛化性最简单和最有效的办法,当有很多数据时,调参就没那么有用 ,固定数据集,调参有用
2. TPU和其他




ASIC容易造,不同于通用GPU,ASIC比较专用,容易开发
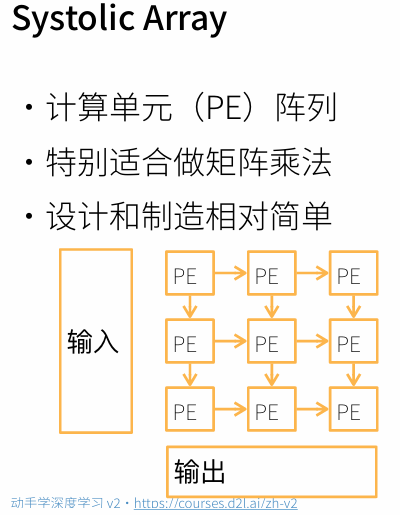
一个Systolic Array相当于一个核
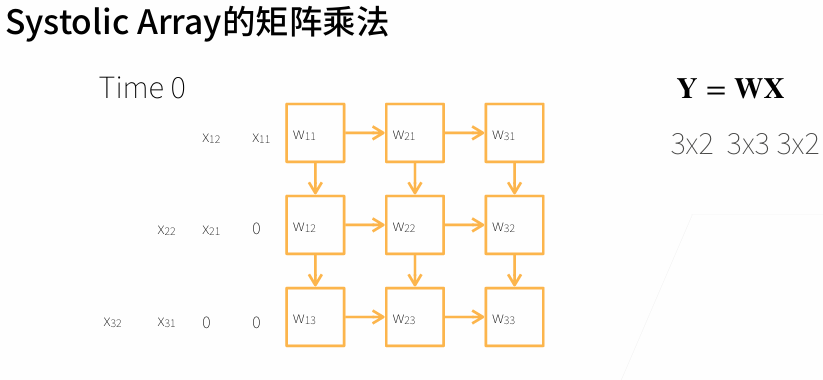
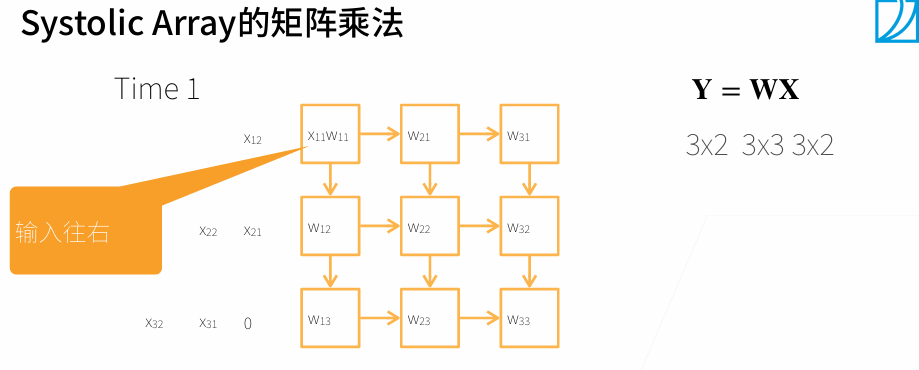
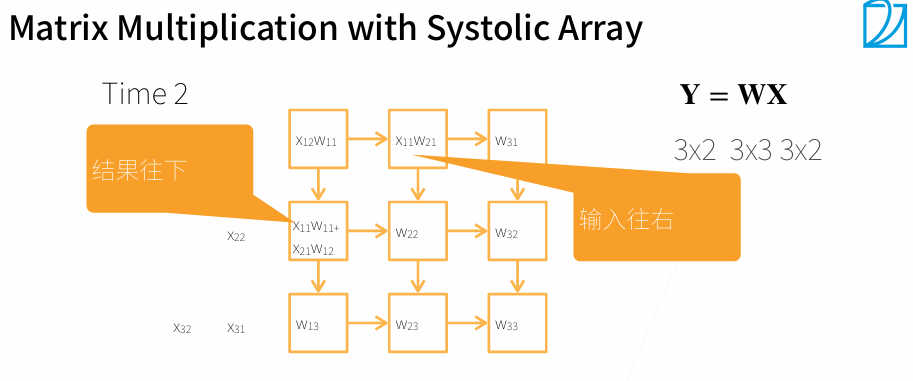
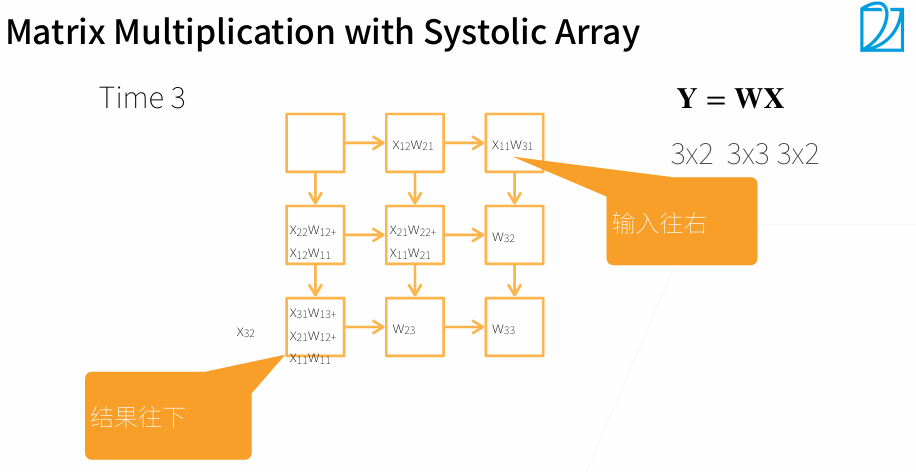
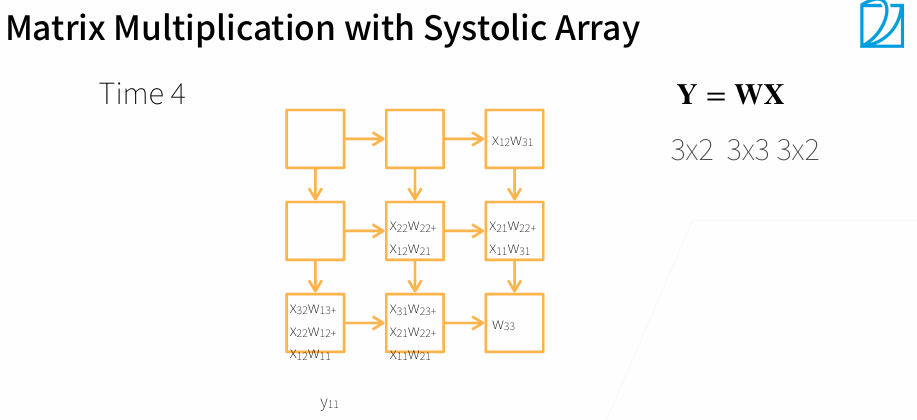
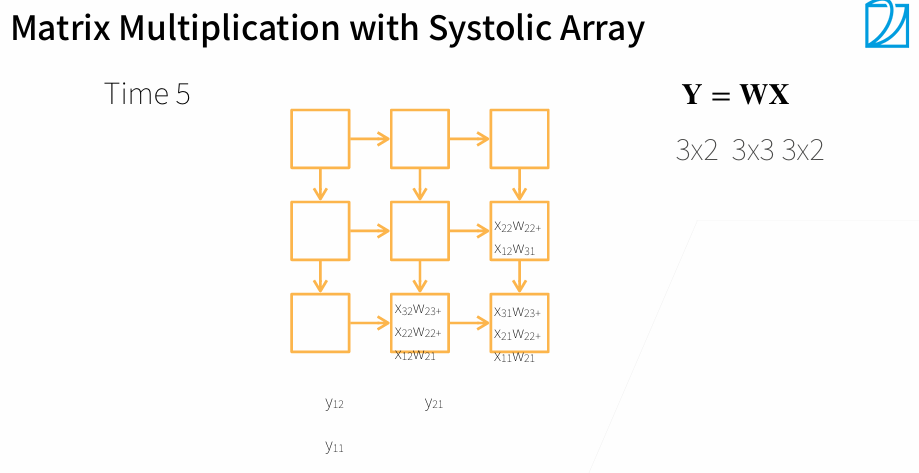
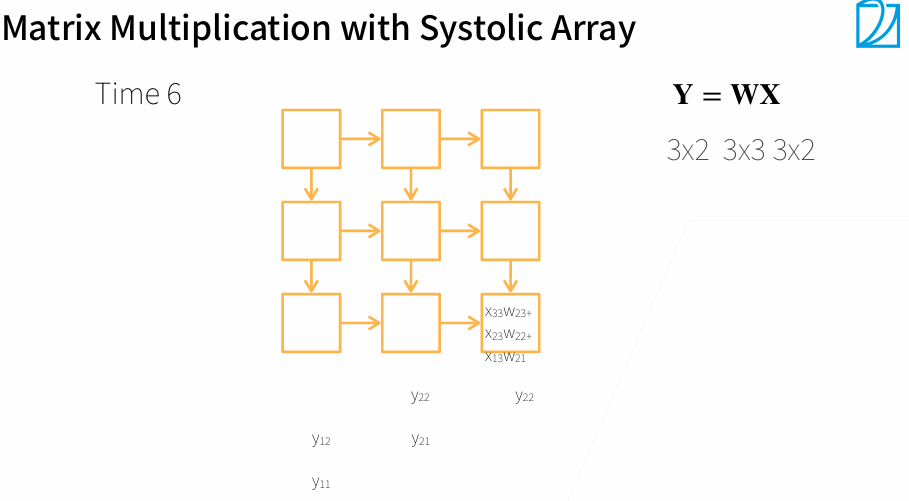
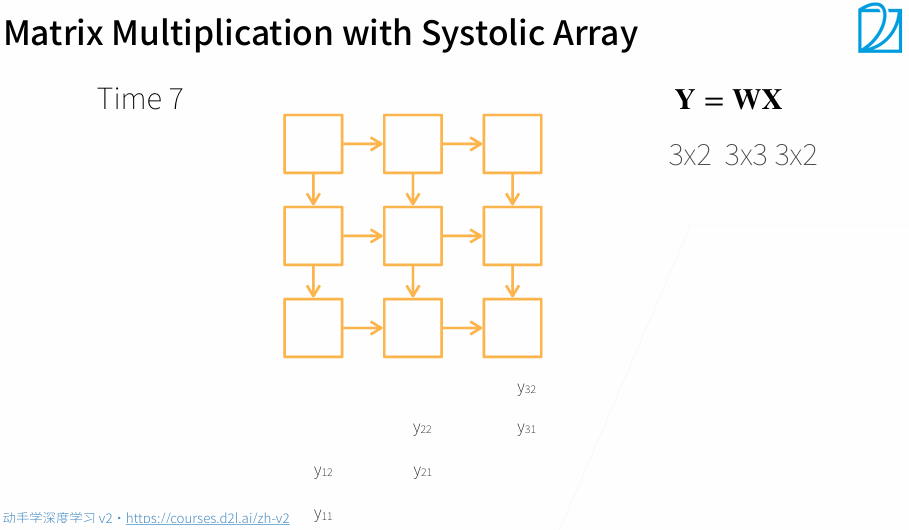

3. 多GPU训练
3.1 理论


数据并行:加入一个batch是128个样本,有两个GPU,每个GPU计算64个样本的梯度再求和
模型并行:ResNet的前50层在GPU0,后50层在GPU1上。在前50层计算完结果后,传给GPU1。transformer常用到。
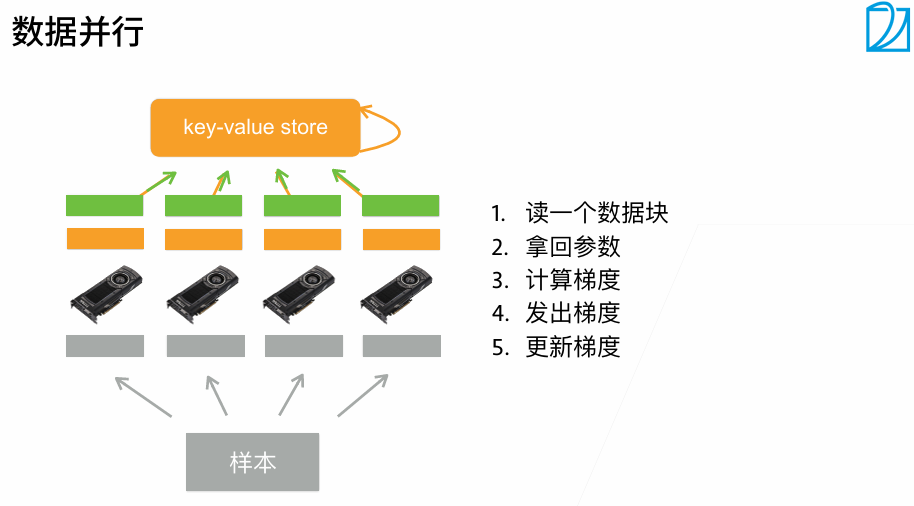
四个卡计算效率差不多,并行性很好

3.2 代码
3.2.1 复杂实现
%matplotlib inline
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l简单网络
scale = 0.01
W1 = torch.randn(size=(20, 1, 3, 3)) * scale
b1 = torch.zeros(20)
W2 = torch.randn(size=(50, 20, 5, 5)) * scale
b2 = torch.zeros(50)
W3 = torch.randn(size=(800, 128)) * scale
b3 = torch.zeros(128)
W4 = torch.randn(size=(128, 10)) * scale
b4 = torch.zeros(10)
params = [W1, b1, W2, b2, W3, b3, W4, b4]def lenet(X, params):h1_conv = F.conv2d(input=X, weight=params[0], bias=params[1])h1_activation = F.relu(h1_conv)h1 = F.avg_pool2d(input=h1_activation, kernel_size=(2, 2), stride=(2, 2))h2_conv = F.conv2d(input=h1, weight=params[2], bias=params[3])h2_activation = F.relu(h2_conv)h2 = F.avg_pool2d(input=h2_activation, kernel_size=(2, 2), stride=(2, 2))h2 = h2.reshape(h2.shape[0], -1)h3_linear = torch.mm(h2, params[4]) + params[5]h3 = F.relu(h3_linear)y_hat = torch.mm(h3, params[6]) + params[7]return y_hatloss = nn.CrossEntropyLoss(reduction='none')向多个设备分发参数
def get_params(params, device):new_params = [p.clone().to(device) for p in params]for p in new_params:p.requires_grad_()return new_paramsnew_params = get_params(params, d2l.try_gpu(0))
print('b1 weight:', new_params[1])
print('b1 grad:', new_params[1].grad)![]()
allreduce 函数将所有向量相加(相加到一块GPU上),并将结果广播给所有 GPU
def allreduce(data):for i in range(1, len(data)):data[0][:] += data[i].to(data[0].device)for i in range(1, len(data)):data[i] = data[0].to(data[i].device)data = [torch.ones((1, 2), device=d2l.try_gpu(i)) * (i + 1) for i in range(2)]
print('before allreduce:\n', data[0], '\n', data[1])
allreduce(data)
print('after allreduce:\n', data[0], '\n', data[1])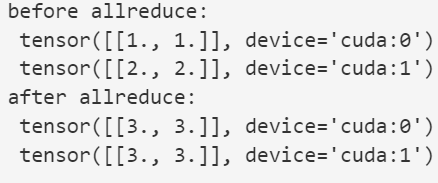
将一个小批量数据均匀地分布在多个 GPU 上
data = torch.arange(20).reshape(4, 5)
devices = [torch.device('cuda:0'), torch.device('cuda:1')]
split = nn.parallel.scatter(data, devices)
print('input:',data)
print('load into', devices)
print('output:', split)
def split_batch(X, y, devices):"""将`X`和`y`拆分到多个设备上"""assert X.shape[0] == y.shape[0]return (nn.parallel.scatter(X, devices), nn.parallel.scatter(y, devices))在一个小批量上实现多 GPU 训练
def train_batch(X, y, device_params, devices, lr):X_shards, y_shards = split_batch(X, y, devices)# 在每个GPU上分别计算损失ls = [loss(lenet(X_shard,device_W), y_shard).sum() for X_shard, y_shard, device_W in zip(X_shards, y_shards, device_params)]for l in ls: # 反向传播在每个GPU上分别执行l.backward()with torch.no_grad():for i in range(len(device_params[0])): # 层数allreduce([device_params[c][i].grad for c in range(len(devices))])# 在每个GPU上分别更新模型参数for param in device_params:d2l.sgd(param, lr, X.shape[0]) # 在这里,我们使用全尺寸的小批量定义训练函数
def train(num_gpus, batch_size, lr):train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)devices = [d2l.try_gpu(i) for i in range(num_gpus)]# 将模型参数复制到num_gpus个GPUdevice_params = [get_params(params, d) for d in devices]num_epochs = 10animator = d2l.Animator('epoch', 'test acc', xlim=[1, num_epochs])timer = d2l.Timer()for epoch in range(num_epochs):timer.start()for X, y in train_iter:# 为单个小批量执行多GPU训练train_batch(X, y, device_params, devices, lr)torch.cuda.synchronize()timer.stop()# 在GPU0上评估模型animator.add(epoch + 1, (d2l.evaluate_accuracy_gpu(lambda x: lenet(x, device_params[0]), test_iter, devices[0]),))print(f'test acc: {animator.Y[0][-1]:.2f}, {timer.avg():.1f} sec/epoch 'f'on {str(devices)}')在单个GPU上运行
train(num_gpus=1, batch_size=256, lr=0.2)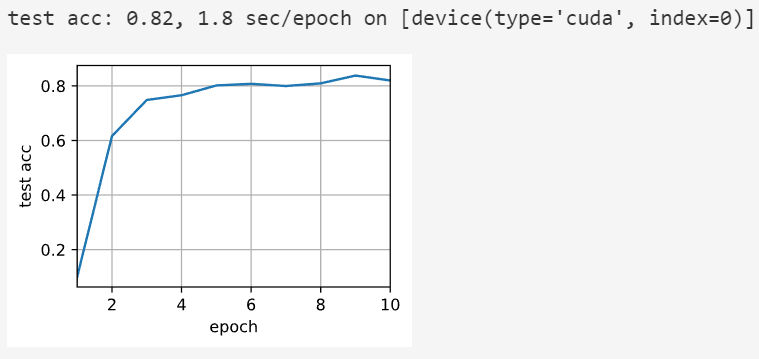
多个GPU
train(num_gpus=2, batch_size=256, lr=0.2)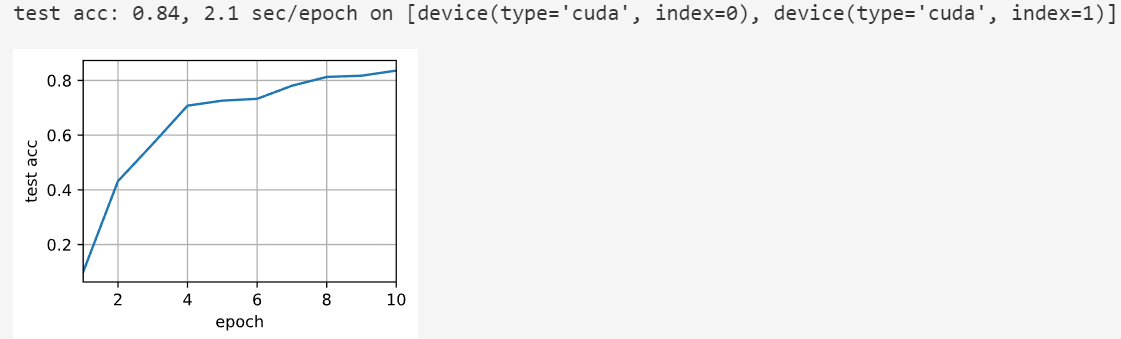
小结
- 有多种方法可以在多个GPU上拆分深度网络的训练。拆分可以在层之间、跨层或跨数据上实现。前两者需要对数据传输过程进行严格编排,而最后一种则是最简单的策略。
- 数据并行训练本身是不复杂的,它通过增加有效的小批量数据量的大小提高了训练效率。
- 在数据并行中,数据需要跨多个GPU拆分,其中每个GPU执行自己的前向传播和反向传播,随后所有的梯度被聚合为一,之后聚合结果向所有的GPU广播。
- 小批量数据量更大时,学习率也需要稍微提高一些。
3.2.2 简洁实现
import torch
from torch import nn
from d2l import torch as d2l简单网络
def resnet18(num_classes, in_channels=1):"""稍加修改的 ResNet-18 模型"""def resnet_block(input_channels, output_channels, num_residuals, first_block=False):blk = []for i in range(num_residuals):if i == 0 and not first_block:# 第一个残差块且不是第一个block时,使用1x1卷积和下采样blk.append(d2l.Residual(output_channels, use_1x1conv=True, strides=2))else:# 其他情况不使用1x1卷积blk.append(d2l.Residual(output_channels, output_channels))return nn.Sequential(*blk)# 网络结构net = nn.Sequential(nn.Conv2d(in_channels, 64, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(64), nn.ReLU())# 添加残差块net.add_module("resnet_block1", resnet_block(64, 64, 2, first_block=True))net.add_module("resnet_block2", resnet_block(64, 128, 2))net.add_module("resnet_block3", resnet_block(128, 256, 2))net.add_module("resnet_block4", resnet_block(256, 512, 2))# 全局平均池化和全连接层net.add_module("global_avg_pool", nn.AdaptiveAvgPool2d((1, 1)))net.add_module("fc", nn.Sequential(nn.Flatten(), nn.Linear(512, num_classes)))return net# 创建网络实例
net = resnet18(10)
devices = d2l.try_all_gpus()网络初始化
net = resnet18(10)
# 获取GPU列表
devices = d2l.try_all_gpus()
# 我们将在训练代码实现中初始化网络训练
def train(net, num_gpus, batch_size, lr):train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)devices = [d2l.try_gpu(i) for i in range(num_gpus)]def init_weights(m):if type(m) in [nn.Linear, nn.Conv2d]:nn.init.normal_(m.weight, std=0.01)net.apply(init_weights)# 在多个GPU上设置模型net = nn.DataParallel(net, device_ids=devices)trainer = torch.optim.SGD(net.parameters(), lr)loss = nn.CrossEntropyLoss()timer, num_epochs = d2l.Timer(), 10animator = d2l.Animator('epoch', 'test acc', xlim=[1, num_epochs])for epoch in range(num_epochs):net.train()timer.start()for X, y in train_iter:trainer.zero_grad()X, y = X.to(devices[0]), y.to(devices[0])l = loss(net(X), y)l.backward()trainer.step()timer.stop()animator.add(epoch + 1, (d2l.evaluate_accuracy_gpu(net, test_iter),))print(f'测试精度:{animator.Y[0][-1]:.2f},{timer.avg():.1f}秒/轮,'f'在{str(devices)}')在单个GPU上训练网络
train(net, num_gpus=1, batch_size=256, lr=0.1)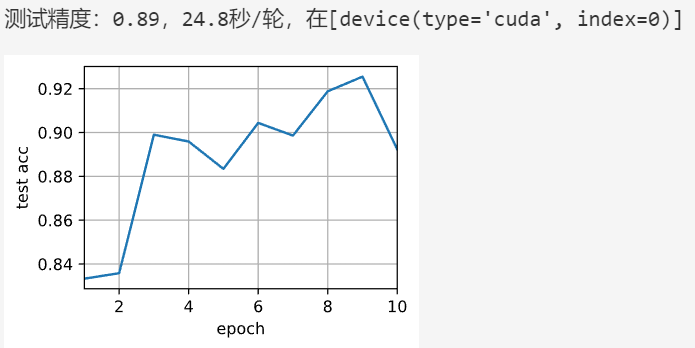
在多个GPU上训练网络
train(net, num_gpus=2, batch_size=512, lr=0.2)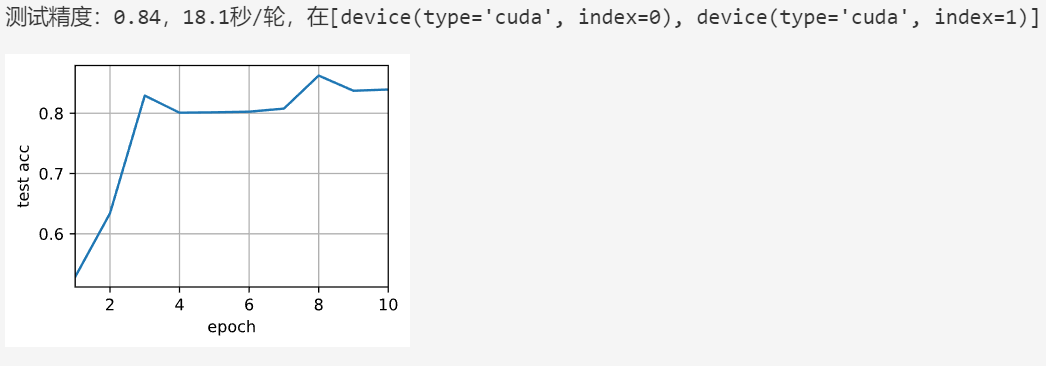
小结
- 神经网络可以在(可找到数据的)单GPU上进行自动评估。
- 每台设备上的网络需要先初始化,然后再尝试访问该设备上的参数,否则会遇到错误。
- 优化算法在多个GPU上自动聚合。
4. 分布式训练

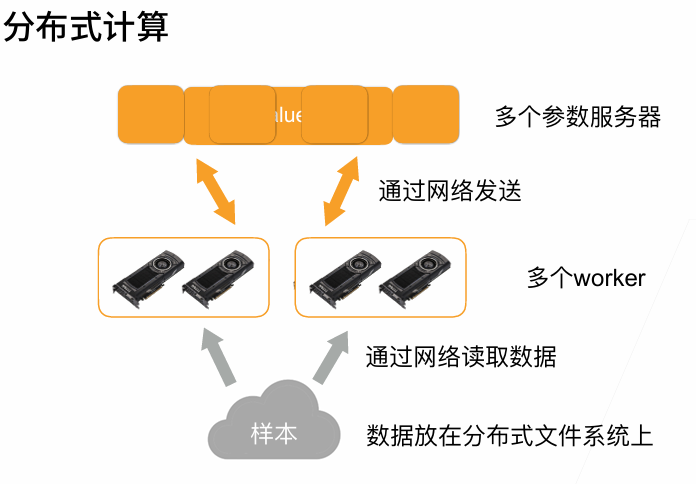
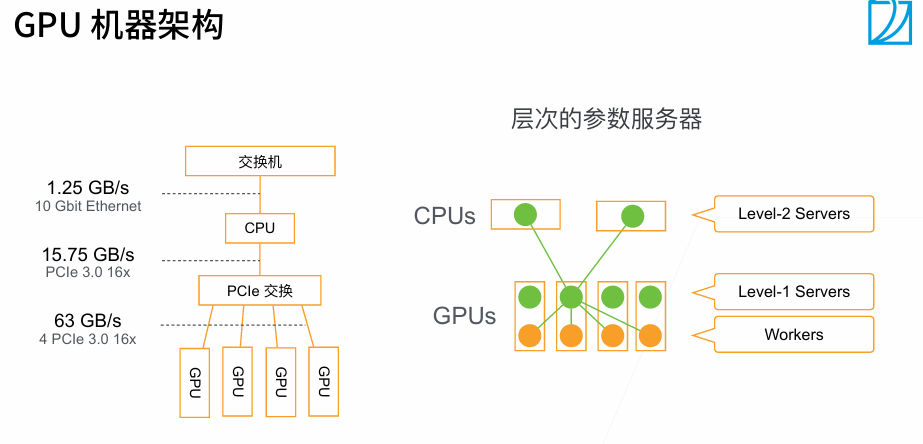
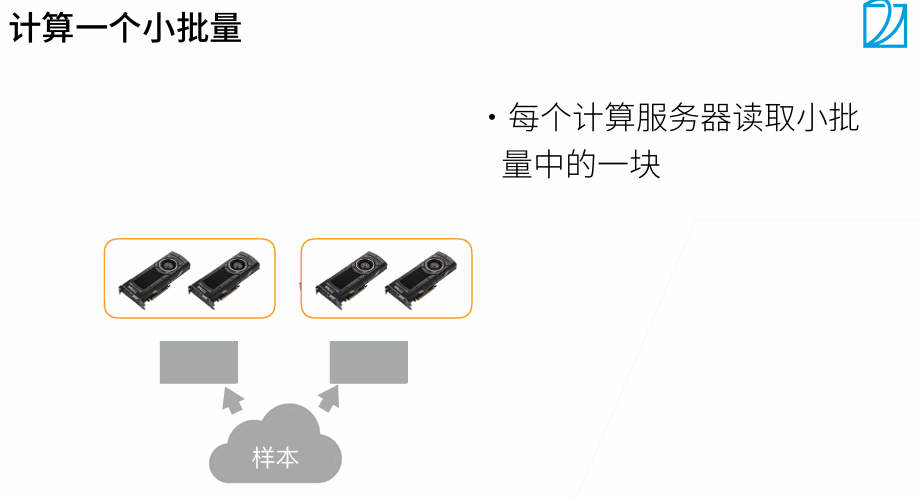
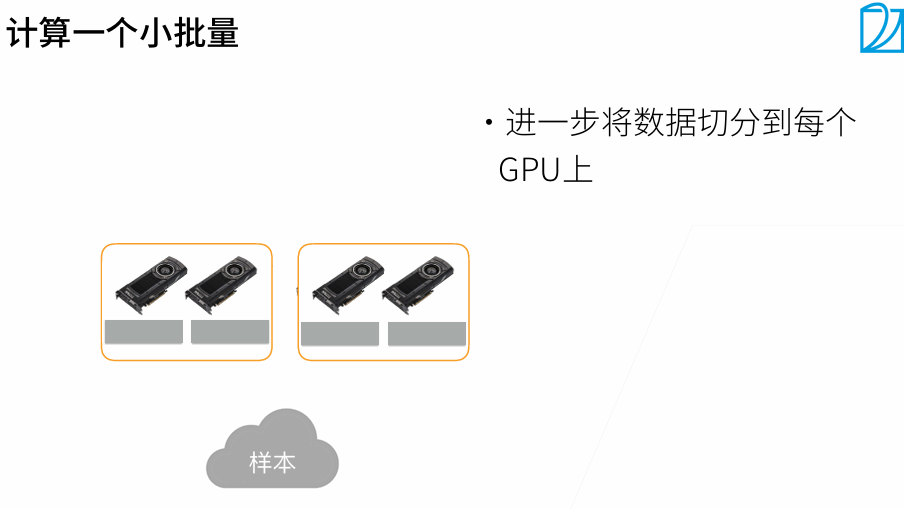
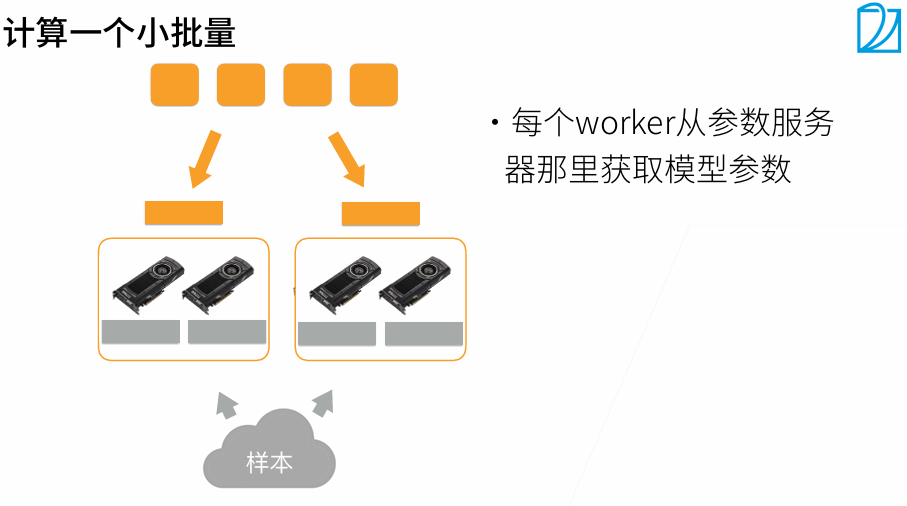
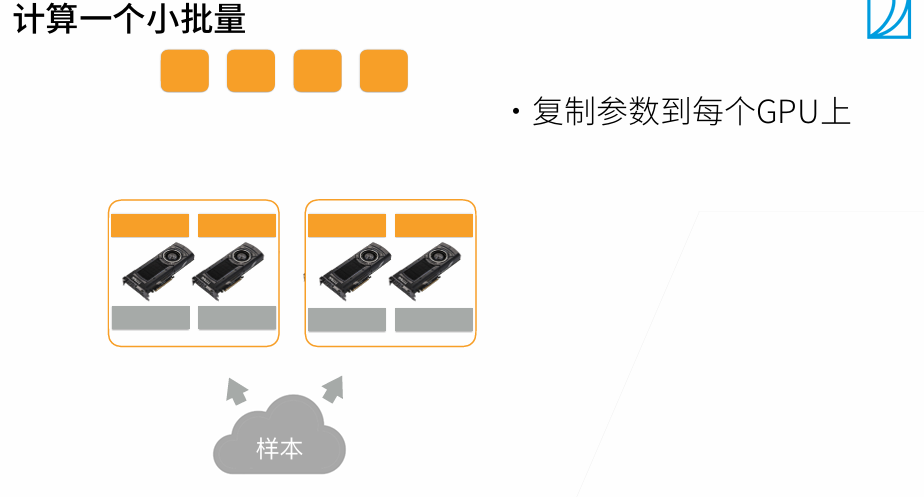
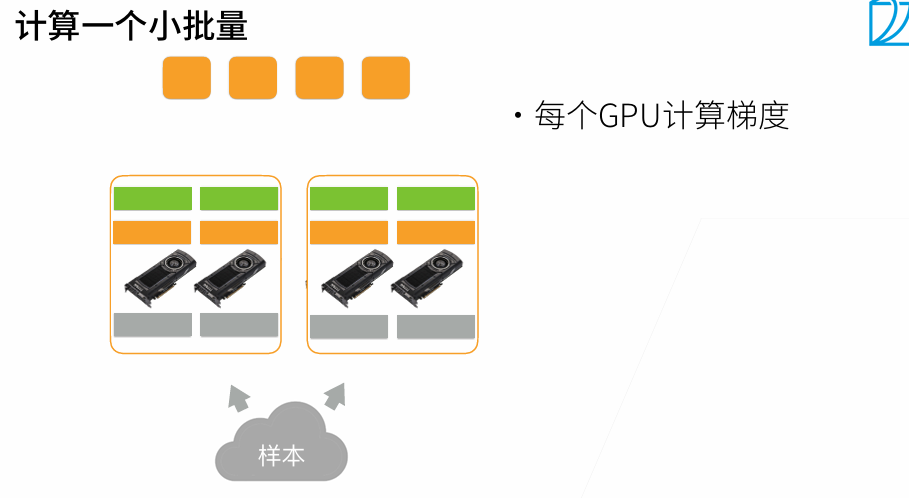
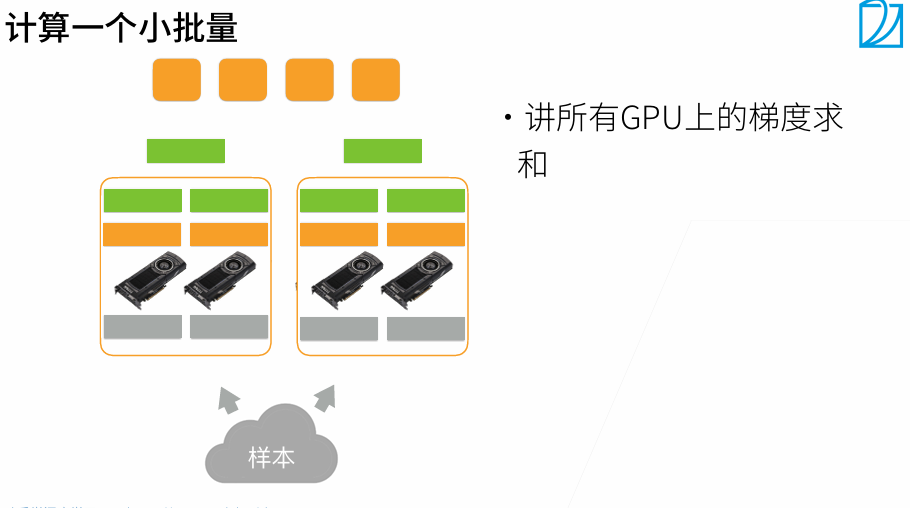
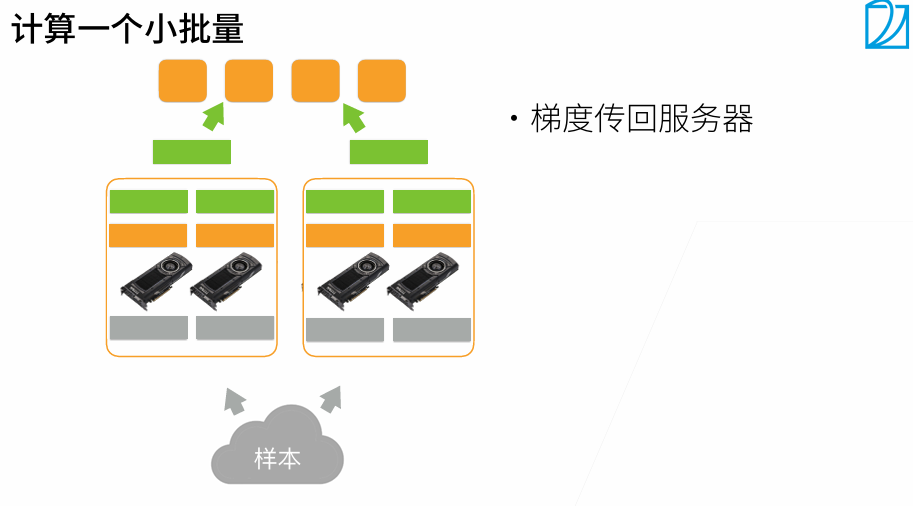
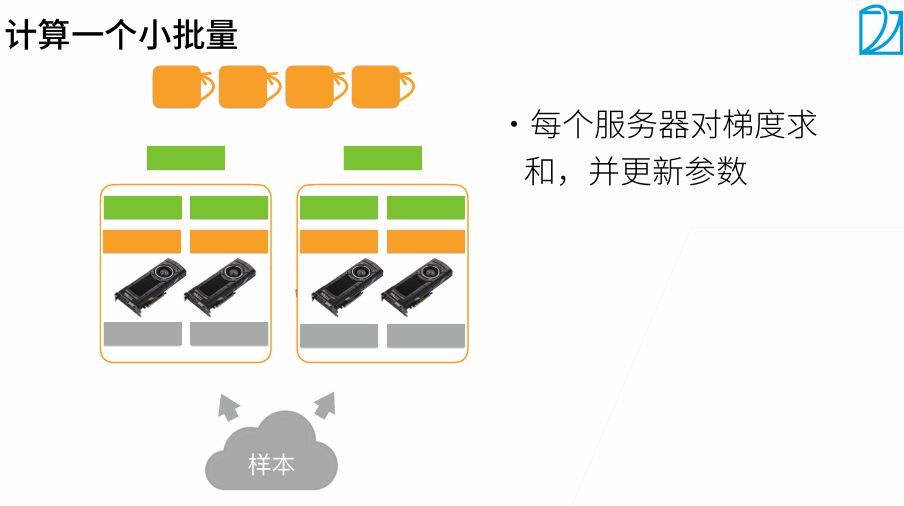


t1最好是大t2 20%左右
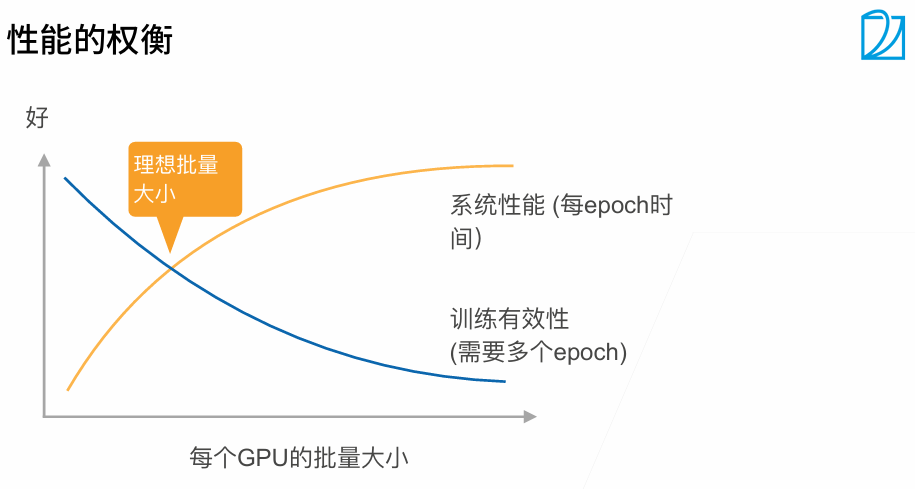
当batchsize变大时,系统性能变好,但是批量越大,需要训练更多epoch达到原始的训练目标


相关文章:

31-35【动手学深度学习】深度学习硬件
1. CPU和GPU 1.1 CPU CPU每秒钟计算的浮点运算数为0.15,GPU为12。GPU的显存很低,16GB(可能32G封顶),CPU可以一直插内存。 左边是GPU(只能做些很简单的游戏,视频处理),中…...
 AI 应用开发平台-本地部署)
Dify的大语言模型(LLM) AI 应用开发平台-本地部署
前言 今天闲着,捣鼓一下 Dify 这个开源平台,在 mac 系统上,本地部署并运行 Dify 平台,下面记录个人在本地部署Dify 的过程。 Dify是什么? Dify是一个开源的大语言模型(LLM)应用开发平台&#…...

《MQTT 从 0 到 1:原理、实战与面试指南全解》
一、MQTT 是什么? MQTT(Message Queuing Telemetry Transport)是一种 轻量级、基于发布/订阅(Pub/Sub)模式的消息传输协议,适用于物联网(IoT)、实时通信等对 低带宽、高延迟、不稳定…...

SpringMVC 通过ajax 实现文件的上传
使用form表单在springmvc 项目中上传文件,文件上传成功之后往往会跳转到其他的页面。但是有的时候,文件上传成功的同时,并不需要进行页面的跳转,可以通过ajax来实现文件的上传 下面我们来看看如何来实现: 方式1&…...
图片识别(TransFormerCNNMLP)
目录 一、Transformer (一)ViT:Transformer 引入计算机视觉的里程碑 (二)Swin-Transformer:借鉴卷积改进 ViT (三)VAN:使用卷积模仿 ViT (四)…...

手术机器人行业新趋势:Kinova多机械臂协同系统如何突破复杂场景适应性瓶颈?
机器人手术历经多阶段技术演进,已成为现代医疗重要方向。其需求增长源于医疗机构对高精度低风险手术方案的需求、微创手术普及及技术进步带来的复杂场景适应性提升。Kinova 轻型机械臂凭借模块化设计与即插即用功能,可快速适配不同手术环境,为…...

国酒华夏实业酒水供应链:全品类覆盖打造一站式购销平台
在消费升级与供应链效率双重驱动的酒水行业变革中,国酒华夏实业凭借全品类覆盖与数字化赋能,构建起集采购、品鉴、文化传播于一体的新型酒水供应链体系。其“一站式购销平台”模式不仅重塑了传统酒水流通链路,更通过精准服务与品质保障&#…...

【Qt】:设置hover属性,没有适应到子控件中
#ButtonStyle:hover 是一个 ID 选择器,仅对设置了 objectName"ButtonStyle" 的控件本身生效,不会自动应用到其子控件(如 QLabel 和 QWidget)。 在ButtonForm中,有一个Qwidget控件,在这个Qwidget中…...

缺乏经验的 PCB 过孔建模方法
您是一名背板设计人员,被指派设计一种新的高速、多千兆位串行链路架构,从多个线卡到背板上的多个交换矩阵交换卡。这些链路必须在第一天以 6GB/s 的速度运行,并且为 10GB/s (IEEE 802.3KR) 做好产品演进的准备。时间表很紧,您需要提出一个背板架构,以允许程序的其余部分…...

搭建人工智能RAG知识库的主流平台与特点概述
在2022年末chatgpt和2024年末deepseek的推动下,人工智能应用如雨后春笋,层出不穷,日新月异。现推荐一些截至目前比较主流的用来搭建RAG的平台。 1. Haystack 特点: 模块化架构:支持端到端问答系统构建,集…...

【QT】在界面A打开界面B时,界面A隐藏,界面B关闭时,界面A复现
在Qt6中,可以通过信号与槽机制实现界面A在关闭界面B时重新显示。以下是具体的实现步骤: 方法一:使用自定义关闭信号 在界面B中定义关闭信号:当界面B关闭时发射该信号。连接信号到界面A的显示槽:在界面A中创建界面B时…...

捡漏岗位:国考报名数据和岗位特征分析
2025 年国考官方数据及权威分析,报录比低于 10:1 的岗位主要集中在中西部艰苦边远地区、特殊专业技术岗位及定向招录岗位。 岗位名称招录机关地区招录人数报名人数报录比报考条件示例一级警长及以下(三)新疆出入境边防检查总站新疆3124:1男性…...

qt---命名规范
1、命名规范 1) 类名:单词首字母大写,单词和单词之间直接连接,无需连接字符 如:MyClass,QPushButton class MainWindow { };2) Qt中内置的类型,头文件和类命名同名。 如: #include <QStri…...

信息系统项目管理师考前练习3
项目组合管理 企业战略调整后,项目组合经理应优先: A. 终止所有不符合新战略的项目 B. 重新评估项目优先级与资源分配 C. 要求所有项目加快交付进度 D. 合并相似项目以减少成本 答案:B 解析:项目组合管理的核心是动态对齐战略,优先重新评估项目价值与资源匹配(第5版强调…...

【算法创新+设计】灰狼算法GWO+扰动算子,求解大规模TSP问题利器
目录 1.灰狼算法GWO原理2.连续空间到离散空间3.核心公式处理4.结果展示5.代码获取6.读者交流 1.灰狼算法GWO原理 【智能算法】灰狼算法(GWO)原理及实现 2.连续空间到离散空间 GWO算法是针对连续空间问题设计的优化方法,而旅行商问题&#…...

GPU P-State 模式说明
在 NVIDIA GPU 上,“P-State”(Performance State)用来表示显卡当前的性能/功耗等级,P0 代表最高性能(最高核心频率、最大功耗),数字越大性能越低、功耗越小。不同 P-State 的主要区…...

真实世界中的贝叶斯网络:Bootstrap、模型平均与非齐次动态的科研应用
在生态与环境科学领域,揭示变量间因果机制是理解复杂系统运行规律的核心挑战。传统实验方法受限于高昂成本与生态扰动风险,而经典统计模型仅能刻画变量相关性,难以突破"相关非因果"的认知瓶颈。贝叶斯网络作为融合图论与概率论的前…...
)
.NET外挂系列:4. harmony 中补丁参数的有趣玩法(上)
一:背景 1. 讲故事 前面几篇我们说完了 harmony 的几个注入点,这篇我们聚焦注入点可接收的几类参数的解读,非常有意思,在.NET高级调试 视角下也是非常重要的,到底是哪些参数,用一张表格整理如下ÿ…...

【VLNs篇】03:VLMnav-端到端导航与视觉语言模型:将空间推理转化为问答
栏目内容论文标题End-to-End Navigation with Vision-Language Models: Transforming Spatial Reasoning into Question-Answering (端到端导航与视觉语言模型:将空间推理转化为问答)核心问题如何利用大型视觉语言模型(VLM)实现端到端的机器人…...
)
云原生攻防4(Kubernetes基础补充)
什么是K8S? Kubernetes 是做什么的? 什么是 Docker? 什么是容器编排? Kubernetes 一词来自希腊语,意思是“飞行员”或“舵手”。这个名字很贴切,Kubernetes 可以帮助你在波涛汹涌的容器海洋中航行。 Kubernetes 是 Google 基于 Borg 开源的容器编排调度引擎,作为 CNCF最…...

redis--redisJava客户端:Jedis详解
在Redis官网中提供了各种语言的客户端,地址: https://redis.io/docs/latest/develop/clients/ Jedis 以Redis命令做方法名称,学习成本低,简单实用,但是对于Jedis实例是线程不安全的(即创建一个Jedis实例&a…...

SpringBoot-SpringBoot源码解读
SpringBoot-SpringBoot源码解读 一、Spring Boot启动过程概述 Spring Boot通过一系列的类和机制,简化了Spring应用的启动流程。当你执行SpringApplication.run()时,Spring Boot会自动完成应用的初始化、环境配置、组件加载、自动配置等任务,…...

黑马程序员C++2024新版笔记 第4章 函数和结构体
1.结构体的基本应用 结构体struct是一种用户自定义的复合数据类型,可以包含不同类型的成员。例如: struct Studet {string name;int age;string gender; } 结构体的声明定义和使用的基本语法: struct 结构体类型 {成员1类型 成员1名称;成…...

【沉浸式求职学习day46】【华为5.7暑期机试题目讲解】
沉浸式求职学习 题目1题目2 题目1 一个超大智能汽车测试场有多个充电桩,每个充电桩的位置由其在二维平面上的坐标(x,y)表示。给定一辆智能汽车的当前位置(car_x,car_y),请设计一个高效的算法,找出给定智能汽车行驶到充电桩行驶距离最近的k个…...

PDF处理控件Aspose.PDF教程:以编程方式将PDF转换为Word
您是否正在寻找在线将 PDF 转换为 Word 的方法?在本指南中,我们将探索如何使用 C#、Java 和 Python 编码解决方案将 PDF 文档转换为可编辑的 Word 文件。开发人员通过代码将 PDF 文件转换为 Word 格式,从而获得显著优势。这种方法可以轻松实现…...

旋转位置RoPE编码详解
一. 旋转位置编码和正余弦位置编码比对 旋转位置编码(RoPE)和正余弦位置编码(Sinusoidal Position Encoding)是两种常用的位置编码方法,它们在处理序列数据时具有不同的数学形式和特性。以下是对两者优劣的详细说明及…...
-动画(2d))
canvas(二)-动画(2d)
<canvas> 动画是通过 JavaScript 动态更新画布内容来实现的。它利用 requestAnimationFrame 方法实现平滑的动画效果,适用于游戏、数据可视化、交互式图形等场景。真的需要数据可视化等场景使用,还是直接引入外部模型还原度比较高,但同…...

Dynamics 365 Business Central Azure application registration
本方法适用于 单租户服务器身份验证。 实现方法 在大多数组织里ERP Admin 不一定有权限 Azure Admin权限,在实施过程中你只需要把以下指引发给你的系统管理员。 请注意后面有系统管理员设置好后,你如何检查。 导航到 https://admin.microsoft.com 并登…...

选择合适的Azure数据库监控工具
Azure云为组织提供了众多服务,使其能够无缝运行应用程序、Web服务和服务器部署,其中包括云端数据库部署。Azure数据库能够与云应用程序实现无缝集成,具备可靠、易扩展和易管理的特性,不仅能提升数据库可用性与性能,同时…...

Access链接Azure SQL
Hi,大家好呀! 最近在给大家分享了SQL Server方面的一些视频,那今天我们也来讲讲Azure SQL。 什么是Azure SQL,这里我们就不介绍了,如果你没有用这个数据库,那你可以简单的把它理解成,就是SQL …...

34、React Server Actions深度解析
一、灵魂契约协议(核心机制) 1. 次元融合架构 "use server";async function borrowBook(bookId: number, readerName: string) {// 模拟数据库操作const result await db.execute(UPDATE books SET available false WHERE id ?,[bookId]…...

Azure 应用服务中的异常处理、日志记录和通知:综合指南
简介 Azure 应用服务是基于云的应用程序,使开发人员能够在云上构建、部署和管理应用程序。与任何应用程序一样,制定适当的异常处理、日志记录和通知实践至关重要,以确保应用程序平稳运行,并快速识别和解决任何问题。在本篇博文中&…...

第16天-使用Python Pillow库常见图像处理场景
1. 打开与显示图像 from PIL import Image# 打开图像文件 img = Image.open("input.jpg")# 显示图像基本信息 print(f"格式: {img.format}") # JPEG print(f"尺寸: {img.size}") # (宽度, 高度) print(f"模式: {img.mode}") …...

VUE3+TS实现图片缩放移动弹窗
完整代码 使用VUE3、TS,实现将图片通过鼠标拖拽缩放以及选择缩放比例。 <template><div><el-dialogv-model"dialogVisible"title"查看图片":close-on-click-modal"false":close-on-press-escape"false"fu…...

关于Vue自定义组件封装的属性/事件/插槽的透传问题
// parent.vue <Myinputv-model"keyWords"placeholder"请输入内容"size"small"input"input"change"change"width"320" ><template #prepend><el-select v-model"select" placeholder&qu…...

智能驾驶中的深度学习:基于卷积神经网络的车道线检测
摘要 智能驾驶是人工智能技术的重要应用领域之一,而车道线检测是实现自动驾驶的基础功能。本文介绍了一种基于深度学习的车道线检测方法,使用卷积神经网络(CNN)对道路图像进行实时分析。文章详细阐述了数据预处理、模型构建、训练优化及实际部署的完整流程,并提供了Pytho…...

在 Excel xll 自动注册操作 中使用东方仙盟软件2————仙盟创梦IDE
// 获取当前工作表名称string sheetName (string)XlCall.Excel(XlCall.xlfGetDocument, 7);// 构造动态名称(例如:Sheet1!MyNamedCell)string fullName $"{sheetName}!MyNamedCell";// 获取引用并设置值var namedRange (ExcelRe…...

【每周一个MCP】:将pytdx封装成MCP
文章目录 配置文件MCP代码(其实github上都有)不错不错,星星之火可以燎原。 https://github.com/ddholiday/onedayoneMCP/tree/main/MCPs/tdx-mcp 配置文件 pytdx有两种读取数据的方式,分别是,从API读取,和从本地读取。 其中,从API读取,需要IP和端口。 这个官方文档…...
)
Vue3中插槽, pinia的安装和使用(超详细教程)
1. 插槽 插槽是指, 将一个组件的代码片段, 引入到另一个组件。 1.1 匿名插槽 通过简单的案例来学习匿名插槽,案例说明,在父组件App.vue中导入了子组件Son1.vue,父组件引用子组件的位置添加了一个片段,比如h2标签,然…...

【Java高阶面经:微服务篇】5.限流实战:高并发系统流量治理全攻略
一、限流阈值的三维度计算模型 1.1 系统容量基准线:压测驱动的安全水位 1.1.1 压力测试方法论 测试目标:确定系统在资源安全水位(CPU≤80%,内存≤70%,RT≤500ms)下的最大处理能力测试工具: 单机压测:JMeter(模拟10万并发)、wrk(低资源消耗)集群压测:LoadRunner …...

学习黑客了解密码学
5分钟了解密码学:从古老艺术到现代科学 🔐 作者: 海尔辛 | 发布时间: 2025-05-21 08:36:35 UTC 密码学简介:保护信息的艺术与科学 📜 密码学是研究如何安全传递和存储信息的学科。它不仅仅是加密和解密,更包含了身份…...

【UE5】环形菜单教程
效果 步骤 1. 下载图片资源:百度网盘 请输入提取码 提取码:fjjx 2. 将图片资源导入工程,如下 3. 新建3个控件蓝图,这里分别命名为“WBP_CircularMenu”、“WBP_Highlight”、“WBP_Icon” 4. 打开“WBP_Icon”,设置“所需” 添加…...

【JVM】学习笔记
1. JVM概述 JVM是一个抽象的计算机,用于运行Java程序。它将Java字节码转化为特定平台的机器代码,确保Java程序具有跨平台性。 2. JVM架构 JVM的架构通常包括以下几个主要部分: 类加载子系统(ClassLoader)ÿ…...
)
物流项目第五期(运费计算实现、责任链设计模式运用)
前四期: 物流项目第一期(登录业务)-CSDN博客 物流项目第二期(用户端登录与双token三验证)-CSDN博客 物流项目第三期(统一网关、工厂模式运用)-CSDN博客 物流项目第四期(运费模板列…...

PrintStream PrintWriter Java 打印流
使用场景: 代替 System.out 输出日志(比如 System.setOut(printStream))需要输出各种类型(如 println(123)、println("hello")) 常用方法: print(), println() → 支持所有基本类型和对象pr…...

前端excel表格解析为json,并模仿excel显示
前端环境:elementUI vue2 <style lang"scss" scoped> 页面效果 jsondata为mock数据,为方便调试其内容可清空,首行(字母坐标)随数据内容自动变化,首列也是一样,模拟excel …...

NumPy 2.x 完全指南【十六】分割数组
文章目录 1. 数组分割1.1 split1.2 array_split1.3 vsplit1.4 hsplit1.5 dsplit1.6 unstack 1. 数组分割 数组分割是指将一个数组拆分为多个子数组的操作,常用于数据处理、并行计算、分块处理等场景。NumPy 提供了多种分割函数,允许用户沿不同方向&…...

vue3 + vite 使用tailwindcss
第一步:安装依赖 vite版本较低(“vite”: “^4.0.0”)所以就使用低版本的tailwindcss npm install -D tailwindcss3.4.1 postcss autoprefixer第二步:配置文件生成 npx tailwindcss init -p会自动生成两个文件postcss.config.js和…...

K个一组链表翻转
目录 1. 题意 2. 解题思路 3. 代码 1. 题意 给一个链表,按 k 进行翻转,也就是 k 2 ,两两进行翻转,如果不够2则不动。 2. 解题思路 首先思考怎么翻转一个链表,反转链表:https://leetcode.cn/problems…...
)
逆向音乐APP:Python爬虫获取音乐榜单 (1)
1. 引言 在数字音乐时代,许多平台如音乐有榜单,限制非付费用户访问高音质或独家内容。然而,从技术研究的角度来看,我们可以通过逆向工程和Python爬虫技术解音乐的API接口,获取付费音乐的播放链接。 2. 技术准备 在当…...