MySql数据库连接池
C++数据库连接池
- 前言
- 1.MySql API 函数讲解
- 1.1 连接数据库的步骤
- 1.2 MySQL C API
- 1.2.1 初始化连接环境
- 1.2.2 连接mysql服务器
- 1.2.3 执行sql语句
- 1.2.4 获取结果集
- 1.2.5 得到结果集的列数
- 1.2.6 获取表头 -> 列名(字段名)
- 1.2.7 得到结果集中各个字段的长度(字节为单位)
- 1.2.8 遍历结果集 (结果集的下一行)
- 1.2.9 资源回收
- 1.2.10 字符编码
- 1.2.11 事务操作
- 1.2.12 打印错误信息
- 1.3、实例代码
- 1.4、C中的变量插入数据库中
- 1.4.1 动态SQL
- 1.4.2 预处理语句 (推荐使用)
- mysql_stmt_init 函数
- mysql_stmt_prepare 函数
- 演示代码
- 数据库连接池
- 连接池的设计
- 细节分析
- 项目代码如下:
- 1. 用C API 封装成C++类
- 2. 连接池设计
- 3. 主函数(测试)
- 4. 代码说明
- 1. 条件变量 wait_for
- 2. shared_ptr 自定义删除器
- 3. 条件变量个数问题
- 4. 单例模式
- 1. 懒汉模式(Lazy Initialization)
- (1)基础懒汉模式(非线程安全)
- (2)线程安全的懒汉模式(加锁)
- (3)C++11 线程安全懒汉模式(`std::call_once`)
- 2. 饿汉模式(Eager Initialization)
- (1)基础饿汉模式
- (2)C++11 改进版(局部静态变量)
- 3. 懒汉 vs 饿汉模式对比
- 4. 推荐方案
前言
- 这里就不带大家去安装MySql以及配置VS的环境了,如果需要就去看之前的博客:MySql安装以及QT、VS连接数据库。
- 这里提醒大家一点,如果配置环境之后,依旧无法运行程序,那么可能是 缺少安全模块的动态库,其实这个库文件就是
openssl的动态库,我们无需自己安装,官方是有提供的。首先打开官网下载地址:https://dev.mysql.com/downloads/
- 这里提醒大家一点,如果配置环境之后,依旧无法运行程序,那么可能是 缺少安全模块的动态库,其实这个库文件就是

下载使用C++连接数据库需要的组件(建议下载和本地 mysql 动态库一致的版本):

可以根据自己的实际需求选择安装版或者绿色版以及32bit或64bit。安装或解压完毕之后,我们就可以得到这样一个目录:

进入到lib64目录:
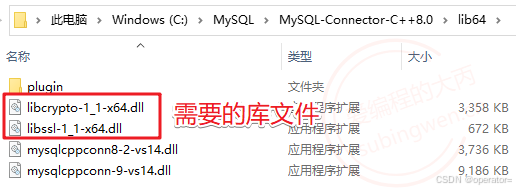
目录中的 libcrypto-1_1-x64.dll 和 libssl-1_1-x64.dll 就是我们需要的动态库,把这 两个动态库拷贝到和连接数据库的可执行程序同一级目录中就可以了。
- 关于基础的MySql的命令,请看这里的博文链接MySql基础命令
1.MySql API 函数讲解
1.1 连接数据库的步骤
众所周知,MySQL数据库是一个典型的 C/S结构,即:客户端和服务器端。如果我们部署好了MySQL服务器,想要在客户端访问服务器端的数据,在编写程序的时候就可以通过官方提供的C语言的API来实现。
在程序中连接MySql服务器,主要分为已经几个步骤:
初始化连接环境
连接mysql的服务器,需要提供如下连接数据:
- 服务器的IP地址
- 服务器监听的端口(默认端口是3306)前面安装的时候有提示
- 连接服务器使用的用户名(默认是 root),和这个用户对应的密码
- 要操作的数据库的名字
连接已经建立, 后续操作就是对数据库数据的添删查改
- 这些操作都是需要通过sql语句来完成的
- 数据查询:通过调用api 执行一个查询的sql语句
- 数据修改(添加/删除/更新):通过调用api 执行一个修改数据的sql语句
如果要进行数据 添加/ 删除/ 更新,需要进行事务的处理
需要对执行的结果进行判断
- 成功:提交事务
- 失败:数据回滚
数据库的读操作 -> 查询 -> 得到结果集
遍历结果集 -> 得到了要查询的数据
释放资源
1.2 MySQL C API
对于以上的操作步骤,在MySQL提供的API中都有对应的操作函数,下面,为大家介绍一下这些API函数的使用。
1.2.1 初始化连接环境
MYSQL *mysql_init(MYSQL *mysql) ;
参数
mysql:一般设置为null返回值: 该函数将分配、初始化、并返回新对象
- 通过返回的这个对象去连接MySQL的服务器
mysql_init() 返回的 MYSQL* 指针 指向一个内部数据结构,该结构存储了与 MySQL 服务器连接相关的所有状态和控制信息。 虽然 MySQL 官方文档并未完全公开其具体字段(因为它是一个不透明类型,用户无需直接访问其内部)。
总结
MYSQL* 指针指向的内存是一个连接控制块,封装了 MySQL 客户端与服务器交互所需的所有上下文信息。开发者无需关心其具体布局,只需通过 API 函数安全地操作它。重点是:
- 始终检查返回值(如
NULL表示失败)。 - 及时释放资源(
mysql_close)。 - 依赖官方 API 而非直接访问内部字段。
1.2.2 连接mysql服务器
MYSQL *mysql_real_connect(MYSQL *mysql, // mysql_init() 函数的返回值const char *host, // mysql服务器的主机地址, 写IP地址即可// localhost, null -> 代表本地连接const char *user, // 连接mysql服务器的用户名, 默认: root const char *passwd, // 连接mysql服务器用户对应的密码, root用户的密码const char *db, // 要使用的数据库的名字unsigned int port, // 连接的mysql服务器监听的端口// 如果==0, 使用mysql的默认端口3306, !=0, 使用指定的这个端口const char *unix_socket,// 本地套接字, 不使用指定为 NULLunsigned long client_flag); // 通常指定为0
返回值:
- 成功: 返回MYSQL* 连接句柄, 对于成功的连接,返回值与第1个参数的值相同。返回值指向的内存和第一个参数指针指向的内存一样
- 失败,返回NULL。
句柄: 是windows中的一个概念, 句柄可以理解为一个实例(或者对象)
1.2.3 执行sql语句
// 执行一个sql语句, 添删查改的sql语句都可以
int mysql_query(MYSQL *mysql, const char *query);
参数:
- mysql:
mysql_real_connect()的返回值- query: 一个
可以执行的sql语句, 结尾的位置不需要加\0;返回值:
- 如果查询成功,返回0。如果是查询, 结果集在mysql 对象中
- 如果出现错误,返回非0值。
1.2.4 获取结果集
MYSQL_RES *mysql_store_result(MYSQL *mysql);
- 作用:
从服务器检索完整的结果集并将其存储在客户端内存中MYSQL_RES对应一块内存, 里边保存着这个查询之后得到的结果集- 如何将行和列的数据从结果集中取出, 需要使用其他函数
- 返回值: 具有多个结果的
MYSQL_RES结果集合。
- 如果出现错误,返回NULL。
- 返回的是
MYSQL_RES类型的指针,可以理解是指向MYSQL_RES数组的首地址
1.2.5 得到结果集的列数
unsigned int mysql_num_fields(MYSQL_RES *result)
- 从结果集中列的个数
- 参数: 调用
mysql_store_result()得到的返回值- 返回值: 结果集中的列数
1.2.6 获取表头 -> 列名(字段名)
MYSQL_FIELD *mysql_fetch_fields(MYSQL_RES *result);
- 参数: 调用
mysql_store_result() 得到的返回值- 返回值:
MYSQL_FIELD*指向一个结构体- 通过查询官方文档, 返回是一个结构体的数组
- 通过这个函数得到结果集中所有列的名字
返回值MYSQL_FIELD对应的是一个结构体,在mysql.h中定义如下:
// mysql.h
// 结果集中的每一个列对应一个 MYSQL_FIELD
typedef struct st_mysql_field {char *name; /* 列名-> 字段的名字 */char *org_name; /* Original column name, if an alias */char *table; /* Table of column if column was a field */char *org_table; /* Org table name, if table was an alias */char *db; /* Database for table */char *catalog; /* Catalog for table */char *def; /* Default value (set by mysql_list_fields) */unsigned long length; /* Width of column (create length) */unsigned long max_length; /* Max width for selected set */unsigned int name_length;unsigned int org_name_length; unsigned int table_length;unsigned int org_table_length;unsigned int db_length;unsigned int catalog_length;unsigned int def_length;unsigned int flags; /* Div flags */unsigned int decimals; /* Number of decimals in field */unsigned int charsetnr; /* Character set */enum enum_field_types type; /* Type of field. See mysql_com.h for types */void *extension;
} MYSQL_FIELD;
函数的使用举例:
// 得到存储头信息的数组的地址
MYSQL_FIELD* fields = mysql_fetch_fields(res);
// 得到列数
int num = mysql_num_fields(res);
// 遍历得到每一列的列名
for(int i=0; i<num; ++i)
{printf("当前列的名字: %s\n", fields[i].name);
}
1.2.7 得到结果集中各个字段的长度(字节为单位)
unsigned long *mysql_fetch_lengths(MYSQL_RES *result);
返回当前行中各列数据的实际长度(以字节为单位,以数组形式返回):
- 如果打算复制字段值,使用该函数 能避免调用
strlen()。- 如果结果集包含二进制数据,必须使用该函数来确定数据的大小,原因在于,对于包含
NULL字符的任何字段,strlen()将返回错误的结果。参数:
- result: 通过查询得到的结果集
返回值:
- 无符号长整数的数组 表示各列的大小。如果出现错误,返回NULL。
示例程序:
MYSQL_ROW row;
unsigned long *lengths;
unsigned int num_fields;//遍历结果集的下一行
row = mysql_fetch_row(result);
if (row)
{num_fields = mysql_num_fields(result); // 得到列数lengths = mysql_fetch_lengths(result);for(int i = 0; i < num_fields; i++){printf("Column %u is %lu bytes in length.\n", i, lengths[i]);}
}
1.2.8 遍历结果集 (结果集的下一行)
typedef char** MYSQL_ROW;MYSQL_ROW mysql_fetch_row(MYSQL_RES *result);
- 遍历结果集的下一行 ,如果想遍历整个结果集, 需要对该函数进行
循环调用- 返回值是
二级指针char **,指向一个什么类型的内存呢?
- 指向一个指针数组, 类型是数组 , 里边的每个元素都是指针,
char*类型char* [];数组中的字符串对应的一列数据- 需要 对
MYSQL_ROW遍历就可以得到每一列的值,MYSQL_ROW实际上就是单行数据集结果- 如果要遍历整个结果集, 需要循环调用这个函数
参数:
- result: 通过查询得到的结果集
返回值:
- 成功: 得到了当前记录中每个字段的值
- 失败:
NULL, 说明数据已经读完了
1.2.9 资源回收
// 释放结果集
void mysql_free_result(MYSQL_RES *result);// 关闭mysql实例
void mysql_close(MYSQL *mysql);
1.2.10 字符编码
// 获取api默认使用的字符编码
// 为当前连接返回默认的字符集。
const char *mysql_character_set_name(MYSQL *mysql)
// 返回值: 默认字符集。 // 设置api使用的字符集
// 第二个参数 csname 就是要设置的字符集 -> 支持中文: utf8
int mysql_set_character_set(MYSQL *mysql, char *csname);
1.2.11 事务操作
// mysql中默认会进行事务的提交
// 因为自动提交事务, 会对我们的操作造成影响
// 如果我们操作的步骤比较多, 集合的开始和结束需要用户自己去设置, 需要改为手动方式提交事务
my_bool mysql_autocommit(MYSQL *mysql, my_bool mode)
//参数:
// 如果模式为“1”,启用autocommit模式;如果模式为“0”,禁止autocommit模式。
//返回值
// 如果成功,返回0,如果出现错误,返回非0值。// 事务提交
my_bool mysql_commit(MYSQL *mysql);
//返回值: 成功: 0, 失败: 非0// 数据回滚
my_bool mysql_rollback(MYSQL *mysql)
//返回值: 成功: 0, 失败: 非0
1.2.12 打印错误信息
// 返回错误的描述
const char *mysql_error(MYSQL *mysql);// 返回错误的编号
unsigned int mysql_errno(MYSQL *mysql);
1.3、实例代码
需要的头文件
#include <mysql.h>
测试程序:
#include <stdio.h>
#include <mysql.h>int main()
{// 1. 初始化连接环境MYSQL* mysql = mysql_init(NULL);if(mysql == NULL)\{printf("mysql_init() error\n");return -1;}// 2. 连接数据库服务器mysql = mysql_real_connect(mysql, "localhost", "root", "root", "scott", 0, NULL, 0);if(mysql == NULL){printf("mysql_real_connect() error\n");return -1;}printf("mysql api使用的默认编码: %s\n", mysql_character_set_name(mysql));// 设置编码为utf8mysql_set_character_set(mysql, "utf8");printf("mysql api使用的修改之后的编码: %s\n", mysql_character_set_name(mysql));printf("恭喜, 连接数据库服务器成功了...\n");// 3. 执行一个sql语句// 查询scott数据库下的dept部门表const char* sql = "select * from dept";// 执行这个sql语句int ret = mysql_query(mysql, sql);if(ret != 0){printf("mysql_query() a失败了, 原因: %s\n", mysql_error(mysql));return -1;}// 4. 取出结果集MYSQL_RES* res = mysql_store_result(mysql);if(res == NULL){printf("mysql_store_result() 失败了, 原因: %s\n", mysql_error(mysql));return -1;}// 5. 得到结果集中的列数int num = mysql_num_fields(res);// 6. 得到所有列的名字, 并且输出MYSQL_FIELD * fields = mysql_fetch_fields(res);for(int i=0; i<num; ++i){printf("%s\t\t", fields[i].name);}printf("\n");// 7. 遍历结果集中所有的行MYSQL_ROW row;while( (row = mysql_fetch_row(res)) != NULL){// 将当前行中的每一列信息读出for(int i=0; i<num; ++i){printf("%s\t\t", row[i]);}printf("\n");}// 8. 释放资源 - 结果集mysql_free_result(res);// 9. 写数据库// 以下三条是一个完整的操作, 对应的是一个事务// 设置事务为手动提交mysql_autocommit(mysql, 0); int ret1 = mysql_query(mysql, "insert into dept values(61, '海军', '圣地玛丽乔亚')");int ret2 = mysql_query(mysql, "insert into dept values(62, '七武海', '世界各地')");int ret3 = mysql_query(mysql, "insert into dept values(63, '四皇', '新世界')");printf("ret1 = %d, ret2 = %d, ret3 = %d\n", ret1, ret2, ret3);if(ret1==0 && ret2==0 && ret3==0){// 提交事务mysql_commit(mysql);}else{mysql_rollback(mysql);}// 释放数据库资源mysql_close(mysql);return 0;
}
1.4、C中的变量插入数据库中
以下是分别使用 动态 SQL 和 预处理语句 实现 MySQL 数据库的 增删查改(CRUD) 操作的完整示例程序。
1.4.1 动态SQL
#include <mysql/mysql.h>
#include <stdio.h>
#include <stdlib.h>// 连接到数据库
MYSQL* connect_to_db(const char *server, const char *user, const char *password, const char *database) {MYSQL *conn = mysql_init(NULL);if (!mysql_real_connect(conn, server, user, password, database, 0, NULL, 0)) {fprintf(stderr, "连接失败: %s\n", mysql_error(conn));exit(1);}return conn;
}// 插入数据
void insert_data(MYSQL *conn, const char *name, int age) {char query[100];snprintf(query, sizeof(query), "INSERT INTO users (name, age) VALUES ('%s', %d)", name, age);if (mysql_query(conn, query)) {fprintf(stderr, "插入失败: %s\n", mysql_error(conn));} else {printf("数据插入成功!\n");}
}// 删除数据
void delete_data(MYSQL *conn, int id) {char query[100];snprintf(query, sizeof(query), "DELETE FROM users WHERE id = %d", id);if (mysql_query(conn, query)) {fprintf(stderr, "删除失败: %s\n", mysql_error(conn));} else {printf("数据删除成功!\n");}
}// 查询数据
void query_data(MYSQL *conn) {if (mysql_query(conn, "SELECT * FROM users")) {fprintf(stderr, "查询失败: %s\n", mysql_error(conn));return;}MYSQL_RES *result = mysql_store_result(conn);if (result == NULL) {fprintf(stderr, "获取结果失败: %s\n", mysql_error(conn));return;}int num_fields = mysql_num_fields(result);MYSQL_ROW row;printf("查询结果:\n");while ((row = mysql_fetch_row(result))) {for (int i = 0; i < num_fields; i++) {printf("%s ", row[i] ? row[i] : "NULL");}printf("\n");}mysql_free_result(result);
}// 更新数据
void update_data(MYSQL *conn, int id, const char *new_name, int new_age) {char query[100];snprintf(query, sizeof(query), "UPDATE users SET name = '%s', age = %d WHERE id = %d", new_name, new_age, id);if (mysql_query(conn, query)) {fprintf(stderr, "更新失败: %s\n", mysql_error(conn));} else {printf("数据更新成功!\n");}
}int main() {const char *server = "localhost";const char *user = "root";const char *password = "password";const char *database = "my_db";MYSQL *conn = connect_to_db(server, user, password, database);// 插入数据insert_data(conn, "Alice", 25);// 查询数据query_data(conn);// 更新数据update_data(conn, 1, "Bob", 30);// 删除数据delete_data(conn, 1);// 查询数据query_data(conn);mysql_close(conn);return 0;
}
注意:这个方法主要是利用
snprintf函数,将C语言中的变量传入字符数组中,下面回顾一下**snprintf** 函数
函数原型
int snprintf(char *str, size_t size, const char *format, ...);
参数说明
str: 指向目标字符串的指针,格式化后的字符串将被写入到这个字符串中。size: 指定要写入的最大字符数(包括字符串结尾的\0),用来避免缓冲区溢出。format: 格式化字符串,类似于printf中的格式字符串。...: 额外的参数,这是与格式化字符串中占位符相对应的值。返回值
- 成功时,返回写入目标字符串中的字符数(不包括
\0,即目标字符串中最后的空字符)。- 如果输出的字符串被截断,则返回所需的字符数,如果返回值大于或等于
size,则表示目标字符串不足以容纳完整的格式化输出。- 如果发生错误,则返回一个负值。
使用示例
下面是一个简单的例子来演示如何使用 snprintf:
#include <stdio.h>int main() {char buffer[50]; // 定义一个字符数组作为缓冲区int value = 42;// 使用 snprintf 将格式化字符串写入缓冲区int n = snprintf(buffer, sizeof(buffer), "The answer is: %d", value);// 输出结果if (n < 0) {printf("Error occurred!\n");} else if (n >= sizeof(buffer)) {printf("Output was truncated. Needed size: %d\n", n);} else {printf("Formatted string: %s\n", buffer);}return 0;
}
说明
- 缓冲区: 在这个例子中,我们定义了一个字符数组
buffer,它将用于存储格式化后的字符串。- snprintf: 我们调用
snprintf来将格式化的字符串写入buffer。我们指定了sizeof(buffer)作为最大输出大小,这可以避免缓冲区溢出。- 返回值处理: 我们检查
snprintf的返回值,以确定输出是否成功以及是否被截断。使用注意事项
- 总是应该指定最大缓冲区大小,以防止缓冲区溢出。
snprintf是一个非常方便的函数,尤其是在构建动态字符串或者需要格式化输出的时候。通过这种方式,
snprintf确保你可以安全地操作字符串,并有效地格式化输出。
1.4.2 预处理语句 (推荐使用)
在使用这种方法之前,需要先介绍两个方法: mysql_stmt_init和 mysql_stmt_prepare创建预处理语句。
mysql_stmt_init 函数
函数原型
MYSQL_STMT *mysql_stmt_init(MYSQL *mysql);
参数说明
| 参数 | 类型 | 说明 |
|---|---|---|
mysql | MYSQL* | 已建立的MySQL连接句柄,由mysql_init()和mysql_real_connect()创建 |
返回值
- 成功:返回一个新的
MYSQL_STMT预处理语句句柄 - 失败:返回NULL,可通过
mysql_error(mysql)获取错误信息
功能
- 初始化一个新的预处理语句对象,为后续操作分配资源
mysql_stmt_prepare 函数
函数原型
int mysql_stmt_prepare(MYSQL_STMT *stmt, const char *query, unsigned long length);
参数说明
| 参数 | 类型 | 说明 |
|---|---|---|
stmt | MYSQL_STMT* | 由mysql_stmt_init()创建的预处理语句句柄 |
query | const char* | 要准备的SQL语句字符串 |
length | unsigned long | SQL语句的长度(字节数) |
返回值
- 成功:返回0
- 失败:返回非0值,可通过
mysql_stmt_error(stmt)获取错误信息
功能
- 准备一个SQL语句进行预处理,解析并优化SQL语句
演示代码
#include <mysql/mysql.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>// 连接到数据库
MYSQL* connect_to_db(const char *server, const char *user, const char *password, const char *database) {MYSQL *conn = mysql_init(NULL);if (!mysql_real_connect(conn, server, user, password, database, 0, NULL, 0)) {fprintf(stderr, "连接失败: %s\n", mysql_error(conn));exit(1);}return conn;
}// 插入数据
void insert_data(MYSQL *conn, const char *name, int age) {//初始化预处理语句MYSQL_STMT *stmt = mysql_stmt_init(conn);const char *query = "INSERT INTO users (name, age) VALUES (?, ?)";// 准备一个SQL语句进行预处理,解析并优化SQL语句if (mysql_stmt_prepare(stmt, query, strlen(query))) {fprintf(stderr, "预处理语句失败: %s\n", mysql_stmt_error(stmt));return;}//使用 MYSQL_BIND 结构体绑定 C 语言变量到 SQL 参数。MYSQL_BIND bind[2];memset(bind, 0, sizeof(bind));// 绑定 namebind[0].buffer_type = MYSQL_TYPE_STRING;bind[0].buffer = (char *)name;bind[0].buffer_length = strlen(name);// 绑定 agebind[1].buffer_type = MYSQL_TYPE_LONG;bind[1].buffer = &age;bind[1].buffer_length = sizeof(age);if (mysql_stmt_bind_param(stmt, bind)) {fprintf(stderr, "绑定参数失败: %s\n", mysql_stmt_error(stmt));mysql_stmt_close(stmt);return;}if (mysql_stmt_execute(stmt)) {fprintf(stderr, "执行失败: %s\n", mysql_stmt_error(stmt));} else {printf("数据插入成功!\n");}mysql_stmt_close(stmt);
}// 删除数据
void delete_data(MYSQL *conn, int id) {//初始化预处理语句MYSQL_STMT *stmt = mysql_stmt_init(conn);const char *query = "DELETE FROM users WHERE id = ?";// 准备一个SQL语句进行预处理,解析并优化SQL语句if (mysql_stmt_prepare(stmt, query, strlen(query))) {fprintf(stderr, "预处理语句失败: %s\n", mysql_stmt_error(stmt));return;}//使用 MYSQL_BIND 结构体绑定 C 语言变量到 SQL 参数。MYSQL_BIND bind;memset(&bind, 0, sizeof(bind));// 绑定 idbind.buffer_type = MYSQL_TYPE_LONG;bind.buffer = &id;bind.buffer_length = sizeof(id);if (mysql_stmt_bind_param(stmt, &bind)) {fprintf(stderr, "绑定参数失败: %s\n", mysql_stmt_error(stmt));mysql_stmt_close(stmt);return;}if (mysql_stmt_execute(stmt)) {fprintf(stderr, "执行失败: %s\n", mysql_stmt_error(stmt));} else {printf("数据删除成功!\n");}mysql_stmt_close(stmt);
}// 查询数据
void query_data(MYSQL *conn) {if (mysql_query(conn, "SELECT * FROM users")) {fprintf(stderr, "查询失败: %s\n", mysql_error(conn));return;}MYSQL_RES *result = mysql_store_result(conn);if (result == NULL) {fprintf(stderr, "获取结果失败: %s\n", mysql_error(conn));return;}int num_fields = mysql_num_fields(result);MYSQL_ROW row;printf("查询结果:\n");while ((row = mysql_fetch_row(result))) {for (int i = 0; i < num_fields; i++) {printf("%s ", row[i] ? row[i] : "NULL");}printf("\n");}mysql_free_result(result);
}// 更新数据
void update_data(MYSQL *conn, int id, const char *new_name, int new_age) {//初始化预处理语句MYSQL_STMT *stmt = mysql_stmt_init(conn);const char *query = "UPDATE users SET name = ?, age = ? WHERE id = ?";// 准备一个SQL语句进行预处理,解析并优化SQL语句if (mysql_stmt_prepare(stmt, query, strlen(query))) {fprintf(stderr, "预处理语句失败: %s\n", mysql_stmt_error(stmt));return;}//使用 MYSQL_BIND 结构体绑定 C 语言变量到 SQL 参数。MYSQL_BIND bind[3];memset(bind, 0, sizeof(bind));// 绑定 new_namebind[0].buffer_type = MYSQL_TYPE_STRING;bind[0].buffer = (char *)new_name;bind[0].buffer_length = strlen(new_name);// 绑定 new_agebind[1].buffer_type = MYSQL_TYPE_LONG;bind[1].buffer = &new_age;bind[1].buffer_length = sizeof(new_age);// 绑定 idbind[2].buffer_type = MYSQL_TYPE_LONG;bind[2].buffer = &id;bind[2].buffer_length = sizeof(id);if (mysql_stmt_bind_param(stmt, bind)) {fprintf(stderr, "绑定参数失败: %s\n", mysql_stmt_error(stmt));mysql_stmt_close(stmt);return;}if (mysql_stmt_execute(stmt)) {fprintf(stderr, "执行失败: %s\n", mysql_stmt_error(stmt));} else {printf("数据更新成功!\n");}mysql_stmt_close(stmt);
}int main() {const char *server = "localhost";const char *user = "root";const char *password = "password";const char *database = "my_db";MYSQL *conn = connect_to_db(server, user, password, database);// 插入数据insert_data(conn, "Alice", 25);// 查询数据query_data(conn);// 更新数据update_data(conn, 1, "Bob", 30);// 删除数据delete_data(conn, 1);// 查询数据query_data(conn);mysql_close(conn);return 0;
}
关键点
- 使用
mysql_stmt_init和mysql_stmt_prepare创建预处理语句。- 使用
MYSQL_BIND结构体绑定 C 语言变量到 SQL 参数。mysql_stmt_bind_param方法进行绑定mysql_stmt_execute方法进行执行- 优点:安全,防止 SQL 注入, 推荐在实际项目中使用。
数据库连接池
我们在进行数据库操作的时候为了提高数据库(关系型数据库)的访问瓶颈,除了在服务器端增加缓存服务器(例如redis)缓存常用的数据之外,还可以 增加连接池,来提高数据库服务器的访问效率。
一般来说,对于数据库操作都是在访问数据库的时候创建连接,访问完毕断开连接。但是如果 在高并发情况下,有些需要频繁处理的操作就会消耗很多的资源和时间,比如:
- 建立通信连接的TCP三次握手
- 数据库服务器的连接认证
- 数据库服务器关闭连接时的资源回收
- 断开通信连接的TCP四次挥手
如果使用数据库连接池会减少这一部分的性能损耗。
接下来会基于MySql数据库(使用MySQL的API连接MySQL数据库)为大家讲解一下,如何使用C++11的相关新特性来实现一个数据库连接池。
连接池的设计
- 连接池只需要一个实例,所以连接池类应该是一个
单例模式的类 - 所有的数据库连接应该维护到一个安全的队列中
- 使用队列的目的是方便连接的添加和删除
- 所谓的安全指的是线程安全,也就是说需要使用互斥锁来保护队列数据的读写。
- 在需要的时候可以 从连接池中得到一个或多个可用的数据库连接
- 如果有可用连接,直接取出
- 如果没有可用连接,阻塞等待一定时长然后再重试
- 如果队列中
没有多余的可用连接,需要动态的创建新连接 - 如果队列中
空闲的连接太多,需要动态的销毁一部分 - 数据库操作完毕,需要将连接归还到连接池中

细节分析
1. 数据库连接的存储:可用使用STL中的队列queue
2. 连接池连接的动态创建:这部分工作需要交给一个单独的线程来处理
3. 连接池连接的动态销毁:这部分工作需要交给一个单独的线程来处理
4. 数据库连接的添加和归还:这是一个典型的生产者和消费者模型
- 消费者:需要访问数据库的线程,数据库连接被取出(消费)
- 生产者:专门负责创建数据库连接的线程
- 处理生产者和消费者模型需要使用条件变量阻塞线程
5. 连接池的默认连接数量:连接池中提供的可用连接的最小数量
- 如果不够就动态创建
- 如果太多就动态销毁
6. 连接池的最大连接数量:能够创建的最大有效数据库连接上限
7. 最大空闲时间:创建出的数据库连接在指定时间长度内一直未被使用,此时就需要销毁该连接。
8. 连接超时:消费者线程无法获取到可用连接是,阻塞等待的时间长度
综上所述,数据库连接池对应的单例模式的类的设计如下:
using namespace std;
/*
* 数据库连接池: 单例模式
* MySqlConn 是一个连接MySQL数据库的类
*/
class ConnectionPool
{
public:// 得到单例对象static ConnectionPool* getConnectPool();// 从连接池中取出一个连接shared_ptr<MySqlConn> getConnection();// 删除拷贝构造和拷贝赋值运算符重载函数ConnectionPool(const ConnectionPool& obj) = delete;ConnectionPool& operator=(const ConnectionPool& obj) = delete;private:// 构造函数私有化ConnectionPool();bool parseJsonFile();void produceConnection();void recycleConnection();void addConnection();string m_ip; // 数据库服务器ip地址string m_user; // 数据库服务器用户名string m_dbName; // 数据库服务器的数据库名string m_passwd; // 数据库服务器密码unsigned short m_port; // 数据库服务器绑定的端口int m_minSize; // 连接池维护的最小连接数int m_maxSize; // 连接池维护的最大连接数int m_maxIdleTime; // 连接池中连接的最大空闲时长int m_timeout; // 连接池获取连接的超时时长queue<MySqlConn*> m_connectionQ;mutex m_mutexQ;condition_variable m_cond;
};
项目代码如下:
1. 用C API 封装成C++类
-
类的定义
#pragma once #include <iostream> using namespace std; #include <chrono> using namespace chrono; #include <string> #include <mysql/mysql.h>class databaseConnect {public://初始化数据库连接databaseConnect();//释放数据库连接~databaseConnect();//连接数据库bool connect(string user, string passwd, string dbName, string ip, unsigned short port = 3306);//更新数据库连接bool update(string sql);//查询数据库连接bool query(string sql);//遍历查询得到的结果集bool next();//得到结果集中的字段值string value(int index);//事物操作bool transaction();//提交事物bool commit();//事物回滚bool rollback();//刷新起始的空闲时间点//在计算空闲时间点中,更新一下起始的时间void refreshAliveTime();//计算连接存活的总时长long long getAliveTime();private:void freeResult();//释放结果集private:MYSQL* m_conn = nullptr;//数据库对象MYSQL_RES* m_result = nullptr;//数据库结果集MYSQL_ROW m_row = nullptr;//结构为MYSQL_ROW的下一行结果(结果集中某一行的结果)steady_clock::time_point m_alivetime; }; -
类内实现
#include "databaseConnect.h"//构造函数初始化的结果:环境初始化+字符集设置utf-8 databaseConnect::databaseConnect() {//mysql 环境初始化m_conn = mysql_init(nullptr);//mysql 字符集设置 utf8mysql_set_character_set(m_conn, "utf8"); }//析构函数,用于关闭环境 databaseConnect::~databaseConnect() {//mysql 环境关闭if (m_conn != nullptr) {mysql_close(m_conn);}//类内私有成员函数,释放结结果集freeResult(); }//数据库连接操作 bool databaseConnect::connect(string user, string passwd, string dbName, string ip, unsigned short port) {//返回的是数据库对象MYSQL* ptr = mysql_real_connect(m_conn, ip.c_str(), user.c_str(), passwd.c_str(), dbName.c_str(), port, nullptr, 0);return ptr != nullptr; }//更新数据库连接包括,删、插入、修改,传入参数是MySql执行语句 bool databaseConnect::update(string sql) {if (mysql_query(m_conn, sql.c_str())) return false;return true; }//查询数据库连接,传入参数是MySql执行语句 bool databaseConnect::query(string sql) {freeResult();//保存结果时,清空上一次的结果if (mysql_query(m_conn, sql.c_str())) return false;// 从服务器检索完整的结果集并将其存储在客户端内存中// 返回值是MYSQL_RES* m_result ,数据库结果集m_result = mysql_store_result(m_conn);return true; }// 遍历查询得到的结果集 // 这里是调用一次next函数,就获取结果集中的下一行 bool databaseConnect::next() {if (m_result != nullptr) {m_row = mysql_fetch_row(m_result);if (m_row != nullptr) return true;}return false; }// 得到结果集中的字段值 //参数index表示是要得到第几列的字段值 string databaseConnect::value(int index) {// 获取结果集中列的个数int listCount = mysql_num_fields(m_result);//若是给出的索引值index越界,那么直接返回if (index >= listCount || index < 0) return string();//否则首先得到字段值,m_row是MYSQL_ROW类型,就是单行结果集的内容char* val = m_row[index];//返回值为char* 有'\0'//取出第index列的属性长度unsigned long length = mysql_fetch_lengths(m_result)[index];//去除'\0',截取数据部分return string(val, length); }//事物操作 bool databaseConnect::transaction() {// 设置false 表示需要自己手动提交return mysql_autocommit(m_conn, false); }//提交事物 bool databaseConnect::commit() {return mysql_commit(m_conn); }//事物回滚 bool databaseConnect::rollback() {return mysql_rollback(m_conn); }// 释放结果集函数 void databaseConnect::freeResult() {//先判断结果集成员MYSQL_RES* m_result是否为空if (m_result) {mysql_free_result(m_result);//释放后,为了保险起见记得置为NULLm_result = nullptr;} }//刷新起始的空闲时间点 //在计算空闲时间点中,更新一下起始的时间 void databaseConnect::refreshAliveTime() {m_alivetime = steady_clock::now(); }//计算连接存活的总时长 //调用类中成员方法refreshAliveTime后,再调用此方法就可以更新当前连接的存活时间 long long databaseConnect::getAliveTime() {nanoseconds res = steady_clock::now() - m_alivetime;milliseconds millisec = duration_cast<milliseconds>(res);return millisec.count(); }
2. 连接池设计
-
连接池类的头文件
#pragma once #include <queue> #include "databaseConnect.h" #include <mutex> #include <condition_variable>class connectPool {public:static connectPool* getConnectPool(); //获取连接池实例对象connectPool(const connectPool& obj) = delete; //单例模式,这里拷贝构造直接禁用connectPool& operator=(const connectPool& obj) = delete; //单例模式,这里的赋值重载也禁用shared_ptr<databaseConnect> getConnection(); //获取数据库连接~connectPool();private:connectPool();//懒汉模式——用到时创建,构造函数必须是私有的,或者直接禁用bool parseJsonFile(); //解析连接数据的一些信息void produceConnection(); //生产者,用于往数据库连接队列中增加数据连接void recycleConnection(); // 回收者(管理者),如果某些连接超时m_maxIdTime,那么就会从数据库连接中删除并断开连接void addConnection();private:string m_ip;string m_user;string m_passwd;string m_dbName;unsigned short m_port;//连接池中,可连接数范围int m_minSize;int m_maxSize;//超时时间int m_timeout; // 当消费者线程发现连接池是空连接的时候,int m_maxIdTime; // 队列中空连接最多空闲时间queue<databaseConnect*> m_connectQ;//队列存放数据库连接mutex m_mutexQ;//操作连接池锁住condition_variable m_cond;//生产者消费者,控制连接池连接个数 }; -
连接池类的源文件
#include "connectPool.h" #include <chrono> #include <jsoncpp/json/json.h> using namespace Json; #include <fstream> #include <thread>// 单例模式,实现一个静态成员方法,这里是得到一个连接池实例, // 并且由于是静态成员,所有的类对象共享一个实例静态成员,且返回的是对象的指针 // 由于是单例模式,所以还需要把连接池的有参构造函、拷贝构造函数都要删除 connectPool* connectPool::getConnectPool() {//这是一个静态局部变量,只能通过此方法中进行获取访问,但是声明周期和程序一样长static connectPool pool;return &pool; }// 解析json文件,这里存储的是连接数据库的以及一些私有成员变量的值 // 反序列化操作 bool connectPool::parseJsonFile() {ifstream ifs("dbconf.json");Reader rd;Value root;rd.parse(ifs, root);if (root.isObject()) {m_ip = root["ip"].asString();m_port = root["port"].asInt();m_user = root["userName"].asString();m_passwd = root["password"].asString();m_dbName = root["dbName"].asString();m_minSize = root["minSize"].asInt();m_maxSize = root["maxSize"].asInt();m_maxIdTime = root["maxIdTime"].asInt();m_timeout = root["timeout"].asInt();return true;}return false; }//生产者函数,往连接池队列中增加新的连接 void connectPool::produceConnection() {while (true) {unique_lock<mutex> locker(m_mutexQ);while (int(m_connectQ.size()) >= m_minSize) {m_cond.wait(locker);}addConnection();m_cond.notify_all(); //通知消费者线程,可以取出连接池队列中的连接} }//管理者函数(回收连接队列中的空闲超时连接) void connectPool::recycleConnection() {//管理连接池,如果连接时间超时,那么就删除连接while (true) {this_thread::sleep_for(chrono::milliseconds(500));//上锁,超出作用域自动析构解锁lock_guard<mutex> locker(m_mutexQ);//如是数据库连接队列中的连接个数超出最小个数,那就可以进一步判断是否存在超时连接while (int(m_connectQ.size()) > m_minSize) {//取出队列头部的连接,因为头部的连接一定是队列中空闲连接时间最长的databaseConnect* conn = m_connectQ.front();//若是这个连接超出m_maxIdTime,那么就从队列中删除//所有的连接在进入队列前都会更新一下计算空闲时长的起始时间点if (conn->getAliveTime() >= m_maxIdTime) {m_connectQ.pop();delete conn;}//若是没有超时,那么就跳出内部的循环,再次进入下一轮的检测else break;}} }//往连接池队列中增加连接 void connectPool::addConnection() {databaseConnect* conn = new databaseConnect;conn->connect(m_user, m_passwd, m_dbName, m_ip, m_port);//刷新一下计算空闲时长的起始时间点//所有的连接在进入队列前都会更新一下计算空闲时长的起始时间点conn->refreshAliveTime();//塞入队列m_connectQ.push(conn); }// 消费者线程,取出连接池队列中的头部连接 shared_ptr<databaseConnect> connectPool::getConnection() {// 上锁,超出作用域自动析构unique_lock<mutex> locker(m_mutexQ);//while循环判断,防止线程不同步,导致的冲突while (m_connectQ.empty()) {// 因为线程在阻塞期间是几乎不消耗资源的,因此当队列中没有连接时,可以先暂停并阻塞m_timeout时间// 此时,线程会释放锁的临界资源,允许其他线程进行修改临界资源// 期间若是有生产者生产连接,就可以解除阻塞,重新上锁if (cv_status::timeout == m_cond.wait_for(locker, chrono::milliseconds(m_timeout))) {//若是超出m_timeout时间队列中依旧没有连接,那么就跳出本次循环进入下一轮循环if (m_connectQ.empty()) continue;}}//自定义删除器,当智能指针计数为0的时候,自动调用这里的匿名函数//当连接不用了,那么我们不是真的要删除,还是要送回 连接池列队中shared_ptr<databaseConnect> connptr(m_connectQ.front(), [this](databaseConnect* conn) {lock_guard<mutex> locker(m_mutexQ);//刷新一下计算空闲时长的起始时间点//所有的连接在进入队列前都会更新一下计算空闲时长的起始时间点conn->refreshAliveTime();m_connectQ.push(conn);});m_connectQ.pop();m_cond.notify_all(); //已经消费一个连接池了,可以通知生产线程了return connptr; }connectPool::connectPool() {//加载配置文件if (!parseJsonFile()) return ;for (int i = 0; i < m_minSize; i++) {addConnection(); }// 添加两个线程,一个线程用于往连接池中生产连接,// 一个子线程用来管理线程池的数量(超出时间就销毁)thread prodecer(&connectPool::produceConnection, this);thread recycler(&connectPool::recycleConnection, this);prodecer.detach();recycler.detach(); }//删除连接池队列里的连接 connectPool::~connectPool() {while (!m_connectQ.empty()) {databaseConnect* conn = m_connectQ.front();m_connectQ.pop();;delete conn;} }
3. 主函数(测试)
#include "connectPool.h"
#include "databaseConnect.h"
/*
1.单线程:使用/不使用连接池不使用:非连接池,单线程,用时:42693912629纳秒,42693毫秒使用:连接池,单线程,用时:9150030844纳秒,9150毫秒
2.多线程:使用/不使用连接池不使用:非连接池,多线程,用时:60792322338纳秒,60792毫秒使用:连接池,多线程,用时:3522916191纳秒,3522毫秒
*/
void op1(int begin, int end) {for (int i = begin; i < end; i++) {databaseConnect conn;conn.connect("starry", "root", "dbConnectPool", "192.168.80.128");char sql[1024] = {0};sprintf(sql,"insert into person values(%d, 18, 'man', 'starry')", i);conn.update(sql);}
}void op2(connectPool* pool, int begin, int end) {for (int i = begin; i < end; i++) {shared_ptr<databaseConnect> conn = pool->getConnection();char sql[1024] = {0};sprintf(sql,"insert into person values(%d, 18, 'man', 'starry')", i);
// string sql = "insert into person values(" + to_string(i) + ", 18, 'man', 'yll')";
// conn->update(sql.c_str());conn->update(sql);}
}void test1() {
#if 0steady_clock::time_point begin = steady_clock::now();op1(0, 5000);steady_clock::time_point end = steady_clock::now();auto length = end - begin;cout << "非连接池,单线程,用时:" << length.count() << "纳秒," << length.count() / 1000000 << "毫秒" << endl;
#elseconnectPool* pool = connectPool::getConnectPool();steady_clock::time_point begin = steady_clock::now();op2(pool, 0, 5000);steady_clock::time_point end = steady_clock::now();auto length = end - begin;cout << "连接池,单线程,用时:" << length.count() << "纳秒," << length.count() / 1000000 << "毫秒" << endl;
#endif
}void test2() {
#if 0steady_clock::time_point begin = steady_clock::now();thread t1(op1, 0, 1000);thread t2(op1, 1000, 2000);thread t3(op1, 2000, 3000);thread t4(op1, 3000, 4000);thread t5(op1, 4000, 5000);t1.join();t2.join();t3.join();t4.join();t5.join();steady_clock::time_point end = steady_clock::now();auto length = end - begin;cout << "非连接池,多线程,用时:" << length.count() << "纳秒," << length.count() / 1000000 << "毫秒" << endl;
#elsesteady_clock::time_point begin = steady_clock::now();connectPool* pool = connectPool::getConnectPool();thread t1(op2, pool, 0, 1000);thread t2(op2, pool, 1000, 2000);thread t3(op2, pool, 2000, 3000);thread t4(op2, pool, 3000, 4000);thread t5(op2, pool, 4000, 5000);t1.join();t2.join();t3.join();t4.join();t5.join();steady_clock::time_point end = steady_clock::now();auto length = end - begin;cout << "连接池,多线程,用时:" << length.count() << "纳秒," << length.count() / 1000000 << "毫秒" << endl;
#endif
}int query() {databaseConnect conn;conn.connect("starry", "root", "dbConnectPool", "192.168.80.128");string sql = "insert into person values(6, 18, 'man', 'starry')";bool flag = conn.update(sql);cout << "flag value" << flag << endl;sql = "select * from person";conn.query(sql);while (conn.next()) {cout << conn.value(0) << ", "<< conn.value(1) << ", "<< conn.value(2) << ", "<< conn.value(3) << endl;}return 0;
}int main() {
// query();//连接测试test1();return 0;
}
4. 代码说明
1. 条件变量 wait_for
m_cond.wait_for(locker, chrono::milliseconds(m_timeout)) 是 C++ 中条件变量(std::condition_variable)的一个成员函数调用,用于线程同步。它的作用是在指定时间内等待条件满足,若超时或条件被触发则继续执行。以下是详细解释:
功能说明
-
等待条件
当前线程会阻塞(进入等待状态),直到以下两种情况之一发生:- 其他线程调用了
notify_one()或notify_all(),且关联的条件(用户定义的逻辑)变为真。 - 超时:等待时间超过指定的
m_timeout毫秒。
- 其他线程调用了
-
自动释放锁
- 在等待期间,
locker(通常是std::unique_lock<std::mutex>)会被自动释放,允许其他线程获取锁并修改共享数据。 - 当条件被触发或超时后,线程会重新获取锁,继续执行后续代码。
- 在等待期间,
-
返回值
- 返回
std::cv_status::timeout表示因超时结束等待。 - 返回
std::cv_status::no_timeout表示条件被触发(需结合谓词检查实际条件)。
- 返回
参数解释
-
locker
必须是已锁定的std::unique_lock<std::mutex>对象,用于保护共享数据的互斥锁。 -
chrono::milliseconds(m_timeout)
指定最大等待时长(单位为毫秒)。例如,100ms表示最多等待100毫秒。
总结
wait_for实现了限时等待条件的功能,结合互斥锁和谓词检查,能有效协调线程间的同步,避免无限阻塞。
2. shared_ptr 自定义删除器
//自定义删除器,当智能指针计数为0的时候,自动调用这里的匿名函数//当连接不用了,那么我们不是真的要删除,还是要送回 连接池列队中shared_ptr<databaseConnect> connptr(m_connectQ.front(), [this](databaseConnect* conn) {lock_guard<mutex> locker(m_mutexQ);//刷新一下计算空闲时长的起始时间点//所有的连接在进入队列前都会更新一下计算空闲时长的起始时间点conn->refreshAliveTime();m_connectQ.push(conn);});
这段代码定义了一个 shared_ptr,用于管理数据库连接对象 databaseConnect 的生命周期。它的特点是自定义了删除器(deleter),当 shared_ptr 的引用计数归零时,不会直接删除连接对象,而是将连接放回连接池队列 m_connectQ 中,同时更新连接的空闲时间戳。以下是详细解析:
关键点总结
- 智能指针 + 自定义删除器:实现资源的自动管理。
- 线程安全:通过互斥锁保护共享资源(队列)。
- 连接复用:通过队列实现连接的缓存和重复利用。
3. 条件变量个数问题
上面的工程代码中,虽然有两个线程函数
// ...................
// ...................
// ...................//生产者函数,往连接池队列中增加新的连接
void connectPool::produceConnection() {while (true) {unique_lock<mutex> locker(m_mutexQ);while (int(m_connectQ.size()) >= m_minSize) {m_cond.wait(locker);}addConnection();m_cond.notify_all(); //通知消费者线程,可以取出连接池队列中的连接}
}// 消费者线程,取出连接池队列中的头部连接
shared_ptr<databaseConnect> connectPool::getConnection()
{// 上锁,超出作用域自动析构unique_lock<mutex> locker(m_mutexQ);//while循环判断,防止线程不同步,导致的冲突while (m_connectQ.empty()) {// 因为线程在阻塞期间是几乎不消耗资源的,因此当队列中没有连接时,可以先暂停并阻塞m_timeout时间// 此时,线程会释放锁的临界资源,允许其他线程进行修改临界资源// 期间若是有生产者生产连接,就可以解除阻塞,重新上锁if (cv_status::timeout == m_cond.wait_for(locker, chrono::milliseconds(m_timeout))) {//若是超出m_timeout时间队列中依旧没有连接,那么就跳出本次循环进入下一轮循环if (m_connectQ.empty()) continue;}}//自定义删除器,当智能指针计数为0的时候,自动调用这里的匿名函数//当连接不用了,那么我们不是真的要删除,还是要送回 连接池列队中shared_ptr<databaseConnect> connptr(m_connectQ.front(), [this](databaseConnect* conn) {lock_guard<mutex> locker(m_mutexQ);//刷新一下计算空闲时长的起始时间点//所有的连接在进入队列前都会更新一下计算空闲时长的起始时间点conn->refreshAliveTime();m_connectQ.push(conn);});m_connectQ.pop();m_cond.notify_all(); //已经消费一个连接池了,可以通知生产线程了return connptr;
}// ...................
// ...................
// ...................这里只使用了一个条件变量,例如在getConnection类方法中,如果调用了m_cond.notify_all();,那么不仅会唤醒生产者线程中的produceConnection类中的的阻塞线程:
while (int(m_connectQ.size()) >= m_minSize) {m_cond.wait(locker);}
同时也会唤醒,getConnection类方法中阻塞部分
while (m_connectQ.empty()) {// 因为线程在阻塞期间是几乎不消耗资源的,因此当队列中没有连接时,可以先暂停并阻塞m_timeout时间// 此时,线程会释放锁的临界资源,允许其他线程进行修改临界资源// 期间若是有生产者生产连接,就可以解除阻塞,重新上锁if (cv_status::timeout == m_cond.wait_for(locker, chrono::milliseconds(m_timeout))) {//若是超出m_timeout时间队列中依旧没有连接,那么就跳出本次循环进入下一轮循环if (m_connectQ.empty()) continue;}}
但是这里是没有问题的,因为阻塞判断的过程中的都是while体循环,如果接触了阻塞,还是会进入下一轮循环去进行条件判断,直到满足条件。
4. 单例模式
在C++中,单例模式(Singleton Pattern) 确保一个类只有一个实例,并提供全局访问点。根据实例化的时机,可以分为 懒汉模式(Lazy Initialization) 和 饿汉模式(Eager Initialization)。
1. 懒汉模式(Lazy Initialization)
特点:
- 延迟初始化:实例在第一次被访问时才创建。
- 线程安全:需要额外处理(如互斥锁或
std::call_once)。 - 适用于资源敏感场景:避免不必要的初始化开销。
(1)基础懒汉模式(非线程安全)
class Singleton {
private:static Singleton* instance;Singleton() {} // 私有构造函数public:static Singleton* getInstance() {if (instance == nullptr) {instance = new Singleton();}return instance;}
};Singleton* Singleton::instance = nullptr; // 静态成员初始化
问题:
- 线程不安全:多个线程同时调用
getInstance()可能导致多次实例化。
(2)线程安全的懒汉模式(加锁)
#include <mutex>class Singleton {
private:static Singleton* instance;static std::mutex mtx;Singleton() {}public:static Singleton* getInstance() {std::lock_guard<std::mutex> lock(mtx); // 加锁if (instance == nullptr) {instance = new Singleton();}return instance;}
};Singleton* Singleton::instance = nullptr;
std::mutex Singleton::mtx;
优化:
- 双重检查锁定(Double-Checked Locking):减少锁的开销。
static Singleton* getInstance() {if (instance == nullptr) { // 第一次检查(不加锁)std::lock_guard<std::mutex> lock(mtx);if (instance == nullptr) { // 第二次检查(加锁)instance = new Singleton();}}return instance;
}
(3)C++11 线程安全懒汉模式(std::call_once)
#include <mutex>class Singleton {
private:static Singleton* instance;static std::once_flag onceFlag;Singleton() {}public:static Singleton* getInstance() {std::call_once(onceFlag, []() {instance = new Singleton();});return instance;}
};Singleton* Singleton::instance = nullptr;
std::once_flag Singleton::onceFlag;
优点:
- 更高效:
std::call_once保证只初始化一次,比手动加锁更安全。
2. 饿汉模式(Eager Initialization)
特点:
- 提前初始化:程序启动时就创建实例。
- 线程安全:无需额外同步机制(C++保证静态变量的线程安全)。
- 适用于初始化开销小的场景。
(1)基础饿汉模式
class Singleton {
private:static Singleton* instance;Singleton() {}public:static Singleton* getInstance() {return instance;}
};Singleton* Singleton::instance = new Singleton(); // 程序启动时初始化
(2)C++11 改进版(局部静态变量)
class Singleton {
private:Singleton() {}public:static Singleton& getInstance() {static Singleton instance; // C++11 保证线程安全return instance;}
};
优点:
- 更简洁:无需手动管理指针。
- 自动析构:程序结束时自动调用析构函数。
3. 懒汉 vs 饿汉模式对比
| 特性 | 懒汉模式 | 饿汉模式 |
|---|---|---|
| 初始化时机 | 第一次访问时 | 程序启动时 |
| 线程安全 | 需要额外处理 | 天然安全 |
| 资源占用 | 按需加载,节省资源 | 提前占用内存 |
| 适用场景 | 初始化开销大、资源敏感 | 初始化快、简单场景 |
4. 推荐方案
- C++11 及以上:使用 局部静态变量(饿汉模式改进版),既线程安全又简洁。
- 需要延迟初始化:使用
std::call_once的懒汉模式。
// 推荐:C++11 饿汉模式(局部静态变量)
class Singleton {
public:static Singleton& getInstance() {static Singleton instance;return instance;}private:Singleton() = default;~Singleton() = default;Singleton(const Singleton&) = delete;Singleton& operator=(const Singleton&) = delete;
};
关键点:
- 禁用拷贝构造和赋值(避免破坏单例)。
- 析构函数私有化(防止外部
delete)。
这样既安全又高效,适用于大多数场景。 🚀
参考部分来源1:爱编程的大丙
参考部分来源2:Github 上的开源项目
相关文章:

MySql数据库连接池
C数据库连接池 前言1.MySql API 函数讲解1.1 连接数据库的步骤1.2 MySQL C API1.2.1 初始化连接环境1.2.2 连接mysql服务器1.2.3 执行sql语句1.2.4 获取结果集1.2.5 得到结果集的列数1.2.6 获取表头 -> 列名(字段名)1.2.7 得到结果集中各个字段的长度(字节为单位)1.2.8 遍历…...
)
C++之fmt库介绍和使用(2)
C之fmt库介绍与使用(2) Author: Once Day Date: 2025年5月19日 一位热衷于Linux学习和开发的菜鸟,试图谱写一场冒险之旅,也许终点只是一场白日梦… 漫漫长路,有人对你微笑过嘛… 全系列文章可参考专栏: 源码分析_Once-Day的博客-CSDN博客 …...

Python的collections模块:数据结构的百宝箱
Python的collections模块:数据结构的百宝箱 对话实录 小白:处理数据时,Python自带的数据结构不够用,有更强大的工具吗? 专家:那可不能错过collections模块,它提供了许多高效实用的数据结构&am…...

吃透 Golang 基础:数据结构之数组
文章目录 吃透 Golang 基础:数据结构之数组概述初始化访问和赋值小结参考资料 吃透 Golang 基础:数据结构之数组 对于 Golang 当中的顺序数据结构,使用频率最高的当然是切片,因为切片非常的灵活。与之相对比,数组常常会…...

第三个小程序动工:一款结合ai的菜谱小程序
1.环境搭建,与初步运行 安装及使用 | Taro 文档 找到一个合适的文件夹,cmd D:\gitee>pnpm install -g tarojs/cli╭──────────────────────────────────────────╮│ …...

小程序涉及提供提供文本深度合成技术,请补充选择:深度合成-AI问答类目
一、问题描述 最近新项目AI咨询小程序审核上线,按照之前小程序的流程,之前审核,提示审核不通过,审核不通过的原因:小程序涉及提供提供文本深度合成技术 (如: AI问答) 等相关服务,请补充选择:深…...
)
数据结构测试模拟题(1)
1、约瑟夫问题 #include<bits/stdc.h> using namespace std; const int N25; int e[N],ne[N],head-1,idx1; int n,m; void add_to_head(int x){e[idx]x;ne[idx]head;headidx; } void add(int k,int x){e[idx]x;ne[idx]ne[k];ne[k]idx; } int main(){cin>>n>>…...

Elasticsearch高级面试题汇总及答案
Elasticsearch高级面试题汇总及答案 这套Elasticsearch面试题汇总大全,希望对大家有帮助哈~ 1、什么是Elasticsearch Analyzer? 分析器用于文本分析,它可以是内置分析器也可以是自定义分析器。 2、Elasticsearch 支持哪些配置管理工具? 1、 Ansible 2、 Chef 3、 Pu…...

界面控件DevExpress WinForms v24.2——PDF Viewer功能升级
DevExpress WinForms拥有180组件和UI库,能为Windows Forms平台创建具有影响力的业务解决方案。DevExpress WinForms能完美构建流畅、美观且易于使用的应用程序,无论是Office风格的界面,还是分析处理大批量的业务数据,它都能轻松胜…...

Apache Apisix配置ip-restriction插件以限制IP地址访问
介绍 ip-restriction 插件可以通过将 IP 地址列入白名单或黑名单来限制对服务或路由的访问。 支持对单个 IP 地址、多个 IP 地址和类似 10.10.10.0/24 的 CIDR(无类别域间路由)范围的限制。 属性 参数名类型必选项默认值有效值描述whitelistarray[st…...

Maven 项目打包时添加本地 Jar 包
在 Maven 项目开发中,我们经常会遇到需要引入本地 Jar 包的场景,比如使用未发布到中央仓库的第三方库、公司内部自定义工具包,或者处理版本冲突的依赖项。本文将详细介绍如何通过 Maven 命令将本地 Jar 包安装到本地仓库,并在项目…...

JavaScript 性能优化:调优策略与工具使用
引言 在当今的 Web 开发领域,性能优化已不再是锦上添花,而是产品成功的关键因素。据 Google 研究表明,页面加载时间每增加 3 秒,跳出率将提高 32%。而移动端用户如果页面加载超过 3 秒,有 53% 的用户会放弃访问。性能…...

48、c# 中 IList 接⼝与List的区别是什么?
在 C# 中,IList 接口和 List 类在集合操作中扮演不同角色,主要区别体现在定义、功能、灵活性、性能及适用场景等方面。以下是详细对比: 1. 定义与本质 IList 接口 抽象契约:仅定义集合的基本操作(如索引访问、添加、…...

在 Azure OpenAI 上使用 Elastic 优化支出和内容审核
作者:来自 Elastic Muthukumar Paramasivam,Bahubali Shetti 及 Daniela Tzvetkova 我们为 Azure OpenAI 正式发布包添加了更多功能,现在提供内容过滤监控和计费见解的增强! 在之前的博客中,我们展示了如何使用 Elasti…...
主从复制)
Redis学习专题(三)主从复制
目录 引言: 1、搭建一主多从 1) 创建/hspredis目录, 并拷贝redis.conf 到 /hspredis 2) vi /hspredis/redis.conf , 进行如下设置 3) 创建3个文件/hspredis/redis6379.conf 、/hspredis/redis6380.conf 、/hspredis/redis6381.conf 并编辑 4) 启动三台redis服…...

设计模式之备忘录模式
在日常开发中,我们经常会遇到这样的场景:需要保存对象的某个历史状态,以便将来恢复。这种需求最常见的例子就是“撤销操作”。在这种情况下,备忘录模式(Memento Pattern)就派上了用场。 目录 1. 概念 2. 代码实现 3. 总结 1. …...
内部执行过程)
深度学习-runner.run(data_loaders, cfg.workflow)内部执行过程
文件:~/catkin_ws/SparseDrive/projects/mmdet3d_plugin/apis/mmdet_train.py 完成数据加载器、优化器、运行器实例化后, RUNNERS.register_module() class IterBasedRunner(BaseRunner):"""Iteration-based Runner.This runner train m…...
Day24)
嵌入式开发学习日志(linux系统编程--文件读写函数)Day24
一、系统编程 标准oi 【输入输出】 stdio.h 头文件 :stdio.h >标准输入输出头文件;/usr/include/stdio.h 二、文件操作 1、关于文件操作的步骤 (1)打开文件; (2)io操作,读写…...

DEBUG:Lombok 失效
DEBUG:Lombok 失效 问题描述 基于 Spring Boot 的项目中,编译时显示找不到 log 属性。查看对应的 class 类,Lombok 正常在编译时生成 log 属性。 同时存在另一个问题,使用Getter注解,但实际使用中该注解并没有生效&…...
)
Qt 控件发展历程 + 目标(1)
文章目录 声明简述控件的发展历程学习目标QWidget属性 简介:这篇文章只是一个引子,介绍一点与控件相关的但不重要的内容(浏览浏览即可),这一章节最为重要的还是要把之后常用且重要的控件属性和作用给学透,学…...
脚本开发介绍)
按键精灵ios/安卓辅助工具高级函数OcrEx文字识别(增强版)脚本开发介绍
函数名称 OcrEx文字识别(增强版) 函数功能 返回指定区域内所有识别到的字符串、左上角坐标、区域宽高、可信度,无需自制字库,识别范围越小,效率越高,结果越准确 注意:安卓版按键APP需在设置…...

零基础入门Selenium自动化测试:自动登录edu邮箱
🌟 Selenium简单概述一下 Selenium 是一个开源的自动化测试工具,主要用于 Web 应用程序的功能测试。它能够模拟用户操作浏览器的行为(如点击按钮、填写表单、导航页面等),应用于前端开发、测试和运维领域。 特点 跨…...
)
MySQL高频面试八连问(附场景化解析)
文章目录 "为什么订单查询突然变慢了?"——从这个问题开始说起一、索引的生死时速(必考题!)二、事务的"套娃"艺术三、锁机制的相爱相杀四、存储引擎的抉择五、慢查询的破案技巧六、分页的深度优化七、高可用架…...

JVM 性能问题排查实战10连击
🗂️ 目录 前言:理论掌握只是起点,定位能力才是核心全局排查模型:三步法1️⃣Full GC 频繁触发:老年代压力过大2️⃣ OOM 爆炸:元空间泄漏 or 缓存未清理3️⃣ CPU 飙升却不是 GC:线程阻塞或热方…...

零基础深入解析 ngx_http_session_log_module
一、引言 在传统的 HTTP 日志中,每个请求都会被单独记录,这对于短连接、异步加载等场景非常直观;但在一些需要以“会话”为单位分析用户行为的场景下,如视频点播、多资源并行加载、长轮询等,单个请求日志难以准确反映…...

10.17 LangChain v0.3核心机制解析:从工具调用到生产级优化的实战全指南
LangChain v0.3 技术生态与未来发展 关键词:LangChain 工具调用, 聊天模型集成, @tool 装饰器, ToolMessage 管理, 多模态交互 使用聊天模型实现工具调用 LangChain v0.3 通过 工具调用(Tool Calling) 机制,将大模型与外部工具深度结合,形成闭环能力链。本节以 GPT-4、L…...

Android Framework学习七:Handler、Looper、Message
文章目录 简介LooperMessageMessageQueueHandlerFramework学习系列文章 简介 Looper当做一台传送装置,MessageQueue是传送带,传送带上放的是Message,Handler用于发送Message分发与接收处理。 Looper frameworks/base/core/java/android/app…...

分钟级降水预报API:精准预测每一滴雨的智慧科技
引言:天气预报进入"分钟时代" 在数字化生活高度发达的今天,人们对天气预报的精确度要求越来越高。传统的24小时预报或小时级预报已无法满足出行、物流、户外活动等场景的精细化需求。分钟级降水预报API的出现,标志着气象服务正式进…...

民政部等部门针对老人权益保障工作发布指导意见
1 品牌资讯 佛慈制药:将探索开发特医食品等产品 李子园将丰富大健康产品矩阵适应银发族需求 京东健康2025年第一季度收入166.45亿元 宁美浩维获融资,致力提供健康管理方案 2 行业动态 固生堂合作华为,联合推动中医药智慧化转型 怡…...

LinkedList源码分析
1. LinkedList初始化 public class LinkedListTest {public static void main(String[] args) {LinkedList<String> list new LinkedList<String>();// 新增list.add("a");list.add("b");list.add("c");list.add("d");l…...

OpenAI Codex 加入Agent编程工具新阵营
上周五,OpenAI推出了一款名为Codex的新型编程系统,该系统能够通过自然语言命令执行复杂的编程任务。Codex标志着OpenAI正式进军正在形成的代理编程工具新阵营。 从GitHub早期的Copilot到当代的Cursor和Windsurf等工具,大多数AI编程助手都是作…...

AMBA三种总线详解并比较
AMBA三种总线详解并比较 AMBA(Advanced Microcontroller Bus Architecture)是 ARM 公司推出的片上总线标准,旨在为 SoC(片上系统)提供高效、灵活的通信架构。 一、总线详解 1. AHB(Advanced High-perform…...

国产视频转换LT6211UX:HDMI2.0转LVDS/MIPI芯片简介,支持4K60Hz
1. LT6211UX HDMI2.0信号输入 支持HDMI2.0b, HDMI1.4和DVI1.0 支持HDCP2.2和HDCP1.4 数据速率高达6Gbps 自适应接收机均衡 支持4k60Hz 支持的3D格式: 对于HDMI -> LVDS: 直接3D输出 2路2D L/R输出 对于HDMI -> MIPI: 框架包装&#x…...

在nextjs项目当中使用wagmi连接MetaMask SDK
Wagmi 是一个为以太坊和 EVM 兼容链构建的 React Hooks 库,专为简化 Web3 应用开发而设计。它提供了一组强大且类型安全的工具,使开发者能够更方便地与钱包(如 MetaMask、WalletConnect 等)和智能合约进行交互。 Wagmi 的全称其实并不是一个传统意义上的缩写,它源自加密社…...

SAP-ABAP:SAP的`TRY...CATCH` 异常处理机制详解
一、异常处理架构与核心机制 1. 异常分类与层次结构 异常类型触发机制处理要求典型子类CX_STATIC_CHECK编译器强制检查(必须声明或捕获)必须显式处理CX_SY_ZERODIVIDE(除零错误)CX_DYNAMIC_CHECK运行时检查(若未处理则触发运行时错误RESUMABLE_FAILURE)推荐显式处理CX_S…...

HarmonyOS NEXT~鸿蒙系统与Uniapp跨平台开发实践指南
HarmonyOS NEXT~鸿蒙系统与Uniapp跨平台开发实践指南 引言:鸿蒙与Uniapp的融合价值 华为鸿蒙系统(HarmonyOS)作为新一代智能终端操作系统,其分布式能力与跨设备协同特性为开发者带来了全新机遇。而Uniapp作为流行的跨平台应用开发框架&…...

python 提交命令 到远程windows中
在Python中,你可以使用多种方式来提交命令到远程Windows机器上。最常见的方法是通过SSH协议(使用paramiko库)或者通过Windows远程管理工具如WinRM(使用python-winrm库)。 使用Paramiko进行SSH连接 Paramiko是一个Pyth…...

【520 特辑】用 HTML/CSS/JavaScript 打造浪漫炫酷的表白网页
一、前言 在 520 这个充满爱意的日子里,程序员该如何用代码表达浪漫?本文将分享一个结合动画特效与交互设计的 520 表白网页案例,通过 HTML/CSS/JavaScript 实现动态爱心、渐变背景、浮动文字等炫酷效果,手把手教你用技术传递心意…...

【QT】QTableWidget获取width为100,与真实值不符问题解决
背景 用stackedWidget内嵌2个QTableWidget页面,实现切换。在进行stackedWidget.width()的获取时候,可以正常获得ui界面设置的宽度值,但是在QTableWidget页面用同样的方式无法成功获取真实值,即使采用获取内容区域宽度(…...

Hive drop column 的解决方法
示例: 创建 text 格式的表 create table t1(c1 int, c2 int) stored as textfile;增加一个字段 alter table t1 add columns (c3 int);使用 replace columns 删除新加的字段 alter table t1 replace columns (c1 int, c2 int);对于 ORC 类型的表,使用…...

Python虚拟环境再PyCharm中自由切换使用方法
Python开发中的环境隔离是必不可少的步骤,通过使用虚拟环境可以有效地管理不同项目间的依赖,避免包冲突和环境污染。虚拟环境是Python官方提供的一种独立运行环境,每个项目可以拥有自己单独的环境,不同项目之间的环境互不影响。在日常开发中,结合PyCharm这样强大的IDE进行…...
)
Spark大数据分析案例(pycharm)
所需文件(将文件放在路径下,自己记住后面要用): 通过百度网盘分享的文件:beauty_p....csv等4个文件 链接:https://pan.baidu.com/s/1pBAus1yRgefveOc7NXRD-g?pwd22dj 提取码:22dj 复制这段内…...

【QT】ModbusTCP读写寄存器类封装
背景 在编写ModbusTCP时候,连接、寄存器读写属于通用的功能,为了便于后续直接复用,选择封装到一个类。本博文在封装展示该类过程中,会提及到编写该类过程中,出现的连接未成功的问题,以及该问题的解决方式。…...

SQLMesh 内置宏详解:@PIVOT等常用宏的核心用法与示例
本文系统解析 SQLMesh 的四个核心内置宏,涵盖行列转换的 PIVOT、精准去重的 DEDUPLICATE、灵活生成日期范围的 DATE_SPINE,以及动态表路径解析的 RESOLVE_TEMPLATE。通过真实案例演示参数配置与 SQL 渲染逻辑,并对比宏调用与传统 SQL 的差异&…...

ajax post请求 解决自动再get请求一次
ajax post请求 解决自动再get请求一次 HTMLjavascriptFlask第一种方法:第二种方法: HTML <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>登录</title></head> &l…...
)
当前主流的传输技术(如OTN、IP-RAN、FlexE等)
好的!当前主流的传输技术(如OTN、IP-RAN、FlexE等)各有其独特的应用场景,下面我会逐一展开讲解,并结合实际案例说明它们如何在不同领域发挥作用。 一、OTN(光传送网) 1. 核心特点 大容量&…...

利用 SQL Server 作业实现异步任务处理,简化系统架构
在现代企业系统中,异步任务是不可或缺的组成部分,例如: 电商系统中的订单超时取消; 报表系统中的异步数据导出; CRM 系统中的客户积分计算。 传统的实现方式通常涉及引入消息队列(如 RabbitMQ、Kafka&a…...

【Java高阶面经】3.熔断机制深度优化:从抖动治理到微服务高可用架构实战
一、熔断抖动的本质剖析与核心成因 1.1 熔断机制的核心价值与抖动危害 熔断机制作为微服务弹性架构的核心组件,通过模拟电路断路器逻辑,在服务出现异常时自动阻断请求链,防止故障扩散引发雪崩。但频繁的“熔断-恢复-熔断”抖动会导致: 用户体验恶化:请求成功率波动大,响…...

如何删除 HP 笔记本电脑中的所有数据:3 种解决方案说明
当您准备删除 HP 笔记本电脑中的所有数据时,无论是为了保护您的隐私还是为设备重新启动做好准备,使用正确的方法非常重要。在本文中,您可以获得 3 个有效的解决方案,帮助您轻松删除计算机中的所有内容。之后,您可以安全…...

以太联 - Intellinet 闪耀台北 SecuTech 国际安全科技应用博览会
2025 年 5 月 7 日至 9 日,台北 SecuTech 国际安全科技应用博览会现场热闹非凡,以太联 - Intellinet 携旗下前沿产品与解决方案精彩亮相,成为展会上一道亮丽的风景线,吸引了众多业内人士的目光,收获了广泛关注与高度认…...