【VLNs篇】03:VLMnav-端到端导航与视觉语言模型:将空间推理转化为问答
| 栏目 | 内容 |
|---|---|
| 论文标题 | End-to-End Navigation with Vision-Language Models: Transforming Spatial Reasoning into Question-Answering (端到端导航与视觉语言模型:将空间推理转化为问答) |
| 核心问题 | 如何利用大型视觉语言模型(VLM)实现端到端的机器人导航,克服传统VLM在精细空间输出和有效利用长上下文进行导航方面的局限性,并避免现有模块化方法带来的系统复杂性和任务特定性。 |
| 提出方案 | 提出了 VLMnav 框架,一个将现成VLM转化为零样本、端到端导航策略的具身框架。 |
| 核心思想 | 将导航问题转化为VLM擅长的“关于图像的问答”任务。通过精心设计的提示策略(包括系统提示、任务描述、视觉注释的潜在动作选项、输出格式要求),让VLM直接从当前视觉观察中选择下一步动作。 |
| 主要创新点 | 1. 端到端零样本导航:首次证明VLM可以作为端到端导航策略进行零样本使用,无需任何针对导航数据的微调或预训练。 2. 统一决策过程:不依赖于传统的感知、规划、控制分离的模块化流程,而是由VLM一步直接选择动作。 3. 新颖的提示工程:开发了一种包含视觉注释(将可选动作直接标注在图像上)和详细文本指令的提示策略,引导VLM进行空间推理和探索决策。 4. 通用性与开放性:该方法不依赖特定领域的专家模型或假设,使其具有开放性和对各种下游导航任务的普适性。 5. 问题转换范式:将复杂的导航决策巧妙地重构为VLM更擅长的、基于视觉信息的问答形式,简化了导航系统的设计。 |
| 与先前工作对比 | - 不同于模块化系统:先前工作常将VLM作为高级推理组件,配合显式3D建图和规划器;VLMnav则避免了这种复杂性和任务特化。 - 不同于微调方法:不需为VLM进行特定导航数据的微调,保留了模型的原始泛化能力。 - 不同于简单提示:克服了简单提示VLM时,其难以生成精细空间输出和有效利用长上下文的问题。 - 直接动作输出:VLM直接选择具体动作,而非像某些方法那样输出高级指令给底层控制器。 |
| 评估方式 | - 在两个流行的具身导航基准(ObjectNav, GOAT Bench)上进行广泛评估。 - 与基线提示方法(如PIVOT)进行性能比较。 - 进行设计分析(消融实验)以理解不同设计决策(如FOV、上下文历史、深度感知质量)的影响。 |
| 主要贡献/发现 | - VLMnav在导航性能上显著优于现有的基线提示方法。 - 证明了通过巧妙的提示工程,VLM有潜力在零样本条件下执行复杂的端到端导航任务。 - 为利用大型基础模型解决具身AI问题提供了一种新的思路和有效框架。 |
| 关键词 | 导航 (Navigation), VLM, 具身AI (Embodied AI), 探索 (Exploration) |
文章目录
- 1 引言
- 2 相关工作
- 3 概述
- 3.1 可导航性
- 3.2 动作提议器
- 3.3 投影
- 3.4 提示
- 3.5 终止
- 4 实验
- 4.1 ObjectNav
- 4.2 Go To Anything Benchmark (GOAT)
- 4.3 探索VLM智能体导航的设计空间
- 5 结论
摘要: 我们提出了VLMnav,一个将视觉语言模型(VLM)转化为端到端导航策略的具身框架。与先前的工作不同,我们不依赖于感知、规划和控制之间的分离;相反,我们使用VLM一步直接选择动作。令人惊讶的是,我们发现VLM可以作为端到端策略进行零样本(zero-shot)使用,即无需任何微调或接触导航数据。这使得我们的方法具有开放性和通用性,适用于任何下游导航任务。我们进行了广泛的研究,以评估我们的方法与基线提示方法相比的性能。此外,我们进行了设计分析,以了解最具影响力的设计决策。我们项目的视觉示例和代码可以在 jirl-upenn.github.io/VLMnav/ 找到。
关键词: 导航,VLM,具身AI,探索
1 引言
在环境中有效导航以实现目标的能力是物理智能的标志。空间记忆以及更高级的空间认知形式,据信在陆地动物和高级脊椎动物历史的早期就开始进化,可能在4亿到2亿年前之间[1]。由于这种能力进化了如此长的时间,它对人类来说几乎感觉是本能的和微不足道的。然而,导航实际上是一个高度复杂的问题。它需要协调低层规划以避开障碍物,同时进行高层推理以解释环境的语义并探索最有可能使智能体实现其目标的方向。
导航问题的很大一部分似乎涉及与回答长上下文图像和视频问题所需的认知过程相似的过程,这是当代视觉语言模型(VLM)擅长的领域[2, 3]。然而,当简单地应用于导航任务时,这些模型面临明显的局限性。具体来说,当给定任务描述并结合观察-动作历史时,VLM通常难以生成精细的空间输出来避开障碍物,并且无法有效利用其长上下文推理能力来支持有效的导航[4, 5, 6]。
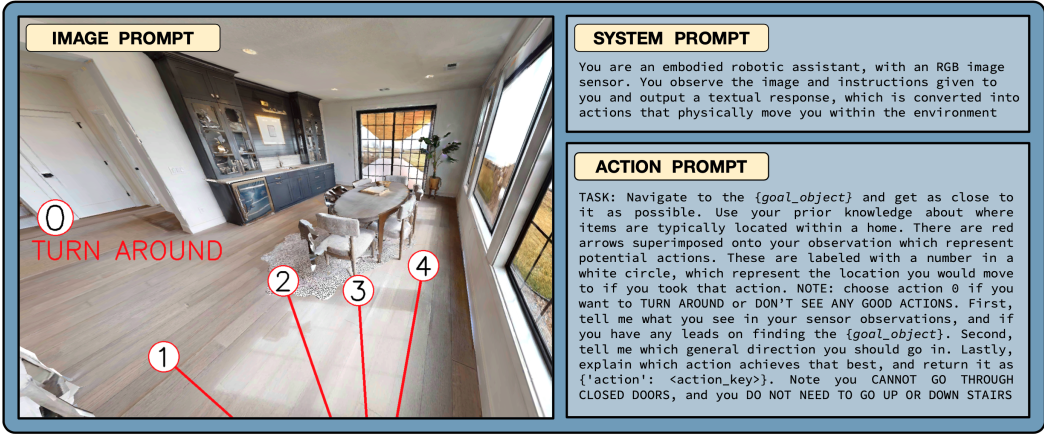
图1:VLMnav的完整动作提示包括三个部分:描述具身性的系统提示,描述任务、潜在动作和输出指令的动作提示,以及显示当前观察结果和带注释动作的图像提示。
为了应对这些挑战,先前的工作已将VLM作为模块化系统的一个组成部分,用于执行高级推理和识别任务。这些系统通常包含一个显式的3D建图模块和一个规划器来处理任务中更具身的部分,例如运动和探索[7, 8, 9, 10, 11]。虽然模块化的优势在于仅将每个组件用于其擅长的子任务,但其缺点是系统复杂性和任务专业化。
在这项工作中,我们表明一个现成的VLM可以用作零样本和端到端的语言条件导航策略。实现这一目标的关键思想是将导航问题转化为VLM擅长的事情:回答关于图像的问题。
为此,我们开发了一种新颖的提示策略,使VLM能够明确地考虑探索和避障问题。这种提示是通用的,因为它可以用于任何基于视觉的导航任务。
与先前的方法相比,我们不使用特定模态的专家[12, 10, 13],不训练任何领域特定的模型[14, 15],也不假设可以从模型中获取概率[12, 10]。
我们在已建立的具身导航基准[16, 17]上评估我们的方法,结果证实我们的方法与现有的提示方法相比显著提高了导航性能。最后,我们通过对几个具身VLM框架组件的消融实验得出设计见解。
2 相关工作
学习端到端导航策略最常见的方法是从头开始使用离线数据集训练模型[18, 19, 20, 21, 22]。然而,收集大规模导航数据具有挑战性,因此,这些模型通常难以泛化到新的任务或分布外的环境。
另一种增强泛化能力的方法是使用机器人特定数据对现有的视觉语言模型(VLM)进行微调[23, 24, 7, 14]。虽然这种方法可以产生更鲁棒的端到端策略,但微调可能会破坏微调数据集中不存在的特征,最终限制模型的泛化能力。
另一条工作路线侧重于零样本使用这些模型[11, 25, 10, 13, 12, 9, 5],通过提示它们使响应与任务规范保持一致。例如,[9, 20]使用CLIP或DETIC特征将视觉观察与语言目标对齐,构建环境的语义地图,
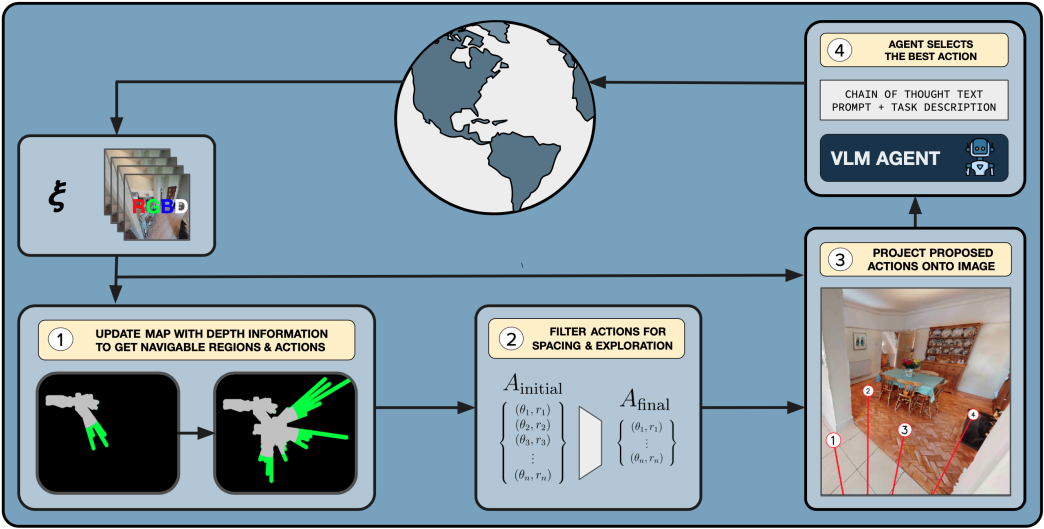
**图2:方法:**我们的方法由四个关键组件组成:(i)可导航性(Navigability),确定智能体实际可以移动到的位置,并相应地更新体素地图。地图更新步骤的示例显示了将新区域标记为已探索(灰色)或未探索(绿色)。(ii)动作提议器(Action Proposer),根据间距和探索来优化最终动作集。(iii)投影(Projection),将动作在图像上进行视觉注释。(iv)提示(Prompting),构建详细的思维链提示以选择一个动作。
并使用传统方法进行规划。其他工作设计了特定的模块来处理探索任务[13, 12, 11, 26]。这些系统通常需要估计置信度以知道何时停止探索,这通常通过使用token或对象概率[12, 10]来完成。此外,许多这些方法还使用低级导航模块,这些模块将动作选择抽象为预训练的点对点策略,例如快速行进法(Fast Marching Method)[20, 9, 13, 11, 10]。
视觉提示方法: 为了增强VLM的任务特定性能,最近的工作涉及在将图像传递给VLM之前对其进行物理修改。例如[27],它注释图像以帮助识别空间概念。[28]引入了“标记集(set-of-mark)”,它为图像中的对象分配唯一的标签,并在文本提示中引用这些标签给VLM。这种视觉增强显著提高了需要视觉接地的任务的性能。在此基础上,[29, 30]将类似的视觉提示方法应用于网页导航任务,并表明VLM能够零样本完成此类任务。
用于具身导航的VLM提示: CONVOI [31] 在图像上叠加数字标记,并提示VLM输出与上下文线索(例如,停留在人行道上)一致的这些标记序列,用作导航路径。与我们的工作不同,他们 (i) 依赖低级规划器进行避障,而不是直接使用VLM的输出作为导航动作,并且 (ii) 不利用VLM引导智能体朝向特定的目标位置。PIVOT [5] 引入了一种与我们最相似的视觉提示方法。他们通过将一步动作表示为指向图像上标记圆圈的箭头来解决导航问题。在每个步骤中,从各向同性高斯分布中采样动作,其均值和方差根据来自VLM的反馈迭代更新。在优化分布后选择最终动作。虽然PIVOT能够处理各种现实世界的导航和操纵任务,但它有两个显著的缺点:(i) 它没有结合深度信息来评估动作提议的可行性,导致运动效率较低;(ii) 它需要多次VLM调用来选择单个动作,导致计算成本和延迟较高。
3 概述
我们提出了VLMnav,一个导航系统,它接收语言或图像指定的目标 G、RGB-D图像 I、姿态 ξ 作为输入,并随后输出动作 a。动作空间包括围绕偏航轴的旋转和沿机器人框架正面轴的位移,这允许所有动作都以极坐标表示。众所周知,VLM难以推理连续坐标[6],因此我们将导航问题转化为从一组离散选项中选择一个动作[28]。我们的核心思想是以避免障碍物碰撞和促进探索的方式选择这些动作选项。
图2总结了我们的方法。我们首先通过使用深度图像估计到障碍物的距离来确定局部区域的可导航性(第3.1节)。与[20, 13, 12, 31, 9, 10, 26]类似,我们使用深度图像和姿态信息来维护场景的自顶向下体素图,并特别将体素标记为已探索或未探索。这样的地图被动作提议器(第3.2节)用来确定一组避免障碍物并促进探索的动作。然后,我们使用投影(第3.3节)组件将这组可能的动作投影到第一人称视角的RGB图像上。最后,VLM将此图像和一个精心设计的提示(在第3.4节中描述)作为输入,以选择一个智能体执行的动作。为了确定情节终止,我们使用一个单独的VLM调用,详见第3.5节。
3.1 可导航性
使用深度图像,我们计算一个可导航性掩码,其中包含机器人可以到达而不会撞到任何障碍物的像素集。
接下来,对于所有方向 θ ∈ fov(视场角),我们使用可导航性掩码来计算智能体可以无碰撞行进的最远直线距离 r。这创建了一组无碰撞的动作 A_initial。图3说明了掩码和可导航动作的示例计算。
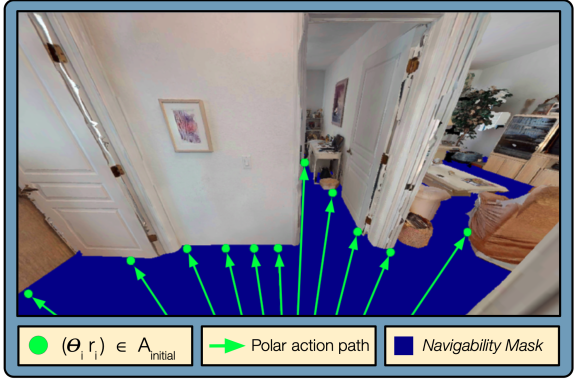
图3:可导航性子程序的示例步骤。可导航性掩码以蓝色显示,构成 A_initial 的极坐标动作以绿色显示。
同时,我们使用深度图像和姿态信息来构建环境的2D体素地图。智能体2米范围内的所有可观察区域都标记为已探索,超出范围的区域标记为未探索。
3.2 动作提议器
我们设计了动作提议器例程来优化 A_initial → A_final,这是一个VLM可解释并促进探索的动作集。利用我们体素地图中积累的信息,我们查看每个动作并定义一个探索指示变量 e_i 为:
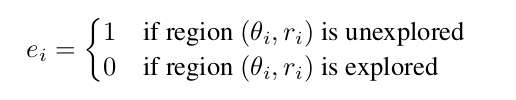
为了构建 A_final,我们需要优先考虑未探索的动作,并确保VLM能够辨别的动作之间有足够的视觉间距。我们首先通过添加未探索的动作来构建 A_final,前提是保持 θ_s 的角间距。
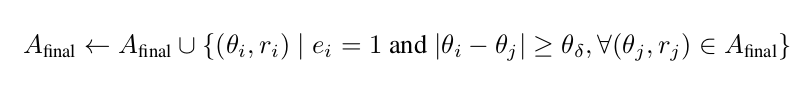
为了充分覆盖所有方向但仍保持探索偏差,我们通过添加受限于更大角间距 θ_△ > θ_s 的已探索动作来补充 A_final:
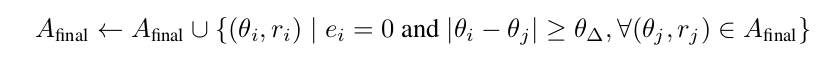
最后,我们希望确保这些动作不会让智能体离障碍物太近,所以我们裁剪
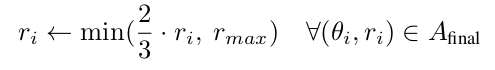
偶尔,智能体可能会卡在没有可导航动作的角落 (A_initial = ∅)。为了解决这个问题,我们添加了一个特殊动作 (π, 0),它将智能体旋转180°。这也允许智能体在快速识别出目标不在某个房间时高效地进出该房间。
提议的集合 A_final 现在具有三个重要特性:(i)动作对应于可导航路径,(ii)动作之间有足够的视觉间距,以及(iii)存在一个工程化的探索偏差。我们将这种探索方法称为探索偏差 (explore bias)。
3.3 投影
将这些动作在VLM可以理解和推理的空间中进行视觉接地是下一步。投影组件接收来自3.2节的 A_final 和RGB图像 I,并输出带注释的图像 Î。与[5]类似,每个动作都被分配一个数字并叠加到图像上。我们将特殊的旋转动作指定为0,并在图像的一侧用标签“转身 (Turn Around)”进行注释。我们发现,对其进行视觉注释,而不是仅仅在文本提示中描述它,有助于将其被选择的概率与其他动作的概率联系起来。
3.4 提示
为了引出最终动作,我们精心设计了一个详细的文本提示 T,它与 Î 一起馈送到VLM中。这个提示主要描述任务的细节、导航目标以及如何解释视觉注释。此外,我们要求模型描述图像的空间布局,并在选择动作之前制定一个高级计划,这正如[32, 33]所发现的那样,可以提高推理质量。对于基于图像的导航目标,目标图像除了 T 和 Î 之外,也会简单地传递给VLM。完整的提示可以在图1中找到。
VLM选择的动作 Pvlm(a*|Î,T) ∈ A_final 然后直接在环境中执行。值得注意的是,这不像其他工作[20, 13, 9, 10, 11]那样涉及任何低级避障策略。
3.5 终止
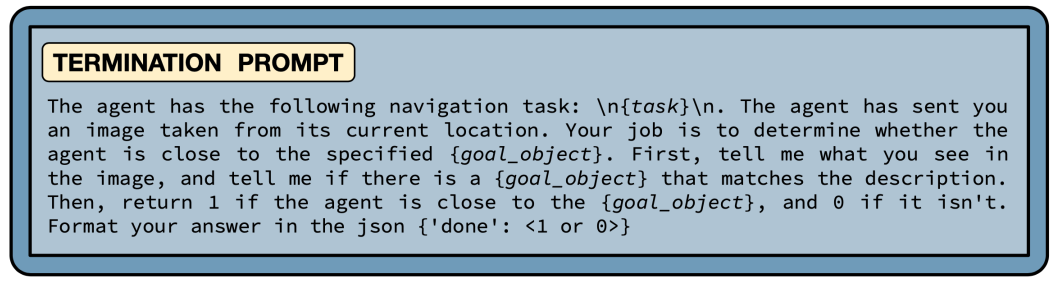
图4:用于确定情节终止的单独提示
要完成导航任务,智能体必须通过在目标对象的阈值距离内调用特殊动作停止来终止情节。与其他利用低级导航策略[20, 13, 9, 10, 11]的方法相比,我们的方法没有明确选择目标坐标进行导航,因此我们面临一个额外的挑战,即确定何时停止。我们的解决方案是使用一个单独的VLM提示,明确询问是否停止,如图4所示。我们这样做有两个原因:
- 注释: 来自第3.3节的箭头和圆圈会给图像带来噪声和混乱,使其更难理解。
- 任务分离: 为了避免任何任务干扰,动作调用仅与导航相关,停止调用仅与停止相关。
为避免在离目标太远时终止情节,我们在VLM连续两次调用停止时终止情节。在VLM第一次调用停止后,我们关闭可导航性和探索偏差组件,以确保智能体不会偏离目标对象。
4 实验
我们在两个流行的具身导航基准上评估我们的方法:ObjectNav [34] 和 GoatBench [17],它们都使用 Habitat-Matterport 3D 数据集 [35, 36] 中的场景。此外,我们分析了端到端VLM智能体的性能如何随设计参数(如视场角、用于提示模型的上下文历史长度以及深度感知质量)的变化而变化。
设置: 与[16]类似,智能体采用半径为0.17米、高度为1.5米的圆柱形身体。我们为智能体配备了一个自我中心的RGB-D传感器,分辨率为(1080, 1920),水平视场角(FOV)为131°。相机向下倾斜25°,与[12]类似,这有助于确定可导航性。在我们的所有实验中,我们使用 Gemini Flash 作为VLM,因为它成本低且效率高。
指标: 与先前的工作[17, 16, 37]一样,我们使用以下指标:(i)成功率(SR):成功完成的情节比例;(ii)路径长度加权成功率(SPL):路径效率的度量。
基线: 我们使用 PIVOT [5] 作为基线,因为它与我们的方法最相似。为了研究我们动作选择方法的影响,我们通过评估 Ours w/o nav 来对其进行消融:该方法与我们的方法相同,但没有可导航性和动作提议器组件。此基线的动作选择是一组静态的、均匀间隔的动作选项,包括转身动作。值得注意的是,这些动作不考虑可导航性或探索。为了进一步评估视觉注释的影响,我们还评估了一个基线 Prompt Only,它看到的动作在文本中描述(“转身”、“向右转”、“向前移动”,…),但没有进行视觉注释。这些不同的提示基线可以在图5中可视化。

**图5:基线:**比较四种不同方法在样本图像上的表现。Ours 包含指向可导航位置的箭头,PIVOT 具有从随机2-D高斯分布采样的箭头,Ours w/o nav 显示均匀间隔的箭头(注意箭头3和5指向墙壁),而 Prompt Only 仅显示原始RGB图像。
我们注意到,在我们的实验和基线中,我们启用了 allow_slide 参数,该参数允许智能体在模拟器中沿障碍物滑动。我们的实验表明,移除此假设会导致性能大幅下降。
4.1 ObjectNav
Habitat ObjectNav 基准要求导航到六个类别之一 [沙发、马桶、电视、植物、椅子、床] 中的一个对象实例。与[16]一样,为了获得最佳路径长度,我们取到该对象所有实例的最短路径的最小值。这些实验使用1.2米[13]的成功阈值进行评估。
| 运行 | SR | SPL |
|---|---|---|
| Ours | 50.4% | 0.210 |
| Ours w/o nav | 33.2% | 0.136 |
| Prompt Only | 29.8% | 0.107 |
| PIVOT [5] | 24.6% | 0.106 |
| Ours w/o sliding | 12.9% | 0.063 |
表1:ObjectNav结果。 我们在ObjectNav基准上评估了四种不同的提示策略,发现我们的方法在准确性(SR)和效率(SPL)方面均表现最佳。消融 allow_slide 参数表明我们的方法依赖于滑过障碍物。
表1总结了我们的结果。我们的方法在SR方面比PIVOT高出25%以上,并且在SPL方面的导航效率几乎翻倍。我们看到我们的动作选择方法非常有效,与 Ours w/o nav 相比,SR提高了17%。移除视觉注释会导致成功率略有下降,但SPL显著降低,表明视觉接地对于导航效率非常重要。有趣的是,我们发现PIVOT的表现比我们的两个消融实验都差。我们将此归因于其动作空间的表达能力有限,这使其无法执行大幅度旋转或完全转身。这通常会导致智能体卡在角落,从而妨碍其恢复和有效导航的能力。
我们注意到,禁用滑动会导致性能大幅下降,这表明虽然我们的方法在模拟中有效,但在现实世界中很可能导致与障碍物碰撞。虽然我们的可导航性模块可以识别可导航的位置,但它没有考虑机器人的特定尺寸和形状,这会导致偶尔的碰撞,因为我们缺乏明确的回溯先前动作的机制,从而导致智能体卡住。
4.2 Go To Anything Benchmark (GOAT)
GOAT Bench [17] 是一个最近的基准测试,它设定了更高水平的导航难度。每个情节包含5-10个子任务,跨越三种不同的目标模态:(i)对象名称,例如冰箱,(ii)对象图像,以及(iii)详细的文本描述,例如位于房间左侧、靠近图片和枕头的灰色沙发。表2显示了我们在val unseen split上的评估结果。
| 运行 | SR | SPL | 图像 SR | 对象 SR | 描述 SR |
|---|---|---|---|---|---|
| Ours | 16.3% | 0.066 | 14.3% | 20.5% | 13.4% |
| Ours w/o nav | 11.8% | 0.054 | 7.8% | 16.5% | 10.2% |
| Prompt Only | 11.3% | 0.037 | 7.7% | 15.6% | 10.1% |
| PIVOT [5] | 8.3% | 0.038 | 7.0% | 11.3% | 5.9% |
表2:GOAT结果。 在更具挑战性的导航任务GOAT Bench上比较提示策略。在所有三种目标模态中,我们的方法都显著优于基线方法。
在所有目标模态中,我们的模型都比基线取得了显著的改进。这些改进在图像目标中尤其明显,我们的模型实现了几乎是所有基线方法两倍的成功率。这突显了我们系统的鲁棒性和通用性。与ObjectNav结果一样,Ours w/o nav 和 Prompt only 的表现相当,并且都优于PIVOT。对于所有提示方法,图像和描述模态都比对象模态更具挑战性,这与[17]中的发现类似。
与SOTA方法的比较: 我们关闭 allow_slide 参数,并与两种最先进的专门方法进行比较:(i)SenseAct-NN [17] 是一种通过强化学习训练的策略,使用学习到的子模块处理不同技能;(ii)Modular GOAT [20] 是一个复合系统,它构建环境的语义记忆地图,并使用低级策略导航到地图中的对象。与SenseAct-NN不同,我们的工作是零样本的,并且与Modular GOAT不同,我们不依赖于低级策略或单独的对象检测模块。
| 运行 | SR | SPL |
|---|---|---|
| SenseAct-NN Skill Chain | 29.5% | 0.113 |
| Modular GOAT | 24.9% | 0.172 |
| Ours w/ sliding | 16.3% | 0.066 |
| Ours | 6.9% | 0.049 |
表3:直接与其他工作比较, 我们看到专门的系统仍然产生更优的性能。我们还注意到这些其他工作使用了更窄的FOV、更低的图像分辨率和不同的动作空间,这可能解释了一些差异。
我们将我们的方法的结果与表3中的这些基线进行比较。有趣的是,这些方法各有优势:强化学习方法可获得最高的成功率。相反,模块化导航系统可实现最高的导航效率。
与这些专门的基线相比,我们的方法在两个指标上都表现出较低的性能,即使在允许滑过障碍物的情况下也是如此。值得注意的是,我们观察到在13.9%的运行中,VLM在距离目标对象1到1.5米时过早地调用了停止。这些实例被归类为失败,因为基准测试仅在智能体距离目标1米以内时才将运行定义为成功。这一发现表明我们的VLM缺乏准确评估到对象距离所需的精细空间感知能力。然而,这也表明在超过30%的运行中,我们的VLM智能体能够接近目标对象,突显了其到达近目标位置的能力。
如先前的实验所示,当不允许滑过物体时,我们方法的性能会急剧下降,因为它经常在障碍物之间受阻,并且没有办法回溯其动作。
4.3 探索VLM智能体导航的设计空间
在本节中,我们研究了在我们的设置中影响基于VLM的智能体导航能力的主要设计选择,所有评估均在ObjectNav数据集上进行。
4.3.1 相机视场角(FOV)对导航有多重要?
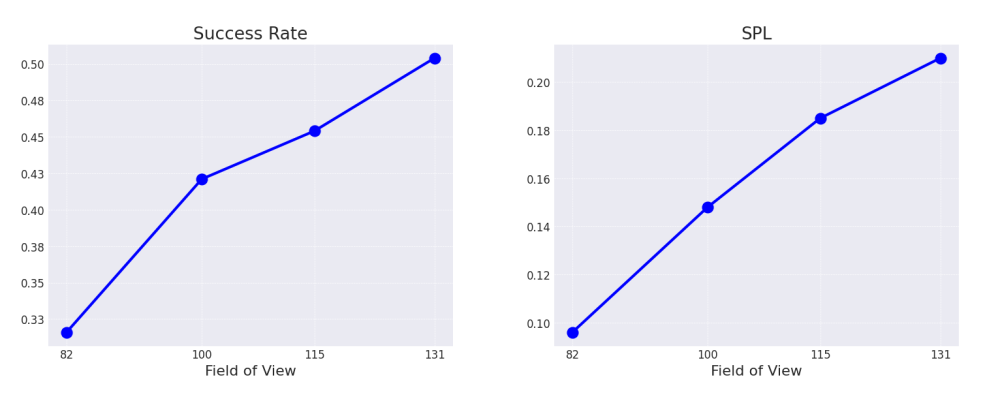
**图6:传感器FOV的影响。**我们评估了四种不同传感器FOV的性能,发现更宽的FOV总是能带来更高的性能。
智能体的导航能力很大程度上取决于其视觉的精细程度。在本节中,我们研究我们的VLM智能体是否能从高分辨率图像中受益。具体来说,我们使用四种不同的FOV运行我们的方法:82° [16]、100°、115°和131°(iPhone 0.5倍摄像头)。如图6所示的实验结果表明,在导航准确性和效率方面都存在积极的扩展行为。
4.3.2 更长的观察-动作历史有帮助吗?
在本节中,我们研究VLM导航智能体是否能有效地使用观察历史。我们以一种简单的方式创建包含观察历史的提示,即,我们连接来自 K 个最近环境步骤的观察和动作,并将此作为上下文输入到VLM中。对于所有这些实验,我们移除了我们的探索偏差(参见第3.2节),以专门隔离更长历史的贡献。
| 历史长度 | SR | SPL |
|---|---|---|
| 无历史 | 46.8% | 0.193 |
| 5 | 42.7% | 0.180 |
| 10 | 45.4% | 0.196 |
| 15 | 40.4% | 0.170 |
表4:添加上下文历史的影响。 我们将我们的方法与保留过去0、5、10和15个观察和动作的替代方案进行比较。我们发现添加上下文历史并不能提高我们方法的性能。
这些实验的结果如表4所示。我们发现,当简单地连接过去的观察和动作时,我们的提示策略无法利用更长的上下文。实际上,当增加历史长度时,性能保持不变或下降。
4.3.3 完美的深度感知有多重要?
在模拟器中,深度传感器提供准确的像素级深度信息,这对于确定可导航性掩码非常重要。为了研究准完美深度感知的重要性,我们评估了两种仅使用RGB的替代方法:(i)Segformer,它使用[38]将属于地面区域的像素进行语义分割。我们将此区域用作可导航性掩码,并绕过对任何深度信息的需求。我们通过将像素数量乘以一个常数因子来估计到障碍物的距离。(ii)ZoeDepth,它使用[39]来估计度量深度值。我们使用这样的预测值而不是来自模拟器的真实距离,并以原始方式计算可导航性。
| 运行 | SR | SPL |
|---|---|---|
| 深度传感器 | 50.4% | 0.210 |
| Segformer [38] | 47.2% | 0.183 |
| ZoeDepth [39] | 39.1% | 0.161 |
表5:深度消融。 我们评估了两种仅需要RGB的替代方法。我们发现语义分割的性能接近于使用真实深度,而估计深度值会导致显著的性能下降。
本研究的结果如表5所示。我们发现来自[39]的深度估计不足以准确识别可导航区域。实际上,深度噪声导致SR下降10%。然而,令人惊讶的是,使用分割掩码代替依赖深度信息被证明是相当有效的,相对于使用完美深度感知,SR仅下降了3%。总的来说,我们的实验表明,基于VLM的导航智能体仅使用RGB信息也能表现良好。
5 结论
在这项工作中,我们提出了VLMnav,一种新颖的视觉提示工程方法,它使现成的VLM能够充当端到端的导航策略。这种方法背后的主要思想是仔细选择动作提议并将它们投影到图像上,从而有效地将导航问题转化为问答问题。通过在ObjectNav和GOAT基准上的评估,我们看到与先前的迭代基线PIVOT(这是视觉导航提示工程的最新技术)相比,性能有了显著提升。我们的设计研究进一步强调了宽视场角的重要性以及仅使用最少传感(即仅RGB图像)部署我们方法的可能性。
我们的方法有一些局限性。禁用 allow_slide 参数后性能急剧下降,表明存在多次与障碍物的碰撞,这在实际部署中可能会产生问题。此外,我们发现像[17]这样的专门系统优于我们的工作。然而,随着VLM能力的不断提高,我们假设我们的方法可以帮助未来的VLM达到或超过专门系统在具身任务中的性能。
相关文章:

【VLNs篇】03:VLMnav-端到端导航与视觉语言模型:将空间推理转化为问答
栏目内容论文标题End-to-End Navigation with Vision-Language Models: Transforming Spatial Reasoning into Question-Answering (端到端导航与视觉语言模型:将空间推理转化为问答)核心问题如何利用大型视觉语言模型(VLM)实现端到端的机器人…...
)
云原生攻防4(Kubernetes基础补充)
什么是K8S? Kubernetes 是做什么的? 什么是 Docker? 什么是容器编排? Kubernetes 一词来自希腊语,意思是“飞行员”或“舵手”。这个名字很贴切,Kubernetes 可以帮助你在波涛汹涌的容器海洋中航行。 Kubernetes 是 Google 基于 Borg 开源的容器编排调度引擎,作为 CNCF最…...

redis--redisJava客户端:Jedis详解
在Redis官网中提供了各种语言的客户端,地址: https://redis.io/docs/latest/develop/clients/ Jedis 以Redis命令做方法名称,学习成本低,简单实用,但是对于Jedis实例是线程不安全的(即创建一个Jedis实例&a…...

SpringBoot-SpringBoot源码解读
SpringBoot-SpringBoot源码解读 一、Spring Boot启动过程概述 Spring Boot通过一系列的类和机制,简化了Spring应用的启动流程。当你执行SpringApplication.run()时,Spring Boot会自动完成应用的初始化、环境配置、组件加载、自动配置等任务,…...

黑马程序员C++2024新版笔记 第4章 函数和结构体
1.结构体的基本应用 结构体struct是一种用户自定义的复合数据类型,可以包含不同类型的成员。例如: struct Studet {string name;int age;string gender; } 结构体的声明定义和使用的基本语法: struct 结构体类型 {成员1类型 成员1名称;成…...

【沉浸式求职学习day46】【华为5.7暑期机试题目讲解】
沉浸式求职学习 题目1题目2 题目1 一个超大智能汽车测试场有多个充电桩,每个充电桩的位置由其在二维平面上的坐标(x,y)表示。给定一辆智能汽车的当前位置(car_x,car_y),请设计一个高效的算法,找出给定智能汽车行驶到充电桩行驶距离最近的k个…...

PDF处理控件Aspose.PDF教程:以编程方式将PDF转换为Word
您是否正在寻找在线将 PDF 转换为 Word 的方法?在本指南中,我们将探索如何使用 C#、Java 和 Python 编码解决方案将 PDF 文档转换为可编辑的 Word 文件。开发人员通过代码将 PDF 文件转换为 Word 格式,从而获得显著优势。这种方法可以轻松实现…...

旋转位置RoPE编码详解
一. 旋转位置编码和正余弦位置编码比对 旋转位置编码(RoPE)和正余弦位置编码(Sinusoidal Position Encoding)是两种常用的位置编码方法,它们在处理序列数据时具有不同的数学形式和特性。以下是对两者优劣的详细说明及…...
-动画(2d))
canvas(二)-动画(2d)
<canvas> 动画是通过 JavaScript 动态更新画布内容来实现的。它利用 requestAnimationFrame 方法实现平滑的动画效果,适用于游戏、数据可视化、交互式图形等场景。真的需要数据可视化等场景使用,还是直接引入外部模型还原度比较高,但同…...

Dynamics 365 Business Central Azure application registration
本方法适用于 单租户服务器身份验证。 实现方法 在大多数组织里ERP Admin 不一定有权限 Azure Admin权限,在实施过程中你只需要把以下指引发给你的系统管理员。 请注意后面有系统管理员设置好后,你如何检查。 导航到 https://admin.microsoft.com 并登…...

选择合适的Azure数据库监控工具
Azure云为组织提供了众多服务,使其能够无缝运行应用程序、Web服务和服务器部署,其中包括云端数据库部署。Azure数据库能够与云应用程序实现无缝集成,具备可靠、易扩展和易管理的特性,不仅能提升数据库可用性与性能,同时…...

Access链接Azure SQL
Hi,大家好呀! 最近在给大家分享了SQL Server方面的一些视频,那今天我们也来讲讲Azure SQL。 什么是Azure SQL,这里我们就不介绍了,如果你没有用这个数据库,那你可以简单的把它理解成,就是SQL …...

34、React Server Actions深度解析
一、灵魂契约协议(核心机制) 1. 次元融合架构 "use server";async function borrowBook(bookId: number, readerName: string) {// 模拟数据库操作const result await db.execute(UPDATE books SET available false WHERE id ?,[bookId]…...

Azure 应用服务中的异常处理、日志记录和通知:综合指南
简介 Azure 应用服务是基于云的应用程序,使开发人员能够在云上构建、部署和管理应用程序。与任何应用程序一样,制定适当的异常处理、日志记录和通知实践至关重要,以确保应用程序平稳运行,并快速识别和解决任何问题。在本篇博文中&…...

第16天-使用Python Pillow库常见图像处理场景
1. 打开与显示图像 from PIL import Image# 打开图像文件 img = Image.open("input.jpg")# 显示图像基本信息 print(f"格式: {img.format}") # JPEG print(f"尺寸: {img.size}") # (宽度, 高度) print(f"模式: {img.mode}") …...

VUE3+TS实现图片缩放移动弹窗
完整代码 使用VUE3、TS,实现将图片通过鼠标拖拽缩放以及选择缩放比例。 <template><div><el-dialogv-model"dialogVisible"title"查看图片":close-on-click-modal"false":close-on-press-escape"false"fu…...

关于Vue自定义组件封装的属性/事件/插槽的透传问题
// parent.vue <Myinputv-model"keyWords"placeholder"请输入内容"size"small"input"input"change"change"width"320" ><template #prepend><el-select v-model"select" placeholder&qu…...

智能驾驶中的深度学习:基于卷积神经网络的车道线检测
摘要 智能驾驶是人工智能技术的重要应用领域之一,而车道线检测是实现自动驾驶的基础功能。本文介绍了一种基于深度学习的车道线检测方法,使用卷积神经网络(CNN)对道路图像进行实时分析。文章详细阐述了数据预处理、模型构建、训练优化及实际部署的完整流程,并提供了Pytho…...

在 Excel xll 自动注册操作 中使用东方仙盟软件2————仙盟创梦IDE
// 获取当前工作表名称string sheetName (string)XlCall.Excel(XlCall.xlfGetDocument, 7);// 构造动态名称(例如:Sheet1!MyNamedCell)string fullName $"{sheetName}!MyNamedCell";// 获取引用并设置值var namedRange (ExcelRe…...

【每周一个MCP】:将pytdx封装成MCP
文章目录 配置文件MCP代码(其实github上都有)不错不错,星星之火可以燎原。 https://github.com/ddholiday/onedayoneMCP/tree/main/MCPs/tdx-mcp 配置文件 pytdx有两种读取数据的方式,分别是,从API读取,和从本地读取。 其中,从API读取,需要IP和端口。 这个官方文档…...
)
Vue3中插槽, pinia的安装和使用(超详细教程)
1. 插槽 插槽是指, 将一个组件的代码片段, 引入到另一个组件。 1.1 匿名插槽 通过简单的案例来学习匿名插槽,案例说明,在父组件App.vue中导入了子组件Son1.vue,父组件引用子组件的位置添加了一个片段,比如h2标签,然…...

【Java高阶面经:微服务篇】5.限流实战:高并发系统流量治理全攻略
一、限流阈值的三维度计算模型 1.1 系统容量基准线:压测驱动的安全水位 1.1.1 压力测试方法论 测试目标:确定系统在资源安全水位(CPU≤80%,内存≤70%,RT≤500ms)下的最大处理能力测试工具: 单机压测:JMeter(模拟10万并发)、wrk(低资源消耗)集群压测:LoadRunner …...

学习黑客了解密码学
5分钟了解密码学:从古老艺术到现代科学 🔐 作者: 海尔辛 | 发布时间: 2025-05-21 08:36:35 UTC 密码学简介:保护信息的艺术与科学 📜 密码学是研究如何安全传递和存储信息的学科。它不仅仅是加密和解密,更包含了身份…...

【UE5】环形菜单教程
效果 步骤 1. 下载图片资源:百度网盘 请输入提取码 提取码:fjjx 2. 将图片资源导入工程,如下 3. 新建3个控件蓝图,这里分别命名为“WBP_CircularMenu”、“WBP_Highlight”、“WBP_Icon” 4. 打开“WBP_Icon”,设置“所需” 添加…...

【JVM】学习笔记
1. JVM概述 JVM是一个抽象的计算机,用于运行Java程序。它将Java字节码转化为特定平台的机器代码,确保Java程序具有跨平台性。 2. JVM架构 JVM的架构通常包括以下几个主要部分: 类加载子系统(ClassLoader)ÿ…...
)
物流项目第五期(运费计算实现、责任链设计模式运用)
前四期: 物流项目第一期(登录业务)-CSDN博客 物流项目第二期(用户端登录与双token三验证)-CSDN博客 物流项目第三期(统一网关、工厂模式运用)-CSDN博客 物流项目第四期(运费模板列…...

PrintStream PrintWriter Java 打印流
使用场景: 代替 System.out 输出日志(比如 System.setOut(printStream))需要输出各种类型(如 println(123)、println("hello")) 常用方法: print(), println() → 支持所有基本类型和对象pr…...

前端excel表格解析为json,并模仿excel显示
前端环境:elementUI vue2 <style lang"scss" scoped> 页面效果 jsondata为mock数据,为方便调试其内容可清空,首行(字母坐标)随数据内容自动变化,首列也是一样,模拟excel …...

NumPy 2.x 完全指南【十六】分割数组
文章目录 1. 数组分割1.1 split1.2 array_split1.3 vsplit1.4 hsplit1.5 dsplit1.6 unstack 1. 数组分割 数组分割是指将一个数组拆分为多个子数组的操作,常用于数据处理、并行计算、分块处理等场景。NumPy 提供了多种分割函数,允许用户沿不同方向&…...

vue3 + vite 使用tailwindcss
第一步:安装依赖 vite版本较低(“vite”: “^4.0.0”)所以就使用低版本的tailwindcss npm install -D tailwindcss3.4.1 postcss autoprefixer第二步:配置文件生成 npx tailwindcss init -p会自动生成两个文件postcss.config.js和…...

K个一组链表翻转
目录 1. 题意 2. 解题思路 3. 代码 1. 题意 给一个链表,按 k 进行翻转,也就是 k 2 ,两两进行翻转,如果不够2则不动。 2. 解题思路 首先思考怎么翻转一个链表,反转链表:https://leetcode.cn/problems…...
)
逆向音乐APP:Python爬虫获取音乐榜单 (1)
1. 引言 在数字音乐时代,许多平台如音乐有榜单,限制非付费用户访问高音质或独家内容。然而,从技术研究的角度来看,我们可以通过逆向工程和Python爬虫技术解音乐的API接口,获取付费音乐的播放链接。 2. 技术准备 在当…...

STM32之串口通信WIFI上云
一、W模块的原理与应用 基本概念 如果打算让硬件设备可以通过云服务器进行通信(数据上报/指令下发),像主流的云服务器有阿里云、腾讯云、华为云,以及其他物联网云平台:巴法云.......,硬件设备需要通过TCP…...

Python爬虫实战:获取天气网最近一周北京的天气数据,为日常出行做参考
1. 引言 随着互联网技术的发展,气象数据的获取与分析已成为智慧城市建设的重要组成部分。天气网作为权威的气象信息发布平台,其数据具有较高的准确性和实时性。然而,人工获取和分析天气数据效率低下,无法满足用户对精细化、个性化气象服务的需求。本文设计并实现了一套完整…...

【Java学习笔记】main方法
main 方法 一、深入理解 main 方法 特变注意!! 1. 在main()方法中,我们可以直接调用 mian 方法所在类的静态方法或静态属性 2. 不能访问该类中的非静态成员,必须创建该类的一个实例对象后,才能通过这个对象去访问类中…...

振动分析 - 献个宝
1.一个自制的振动能量分析工具 这个分析工具似乎真的定位到了故障的具体位置。 1.1对一组实验室虚拟信号的分析结果: 1.2 对现场真实数据的分析结果 依照边频带的调制,和边频的缝隙宽度,基本定位到问题。 追加几份待看的文档: 齿轮结构的频谱特征 - 知乎使用 FFT 获得…...
)
数学实验(Matlab绘图基础)
一、二维曲线的绘制 Matlab绘图原理 MATLAB绘图的核心原理基于数据点或函数离散化,通过描点连线生成图形。以下是具体解析: 1.数据离散化 二维数据通过(x, y)坐标点表示,连续函数需离散化处理(如t0:0.01…...

【android bluetooth 协议分析 02】【bluetooth hal 层详解 3】【高通蓝牙hal主要流程介绍-上】
1. 背景 本节主要讨论 高通 蓝牙 hal 中,的一些流程。 看看你是否都清楚如下问题: 高通芯片电如何控制?串口是在哪里控制的?固件如何下载?初始化流程是怎么样的? 如果你已经对上述讨论的问题,…...

Linux | tmux | 无法复制粘贴
问题:在Linux中使用tmux时,总是没法使用复制粘贴功能; 解决: 如果希望直接用鼠标选择并复制(类似普通终端),可以: 在 ~/.tmux.conf 中添加:sh set -g mouse on;重新加载 tmux 配置…...

如何通过小贝加速实现精准网络故障排查
在日常使用电脑的过程中,我们常常需要监控系统运行状态、优化性能或排查网络问题。最近发现一款名为小贝加速的桌面工具,在此分享关于小贝加速如何实现网络监控。 系统优化 该工具提供了简洁明了的系统优化功能。通过扫描可以清理系统冗余文件、释放内存…...

Nginx 网站服务
目录 一:基于授权的访问控制 1:基于授权的访问控制简介 2:基于授权的访问控制步骤 二:基于客户端的访问控制 1:基于客户端的访问控制简介 2:基于客户端的访问控制步骤 三:Nginx 虚拟主机…...

Python 字典的用法和技巧
字典的创建与初始化 Python 字典是一种可变容器模型,可存储任意类型对象。字典的每个键值对用冒号分隔,键值对之间用逗号分隔,整个字典包括在花括号中。 # 创建一个空字典 empty_dict {}# 创建一个包含键值对的字典 my_dict {name: Alice…...

电力设备制造企业数字化转型路径研究:从生产优化到生态重构
电力设备制造业作为支撑能源革命的核心领域,其数字化转型不仅关乎企业降本增效,更是实现“双碳”目标与新型电力系统建设的关键抓手。本文基于行业标杆案例与实践经验,系统梳理电力设备企业数字化转型的五大核心路径。 一、生产流程智能化&a…...

初识GPU加速:如何利用GPU提升AI训练效率
随着人工智能(AI)和深度学习技术的快速发展,训练深度神经网络(DNN)已经变得越来越复杂和计算密集。传统的CPU已经无法满足大量计算任务的需求,因此,GPU(图形处理单元)成为了训练深度学习模型时的必备工具。本篇文章将介绍如何利用GPU加速AI训练效率,以及在使用GPU时应…...

深入解析异步编程:Java NIO、Python `async/await` 与 C# `async/await` 的对比
在现代编程中,异步编程已成为处理 I/O 密集型任务(如网络请求、文件操作等)的高效方式。不同的编程语言提供了各自的异步编程模型,以提高程序的性能和资源利用率。本文将深入解析 Java 的 NIO、Python 的 async/await 和 C# 的 as…...

阿里云数据盘级别
数据盘PL0、PL1、PL2和PL3的区别体现在性能、容量范围以及应用场景等方面。具体分析如下: 性能 PL0:单盘最大IOPS为10,000,最大吞吐量为180MB/s。适用于中小型MySQL和SQLServer等数据库场景,中小规模ELK日志集群,SAP和…...

使用 Spring AI Alibaba 集成阿里云百炼大模型应用
随着人工智能技术的飞速发展,大模型在各个领域的应用越来越广泛。阿里云百炼大模型提供了强大的语言理解和生成能力,但如何将其高效地集成到实际应用中,一直是开发者关注的焦点。本文将详细介绍如何使用 Spring AI Alibaba 集成阿里云百炼大模…...
)
阿里云合集(不定期更新)
一、阿里云申请免费域名证书流程:https://blog.csdn.net/humors221/article/details/143266059 二、阿里云发送国内短信怎样编程:https://blog.csdn.net/humors221/article/details/139544193 三、阿里云ECS服务器磁盘空间不足的几个文件:h…...

零基础设计模式——创建型模式 - 抽象工厂模式
第二部分:创建型模式 - 抽象工厂模式 (Abstract Factory Pattern) 我们已经学习了单例模式(保证唯一实例)和工厂方法模式(延迟创建到子类)。现在,我们来探讨创建型模式中更为复杂和强大的一个——抽象工厂…...

ConcurrentHashMap导致的死锁事故
事故现象 某线上服务共100台容器,第二天上午流量高峰期部分容器(约10%)cpu飙升,升至100%。 部分堆栈信息 堆栈信息如下如所示: 当前线程堆栈显示在JsonContext.get方法中调用computeIfAbsent,其Lambda表…...