第9.2讲、Tiny Decoder(带 Mask)详解与实战
自己搭建一个 Tiny Decoder(带 Mask),参考 Transformer Encoder 的结构,并添加 Masked Multi-Head Self-Attention,它是 Decoder 的核心特征之一。
1. 背景与动机
Transformer 架构已成为自然语言处理(NLP)领域的主流。其 Encoder-Decoder 结构广泛应用于机器翻译、文本生成等任务。Decoder 的核心特征是 Masked Multi-Head Self-Attention,它保证了自回归生成时不会"偷看"未来信息。本文将带你从零实现一个最小可运行的 Tiny Decoder,并深入理解其原理。
2. Tiny Decoder 架构简述
一个标准 Transformer Decoder Layer 包括:
- Masked Multi-Head Self-Attention
- Encoder-Decoder Attention(跨注意力)
- Feed Forward Network (FFN)
- LayerNorm + Residual Connection
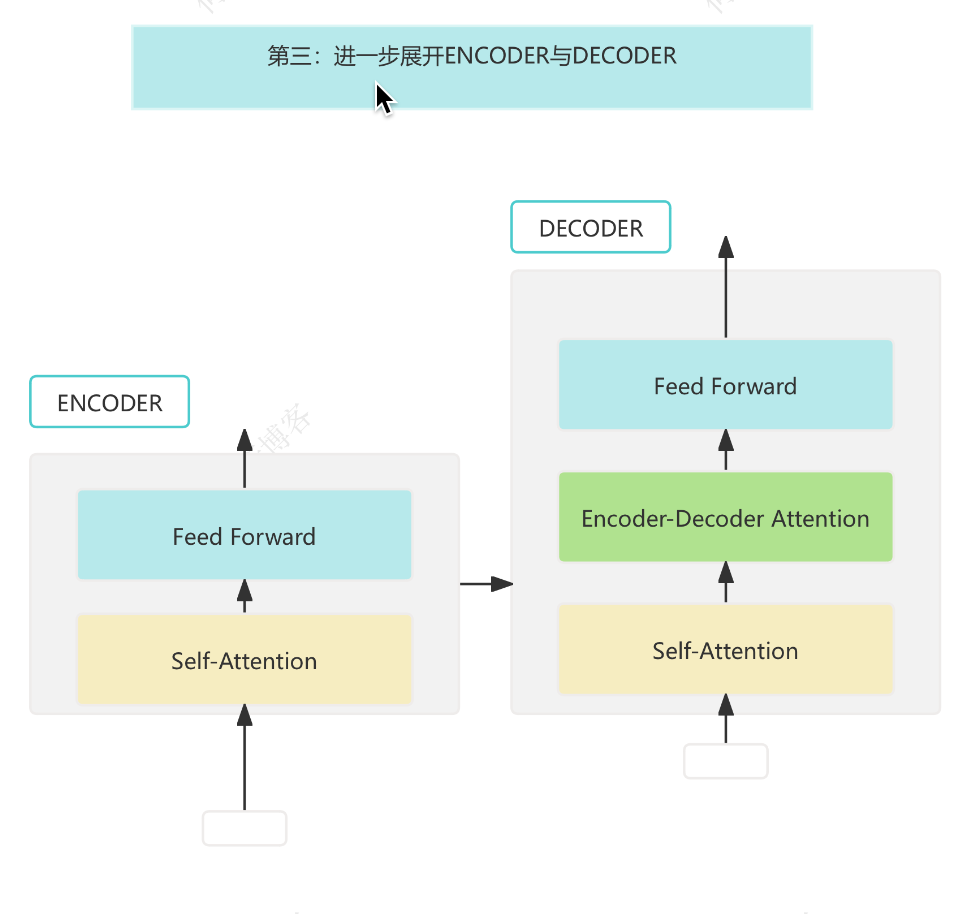
为了简化,我们暂时不引入 Encoder-Decoder Attention,只聚焦于:
Masked Self-Attention + FFN
3. 什么是 Masked Attention?
Masked Attention 的作用是在 Decoder 生成序列时,禁止看到"未来"的 token,防止信息泄露。
用一个 Mask 矩阵来实现,例如:
Mask for length 4:
[[0, -inf, -inf, -inf],[0, 0, -inf, -inf],[0, 0, 0, -inf],[0, 0, 0, 0]]
这个 Mask 会加在 Attention 的 logits 上(即 QKᵗ / sqrt(dk)),将不允许的位置置为 -inf,softmax 之后就是 0。
4. Tiny Decoder 核心代码(简化 PyTorch 实现)
import torch
import torch.nn as nn
import torch.nn.functional as F
import math# 带掩码的多头自注意力机制
class MaskedSelfAttention(nn.Module):def __init__(self, d_model, num_heads):super().__init__()assert d_model % num_heads == 0 # 保证可以均分到每个头self.d_model = d_modelself.num_heads = num_headsself.d_k = d_model // num_heads # 每个头的维度# 用一个线性层同时生成 Q、K、Vself.qkv_proj = nn.Linear(d_model, 3 * d_model)# 输出投影self.out_proj = nn.Linear(d_model, d_model)def forward(self, x):# x: (batch, seq_len, d_model)B, T, C = x.size()# 生成 Q、K、V,并分头qkv = self.qkv_proj(x).reshape(B, T, 3, self.num_heads, self.d_k).permute(2, 0, 3, 1, 4)q, k, v = qkv[0], qkv[1], qkv[2] # (B, heads, T, d_k)# 计算注意力分数 (QK^T / sqrt(d_k))attn_logits = (q @ k.transpose(-2, -1)) / math.sqrt(self.d_k) # (B, heads, T, T)# 构造下三角 Mask,防止看到未来信息mask = torch.tril(torch.ones(T, T)).to(x.device)attn_logits = attn_logits.masked_fill(mask == 0, float('-inf'))# softmax 得到注意力权重attn = F.softmax(attn_logits, dim=-1)# 加权求和得到输出out = attn @ v # (B, heads, T, d_k)# 合并多头out = out.transpose(1, 2).contiguous().reshape(B, T, C)# 输出投影return self.out_proj(out)# 前馈神经网络
class FeedForward(nn.Module):def __init__(self, d_model, d_ff):super().__init__()# 两层全连接+ReLUself.ff = nn.Sequential(nn.Linear(d_model, d_ff),nn.ReLU(),nn.Linear(d_ff, d_model))def forward(self, x):# 前馈变换return self.ff(x)# Tiny Decoder 层,包含 Masked Self-Attention 和前馈网络
class TinyDecoderLayer(nn.Module):def __init__(self, d_model=128, num_heads=4, d_ff=512):super().__init__()self.self_attn = MaskedSelfAttention(d_model, num_heads) # 掩码自注意力self.ff = FeedForward(d_model, d_ff) # 前馈网络self.norm1 = nn.LayerNorm(d_model) # 层归一化1self.norm2 = nn.LayerNorm(d_model) # 层归一化2def forward(self, x):# x: (batch, seq_len, d_model)# 先归一化,再做自注意力,并加残差x = x + self.self_attn(self.norm1(x))# 再归一化,前馈网络,并加残差x = x + self.ff(self.norm2(x))return x
5. 使用示例
x = torch.randn(2, 10, 128) # Decoder输入
context = torch.randn(2, 15, 128) # Encoder输出
decoder = TinyDecoderLayer()
y = decoder(x, context) # output shape: (2, 10, 128)
6. 进阶扩展
6.1 添加 Encoder-Decoder Attention
Encoder-Decoder Attention 允许 Decoder 在生成时参考 Encoder 的输出(即源语言信息),是机器翻译等任务的关键。其实现方式与 Self-Attention 类似,只是 Q 来自 Decoder,K/V 来自 Encoder。
伪代码:
class CrossAttention(nn.Module):def __init__(self, d_model, num_heads):# ...同 MaskedSelfAttention ...def forward(self, x, context):# x: (B, T_dec, d_model), context: (B, T_enc, d_model)# Q from x, K/V from context# ...实现...
在 Decoder Layer 中插入:
self.cross_attn = CrossAttention(d_model, num_heads)
# forward:
x = x + self.cross_attn(self.norm_cross(x), context)
6.2 多层 Decoder 堆叠
实际应用中,Decoder 通常由多层堆叠而成:
class TinyDecoder(nn.Module):def __init__(self, num_layers, d_model, num_heads, d_ff):super().__init__()self.layers = nn.ModuleList([TinyDecoderLayer(d_model, num_heads, d_ff) for _ in range(num_layers)])def forward(self, x):for layer in self.layers:x = layer(x)return x
6.3 加入 Positional Encoding
Transformer 不具备序列顺序感知能力,需加上 Positional Encoding:
class PositionalEncoding(nn.Module):def __init__(self, d_model, max_len=5000):super().__init__()pe = torch.zeros(max_len, d_model)position = torch.arange(0, max_len).unsqueeze(1)div_term = torch.exp(torch.arange(0, d_model, 2) * (-math.log(10000.0) / d_model))pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)self.register_buffer('pe', pe)def forward(self, x):return x + self.pe[:x.size(1)]
7. 完整训练例子(伪代码)
# 假设有输入数据 input_seq, target_seq
x = embedding(input_seq)
x = pos_encoding(x)
decoder = TinyDecoder(num_layers=2, d_model=128, num_heads=4, d_ff=512)
output = decoder(x)
# 计算 loss, 反向传播
8. 小结
- Decoder 的关键是 Masked Self-Attention,通过
tril的下三角掩码防止泄漏未来信息。 - 可以用
torch.tril快速构造下三角 Mask。 - Decoder 层和 Encoder 类似,但注意力机制加了 Mask,而且通常会多出 Encoder-Decoder Attention。
- 可扩展为多层、加入位置编码、跨注意力等,逐步构建完整的 Transformer Decoder。
*如果不加 Mask,允许 Decoder 看到未来 token,会导致模型训练"作弊",推理时表现极差,生成文本质量低下,模型失去实际应用价值。因此,Masked Self-Attention 是保证自回归生成和模型泛化能力的关键机制。
9. 参考资料
- Attention is All You Need
- The Annotated Transformer
- PyTorch 官方文档
相关文章:
详解与实战)
第9.2讲、Tiny Decoder(带 Mask)详解与实战
自己搭建一个 Tiny Decoder(带 Mask),参考 Transformer Encoder 的结构,并添加 Masked Multi-Head Self-Attention,它是 Decoder 的核心特征之一。 1. 背景与动机 Transformer 架构已成为自然语言处理(NLP…...

Java接口P99含义解析
假设你开了一家奶茶店(接口就是你的奶茶制作流水线),每天要处理100杯订单: 🚀 P99是什么? 平均响应时间:就像说"平均每杯奶茶2分钟做好",但可能有10杯让客人等10分钟P99…...

【Oracle 专栏】清理用户及表空间
Oracle相关文档,希望互相学习,共同进步 风123456789~-CSDN博客 1.背景 今天需要清理一台服务器中之前的库,目前不再使用,以便释放空间。 如:清理 NH_MCRO_COLLECT 用户 2. 实验清理 2.1 查询:清…...

Qt功能区:Ribbon控件
控件 1. 按钮1.1 多选按钮1.2 2. 下拉列表框SARibbonComboBox2.1 简介2.2 代码实现 1. 按钮 1.1 多选按钮 软件功能:用于实现Category的名称居中。 SARibbonCheckBox继承于QCheckBox,使用方法完全相同。 SARibbonCheckBox* checkBox new SARibbonChe…...

eclipse 生成函数说明注释
在Eclipse中生成函数说明注释(JavaDoc风格)可以通过以下方法实现: 快捷键方式: 将光标放在函数上方输入/**后按回车键Eclipse会自动生成包含参数和返回值的注释模板 菜单方式: 选中函数点击菜单栏 Source > Gen…...

【Qt】QImage实战
QImage::Format_Mono, QImage::Format_RGB32, QImage::Format_ARGB32, QImage::Format_ARGB32_Premultiplied, 和 QImage::Format_RGB555 是 Qt 中不同的图像像素格式,它们在存储方式、颜色深度、是否支持透明通道以及适用场景上各有不同。下面是它们的详细对比&…...

tomcat知识点
1. JDK JDK是 Java 语言的软件开发工具包,JDK是整个java开发的核心,它包含JAVA工具还包括完整的 JRE(Java Runtime Environment)Java运行环境,包括了用于产品环境的各种库类,以及给开发人员使用的补充库。 JDK包含了一批用于Java开发的组件,其中包括: javac:编译器,将…...
)
Linux虚拟文件系统(2)
2.3 目录项-dentry 目录项,即 dentry,用来记录文件的名字、索引节点指针以及与其他目录项的关联关系。多个关联的目录项,就构成了文件系统的目录结构。和上一章中超级块和索引节点不同,目录项并不是实际存在于磁盘上的,…...

遥感影像-语义分割数据集:光伏数据集详细介绍及训练样本处理流程
原始数据集详情 简介:数据集包括504张亚米级卫星图片的农业光伏数据集,该数据集用于亚米级影像中的农业光伏提取任务。 KeyValue卫星类型亚米级卫星覆盖区域未知场景未知分辨率0.5m数量504张单张尺寸1024*1024原始影像位深8位标签图片位深8位原始影像通…...

【Java高阶面经:微服务篇】4.大促生存法则:微服务降级实战与高可用架构设计
一、降级决策的核心逻辑:资源博弈下的生存选择 1.1 大促场景的资源极限挑战 在电商大促等极端流量场景下,系统面临的资源瓶颈呈现指数级增长: 流量特征: 峰值QPS可达日常的50倍以上(如某电商大促下单QPS从1万突增至50万)流量毛刺持续时间短(通常2-4小时),但对系统稳…...

工业物联网网关在变电站远程监控中的安全传输解决方案
一、项目背景 随着智能电网的快速发展,对变电站的智能化监控需求日益迫切。传统变电站采用人工巡检和就地监控的方式,存在效率低、实时性差、数据不准确等问题,难以满足现代电力系统对变电站安全、稳定、高效运行的要求。而智能变电站通过引…...

车载诊断架构 --- LIN 节点 ECU 故障设计原则
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 钝感力的“钝”,不是木讷、迟钝,而是直面困境的韧劲和耐力,是面对外界噪音的通透淡然。 生活中有两种人,一种人格外在意别人的眼光;另一种人无论…...

编程技能:字符串函数09,strncmp
专栏导航 本节文章分别属于《Win32 学习笔记》和《MFC 学习笔记》两个专栏,故划分为两个专栏导航。读者可以自行选择前往哪个专栏。 (一)WIn32 专栏导航 上一篇:编程技能:字符串函数08,strcmp 回到目录…...

UML 时序图 使用案例
UML 时序图 UML 时序图 (Sequence Diagram)时序图的主要元素消息类型详解时序图示例时序图绘制步骤时序图的应用场景 UML 时序图 (Sequence Diagram) 时序图是UML(统一建模语言)中用于展示对象之间交互行为的动态视图,它特别强调消息的时间顺序。 时序图的主要元素…...

业务逻辑篇水平越权垂直越权未授权访问检测插件SRC 项目
# 逻辑越权 - 检测原理 - 水平 & 垂直 & 未授权 1 、水平越权:同级别的用户之间权限的跨越 2 、垂直越权:低级别用户到高级别用户权限的跨越 3 、未授权访问:通过无级别用户能访问到需验证应用 PHPStudy Metinfo4.0 会员后台中…...

Android开发——不同布局的定位属性 与 通用属性
目录 不同布局的定位属性1. 线性布局(LinearLayout)2. 相对布局(RelativeLayout)3. 约束布局(ConstraintLayout)4. 表格布局(TableLayout)5. 网格布局(GridLayout&#x…...

【DB2】SQL1639N 处理
背景 测试环境21套DB2需要创建只读用户并赋予权限,在20套都成功的情况下,有一套报错了,具体细节为,赋权成功,但是使用被赋权的账户连接失败,报错如下 SQL1639N The database server was unable to perfor…...

禾纳EAT3152AP MOS电源芯片PIN TO PIN替代泰德TDM3307/2307方案
AET3152AP特性 VDS-30V,ID-40A RDS (ON)11mΩ (TYP.)VGS-10V, ID-10A RDS (ON)15mΩ (TYP.)VGS-4.5V, ID-5A 快速切换 l 低电阻 不含卤素和锑,符合Rohs标准 温度范围:-55℃~125℃ 封装:PDFN3030 AET3152AP应用 交换机切换 便携式/台式机中的…...

Python Day28 学习
继续聚类算法的学习 浙大疏锦行 DBSCAN聚类 Q1. 该算法的原理是什么? 总体而言,DBSCAN聚类是一种基于密度的聚类算法,适合发现任意形状的簇和检测噪声点 Q2. 代码实现 import numpy as np import pandas as pd from sklearn.cluster impo…...

企业网站架构部署与优化-Nginx核心功能
目录 #1.1正向代理 1.1.1编译安装Nginx 1.1.2配置正向代理 #2.1反向代理 2.1.1配置nginx七层代理 2.1.2配置nginx四层代理 1.1正向代理 正向代理(Forward Proxy)是一种位于客户端和目标服务器之间的服务器,用于代表客户端向服务器发送请求并…...

Java 多态
文章目录 多态向上转型和向下转型向上转型和重写重写和重载的区别动态绑定和静态绑定用代码来解释什么是多态向下转型 多态的优点 总结 多态 什么是多态?为什么要使用多态? 简单来说是多种形态,具体来说是去完成某个事情,当不同对…...

机器学习中的泛化能力
我们常常提到模型的泛化能力,什么是泛化能力呢? 百度百科这样解释:是指机器学习算法对新鲜样本的适应能力。 学习的目的是学到隐含在数据背后的规律,对具有同一规律的学习集以外的数据,经过训练的网络也能给出合适的输…...

第七章:数据存储策略与状态恢复机制实录
经过状态机、UI交互、逻辑驱动等章节的打磨,前端体系已经具备较强的调度与展示能力。但真正能决定组件在异常情况下能否“满血复活”的关键,落在了“状态恢复”这一关卡。尤其在安卓端环境复杂、网络波动频繁的前提下,若没有稳定的本地数据存…...

digitalworld.local: FALL靶场
digitalworld.local: FALL 来自 <digitalworld.local: FALL ~ VulnHub> 1,将两台虚拟机网络连接都改为NAT模式 2,攻击机上做namp局域网扫描发现靶机 nmap -sn 192.168.23.0/24 那么攻击机IP为192.168.23.182,靶场IP192.168.23.4 3&…...
 接口)
Java Collection(集合) 接口
Date: 2025-05-21 20:21:32 author: lijianzhan Java 集合框架提供了一组接口和类,以实现各种数据结构和算法。 以下是关于 Java 集合的核心内容说明: /*** Java Collection Framework 说明:** 在 Java 中,集合(Collec…...

直线型绝对值位移传感器:精准测量的科技利刃
在科技飞速发展的今天,精确测量成为了众多领域不可或缺的关键环节。无论是工业自动化生产线上的精细操作,还是航空航天领域中对零部件位移的严苛把控,亦或是科研实验中对微小位移变化的精准捕捉,都离不开一款高性能的测量设备——…...
)
Kotlin 极简小炒 P9 - 数组(数组的创建、数组元素的访问与修改、数组遍历、数组操作、多维数组、数组与可变参数)
Kotlin 概述 Kotlin 由 JetBrains 开发,是一种在 JVM(Java 虚拟机)上运行的静态类型编程语言 Kotlin 旨在提高开发者的编码效率和安全性,同时保持与 Java 的高度互操作性 Kotlin 是 Android 应用开发的首选语言,也可…...

Server-Driven UI:Kotlin 如何重塑动态化 Android 应用开发
以下是一篇整合详细代码示例的完整博客,深入探讨Kotlin在Server-Driven UI(SDUI)中的核心作用: Server-Driven UI:Kotlin 如何重塑动态化 Android 应用开发 1. Server-Driven UI 的核心价值 SDUI通过将UI描述与业务逻…...

基于多传感器融合的智能驾驶环境感知系统
摘要 随着自动驾驶技术的发展,单一传感器的局限性日益凸显。本文提出了一种基于多传感器(摄像头、毫米波雷达、激光雷达)融合的环境感知系统,通过深度学习算法实现车辆周围环境的精确感知。文章详细介绍了传感器标定、数据融合、目标检测与跟踪等关键技术,并提供了Python…...
装饰制品检测)
JC/T 2848-2024 玻璃纤维增强石膏(GRG)装饰制品检测
玻璃纤维增强石膏装饰制品是指以玻璃纤维为主要增强材料,高强石膏为主要胶凝材料,适当掺入集料,外加剂的石膏装饰制品,GRG具有防火,隔音,被广泛应用于,墙板,装饰构件等。 JC/T 2848…...
)
每日算法 -【Swift 算法】寻找字符串中最长回文子串(三种经典解法全解析)
🧩 最长回文子串问题:三种经典解法全解析(含代码注释) 本文将系统讲解“最长回文子串”问题的三种常见解法:中心扩展法、动态规划、马拉车算法(Manacher’s Algorithm),并进行对比与…...

【Java高阶面经:数据库篇】13. MySQL 并发控制秘籍:MVCC 协议与隔离级别深度解析
一、MVCC核心原理:多版本并发控制的基石 1.1 为什么需要MVCC? 在传统锁机制中,读写操作会互相阻塞,导致高并发场景下性能下降。MVCC通过多版本数据快照避免读写阻塞,实现: 读不加锁:快照读(普通SELECT)不阻塞写操作写不阻塞读:写操作生成新版本,读操作访问历史版本…...

分布式集群中的共识算法及其在时序数据库IoTDB中的应用
一、引言 在分布式集群环境中,为了实现海量数据的横向扩展,数据通常被划分为多个子集并分散存储在集群的各个节点上。为了确保数据的高可用性,每个数据子集都会在多个物理节点上存储副本。然而,这种多副本机制也带来了新的挑战&a…...

Java面试实录:从JVM调优到Spring Cloud实践
Java大厂面试:当严肃面试官遇上搞笑程序员 场景设定 面试官:拥有多年行业经验的技术专家,对Java及相关技术栈有着深入的理解。明哥:一位自认为是“水货”的程序员,擅长用幽默化解紧张气氛,但面对复杂问题…...

自定义协议与序列反序列化
目录 引子: 一、再谈 "协议" 二、自定义协议与网络版计算器 1.约定方案一: 2.约定方案二: 3.我们采用的协议 三、网络计算器代码 Log.hpp 日志 Makefile Socket.hpp 套接字封装 Protocol.hpp 协议 序列化反序列化 结构化数据格式规定 TcpSe…...

SAP-ABAP:ABAP异常处理与SAP现代技术融合—— 面向云原生、微服务与低代码场景的创新实践
专题三:ABAP异常处理与SAP现代技术融合 —— 面向云原生、微服务与低代码场景的创新实践 一、SAP技术演进与异常处理的挑战 随着SAP技术栈向云端、微服务化和低代码方向演进,异常处理面临新场景: Fiori UX敏感度:用户期望前端友…...

JavaScript面试题之消息队列
JavaScript消息队列详解:单线程的异步魔法核心 在JavaScript的单线程世界中,消息队列(Message Queue)是实现异步编程的核心机制,它像一位高效的调度员,让代码既能“一心多用”又避免卡顿。本文将深入剖析消…...
)
【低代码】如何使用明道云调用 Flask 视图函数并传参(POST 方法实践)
在自动化办公或业务流程管理中,明道云提供了强大的 HTTP 请求节点,可以直接调用第三方 API,包括我们常见的 Flask 服务端接口。本文将详细介绍如何使用明道云通过 POST 方法调用 Flask 视图函数并传参,包括配置要点与 Python 后端的参数接收方法。 一、场景介绍 我们希望…...

广州卓远VR受邀参加2025智能体育典型案例调研活动,并入驻国体华为运动健康联合实验室!
近日,“2025年智能体育典型案例调研活动”在东莞松山湖成功举办。本次调研活动由国家体育总局体育科学研究所和中国信息通信研究院联合主办,旨在深入贯彻中央关于培育新型消费的战略部署,通过激活智能健身产品消费潜力,加快运动健…...

【WebRTC】源码更改麦克风权限
WebRTC源码更改麦克风权限 仓库: https://webrtc.googlesource.com/src.git分支: guyl/m125节点: b09c2f83f85ec70614503d16e4c530484eb0ee4f...

spring cloud alibaba-Geteway详解
spring cloud alibaba-Gateway详解 Gateway介绍 在 Spring Cloud Alibaba 生态系统中,Gateway 是一个非常重要的组件,用于构建微服务架构中的网关服务。它基于 Spring Cloud Gateway 进行扩展和优化,提供了更强大的功能和更好的性能。 Gat…...

结课作业01. 用户空间 MPU6050 体感鼠标驱动程序
目录 一. qt界面实现 二. 虚拟设备模拟模拟鼠标实现体感鼠标 2.1 函数声明 2.2 虚拟鼠标实现 2.2.1 虚拟鼠标创建函数 2.2.2 鼠标移动函数 2.2.3 鼠标点击函数 2.3 mpu6050相关函数实现 2.3.1 i2c设备初始化 2.3.2 mpu6050寄存器写入 2.3.3 mpu6050寄存器读取 2.3.…...

Linux操作系统:信号
信号的基本介绍 信号是系统响应某个条件而产生的事件,进程接收到信号会执行响应的操作; (1)信号的储存位置 vim /usr/include/x86_64-linux-gnu/bits/signum.h 旧版 新版: vim /usr/include/x86_64-linux-gnu/bit…...
函数createBoxMaxFilter())
OpenCV CUDA模块特征检测与描述------用于创建一个最大值盒式滤波器(Max Box Filter)函数createBoxMaxFilter()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 createBoxMaxFilter()函数创建的是一个 最大值滤波器(Maximum Filter),它对图像中每个像素邻域内的像素值取最…...

有没有其他影视app可以像群晖video station一样可以被Windows的本地网络驱动器找到
你是在寻找可以通过Windows本地网络(SMB共享)访问的影视媒体服务程序,就像群晖的 Video Station 一样,可以浏览、播放或挂载电影资源。以下是一些可选方案: ✅ 具备与 Synology Video Station 类似功能,并支…...

【神经网络与深度学习】流模型的通俗易懂的原理
流模型(Flow-based Model)简介 引言 流模型是一种强大的生成模型,它通过可逆变换将简单的概率分布转化为复杂的数据分布。相比于扩散模型和生成对抗网络(GAN),流模型可以精确计算数据的概率,并…...

OpenCV CUDA模块图像特征检测与描述------图像中快速检测特征点类cv::cuda::FastFeatureDetector
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 cv::cuda::FastFeatureDetector 是 OpenCV 的 CUDA 加速模块中的一部分,用于在图像中快速检测特征点。FAST(Features fro…...

分享一些多模态文档解析思路
多模态文档解析思路小记 作者:Arlene 原文:https://zhuanlan.zhihu.com/p/1905635679293122466 多模态文档解析内容涉及:文本、表格和图片 解析思路v1 基于mineru框架对pdf文件进行初解析 其具备较完整的布局识别和内容识别,并将…...

【OCCT+ImGUI系列】009-Geom2d-Geom2d_AxisPlacement
一、Geom2d_AxisPlacement 简介 在 OpenCASCADE 的二维几何库中,Geom2d_AxisPlacement 是一个用于定义二维坐标系的几何类,主要包含一个原点(gp_Pnt2d)和一个方向向量(gp_Dir2d)。它在构造与控制二维几何对…...

【深度学习:理论篇】--Pytorch之nn.Module详解
目录 1.torch.nn.Module--概述 2.torch.nn.Module--简介 3.torch.nn.Module--实现 3.1.Sequential来包装层 3.2.children和modules 1.torch.nn.Module--概述 1. PyTorch vs. Keras 的设计差异 Keras(高层框架): 推荐通过继承 Layer 类…...