Vortex GPGPU的github流程跑通与功能模块波形探索(三)
文章目录
- 前言
- 一、./build/ci下的文件结构
- 二、基于驱动进行仿真过程牵扯的文件
- 2.1 blackbox.sh文件
- 2.2 demo文件
- 2.3 额外牵扯到的ramulator
- 2.3.1 ramulator简单介绍
- 2.3.2 ramulator使用方法
- 2.3.3 ramulator的输出
- 2.3.4 ramulator的复现
- 2.3.4.1 调试与验证(第 4.1 节)
- 2.3.4.2 与其他模拟器的比较(第 4.2 节)
- 2.3.4.3 DRAM标准的横断面研究(第 4.3 节)
- 2.3.5 功耗测试
- 2.3.6 简单使用Ramulator的命令并阅读输入配置文件和输出文件
- 2.4 额外牵扯到的GEM5
- 2.4.1 GEM5简单介绍
- 2.4.2 GEM5的源代码树
- 2.4.3 基于gem5驱动的ramulator尝试
- 总结
前言
尽管通过如下命令分别产生了vcd波形文件和逐条指令的csv文件:
# 导出vcd波形文件
./ci/blackbox.sh --driver=rtlsim --app=demo --debug=1# 导出逐条指令的csv文件
./ci/trace_csv.py -trtlsim run.log -otrace_rtlsim.csv
但在看波形前,还是先确认blackbox.sh文件和trace_csv.py文件分别哪个源文件通过什么样的选项限制得到波形文件。
一、./build/ci下的文件结构
./build/ci下的文件结构如下:
dention@dention-virtual-machine:~/Desktop/vortex/vortex/build/ci$ tree
.
├── blackbox.sh
├── datagen.py
├── install_dependencies.sh
├── regression.sh
├── toolchain_env.sh
├── toolchain_install.sh
├── toolchain_prebuilt.sh
├── trace_csv.py
└── travis_run.py0 directories, 9 files
二、基于驱动进行仿真过程牵扯的文件
2.1 blackbox.sh文件
blackbox.sh文件内容如下,一点点分析,首先是show_usage()和show_help()函数:
show_usage()
{echo "Vortex BlackBox Test Driver v1.0"echo "Usage: $0 [[--clusters=#n] [--cores=#n] [--warps=#n] [--threads=#n] [--l2cache] [--l3cache] [[--driver=#name] [--app=#app] [--args=#args] [--debug=#level] [--scope] [--perf=#class] [--rebuild=#n] [--log=logfile] [--help]]"
}show_help()
{show_usageecho " where"echo "--driver: gpu, simx, rtlsim, oape, xrt"echo "--app: any subfolder test under regression or opencl"echo "--class: 0=disable, 1=pipeline, 2=memsys"echo "--rebuild: 0=disable, 1=force, 2=auto, 3=temp"
}
功能相同,都用于显示脚本的基本使用方法,测一下:
# 测试show_help()的功能
dention@dention-virtual-machine:~/Desktop/vortex/vortex/build$ ./ci/blackbox.sh --help
Vortex BlackBox Test Driver v1.0
Usage: ./ci/blackbox.sh [[--clusters=#n] [--cores=#n] [--warps=#n] [--threads=#n] [--l2cache] [--l3cache] [[--driver=#name] [--app=#app] [--args=#args] [--debug=#level] [--scope] [--perf=#class] [--rebuild=#n] [--log=logfile] [--help]]where
--driver: gpu, simx, rtlsim, oape, xrt
--app: any subfolder test under regression or opencl
--class: 0=disable, 1=pipeline, 2=memsys
--rebuild: 0=disable, 1=force, 2=auto, 3=temp# 测试show_usage()的功能
dention@dention-virtual-machine:~/Desktop/vortex/vortex/build$ ./ci/blackbox.sh --invalid-option
Vortex BlackBox Test Driver v1.0
Usage: ./ci/blackbox.sh [[--clusters=#n] [--cores=#n] [--warps=#n] [--threads=#n] [--l2cache] [--l3cache] [[--driver=#name] [--app=#app] [--args=#args] [--debug=#level] [--scope] [--perf=#class] [--rebuild=#n] [--log=logfile] [--help]]
接下来是初始化变量:
SCRIPT_DIR=$(dirname "$0") # 获取脚本所在目录
ROOT_DIR=$SCRIPT_DIR/.. # 设置所在目录为根目录# 以下变量和show_help()相对应
DRIVER=simx
APP=sgemm
CLUSTERS=1
CORES=1
WARPS=4
THREADS=4
L2=
L3=
DEBUG=0
DEBUG_LEVEL=0
SCOPE=0
HAS_ARGS=0
PERF_CLASS=0
REBUILD=2
TEMPBUILD=0
LOGFILE=run.log
然后是解析紧跟着./ci/blackbox.sh后的参数:
for i in "$@"
do
case $i in--driver=*)DRIVER=${i#*=}shift;;--app=*)APP=${i#*=}shift;;--clusters=*)CLUSTERS=${i#*=}shift;;--cores=*)CORES=${i#*=}shift;;--warps=*)WARPS=${i#*=}shift;;--threads=*)THREADS=${i#*=}shift;;--l2cache)L2=-DL2_ENABLEshift;;--l3cache)L3=-DL3_ENABLEshift;;--debug=*)DEBUG_LEVEL=${i#*=}DEBUG=1shift;;--scope)SCOPE=1CORES=1shift;;--perf=*)PERF_FLAG=-DPERF_ENABLEPERF_CLASS=${i#*=}shift;;--args=*)ARGS=${i#*=}HAS_ARGS=1shift;;--rebuild=*)REBUILD=${i#*=}shift;;--log=*)LOGFILE=${i#*=}shift;;--help)show_helpexit 0;;*)show_usageexit -1;;
esac
done
其中上述的解析种--help和*分别指向了前面测试show_help()和show_usage()功能的方法。
然后就是设置驱动测试程序:
case $DRIVER ingpu)DRIVER_PATH=;;simx)DRIVER_PATH=$ROOT_DIR/runtime/simx;;rtlsim)DRIVER_PATH=$ROOT_DIR/runtime/rtlsim;;opae)DRIVER_PATH=$ROOT_DIR/runtime/opae;;xrt)DRIVER_PATH=$ROOT_DIR/runtime/xrt;;*)echo "invalid driver: $DRIVER"exit -1;;
esac
其中./runtime下的文件如下:
dention@dention-virtual-machine:~/Desktop/vortex/vortex/build/runtime$ ls
common.mk librtlsim.so libvortex-opae.so libvortex.so libxrtsim.so.obj_dir rtlsim vortex_afu.h
libopae-c-sim.so librtlsim.so.obj_dir libvortex-rtlsim.so libvortex-xrt.so Makefile simx xrt
libopae-c-sim.so.obj_dir libsimx.so libvortex-simx.so libxrtsim.so opae stub
除了gpu这个驱动选项外,可以比较好的对应起来!
然后是配置应用的路径:
if [ -d "$ROOT_DIR/tests/opencl/$APP" ];
thenAPP_PATH=$ROOT_DIR/tests/opencl/$APP
elif [ -d "$ROOT_DIR/tests/regression/$APP" ];
thenAPP_PATH=$ROOT_DIR/tests/regression/$APP
elseecho "Application folder not found: $APP"exit -1
fi
可以发现这里限制了测试用例的路径为./tests/regression和./tests/opencl,看了./tests下的其他文件夹:
dention@dention-virtual-machine:~/Desktop/vortex/vortex/build/tests$ ls
kernel Makefile opencl regression riscv unittestdention@dention-virtual-machine:~/Desktop/vortex/vortex/build/tests/regression$ ls
basic common.mk conv3x demo diverge dogfood fence io_addr Makefile matmul mstress printf sgemm2x sgemmx sort stencil3d vecaddxdention@dention-virtual-machine:~/Desktop/vortex/vortex/build/tests/opencl$ ls
bfs common.mk dotproduct kmeans Makefile oclprintf psum sfilter sgemm2 spmv transpose
blackscholes conv3 guassian lbm nearn psort saxpy sgemm sgemm3 stencil vecadddention@dention-virtual-machine:~/Desktop/vortex/vortex/build/tests/kernel$ ls
common.mk conform fibonacci hello Makefiledention@dention-virtual-machine:~/Desktop/vortex/vortex/build/tests/unittest$ ls
common.mk Makefile vx_mallocdention@dention-virtual-machine:~/Desktop/vortex/vortex/build/tests/riscv$ ls
benchmarks_32 benchmarks_64 common.mk isa Makefile riscv-vector-tests
从kernel、riscv的测试用例文件名中大致可以推测,应该也可能可以对这俩文件夹下的测试用例进行测试。咱不妨尝试对比一下./opencl/Makefile和./regression/Makefile:
dention@dention-virtual-machine:~/Desktop/vortex/vortex/build/tests$ diff ./opencl/Makefile ./regression/Makefile
5,24c5,18
< $(MAKE) -C vecadd
< $(MAKE) -C sgemm
... # 省略一部分
< $(MAKE) -C blackscholes
< $(MAKE) -C bfs
---
> $(MAKE) -C basic
> $(MAKE) -C demo
... # 省略一部分
> $(MAKE) -C sgemm2x
> $(MAKE) -C stencil3d
27,45c21,34
< $(MAKE) -C vecadd run-simx
< $(MAKE) -C sgemm run-simx
... # 省略一部分
< $(MAKE) -C blackscholes run-simx
< $(MAKE) -C bfs run-simx
---
> $(MAKE) -C basic run-simx
> $(MAKE) -C demo run-simx
... # 省略一部分
> $(MAKE) -C sgemm2x run-simx
> $(MAKE) -C stencil3d run-simx
48,66c37,50
< $(MAKE) -C vecadd run-rtlsim
< $(MAKE) -C sgemm run-rtlsim
... # 省略一部分
< $(MAKE) -C blackscholes run-rtlsim
< $(MAKE) -C bfs run-rtlsim
---
> $(MAKE) -C basic run-rtlsim
> $(MAKE) -C demo run-rtlsim
... # 省略一部分
> $(MAKE) -C sgemm2x run-rtlsim
> $(MAKE) -C stencil3d run-rtlsim
69,88c53,66
< $(MAKE) -C vecadd clean
< $(MAKE) -C sgemm clean
... # 省略一部分
< $(MAKE) -C blackscholes clean
< $(MAKE) -C bfs clean
\ No newline at end of file
---
> $(MAKE) -C basic clean
> $(MAKE) -C demo clean
... # 省略一部分
> $(MAKE) -C sgemm2x clean
> $(MAKE) -C stencil3d clean
\ No newline at end of file
从以上差异可以看出./opencl/Makefile和./regression/Makefile仅支持simx和rtlsim这两种模式。此外./kernel/Makefile和./riscv/Makefile也仅支持simx和rtlsim,估计应该可以设置opae和xrt这两种选项,不过实际上执行./ci/blackbox.sh --driver=opae和./ci/blackbox.sh --driver=xrt可以直接运行出结果。结果如下:
dention@dention-virtual-machine:~/Desktop/vortex/vortex/build$ ./ci/blackbox.sh --driver=opae
Running: make -C ./ci/../runtime/opae > /dev/null
Running: make -C ./ci/../tests/opencl/sgemm run-opae
make: Entering directory '/home/dention/Desktop/vortex/vortex/build/tests/opencl/sgemm'
SCOPE_JSON_PATH=/home/dention/Desktop/vortex/vortex/build/runtime/scope.json OPAE_DRV_PATHS=libopae-c-sim.so LD_LIBRARY_PATH=/home/dention/tools/pocl/lib:/home/dention/Desktop/vortex/vortex/build/runtime:/home/dention/tools/llvm-vortex/lib:/lib/x86_64-linux-gnu/: POCL_VORTEX_XLEN=32 LLVM_PREFIX=/home/dention/tools/llvm-vortex POCL_VORTEX_BINTOOL="OBJCOPY=/home/dention/tools/llvm-vortex/bin/llvm-objcopy /home/dention/Desktop/vortex/vortex/kernel/scripts/vxbin.py" POCL_VORTEX_CFLAGS="-march=rv32imaf -mabi=ilp32f -O3 -mcmodel=medany --sysroot=/home/dention/tools/riscv32-gnu-toolchain/riscv32-unknown-elf --gcc-toolchain=/home/dention/tools/riscv32-gnu-toolchain -fno-rtti -fno-exceptions -nostartfiles -nostdlib -fdata-sections -ffunction-sections -I/home/dention/Desktop/vortex/vortex/build/hw -I/home/dention/Desktop/vortex/vortex/kernel/include -DXLEN_32 -DNDEBUG -Xclang -target-feature -Xclang +vortex -Xclang -target-feature -Xclang +zicond -mllvm -disable-loop-idiom-all " POCL_VORTEX_LDFLAGS="-Wl,-Bstatic,--gc-sections,-T/home/dention/Desktop/vortex/vortex/kernel/scripts/link32.ld,--defsym=STARTUP_ADDR=0x80000000 /home/dention/Desktop/vortex/vortex/build/kernel/libvortex.a -L/home/dention/tools/libc32/lib -lm -lc /home/dention/tools/libcrt32/lib/baremetal/libclang_rt.builtins-riscv32.a" VORTEX_DRIVER=opae ./sgemm -n32
Workload size=32
CONFIGS: num_threads=4, num_warps=4, num_cores=1, num_clusters=1, socket_size=1, local_mem_base=0xffff0000, num_barriers=2
Create context
Create program from kernel source
Upload source buffers
Execute the kernel
Elapsed time: 14155 ms
Download destination buffer
Verify result
PASSED!
PERF: instrs=289393, cycles=159694, IPC=1.812172
make: Leaving directory '/home/dention/Desktop/vortex/vortex/build/tests/opencl/sgemm'dention@dention-virtual-machine:~/Desktop/vortex/vortex/build$ ./ci/blackbox.sh --driver=xrt
Running: make -C ./ci/../runtime/xrt > /dev/null
Running: make -C ./ci/../tests/opencl/sgemm run-xrt
make: Entering directory '/home/dention/Desktop/vortex/vortex/build/tests/opencl/sgemm'
SCOPE_JSON_PATH=/home/dention/Desktop/vortex/vortex/build/runtime/scope.json LD_LIBRARY_PATH=/lib:/home/dention/tools/pocl/lib:/home/dention/Desktop/vortex/vortex/build/runtime:/home/dention/tools/llvm-vortex/lib:/lib/x86_64-linux-gnu/: POCL_VORTEX_XLEN=32 LLVM_PREFIX=/home/dention/tools/llvm-vortex POCL_VORTEX_BINTOOL="OBJCOPY=/home/dention/tools/llvm-vortex/bin/llvm-objcopy /home/dention/Desktop/vortex/vortex/kernel/scripts/vxbin.py" POCL_VORTEX_CFLAGS="-march=rv32imaf -mabi=ilp32f -O3 -mcmodel=medany --sysroot=/home/dention/tools/riscv32-gnu-toolchain/riscv32-unknown-elf --gcc-toolchain=/home/dention/tools/riscv32-gnu-toolchain -fno-rtti -fno-exceptions -nostartfiles -nostdlib -fdata-sections -ffunction-sections -I/home/dention/Desktop/vortex/vortex/build/hw -I/home/dention/Desktop/vortex/vortex/kernel/include -DXLEN_32 -DNDEBUG -Xclang -target-feature -Xclang +vortex -Xclang -target-feature -Xclang +zicond -mllvm -disable-loop-idiom-all " POCL_VORTEX_LDFLAGS="-Wl,-Bstatic,--gc-sections,-T/home/dention/Desktop/vortex/vortex/kernel/scripts/link32.ld,--defsym=STARTUP_ADDR=0x80000000 /home/dention/Desktop/vortex/vortex/build/kernel/libvortex.a -L/home/dention/tools/libc32/lib -lm -lc /home/dention/tools/libcrt32/lib/baremetal/libclang_rt.builtins-riscv32.a" VORTEX_DRIVER=xrt ./sgemm -n32
Workload size=32
CONFIGS: num_threads=4, num_warps=4, num_cores=1, num_clusters=1, socket_size=1, local_mem_base=0xffff0000, num_barriers=2
info: device name=vortex_xrtsim, memory_capacity=0x100000000 bytes, memory_banks=2.
Create context
Create program from kernel source
Upload source buffers
allocating bank0...
reusing bank0...
Execute the kernel
reusing bank0...
reusing bank0...
allocating bank1...
Elapsed time: 12817 ms
Download destination buffer
Verify result
PASSED!
freeing bank0...
freeing bank1...
allocating bank0...
PERF: instrs=289393, cycles=159485, IPC=1.814547
make: Leaving directory '/home/dention/Desktop/vortex/vortex/build/tests/opencl/sgemm'
(有点意思的是,这俩cycles不一样,为后续探索多了点理由!!!!)
此外,以下这段可以接着修改:
if [ -d "$ROOT_DIR/tests/opencl/$APP" ];
thenAPP_PATH=$ROOT_DIR/tests/opencl/$APP
elif [ -d "$ROOT_DIR/tests/regression/$APP" ];
thenAPP_PATH=$ROOT_DIR/tests/regression/$APP
elseecho "Application folder not found: $APP"exit -1
fi||||\/
## 加入除了opencl和regression之外的kernel和riscv
# kernel支持的APP包括:conform hello fibonacci
# riscv支持的APP包括:benchmarks_${XLEN}
# opencl支持的APP包括:fs dotproduct kmeans oclprintf psum sfilter sgemm2 spmv transpose blackscholes conv3 guassian lbm nearn psort saxpy sgemm sgemm3 stencil vecadd
# regression支持的APP包括:basic conv3x demo diverge dogfood fence io_addr matmul mstress printf sgemm2x sgemmx sort stencil3d vecaddx# 默认的设置:DRIVER=simx APP=sgemm
接下来是运行应用:
if [ "$DRIVER" = "gpu" ];
then# running applicationif [ $HAS_ARGS -eq 1 ]thenecho "running: OPTS=$ARGS make -C $APP_PATH run-$DRIVER"OPTS=$ARGS make -C $APP_PATH run-$DRIVERstatus=$?elseecho "running: make -C $APP_PATH run-$DRIVER"make -C $APP_PATH run-$DRIVERstatus=$?fiexit $status
fi
插入一次测试,由于笔记本并不支持NVIDIA GPU,但还是测了一下,不出意外,塌方了:
dention@dention-virtual-machine:~/Desktop/vortex/vortex/build$ ./ci/blackbox.sh --driver=gpu
Running: make -C ./ci/../tests/opencl/sgemm run-gpu
make: Entering directory '/home/dention/Desktop/vortex/vortex/build/tests/opencl/sgemm'
g++ -std=c++17 -Wall -Wextra -Wfatal-errors -Wno-deprecated-declarations -Wno-unused-parameter -Wno-narrowing -pthread -I/home/dention/tools/pocl/include -O2 -DNDEBUG main.cc.o -Wl,-rpath,/home/dention/tools/llvm-vortex/lib -lOpenCL -o sgemm.host
/usr/bin/ld: cannot find -lOpenCL: No such file or directory
collect2: error: ld returned 1 exit status
make: *** [../common.mk:88: sgemm.host] Error 1
make: Leaving directory '/home/dention/Desktop/vortex/vortex/build/tests/opencl/sgemm'
看着error是链接阶段找不到-lOpenCL库,开始检查:
dention@dention-virtual-machine:~/Desktop/vortex/vortex/build$ ldconfig -p | grep OpenCL
libOpenCL.so.1 (libc6,x86-64) => /lib/x86_64-linux-gnu/libOpenCL.so.1
这说明有库但没链接上,想了想可能是pkg-config没有正确配置OpenCL库。
dention@dention-virtual-machine:~/Desktop/vortex/vortex/build$ pkg-config --libs OpenCL
Package OpenCL was not found in the pkg-config search path.
Perhaps you should add the directory containing `OpenCL.pc'
to the PKG_CONFIG_PATH environment variable
No package 'OpenCL' found
所以接下来就是:
sudo apt-get install pkg-config opencl-headers ocl-icd-opencl-dev
export LD_LIBRARY_PATH=/lib/x86_64-linux-gnu/:$LD_LIBRARY_PATH
export LDFLAGS="-L/lib/x86_64-linux-gnu/ -lOpenCL"
export CPPFLAGS="-I/home/dention/tools/pocl/include"
然后:
dention@dention-virtual-machine:~/Desktop/vortex/vortex/build$ ./ci/blackbox.sh --driver=gpu
Running: make -C ./ci/../tests/opencl/sgemm run-gpu
make: Entering directory '/home/dention/Desktop/vortex/vortex/build/tests/opencl/sgemm'
./sgemm.host -n32
Workload size=32
OpenCL Error: 'clGetPlatformIDs(1, &platform_id, NULL)' returned -1001!
make: *** [../common.mk:91: run-gpu] Error 255
make: Leaving directory '/home/dention/Desktop/vortex/vortex/build/tests/opencl/sgemm'
能输出Workload size=32的信息,只是说相关的设备没找到,大概率就是没匹配到gpu版本的opencv,因此报错。有条件的可以试试!
接下来是配置和构建:
CONFIGS="-DNUM_CLUSTERS=$CLUSTERS -DNUM_CORES=$CORES -DNUM_WARPS=$WARPS -DNUM_THREADS=$THREADS $L2 $L3 $PERF_FLAG $CONFIGS"
echo "CONFIGS=$CONFIGS"if [ $REBUILD -ne 0 ]
thenBLACKBOX_CACHE=blackbox.$DRIVER.cacheif [ -f "$BLACKBOX_CACHE" ]thenLAST_CONFIGS=`cat $BLACKBOX_CACHE`fiif [ $REBUILD -eq 1 ] || [ "$CONFIGS+$DEBUG+$SCOPE" != "$LAST_CONFIGS" ];thenmake -C $DRIVER_PATH clean-driver > /dev/nullecho "$CONFIGS+$DEBUG+$SCOPE" > $BLACKBOX_CACHEfi
fi
根据用户指定的配置(如集群数、核心数等),生成CONFIGS字符串。如果REBUILD不为0,脚本会检查是否需要重新构建驱动程序。如果配置发生变化或用户强制重新构建,脚本会清理旧的构建文件并重新构建。
接下来是运行应用:
if [ $DEBUG -ne 0 ]
then# running applicationif [ $TEMPBUILD -eq 1 ]then# setup temp directoryTEMPDIR=$(mktemp -d)mkdir -p "$TEMPDIR/$DRIVER"# driver initializationif [ $SCOPE -eq 1 ]thenecho "running: DESTDIR=$TEMPDIR/$DRIVER DEBUG=$DEBUG_LEVEL SCOPE=1 CONFIGS=$CONFIGS make -C $DRIVER_PATH"DESTDIR="$TEMPDIR/$DRIVER" DEBUG=$DEBUG_LEVEL SCOPE=1 CONFIGS="$CONFIGS" make -C $DRIVER_PATH > /dev/nullelseecho "running: DESTDIR=$TEMPDIR/$DRIVER DEBUG=$DEBUG_LEVEL CONFIGS=$CONFIGS make -C $DRIVER_PATH"DESTDIR="$TEMPDIR/$DRIVER" DEBUG=$DEBUG_LEVEL CONFIGS="$CONFIGS" make -C $DRIVER_PATH > /dev/nullfi# running applicationif [ $HAS_ARGS -eq 1 ]thenecho "running: VORTEX_RT_PATH=$TEMPDIR OPTS=$ARGS make -C $APP_PATH run-$DRIVER > $LOGFILE 2>&1"DEBUG=1 VORTEX_RT_PATH=$TEMPDIR OPTS=$ARGS make -C $APP_PATH run-$DRIVER > $LOGFILE 2>&1status=$?elseecho "running: VORTEX_RT_PATH=$TEMPDIR make -C $APP_PATH run-$DRIVER > $LOGFILE 2>&1"DEBUG=1 VORTEX_RT_PATH=$TEMPDIR make -C $APP_PATH run-$DRIVER > $LOGFILE 2>&1status=$?fi# cleanup temp directorytrap "rm -rf $TEMPDIR" EXITelse# driver initializationif [ $SCOPE -eq 1 ]thenecho "running: DEBUG=$DEBUG_LEVEL SCOPE=1 CONFIGS=$CONFIGS make -C $DRIVER_PATH"DEBUG=$DEBUG_LEVEL SCOPE=1 CONFIGS="$CONFIGS" make -C $DRIVER_PATH > /dev/nullelseecho "running: DEBUG=$DEBUG_LEVEL CONFIGS=$CONFIGS make -C $DRIVER_PATH"DEBUG=$DEBUG_LEVEL CONFIGS="$CONFIGS" make -C $DRIVER_PATH > /dev/nullfi# running applicationif [ $HAS_ARGS -eq 1 ]thenecho "running: OPTS=$ARGS make -C $APP_PATH run-$DRIVER > $LOGFILE 2>&1"DEBUG=1 OPTS=$ARGS make -C $APP_PATH run-$DRIVER > $LOGFILE 2>&1status=$?elseecho "running: make -C $APP_PATH run-$DRIVER > $LOGFILE 2>&1"DEBUG=1 make -C $APP_PATH run-$DRIVER > $LOGFILE 2>&1status=$?fifiif [ -f "$APP_PATH/trace.vcd" ]thenmv -f $APP_PATH/trace.vcd .fi
elseif [ $TEMPBUILD -eq 1 ]then# setup temp directoryTEMPDIR=$(mktemp -d)mkdir -p "$TEMPDIR/$DRIVER"# driver initializationif [ $SCOPE -eq 1 ]thenecho "running: DESTDIR=$TEMPDIR/$DRIVER SCOPE=1 CONFIGS=$CONFIGS make -C $DRIVER_PATH"DESTDIR="$TEMPDIR/$DRIVER" SCOPE=1 CONFIGS="$CONFIGS" make -C $DRIVER_PATH > /dev/nullelseecho "running: DESTDIR=$TEMPDIR/$DRIVER CONFIGS=$CONFIGS make -C $DRIVER_PATH"DESTDIR="$TEMPDIR/$DRIVER" CONFIGS="$CONFIGS" make -C $DRIVER_PATH > /dev/nullfi# running applicationif [ $HAS_ARGS -eq 1 ]thenecho "running: VORTEX_RT_PATH=$TEMPDIR OPTS=$ARGS make -C $APP_PATH run-$DRIVER"VORTEX_RT_PATH=$TEMPDIR OPTS=$ARGS make -C $APP_PATH run-$DRIVERstatus=$?elseecho "running: VORTEX_RT_PATH=$TEMPDIR make -C $APP_PATH run-$DRIVER"VORTEX_RT_PATH=$TEMPDIR make -C $APP_PATH run-$DRIVERstatus=$?fi# cleanup temp directorytrap "rm -rf $TEMPDIR" EXITelse# driver initializationif [ $SCOPE -eq 1 ]thenecho "running: SCOPE=1 CONFIGS=$CONFIGS make -C $DRIVER_PATH"SCOPE=1 CONFIGS="$CONFIGS" make -C $DRIVER_PATH > /dev/nullelseecho "running: CONFIGS=$CONFIGS make -C $DRIVER_PATH"CONFIGS="$CONFIGS" make -C $DRIVER_PATH > /dev/nullfi# running applicationif [ $HAS_ARGS -eq 1 ]thenecho "running: OPTS=$ARGS make -C $APP_PATH run-$DRIVER"OPTS=$ARGS make -C $APP_PATH run-$DRIVERstatus=$?elseecho "running: make -C $APP_PATH run-$DRIVER"make -C $APP_PATH run-$DRIVERstatus=$?fifi
fiexit $status
具体功能可以分为三点:
1、如果启用了调试模式(DEBUG=1),脚本会根据配置运行应用,并将输出保存到日志文件中。
2、如果启用了临时构建(TEMPBUILD=1),脚本会创建一个临时目录来构建和运行应用,运行完成后清理临时目录。
3、如果未启用调试模式,脚本会直接运行应用。
以上blackbox.sh已经从blackbox变成whitebox了,咱先告一个段落!
2.2 demo文件
这个文件直接和波形挂钩,或者说直接和指令挂钩,为了看明白RTL代码,该文件绕不开。
在编译之前,./demo的文件内容如下:
dention@dention-virtual-machine:~/Desktop/vortex/vortex/tests/regression/demo$ tree
.
├── common.h
├── kernel.cpp
├── main.cpp
└── Makefile0 directories, 4 files
而在编译之后,./demo的文件内容如下:
dention@dention-virtual-machine:~/Desktop/vortex/vortex/build/tests/regression/demo$ tree
.
├── demo
├── kernel.dump
├── kernel.elf
├── kernel.vxbin
├── Makefile
├── ramulator.stats.log
└── trace├── ramulator.log.ch0└── ramulator.log.ch11 directory, 8 files
其中ramulator.stats.log根据文件名,结合2.3.3的1可以判断是通过ramulator输出的日志文件,其内容如下:
Frontend:impl: GEM5MemorySystem:impl: GenericDRAMtotal_num_other_requests: 0total_num_write_requests: 7372total_num_read_requests: 1480memory_system_cycles: 22034DRAM:impl: HBM2AddrMapper:impl: RoBaRaCoChController:impl: Genericid: Channel 0avg_read_latency_0: 60.5959473read_queue_len_avg_0: 1.16075158write_queue_len_0: 340590queue_len_0: 366166num_other_reqs_0: 0num_write_reqs_0: 5508read_latency_0: 44841priority_queue_len_avg_0: 0row_hits_0: 4367priority_queue_len_0: 0row_misses_0: 21row_conflicts_0: 36read_row_misses_0: 4queue_len_avg_0: 16.618227read_row_conflicts_core_0: 22read_row_hits_0: 712write_queue_len_avg_0: 15.4574747read_row_conflicts_0: 22write_row_misses_0: 17write_row_conflicts_0: 14read_queue_len_0: 25576write_row_hits_0: 3655read_row_hits_core_0: 712read_row_misses_core_0: 4num_read_reqs_0: 740Scheduler:impl: FRFCFSRefreshManager:impl: AllBankRowPolicy:impl: OpenRowPolicyControllerPlugin:impl: TraceRecorderController:impl: Genericid: Channel 1read_queue_len_avg_1: 0.92838341priority_queue_len_1: 0write_queue_len_1: 336405num_write_reqs_1: 6379row_hits_1: 4335row_misses_1: 33avg_read_latency_1: 53.7567558queue_len_avg_1: 16.1959248read_queue_len_1: 20456read_row_misses_1: 2priority_queue_len_avg_1: 0read_row_hits_1: 703queue_len_1: 356861read_row_conflicts_1: 33num_read_reqs_1: 740num_other_reqs_1: 0row_conflicts_1: 56write_row_hits_1: 3632write_queue_len_avg_1: 15.2675409write_row_misses_1: 31write_row_conflicts_1: 23read_row_hits_core_0: 703read_row_misses_core_0: 2read_latency_1: 39780read_row_conflicts_core_0: 33Scheduler:impl: FRFCFSRefreshManager:impl: AllBankRowPolicy:impl: OpenRowPolicyControllerPlugin:impl: TraceRecorder
单纯就输出而言,其实和2.3.6的日志输出有所不同,但从trace的结果来看,八九不离十,估计有脚本经过进一步处理!
然后再看看kernel.dump文件,太多了,贴一部分:
kernel.elf: file format elf32-littleriscvDisassembly of section .init:80000000 <_start>:
80000000: f3 22 10 fc csrr t0, nw
80000004: 17 03 00 00 auipc t1, 0x0
80000008: 13 03 c3 15 addi t1, t1, 0x15c
8000000c: 0b 90 62 00 vx_wspawn t0, t1
80000010: 93 02 f0 ff li t0, -0x1
80000014: 0b 80 02 00 vx_tmc t0
80000018: ef 00 80 11 jal 0x80000130 <init_regs>
看到这,估计有熟悉的感觉了,trace_rtlsim.csv的部分内容如下:
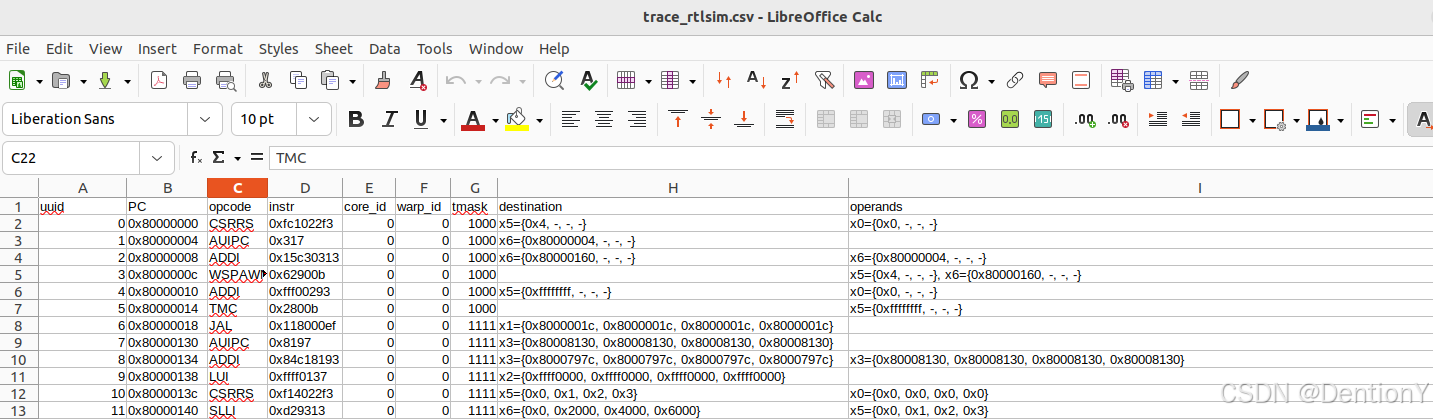
这不就对上了!
再看看ramulator.log.ch0和ramulator.log.ch1:
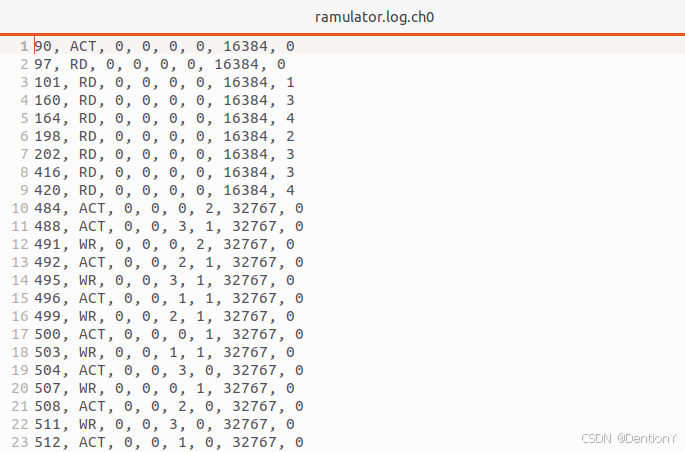
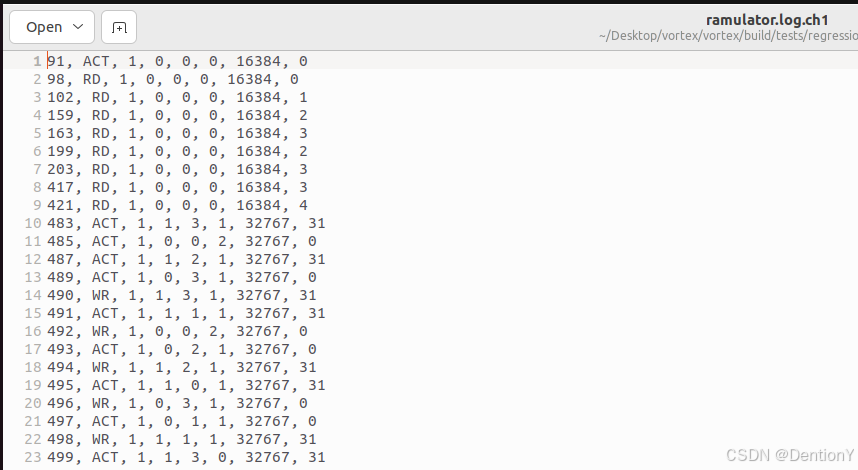
HBM2的两个channel的trace情况有差异,从第一个数字的角度来考虑,感觉是乒乓读取操作了!不过具体含义还得仔细推敲,这个值得挖一挖!
另外就是输入文件的功能,这个放到下一篇介绍!这一篇内容太多了!
├── common.h
├── kernel.cpp
├── main.cpp
└── Makefile
2.3 额外牵扯到的ramulator
2.3.1 ramulator简单介绍
此处简单尝试ramulator,而不去研究这个黑盒的原理,只研究测试用例的输入和输出及其含义:
# 下载ramulator
proxychains4 git clone --recursive https://github.com/CMU-SAFARI/ramulator.git
# 编译
cd ramulator
make -j8
根据官网的描述(直接照搬官网原文的直接翻译了):在2023年8月发布了一个更新版本的Ramulator,称为Ramulator 2.0。Ramulator 2.0更易于使用、扩展和修改。它还支持当时的最新DRAM标准(例如,DDR5、LPDDR5、HBM3、GDDR6)。Ramulator是一个快速且精确到周期的DRAM模拟器,支持广泛的商业和学术DRAM标准:
DDR3 (2007), DDR4 (2012)
LPDDR3 (2012), LPDDR4 (2014)
GDDR5 (2009)
WIO (2011), WIO2 (2014)
HBM (2013)
Ramulator的初始发布在以下论文中描述:
Y. Kim, W. Yang, O. Mutlu. "Ramulator: A Fast and Extensible DRAM Simulator". In IEEE Computer Architecture Letters, March 2015.
关于新特性的信息,以及使用Ramulator进行的广泛内存特性分析,请阅读:
S. Ghose, T. Li, N. Hajinazar, D. Senol Cali, O. Mutlu. "Demystifying Complex Workload–DRAM Interactions: An Experimental Study". In Proceedings of the ACM International Conference on Measurement and Modeling of Computer Systems (SIGMETRICS), June 2019 (slides). In Proceedings of the ACM on Measurement and Analysis of Computing Systems (POMACS), 2019.
2.3.2 ramulator使用方法
Ramulator支持三种常见的不同使用模式和补充方法。
1、内存轨迹驱动:Ramulator直接从文件中读取内存轨迹,并仅模拟DRAM子系统。轨迹文件中的每一行代表一个内存请求,以十六进制地址开头,后跟'R'或'W'表示读或写。
官网提供的测试用例如下:
$ cd ramulator$ make -j$ ./ramulator configs/DDR3-config.cfg --mode=dram dram.traceSimulation done. Statistics written to DDR3.stats# NOTE: dram.trace is a very short trace file provided only as an example.$ ./ramulator configs/DDR3-config.cfg --mode=dram --stats my_output.txt dram.traceSimulation done. Statistics written to my_output.txt# NOTE: optional --stats flag changes the statistics output filename
2、CPU轨迹驱动:Ramulator直接从文件中读取指令轨迹,并模拟一个简化的“核心”模型,该模型向DRAM子系统生成内存请求。轨迹文件中的每一行代表一个内存请求,可以有以下两种格式之一。
<num-cpuinst> <addr-read>:对于包含两个标记的行,第一个标记表示在内存请求之前的CPU(即非内存)指令数量,第二个标记是读取的十进制地址。
<num-cpuinst> <addr-read> <addr-writeback>:对于包含三个标记的行,第三个标记是写回请求的十进制地址,这是由之前的读取请求引起的脏缓存行驱逐。
官网提供的测试用例如下:
$ cd ramulator$ make -j$ ./ramulator configs/DDR3-config.cfg --mode=cpu cpu.traceSimulation done. Statistics written to DDR3.stats# NOTE: cpu.trace is a very short trace file provided only as an example.$ ./ramulator configs/DDR3-config.cfg --mode=cpu --stats my_output.txt cpu.traceSimulation done. Statistics written to my_output.txt# NOTE: optional --stats flag changes the statistics output filename
3、gem5驱动:Ramulator作为完整系统模拟器(gem5)的一部分运行,从其中接收生成的内存请求。
官网提供的测试用例如下:
$ hg clone http://repo.gem5.org/gem5-stable$ cd gem5-stable$ hg update -c 10231 # Revert to stable version from 5/31/2014 (10231:0e86fac7254c)$ patch -Np1 --ignore-whitespace < /path/to/ramulator/gem5-0e86fac7254c-ramulator.patch$ cd ext/ramulator$ mkdir Ramulator$ cp -r /path/to/ramulator/src Ramulator# Compile gem5# Run gem5 with `--mem-type=ramulator` and `--ramulator-config=configs/DDR3-config.cfg`
默认情况下,gem5使用原子CPU并采用原子内存访问方式,即实际上并没有使用像Ramulator这样详细的内存模型。若要以时序模式运行gem5,则需要通过命令行参数--cpu-type指定CPU类型。例如:--cpu-type=timing。
4、对于某些DRAM标准,Ramulator还能够通过依赖VAMPIRE或DRAMPower 作为后端来报告功耗。
2.3.3 ramulator的输出
Ramulator在每次运行时会报告一系列统计信息,这些信息会被写入一个文件。Statistics.h提供了一系列与gem5兼容的统计类。
1、内存轨迹/CPU轨迹驱动:当以内存轨迹驱动或CPU轨迹驱动模式运行时,Ramulator会将这些统计信息写入一个文件。默认情况下,文件名将是 <standard_name>.stats(例如,DDR3.stats)。你可以通过在--mode选项之后的命令行中添加--stats <filename>来将统计文件写入不同的文件名。
注意此条里的默认情况下,文件名将是 <standard_name>.stats(例如,DDR3.stats)是很关键的线索!
2、gem5驱动:Ramulator会自动将其统计信息集成到gem5中。Ramulator的统计信息会直接写入gem5的统计文件中,并且每个统计信息的名称前会加上 ramulator.前缀。
2.3.4 ramulator的复现
2.3.4.1 调试与验证(第 4.1 节)
为了调试和验证,Ramulator可以打印其发出的每条DRAM命令的轨迹,以及它们的地址和时序信息。为此,请在配置文件中启用print_cmd_trace变量。
2.3.4.2 与其他模拟器的比较(第 4.2 节)
为了将Ramulator与其他DRAM模拟器进行比较,我们提供了一个脚本,用于自动化此过程:test_ddr3.py。然而,在运行此脚本之前,你必须在脚本的源代码中指定的行中指定它们的可执行文件和配置文件的位置:
Ramulator
DRAMSim2 (https://wiki.umd.edu/DRAMSim2):test_ddr3.py 第 39-40 行
USIMM (http://www.cs.utah.edu/~rajeev/jwac12):test_ddr3.py 第 54-55 行
DrSim (http://lph.ece.utexas.edu/public/Main/DrSim):test_ddr3.py 第 66-67 行
NVMain (http://wiki.nvmain.org):test_ddr3.py 第 78-79 行
5种模拟器都使用相同的参数进行了配置:
DDR3-1600K (11-11-11),1 通道,1 级,2Gb x8 芯片
FR-FCFS 调度
Open-Row 策略
32/32 条目读/写队列
写队列的高/低水位线:28/16
最后,运行test_ddr3.py <num-requests>来启动模拟。请确保在模拟期间没有其他活动进程,以获得准确的内存使用量和CPU时间测量。
2.3.4.3 DRAM标准的横断面研究(第 4.3 节)
请使用cputraces文件夹中提供的CPU轨迹(SPEC 2006)来运行基于CPU轨迹的模拟。
2.3.5 功耗测试
为了估算功耗,Ramulator可以将它发出的每条DRAM命令的轨迹以 DRAMPower格式记录到一个文件中。为此,请在配置文件中启用record_cmd_trace变量。生成的DRAM命令轨迹(例如,cmd-trace-chan-N-rank-M.cmdtrace)应被输入到一个兼容的DRAM功耗模拟器(如VAMPIRE或DRAMPower)中,并使用正确的配置(标准/速度/组织)来估算单个等级(rank)的能耗/功耗(这是VAMPIRE和DRAMPower的一个当前限制)。
2.3.6 简单使用Ramulator的命令并阅读输入配置文件和输出文件
运行的命令如下:
# 使用内存轨迹驱动模式
dention@dention-virtual-machine:~/Desktop/ramulator$ ./ramulator configs/DDR3-config.cfg --mode=dram --stats my_output_DDR3_mode_dram.txt dram.trace
Simulation done. Statistics written to my_output_DDR3_mode_dram.txt# 使用CPU轨迹驱动模式
dention@dention-virtual-machine:~/Desktop/ramulator$ ./ramulator configs/DDR3-config.cfg --mode=cpu --stats my_output_DDR3_mode_cpu.txt cpu.trace
tracenum: 1
trace_list[0]: cpu.trace
Warmup complete! Resetting stats...
Starting the simulation...
CPU heartbeat, cycles: 50000000
CPU heartbeat, cycles: 100000000
CPU heartbeat, cycles: 150000000
CPU heartbeat, cycles: 200000000
CPU heartbeat, cycles: 250000000
CPU heartbeat, cycles: 300000000
CPU heartbeat, cycles: 350000000
CPU heartbeat, cycles: 400000000
CPU heartbeat, cycles: 450000000
CPU heartbeat, cycles: 500000000
CPU heartbeat, cycles: 550000000
CPU heartbeat, cycles: 600000000
CPU heartbeat, cycles: 650000000
CPU heartbeat, cycles: 700000000
CPU heartbeat, cycles: 750000000
Simulation done. Statistics written to my_output_DDR3_mode_cpu.txt
输入配置文件DDR3-config.cfg是:
########################
# Example config file
# Comments start with #
# There are restrictions for valid channel/rank numbersstandard = DDR3channels = 1ranks = 1speed = DDR3_1600Korg = DDR3_2Gb_x8
# record_cmd_trace: (default is off): on, offrecord_cmd_trace = off
# print_cmd_trace: (default is off): on, offprint_cmd_trace = off### Below are parameters only for CPU tracecpu_tick = 4mem_tick = 1
### Below are parameters only for multicore mode
# When early_exit is on, all cores will be terminated when the earliest one finishes.early_exit = on
# early_exit = on, off (default value is on)
# If expected_limit_insts is set, some per-core statistics will be recorded when this limit (or the end of the whole trace if it's shorter than specified limit) is reached. The simulation won't stop and will roll back automatically until the last one reaches the limit.expected_limit_insts = 200000000
# warmup_insts = 100000000warmup_insts = 0cache = no
# cache = no, L1L2, L3, all (default value is no)translation = None
# translation = None, Random (default value is None)
#
########################
简单解释这里的配置,首先是DRAM标准和配置:
standard = DDR3 # 指定使用的DRAM标准为DDR3。channels = 1 # 指定通道数为1。ranks = 1 # 指定每个通道的等级数为1。speed = DDR3_1600K # 指定DRAM的速度等级为DDR3_1600K。org = DDR3_2Gb_x8 # 指定DRAM的组织方式为DDR3_2Gb_x8,即每个芯片为2Gb,数据宽度为8位。
然后是CPU轨迹相关参数:
cpu_tick = 4 # 指定 CPU 的时钟周期(tick)为 4。
mem_tick = 1 # 指定内存的时钟周期(tick)为 1。
最后是多核模式相关参数:
### Below are parameters only for multicore mode
# When early_exit is on, all cores will be terminated when the earliest one finishes.early_exit = on # 在多核模式下,如果设置为on,则当最早的核完成时,所有核都将被终止。
# early_exit = on, off (default value is on)
# If expected_limit_insts is set, some per-core statistics will be recorded when this limit (or the end of the whole trace if it's shorter than specified limit) is reached. The simulation won't stop and will roll back automatically until the last one reaches the limit.expected_limit_insts = 200000000 # 设置每个核预期执行的指令数上限。当达到这个限制(或整个轨迹的结束,如果它比指定的限制短)时,将记录一些每个核的统计信息。模拟不会停止,并会自动回滚,直到最后一个核达到限制。
# warmup_insts = 100000000warmup_insts = 0 # 设置预热指令数。这里设置为0,表示不进行预热。cache = no # 指定是否启用缓存。这里设置为no,表示不启用缓存。
# cache = no, L1L2, L3, all (default value is no)translation = None # 指定地址转换方式。这里设置为None,表示不进行地址转换。
# translation = None, Random (default value is None)
类似配置文件太多了:

核心文件应该是:
不过先不做解读了。此外dram.trace是:
0x12345680 R
0x4cbd56c0 W
0x35d46f00 R
0x696fed40 W
0x7876af80 R
cpu.trace是:
3 20734016
1 20846400
6 20734208
8 20841280 20841280
0 20734144
2 20918976 20734016
这俩确实没看出来是个啥!先跳过!
输出包括了my_output_DDR3_mode_dram.txt和my_output_DDR3_mode_cpu.txt,my_output_DDR3_mode_dram.txt的内容如下:
ramulator.active_cycles_0 57 # Total active cycles for level _0ramulator.busy_cycles_0 57 # (All-bank refresh only. busy cycles only include refresh time in rank level) The sum of cycles that the DRAM part is active or under refresh for level _0ramulator.serving_requests_0 148 # The sum of read and write requests that are served in this DRAM element per memory cycle for level _0ramulator.average_serving_requests_0 2.551724 # The average of read and write requests that are served in this DRAM element per memory cycle for level _0ramulator.active_cycles_0_0 57 # Total active cycles for level _0_0ramulator.busy_cycles_0_0 57 # (All-bank refresh only. busy cycles only include refresh time in rank level) The sum of cycles that the DRAM part is active or under refresh for level _0_0ramulator.serving_requests_0_0 148 # The sum of read and write requests that are served in this DRAM element per memory cycle for level _0_0ramulator.average_serving_requests_0_0 2.551724 # The average of read and write requests that are served in this DRAM element per memory cycle for level _0_0ramulator.active_cycles_0_0_0 0 # Total active cycles for level _0_0_0ramulator.busy_cycles_0_0_0 0 # (All-bank refresh only. busy cycles only include refresh time in rank level) The sum of cycles that the DRAM part is active or under refresh for level _0_0_0ramulator.serving_requests_0_0_0 0 # The sum of read and write requests that are served in this DRAM element per memory cycle for level _0_0_0
ramulator.average_serving_requests_0_0_0 0.000000 # The average of read and write requests that are served in this DRAM element per memory cycle for level _0_0_0ramulator.active_cycles_0_0_1 0 # Total active cycles for level _0_0_1ramulator.busy_cycles_0_0_1 0 # (All-bank refresh only. busy cycles only include refresh time in rank level) The sum of cycles that the DRAM part is active or under refresh for level _0_0_1ramulator.serving_requests_0_0_1 0 # The sum of read and write requests that are served in this DRAM element per memory cycle for level _0_0_1
ramulator.average_serving_requests_0_0_1 0.000000 # The average of read and write requests that are served in this DRAM element per memory cycle for level _0_0_1ramulator.active_cycles_0_0_2 49 # Total active cycles for level _0_0_2ramulator.busy_cycles_0_0_2 49 # (All-bank refresh only. busy cycles only include refresh time in rank level) The sum of cycles that the DRAM part is active or under refresh for level _0_0_2ramulator.serving_requests_0_0_2 49 # The sum of read and write requests that are served in this DRAM element per memory cycle for level _0_0_2
ramulator.average_serving_requests_0_0_2 0.844828 # The average of read and write requests that are served in this DRAM element per memory cycle for level _0_0_2ramulator.active_cycles_0_0_3 43 # Total active cycles for level _0_0_3ramulator.busy_cycles_0_0_3 43 # (All-bank refresh only. busy cycles only include refresh time in rank level) The sum of cycles that the DRAM part is active or under refresh for level _0_0_3ramulator.serving_requests_0_0_3 43 # The sum of read and write requests that are served in this DRAM element per memory cycle for level _0_0_3
ramulator.average_serving_requests_0_0_3 0.741379 # The average of read and write requests that are served in this DRAM element per memory cycle for level _0_0_3ramulator.active_cycles_0_0_4 0 # Total active cycles for level _0_0_4ramulator.busy_cycles_0_0_4 0 # (All-bank refresh only. busy cycles only include refresh time in rank level) The sum of cycles that the DRAM part is active or under refresh for level _0_0_4ramulator.serving_requests_0_0_4 0 # The sum of read and write requests that are served in this DRAM element per memory cycle for level _0_0_4
ramulator.average_serving_requests_0_0_4 0.000000 # The average of read and write requests that are served in this DRAM element per memory cycle for level _0_0_4ramulator.active_cycles_0_0_5 41 # Total active cycles for level _0_0_5ramulator.busy_cycles_0_0_5 41 # (All-bank refresh only. busy cycles only include refresh time in rank level) The sum of cycles that the DRAM part is active or under refresh for level _0_0_5ramulator.serving_requests_0_0_5 41 # The sum of read and write requests that are served in this DRAM element per memory cycle for level _0_0_5
ramulator.average_serving_requests_0_0_5 0.706897 # The average of read and write requests that are served in this DRAM element per memory cycle for level _0_0_5ramulator.active_cycles_0_0_6 0 # Total active cycles for level _0_0_6ramulator.busy_cycles_0_0_6 0 # (All-bank refresh only. busy cycles only include refresh time in rank level) The sum of cycles that the DRAM part is active or under refresh for level _0_0_6ramulator.serving_requests_0_0_6 0 # The sum of read and write requests that are served in this DRAM element per memory cycle for level _0_0_6
ramulator.average_serving_requests_0_0_6 0.000000 # The average of read and write requests that are served in this DRAM element per memory cycle for level _0_0_6ramulator.active_cycles_0_0_7 15 # Total active cycles for level _0_0_7ramulator.busy_cycles_0_0_7 15 # (All-bank refresh only. busy cycles only include refresh time in rank level) The sum of cycles that the DRAM part is active or under refresh for level _0_0_7ramulator.serving_requests_0_0_7 15 # The sum of read and write requests that are served in this DRAM element per memory cycle for level _0_0_7
ramulator.average_serving_requests_0_0_7 0.258621 # The average of read and write requests that are served in this DRAM element per memory cycle for level _0_0_7ramulator.read_transaction_bytes_0 192 # The total byte of read transaction per channelramulator.write_transaction_bytes_0 128 # The total byte of write transaction per channelramulator.row_hits_channel_0_core 0 # Number of row hits per channel per coreramulator.row_misses_channel_0_core 4 # Number of row misses per channel per coreramulator.row_conflicts_channel_0_core 1 # Number of row conflicts per channel per coreramulator.read_row_hits_channel_0_core 0 # Number of row hits for read requests per channel per core[0] 0.0 #
ramulator.read_row_misses_channel_0_core 3 # Number of row misses for read requests per channel per core[0] 3.0 #
ramulator.read_row_conflicts_channel_0_core 0 # Number of row conflicts for read requests per channel per core[0] 0.0 # ramulator.write_row_hits_channel_0_core 0 # Number of row hits for write requests per channel per core[0] 0.0 #
ramulator.write_row_misses_channel_0_core 1 # Number of row misses for write requests per channel per core[0] 1.0 #
ramulator.write_row_conflicts_channel_0_core 1 # Number of row conflicts for write requests per channel per core[0] 1.0 # ramulator.useless_activates_0_core 0 # Number of useless activations. E.g, ACT -> PRE w/o RD or WRramulator.read_latency_avg_0 44.333333 # The average memory latency cycles (in memory time domain) per request for all read requests in this channelramulator.read_latency_sum_0 133 # The memory latency cycles (in memory time domain) sum for all read requests in this channelramulator.req_queue_length_avg_0 1.896552 # Average of read and write queue length per memory cycle per channel.ramulator.req_queue_length_sum_0 110 # Sum of read and write queue length per memory cycle per channel.ramulator.read_req_queue_length_avg_0 1.172414 # Read queue length average per memory cycle per channel.ramulator.read_req_queue_length_sum_0 68 # Read queue length sum per memory cycle per channel.ramulator.write_req_queue_length_avg_0 0.724138 # Write queue length average per memory cycle per channel.ramulator.write_req_queue_length_sum_0 42 # Write queue length sum per memory cycle per channel.ramulator.record_read_hits 0.0 # record read hit count for this core when it reaches request limit or to the end[0] 0.0 # ramulator.record_read_misses 0.0 # record_read_miss count for this core when it reaches request limit or to the end[0] 0.0 # ramulator.record_read_conflicts 0.0 # record read conflict count for this core when it reaches request limit or to the end[0] 0.0 # ramulator.record_write_hits 0.0 # record write hit count for this core when it reaches request limit or to the end[0] 0.0 # ramulator.record_write_misses 0.0 # record write miss count for this core when it reaches request limit or to the end[0] 0.0 # ramulator.record_write_conflicts 0.0 # record write conflict for this core when it reaches request limit or to the end[0] 0.0 # ramulator.dram_capacity 2147483648 # Number of bytes in simulated DRAMramulator.dram_cycles 58 # Number of DRAM cycles simulatedramulator.incoming_requests 5 # Number of incoming requests to DRAMramulator.read_requests 3 # Number of incoming read requests to DRAM per core[0] 3.0 # ramulator.write_requests 2 # Number of incoming write requests to DRAM per core[0] 2.0 # ramulator.ramulator_active_cycles 57 # The total number of cycles that the DRAM part is active (serving R/W)ramulator.incoming_requests_per_channel 5.0 # Number of incoming requests to each DRAM channel[0] 5.0 #
ramulator.incoming_read_reqs_per_channel 3.0 # Number of incoming read requests to each DRAM channel[0] 3.0 # ramulator.physical_page_replacement 0 # The number of times that physical page replacement happens.ramulator.maximum_bandwidth 12800000000 # The theoretical maximum bandwidth (Bps)ramulator.in_queue_req_num_sum 110 # Sum of read/write queue lengthramulator.in_queue_read_req_num_sum 68 # Sum of read queue lengthramulator.in_queue_write_req_num_sum 42 # Sum of write queue lengthramulator.in_queue_req_num_avg 1.896552 # Average of read/write queue length per memory cycleramulator.in_queue_read_req_num_avg 1.172414 # Average of read queue length per memory cycleramulator.in_queue_write_req_num_avg 0.724138 # Average of write queue length per memory cycleramulator.record_read_requests 0.0 # record read requests for this core when it reaches request limit or to the end[0] 0.0 # ramulator.record_write_requests 0.0 # record write requests for this core when it reaches request limit or to the end[0] 0.0 #
简单看下注释内容,如下:
| 分类 | 统计项 | 值 | 注释 |
|---|---|---|---|
| DRAM 活动周期和忙周期 | ramulator.active_cycles_0 | 57 | 级别 _0 的总活动周期 |
| DRAM 活动周期和忙周期 | ramulator.busy_cycles_0 | 57 | 级别 _0 的总忙周期(仅包括刷新时间) |
| DRAM 服务请求 | ramulator.serving_requests_0 | 148 | 级别 _0 每个内存周期内服务的读写请求总数 |
| DRAM 服务请求 | ramulator.average_serving_requests_0 | 2.551724 | 级别 _0 每个内存周期内服务的读写请求的平均数 |
| 多级统计 | ramulator.active_cycles_0_0 | 57 | 级别 _0_0 的总活动周期 |
| 多级统计 | ramulator.busy_cycles_0_0 | 57 | 级别 _0_0 的总忙周期(仅包括刷新时间) |
| 多级统计 | ramulator.serving_requests_0_0 | 148 | 级别 _0_0 每个内存周期内服务的读写请求总数 |
| 多级统计 | ramulator.average_serving_requests_0_0 | 2.551724 | 级别 _0_0 每个内存周期内服务的读写请求的平均数 |
| 读写事务字节数 | ramulator.read_transaction_bytes_0 | 192 | 每个通道的读事务总字节数 |
| 读写事务字节数 | ramulator.write_transaction_bytes_0 | 128 | 每个通道的写事务总字节数 |
| 行命中、未命中和冲突 | ramulator.row_hits_channel_0_core | 0 | 每个通道每个核心的行命中次数 |
| 行命中、未命中和冲突 | ramulator.row_misses_channel_0_core | 4 | 每个通道每个核心的行未命中次数 |
| 行命中、未命中和冲突 | ramulator.row_conflicts_channel_0_core | 1 | 每个通道每个核心的行冲突次数 |
| 读写队列长度 | ramulator.req_queue_length_avg_0 | 1.896552 | 每个通道每个内存周期内读写队列长度的平均值 |
| 读写队列长度 | ramulator.req_queue_length_sum_0 | 110 | 每个通道每个内存周期内读写队列长度的总和 |
| DRAM 容量和周期 | ramulator.dram_capacity | 2147483648 | 模拟的 DRAM 容量(字节) |
| DRAM 容量和周期 | ramulator.dram_cycles | 58 | 模拟的 DRAM 周期数 |
| 其他统计信息 | ramulator.incoming_requests | 5 | 到达 DRAM 的请求数 |
| 其他统计信息 | ramulator.read_requests | 3 | 每个核心到达 DRAM 的读请求数 |
| 其他统计信息 | ramulator.write_requests | 2 | 每个核心到达 DRAM 的写请求数 |
| 队列长度统计 | ramulator.in_queue_req_num_sum | 110 | 读写队列长度的总和 |
| 队列长度统计 | ramulator.in_queue_read_req_num_sum | 68 | 读队列长度的总和 |
| 队列长度统计 | ramulator.in_queue_write_req_num_sum | 42 | 写队列长度的总和 |
| 平均队列长度 | ramulator.in_queue_req_num_avg | 1.896552 | 每个内存周期内读写队列长度的平均值 |
| 平均队列长度 | ramulator.in_queue_read_req_num_avg | 1.172414 | 每个内存周期内读队列长度的平均值 |
| 平均队列长度 | ramulator.in_queue_write_req_num_avg | 0.724138 | 每个内存周期内写队列长度的平均值 |
my_output_DDR3_mode_cpu.txt的内容如下:
ramulator.active_cycles_0 122445958 # Total active cycles for level _0ramulator.busy_cycles_0 122445958 # (All-bank refresh only. busy cycles only include refresh time in rank level) The sum of cycles that the DRAM part is active or under refresh for level _0ramulator.serving_requests_0 429759559 # The sum of read and write requests that are served in this DRAM element per memory cycle for level _0ramulator.average_serving_requests_0 2.273115 # The average of read and write requests that are served in this DRAM element per memory cycle for level _0ramulator.active_cycles_0_0 122445958 # Total active cycles for level _0_0ramulator.busy_cycles_0_0 126324102 # (All-bank refresh only. busy cycles only include refresh time in rank level) The sum of cycles that the DRAM part is active or under refresh for level _0_0ramulator.serving_requests_0_0 429759559 # The sum of read and write requests that are served in this DRAM element per memory cycle for level _0_0ramulator.average_serving_requests_0_0 2.273115 # The average of read and write requests that are served in this DRAM element per memory cycle for level _0_0ramulator.active_cycles_0_0_0 106259048 # Total active cycles for level _0_0_0ramulator.busy_cycles_0_0_0 106259048 # (All-bank refresh only. busy cycles only include refresh time in rank level) The sum of cycles that the DRAM part is active or under refresh for level _0_0_0ramulator.serving_requests_0_0_0 107522760 # The sum of read and write requests that are served in this DRAM element per memory cycle for level _0_0_0
ramulator.average_serving_requests_0_0_0 0.568717 # The average of read and write requests that are served in this DRAM element per memory cycle for level _0_0_0ramulator.active_cycles_0_0_1 104663261 # Total active cycles for level _0_0_1ramulator.busy_cycles_0_0_1 104663261 # (All-bank refresh only. busy cycles only include refresh time in rank level) The sum of cycles that the DRAM part is active or under refresh for level _0_0_1ramulator.serving_requests_0_0_1 107556805 # The sum of read and write requests that are served in this DRAM element per memory cycle for level _0_0_1
ramulator.average_serving_requests_0_0_1 0.568897 # The average of read and write requests that are served in this DRAM element per memory cycle for level _0_0_1ramulator.active_cycles_0_0_2 0 # Total active cycles for level _0_0_2ramulator.busy_cycles_0_0_2 0 # (All-bank refresh only. busy cycles only include refresh time in rank level) The sum of cycles that the DRAM part is active or under refresh for level _0_0_2ramulator.serving_requests_0_0_2 0 # The sum of read and write requests that are served in this DRAM element per memory cycle for level _0_0_2
ramulator.average_serving_requests_0_0_2 0.000000 # The average of read and write requests that are served in this DRAM element per memory cycle for level _0_0_2ramulator.active_cycles_0_0_3 115429984 # Total active cycles for level _0_0_3ramulator.busy_cycles_0_0_3 115429984 # (All-bank refresh only. busy cycles only include refresh time in rank level) The sum of cycles that the DRAM part is active or under refresh for level _0_0_3ramulator.serving_requests_0_0_3 214679974 # The sum of read and write requests that are served in this DRAM element per memory cycle for level _0_0_3
ramulator.average_serving_requests_0_0_3 1.135501 # The average of read and write requests that are served in this DRAM element per memory cycle for level _0_0_3ramulator.active_cycles_0_0_4 0 # Total active cycles for level _0_0_4ramulator.busy_cycles_0_0_4 0 # (All-bank refresh only. busy cycles only include refresh time in rank level) The sum of cycles that the DRAM part is active or under refresh for level _0_0_4ramulator.serving_requests_0_0_4 0 # The sum of read and write requests that are served in this DRAM element per memory cycle for level _0_0_4
ramulator.average_serving_requests_0_0_4 0.000000 # The average of read and write requests that are served in this DRAM element per memory cycle for level _0_0_4ramulator.active_cycles_0_0_5 0 # Total active cycles for level _0_0_5ramulator.busy_cycles_0_0_5 0 # (All-bank refresh only. busy cycles only include refresh time in rank level) The sum of cycles that the DRAM part is active or under refresh for level _0_0_5ramulator.serving_requests_0_0_5 0 # The sum of read and write requests that are served in this DRAM element per memory cycle for level _0_0_5
ramulator.average_serving_requests_0_0_5 0.000000 # The average of read and write requests that are served in this DRAM element per memory cycle for level _0_0_5ramulator.active_cycles_0_0_6 0 # Total active cycles for level _0_0_6ramulator.busy_cycles_0_0_6 0 # (All-bank refresh only. busy cycles only include refresh time in rank level) The sum of cycles that the DRAM part is active or under refresh for level _0_0_6ramulator.serving_requests_0_0_6 0 # The sum of read and write requests that are served in this DRAM element per memory cycle for level _0_0_6
ramulator.average_serving_requests_0_0_6 0.000000 # The average of read and write requests that are served in this DRAM element per memory cycle for level _0_0_6ramulator.active_cycles_0_0_7 0 # Total active cycles for level _0_0_7ramulator.busy_cycles_0_0_7 0 # (All-bank refresh only. busy cycles only include refresh time in rank level) The sum of cycles that the DRAM part is active or under refresh for level _0_0_7ramulator.serving_requests_0_0_7 0 # The sum of read and write requests that are served in this DRAM element per memory cycle for level _0_0_7
ramulator.average_serving_requests_0_0_7 0.000000 # The average of read and write requests that are served in this DRAM element per memory cycle for level _0_0_7ramulator.read_transaction_bytes_0 1828569600 # The total byte of read transaction per channelramulator.write_transaction_bytes_0 914284416 # The total byte of write transaction per channelramulator.row_hits_channel_0_core 42766197 # Number of row hits per channel per coreramulator.row_misses_channel_0_core 90897 # Number of row misses per channel per coreramulator.row_conflicts_channel_0_core 0 # Number of row conflicts per channel per coreramulator.read_row_hits_channel_0_core 28491232 # Number of row hits for read requests per channel per core[0] 28491232.0 #
ramulator.read_row_misses_channel_0_core 80168 # Number of row misses for read requests per channel per core[0] 80168.0 #
ramulator.read_row_conflicts_channel_0_core 0 # Number of row conflicts for read requests per channel per core[0] 0.0 # ramulator.write_row_hits_channel_0_core 14274965 # Number of row hits for write requests per channel per core[0] 14274965.0 #
ramulator.write_row_misses_channel_0_core 10729 # Number of row misses for write requests per channel per core[0] 10729.0 #
ramulator.write_row_conflicts_channel_0_core 0 # Number of row conflicts for write requests per channel per core[0] 0.0 # ramulator.useless_activates_0_core 0 # Number of useless activations. E.g, ACT -> PRE w/o RD or WRramulator.read_latency_avg_0 151.034782 # The average memory latency cycles (in memory time domain) per request for all read requests in this channelramulator.read_latency_sum_0 6472919250 # The memory latency cycles (in memory time domain) sum for all read requests in this channelramulator.req_queue_length_avg_0 50.407613 # Average of read and write queue length per memory cycle per channel.ramulator.req_queue_length_sum_0 9530162547 # Sum of read and write queue length per memory cycle per channel.ramulator.read_req_queue_length_avg_0 35.435893 # Read queue length average per memory cycle per channel.ramulator.read_req_queue_length_sum_0 6699579776 # Read queue length sum per memory cycle per channel.ramulator.write_req_queue_length_avg_0 14.971719 # Write queue length average per memory cycle per channel.ramulator.write_req_queue_length_sum_0 2830582771 # Write queue length sum per memory cycle per channel.ramulator.record_read_hits 28491232.0 # record read hit count for this core when it reaches request limit or to the end[0] 28491232.0 # ramulator.record_read_misses 80168.0 # record_read_miss count for this core when it reaches request limit or to the end[0] 80168.0 # ramulator.record_read_conflicts 0.0 # record read conflict count for this core when it reaches request limit or to the end[0] 0.0 # ramulator.record_write_hits 14274965.0 # record write hit count for this core when it reaches request limit or to the end[0] 14274965.0 # ramulator.record_write_misses 10729.0 # record write miss count for this core when it reaches request limit or to the end[0] 10729.0 # ramulator.record_write_conflicts 0.0 # record write conflict for this core when it reaches request limit or to the end[0] 0.0 # ramulator.dram_capacity 2147483648 # Number of bytes in simulated DRAMramulator.dram_cycles 189061970 # Number of DRAM cycles simulatedramulator.incoming_requests 57142857 # Number of incoming requests to DRAMramulator.read_requests 42857143 # Number of incoming read requests to DRAM per core[0] 42857143.0 # ramulator.write_requests 14285714 # Number of incoming write requests to DRAM per core[0] 14285714.0 # ramulator.ramulator_active_cycles 122445958 # The total number of cycles that the DRAM part is active (serving R/W)ramulator.incoming_requests_per_channel 57142857.0 # Number of incoming requests to each DRAM channel[0] 57142857.0 #
ramulator.incoming_read_reqs_per_channel 42857143.0 # Number of incoming read requests to each DRAM channel[0] 42857143.0 # ramulator.physical_page_replacement 0 # The number of times that physical page replacement happens.ramulator.maximum_bandwidth 12800000000 # The theoretical maximum bandwidth (Bps)ramulator.in_queue_req_num_sum 9530162547 # Sum of read/write queue lengthramulator.in_queue_read_req_num_sum 6699579776 # Sum of read queue lengthramulator.in_queue_write_req_num_sum 2830582771 # Sum of write queue lengthramulator.in_queue_req_num_avg 50.407613 # Average of read/write queue length per memory cycleramulator.in_queue_read_req_num_avg 35.435893 # Average of read queue length per memory cycleramulator.in_queue_write_req_num_avg 14.971719 # Average of write queue length per memory cycleramulator.record_read_requests 42857143.0 # record read requests for this core when it reaches request limit or to the end[0] 42857143.0 # ramulator.record_write_requests 14285714.0 # record write requests for this core when it reaches request limit or to the end[0] 14285714.0 # ramulator.L3_cache_read_miss 0 # cache read miss countramulator.L3_cache_write_miss 0 # cache write miss countramulator.L3_cache_total_miss 0 # cache total miss countramulator.L3_cache_eviction 0 # number of evict from this level to lower levelramulator.L3_cache_read_access 0 # cache read access countramulator.L3_cache_write_access 0 # cache write access countramulator.L3_cache_total_access 0 # cache total access countramulator.L3_cache_mshr_hit 0 # cache mshr hit countramulator.L3_cache_mshr_unavailable 0 # cache mshr not available countramulator.L3_cache_set_unavailable 0 # cache set not availableramulator.cpu_cycles 756247878 # cpu cycle numberramulator.record_cycs_core_0 756247878 # Record cycle number for calculating weighted speedup. (Only valid when expected limit instruction number is non zero in config file.)ramulator.record_insts_core_0 200000000 # Retired instruction number when record cycle number. (Only valid when expected limit instruction number is non zero in config file.)ramulator.memory_access_cycles_core_0 184376713 # memory access cycles in memory time domainramulator.cpu_instructions_core_0 200000000 # cpu instruction number
同前面相同的操作,如下:
| 分类 | 统计项 | 值 | 注释 |
|---|---|---|---|
| DRAM 活动周期和忙周期 | ramulator.active_cycles_0 | 122445958 | 级别 _0 的总活动周期 |
| DRAM 活动周期和忙周期 | ramulator.busy_cycles_0 | 122445958 | 级别 _0 的总忙周期(仅包括刷新时间) |
| DRAM 服务请求 | ramulator.serving_requests_0 | 429759559 | 级别 _0 每个内存周期内服务的读写请求总数 |
| DRAM 服务请求 | ramulator.average_serving_requests_0 | 2.273115 | 级别 _0 每个内存周期内服务的读写请求的平均数 |
| 多级统计 | ramulator.active_cycles_0_0 | 122445958 | 级别 _0_0 的总活动周期 |
| 多级统计 | ramulator.busy_cycles_0_0 | 126324102 | 级别 _0_0 的总忙周期(仅包括刷新时间) |
| 多级统计 | ramulator.serving_requests_0_0 | 429759559 | 级别 _0_0 每个内存周期内服务的读写请求总数 |
| 多级统计 | ramulator.average_serving_requests_0_0 | 2.273115 | 级别 _0_0 每个内存周期内服务的读写请求的平均数 |
| 多级统计 | ramulator.active_cycles_0_0_0 | 106259048 | 级别 _0_0_0 的总活动周期 |
| 多级统计 | ramulator.busy_cycles_0_0_0 | 106259048 | 级别 _0_0_0 的总忙周期(仅包括刷新时间) |
| 多级统计 | ramulator.serving_requests_0_0_0 | 107522760 | 级别 _0_0_0 每个内存周期内服务的读写请求总数 |
| 多级统计 | ramulator.average_serving_requests_0_0_0 | 0.568717 | 级别 _0_0_0 每个内存周期内服务的读写请求的平均数 |
| 多级统计 | ramulator.active_cycles_0_0_1 | 104663261 | 级别 _0_0_1 的总活动周期 |
| 多级统计 | ramulator.busy_cycles_0_0_1 | 104663261 | 级别 _0_0_1 的总忙周期(仅包括刷新时间) |
| 多级统计 | ramulator.serving_requests_0_0_1 | 107556805 | 级别 _0_0_1 每个内存周期内服务的读写请求总数 |
| 多级统计 | ramulator.average_serving_requests_0_0_1 | 0.568897 | 级别 _0_0_1 每个内存周期内服务的读写请求的平均数 |
| 多级统计 | ramulator.active_cycles_0_0_2 | 0 | 级别 _0_0_2 的总活动周期 |
| 多级统计 | ramulator.busy_cycles_0_0_2 | 0 | 级别 _0_0_2 的总忙周期(仅包括刷新时间) |
| 多级统计 | ramulator.serving_requests_0_0_2 | 0 | 级别 _0_0_2 每个内存周期内服务的读写请求总数 |
| 多级统计 | ramulator.average_serving_requests_0_0_2 | 0.000000 | 级别 _0_0_2 每个内存周期内服务的读写请求的平均数 |
| 多级统计 | ramulator.active_cycles_0_0_3 | 115429984 | 级别 _0_0_3 的总活动周期 |
| 多级统计 | ramulator.busy_cycles_0_0_3 | 115429984 | 级别 _0_0_3 的总忙周期(仅包括刷新时间) |
| 多级统计 | ramulator.serving_requests_0_0_3 | 214679974 | 级别 _0_0_3 每个内存周期内服务的读写请求总数 |
| 多级统计 | ramulator.average_serving_requests_0_0_3 | 1.135501 | 级别 _0_0_3 每个内存周期内服务的读写请求的平均数 |
| 多级统计 | ramulator.active_cycles_0_0_4 | 0 | 级别 _0_0_4 的总活动周期 |
| 多级统计 | ramulator.busy_cycles_0_0_4 | 0 | 级别 _0_0_4 的总忙周期(仅包括刷新时间) |
| 多级统计 | ramulator.serving_requests_0_0_4 | 0 | 级别 _0_0_4 每个内存周期内服务的读写请求总数 |
| 多级统计 | ramulator.average_serving_requests_0_0_4 | 0.000000 | 级别 _0_0_4 每个内存周期内服务的读写请求的平均数 |
| 多级统计 | ramulator.active_cycles_0_0_5 | 0 | 级别 _0_0_5 的总活动周期 |
| 多级统计 | ramulator.busy_cycles_0_0_5 | 0 | 级别 _0_0_5 的总忙周期(仅包括刷新时间) |
| 多级统计 | ramulator.serving_requests_0_0_5 | 0 | 级别 _0_0_5 每个内存周期内服务的读写请求总数 |
| 多级统计 | ramulator.average_serving_requests_0_0_5 | 0.000000 | 级别 _0_0_5 每个内存周期内服务的读写请求的平均数 |
| 多级统计 | ramulator.active_cycles_0_0_6 | 0 | 级别 _0_0_6 的总活动周期 |
| 多级统计 | ramulator.busy_cycles_0_0_6 | 0 | 级别 _0_0_6 的总忙周期(仅包括刷新时间) |
| 多级统计 | ramulator.serving_requests_0_0_6 | 0 | 级别 _0_0_6 每个内存周期内服务的读写请求总数 |
| 多级统计 | ramulator.average_serving_requests_0_0_6 | 0.000000 | 级别 _0_0_6 每个内存周期内服务的读写请求的平均数 |
| 多级统计 | ramulator.active_cycles_0_0_7 | 0 | 级别 _0_0_7 的总活动周期 |
| 多级统计 | ramulator.busy_cycles_0_0_7 | 0 | 级别 _0_0_7 的总忙周期(仅包括刷新时间) |
| 多级统计 | ramulator.serving_requests_0_0_7 | 0 | 级别 _0_0_7 每个内存周期内服务的读写请求总数 |
| 多级统计 | ramulator.average_serving_requests_0_0_7 | 0.000000 | 级别 _0_0_7 每个内存周期内服务的读写请求的平均数 |
| 读写事务字节数 | ramulator.read_transaction_bytes_0 | 1828569600 | 每个通道的读事务总字节数 |
| 读写事务字节数 | ramulator.write_transaction_bytes_0 | 914284416 | 每个通道的写事务总字节数 |
| 行命中、未命中和冲突 | ramulator.row_hits_channel_0_core | 42766197 | 每个通道每个核心的行命中次数 |
| 行命中、未命中和冲突 | ramulator.row_misses_channel_0_core | 90897 | 每个通道每个核心的行未命中次数 |
| 行命中、未命中和冲突 | ramulator.row_conflicts_channel_0_core | 0 | 每个通道每个核心的行冲突次数 |
| 行命中、未命中和冲突 | ramulator.read_row_hits_channel_0_core | 28491232 | 每个通道每个核心的读行命中次数 |
| 行命中、未命中和冲突 | ramulator.read_row_misses_channel_0_core | 80168 | 每个通道每个核心的读行未命中次数 |
| 行命中、未命中和冲突 | ramulator.read_row_conflicts_channel_0_core | 0 | 每个通道每个核心的读行冲突次数 |
| 行命中、未命中和冲突 | ramulator.write_row_hits_channel_0_core | 14274965 | 每个通道每个核心的写行命中次数 |
| 行命中、未命中和冲突 | ramulator.write_row_misses_channel_0_core | 10729 | 每个通道每个核心的写行未命中次数 |
| 行命中、未命中和冲突 | ramulator.write_row_conflicts_channel_0_core | 0 | 每个通道每个核心的写行冲突次数 |
| 其他统计信息 | ramulator.useless_activates_0_core | 0 | 无用激活次数 |
| 其他统计信息 | ramulator.read_latency_avg_0 | 151.034782 | 每个通道的平均读延迟(内存时间域) |
| 其他统计信息 | ramulator.read_latency_sum_0 | 6472919250 | 每个通道的读延迟总和(内存时间域) |
| 读写队列长度 | ramulator.req_queue_length_avg_0 | 50.407613 | 每个通道每个内存周期内读写队列长度的平均值 |
| 读写队列长度 | ramulator.req_queue_length_sum_0 | 9530162547 | 每个通道每个内存周期内读写队列长度的总和 |
| 读写队列长度 | ramulator.read_req_queue_length_avg_0 | 35.435893 | 每个通道每个内存周期内读队列长度的平均值 |
| 读写队列长度 | ramulator.read_req_queue_length_sum_0 | 6699579776 | 每个通道每个内存周期内读队列长度的总和 |
| 读写队列长度 | ramulator.write_req_queue_length_avg_0 | 14.971719 | 每个通道每个内存周期内写队列长度的平均值 |
| 读写队列长度 | ramulator.write_req_queue_length_sum_0 | 2830582771 | 每个通道每个内存周期内写队列长度的总和 |
| DRAM 容量和周期 | ramulator.dram_capacity | 2147483648 | 模拟的 DRAM 容量(字节) |
| DRAM 容量和周期 | ramulator.dram_cycles | 189061970 | 模拟的 DRAM 周期数 |
| 其他统计信息 | ramulator.incoming_requests | 57142857 | 到达 DRAM 的请求数 |
| 其他统计信息 | ramulator.read_requests | 42857143 | 每个核心到达 DRAM 的读请求数 |
| 其他统计信息 | ramulator.write_requests | 14285714 | 每个核心到达 DRAM 的写请求数 |
| 队列长度统计 | ramulator.in_queue_req_num_sum | 9530162547 | 读写队列长度的总和 |
| 队列长度统计 | ramulator.in_queue_read_req_num_sum | 6699579776 | 读队列长度的总和 |
| 队列长度统计 | ramulator.in_queue_write_req_num_sum | 2830582771 | 写队列长度的总和 |
| 平均队列长度 | ramulator.in_queue_req_num_avg | 50.407613 | 每个内存周期内读写队列长度的平均值 |
| 平均队列长度 | ramulator.in_queue_read_req_num_avg | 35.435893 | 每个内存周期内读队列长度的平均值 |
| 平均队列长度 | ramulator.in_queue_write_req_num_avg | 14.971719 | 每个内存周期内写队列长度的平均值 |
以上关于Ramulator的介绍暂时到此为止!
2.4 额外牵扯到的GEM5
2.4.1 GEM5简单介绍
GEM5模拟器是一个用于计算机系统架构研究的模块化平台,涵盖了系统级架构以及处理器微架构。它主要用于评估新的硬件设计、系统软件变更,以及编译时和运行时的系统优化。
2.4.2 GEM5的源代码树
主源代码树包括以下子目录:
- build_opts:gem5 的预设默认配置
- build_tools:gem5 构建过程内部使用的工具
- configs:示例模拟配置脚本
- ext:构建 gem5 所需的不太常见的外部包
- include:供其他程序使用的头文件
- site_scons:构建系统的模块化组件
- src:gem5 模拟器的源代码。C++ 源代码、Python 包装器和 Python 标准库都位于此目录中。
- system:为模拟系统提供的一些可选系统软件的源代码
- tests:回归测试
- util:有用的工具程序和文件
因为GEM5模拟器确实很复杂,我暂时不想牵扯太多,只把前面与Ramulator相关的GEM5进行跑通!
2.4.3 基于gem5驱动的ramulator尝试
这个有点棘手,放到下一篇展开!遇到了不少bug,得修一修!
总结
这一篇为分析RTL代码做了点准备,探索了blackbox.sh的输入输出,ramulator的输入输出以及简单介绍了GEM5。
挖了不少坑:
1、xrt和opae两种驱动模式得到的cycles不一样;
2、HBM2的两个channel的trace情况探讨。
留给下一篇的:
1、trace_csv.py解读;
2、demo下的四个文件解读;
3、基于gem5驱动的ramulator尝试。
相关文章:
)
Vortex GPGPU的github流程跑通与功能模块波形探索(三)
文章目录 前言一、./build/ci下的文件结构二、基于驱动进行仿真过程牵扯的文件2.1 blackbox.sh文件2.2 demo文件2.3 额外牵扯到的ramulator2.3.1 ramulator简单介绍2.3.2 ramulator使用方法2.3.3 ramulator的输出2.3.4 ramulator的复现2.3.4.1 调试与验证(第 4.1 节…...

Ubuntu 安装 Node.js 指定版本指南
Ubuntu 安装 Node.js 指定版本指南(适用于生产与开发环境) 在没有安装 NVM 的服务器环境中(如 Docker、CI/CD、虚拟机等),建议使用 Node.js 官方的二进制包源(PPA)来快速安装特定版本的 Node.j…...

使用 Java 开发 Android 应用:Kotlin 与 Java 的混合编程
使用 Java 开发 Android 应用:Kotlin 与 Java 的混合编程 在开发 Android 应用程序时,我们通常可以选择使用 Java 或 Kotlin 作为主要的编程语言。然而,有些开发者可能会想要在同一个项目中同时使用这两种语言,这就是所谓的混合编…...

安防监控网络摄像机画面异常问题与视频监控管理平台EasyCVR应用
一、方案背景 在安防监控领域,画面卡顿、时有时无等问题犹如隐藏的潜在风险点,不仅严重干扰监控系统的正常运行,更可能在安全防护的关键时刻出现故障,让潜在的风险与隐患有机可乘。想要彻底攻克这些顽疾,就需要我们抽…...

MATLAB中进行语音信号分析
在MATLAB中进行语音信号分析是一个涉及多个步骤的过程,包括时域和频域分析、加窗、降噪滤波、端点检测以及特征提取等。 1. 加载和预览语音信号 首先,你需要加载一个语音信号文件。MATLAB支持多种音频文件格式,如.wav。 [y, fs] audiorea…...
)
Kotlin 协程 (三)
协程通信是协程之间进行数据交换和同步的关键机制。Kotlin 协程提供了多种通信方式,使得协程能够高效、安全地进行交互。以下是对协程通信的详细讲解,包括常见的通信原语、使用场景和示例代码。 1.1 Channel 定义:Channel 是一个消息队列&a…...

AI 商业化部署中,ollama 和 vllm 的选型对比
介绍 ollama Ollama是指一个开源的大模型服务工具,旨在简化大型语言模型(LLM)的本地部署、运行和管理。它让用户能够在本地设备上轻松运行和管理各种大语言模型,无需依赖云端服务。 vllm 在深度学习推理领域,vLLM框…...

mysql的乐观锁与悲观锁
1.悲观锁 含义:假设会发生冲突,因此在操作数据之前对数据加锁,确保其他事务无法访问该数据。 应用场景:适用于并发冲突多,写多读少的场景,通过加锁的方式确保数据的安全性。 实现方式:使用行…...

进程——概念及状态
目录 概念 介绍 举例 进程状态 概念 解释 实例 R S T t Z 孤儿进程 概念 介绍 大多数初学者会认为进程就是从硬盘加载到内存的可执行文件(当可执行文件被加载到内存里称为程序),实际上并不是这样的,进程其实是操作系…...

服务器数据恢复—Linux系统服务器崩溃且重装系统的数据恢复案例
服务器数据恢复环境: linux操作系统服务器中有一组由4块SAS接口硬盘组建的raid5阵列。 服务器故障: 服务器工作过程中突然崩溃。管理员将服务器操作系统进行了重装。 用户方需要恢复服务器中的数据库、办公文档、代码文件等。 服务器数据恢复过程&#…...

【git】git commit模板
【git】git commit模板 目录 【git】git commit模板1.使用git commit 模板操作步骤:使用示例: 2. gitlab merge 模板 1.使用git commit 模板 操作步骤: 设置模板路径,其中path就是commit模板路径 git config --global commit.template path设…...
以及驱动电路设计注意事项)
IGBT选型时需关注的参数,适用场景(高压大电流低频)以及驱动电路设计注意事项
概述 IGBT(绝缘栅双极型晶体管)是电力控制和电力转换的核心器件,是由BJT(双极型晶体管)和MOS(绝缘栅型场效应管)组成的复合全控型电压驱动式功率半导体器件。有高输入阻抗(MOSFET优点…...
)
hghac集群服务器时间同步(chrony同步)
文章目录 环境文档用途详细信息 环境 系统平台:银河麒麟(龙芯)svs,银河麒麟 (X86_64),银河麒麟 (飞腾),银河麒麟 (鲲鹏),银河麒麟 (海光),银河麒…...

Linux 特权管理与安全——从启用 Root、Sudo 提权到禁用与防护的全景解析
一、前言 为什么关注特权? Root(超级用户)拥有系统所有权限,一旦被滥用或入侵,后果不堪设想。运维与安全的平衡 既需要日常运维中快速提权执行管理任务,又要避免过度开放特权带来的风险。攻防同源理念 了解…...

初识Linux · 数据链路层
目录 前言: 以太网帧协议 ARP协议 ARP协议理解 ARP协议字段 交换机 前言: 前文我们通过OSI模型,一直到TCP/IP四层模型,经过了三篇文章左右的功夫,我们把网络层介绍完毕,主要还是介绍的IP协议的iphdr…...

Linux探秘:驾驭开源,解锁高效能——基础指令
♥♥♥~~~~~~欢迎光临知星小度博客空间~~~~~~♥♥♥ ♥♥♥零星地变得优秀~也能拼凑出星河~♥♥♥ ♥♥♥我们一起努力成为更好的自己~♥♥♥ ♥♥♥如果这一篇博客对你有帮助~别忘了点赞分享哦~♥♥♥ ♥♥♥如果有什么问题可以评论区留言或者私信我哦~♥♥♥ ✨✨✨✨✨✨ 个…...

【Linux】第二十二章 访问网络附加内存
1. NFS的主要功能是什么? NFS是由Linux、UNIX及类似操作系统使用的互联网标准协议,主要功能就是提供网络文件共享,允许不同的计算机系统之间通过网络共享文件,它使得网络上的计算机能够像访问本地文件系统一样访问远程计算机上的…...

Revit BIM 模型批量转换为 Datasmith 格式教程
Revit BIM 模型批量转换为 Datasmith 格式教程 一、背景与痛点 在建筑信息模型(BIM)与游戏开发的协同工作中,常需将 Revit 模型导入虚幻引擎(UE)。虽然 Revit 的 Datasmith 插件可实现单文件转换,但面对成百上千个模型时,手动操作效率极低。本文将分享如何开发一个自动…...

Linux 磁盘扩容实战案例:从问题发现到完美解决
Linux 磁盘扩容实战案例:从问题发现到完美解决 案例背景 某企业服务器根目录 (/) 空间不足,运维人员通过 df -h 发现 /dev/vda1 分区已 100% 占满(99G 已用)。检查发现物理磁盘 /dev/vda 已扩展至 200G,但分区和文件…...

Linux 系统不终止进程的情况下关闭长连接
使用 tcpkill 中断指定 TCP 连接 适用场景:需主动中断已知源IP或目标端口的连接,无需进程重启。 安装 dsniff 工具(包含 tcpkill): yum -y install dsniff 捕获并杀死特定连接(例如目标IP 192.168.1.10…...

从零开始创建React项目及制作页面
一、React 介绍 React 是一个由 Meta(原Facebook) 开发和维护的 开源JavaScript库,主要用于构建用户界面(User Interface, UI)。它是前端开发中最流行的工具之一,广泛应用于单页应用程序(SPA&a…...

Unity-编辑器扩展
之前我们关于Unity的讨论都是针对于Unity底层的内容或者是代码层面的东西,这一次我们来专门研究Unity可视化的编辑器,在已有的基础上做一些扩展。 基本功能 首先我们来认识三个文件夹: Editor,Gizmos,Editor Defaul…...

系分论文《论遗产系统演化》
系统分析师论文范文系列 摘要 2022年6月,某金融机构启动核心业务系统的技术升级项目,旨在对其运行超过十年的遗留系统进行演化改造。该系统承担着账户管理、支付结算等关键业务功能,但其技术架构陈旧、扩展性不足,难以适应数字化转型与业务快速增长的需求。作为系统分析师,…...
Django 项目基础操作)
Django基础(二)Django 项目基础操作
一、实验目标 熟悉 Django 基本命令 理解 Django 项目和应用的目录结构 掌握项目初始化、应用创建与注册、项目启动、视图函数编写、路由配置、数据库配置等基础操作 二、Django 项目初始化 进入虚拟环境 source venv/bin/activate创建 Django 项目 django-admin startproje…...

【图像大模型】Stable Video Diffusion:基于时空扩散模型的视频生成技术深度解析
Stable Video Diffusion:基于时空扩散模型的视频生成技术深度解析 一、架构设计与技术演进1.1 核心模型架构1.2 技术创新点1.2.1 运动预测网络1.2.2 层级式训练策略 二、系统架构解析2.1 完整生成流程2.2 性能指标对比 三、实战部署指南3.1 环境配置3.2 基础推理代码…...
远程线程注入)
【免杀】C2免杀技术(七)远程线程注入
远程线程注入(Remote Thread Injection)是一种常见的进程注入技术,经常用于红队渗透、恶意软件加载、持久化控制等场景中,尤其在免杀(AV/EDR bypass)应用领域中,是一种历史悠久但依然有效的手段…...

二、【环境搭建篇】:Django 和 Vue3 开发环境准备
【环境搭建篇】:Django 和 Vue3 开发环境准备 前言为什么我们需要特定的开发环境?准备工作第一步:搭建后端开发环境 (Python, Django, DRF)1. 安装 Python2. 创建和激活 Python 虚拟环境3. 在虚拟环境中安装 Django 和 DRF 第二步:…...

【神经网络与深度学习】激活函数的可微可导
引言: 在深度学习领域,激活函数扮演着至关重要的角色。它不仅影响神经网络的非线性建模能力,还直接关系到梯度计算的稳定性。在优化过程中,我们通常要求激活函数具有良好的数学性质,其中可微性是一个关键条件。相比简单…...
)
【Tauri2】046—— tauri_plugin_clipboard_manager(一)
目录 前言 正文 安装 Rust中的使用 对文字的操作 看看write_text的函数签名 看看read_text的函数签名 对图像的操作 对html的操作 总结 前言 这篇就来看看clipboard这个插件。 参考如下 Clipboard | Taurihttps://tauri.app/plugin/clipboard/ 正文 安装 执行下…...

高效选课系统:一键管理你的课程表
选课流程 数据模型 我的课程表Controller Api(value "我的课程表接口", tags "我的课程表接口") Slf4j RestController public class MyCourseTablesController {Autowiredprivate MyCourseTablesService myCourseTablesService;ApiOperation("添加…...

Pytorch分布式训练,数据并行,单机多卡,多机多卡
分布式训练 所有代码可以见我github 仓库:https://github.com/xiejialong/ddp_learning.git 数据并行(Data Parallelism,DP) 跨多个gpu训练模型的最简单方法是使用 torch.nn.DataParallel. 在这种方法中,模型被复制…...

Secarmy Village: Grayhat Conference靶场
Secarmy Village: Grayhat Conference 来自 <Secarmy Village: Grayhat Conference ~ VulnHub> 1,将两台虚拟机网络连接都改为NAT模式 2,攻击机上做namp局域网扫描发现靶机 nmap -sn 192.168.23.0/24 那么攻击机IP为192.168.23.182,靶…...

centos 9 Kickstart + Ansible自动化部署 —— 筑梦之路
目标 利用 Kickstart 完成 centos 9 系统的全自动安装(裸金属/虚拟机)。 安装完成后自动接入 Ansible 进行软件包、服务、用户、配置等系统初始化操作。 实现一套通用、可重复、可维护的自动化交付流程。 KS文件 # ks.cfg 示例 install lang zh_CN.…...

HarmonyOS应用开发入门宝典——项目驱动学习法实践
学习一项新技能,最好也是最快的方法就是动手实战。学习鸿蒙也一样,给自己定一个小目标,直接找项目练,这样进步是最快的。记住,最好的学习时机永远是现在,最好的老师永远是你正在开发的项目。 一、为什么选择…...

Python类的力量:第六篇:设计模式——Python面向对象编程的“架构蓝图”
文章目录 前言:从“代码堆砌”到“模式复用”的思维跃迁 一、创建型模式:对象创建的“智能工厂”1. 单例模式(Singleton):全局唯一的“资源管家”2. 工厂模式(Factory):对象创建的“…...

第50天-使用Python+Qt+DeepSeek开发AI运势测算
1. 环境准备 bash 复制 下载 pip install pyside6 requests python-dotenv 2. 获取DeepSeek API密钥 访问DeepSeek官网注册账号 进入控制台创建API密钥 在项目根目录创建.env文件: env 复制 下载 DEEPSEEK_API_KEY=your_api_key_here 3. 创建主应用框架 python 复制…...

CentOS系统上挂载磁盘
在CentOS系统上挂载磁盘,主要包括查看磁盘设备、分区(若需要)、格式化、创建挂载点和挂载等步骤,以下是详细操作: 1. 查看磁盘设备 使用fdisk -l或lsblk命令查看系统识别到的磁盘设备。 fdisk -l:列出所…...
 本地hadoop虚拟机系统设置)
(一) 本地hadoop虚拟机系统设置
1.配置固定IP地址(每一台都配置) 开启node1,修改主机名为node1,并修改固定IP为:192.168.88.131 # 修改主机名 hostnamectl set-hostname node1# 修改IP vim /etc/sysconfig/network-scripts/ifcfg-ens33 IPADDR"…...

亿级核心表如何优雅扩展字段
1 导语 亿级数据的核心表新增一个字段,远不止一句简单的“ALTER TABLE”,锁表风险、页分裂、索引性能衰减……每一个问题都可能引发线上事故。如何在不影响业务的前提下,只需简单的配置,即可实现字段的动态扩展?本文将…...

单端传输通道也会有奇偶模现象喔
奇模(Odd mode)与偶模(Even mode)对差动对是很关键的要素,其会影响奇/偶模阻抗与相位速度,设计不良甚会让共模噪声引入整个差动对使讯号质量下降。 然而对单端信号系统而言呢? 如果说一对side b…...

VUE3 中的 ResizeObserver 警告彻底解决方案
问题背景 今天在使用 Vue 3 Ant Design Vue 开发后台管理系统时,在页面频繁触发 元素尺寸变化(如表格滚动、窗口缩放) 的时候,控制台频繁出现如下警告: ResizeObserver loop completed with undelivered notificati…...

IDEA2025版本使用Big Data Tools连接Linux上Hadoop的HDFS
目录 Windows的准备 1. 将与Linux上版本相同的hadoop压缩包解压到本地 编辑2.设置$HADOOP HOME环境变量指向:E:\hadoop-3.3.4 3.下载hadoop.dll和winutils.exe文件 4.将hadoop.dll和winutils.exe放入$HADOOP HOME/bin中 IDEA中操作 1.下载Big Data Tools插件 2.添加并连…...

Gas优化利器:Merkle 树如何助力链上数据效率革命
目录 前言原理Merkle树示意图实战演示:构建 Merkle 树并在合约中验证离线构建 Merkle 树(手动计算Merkle树、生成mermaid示意图)编写Merkle.js脚本执行Merkle.js脚本执行结果展示mermaid流程图展示离线构建 Merkle 树(merkletreejs计算Merkle树、验证哈希路径)编写Merkle.…...

R语言空间分析实战:地理加权回归联合主成份与判别分析破解空间异质性难题
在自然和社会科学领域有大量与地理或空间有关的数据,这一类数据一般具有严重的空间异质性,而通常的统计学方法并不能处理空间异质性,因而对此类型的数据无能为力。以地理加权回归为基础的一系列方法:经典地理加权回归,…...
)
kafka入门(二)
Java客户端访问Kafka 引入maven依赖 <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka‐clients</artifactId> <version>2.4.1</version> </dependency> 消息发送端代码 package com.tuling.kafka.ka…...

学习日记-day11-5.20
完成目标: comment.java package com.zcr.pojo; import org.hibernate.annotations.GenericGenerator;import javax.persistence.*; //JPA操作表中数据,可以将对应的实体类映射到一张表上Entity(name "t_comment")//表示当前的实体类与哪张表…...

手淘不易被清洗销量的4个成交入口
在淘宝运营中,销量是店铺权重的重要指标之一,但平台对虚假交易的打击力度越来越大,许多商家因销量被清洗而损失惨重。那么,通过什么样的手淘成交入口稳定不易清洗呢?经过实测,我们总结了以下手淘4个不易被清…...

【Linux】Linux 多线程
目录 1. Linux线程概念2. 重谈进程地址空间---页表2.1 如何由虚拟地址转化为物理地址的 3. pthread库调用接口3.1 线程的创建---pthread_create3.2 线程等待---pthread_join3.3 线程的退出3.4 分离线程 4. 线程库5. 线程ID6. Linux线程互斥6.1 锁6.2 锁的接口6.2.1 互斥量的初始…...

DAY31
知识点回顾 规范的文件命名规范的文件夹管理机器学习项目的拆分编码格式和类型注解 作业:尝试针对之前的心脏病项目,准备拆分的项目文件,思考下哪些部分可以未来复用。 浙大疏锦行...

大模型应用开发“扫盲”——基于市场某款智能问数产品的技术架构进行解析与学习
本文将从一款问数产品相关技术架构,针对大模型应用开发中的基础知识进行“扫盲”式科普,文章比较适合新手小白,属于是我的学习笔记整理,大佬可以划走啦~产品关键信息已经进行模糊处理,如有侵权请联系删除。 文章目录 前…...