【深度学习:理论篇】--Pytorch之nn.Module详解
目录
1.torch.nn.Module--概述
2.torch.nn.Module--简介
3.torch.nn.Module--实现
3.1.Sequential来包装层
3.2.children和modules
1.torch.nn.Module--概述
1. PyTorch vs. Keras 的设计差异
- Keras(高层框架):
- 推荐通过继承
Layer类自定义层,而非直接继承Model(官方建议)。 - 严格区分“层”和“模型”,强调模块化组合。
- 推荐通过继承
- PyTorch(灵活统一):
- 没有严格的层/模型区分,自定义层、模块或整个模型,统一继承
nn.Module。 - 比如
Linear(全连接层)、Sequential(顺序容器)都是Module的子类。
- 没有严格的层/模型区分,自定义层、模块或整个模型,统一继承
2. 为什么只用 nn.Module,不用 autograd.Function?
nn.Module的优势:- 自动管理参数(如
parameters())、支持 GPU/CPU 切换、内置训练/评估模式(train()/eval())。 - 无需手动写反向传播,PyTorch 自动计算梯度。
- 自动管理参数(如
autograd.Function的局限:- 需手动实现
forward和backward,复杂且容易出错,仅适用于特殊需求(如自定义不可导操作)。
- 需手动实现
“一切皆 Module”:PyTorch 通过 nn.Module 提供统一接口,无论是单层、多层的块,还是完整模型,都按相同方式组织。
2.torch.nn.Module--简介
class Module(object):的主要模块:
| 类别 | 方法 | 功能说明 |
|---|---|---|
| 初始化与核心 | __init__(self) | 构造函数,初始化模块(需调用 super().__init__()) |
forward(self, *input) | 必须重写,定义前向传播逻辑 | |
__call__(self, *input, **kwargs) | 使实例可调用(如 model(x)),自动调用 forward() | |
| 模块管理 | add_module(name, module) | 添加子模块(如 self.add_module('linear', nn.Linear(10, 2))) |
children() | 返回直接子模块的迭代器(不递归) | |
named_children() | 返回 (name, module) 对的迭代器(直接子模块) | |
modules() | 递归返回所有子模块的迭代器 | |
named_modules() | 递归返回 (name, module) 对的迭代器 | |
| 参数管理 | parameters(recurse=True) | 返回所有参数的迭代器(默认递归子模块) |
named_parameters() | 返回 (name, parameter) 对的迭代器(如 'linear.weight') | |
| 设备移动 | cuda(device=None) | 将模块参数和缓冲区移动到 GPU |
cpu() | 将模块参数和缓冲区移动到 CPU | |
| 训练/评估模式 | train(mode=True) | 设置为训练模式(影响 Dropout、BatchNorm 等) |
eval() | 设置为评估模式(等价于 train(False)) | |
| 梯度管理 | zero_grad() | 重置所有参数的梯度(默认设为 None,PyTorch 1.7+ 推荐) |
| 辅助方法 | __repr__() | 返回模块的字符串表示(打印模型结构) |
__dir__() | 返回模块的属性列表(通常无需直接调用) |
注意:
我们在定义自已的网络的时候,需要继承nn.Module类,并重新实现构造函数__init__构造函数和forward这两个方法。但有一些注意技巧:
- 一般把网络中具有可学习参数的层(如全连接层、卷积层等)放在构造函数__init__()中,当然我也可以吧不具有参数的层也放在里面;
- 一般把不具有可学习参数的层(如ReLU、dropout、BatchNormanation层)可放在构造函数中,也可不放在构造函数中,如果不放在构造函数__init__里面,则在forward方法里面可以使用nn.functional来代替
- forward方法是必须要重写的,它是实现模型的功能,实现各个层之间的连接关系的核心。
总结:使用pytorch定义神经网络时,
1.必须继承那nn.Module
2.必须包含__init__构造函数和forward前向传播这两个方法
3.__init__是定义网络结构,forward是前向传播
举例:
import torch
import torch.nn as nnclass MyNet(nn.Module):def __init__(self):super(MyNet, self).__init__()self.conv1 = nn.Conv2d(3, 32, 3, 1, 1) # 输入3通道,输出32通道self.relu1 = nn.ReLU()self.max_pooling1 = nn.MaxPool2d(2, 1) # kernel_size=2, stride=1self.conv2 = nn.Conv2d(32, 32, 3, 1, 1) # 注意:输入应为32通道(修正处)self.relu2 = nn.ReLU()self.max_pooling2 = nn.MaxPool2d(2, 1)# 计算全连接层输入尺寸(需根据实际输出调整)self.dense1 = nn.Linear(32 * 222 * 222, 128) # 临时值,后面会修正self.dense2 = nn.Linear(128, 10)def forward(self, x):x = self.conv1(x)x = self.relu1(x)x = self.max_pooling1(x)x = self.conv2(x)x = self.relu2(x)x = self.max_pooling2(x)x = x.view(x.size(0), -1) # 展平x = self.dense1(x)x = self.dense2(x)return x# 创建输入张量(假设输入为224x224的RGB图像)
x = torch.randn(4, 3, 224, 224) # batch_size=4, 通道=3, 高=224, 宽=224# 实例化模型
model = MyNet()# 打印网络结构
print("模型结构:")
print(model)# 前向传播
print("\n输入形状:", x.shape)
output = model(x)
print("输出形状:", output.shape) # 应为 [4, 10]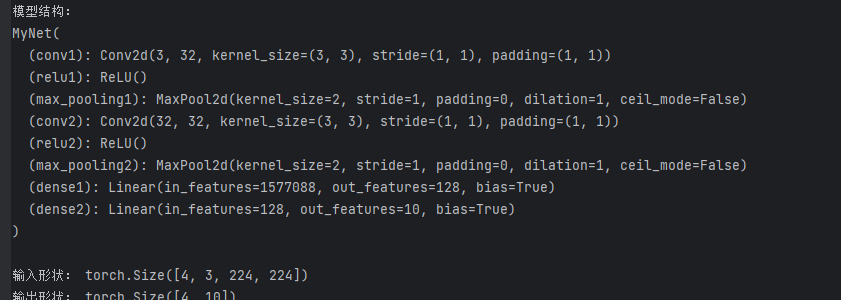
在forward里面实现所有层的连接关系,当然这里依然是顺序连接的
总结:所有放在构造函数__init__里面的层的都是这个模型的“固有属性”.
注意:model(x)相当于model.forward(x)
3.torch.nn.Module--实现
Module类是非常灵活的,可以有很多灵活的实现方式,下面将一一介绍。
3.1.Sequential来包装层
即将几个层包装在一起作为一个大的层(块),前面的一篇文章详细介绍了Sequential类的使用,包括常见的三种方式,以及每一种方式的优缺点,参见:pytorch教程之nn.Sequential类详解——使用Sequential类来自定义顺序连接模型-CSDN博客
方式一:
import torch.nn as nn
from collections import OrderedDict
class MyNet(nn.Module):def __init__(self):super(MyNet, self).__init__()self.conv_block = nn.Sequential(nn.Conv2d(3, 32, 3, 1, 1),nn.ReLU(),nn.MaxPool2d(2))self.dense_block = nn.Sequential(nn.Linear(32 * 3 * 3, 128),nn.ReLU(),nn.Linear(128, 10))# 在这里实现层之间的连接关系,其实就是所谓的前向传播def forward(self, x):conv_out = self.conv_block(x)res = conv_out.view(conv_out.size(0), -1)out = self.dense_block(res)return outmodel = MyNet()
print(model)
'''运行结果为:
MyNet((conv_block): Sequential((0): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(1): ReLU()(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False))(dense_block): Sequential((0): Linear(in_features=288, out_features=128, bias=True)(1): ReLU()(2): Linear(in_features=128, out_features=10, bias=True))
)
'''方式二:
import torch.nn as nn
from collections import OrderedDict
class MyNet(nn.Module):def __init__(self):super(MyNet, self).__init__()self.conv_block = nn.Sequential(OrderedDict([("conv1", nn.Conv2d(3, 32, 3, 1, 1)),("relu1", nn.ReLU()),("pool", nn.MaxPool2d(2))]))self.dense_block = nn.Sequential(OrderedDict([("dense1", nn.Linear(32 * 3 * 3, 128)),("relu2", nn.ReLU()),("dense2", nn.Linear(128, 10))]))def forward(self, x):conv_out = self.conv_block(x)res = conv_out.view(conv_out.size(0), -1)out = self.dense_block(res)return outmodel = MyNet()
print(model)
'''运行结果为:
MyNet((conv_block): Sequential((conv1): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(relu1): ReLU()(pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False))(dense_block): Sequential((dense1): Linear(in_features=288, out_features=128, bias=True)(relu2): ReLU()(dense2): Linear(in_features=128, out_features=10, bias=True))
)
'''方式三:
import torch.nn as nn
from collections import OrderedDict
class MyNet(nn.Module):def __init__(self):super(MyNet, self).__init__()self.conv_block=torch.nn.Sequential()self.conv_block.add_module("conv1",torch.nn.Conv2d(3, 32, 3, 1, 1))self.conv_block.add_module("relu1",torch.nn.ReLU())self.conv_block.add_module("pool1",torch.nn.MaxPool2d(2))self.dense_block = torch.nn.Sequential()self.dense_block.add_module("dense1",torch.nn.Linear(32 * 3 * 3, 128))self.dense_block.add_module("relu2",torch.nn.ReLU())self.dense_block.add_module("dense2",torch.nn.Linear(128, 10))def forward(self, x):conv_out = self.conv_block(x)res = conv_out.view(conv_out.size(0), -1)out = self.dense_block(res)return outmodel = MyNet()
print(model)
'''运行结果为:
MyNet((conv_block): Sequential((conv1): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(relu1): ReLU()(pool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False))(dense_block): Sequential((dense1): Linear(in_features=288, out_features=128, bias=True)(relu2): ReLU()(dense2): Linear(in_features=128, out_features=10, bias=True))
)
'''3.2.children和modules
特别注意:Sequential类虽然继承自Module类,二者有相似部分,但是也有很多不同的部分,集中体现在:
Sequenrial类实现了整数索引,故而可以使用model[index] 这样的方式获取一个曾,但是Module类并没有实现整数索引,不能够通过整数索引来获得层
def children(self):"""返回当前模块的直接子模块的迭代器(不包括子模块的子模块)。"""# 示例:若当前模块包含子模块 conv1 和 fc1,则 children() 返回 [conv1, fc1]def named_children(self):"""返回当前模块的直接子模块的迭代器,并附带子模块的名称(格式:(name, module))。"""# 示例:返回 [('conv1', Conv2d(...)), ('fc1', Linear(...))]def modules(self):"""递归返回当前模块及其所有子模块的迭代器(深度优先遍历)。"""# 示例:返回 [当前模块, conv1, conv1.weight, ..., fc1, ...]def named_modules(self, memo=None, prefix=''):"""递归返回当前模块及其所有子模块的迭代器,并附带模块的完整路径名称(格式:(name, module))。"""# 示例:返回 [('', 当前模块), ('conv1', conv1), ('conv1.weight', conv1.weight), ...]'''
注意:这几个方法返回的都是一个Iterator迭代器,故而通过for循环访问,当然也可以通过next
'''
import torch.nn as nn
from collections import OrderedDict
class MyNet(nn.Module):def __init__(self):super(MyNet, self).__init__()self.conv_block=torch.nn.Sequential()self.conv_block.add_module("conv1",torch.nn.Conv2d(3, 32, 3, 1, 1))self.conv_block.add_module("relu1",torch.nn.ReLU())self.conv_block.add_module("pool1",torch.nn.MaxPool2d(2))self.dense_block = torch.nn.Sequential()self.dense_block.add_module("dense1",torch.nn.Linear(32 * 3 * 3, 128))self.dense_block.add_module("relu2",torch.nn.ReLU())self.dense_block.add_module("dense2",torch.nn.Linear(128, 10))def forward(self, x):conv_out = self.conv_block(x)res = conv_out.view(conv_out.size(0), -1)out = self.dense_block(res)return outmodel = MyNet()1.model.children()方法
for i in model.children():print(i)print(type(i)) # 查看每一次迭代的元素到底是什么类型,实际上是 Sequential 类型,所以有可以使用下标index索引来获取每一个Sequenrial 里面的具体层'''运行结果为:
Sequential((conv1): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(relu1): ReLU()(pool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
<class 'torch.nn.modules.container.Sequential'>
Sequential((dense1): Linear(in_features=288, out_features=128, bias=True)(relu2): ReLU()(dense2): Linear(in_features=128, out_features=10, bias=True)
)
<class 'torch.nn.modules.container.Sequential'>
'''
(2)model.named_children()方法
for i in model.children():print(i)print(type(i)) # 查看每一次迭代的元素到底是什么类型,实际上是 返回一个tuple,tuple 的第一个元素是'''运行结果为:
('conv_block', Sequential((conv1): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(relu1): ReLU()(pool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
))
<class 'tuple'>
('dense_block', Sequential((dense1): Linear(in_features=288, out_features=128, bias=True)(relu2): ReLU()(dense2): Linear(in_features=128, out_features=10, bias=True)
))
<class 'tuple'>
'''(3)model.modules()方法
for i in model.modules():print(i)print("==================================================")
'''运行结果为:
MyNet((conv_block): Sequential((conv1): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(relu1): ReLU()(pool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False))(dense_block): Sequential((dense1): Linear(in_features=288, out_features=128, bias=True)(relu2): ReLU()(dense2): Linear(in_features=128, out_features=10, bias=True))
)
==================================================
Sequential((conv1): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(relu1): ReLU()(pool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
==================================================
Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
==================================================
ReLU()
==================================================
MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
==================================================
Sequential((dense1): Linear(in_features=288, out_features=128, bias=True)(relu2): ReLU()(dense2): Linear(in_features=128, out_features=10, bias=True)
)
==================================================
Linear(in_features=288, out_features=128, bias=True)
==================================================
ReLU()
==================================================
Linear(in_features=128, out_features=10, bias=True)
==================================================
'''(4)model.named_modules()方法
for i in model.named_modules():print(i)print("==================================================")
'''运行结果是:
('', MyNet((conv_block): Sequential((conv1): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(relu1): ReLU()(pool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False))(dense_block): Sequential((dense1): Linear(in_features=288, out_features=128, bias=True)(relu2): ReLU()(dense2): Linear(in_features=128, out_features=10, bias=True))
))
==================================================
('conv_block', Sequential((conv1): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(relu1): ReLU()(pool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
))
==================================================
('conv_block.conv1', Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)))
==================================================
('conv_block.relu1', ReLU())
==================================================
('conv_block.pool1', MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False))
==================================================
('dense_block', Sequential((dense1): Linear(in_features=288, out_features=128, bias=True)(relu2): ReLU()(dense2): Linear(in_features=128, out_features=10, bias=True)
))
==================================================
('dense_block.dense1', Linear(in_features=288, out_features=128, bias=True))
==================================================
('dense_block.relu2', ReLU())
==================================================
('dense_block.dense2', Linear(in_features=128, out_features=10, bias=True))
==================================================
'''(1)model的modules()方法和named_modules()方法都会将整个模型的所有构成(包括包装层、单独的层、自定义层等)由浅入深依次遍历出来,只不过modules()返回的每一个元素是直接返回的层对象本身,而named_modules()返回的每一个元素是一个元组,第一个元素是名称,第二个元素才是层对象本身。
(2)如何理解children和modules之间的这种差异性。注意pytorch里面不管是模型、层、激活函数、损失函数都可以当成是Module的拓展,所以modules和named_modules会层层迭代,由浅入深,将每一个自定义块block、然后block里面的每一个层都当成是module来迭代。而children就比较直观,就表示的是所谓的“孩子”,所以没有层层迭代深入。
相关文章:

【深度学习:理论篇】--Pytorch之nn.Module详解
目录 1.torch.nn.Module--概述 2.torch.nn.Module--简介 3.torch.nn.Module--实现 3.1.Sequential来包装层 3.2.children和modules 1.torch.nn.Module--概述 1. PyTorch vs. Keras 的设计差异 Keras(高层框架): 推荐通过继承 Layer 类…...

SQLMesh 宏操作符详解:@IF 的条件逻辑与高级应用
SQLMesh 的 IF 宏提供了一种在 SQL 查询中嵌入条件逻辑的方法,允许根据运行时条件动态调整查询结构。本文深入探讨 IF 的语法、使用场景及实际案例,帮助开发者构建更灵活、可维护的 SQL 工作流。 1. IF 宏简介 IF 是 SQLMesh 提供的条件逻辑宏ÿ…...

最新版Chrome浏览器调用ActiveX控件之eDrawings Viewer专用包v2.0.42版本发布
背景 eDrawings是一款轻量级的2D和3D浏览/可视化软件,主要用于查看和分享由SolidWorks创建的3D模型和2D工程图。它支持多种CAD文件格式,使得用户能够方便地在不同CAD系统之间转换和查看设计数据。适用于设计师和工程师之间的即时协作,通过电…...

人工智能应用时代:个人成长与职业突围的底层逻辑
当人工智能从实验室走向现实场景,从概念热词变为生产力工具,一场静默却深刻的变革正在重塑人类社会的运行规则。无论是算法驱动的智能推荐、语言模型支撑的自动化创作,还是工业机器人对传统生产线的颠覆,人工智能应用已渗透至社会…...
)
STM32之串口通信蓝牙(BLE)
一、串口通信的原理与应用 通信的方式 处理器与外部设备之间或者处理器与处理器之间通信的方式分两种:串行通信和并行通信。 串行通信 传输原理:数据按位依次顺序传输(每一位占据固定的时间长度 MSB or LSB) 优点:…...

【Spring Boot】配置实战指南:Properties与YML的深度对比与最佳实践
目录 1.前言 2.正文 2.1配置文件的格式 2.2properties 2.2.1基础语法 2.2.2value读取配置文件 2.2.3缺点 2.3yml 2.3.1基础语法 2.3.2配置不同数据类型 2.3.3配置读取 2.3.4配置对象和集合 2.3.5优缺点 2.4综合练习:验证码案例 2.4.1分析需求 2.4.2…...

数据结构篇--优先级队列排序--实验报告
实验简介框架代码实验步骤运行结果实验总结 实验概述 优先队列排序算法的基本思想是: 将所有待排序元素依次插入到优先队列中,然后按照从大到小的顺序,通过重复删除优先队列中的最大元素,取出所有元素,从而实现排序…...

【图像大模型】基于深度对抗网络的图像超分辨率重建技术ESRGAN深度解析
基于深度对抗网络的图像超分辨率重建技术ESRGAN深度解析 一、技术背景与核心创新1.1 图像超分辨率技术演进1.2 核心技术创新对比 二、算法原理深度解析2.1 网络架构设计2.1.1 RRDB模块结构 2.2 损失函数设计2.2.1 对抗损失(Adversarial Loss)2.2.2 感知损…...

Ubuntu 20.04卸载并重装 PostgreSQL
在 Ubuntu 下彻底卸载并重新安装 PostgreSQL(包括所有版本及其数据目录)的步骤 下面是一个在 Ubuntu 下彻底卸载并重新安装 PostgreSQL(包括所有版本及其数据目录)的步骤。 文章目录 在 Ubuntu 下彻底卸载并重新安装 PostgreSQL&…...

debian系统redis-dump安装
1. Ruby 环境 Redis-dump 是一个 Ruby 工具,需先安装 Ruby 和 RubyGems。 安装命令: sudo apt update sudo apt install ruby-full build-essential[roota29d39f5fd10:/opt/redis-dump/bin# apt install ruby-full build-essential Reading pac…...

AI智能分析网关V4玩手机检测算法精准管控人员手机行为,搭建智慧化安防监管体系
一、背景 移动终端普及使随意用机成为常态,在生产车间、加油站、考场、手术室等场景,人员使用手机易引发生产事故、爆炸、作弊、仪器干扰等问题。传统人工巡查存在覆盖不足、响应慢、主观性强等局限,难以满足现代安全管理需求。AI智能分析…...

支持向量存储:PostgresSQL及pgvector扩展详细安装步骤!老工程接入RAG功能必备!
之前文章和大家分享过,将会出一篇专栏(从电脑装ubuntu系统,到安装ubuntu的常用基础软件:jdk、python、node、nginx、maven、supervisor、minio、docker、git、mysql、redis、postgresql、mq、ollama等),目前…...

小土堆pytorch--神经网络-非线性激活线性层及其他层介绍
1. 神经网络-非线性激活 1.1 relu与sigmoid 1.1.1 ReLU(Rectified Linear Unit,修正线性单元 ) 定义与数学表达:数学定义为 f ( x ) max ( 0 , x ) f(x) \max(0, x) f(x)max(0,x) ,即当输入 x > 0 x > …...
)
【Vue3】数据的返回和响应式处理(ref reactive)
目录 一、拉开序幕的setup 二、ref函数 2.1 访问对象的响应式处理 小结:ref函数 三、reactive函数 3.1 reactive同样也可以修改数组: 3.2 reactive小结: 四、Vue3中的响应式原理 4.1 vue2的响应式,对象属性的添加 4.2…...

【Rust智能指针】Rust智能指针原理剖析与应用指导
✨✨ 欢迎大家来到景天科技苑✨✨ 🎈🎈 养成好习惯,先赞后看哦~🎈🎈 🏆 作者简介:景天科技苑 🏆《头衔》:大厂架构师,华为云开发者社区专家博主,…...
(详解使用muduo库))
C++ - 仿 RabbitMQ 实现消息队列(3)(详解使用muduo库)
C - 仿 RabbitMQ 实现消息队列(3)(详解使用muduo库) muduo库的基层原理核心概念总结:通俗例子:餐厅模型优势体现典型场景 muduo库中的主要类EventloopMuduo 的 EventLoop 核心解析1. 核心机制:事…...

Java异常处理全解析:从基础到自定义
目录 🚀前言🤔异常的定义与分类💯运行时异常💯编译时异常💯异常的基本处理 🌟异常的作用🐧自定义异常💯自定义运行时异常💯自定义编译时异常 ✍️异常的处理方案…...

C++初阶-vector的模拟实现2
目录 1.vector已经实现的代码总结 2.vector::resize的模拟实现 3.vector::vector(const vector& v)拷贝构造函数的模拟实现 4.vector::operator(const vector& x)的模拟实现(原始写法) 5.vector::swap的模拟实现 6.vector::operator(const …...

【图数据库】--Neo4j 安装
目录 1.Neo4j --概述 2.JDK安装 3.Neo4j--下载 3.1.下载资源包 3.2.创建环境变量 3.3.运行 Neo4j 是目前最流行的图形数据库(Graph Database),它以节点(Node)、关系(Relationship)和属性(Property)的形式存储数据,专门为处理高度连接的数据而设计。…...

elementui初学1
当然可以!下面是从零开始创建一个最简单的 Element UI 程序的完整流程,基于 Vue 2 Element UI(如果你想用 Vue 3,请告诉我,我可以给你 Element Plus 的版本)。 ✅ 一、准备环境 确保你已经安装了…...

lanqiaoOJ 4185:费马小定理求逆元
【题目来源】 https://www.lanqiao.cn/problems/4185/learning/ 【题目描述】 给出 n,p,求 。其中, 指存在某个整数 0≤a<p,使得 na mod p1,此时称 a 为 n 的逆元,即 。数据保证 p 是质数且 n mod p≠0…...
)
计算机视觉与深度学习 | Python实现CEEMDAN-ISOS-VMD-GRU-ARIMA时间序列预测(完整源码和数据)
以下是结合CEEMDAN、ISOS-VMD、GRU和ARIMA的时间序列预测的Python完整实现方案。本方案包含完整的代码、数据生成逻辑和实现细节说明。 完整代码实现 import numpy as np import pandas as pd from PyEMD import CEEMDAN from vmdpy import VMD from scipy.optimize import di…...

前端开发遇到 Bug,怎么办?如何利用 AI 高效解决问题
前端开发遇到 Bug,怎么办?如何利用 AI 高效解决问题 作为前端开发者,遇到 Bug 几乎是日常。无论是样式错乱、功能异常,还是接口数据不对,Bug 总能让人头疼。但随着人工智能(AI)技术的发展&…...

博主总结框架
1.博主总结框架 1.1 计算机基础类(数据结构、计算机网络、操作系统等) (1)数据结构 (2)操作系统 (3)计算机网络 (4)其他 物联网入门框架 1.2 计算机图形…...

国产化Excel处理组件Spire.XLS for .NET系列教程:通过 C# 将 TXT 文本转换为 Excel 表格
在数据处理和管理场景中,将原始文本文件(TXT)高效转换为结构化的 Excel 电子表格是一项常见要求。对于那些需要自动生成报表或者处理日志文件的开发人员而言,借助 C# 实现 TXT 到 Excel 的转换工作,可以简化数据组织和…...

网络安全--PHP第一天
目标 熟悉信息传递架构 基于phpstydy-mysql-php 前置条件 需要先在数据库中创建相应的库和表名并配置表的结构 该文件为数据库配置文件 名字为config.php <?php $dbip localhost;//连接数据库的地址 远程连接需要输入ip等 $dbuser root;//连接数据库的用户 $dbpass ro…...

结构型:组合模式
目录 1、核心思想 2、实现方式 2.1 模式结构 2.2 实现案例 3、优缺点分析 4、适用场景 1、核心思想 目的:将总是在重复、迭代地显示的某种自相似性的结构(部分与整体结构特征相似),例如树形结构,以统一的方式处…...

Node.js多版本安装工具NVM详细使用教程
一、nvm 简介 nvm(Node Version Manager)是一个用于管理多个 Node.js 版本的命令行工具,允许开发者在单个系统中轻松切换、安装和卸载不同版本的 Node.js。它是前端和后端开发中处理 Node.js 版本兼容性问题的核心工具之一。 二、nvm 安装 …...

深度解析 Java 中介者模式:重构复杂交互场景的优雅方案
一、中介者模式的核心思想与设计哲学 在软件开发的历史长河中,对象间的交互管理一直是架构设计的核心难题。当多个对象形成复杂的网状交互时,系统会陷入 "牵一发而动全身" 的困境。中介者模式(Mediator Pattern)作为行…...
深度学习---计算机视觉基础)
(八)深度学习---计算机视觉基础
分类问题回归问题聚类问题各种复杂问题决策树√线性回归√K-means√神经网络√逻辑回归√岭回归密度聚类深度学习√集成学习√Lasso回归谱聚类条件随机场贝叶斯层次聚类隐马尔可夫模型支持向量机高斯混合聚类LDA主题模型 一.图像数字化表示及建模基础 二.卷积神经网络CNN基本原…...

深入剖析原型模式:原理、实现与应用实践
在软件开发的世界里,设计模式如同建筑师手中的蓝图,为复杂系统的构建提供了行之有效的解决方案。其中,原型模式(Prototype Pattern)作为创建型设计模式的重要一员,以其独特的对象创建方式,在提高代码复用性、增强系统灵活性等方面发挥着关键作用。本文将深入剖析原型模式…...

【论文阅读 | CVPR 2024 |RSDet:去除再选择:一种用于 RGB - 红外目标检测的由粗到精融合视角】
论文阅读 | CVPR 2024 |RSDet:去除再选择:一种用于 RGB - 红外目标检测的由粗到精融合视角 1.摘要&&引言2. 方法2.1 “由粗到细”融合策略2.2 冗余光谱去除模块(RSR)2.3 动态特征选择模块(DFS)2.4 去除与选择检…...

WinForms 应用中集成 OpenCvSharp 实现基础图像处理
引言 欢迎关注dotnet研习社,今天我们要讨论的主题是WinForms 应用中集成 OpenCvSharp 实现基础图像处理。 在常规的图像处理软件开发中,图像处理功能是这些应用程序的核心组成部分。无论是简单的照片编辑工具,还是复杂的计算机视觉应用&…...

apache http client连接池实现原理
在java开发中我们经常会涉及到http 请求接口,一般有几种方式: java自带的 HttpURLConnectionokHttpClientapache http client 一般我们使用apache http client会比较多点,在代码中会进行如下调用方式: private static class Htt…...

adb抓包
目录 抓包步骤 步骤 1: 获取应用的包名 步骤 2: 查看单个应用的日志 步骤 3: 使用日志级别过滤器 步骤 4: 高级日志过滤 可能的原因: 解决方案: 额外提示: 日志保存 抓包步骤 连接设备 adb devices 步骤 1: 获取应用的包名 首先…...

C语言---结构体 、联合体、枚举
一、初识结构体 1、结构体类型 结构体和数组都是集合,但是结构体有成员,类型可以不同;数组有成员,类型相同。 int main() {struct tag{member--list //一个或者多个成员,成员变量}variable--list;//可以省略&#x…...

Web Workers 使用指南
文章目录 前言基础使用高级特性 使用 ES Modules实际应用场景图像处理大数据处理轮询任务 性能优化技巧现代开发方式使用 worker-loader (Webpack) Vite中的Worker使用 限制与注意事项DOM限制:通信限制:同源策略:最佳实践 前言 Web Workers 是浏览器提供的 JavaScript 多线程解…...
)
JVM 与容器化部署调优实践(Docker + K8s)
📌 文章目录 📘 前言1️⃣ 容器环境下 JVM 面临的新挑战2️⃣ JVM 的容器资源感知机制详解3️⃣ JVM 内存调优:如何正确使用堆内存4️⃣ JVM CPU 调优:GC 与编译线程控制5️⃣ Kubernetes 典型配置误区与对策6️⃣ 实战案例&#…...

Android OkHttp控制链:深入理解网络请求的流程管理
OkHttp作为Android和Java平台上广泛使用的HTTP客户端,其核心设计之一就是"控制链"(Chain)机制。本文将深入探讨OkHttp控制链的工作原理、实现细节以及如何利用这一机制进行高级定制。 一、什么是OkHttp控制链 OkHttp控制链是一种责任链模式的实现&#…...

《易经》的数学表达:初级版和高级版
《易经》的数学表达, 一、初级版,可基于以下框架构建, 涵盖符号系统、结构代数及变换规则: 此框架将《易经》抽象为离散数学结构,兼容符号逻辑、概率论与群论,为算法化占断、卦象拓扑分析及跨文化比较提供…...
)
卷积神经网络基础(十)
之前我们学习了SGD、Momentum和AdaGrad三种优化方法,今天我们将继续学习Adam方法。 6.1.6 Adam 我们知道Momentum参照的是小球在碗中滚动的物理规则进行移动而实现的,AdaGrad为参数的每个元素适当地调整更新步伐。那如果我们将这两种方法融合在一起会不…...
安装到指定路径)
怎么把cursor(Cursor/ollama)安装到指定路径
使用PowerShell命令 打开电脑开始菜单,输入powerShell,使用管理员权限打开powerShell窗口,使用cd命令到cursor或ollama安装包的下载目录,如我的Cursor所在的目录为D:\environment\cursor\soft,输入以下 cd E:\downloa…...

第21天-pyttsx3语音播放功能
示例1:语音参数控制(语速/音量/音调) import pyttsx3def speech_demo():engine = pyttsx3.init()# 获取当前语音参数print("默认语速:", engine.getProperty(rate))print("默认音量:", engine.getProperty(volume))print("可用语音:", engin…...
优化显存和加速方案)
Multi-Query Attention:传统自注意力( Self-Attention)优化显存和加速方案
本文导读:Multi-Query Attention(MQA)是 Google Research 2022 年提出的一项轻量化注意力技术,通过“多查询、单键值”的设计,把自注意力层的 KV 缓存从 O(hnd) 降到 O(nd),在不牺牲模型精度的前提下大幅节…...

学习路之uniapp--unipush2.0推送功能--服务端推送消息
学习路之uniapp--unipush2.0推送功能--服务端推送消息 一、二、三、 一、 二、 三、...

如何使用AI搭建WordPress网站
人工智能正迅速成为包括网页设计在内的许多行业在其功能设置中添加的一种工具。在数字设计和营销领域,许多成熟的工具都在其产品中添加了人工智能功能。WordPress 也是如此。作为目前最流行的网站建设工具之一,WordPress 的人工智能插件越来越多也就不足…...

Java 项目管理工具:Maven 与 Gradle 的深度对比与选择
Java 项目管理工具:Maven 与 Gradle 的深度对比与选择 在 Java 开发领域,项目管理工具对于项目的构建、依赖管理等起着至关重要的作用。Maven 和 Gradle 是目前最主流的两款工具,它们各自有着独特的优势和适用场景。本文将对 Maven 与 Gradl…...

Elasticsearch简单集成java框架方式。
Elasticsearch 在 Java 中最常用的客户端是什么?如何初始化一个 RestHighLevelClient?如何用 Spring Boot 快速集成 Elasticsearch?Spring Data Elasticsearch 如何定义实体类与索引的映射? 最常用的 Java 客户端 目前官方推荐使用…...
 ✨ | Hidden Search Widget (交互式搜索框))
50天50个小项目 (Vue3 + Tailwindcss V4) ✨ | Hidden Search Widget (交互式搜索框)
📅 我们继续 50 个小项目挑战!—— Hidden Search Widget 组件 仓库地址:https://github.com/SunACong/50-vue-projects 项目预览地址:https://50-vue-projects.vercel.app/ ✨ 组件目标 点击按钮展开隐藏的搜索框 再次点击按钮…...

python爬虫和逆向:百度翻译数据采集的几种方式
更多内容请见: 爬虫和逆向教程-专栏介绍和目录 文章目录 一、官方API方式(推荐)1.1 百度翻译开放平台API二、网页版逆向方式(代码可直接运行)2.1 拿到js加密方法2.2 python解密代码三、浏览器自动化方式3.1 Selenium自动化操作3.2 Playwright自动化四、移动端API逆向4.1 分…...