PEFT简介及微调大模型DeepSeek-R1-Distill-Qwen-1.5B
🤗 PEFT(参数高效微调)是由Huggingface团队开发的开源框架,专为大型预训练模型(如GPT、LLaMA、T5等)设计,用于高效地将大型预训练模型适配到各种下游应用,而无需对模型的所有参数进行微调,因为微调成本过高。PEFT 方法仅微调少量(额外的)模型参数,从而显著降低计算和存储成本,同时获得与完全微调模型相当的性能。这使得在消费级硬件上训练和存储大型语言模型 (LLMs) 变得更加容易。
一、介绍与安装
1、作用
-
降低计算与存储成本
PEFT通过冻结大部分预训练参数,仅调整少量新增或特定层参数(如低秩矩阵、适配器模块),可将训练参数量缩减至原模型的0.1%-1%。例如,微调12B参数的模型时,显存需求从80GB降至18GB,模型保存文件仅需几MB。 -
缓解灾难性遗忘
传统全参数微调可能覆盖预训练阶段学到的通用知识,而PEFT通过保留主体参数,使模型在适应新任务时仍保持原有能力。 -
支持多任务适配
PEFT允许在同一模型中集成多种任务的适配器(Adapter),例如LoRA或Prefix Tuning,实现灵活的多任务学习。
2、支持的高效微调方法
-
LoRA(低秩适应):通过向权重矩阵添加低秩分解的增量矩阵(如秩r=8)进行微调,适用于文本生成、分类等任务。
-
Prefix Tuning/Prompt Tuning:在输入层添加可学习的连续提示(Prompt),引导模型输出,适合少样本学习。
-
AdaLoRA:动态调整低秩矩阵的秩,增强复杂任务(如多领域适应)的灵活性。
-
IA3:通过向量缩放激活层参数,在少样本场景下性能超越全参数微调。
3、技术优势
- 生态友好
无缝对接Transformers、Accelerate等库,支持分布式训练与混合精度计算,简化部署流程。 - 性能无损
实验表明,PEFT微调后的模型性能与全参数微调相当,甚至在某些少样本任务中表现更优。 - 存储高效
适配器文件体积小(如LoRA的adapter_model.bin仅几MB),便于共享与版本管理。
4、安装
- 方式一:从 PyPI 安装🤗PEFT
pip install peft
- 方式二:Source
pip install git+https://github.com/huggingface/peft
二、微调大模型DeepSeek-R1-Distill-Qwen-1.5B
1、使用modelscope 下载数据集和模型
- 下载数据集
#数据集下载
!modelscope download --dataset himzhzx/muice-dataset-train.catgirl --local_dir ./data
- 下载模型
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download("deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B",cache_dir='./models')
2、改造数据集
由于 transformers 的 Trainer 训练器默认 接收的的数据集格式化为 :
{'input_ids':'xxx','attention_mask':'xxx','labels':'xxx',
}
需要对上述下载的数据集进行改造,改造代码如下:
#数据集处理
class Mydata(Dataset):def __init__(self, tokenizer, max_len = 255):with open("./data/muice-dataset-train.catgirl.json", 'r', encoding='utf-8') as f:self.json_data = json.load(f)self.tokenizer = tokenizerself.max_len = max_lendef __len__(self):return len(self.json_data)def __getitem__(self, index):data = self.json_data[index]question = data['instruction']answener = data['output']q = self.tokenizer.apply_chat_template([{'role':'user','content':question}],tokenize = False,add_generation_prompt = True)q_input_ids = self.tokenizer.encode(q)a_input_ids = self.tokenizer.encode(answener)input_ids = q_input_ids + a_input_idsattention_mask = [1]*len(input_ids)labels = [-100]*len(q_input_ids) + a_input_idsif len(input_ids) > self.max_len:input_ids = input_ids[:self.max_len]attention_mask = attention_mask[:self.max_len]labels = labels[:self.max_len]else:padding_len = self.max_len - len(input_ids)input_ids = input_ids + [self.tokenizer.pad_token_id] * padding_lenattention_mask = attention_mask + [0]*padding_lenlabels = labels + [-100]*padding_lenreturn {'input_ids':torch.tensor(input_ids, dtype=torch.long),'attention_mask':torch.tensor(attention_mask, dtype=torch.long),'labels':torch.tensor(labels, dtype=torch.long)}dataset = Mydata(tokenizer)# dataset[0]train_data = DataLoader(dataset, batch_size=32, shuffle=True)for i in train_data:print(i)break
3、配置 Lora 参数
#配置 lora 参数
lora_config = LoraConfig(r=16,lora_alpha=32,lora_dropout=0.05,task_type=TaskType.CAUSAL_LM,target_modules=['q_proj','v_proj','k_proj', 'o_proj']
)
#将 lora 与原始模型 合并在一起
lora_model = get_peft_model(model, lora_config)#打印模型总参数,以及可训练参数和占比
lora_model.print_trainable_parameters()
4、开始训练
#配置训练参数output_dir = './lora/train'train_arg = TrainingArguments(output_dir=output_dir,per_device_train_batch_size=4,gradient_accumulation_steps=8,num_train_epochs=3,logging_steps=10,save_steps=500,learning_rate=2e-5,save_total_limit=2,fp16=False,report_to="none"
)#创建Trainer
trainer = Trainer(model=lora_model,args=train_arg,train_dataset=dataset,processing_class=tokenizer
)#开始训练
trainer.train()
训练过程:
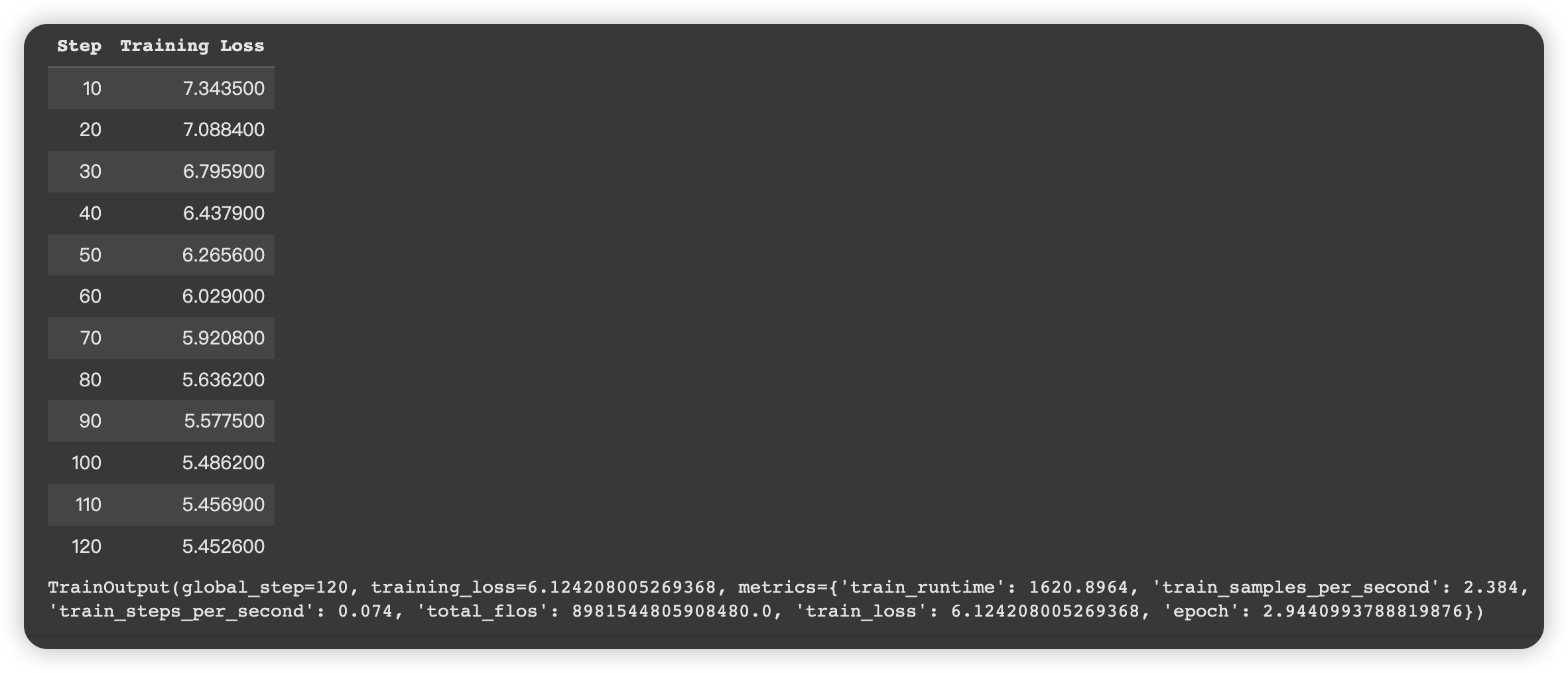
5、模型保存
#将 lora 权重合并到 基础模型上
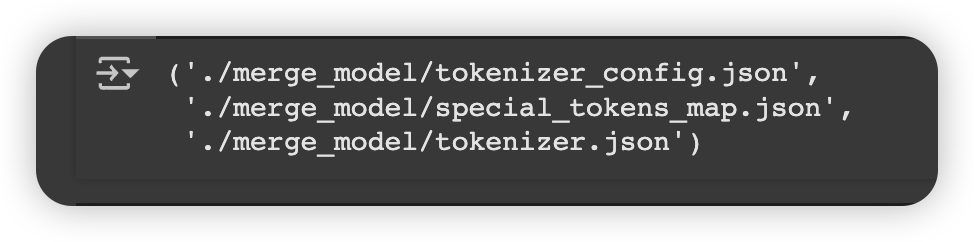
merge_model = lora_model.merge_and_unload() #合并
merge_model.save_pretrained("./merge_model") #保存
tokenizer.save_pretrained("./merge_model") #保存
完整代码下载:git源码
相关文章:

PEFT简介及微调大模型DeepSeek-R1-Distill-Qwen-1.5B
🤗 PEFT(参数高效微调)是由Huggingface团队开发的开源框架,专为大型预训练模型(如GPT、LLaMA、T5等)设计,用于高效地将大型预训练模型适配到各种下游应用,而无需对模型的所有参数进行…...

Python训练营打卡 Day31
文件的规范拆分和写法 今日的示例代码包含2个部分 notebook文件夹内的ipynb文件,介绍下今天的思路项目文件夹中其他部分:拆分后的信贷项目,学习下如何拆分的,未来你看到的很多大项目都是类似的拆分方法 知识点回顾:文件…...

Google精准狙击OpenAI Codex,发布AI编程助手Jules!
自从OpenAI推出 Codex之后,Google就憋不住了,悄悄得瞄准了OpenAI的最新成果。 原计划是是打算在明天举行的Google I/O年度开发者大会上发布相关产品,但Google似乎已经一刻也等不了了。 就在昨天,谷歌正式推出了其AI编程——Ju…...
“验血单信息”批量生成打印(学校、班级、姓名、性别))
【办公类-18-04】(Python)“验血单信息”批量生成打印(学校、班级、姓名、性别)
背景说明 督导结束了,准备春游(夏游),搭档在给孩子写打卡单、心愿单,感慨“好多字都不会写了!” 此时,保健老师来发体检材料,叮嘱红色验血单的填写方法。 我觉得我的字也是一塌糊涂。我想用以前做“毕业证书”的方式,将班级幼儿信息打印在体检单上。 【办公类-18-03…...

如何使用通义灵码提高前端开发效率
工欲善其事,必先利其器。对于前端开发而言,使用VSCode已经能够极大地提高前端的开发效率了。但有了AI加持后,前端开发的效率又更上一层楼了! 本文采用的AI是通义灵码插件提供的通义千问大模型,是目前AI性能榜第一梯队…...

苍穹外卖04 新增菜品菜品分页查询删除菜品修改菜品
2-6 新增菜品 02 05-新增菜品_需求分析和设计 03 06-新增菜品_代码开发_1 文件上传接口开发: 在这一部分我们主要在于对阿里云oss的代码开发和实现 1.配置阿里云oss: alioss:endpoint: oss-cn-beijing-internal.aliyuncs.comaccess-key-id: access-ke…...

C++ 读取英伟达显卡名称、架构及算力
C++ 读取英伟达显卡名称、架构及算力 通过CUDA Runtime API获取计算能力(推荐)CUDA计算能力(Compute Capability)的版本号直接对应显卡架构(如8.6=Ampere,9.0=Hopper)。实现步骤: 1.安装依赖: 安装 NVIDIA CUDA Toolkit。确保显卡驱动支持CUDA。2. C…...

VitePress 中以中文字符结尾的字体加粗 Markdown 格式无法解析
背景 在编写vitepress项目过程中,发现了一个markdown格式解析的问题。 md文件中,以中文句号结尾的字体加粗,无法正确解析: 不只是中文句号,只要是加粗语句中以中文字符结尾,都无法被正确解析 需要将中文…...

2.前端汇总
框架 html5 html语法 css css3 css语法 框架 tailwind css 官网 JavaScript JavaScript语法 typescript 语法 nodejs 语法 vue3 官网 组件 vite 打包 vue router -路由 pinia - 状态管理 ui element plus axios - ajax 后台管理系统前端快速开发框架 …...

外部因素导致的 ADC误差来源分析
前面分享了ADC自身因素带来的误差,现在再分享一波由于外部因素导致的ADC采样误差。 一、模拟信号源输入减少带来的误差 看一个STM32的ADC转换器的示意图: 从图中可以看到,输入源与采样引脚之间存在阻抗RAIN,流入引脚的电压可能因…...

集成运算放大器知识汇总
一、集成运放的组成 集成运算放大器,就是通过内部元器件的电参量关系将电参量进行运算,达到放大的目的。我们拆解来看: 集成:将电路封装,留出接口,使其模块化,便于移植。运算:这里…...
)
HBCPC2025 补题 (F、I)
HBCPC2025 补题 补题连接:Codeforces I 感染 做法1:std做法:树上dp统计贡献找最大 #include <bits/stdc.h> using namespace std; typedef long long ll; #define endl \n #define int long long #define pb push_back #define pii pair<int,…...

针对 CSDN高质量博文发布 的详细指南
结合技术写作规范与平台特性,分为 内容规划、写作技巧、排版优化、发布策略 四部分,确保专业性与传播效果: 一、内容规划:精准定位与深度挖掘 选题策略 热点结合:追踪技术趋势(如2025年AIGC、量子计算&am…...

python读写bin文件
import numpy as np# 创建二进制数据 data np.array([0x33, 0x34, 0x35, 0x36], dtypenp.uint8)# 写入bin文件 with open(example.bin, wb) as f:data.tofile(f)print("bin文件生成成功")data np.fromfile(example.bin, dtypenp.uint8) print("numpy读取结果:…...
)
矩阵的秩(Rank)
矩阵的秩(Rank)是线性代数中的核心概念,表示矩阵中线性无关的行(或列)的最大数量,反映了矩阵所包含的“独立信息”的多少。以下是其核心要点: 1. 秩的定义 行秩:矩阵中线性无关的行…...

Vue响应式系统演进与实现解析
一、Vue 2 响应式实现详解 1. 核心代码实现 // 依赖收集器(观察者模式) class Dep {constructor() {this.subscribers new Set();}depend() {if (activeEffect) {this.subscribers.add(activeEffect);}}notify() {this.subscribers.forEach(effect &g…...
)
【SPIN】高级时序规范(SPIN学习系列--6)
时序操作符[](总是)和 <>(最终)可应用于任何LTL公式,因此 []<><>A 和 <>[]<>(A ∧ []B) 在语法上是正确的。本书不涉及LTL的演绎理论(如公理、推理规则及公式的结合律、交换…...

C语言学习之内存函数
今天我们来学习一下C语言中内存函数 以下内存函数的使用均需要包含头文件<string.h> 目录 memcpy函数的使用及其模拟实现 memcpy函数的模拟实现 memmove函数的使用和模拟实现 memmove函数的模拟实现 memset函数的使用 memcmp函数的使用 memcpy函数的使用及其模拟实现…...

Python 数据库编程
一、数据库连接基础 1. 标准流程 import database_module # 如mysql.connector, sqlite3等 # 1. 建立连接 connection database_module.connect( host"localhost", user"username", password"password", database"dbnam…...

软考软件评测师——软件工程之开发模型与方法
目录 一、核心概念 二、主流模型详解 (一)经典瀑布模型 (二)螺旋演进模型 (三)增量交付模型 (四)原型验证模型 (五)敏捷开发实践 三、模型选择指南 四…...

机器学习入门
机器学习入门 1 . 机器学习是什么? 机器学习(Machine Learning, ML)是一种用数据经验替代显式规则编程来完成任务的方法──模型从样本 (X, y) 中学习 映射函数 f: X → Y,并在新样本上做出预测。和传统“if … else”程序相比&…...
)
git学习与使用(远程仓库、分支、工作流)
文章目录 前言简介git的工作流程git的安装配置git环境:git config --globalgit的基本使用新建目录初始化仓库(repository)添加到暂存区新增/修改/删除 文件状态会改变 提交到仓库查看提交(commit)的历史记录git其他命令…...

制造业或跨境电商相关行业三种模式:OEM、ODM、OBM
一、基础概念对比 模式定义核心能力利润来源控制权OEM代工生产(贴牌生产)纯生产制造能力加工费(薄利)品牌方掌控一切ODM设计生产(自主设计代工)设计研发能力设计溢价生产利润制造商掌握设计OBM自主品牌&am…...

APPtrace 智能参数系统:重构 App 用户增长与运营逻辑
一、免填时代:APPtrace 颠覆传统参数传递模式 传统 App 依赖「邀请码 / 手动绑定」实现用户关联,流程繁琐导致 20%-30% 的用户流失。APPtrace 通过 **「链接参数自动传递 安装后智能识别」** 技术,让用户在无感知状态下完成关系绑定、场景还…...

在 Excel 中使用 C# .NET 用户定义函数 操作步骤
点开选项 点击加载项 点击跳转 点击浏览 选择仙盟excel...

PyTest
一、基本用法: 1.测试框架做了什么: (1).测试发现 a.创建test_开头的文件 b.创建Test开头的类 c.创建test_开头的函数或方法 pytest中以每一个函数或方法作为一个用例 pytest主要以名字区分普通函数(方法)、用例 pytest的启动方式:在给定的项目中执行pytest命令即可 p…...

Python Day27 学习
今天学习讲义Day17的内容:无监督算法中的聚类浙大疏锦行 Q1. 什么是聚类? 本质上就是一种分组分类 关于聚类的准备工作: 代码实现 # 先运行之前预处理好的代码 import pandas as pd import pandas as pd #用于数据处理和分析ÿ…...

在 Win 10 上,Tcl/Tk 脚本2个示例
set PATH 新增 D:\Git\mingw64\bin where tclsh D:\Git\mingw64\bin\tclsh.exe where wish D:\Git\mingw64\bin\wish.exe 编写 test_tk.tcl 如下 #!/usr/bin/tclsh # test 文件对话框 package require Tk# 弹出文件选择对话框,限制选择.txt文件 set filePath […...

渐开线少齿差传动学习笔记
之前看到了一个渐开线一齿差的视频,觉得比较有意思,想自己动手做一个看看,下面是最开始尝试的一个失败的结果,不知道小伙伴们发现问题了没? 本来就是想凑一凑看看,但是发现不是凑起来不是件容易的事。那么…...
)
基于CATIA参数化圆锥建模的自动化插件开发实践——NX建模之圆锥体命令的参考与移植(二)
引言 在CATIA二次开发领域,参数化建模技术可提升复杂几何体的创建效率达60%。本文基于PySide6 GUI框架与pycatia接口库,深度解析锥体自动化建模工具的开发实践。该工具创新性地融合了NX的交互逻辑与CATIA的混合建模技术,实现双模式输入(高度/锥角)的智能参数转换,较传统…...

Java集合框架详解:单列集合与双列集合
目录 1. 引言:为什么需要集合框架 2. 基础概念:集合框架概述 2.1 集合框架的结构 编辑 编辑 2.2 集合与数组的比较 3. 前置知识:理解集合框架背后的基础数据结构 3.1 数组 3.2 链表 3.3 哈希表 3.4 二叉树与二叉查找树 3.5 红…...

leetcode 33. Search in Rotated Sorted Array
题目描述 可以发现的是,将数组从中间分开成左右两部分的时候,一定至少有一部分的数组是有序的。左部分[left,mid-1],右部分[mid1,right]。 第一种情况:左右两部分都是有序的,说明nums[mid]就是整个数组的最大值。此时…...

OpenCV 图像色彩空间转换
一、知识点: 1、色彩空间转换函数 (1)、void cvtColor( InputArray src, OutputArray dst, int code, int dstCn 0, AlgorithmHint hint cv::ALGO_HINT_DEFAULT ); (2)、将图像从一种颜色空间转换为另一种。 (3)、参数说明: src: 输入图像,即要进行颜…...

python-leetcode 69.最小栈
题目: 设计一个支持push,pop,top,操作,并能在常数时间内检索到最小元素的栈。 辅助栈法: 1:使用两个栈,一个主栈用于存储所有元素,另一个辅助栈用于存储当前元素的最小值 2: 每次push时,将元…...

C#基础:yield return关键字的特点
一、特点 1.最终返回的结果是IEnumerable<T> 2.使用yield return时,返回的是单个元素(即T) 3.好处:延迟加载,需要时才计算 二、验证 通过打断点可知,只有当listB遍历的时候,才会进入Get…...

机器学习 集成学习方法之随机森林
集成学习方法之随机森林 1 集成学习2 随机森林的算法原理2.1 Sklearn API2.2 示例 1 集成学习 机器学习中有一种大类叫集成学习(Ensemble Learning),集成学习的基本思想就是将多个分类器组合,从而实现一个预测效果更好的集成分类…...

【Vue篇】组件的武林绝学:状态风暴下的乾坤挪移术
引言 🔍 Vue组件迷雾重重? ✧ Scoped如何实现样式隔离? ✧ Data为何必须是函数? ✧ 父子组件如何跨域通信? ✧ Props单向数据流如何破局? 🚀 本文直击组件化七大核心: ▸ 样式隔离原…...
)
使用亮数据代理IP+Python爬虫批量爬取招聘信息训练面试类AI智能体(手把手教学版)
文章目录 一、为什么要用代理IP?(重要!!!)二、环境准备(三件套走起)2.1 安装必备库(pip大法好)2.2 获取亮数据代理(官网注册送试用) 三、编写爬虫代码&#x…...

【MySQL】第七弹——复习总结 视图
文章目录 🌏客户端和数据库操作🌏表操作🌏CRUD 增删改查总结🌏数据库约束🌏表的设计🌏分组查询🌏聚合函数🌏联合查询🌏SQL语句中各部分的执行顺序🪐视图 &…...

基于Springboot + vue3实现的工商局商家管理系统
项目描述 本系统包含管理员、商家两个角色。 管理员角色: 用户管理:管理系统中所有用户的信息,包括添加、删除和修改用户。 许可证申请管理:管理商家的许可证申请,包括搜索、修改或删除许可证申请。 许可证审批管理…...

前端开发——前端样式BUG调试全指南2025终极版
前端开发——前端样式BUG调试全指南2025终极版 前端样式BUG调试指南(2025终极版)一、调试方法论与工具链1. 问题定位三板斧(1) 现象复现与特征提取(2) 现代调试工具组合拳(3) 三维问题定位法 2. 深度排查六步法步骤1:样式覆盖检测步骤2&#…...

【DeepSeek】为什么需要linux-header
编译Linux驱动程序时,通常需要 Linux内核头文件(linux-headers),而不是完整的源代码(linux-source)。以下是详细解释: 1. 为什么需要内核头文件? 头文件的作用: 内核头文…...

c语言刷题之实际问题
小乐乐定闹钟 代码如下: 小乐乐排电梯 代码如下: 小乐乐与欧几里得 代码如下: 小乐乐改数字 代码如下: 小乐乐走台阶 代码如下: 台阶为1,2时走法分别1,2种 1:(1) 2:(1,1),(2) 要走完n阶时,即我…...

【图像大模型】Kolors:基于自监督学习的通用视觉色彩增强系统深度解析
Kolors:基于自监督学习的通用视觉色彩增强系统深度解析 一、项目架构与技术原理1.1 系统定位与核心能力1.2 核心算法突破1.2.1 色彩感知表征学习1.2.2 动态色彩变换矩阵 二、系统实现与训练策略2.1 训练框架设计2.1.1 自监督预训练 2.2 损失函数设计 三、实战部署指…...

生产消费者模型 读写者模型
概念 生产者消费者模式就是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据…...

每日Prompt:双重曝光
提示词 双重曝光,Midjourney 风格,融合、混合、叠加的双重曝光图像,双重曝光风格。一幅由 Yukisakura 创作的杰出杰作,展现了一个奇妙的双重曝光构图,将阿拉贡阿拉松之子的剪影与生机勃勃春季里中土世界视觉上引人注目…...

基于springboot3 VUE3 火车订票系统前后端分离项目适合新手学习的项目包含 智能客服 换乘算法
博主介绍:专注于Java(springboot ssm 等开发框架) vue .net php phython node.js uniapp 微信小程序 等诸多技术领域和毕业项目实战、企业信息化系统建设,从业十五余年开发设计教学工作 ☆☆☆ 精彩专栏推荐订阅☆☆☆☆☆…...

DAY29 超大力王爱学Python
知识点回顾 类的装饰器装饰器思想的进一步理解:外部修改、动态类方法的定义:内部定义和外部定义 作业:复习类和函数的知识点,写下自己过去29天的学习心得,如对函数和类的理解,对python这门工具的理解等&…...

jvm对象压缩
最近在看一些文章,知道64位jvm在启动时指定-XX:UseCompressedOops后就会开启压缩,但是怎么压缩的,以及什么情况下压缩失效,没有一篇文章讲的特别透彻,在这里记录一下,后面抽时间进行更新。 参考文档 https…...
)
TripGenie:畅游济南旅行规划助手:个人工作纪实(十八)
本周,我增加了网页搜索并在右侧显示搜索链接与标题的功能,通过这个功能,可以帮助用户搜索网络上关于济南旅游的信息,提高用户检索信息的速度,用户可以通过点击网页链接了解更多关于济南的信息。 首先,我设计…...