五、【API 开发篇(下)】:使用 Django REST Framework构建测试用例模型的 CRUD API
【API 开发篇】:使用 Django REST Framework构建测试用例模型的 CRUD API
- 前言
- 第一步:增强 Serializers (序列化器) - 处理关联和选择项
- 第二步:创建 TestCaseViewSet (视图集) - 支持过滤
- 第三步:注册 TestCaseViewSet 到 Router
- 第四步:测试 TestCase API
- 总结
前言
在上一篇项目与模块的 API 开发中,我们掌握了 ModelSerializer 和 ModelViewSet 的基本用法,并利用 DefaultRouter 快速生成了 URL。
对于 TestCase 模型,我们可能会遇到以下需求:
- 关联数据显示: 在获取测试用例列表或详情时,我们可能希望不仅仅看到所属模块的 ID (
module_id),还想直接看到模块的名称,甚至项目的名称。 - 写入时处理关联: 创建或更新测试用例时,前端可能会传递模块的 ID,后端需要正确处理这种关联。
- 更复杂的字段处理:
TestCase模型中有choices类型的字段 (如priority,case_type),还有可能需要特殊处理的文本字段 (如steps_text)。 - 特定业务逻辑的过滤: 例如,我们可能需要根据项目 ID 来筛选测试用例,或者根据模块 ID 来筛选测试用例。
第一步:增强 Serializers (序列化器) - 处理关联和选择项
我们需要为 TestCase 模型创建一个序列化器,并考虑如何更好地展示关联数据和处理选择项。
打开 api/serializers.py 文件,在 ModuleSerializer 之后添加 TestCaseSerializer:
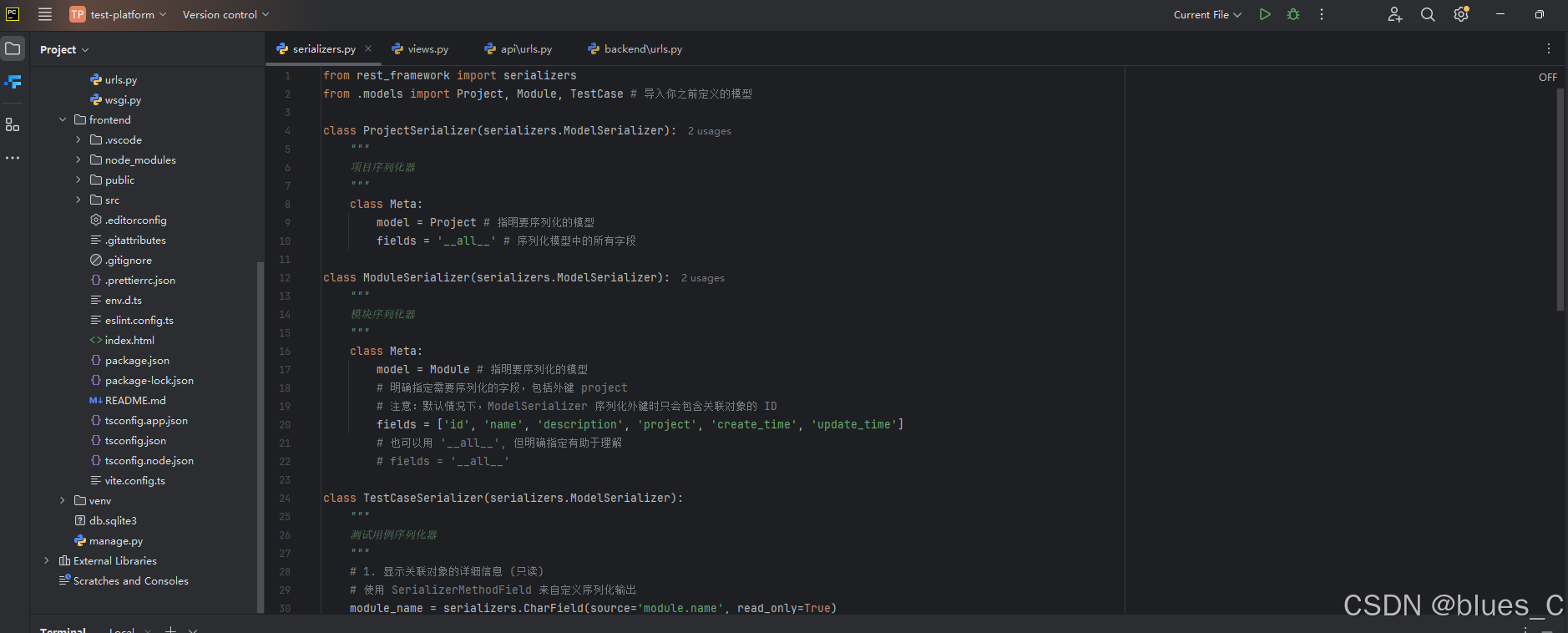
# test-platform/api/serializers.pyfrom rest_framework import serializers
from .models import Project, Module, TestCase# ... (ProjectSerializer 和 ModuleSerializer 代码保持不变) ...class TestCaseSerializer(serializers.ModelSerializer):"""测试用例序列化器"""# 1. 显示关联对象的详细信息 (只读)# 使用 SerializerMethodField 来自定义序列化输出module_name = serializers.CharField(source='module.name', read_only=True)project_name = serializers.CharField(source='module.project.name', read_only=True)project_id = serializers.IntegerField(source='module.project.id', read_only=True) # 方便前端筛选# 2. 对于 choices 字段,我们可以让前端直接看到可选项的描述文本 (只读)# DRF 默认会返回 choice 的实际存储值 (如 'P0')# 如果需要返回描述文本 (如 'P0 - 最高'),可以使用 `SerializerMethodField` 或 `ChoiceField`# 这里我们选择在前端处理显示,后端保持原始值,但可以添加一个 `get_xxx_display` 的方法到模型中,DRF 会自动识别# 或者,更简单的方式是,让前端直接获取这些 choices,这里我们暂时保持默认。# 如果想在序列化时直接获得 display 值,可以这样做:priority_display = serializers.CharField(source='get_priority_display', read_only=True)case_type_display = serializers.CharField(source='get_case_type_display', read_only=True)class Meta:model = TestCase# fields = '__all__' # 默认会包含 module (仅ID), create_time, update_time 等# 我们明确指定字段,并包含自定义的只读字段fields = ['id', 'name', 'description', 'module', 'module_name', 'project_id', 'project_name','priority', 'priority_display', 'precondition', 'steps_text', 'expected_result','case_type', 'case_type_display', 'maintainer','create_time', 'update_time']# 3. 写入时只接受 module_id# read_only_fields 用于指定哪些字段仅在序列化输出时显示,不在反序列化(创建/更新)时接受输入# 我们已经在自定义字段上加了 read_only=True,这里可以不用再写# read_only_fields = ['module_name', 'project_name', 'project_id', 'priority_display', 'case_type_display', 'create_time', 'update_time']# 如果想在创建/更新时只允许传入 module 的 id,而 module_name 等是只读的,# 并且希望在API文档中明确,可以像下面这样配置 extra_kwargsextra_kwargs = {'create_time': {'read_only': True},'update_time': {'read_only': True},'module': {'write_only': False, 'help_text': "关联的模块ID"}, # module 字段本身可读可写 (ID)}
代码解释:
-
显示关联对象的名称 (如
module_name,project_name):module_name = serializers.CharField(source='module.name', read_only=True):- 我们定义了一个新的字段
module_name。 source='module.name'告诉 DRF 这个字段的值应该从当前TestCase实例的module属性的name属性获取 (即testcase_instance.module.name)。这利用了 Django 模型反向查询的特性。read_only=True表示这个字段只用于序列化输出(即 GET 请求的响应),不能用于反序列化输入(即 POST 或 PUT 请求的请求体)。当我们创建或更新测试用例时,我们仍然通过传递module字段(模块的 ID)来指定其所属模块。
- 我们定义了一个新的字段
project_name = serializers.CharField(source='module.project.name', read_only=True): 类似地,获取项目名称。project_id = serializers.IntegerField(source='module.project.id', read_only=True): 获取项目ID,方便前端进行筛选或构建链接。
-
显示 Choices 字段的描述文本 (如
priority_display):priority_display = serializers.CharField(source='get_priority_display', read_only=True):- Django 模型字段如果定义了
choices,会自动拥有一个get_FIELD_display()方法(例如,priority字段有get_priority_display()方法)。这个方法会返回该字段当前值的可读描述。 - 通过
source='get_priority_display',我们可以直接在序列化器中调用这个方法来获取描述文本。 read_only=True同样表示这是只读的。
- Django 模型字段如果定义了
-
Meta类中的配置:fields = [...]: 我们明确列出了所有希望在 API 中暴露的字段,包括我们自定义的只读字段。extra_kwargs:'module': {'write_only': False, 'help_text': "关联的模块ID"}:write_only=False(默认值) 意味着module字段(它代表模块的 ID)在读取和写入时都有效。help_text会在 DRF 的可浏览 API 界面中显示为提示信息,方便 API 使用者理解。
- 我们已经为自定义的
xxx_name和xxx_display字段设置了read_only=True,所以它们自然不会在写入时被接受。 create_time和update_time通常也应该是只读的,因为它们由auto_now_add和auto_now自动管理。
更新 ModuleSerializer 以包含项目名称 (可选但推荐)
为了保持一致性,我们也可以在 ModuleSerializer 中添加 project_name 字段,这样在查看模块列表或详情时也能直接看到项目名称。
修改 api/serializers.py 中的 ModuleSerializer:
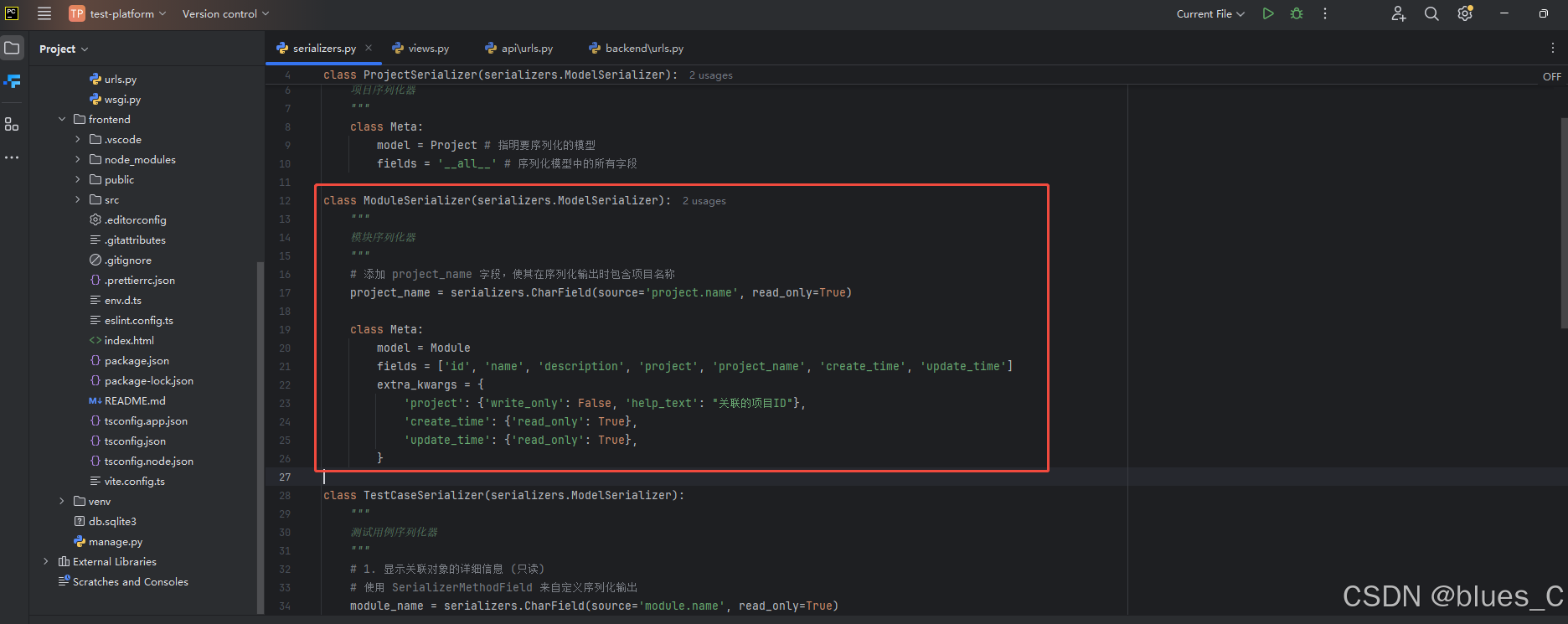
# test-platform/api/serializers.py# ... (ProjectSerializer 保持不变) ...class ModuleSerializer(serializers.ModelSerializer):"""模块序列化器"""# 添加 project_name 字段,使其在序列化输出时包含项目名称project_name = serializers.CharField(source='project.name', read_only=True)class Meta:model = Modulefields = ['id', 'name', 'description', 'project', 'project_name', 'create_time', 'update_time']extra_kwargs = {'project': {'write_only': False, 'help_text': "关联的项目ID"},'create_time': {'read_only': True},'update_time': {'read_only': True},}# ... (TestCaseSerializer 保持不变) ...
现在,当获取模块信息时,响应中也会包含 project_name。
第二步:创建 TestCaseViewSet (视图集) - 支持过滤
接下来,创建 TestCaseViewSet。我们将继承 ModelViewSet 并可能添加一些自定义的过滤逻辑。
打开 api/views.py 文件,添加 TestCaseViewSet:
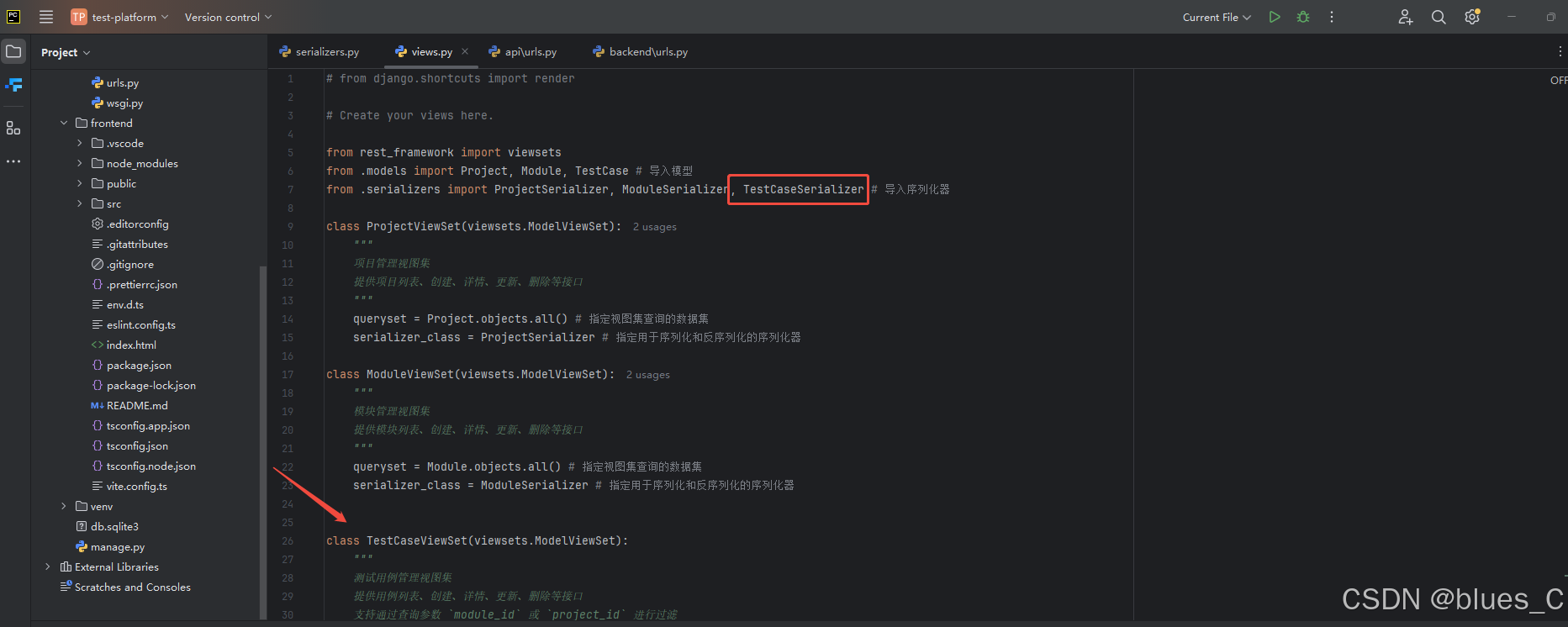
# test-platform/api/views.pyfrom rest_framework import viewsets
# 如果需要更细致的权限控制,可以导入 permissions
# from rest_framework import permissions
from .models import Project, Module, TestCase
from .serializers import ProjectSerializer, ModuleSerializer, TestCaseSerializer # 导入 TestCaseSerializer# ... (ProjectViewSet 和 ModuleViewSet 代码保持不变) ...class TestCaseViewSet(viewsets.ModelViewSet):"""测试用例管理视图集提供用例列表、创建、详情、更新、删除等接口支持通过查询参数 `module_id` 或 `project_id` 进行过滤"""queryset = TestCase.objects.all() # 默认查询所有测试用例serializer_class = TestCaseSerializer# permission_classes = [permissions.IsAuthenticated] # 示例:可以添加权限控制,要求用户已登录# 自定义 get_queryset 方法以支持动态过滤def get_queryset(self):"""重写get_queryset方法,根据请求参数动态过滤查询集"""queryset = super().get_queryset() # 获取基础查询集# 1. 根据 module_id 过滤module_id = self.request.query_params.get('module_id', None)if module_id is not None:# 确保 module_id 是有效的整数try:module_id = int(module_id)queryset = queryset.filter(module_id=module_id)except ValueError:# 如果 module_id 不是有效的整数,可以忽略或返回错误pass # 或者 raise serializers.ValidationError("module_id 必须是整数")# 2. 根据 project_id 过滤 (通过模块关联到项目)project_id = self.request.query_params.get('project_id', None)if project_id is not None:# 确保 project_id 是有效的整数try:project_id = int(project_id)# TestCase -> Module -> Projectqueryset = queryset.filter(module__project_id=project_id)except ValueError:passreturn queryset.order_by('-create_time') # 默认按创建时间降序
代码解释:
queryset = TestCase.objects.all(): 默认情况下,视图集将操作所有TestCase对象。serializer_class = TestCaseSerializer: 指定使用我们刚刚创建的TestCaseSerializer。def get_queryset(self):: 我们重写了ModelViewSet的get_queryset方法。这个方法在每次需要获取查询集(例如,列表视图或详情视图)时都会被调用。queryset = super().get_queryset(): 首先调用父类的get_queryset方法获取基础查询集(即TestCase.objects.all())。module_id = self.request.query_params.get('module_id', None):self.request是 DRF 封装的 HTTP 请求对象。query_params是一个类似字典的对象,包含了 URL 中的查询参数 (例如?module_id=1&name=test)。.get('module_id', None)尝试获取名为module_id的查询参数,如果不存在则返回None。
if module_id is not None: ... queryset = queryset.filter(module_id=module_id): 如果module_id参数存在,就使用 Django ORM 的filter()方法来筛选出属于该模块的测试用例。project_id = self.request.query_params.get('project_id', None): 类似地获取project_id参数。if project_id is not None: ... queryset = queryset.filter(module__project_id=project_id):- 如果
project_id参数存在,我们使用module__project_id=project_id来进行过滤。 - 这里的
module__project_id是 Django ORM 的跨关系查询语法,意思是“通过TestCase的module字段,找到关联的Module对象,再通过该Module对象的project字段,找到关联的Project对象,并筛选出其id等于project_id的那些TestCase”。
- 如果
return queryset.order_by('-create_time'): 最后返回经过筛选和排序的查询集。
通过这种方式,我们的 /api/testcases/ 端点现在可以接受 module_id 和 project_id 作为查询参数来进行动态过滤。例如:
/api/testcases/?module_id=5:获取模块 ID 为 5 的所有测试用例。/api/testcases/?project_id=2:获取项目 ID 为 2 的所有测试用例。/api/testcases/?project_id=2&module_id=5:获取项目 ID 为 2 且模块 ID 为 5 的所有测试用例 (虽然此时project_id是冗余的,因为模块已确定项目)。
第三步:注册 TestCaseViewSet 到 Router
现在,我们需要将新的 TestCaseViewSet 添加到我们的 URL 路由中。
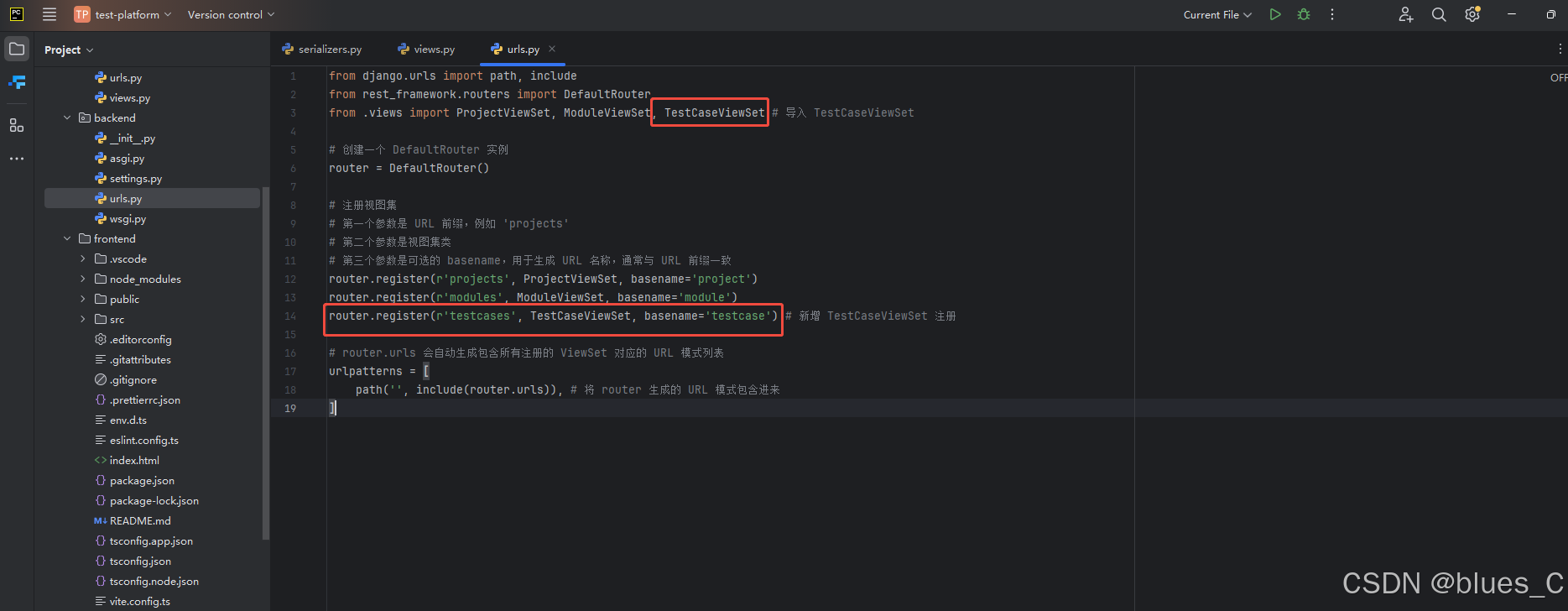
打开 api/urls.py 文件,修改如下:
# test-platform/api/urls.pyfrom django.urls import path, include
from rest_framework.routers import DefaultRouter
from .views import ProjectViewSet, ModuleViewSet, TestCaseViewSet # 导入 TestCaseViewSet# 创建一个 DefaultRouter 实例
router = DefaultRouter()# 注册视图集
router.register(r'projects', ProjectViewSet, basename='project')
router.register(r'modules', ModuleViewSet, basename='module')
router.register(r'testcases', TestCaseViewSet, basename='testcase') # 新增 TestCaseViewSet 注册urlpatterns = [path('', include(router.urls)),
]
我们只是在 router.register(...) 中添加了一行来注册 TestCaseViewSet。DRF 的 Router 会自动为它生成所有标准的 CRUD URL。
第四步:测试 TestCase API
万事俱备,只欠测试!
-
确保数据库中有一些关联数据:
- 如果你还没有,请先通过 Django Admin (
http://127.0.0.1:8000/admin/) 或之前创建的 Project/Module API (http://127.0.0.1:8000/api/projects/和http://127.0.0.1:8000/api/modules/) 创建至少:- 一个项目 (例如,Project A, ID=1)
- 在该项目下的一个模块 (例如,Module X under Project A, ID=1, project=1)
- 另一个项目 (例如,Project B, ID=2)
- 在该项目下的一个模块 (例如,Module Y under Project B, ID=2, project=2)
- 如果你还没有,请先通过 Django Admin (
-
启动 Django 开发服务器:
python manage.py runserver -
访问 DRF 的可浏览 API 界面:
在浏览器中访问http://127.0.0.1:8000/api/。你能看到新添加的testcasesAPI 端点。
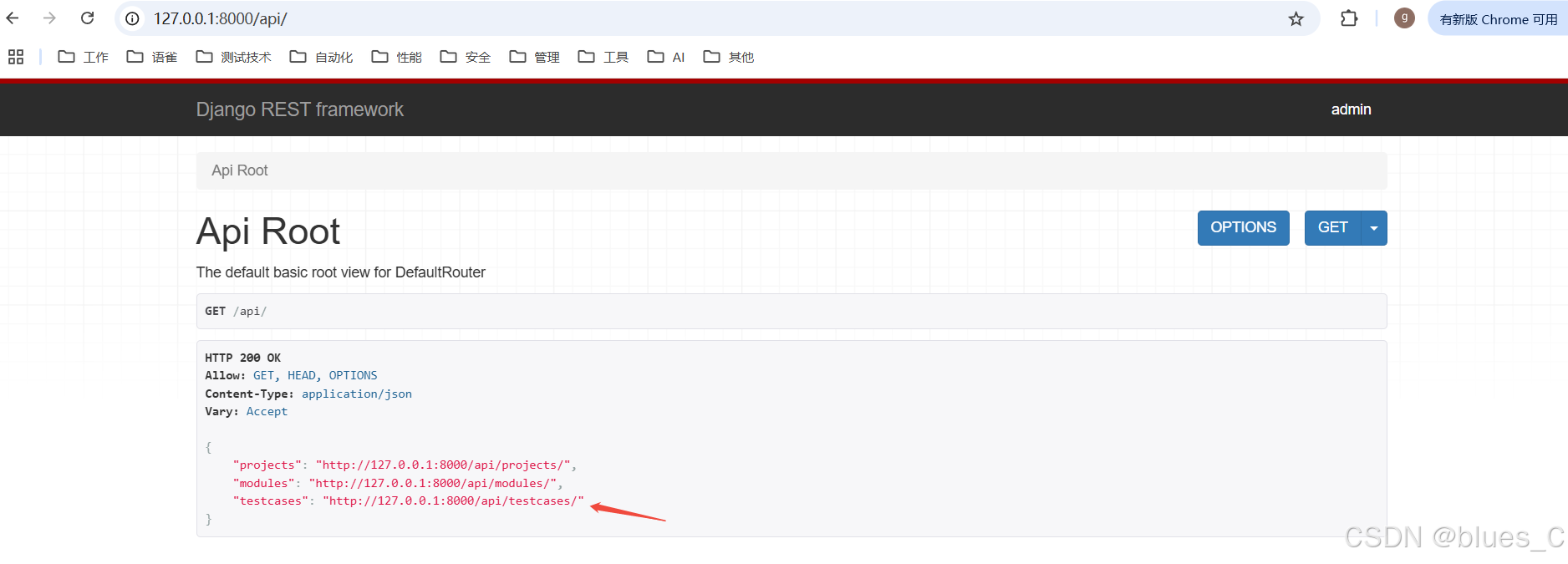
-
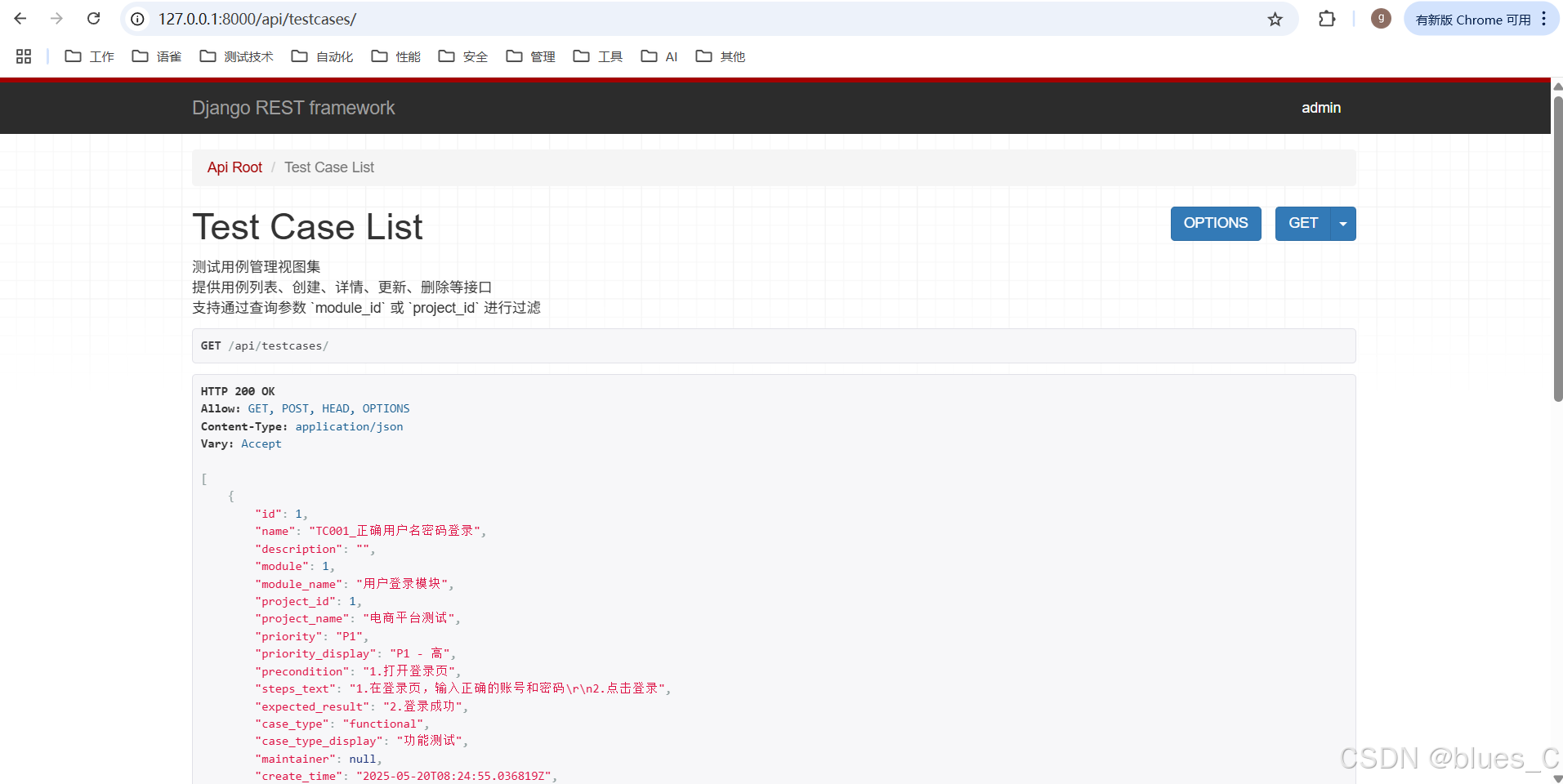
测试 TestCase API -
GET /api/testcases/(列表):
点击http://127.0.0.1:8000/api/testcases/链接。- 注意看响应中,会有之前数据,会包含我们定义的
module_name,project_name,priority_display等字段。
- 注意看响应中,会有之前数据,会包含我们定义的
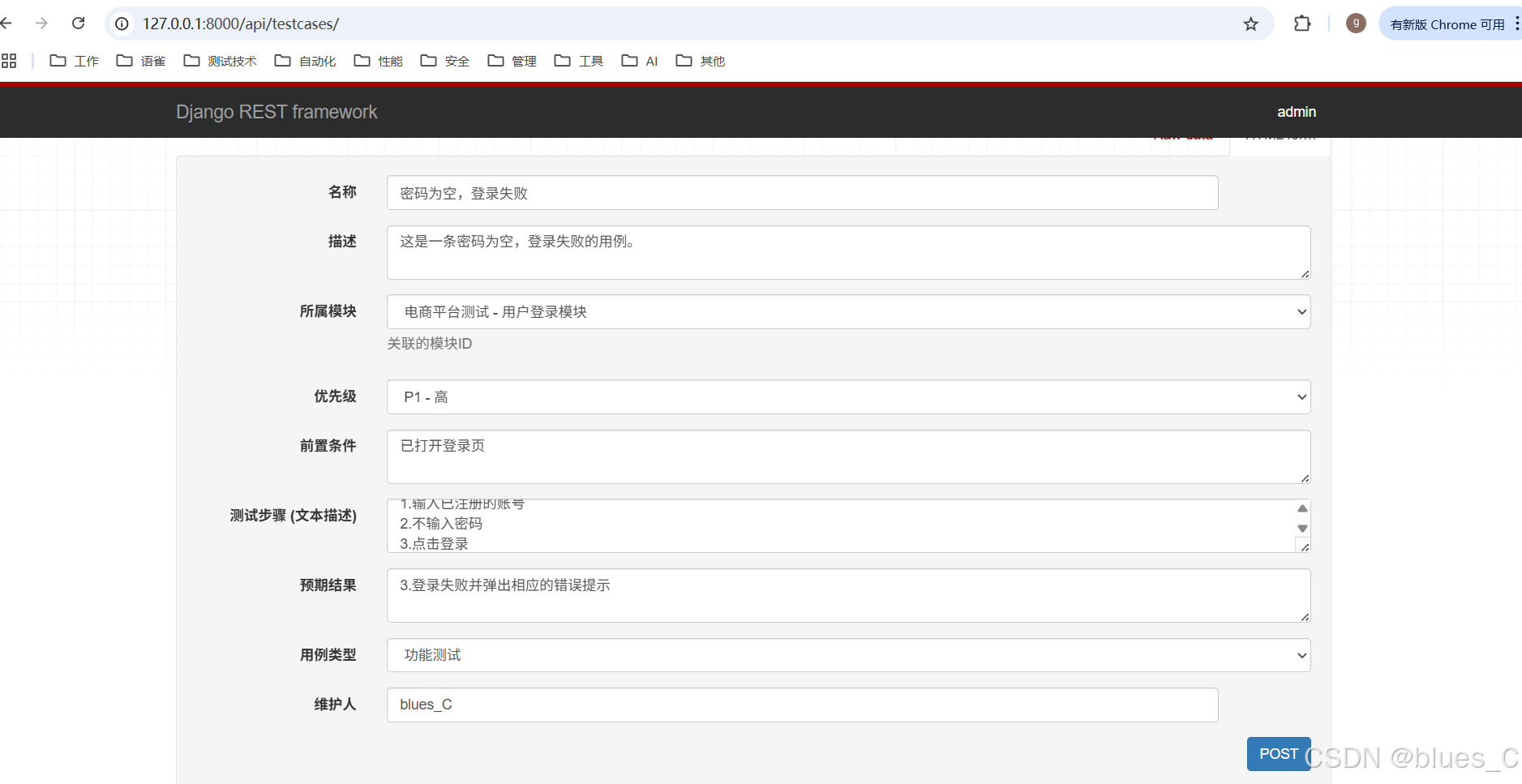
-
测试 TestCase API -
POST /api/testcases/(创建):
在http://127.0.0.1:8000/api/testcases/页面的底部表单中:- 输入名称、描述、选择所属模块等字段,
- 点击 “POST”。
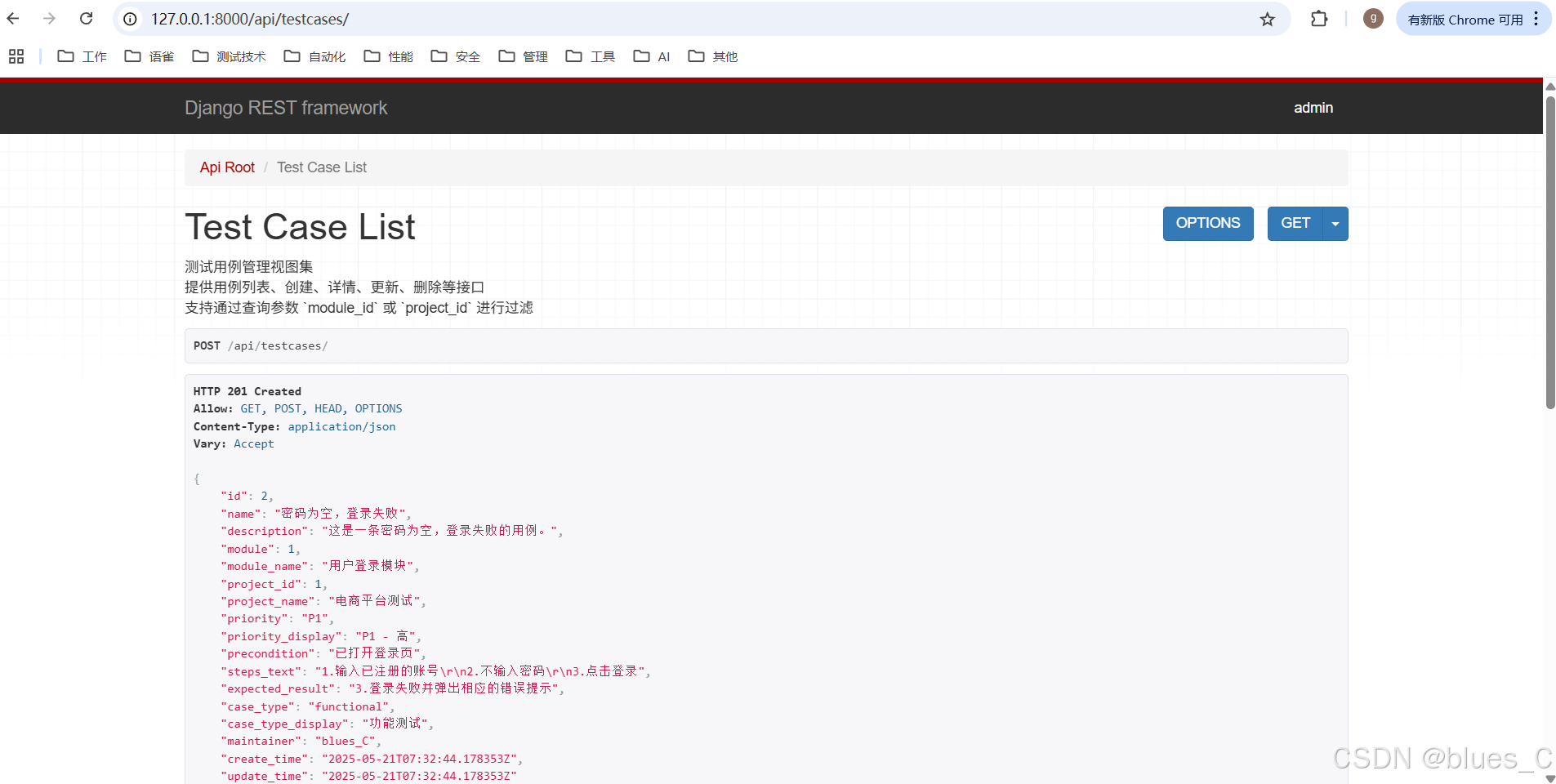
如果成功,你会看到返回的创建后的用例数据,其中包含了
module_name,project_name等。并且列表会刷新。
-
测试 TestCase API -
GET /api/testcases/?module_id={id}(按模块过滤):- 假设你创建的 Module X 的 ID 是
1。在浏览器地址栏输入http://127.0.0.1:8000/api/testcases/?module_id=1并回车。 - 你只能看到属于 Module 1 的测试用例。
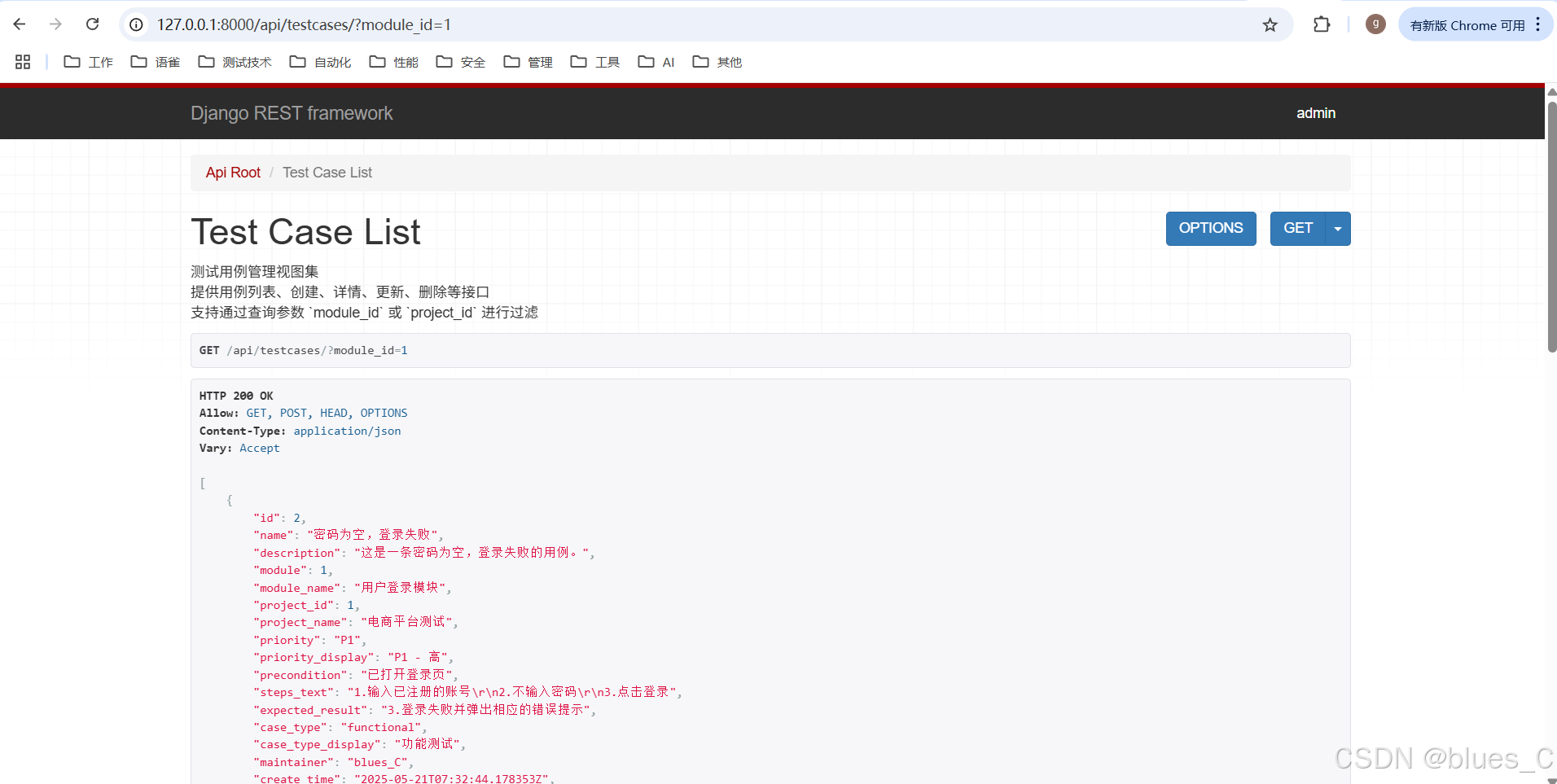
- 假设你创建的 Module X 的 ID 是
-
测试 TestCase API -
GET /api/testcases/?project_id={id}(按项目过滤):- 假设你创建的 Project A 的 ID 是
1。在浏览器地址栏输入http://127.0.0.1:8000/api/testcases/?project_id=1并回车。 - 你只能看到属于 Project 1 下所有模块的测试用例。
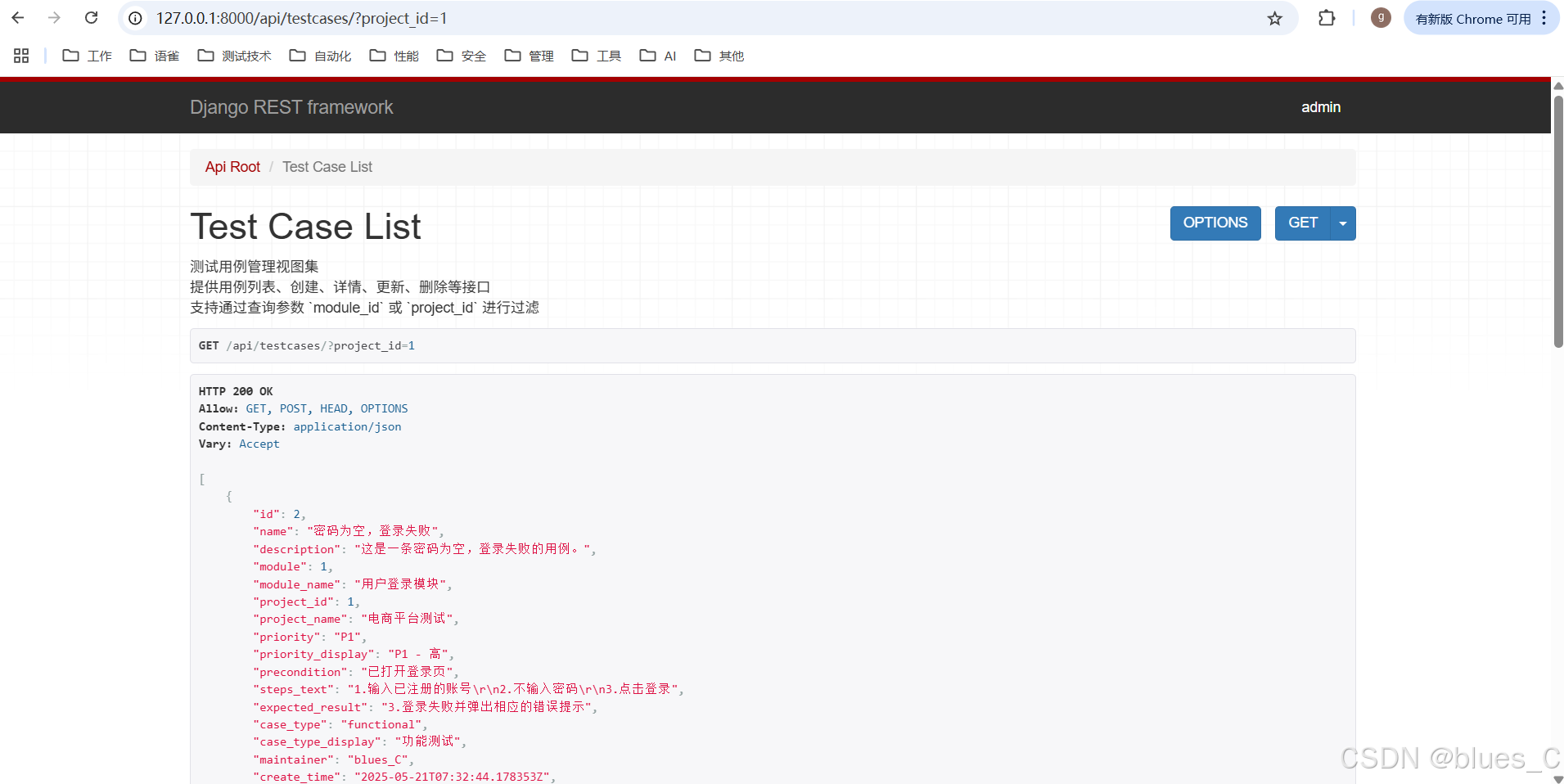
- 假设你创建的 Project A 的 ID 是
-
测试其他操作:
- GET
/api/testcases/{id}/(详情): 点击列表中的某个用例链接。 - PUT
/api/testcases/{id}/(更新): 在详情页面修改数据并提交。 - PATCH
/api/testcases/{id}/(部分更新): 类似 PUT,但只提供需要修改的字段。 - DELETE
/api/testcases/{id}/(删除): 在详情页面点击删除按钮。
- GET
通过这些测试,你能验证 TestCase API 的所有功能,包括关联数据显示和动态过滤。
总结
在这篇文章中,我们成功地为 TestCase 模型构建了功能更完善的 API 接口:
- ✅ 增强了
TestCaseSerializer,使其能够:- 通过
source参数和模型方法 (get_FIELD_display) 显示关联对象的名称和choices字段的可读描述。 - 明确了哪些字段是只读的,哪些是可写的。
- 通过
- ✅ 更新了
ModuleSerializer以包含project_name。 - ✅ 创建了
TestCaseViewSet,并重写了get_queryset方法,以支持根据module_id和project_idURL 查询参数进行动态过滤。 - ✅ 将
TestCaseViewSet注册到了 DRF Router 中。 - ✅ 通过 DRF 的可浏览 API 界面全面测试了
TestCaseAPI 的创建、读取(包括过滤)、更新和删除功能。
至此,我们测试平台的后端核心数据(项目、模块、测试用例)的 CRUD API 已经基本完成!这些 API 将为我们接下来的前端开发提供坚实的数据基础。
相关文章:
】:使用 Django REST Framework构建测试用例模型的 CRUD API)
五、【API 开发篇(下)】:使用 Django REST Framework构建测试用例模型的 CRUD API
【API 开发篇】:使用 Django REST Framework构建测试用例模型的 CRUD API 前言第一步:增强 Serializers (序列化器) - 处理关联和选择项第二步:创建 TestCaseViewSet (视图集) - 支持过滤第三步:注册 TestCaseViewSet 到 Router第…...
)
IDEA推送到gitlab,jenkins识别,然后自动发布到需要的主机(流水线)
jenkins流水线 新建项目 找到流水线选择脚本 3.点击流水线语法开始编辑脚本 4.生成流水线脚本复制 5.修改脚本 6.继续添加(手打) 7.继续生成添加 8.最终脚本 9.保存测试 10.构建 11.访问主页查看是否修改...
】:使用 Django REST Framework 构建项目与模块 CRUD API)
四、【API 开发篇 (上)】:使用 Django REST Framework 构建项目与模块 CRUD API
【API 开发篇 】:使用 Django REST Framework 构建项目与模块 CRUD API 前言为什么选择 Django REST Framework (DRF)?第一步:创建 Serializers (序列化器)第二步:创建 ViewSets (视图集)第三步:配置 URLs (路由)第四步…...

vscode连接本地Ubuntu
因为在学习项目的时候,自己的云服务器性能太差一直要编译很长时间,而且总是连接失败,所以搞了一个Ubuntu25.04的系统在自己的vmare中。 其中参考了以下文章。 Ubuntu 24.04 桌面版安装指南(2025版) | 官网镜像下载启动盘制作保姆级图文教程…...

idea无法识别Maven项目
把.mvn相关都删除了 导致Idea无法识别maven项目 或者 添加导入各个模块 最后把父模块也要导入...

Redis应用--缓存
目录 一、什么是缓存 1.1 二八定律 二、使用Redis作为缓存 三、缓存的更新策略 3.1 定期更新 3.2 实时生成 四、缓存预热、缓存穿透、缓存雪崩和缓存击穿 4.1 缓存预热 4.2 缓存穿透 4.3 缓存雪崩 4.4 缓存击穿 一、什么是缓存 缓存(cache)是计算机的一个经典的概念…...

大语言模型与人工智能:技术演进、生态重构与未来挑战
目录 技术演进:从专用AI到通用智能的跃迁核心能力:LLM如何重构AI技术栈应用场景:垂直领域的技术革命生态关系:LLM与AI技术矩阵的协同演进挑战局限:智能天花板与伦理困境未来趋势:从语言理解到世界模型1. 技术演进:从专用AI到通用智能的跃迁 1.1 三次技术浪潮的跨越 #me…...
)
多模态大语言模型arxiv论文略读(八十六)
EVALALIGN: Supervised Fine-Tuning Multimodal LLMs with Human-Aligned Data for Evaluating Text-to-Image Models ➡️ 论文标题:EVALALIGN: Supervised Fine-Tuning Multimodal LLMs with Human-Aligned Data for Evaluating Text-to-Image Models ➡️ 论文作…...

C++--string类对象
一,引言 string类对象在于更好的处理字符串问题,为对于字符串这一类型提供更加方便的接口和运算符的重载。本片文章首先会引入auto关键字和范围for两个C11小语法。之后按照如下网站所提供的顺序经行讲解。cplusplus.com - The C Resources Networkhttps://legacy.c…...
)
云计算与大数据进阶 | 28、存储系统如何突破容量天花板?可扩展架构的核心技术与实践—— 分布式、弹性扩展、高可用的底层逻辑(下)
在上篇中,我们围绕存储系统可扩展架构详细探讨了基础技术原理与典型实践。然而,在实际应用场景中,存储系统面临的挑战远不止于此。随着数据规模呈指数级增长,业务需求日益复杂多变,存储系统还需不断优化升级࿰…...

Python _day31
DAY 31 文件的规范拆分和写法 今日的示例代码包含2个部分 notebook文件夹内的ipynb文件,介绍下今天的思路项目文件夹中其他部分:拆分后的信贷项目,学习下如何拆分的,未来你看到的很多大项目都是类似的拆分方法 知识点回顾 规范的文…...

【JavaWeb】MyBatis
1 介绍 什么是MyBatis? MyBatis是一款优秀的 持久层 框架,用于简化JDBC的开发。 MyBatis本是 Apache的一个开源项目iBatis,2010年这个项目由apache迁移到了google code,并且改名为MyBatis 。2013年11月迁移到Github。 MyBatis官网https://my…...

vue2实现【瀑布流布局】
瀑布流 1. 解释2. 形成结构和样式3. 自定义指令 1. 解释 瀑布流特征: 等宽不等高:元素宽度固定,高度根据内容自适应。错落排列:元素像瀑布一样从上到下依次填充,自动寻找最短列插入 体现:图中第一排1&…...
:敏感点、权衡点、风险点和非风险点)
系统架构设计(十六):敏感点、权衡点、风险点和非风险点
术语定义 概念定义说明敏感点(Sensitivity Point)架构设计中对某个质量属性有显著影响的点,一旦改变该点,会显著影响系统的某个质量属性。风险点(Risk Point)由于架构决策带来的潜在失败风险,可…...

优化dp贪心数论
这次三个题目都来自牛客周赛93,个人觉得出的很好,收获颇多。 1.简单贪心 题目意思: 任意选定两个数字,相加之和替代两个数字中的一个,另一个抹除。求操作之后最大字典序之和 思路: 最大字典序之和&…...

详解MySQL 的 binlog,redo log,undo log
MySQL 的 binlog、redo log 和 undo log 是数据库事务处理与数据一致性的核心组件,各自承担不同的职责。 1. binlog(二进制日志) 定位:MySQL Server 层实现的逻辑日志,与存储引擎无关。作用: 主从复制&…...

SymPy|主元、重新表示、分数、约分表达式、极限、级数、ode、获取值、输出形式
SymPy 是一个 Python 的符号计算库,广泛应用于数学计算、物理建模、工程分析等领域。本文将详细介绍 SymPy 在处理主元操作、重新表示、分数、约分表达式、极限、级数、常微分方程(ODE)以及获取值和输出形式等方面的应用,通过完整…...

Java 05正则表达式
正则表达式 1.简介 一个字符串,指定一些规则,来校验其他的字符串 String s"";规则 需要进行匹配的字符串.matches(s);来判断2.字符类**(单个) [abc] String s"[ABC]"; "A".matches(s);返回true…...

IEEE 802.1Q协议下封装的VLAN数据帧格式
1.概要 802.1d定义了生成树 802.1w定义了快速生成树 802.1s定义了多生成树 802.1q定义了VLAN 2.说明 IEEE802.1q协议的作用是(生成VLAN标记)VLAN编号取值范围:0-4095,其中0和4095是保留编号,所最大值是ÿ…...

VMware三种网络配置对比
桥接模式(Bridged Mode) 核心特点: 虚拟机被视为局域网中的独立设备,直接使用物理网络适配器,需配置与宿主机同一网段的IP地址。 典型场景: 虚拟机需对外提供服务(如Web…...

再来1章linux系列-19 防火墙 iptables 双网卡主机的内核 firewall-cmd firewalld的高级规则
学习目标: 实验实验需求实验配置内容和分析 (每一个设备的每一步操作)实验结果验证其他 学习内容: 实验实验需求实验配置内容和分析 (每一个设备的每一步操作)实验结果验证其他 1.实验 2.实验需求 图…...

Word 转 HTML API 接口
Word 转 HTML API 接口 图像/转换 Word 文档转换为 HTML 文件转换 / 超高精度与还原度 文件转换 / Word。 1. 产品功能 超高精度与还原度的 HTML 文件转换;支持将 Word 文档转换为 HTML 格式;支持 .doc 和 .docx 格式;保持原始 Word 文档的…...

深入解析MATLAB codegen生成MEX文件的原理与优势
一、MATLAB codegen底层工作机制 1.1 MATLAB执行引擎的局限性 MATLAB作为解释型语言,其执行过程包含多个关键步骤: 语法解析:将.m文件代码转换为抽象语法树(AST) 类型推断:运行时动态确定变量类型 内存管理:自动处…...

PEFT简介及微调大模型DeepSeek-R1-Distill-Qwen-1.5B
🤗 PEFT(参数高效微调)是由Huggingface团队开发的开源框架,专为大型预训练模型(如GPT、LLaMA、T5等)设计,用于高效地将大型预训练模型适配到各种下游应用,而无需对模型的所有参数进行…...

Python训练营打卡 Day31
文件的规范拆分和写法 今日的示例代码包含2个部分 notebook文件夹内的ipynb文件,介绍下今天的思路项目文件夹中其他部分:拆分后的信贷项目,学习下如何拆分的,未来你看到的很多大项目都是类似的拆分方法 知识点回顾:文件…...

Google精准狙击OpenAI Codex,发布AI编程助手Jules!
自从OpenAI推出 Codex之后,Google就憋不住了,悄悄得瞄准了OpenAI的最新成果。 原计划是是打算在明天举行的Google I/O年度开发者大会上发布相关产品,但Google似乎已经一刻也等不了了。 就在昨天,谷歌正式推出了其AI编程——Ju…...
“验血单信息”批量生成打印(学校、班级、姓名、性别))
【办公类-18-04】(Python)“验血单信息”批量生成打印(学校、班级、姓名、性别)
背景说明 督导结束了,准备春游(夏游),搭档在给孩子写打卡单、心愿单,感慨“好多字都不会写了!” 此时,保健老师来发体检材料,叮嘱红色验血单的填写方法。 我觉得我的字也是一塌糊涂。我想用以前做“毕业证书”的方式,将班级幼儿信息打印在体检单上。 【办公类-18-03…...

如何使用通义灵码提高前端开发效率
工欲善其事,必先利其器。对于前端开发而言,使用VSCode已经能够极大地提高前端的开发效率了。但有了AI加持后,前端开发的效率又更上一层楼了! 本文采用的AI是通义灵码插件提供的通义千问大模型,是目前AI性能榜第一梯队…...

苍穹外卖04 新增菜品菜品分页查询删除菜品修改菜品
2-6 新增菜品 02 05-新增菜品_需求分析和设计 03 06-新增菜品_代码开发_1 文件上传接口开发: 在这一部分我们主要在于对阿里云oss的代码开发和实现 1.配置阿里云oss: alioss:endpoint: oss-cn-beijing-internal.aliyuncs.comaccess-key-id: access-ke…...

C++ 读取英伟达显卡名称、架构及算力
C++ 读取英伟达显卡名称、架构及算力 通过CUDA Runtime API获取计算能力(推荐)CUDA计算能力(Compute Capability)的版本号直接对应显卡架构(如8.6=Ampere,9.0=Hopper)。实现步骤: 1.安装依赖: 安装 NVIDIA CUDA Toolkit。确保显卡驱动支持CUDA。2. C…...

VitePress 中以中文字符结尾的字体加粗 Markdown 格式无法解析
背景 在编写vitepress项目过程中,发现了一个markdown格式解析的问题。 md文件中,以中文句号结尾的字体加粗,无法正确解析: 不只是中文句号,只要是加粗语句中以中文字符结尾,都无法被正确解析 需要将中文…...

2.前端汇总
框架 html5 html语法 css css3 css语法 框架 tailwind css 官网 JavaScript JavaScript语法 typescript 语法 nodejs 语法 vue3 官网 组件 vite 打包 vue router -路由 pinia - 状态管理 ui element plus axios - ajax 后台管理系统前端快速开发框架 …...

外部因素导致的 ADC误差来源分析
前面分享了ADC自身因素带来的误差,现在再分享一波由于外部因素导致的ADC采样误差。 一、模拟信号源输入减少带来的误差 看一个STM32的ADC转换器的示意图: 从图中可以看到,输入源与采样引脚之间存在阻抗RAIN,流入引脚的电压可能因…...

集成运算放大器知识汇总
一、集成运放的组成 集成运算放大器,就是通过内部元器件的电参量关系将电参量进行运算,达到放大的目的。我们拆解来看: 集成:将电路封装,留出接口,使其模块化,便于移植。运算:这里…...
)
HBCPC2025 补题 (F、I)
HBCPC2025 补题 补题连接:Codeforces I 感染 做法1:std做法:树上dp统计贡献找最大 #include <bits/stdc.h> using namespace std; typedef long long ll; #define endl \n #define int long long #define pb push_back #define pii pair<int,…...

针对 CSDN高质量博文发布 的详细指南
结合技术写作规范与平台特性,分为 内容规划、写作技巧、排版优化、发布策略 四部分,确保专业性与传播效果: 一、内容规划:精准定位与深度挖掘 选题策略 热点结合:追踪技术趋势(如2025年AIGC、量子计算&am…...

python读写bin文件
import numpy as np# 创建二进制数据 data np.array([0x33, 0x34, 0x35, 0x36], dtypenp.uint8)# 写入bin文件 with open(example.bin, wb) as f:data.tofile(f)print("bin文件生成成功")data np.fromfile(example.bin, dtypenp.uint8) print("numpy读取结果:…...
)
矩阵的秩(Rank)
矩阵的秩(Rank)是线性代数中的核心概念,表示矩阵中线性无关的行(或列)的最大数量,反映了矩阵所包含的“独立信息”的多少。以下是其核心要点: 1. 秩的定义 行秩:矩阵中线性无关的行…...

Vue响应式系统演进与实现解析
一、Vue 2 响应式实现详解 1. 核心代码实现 // 依赖收集器(观察者模式) class Dep {constructor() {this.subscribers new Set();}depend() {if (activeEffect) {this.subscribers.add(activeEffect);}}notify() {this.subscribers.forEach(effect &g…...
)
【SPIN】高级时序规范(SPIN学习系列--6)
时序操作符[](总是)和 <>(最终)可应用于任何LTL公式,因此 []<><>A 和 <>[]<>(A ∧ []B) 在语法上是正确的。本书不涉及LTL的演绎理论(如公理、推理规则及公式的结合律、交换…...

C语言学习之内存函数
今天我们来学习一下C语言中内存函数 以下内存函数的使用均需要包含头文件<string.h> 目录 memcpy函数的使用及其模拟实现 memcpy函数的模拟实现 memmove函数的使用和模拟实现 memmove函数的模拟实现 memset函数的使用 memcmp函数的使用 memcpy函数的使用及其模拟实现…...

Python 数据库编程
一、数据库连接基础 1. 标准流程 import database_module # 如mysql.connector, sqlite3等 # 1. 建立连接 connection database_module.connect( host"localhost", user"username", password"password", database"dbnam…...

软考软件评测师——软件工程之开发模型与方法
目录 一、核心概念 二、主流模型详解 (一)经典瀑布模型 (二)螺旋演进模型 (三)增量交付模型 (四)原型验证模型 (五)敏捷开发实践 三、模型选择指南 四…...

机器学习入门
机器学习入门 1 . 机器学习是什么? 机器学习(Machine Learning, ML)是一种用数据经验替代显式规则编程来完成任务的方法──模型从样本 (X, y) 中学习 映射函数 f: X → Y,并在新样本上做出预测。和传统“if … else”程序相比&…...
)
git学习与使用(远程仓库、分支、工作流)
文章目录 前言简介git的工作流程git的安装配置git环境:git config --globalgit的基本使用新建目录初始化仓库(repository)添加到暂存区新增/修改/删除 文件状态会改变 提交到仓库查看提交(commit)的历史记录git其他命令…...

制造业或跨境电商相关行业三种模式:OEM、ODM、OBM
一、基础概念对比 模式定义核心能力利润来源控制权OEM代工生产(贴牌生产)纯生产制造能力加工费(薄利)品牌方掌控一切ODM设计生产(自主设计代工)设计研发能力设计溢价生产利润制造商掌握设计OBM自主品牌&am…...

APPtrace 智能参数系统:重构 App 用户增长与运营逻辑
一、免填时代:APPtrace 颠覆传统参数传递模式 传统 App 依赖「邀请码 / 手动绑定」实现用户关联,流程繁琐导致 20%-30% 的用户流失。APPtrace 通过 **「链接参数自动传递 安装后智能识别」** 技术,让用户在无感知状态下完成关系绑定、场景还…...

在 Excel 中使用 C# .NET 用户定义函数 操作步骤
点开选项 点击加载项 点击跳转 点击浏览 选择仙盟excel...

PyTest
一、基本用法: 1.测试框架做了什么: (1).测试发现 a.创建test_开头的文件 b.创建Test开头的类 c.创建test_开头的函数或方法 pytest中以每一个函数或方法作为一个用例 pytest主要以名字区分普通函数(方法)、用例 pytest的启动方式:在给定的项目中执行pytest命令即可 p…...

Python Day27 学习
今天学习讲义Day17的内容:无监督算法中的聚类浙大疏锦行 Q1. 什么是聚类? 本质上就是一种分组分类 关于聚类的准备工作: 代码实现 # 先运行之前预处理好的代码 import pandas as pd import pandas as pd #用于数据处理和分析ÿ…...