HTML应用指南:利用POST请求获取全国申通快递服务网点位置信息
申通快递(STO Express)作为中国领先的综合物流服务商,自1993年创立以来,始终秉持“正道经营、长期主义”的发展理念,深耕快递物流领域,开创了行业加盟制先河。经过30余年的发展,申通已成长为国家5A级物流企业,并跻身《财富》中国500强及全国工商联“中国民营企业500强”榜单,成为A股上市企业。目前,申通构建了覆盖全国300余城市的物流网络,拥有独立网点超5,000个、服务站点及门店逾55,000个,业务范围延伸至全球150多个国家和地区,形成了仓、揽、转、运、派全链路一体化服务能力。
在数字化时代,申通加速推进“数智化+网点生态”战略,通过技术创新与精细化运营提升服务效率。其科技力以多级信息安全防控体系为基底,保障万亿级包裹数据安全,同时依托全网数智化升级实现全链路降本增效。例如,漳州传化公路港枢纽的投用显著提升了闽南区域分拨效率,而AI预测模型则助力网点库存与路由规划的动态优化。此外,申通通过“五星五力”服务体系(运营力、体验力、差异力、价格力、科技力)深化客户合作,为商家提供定制化解决方案,满足从仓配一体化到即时配送的多元化需求。
通过对这些服务网点数据的深入分析,我们可以全面掌握申通快递在国内市场的布局特点与发展趋势。例如,通过分析各城市的网点密度、选址特征以及周边消费环境,可以精准洞察不同地区的物流需求差异,为申通未来的服务优化、新网点开设规划以及市场拓展策略提供有力的数据支持与决策依据。同时,用户也可以借助这些数据,方便快捷地查询到最近的申通快递网点,实现快速寄件或预约上门取件服务,极大地提升了用户体验。
申通快递网点位置查询:申通快递官网
我们第一步先找到服务网点数据的存储位置,然后看3个关键部分标头、负载、 预览;
标头:通常包括URL的连接,也就是目标资源的位置;
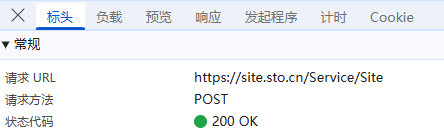
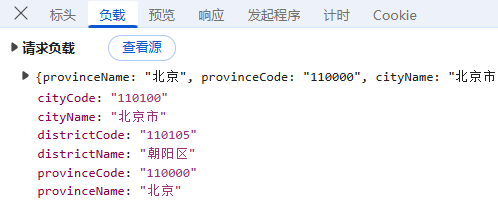
负载:对于POST请求:负载通常包含了传递的参数,这里我们可以看到它的传参包括各级行政区名称,是明文传输;
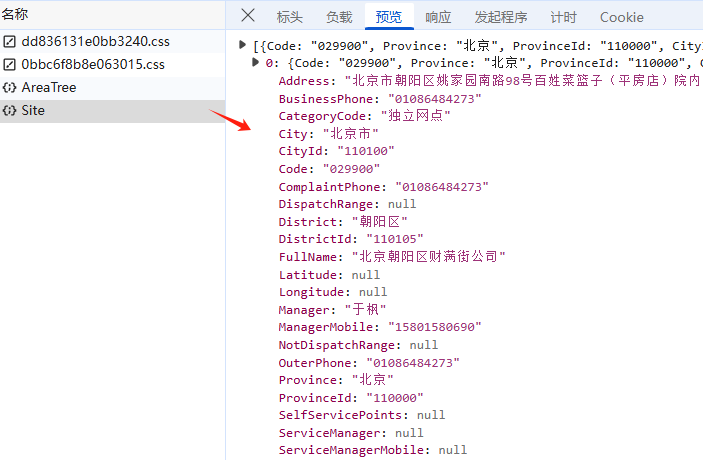
预览:指的是对响应内容的快速查看或摘要显示,可以帮助用户快速了解返回的数据结构或内容片段;
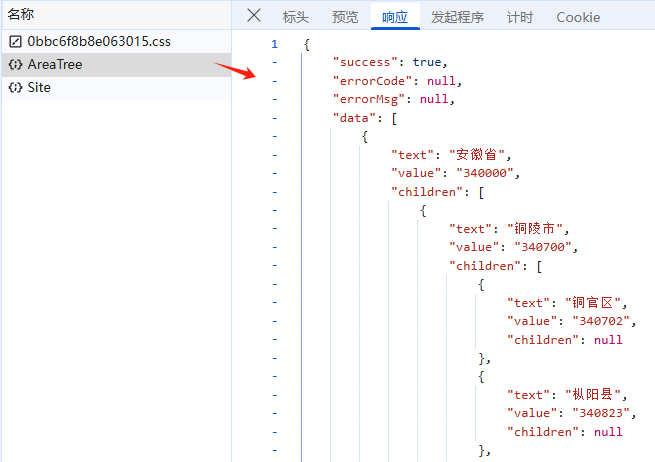
接下来就是数据获取部分,先讲一下方法思路,一共三个步骤;
方法思路
- 找到对应行政区划树的数据存储位置,生成一个行政区对应关系字典;
- 我们通过改变查询负载的内容(各级行政区名称),来遍历全国服务网点数据,获取所有服务网点的相关标签数据;
- 坐标转换,通过coord-convert库实现GCJ-02转WGS84;
第一步:通过页面测试发现,申通服务网点查询页面采用的策略是,通过三级行政区明文这样的结构数据,进行查询的;

接下来,我们找到行政区划树的数据存储位置,通过脚本把数据另存为本地json,通过读取json的三级行政区字典进行遍历全国服务网点信息;
完整代码#运行环境 Python 3.11
import requests
import json
import osdef fetch_and_save_area_tree_json_simplified():url = "https://site.sto.cn/Service/AreaTree"method = "POST"headers = {"accept": "application/json, text/plain, */*","referer": "https://www.sto.cn/","user-agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Mobile Safari/537.36 Edg/136.0.0.0","Content-Type": "application/json"}payload = {} # 空的 JSON 负载area_tree_data = None # 用于存储解析后的数据filename = "sto_area_tree_data.json" # 指定保存的文件名try:print(f"正在发送 {method} 请求获取行政区划数据: {url}")response = requests.post(url, headers=headers, json=payload)response.raise_for_status() # 检查HTTP状态码,非2xx会抛出异常print(f"成功收到响应,状态码: {response.status_code}")# 尝试解析JSONtry:area_tree_data = response.json()print("响应解析为 JSON 成功。")except json.JSONDecodeError as e:print(f"错误: JSON解析失败: {e}")print(f"原始响应内容 (部分):\n{response.text[:500]}{'...' if len(response.text) > 500 else ''}")# JSON解析失败,area_tree_data 将保持 Noneexcept requests.exceptions.RequestException as e:print(f"错误: 请求发生错误: {e}")if hasattr(e, 'response') and e.response is not None:print("错误状态码:", e.response.status_code)#print("错误响应体:", e.response.text) # 简化,不打印错误响应体# 请求失败,area_tree_data 将保持 Noneexcept Exception as e:print(f"错误: 发生未知错误: {e}")# 发生其他错误,area_tree_data 将保持 None# --- 保存数据到JSON文件 ---if area_tree_data is not None:try:print(f"正在将数据保存到文件: {filename}")with open(filename, 'w', encoding='utf-8') as f:json.dump(area_tree_data, f, ensure_ascii=False, indent=4)print(f"数据已成功保存到 {filename}")except Exception as e:print(f"错误: 保存文件时发生错误: {e}")else:print("未获取到有效行政区划数据,不保存文件。")if __name__ == "__main__":fetch_and_save_area_tree_json_simplified()等待脚本执行完成,将输出一个json文件sto_area_tree_data.json,为了更直观的展示,我们可以复制json里面的数据,并放在json可视化的工具里进行展示,这里用的在线工具是编辑器 | JSON For You | 在线JSON工具,我们可以看到三级行政区及其行政区编码;

第二步:读取之前生成的JSON文件,并使用这些数据来查询第三级(网点)信息,并根据标签进行保存,另存为csv;
方法思路
- 读取本地的 sto_area_tree_data.json 行政区划文件;
- 遍历该文件的层级结构,提取每个区县的名称和代码;
- 对于每个区县,调用申通的网点查询 API;
- 收集所有区县的网点数据;
- 将汇总的所有网点数据保存到一个 CSV 文件。
完整代码#运行环境 Python 3.11
import requests
import json
import pandas as pd
import os
import time # 导入 time 库用于添加延迟# --- 文件路径配置 ---
AREA_TREE_FILE = "sto_area_tree_data.json" # 行政区划数据文件
OUTPUT_CSV_FILE = "all_sto_sites_data.csv" # 汇总保存的网点数据文件# --- API 配置 ---
SITE_API_URL = "https://site.sto.cn/Service/Site"
SITE_API_HEADERS = {"accept": "application/json, text/plain, */*","referer": "https://www.sto.cn/","user-agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Mobile Safari/537.36 Edg/136.0.0.0"
}# --- 网点查询相关函数 ---
def fetch_sto_site_data(payload):"""发送请求获取申通网点数据。返回一个列表(如果成功)或 None。"""url = SITE_API_URLheaders = SITE_API_HEADERStry:# print(f"正在请求数据,地区: {payload.get('provinceName', '')}-{payload.get('cityName', '')}-{payload.get('districtName', '')}") # 简化打印response = requests.post(url, headers=headers, json=payload)response.raise_for_status() # 检查HTTP状态码,非2xx会抛出异常site_data_list = response.json()# 检查解析结果是否为列表if isinstance(site_data_list, list):# print(f" -> 成功获取 {len(site_data_list)} 条网点数据。") # 简化打印return site_data_listelse:print(f" -> 警告: API返回数据结构与预期不符(不是列表)。原始响应前200字符: {response.text[:200]}{'...' if len(response.text) > 200 else ''}")return Noneexcept requests.exceptions.RequestException as e:print(f" -> 请求发生错误: {e}")return Noneexcept json.JSONDecodeError:print(" -> 错误: 无法解析响应为 JSON 格式。")print(f" -> 原始响应内容前200字符: {response.text[:200]}{'...' if len(response.text) > 200 else ''}")return Noneexcept Exception as e:print(f" -> 发生未知错误: {e}")return Nonedef save_data_to_csv(data_list, filename):"""将数据列表保存到 CSV 文件。"""if not data_list:print("没有数据可保存到 CSV。")returntry:df = pd.DataFrame(data_list)df.to_csv(filename, index=False, encoding='utf-8-sig')print(f"所有网点数据已成功保存到 {filename}")except Exception as e:print(f"保存 CSV 文件时发生错误: {e}")# --- 行政区划数据处理函数 ---def load_area_tree_data(filename=AREA_TREE_FILE):"""从本地 JSON 文件加载行政区划数据。"""if not os.path.exists(filename):print(f"错误: 行政区划数据文件未找到: {filename}")print("请先运行获取行政区划数据的脚本来生成此文件。")return Nonetry:print(f"正在从文件加载行政区划数据: {filename}")with open(filename, 'r', encoding='utf-8') as f:full_data = json.load(f)print("行政区划数据加载成功。")# 检查顶层结构并提取 data 列表if isinstance(full_data, dict) and full_data.get("success") is True and isinstance(full_data.get("data"), list):return full_data.get("data") # 返回 data 键对应的列表else:print("错误: 行政区划数据文件结构与预期不符(未找到 success=True 的字典或 data 列表)。")# 可以打印部分数据结构帮助调试# print(f"文件内容顶层键: {list(full_data.keys()) if isinstance(full_data, dict) else '非字典'}")return Noneexcept json.JSONDecodeError:print(f"错误: 无法解析文件 {filename} 为 JSON 格式。")return Noneexcept Exception as e:print(f"加载行政区划文件时发生错误: {e}")return None# 修改 traverse_area_tree 函数以匹配新的 JSON 结构 ("text", "value", "children")
def traverse_area_tree(data_list, current_province=None, current_province_id=None, current_city=None, current_city_id=None):"""遍历行政区划树数据,找到区县级别并生成其信息。数据结构假设:[ { "text": "省", "value": "省ID", "children": [ { "text": "市", "value": "市ID", "children": [...] } ] } ]Args:data_list: 当前层级的行政区划列表。current_province: 当前处理到的省级名称。current_province_id: 当前处理到的省级ID。current_city: 当前处理到的市级名称。current_city_id: 当前处理到的市级ID。Yields:dict: 包含区县信息的字典 (provinceName, provinceCode, cityName, cityCode, districtName, districtCode)"""if not isinstance(data_list, list):return # 不是列表则停止遍历当前分支for item in data_list:if not isinstance(item, dict):continue# 使用新的键名: "text" -> 名称, "value" -> ID, "children" -> 子节点列表area_id = item.get("value")area_name = item.get("text")child_areas = item.get("children") # get() 返回 None 如果键不存在或值为 nullif area_name is None or area_id is None:continue# 根据嵌套层级判断省市县# 注意直辖市的数据结构可能特殊,例如北京市下直接是区if current_province is None: # 第一级:省/直辖市# 确保 children 是列表,如果为 null 或非列表则跳过该分支if isinstance(child_areas, list):yield from traverse_area_tree(child_areas, current_province=area_name, current_province_id=area_id)elif current_city is None: # 第二级:市 (对于直辖市,这层可能不存在或直接是区)# 检查 children 是否为列表。如果是列表,继续遍历市下面的区县# 如果 children 不是列表(比如为 null),则说明当前 area_name 可能已经是区县了(处理直辖市结构如北京、上海等)if isinstance(child_areas, list):yield from traverse_area_tree(child_areas, current_province=current_province, current_province_id=current_province_id, current_city=area_name, current_city_id=area_id)else: # 如果第二级的 children 不是列表,则假设当前 item 就是一个区县# 这适用于 省(直辖市) -> 区县... 的结构# 此时,我们将市级名称和代码设置为与省级相同,或者根据实际API要求处理# 这里设置为与省级相同,因为网点查询API需要cityCode和cityNameyield {"provinceName": current_province,"provinceCode": current_province_id,"cityName": current_province, # 对于直辖市,市名通常与省名相同"cityCode": current_province_id, # 对于直辖市,市代码通常与省代码相同"districtName": area_name, # 当前项是区县名"districtCode": area_id # 当前项是区县代码}else: # 第三级:区县 (在 省 -> 市 -> 区县 结构下)# 这是标准的区县层级,不需要再检查 childrenyield {"provinceName": current_province,"provinceCode": current_province_id,"cityName": current_city,"cityCode": current_city_id,"districtName": area_name,"districtCode": area_id}# --- 主执行逻辑 ---
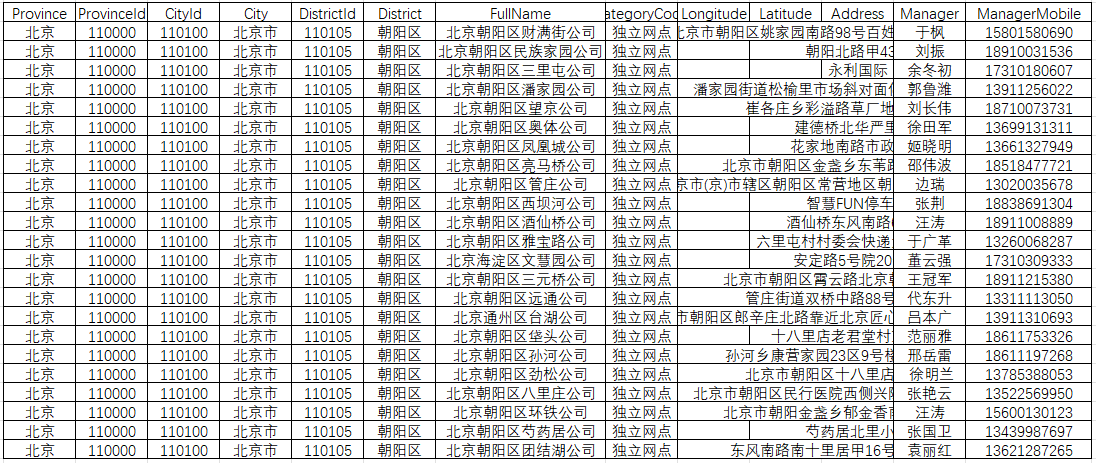
def fetch_all_sto_sites():"""获取所有申通网点的数据,遍历区县并查询。"""all_site_data = [] # 存储所有网点数据# 1. 加载行政区划数据# load_area_tree_data 现在会返回 data 键下的列表area_data_list = load_area_tree_data(AREA_TREE_FILE)if area_data_list: # 检查 load_area_tree_data 是否成功返回列表# 2. 遍历行政区划数据,获取区县列表print("\n正在遍历行政区划数据,查找区县...")district_payloads = []# 调用遍历函数,并收集区县信息for district_info in traverse_area_tree(area_data_list):district_payloads.append(district_info)print(f"找到 {len(district_payloads)} 个区县需要查询。")# 在开始查询前,先创建一个空的CSV文件(参考您的代码)save_data_to_csv([], OUTPUT_CSV_FILE)# 3. 遍历区县列表,查询网点数据if district_payloads:print("\n开始按区县查询网点数据...")total_districts = len(district_payloads)# 可以选择只处理部分区县进行测试# district_payloads = district_payloads[:10] # 只处理前10个区县for i, payload in enumerate(district_payloads, 1):print(f"\n处理第 {i}/{total_districts} 个区县: {payload.get('provinceName')}-{payload.get('cityName')}-{payload.get('districtName')}...")site_data_for_district = fetch_sto_site_data(payload)if site_data_for_district:print(f" -> 获取到 {len(site_data_for_district)} 条网点数据。")# 为每个网点数据添加查询时使用的省市县信息for site in site_data_for_district:site['ProvinceName_Query'] = payload.get('provinceName')site['ProvinceCode_Query'] = payload.get('provinceCode')site['CityName_Query'] = payload.get('cityName')site['CityCode_Query'] = payload.get('cityCode')site['DistrictName_Query'] = payload.get('districtName')site['DistrictCode_Query'] = payload.get('districtCode')# 将当前区县的数据直接保存到CSV,而不是全部收集后再保存# 这可以避免一次性加载大量数据到内存,参考您提供的代码结构try:df_district = pd.DataFrame(site_data_for_district)# 使用 append 模式 'a',header=False 表示不写入头部(第一次写入时会写入)df_district.to_csv(OUTPUT_CSV_FILE, mode='a', header=not os.path.exists(OUTPUT_CSV_FILE) or os.stat(OUTPUT_CSV_FILE).st_size == 0, index=False, encoding='utf-8-sig')print(f" -> 已追加 {len(site_data_for_district)} 条数据到 {OUTPUT_CSV_FILE}")except Exception as e:print(f" -> 错误: 保存区县数据到 CSV 时发生错误: {e}")# 添加延迟,避免请求过快time.sleep(0.2) # 延迟 0.2 秒,可以根据需要调整print("\n所有区县网点数据查询完成。")# 注意:由于是按区县追加保存,all_site_data 列表不再需要,最终结果在CSV文件中else:print("未找到区县信息,跳过网点查询。")else:print("行政区划数据加载失败,无法进行网点查询。")print("\n程序执行完毕。")if __name__ == "__main__":fetch_all_sto_sites()获取数据标签如下,Province(行政区)、ProvinceId(行政区编码)、CityId(市级编码)、City(市级)、 DistrictId(县级编码)、District(县级)、FullName(服务点名称)、Longitude,Latitude(坐标)、Address(详细地址)、Manager(经理)、ManagerMobile(经理电话),其他一些非关键标签,这里省略;
第三步:地理编码和坐标系转换,这里因为我们获取的坐标系为空,需要把获取的门店地址进行地理编码,具体实现方法可以参考我这篇文章:地址转坐标:利用高德API进行批量地理编码_高德地图api-CSDN博客;
这里直接下载转换结果,坐标系GCJ-02,当然还有个别地址描述太模糊的或者格式无法识别,会查不出坐标,手动查一下坐标即可,大部分还是可以查到的,因为当前坐标系是GCJ02,需要批量转成WGS84/BD09的话可以用免费这个网站:批量转换工具:地图坐标系批量转换 - 免费在线工具 (latlongconverter.online),也可以通过coord-convert库实现GCJ-02转WGS84;
对CSV文件中的服务网点坐标列进行转换。完成坐标转换后,再将数据导入ArcGIS进行可视化;
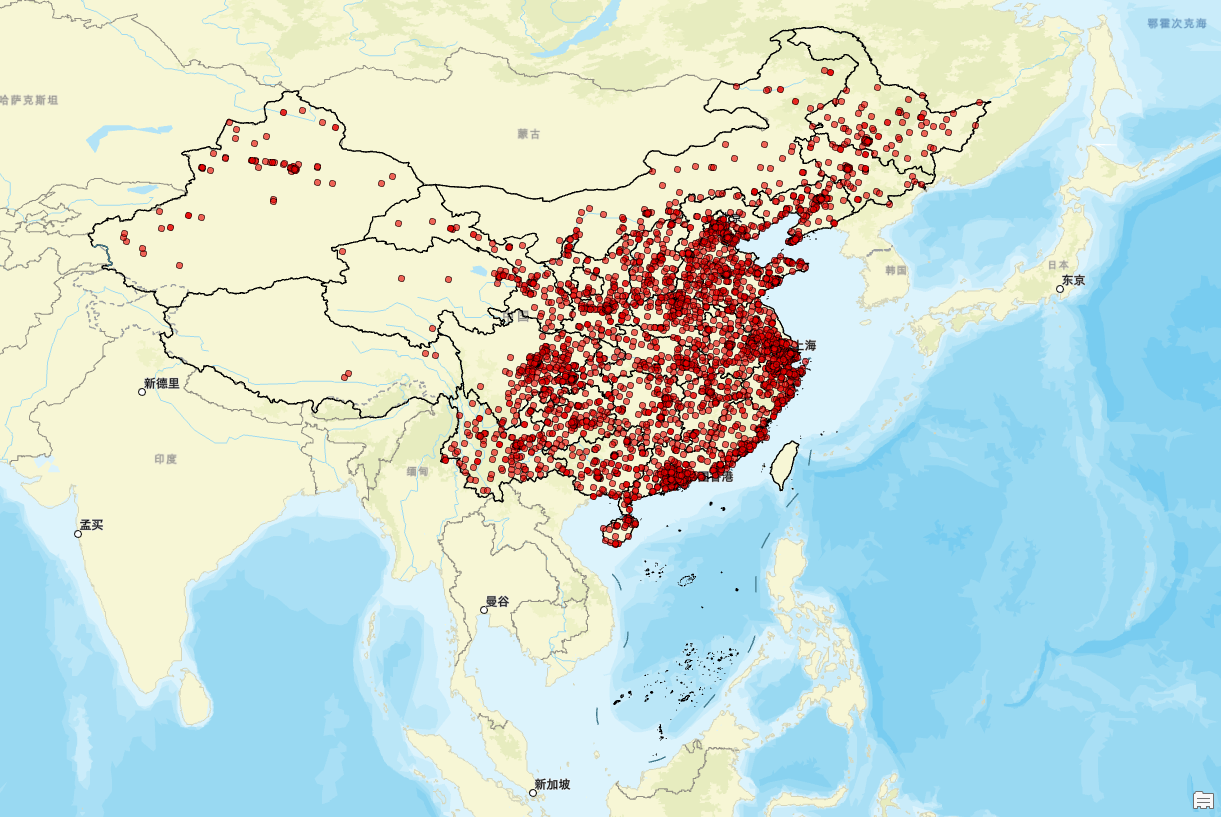
接下来,我们进行看图说话:
东部密集,西部稀疏: 在地图上可以清晰地看到,申通快递在东部沿海地区和中部地区的网点密度非常高。特别是在长三角、珠三角以及京津冀这样的经济核心区,网点几乎连成一片,显示出极高的覆盖度。这些区域不仅人口密集,而且商业活动频繁,是快递服务需求最大的地方。而在西部和北部,尤其是像西藏、新疆等边远省份,网点则显得零散得多,反映了这些地区相对较低的人口密度和经济发展水平。
城市集中,乡村覆盖: 大城市的中心及其周边地带,如北京、上海、广州等地,可以看到申通快递网点密布,形成了高效的服务网络。与此同时,在一些中小城市乃至乡镇,也有网点的存在,这表明申通正致力于扩大其在全国范围内的服务覆盖面,确保即使是较小的城市也能享受到便捷的快递服务。
交通干线沿线布局: 地图上的一个显著特点是,许多申通快递的网点都位于主要交通线路附近,比如高速公路旁或者铁路枢纽周围。这种布局策略有助于加快货物的运输速度,并提高整体物流效率,同时也便于与其他物流公司或节点之间的协作。
省会城市及重要交通枢纽是重点布局区域: 省会城市和其他重要的交通枢纽城市,例如武汉、成都等,拥有大量的申通快递网点。这些城市不仅是各自省份的政治、经济中心,也是物流的关键节点,因此成为了申通快递布局的重点区域。
边远地区和特殊地形区域分布较少: 对于那些地理位置偏远、地形复杂的地区,如山区或高原地带,申通快递的网点数量明显减少。然而,即便是在这些地方,通过与当地的合作或代理模式,仍然能够提供一定程度的服务,确保全国范围内都有一定的服务可达性。
文章仅用于分享个人学习成果与个人存档之用,分享知识,如有侵权,请联系作者进行删除。所有信息均基于作者的个人理解和经验,不代表任何官方立场或权威解读。
相关文章:

HTML应用指南:利用POST请求获取全国申通快递服务网点位置信息
申通快递(STO Express)作为中国领先的综合物流服务商,自1993年创立以来,始终秉持“正道经营、长期主义”的发展理念,深耕快递物流领域,开创了行业加盟制先河。经过30余年的发展,申通已成长为国家…...

《医院运营管理典型应用数据资源建设指南2025》全面分析
引言:医院数据资源建设的时代背景与意义 医院运营管理数据资源建设正迎来前所未有的发展机遇与挑战。在深化支付改革与公立医院高质量发展政策驱动下,医院亟需建立智慧化运营管理体系,而数据资源作为关键要素,其建设水平直接关系到医院管理的科学性与效率。《医院运营管理…...

.NET外挂系列:3. 了解 harmony 中灵活的纯手工注入方式
一:背景 1. 讲故事 上一篇我们讲到了 注解特性,harmony 在内部提供了 20个 HarmonyPatch 重载方法尽可能的让大家满足业务开发,那时候我也说了,特性虽然简单粗暴,但只能解决 95% 的问题,言外之意还有一些…...

taro 小程序 CoverImage Image src无法显示图片的问题
目录 一、问题描述 二、解决方案 一、问题描述 使用taro开发的微信小程序图片无法正常显示,并报如下错误: [渲染层网络层错误] Failed to load local image resource /assets/icon/message.png the server responded with a status of 500 (HTTP/1.…...

05_核支持向量机
描述 核支持向量机(通常简称为SVM)可以推广到更复杂模型的扩展,这些模型无法被输入空间的超平面定义。 SVM 的核心思想是找到一个最优的超平面,将不同类别的数据分开。这个超平面不仅要能够正确分类数据,还要使得两个…...

[解决方案] Word转PDF
背景: 之前做过一些pdf导出, 客户提了一个特别急的需求, 要求根据一个模版跟一个csv的数据源, 批量生成PDF, 因为之前用过FOP, 知道调整样式需要特别长的时间, 这个需求又特别急, 所…...
)
Oracle 11g post PSU Oct18 设置ssl连接(使用wallets)
说明 oracle 11g 从PSU 2018Oct(含)及之后的补丁不支持MD5. 要使用JDBC SSL要使用TSL1.2. 有两种方法,一种使用wallet, 一种使用JKS. 本文档使用wallets. 1. 为什么用TSL 1.2 https://blogs.oracle.com/developers/post/ssl-connection-to…...

linux关闭某端口暂用的进程
查看是哪个端口暂用 sudo netstat -tulpn | grep :80根据图片 显示 80端口暂用的 进程id是 3002 结束进程id为3002的进程 sudo kill -9 3002...

web开发全过程总结
目录 利用pnpm创建vue3的文件 使用pnpm创建项目 项目配置 在idea中创建Spring Boot项目 配置基础项目架构(三层架构) 利用pnpm创建vue3的文件 1.打开cmd,以管理员的身份运行 2.切换到自己想要建立项目的文件的目录下或者直接在文件中以cmd的形式打开 输入指令安装pnpm n…...

经典Java面试题的答案——Java 基础
大家好,我是九神。这是互联网技术岗的分享专题,废话少说,进入正题: 1.JDK 和 JRE 有什么区别? JDK:Java Development Kit 的简称,java 开发工具包,提供了 java 的开发环境和运行环境…...

Fiddler 指定链接断点
问题背景 在使用Fiddler进行抓包和mock数据时,由于前端页面通常依赖多个前置接口(如JS、CSS、登录态等),导致抓包过程中难以精准定位到目标接口。这种复杂性增加了调试和mock数据的难度。 常见挑战 前置接口过多:页…...

C# 语法篇:字段的定义和运算
对于字段来说,是在对象创建时就被初始化了;而构造函数的运行是在这之后。 因此,不能对字段进行需要用到“构造函数赋值的变量”的运算,因为此时这些变量的值都为0或者随机值,编译器不允许这时候做运算。 因此…...

音频应用的MediaSession冲突
前提条件 系统级应用,使用了sharedUserId 应用在AndroidManifest.xml中声明了系统级UID:android:sharedUserId"android.uid.system"该配置使应用具有系统级权限,可以访问系统级API和资源 使用MediaSession框架 应用通过MediaSessi…...

【QT】类A接收TCP数据并通过信号通知类B解析
以下是基于Qt的完整示例代码,包含类A接收TCP数据并通过信号通知类B解析的实现: ------------------ ClassA.h 网络数据接收类 ------------------ #pragma once#include <QTcpServer> #include <QTcpSocket> #include <QObject>class…...
Docker安装Jitsi Meet指南-使用内网IP访问)
【Jitsi Meet】(腾讯会议的平替)Docker安装Jitsi Meet指南-使用内网IP访问
Docker安装Jitsi Meet指南-使用内网IP访问 下载官方代码配置环境变量复制示例环境文件并修改配置:编辑 .env 文件: 修改 docker-compose.yml 文件生成自签名证书启动服务最终验证 腾讯会议的平替。我们是每天开早晚会的,都是使用腾讯会议。腾…...

微服务架构中的多进程通信--内存池、共享内存、socket
目录 1 引言 2 整体架构简介 3 疑问 3.1 我们的共享内存消息机制是用的posix还是system V 3.2 rmmt中,不同线程之间的比如访问同一个内存,用的什么锁控制的 3.3 疑问:假如一个进程发送给了另外两个进程,然后另外两个进程都同…...

使用 adb 命令截取 Android 设备的屏幕截图
使用 adb 命令截取 Android 设备的屏幕截图。以下是两种常见的方法: 方法一:截屏后保存到电脑 adb shell screencap -p /sdcard/screenshot.png adb pull /sdcard/screenshot.png解释: adb shell screencap -p /sdcard/screenshot.png&…...

Jenkins服务器配置密钥对
1. 在 Jenkins 服务器上执行以下命令 # 生成 SSH 密钥对 ssh-keygen -t rsa -b 2048 -f ~/.ssh/id_rsa -N ""# 查看公钥内容 cat ~/.ssh/id_rsa.pub 2. 将显示的公钥内容复制,然后在目标服务器上执行 # 在目标服务器上执行 mkdir -p /root/.ssh chmod …...

Docker中部署Alertmanager
在 Docker 中部署 Alertmanager(通常与 Prometheus 告警系统配合使用)的步骤如下: 一、拉取镜像prom/alertmanager docker pull prom/alertmanager二、 创建 Alertmanager 配置文件 首先准备Alertmanager的配置文件 alertmanager.yml(如存…...
与C51兼容方法)
Keil软件中STM32(ARM)与C51兼容方法
推荐其他UP主:Keil5安装教程(包含C51与MDK共存) - Kojull - 博客园 我已经实现了!...

青少年编程与数学 02-019 Rust 编程基础 19课题、项目发布
青少年编程与数学 02-019 Rust 编程基础 19课题、项目发布 一、准备工作1. 创建和配置项目2. 编写代码和测试3. 文档注释 二、构建发布版本1. 构建优化后的可执行文件2. 静态链接(可选) 三、发布到 crates.io1. Crates.io核心功能使用方法特点最新动态 2…...

一洽小程序接入说明
接入说明 文档以微信小程序作为示例介绍,其他小程序接入操作与此类似 1、添加校验文件 开发者使用微信小程序提供的 webview 组件可以实现打开一洽的H5对话 小程序的“域名配置”中添加一洽的对话域名地址,需要获取校验文件提供给一洽放在域名根目录下…...

RabbitMQ的基本使用
RabbitMQ 是一个非常流行的消息中间件,用于实现生产者与消费者之间的异步通信。它基于 AMQP 协议(高级消息队列协议),支持多种编程语言和平台。 以下是 RabbitMQ 的基本使用说明,包括安装、核心概念、基本操作和 Pyth…...

CSS专题之常见布局
前言 石匠敲击石头的第 13 次 作为一名前端开发,在日常开发中,写页面是必不可少的工作,但有时候发现很多的页面结构都是类似的,所以打算写一篇文章来梳理一下日常开发中常见的布局,如果哪里写的有问题欢迎指出。 单列…...

CentOS 7连接公司网络配置指南
在物理主机上安装了一个CentOS 7,需要连接公司的网络,但是公司的网络需要输入用户名密码才能连接 解决方案 需要 同时设置 wifi-sec.key-mgmt 和 802-1x 参数。以下是分步操作: 1. 创建基础 Wi-Fi 连接 sudo nmcli con add con-name &quo…...

RustDesk CentOS自建中继节点
一、需开放端口 TCP: 21115, 21116, 21117, 21118, 21119 UDP: 21116 二、安装docker 1.使用 root 权限登录 CentOS。确保 yum 包更新到最新 yum update 2. 卸载旧版本 yum remove docker 3. 安装 Docker 所需依赖 yum -y install yum-utils device-mapper-persistent-d…...

CentOS 7上部署BIND9 DNS服务器指南
场景假设: 我们要为内部网络 192.168.1.0/24 搭建一个权威 DNS 服务器。 域名:mylab.localDNS 服务器 IP:192.168.1.10我们将配置正向解析 (hostname -> IP) 和反向解析 (IP -> hostname)。 一、安装 BIND9 更新系统并安装 BIND 及工…...

面试突击:消息中间件之RabbitMQ
一:你们项目中哪里用到了RabbitMQ ? 难易程度:☆☆☆ 出现频率:☆☆☆☆ 我们项目中很多地方都使用了RabbitMQ , RabbitMQ 是我们项目中服务通信的主要方式之一 , 我们项目中服务通信主要有两种方式实现 : 通过Feign实现服务调用通过MQ实现服…...

基于 ESP32 与 AWS 全托管服务的 IoT 架构:MQTT + WebSocket 实现设备-云-APP 高效互联
目录 一、总体架构图 二、设备端(ESP32)低功耗设计(适配 AWS IoT) 1.MQTT 设置(ESP32 连接 AWS IoT Core) 2.低功耗策略总结(ESP32) 三、云端架构(基于 AWS Serverless + IoT Core) 1.AWS IoT Core 接入 2.云端 → APP:WebSocket 推送方案 流程: 3.数据存…...
)
将 /dev/vdb1 的空间全部合并到 /dev/mapper/centos-root(即扩展 CentOS 的根分区)
要将 /dev/vdb1 的 1TB 空间合并到 /dev/mapper/centos-root(即扩展 CentOS 的根分区),可以采用 LVM(逻辑卷管理) 的方式。以下是详细步骤: 步骤 1:检查当前磁盘和 LVM 情况 1.1 确认 /dev/vdb…...

CentOS Stream安装MinIO教程
1. 下载 MinIO 二进制文件 # 进入 MinIO 安装目录 sudo cd /usr/local/bin/# 下载 MinIO 二进制文件(替换为最新版本链接) wget https://dl.min.io/server/minio/release/linux-amd64/minio chmod x minio2. 创建专用用户和存储目录 # 创建 minio 用户…...

游戏引擎学习第299天:改进排序键 第二部分
回顾并为当天内容做准备 我们会现场编写完整的游戏代码。回顾上周发现自己对游戏中正确的排序规则并没有清晰的理解。主要原因是我们更擅长三维游戏开发,缺乏二维游戏和二维游戏技术的经验,对于二维精灵排序、模拟三维效果的最佳方案等没有太多技巧和经…...
)
设计模式----软考中级软件设计师(自用学习笔记)
目录 1、设计模式的要素 2、设计模式的分类 3、简单工厂模式 4、工厂方法 5、抽象工厂 6、生成器 7、原型 8、单例模式 9、适配器 10、桥接 11、组合模式 12、装饰 13、外观 14、享元 15、代理 16、责任链 17、命令 18、解释器 19、迭代器 20、中介者 21、…...

uniapp如何设置uni.request可变请求ip地址
文章目录 简介方法一:直接在请求URL中嵌入变量方法二:使用全局变量方法三:使用环境变量方法四:服务端配置方法五:使用配置文件(如config.js):总结 简介 在uni-app中,uni.request 用…...

Centos上搭建 OpenResty
一、OpenResty简介 OpenResty 是基于 Nginx 的扩展平台,完全兼容 Nginx 的核心功能(如 HTTP 服务和反向代理),同时通过内嵌 LuaJIT 支持,允许开发者用 Lua 脚本灵活扩展业务逻辑。它简化了动态逻辑的实现。 二、安装…...
:Android Things开发探索)
Kotlin与物联网(IoT):Android Things开发探索
在物联网(IoT)领域,Kotlin 凭借其简洁性、安全性和与 Java 生态的无缝兼容性,逐渐成为 Android Things 开发的有力工具。尽管 Google 已于 2022 年宣布停止对 Android Things 的官方支持,但其技术思想仍值得探索&#…...
)
WIFI信号状态信息 CSI 深度学习篇之CNN(Python)
本博客是一篇非新手导向的CNN处理CSI图像帧的教程,基于tensorflow框架构建CNN模型进行训练,训练对象依然是前述博客中所提到的CSI图像帧(500 x 90 x 1)。代码里用到了深度可分离卷积,这种结构在减少计算量和参数数量方…...
)
深度学习实战 04:卷积神经网络之 VGG16 复现三(训练)
在后续的系列文章中,我们将逐步深入探讨 VGG16 相关的核心内容,具体涵盖以下几个方面: 卷积原理篇:详细剖析 VGG 的 “堆叠小卷积核” 设计理念,深入解读为何 332 卷积操作等效于 55 卷积,以及 333 卷积操作…...

欧拉系统离线部署docker
https://www.cnblogs.com/hsh96/p/18150538 Docker 离线安装指南 本文介绍了如何在 Linux 系统上进行 Docker 的离线安装。首先,确保欧拉系统安装的是server版本,否则没有tar工具。 您需要下载 Docker 的离线安装包。您可以从以下链接获取所需的安装包&a…...

Java 中 final 与 static 的区别
Java 中 final 与 static 的区别 在 Java 中,final 和 static 是两个不同的关键字,它们的核心作用和不可变性特性有本质区别: 一、final 的核心作用 1. 变量(不可变引用) 不可重新赋值:final 修饰的变量…...

多模态实时交互边界的高效语音语言模型 VITA-Audio 介绍
介绍 VITA-Audio是由Zuwei Long等研究者提出的端到端大型语音语言模型,其核心目标是通过跨模态令牌生成技术,解决传统语音交互系统中首音频令牌生成延迟高的问题。该模型的创新点主要体现在: 低延迟:VITA-Audio 是首个能够在初次…...

LLM | 论文精读 | NAACL 2025 | Clarify When Necessary:教语言模型何时该“问一句”再答!
🔍 解读 NAACL 2025 重磅论文《Clarify When Necessary》:教语言模型何时该“问一句”再答! 🧩 一、现实问题:大模型“看不懂装懂”有多危险? 我们每天用的 ChatGPT、Claude 等大型语言模型(LL…...
)
MySQL 8.0 OCP 英文题库解析(七)
Oracle 为庆祝 MySQL 30 周年,截止到 2025.07.31 之前。所有人均可以免费考取原价245美元的MySQL OCP 认证。 从今天开始,将英文题库免费公布出来,并进行解析,帮助大家在一个月之内轻松通过OCP认证。 本期公布试题51~60 试题51:…...

深度解析Vue项目Webpack打包分包策略 从基础配置到高级优化,全面掌握性能优化核心技巧
深度解析Vue项目Webpack打包分包策略 从基础配置到高级优化,全面掌握性能优化核心技巧 一、分包核心价值与基本原理 1.1 为什么需要分包 首屏加载优化:减少主包体积,提升TTI(Time to Interactive)缓存利用率提升&am…...

MySQL——基本查询内置函数
目录 CRUD Create Retrieve where order by limit Update Delete 去重操作 聚合函数 聚合统计 内置函数 日期函数 字符函数 数学函数 其它函数 实战OJ 批量插入数据 找出所有员工当前薪水salary情况 查找最晚入职员工的所有信息 查找入职员工时间升序排…...

实现图片自动压缩算法,canvas压缩图片方法
背景: 在使用某些支持webgl的图形库(eg:PIXI.js,fabric.js)场景中,如果加载的纹理超过webgl可处理的最大纹理限制,会导致渲染的纹理缺失,甚至无法显示。 方案 实现图片自动压缩算…...

零基础设计模式——创建型模式 - 单例模式
第二部分:创建型模式 - 单例模式 (Singleton Pattern) 欢迎来到创建型模式的第一站——单例模式!这是最简单也最常用的设计模式之一。 核心思想:关注对象的创建过程,将对象的创建与使用分离,降低系统的耦合度。 单例…...

数据挖掘:从数据堆里“淘金”,你的数据价值被挖掘了吗?
数据挖掘:从数据堆里“淘金”,你的数据价值被挖掘了吗? 在这个数据爆炸的时代,我们每天都在产生海量信息:社交媒体上的点赞、网购时的浏览记录,甚至是健身手环记录下的步数。这些数据本身可能看似杂乱无章…...

k8s1.27版本集群部署minio分布式
需求: 1.创建4个pv,一个pv一个minio-pod。使用sts动态分配pvc(根据存储类找到pv)。----持久化 2.暴露minio的9001端口。(nodeport)----管理界面 镜像:minio/minio:RELEASE.2023-03-20T20-16-18Z--->换国内源 说明…...

雷军:芯片,手机,平板,SUV一起发
大家好,我是小悟。 5月19日,雷军在微博上宣布,5月22日晚7点将举办小米战略新品发布会。 这场被官方称为“人车家全生态”战略升级的重要活动,一口气带来了小米手机SoC芯片“玄戒O1”、旗舰手机小米15S Pro、小米平板7 Ultra&…...