Index-AniSora技术升级开源:动漫视频生成强化学习
B站升级动画视频生成模型Index-AniSora技术并开源,支持番剧、国创、漫改动画、VTuber、动画PV、鬼畜动画等多种二次元风格视频镜头一键生成!
整个工作技术原理基于B站提出的 AniSora: Exploring the Frontiers of Animation Video Generation in the Sora Era实现,该工作已经被IJCAI25接收。再次基础上进一步提出了首个专为二次元视频生成打造的强化学习技术框架,全面提升动画内容的生产效率与质量Aligning Anime Video Generation with Human Feedback(https://arxiv.org/abs/2504.10044)
所有的工作全部开源!快戳地址:https://github.com/bilibili/Index-anisora/tree/main
上Demo!
B站自研AI动画视频生成模型?人人都可以手搓动画?Index-Anisora视频生成模型发布
我们提出了一套专门用于动漫视频生成任务的对齐管线,其整体框架如图1所示。我们构建了首个面向动漫领域的高质量奖励数据集,共包含 30,000 条人工标注的动漫视频样本。人工评估包括两个方面:视觉外观(Visual Appearance)与 视觉一致性(Visual Consistency)。其中,视觉外观的评价仅考虑视频帧的质量,包括视觉平滑度(VS)、视觉运动(VM)与视觉吸引力(VA)三个维度。而视觉一致性则进一步扩展了基本的文本-视频一致性(TC),引入了图像到视频(I2V)任务中的图像-视频一致性(IC)与动漫内容中特有的角色一致性(CC),确保更全面的评价。通过这六个维度,我们对动漫视频的整体质量进行系统性评估,从而更准确地反映人类在奖励建模中的偏好。基于此,我们进一步提出了 AnimeReward,一个专为动漫视频生成对齐设计的多维度高可信奖励系统。由于不同维度所关注的视觉特征存在差异,我们为不同维度采用专门的视觉-语言模型进行奖励回归,以更贴近地拟合人类偏好。我们进一步提出了 差距感知偏好优化(GAPO) ,显式地将正负样本对之间的偏好差距融入损失函数,从而提升对齐训练的效率和最终性能。
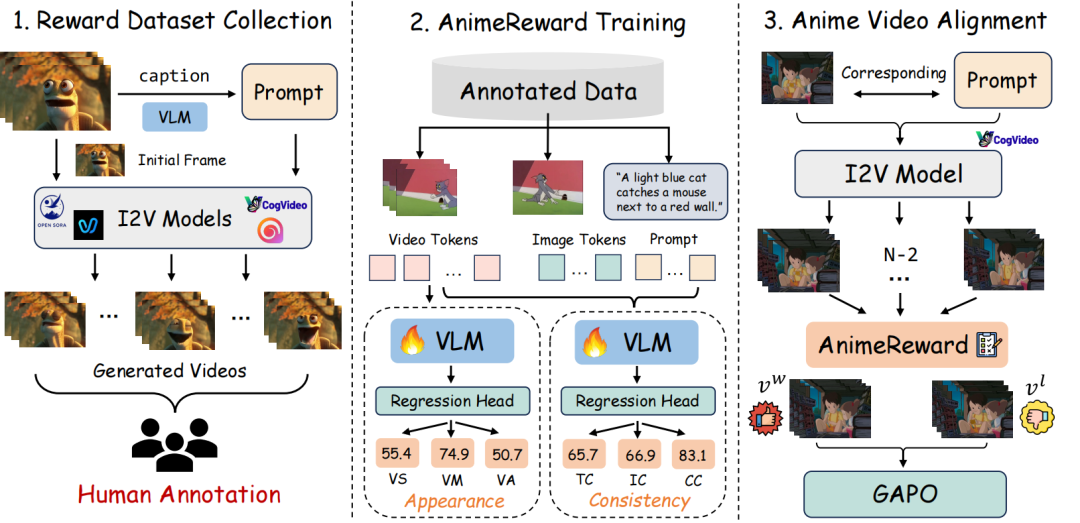
图1 对齐管线整体概述
方法
1.动漫奖励数据集构建
为了增强数据集的动作类别多样性,我们收集的视频样本涵盖多种动作类别,包括说话、行走、挥手、亲吻、哭泣、拥抱、推拉等典型行为场景。通过人工标注,我们从 100 多种常见动作中总结出标准化的动作标签,对每个标签收集约 30~50 个视频片段,最终得到 5000 条真实动漫视频作为基础数据源。在文本提示词的设计方面,我们采用 Qwen2-VL 模型[1]对视频打标自动生成提示词,并使用 CogVideoX[2]中提出的提示词优化策略,生成文本提示。原始图像采用每个视频的第三帧,以作为图像到视频生成的输入。基于这些提示词和原始图像,我们使用了 5 个先进的图像到视频生成模型(Hailuo、Vidu、OpenSora[3]、OpenSora-Plan[4]和 CogVideoX[2]),生成多样化的动漫视频。结合初始的 5000 条GT视频,我们构建了一个包含 30000 条动漫视频的奖励数据集,用于奖励模型的训练。此外,我们还构建了一个包含 6000 条动漫视频的测试集,并严格保证测试集与训练集在初始图像和提示内容上无重叠,以确保测试评估的准确性与泛化性。
为了全方位评估生成动漫视频的质量,人工标注从两个方面衡量视频质量:视觉外观与视觉一致性。其中,视觉外观主要衡量视频的基础质量,关注其视觉表现,包括视觉的平滑度(visual smoothness)、运动幅度(visual motion)以及整体的视觉吸引力(visual appeal);而视觉一致性则更加侧重于多模态之间的协调性,具体包含文本与视频的语义对齐(text-video consistency)、图像与视频的时空一致性(image-video consistency),以及动漫角色在视频中的稳定性(character consistency)。我们共邀请了 6 名专业标注人员参与标注过程,对每段视频从上述 6 个维度分别打分,评分范围为 1 到 5 分,5 分表示质量最佳。每个维度的最终得分由所有标注者的打分取平均值,以确保评价的客观性和鲁棒性。
2.AnimeReward训练
与依赖单一视觉-语言模型(VLM)统一训练回归所有维度的奖励分数的方法不同,AnimeReward 对不同维度使用专门的VLM,通过奖励分数回归分别训练它们。
2.1 Visual Smoothness
对于动漫视频的视觉平滑度评估,我们基于Mantis-8B-Idefics2模型[5],微调其视觉编码器,并在其后接入一个回归头,来让模型输出拟合人工打分结果。给定一个视频,我们的模型的平滑度评分机制如下:
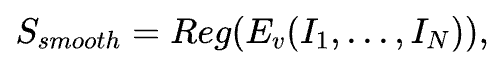
其中,I_i 表示视频的第 i 帧,N 为视频的总帧数,Ev表示视觉编码器,Reg 为回归头模块。
2.2 Visual Motion
我们基于 ActionCLIP[6] 构建了一个动作评分模型,用于评估动漫视频中主要人物的运动幅度。在模型训练过程中,我们设计了一系列动作提示语(motion prompts),用于引导模型学习不同运动幅度的语义表达。例如:
-
“主角在视频中有大幅度动作,如奔跑、跳跃、跳舞或挥手。”
-
“主角在视频中保持静止,没有明显的动作。”
最终,模型根据输入视频与预设动作提示语之间的余弦相似度,计算出动作评分:
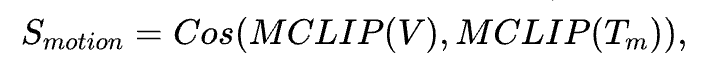
其中,MCLIP 表示动作模型,V 表示待评估的视频片段,Tm 表示设计好的动作提示语。
2.3 Visual Appeal
视觉吸引力用于评估生成视频的基础质量,侧重于其整体美学表现。以往研究通常采用在真实世界图像数据集上训练的美学评分模型来进行评估。然而,这类模型在应用于动漫视频时效果不佳,不同方法生成的视频在评分上差异不明显,难以体现真实的美学偏好差异。为了解决这一问题,我们首先从视频中提取关键帧,然后对它们进行编码,训练一个美学回归模型来学习人类对动漫图像的审美标准,从而更精准地评估其视觉吸引力。吸引力评分的计算公式如下所示:
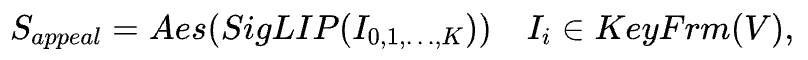
其中,I_i 表示关键帧,K是提取的关键帧数量,SigLIP 为特征编码器,Aes 表示美学评分模型。
2.4 Text-Video Consistency
为了评估文本与视频的一致性,我们利用动漫文本-视频对,微调了视觉编码器与文本编码器,并在其上接入回归头,以学习文本与视频之间的语义对齐程度。文本-视频一致性分数的计算公式如下:
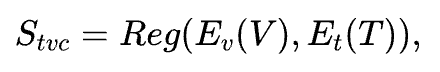
其中,Reg 表示回归头,Ev 和Et 分别表示视觉编码器和文本编码器。模型通过联合文本提示T 与对应视频V,学习它们之间的语义匹配关系。
2.5 Image-Video Consistency
在图像到视频生成任务中,生成视频应与输入图像尽量保持外观上的一致性。类似于文本-视频一致性的评估方法,我们微调了视觉编码器与回归头,对图像与视频之间的外观一致性进行建模评分:
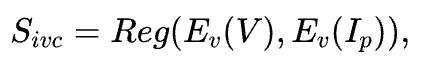
其中,V 表示待评估的视频片段,Ip 表示输入图像,Ev 为视觉编码器,Reg为回归头。
2.6 Character Consistency
在动漫视频生成中,角色一致性是一个重要的因素。如果主角的身份和风格在视频中发生变化,即使视频质量较高,也可能存在侵权风险。因此,我们设计了一套系统性流程来评估角色一致性,流程包括:角色检测、分割与识别等多个阶段,该模型的框架如图2所示。具体而言,我们首先使用 GroundingDINO[7]、SAM[8] 以及追踪工具,对视频中的每一帧提取角色的掩膜(mask)。随后,我们使用 BLIP[9] 模型进行微调,以学习提取的人物掩膜与其对应的动漫角色(IP)之间的关联。
在推理阶段,我们通过计算生成视频中的动漫角色特征与角色库的对应特征之间的余弦相似度,来衡量角色在视频中的一致性。具体评分方式如下:
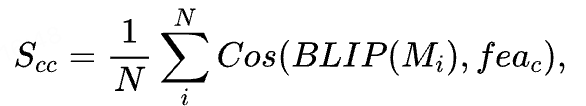
其中,N 表示采样的角色帧数量,Mi 表示提取得到的第 i 帧的角色掩膜,fea_c表示对应参考角色的特征表示。
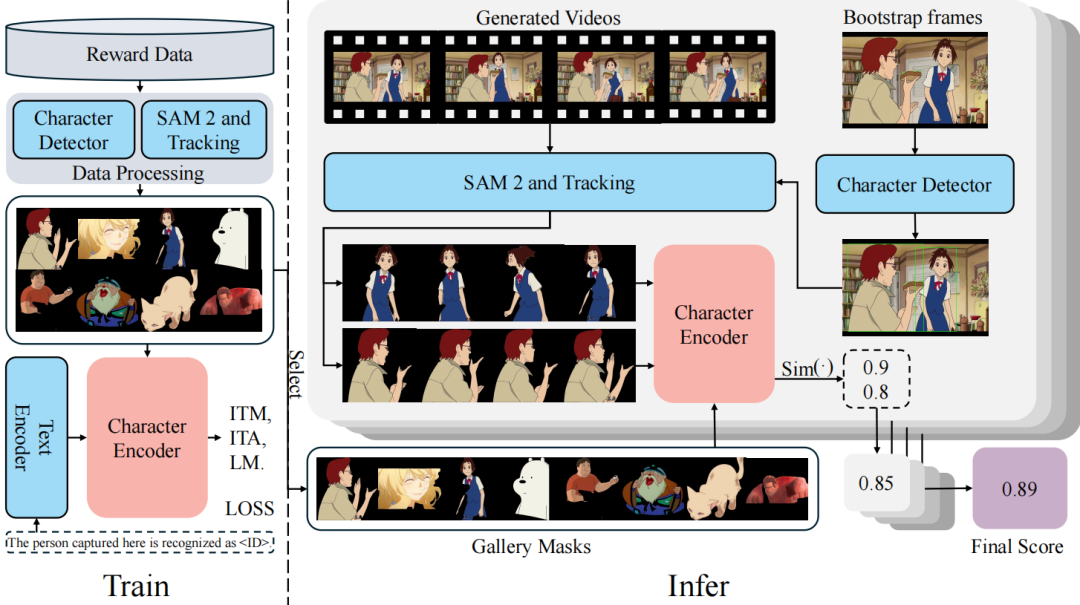
图2 角色一致性训练和推理框架

那么该视频的整体奖励分数R(v) 通过对所有维度的评分取平均得到,公式如下:
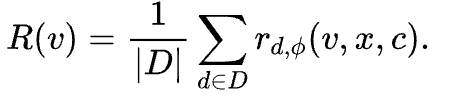
通过对人类偏好的学习,AnimeReward 能够为动漫视频生成对齐提供高质量的偏好反馈信号,提升视频生成模型的整体表现与人类认知的一致性。
3.动漫视频生成对齐

对于每个偏好样本对(vw,vl),我们将正负样本的奖励增益差值作为差距权重因子,作用于原始 DPO 损失函数,得到 GAPO 的损失函数:
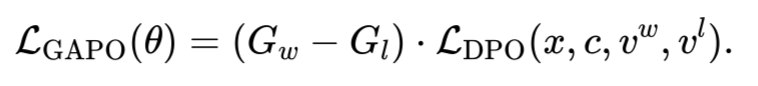
通过在对齐训练中显示引入偏好差距信息,GAPO 在优化时显著放大了偏好差异明显的样本对的影响,同时抑制了偏好差异较小的样本对的干扰,从而更高效地提升模型对人类偏好的对齐能力,特别是在动漫视频生成这类主观性强的任务中具有重要意义。
实验
数据集
在对齐训练中,我们采用开源模型 CogVideoX-5B[2]作为基线模型。我们首先构建了一个包含 2000 条原始动漫图像及其对应文本提示的初始训练集。基于该数据集,我们使用基线模型为每组数据采样生成 段动漫视频,再利用 AnimeReward ,对每组生成视频进行偏好奖励评分,选择其中得分最高和得分最低的两个视频,构成一个偏好样本对。最终得到包含 2000 对偏好样本的集合作为后续偏好对齐优化的训练集。
实验结果
我们采用自动化评测和人工评测两种方式来评估模型的对齐效果。自动评测包含VBench-I2V[11], VideoScore[12]和我们提出的AnimeReward三种方法。人工评测邀请了三位专业的评测人员给出主观评价。只有当三位评测者中至少两位都认为视频 比 更好或更差时,视频 才会被认为赢或输 。
VBench-I2V [11]基准的评测结果如表1所示,我们提出的偏好对齐方法在总分上取得了最优表现,在几乎所有评估指标上均显著优于基线模型,并在大多数情况下超越了 SFT(监督微调)模型。值得注意的是,在 I2V Subject 和 Subject Consistency 两个关键指标上的提升尤为显著,表明我们的对齐方法能够帮助视频生成模型在保持动漫角色一致性方面具备更强的能力。如表2所示,在 AnimeReward 评价体系下,除 Visual Motion 外,我们的方法在所有维度上均实现了大幅提升,说明我们的对齐模型在视觉外观与一致性方面更贴近人类偏好。在 VideoScore [12]评估中,我们的方法在三个维度上均优于基线模型与 SFT 模型,表现出更好的视觉质量和时序稳定性。同时,我们也观察到了,在动态程度(即 Visual Motion/ Dynamic Degree)这一指标上,对齐后的模型表现略逊于基线与 SFT 方法。对此,我们认为,高动态程度的视频更容易引发空间扭曲与伪影,从而大大降低整体视觉质量,对人类主观偏好产生负面影响。这一结果也表明,人类通常喜欢具有更高视觉质量、更强一致性与更好稳定性的视频内容,而非单纯追求高动态幅度的生成结果。

表1 在VBench-I2V上的定量性能比较

表2 在AnimeReward和VideoScore上的量化性能比较
图3展示了人工评测的对比实验结果,我们的对齐模型相较于基线模型与 SFT 模型展现出显著优势,整体胜率超过 60%。尽管 SFT 模型使用了偏好分数最高的优质样本进行训练,但其生成视频的质量并未得到明显提升,甚至在人工评测中的胜率低于基线模型。
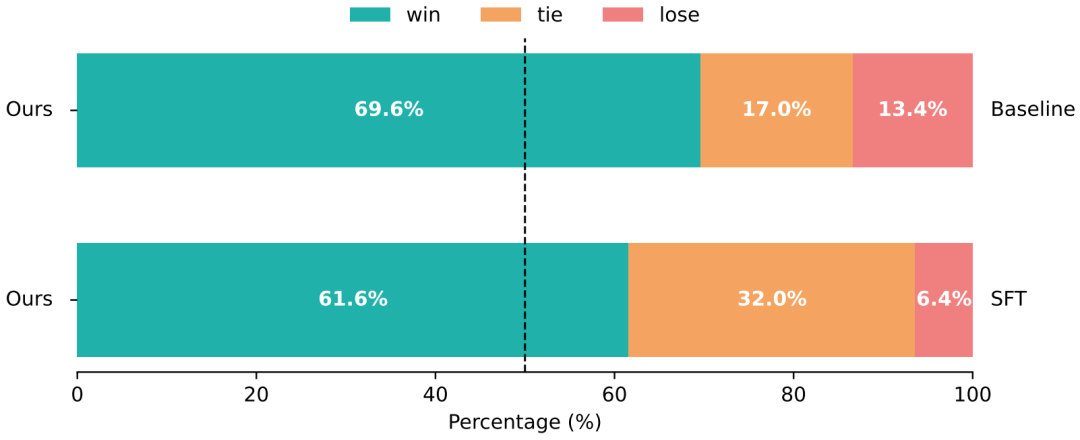
图3 不同模型生成的动漫视频的人工评测结果
消融研究
为验证我们提出的差距感知偏好优化(GAPO) 相较于传统DPO的优势,我们在保持实验设置一致的前提下,仅更换偏好优化算法,进行对比实验。我们在前述三种评价体系上对不同模型进行了系统评估,实验结果如表3所示。其中,AnimeReward(AR) 和 VideoScore(VS) 的最终得分为各维度得分的平均值。从结果来看,GAPO 在三个评价体系中均取得了最优表现,尤其在 VBench-I2V (V-I2V) 和 AnimeReward(AR)上相较 DPO 获得了显著提升。
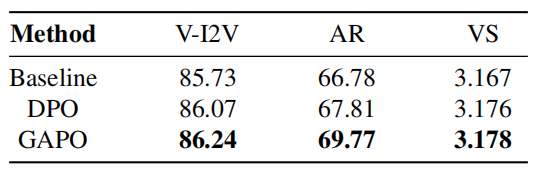
表3 对GAPO在三个评价体系上的消融研究结果
为验证 AnimeReward 奖励模型在动漫视频偏好对齐任务中的优势,我们设计了对比实验,使用 VideoScore [12]作为替代的奖励模型进行对齐训练。实验结果如表4所示。从结果可以看出,使用 AnimeReward 训练的模型在两个评价体系中均优于使用 VideoScore 训练的模型;而 VideoScore 仅仅在其自身评价体系中取得优势。为了更客观地评估两者的对齐性能,我们在图4展示了它们相对于基线模型在第三方评价基准 VBench-I2V [11]各个维度上的可视化评价结果。除 Dynamic Degree 外,基于 AnimeReward 的对齐模型在其余 7 个维度上全面优于 VideoScore。
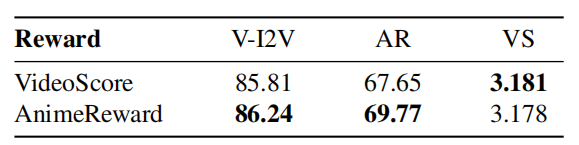
表4 基于不同奖励模型的消融研究结果
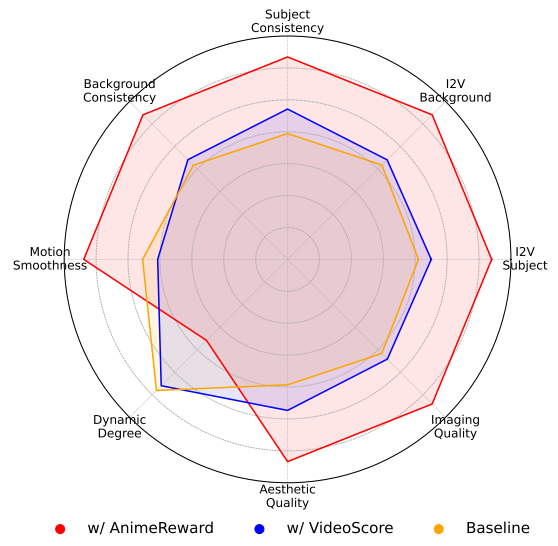
图4 基于不同奖励模型在VBench-I2V多个维度上的可视化评估结果
结论
本文提出了首个针对动漫视频生成的奖励模型 AnimeReward,旨在模拟人类偏好对生成动漫视频进行全方位的评价。我们基于两大方面设计了六个评价维度,从多个角度衡量生成动漫视频的质量。基于 AnimeReward,我们进一步提出了一种新颖的优化对齐策略 差距感知偏好优化(Gap-Aware Preference Optimization, GAPO),在优化损失中显式引入偏好差距信息,从而高效提升生成模型的对齐性能。实验结果表明,仅仅依赖基线模型生成的视频数据,我们提出的对齐管线依然能够显著提升动漫视频的生成质量,使结果更贴近人类偏好,验证了该方法在偏好对齐任务中的有效性与实用性。
demo
-
对齐效果
提示词:画面中展现了石块发生爆炸的场景,发出刺眼的光芒,碎石四处飞散
对齐前⬇️

对齐后⬇️

提示词:画面中一个人在快速向前奔跑,他奔跑的速度很快使得人物有些模糊
对齐前⬇️

对齐后⬇️

提示词:老人的目光紧盯着那颗宝石,右手轻微摆动着手中的放大镜,嘴巴在说话,仿佛它掌握着解开某种古老知识或秘密的关键。
对齐前⬇️

对齐后⬇️

参考文献
[1] Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution. arXiv preprint arXiv:2409.12191, 2024.
[2] Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, et al. Cogvideox: Text-to-video diffusion models with an expert transformer. arXiv preprint arXiv:2408.06072, 2024.
[3] Zangwei Zheng, Xiangyu Peng, Tianji Yang, Chenhui Shen, Shenggui Li, Hongxin Liu, Yukun Zhou, Tianyi Li, and Yang You. Open-sora: Democratizing efficient video production for all. arXiv preprint arXiv:2412.20404, 2024.
[4] Bin Lin, Yunyang Ge, Xinhua Cheng, Zongjian Li, Bin Zhu, Shaodong Wang, Xianyi He, Yang Ye, Shenghai Yuan, Liuhan Chen, et al. Open-sora plan: Open-source large video generation model. arXiv preprint arXiv:2412.00131, 2024.
[5] Dongfu Jiang, Xuan He, Huaye Zeng, Cong Wei, Max Ku, Qian Liu, and Wenhu Chen. Mantis: Interleaved multi-image instruction tuning. arXiv preprint arXiv:2405.01483, 2024.
[6] Mengmeng Wang, Jiazheng Xing, and Yong Liu. Actionclip: A new paradigm for video action recognition. arXiv preprint arXiv:2109.08472, 2021.
[7] Tianhe Ren, Qing Jiang, Shilong Liu, Zhaoyang Zeng, Wenlong Liu, Han Gao, Hongjie Huang, Zhengyu Ma, Xiaoke Jiang, Yihao Chen, et al. Grounding dino 1.5: Advance the "edge" of open-set object detection. arXiv preprint arXiv:2405.10300, 2024.
[8] Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, et al. Sam 2: Segment anything in images and videos. In ICLR, 2025.
[9] Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In ICML, 2022.
[10] Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. In NeurIPS, 2023.
[11] Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, et al. Vbench: Comprehensive benchmark suite for video generative models. In CVPR, 2024.
[12] Xuan He, Dongfu Jiang, Ge Zhang, Max Ku, Achint Soni, Haonan Chen, Abhranil Chandra, Ziyan Jiang, et al. Videoscore: Building automatic metrics to simulate fine-grained human feedback for video generation. In EMNLP, 2024.
-End-
作者丨Bwin、HarryJ、高树、seasonyang
相关文章:

Index-AniSora技术升级开源:动漫视频生成强化学习
B站升级动画视频生成模型Index-AniSora技术并开源,支持番剧、国创、漫改动画、VTuber、动画PV、鬼畜动画等多种二次元风格视频镜头一键生成! 整个工作技术原理基于B站提出的 AniSora: Exploring the Frontiers of Animation Video Generation in the So…...

游戏引擎学习第297天:将实体分离到Z层中
回顾并为今天的内容做准备 昨天我们做了雾效混合(fog blend)和透明度混合(alpha blending)的尝试,现在正在进行渲染部分的深度(Z)清理工作。今天的重点是把“切片”(slices…...

全局对比度调整
目录 一、全局对比度调整原理 二、饱和度保持 一、全局对比度调整原理 Figure1.2 展示了一幅全局对比度较低的图像及其亮度直方图。该直方图分布范围较窄,像素的强度仅集中在中间调区域,不存在明亮或深色的像素,因此图像中的细节难以区分,可用动态范围未得到有效利用。在动…...

Canvas SVG BpmnJS编辑器中Canvas与SVG职能详解
Canvas详解与常见API 一、Canvas基础 核心特性 • 像素级绘图:Canvas是基于位图的绘图技术,通过JavaScript操作像素实现图形渲染,适合动态、高性能场景(如游戏、数据可视化)。 • 即时模式:每次绘制需手动…...

【图像大模型】Stable Diffusion 3 Medium:多模态扩散模型的技术突破与实践指南
Stable Diffusion 3 Medium:多模态扩散模型的技术突破与实践指南 一、架构设计与技术演进1.1 核心架构革新1.2 关键技术突破1.2.1 整流流(Rectified Flow)1.2.2 动态掩码训练 二、系统架构解析2.1 完整推理流程2.2 性能对比 三、实战部署指南…...

PID项目---硬件设计
该项目是立创训练营项目,这些是我个人学习的记录,记得比较潦草 1.硬件-电路原理电赛-TI-基于MSPM0的简易PID项目_哔哩哔哩_bilibili 这个地方接地是静电的考量 这个保护二极管是为了在电源接反的时候保护电脑等设备 大电容的作用:当电机工作…...

渗透测试流程
2.1 信息收集 2.1.1 资产监控与架构分析 目标:明确目标范围(IP、域名、子公司资产),识别网络架构(云服务/CDN/反向代理)。 工具与技巧: 使用FOFA、Shodan搜索关联资产(如title="目标公司")。 通过nslookup或dig解析域名,确认真实IP是否隐藏于CDN…...

PCIe EP/RC 核心功能解释
1. Bar访问(BAR Access) BAR(Base Address Register) 是 PCIe 设备上的 地址窗口,用于主机与设备之间的 寄存器访问。功能: 主机通过 BAR 访问 EP 卡的 控制寄存器 或 数据缓冲区。每个 BAR 对应一段物理内…...

srs-7.0 支持obs推webrtc流
demo演示 官方教程: https://ossrs.net/lts/zh-cn/blog/Experience-Ultra-Low-Latency-Live-Streaming-with-OBS-WHIP 实现原理就是通过WHIP协议来传输 SDP信息 1、运行 ./objs/srs -c conf/rtc.conf 2、obs推流 3、web端播放webrtc流 打开web:ht...

SQLynx 团队协作实践:提升数据库开发效率的解决方案
在数据库开发与管理场景中,团队协作的效率直接影响项目进度与质量。传统协作方式常面临权限混乱、代码复用率低、跨地域协作困难等问题,而 SQLynx 作为一款轻量化 Web SQL 工具,凭借其独特的团队协作功能,为这些难题提供了有效解决…...

基于自然语言转SQL的BI准确率如何?
基于自然语言转SQL的商业智能(BI)工具的准确率受多种因素影响,目前整体处于中等偏上水平,但尚未达到完全精准的程度。以下从技术原理、影响准确率的因素、实际应用场景及未来趋势等方面展开分析: 一、技术原理与当前准…...

「华为」持续加码人形机器人赛道!
温馨提示:查看运营团队2025年最新原创报告(共210页) —— 正文: 现阶段,全球大厂入局具身智能赛道典型代表:[英伟达]和[特斯拉],是全球科技巨头/大厂(谷歌、微软、Meta、OpenAI、华…...

Visual Studio 2022 无法编译.NET 9 项目的原因和解决方法
Visual Studio 2022 无法运行.NET 9 项目的原因和解决方法。 目录 1. Visual Studio 2022 无法编译TargetFramework是.NET 9 项目 2. 解决方法 3. 用Visual Studio Code开发 1. Visual Studio 2022 无法编译TargetFramework是.NET 9 项目 本机安装了Visual Studio 2022 版…...
String(中)String的常用接口(构造接口,析构接口,迭代器,遍历修改,容量管理与数据访问))
C++从入门到实战(十六)String(中)String的常用接口(构造接口,析构接口,迭代器,遍历修改,容量管理与数据访问)
C从入门到实战(十六)String(中)详细讲解String的常用接口 前言一、std::string二、string的构造接口1. 默认构造函数:创建空字符串2. 拷贝构造函数:复制已有字符串3. 从已有字符串截取部分4. 用C风格字符串…...

RabbitMQ ⑤-顺序性保障 || 消息积压 || 幂等性
幂等性保障 幂等性(Idempotency) 是计算机科学和网络通信中的一个重要概念,指的是某个操作无论被执行多少次,所产生的效果与执行一次的效果相同。 应用程序的幂等性: 在应用程序中,幂等性就是指对一个系统…...

go.mod:5: unknown directive: toolchain
Go语言版本较旧,而项目使用了较新版本的Go语言特性。错误信息"unknown directive: toolchain"表明go.mod文件中使用了"toolchain"指令,这是在Go 1.21版本中新引入的特性,但您当前安装的Go版本不支持这个指令。 解决方法…...

分布式序列生成方案 : Redis Incr | 基于Redisson创建自增获取序号,每天更换一个key, key到期时间1天,用于创建订单号、快递单号
文章目录 引言I 在 Spring Boot 应用程序中集成 Redisson1. Maven2. 配置 Redisson 客户端3. 创建 Redisson 配置类4. 自动装配 RedissonClientII 应用: 基于Redisson创建自增获取序号生成每日自增序号创建订单号创建快递单号封装 :系统自动生成单号引言 应用: 创建订单号、…...
App Input事件接收器InputEventReceiver)
Android7 Input(八)App Input事件接收器InputEventReceiver
概述 上一个章节,我们讲解了App如何使用InputChannel通道与input系统服务建立通信的桥梁的过程,本章我们讲述App如何从input系统服务中获取上报的输入事件,也就是我们本章讲述的InputEventReceiver。 本文涉及的源码路径 frameworks/base/c…...

阿里云服务器Ubuntu的git clone失败问题解决方案
一、问题 我们再使用阿里云服务器或者别的服务器,git clone失败 二、解决方案 1. 确认SSH密钥是否存在并正确配置 检查密钥文件: ls -al ~/.ssh 确认存在 id_rsa(私钥)和 id_rsa.pub(公钥ÿ…...
基础功能与xml使用)
Mujoco 学习系列(二)基础功能与xml使用
这篇文章是 Mujoco 学习系列第二篇,主要介绍一些基础功能与 xmI 使用,重点在于如何编写与读懂 xml 文件。 运行这篇博客前请先确保正确安装 Mujoco 并通过了基本功能与GUI的验证,即至少完整下面这个博客的 第二章节 内容: Mujoc…...

8 定时任务与周期性调度
在构建复杂的分布式系统时,我们经常会遇到需要“定时”或“周期性”执行的任务。比如,每天凌晨生成报表,每小时同步一次数据,或者在特定时间发送提醒邮件。这些任务如果都依赖人工触发,不仅效率低下,而且容…...
)
idea 插件开发自动发布到 nexus 私服中(脚本实例)
如下脚本内容为 idea 插件开发项目中的 build.gradle.kts 文件示例,其中自定了 updatePluginsXml 和 uploadPluginToNexus 两个任务,一个用来自动修改 nexus 中的配置文件,一个用来自动将当前插件打包后的 zip 文件上传到 nexus 私服中。 脚…...

关于 APK 反编译与重构工具集
一、apktool — APK 解包 / 重打包 apktool 是一款开源的 Android APK 工具,用于: 反编译 APK 查看资源和布局文件 生成 smali 文件(DEX 的反汇编) 对 APK 进行修改后重新打包 它不能还原 Java 源码,只能将 D…...

【课堂笔记】核方法和Mercer定理
文章目录 Kernal引入定义Mercer定理描述有限情形证明一般情形证明 Kernal 引入 在实际数据中常常遇到不可线性分割的情况,此时通常需要将其映射到高维空间中,使其变得线性可分。例如二维数据: 通过映射 ϕ ( x 1 , x 2 ) ( x 1 2 , 2 x 1…...

Cribl 中 Parser 扮演着重要的角色 + 例子
先看文档: Parser | Cribl Docs Parser The Parser Function can be used to extract fields out of events or reserialize (rewrite) events with a subset of fields. Reserialization will preserve the format of the events. For example, if an event contains comma…...
)
MVDR源码(可直接运行)
该代码可正常运行,信号使用的是模拟信号,可改为指定信号。 本代码使用了一个基于MVDR(最小方差无失真响应)算法的麦克风阵列声源定位方法。代码首先设置了麦克风阵列的参数,包括阵元数量、采样率、信号频率等ÿ…...
MyBatis入门基础与利用IDEA从零开始搭建你的第一个MyBatis系统)
MyBatis实战指南(一)MyBatis入门基础与利用IDEA从零开始搭建你的第一个MyBatis系统
MyBatis实战指南(一)MyBatis入门基础与利用IDEA从零开始搭建你的第一个MyBatis系统 一、什么是MyBatis1. MyBatis 是什么?2. JDBC 的三大痛点3. MyBatis 的核心优势1. 告别重复代码,专注核心逻辑2. 灵活控制 SQL,适应各…...
)
React Flow 数据持久化:Django 后端存储与加载的最佳实践(含详细代码解析)
在构建 React Flow 应用时,前端呈现的节点与连线构成的可视化流程只是冰山一角,其背后的数据持久化与灵活调取才是确保应用稳定运行、支持用户数据回溯与协作的关键。因此,后端存储与加载 React Flow 信息的环节,就如同整个应用的…...

第32节:基于ImageNet预训练模型的迁移学习与微调
1. 引言 在深度学习领域,迁移学习(Transfer Learning)已经成为解决计算机视觉任务的重要方法,特别是在数据量有限的情况下。其中,基于ImageNet数据集预训练的模型因其强大的特征提取能力而被广泛应用于各种视觉任务。本文将详细介绍迁移学习的概念、ImageNet预训练模型的特…...

接口自动化可视化展示
目的将接口返回的实际对比返回 前端:使用Geeker-Admin二次开发使用 后端 flaskpythonrequests 实际实现展示 接口测试通过 接口测试不通过 接口数据的增删改查...

Hbuilder X4.65新建vue3项目存在的问题以及解决办法
有关Vue的多篇文章: 1.使用Vue创建前后端分离项目的过程:使用Vue创建前后端分离项目的过程(前端部分)_vue前端项目打包的dish-CSDN博客 2.vue3实现自定义导航菜单:vue3实现自定义导航菜单_vue3 导航栏-CSDN博客 3…...
)
SpringBoot 项目实现操作日志的记录(使用 AOP 注解模式)
本文是博主在做关于如何记录用户操作日志时做的记录,常见的项目中难免存在一些需要记录重要日志的部分,例如权限和角色设定,重要数据的操作等部分。 博主使用 Spring 中的 AOP 功能,结合注解的方式,对用户操作过的一些…...

C/C++ 整数类型的长度
参考 cppreference.cn 在某些语言中,整数类型的长度是固定的,如java中 char 8short 16int 32long 64 可是C/C 与机器相关,整数类型长度与平台有关 先可以记一个简单的 按照C标准: char > 8short > 16int > 16long &g…...

解决npm install报错:getaddrinfo ENOTFOUND registry.nlark.com
问题背景 在使用 npm install 安装依赖时,突然遇到以下错误: npm ERR! network request to https://registry.nlark.com/fsevents/download/fsevents-2.3.2.tgz failed, reason: getaddrinfo ENOTFOUND registry.nlark.com这表明 npm 在尝试从 registr…...

PostgreSQL简介安装
目录 一. PostgreSQL 1. 简介 2. 特点 3. 优势 4. 架构 5. 应用场景 二. 安装PostgerSQL 1. 编译安装 (1) 安装编译安装所需环境 (2) 编译安装 (3) 配置环境变量 (4) 登录数据库 2. DNF安装 (1) 安装postgreSQL (2) 初始化数据库 (3) 登录数据库 三. postgreSQ…...

vue3+elementPlus穿梭框拖拽
安装 npm install sortablejs --save <template><div class"transfer" ref"transfer"><div><el-transfer v-model"inputForm" :data"data" :titles"titles"><template #default"{ option }…...
)
牛客周赛 Round 93题解(个人向A-E)
牛客周赛 Round 93题解(个人向A-E) 题目链接:https://ac.nowcoder.com/acm/contest/109904 a题 签到题,直接按题意模拟即可 #include <bits/stdc.h> using namespace std; #define ll long long int main() {ios::sync_…...

MySQL高可用之ProxySQL + MGR 实现读写分离实战
部署MGR 1、MGR 前置介绍 阿里云RDS集群方案用的就是MGR模式! 1.1、什么是 MGR MGR(MySQL Group Replication)是MySQL 5.7.17版本诞生的,是MySQL自带的一个插件,可以灵活部署。保证数据一致性又可以自动切换&#x…...

React TS中如何化简DOM事件的定义
概要 我们在做TS开发时候,总要面对各种类型的定义。React使用自己的Sythetic Event机制管理DOM事件,不同于原生的DOM事件定义,所以在TS中,事件的类型定义更加繁琐。 本文提供一中简化定义的方法,在使用中,…...

BigemapPro蒙版使用技巧:精准导出地图范围
在地图制图过程中,我们常常会遇到需要按照特定边界裁剪地图,或者对指定范围以外的地图进行模糊处理等情况,这时"添加蒙版"功能就非常实用。 BigemapPro的蒙版功能,可满足用户按自定义形状裁剪地图、控制区域外显示效果&…...

CesiumEarth v1.15 更新
更新: CesiumEarth 更新至1.15.0版本,包含浏览器在线版、Desktop Windows版本、Desktop 安卓版本 界面优化: 项目列表已适配手机屏幕 功能 扩展模块更新 1、在底部工具栏区域,所有已生效(已勾选࿰…...

SOC-ESP32S3部分:2-2-VSCode进行编译烧录
飞书文档https://x509p6c8to.feishu.cn/wiki/CTzVw8p4LiaetykurbTciA42nBf?fromScenespaceOverview 无论是使用Window搭建IDF开发环境,还是使用Linux Ubuntu搭建IDF开发环境,我们都建议使用VSCode进行代码编写和编译,VSCode界面友好&#x…...

机器学习 day05
文章目录 前言一、模型选择与调优1.交叉验证2.超参数搜索 前言 通过今天的学习,我掌握了机器学习中模型的选择与调优,包括交叉验证,超参数搜索的概念与基本用法。 一、模型选择与调优 模型的选择与调优有许多方法,这里主要介绍较…...

关于element-ui的table type=“expand“ 嵌套表格展开异常问题解决方案
也许是很久没用这个库了 今天找这个问题还花了一会儿时间 也是蛮简单的一个问题 排查过程就不说了 直接说结果吧 记录一下 发现问题 展开第一列的时候表格没问题 收起的时候 莫名其妙多了一个展开的按钮 代码咋一看没什么问题 百思不解不得其解 甚至怀疑row-key的问题 检查了数…...
)
Pichome 开源网盘程序index.php 文件读取漏洞(CVE-2025-1743)
免责声明 本文档所述漏洞详情及复现方法仅限用于合法授权的安全研究和学术教育用途。任何个人或组织不得利用本文内容从事未经许可的渗透测试、网络攻击或其他违法行为。使用者应确保其行为符合相关法律法规,并取得目标系统的明确授权。 对于因不当使用本文信息而造成的任何直…...
----图书管理系统(初))
[SpringBoot]Spring MVC(6.0)----图书管理系统(初)
图书管理系统 需求: 1. 登录: 用户输入账号,密码完成登录功能. 2. 列表展示: 展示图书. 准备工作 将前端代码复制到 static 目录下. 约定前后端交互接口 两个功能: 用户登录 和 图书列表展示. 需求分析: 1. 用户登录 url : /user/login param : userName 和 password return …...

C语言:基础篇之常见概念
文章目录 1.C语言是什么?2.C语言的历史和辉煌3.编译器的选择VS20223.1 编译和链接3.2 编译器的对比3.3 VS2022 的优缺点 4.VS项目和源文件、头文件介绍5.第一个C语言程序6.main函数7.printf和库函数8.关键字介绍9.字符和ASCII编码10.字符串和\011.转义字符12.语句和…...

Ansible模块——管理100台Linux的最佳实践
使用 Ansible 管理 100 台 Linux 服务器时,推荐遵循以下 最佳实践,以提升可维护性、可扩展性和安全性。以下内容结合实战经验进行总结,适用于中大型环境(如 100 台服务器): 一、基础架构设计 1. 分组与分层…...

算法与数据结构:质数、互质判定和裴蜀定理
文章目录 质数质数判定质数筛选质因数分解互质判定裴蜀定理 质数 首先回顾「质数」的定义:若一个正整数无法被除了 1 和它自身之外的任何自然数整除,则称该数为质数(或素数),否则称该正整数为合数。 根据上述定义&…...

基于C#的Modbus通信协议全面解析与实现指南
目录 1. Modbus协议概述 1.1 Modbus网络结构 1.2 Modbus功能码 2. Modbus RTU模式实现 2.1 RTU模式特点 2.2 CRC-16校验算法 2.3 使用NModbus4库实现RTU通信 3. Modbus TCP/IP模式实现 3.1 TCP模式特点 3.2 MBAP报文头结构 3.3 使用NModbus实现TCP通信 3.4 原生TCP套…...