Pytorch分布式训练,数据并行,单机多卡,多机多卡
分布式训练
所有代码可以见我github 仓库:https://github.com/xiejialong/ddp_learning.git
数据并行(Data Parallelism,DP)
跨多个gpu训练模型的最简单方法是使用 torch.nn.DataParallel. 在这种方法中,模型被复制到所有可用的GPU上,并且所有进程都由第一个GPU(也称为主进程)管理。该方法将输入拆分到gpu上,并行计算梯度,并在主进程上更新模型参数之前对它们进行平均。更新后,主进程将更新后的参数广播给所有其他gpu。
DataParallel并不推荐,有以下原因:
- 额外开支较大:虽然它很容易使用,但它有一些通信开销,因为要等待所有gpu完成反向传播、收集梯度并广播更新的参数。为了获得更好的性能,特别是在扩展到多个节点时,请使用分布式数据并行
DistributedDataParallel(DDP)。 - 显存占用大:主GPU的内存使用率比其他GPU高,因为它收集了其他GPU的所有梯度。因此,如果您在单个GPU上已经存在内存问题,那么dataparlil将使其变得更糟。
注意,dataparllel在反向传播后平均gpu之间的梯度。确保相应地缩放学习率(乘以gpu的数量)以保持相同的有效学习率。这同样适用于批处理大小,提供给数据加载器的批处理大小在gpu上进行划分<
例子:
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
import osclass MyModel(nn.Module): # 模型定义def __init__(self):super().__init__()self.net = nn.Sequential(nn.Linear(10, 10000), nn.Linear(10000, 5000),nn.Linear(5000, 2))def forward(self, x):return self.net(x)class MyData(Dataset): # 数据集定义def __init__(self):super().__init__()self.data_x = torch.concat([torch.rand(size=(10000, 10)) + torch.zeros(size=(10000, 10)), torch.rand(size=(10000, 10)) + torch.ones(size=(10000, 10))], dim=0)self.data_y = torch.concat([torch.zeros(size=(10000, ), dtype=torch.long), torch.ones(size=(10000, ), dtype=torch.long)], dim=0)def __getitem__(self, index):x = self.data_x[index]y = self.data_y[index]return x, ydef __len__(self):return len(self.data_x)train_data = MyData() # 实例化数据集
train_loader = DataLoader(dataset=train_data, batch_size=64, shuffle=True)
model = MyModel() # 实例化模型
if torch.cuda.device_count() > 1:model = nn.DataParallel(model)
model = model.cuda()optimizer = optim.Adam(model.parameters(), lr=0.0001) # 定义优化器
criterion = nn.CrossEntropyLoss() # 定义评价器
print(len(train_loader))
for data, target in train_loader:data, target = data.cuda(), target.cuda() # 数据放入显卡optimizer.zero_grad() # 梯度归零output = model(data) # 模型推理loss = criterion(output, target) # 计算lossloss.backward() # 反向传播梯度optimizer.step() # 模型参数更新print(loss.item())
分布式数据并行(Distributed Data Parallelism, DDP)
为了获得更好的性能,PyTorch提供了torch.nn.parallel.distributedDataParallel(DDP),它对于多gpu训练更有效,特别是对于多节点设置。事实上,当使用DDP时,训练代码分别在每个GPU上执行,每个GPU直接与其他GPU通信,并且仅在必要时进行通信,从而减少了通信开销。在DDP方法中,主进程的作用大大减少,每个GPU负责自己的向前和向后传递,以及参数更新。向前传递后,开始向后传递,每个GPU开始将自己的梯度发送给所有其他GPU,每个GPU接收所有其他GPU的梯度之和。这个过程被称为all-reduce操作。之后,每个GPU都有完全相同的梯度,并更新其自己的模型副本的参数。Reduce:分布式计算中的一种常见操作,其中计算结果跨多个进程聚合。All -reduce意味着所有进程都调用Reduce操作来接收来自所有其他进程的结果。
基于torch.multiprocessing的启动方式
启动程序时不需要在命令行输入额外的参数,写起来也比较容易,但是调试较麻烦
import os
import torch
import torch.distributed as dist # 分布式库
import torch.multiprocessing as mp # 多线程
from torch.utils.data import Dataset, DataLoader, DistributedSampler # 数据集库
import torch.nn as nn # 网络结构库
import torch.optim as optim # 优化器库
from torch.amp import autocast, GradScaler # 混合精度库os.environ["CUDA_VISIBLE_DEVICES"]='2,3'scaler = GradScaler() # 自动缩放梯度class MyModel(nn.Module): # 模型定义def __init__(self):super().__init__()self.net = nn.Sequential(nn.Linear(10, 10000), nn.Linear(10000, 5000),nn.Linear(5000, 2))def forward(self, x):return self.net(x)class MyData(Dataset): # 数据集定义def __init__(self):super().__init__()self.data_x = torch.concat([torch.rand(size=(10000, 10)) + torch.zeros(size=(10000, 10)), torch.rand(size=(10000, 10)) + torch.ones(size=(10000, 10))], dim=0)self.data_y = torch.concat([torch.zeros(size=(10000, ), dtype=torch.long), torch.ones(size=(10000, ), dtype=torch.long)], dim=0)def __getitem__(self, index):x = self.data_x[index]y = self.data_y[index]return x, ydef __len__(self):return len(self.data_x)def worker(rank, world_size):dist.init_process_group("nccl", rank=rank, world_size=world_size) # 定义通信方式torch.cuda.set_device(rank) # 设置当前线程控制的GPUprint("init model")model = MyModel().cuda()print(f"init ddp rank {rank}")ddp_model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[rank]) traindata = MyData()train_sampler = DistributedSampler(dataset=traindata, shuffle=True) # 定义分布式数据采集器train_loader = DataLoader(traindata, batch_size=64,sampler=train_sampler, num_workers=4, pin_memory=True) # 定义数据加载器optimizer = optim.Adam(ddp_model.parameters(), lr=0.0001) # 定义优化器criterion = nn.CrossEntropyLoss() # 定义评价函数print("train")accumulation_steps = 4 # 设置梯度累计次数optimizer.zero_grad(set_to_none=True) # 重设梯度for batch_idx, (inp, target) in enumerate(train_loader):inp, target = inp.cuda(), target.cuda()with autocast(device_type="cuda"): # 开启混合精度训练output = ddp_model(inp)loss = criterion(output, target)loss = loss / accumulation_steps # 归一化损失scaler.scale(loss).backward() # 混合精度训练下进行损失缩放并执行后向传播if (batch_idx + 1) % accumulation_steps == 0:# optimizer.step() # 更新权重scaler.step(optimizer) # 混合精度下的权重更新scaler.update()optimizer.zero_grad(set_to_none=True) # 每次更新完进行梯度清零print(loss)dist.barrier()dist.destroy_process_group()if __name__ == "__main__":world_size = torch.cuda.device_count()mp.spawn(worker, nprocs=world_size, args=(world_size,))
启动多GPU训练的命令(高版本被移除rank):
python -m torch.distributed.launch --nproc_per_node=4 train.py
或使用torchrun
torchrun --nproc_per_node=4 train.py
基于torch.distributed的启动方式
一个完整的训练架构
参考:
https://blog.csdn.net/wxc971231/article/details/132827787
import os
import torch
import torch.nn as nn
import torch.optim as optim
import torch.distributed as dist
from torch.utils.data import Dataset, DataLoader, DistributedSampler
import argparse
import numpy as np
from tqdm import tqdm
os.environ["CUDA_VISIBLE_DEVICES"]="2,3"class MyModel(nn.Module): # 模型定义def __init__(self):super().__init__()self.net = nn.Sequential(nn.Linear(10, 10000), nn.Linear(10000, 5000),nn.Linear(5000, 2))def forward(self, x):return self.net(x)class MyData(Dataset): # 数据集定义def __init__(self):super().__init__()self.data_x = torch.concat([torch.rand(size=(10000, 10)) + torch.zeros(size=(10000, 10)), torch.rand(size=(10000, 10)) + torch.ones(size=(10000, 10))], dim=0)self.data_y = torch.concat([torch.zeros(size=(10000, ), dtype=torch.long), torch.ones(size=(10000, ), dtype=torch.long)], dim=0)def __getitem__(self, index):x = self.data_x[index]y = self.data_y[index]return x, ydef __len__(self):return len(self.data_x)def load_train_objs(ags):train_dataset = MyData() # 定义数据集train_sampler = DistributedSampler(train_dataset, num_replicas=ags.world_size, rank=ags.rank, shuffle=True) # 将数据集进行均分train_loader = DataLoader(train_dataset, batch_size=args.batch_size, sampler=train_sampler, pin_memory=True) # 定义数据加载器model = MyModel() # 定义模型model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model)model.to(ags.device)ddp_model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[ags.local_rank]) # 把模型放入不同的gpureturn train_loader, ddp_modeldef init_ddp_env(args):# 分布式同行环境初始化dist.init_process_group(backend='nccl', init_method="env://")# 获取全局/本地 rank、world_sizeargs.rank = int(os.environ.get("RANK", -1))args.local_rank = int(os.environ.get("LOCAL_RANK", -1))args.world_size = int(os.environ.get("WORLD_SIZE", -1))# 设置GPU显卡绑定torch.cuda.set_device(args.local_rank)args.device = torch.device("cuda")# 打印绑定信息print(f"[RANK {args.rank} | LOCAL_RANK {args.local_rank}] Using CUDA device {torch.cuda.current_device()}: {torch.cuda.get_device_name(torch.cuda.current_device())} | World size: {args.world_size}")dist.barrier() # 等待所有进程都初始化完毕,即所有GPU都要运行到这一步以后再继续class Trainer:def __init__(self, args, model: torch.nn.Module, train_loader: DataLoader, optimizer: torch.optim.Optimizer, criterion):self.model = modelself.train_loader = train_loaderself.optimizer = optimizerself.criterion = criterionself.device = args.deviceself.snapshot_path = args.snapshot_pathself.gpu_id = args.local_rankself.max_epochs = args.max_epochsself.save_every = args.save_everyself.epochs_run = 0if os.path.exists(args.resume_path):print('loading snapshot')self._load_snapshot(args.resume_path)def _load_snapshot(self, resume_path):''' 加载 snapshot 并重启训练 '''loc = f"cuda:{self.gpu_id}"snapshot = torch.load(resume_path, map_location=loc)self.model.load_state_dict(snapshot["MODEL_STATE"])self.epochs_run = snapshot["EPOCHS_RUN"]print(f"Resuming training from snapshot at Epoch {self.epochs_run}")def _run_batch(self, inp, targets):self.optimizer.zero_grad()output = self.model(inp)loss = self.criterion(output, targets)loss.backward()self.optimizer.step()return loss.item()def _run_epoch(self, epoch):epoch_losses = []self.train_loader.sampler.set_epoch(epoch) # 设置 epoch 保证多 GPU 上数据不重叠for inp, targets in self.train_loader:inp = inp.to(self.device)targets = targets.to(self.device)loss = self._run_batch(inp, targets)epoch_losses.append(loss)return np.mean(epoch_losses)def _save_snapshot(self, epoch):# 在 snapshot 中保存恢复训练所必须的参数snapshot = {"MODEL_STATE": self.model.state_dict(), # 由于多了一层 DDP 包装,通过 .module 获取原始参数 "EPOCHS_RUN": epoch,}save_path = os.path.join(self.snapshot_path, f"epoch_{epoch}.pt")torch.save(snapshot, save_path)# print(f"Epoch {epoch} | Training snapshot saved at {save_path}")def train(self):# 现在从 self.epochs_run 开始训练,统一重启的情况with tqdm(total=self.max_epochs, desc=f"[GPU{self.gpu_id}] Training", position=self.gpu_id, initial=self.epochs_run) as pbar:for epoch in range(self.epochs_run, self.max_epochs + self.epochs_run):epoch_loss = self._run_epoch(epoch) # 各个 GPU 上都在跑一样的训练进程,这里指定 rank0 进程保存 snapshot 以免重复保存if self.gpu_id == 0 and epoch % self.save_every == 0:self._save_snapshot(epoch)pbar.set_postfix({'epoch': epoch, 'loss':'{:.2f}'.format(epoch_loss)})pbar.update()def worker(args):init_ddp_env(args) # 初始化分布式环境train_loader, ddp_model = load_train_objs(args) # 导入分布式数据导入器和模型optimizer = optim.Adam(ddp_model.parameters(), lr=args.lr)criterion = nn.CrossEntropyLoss()trainer = Trainer(args, ddp_model, train_loader, optimizer, criterion)trainer.train()if __name__=="__main__":import argparseparser = argparse.ArgumentParser(description='simple distributed training job')parser.add_argument('--rank', default=-1, type=int, help='Rank (default: -1)')parser.add_argument('--world_size', default=1, type=int, help='world_size (default: -1)')parser.add_argument('--local_rank', default=-1, type=int, help='local_rank (default: 1)')parser.add_argument('--device', default="cuda", type=str, help='local_rank (default: 1)')parser.add_argument('--batch_size', default=32, type=int, help='Input batch size on each device (default: 32)')parser.add_argument('--lr', default=0.001, type=float, help='Learing rate (default: 0.001)')parser.add_argument('--snapshot_path', default="checkpoints/", type=str, help='Path of checkpoints (default: checkpoints/)')parser.add_argument('--save_every', default=1, type=int, help='Frequence of checkpoint save')parser.add_argument('--max_epochs', default=5, type=int, help='Total epoch')parser.add_argument('--resume_path', default="checkpoints/epoch_2.pt", type=str, help='Path of resume file')args = parser.parse_args()worker(args)# torchrun --nnodes=2 --nproc_per_node=2 --node_rank=0 --master_addr=xxx --master_port=xx xxx.py
# --nnodes: 表示参与训练的总机器数
# --nproc_per_node:表示每台机器上要启动几个训练进程,一个进程对应一个 GPU,因通常设置为你机器上要用到的GPU数。整个分布式环境下,总训练进程数 = nnodes * nproc_per_node
# --node_rank:表示当前机器是第几台机器,从 0 开始编号,必须每台机器都不同
# --master_addr 和 --master_port:指定主节点的 IP 和端口,用于 rendezvous(进程对齐)和通信初始化,所有机器必须填写相同的值!
多机多卡的启动和bash
参考:https://cloud.tencent.com/developer/article/2514642
下面是一个简单的分布式训练代码
import os
from time import sleep
import torch
import torch.distributed as dist
import torch.nn as nn
import torch.optim as optim
import datetimefrom torch.nn.parallel import DistributedDataParallel as DDPclass ToyModel(nn.Module):def __init__(self):super(ToyModel, self).__init__()self.net1 = nn.Linear(10, 10)self.relu = nn.ReLU()self.net2 = nn.Linear(10, 5)def forward(self, x):return self.net2(self.relu(self.net1(x)))def train():local_rank = int(os.environ["LOCAL_RANK"])rank = int(os.environ["RANK"])while True:print(f"[{os.getpid()}] (rank = {rank}, local_rank = {local_rank}) training...")model = ToyModel().cuda(local_rank)ddp_model = DDP(model, [local_rank])loss_fn = nn.MSELoss()optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)optimizer.zero_grad()outputs = ddp_model(torch.randn(20, 10).to(local_rank))labels = torch.randn(20, 5).to(local_rank)loss = loss_fn(outputs, labels)loss.backward()print(f"[{os.getpid()}] (rank = {rank}, local_rank = {local_rank}) loss = {loss.item()}\n")optimizer.step()sleep(1)def run():env_dict = {key: os.environ[key]for key in ("MASTER_ADDR", "MASTER_PORT", "WORLD_SIZE", "LOCAL_WORLD_SIZE")}print(f"[{os.getpid()}] Initializing process group with: {env_dict}")dist.init_process_group(backend="nccl", timeout=datetime.timedelta(seconds=30))train()dist.destroy_process_group()if __name__ == "__main__":run()
在多个主机上执行
torchrun --nproc_per_node=M --nnode=N --node_rank=0 --master_addr='xxx.xxx.xxx.xxx' --master_port=1234 ddp_multi_master.py
注意这里参数M表示你单个机器上的显卡数,N是你有几台机器,--node_rank,这里是不同机器上的区别,主机上设置0,其他机器上设置1,2,…,N-1.
也可以写bash文件执行更方便
#!/bin/bash
# 设置基本参数
MASTER_ADDR=xxx.xxx.xxx.xxx # 主机IP
MASTER_PORT=29400 # 主机端口
NNODES=2 # 参与训练的总机器数
NPROC_PER_NODE=2 # 每台机器上的进程数# 所有网卡的IP地址,用于筛选
ALL_LOCAL_IPS=$(hostname -I)
# 根据本机 IP 配置通信接口
if [[ "$ALL_LOCAL_IPS" == *"xxx.xxx.xxx.xxx"* ]]; thenNODE_RANK=0 # 表示当前机器是第0台机器IFNAME=eno1 # 机器0的网卡名称mytorchrun=~/anaconda3/envs/lora/bin/torchrun # 虚拟环境下torchrun的位置
elif [[ "$ALL_LOCAL_IPS" == *"xxx.xxx.xxx.xxx"* ]]; thenNODE_RANK=1 # 表示当前机器是第1台机器IFNAME=enp6s0 # 机器1的网卡名称mytorchrun=/home/users1/xjl/miniconda3/envs/lora/bin/torchrun
elseexit 1
fi# 设置 RDMA 接口
export NCCL_IB_DISABLE=0 # 是否禁用InfiniBand
export NCCL_IB_HCA=mlx5_1 # 使用哪个RDMA接口进行通信
export NCCL_SOCKET_IFNAME=$IFNAME # 使用哪个网卡进行通信
export NCCL_DEBUG=INFO # 可选:调试用export GLOO_IB_DISABLE=0 # 是否禁用InfiniBand
export GLOO_SOCKET_IFNAME=$IFNAME # 使用哪个网卡进行通信
export PYTHONUNBUFFERED=1 # 实时输出日志# 启动分布式任务
$mytorchrun \--nnodes=$NNODES \--nproc_per_node=$NPROC_PER_NODE \--node_rank=$NODE_RANK \--master_addr=$MASTER_ADDR \--master_port=$MASTER_PORT \ddp_multi_master.py
主机输出信息:
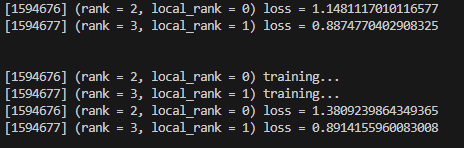
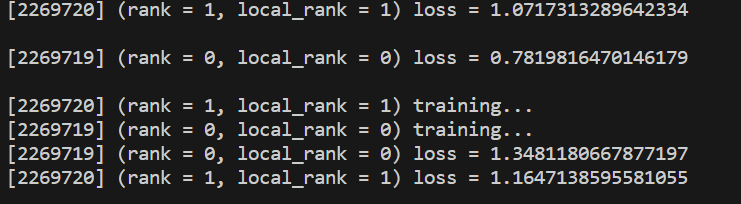
从机输出信息:
相关文章:

Pytorch分布式训练,数据并行,单机多卡,多机多卡
分布式训练 所有代码可以见我github 仓库:https://github.com/xiejialong/ddp_learning.git 数据并行(Data Parallelism,DP) 跨多个gpu训练模型的最简单方法是使用 torch.nn.DataParallel. 在这种方法中,模型被复制…...

Secarmy Village: Grayhat Conference靶场
Secarmy Village: Grayhat Conference 来自 <Secarmy Village: Grayhat Conference ~ VulnHub> 1,将两台虚拟机网络连接都改为NAT模式 2,攻击机上做namp局域网扫描发现靶机 nmap -sn 192.168.23.0/24 那么攻击机IP为192.168.23.182,靶…...

centos 9 Kickstart + Ansible自动化部署 —— 筑梦之路
目标 利用 Kickstart 完成 centos 9 系统的全自动安装(裸金属/虚拟机)。 安装完成后自动接入 Ansible 进行软件包、服务、用户、配置等系统初始化操作。 实现一套通用、可重复、可维护的自动化交付流程。 KS文件 # ks.cfg 示例 install lang zh_CN.…...

HarmonyOS应用开发入门宝典——项目驱动学习法实践
学习一项新技能,最好也是最快的方法就是动手实战。学习鸿蒙也一样,给自己定一个小目标,直接找项目练,这样进步是最快的。记住,最好的学习时机永远是现在,最好的老师永远是你正在开发的项目。 一、为什么选择…...

Python类的力量:第六篇:设计模式——Python面向对象编程的“架构蓝图”
文章目录 前言:从“代码堆砌”到“模式复用”的思维跃迁 一、创建型模式:对象创建的“智能工厂”1. 单例模式(Singleton):全局唯一的“资源管家”2. 工厂模式(Factory):对象创建的“…...

第50天-使用Python+Qt+DeepSeek开发AI运势测算
1. 环境准备 bash 复制 下载 pip install pyside6 requests python-dotenv 2. 获取DeepSeek API密钥 访问DeepSeek官网注册账号 进入控制台创建API密钥 在项目根目录创建.env文件: env 复制 下载 DEEPSEEK_API_KEY=your_api_key_here 3. 创建主应用框架 python 复制…...

CentOS系统上挂载磁盘
在CentOS系统上挂载磁盘,主要包括查看磁盘设备、分区(若需要)、格式化、创建挂载点和挂载等步骤,以下是详细操作: 1. 查看磁盘设备 使用fdisk -l或lsblk命令查看系统识别到的磁盘设备。 fdisk -l:列出所…...
 本地hadoop虚拟机系统设置)
(一) 本地hadoop虚拟机系统设置
1.配置固定IP地址(每一台都配置) 开启node1,修改主机名为node1,并修改固定IP为:192.168.88.131 # 修改主机名 hostnamectl set-hostname node1# 修改IP vim /etc/sysconfig/network-scripts/ifcfg-ens33 IPADDR"…...

亿级核心表如何优雅扩展字段
1 导语 亿级数据的核心表新增一个字段,远不止一句简单的“ALTER TABLE”,锁表风险、页分裂、索引性能衰减……每一个问题都可能引发线上事故。如何在不影响业务的前提下,只需简单的配置,即可实现字段的动态扩展?本文将…...

单端传输通道也会有奇偶模现象喔
奇模(Odd mode)与偶模(Even mode)对差动对是很关键的要素,其会影响奇/偶模阻抗与相位速度,设计不良甚会让共模噪声引入整个差动对使讯号质量下降。 然而对单端信号系统而言呢? 如果说一对side b…...

VUE3 中的 ResizeObserver 警告彻底解决方案
问题背景 今天在使用 Vue 3 Ant Design Vue 开发后台管理系统时,在页面频繁触发 元素尺寸变化(如表格滚动、窗口缩放) 的时候,控制台频繁出现如下警告: ResizeObserver loop completed with undelivered notificati…...

IDEA2025版本使用Big Data Tools连接Linux上Hadoop的HDFS
目录 Windows的准备 1. 将与Linux上版本相同的hadoop压缩包解压到本地 编辑2.设置$HADOOP HOME环境变量指向:E:\hadoop-3.3.4 3.下载hadoop.dll和winutils.exe文件 4.将hadoop.dll和winutils.exe放入$HADOOP HOME/bin中 IDEA中操作 1.下载Big Data Tools插件 2.添加并连…...

Gas优化利器:Merkle 树如何助力链上数据效率革命
目录 前言原理Merkle树示意图实战演示:构建 Merkle 树并在合约中验证离线构建 Merkle 树(手动计算Merkle树、生成mermaid示意图)编写Merkle.js脚本执行Merkle.js脚本执行结果展示mermaid流程图展示离线构建 Merkle 树(merkletreejs计算Merkle树、验证哈希路径)编写Merkle.…...

R语言空间分析实战:地理加权回归联合主成份与判别分析破解空间异质性难题
在自然和社会科学领域有大量与地理或空间有关的数据,这一类数据一般具有严重的空间异质性,而通常的统计学方法并不能处理空间异质性,因而对此类型的数据无能为力。以地理加权回归为基础的一系列方法:经典地理加权回归,…...
)
kafka入门(二)
Java客户端访问Kafka 引入maven依赖 <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka‐clients</artifactId> <version>2.4.1</version> </dependency> 消息发送端代码 package com.tuling.kafka.ka…...

学习日记-day11-5.20
完成目标: comment.java package com.zcr.pojo; import org.hibernate.annotations.GenericGenerator;import javax.persistence.*; //JPA操作表中数据,可以将对应的实体类映射到一张表上Entity(name "t_comment")//表示当前的实体类与哪张表…...

手淘不易被清洗销量的4个成交入口
在淘宝运营中,销量是店铺权重的重要指标之一,但平台对虚假交易的打击力度越来越大,许多商家因销量被清洗而损失惨重。那么,通过什么样的手淘成交入口稳定不易清洗呢?经过实测,我们总结了以下手淘4个不易被清…...

【Linux】Linux 多线程
目录 1. Linux线程概念2. 重谈进程地址空间---页表2.1 如何由虚拟地址转化为物理地址的 3. pthread库调用接口3.1 线程的创建---pthread_create3.2 线程等待---pthread_join3.3 线程的退出3.4 分离线程 4. 线程库5. 线程ID6. Linux线程互斥6.1 锁6.2 锁的接口6.2.1 互斥量的初始…...

DAY31
知识点回顾 规范的文件命名规范的文件夹管理机器学习项目的拆分编码格式和类型注解 作业:尝试针对之前的心脏病项目,准备拆分的项目文件,思考下哪些部分可以未来复用。 浙大疏锦行...

大模型应用开发“扫盲”——基于市场某款智能问数产品的技术架构进行解析与学习
本文将从一款问数产品相关技术架构,针对大模型应用开发中的基础知识进行“扫盲”式科普,文章比较适合新手小白,属于是我的学习笔记整理,大佬可以划走啦~产品关键信息已经进行模糊处理,如有侵权请联系删除。 文章目录 前…...

List优雅分组
一、前言 最近小永哥发现,在开发过程中,经常会遇到需要对list进行分组,就是假如有一个RecordTest对象集合,RecordTest对象都有一个type的属性,需要将这个集合按type属性进行分组,转换为一个以type为key&…...
)
打破建筑与制造数据壁垒:Revit 到 STP 格式转换全攻略(含插件应用 + 迪威模型实战)
引言 在建筑信息模型(BIM)与计算机辅助设计(CAD)领域,数据在不同软件和系统间的高效流转至关重要。Revit 作为 BIM 技术应用的主流软件,常用于建筑设计、施工和运维管理;而 STP(STE…...
)
RISC-V 开发板 MUSE Pi Pro USB 测试(3.0 U盘,2.0 UVC摄像头)
视频讲解: RISC-V 开发板 MUSE Pi Pro USB 测试(3.0 U盘,2.0 UVC摄像头) 总共开发板有4个USB的A口,1个USB的TypeC口,我们插上两个USB3.0的U盘和一个USB2.0的UVC摄像头来进行测试 lsusb -tv 可以看到有3个US…...

驱动相关基础
一、驱动分类与区别 字符设备驱动 一个字节一个字节进行读写操作的设备,以字符流的形式进行数据传输(如鼠标、键盘、串口)。 块设备驱动 以块为单位进行读写操作的设备,块的大小通常为 512 字节、1024 字节。 块设备驱动主…...

【node.js】核心进阶
个人主页:Guiat 归属专栏:node.js 文章目录 1. Node.js高级异步编程1.1 Promise深入理解1.1.1 创建和使用Promise1.1.2 Promise组合模式 1.2 Async/Await高级模式1.2.1 基本使用1.2.2 并行执行1.2.3 顺序执行与错误处理 1.3 事件循环高级概念1.3.1 事件循…...
)
高频Java面试题深度拆解:String/StringBuilder/StringBuffer三剑客对决(万字长文预警)
文章目录 一、这道题的隐藏考点你Get到了吗?二、内存模型里的暗战(图解警告)2.1 String的不可变性之谜2.2 可变双雄的内存游戏 三、线程安全背后的修罗场3.1 StringBuffer的同步真相3.2 StringBuilder的裸奔哲学 四、性能对决:用数…...

量子计算的曙光:从理论奇点到 IT 世界的颠覆力量
在信息技术(IT)的飞速发展中,一项前沿技术正以耀眼的光芒照亮未来——量子计算(Quantum Computing)。2025 年,随着量子硬件的突破、算法的优化以及企业对超算能力的渴求,量子计算从科幻梦想逐步…...

c++使用protocol buffers
在 C 里使用 Protocol Buffer,要先定义消息结构,接着生成 C 代码,最后在程序里使用这些生成的代码。 定义消息结构 首先要创建一个.proto文件,在其中定义消息类型和字段。 // person.proto syntax "proto3"; // 指…...

AI驱动发展——高能受邀参加华为2025广东新质生产力创新峰会
当AI浪潮席卷全球产业版图,一场以"智变"驱动"质变"的变革正在发生。5月15日,华为中国行2025广东新质生产力创新峰会璀璨启幕,作为华为生态战略合作伙伴,高能计算机与行业领军者同台论道,共同解码A…...

怎样解决photoshop闪退问题
检查系统资源:在启动 Photoshop 之前,打开任务管理器检查 CPU 和内存的使用情况。如果发现资源占用过高,尝试关闭不必要的程序或重启计算机以释放资源。更新 Photoshop 版本:确保 Photoshop 是最新版本。Adobe 经常发布更新以修复…...
)
AWS CodePipeline+ Elastic Beanstalk(AWS中国云CI/CD)
问题 最近需要利用AWS云上面的CI/CD部署Spring应用。 一图胜千言 步骤 打开CodePipeline网页,开始管道创建,如下图: 管道设置,如下图: 这里主要设置管道名称,至于服务角色,直接让codepipel…...

人工智能核心知识:AI Agent 的四种关键设计模式
人工智能核心知识:AI Agent 的四种关键设计模式 一、引言 在人工智能领域,AI Agent(人工智能代理)是实现智能行为和决策的核心实体。它能够感知环境、做出决策并采取行动以完成特定任务。为了设计高效、灵活且适应性强的 AI Age…...

Electron+vite+vue3 从0到1搭建项目,开发Win、Mac客户端
随着前端技术的发展,出现了所谓的大前端。 大前端则是指基于前端技术延伸出来的各种终端平台及应用场景,包括APP、桌面端、手表终端、服务端等。 本篇文章主要是和大家一起学习一下使用Electron 如何打包出 Windows 和 Mac 所使用的客户端APPÿ…...

GitLab部署
学git Git最新最新详细教程、安装(从入门到精通!!!!企业级实战!!!工作必备!!!结合IDEA、Github、Gitee实战!!!…...

基于R语言地理加权回归、主成份分析、判别分析等空间异质性数据分析技术
在自然和社会科学领域,存在大量与地理或空间相关的数据,这些数据通常具有显著的空间异质性。传统的统计学方法在处理这类数据时往往力不从心。基于R语言的一系列空间异质性数据分析方法,如地理加权回归(GWR)、地理加权…...
)
指针深入理解(二)
volatile关键字 防止优化指向内存地址, typedef 指针可以指向C语言所有资源 typedef 就是起一个外号。 指针运算符加减标签操作 指针加的是地址,并且增加的是该指针类型的一个单位,指针变量的步长可以用sizeof(p[0]) 这两个的p1是不一样…...
)
django回忆录(Python的一些基本概念, pycharm和Anaconda的配置, 以及配合MySQL实现基础功能, 适合初学者了解)
django 说实在的, 如果是有些Python基础或者编程基础, 使用django开发本地网站的速度还是很快的, 特别是配合ai进行使用. 本人使用该框架作业的一个主要原因就是因为要做数据库大作业, 哥们想速通, 结果由于我一开始没有接触过这些方面的知识, 其实也不算快, 而且现在我也没有…...

leetcode hot100刷题日记——5.无重复字符的最长字串
解答:滑动窗口思想(见官方题解) //方法1 class Solution { public:int lengthOfLongestSubstring(string s) {//哈希表记录是否有重复字符unordered_set<char>c;int maxlength0;int ns.size();//右指针初始化为-1,可以假设…...

一文讲清python、anaconda的安装以及pycharm创建工程
软件下载 Pycharm下载地址: https://download-cdn.jetbrains.com.cn/python/pycharm-community-2024.1.1.exe?_gl1*1xfh3l8*_gcl_au*MTg1NjU2NjA0OC4xNzQ3MTg3Mzg1*FPAU*MTg1NjU2NjA0OC4xNzQ3MTg3Mzg1*_ga*MTA2NzE5ODc1NS4xNzI1MzM0Mjc2*_ga_9J976DJZ68*czE3NDczMD…...

[每日一题] 3355. 零数组变换 i
文章目录 1. 题目链接2. 题目描述3. 题目示例4. 解题思路5. 题解代码6. 复杂度分析 1. 题目链接 3355. 零数组变换 I - 力扣(LeetCode) 2. 题目描述 给定一个长度为 n 的整数数组 nums 和一个二维数组 queries,其中 queries[i] [li, ri]。…...

【笔记】与PyCharm官方沟通解决开发环境问题
#工作记录 2025年5月20日 星期二 背景 在此前的笔记中,我们提到了向PyCharm官方反馈了几个关于Conda环境自动激活、远程解释器在社区版中的同步问题以及Shell脚本执行时遇到的问题。这些问题对日常开发流程产生了一定影响,因此决定联系官方支持寻求解…...

mariadb-cenots8安装
更新系统:安装完成 CentOS 8 后,连接到互联网,打开终端并运行以下命令来更新系统,以获取最新的软件包和安全补丁。 bash sudo yum update -y安装 MariaDB:运行以下命令来安装 MariaDB。 bash sudo yum install mariadb…...
:用Widgets实现三维交互控制)
Python实现VTK - 自学笔记(4):用Widgets实现三维交互控制
核心知识点 交互器样式(vtkInteractorStyle):自定义鼠标/键盘交互逻辑三维控件(3D Widgets):使用预制控件实现复杂交互回调机制:实现动态数据更新参数化控制:通过控件调整算法参数import vtk# 1. 创建圆锥体数据源 cone = vtk.vtkConeSour…...

在tp6模版中加减法
实际项目中,我们经常需要标签变量加减运算的操作。但是,在ThinkPHP中,并不支持模板变量直接运算的操作。幸运的是,它提供了自定义函数的方法,我们可以利用自定义函数解决:ThinkPHP模板自定义函数语法如下&a…...

Linux:库与链接
库是预先编译好、可执⾏的⼆进制码,可以被操作系统加载到内存中执⾏。 库有两种: 静态库:.a(Linux)、.lib(Windows) 动态库:.so(Linux)、.dil(Windows) 静态库 1.程序在链接时把库的代码链接到可执⾏⽂件中,运⾏时…...

T008-网络管理常用命令:ping,ipconfig,nslookup,route,netstat
ipconfig:网络诊断命令,显示 IP 地址、掩码、网关信息,清除/显示 DNS 缓存信息; route:主要用于管理路由表,确定数据包如何从源主机通过网络到达目的主机 nslookup:用于查询域名到IP地址&…...

Qt文件:XML文件
XML文件 1. XML文件结构1.1 基本结构1.2 XML 格式规则1.3 XML vs HTML 2. XML文件操作2.1 DOM 方式(QDomDocument)读取 XML写入XML 2.2 SAX 方式(QXmlStreamReader/QXmlStreamWriter)读取XML写入XML 2.3 对比分析 3. 使用场景3.1 …...
)
MySQL 8.0 OCP 英文题库解析(六)
Oracle 为庆祝 MySQL 30 周年,截止到 2025.07.31 之前。所有人均可以免费考取原价245美元的MySQL OCP 认证。 从今天开始,将英文题库免费公布出来,并进行解析,帮助大家在一个月之内轻松通过OCP认证。 本期公布试题41~50 试题4…...

微软开放代理网络愿景
🌐 Microsoft的开放式智能代理网络愿景 2025年05月20日 | AI日报  欢迎各位人工智能爱好者 微软刚刚在Build 2025大会上开启了备受期待的AI周活动,通过发布大…...

阿尔泰科技助力电厂——520为爱发电!
当城市的霓虹在暮色中亮起,当千万个家庭在温暖中共享天伦,总有一群默默的 "光明守护者" 在幕后坚守 —— 它们是为城市输送能量的电厂,更是以科技赋能电力行业的阿尔泰科技。值此 520 爱意满满的日子,阿尔泰科技用硬核技…...