MySQL基础关键_014_MySQL 练习题
目 录
一、有以下表,请用一条 SQL 语句查询出每门课程都大于 80 分的学生
二、综合题1(数据自行模拟)
1.查询身份证号为“440401430103082”的申请日期
2.查询同一个身份证号有两条及以上记录的身份证号码及记录个数
3.将身份证号码为“440401430103082”的记录在两个表中的申请状态均改为“07”
4.删除“g_cardapplydetail”表中所有姓“宋”的记录
三、 综合题2
1.统计不及格(0~59)、良好(60~80)、优秀(80~100)的课程数
2. 计算每科都及格者的平均成绩
四、 综合题3(数据自行模拟)
1.请用一条SQL语句查询不同部门中担任“钳工”的职工平均工资
2.请用一条SQL语句查询不同部门中担任“钳工”的职工平均工资高于2000的部门
五、综合题4(数据自行模拟)
1.查询所有居住地与工作的公司在同一城市的员工的姓名
2. 查询比“木易十三炼钢厂”所有员工收入都高的员工姓名
3.查询平均年薪在20000元以上的公司及其平均年薪
六、综合题5
1.查询每个客户的所有订单并按照地址排序,要求输出格式为:address client_name phone order_id
2.查询每个客户订购的图书总价,要求输出格式为:client_name total_price
3.如果要求每个订单可以包含多种图书,应该如何修改order表的主键?
4.为了保证每个订单只被一个客户拥有,应该在clientorder表上增加怎样的约束?
七、综合题6(数据自行模拟)
1.查询1号课比2号课成绩高的学生的学号
2.查询平均成绩大于60分的学号和平均成绩
3.查询所有学生的学号、姓名、选课数、总成绩
4.查询姓“李”的老师的个数
5.查询没选过“叶平”老师课的学号、姓名
八、 综合题7(数据自行模拟)
1.查询没有选修课程编号为C1的学生姓名
2.查询每门课程的名称和平均成绩,并按照成绩排序
3.选了2门课以上的学生姓名
九、补充1:行列互换
十、通过 SQL 语句得出表中结果
十一、补充2:窗口函数
十二、有一张表有如下数据,写出一条 SQL 将数字连续性和断点展现出来
一、有以下表,请用一条 SQL 语句查询出每门课程都大于 80 分的学生
| name | course | grade |
|---|---|---|
| 张筱筱 | 语文 | 81 |
| 张筱筱 | 数学 | 75 |
| 李政强 | 英语 | 90 |
# 初始化
drop table if exists t_student;
create table t_student(name varchar(255),course varchar(255),grade double(3,1)
);
insert into t_student values('张筱筱', '语文', 81);
insert into t_student values('张筱筱', '数学', 75);
insert into t_student values('李政强', '英语', 90);-- 1.查询成绩小于等于 80 的学生姓名
select distinct name from t_student where grade <= 80;-- sum.查询剩余学生
select distinct name from t_student where name not in(select distinct name from t_student where grade <= 80);
二、综合题1(数据自行模拟)
| 字段 | 说明 | 类型 | 长度 |
|---|---|---|---|
| g_applyno | 申请单号(关键字) | varchar | 8 |
| g_applydate | 申请日期 | bigint | 8 |
| g_state | 申请状态 | varchar | 2 |
| 字段 | 说明 | 类型 | 长度 |
|---|---|---|---|
| g_applyno | 申请单号(关键字) | varchar | 8 |
| g_stateg_name | 申请人姓名 | varchar | 8 |
| g_idcard | 申请人身份证号 | varchar | 30 |
| g_state | 申请状态 | varchar | 2 |
# 初始化(随机模拟)
drop table if exists g_cardapply;create table g_cardapply(g_applyno varchar(8) primary key,g_applydate bigint(8),g_state varchar(2)
);insert into g_cardapply values(1,20080808, '01');
insert into g_cardapply values(2,20221011, '01');
insert into g_cardapply values(3,20230323, '01');
insert into g_cardapply values(4,20071212, '02');
insert into g_cardapply values(5,20091211, '02');drop table if exists g_cardapplydetail;create table g_cardapplydetail(g_applyno varchar(8),g_name varchar(8),g_idcard varchar(30),g_state varchar(2)
);insert into g_cardapplydetail values('1','黄梓婷','440401430103082','01');
insert into g_cardapplydetail values('2','黄梓婷','440401430103082','01');
insert into g_cardapplydetail values('3','黄梓婷','440401430103082','01');
insert into g_cardapplydetail values('4','宋刚','440401430111111','02');
insert into g_cardapplydetail values('5','邱钰红','440401430122222','02');1.查询身份证号为“440401430103082”的申请日期
-- 1.查询对应的申请日期
select a.g_applydate from g_cardapply a join g_cardapplydetail b on a.g_applyno = b.g_applyno where b.g_idcard = '440401430103082';-- 2.转成日期格式(可选)
select str_to_date(cast(a.g_applydate as char), '%Y%m%d') from g_cardapply a join g_cardapplydetail b on a.g_applyno = b.g_applyno where b.g_idcard = '440401430103082';
2.查询同一个身份证号有两条及以上记录的身份证号码及记录个数
select g_idcard, count(*) from g_cardapplydetail group by g_idcard having count(*) >= 2;
3.将身份证号码为“440401430103082”的记录在两个表中的申请状态均改为“07”
update g_cardapply a join g_cardapplydetail b on a.g_applyno = b.g_applyno and b.g_idcard = '440401430103082' set a.g_state = '07', b.g_state = '07';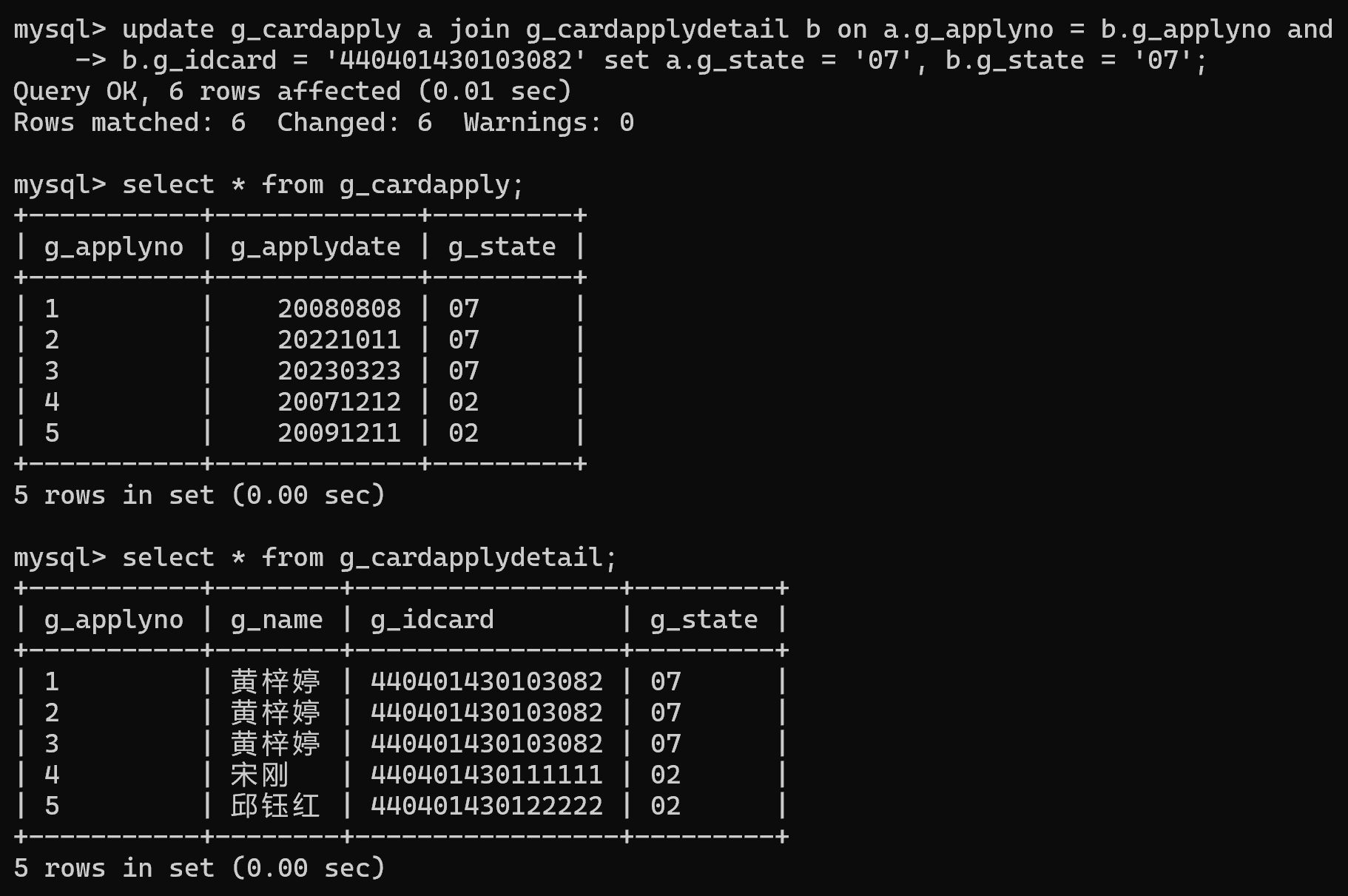
4.删除“g_cardapplydetail”表中所有姓“宋”的记录
delete a, b from g_cardapplydetail a join g_cardapply b on a.g_applyno = b.g_applyno where a.g_name like '宋%';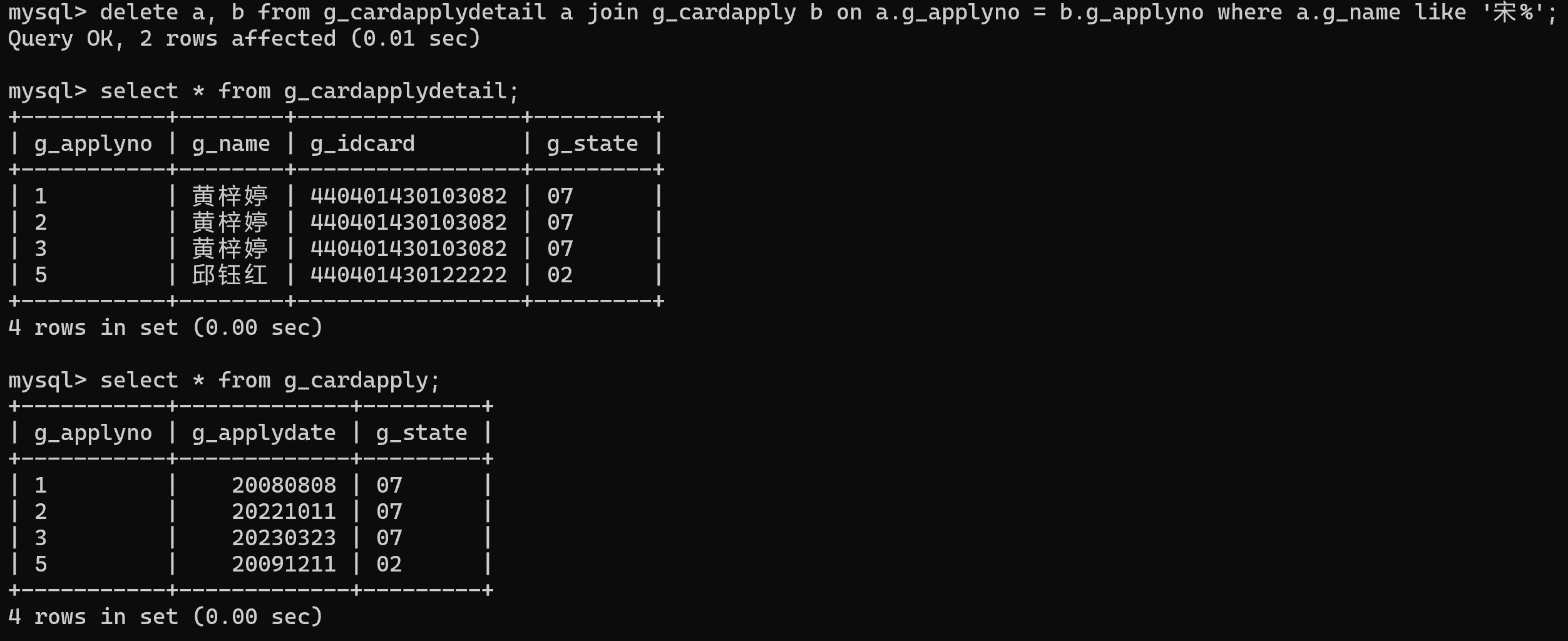
三、 综合题2
| name | subject | score | stuid |
|---|---|---|---|
| 秦世华 | 数学 | 89 | 1 |
| 秦世华 | 语文 | 80 | 1 |
| 秦世华 | 英语 | 70 | 1 |
| 张载 | 数学 | 90 | 2 |
| 张载 | 语文 | 70 | 2 |
| 张载 | 英语 | 80 | 2 |
# 初始化
drop table if exists stuscore;
create table stuscore(name varchar(255),subject varchar(255),score int,stuid int
);
insert into stuscore values('秦世华','数学',89,1);
insert into stuscore values('秦世华','语文',80,1);
insert into stuscore values('秦世华','英语',70,1);
insert into stuscore values('张载','数学',90,2);
insert into stuscore values('张载','语文',70,2);
insert into stuscore values('张载','英语',80,2);1.统计不及格(0~59)、良好(60~80)、优秀(80~100)的课程数
-- 方法一
# 1.分组
select case when score >= 0 and score < 60 then '不及格' when score >= 60 and score < 81 then '良好' when score >= 81 and score <= 100 then '优秀' else '错误' end as assess from stuscore;# 2.计数
select case when score >= 0 and score < 60 then '不及格' when score >= 60 and score < 81 then '良好' when score >= 81 and score <= 100 then '优秀' else '错误' end as assess, count(*)
from stuscore
group by assess;-- 方法二
# 1.不及格
select count(*) from stuscore where score between 0 and 59;# 2.良好
select count(*) from stuscore where score between 60 and 80;# 3.优秀
select count(*) from stuscore where score between 81 and 100;# 4.sum
select '不及格' as assess, count(*)
from stuscore
where score between 0 and 59
union all
select '良好', count(*)
from stuscore
where score between 60 and 80
union all
select '优秀', count(*)
from stuscore
where score between 81 and 100;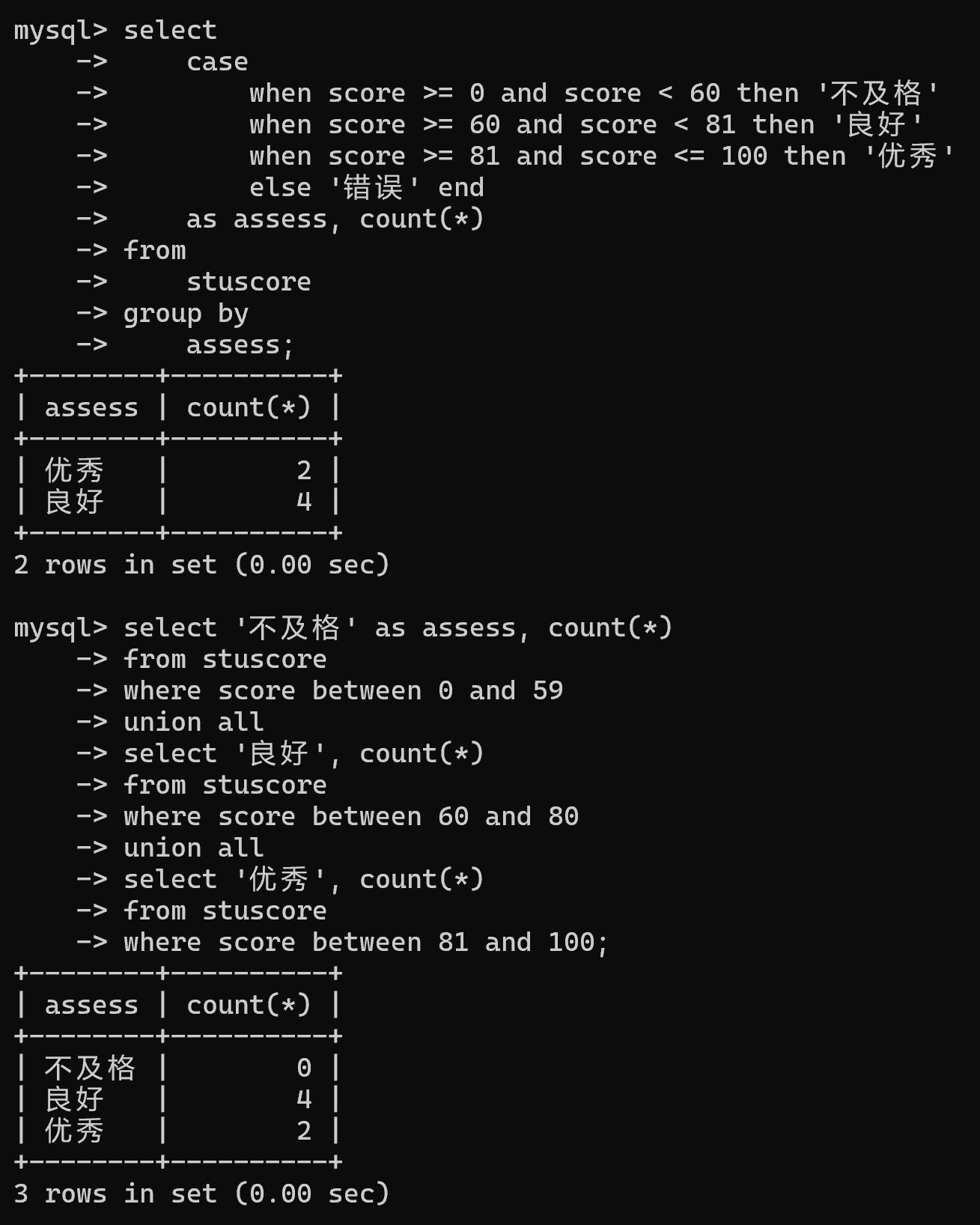
2. 计算每科都及格者的平均成绩
# 1.查询不及格者
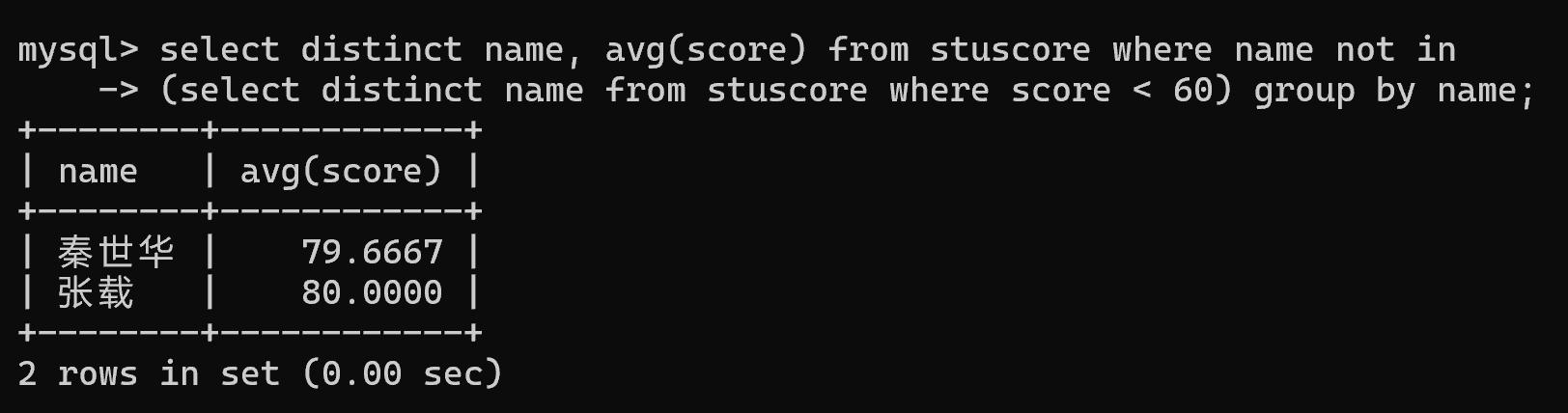
select distinct name from stuscore where score < 60;# 2.查询每科都及格者
select distinct name, avg(score) from stuscore where name not in(select distinct name from stuscore where score < 60) group by name;
四、 综合题3(数据自行模拟)
有一个表 wcmemploy(工号、姓名、部门名、工种、薪资)。
# 初始化(自行模拟)
drop table if exists wcmemploy;create table wcmemploy(no int,name varchar(255),dname varchar(255),job varchar(255),sal double(10,2)
);insert into wcmemploy values(1, '柳芝芝', 'A', '钳工', 1500);
insert into wcmemploy values(2, '王岩明', 'A', '钳工', 2800);
insert into wcmemploy values(3, '冯刚', 'A', '油漆工', 3000);
insert into wcmemploy values(4, '赵龍', 'A', '水电工', 4500);
insert into wcmemploy values(5, '钱百道', 'B', '钳工', 1800);
insert into wcmemploy values(6, '毛自立', 'B', '钳工', 2600);
insert into wcmemploy values(7, '朱雯睿', 'B', '油漆工', 2800);
insert into wcmemploy values(8, '张怡然', 'B', '水电工', 5000);
insert into wcmemploy values(9, '孙苗', 'C', '油漆工', 6000);
insert into wcmemploy values(10, '黄山', 'C', '钳工', 2000);
insert into wcmemploy values(11, '韩小明', 'C', '水电工', 5000);
insert into wcmemploy values(12, '武政熙', 'C', '钳工', 2000);
insert into wcmemploy values(13, '阮雨薇', 'D', '水电工', 5000);
insert into wcmemploy values(14, '方则天', 'D', '油漆工', 2500);
insert into wcmemploy values(15, '李昂', 'D', '钳工', 3000);
insert into wcmemploy values(16, '佟建国', 'D', '钳工', 4000);
insert into wcmemploy values(17, '周章正', 'D', '钳工', 3300);1.请用一条SQL语句查询不同部门中担任“钳工”的职工平均工资
select dname, avg(sal) from wcmemploy where job = '钳工' group by dname;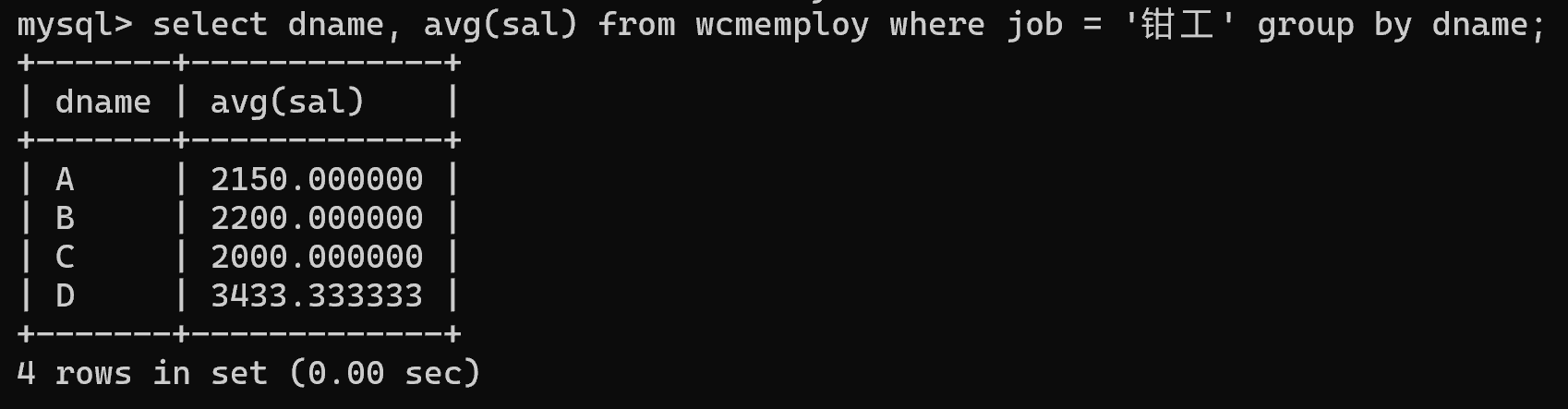
2.请用一条SQL语句查询不同部门中担任“钳工”的职工平均工资高于2000的部门
select dname, avg(sal) from wcmemploy where job = '钳工' group by dname having avg(sal) > 2000;
五、综合题4(数据自行模拟)
- employee是雇员信息表:
- 雇员姓名(主键):person_name;
- 街道:street;
- 城市:city。
- company是公司信息表:
- 公司名称(主键):company_name;
- 城市:city。
- works是雇员工作信息表:
- 雇员姓名(主键):person_name;
- 公司名称:company_name;
- 年薪:salary。
- manages是雇员工作关系表:
- 雇员姓名(主键):person_name;
- 经理姓名:manager_name。
# 初始化(数据自行模拟)
drop table if exists employee;
create table employee(`person_name` varchar(255) primary key,street varchar(255),city varchar(255)
);
insert into employee values('鲁班七号','街道1','天津');
insert into employee values('澜','街道2','天津');
insert into employee values('艾琳','街道3','天津');
insert into employee values('朵莉亚','街道4','天津');
insert into employee values('后羿','街道5','大同');
insert into employee values('妲己','街道6','北京');
insert into employee values('安琪拉','街道7','北京');
insert into employee values('刘禅','街道8','北京');
insert into employee values('蔡文姬','街道9','大同');
insert into employee values('曹操','街道10','大同');drop table if exists company;
create table company(`company_name` varchar(255) primary key,city varchar(255)
);
insert into company values('春华秋实咖啡后厨工厂', '北京');
insert into company values('御龙印刷厂', '大同');
insert into company values('木易十三炼钢厂', '天津');drop table if exists works;
create table works(`person_name` varchar(255) primary key,`company_name` varchar(255),salary double(10,2)
);
insert into works values('鲁班七号','春华秋实咖啡后厨工厂', 22000);
insert into works values('澜','春华秋实咖啡后厨工厂', 99999);
insert into works values('艾琳','春华秋实咖啡后厨工厂', 6000);
insert into works values('朵莉亚','春华秋实咖啡后厨工厂', 11000);
insert into works values('后羿','御龙印刷厂', 31000);
insert into works values('妲己','御龙印刷厂', 11000);
insert into works values('安琪拉','御龙印刷厂', 5000);
insert into works values('刘禅','御龙印刷厂', 8000);
insert into works values('蔡文姬','木易十三炼钢厂', 12000);
insert into works values('曹操','木易十三炼钢厂', 21000);drop table if exists manages;
create table manages(`person_name` varchar(255) primary key,`manager_name` varchar(255)
);
insert into manages values('鲁班七号','澜');
insert into manages values('澜','艾琳');
insert into manages values('艾琳','朵莉亚');
insert into manages values('朵莉亚','后羿');
insert into manages values('后羿','妲己');
insert into manages values('妲己','安琪拉');
insert into manages values('安琪拉','刘禅');
insert into manages values('刘禅','蔡文姬');
insert into manages values('蔡文姬','曹操');
insert into manages values('曹操',NULL);1.查询所有居住地与工作的公司在同一城市的员工的姓名
select w.person_name from works w join employee e on w.person_name = e.person_name join company c on w.company_name = c.company_name where e.city = c.city;
2. 查询比“木易十三炼钢厂”所有员工收入都高的员工姓名
-- 1.查找“木易十三炼钢厂”的最高薪资
select max(salary) from works where company_name = '木易十三炼钢厂';-- 2.查找高于该薪资的员工姓名
select person_name, salary from works where salary > (select max(salary) from works where company_name = '木易十三炼钢厂');
3.查询平均年薪在20000元以上的公司及其平均年薪
select company_name, avg(salary) as average_salary from works group by company_name having average_salary > 20000;

六、综合题5
以下是一个简化的书店订单管理系统,有四张表。
| client_id | client_name | phone | address |
|---|---|---|---|
| 1 | Zhao | 1981314520 | 海淀区 |
| 2 | Wang | 1365201314 | 朝阳区 |
| 3 | Sun | 1732513140 | 大兴区 |
| 4 | Li | 1913324567 | 东城区 |
| order_id | book_id |
|---|---|
| 11 | 21 |
| 12 | 22 |
| 13 | 23 |
| 14 | 24 |
| 15 | 21 |
| 16 | 22 |
| 17 | 23 |
| 18 | 24 |
| client_id | order_id |
|---|---|
| 1 | 11 |
| 1 | 12 |
| 2 | 13 |
| 2 | 14 |
| 3 | 15 |
| 3 | 16 |
| 4 | 17 |
| 4 | 18 |
| book_id | book_name | price |
|---|---|---|
| 21 | 管理学 | 30.00 |
| 22 | 计算机网络 | 50.00 |
| 23 | 国家地理杂志 | 90.00 |
| 24 | 西游记 | 20.00 |
# 初始化
drop table if exists client;
create table client(client_id int,client_name varchar(255),phone varchar(255),address varchar(255)
);
insert into client values(1,'Zhao', 1981314520, '海淀区');
insert into client values(2,'Wang', 1365201314, '朝阳区');
insert into client values(3,'Sun', 1732513140, '大兴区');
insert into client values(4,'Li', 1913324567, '东城区');drop table if exists `order`;
create table `order`(order_id int,book_id int
);
insert into `order` values(11,21);
insert into `order` values(12,22);
insert into `order` values(13,23);
insert into `order` values(14,24);
insert into `order` values(15,21);
insert into `order` values(16,22);
insert into `order` values(17,23);
insert into `order` values(18,24);drop table if exists clientorder;
create table clientorder(client_id int,order_id int
);
insert into clientorder values(1,11);
insert into clientorder values(1,12);
insert into clientorder values(2,13);
insert into clientorder values(2,14);
insert into clientorder values(3,15);
insert into clientorder values(3,16);
insert into clientorder values(4,17);
insert into clientorder values(4,18);drop table if exists book;
create table book(book_id int,book_name varchar(255),price double(10,2)
);
insert into book values(21, '管理学', 30);
insert into book values(22, '计算机网络', 50);
insert into book values(23, '国家地理杂志', 90);
insert into book values(24, '西游记', 20);1.查询每个客户的所有订单并按照地址排序,要求输出格式为:address client_name phone order_id
select c.address, c.client_name, c.phone, co.order_id from client c join clientorder co on c.client_id = co.client_id order by c.address;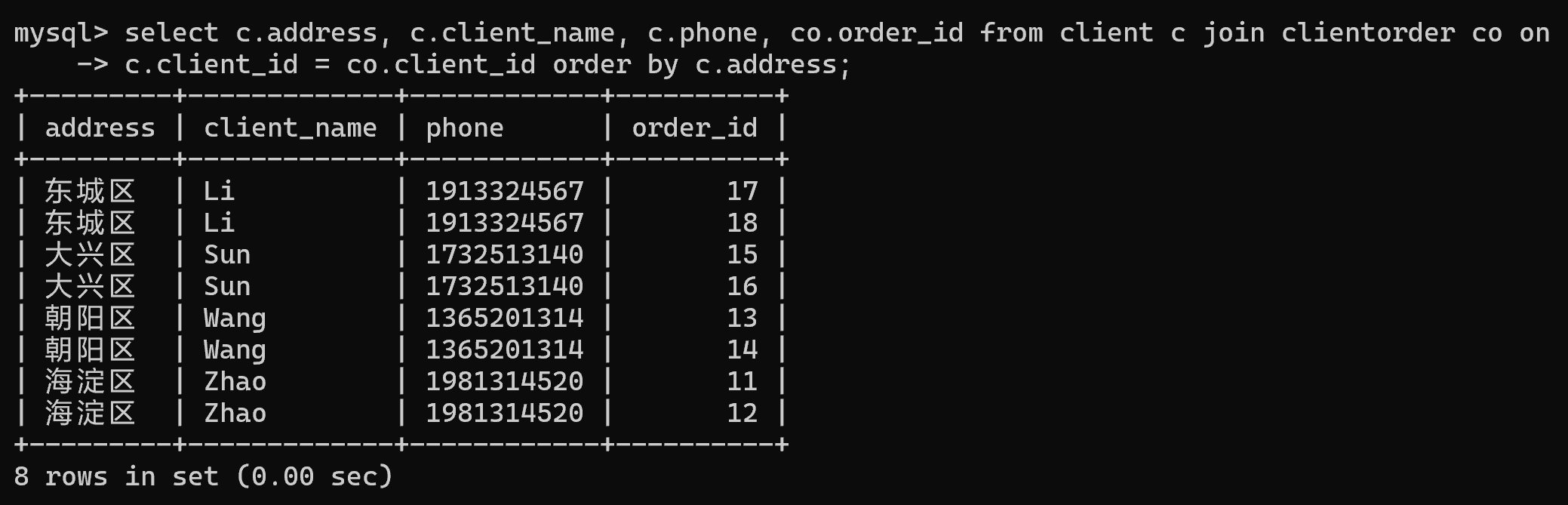
2.查询每个客户订购的图书总价,要求输出格式为:client_name total_price
-- 1.查询客户的所有订单
select c.client_name, co.order_id from client c join clientorder co on c.client_id = co.client_id;-- 2.查询客户购买的图书id
select c.client_name, co.order_id, o.book_id from client c join clientorder co on c.client_id = co.client_id join `order` o on co.order_id = o.order_id;-- 3.查询每个客户订购金额
select c.client_name, co.order_id, o.book_id, b.price from client c join clientorder co on c.client_id = co.client_id join `order` o on co.order_id = o.order_id join book b on o.book_id = b.book_id;-- 4.查询总额按照客户姓名分组
select c.client_name, sum(b.price) as total_price
from client c
join clientorder co
on c.client_id = co.client_id
join `order` o
on co.order_id = o.order_id
join book b
on o.book_id = b.book_id
group by c.client_name;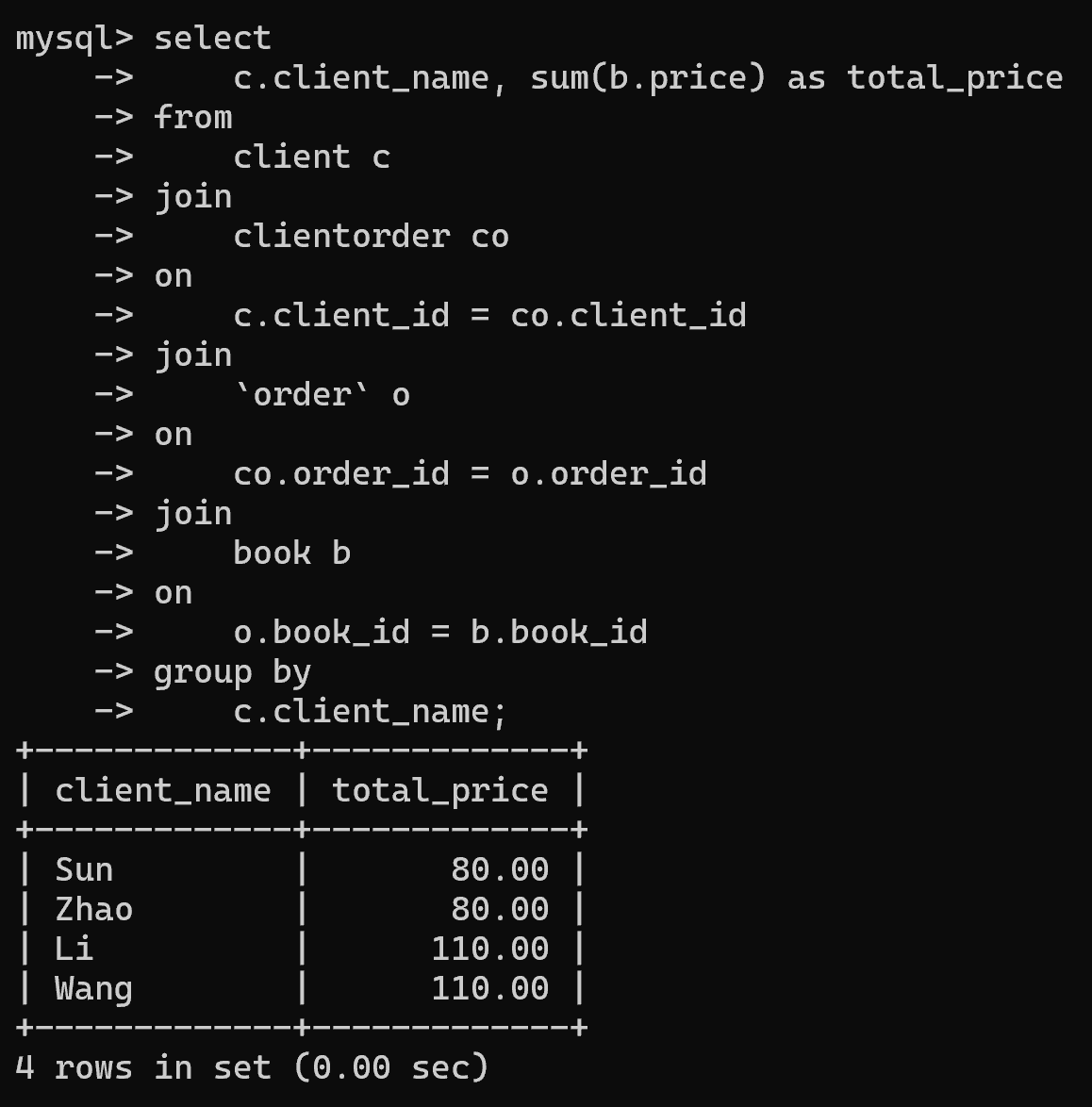
3.如果要求每个订单可以包含多种图书,应该如何修改order表的主键?
答:修改 order 表为联合主键,即将 order_id 字段和 book_id 字段都设置为主键。
4.为了保证每个订单只被一个客户拥有,应该在clientorder表上增加怎样的约束?
答:为 clientorder 表中的 order_id 字段添加唯一性约束即可。
七、综合题6(数据自行模拟)
- 学生表 student(s#:学号,sname:学生姓名,sage:学生年龄,ssex:学生性别);
- 课程表 course(c#:课程编号,cname:课程名称,t#:教师工号);
- 成绩表 sc(s#:学号,c#:课程编号,score:成绩);
- 教师表 teacher(t#:工号,tname:教师姓名)。
# 初始化(数据自行模拟)
drop table if exists student;
create table student(`s#` int,sname varchar(255),sage int,ssex char(1)
);
insert into student values(1,'学生1', 20, '男');
insert into student values(2,'学生2', 20, '男');
insert into student values(3,'学生3', 20, '男');
insert into student values(4,'学生4', 20, '男');drop table if exists course;
create table course(`c#` int,cname varchar(255),`t#` int
);
insert into course values(1,'数学',1);
insert into course values(2,'语文',1);
insert into course values(3,'英语',2);
insert into course values(4,'政治',2);drop table if exists sc;
create table sc(`s#` int,`c#` int,score int
);
insert into sc values(1,1,65);
insert into sc values(1,2,66);
insert into sc values(1,3,66);
insert into sc values(1,4,69);
insert into sc values(2,1,55);
insert into sc values(2,2,66);
insert into sc values(2,3,75);
insert into sc values(2,4,86);
insert into sc values(3,1,96);
insert into sc values(3,2,99);
insert into sc values(3,3,70);
insert into sc values(3,4,60);
insert into sc values(4,3,65);
insert into sc values(4,4,99);;drop table if exists teacher;
create table teacher(`t#` int,tname varchar(255)
);
insert into teacher values(1,'叶平');
insert into teacher values(2,'李白');1.查询1号课比2号课成绩高的学生的学号
-- 1.查询所有2号课成绩
select * from sc where `c#` = 2;-- 2.查询所有1号课成绩
select * from sc where `c#` = 1;-- 3.查询1号课成绩高于2号课最高成绩的学生学号
select a.`s#` from (select * from sc where `c#` = 2) a join (select * from sc where `c#` = 1) b on a.`s#` = b.`s#` where b.score > a.score;
2.查询平均成绩大于60分的学号和平均成绩
select `s#`, avg(score) from sc group by `s#` having avg(score) > 60;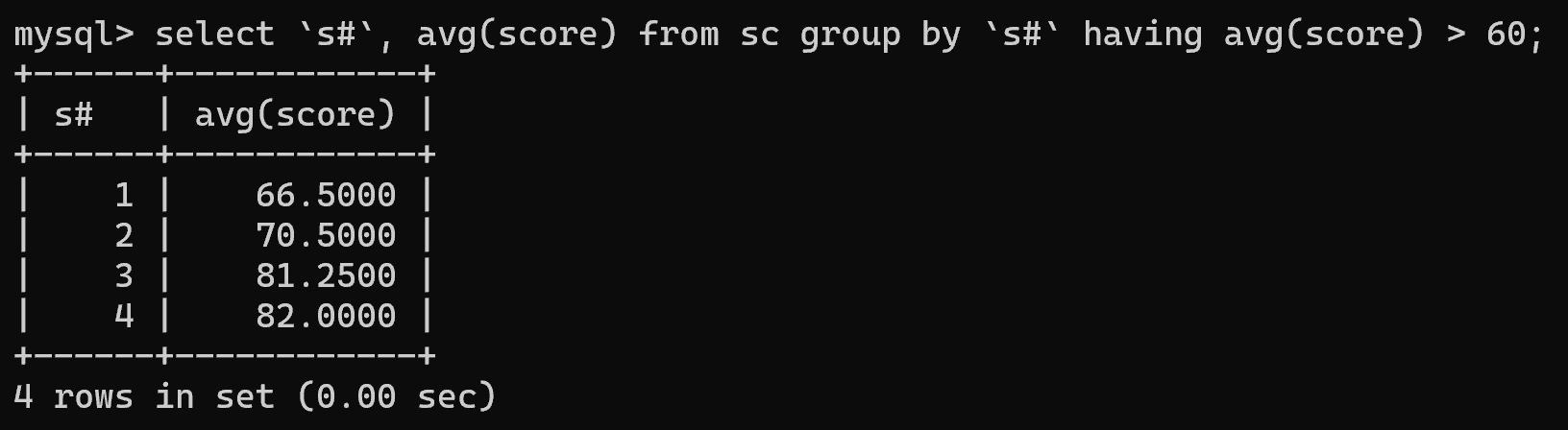
3.查询所有学生的学号、姓名、选课数、总成绩
-- 1.查询每个学生选课数、平均成绩
select `s#`, count(`c#`) as course_count, sum(score) as sum_score from sc group by `s#`;-- 2.查询学生学号、姓名、选课数、平均成绩
select s.`s#`, s.sname, a.course_count, a.sum_score
from (select `s#`, count(`c#`) as course_count, sum(score) as sum_score from sc group by `s#`) a
join student s
on s.`s#` = a.`s#`;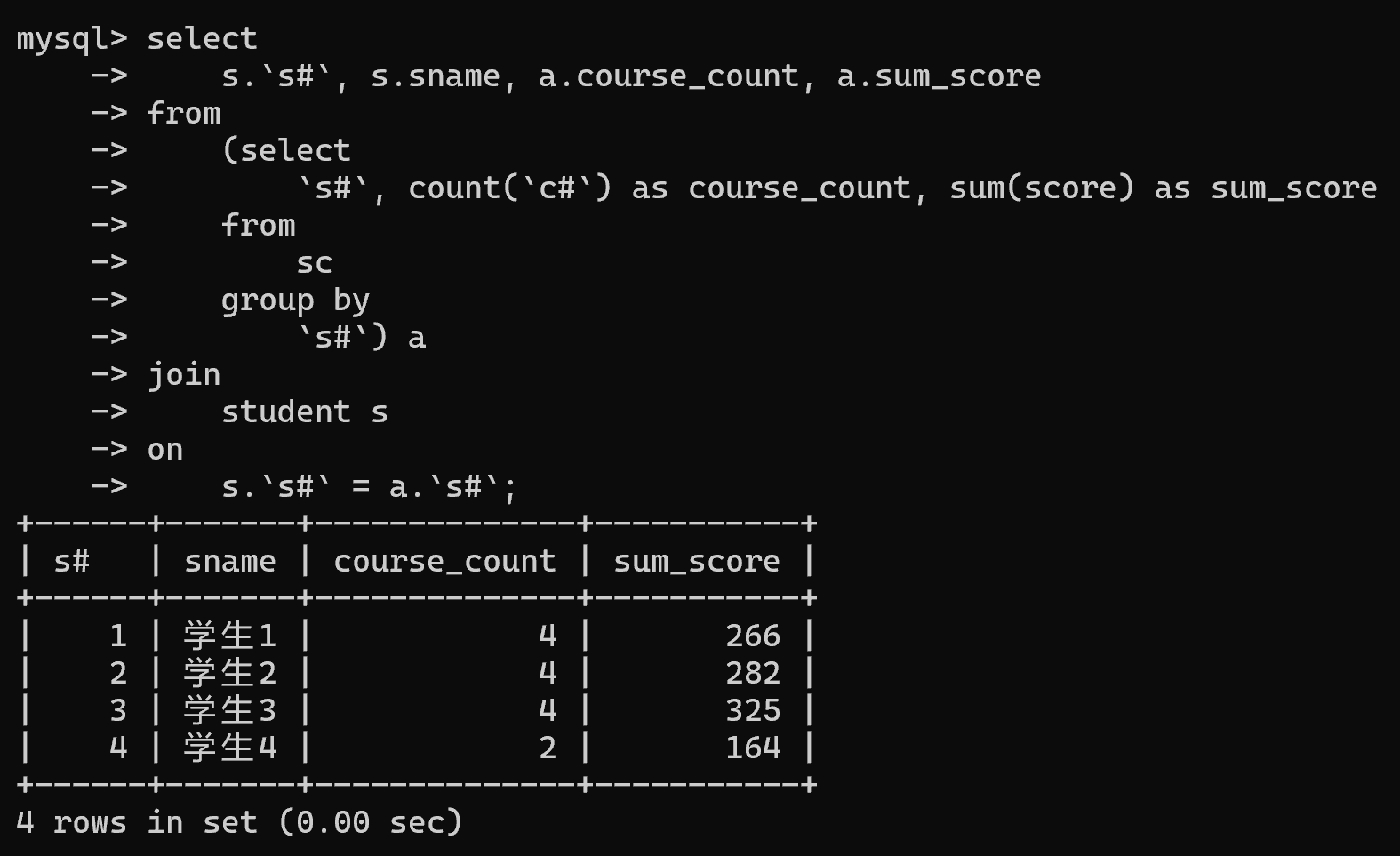
4.查询姓“李”的老师的个数
select count(*) from teacher where tname like '李%';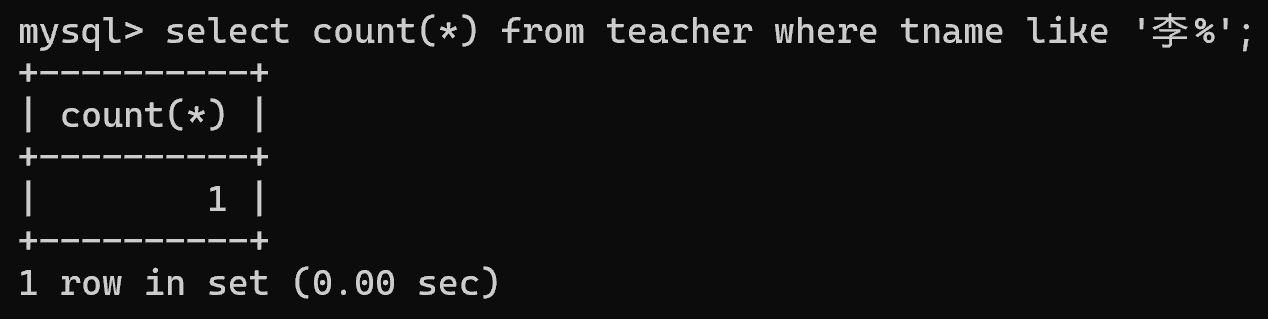
5.查询没选过“叶平”老师课的学号、姓名
-- 1.查询“叶平”老师的id
select `t#` from teacher where tname = '叶平';-- 2.查询“叶平”老师所授课程id
select `c#` from course where `t#` = (select `t#` from teacher where tname = '叶平');-- 3.查询选过“叶平”老师课程id的学生学号
select distinct `s#` from sc where `c#` in (select `c#` from course where `t#` = (select `t#` from teacher where tname = '叶平'));-- 4.查询未选过“叶平”老师课程id的学生学号
select `s#`, sname from student where `s#` not in (select distinct `s#` from sc where `c#` in (select `c#` from course where `t#` = (select `t#` from teacher where tname = '叶平')));
八、 综合题7(数据自行模拟)
- 学生表 student:
- s_id,int;
- sname,varchar。
- 课程表 class:
- c_id,int;
- cname,varchar。
- 选课表 choose_class:
- id,int;
- s_id,int;
- c_id,int;
- grade,int。
# 初始化(数据自行模拟)
drop table if exists student;
create table student(s_id int,sname varchar(255)
);
insert into student values(1,'学生1');
insert into student values(2,'学生2');
insert into student values(3,'学生3');
insert into student values(4,'学生4');drop table if exists `class`;
create table `class`(c_id varchar(255),c_name varchar(255)
);
insert into `class` values('C1', 'java');
insert into `class` values('C2', 'oracle');
insert into `class` values('C3', 'mysql');drop table if exists chosen_class;
create table chosen_class(id int,s_id int,c_id varchar(255),grade int
);
insert into chosen_class values(1,1,'C1', 66);
insert into chosen_class values(2,2,'C1', 77);
insert into chosen_class values(3,3,'C2', 88);
insert into chosen_class values(4,3,'C3', 99);
insert into chosen_class values(5,3,'C1', 22);
insert into chosen_class values(7,4,'C2', 33);
insert into chosen_class values(8,4,'C3', 56);1.查询没有选修课程编号为C1的学生姓名
-- 1.查询选修课程“C1”的学生id
select s_id from chosen_class where c_id = 'C1';-- 2.查询为选修“C1”课程的学生姓名
select sname from student where s_id not in (select s_id from chosen_class where c_id = 'C1');
2.查询每门课程的名称和平均成绩,并按照成绩排序
-- 1.查询每门课程的平均成绩
select c_id, avg(grade) as average_grade from chosen_class group by c_id;-- 2.查询每门课程的名称和平均成绩
select c.c_name, a.average_grade from (select c_id, avg(grade) as average_grade from chosen_class group by c_id) a join class c on c.c_id = a.c_id;
3.选了2门课以上的学生姓名
-- 1.查询选修2门课以上的学生id
select s_id from chosen_class group by s_id having count(c_id) > 2;-- 2.查询选修2门课以上的学生姓名
select sname from student where s_id = (select s_id from chosen_class group by s_id having count(c_id) > 2);
九、补充1:行列互换
- 行列互换即数据透视,将原本横向排列的数据透视为纵向排列的数据;
- 借助“case when”和“group by”完成。
十、通过 SQL 语句得出表中结果
# 初始化
drop table if exists t_temp;
create table t_temp(year int,season varchar(255),count int
);
insert into t_temp values(2010,'一季度',100);
insert into t_temp values(2010,'二季度',200);
insert into t_temp values(2010,'三季度',300);
insert into t_temp values(2010,'四季度',400);
insert into t_temp values(2011,'一季度',150);
insert into t_temp values(2011,'二季度',250);
insert into t_temp values(2011,'三季度',350);
insert into t_temp values(2011,'四季度',450);| year | 一季度 | 二季度 | 三季度 | 四季度 |
|---|---|---|---|---|
| 2010 | 100 | 200 | 300 | 400 |
| 2011 | 150 | 250 | 350 | 450 |
select year, max(case season when '一季度' then count else 0 end) as '一季度',max(case season when '二季度' then count else 0 end) as '二季度',max(case season when '三季度' then count else 0 end) as '三季度',max(case season when '四季度' then count else 0 end) as '四季度'
from t_temp
group byyear;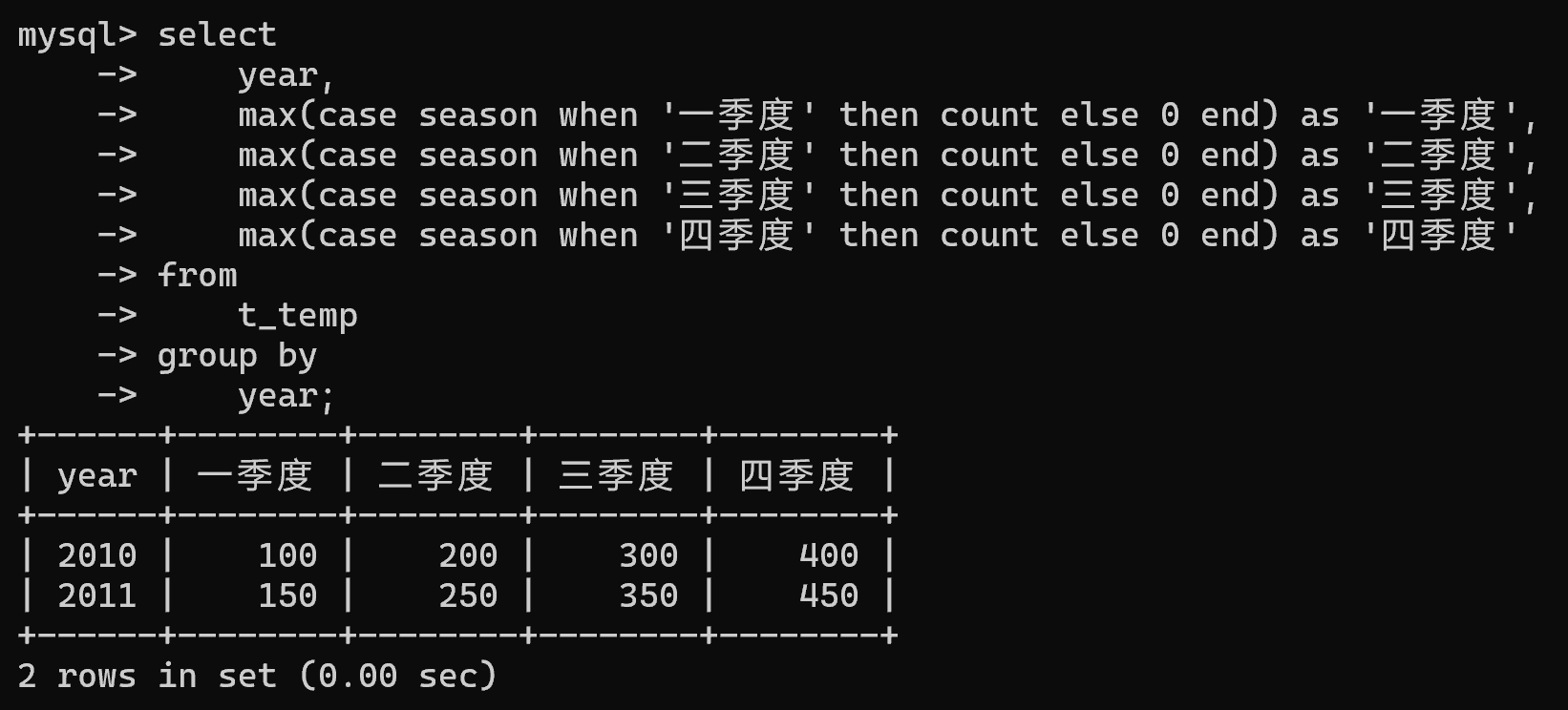
十一、补充2:窗口函数
- MySQL 8 及以上支持如下常用窗口函数:
ROW_NUMBER():排名函数,返回当前结果集中每个行的行号;
RANK():排名函数,计算分组结果中的排名,相同的行排名相同且没有空缺,下一个行排名跳过空缺;
DENSE_RANK():排名函数,计算分组结果中的排名,相同的行排名相同,排名连续,没有空缺;
NTILE():将分组结果等分为指定的组数,计算每组的大小;
LAG():返回分组内前一行的值;
LEAD():返回分组内后一行的值;
FIRST_VALUE():返回分组内第一个值;
LAST_VALUE():返回分组内最后一个值;
AVG()、SUM()、COUNT()、MIN()、MAX():聚合函数,可以配合 OVER() 进行窗口操作。
十二、有一张表有如下数据,写出一条 SQL 将数字连续性和断点展现出来
| A |
|---|
| 1 |
| 2 |
| 3 |
| 5 |
| 6 |
| 7 |
| 8 |
| 10 |
| 开始数字 | 结束数字 |
|---|---|
| 1 | 3 |
| 5 | 8 |
| 10 | 10 |
# 初始化
drop table if exists t;
create table t(A int
);
insert into t values(1);
insert into t values(2);
insert into t values(3);
insert into t values(5);
insert into t values(6);
insert into t values(7);
insert into t values(8);
insert into t values(10);
-- 1.查询 a 上一条数据
select a, (lag(a) over(order by a asc)) as pre from t;-- 2.查询开始数字并生成行号
select x.a, row_number() over(order by x.a asc) as `row_number` from (select a, (lag(a) over(order by a asc)) as pre from t) x where x.a - x.pre != 1 or x.pre is null;-- 3.查询 a 下一条数据
select a, (lead(a) over(order by a asc)) as next from t;-- 4.查询结束数字并生成行号
select y.a, row_number() over(order by y.a asc) as `row_number` from (select a, (lead(a) over(order by a asc)) as next from t) y where y.next - y.a != 1 or y.next is null;-- 5.按照行号连接
select u.a, v.a
from (select x.a, row_number() over(order by x.a asc) as `row_number` from (select a, (lag(a) over(order by a asc)) as pre from t) x where x.a - x.pre != 1 or x.pre is null) u
join (select y.a, row_number() over(order by y.a asc) as `row_number` from (select a, (lead(a) over(order by a asc)) as next from t) y where y.next - y.a != 1 or y.next is null) v
on u.`row_number` = v.`row_number`;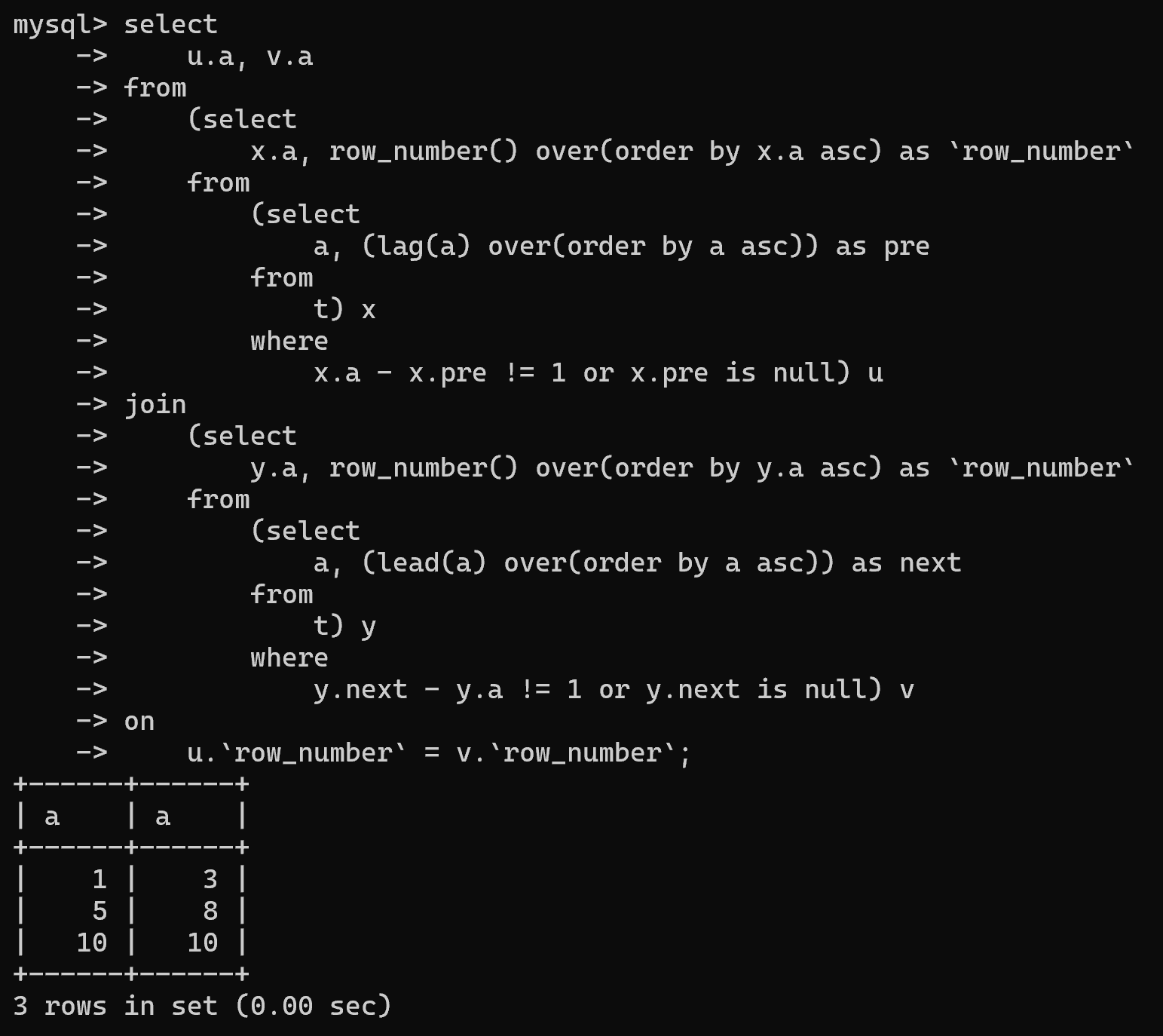
相关文章:

MySQL基础关键_014_MySQL 练习题
目 录 一、有以下表,请用一条 SQL 语句查询出每门课程都大于 80 分的学生 二、综合题1(数据自行模拟) 1.查询身份证号为“440401430103082”的申请日期 2.查询同一个身份证号有两条及以上记录的身份证号码及记录个数 3.将身份证号码为“4…...

femap许可与云计算集成
随着云计算技术的迅猛发展,越来越多的企业开始将关键应用和服务迁移到云端,以享受其带来的弹性扩展、高效管理和成本优化等优势。Femap作为一款强大的电磁仿真工具,通过与云计算的集成,将为企业带来前所未有的许可管理和仿真分析体…...

uni-app项目从0-1基础架构搭建全流程
前情 最近新接了一个全新项目,我负责从0开始搭建小程序,我选用的技术栈是uni-app技术栈,UI库选择的是uview-plus,CSS引入现在流行的tainlwindcss,实现CSS原子化书写,实现小程序分包,分包中实现…...

轻量级高性能推理引擎MNN 学习笔记 04.线性回归
1. 线性回归 MNN 官方给的iOS Demo中,输入是图片,输出是分类结果,相对来讲,略微有些复杂,我们现在用一个最简单的线性回归模型,来说明MNN的用法。 该线性回归是yaxb (其中a2,b0.01)…...

使用 React PDF 构建 React.js PDF 查看器的指南
在本文中,我们将重点介绍在React.js中制作 PDF 查看器的最受欢迎的开源库。具体来说,我们将利用著名的开源库react-pdf的功能,指导您完成创建 React.js PDF 查看器的过程。 通过本教程,您将在第一部分学习如何使用 React-PDF 在 …...

动力电池点焊机厂家:驱动新能源制造的精密力量|比斯特自动化
在新能源汽车、储能系统等产业蓬勃发展的背景下,动力电池点焊机作为电池模组生产的核心设备,正经历着技术迭代与市场需求的双重升级。这类厂家通过持续研发与创新,不仅满足了电池制造企业对焊接精度、效率与稳定性的严苛要求,更推…...
)
React的合成事件(SyntheticEventt)
文章目录 前言 前言 React的合成事件(SyntheticEvent)是React为了统一不同浏览器的事件处理行为而封装的一套跨浏览器事件系统。它与原生事件的主要区别如下: 1. 事件绑定方式 • 合成事件:使用驼峰命名法绑定事件(如…...

知识中台Top5:Baklib上榜推荐
Baklib知识中台优势 在数字化转型浪潮中,Baklib凭借其知识中台的核心设计理念,构建了企业级知识管理的差异化竞争力。区别于传统文档管理系统,该平台通过四库体系(知识资源库、场景规则库、服务模型库、应用组件库)实…...

在Windows系统中使用C++与Orthanc交互:基于DICOMweb的医学影像应用开发
🧑 博主简介:CSDN博客专家、CSDN平台优质创作者,高级开发工程师,数学专业,10年以上C/C, C#, Java等多种编程语言开发经验,拥有高级工程师证书;擅长C/C、C#等开发语言,熟悉Java常用开…...

视频太大?用魔影工厂压缩并转MP4,画质不打折!
在日常生活中,我们常常需要将视频文件转换成不同的格式以适应各种设备或平台的播放需求。魔影工厂作为一款功能强大且操作简单的视频转换工具,深受用户喜爱。本文中简鹿办公将手把手教你如何使用魔影工厂将视频转换为MP4格式,并进行个性化设置…...

Wan2.1 通过首尾帧生成视频
Wan2.1 通过首尾帧生成视频 flyfish 使用 Wan2.1-FLF2V-14B-720P 模型,通过输入两张图像(起始帧和结束帧),生成一段连贯的视频。 First Last Frame-to-Video 即 “首末帧到视频” 技术 import numpy as np import torch import…...

宝塔+fastadmin:给项目添加定时任务
一、定时任务脚本编写 1. 使用 shebang 声明执行器 #!/usr/bin/env php 这是 Unix/Linux 系统中脚本文件的标准开头。表示这个脚本使用系统环境变量中的 php 来执行。2. 定义 ThinkPHP 入口路径并加载框架 define(APP_PATH, __DIR__ . /../../application/); require __DIR__…...

[自动化集成] 使用明道云上传附件并在Python后端处理Excel的完整流程
在企业日常自动化场景中,使用低代码平台如明道云搭建前端界面,结合自定义Python后端服务,实现灵活数据处理是一种高效的组合方式。本文将分享一个典型的集成用例:用户通过明道云上传文本和Excel附件,Python后端接收并解析这些信息,最终实现完整的数据处理闭环。 项目背景…...

前端项目采用响式布局
要让整个前端项目采用响应式布局,可以从多个方面进行优化,以下是一些具体的建议和实现方法: 1. 使用 ElementPlus 的响应式特性 ElementPlus 组件库本身提供了一些响应式的能力,例如 el-col 组件可以用于创建响应式的网格布局。…...

【Unity】DOTween的常用函数解释
DOTween插件常用函数解释 1.DOTween.To(通用变化动画) 解释:将某一个值在一定的时间内变化到另一个值(通用的函数),可用于大部分的动画变化 使用示例: using UnityEngine; using DG.Tweenin…...

飞桨paddle import fluid报错【已解决】
跟着飞桨的安装指南安装了paddle之后 pip install paddlepaddle有一个验证: import paddle.fluid as fluid fluid.install check.run check()报错情况如下,但是我在pip list中,确实看到了paddle安装上了 我import paddle别的包,…...

ELK简介和docker版安装
使用场景 主要还是给开发人员“打捞日志”用的。 ELK 是由三个开源工具组成的套件(Elasticsearch、Logstash 和 Kibana),主要用于日志的收集、分析和可视化。以下是 ELK 常见的使用场景: 日志集中化管理 收集来自多个服务器或服…...

DockerHub被封禁,怎么将镜像传到国内?一种简单合规的镜像同步到国内方案[最佳实践]
Docker将容器化技术普及,推动云计算向云原生的演进。Docker的核心创新技术之一是容器镜像,它是一种文件的打包方式,将应用程序运行的操作系统、库、运行环境等依赖全部打包一起。在其他任意环境,只要可以运行docker服务࿰…...

飞桨paddle ‘ParallelEnv‘ object has no attribute ‘_device_id‘【已解决】
书借上回,自从我反复重装paddle之后,我发现了,只要pip list中有库,但是代码报错,那就是飞桨没把代码更新完全,只能自己去改源代码 我又遇到报错了: 根据报错信息,找到ParallelEnv报…...
)
网络安全面试题(一)
文章目录 一、基础概念与模型1. 什么是通信协议?列举三种常见的网络通信模型?2. 解释OSI七层模型及各层功能3. TCP/IP四层模型与OSI模型的对应关系是什么?4. 五层协议体系结构与TCP/IP模型的区别?5. 什么是面向连接与非面向连接的服务&…...

【Leetcode 每日一题】3355. 零数组变换 I
问题背景 给定一个长度为 n n n 的整数数组 n u m s nums nums 和一个二维数组 q u e r i e s queries queries,其中 q u e r i e s [ i ] [ l i , r i ] queries[i] [l_i, r_i] queries[i][li,ri]。 对于每个查询 q u e r i e s [ i ] queries[i] quer…...

RK3588 ArmNN CPU/GPU ResNet50 FP32/FP16/INT8 推理测试
RK3588 ArmNN CPU/GPU ResNet50 FP32/FP16/INT8 推理测试 **背景与目标** 一.性能数据【INT8模型在CPU上推理的结果已经不对,暂未分析原因】二.操作步骤2.1 在x86-Linux上生成onnx模型,以及tflite量化模型(避免在RK3588上安装过多依赖)2.1.1 创建容器2.1.2 安装依赖2.1.3 下载推…...
)
力扣第5题:最长回文子串(动态规划)
小学生一枚,自学信奥中,没参加培训机构,所以命名不规范、代码不优美是在所难免的,欢迎指正。 标签: 字符串、动态规划、中心扩散法 语言: C 题目: 给你一个字符串s,找到s中最长的…...

HCIP实验五
一、实验拓扑图: 二、实验需求分析: 1. PreVal策略:要求确保R4通过R2到达192.168.10.0/24 ,需在R4上针对去往该网段路由配置PreVal策略,为经R2的路径赋予更高优先值,影响本地路由表选路。 2. AS Path策略…...

python Numpy-数组
目录 Numpy: 一、Ndarray 1 定义 2 数组的属性方法 2.1 数组的维度:np.ndarray.shape 2.2 元素的类型:np.ndarray.dtype 2.3 数组元素的个数:np.ndarray.size 2.4 转置 3 ndarray 所存储元素的数据类型 4 数组创建 4.1 a…...

数据库分库分表从理论到实战
1.分库分表基础理论 1.1 分库分表基本概念 定义:分库分表是一种将单一数据库中的数据分散存储到多个数据库或表中的技术方案,其核心思想是通过"分而治之"的方式解决数据库性能瓶颈问题。分库:将表按业务或数据量拆分到不同数据库中…...

Java异常处理与File类终极指南
Java异常处理与File类终极指南 目录 异常体系全维度拆解异常处理十五种高阶模式自定义异常企业级实践File类深度探索与NIO进化论分布式系统异常处理架构性能调优与安全防护全网最全异常代码库一、异常体系全维度拆解 1.1 Java异常DNA解析 // 异常类的核心继承关系 public cla…...

pmap中的mode列,脏页,写时复制
写时复制(Copy-on-Write,简称 COW) 是一种计算机编程中的优化技术,主要用于内存或存储资源的管理。其核心思想是:只有在真正需要修改数据时,才会执行实际的复制操作,从而避免不必要的资源开销。…...

通过COM获取正在运行的Excel实例并关闭 c#实现
利用COM对象模型获取正在运行的Excel实例并关闭。示例代码如下: using Excel Microsoft.Office.Interop.Excel; using System.Runtime.InteropServices; try { Excel.Application excelApp (Excel.Application)Marshal.GetActiveObject("Excel.Applicatio…...

运行在华为云kubernetes应用接入APM服务
1 APM概述 在云时代微服务架构下应用日益丰富,纷杂的应用异常问题接踵而来。应用运维面临巨大挑战: 分布式应用关系错综复杂,应用性能问题分析定位困难,应用运维面临如何保障应用正常、快速完成问题定位、迅速找到性能瓶颈的挑战…...

虚幻引擎5-Unreal Engine笔记之摄像头camera
虚幻引擎5-Unreal Engine笔记之摄像头camera code review! 目录 第一部分:摄像头的基础概念 1.1 UE5 中摄像头的定义与作用1.2 UE5 中摄像头的类型与分类 第二部分:摄像头的代码结构与分类 2.1 摄像头是类还是组件?2.2 组件的本质ÿ…...

mysql的基础命令
1.SQL的基本概念 SQL 是用于管理和操作关系型数据库的标准编程语言。是所有关系型数据库(如 MySQL、PostgreSQL、Oracle 等)的通用语言。 SQL语句分类 DDL: Data Defination Language 数据定义语言 CREATE,DROP,ALTER DML: Da…...

去中心化算力池:基于IPFS+智能合约的跨校GPU资源共享平台设计
点击 “AladdinEdu,同学们用得起的【H卡】算力平台”,H卡级别算力,按量计费,灵活弹性,顶级配置,学生专属优惠。 一、问题背景:高校算力孤岛的困境 现状痛点 各高校GPU集群利用率差异显著&…...
:ORM技术)
数据库(二):ORM技术
什么是 ORM? ORM(Object-Relational Mapping) 是一种用于实现 对象模型(面向对象)与关系模型(数据库)之间映射的技术,使程序员可以通过操作对象的方式访问数据库数据,而无…...

Oracle基础知识
目录 1.别名的使用 2.AND的优先级高于OR 3.where后面可以接别名,order by后面不可以 4.Oracle中SQL的执行顺序(重点) 5.dual万用表 6.是否区分大小写 7.Oracle常用数据类型 8.Oracle常用函数 (1)length字符、lengthb字节和cast强制类型转换 (2)数据类型转…...

使用 vite-plugin-dynamic-base 实现运行时动态设置上下文路径
我们一般会在编译之前设置上下文,那么如何在编译之后动态设置上下文的路径? 本文使用的技术栈是 Go(Gin) Vue.js(Vite) 本文使用到的第三方包:https://github.com/chenxch/vite-plugin-dynam…...

spark-shuffle 类型及其对比
1. Hash Shuffle 原理:将数据按照分区键进行哈希计算,将相同哈希值的数据发送到同一个Reducer中。特点:实现简单,适用于数据分布均匀的场景。但在数据分布不均匀时,容易导致某些Reducer处理的数据量过大,产…...

力扣-快乐数
1.题目要求 2.题目链接 202. 快乐数 - 力扣(LeetCode) 3.题目分析 首先,因为需要频繁地用到数字变为各个位上的平方的过程,我们可以将"对于一个正整数,每一次将该数替换为它每个位置的数字的平方和"这一操作抽象出来,定义成一个…...

每日算法刷题Day10 5.19:leetcode不定长滑动窗口求最长/最大4道题,结束定长滑动窗口,用时1h
不定长滑动窗口 不定长滑动窗口主要分为三类:求最长子数组,求最短子数组,以及求子数组个数。 注:滑动窗口相当于在维护一个队列。右指针的移动可以视作入队,左指针的移动可以视作出队。 滑动窗口【基础算法精讲 03】…...

FreeSWITCH 纯内网配置
纯内网,且同一个网段,Fs 可简化配置,要点是: 1. 不需要事先配置 directory,任意号码都可以注册,且无挑战 2. 呼叫无挑战 不需要考虑那么多安全问题 配置如下: 1. 全局变量 <X-PRE-PROCESS cmd"…...

STL中list的模拟
这里写目录标题 list 的节点 —— ListNodelist 的 “导览员” —— ListIteratorlist 的核心 —— list 类构造函数迭代器相关操作容量相关操作 结尾 在 C 的 STL(标准模板库)中,list 是一个十分重要的容器,它就像一个灵活的弹簧…...

【iOS】类结构分析
前言 之前我们已经探索得出对象的本质就是一个带有isa指针的结构体,这篇文章来分析一下类的结构以及类的底层原理。 类的本质 类的本质 我们在main函数中写入以上代码,然后利用clang对其进行反编译,可以得到c文件 可以看到底层使用Class接…...

Android 万能AI证件照 v1.3.2
在日常的生活和工作场景里,证件照的身影随处可见。找工作投简历时,它是展现你形象的 “第一张名片”;办理各类证件,缺了它可不行;参加各种考试报名,同样需要它。可以说,证件照虽小,却…...

【Java】封装在 Java 中是怎样实现的?
包 关于包有两个关键字 package : 声明当前类属于哪个包 和 import : 允许当前类使用其他类或接口时不使用全限定名 , 也就是导包 . IDEA 的普通项目文件包括 src : 包含源码和资源文件 和 out : 包含编译产物字节码文件 . 在 IDEA 开发环境建包会在 src 源码目录中生成 , 可…...

牛客网 NC14736 双拆分数字串 题解
牛客网 NC14736 双拆分数字串 题解 题目分析 解题思路 通过分析,我们可以发现: 当n≤3时,无法构造出双拆分数字串,因为数字位数太少对于n>3的情况,我们可以构造两种特殊形式: 当n为奇数时,…...
 瓶颈)
超长文本注意力机制如何突破传统 O(n²) 瓶颈
介绍了当前在超长文本(可达百万级及以上 Token)生成与预测中,注意力机制如何突破传统 O(n) 瓶颈,并阐释多种高效注意力算法如何支持 超长上下文处理能力。 概览 当前主流 Transformer 在处理长序列时,由于每个 Token…...

异丙肌苷市场:现状、挑战与未来展望
摘要 本文聚焦异丙肌苷市场,深入分析了其市场规模与增长趋势、应用价值与市场驱动因素、面临的挑战以及竞争格局。异丙肌苷作为一种具有重要应用价值的改性核苷衍生物,在药物研发和治疗领域展现出潜力,但市场发展也面临诸多挑战。文章最后为…...

JAVA面向对象——对象和类的基本语法
JAVA面向对象——对象和类的基本语法 一、面向对象编程基础 1. 程序中的数据存储方式 基本类型:变量(如 int max 15;)。数据结构:数组(一维/二维)、对象(特殊数据结构,用于存储复…...
)
【windows】音视频处理工具-FFmpeg(合并/分离)
一、FFmpeg介绍 FFmpeg是一个开源的跨平台音视频处理框架。 法国计算机程序员 Fabrice Bellard 于 2000 年创建。 “FF”(代表 “Fast Forward”,快进之意)与 “mpeg”(流行的视频压缩标准 MPEG,即运动图像专家组&am…...

Java并发编程:从基础到高级实战
在现代软件开发中,并发编程已成为不可或缺的核心技能。随着多核处理器的普及和分布式系统的发展,能否编写高效、线程安全的并发程序直接决定了应用程序的性能和可靠性。Java作为一门成熟的企业级编程语言,提供了丰富的并发编程工具和API&…...