【寻找Linux的奥秘】第七章:虚拟地址空间

前言
本专题将基于Linux操作系统来带领大家学习操作系统方面的知识以及学习使用Linux操作系统。上一章我们简单认识了环境变量,本章将讲解操作系统中另一个重要的概念——程序地址空间。
1. 初步认识
之前在我们学习C语言和C++时我们知道,在我们的程序中不同类型的数据存储在不同的内存区域中,如下图所示(以32位平台为例):
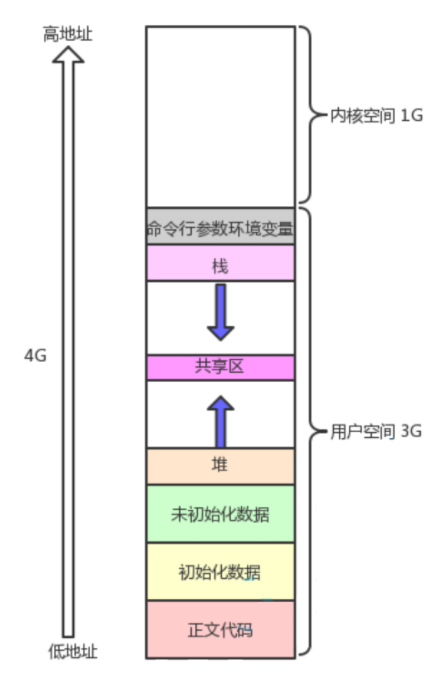
我们再次来认识一下每个区域的名称以及保存什么类型的数据:
| 区域 | 与上图对应 | 存放内容类型 | 特点说明 |
|---|---|---|---|
| 内核空间 | 内核空间 | 内核代码、内核数据结构、驱动、系统调用接口等 | 用户态不可访问,系统保护区 |
| 栈(Stack) | 栈 | 函数调用栈帧、局部变量、函数参数、返回地址等 | 向下增长,自动分配和释放 |
| 共享库区域 | 共享区 | 动态链接库(如libc.so) | 映射方式加载,可供多个进程共享 |
| 堆(Heap) | 堆 | 动态分配的变量(如:malloc、new) | 向上增长,由程序员控制释放 |
| BSS段 | 未初始化数据 | 未初始化的全局变量和静态变量(默认为0) | 加载时系统自动清零 |
| 数据段(Data) | 初始化数据 | 已初始化的全局变量和静态变量 | 来自程序的数据部分 |
| 代码段(Text) | 正文代码 | 可执行指令(函数体、主函数、库函数) | 权限通常为只读,防止被修改 |
光看显然是不够的,下面让我们用代码进行验证,看看这些是不是结论是不是正确的:
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int g_unval;
int g_val = 100;
int main(int argc, char *argv[], char *env[])
{const char *str = "helloworld";printf("code addr: %p\n", main);printf("init global addr: %p\n", &g_val);printf("uninit global addr: %p\n", &g_unval);static int test = 10;char *heap_mem = (char*)malloc(10);char *heap_mem1 = (char*)malloc(10);char *heap_mem2 = (char*)malloc(10);char *heap_mem3 = (char*)malloc(10);printf("heap addr: %p\n", heap_mem); //heap_mem(0), &heap_mem(1)printf("heap addr: %p\n", heap_mem1); //heap_mem(0), &heap_mem(1)printf("heap addr: %p\n", heap_mem2); //heap_mem(0), &heap_mem(1)printf("heap addr: %p\n", heap_mem3); //heap_mem(0), &heap_mem(1)printf("test static addr: %p\n", &test); //heap_mem(0), &heap_mem(1)printf("stack addr: %p\n", &heap_mem); //heap_mem(0), &heap_mem(1)printf("stack addr: %p\n", &heap_mem1); //heap_mem(0), &heap_mem(1)printf("stack addr: %p\n", &heap_mem2); //heap_mem(0), &heap_mem(1)printf("stack addr: %p\n", &heap_mem3); //heap_mem(0), &heap_mem(1)printf("read only string addr: %p\n", str);for(int i = 0 ;i < argc; i++){printf("argv[%d]: %p\n", i, argv[i]);} for(int i = 0; env[i]; i++){printf("env[%d]: %p\n", i, env[i]);} return 0;
}
我们来看一下运行结果:
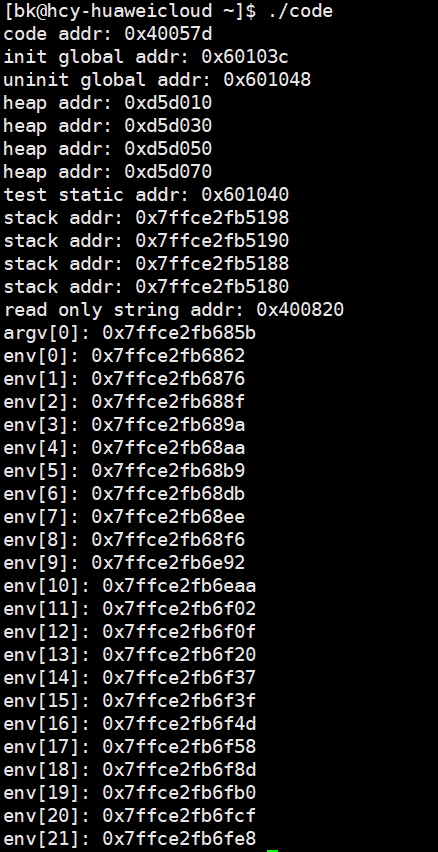
可以看到这些数据对应的地址的大小变化与上图是一致的。那么,这些地址是我们的数据在内存上的真实地址吗?
2. 深入了解
俗话说的好:“实践是检验真理的唯一标准。”下面,让我们通过一段代码来探究一下这个问题:
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int g_val = 0;
int main()
{pid_t id = fork();if(id < 0){perror("fork");return 0;} else if(id == 0){ //childprintf("child[%d]: %d : %p\n", getpid(), g_val, &g_val);}else{ //parentprintf("parent[%d]: %d : %p\n", getpid(), g_val, &g_val);} sleep(1);return 0;
}
上述代码的逻辑也十分简单:我们创建一个子进程,父进程和子进程执行不同的逻辑,打印全局变量g_val的值以及它的地址。下面让我们来看一下运行结果:

可以看到,父进程和子进程对于全局变量g_val打印的地址是相同的,这也很好理解,我们在前面讲解进程的时候说过:子进程会复制父进程的代码,并且访问的是同一变量,只有当子进程要对变量进行修改时,会发生写时拷贝,这样,父子进程在修改变量时便只会修改属于自己的那一份,使进程之间具有了独立性。
那么接下来让我们修改一下代码,让子进程对g_val变量进行修改,再观察运行结果。代码如下:
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int g_val = 0;
int main()
{pid_t id = fork();if(id < 0){perror("fork");return 0;} else if(id == 0){ //childg_val = 100;printf("child[%d]: %d : %p\n", getpid(), g_val, &g_val);}else{ //parentsleep(2)printf("parent[%d]: %d : %p\n", getpid(), g_val, &g_val);} sleep(1);return 0;
}
上述代码中,我们让子进程先进行打印,后让父进程打印,也就是先让子进程获得g_val的地址,后让父进程获得g_val的地址。下面让我们来看一看运行结果:

可以看到运行结果出乎我们的意料。子进程不是应该发生写时拷贝吗?为什么父子进程中的g_val的地址一样?为什么相同的地址会有两个不同的值出现?
我们一点点来分析:
- 首先:变量内容不一样,说明父子进程输出的变量不是同一个变量,也就是说子进程的确是进行了写时拷贝;
- 其次:我们看到两个不同的变量却有相同的地址,那么只有两种情况可以解释:要么是出现了bug,要么这个地址不是真实的物理地址。
结果已经很明显了,这显然不是bug,唯一的解释就是这些地址不是我们真实的物理地址,在Linux中,这种地址叫做虚拟地址。我们在C/C++语言中见到的所有地址,全部都是虚拟地址。物理地址用户是看不到的,由OS统一管理。管理的方式就是将虚拟地址和物理地址通过页表的方式进行映射。
页表
我们简单来认识一下什么是页表:在操作系统(OS)中,页表(Page Table)是用于实现虚拟内存管理的关键数据结构。
页表是操作系统为每一个进程维护的一个数据结构,用来将虚拟地址转换为物理地址。当程序运行时,它访问的是虚拟地址,而不是直接访问物理内存。CPU 通过页表将这些虚拟地址映射成实际的物理地址,从而访问真正的内存。
在页表中除了有虚拟地址以及其所对应的物理地址,还包括这块空间的读写权限等信息。
对于页表我们目前只需要了解它的作用即可。现在我们知道了,我们目前所看到以及访问的地址都是虚拟地址,对于每一个进程都有一块属于自己的虚拟地址空间,也叫做进程地址空间。
对于32位机器下虚拟地址空间大小通常为4G(从0x00000000到0xFFFFFFFF),64位机器下虚拟地址空间大小通常为8G。(从0地址开始,32位机器表示 CPU 使用 32 位的虚拟地址,那么 32 位地址最多能表示地址的数量也就是232字节,也就是4G)
那么对于上面的代码我们就可以进行解释了:
当子进程被创建时,两个进程的页表都指向同一份物理内存(包括代码段),也就是说父子进程都指向同一块物理空间:
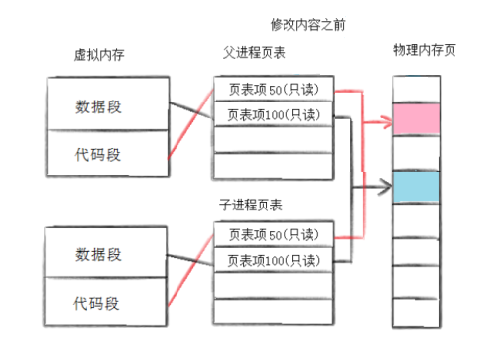
一旦某个进程尝试修改内存如写堆或数据段,就相当于上述代码中子进程更改g_val的值,操作系统就会为它分配一个新的物理内存,拷贝旧数据,并把页表中之前的物理地址进行更改:
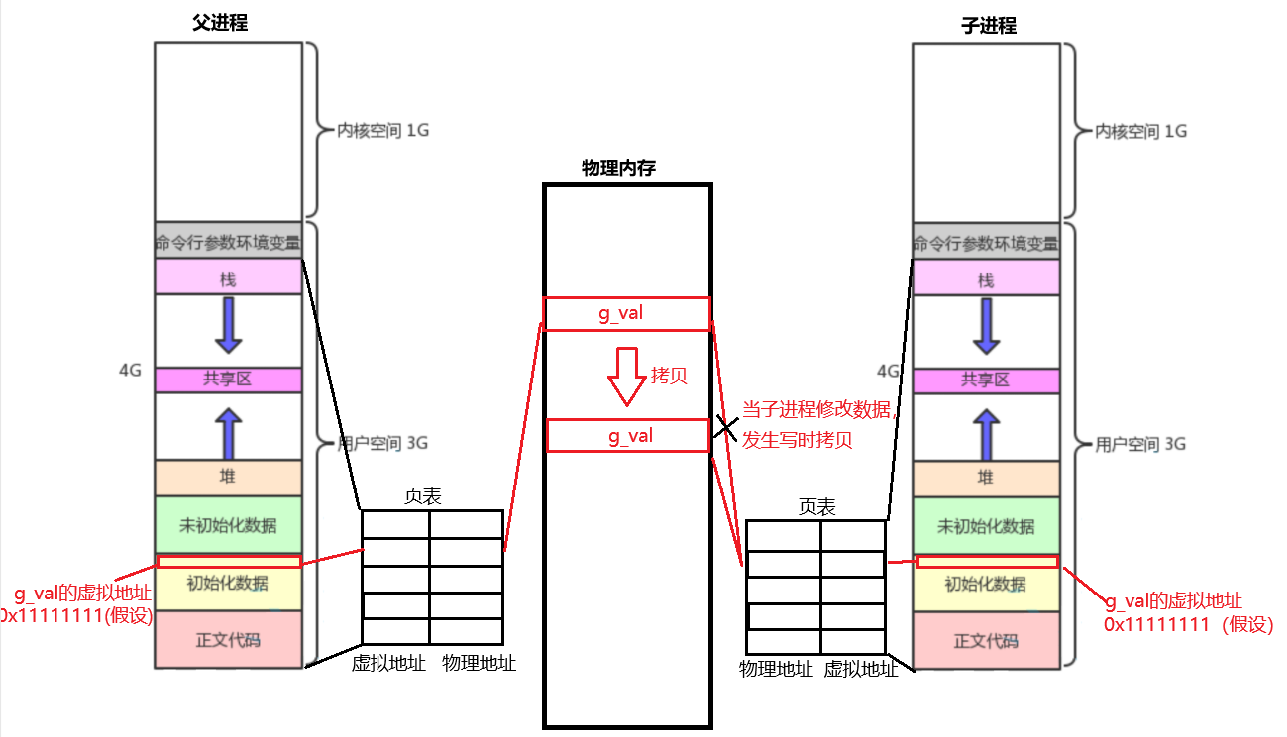
这样一来,虽然我们查看的地址相同,那是因为我们查看的是虚拟地址,而实际上这个虚拟地址所映射的物理地址已经发生了改变,子进程的数据有了自己新的物理空间,从而保障了进程之间的独立性。
3. 理解虚拟地址空间
我们已经简单的了解了虚拟地址空间,也知道了虚拟地址空间的存在可以有效地对物理地址进行保护。那么虚拟地址空间究竟是什么呢?我们该如何去理解它呢?
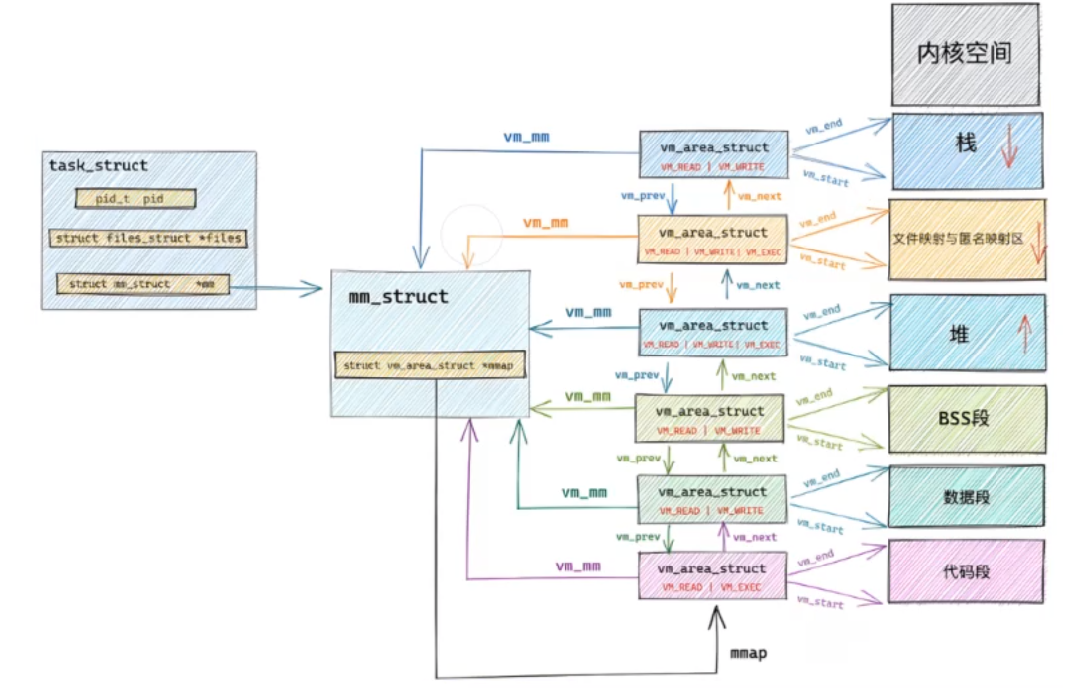
虚拟地址空间的本质是一个数据结构struct mm_struct(在Linux中的名字),这是因为每一个进程都有其对应的虚拟地址空间,我们需要对这些空间进行管理,所以也需要先进行组织。虚拟地址空间也是描述进程的一种属性,所以结构体mm_struct也存放在task_struct(PCB)中。
那么是不是说对于每一个进程我们都会给其分配一个的4G的物理空间呢(32位机器)?实际上并不是,这里所谓的4G是每一个虚拟地址空间的最大大小。也就是说实际上每一个进程所占据的物理内存实际上要远小于虚拟内存(具体原因后面再说),虚拟地址空间的大小只是让每一个进程都认为自己有4G的物理内存,或者说让进程认为自己在独占物理内存。
那么在mm_struct中是如何来划分每个区域的大小呢?实际上在mm_struct中我们用整数来表示每一个区域的开始和结束,也就是说我们只需要知道一个区域的开始和结束便可以划分出一块区域,因为我们的虚拟地址空间的大小是固定的。当需要调整区域大小时,只需要调整相应区域的开始与结束的数字即可。
下面让我们看一看Linux的内核代码中是否和我们描述的一样(2.6.18版本):

这里面包括了各个区域的开始和结束。
我们再来梳理一下进程与虚拟地址空间的关系:
当我们的程序写好后相应的数据和代码都保存在磁盘中,程序运行时变为一个进程,这时磁盘中的代码和数据便会加载到物理内存中,以代码为例,例如我们的程序代码有10兆字节,那么OS就会在物理内存中给它分配10兆大小的空间,对进程的虚拟地址空间中的代码段也分配相应的大小,然后通过页表将虚拟地址和物理地址形成一一对应的映射关系。
也就是说我们要把一个程序加载到内存需要做两件事情:
- 在对应的虚拟地址空间中申请指定大小的空间(调整区域划分)。
- 加载程序,申请物理空间。
然后再通过页表构建映射关系即可。那我们其实就可以理解为是OS将物理地址转为虚拟地址提供给上层用户使用。
我们知道mm_struct是一个结构体,那么当我们构建它时也需要进行初始化,那么它初始化的值是从哪得到的呢?大部分的值是我们的程序加载到内存的过程中拿到的。
可以说,mm_struct结构是对整个进程空间的描述。每⼀个进程都会有⾃⼰独⽴的mm_struct,这样每⼀个进程都会有⾃⼰独⽴的地址空间,这样才能互不⼲扰。
每⼀个进程都有⾃⼰独⽴的mm_struct,mm_struct结构体中存在许多虚拟内存区域(VMA)。那么这些VMA肯定是要组织起来的,VMA的组织⽅式有两种:
- 当VMA较少时采取单链表,由
mmap指针指向这个链表; - 当VMA较多时采取红⿊树进⾏管理,由
mm_rb指向这棵树。
Linux内核使⽤ vm_area_struct 结构来表⽰⼀个独⽴的VMA,由于每个不同质的虚拟内存区域功能和内部机制都不同,因此⼀个进程使⽤多个vm_area_struct结构来分别表⽰不同类型的虚拟内存区域,对于堆和栈来说可能会存在多个vm_area_struct,因为它们的大小是动态分配的。上⾯提到的两种组织⽅式使⽤的就是vm_area_struct结构来连接各个VMA,⽅便进程快速访问。
下面是Linux内核中vm_area_struct结构体的定义:
struct vm_area_struct {unsigned long vm_start; //虚存区起始unsigned long vm_end; //虚存区结束struct vm_area_struct *vm_next, *vm_prev; //前后指针struct rb_node vm_rb; //红⿊树中的位置unsigned long rb_subtree_gap;struct mm_struct *vm_mm; //所属的 mm_structpgprot_t vm_page_prot;unsigned long vm_flags; //标志位struct {struct rb_node rb;unsigned long rb_subtree_last;} shared;struct list_head anon_vma_chain;struct anon_vma *anon_vma;const struct vm_operations_struct *vm_ops; //vma对应的实际操作unsigned long vm_pgoff; //⽂件映射偏移量struct file * vm_file; //映射的⽂件void * vm_private_data; //私有数据atomic_long_t swap_readahead_info;
#ifndef CONFIG_MMUstruct vm_region *vm_region; /* NOMMU mapping region */
#endif
#ifdef CONFIG_NUMAstruct mempolicy *vm_policy; /* NUMA policy for the VMA */
#endiftruct vm_userfaultfd_ctx vm_userfaultfd_ctx;
} __randomize_layout;
我们还可以通过图示来更加深入的理解:
4. 为什么存在虚拟地址空间
4.1 进程隔离和安全性
在早期的计算机中,要运⾏⼀个程序,会把这些程序全都装⼊内存,程序都是直接运⾏在内存上的,也就是说程序中访问的内存地址都是实际的物理内存地址。当计算机同时运⾏多个程序时,必须保证这些程序⽤到的内存总量要⼩于计算机实际物理内存的⼤⼩。
那当程序同时运⾏多个程序时,操作系统是如何为这些程序分配内存的呢?例如某台计算机总的内存⼤⼩是128M,现在同时运⾏两个程序A和B,A需占⽤内存10M,B需占⽤内存110。计算机在给程序分配内存时会采取这样的⽅法:先将内存中的前10M分配给程序A,接着再从内存中剩余的118M中划分出110M分配给程序B。
这种分配⽅法可以保证程序A和程序B都能运⾏,但是这种简单的内存分配策略问题很多:
- **安全⻛险:**每个进程都可以访问任意的内存空间,这也就意味着任意⼀个进程都能够去读写系统相关内存区域,如果是⼀个⽊⻢病毒,那么他就能随意的修改内存空间,让设备直接瘫痪。
- **地址不确定:**众所周知,编译完成后的程序是存放在硬盘上的,当运⾏的时候,需要将程序搬到内存当中去运⾏,如果直接使⽤物理地址的话,我们⽆法确定内存现在使⽤到哪⾥了,也就是说拷⻉的实际内存地址每⼀次运⾏都是不确定的,⽐如:第⼀次执⾏
a.out时候,内存当中⼀个进程都没有运⾏,所以搬移到内存地址是0x00000000,但是第⼆次的时候,内存已经有10个进程在运⾏了,那执⾏a.out的时候,内存地址就不⼀定了 - **效率低下:**如果直接使⽤物理内存的话,⼀个进程就是作为⼀个整体(内存块)操作的,如果出现物理内存不够⽤的时候,我们⼀般的办法是将不常⽤的进程拷⻉到磁盘的交换分区中,好腾出内存,但是如果是物理地址的话,就需要将整个进程⼀起拷⾛,这样,在内存和磁盘之间拷⻉时间太⻓,效率较低。
当有了虚拟地址空间和分页机制就能解决这些问题:
- 地址空间和⻚表是OS创建并维护的,也就意味着,凡是想使⽤地址空间和⻚表进⾏映射,也⼀定要在OS的监管之下来进⾏访问。这样就保护了物理内存中的所有的合法数据,包括各个进程以及内核的相关有效数据。
举一个很简单的例子:为什么当我们在程序中对一个常量字符串进行更改时程序会崩溃?最根本的原因就是当我们在查找页表时,页表对于这一部分地址的数据的权限是只读,所以我们的操作就是不合法操作,程序自然就会崩溃。
4.2 简化程序设计
我们要知道,一个程序的代码和数据加载到物理内存上是无序的,也就是说对于一部分数据哪里有位置就加载到哪,也就是说一个程序加载到物理内存上时它的代码和数据的位置都是随机的,这很不方便我们进行管理,有了虚拟地址空间,我们不仅可以将这些在物理上无序的地址变得看似有序。因此程序员在写程序时不必考虑系统中已有进程的内存分配情况。
- 所有程序都认为内存从地址
0x00000000开始,逻辑简单。 - 不需要关心其他程序的存在或物理内存的布局。
因为⻚表的映射的存在,程序在物理内存中理论上就可以任意位置加载。它可以将地址空间上的虚拟地址和物理地址进⾏映射,在进程视⻆所有的内存分布都可以是有序的。
4.3 解耦合
因为有虚拟地址空间的存在和⻚表的映射的存在,我们的物理内存中可以对未来的数据进⾏任意位置的加载!物理内存的分配和进程的管理就可以做到没有关系,进程管理模块和内存管理模块就完成了解耦合。
因为有地址空间的存在,所以我们在C、C++语⾔上
new,malloc空间的时候,其实是在虚拟地址空间上申请的,物理内存甚⾄可以⼀个字节都不给你。⽽当你真正进⾏对物理地址空间访问的时候,才执⾏内存的相关管理算法,帮你申请内存,构建⻚表映射关系(延迟分配),这是由操作系统⾃动完成,⽤⼾包括进程完全0感知!
4.4 支持虚拟内存和更大地址空间
在没有虚拟地址空间的情况下,进程只能访问直接映射到物理内存的地址,也就是说,进程需要直接管理和访问实际的物理内存。每个进程的虚拟地址空间是由操作系统抽象出来的,它在进程和物理内存之间提供了一层“虚拟化”。
虚拟地址空间 让每个进程感觉到自己拥有完整且独立的内存地址空间,而不需要关心实际的物理内存布局。操作系统通过虚拟内存机制将虚拟地址映射到物理内存中。
- 每个进程都有自己的虚拟地址空间,操作系统可以在虚拟地址空间中分配更多的内存区域,而不受物理内存的限制。程序可以使用比实际物理内存更大的内存空间。
- 通过页面置换等机制,把不常用数据临时换到磁盘,而不是一直占用物理内存。
- 支持大程序运行在小物理内存的机器上。
比如你物理内存只有 8GB,但程序可以运行 16GB 的数据。
对于虚拟地址空间还有更多的知识,本章我们进行初步的认识和了解。更多的我们将在后面随着学习的深入再慢慢了解。
尾声
本章讲解就到此结束了,若有纰漏或不足之处欢迎大家在评论区留言或者私信,同时也欢迎各位一起探讨学习。感谢您的观看!
相关文章:

【寻找Linux的奥秘】第七章:虚拟地址空间
前言 本专题将基于Linux操作系统来带领大家学习操作系统方面的知识以及学习使用Linux操作系统。上一章我们简单认识了环境变量,本章将讲解操作系统中另一个重要的概念——程序地址空间。 1. 初步认识 之前在我们学习C语言和C时我们知道,在我们的程序中不…...
 2-0 等级保护制度现行技术标准)
网络安全-等级保护(等保) 2-0 等级保护制度现行技术标准
################################################################################ 第二章:现行等保标准要求,通过表格方式详细拆分了等保的相关要求。 GB 17859-1999 计算机信息系统 安全保护等级划分准则【现行】 GB/T22240-2020 《信息安全技术…...

Linux:进程信号---信号的保存与处理
文章目录 1. 信号的保存1.1 信号的状态管理 2. 信号的处理2.1 用户态与内核态2.2 信号处理和捕捉的内核原理2.3 sigaction函数 3. 可重入函数4. Volatile5. SIGCHLD信号 序:在上一章中,我们对信号的概念及其识别的底层原理有了一定认识,也知道…...
)
【Linux】C语言模拟实现shell命令行(程序替换原理)
目录 一、自动化构建工具(makefile) 二、输出提示符 三、获取用户输入的数据 四、将用户输入的指令字符串进行分割: 五、执行用户输入的命令 六、发现cd命令用不了(内建命令) 原因在于: 七、处理内…...
)
WordPress Madara插件存在文件包含漏洞(CVE-2025-4524)
免责声明 本文档所述漏洞详情及复现方法仅限用于合法授权的安全研究和学术教育用途。任何个人或组织不得利用本文内容从事未经许可的渗透测试、网络攻击或其他违法行为。使用者应确保其行为符合相关法律法规,并取得目标系统的明确授权。 对于因不当使用本文信息而造成的任何直…...

【Java】泛型在 Java 中是怎样实现的?
先说结论 , Java 的泛型是伪泛型 , 在运行期间不存在泛型的概念 , 泛型在 Java 中是 编译检查 运行强转 实现的 泛型是指 允许在定义类 , 接口和方法时使用的类型参数 , 使得代码可以在不指定具体类型的情况下操作不同的数据类型 , 从而实现类型安全的代码复用 的语言机制 . …...

Lambda表达式的高级用法
今天来分享下Java的Lambda表达式,以及它的高级用法。 使用它可以提高代码的简洁度,使代码更优雅。 一、什么是lambda表达式 Lambda 表达式是 Java 8 引入的特性,用于简化匿名内部类的语法,使代码更简洁,尤其在处理函…...

ctfhub技能书http协议
http://challenge-ffe8afcf1a75b867.sandbox.ctfhub.com:10800/index.php curl -v -X CTFHUB http://challenge-ffe8afcf1a75b867.sandbox.ctfhub.com:10800/index.php curl:用于发送 HTTP 请求的命令行工具。 -v(--verbose):开启…...
)
面试题 - 微服务相关的经典问题(33道)
1.什么是微服务? 微服务(Microservices)是一种软件架构风格,将一个大型应用程序划分为一组小型、自治且松耦合的服务。每个微服务负责执行特定的业务功能,并通过轻量级通信机制(如HTTP)相互协作…...

在C#中对List<T>实现多属性排序
本文介绍了四种实现多级排序的方法:1. LINQ链式调用:使用OrderBy和ThenBy实现多级排序,直观易读,适合动态需求,返回新列表。2. 自定义比较器(IComparer):适用于复杂或高频排序&#…...

C++初阶-vector的模拟实现3
目录 1.预备知识:initializer_list 1.1初步了解 1.2关于initializer_list的deepseek的回答 C中的 std::initializer_list 主要特性 常见用途 1. 接受列表的构造函数和函数 2. 基于范围的 for 循环 重要注意事项 实现示例 2.vector::vector(initializer_li…...

详解鸿蒙仓颉开发语言中的日志打印问题
一门新的开发语言在诞生初期,由于它本身的特性和使用人数暂时较少,会容易出现一些大家不太容易理解的问题,或者说有一些坑。今天就详细分享一下仓颉开发语言中的日志打印相关内容,带大家踩一踩坑。 AppLog 在新创建的项目中&…...

dify基于文本模型实现微调Fine-tune语料构造工作流
主要是分为5个部分。分别是:开始、文档提取器、代码执行、LLM大语言模型、结束 5个部分 打开dify,创建一个空白页面-选择工作流,我们给应用起个名字。 创建完成后,进入工作流画布界面 开始 在开始节点中新建2个输入参数。1个是用…...

手机充电协议
1、手机快充 公有:PD、QC(高通骁龙芯片) 私有: 华为:FCP(fast charge protocol) 、SCP( super charge protocol) 、 小米: Mi Turbo Charge oppo:VOOC/SuperVOOC vivo:FlashCharge、…...

HarmonyOS 应用开发,如何引入 Golang 编译的第三方 SO 库
本指南基于笔者临时修复的 ohos_golang_go 项目fork,解决HO 应用导入 cgo编译产物时的 crash 问题。 1. 下载 ohos_golang_go git clone https://gitcode.com/deslord/ohos_golang_go.git📌 该仓库为笔者临时修复版本,修复了 CGO 编译模式下…...

polarctf-web-[某函数的复仇]
考点: 匿名构造函数(create_function) 题目来源:polarctf-web-[某函数的复仇] 解题: 代码审计: <?phphighlight_file(__FILE__);//flag:/flagif(isset($_POST[shaw])){$shaw $_POST[shaw];$root $_GET[root];if(preg_mat…...

Node.js Express 项目现代化打包部署全指南
Node.js Express 项目现代化打包部署全指南 一、项目准备阶段 1.1 依赖管理优化 # 生产依赖安装(示例) npm install express mongoose dotenv compression helmet# 开发依赖安装 npm install nodemon eslint types/node --save-dev1.2 环境变量配置 /…...

华为云Flexus+DeepSeek征文|Flexus云服务器Dify-LLM资源部署极致体验Agent
前引:重磅来袭!本次以DeepSeek-V3/R1商用大模型和Dify-LLM应用平台一键部署为核心,专为新手打造“开箱即用”的AI开发体验。无论你是想快速搭建企业级AI应用,还是探索大模型落地的无限可能,只需跟随小编实现三步走&…...
:LeetCode 73. 矩阵置零(Set Matrix Zeroes)详解)
Java详解LeetCode 热题 100(18):LeetCode 73. 矩阵置零(Set Matrix Zeroes)详解
文章目录 1. 题目描述2. 理解题目3. 解法一:使用两个额外数组标记法3.1 思路3.2 Java代码实现3.3 代码详解3.4 复杂度分析3.5 适用场景 4. 解法二:使用矩阵的第一行和第一列作为标记4.1 思路4.2 Java代码实现4.3 代码详解4.4 复杂度分析4.5 适用场景 5. …...

MySQL刷题 Day08
LC 1341电影评分 本题思路简单,但一不注意就错了 : 不难想到用union,写出如下代码: (select u.name results from MovieRating mr left join Users u on mr.user_id u.user_id group by mr.user_id order by count(mr.user_id…...

linux查看本机服务器的外网IP命令
在 Linux 中查看本机服务器的外网 IP(公网 IP)可以通过以下几种方法: 1. 使用 curl 查询外部服务(推荐) curl ifconfig.me或: curl icanhazip.com或: curl ipinfo.io/ip这些服务会返回你的公…...

DVWA-XSS
DOM low 这是一个下拉框的形式,但是如果我们不让他等于English呢,换成js代码呢? <script>alert(xss);</script> Medium <script> 标签,但仅使用简单的字符串匹配进行替换(比如移除 "<scr…...

第15天-NumPy科学计算实战:从基础到图像处理
一、NumPy核心优势 高效数组运算:矢量操作比纯Python快10-100倍 广播机制:不同形状数组的算术运算 内存优化:连续内存块存储,支持大数据处理 丰富API:线性代数、傅里叶变换、随机数生成等 二、环境准备 pip install numpy matplotlib 三、基础操作演示 1. 创建数组 im…...

Spring Boot + +小程序, 快速开发零工市场小程序
现在零工经济发展的越来越好,不止是很多人想要利用空余时间找零工赚外快,也有很多企业有灵活用工的需求,根据这样的需求,我们利用Spring Boot 和小程序,快速开发出了零工市场小程序。 利用 Spring Boot 开发零工市场小…...

Vue 3.0中核心的Composition API
在当今快速发展的前端生态系统中,Vue 3.0以其革命性的Composition API重新定义了组件开发的范式。作为Vue框架的一次重大进化,Composition API不仅解决了Options API在复杂组件中面临的逻辑复用和组织难题,更为开发者提供了更灵活、更强大的代…...

洛谷B3840 [GESP202306 二级] 找素数
题目描述 小明刚刚学习了素数的概念:如果一个大于 1 的正整数,除了 1 和它自身外,不能被其他正整数整除,则这个正整数是素数。现在,小明想找到两个正整数 A 和 B 之间(包括 A 和 B)有多少个素数…...

Axure设计之带分页的穿梭框原型
穿梭框(Transfer)是一种常见且实用的交互组件,广泛应用于需要批量选择或分配数据的场景。 一、应用场景 其典型应用场景包括: 权限管理系统:批量分配用户角色或系统权限数据筛选工具:在大数据集中选择特…...

VsCode开发环境之Node.js离线部署
1.下载node部署文件 地址为:CNPM Binaries Mirror 2.下载后解压 3.验证版本 4.配置环境变量 5.外网寻找一个对应项目的npm文件--node_modules 6.node_modules文件夹复制到node.js的路径下 7.接着就可以正常运行了。...

补充Depends 和 request: Request 依赖注入用法的注意事项
不要在非路由函数(如类的 __init__ 方法或普通模块函数)中直接使用 Depends() 或 request。 Depends 和 request: Request 是 FastAPI 提供的依赖注入机制的一部分,仅适用于FastAPI 路由函数或由 FastAPI 调用的依赖函数中。在类初始化、模块…...
)
uniapp-商城-64-后台 商品列表(商品修改---页面跳转,深浅copy应用,递归调用等)
完成了商品的添加和展示,下面的文字将继续进行商品页面的处理,主要为商品信息的修改的页面以及后天逻辑的处理。 本文主要介绍了商品信息修改页面的实现过程。首先,页面布局包括编辑和删除功能,未来还可添加上架和下架按钮。通过c…...
)
【MySQL】联合查询(上)
目录 一. 什么是联合查询 二. 笛卡尔积 三. 内连接查询 示例演示 四. 外连接 示例演示 五. 自连接 自连接 示例演示 一. 什么是联合查询 在之前学习的增删改查中都是对于单表进行查询,但是因为在数据库设计时需要遵循范式的要求,数据就会被拆分到多…...
)
Model 是 Agent 的大脑(以camel为例)
Model 是 Agent 的大脑,负责处理所有输入和输出数据。通过有效调用不同的模型,智能体可以根据任务需求执行文本分析、图像识别和复杂推理等操作。CAMEL 提供了一系列标准和可定制的接口,并与各种组件无缝集成,以赋能大语言模型&am…...

Linux条件变量
在 Linux 系统中,pthread_cond_init() 函数和条件变量(Condition Variable)是多线程编程中用于线程同步的核心机制。它们通过协调线程间的等待与通知逻辑,解决共享资源的竞争问题。以下从功能、工作机制、使用场景和注意事项等方面…...

k8s-NetworkPolicy
在 Kubernetes 中,NetworkPolicy 是一种资源对象,用于定义 Pod 之间的网络通信策略。它允许你控制哪些 Pod 可以相互通信,以及如何通信。通过使用 NetworkPolicy,可以实现更细粒度的网络访问控制,增强集群的安全性。 1…...

什么是“架构孤岛”?如何识别与整合?为什么现代企业在追求敏捷开发的同时,反而更容易陷入架构孤岛陷阱?
在现代信息技术飞速发展的时代,系统架构日益复杂,组织在构建与演进其信息系统时,面临着前所未有的挑战。然而,就在不断追求敏捷性、可扩展性与数字化创新的过程中,一个被广泛忽视却日益严峻的问题悄然浮现——“架构孤岛”。它们像岛屿一样,彼此孤立,通信不畅,数据难以…...

nfs存储IO等待,导致k8s业务系统卡慢问题处理
注:服务器配置:64C,128G,麒麟v10系统,系统磁盘使用空间(5T)均低于50%,存储磁盘iops约为800左右 发现业务系统卡慢,使用top 命令查看.系统负载较高长期保持在60以上,发现wa值的指标参数长期高于15,返现CPU用于写入磁盘IO等待的时间较高,系统的磁盘I/O压力较大. 配合开发查看日志…...

如何使用两块硬盘作为 Ubuntu24 的系统盘,实现坏掉一块不影响系统运行。
最近我想使用Ubuntu组一个NAS系统,想实现系统盘冗余,各位大佬可以给点建议吗。 Deep Seek 为了实现两块硬盘作为 Ubuntu 24 系统盘的冗余配置(RAID 1),确保一块硬盘损坏时系统仍可运行,以下是详细步骤&am…...

电子电气架构 --- 细化造车阶段流程
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 钝感力的“钝”,不是木讷、迟钝,而是直面困境的韧劲和耐力,是面对外界噪音的通透淡然。 生活中有两种人,一种人格外在意别人的眼光;另一种人无论…...

物联网之使用Vertx实现UDP最佳实践【响应式】
小伙伴们,你们好呀,我是老寇,跟我一起学习使用Vertx实现UDP-Server 实现UDP【响应式】 Vertx-Core地址 注意 UDP是无连接的传输,这意味着您与远程客户端没有建立持续的连接。 所以,您发送和接收的数据包都要包含有…...

代码管理平台Gitlab如何通过快解析实现远程访问?
一、Gitlab功能介绍 Gitlab是被广泛使用的基于git的开源代码管理平台,用于管理、存储开发人员代码,同时可以协同开发 二、外网试用Gitlab遇到的问题 运维人员将Gitlab服务器部署在总部机房,而分公司开发人员和出差运维人员就无法访问Gitlab…...

七彩喜防摔马甲:科技守护银发安全的“隐形铠甲”
随着现代人生活方式的多样化,尤其是在户外运动和骑行等活动中,安全问题日益受到重视。 七彩喜防摔马甲,作为一款兼具防护性与舒适性的智能穿戴设备,正在改变人们对传统防护装备的认知。 创新设计 防摔马甲的设计灵感来源于人体…...

IDEA推送到gitlab,jenkins识别,然后自动发布到需要的主机
实验环境 192.168.8.100 gitlab 192.168.8.200 jenkins mvn 192.168.8.10 测试主机 默认都关闭了防火墙和setenforce 实验要求 实验在IDEA上面推送代码然后gitlab推送给jenkins,然后mvn构建,最后发布到测试主机上面 实验开始 在tomcat上安装manve…...
】:使用 Django REST Framework构建测试用例模型的 CRUD API)
五、【API 开发篇(下)】:使用 Django REST Framework构建测试用例模型的 CRUD API
【API 开发篇】:使用 Django REST Framework构建测试用例模型的 CRUD API 前言第一步:增强 Serializers (序列化器) - 处理关联和选择项第二步:创建 TestCaseViewSet (视图集) - 支持过滤第三步:注册 TestCaseViewSet 到 Router第…...
)
IDEA推送到gitlab,jenkins识别,然后自动发布到需要的主机(流水线)
jenkins流水线 新建项目 找到流水线选择脚本 3.点击流水线语法开始编辑脚本 4.生成流水线脚本复制 5.修改脚本 6.继续添加(手打) 7.继续生成添加 8.最终脚本 9.保存测试 10.构建 11.访问主页查看是否修改...
】:使用 Django REST Framework 构建项目与模块 CRUD API)
四、【API 开发篇 (上)】:使用 Django REST Framework 构建项目与模块 CRUD API
【API 开发篇 】:使用 Django REST Framework 构建项目与模块 CRUD API 前言为什么选择 Django REST Framework (DRF)?第一步:创建 Serializers (序列化器)第二步:创建 ViewSets (视图集)第三步:配置 URLs (路由)第四步…...

vscode连接本地Ubuntu
因为在学习项目的时候,自己的云服务器性能太差一直要编译很长时间,而且总是连接失败,所以搞了一个Ubuntu25.04的系统在自己的vmare中。 其中参考了以下文章。 Ubuntu 24.04 桌面版安装指南(2025版) | 官网镜像下载启动盘制作保姆级图文教程…...

idea无法识别Maven项目
把.mvn相关都删除了 导致Idea无法识别maven项目 或者 添加导入各个模块 最后把父模块也要导入...

Redis应用--缓存
目录 一、什么是缓存 1.1 二八定律 二、使用Redis作为缓存 三、缓存的更新策略 3.1 定期更新 3.2 实时生成 四、缓存预热、缓存穿透、缓存雪崩和缓存击穿 4.1 缓存预热 4.2 缓存穿透 4.3 缓存雪崩 4.4 缓存击穿 一、什么是缓存 缓存(cache)是计算机的一个经典的概念…...

大语言模型与人工智能:技术演进、生态重构与未来挑战
目录 技术演进:从专用AI到通用智能的跃迁核心能力:LLM如何重构AI技术栈应用场景:垂直领域的技术革命生态关系:LLM与AI技术矩阵的协同演进挑战局限:智能天花板与伦理困境未来趋势:从语言理解到世界模型1. 技术演进:从专用AI到通用智能的跃迁 1.1 三次技术浪潮的跨越 #me…...
)
多模态大语言模型arxiv论文略读(八十六)
EVALALIGN: Supervised Fine-Tuning Multimodal LLMs with Human-Aligned Data for Evaluating Text-to-Image Models ➡️ 论文标题:EVALALIGN: Supervised Fine-Tuning Multimodal LLMs with Human-Aligned Data for Evaluating Text-to-Image Models ➡️ 论文作…...