第9.1讲、Tiny Encoder Transformer:极简文本分类与注意力可视化实战
项目简介
本项目实现了一个极简版的 Transformer Encoder 文本分类器,并通过 Streamlit 提供了交互式可视化界面。用户可以输入任意文本,实时查看模型的分类结果及注意力权重热力图,直观理解 Transformer 的内部机制。项目采用 HuggingFace 的多语言 BERT 分词器,支持中英文等多种语言输入,适合教学、演示和轻量级 NLP 应用开发。
主要功能
- 多语言支持:集成 HuggingFace
bert-base-multilingual-cased分词器,支持 100+ 语言。 - 极简 Transformer 结构:自定义实现位置编码、单层/多层 Transformer Encoder、分类头,结构清晰,便于学习和扩展。
- 注意力可视化:可实时展示输入文本的注意力热力图和每个 token 被关注的占比,帮助理解模型关注机制。
- 高效演示:训练时仅用 AG News 数据集的前 200 条数据,并只训练 10 个 batch,保证页面加载和交互速度。
代码结构与核心实现
1. 数据加载与预处理
使用 HuggingFace datasets 库加载 AG News 数据集,并用 BERT 分词器对文本进行编码:
from datasets import load_dataset
from transformers import AutoTokenizertokenizer = AutoTokenizer.from_pretrained("bert-base-multilingual-cased")
dataset = load_dataset("ag_news")
dataset["train"] = dataset["train"].select(range(200)) # 只用前200条数据def encode(example):tokens = tokenizer(example["text"],padding="max_length",truncation=True,max_length=64,return_tensors="pt")return {"input_ids": tokens["input_ids"].squeeze(0),"label": example["label"]}encoded_train = dataset["train"].map(encode)
2. Tiny Encoder 模型结构
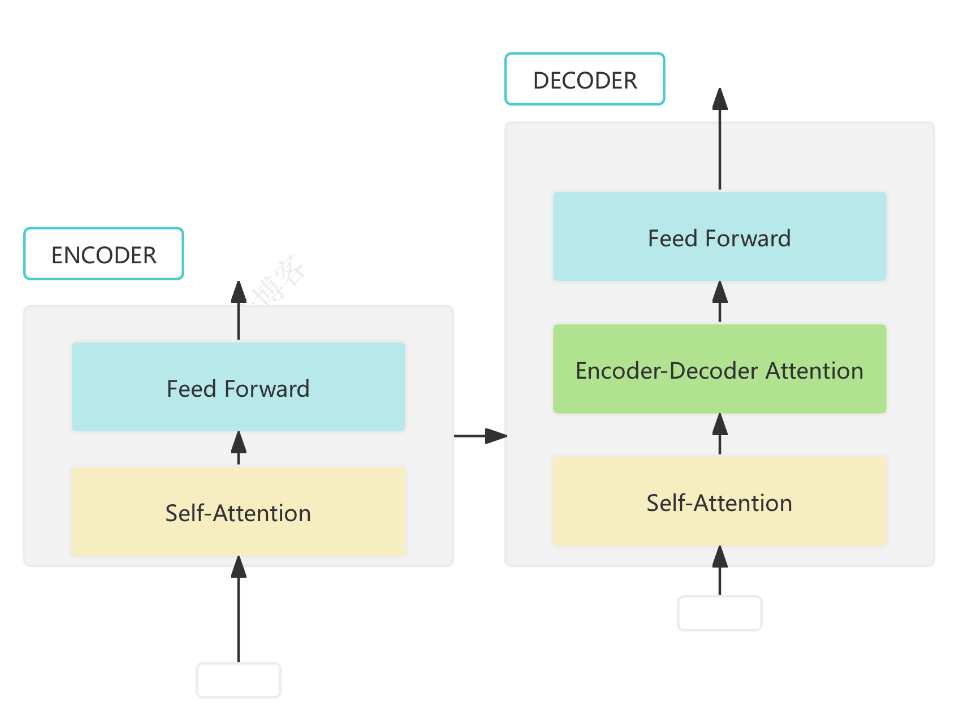
模型包含词嵌入层、位置编码、若干 Transformer Encoder 层和分类头,支持输出每层的注意力权重:
import torch.nn as nnclass PositionalEncoding(nn.Module):# ... 位置编码实现,见下文详细代码 ...class TransformerEncoderLayerWithTrace(nn.Module):# ... 支持 trace 的单层 Transformer Encoder,见下文详细代码 ...class TinyEncoderClassifier(nn.Module):# ... 嵌入、位置编码、编码器堆叠、分类头,见下文详细代码 ...
3. 训练流程
采用交叉熵损失和 Adam 优化器,仅训练 10 个 batch,极大提升演示速度:
import torch.optim as optim
from torch.utils.data import DataLoadertrain_loader = DataLoader(encoded_train, batch_size=16, shuffle=True)
model = TinyEncoderClassifier(...)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)model.train()
for i, batch in enumerate(train_loader):if i >= 10: # 只训练10个batchbreakinput_ids = batch["input_ids"]labels = batch["label"]logits, _ = model(input_ids)loss = criterion(logits, labels)optimizer.zero_grad()loss.backward()optimizer.step()
4. Streamlit 可视化界面
- 提供文本输入框,用户可输入任意文本。
- 实时推理并展示分类结果。
- 可视化 Transformer 第一层各个注意力头的权重热力图和每个 token 被关注的占比(条形图)。
import streamlit as st
import seaborn as sns
import matplotlib.pyplot as pltuser_input = st.text_input("请输入文本:", "We all have a home called China.")
if user_input:# ... 推理与注意力可视化代码,见下文详细代码 ...
训练与推理流程详解
-
数据加载与预处理
- 加载 AG News 数据集,仅取前 200 条样本。
- 用多语言 BERT 分词器编码文本,填充/截断到 64 长度。
-
模型结构
- 词嵌入层将 token id 映射为向量。
- 位置编码为每个 token 添加可区分的位置信息。
- 堆叠若干 Transformer Encoder 层,支持输出注意力权重。
- 分类头对第一个 token 的输出做分类(类似 BERT 的 [CLS])。
-
训练流程
- 损失函数为交叉熵,优化器为 Adam。
- 只训练 1 个 epoch,且只训练 10 个 batch,保证演示速度。
-
推理与可视化
- 用户输入文本,模型输出预测类别编号。
- 可视化注意力热力图和每个 token 被关注的占比,直观展示模型关注点。
适用场景
- Transformer 原理教学与可视化演示
- 注意力机制理解与分析
- 多语言文本分类任务的快速原型开发
- NLP 课程、讲座、实验室演示
完整案例说明:
Tiny Encoder
1. 代码主要功能
该脚本实现了一个基于 Transformer Encoder 的文本分类模型,并通过 Streamlit 提供了可视化界面,
支持输入一句话并展示模型的分类结果及注意力权重热力图。
2. 主要模块说明
- Tokenizer 初始化:
- 使用 HuggingFace 的多语言 BERT Tokenizer 对输入文本进行分词和编码。
- 模型结构:
- 包含词嵌入层、位置编码、若干 Transformer Encoder 层(带注意力权重 trace)、分类器。
- 数据处理与训练:
- 加载 AG News 数据集,编码文本,训练模型并保存。
- 若已存在训练好的模型则直接加载。
- Streamlit 可视化:
- 提供文本输入框,实时推理并展示分类结果。
- 可视化 Transformer 第一层各个注意力头的权重热力图。
3. 数据流向说明
- 输入:
- 用户在 Streamlit 网页输入一句英文(或多语言)文本。
- 分词与编码:
- Tokenizer 将文本转为固定长度的 token id 序列(input_ids)。
- 模型推理:
- input_ids 输入 TinyEncoderClassifier,经过嵌入、位置编码、若干 Transformer 层,输出 logits(分类结果)和注意力权重(trace)。
- 分类输出:
- 取 logits 最大值作为类别预测,显示在网页上。
- 注意力可视化:
- 取第一层注意力权重,分别绘制每个 head 的热力图,帮助理解模型关注的 token 关系。
4. 适用场景
- 适合教学、演示 Transformer 注意力机制和文本分类原理。
- 可扩展用于多语言文本分类任务。
import math
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from transformers import AutoTokenizer
from datasets import load_dataset
import streamlit as st
import seaborn as sns
import matplotlib.pyplot as plt# ============================
# 位置编码模块
# ============================
class PositionalEncoding(nn.Module):"""位置编码模块:为输入的 token 序列添加可区分位置信息。使用正弦和余弦函数生成不同频率的编码。"""def __init__(self, d_model, max_len=512):super().__init__()# 创建一个 (max_len, d_model) 的全零张量,用于存储位置编码pe = torch.zeros(max_len, d_model)# 生成位置索引 (max_len, 1)position = torch.arange(0, max_len).unsqueeze(1)# 计算每个维度对应的分母项(不同频率)div_term = torch.exp(torch.arange(0, d_model, 2) * (-math.log(10000.0) / d_model))# 偶数位置用 sin,奇数位置用 cospe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)# 增加 batch 维度,形状变为 (1, max_len, d_model)pe = pe.unsqueeze(0)# 注册为 buffer,模型保存时一同保存,但不是参数self.register_buffer('pe', pe)def forward(self, x):"""输入:x,形状为 (batch, seq_len, d_model)输出:加上位置编码后的张量,形状同输入"""return x + self.pe[:, :x.size(1)]# ============================
# 单层 Transformer Encoder,支持输出注意力权重
# ============================
class TransformerEncoderLayerWithTrace(nn.Module):"""单层 Transformer Encoder,支持输出注意力权重。包含多头自注意力、前馈网络、残差连接和层归一化。"""def __init__(self, d_model, nhead, dim_feedforward):super().__init__()# 多头自注意力层self.self_attn = nn.MultiheadAttention(d_model, nhead, batch_first=True)# 前馈网络第一层self.linear1 = nn.Linear(d_model, dim_feedforward)self.dropout = nn.Dropout(0.1)# 前馈网络第二层self.linear2 = nn.Linear(dim_feedforward, d_model)# 层归一化self.norm1 = nn.LayerNorm(d_model)self.norm2 = nn.LayerNorm(d_model)# Dropout 层self.dropout1 = nn.Dropout(0.1)self.dropout2 = nn.Dropout(0.1)def forward(self, src, trace=False):"""前向传播。参数:src: 输入序列,形状为 (batch, seq_len, d_model)trace: 是否返回注意力权重返回:src: 输出序列attn_weights: 注意力权重(如果 trace=True)"""# 多头自注意力,attn_weights 形状为 (batch, nhead, seq_len, seq_len)attn_output, attn_weights = self.self_attn(src, src, src, need_weights=trace)# 残差连接 + 层归一化src2 = self.dropout1(attn_output)src = self.norm1(src + src2)# 前馈网络src2 = self.linear2(self.dropout(torch.relu(self.linear1(src))))# 残差连接 + 层归一化src = self.norm2(src + self.dropout2(src2))# 返回输出和注意力权重(可选)return src, attn_weights if trace else None# ============================
# Tiny Transformer 分类模型
# ============================
class TinyEncoderClassifier(nn.Module):"""Tiny Transformer 分类模型:包含嵌入层、位置编码、若干 Transformer 编码器层和分类头。支持输出每层的注意力权重。"""def __init__(self, vocab_size, d_model, n_heads, d_ff, num_layers, max_len, num_classes):super().__init__()# 词嵌入层,将 token id 映射为向量self.embedding = nn.Embedding(vocab_size, d_model)# 位置编码模块self.pos_encoder = PositionalEncoding(d_model, max_len)# 堆叠多个 Transformer 编码器层self.layers = nn.ModuleList([TransformerEncoderLayerWithTrace(d_model, n_heads, d_ff) for _ in range(num_layers)])# 分类头,对第一个 token 的输出做分类self.classifier = nn.Linear(d_model, num_classes)def forward(self, input_ids, trace=False):"""前向传播。参数:input_ids: 输入 token id,形状为 (batch, seq_len)trace: 是否输出注意力权重返回:logits: 分类输出 (batch, num_classes)traces: 每层的注意力权重(可选)"""# 词嵌入x = self.embedding(input_ids)# 加位置编码x = self.pos_encoder(x)traces = []# 依次通过每一层 Transformer 编码器for layer in self.layers:x, attn = layer(x, trace=trace)if trace:traces.append({"attn_map": attn})# 只取第一个 token 的输出做分类(类似 BERT 的 [CLS])logits = self.classifier(x[:, 0])return logits, traces if trace else None# ============================
# 模型构建与训练函数,显式使用CPU
# ============================
@st.cache_resource(show_spinner=False)
def build_and_train_model(d_model, n_heads, d_ff, num_layers):device = torch.device('cpu') # 显式指定使用CPUtokenizer = AutoTokenizer.from_pretrained("bert-base-multilingual-cased")dataset = load_dataset("ag_news")dataset["train"] = dataset["train"].select(range(200)) # 只用前200条数据MAX_LEN = 64def encode(example):tokens = tokenizer(example["text"], padding="max_length", truncation=True, max_length=MAX_LEN, return_tensors="pt")return {"input_ids": tokens["input_ids"].squeeze(0), "label": example["label"]}encoded_train = dataset["train"].map(encode)encoded_train.set_format(type="torch")train_loader = DataLoader(encoded_train, batch_size=16, shuffle=True)model = TinyEncoderClassifier(vocab_size=tokenizer.vocab_size,d_model=d_model,n_heads=n_heads,d_ff=d_ff,num_layers=num_layers,max_len=MAX_LEN,num_classes=4).to(device) # 模型放到CPUcriterion = nn.CrossEntropyLoss()optimizer = optim.Adam(model.parameters(), lr=1e-3)model.train()for epoch in range(1): # 训练1个epochfor i, batch in enumerate(train_loader):if i >= 10: # 只训练10个batchbreakinput_ids = batch["input_ids"].to(device) # 输入转到CPUlabels = batch["label"].to(device)logits, _ = model(input_ids)loss = criterion(logits, labels)optimizer.zero_grad()loss.backward()optimizer.step()return model, tokenizer# ============================
# Streamlit 页面设置
# ============================
st.set_page_config(page_title="TinyEncoder")
st.title("🌍 Tiny Encoder Transformer")# 固定模型参数
# d_model: 隐藏层维度,
# n_heads: 注意力头数,
# d_ff: 前馈层维度,
# num_layers: Transformer 层数
d_model = 64
n_heads = 2
d_ff = 128
num_layers = 1# 构建并训练模型
with st.spinner("模型构建中..."):model, tokenizer = build_and_train_model(d_model, n_heads, d_ff, num_layers)# ============================
# 推理与注意力权重可视化
# ============================
model.eval()
device = torch.device('cpu')
model.to(device)user_input = st.text_input("请输入文本:", "We all have a home called China.")
if user_input:tokens = tokenizer(user_input, return_tensors="pt", max_length=64, padding="max_length", truncation=True)input_ids = tokens["input_ids"].to(device) # 放CPUwith torch.no_grad():logits, traces = model(input_ids, trace=True)pred_class = torch.argmax(logits, dim=-1).item()st.markdown(f"### 🔍 预测类别编号: `{pred_class}`")if traces:attn_map = traces[0]["attn_map"]if attn_map is not None:seq_len = input_ids.shape[1]token_list = tokenizer.convert_ids_to_tokens(input_ids[0])if '[PAD]' in token_list:valid_len = token_list.index('[PAD]')else:valid_len = seq_lentoken_list = token_list[:valid_len]if attn_map.dim() == 4:# [batch, heads, seq_len, seq_len]heads = attn_map.size(1)fig, axes = plt.subplots(1, heads, figsize=(5 * heads, 3))if heads == 1:axes = [axes]for i in range(heads):matrix = attn_map[0, i][:valid_len, :valid_len].cpu().detach().numpy()sns.heatmap(matrix, ax=axes[i], cbar=False, xticklabels=token_list, yticklabels=token_list)axes[i].set_title(f"Head {i}")axes[i].tick_params(labelsize=6)# 显示每个 token 被关注的占比attn_sum = matrix.sum(axis=0)attn_ratio = attn_sum / attn_sum.sum()fig2, ax2 = plt.subplots(figsize=(5, 2))ax2.bar(range(valid_len), attn_ratio)ax2.set_xticks(range(valid_len))ax2.set_xticklabels(token_list, rotation=90, fontsize=6)ax2.set_title(f"Head {i} Token Attention Ratio")st.pyplot(fig2)st.pyplot(fig)elif attn_map.dim() == 3:# [heads, seq_len, seq_len]heads = attn_map.size(0)fig, axes = plt.subplots(1, heads, figsize=(5 * heads, 3))if heads == 1:axes = [axes]for i in range(heads):matrix = attn_map[i][:valid_len, :valid_len].cpu().detach().numpy()sns.heatmap(matrix, ax=axes[i], cbar=False, xticklabels=token_list, yticklabels=token_list)axes[i].set_title(f"Head {i}")axes[i].tick_params(labelsize=6)# 显示每个 token 被关注的占比attn_sum = matrix.sum(axis=0)attn_ratio = attn_sum / attn_sum.sum()fig2, ax2 = plt.subplots(figsize=(5, 2))ax2.bar(range(valid_len), attn_ratio)ax2.set_xticks(range(valid_len))ax2.set_xticklabels(token_list, rotation=90, fontsize=6)ax2.set_title(f"Head {i} Token Attention Ratio")st.pyplot(fig2)st.pyplot(fig)elif attn_map.dim() == 2:# [seq_len, seq_len]fig, ax = plt.subplots(figsize=(5, 3))sns.heatmap(attn_map[:valid_len, :valid_len].cpu().detach().numpy(), ax=ax, cbar=False, xticklabels=token_list, yticklabels=token_list)ax.set_title("Attention Map")ax.tick_params(labelsize=6)st.pyplot(fig)# 显示每个 token 被关注的占比matrix = attn_map[:valid_len, :valid_len].cpu().detach().numpy()attn_sum = matrix.sum(axis=0)attn_ratio = attn_sum / attn_sum.sum()fig2, ax2 = plt.subplots(figsize=(5, 2))ax2.bar(range(valid_len), attn_ratio)ax2.set_xticks(range(valid_len))ax2.set_xticklabels(token_list, rotation=90, fontsize=6)ax2.set_title("Token Attention Ratio")st.pyplot(fig2)else:st.warning("注意力权重维度异常,无法可视化。")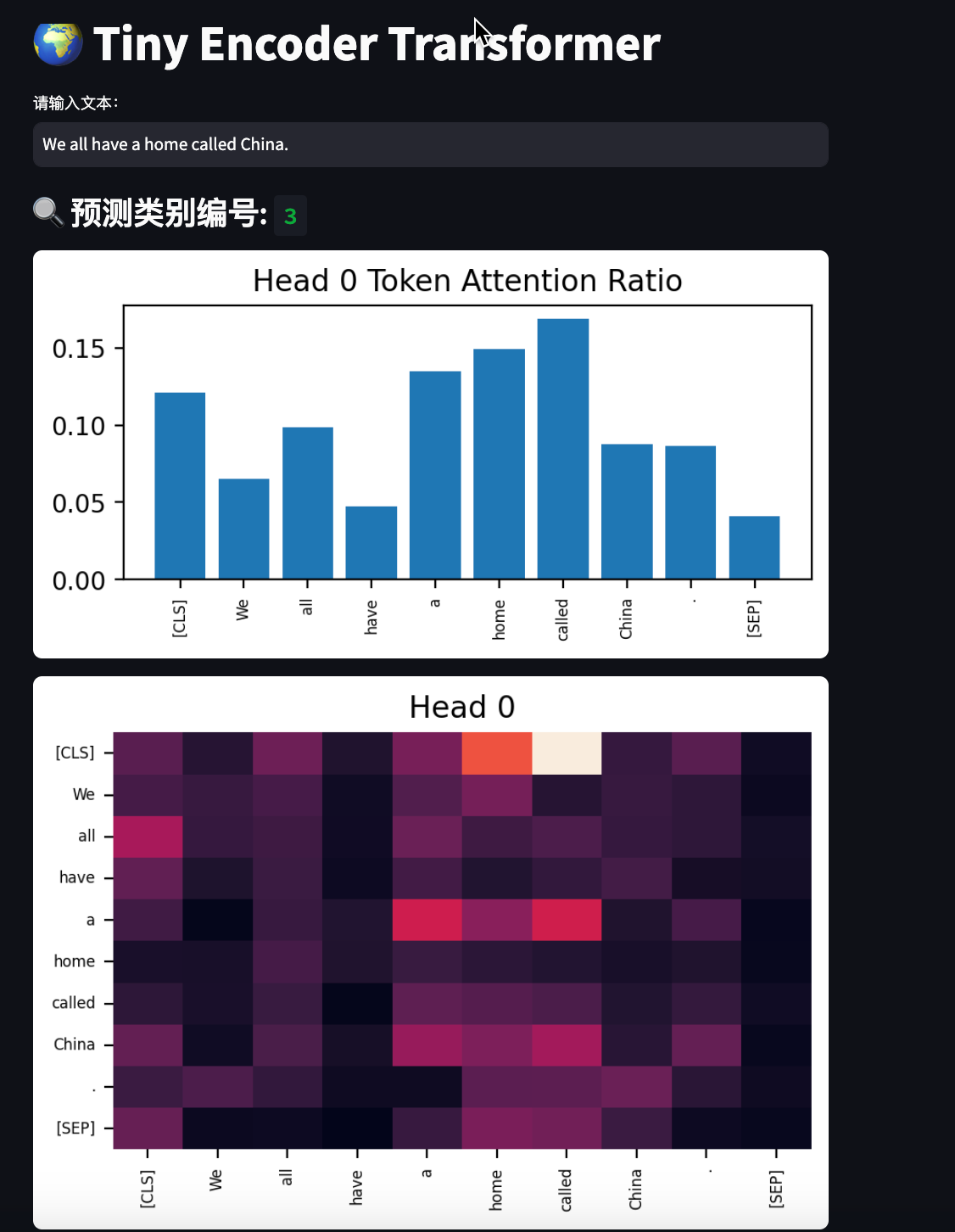
相关文章:

第9.1讲、Tiny Encoder Transformer:极简文本分类与注意力可视化实战
项目简介 本项目实现了一个极简版的 Transformer Encoder 文本分类器,并通过 Streamlit 提供了交互式可视化界面。用户可以输入任意文本,实时查看模型的分类结果及注意力权重热力图,直观理解 Transformer 的内部机制。项目采用 HuggingFace …...

asp.net web form nlog的安装
一、安装NuGet包 核心包安装 NLog提供日志记录核心功能 NLog.Config自动生成默认配置文件模板 配置NLog文件 配置文件创建 项目根目录自动生成NLog.config文件(通过NuGet安装NLog.Config时创建) <?xml version"1.0" encoding&…...

定时器的两种实现方式
1、基于优先级队列/堆 队列是先进先出,优先级队列是优先级越高就存放在队列之前,我们可以将过期时间越早设置为优先级越高,那么临近过期时间的任务就会在队列前面,距离过期时间越晚的任务就在队列后面。 可以分配一个线程&#…...

2025.05.21华为暑期实习机考真题解析第一题
📌 点击直达笔试专栏 👉《大厂笔试突围》 💻 春秋招笔试突围在线OJ 👉 笔试突围OJ 01. 智能云任务分发系统 问题描述 卢小姐负责一家云计算公司的任务分发系统开发。该系统需要根据任务优先级和到达顺序进行智能调度,支持以下两种操作: 添加任务 add task_id pri…...

计算机网络-MPLS VPN报文转发
上一章学习了MPSL VPN的路由交互过程,VPN间学习到路由之后可以进行报文的转发了。 一、MPLS VPN报文转发过程 以图中用户X的站点B访问站点A的192.168.1.0/24网段为例,报文转发过程如下: 1.CE3上存在到192.168.1.0/24网段路由,发…...

关于sql 查询性能优化的小经验
最近接到一些sql优化的任务。数据库类型:DB2 有一个长sql查询效率低,大概要几十秒,大概查询逻辑如下: select * from tableA a where exists (select 1 from tableB b where a.idb.id ) or exists (select 1 from tableC c whe…...

Pandas:数据分析步骤、分组函数groupby和基础画图
本文目录: 一、概念(一)数据分析的基本步骤(二)两个属性:loc[行标签,列标签 ] 和 iloc[行索引位置,列索引位置 ]1.基本规则2.两属性的相同和不同对比 二、加载数据(一)按列加载数据&…...

游戏引擎学习第302天:使用精灵边界进行排序
在 game_render_group.cpp 中:正确计算 GetBoundFor() 里的 SpriteBound 值 我们正在进行游戏的排序问题调试。虽然这是一个二维游戏,但包含一些三维元素,因此排序变得比较复杂和棘手。混合二维和三维元素时,需要依赖一些比较主观…...

【完整版】基于laravel开发的开源交易所源码|BTC交易所/ETH交易所/交易所/交易平台/撮合交易引擎
功能说明 源码简介与安装环境说明: 开源交易所,基于laravel开发的交易所 | BTC交易所 | ETH交易所 | 交易所 | 交易平台 | 撮合交易引擎。本项目有完整的撮合交易引擎源码、后台管理(后端前端)、前台(交易页面、活动页…...

DeepSeek赋能智能家居:构建高智能、低延迟的物联网生态
一、DeepSeek技术架构解析 DeepSeek采用分层架构设计,兼容边缘计算与云端协同,核心模块包括: 1. 设备接入层 多协议适配:支持MQTT、CoAP、Zigbee、WiFi等主流协议,内置设备描述语言(DDL)解析器,可自动发现并注册新设备。数据预处理:对传感器数据(如温度、光照、加速…...

鸿蒙开发:应用上架第二篇,申请发布证书
前言 本文基于Api13 通过第一篇文章,我们拿到了密钥库.p12文件和证书请求csr文件,这两个文件都是非常重要的,一定要保存好,我们也基本知道了应用的打包,签名信息文件是必须的,而对于签名信息,也…...

Android Framework开发环境搭建
本文分享下在Windows和ubuntu系统搭建framework 开发环境的过程。 Window系统版本win11 一.在windows搭建android framework开发环境。 到下面网站下载android studio 。 developer.android.google.cn/studio?hlzh-cn 在as 的sdk manager 中安装SDK Platform和SDK Tools。 2…...

关于收集 Android Telephony 网络信息的设计思考
需求 收集service state change、ims fail 等相关无线移动网络状态的信息,并保存,对外提供数据查询、删除、更新的功能。 架构设计与实现建议 1. 架构设计建议 针对在 Android Telephony 数据模块中实现网络状态信息收集并调用 Provider App 存储的需求,建议采用 分层的…...

弱网服务器群到底有什么用
在当今数字化的时代,大家都在追求高速、稳定的网络体验,但你是否想过,弱网服务器群其实也有着不可小觑的作用。让我们来聊聊什么是弱网服务器群。简单来说,它是一组在网络条件相对较差情况下运行的服务器集合。 弱网服务器群组是一…...

如何提高独立服务器的安全性?
独立服务器相对于其它服务器来说,整体的硬件设备都是独立的同时还有着强大的服务器性能,其中CPU设备能够决定着服务器的运算能力,所以独立服务器的安全性受到企业格外的重视,严重的话会给企业造成巨大的资金损失。 那么࿰…...

ubuntu 搭建FTP服务,接收部标机历史音视频上报服务器
1.安装vsftpd 1.1.安装命令 sudo apt update sudo apt install vsftpd 1.2.备份原始配置文件 sudo cp /etc/vsftpd.conf /etc/vsftpd.conf.bak 1.3.配置 vsftpd 编辑配置文件 /etc/vsftpd.conf: sudo vim /etc/vsftpd.conf 将以下参数修改为对应值ÿ…...

在离线 OpenEuler-22.03 服务器上升级 OpenSSH 的完整指南
当然可以!以下是一篇结构清晰、语言通俗易懂的技术博客草稿,供你参考和使用: 在离线 OpenEuler-22.03 服务器上升级 OpenSSH 的完整指南 背景介绍 最近在对一台内网的 OpenEuler-22.03 服务器进行安全扫描时,发现其 SSH 版本存在…...

用java实现内网通讯,可多开客户端链接同一个服务器
创建一个客户端:package Socket;import java.io.IOException; import java.io.OutputStream; import java.net.Socket; import java.nio.charset.StandardCharsets; import java.util.Scanner;/* 聊天案例客户端 */ public class Client {private Socket socket;/**…...

蓝耘服务器部署ppocr-gpu项目
一、存在的问题。 conda install 总是访问失败。 二、云服务器选择 三、安装Anaconda3 进入云服务器后删除minconda文件夹 官网: https://repo.anaconda.com/archive/ 在里面找到自己系统的安装包,然后右击复制链接安装。 一定要选择Anaconda,因为…...

离线服务器算法部署环境配置
本文将详细记录我如何为一台全新的离线服务器配置必要的运行环境,包括基础编译工具、NVIDIA显卡驱动以及NVIDIA-Docker,以便顺利部署深度学习算法。 前提条件: 目标离线服务器已安装操作系统(本文以Ubuntu 18.04为例)…...

现代人工智能系统的实用设计模式
关键要点 AI设计模式是为现代AI驱动的软件中常见问题提供的可复用解决方案,帮助团队避免重复造轮子。我们将其分为五类:提示与上下文(Prompting & Context)、负责任的AI(Responsible AI)、用户体验&…...

数据集下载并保存本地进行加载
一、huggingface 1、下载数据集 #数据集下载 from datasets import load_datasetds load_dataset("FreedomIntelligence/medical-o1-reasoning-SFT", "zh",cache_dir ./dir)输出测试 2、保存数据集 #数据保存 ds.save_to_disk("./local_datase…...
)
物流项目第六期(短信微服务——对接阿里云第三方短信服务JAVA代码实现、策略模式 + 工厂模式的应用)
前五期: 物流项目第一期(登录业务)-CSDN博客 物流项目第二期(用户端登录与双token三验证)-CSDN博客 物流项目第三期(统一网关、工厂模式运用)-CSDN博客 物流项目第四期(运费模板列…...

嵌入式学习的第二十五天-系统编程-文件相关函数-标准I0+文件IO
一、文件的读和写 1.fwrite(读) size_t fread(void *ptr, size_t size, size_t nmemb, FILE *stream); 功能:从指定的stream流对象中获取nmemeb个大小为size字节的数据块到ptr所在的本地内存中。 参数:ptr 要存储数据的本地…...

MySQL 8.0 OCP 1Z0-908 171-180题
Q171.Examine this MySQL client command to connect to a remote database: mysql-h remote-example.org-u root–protocolTCP–ssl-mode Which two–ss1-mode values will ensure that an X.509-compliant certificate will be used to establish the SSL/TLS connection to …...

实现动态增QuartzJob,通过自定义注解调用相应方法
:::tip 动态增加Quartz定时任务,通过自定义注解来实现具体的定时任务方法调用。 ::: 相关依赖如下 <!-- 用来动态创建 Quartz 定时任务 --> <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-start…...

Linux网络 网络基础一
1. 计算机网络背景 1.1 网络发展 独立模式:计算机之间相互独立。 网络互联:多台计算机连接在一起,完成数据共享。 局域网LAN:计算机数量更多了,通过交换机和路由器连接在一起。 广域网WAN:将远隔千里的…...

auto关键字解析
前言 在11标准之前,auto在c中是声明存储器类型的关键字。而在11标准中它的功能变为了类型推导。 对此, 在这里引入Cprimer中的原句: 编程时常常需要把表达式的值赋给变量,这就要求在声明变量的时候清楚的知道表达式的类型。然而…...

[实战]用户系统-1-基础功能完善
[实战]用户系统-1 目标响应格式化新建lib-interceptor增加res拦截器新建lib-filter完善异常处理日志处理新建lib-logger新增mongodb的model代码进度目标 我们的用户系统实战,将会实现以下功能,登录,注册,登出,修改用户信息,上传头像,响应的格式化,请求拦截,vip标识。…...

C#SQLServer数据库通用访问类
using System; using System.Collections.Generic; using System.Data; using System.Data.SqlClient; using System.Linq; using System.Text; using System.Threading.Tasks; namespace thinger.cn.ADO.NETTeach { /// /// 数据库的通用类 /// public class SQLHelperBase…...
)
Linux中进程控制(上)
目录 进程创建 写时拷贝 fork常用场景 fork调用失败的原因 进程终止 进程退出场景 退出码 _exit函数 exit函数 进程等待 进程等待必要性 进程等待方法 wait方法 编辑 waitpid方法 获取⼦进程status 阻塞和非阻塞等待 进程创建 在linux中fork函数是⾮常重要的…...

为什么服务器突然变慢?从硬件到软件的排查方法
服务器突然变慢是许多系统管理员和网站运维人员经常遇到的问题。这种情况可能会影响网站性能、用户体验以及整个业务流程。了解服务器变慢的原因并采取相应的排查措施是至关重要的。本文将介绍服务器突然变慢的可能原因,从硬件到软件方面逐一排查,并提供…...

碳交易系统九大构成
碳交易系统九大构成 碳排放权交易系统的核心要素包括覆盖范围、配额总量、配额分配、排放监测、报送与核查,履约考核、抵消机制、交易机制、市场监管及配套的法律法规体系。 图源《中国碳排放权交易市场:从原理到实践》 1、覆盖范围 碳排放权交易体系…...
详解与实战)
第9.2讲、Tiny Decoder(带 Mask)详解与实战
自己搭建一个 Tiny Decoder(带 Mask),参考 Transformer Encoder 的结构,并添加 Masked Multi-Head Self-Attention,它是 Decoder 的核心特征之一。 1. 背景与动机 Transformer 架构已成为自然语言处理(NLP…...

Java接口P99含义解析
假设你开了一家奶茶店(接口就是你的奶茶制作流水线),每天要处理100杯订单: 🚀 P99是什么? 平均响应时间:就像说"平均每杯奶茶2分钟做好",但可能有10杯让客人等10分钟P99…...

【Oracle 专栏】清理用户及表空间
Oracle相关文档,希望互相学习,共同进步 风123456789~-CSDN博客 1.背景 今天需要清理一台服务器中之前的库,目前不再使用,以便释放空间。 如:清理 NH_MCRO_COLLECT 用户 2. 实验清理 2.1 查询:清…...

Qt功能区:Ribbon控件
控件 1. 按钮1.1 多选按钮1.2 2. 下拉列表框SARibbonComboBox2.1 简介2.2 代码实现 1. 按钮 1.1 多选按钮 软件功能:用于实现Category的名称居中。 SARibbonCheckBox继承于QCheckBox,使用方法完全相同。 SARibbonCheckBox* checkBox new SARibbonChe…...

eclipse 生成函数说明注释
在Eclipse中生成函数说明注释(JavaDoc风格)可以通过以下方法实现: 快捷键方式: 将光标放在函数上方输入/**后按回车键Eclipse会自动生成包含参数和返回值的注释模板 菜单方式: 选中函数点击菜单栏 Source > Gen…...

【Qt】QImage实战
QImage::Format_Mono, QImage::Format_RGB32, QImage::Format_ARGB32, QImage::Format_ARGB32_Premultiplied, 和 QImage::Format_RGB555 是 Qt 中不同的图像像素格式,它们在存储方式、颜色深度、是否支持透明通道以及适用场景上各有不同。下面是它们的详细对比&…...

tomcat知识点
1. JDK JDK是 Java 语言的软件开发工具包,JDK是整个java开发的核心,它包含JAVA工具还包括完整的 JRE(Java Runtime Environment)Java运行环境,包括了用于产品环境的各种库类,以及给开发人员使用的补充库。 JDK包含了一批用于Java开发的组件,其中包括: javac:编译器,将…...
)
Linux虚拟文件系统(2)
2.3 目录项-dentry 目录项,即 dentry,用来记录文件的名字、索引节点指针以及与其他目录项的关联关系。多个关联的目录项,就构成了文件系统的目录结构。和上一章中超级块和索引节点不同,目录项并不是实际存在于磁盘上的,…...

遥感影像-语义分割数据集:光伏数据集详细介绍及训练样本处理流程
原始数据集详情 简介:数据集包括504张亚米级卫星图片的农业光伏数据集,该数据集用于亚米级影像中的农业光伏提取任务。 KeyValue卫星类型亚米级卫星覆盖区域未知场景未知分辨率0.5m数量504张单张尺寸1024*1024原始影像位深8位标签图片位深8位原始影像通…...

【Java高阶面经:微服务篇】4.大促生存法则:微服务降级实战与高可用架构设计
一、降级决策的核心逻辑:资源博弈下的生存选择 1.1 大促场景的资源极限挑战 在电商大促等极端流量场景下,系统面临的资源瓶颈呈现指数级增长: 流量特征: 峰值QPS可达日常的50倍以上(如某电商大促下单QPS从1万突增至50万)流量毛刺持续时间短(通常2-4小时),但对系统稳…...

工业物联网网关在变电站远程监控中的安全传输解决方案
一、项目背景 随着智能电网的快速发展,对变电站的智能化监控需求日益迫切。传统变电站采用人工巡检和就地监控的方式,存在效率低、实时性差、数据不准确等问题,难以满足现代电力系统对变电站安全、稳定、高效运行的要求。而智能变电站通过引…...

车载诊断架构 --- LIN 节点 ECU 故障设计原则
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 钝感力的“钝”,不是木讷、迟钝,而是直面困境的韧劲和耐力,是面对外界噪音的通透淡然。 生活中有两种人,一种人格外在意别人的眼光;另一种人无论…...

编程技能:字符串函数09,strncmp
专栏导航 本节文章分别属于《Win32 学习笔记》和《MFC 学习笔记》两个专栏,故划分为两个专栏导航。读者可以自行选择前往哪个专栏。 (一)WIn32 专栏导航 上一篇:编程技能:字符串函数08,strcmp 回到目录…...

UML 时序图 使用案例
UML 时序图 UML 时序图 (Sequence Diagram)时序图的主要元素消息类型详解时序图示例时序图绘制步骤时序图的应用场景 UML 时序图 (Sequence Diagram) 时序图是UML(统一建模语言)中用于展示对象之间交互行为的动态视图,它特别强调消息的时间顺序。 时序图的主要元素…...

业务逻辑篇水平越权垂直越权未授权访问检测插件SRC 项目
# 逻辑越权 - 检测原理 - 水平 & 垂直 & 未授权 1 、水平越权:同级别的用户之间权限的跨越 2 、垂直越权:低级别用户到高级别用户权限的跨越 3 、未授权访问:通过无级别用户能访问到需验证应用 PHPStudy Metinfo4.0 会员后台中…...

Android开发——不同布局的定位属性 与 通用属性
目录 不同布局的定位属性1. 线性布局(LinearLayout)2. 相对布局(RelativeLayout)3. 约束布局(ConstraintLayout)4. 表格布局(TableLayout)5. 网格布局(GridLayout&#x…...

【DB2】SQL1639N 处理
背景 测试环境21套DB2需要创建只读用户并赋予权限,在20套都成功的情况下,有一套报错了,具体细节为,赋权成功,但是使用被赋权的账户连接失败,报错如下 SQL1639N The database server was unable to perfor…...