超小多模态视觉语言模型MiniMind-V 训练
简述
MiniMind-V 是一个超适合初学者的项目,让你用普通电脑就能训一个能看图说话的 AI。训练过程就像教小孩:先准备好图文材料(数据集),教它基础知识(预训练),再教具体技能(微调),最后测试它学会没。整个过程简单、便宜、快,1小时就能搞定,特别适合想玩 AI 又没大预算的人!
GitHub - jingyaogong/minimind-v: 🚀 「大模型」1小时从0训练26M参数的视觉多模态VLM!🌏 Train a 26M-parameter VLM from scratch in just 1 hours!🚀 「大模型」1小时从0训练26M参数的视觉多模态VLM!🌏 Train a 26M-parameter VLM from scratch in just 1 hours! - jingyaogong/minimind-v![]() https://github.com/jingyaogong/minimind-v
https://github.com/jingyaogong/minimind-v
MiniMind-V 是什么?
MiniMind-V 是一个开源项目,目标是让你从零开始训练一个视觉语言模型(VLM)。简单来说,VLM 是一种能同时理解文字和图片的 AI。比如,你给它一张狗的照片,问“这是啥?”,它能回答“这是只狗!”
这个项目的亮点是:
- 超轻量:只有2600万个参数(相比像 GPT-3 那样的模型有几十亿参数,简直是小巫见大巫)。
- 训练快:在一块不错的个人显卡(比如 NVIDIA 3090)上,1小时就能训好。
- 成本低:租个 GPU 服务器训练,费用大概1.3块钱(约0.2美元)。
- 适合新手:代码简单,硬件要求不高,普通电脑也能跑。
就像是打造一个能看图说话的小 AI 脑子,不需要超级计算机!想象 VLM 是一个有两种超能力的 AI:
- 文字能力:能像聊天机器人(比如 ChatGPT)一样理解和生成文字。
- 图像能力:能“看”图片,识别里面的内容。
MiniMind-V 是基于一个叫 MiniMind 的文字模型,加上一个视觉编码器(把图片变成 AI 能懂的数据),让它能同时处理文字和图片。简单来说,MiniMind-V 接收文字和图片,处理后生成回答。流程是这样的:
- 输入:你给它文字和图片。比如,问“图片里是什么?”并附上一张图。图片在代码里用特殊符号(像“@@@…@@@”)表示。
- 处理图片:图片被送进一个叫 CLIP-ViT-Base-Patch16 的视觉编码器。它把图片切成小块(像拼图),转化成一串数字(叫“令牌”),AI 就能理解了。
- 处理文字:你的问题(比如“图片里是什么?”)也被转成令牌。
- 融合图文:图片令牌通过简单的数学运算(线性变换)调整到跟文字令牌“说同一种语言”。这样 AI 就能同时处理两者。
- 输出:这些令牌被送进语言模型,生成回答,比如“图片里是一只狗在公园玩”。
这让 MiniMind-V 能描述图片、回答关于图片的问题,甚至同时聊多张图。
MiniMind-V的结构仅增加Visual Encoder和特征投影两个子模块,增加模态混合分支,以支持多种模态信息的输入,引用官方给的图来说明
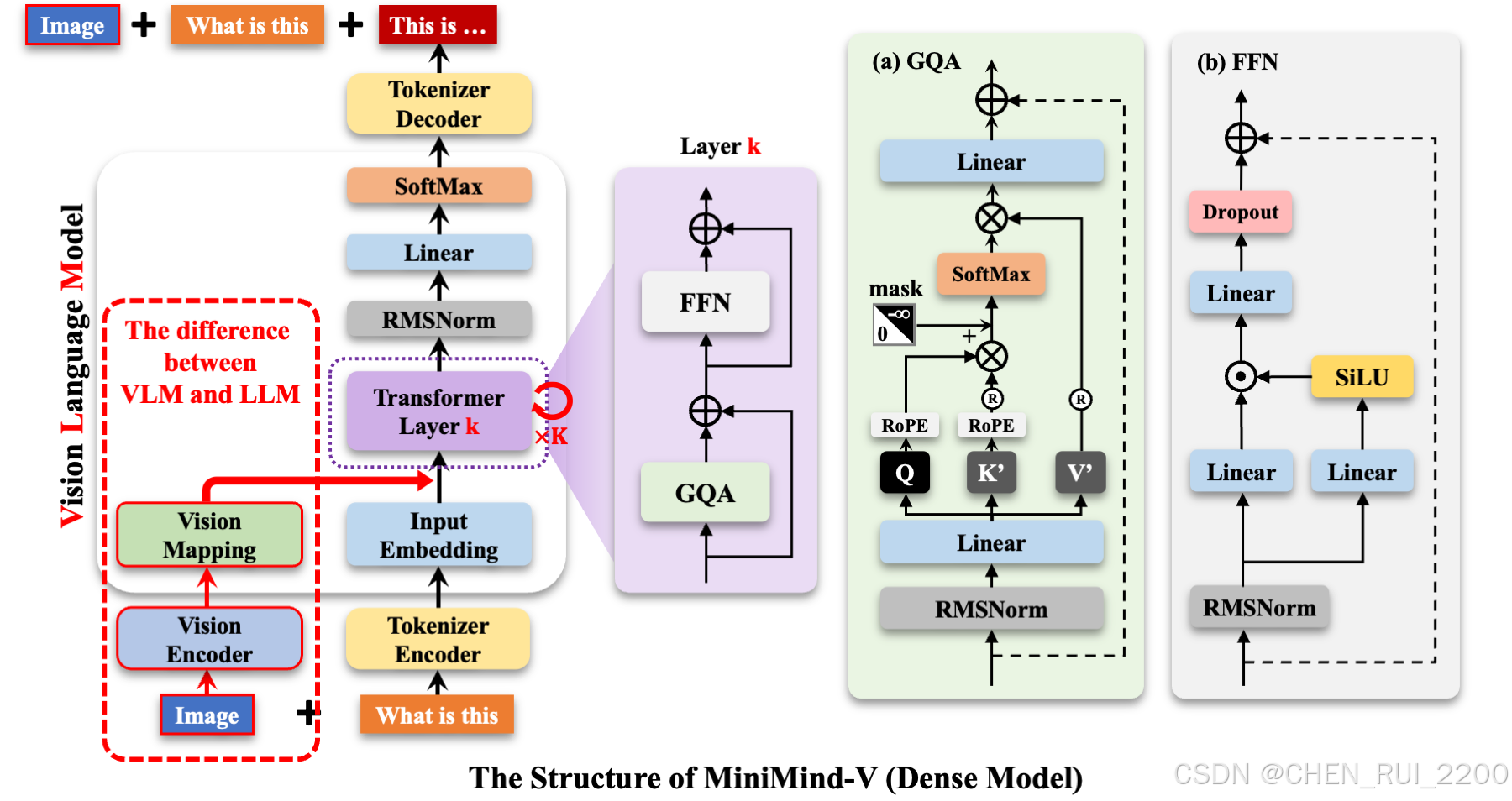
在minimind-v中,使用196个字符组成的 @@@...@@@ 占位符代替图像,之所以是196个字符,前面有所提及: 任何图像都被clip模型encoder为196×768维的token, 因此minimind-v的prompt为:
@@@......@@@\n这个图片描述的是什么内容?计算完embedding和projection,并对图像部分token替换后整个计算过程到输出则和LLM部分没有任何区别。
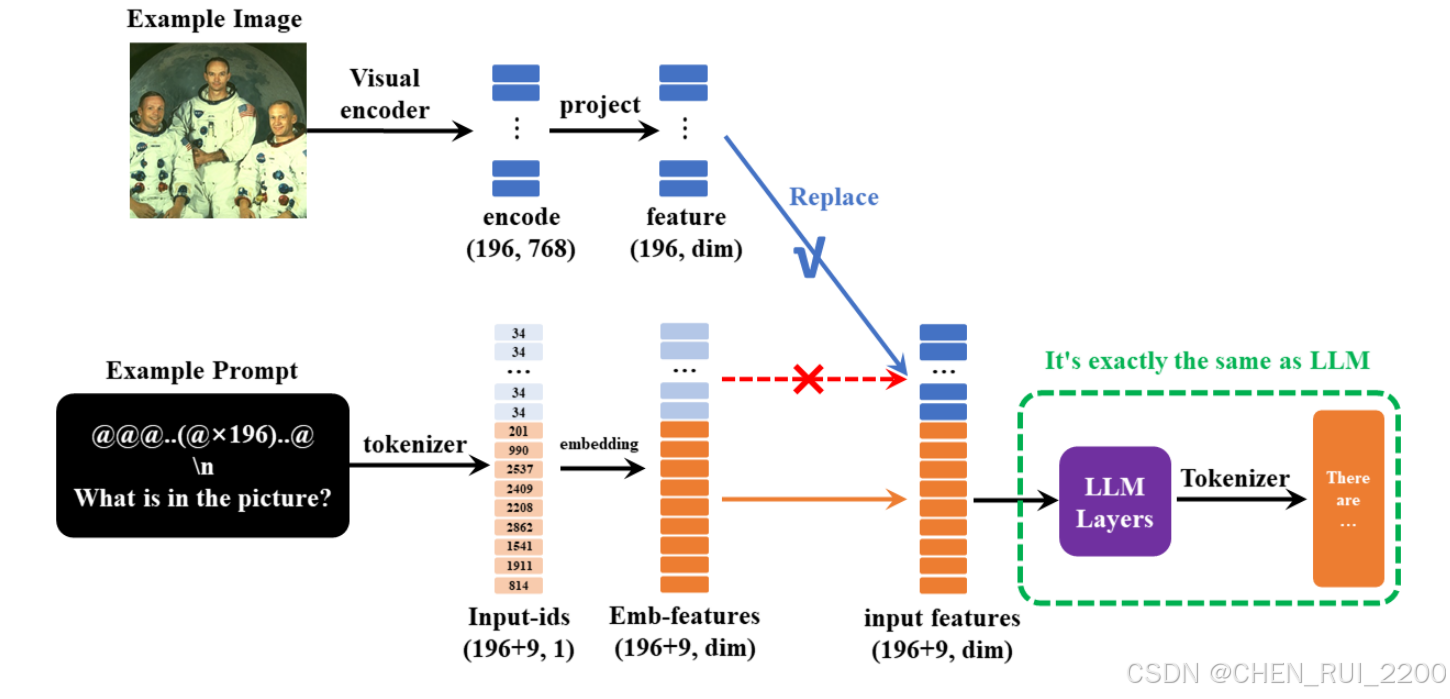
一次性多图的实现方法就是通过注入多个<image>图像占位符进行实现,不需要修改任何框架
MiniMind-V 怎么训练?
训练 VLM 就像教小孩学会看图说话。你得给它看很多例子(数据),慢慢引导它学会规律。以下是训练步骤,用最简单的语言解释:
1. 准备材料(数据和工具)
- 数据集:需要一堆图片和对应的文字说明或问题。比如,一张猫的图片配上“这是一只猫”或者“这是什么动物?”。MiniMind-V 的数据集(约5GB)包括图片和文字文件(JSONL 格式),放在 ./dataset 文件夹。你得下载并解压。
- 预训练语言模型:MiniMind-V 用一个叫 MiniMind 的文字模型作为基础。这个模型已经会聊天了,相当于给 AI 一个起点。你下载它的权重(预训练数据),放进 ./out 文件夹。
- 视觉编码器:用一个叫 CLIP 的预训练模型(clip-vit-base-patch16)来处理图片。CLIP 已经很会看图了,不用从头训。你下载它到 ./model/vision_model 文件夹。
- 软件环境:安装代码需要的 Python 库(列在 requirements.txt 里),就像做饭前把厨房工具准备好。
2. 预训练(学基础知识)
- 干啥:预训练是教 AI 怎么把图片和文字“连起来”。你给它看一大堆图文对(比如一棵树的图片配“这是一棵树”),让它学会图片和文字的关联。
- 咋做:运行代码 1-pretrain_vlm.py,把数据集喂给模型。CLIP 把图片转成令牌(每张图生成196个令牌,每个令牌是768个数字)。这些令牌跟文字令牌混在一起,模型学着预测接下来是什么(比如看到狗的图片和“这”之后,预测“是只狗”)。
- 时间和资源:用 NVIDIA 3090 显卡,大概1小时搞定。因为模型小(2600万参数),数据集也不大,跑得快。训练完会生成一个文件(比如 vlm_pretrain.pth),保存学到的东西。
- 可跳过:如果硬盘空间不够,你可以用项目提供的预训练权重跳过这一步,但自己训会让模型更强。
3. 监督微调(SFT)(教具体技能)
- 干啥:微调是教 AI 怎么回答具体问题或按指令办事。比如,你给它看一张日落图,问“这是啥?”,它得学会回答“这是日落”。
- 咋做:运行代码 train_sft_vlm.py,用一个包含问题-答案对(带图片)的数据集。模型反复练习生成正确答案,调整自己变得更聪明。就像考试前刷题一样。
- 输出:生成一个文件(比如 vlm_sft.pth),保存微调后的模型。这让 AI 在实际任务(比如聊图片)上表现更好。
- 为啥重要:微调让模型更实用,能真正帮你解决问题,而不是只会背图文对。
4. 测试模型(看看学得咋样)
- 干啥:训练完后,你可以用代码 3-test_vlm.py 测试模型。给它一张图和一个问题,看它回答得对不对。
- 例子:你上传一张狗的图片,问“这是啥?”,模型应该回答“这是只狗”。如果答错了,说明训练可能还得调调。
5 重点分析下
这个继承自语言模型的视觉语言模型
class MiniMindVLM(MiniMindForCausalLM):config_class = VLMConfigdef __init__(self, params: VLMConfig = None, vision_model_path="./model/vision_model/clip-vit-base-patch16"):super().__init__(params)if not params: params = VLMConfig()self.params = paramsself.vision_encoder, self.processor = self.__class__.get_vision_model(vision_model_path)self.vision_proj = VisionProj(hidden_size=params.hidden_size)模型的整体功能
MiniMindVLM 是一个视觉语言模型,它的核心任务是:
- 输入:接收文本(以 input_ids 表示,类似分词后的文字编号)和/或图像(以 pixel_values 表示,类似像素数据)。
- 输出:生成预测结果(logits,表示每个词的概率分布),可以用来生成文本或回答问题。
- 额外功能:支持缓存(past_key_values)以加速生成,支持混合专家(MoE)机制(通过 aux_loss),并能处理视觉和文本的混合输入。
从代码看,模型的结构可以分为以下几个主要部分:
- 嵌入层(embed_tokens):将输入的文本 token 转为向量表示。
- 视觉编码器(vision_encoder):处理图像输入,生成图像特征。
- 变换器层(model.layers):核心的神经网络层,处理文本和图像特征。
- 输出头(lm_head):将处理后的特征转为预测结果。
- 辅助组件:如归一化(norm)、位置编码(freqs_cos 和 freqs_sin)和混合专家损失(aux_loss)。
forward方法
def forward(self,input_ids: Optional[torch.Tensor] = None,attention_mask: Optional[torch.Tensor] = None,past_key_values: Optional[List[Tuple[torch.Tensor, torch.Tensor]]] = None,use_cache: bool = False,logits_to_keep: Union[int, torch.Tensor] = 0,pixel_values: Optional[torch.FloatTensor] = None,**args):- input_ids:文本输入的 token ID(形状 [batch_size, seq_length]),表示分词后的文本序列。例如,“你好”可能被编码为 [101, 203, 102]。
- attention_mask:注意力掩码,标记哪些 token 需要关注(1 表示关注,0 表示忽略),用于处理变长序列。
- past_key_values:缓存的键值对,用于加速自回归生成(比如生成长文本时复用之前的计算结果)。
- use_cache:是否启用缓存,True 时返回 past_key_values。
- logits_to_keep:指定输出的 logits 范围(整数或索引),控制返回哪些位置的预测结果。
- pixel_values:图像输入(形状可能是 [batch_size, num_images, channels, height, width]),表示一批图片的像素数据。
- args:其他未使用的参数,增加灵活性。
模型支持同时处理文本和图像(pixel_values 可选),并且通过 past_key_values 和 use_cache 支持增量生成,说明这是一个自回归变换器模型(类似 GPT),但增加了视觉处理能力。
其中图像处理的方法
if pixel_values is not None and start_pos == 0:if len(pixel_values.shape) == 6:pixel_values = pixel_values.squeeze(2)bs, num, c, im_h, im_w = pixel_values.shapestack_dim = 1 if bs > 1 else 0vision_tensors = torch.stack([MiniMindVLM.get_image_embeddings(pixel_values[:, i, :, :, :], self.vision_encoder)for i in range(num局化num)], dim=stack_dim)hidden_states = self.count_vision_proj(tokens=input_ids, h=hidden_states, vision_tensors=vision_tensors,seqlen=input_ids.shape[1])- 形状调整:
- 如果 pixel_values 是 6 维(可能包含额外维度),用 squeeze(2) 移除第 2 维。
- 解析形状为 [batch_size, num_images, channels, height, width],表示每批有 num_images 张图片。
- 图像编码:
- 遍历每张图片(pixel_values[:, i, :, :, :]),用 self.vision_encoder(可能是 CLIP 模型)生成图像嵌入(get_image_embeddings)。
- 将所有图像嵌入堆叠为 vision_tensors(形状取决于批次大小)。
- 融合图像和文本:
- self.count_vision_proj:将图像嵌入(vision_tensors)与文本嵌入(hidden_states)融合,生成新的 hidden_states。
- 融合考虑了 input_ids 和序列长度(seqlen),可能通过投影层(线性变换)将图像特征映射到文本特征空间。
结构功能:
- vision_encoder 是一个独立的视觉编码器(这里使用的是CLIP-ViT-Base-Patch16),专门处理图像,输出固定维度的特征向量。
- count_vision_proj 是一个投影层,将图像特征与文本特征对齐,表明模型在结构上将视觉和语言信息融合到一个统一的表示空间。
- 图像处理只在序列开始(start_pos == 0)执行,说明图像特征在生成后续 token 时会被缓存(通过 past_key_values)。
位置编码
使用旋转位置编码(Rotary Position Embedding, RoPE)
position_embeddings = (self.model.freqs_cos[start_pos:start_pos + seq_length],self.model.freqs_sin[start_pos:start_pos + seq_length]
)归一化和混合专家损失
hidden_states = self.model.norm(hidden_states)aux_loss = sum(layer.mlp.aux_lossfor layer in self.model.layersif isinstance(layer.mlp, MOEFeedForward)
)混合专家(MoE)损失:
- 检查每层的 mlp(前馈网络)是否是 MOEFeedForward 类型。
- 如果是,累加其 aux_loss(辅助损失,可能用于 MoE 的负载均衡)。
-
aux_loss 是 MoE 的正则化项,确保专家使用均衡,说明模型可能在性能和效率间做了优化。
6. 模型特点与设计亮点
- 视觉-语言融合:
- 通过 vision_encoder 和 count_vision_proj,模型将图像和文本特征统一到同一表示空间,支持多模态任务(如图像描述、视觉问答)。
- 图像处理只在序列开始执行,优化了增量生成的效率。
- 高效变换器:
- 使用旋转位置编码(RoPE),减少位置编码的内存开销。
- 支持 MoE 机制(MOEFeedForward),通过稀疏激活降低计算量,适合轻量模型(MiniMind-V 只有 2600 万参数)。
- 缓存机制(past_key_values)加速长序列生成。
- 灵活输出:
- logits_to_keep 允许控制输出范围,优化计算或生成特定长度的序列。
- self.OUT 提供多种输出(logits、hidden_states、past_key_values),支持多种下游任务。
- 轻量设计:
- 结合 Dropout 和 LayerNorm,模型训练稳定,适合在消费级 GPU上运行。
- MiniMind-V 的小规模(2600 万参数)和快速训练(1 小时)表明它在结构上做了大量优化。
模型训练
下载模型基座
下载clip模型到 ./model/vision_model 目录下,CLIP-ViT-Base-Patch16 像一个“图像翻译器”,把图片内容翻译成语言模型能懂的“数字语言”(特征向量)。语言模型像一个“讲故事的人”,根据文本和 CLIP 提供的图像信息,生成答案或描述。
git clone https://www.modelscope.cn/models/openai-mirror/clip-vit-base-patch16- CLIP:由 OpenAI 开发的全称是 “Contrastive Language-Image Pretraining”(对比式语言-图像预训练)。它是一个多模态模型,能够同时理解图像和文本,通过在大规模图文对数据上预训练,学会将图像和文本映射到同一个特征空间。
- ViT:表示 “Vision Transformer”,是 CLIP 的视觉部分,使用 Transformer 架构处理图像。
- Base:表示模型规模中等(相比 Small 或 Large)。
- Patch16:表示将图像分割成 16x16 像素的 patch(小块),作为输入处理。
下载纯语言模型权重到 ./out 目录下(作为训练VLM的基座语言模型)
wget -c https://huggingface.co/jingyaogong/MiniMind2-V-PyTorch/blob/main/lm_512.pth训练
下载数据集
minimind-v_dataset 是一个由 Jingyao Gong 提供的数据集,主要用于机器学习和计算机视觉任务。以下是该数据集的主要特点:
- 模态:图像
- 文件格式:imagefolder
- 数据集大小:小于 1K
- 相关文献:包含两篇 ArXiv 论文(arxiv: 2304.08485 和 arxiv: 2310.03744)
- 文件结构:
- 包含多个 JSONL 文件和压缩的图像文件,如
pretrain_images.zip和sft_images.zip。 - 还包括 README 文件,提供数据集的详细说明。
- 包含多个 JSONL 文件和压缩的图像文件,如
该数据集适合用于预训练和微调模型,特别是在视觉语言模型(VLM)相关的研究中。
from huggingface_hub import list_repo_files, hf_hub_download
import os# 数据集的 repo_id
repo_id = "jingyaogong/minimind-v_dataset"
save_dir = "./dataset"# 创建保存目录
os.makedirs(save_dir, exist_ok=True)# 获取数据集中的所有文件列表
files = list_repo_files(repo_id=repo_id, repo_type="dataset")
print("Found files:", files)# 下载每个文件
for file in files:print(f"Downloading {file}...")hf_hub_download(repo_id=repo_id,filename=file,repo_type="dataset",local_dir=save_dir,local_dir_use_symlinks=False # 直接保存文件,避免符号链接)print(f"Saved {file} to {save_dir}")print("All files downloaded!")
开启训练
预训练(学图像描述)
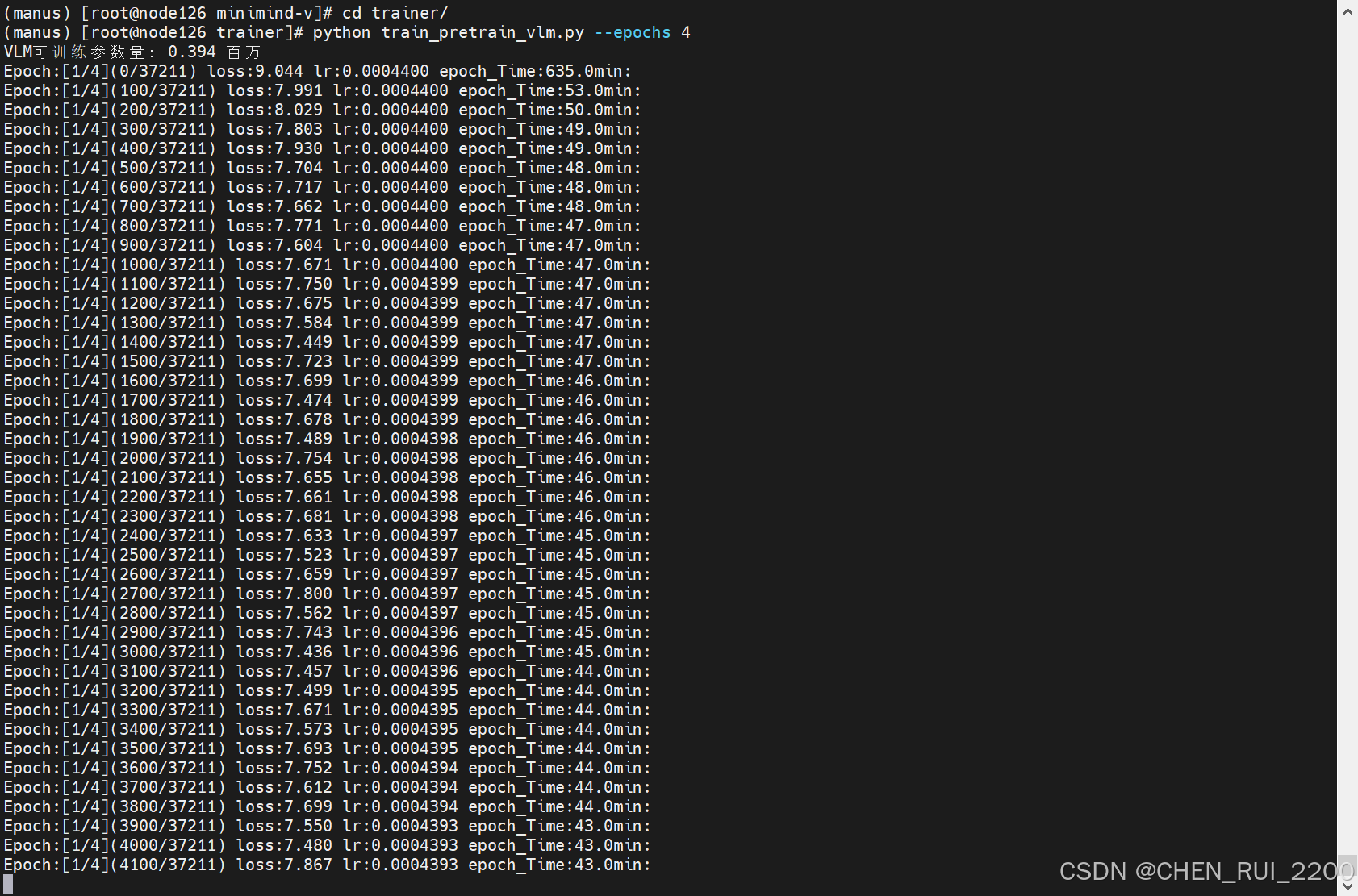
预训练从595K条数据集中学习图片的通用知识,比如鹿是鹿,狗是狗。
torchrun --nproc_per_node 2 train_pretrain_vlm.py --epochs 4
监督微调(学看图对话方式)
指令微调从300K条真实对话数据集中学习对图片提问的真实问答格式,更符合与人类的交流习惯。训练时均冻结visual encoder也就是clip模型梯度, 只训练Projection和LLM两部分。 预训练中,只设置Projection和LLM的最后一层参数可学习。 指令微调中,设置Projection和LLM的全部参数可学习。SFT 代码里把下面注释代码放开冻结参数
# 只解冻注意力机制中的投影层参数for name, param in model.model.named_parameters():if any(proj in name for proj in ['q_proj', 'k_proj', 'v_proj', 'o_proj']):param.requires_grad = True实际上作者是在保存模型权重的时候过滤 vision_encoder 参数
if (step + 1) % args.save_interval == 0 and (not ddp or dist.get_rank() == 0):model.eval()moe_path = '_moe' if model_config.use_moe else ''...clean_state_dict = {key: value for key, value in state_dict.items() if not key.startswith('vision_encoder.')}clean_state_dict = {k: v.half() for k, v in clean_state_dict.items()} # 半精度保存torch.save(clean_state_dict, ckp)- 保存模型权重时,显式过滤掉以 vision_encoder. 开头的参数(即 CLIP 模型的参数)。
- 这表明开发者假设 CLIP 模型的参数不需要保存,可能因为它们在训练中保持不变(冻结)或直接使用预训练权重。
-
虽然训练代码没有冻结 vision_encoder,但保存权重时过滤 vision_encoder 参数,暗示开发者可能预期 CLIP 模型不参与训练,或者认为它的权重不需要更新。
为什么需要冻结 CLIP 模型?
- 预训练优势:CLIP 模型(clip-vit-base-patch16)已经在大型图文数据集上预训练,特征提取能力强,无需进一步微调。
- 计算效率:CLIP 模型参数量较大(约 8600 万),冻结它可以减少显存占用和计算量,加速训练(MiniMind-V 强调轻量高效)。
- 任务需求:监督微调(SFT)阶段主要优化语言生成能力(LLM)和图文对齐(Projection),CLIP 的视觉特征通常保持不变。
模型转换
if __name__ == '__main__':lm_config = VLMConfig(hidden_size=512, num_hidden_layers=16, max_seq_len=8192, use_moe=False)torch_path = f"../out/sft_vlm_{lm_config.hidden_size}{'_moe' if lm_config.use_moe else ''}.pth"transformers_path = '../MiniMind2-V'convert_torch2transformers_minimind(torch_path, transformers_path)运行 web_demo(待后续训练结束补充)
相关文章:

超小多模态视觉语言模型MiniMind-V 训练
简述 MiniMind-V 是一个超适合初学者的项目,让你用普通电脑就能训一个能看图说话的 AI。训练过程就像教小孩:先准备好图文材料(数据集),教它基础知识(预训练),再教具体技能…...
:从概念到实践)
深入理解仿函数(Functors):从概念到实践
文章目录 1. 什么是仿函数?2. 仿函数与普通函数的区别3. 标准库中的仿函数4. 仿函数的优势4.1 状态保持4.2 可定制性4.3 性能优势 5. 现代C中的仿函数5.1 Lambda表达式5.2 通用仿函数 6. 仿函数的高级应用(使用C2020标准库及以上版本)6.1 函数…...

第二届parloo杯的RSA_Quartic_Quandary
(害,还是太菜了,上去秒了一道题之后就动不了了,今晚做个记录,一点点的往回拾起吧) # from Crypto.Util.number import getPrime, bytes_to_long # import math # # FLAG b************** # # # def gene…...

团队氛围紧张,如何提升工作积极性?
当团队氛围长期处于紧张状态时,员工的积极性、创造力和凝聚力会显著下降。要有效提升工作积极性,应从建设心理安全环境、优化管理沟通方式、提升认可与激励机制、加强情感联结与归属感等方面系统改善。其中,建设心理安全环境是最重要的基础&a…...

vuex的基本使用
个人简介 👨💻个人主页: 魔术师 📖学习方向: 主攻前端方向,正逐渐往全栈发展 🚴个人状态: 研发工程师,现效力于政务服务网事业 🇨🇳人生格言&…...

chrome因使用selenium无图模式导致不再加载图片问题解决
因为使用了selenium的无图模式访问chrome的本地用户数据导致正常使用chrome访问网页时图片不加载。现在页面出现验证码,验证码显示不了。 第一步:关闭所有chrome 第二步:找到Perferences文件 文件的目录为:C:\Users\用户名\AppDa…...
)
并发编程(5)
抛异常时会释放锁。 当线程在 synchronized 块内部抛出异常时,会自动释放对象锁。 public class ExceptionUnlockDemo {private static final Object lock new Object();public static void main(String[] args) {Thread t1 new Thread(() -> {synchronized …...

自己拥有一台服务器可以做哪些事情
上大学时候,买了自己的第一台服务器在HoRain Cloud上,结果没有好好利用,刚工作时候,又买了一台HoRain Cloud服务器,就想着好好利用。 可以搭建一些学习环境,比如说数据库,gitlab什么的 …...

Node.js聊天室开发:从零到上线的完整指南
为让你全面了解Node.js聊天室开发,我会先介绍开发背景与技术栈,再按搭建项目、实现核心功能、部署上线的流程展开,还会分享优化思路。 Node.js聊天室开发实战:从入门到上线 在即时通讯日益普及的今天,基于Node.js搭建…...

Unity 如何使用Timeline预览、播放特效
在使用unity制作和拟合动画时,我们常用到Timeline,前后拖动滑轨,预览动画正放倒放非常方便。如果我们想对特效也进行这个操作,可以使用下文的步骤。 至此,恭喜你又解锁了一个新的技巧。如果我的分享对你有帮助…...
)
实物工厂零件画图案例(下)
文章目录 总练习模块文章索引气动顶针轴直线轴承座法兰盘平皮带中空传动轴减速机V带轮减速机箱体 简介:点击此处可以下载该文章的案例模型,加上这篇文章总共有七篇文章是用来练习solidworks软件应用与建模思路的,大概有30多个案例模型&#x…...
整个项目开源github)
esp32课设记录(五)整个项目开源github
我把该项目开源到了github:https://github.com/whyovo/ESP32_course_project 以下是readme文档: ESP32 课设 项目概述 这是一个基于ESP32的课设,实现了多种功能模式的集成,包括信息显示、图片展示、MQTT通信、摩尔斯电码处理以…...

力扣每日一题5-19
class Solution { public String triangleType(int[] nums) { Arrays.sort(nums); if (nums[0] nums[1] < nums[2]) return “none”; if (nums[0] nums[1] && nums[1] nums[2]) return “equilateral”; if (nums[0] nums[1] || nums[1] nums[2]) return “is…...

CI/CD 深度实践:灰度发布、监控体系与回滚机制详解
CI/CD 深度实践:灰度发布、监控体系与回滚机制详解 一、引言 在现代软件开发中,持续集成与持续交付(CI/CD)是加快交付速度、提升质量的关键。面对复杂的分布式系统和海量用户,如何安全、快速地发布新版本,…...

【日常笔记】wps如何将值转换成东西南北等风向汉字
在WPS表格中,若要将数值(如角度值)转换成“东、南、西、北”等风向汉字,可通过以下步骤结合自定义函数或条件判断实现: 一、wps如何将值转换 方法一:使用LOOKUP函数(简化公式)&…...

RabbitMQ的简介
三个概念 生产者:生产消息的服务消息代理:消息中间件,如RabbitMQ消费者:获取使用消息的服务 消息队列到达消费者的两种形式 队列(queue):点对点消息通信(point-to-point) 消息进入队…...

中职大数据实验室解决方案分享
第1部分概述 1.1政策背景 2021年3月,教育部印发《职业教育专业目录(2021年)》,共设置19个专业大类、97个专业类、1349个专业。新版《目录》聚焦推进数字化升级改造,构建未来技术技能,优化和加强了5G、人工智能、大数据、云计算、…...
)
阿里云web端直播(前端部分)
阿里云:Web播放器快速接入_视频点播(VOD)-阿里云帮助中心 import Aliplayer from aliyun-aliplayerimport aliyun-aliplayer/build/skins/default/aliplayer-min.css<div id"J_prismPlayer" style"width: 300px; height: 300px;" />var …...

从虚拟仿真到行业实训再到具身智能--华清远见嵌入式物联网人工智能全链路教学方案
2025年5月23-25日,第63届中国高等教育博览会(高博会)将在长春中铁东北亚国际博览中心举办。作为国内高等教育领域规模大、影响力广的综合性展会,高博会始终聚焦教育科技前沿,吸引全国高校管理者、一线教师、教育科技企…...

阿里云国际站与国内站:局势推进中的多维差异
在当今数字化浪潮席卷全球,云计算成为企业与开发者关键助力的局势下,阿里云作为行业翘楚,其国际站与国内站备受关注。两者虽同宗同源,却在诸多方面存在着显著差异,这些差异犹如隐藏在幕后的齿轮,悄然影响着…...

Docker项目部署深度解析:从基础命令到复杂项目部署
Docker项目部署深度解析:从基础命令到复杂项目部署 注:根据黑马程序员javawebAI视频课程总结: 视频地址 详细讲义地址 一、传统部署困境与Docker破局之道 在传统Linux部署场景中,新手常被三大难题困扰: 命令记忆负…...
)
reserve学习笔记(花指令)
这是闲来无事逛博客时看到的一篇相关文章,觉得挺有意思。 定义 首先花指令其实就是没有用的指令(垃圾指令),它穿插在真正的代码中,会导致反编译时出现问题,从而会影响我们的静态分析 分类以及讲解 花指…...

docker运行Redis
创建目录 mkdir -p /home/jie/docker/redis/{conf,data,logs}添加权限 chmod -R 777 /home/jie/docker/redis创建配置文件 cat > /home/jie/docker/redis/conf/redis.conf << EOF # 基本配置 bind 0.0.0.0 protected-mode yes port 6379# 安全配置 密码是root require…...

Django 项目中,将所有数据表注册到 Django 后台管理系统
在 Django 项目中,将所有数据表注册到 Django 后台管理系统中需要为每个模型(Model)创建一个对应的 ModelAdmin 类,并在 admin.py 文件中注册这些模型。以下是一个详细的步骤指南: 确保你的模型已定义 首先,确保你已经在 models.py 文件中定义了所有的数据模型。例如:py…...

pyspark测试样例
from pyspark.sql import SparkSession from pyspark.sql.functions import col, lit, concat 创建 SparkSession spark SparkSession.builder.appName(“SparkSQLExample”).getOrCreate() 创建 DataFrame(可以是从 CSV、JSON 等文件读取) data […...

Python学习笔记--使用Django操作mysql
注意:本笔记基于python 3.12,不同版本命令会有些许差别!!! Django 模型 Django 对各种数据库提供了很好的支持,包括:PostgreSQL、MySQL、SQLite、Oracle。 Django 为这些数据库提供了统一的调…...

HarmonyOS Next应用分层架构下组件封装开发实践
基于鸿蒙应用分层架构的ArkUI组件封装实践 在鸿蒙应用开发中,合理利用 ArkUI 组件进行封装,可以实现代码复用,提升开发效率。本文将结合鸿蒙应用分层架构的特点,详细探讨几个典型的 ArkUI 组件封装场景及其实现方案。 华为鸿蒙应…...

全能视频处理工具介绍说明
软件介绍 本文介绍的软件是FFmpeg小白助手,它是一款视频处理工具。 使用便捷性 这款FFmpeg小白助手无需安装,解压出来就能够直接投入使用。 主要功能概述 该工具主要具备格式转换、文件裁剪、文件压缩、文件合并这四大功能。 格式转换能力 软件支持…...

CSS实现过多的文本进行省略号显示
单行文本省略 .ellipsis {white-space: nowrap; /* 禁止换行 */overflow: hidden; /* 溢出内容隐藏 */text-overflow: ellipsis; /* 溢出部分显示为省略号 */width: 200px; /* 必须设置宽度 */ } 多行文本省略(跨浏览器方案)…...

十三、Hive 行列转换
作者:IvanCodes 日期:2025年5月19日 专栏:Hive教程 在Hive中,数据的形态转换是数据清洗、分析和报表制作中的核心环节。行列转换尤为关键,它能将数据从一种组织形式变为另一种,以适应不同的业务洞察需求。本…...

Django之验证码功能
验证码功能 目录 1.绘制验证码 2.在登录页面里面实现验证码的功能 3.代码展示集合 这篇文章, 内容不是很多, 不过验证码, 是在网页里面比较常见的功能, 所有我们还是要掌握它!!! 一、绘制验证码 绘制验证码, 我们需要用到图像, 然后在…...

代码随想录算法训练营 Day51 图论Ⅱ岛屿问题Ⅰ
图论 题目 99. 岛屿数量 使用 DFS 实现方法 判断岛屿方法 1. 遍历图,若遍历到了陆地 grid[i][j] 1 并且陆地没有被访问,在这个陆地的基础上进行 DFS 方法,或者是 BFS 方法 2. 对陆地进行 DFS 的时候时刻注意以访问的元素添加访问标记 //…...

Python Django 的 ORM 编程思想及使用步骤
目录 一、ORM 编程思想概述 二、Python 中使用 ORM 的主要优势 2.1 简化数据库操作 2.2 提高开发效率 2.3 减少错误 2.4 增强代码的可维护性 2.5 降低耦合性 三、Django 中使用 ORM 的详细步骤 3.1 创建应用模块 3.2 配置数据库信息 3.3 确定数…...

设计一个程序,将所有的小写字母转换为大写字母
汇编语言程序设计实验 实验内容 设计一个程序,将所有的小写字母转换为大写字母,此程序不能改变除字母a~z外的任何其它字符。 实验分析 实现的功能是将所有的小写字母转换为大写字母,此程序不能改变除字母a~z外的任何其它字符。可以分为以…...

Rust 学习笔记:关于错误处理的练习题
Rust 学习笔记:关于错误处理的练习题 Rust 学习笔记:关于错误处理的练习题想看到回溯,需要把哪个环境变量设置为 1?以下哪一项不是使用 panic 的好理由?以下哪一项最能描述为什么 File::open 返回的是 Result 而不是 O…...

使用docker——10分钟内 完成一个高可用的 MongoDB 副本集部署
实验目的 掌握 Docker 容器化部署 MongoDB 副本集 的方法 理解 主从同步、故障转移、数据一致性 等核心机制 熟悉 MongoDB 集群管理命令 和 运维监控技巧 🔧 实验环境 操作系统: Rocky Linux 9 / CentOS 7 软件依赖: Docker 20.10 docker-compose 1.29 硬件要…...

信息化的编程未来发展
信息化与数字化与编程领域与AI的爆炸发展是最近十几年瞠目结舌的事情,列举一下相关词汇: C#、AI、C、Python、.NET、API 、IDE、asp、JavaScript网页端、Visua Studio、VR、Github、OpenGL-webGL-计算机图形学、面向对象 、类库、GIS、GPU计算与显卡、可…...
)
计算机视觉与深度学习 | EMD-KPCA-LSTM、EMD-LSTM、LSTM回归预测对比,多输入单输出(Matlab完整程序和数据)
以下是针对EMD-KPCA-LSTM、EMD-LSTM和LSTM回归预测对比的完整可运行MATLAB实现。包含数据生成、特征处理、模型构建和性能评估全流程,并提供关键代码注释和注意事项。 完整代码实现(含数据生成) %% 清理环境 clear; clc; close all; warning off;%% 生成模拟数据(正弦波+噪…...

Ollama 如何在显存资源有限的情况下合理分配给不同的服务?
在显存资源有限的情况下,合理分配显存给不同服务需要结合硬件特性、软件配置和模型优化技术。以下是几种有效的方法: 1. 使用 Ollama 自身的资源限制参数 Ollama 提供了一些命令行参数来限制单个模型的资源使用: --ram:限制模型…...

2025-05-19 学习记录--Python-简易用户登录系统 + 计算天数
合抱之木,生于毫末;九层之台,起于累土;千里之行,始于足下。💪🏻 一、简易用户登录系统 ⭐️ # 用户登录系统 # 用户名、密码、黑名单 users [{name: 小红, password: 123, status:True},{name…...

APP小程序抓包和下游代理
本文仅作学习/技术记录和交流,请勿进行非法活动,否则后果自负! 本文将主要围绕对小程序、APP的抓包方法,同时介绍下游代理。 在本文中我们将用到 Burpsuite、Yakit 和 Proxifier来完成。 小程序&APP抓包 对于小程序或APP抓…...

UE 材质几个输出向量节点
PixelNormalWS...
)
【八股战神篇】Java多线程高频面试题(JUC)
目录 专栏简介 一 如何创建线程? 延伸 1. 创建 Java 线程的本质 二 说说线程的生命周期? 延伸 1.描述一下线程的生命周期图 2.线程的优先级对线程执行有何影响? 3.如何确保三个线程按照特定顺序执行? 三 并发和并行的区…...

【esp32 mqtt】 连接亚马逊-加密传输信息
文章目录 1 加密文件1.1 服务端证书1.2 客户端CA证书1.3 客户端私钥1.4 三者协同工作的流程 2 亚马逊创建物品3 esp32 程序编写3.1 证书文件读取3.2 MQTT配置3.2.1 配置结构体3.2.2 初始化客户端3.2.3 注册事件3.2.4 开启mqtt3.2.5 示例 3.3 事件回调函数3.2.1 示例 3.4 接收到…...
)
用于判断主子关系的方法的实现(orm是efcore)
HasParentChildRelationship 方法:主要用于判断给定实体集合中是否存在主子关系,通过检查实体的导航属性来实现。CheckForDependencies 方法:是一个辅助方法,负责具体的依赖关系检查,包括对已访问实体的跟踪࿰…...

《Effective Python》第三章 循环和迭代器——在遍历参数时保持防御性
引言 本文基于《Effective Python: 125 Specific Ways to Write Better Python, 3rd Edition》一书的 Chapter 3: Loops and Iterators 中的 Item 21: Be Defensive when Iterating over Arguments。该条目深入探讨了在 Python 中处理迭代器(iterator)和…...

【python基础知识】Day30 模块和库的导入
学习python 学习python基础语法 处理任务需要用到的库 一、导入官方库的三种手段 1 标准导入:导入整个库 # 方式1:导入整个模块 import math# 导入库后,输出测试 print("方式1:使用 import math") print(f"圆周率…...

leetcode hot100刷题日记——4.盛最多水的容器
解答: 我的思路: class Solution{public:int maxArea(vector<int>& height){//遍历,我暴力找一下,时间超限// int vol0;// for(int i0;i<height.size()-1;i){// for(int ji1;j<height.size();j){// volmax(vol,…...

大二周周练翻译
翻译题 文章目录 翻译题[toc]中国茶道数字经济茶马古道中国父母现状电子商务长城大学生就业一带一路中国结 相遇的意义,是被你改变的那部分的我,代替你永远陪在我身边 点个赞呗! 中国茶道 China is a country with a time-honored civilizat…...

深度学习————模型保存与部署
第一部分:模型保存基础 什么是模型保存? 当你训练好一个深度学习模型后,它会拥有“学习到的参数”,这些参数(权重、偏置等)构成了模型的“知识”。如果不保存这些参数,那么训练好的模型在关闭…...