day 21 常见降维算法
一、无监督降维
定义:这类算法在降维过程中不使用任何关于数据样本的标签信息(比如类别标签、目标值等)。它们仅仅根据数据点本身的分布、方差、相关性、局部结构等特性来寻找低维表示。
输入:只有特征矩阵 X。
目标:
- 保留数据中尽可能多的方差,从而保留数据的主要信息,以实现降维。
- 保留数据的局部或全局流形结构(如 LLE, Isomap, t-SNE, UMAP),将高维数据映射到低维空间,以保持数据点之间的相对位置关系。
- 找到能够有效重构原始数据的紧凑表示(如 Autoencoder)。
- 找到统计上独立的成分(如 ICA)。
典型算法:
- PCA:主成分分析(Principal Component Analysis)
- SVD:奇异值分解(Singular Value Decomposition)
- t - SNE:t 分布随机邻域嵌入(t - distributed Stochastic Neighbor Embedding)
- UMAP:均匀流形近似与投影(Uniform Manifold Approximation and Projection)
- LLE:局部线性嵌入(Locally Linear Embedding)
- Isomap:等距映射(Isometric Mapping)
- Autoencoders:自动编码器
- ICA:独立成分分析(Independent Component Analysis)
二、有监督降维
定义:这类算法在降维过程中会利用数据样本的标签信息(通常是类别标签 y)。目标是找到对后续分类或回归任务更有利的低维子空间。
输入:特征矩阵 X 和 对应的标签向量 y。
目标:
- 最大化不同类别之间的可分性,同时最小化同一类别内部的离散度(如 LDA),即让不同类别数据点尽可能分开,同一类别数据点尽可能聚集。
- 找到对预测目标变量 y 最有信息量的特征组合。
典型算法:
- LDA(Linear Discriminant Analysis) :通过最大化类间散度与类内散度之比来寻找投影方向;
- NCA (Neighbourhood Components Analysis):基于距离度量学习,通过优化样本近邻分类概率来学习距离度量从而实现降维。
三、核心思想区别
PCA等无监督降维旨在找到数据中方差最大的方向(即主成分),然后将数据投影到由这些最重要的主成分构成的新的、维度更低子空间上。新的特征(主成分)是原始特征的线性组合,并且它们之间是正交的(不相关)。它关注的是数据整体的分布特征,试图在低维空间中最大程度地重构原始数据的变化。但是这些方差大的方向不一定与物体的类别有直接关联。
而LDA 的核心目标是最大化不同类别之间的可分性,同时小化同一类别内部的离散度。在分类任务中,这个目标与直接提高分类性能紧密相关。它依据类别信息来确定投影方向,使得投影后的低维数据能够更好地服务于分类。
因此,在分类任务中,LDA通常比PCA更直接有效。
四、算法介绍
主成分分析(PCA)
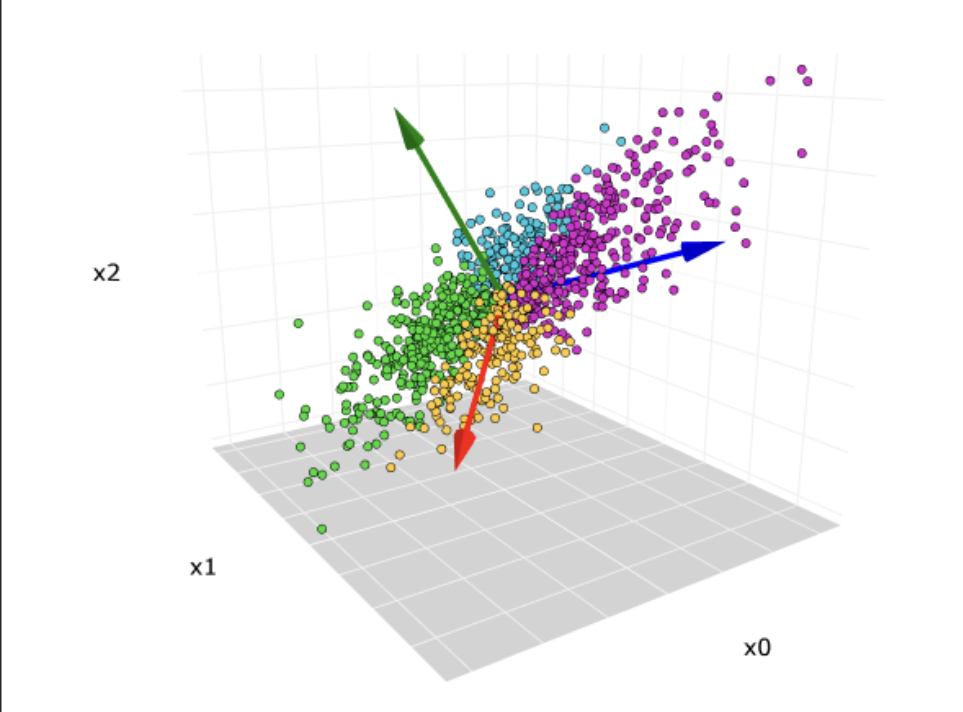
PCA 是一种线性降维方法,通过将原始特征进行线性组合来确定主成分,寻找的是一个能够最好地捕捉数据方差的线性子空间。即PCA 只能捕捉数据中的线性关系,对于高度非线性的数据结构处理能力有限,在降维时会因为其线性假设,将非线性结构 “扁平化”,从而丢失重要信息。
PCA 可以看作是将 SVD 应用于经过均值中心化的数据矩阵,并基于 SVD 的结果(右奇异向量、奇异值等)进行主成分确定、方差分析以及降维等特定解释和操作的一种方法。
核心步骤


PCA 与 SVD 的联系
主成分方向
V 矩阵的列向量(即右奇异向量)就是主成分 (PCs)。V 的第一列是第一主成分(方差最大的方向),第二列是第二主成分(方差次大且与第一主成分正交的方向),以此类推。这些向量告诉你原始特征是如何线性组合形成各个主成分的。
解释的方差

主成分得分

PCA 的本质概括
- 对数据进行均值中心化是 PCA 的常见预处理步骤,它使数据围绕原点分布,有助于后续计算数据的协方差矩阵以及寻找主成分方向。
- 对中心化后的数据进行 SVD 分解,其右奇异向量对应着 PCA 中的主成分方向。
- SVD 得到的奇异值大小与主成分所解释的方差成正比,可用于评估每个主成分的重要性。
- 通过左奇异向量与奇异值的乘积或者中心化后的数据与右奇异向量的乘积,可以将原始数据投影到由主成分构成的低维空间,获得降维后的数据表示。
PCA 适用场景
- 目标是最大化方差:PCA 旨在找到数据中方差最大的方向,将数据投影到这些方向上,能保留数据中尽可能多的方差,也就保留了大部分信息。当数据中存在噪声时,信号往往具有比噪声更大的方差,通过 PCA 保留高方差成分,可实现去噪;而当特征间存在相关性时,PCA 能找到这些相关特征共同变化最大的方向,从而提取关键信息。
- 数据分布大致呈椭球形或存在线性相关性:对于呈椭球形分布的数据,PCA 能找到这个椭球的主轴方向,这些主轴方向就是方差最大的方向,也就是主成分方向。线性相关性意味着特征之间存在线性关系,这与 PCA 寻找线性组合来确定主成分的方式相契合。
- 作为其他线性模型的预处理步骤:许多线性模型如逻辑回归、线性 SVM 对特征的相关性较为敏感。PCA 通过将原始特征转换为不相关的主成分,可以避免多重共线性问题。
- 探索性数据分析 (EDA):在对数据了解甚少的初期,PCA 可以快速揭示数据中变异的主要模式,帮助分析人员初步了解数据的结构和主要特征,为后续更深入的分析提供方向。
- 降噪:基于噪声方差低于信号方差的假设,PCA 在降维过程中舍弃低方差成分,而这些低方差成分往往包含较多噪声,从而达到降噪的效果。
- 原始特征数量多且存在多重共线性:多重共线性会给模型训练带来不稳定等问题。PCA 通过生成少数几个不相关的主成分,既减少了特征数量,又解决了多重共线性问题。
PCA 慎用场景
- 高度非线性数据:PCA 基于线性假设,对于分布在复杂非线性流形上的数据,会将其投影到一个线性子空间,可能会丢失关键的非线性关系。相比之下,t-SNE、UMAP、LLE、Isomap 等非线性降维技术能更好地处理这类数据。
- 方差并非衡量重要性的唯一标准:PCA 是无监督方法,仅依据方差来确定主成分的重要性。但在某些有监督任务如分类中,类别标签所蕴含的信息至关重要,方差较小的方向可能对区分不同类别起着关键作用,此时像 LDA 这种有监督降维方法会更合适。
- 主成分的可解释性:尽管主成分是原始特征的线性组合,但这种组合方式可能较为复杂,不像原始特征那样具有直观的物理解释。例如,原始特征可能是具体的身高、体重等可直接理解的变量,而主成分可能是这些变量复杂加权后的结果,难以直接赋予实际意义。
- 数据特征尺度差异巨大:特征尺度不同会导致方差计算受尺度大的特征主导,使得 PCA 确定的主成分时忽略其他特征。因此在应用 PCA 前进行数据标准化是非常必要的。
代码实例
from sklearn.model_selection import train_test_split
X = data.drop(['Credit Default'], axis=1) # 特征,axis=1表示按列删除
y = data['Credit Default']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
from sklearn.metrics import classification_report, confusion_matrix
import warnings #用于忽略警告信息
warnings.filterwarnings("ignore") # 忽略所有警告信息# 评估基准模型,这里确实不需要验证集
print("--- 1. 默认参数随机森林 (训练集 -> 测试集) ---")
import time
start_time = time.time() # 记录开始时间
rf_model = RandomForestClassifier(random_state=42)
rf_model.fit(X_train, y_train) # 在训练集上训练
rf_pred = rf_model.predict(X_test) # 在测试集上预测
end_time = time.time() # 记录结束时间print(f"训练与预测耗时: {end_time - start_time:.4f} 秒")
print("\n默认随机森林 在测试集上的分类报告:")
print(classification_report(y_test, rf_pred))
print("默认随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred))from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler # 特征缩放
from sklearn.decomposition import PCA # 主成分分析
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA # 线性判别分析
# UMAP 需要单独安装: pip install umap-learn -i https://pypi.tuna.tsinghua.edu.cn/simple
import umap
import numpy as np # 确保numpy导入print(f"\n--- 2. PCA 降维 + 随机森林 (不使用 Pipeline) ---")# 步骤 1: 特征缩放
scaler_pca = StandardScaler()
X_train_scaled_pca = scaler_pca.fit_transform(X_train)
X_test_scaled_pca = scaler_pca.transform(X_test) # 使用在训练集上fit的scaler# 步骤 2: PCA降维
# 选择降到10维,或者你可以根据解释方差来选择,例如:
pca_expl = PCA(random_state=42)
# 训练集上拟合PCA
pca_expl.fit(X_train_scaled_pca)
# 计算累计方差贡献率
cumsum_variance = np.cumsum(pca_expl.explained_variance_ratio_)
# 确定保留95%方差所需的主成分数量
n_components_to_keep_95_var = np.argmax(cumsum_variance >= 0.95) + 1
print(f"为了保留95%的方差,需要的主成分数量: {n_components_to_keep_95_var}")

# 我们测试下降低到10维的效果
n_components_pca = 10
pca_manual = PCA(n_components=n_components_pca, random_state=42)X_train_pca = pca_manual.fit_transform(X_train_scaled_pca)
X_test_pca = pca_manual.transform(X_test_scaled_pca) # 使用在训练集上fit的pcaprint(f"PCA降维后,训练集形状: {X_train_pca.shape}, 测试集形状: {X_test_pca.shape}")
start_time_pca_manual = time.time()
# 步骤 3: 训练随机森林分类器
rf_model_pca = RandomForestClassifier(random_state=42)
rf_model_pca.fit(X_train_pca, y_train)# 步骤 4: 在测试集上预测
rf_pred_pca_manual = rf_model_pca.predict(X_test_pca)
end_time_pca_manual = time.time()print(f"手动PCA降维后,训练与预测耗时: {end_time_pca_manual - start_time_pca_manual:.4f} 秒")print("\n手动 PCA + 随机森林 在测试集上的分类报告:")
print(classification_report(y_test, rf_pred_pca_manual))
print("手动 PCA + 随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred_pca_manual))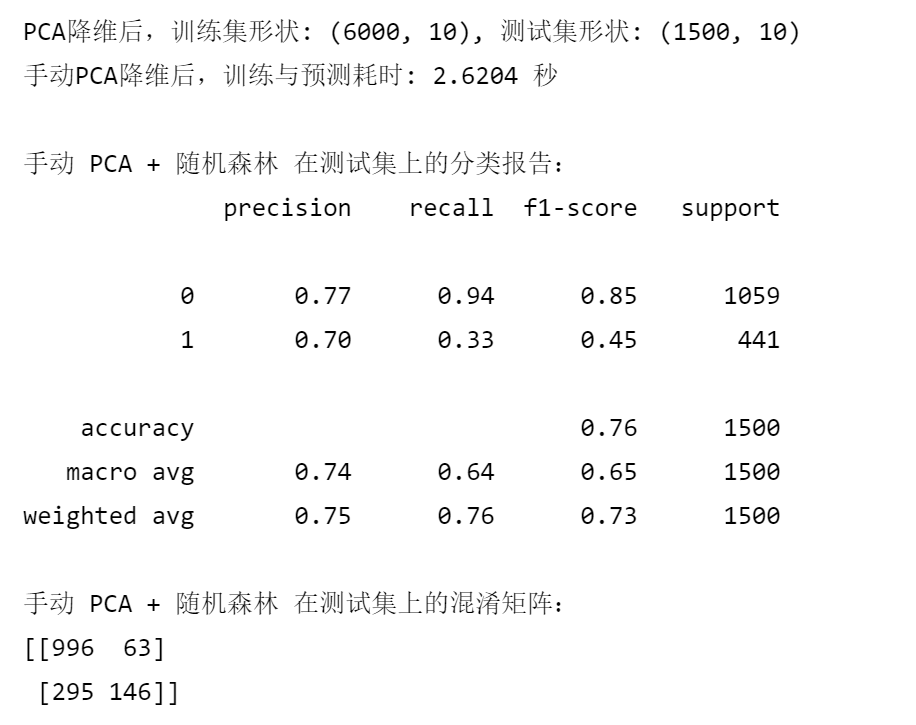
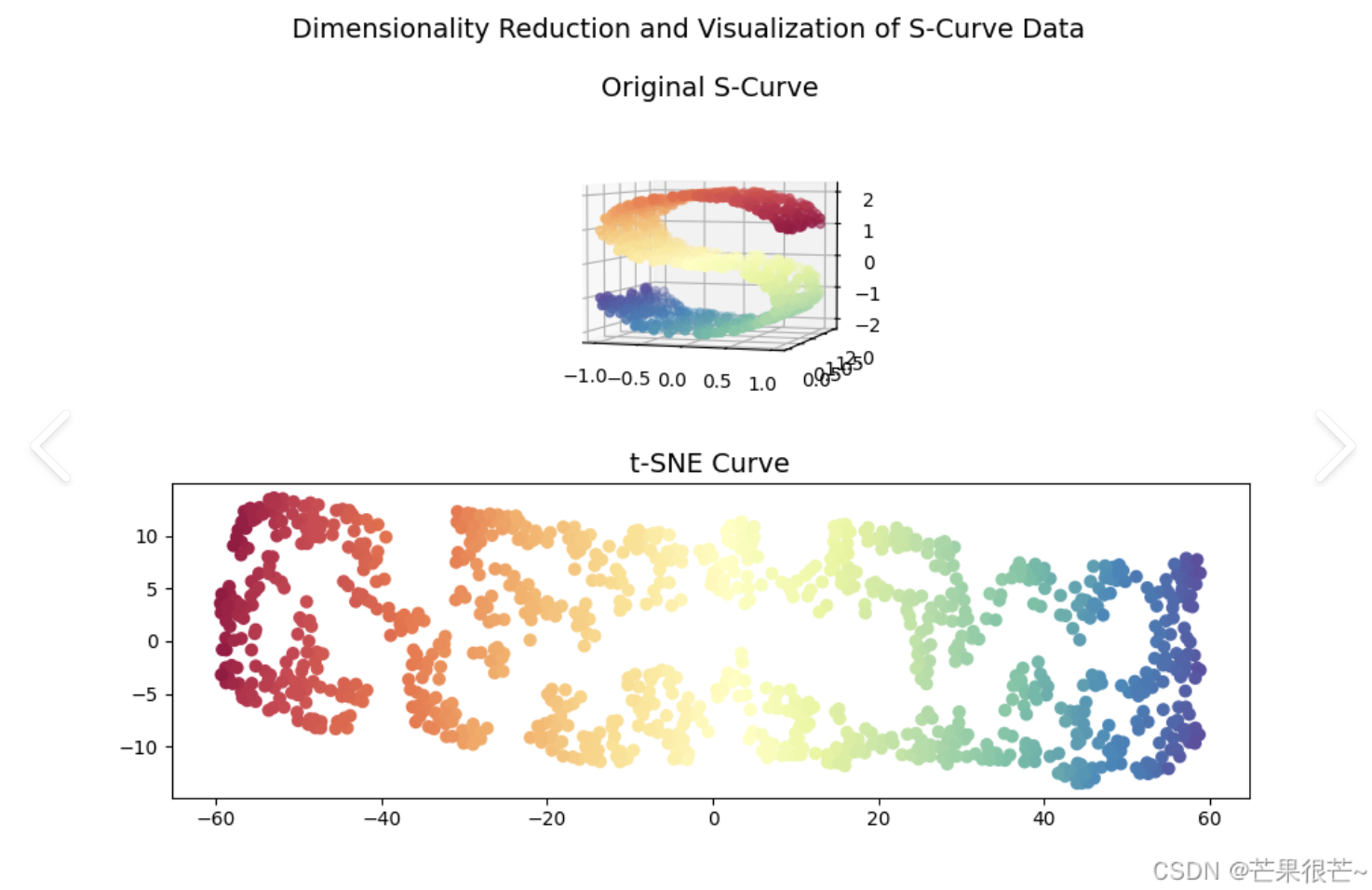
t-分布随机邻域嵌入 (t-SNE)
在高维空间里,如果一些数据点彼此靠近,意味着它们具有相似性,t - SNE 在将数据映射到低维空间时,会尽力让这些原本相似的点依旧相互靠近。它特别擅长于将高维数据集投影到二维或三维空间进行可视化,从而揭示数据中的簇结构或流形结构。
t-SNE 与 PCA/SVD 的主要差异

适用场景
- 高维数据可视化:t - SNE 通过将数据映射到低维空间,使得我们可以直观地观察到数据的分布特征,例如不同类别的数据是否形成了明显的簇,以及这些簇之间的关系等。
- 复杂非线性结构数据:当数据具有复杂的非线性结构,如分布在弯曲的流形上时,t - SNE能够更好地处理这类非线性数据,在低维空间中呈现出与高维空间相似的局部关系。
- 探索性数据分析:在对数据缺乏先验了解时,t - SNE 有助于发现数据中未知的群体。通过可视化,我们可以观察到数据点的聚集情况,从而发现那些可能代表不同潜在群体的簇。
使用注意事项
- 计算成本高:对于大规模数据集,t - SNE 的计算量极大,运行时间长。在这种情况下,建议先使用 PCA 将数据维度降低到一个适中的维度(如50),再应用 t - SNE。
- 超参数敏感:
- Perplexity(困惑度):该参数对 t - SNE 的结果影响显著。较小的困惑度使得算法更关注数据点非常局部的邻域结构,而较大的困惑度则会考虑更广泛的邻域信息。常见的取值范围是 5 到 50,需尝试不同值。
- n_iter(迭代次数):为使算法收敛,需要足够的迭代次数。默认值 1000。
- learning_rate(学习率):学习率影响算法在优化过程中的步长,进而影响收敛情况。
- 结果的解释:
- 簇的大小和密度:t - SNE 在可视化时会将所有簇展开到相似的密度。因此,在解读结果时,不能依据可视化图中簇的大小来判断原始数据中相应簇的规模。
- 点之间的距离:t - SNE 主要致力于保持数据点的局部邻域关系,图中点之间的距离在全局上没有实际意义,不能依据全局距离来推断高维空间中的实际情况。
- 多次运行结果可能不同:由于 t - SNE 的优化过程包含随机初始化,并且使用梯度下降等方法,多次运行可能会得到略有不同的可视化结果。不过,数据中真正有意义的簇结构通常是相对稳定的,不会因多次运行而发生本质变化。
- 不适合作为通用的有监督学习预处理步骤:t - SNE 的设计目标是可视化和保持局部结构,与有监督学习中追求最大化类别可分性(如 LDA)或保留全局方差(如 PCA 在某些场景下)以提高分类器性能的需求不同。因此,它通常不作为直接提升分类器性能的降维预处理步骤。
代码实例
from sklearn.manifold import TSNE
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix
import time
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns print(f"\n--- 3. t-SNE 降维 + 随机森林 ---")
print(" 标准 t-SNE 主要用于可视化,直接用于分类器输入可能效果不佳。")# 步骤 1: 特征缩放
scaler_tsne = StandardScaler()
X_train_scaled_tsne = scaler_tsne.fit_transform(X_train)
X_test_scaled_tsne = scaler_tsne.transform(X_test) # 使用在训练集上fit的scaler# 步骤 2: t-SNE 降维
# 我们将降维到与PCA相同的维度(例如10维)或者一个适合分类的较低维度。
# t-SNE通常用于2D/3D可视化,但也可以降到更高维度。
# 然而,降到与PCA一样的维度(比如10维)对于t-SNE来说可能不是其优势所在,
# 并且计算成本会显著增加,因为高维t-SNE的优化更困难。
# 为了与PCA的 n_components=10 对比,我们这里也尝试降到10维。
# 但请注意,这可能非常耗时,且效果不一定好。
# 通常如果用t-SNE做分类的预处理(不常见),可能会选择非常低的维度(如2或3)。# n_components_tsne = 10 # 与PCA的例子保持一致,但计算量会很大
n_components_tsne = 2 # 更典型的t-SNE用于分类的维度,如果想快速看到结果# 如果你想严格对比PCA的10维,可以将这里改为10,但会很慢# 对训练集进行 fit_transform
tsne_model_train = TSNE(n_components=n_components_tsne,perplexity=30, # 常用的困惑度值n_iter=1000, # 足够的迭代次数init='pca', # 使用PCA初始化,通常更稳定learning_rate='auto', # 自动学习率 (sklearn >= 1.2)random_state=42, # 保证结果可复现n_jobs=-1) # 使用所有CPU核心
print("正在对训练集进行 t-SNE fit_transform...")
start_tsne_fit_train = time.time()
X_train_tsne = tsne_model_train.fit_transform(X_train_scaled_tsne)
end_tsne_fit_train = time.time()
print(f"训练集 t-SNE fit_transform 完成,耗时: {end_tsne_fit_train - start_tsne_fit_train:.2f} 秒")# 对测试集进行 fit_transform
# 再次强调:这是独立于训练集的变换
tsne_model_test = TSNE(n_components=n_components_tsne,perplexity=30,n_iter=1000,init='pca',learning_rate='auto',random_state=42, # 保持参数一致,但数据不同,结果也不同n_jobs=-1)
print("正在对测试集进行 t-SNE fit_transform...")
start_tsne_fit_test = time.time()
X_test_tsne = tsne_model_test.fit_transform(X_test_scaled_tsne) # 注意这里是 X_test_scaled_tsne
end_tsne_fit_test = time.time()
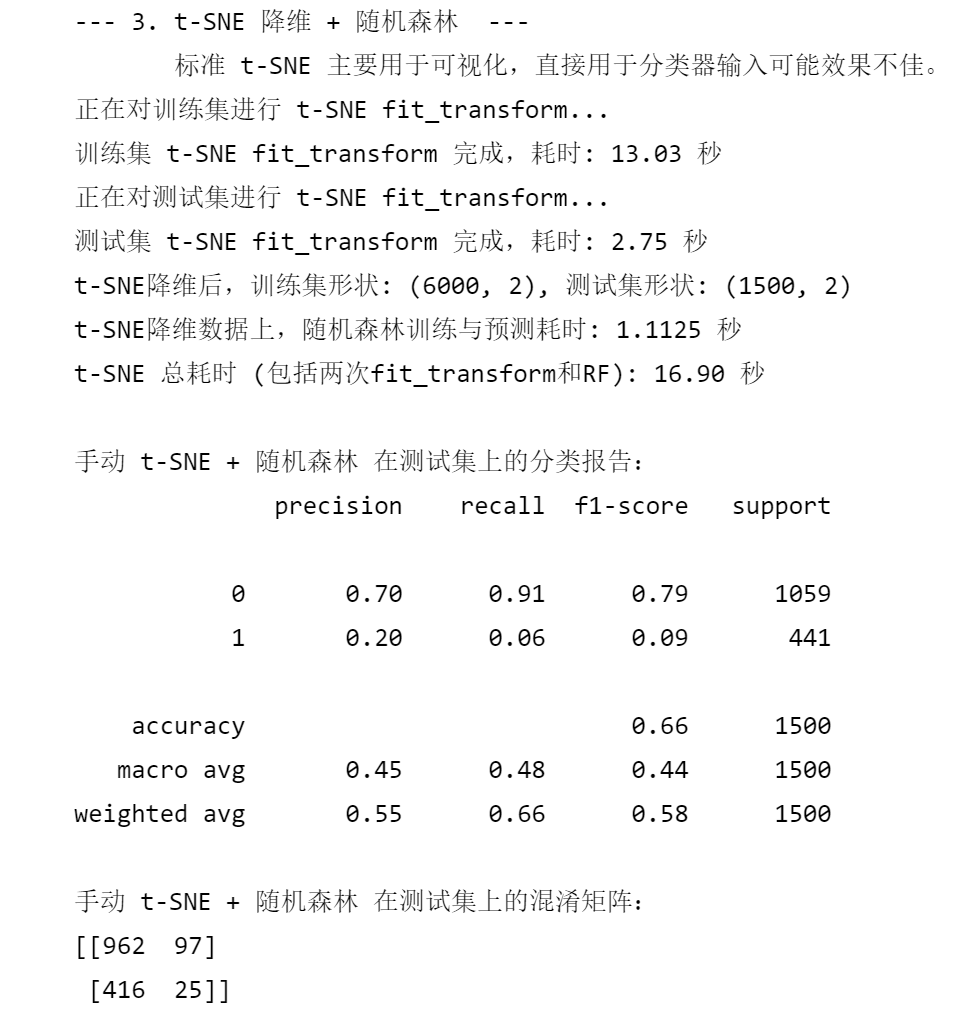
print(f"测试集 t-SNE fit_transform 完成,耗时: {end_tsne_fit_test - start_tsne_fit_test:.2f} 秒")print(f"t-SNE降维后,训练集形状: {X_train_tsne.shape}, 测试集形状: {X_test_tsne.shape}")start_time_tsne_rf = time.time()
# 步骤 3: 训练随机森林分类器
rf_model_tsne = RandomForestClassifier(random_state=42)
rf_model_tsne.fit(X_train_tsne, y_train)# 步骤 4: 在测试集上预测
rf_pred_tsne_manual = rf_model_tsne.predict(X_test_tsne)
end_time_tsne_rf = time.time()print(f"t-SNE降维数据上,随机森林训练与预测耗时: {end_time_tsne_rf - start_time_tsne_rf:.4f} 秒")
total_tsne_time = (end_tsne_fit_train - start_tsne_fit_train) + \(end_tsne_fit_test - start_tsne_fit_test) + \(end_time_tsne_rf - start_time_tsne_rf)
print(f"t-SNE 总耗时 (包括两次fit_transform和RF): {total_tsne_time:.2f} 秒")print("\n手动 t-SNE + 随机森林 在测试集上的分类报告:")
print(classification_report(y_test, rf_pred_tsne_manual))
print("手动 t-SNE + 随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred_tsne_manual))
线性判别分析 (LDA)
核心定义与目标
- 作为有监督降维算法与分类器:LDA 具有双重身份。作为降维算法,利用数据点类别信息,将高维数据投影到低维空间。作为分类器,基于降维后的数据直接对新样本进行类别预测。
- 类间距离最大化与类内方差最小化:想象有两类数据点,分别代表苹果和橙子。LDA 的目标是找到一个投影方向,使得投影后苹果的数据点尽可能聚集在一起,橙子的数据点也尽可能聚集在一起,同时让苹果和橙子这两组数据点之间的距离尽可能大。
工作原理
类间散布矩阵衡量的是不同类别间的离散程度,类内散布矩阵衡量的是同一类别内部数据点离散程度。LDA 通过寻找合适的投影方向,使得类间散布矩阵与类内散布矩阵的行列式之比最大化。
从直观上理解,就是让不同类别之间的 “距离”(离散程度)相对同一类别内部的 “距离” 变得更大,从而实现更好的类别区分。
关键特性
- 有监督性:与 PCA 只关注数据本身特征不同,LDA 在计算过程中依赖类别标签。
- 降维目标维度:降维后维度上限为 min (n_features, n_classes - 1) 。以人脸识别为例,如果要区分 10 个人(n_classes = 10),且原始图像数据有 1000 个特征(n_features = 1000),那么 LDA 最多能将数据降到 9 维。这是因为 LDA 旨在找到能够区分不同类别的方向,类别数限制了可区分方向的最大数量。
- 线性变换:LDA 通过线性组合原始特征来创建新的判别特征。就像用不同的系数去加权各个原始特征,然后把它们相加得到新的特征。
- 数据假设:理论上假设数据服从多元高斯分布且所有类别具有相同协方差矩阵。以鸢尾花数据集为例,该数据集有三个类别(山鸢尾、变色鸢尾、维吉尼亚鸢尾),LDA 假设每个类别内的花的各种特征(如花瓣长度、宽度等)服从多元高斯分布,并且这三个类别的花在这些特征上的协方差矩阵相同。在实际中,只要数据分布大致满足这些假设,LDA 就能有效工作。
输入要求
- 特征 (X):要求是数值型特征。如果有类别型特征,比如颜色(红、绿、蓝),就需要先转化为数值形式,常见的是独热编码,将颜色特征转化为 [1, 0, 0]、[0, 1, 0]、[0, 0, 1] 。
- 标签 (y):是一维数组或 Series,代表每个样本的类别。例如在一个疾病诊断数据集中,标签可以是 [0(健康), 1(患病), 0, 1] 这样的形式,直接表示每个样本所属的类别,类别数量直接影响 LDA 降维的上限。
- 与特征 (X) 和标签 (y) 的关系
- 标签 (y) 的驱动作用:标签 y 中的类别结构决定了 LDA 降维的方向。比如在动物分类中,如果类别是猫、狗、兔子,LDA 会根据这些类别信息,寻找能将这三类动物区分开的特征组合。
- 特征 (X) 的基础作用:特征 X 提供了构建判别特征的原始素材。如果原始特征与类别之间没有相关性,那么 LDA 很难找到有效的判别特征。例如在预测天气的任务中,如果使用的特征与天气无关(如人的名字),LDA 就无法有效区分不同的天气类别。
优点
- 提升分类性能:由于 LDA 直接优化类别可分性,在分类任务前使用 LDA 降维,能让后续分类器更容易区分不同类别。例如在垃圾邮件分类中,先使用 LDA 降维,能使垃圾邮件和正常邮件在低维空间中更易区分,从而提升分类器的准确率。
- 计算相对高效:相比于一些复杂的非线性降维方法,LDA 的计算过程相对简单,计算量较小,在处理大规模数据时能节省计算资源和时间。
- 判别意义明确:生成的低维特征是为了区分不同类别而构建的,具有明确的物理意义。例如在区分不同品种的植物时,新生成的低维特征可能直接代表了与品种区分最相关的植物特征组合。
局限性与注意事项
- 降维维度受限:当类别数较少时,降维程度有限。比如在一个二分类问题中,LDA 最多只能将数据降到 1 维,相比 PCA 可以降到更低维度,LDA 在这种情况下的降维能力较弱。
- 对非线性结构处理不佳:如果数据的类别边界是非线性的,LDA 难以准确捕捉。例如数据分布呈螺旋状,LDA 由于是线性方法,无法像非线性降维方法那样很好地将不同类别区分开。
- 对数据假设的依赖:如果数据严重偏离多元高斯分布和等协方差假设,LDA 的性能会受到影响。比如在一些具有极端偏态分布的数据集中,LDA 可能无法有效工作。
- 类别重叠问题:当不同类别在原始特征空间中高度重叠时,LDA 很难找到有效的投影方向来区分它们,导致区分能力受限。
适用场景
- 提升分类模型性能:在大多数分类任务中,如文本分类、图像分类等,使用 LDA 降维可以作为预处理步骤,提高后续分类器的性能。
- 利用类别信息区分数据:当已知类别信息对区分数据至关重要时,LDA 能发挥很好的作用。例如在医学诊断中,已知疾病类别,LDA 可以利用这些类别信息,从患者的各种检测指标中提取最具判别性的特征。
- 数据可视化:如果能将数据降到 2D 或 3D,LDA 可用于数据可视化。比如在一个多类别图像数据集上,使用 LDA 将数据降到 2 维,然后在平面上绘制不同类别的数据点,可直观观察不同类别之间的区分情况。
代码实例
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix
import time
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D # 如果需要3D绘图
import seaborn as snsprint(f"\n--- 4. LDA 降维 + 随机森林 ---")# 步骤 1: 特征缩放
scaler_lda = StandardScaler()
X_train_scaled_lda = scaler_lda.fit_transform(X_train)
X_test_scaled_lda = scaler_lda.transform(X_test) # 使用在训练集上fit的scaler# 步骤 2: LDA 降维
n_features = X_train_scaled_lda.shape[1]
if hasattr(y_train, 'nunique'):n_classes = y_train.nunique()
elif isinstance(y_train, np.ndarray):n_classes = len(np.unique(y_train))
else:n_classes = len(set(y_train))max_lda_components = min(n_features, n_classes - 1)# 设置目标降维维度
n_components_lda_target = 10if max_lda_components < 1:print(f"LDA 不适用,因为类别数 ({n_classes})太少,无法产生至少1个判别组件。")X_train_lda = X_train_scaled_lda.copy() # 使用缩放后的原始特征X_test_lda = X_test_scaled_lda.copy() # 使用缩放后的原始特征actual_n_components_lda = n_featuresprint("将使用缩放后的原始特征进行后续操作。")
else:# 实际使用的组件数不能超过LDA的上限,也不能超过我们的目标(如果目标更小)actual_n_components_lda = min(n_components_lda_target, max_lda_components)if actual_n_components_lda < 1: # 这种情况理论上不会发生,因为上面已经检查了 max_lda_components < 1print(f"计算得到的实际LDA组件数 ({actual_n_components_lda}) 小于1,LDA不适用。")X_train_lda = X_train_scaled_lda.copy()X_test_lda = X_test_scaled_lda.copy()actual_n_components_lda = n_featuresprint("将使用缩放后的原始特征进行后续操作。")else:print(f"原始特征数: {n_features}, 类别数: {n_classes}")print(f"LDA 最多可降至 {max_lda_components} 维。")print(f"目标降维维度: {n_components_lda_target} 维。")print(f"本次 LDA 将实际降至 {actual_n_components_lda} 维。")lda_manual = LinearDiscriminantAnalysis(n_components=actual_n_components_lda, solver='svd')X_train_lda = lda_manual.fit_transform(X_train_scaled_lda, y_train)X_test_lda = lda_manual.transform(X_test_scaled_lda)print(f"LDA降维后,训练集形状: {X_train_lda.shape}, 测试集形状: {X_test_lda.shape}")start_time_lda_rf = time.time()
# 步骤 3: 训练随机森林分类器
rf_model_lda = RandomForestClassifier(random_state=42)
rf_model_lda.fit(X_train_lda, y_train)# 步骤 4: 在测试集上预测
rf_pred_lda_manual = rf_model_lda.predict(X_test_lda)
end_time_lda_rf = time.time()print(f"LDA降维数据上,随机森林训练与预测耗时: {end_time_lda_rf - start_time_lda_rf:.4f} 秒")print("\n手动 LDA + 随机森林 在测试集上的分类报告:")
print(classification_report(y_test, rf_pred_lda_manual))
print("手动 LDA + 随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred_lda_manual))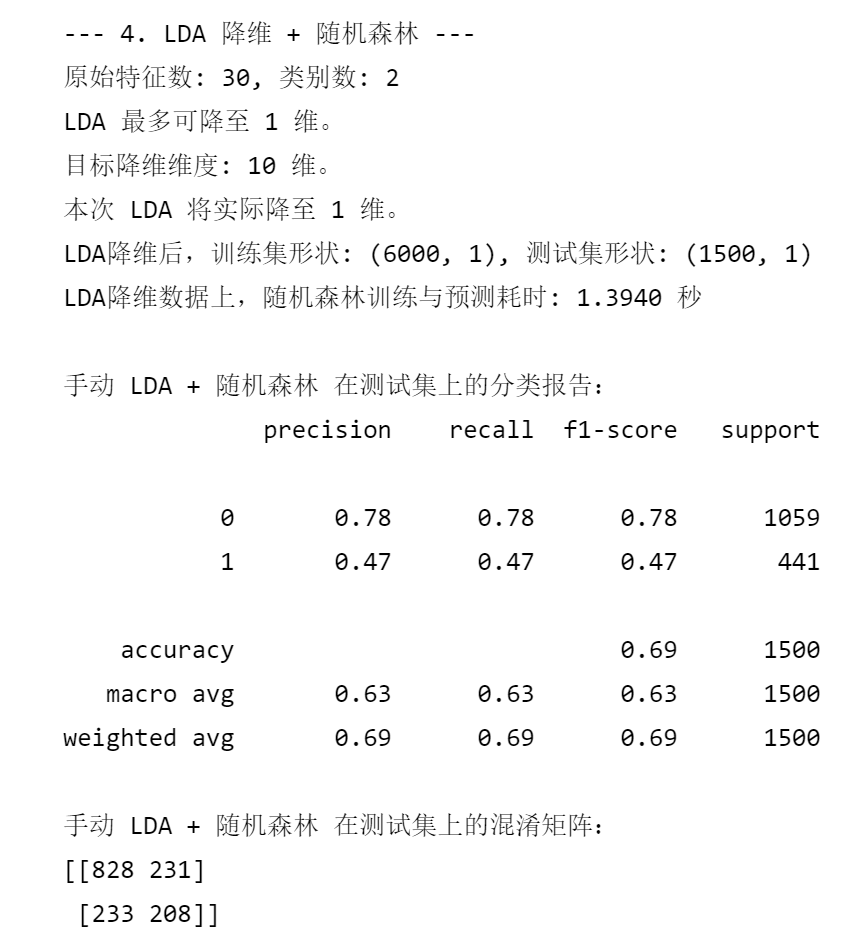
@浙大疏锦行
相关文章:

day 21 常见降维算法
一、无监督降维 定义:这类算法在降维过程中不使用任何关于数据样本的标签信息(比如类别标签、目标值等)。它们仅仅根据数据点本身的分布、方差、相关性、局部结构等特性来寻找低维表示。 输入:只有特征矩阵 X。 目标:…...

代理IP高可用性与稳定性方案:负载均衡、节点健康监测与智能切换策略
一、负载均衡策略:动态分配与场景适配 多算法协同调度 轮询与加权轮询:适用于定时数据采集等低频任务,通过静态IP池按顺序分配请求,避免单一节点过载。例如,静态IP池可支持电商商品价格监控,按固定周期切换…...

C语言:在操作系统中,链表有什么应用?
在操作系统中,链表是一种重要的数据结构,凭借其灵活的内存管理和高效的插入/删除特性,被广泛应用于多个核心模块。以下是其主要应用场景及详细说明: 1. 内存管理:空闲内存块管理 应用场景:操作系统需要管…...

RocketMQ
一、引言 Message Queue(消息 队列),从字⾯上理解:⾸先它是⼀个队列。FIFO先进先出的数据结构——队列。消息队列就是所谓的存放消息的队列。 消息队列解决的不是存放消息的队列的⽬的,解决的是通信问题。 …...

学习BI---QuickBI介绍
BI是什么 BI 数据仓库(存数据) OLAP(多维分析) 数据挖掘(找规律) 可视化(图表/看板) 人话解释就是把企业里乱七八糟的数据变成老板能看懂的报告,帮他们做更聪明的决…...

【数据结构】AVL树的实现
文章目录 1. AVL 的概念2. AVL 树的实现2.1 AVL 树的结构2.2 AVL 树的插入2.2.1 AVL 树插入一个值的大致过程2.2.2 平衡因子更新 2.3 旋转2.3.1 旋转的原则2.3.2 右单旋2.3.3 左单旋2.3.4 左右双旋2.3.5 右左双选 2.4 AVL 树的查找2.5 AVL 树平衡检测 1. AVL 的概念 AVL树是最…...

基于Zynq SDK的LWIP UDP组播开发实战指南
一、为什么选择LWIP组播? 在工业控制、智能安防、物联网等领域,一对多的高效数据传输需求日益增长。Zynq-7000系列SoC凭借其ARM+FPGA的独特架构,结合LWIP轻量级网络协议栈,成为嵌入式网络开发的理想选择。本文将带您实现: LWIP组播配置全流程动态组播组切换技术零拷贝数据…...

【esp32 控制台】-命令
文章目录 1 esp32控制台简介2 控制台命令编程2.1 控制台配置交互设备初始化控制台初始化等待命令输入 2.2 命令实现2.2.1 命令注册 踩坑记录 1 esp32控制台简介 可以通过idf.py monitor调出idf的控制台,结束控制台用ctrl ]。 esp32的控制台就像linux中的shell一样…...

DApp开发全流程解析:模式设计、功能参考与合约管理实践
DApp开发全流程解析:模式设计、功能参考与合约管理实践 引言:Web3.0时代的DApp开发范式 随着区块链技术的成熟,DApp(去中心化应用)已成为Web3.0生态的核心载体。截至2025年,全球DApp数量突破10万…...

I/O多路复用:poll与epoll
一、select/poll与epoll对比 核心区别 特性select/pollepoll内核数据结构数组(线性结构)红黑树(存储监听的fd)内存拷贝每次调用需将fd列表从用户态拷贝到内核态仅在注册fd时拷贝一次(epoll_ctl)内核事件检…...

【调制识别】PGD攻击中参数的含义
在PGD(Projected Gradient Descent)对抗攻击中,代码如下: # 定义PGD对抗样本生成类 class AttackPGD(nn.Module): def __init__(self, model, config):super(AttackPGD, self).__init__()self.model model …...

设备数据看板助力自动化工厂实现生产智能精细化管理
工厂数字化转型需要实现自动化设备生产现场可视化、设备系统间的互联互通,以及数据的智能决策。然而,当前许多制造企业仍面临着传统单机设备同质化严重、数字化服务能力不足、售后成本高企、系统集成效率低下等挑战。企业如何通过自动化装备看板和实时数…...

单点登录是是什么?具体流程是什么?
SSO⼀般都需要⼀个独⽴的认证中⼼(passport),⼦系统的登录均得通过passport,⼦系统本⾝将不参与登录操作,当⼀个系统成功登录以后,passport将会颁发⼀个令牌给各个⼦系统,⼦系统可以拿着令牌会获…...

什么业务需要用到waf
Web应用防火墙(Web Application Firewall,简称WAF)主要用于保护Web应用程序免受各种网络攻击,以下是需要用到WAF的业务类型及具体场景: 一、电子商务业务 业务特点:涉及用户注册、登录、支付等敏感操作&a…...

java中的Servlet4.x详解
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站 Servlet 4.x 是 Java EE 8(现 Jakarta EE)规范的一部分,于 2017 年正式发布。作为 Servlet 技术的重大更…...

## Docker 中 Elasticsearch 启动失败:日志文件权限问题排查与解决
好的,这是一份关于你遇到的 Docker Elasticsearch 启动报错问题的笔记,包含问题描述、我的分析判断以及最终的解决方案,适合用于整理成文章。 Docker 中 Elasticsearch 启动失败:日志文件权限问题排查与解决 在使用 Docker部署 E…...

JavaScript:PC端特效--缓动动画
一、缓动效果原理 缓动动画就是让元素运动速度有所变化,最常见的就是让元素慢慢停下来 思路: 让盒子每次移动的距离慢慢变小,速度就会慢慢降下来核心算法:(目标值-现在位置)/10作为每次移动距离的步长停…...

【深度学习新浪潮】什么是多模态大模型?
多模态大模型是人工智能领域的前沿技术方向,它融合了多种数据模态(如文本、图像、语音、视频、传感器数据等),并通过大规模参数模型实现跨模态的联合理解与生成。简单来说,这类模型就像人类一样,能同时“看”“听”“读”“说”,并将不同信息关联起来,完成复杂任务。 …...

C++23 std::mdspan:多维数组处理新利器
文章目录 引言C23简介std::mdspan的定义与特点定义特点 std::mdspan的优势零成本抽象的多维数据访问减少内存开销提高代码灵活性 std::mdspan的应用场景科学计算图形学 相关提案示例代码使用动态扩展使用静态和动态扩展 总结 引言 在C的发展历程中,每一个新版本都带…...

09、底层注解-@Import导入组件
09、底层注解-Import导入组件 Import是Spring框架中的一个注解,用于将组件导入到Spring的应用上下文中。以下是Import注解的详细介绍: #### 基本用法 - **导入配置类** java Configuration public class MainConfig { // 配置内容 } Configuration Impo…...

码蹄集——N是什么、棋盘
MT1223 N是什么 给定一系列数字3、10、21、36…,输入正整数N,输出上述序列的第N个值。从N1开始计数。 格式 输入格式:输入正整数N 输出格式:输出整型 样例 1 输入:5 输出:55 备注:N小于…...
知识详解和注意事项)
C++中聚合类(Aggregate Class)知识详解和注意事项
一、聚合类(Aggregate Class)概念 聚合(Aggregate) 是 C 中一类特殊的类类型,无用户自定义构造函数、无私有或受保护非静态数据成员、无虚函数、无基类(C11 起基类必须也是聚合且无私有/受保护成员&#x…...

python打卡day30
模块和库的导入 知识点回顾: 导入官方库的三种手段导入自定义库/模块的方式导入库/模块的核心逻辑:找到根目录(python解释器的目录和终端的目录不一致) 作业:自己新建几个不同路径文件尝试下如何导入 python的学习就像…...

PostGIS实现栅格数据导出图片标准格式【ST_AsGDALRaster】
ST_AsGDALRaster 函数应用详解:将栅格数据导出为标准图片格式 [文章目录] 一、函数概述 二、函数参数详解 三、关键功能示例 四、GDAL 选项配置指南 五、性能优化建议 六、注意事项与限制 七、应用场景 八、总结 一、函数概述 ST_AsGDALRaster是PostGIS中…...

4.6 sys模块
sys --- 仅作了解 面试之前冲击一下 python的垃圾回收机制 import sys # 1. api_version : 获取python的内部版本号 print(sys.api_version) #1013 # 2. copyright: 获取cpython的版本 print(sys.copyright) #3.getfilesystemencoding() getdefaultencoding():获…...
——ECG信号处理-第十三课」2025年5月19日)
「HHT(希尔伯特黄变换)——ECG信号处理-第十三课」2025年5月19日
一、引言 心电信号(ECG)是反映心脏电活动的重要生理信号,其特征提取对于心脏疾病的诊断和监测具有关键意义。Hilbert - Huang Transform(HHT)作为一种强大的信号处理工具,在心电信号特征提取领域得到了广泛…...

枪机定焦系统的自动控制装置
枪机定焦系统,作为一种监控设备,通常被广泛应用于各种需要高清、远距离监控的场合。该系统的主要特点是其镜头焦距固定,不能手动或自动调节,从而确保了监控画面的稳定性和清晰度。当提到枪机定焦系统采用自动功能时,可…...

【Unity】Unity中将字典序列化
Unity中将字典序列化,在预制体上能够看到字典的内容,也可以直接在预制体上拖拽给字典赋值 直接上代码 using System; using System.Collections; using System.Collections.Generic; using System.Linq; using UnityEngine;public class SerializableD…...

VTK|箱体切割器
文章目录 效果实现类头文件实现类源文件如何调用项目git链接 效果 实现类头文件 /*** file BoxClipperController.h* brief 该头文件定义了 BoxClipperController 类,用于管理基于盒子的网格数据裁剪操作。* details 该类提供了使用 vtkBoxWidget 对网格数据进行裁…...

CS50x 01 c
1 getchar() 在 C 语言里,getchar()是一个十分常用的函数,其功能是从标准输入(一般指键盘)读取单个字符。下面为你详细介绍它的用法。 基本语法 getchar()函数的原型定义在<stdio.h>头文件中,语法形式如下&am…...

确保高质量的音视频通话,如何最大化利用视频带宽
在当今数字时代,音视频内容随处可见,对于开发者来说,理解互联网带宽变得至关重要。我们的在线体验质量,无论是观看高清电影还是演唱会直播,都严重依赖于互联网带宽的概念。在本文中,我们将揭示视频带宽的复…...

@RequestParam 和 @RequestBody、HttpServletrequest 与HttpServletResponse
在Java Web开发中,RequestParam、RequestBody、HttpServletRequest 和 HttpServletResponse 是常用的组件,它们用于处理HTTP请求和响应。下面分别介绍它们的使用场景和使用方法: 1. RequestParam RequestParam 是Spring MVC框架中的注解&am…...

HashMap 的特点及应用场景
一、HashMap 核心特点 1. 基本特性 键值对存储:基于 Map 接口实现,存储 Key-Value 对 允许 null 键/值:可以有一个 null 键和多个 null 值 非线程安全:多线程环境下需要额外的同步措施 无序存储:不保证元素的插入顺…...

day30 python 模块、包与库的高效使用指南
目录 一、Python库的分类与适用场景 表格 1.1 基础工具库 1.2 科学计算库 1.3 数据分析库 1.4 Web开发库 1.5 机器学习库 1.6 自动化脚本库 1.7 网络爬虫库 二、模块与包的导入方式 2.1 标准导入 2.2 从模块中导入特定项 2.3 非标准导入(不推荐&#x…...

JVM核心配置参数详解与调优指南
精心整理了最新的面试资料和简历模板,有需要的可以自行获取 点击前往百度网盘获取 点击前往夸克网盘获取 引言 Java虚拟机(JVM)的配置参数直接影响应用程序的性能、稳定性和资源利用率。合理配置参数能够显著提升吞吐量、降低延迟并避免内存…...

python打卡第30天
知识点回顾: 一,导入官方库的三种手段。 使用 import 直接导入整个模块 import module_name 使用 from ... import ... 导入特定功能 from module_name import function_name 使用 as 关键字重命名模块或功能 import module_name as alias # 或 from mod…...

数据要素及征信公司数据要素实践
数据要素及征信公司数据要素实践 1.数据要素的定义与核心特征2.征信公司应用数据要素的实践路径3.总结1.数据要素的定义与核心特征 数据要素是数字经济时代的新型生产要素,指以电子形式存在、通过计算方式参与生产经营活动并创造价值的数据资源。 其核心特征包括: 新型生产…...

耗时十分钟,做了一个 uniapp 灵感泡泡机
最近,我用 UniApp 搭配 CodeBuddy 实现了一个充满童话感的小应用,名叫 IdeaBubbles(灵感泡泡机)。它是一个单页 WebApp,用来记录那些转瞬即逝的灵感时刻。整个界面以梦幻气泡和彩虹玻璃拟态为主题,视觉效果…...

《Head First 设计模式》第二章 - 笔记
本书是本人写的设计模式的笔记,写下核心要点,如果你掌握过设计模式,想快速阅读本书内容,这个笔记适合你阅读。如果你是新手,有 java 基础和 oo 设计原则基础,你适合跟我一样从零阅读本书。 第一章 观察者模…...

matlab绘制光学传递函数mtf曲线
在 MATLAB 中绘制光学系统的光学传递函数(Modulation Transfer Function,MTF)曲线可以通过以下步骤实现。MTF 是描述光学系统对物体细节的传递能力的函数,通常用于分析成像系统的性能。 假设我们有一个理想的光学系统,…...

贵州某建筑物挡墙自动化监测
1. 项目简介 某建筑物位于贵州省某县城区内,靠近县城主干道,周边配套学校、医院、商贸城。建筑物临近凤凰湖、芙蓉江等水系,主打“湖景生态宜居”。改建筑物总占地面积:约5.3万平方米;总建筑面积:约15万平…...

自定义协议与序列化
前言 书接上回,我们上一篇提到了协议并且我们草率的写了一个协议,然后又对TCP的R和W留了一个伏笔,我们今天彻底做个了断。 UDP是面向数据报的,它要么不读,要么就是一次读完的,所以不存在数据断断续续的问…...

MySQL中的Change Buffer是什么,它有什么作用?
MySQL 中的 Change Buffer(更改缓冲区)是 InnoDB 存储引擎使用的一种特殊数据结构,主要用于优化对二级索引(secondary indexes)的写操作性能。 它的核心作用是: 当对表进行 INSERT、UPDATE 或 DELETE 操作…...

Ubuntu 20.04之Docker安装ES7.17.14和Kibana7.17.14
你需要已经安装如下运行环境: Ubuntu 20.04 docker 28 docker-compose 1.25 一、手动拉取镜像 docker pull docker.elastic.co/kibana/kibana:7.17.14docker pull docker.elastic.co/elasticsearch/elasticsearch:7.17.14 或者手动导入镜像 docker load -i es7.17.14.ta…...

ThreadLocal作一个缓存工具类
1、工具类 import java.util.HashMap; import java.util.Map;public class ThreadLocalUtil {// 使用Map存储多类型数据private static final ThreadLocal<Map<String, Object>> CONTEXT_HOLDER new ThreadLocal<>();// 存储数据public static void set(Str…...

DeepSeek在旅游行业的智能化革命
2025年,从贵州全域智慧旅游平台的行程规划革命,到黄山景区"AI旅行助手"的实时服务升级,再到宁夏"游宁AI"的全域智能导览,DeepSeek通过技术创新与行业场景的深度融合,正在重新定义"智慧旅游"的内涵。这场变革不仅体现在效率提升层面,更通过…...

说一下响应状态码有哪些?
HTTP响应状态码分类(RFC 7231标准) 1. 1xx(信息类) 临时响应,表示请求已被接收,需要继续处理 100 Continue:客户端应继续发送请求体 101 Switching Protocols:服务器同意升级协议(如WebSocket) 102 Processing(WebDAV):服务器正在处理但未完成 2. 2xx(成功类)…...

ABAP实战案例--获取当前数据由哪个用户锁住
1、业务场景: A用户正在打开订单,订单已上锁;B用户打开时只允许查看并提醒由哪个用户正在操作该笔订单。 2、函数使用:ENQUEUE_READ 代码示例: DATA:LV_MESSAGE TYPE SY-MSGV1,LV_UNAME TYPE UNAME.DATA:LV_GARG …...

CSS 选择器入门
一、CSS 选择器基础:快速掌握核心概念 什么是选择器? CSS 选择器就像 “网页元素的遥控器”,用于定位 HTML 中的特定元素并应用样式。 /* 结构:选择器 { 属性: 值; } */ p { color: red; } /* 选择所有<p>元素,…...

【深度学习新浪潮】如何入门人工智能?
入门人工智能(AI)需要结合数学基础、编程技能、机器学习理论和实践项目,逐步深入。以下是一个系统的学习路径,适合零基础或初学者参考: 一、打好基础:数学与编程 1. 数学基础(关键) AI的核心依赖数学,尤其是以下领域: 线性代数:向量、矩阵运算、特征分解等(用于…...