数据库实验——备份与恢复
一、目的(本次实验所涉及并要求掌握的知识点)
1.掌握SQL server的备份与恢复
二、实验内容与设计思想(设计思路、主要数据结构、主要代码结构、主要代码段分析)
验证性实验
实验1:在资源管理器中建立备份设备实验
第一步:在SQL Server管理平台的【对象资源管理器】窗口中展开【服务器对象】的子节点【备份设备】上单击鼠标右键,弹出快捷菜单,如右图所示。
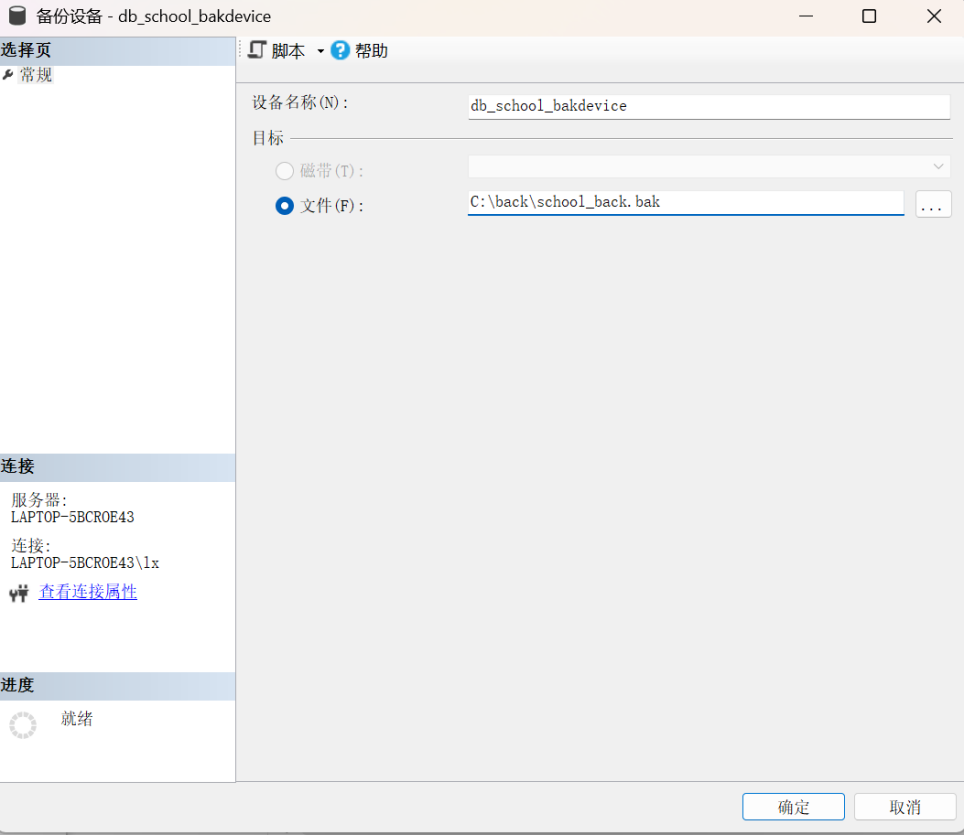
第二步:单击新建备份设备选项,打开【备份设备】对话框。在【设备名称】文件框中输入“db_school_bakdevice”;在不存在磁带机的情况下,【目标】目标选项自动选中【文件】单选项,在【文件】选项对应的文本框中输入文件路径和名称“C:\back\school_back.bak”,如下图所示。
实验2:在资源管理器中删除备份设备实验
在SQL Server管理平台的【对象资源管理器】窗口中展开【服务器对象】的子节点【备份设备】。在节点【db_school_bakdevice】上单击鼠标右键,弹出快捷菜单中删除该设备,如下图所示。
实验3:通过命令方式建立和删除备份设备实验
1. 建立备份设备
我们可以通过执行系统存储过程sp_addumpdevice的形式,建立一个磁盘备份设备,基本语法是:
EXEC sp_addumpdevice 'device_type' , 'logical_name' , 'physical_name',
其中各个参数的含义是:
device_type:设备类型,‘disk|tape’, “disk”表示磁盘,“tape”表示磁带。
logical_name:逻辑磁盘备份设备名。
physical_name:物理磁盘备份设备名。
--例1:使用T-SQL语句的存储过程sp_addumpdevice命令行创建磁盘备份设备的物理备份设备名为“E:\backup\student_bak”,逻辑备份设备名为“db_student_bakdevice”。
exec sp_addumpdevice 'disk','db_student_bakdevice','E:\backup\student_bak'
2.删除备份设备
删除一个磁盘备份设备的基本语法是:
EXEC sp_dropdevice 'logical_name' , ‘delfile'
其中各个参数的含义是:
logical_name:逻辑磁盘备份设备名。
delfile:表示是否同时删除磁盘备份物理设备名。
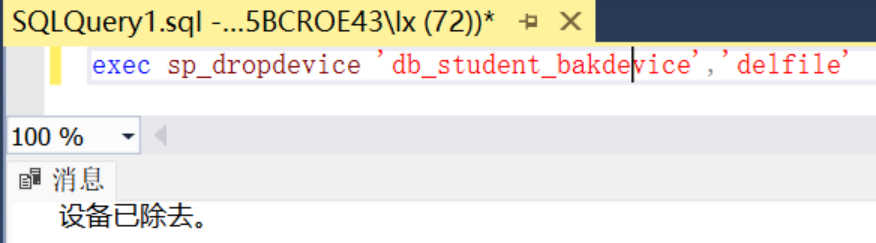
--例2:使用T-SQL语句的存储过程sp_dropdevice命令行删除前面刚创建的磁盘备份设备。
exec sp_dropdevice 'db_student_bakdevice',delfile'
实验1:在资源管理器中进行完全数据备份实验
第一步:打开资源管理器,鼠标右击school数据库,在展开的菜单中选择任务中的备份项。
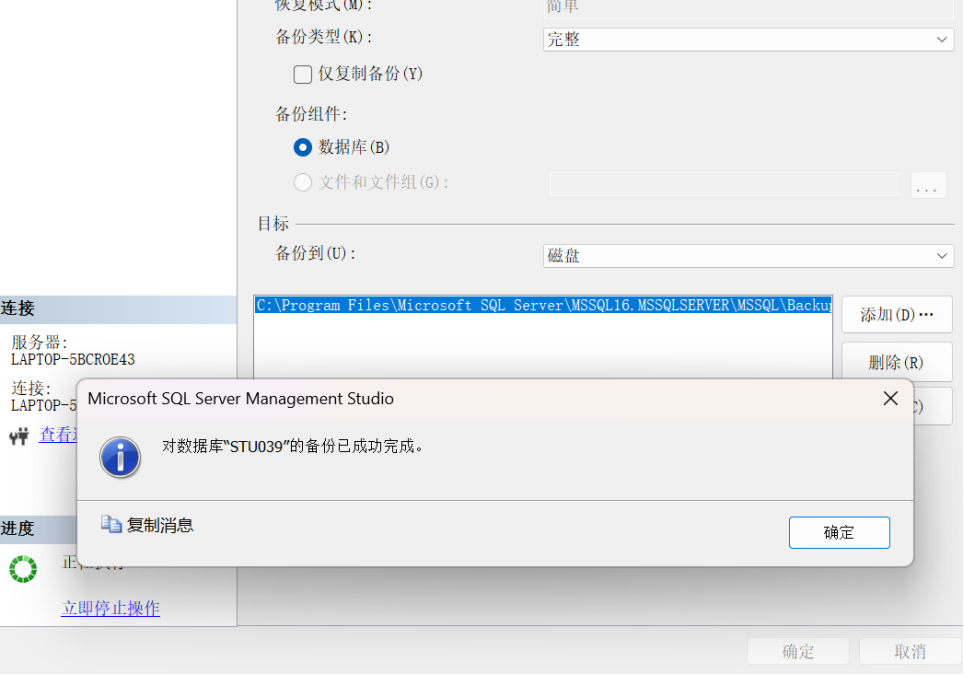
第二步:在展开的备份数据库界面中,选择备份类型为“完整”,备份组件为数据库,在备份目标为备份到磁盘,选择添加磁盘的具体的路径及备份文件名为C:\school_fullback.bak,如图所示。点击确定后完成完全数据备份的工作,所生成的C:\school_fullback.bak文件将在后面数据库恢复中被重新应用。
实验2:通过命令行进行完全数据备份实验
第一步:sp_addumpdevice 是系统存储过程,用于创建磁盘备份文件,其基本命令行如下所示:
sp_addumpdevice [@devtype=]'device_type',[@logicalname=]'logical_name',[ @physicalname = ] 'physical_name'[,{[@cntrltype = ] controller_type|[@devstatus=]'device_status' }]
use master--首先,进入master数据库。
Go
--下面,在C盘下建立文件夹back,然后分别执行下面的三个磁盘备份文件。
exec sp_addumpdevice 'disk','backup_file1','c:\back\backup_file1.bak'
exec sp_addumpdevice 'disk','backup_file2','c:\back\backup_file2.bak'
exec sp_addumpdevice 'disk','backup_log','c:\back\backup_log.bak'
实验2:通过命令行进行完全数据备份实验
第二步:将school数据库备份到第一步建立的磁盘备份文件中。
BACKUP DATABASE{database_name|@database_name_var} <file_or_filegroup> [ ,...f ]
TO <backup_device> [ ,...n ] ..[[,]{INIT|NOINIT}]
backup database school to backup_file1 with noinit
backup database school to backup_file2 with init
--请反复执行这两句话,那么我们可以很快从磁盘文件的空间变化中发现init和no init的区别:
--可见,init由于重新建立磁盘备份,因此文件并没有增长;而由于noinit是追加备份,因此磁盘文件增长非常明显。当然,我们也可以不需要使用磁盘备份文件,而通过直接指定磁盘路径的方式实现对数据库文件进行备份。
BACKUP DATABASE school TO DISK='D:\ Mydiffbackup.bak'
实验1:通过命令行进行差异数据备份实验
BACKUP DATABASE school TO DISK='D:\school_back.bak' WITH DIFFERENTIAL
--或者
backup database school to backup_file2 WITH DIFFERENTIAL
实验2:在管理平台中进行差异数据备份实验
打开备份向导。在“备份数据库”窗口中,选择备份类型为“差异”。在备份的目标中,指定备份到的磁盘文件位置(本例中为C:\back\school.bak文件),如图所示。然后单击“确定”按钮。备份完成后,可以找到C:\back\school.bak文件。差异备份文件要比完全备份文件小得多,因为它仅备份自上次完整备份后更改过的数据。
实验1:在管理平台中进行日志文件备份实验
打开备份向导。在“备份数据库”窗口中,选择备份类型为“事务日志”。在备份的目标中,指定备份到的磁盘文件位置(本例中为c:\back\backup_log.bak文件),如图所示。然后单击“确定”按钮。备份完成后,可以找到c:\back\backup_log.bak文件。
实验2:通过命令行进行日志文件备份实验
--备份事务日志,追加到现有日志文件
backup log school to disk='d:\school_log.bak' WITH NOINIT
--清空日志文件
backup log school with no_log
--备份事务日志,重写现有日志文件,并尽可能的将所有发生的操作信息到日志文件中
BACKUP LOG school TO DISK='c:\school_log.bak' WITH INIT,NO_TRUNCATE
--如果不想要日志或者是日志已没有什么作用时,可以考虑以下的实现方案:
backup log DBNAME with [no_log|truncate_only][no_truncate]
实验1:在管理平台中利用完全数据备份还原数据库实验
第一步:首先新建一个空的school数据库,而后用鼠标右键单击“对象资源管理器”中的“school”数据库对象。在弹出的快捷菜单中选择“任务”→“还原” →“数据库”选项,如图所示
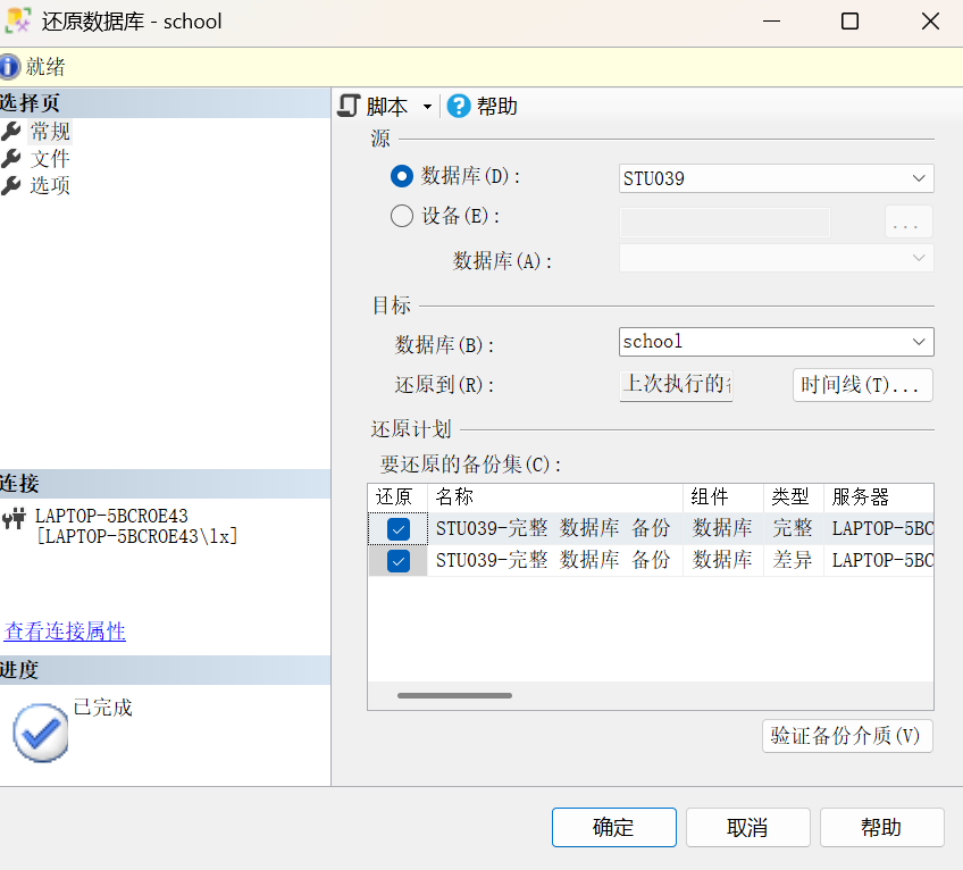
第二步:在“还原数据库”窗口中,选择还原的数据库为“school”,选择用于还原的备份集为在备份操作中备份的完整数据集,如图所示
在“还原数据库”窗口中选择选项,在还原选项中选“覆盖现有数据库”复选框,如图所示,按“确定”按钮。还原操作完成后,打开“school”数据库,可以看到其中的数据进行了还原。在school中看不到进行完整备份后新增加的school数据,因为还原过程进行了完整备份的还原。
实验2:在管理平台中中利用差异数据备份还原数据库实验
第一步:在实验1的基础上,将school数据库的student表中插入一条学生记录后(假设姓名是关羽,如图所示),选择一次差异数据备份,备份至backup_file2.bak文件中。如图所示。
第二步:删除school数据库,而后先进性一次完全数据备份,但是过程和实验1却不完全一致。在还原数据库的常规选项中的操作过程相同,但是在“选项”中,必须设置其恢复状态为“不对数据库进行任何操作,不回滚未提交事务”,如图所示。即将数据库临时“挂起”,处于恢复状态。
三、实验使用环境(本次实验所使用的平台和相关软件)
Win11,Sql server 2022
四、实验步骤和调试过程(实验步骤、测试数据设计、测试结果分析)
(一)验证性实验
实验1:在资源管理器中建立备份设备实验
第一步:在SQL Server管理平台的【对象资源管理器】窗口中展开【服务器对象】的子节点【备份设备】上单击鼠标右键,弹出快捷菜单,如右图所示。
第二步:单击新建备份设备选项,打开【备份设备】对话框。在【设备名称】文件框中输入“db_school_bakdevice”;在不存在磁带机的情况下,【目标】目标选项自动选中【文件】单选项,在【文件】选项对应的文本框中输入文件路径和名称“C:\back\school_back.bak”,如下图所示。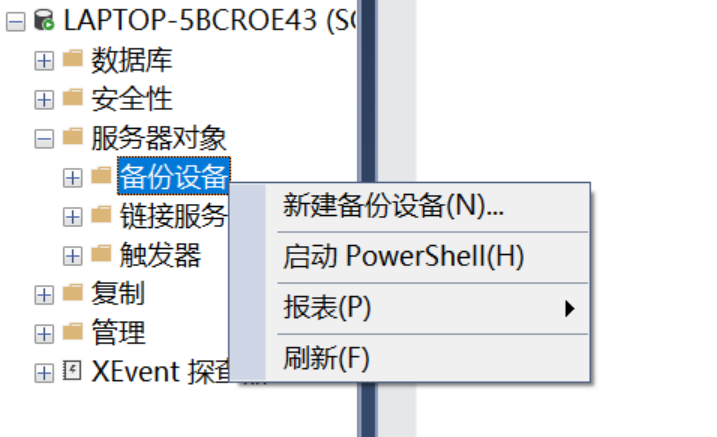
实验2:在资源管理器中删除备份设备实验
在SQL Server管理平台的【对象资源管理器】窗口中展开【服务器对象】的子节点【备份设备】。在节点【db_school_bakdevice】上单击鼠标右键,弹出快捷菜单中删除该设备,如下图所示。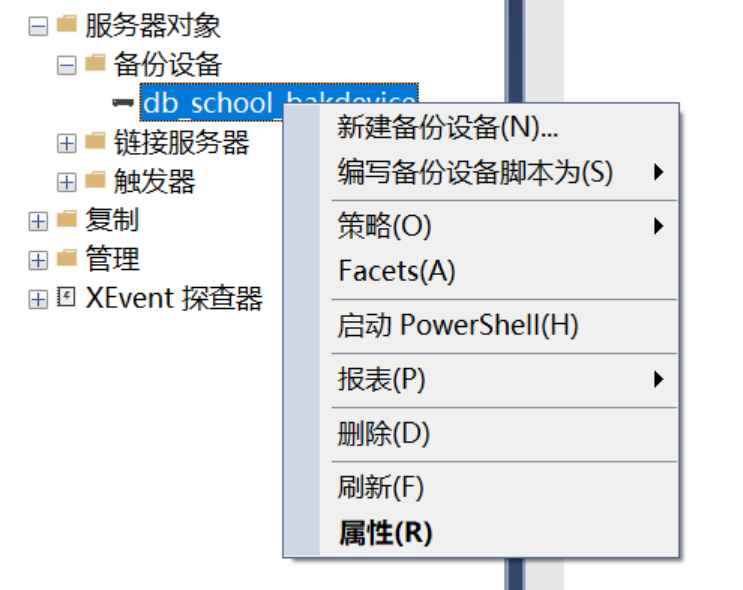
实验3:通过命令方式建立和删除备份设备实验
1. 建立备份设备
我们可以通过执行系统存储过程sp_addumpdevice的形式,建立一个磁盘备份设备,基本语法是:
EXEC sp_addumpdevice 'device_type' , 'logical_name' , 'physical_name',
其中各个参数的含义是:
device_type:设备类型,‘disk|tape’, “disk”表示磁盘,“tape”表示磁带。
logical_name:逻辑磁盘备份设备名。
physical_name:物理磁盘备份设备名。
--例1:使用T-SQL语句的存储过程sp_addumpdevice命令行创建磁盘备份设备的物理备份设备名为“E:\backup\student_bak”,逻辑备份设备名为“db_student_bakdevice”。
exec sp_addumpdevice 'disk','db_student_bakdevice','E:\backup\student_bak'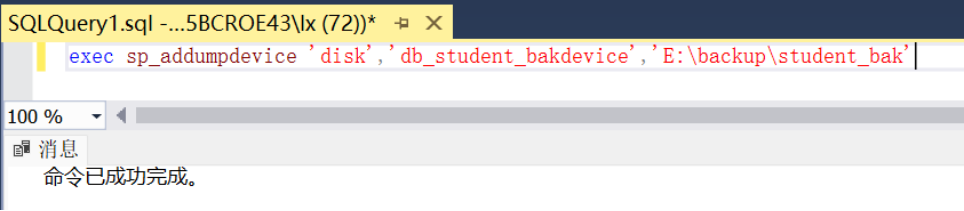
2.删除备份设备
删除一个磁盘备份设备的基本语法是:
EXEC sp_dropdevice 'logical_name' , ‘delfile'
其中各个参数的含义是:
logical_name:逻辑磁盘备份设备名。
delfile:表示是否同时删除磁盘备份物理设备名。
--例2:使用T-SQL语句的存储过程sp_dropdevice命令行删除前面刚创建的磁盘备份设备。
exec sp_dropdevice 'db_student_bakdevice',delfile'
实验1:在资源管理器中进行完全数据备份实验
第一步:打开资源管理器,鼠标右击school数据库,在展开的菜单中选择任务中的备份项。
第二步:在展开的备份数据库界面中,选择备份类型为“完整”,备份组件为数据库,在备份目标为备份到磁盘,选择添加磁盘的具体的路径及备份文件名为C:\school_fullback.bak,如图所示。点击确定后完成完全数据备份的工作,所生成的C:\school_fullback.bak文件将在后面数据库恢复中被重新应用。 
第一步:sp_addumpdevice 是系统存储过程,用于创建磁盘备份文件,其基本命令行如下所示:
sp_addumpdevice [@devtype=]'device_type',[@logicalname=]'logical_name',[ @physicalname = ] 'physical_name'[,{[@cntrltype = ] controller_type|[@devstatus=]'device_status' }]
use master--首先,进入master数据库。
Go
--下面,在C盘下建立文件夹back,然后分别执行下面的三个磁盘备份文件。
exec sp_addumpdevice 'disk','backup_file1','c:\back\backup_file1.bak'
exec sp_addumpdevice 'disk','backup_file2','c:\back\backup_file2.bak'
exec sp_addumpdevice 'disk','backup_log','c:\back\backup_log.bak'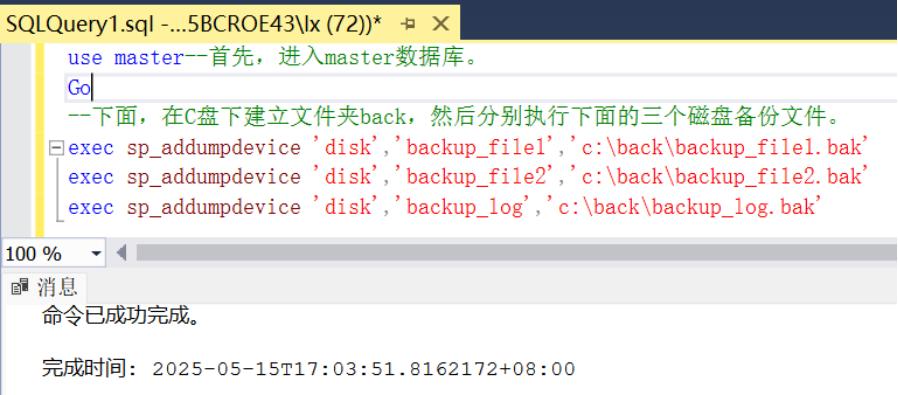
实验2:通过命令行进行完全数据备份实验
第二步:将school数据库备份到第一步建立的磁盘备份文件中。
BACKUP DATABASE{database_name|@database_name_var} <file_or_filegroup> [ ,...f ]
TO <backup_device> [ ,...n ] ..[[,]{INIT|NOINIT}]
backup database school to backup_file1 with noinit
backup database school to backup_file2 with init
--请反复执行这两句话,那么我们可以很快从磁盘文件的空间变化中发现init和no init的区别:
--可见,init由于重新建立磁盘备份,因此文件并没有增长;而由于noinit是追加备份,因此磁盘文件增长非常明显。当然,我们也可以不需要使用磁盘备份文件,而通过直接指定磁盘路径的方式实现对数据库文件进行备份。
BACKUP DATABASE school TO DISK='D:\ Mydiffbackup.bak'
实验1:通过命令行进行差异数据备份实验
BACKUP DATABASE school TO DISK='D:\school_back.bak' WITH DIFFERENTIAL
--或者
backup database school to backup_file2 WITH DIFFERENTIAL
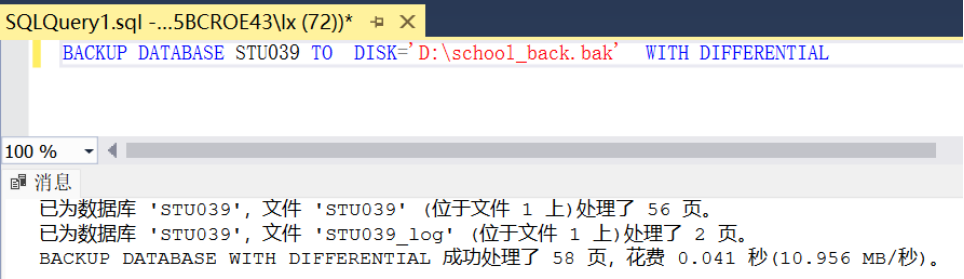
打开备份向导。在“备份数据库”窗口中,选择备份类型为“差异”。在备份的目标中,指定备份到的磁盘文件位置(本例中为C:\back\school.bak文),如图所示。然后单击“确定”按钮。备份完成后,可以找到C:\back\school.bak文件。差异备份文件要比完全备份文件小得多,因为它仅备份自上次完整备份后更改过的数据。
实验1:在管理平台中进行日志文件备份实验
打开备份向导。在“备份数据库”窗口中,选择备份类型为“事务日志”。在备份的目标中,指定备份到的磁盘文件位置(本例中为c:\back\backup_log.bak文件),如图所示。然后单击“确定”按钮。备份完成后,可以找到c:\back\backup_log.bak文件。 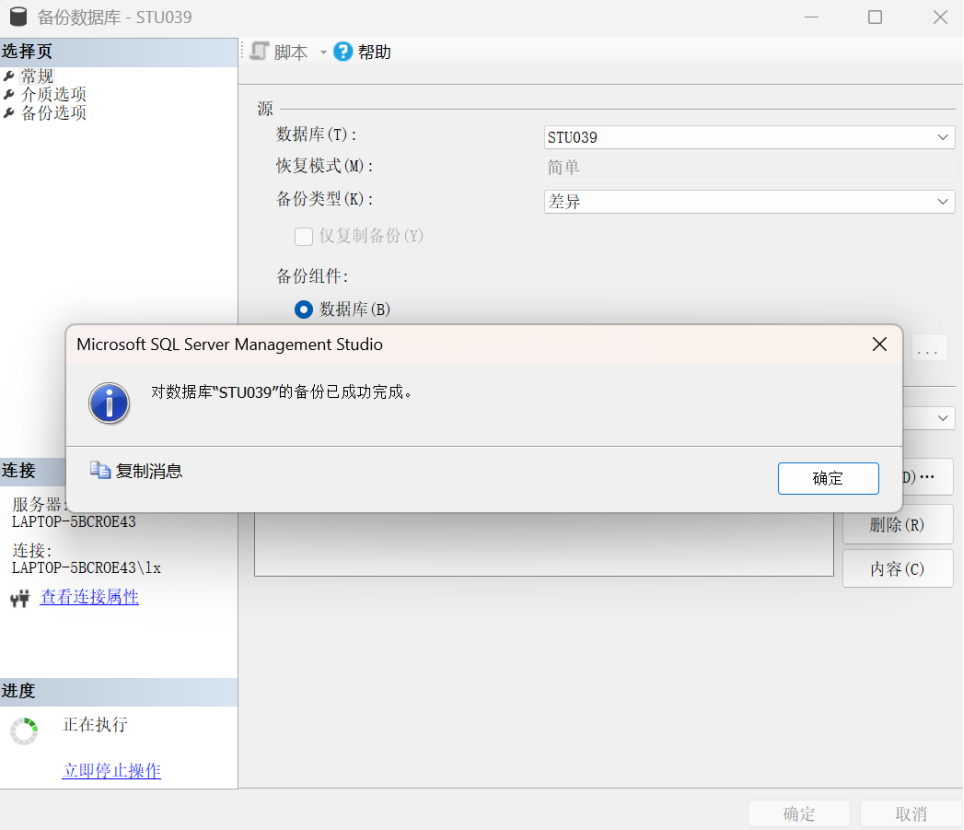
实验2:通过命令行进行日志文件备份实验
--备份事务日志,追加到现有日志文件
backup log school to disk='d:\school_log.bak' WITH NOINIT
--清空日志文件
backup log school with no_log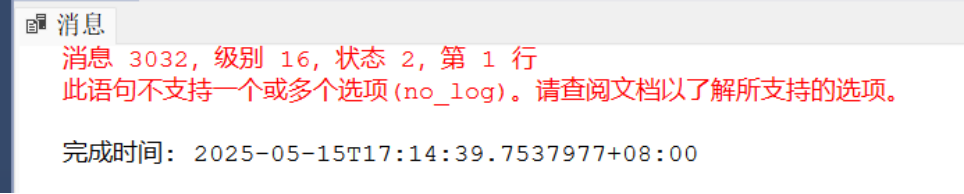
--备份事务日志,重写现有日志文件,并尽可能的将所有发生的操作信息到日志文件中
BACKUP LOG school TO DISK='c:\school_log.bak' WITH INIT,NO_TRUNCATE 
--如果不想要日志或者是日志已没有什么作用时,可以考虑以下的实现方案:
backup log DBNAME with [no_log|truncate_only][no_truncate]
实验1:在管理平台中利用完全数据备份还原数据库实验
第一步:首先新建一个空的school数据库,而后用鼠标右键单击“对象资源管理器”中的“school”数据库对象。在弹出的快捷菜单中选择“任务”→“还原” →“数据库”选项,如图所示
第二步:在“还原数据库”窗口中,选择还原的数据库为“school”,选择用于还原的备份集为在备份操作中备份的完整数据集,如图所示
在“还原数据库”窗口中选择选项,在还原选项中选“覆盖现有数据库”复选框,如图所示,按“确定”按钮。还原操作完成后,打开“school”数据库,可以看到其中的数据进行了还原。在school中看不到进行完整备份后新增加的school数据,因为还原过程进行了完整备份的还原。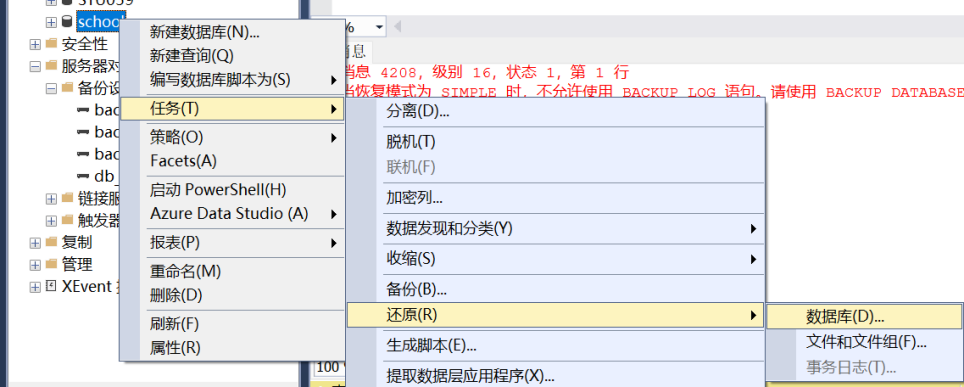
实验2:在管理平台中中利用差异数据备份还原数据库实验
第一步:在实验1的基础上,将school数据库的student表中插入一条学生记录后(假设姓名是关羽,如图所示),选择一次差异数据备份,备份至backup_file2.bak文件中。如图所示。
第二步:删除school数据库,而后先进性一次完全数据备份,但是过程和实验1却不完全一致。在还原数据库的常规选项中的操作过程相同,但是在“选项”中,必须设置其恢复状态为“不对数据库进行任何操作,不回滚未提交事务”,如图所示。即将数据库临时“挂起”,处于恢复状态。
综合实训 SQL Server备份方法实训
--实验1:首先开始进行完全数据备份
backup database d1 to bak1 with init
backup database d1 to bak1 with noinit
--注意,参数init和noinit的差异性
use master
go
-- 创建名为bak1的磁盘备份设备,指定实际存储路径,这里假设路径为D:\backup\bak1.bak,需根据实际情况调整
exec sp_addumpdevice 'disk', 'bak1', 'D:\backup\bak1.bak'
go
-- 第一次备份使用INIT参数,创建新的备份集并覆盖现有备份
backup database d1 to bak1 with init
-- 后续备份使用NOINIT参数,追加到现有备份集
backup database d1 to bak1 with noinit
--实验2:下面开始进行差异备份,第一次备份时应做完全备份 ★ ★ ★
backup database d2 to bak2 with init,name='d2_full'
--建立表b1 R1
create table b1(c1 int not null,c2 char(10) not null)
--每次插入更新的数据后,都进行差异数据备份 R2
backup database d2 to bak2 with differential,name='d2_diff1'
insert b1 values(1,'a')
backup database d2 to bak2 with differential,name='d2_diff2‘ R3
insert b1 values(2,'b')
backup database d2 to bak2 with differential,name='d2_diff3‘ R4
insert b1 values(3,'c')
backup database d2 to bak2 with differential,name='d2_diff4‘ R5
restore headeronly from bak2

use master
go
-- 创建磁盘类型的备份设备bak2,指定实际存储路径,这里假设路径为D:\backup\bak2.bak,需根据实际情况调整
exec sp_addumpdevice 'disk', 'bak2', 'D:\backup\bak2.bak'
go
-- 首先进行完全备份,使用INIT创建新备份集
backup database d2 to bak2 with init,name='d2_full'
-- 创建测试表
create table b1(c1 int not null,c2 char(10) not null)
-- 每次数据变更后进行差异备份
backup database d2 to bak2 with differential,name='d2_diff1'
insert b1 values(1,'a')
backup database d2 to bak2 with differential,name='d2_diff2'
insert b1 values(2,'b')
backup database d2 to bak2 with differential,name='d2_diff3'
insert b1 values(3,'c')
backup database d2 to bak2 with differential,name='d2_diff4'
-- 查看备份集信息
restore headeronly from bak2
五、实验小结(实验中遇到的问题及解决过程、实验中产生的错误及原因分析、实验体会和收获)
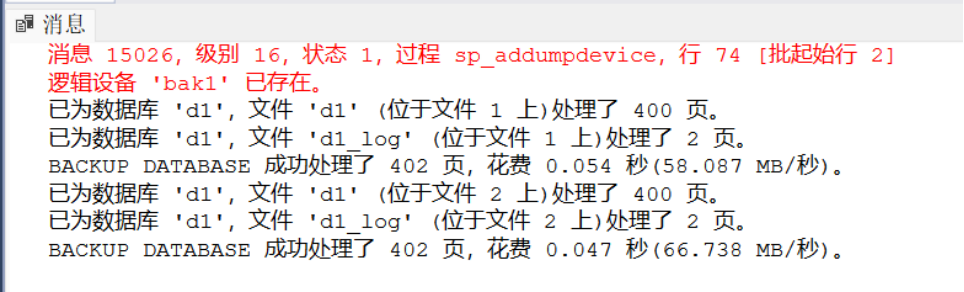
1.“无法打开备份设备 'bak1 (D:\backup\bak1.bak)' 。出现操作系统错误 3 (系统找不到指定的路径。)” 说明指定的备份文件存储路径 D:\backup 不存在。
解决办法:
手动创建路径:打开文件资源管理器,在 D: 盘下手动创建名为 backup 的文件夹。同时,要确保 SQL Server 服务账户(一般是 NT Service\MSSQLSERVER )对该文件夹有读写权限。可以通过文件夹属性 - 安全选项卡来检查和设置权限。
2.
该错误提示表明在执行备份操作时,指定的备份设备bak1不存在。
解决办法:
使用存储过程创建备份设备,可以通过sp_addumpdevice存储过程来创建备份设备。
3.逻辑设备已存在的冲突
执行sp_addumpdevice时提示 “逻辑设备‘bak1’已存在”。因为目标逻辑设备名称已被占用。
解决方法:直接使用已存在的设备名称进行备份,无需重复创建。
4.简单恢复模式下无法备份日志的错误
执行BACKUP LOG时提示 “当恢复模式为 SIMPLE 时,不允许使用 BACKUP LOG 语句”。数据库恢复模式为 “简单”,不支持事务日志备份。
解决方法:将数据库恢复模式改为 “完整” 或 “大容量日志”
实验体会和收获
熟练掌握了 SQL Server 中备份设备的创建与删除(通过 SSMS 图形界面和sp_addumpdevice/sp_dropdevice命令)。
理解了完全备份、差异备份和日志备份的区别与应用场景:
完全备份:完整复制数据库,占用空间大,用于初始备份。
差异备份:仅备份自上次完全备份后的变更,依赖完全备份。
日志备份:记录事务日志,需配合完整恢复模式使用,用于数据点恢复。
学会使用RESTORE HEADERONLY/FILELISTONLY等命令查询备份集信息,辅助恢复操作。
本次实验通过理论与实践结合,系统学习了 SQL Server 备份与恢复的全流程,熟悉了不同备份类型的操作细节及常见问题处理。未来需进一步结合实际场景,优化备份策略,确保数据库在故障情况下能够快速、完整地恢复,保障数据安全与业务连续性。
相关文章:

数据库实验——备份与恢复
一、目的(本次实验所涉及并要求掌握的知识点) 1.掌握SQL server的备份与恢复 二、实验内容与设计思想(设计思路、主要数据结构、主要代码结构、主要代码段分析) 验证性实验 实验1:在资源管理器中建立备份设备实验 …...

抓包分析工具与流量监控软件
目录 一、抓包分析工具:定位问题的“放大镜” 1.1 工作原理简述 1.2 主流工具盘点 1.3 抓包的实战应用 二、流量监控软件:网络全景的“雷达系统” 2.1 功能特征 2.2 常用工具概览 2.3 实战应用场景 五、结语:深入可见,安…...

Go语言实战:使用 excelize 实现多层复杂Excel表头导出教程
Go 实现支持多层复杂表头的 Excel 导出工具 目录 项目介绍依赖说明核心结构设计如何支持多层表头完整使用示例总结与扩展 项目介绍 在实际业务系统中,Excel 文件导出是一项常见功能,尤其是报表类需求中常见的复杂多级表头,常规表格组件往…...

【算法】定长滑动窗口5.20
定长滑动窗口算法: 算法思路 滑动窗口遍历字符串:窗口大小为 k ,遍历字符串每个字符,维护窗口内元音字母数量。 统计窗口内元音:当字符是元音(a/e/i/o/u)时,计数器 vowel 加 1。…...

Java操作Elasticsearch 之 [Java High Level REST Clientedit]
<a name"VbjtD"></a> 1. 简述 Elasticsearch 是基于 Lucene 开发的一个分布式全文检索框架,向 Elasticsearch 中存储和从 Elasticsearch 中查询,格式是json。向 Elasticsearch 中存储数据,其实就是向 es 中的 index 下…...

数据集划分与格式转换:从原始数据到模型训练的关键步骤
在计算机视觉项目中,数据集的合理划分和格式转换是实现高效模型训练的基础。本文将详细介绍如何将图片和标注数据按比例切分为训练集和测试集,以及常见的数据格式转换方法,包括 JSON 转 YOLO 格式和 XML 转 TXT 格式。 一、将图片和标注数据…...

MinerU
简介 MinerU 是一款功能全面的文档处理系统,旨在将 PDF 和其他文档格式转换为机器可读的格式,例如 Markdown 和 JSON。该系统专注于在保留文档结构的同时,准确提取文档内容,处理复杂的布局,并转换公式和表格等特殊元素…...

Vue百日学习计划Day46-48天详细计划-Gemini版
Day 46: <KeepAlive> - 组件缓存与优化 (~3 小时) 本日目标: 理解 <KeepAlive> 的作用,学会如何使用它来缓存组件实例,从而优化应用性能和用户体验。所需资源: Vue 3 官方文档 (<KeepAlive>): https://cn.vuejs.org/guide/built-ins/…...

微软的 Windows Linux 子系统现已开源
微软宣布其 Windows Linux 子系统 (WSL) 开源,开放代码供社区成员贡献。自近九年前推出适用于 Windows 10 的 WSL 以来,微软多年来一直致力于开源这项在 Windows 中启用 Linux 环境的功能。 Windows 首席执行官 Pavan Davuluri 表示:“这是开…...

Axure中使用动态面板实现图标拖动交换位置
要在Axure中实现图标拖动交换位置的功能,可以通过动态面板结合交互事件来实现。 实现步骤 准备图标元素 将每个图标转换为动态面板(方便拖动和交互)。 设置拖动交互 选中图标动态面板 → 添加“拖动时”交互 → 选择“移动”当前动态面板&am…...

深入浅出:Spring Cloud Gateway 扩展点实践指南
文章目录 前言一、为什么需要扩展 Spring Cloud Gateway?二、Spring Cloud Gateway 核心扩展点三、扩展点实战:代码与配置详解3.1 全局过滤器(GlobalFilter)3.2 路由过滤器(GatewayFilter)2.3 自定义路由断…...

SCAU18923--二叉树的直径
18923 二叉树的直径 时间限制:1000MS 代码长度限制:10KB 提交次数:0 通过次数:0 题型: 编程题 语言: G;GCC Description 给定一棵二叉树,你需要计算它的直径长度。一棵二叉树的直径长度是任意两个结点路径长度中的最大值。这条路径可能穿过也可能不穿过根结点…...

理解 RESTful 风格:现代 Web 服务的基石
在当今的互联网时代,Web 服务成为了连接各种应用和系统的关键。而 RESTful 风格,作为一种广泛采用的架构风格,为设计和实现 Web 服务提供了一套简洁而强大的指导原则。本文将深入探讨 RESTful 风格的核心概念、优势以及如何在实际项目中应用它…...
——RAG(Retrieval-Augmented Generation,检索增强生成))
大模型(3)——RAG(Retrieval-Augmented Generation,检索增强生成)
文章目录 1. 核心组成2. 工作流程3. 训练方式4. 优势与局限5. 应用场景6. 典型模型变体总结 RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合了信息检索与文本生成的技术,旨在通过引入外部知识库提升生成内容的准确性…...

电子科技大学软件工程实践期末
Java基础 面向对象 Java高级编程 2023: 软件工程基础 ch1软件工程概述 软件的概念和特点 软件危机的概念以及产生的原因 软件工程的定义 三要素 应用软件工程的原因 三要素:工具,方法,过程 ch2 软件过程 软件生命周期 软件过程…...

线上jvm假死问题排查
1.线上告警接口超时 看接口是用户服务,查看nacos服务实例,发现有一个节点已经下线了 3.找到对应节点所在服务器,jps -l 命令发现用户服务还在,初步判断是假死 4.使用 jstat -gc 进程id 1000 每秒打印gc情况,发现频繁…...

Redis中SETNX、Lua 脚本和 Redis事务的对比
在 Redis 中,SETNX、Lua 脚本 和 Redis 事务 都可以用于实现原子性操作,但它们的适用场景和能力范围不同。以下是详细对比和原因分析: 1. SETNX 的原子性与局限性 (1) 原子性保证 SETNX(SET if Not eXists) 是 Redis…...

Nginx配置记录访问信息
文章目录 方法一:使用Nginx原生配置记录访问信息方法二:使用Nginx_headers_more模块记录更加详细的信息 Nginx被广泛应用于各种场景如:Web服务器、反向代理服务器、负载均衡器、Web应用防火墙(WAF)等 在实际的产品开发中,无论是功…...

基于机载激光雷达数据的森林生物量估测:AI驱动的遥感革新
一、技术背景与意义 森林生物量是生态系统碳循环和碳汇估算的核心参数。传统遥感方法(如光学影像)在三维结构解析上存在局限,而机载激光雷达(LiDAR)凭借高精度点云数据,能够捕捉森林的垂直结构信息。结合人…...

Redis中的事务和原子性
在 Redis 中,事务 和 原子性 是两个关键概念,用于保证多个操作的一致性和可靠性。以下是 Redisson 和 Spring Data Redis 在处理原子性操作时的区别与对比: 1. Redis 的原子性机制 Redis 本身通过以下方式保证原子性: 单线程模型…...

SSL证书:谷歌算法排名的安全基石与信任杠杆
一、技术演进:从安全信号到算法基石 谷歌对SSL证书的重视始于2014年,当时HTTPS首次被纳入排名算法信号。经过十年迭代,SSL证书已从“加分项”升级为“基础门槛”。2025年算法更新中,其权重占比达2%,与页面加载速度、移…...

XXX企业云桌面系统建设技术方案书——基于超融合架构的安全高效云办公平台设计与实施
目录 1. 项目背景与目标1.1 背景分析1.2 建设目标2. 需求分析2.1 功能需求用户规模与场景终端兼容性2.2 非功能需求3. 系统架构设计3.1 总体架构图流程图说明3.2 技术选型对比3.3 网络设计带宽规划公式4. 详细实施方案4.1 分阶段部署计划4.2 桌面模板配置4.3 测试方案性能测试工…...

【GESP真题解析】第 18 集 GESP 一级 2024 年 12 月编程题 1:温度转换
大家好,我是莫小特。 这篇文章给大家分享 GESP 一级 2024 年 12 月编程题第 1 题:温度转换。 题目链接 洛谷链接:B4062 温度转换 一、完成输入 根据题意,输入只有一行,为实数,数据范围: 0 &l…...

鸿蒙开发进阶:深入解析ArkTS语言特性与高性能编程实践
一、前言 在鸿蒙生态蓬勃发展的当下,开发者对于高效、优质的应用开发语言需求愈发迫切。ArkTS 作为鸿蒙应用开发的核心语言,在继承 TypeScript 优势的基础上,进行了诸多优化与扩展,为开发者带来了全新的编程体验。本文将深入剖析…...
)
现代计算机图形学Games101入门笔记(十七)
双向路径追踪 外观建模 散射介质 人的头发不能用在动画的毛发上。 动物的髓质Medulla特别大 双层圆柱模型应用 BSSRDF是BRDF的延伸。 天鹅绒用BRDF不合理,转成散射介质。 法线分布 光追很难处理微表面模型 光在微型细节上,光是一个波,会发生衍…...

工单派单应用:5 大核心功能提升协作效率
一、工单管理:全流程一目了然 快速创建:录入任务内容、优先级,从源头明确目标 状态分类:待处理 / 进行中 / 已完成工单一目了然,个人进度随时掌控 灵活分配:公海池抢单机制,成员按能力自主接…...

maven 多个模块之间互相引入加载配置的偶遇问题
因为子项目添加了:<!-- aliyun sms SDK --> <dependency><groupId>com.aliyun</groupId><artifactId>aliyun-java-sdk-core</artifactId><version>4.6.3</version> </dependency>导致原本运行良好的构建模块,…...

【蓝桥杯嵌入式】【模块】五、ADC相关配置及代码模板
1. 前言 最近在准备16届的蓝桥杯嵌入式赛道的国赛,打算出一个系列的博客,记录STM32G431RBT6这块比赛用板上所有模块可能涉及到的所有考点,如果有错误或者遗漏欢迎各位大佬斧正。 本系列博客会分为以下两大类: 1.1. 单独模块的讲…...

DP2 跳台阶【牛客网】
文章目录 零、原题链接一、题目描述二、测试用例三、解题思路四、参考代码 零、原题链接 DP2 跳台阶 一、题目描述 二、测试用例 三、解题思路 基本思路: 动态规划题目的难点基本在于构造状态转移方程,对应这题,我们可以发现每次跳跃我…...

KC 喝咖啡/书的复制/奶牛晒衣服/ 切绳子
二分的解题思路: 常解决最小值最大化和最大值最小化问题 步骤解析 确定答案范围 设定初始左边界 left 和右边界 right,确保解在此区间内。例如: 求最小最大值时,left 可取单个元素的最大值,right 取所有元素总和。 …...

Jedis快速入门【springboot】
引入依赖 <dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId><version>6.0.0</version> </dependency> 创立jedis对象,建立连接 private Jedis jedis; BeforeEach void setUp(){//1 …...

SpringBoot 商城系统高并发引起的库存超卖库存问题 乐观锁 悲观锁 抢购 商品秒杀 高并发
介绍 在高并发场景下,特别是商品秒杀、抢购等情况下,库存超卖问题是一个常见且棘手的问题。为了解决这个问题,Spring Boot 常使用乐观锁和悲观锁来保证数据的正确性和一致性。 悲观锁 悲观锁假设在多线程或多进程环境中,资源会被…...

[python] 轻量级定时任务调度库schedule使用指北
schedule是一款专为简化定时任务调度而设计的Python库,它通过直观的语法降低了周期性任务的实现门槛。作为进程内调度器,它无需额外守护进程,轻量且无外部依赖,适合快速搭建自动化任务。不过,该库在功能完整性上有所取…...

MySQL:to many connections连接数过多
当你遇到 MySQL: Too many connections 错误时,意味着当前连接数已达到 MySQL 配置的最大限制。这通常是由于并发连接过多或连接未正确关闭导致的。 一、查看当前连接数 查看 MySQL 当前允许的最大连接数 SHOW VARIABLES LIKE max_connections;查看当前使用的最大…...

uthash是一个非常轻量级的库
如大家所知,uthash是一个非常轻量级的库。该库的使用非常简单,无需格外的静态库或动态库,仅需导入目标的头文件即可。 这种配置方式虽然简单,但是使用操作却需要用到大量的宏函数。在使用宏函数时不像使用普通函数一样自由和遍历…...
:基于LlaMAFactory的LoRA微调(上))
大模型的开发应用(三):基于LlaMAFactory的LoRA微调(上)
基于LlaMAFactory的LoRA微调(上) 0 前言1 LoRA微调1 LoRA微调的原理1.2 通过peft库为指定模块添加旁支1.3 lora前后结构输出结果对比1.4 使用PyTorch复现 LoRA.Linear1.5 使用peft进行LoRA微调案例 2 LLaMA-Factory2.1 LLaMA-Factory简介2.2 LLaMA-Facto…...

跨域_Cross-origin resource sharing
同源是指"协议域名端口"三者相同,即便两个不同的域名指向同一个ip,也非同源 1.什么是CORS? CORS是一个W3C标准,全称是"跨域资源共享"(Cross-origin resource sharing)。它允许浏览器向跨源服务器ÿ…...

奥威BI:打破AI数据分析伪场景,赋能企业真实决策价值
在当今企业数字化转型的浪潮中,AI数据分析产品如雨后春笋般涌现,但许多看似创新的功能设计实则难以落地,沦为“伪需求场景”。这些伪场景不仅浪费企业资源,还可能误导决策,阻碍企业数字化转型进程。在此背景下…...

LLaMA-Factory全解析:大模型微调的开源利器与实战指
技术演进背景与核心价值架构设计与关键技术解析环境搭建与工具链配置全流程微调实战指南企业级应用与高级功能性能优化与安全部署未来发展趋势展望1. 技术演进背景与核心价值 1.1 大模型微调的技术痛点 当前开源大模型(如LLaMA、Qwen、Baichuan等)在通用领域表现优异,但垂…...
)
python-数据可视化(大数据、数据分析、可视化图像、HTML页面)
通过 Python 读取 XLS 、CSV文件中的数据,对数据进行处理,然后生成包含柱状图、扇形图和折线图的 HTML 报告。这个方案使用了 pandas 处理数据,matplotlib 生成图表,并将图表嵌入到 HTML 页面中。 1.XSL文件生成可视化图像、生成h…...
 - 环境搭建)
Jmeter(一) - 环境搭建
1.JMeter 介绍 Apache JMeter是100%纯JAVA桌面应用程序,被设计为用于测试客户端/服务端结构的软件(例如web应用程序)。它可以用来测试静态和动态资源的性能,例如:静态文件,Java Servlet,CGI Scripts,Java Object,数据库和FTP服务器…...

OpenCV CUDA 模块特征检测与描述------在GPU上执行特征描述符匹配的类cv::cuda::DescriptorMatcher
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 cv::cuda::DescriptorMatcher 是 OpenCV 的 CUDA 模块中用于在 GPU 上执行特征描述符匹配的类。它允许你利用 NVIDIA GPU 的并行计算能力来加速特…...

idea如何让文件夹分层显示,而不是圆点分割
网上说是点击小齿轮的都是过时了,对于新版idea不适用,直接上图 1、如图 2、如图 注意也是去掉Compact Middle Packages,只不过新版的方式UI和老版本的不一样了...

5:OpenCV—直方图均衡化
直方图均衡 直方图均衡是一种用于增强和调整图像对比度的图像处理技术。它通过重新分配图像的像素值,使得图像的灰度级在整个范围内均匀分布,从而增强图像的视觉效果。 图像的直方图是像素强度分布的图形表示。它提供了像素值集中位置以及是否存在异常偏…...

内存分页法
现在有个场景,页面需要分页处理,但是后端在查询完数据库后又会进行筛选,就会导致后端的查询数目跟请求的每页条数是不一样。 解决方案:内存分页法 在内存筛选后手动实现分页逻辑,保证返回数量与请求的 pageSize 一致…...

深入解析FramePack:高效视频帧打包技术原理与实践
摘要 本文深入探讨FramePack技术在视频处理领域的核心原理,解析其在不同场景下的应用优势,并通过OpenCV代码示例演示具体实现方法,为开发者提供可落地的技术解决方案。 目录 1. FramePack技术背景 2. 核心工作原理剖析 3. 典型应用场景 …...
)
【EI会议火热征稿中】第二届云计算与大数据国际学术会议(ICCBD 2025)
# ACM独立出版 | EI检索稳定、往届会后4个半月完成EI检索 # 热门征稿主题:大数据、5G/6G、物联网、云计算 # 早投稿早送审早录用! 重要信息 大会官网:www.iccbd.net 会议主页:【ACM独立出版|EI稳定】第二届云计算与大数据国际…...

对未来软件的看法
有了大模型之后,TypeScript这样增强型javascript语言可能更方便AI来调试。未来的应用会越来越广泛。node.js vue.js会越来越流行。因为方便AI调试,处理错误。 未来,随着 AI 编程工具对 TypeScript 的深度支持(如自动类型推导、错误…...

新兴技术与安全挑战
7.1 云原生安全(K8s安全、Serverless防护) 核心风险与攻击面 Kubernetes配置错误: 风险:默认开放Dashboard未授权访问(如kubectl proxy未鉴权)。防御:启用RBAC,限制ServiceAccount权限。Serverless函数注入: 漏洞代码(AWS Lambda):def lambda_handler(event, cont…...

Prompt Tuning:轻量级大模型微调全攻略
Prompt Tuning(提示调优)步骤金额流程 传统的 Prompt Tuning(提示调优) 是一种轻量级的大模型微调技术,核心是通过优化连续的提示向量(而非模型参数)来适配特定任务。 一、核心步骤概述 准备任务与数据 明确任务类型(如分类、问答等),准备输入文本和目标标签。加载…...