排序复习/下(C语言版)
目录
1.快速排序(hoare法)
单趟:
整体:
代码优化:
编辑三数取中代码:
小区间优化代码:
hoare法疑问解答:
2.快速排序(挖坑法)
3.快速排序(前后指针法)
性能分析:
全部代码(递归版):
4.快速排序(非递归)
5.归并排序
性能分析:
6.归并排序(非递归)
全部代码:
7.计数排序(非比较排序)
性能分析:
8.排序稳定性
1.快速排序(hoare法)
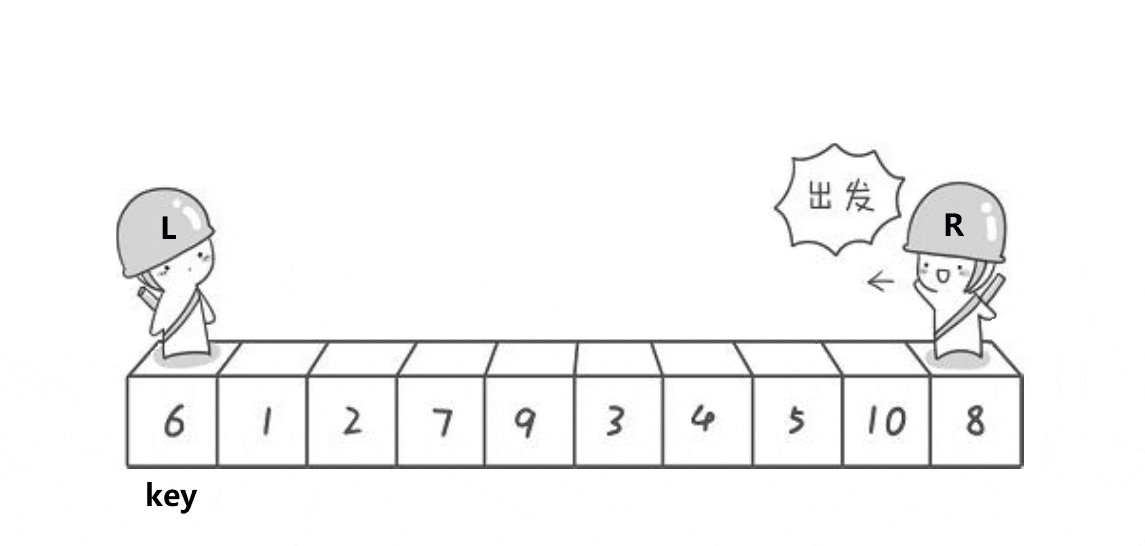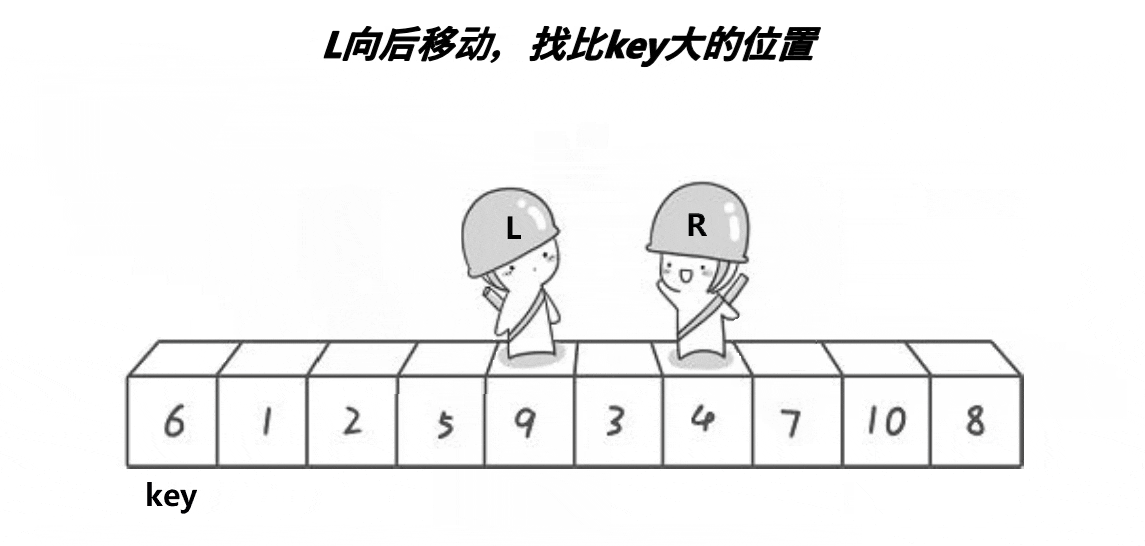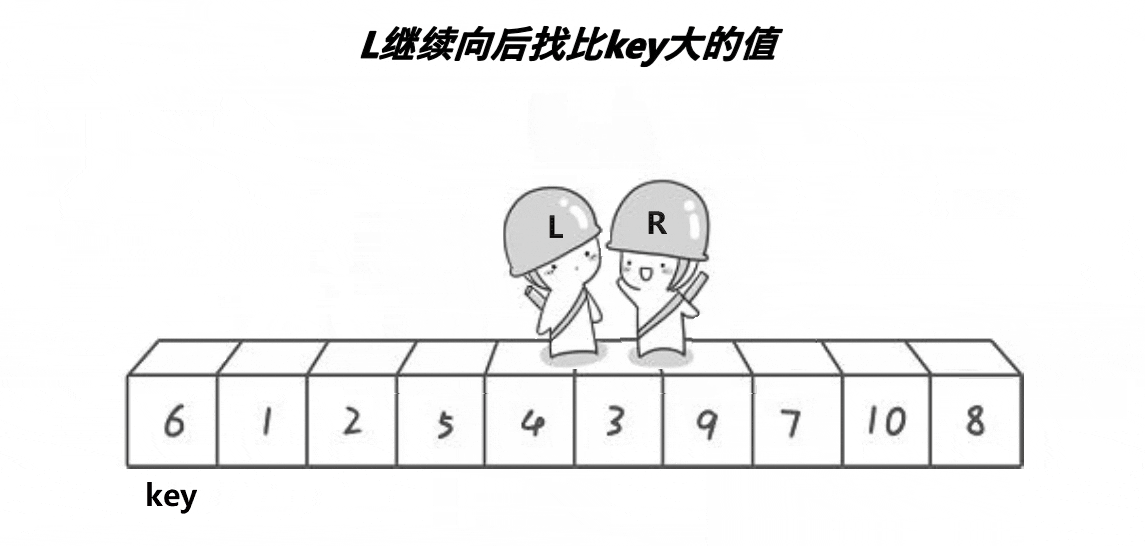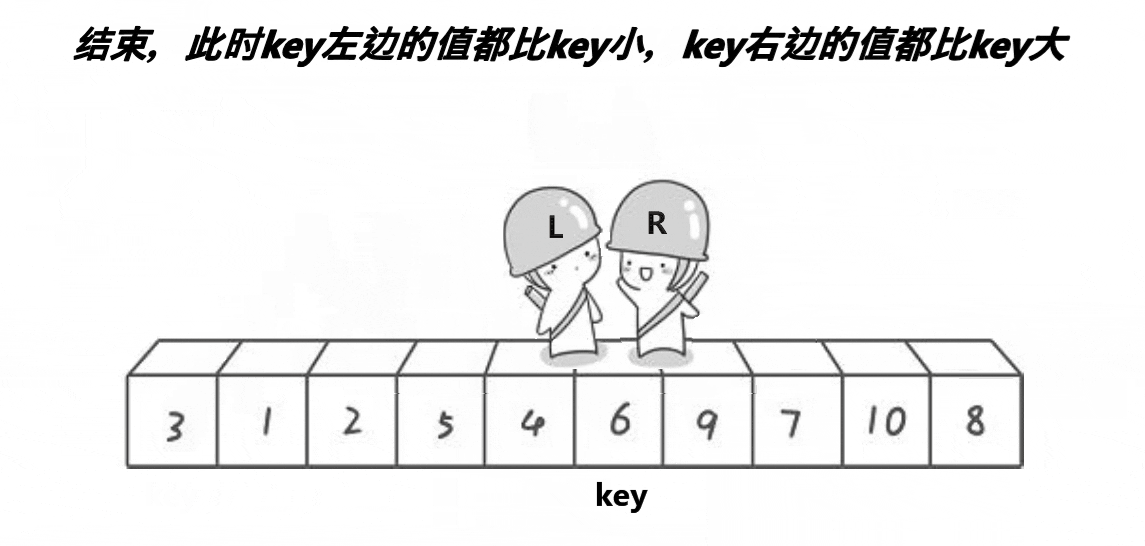
单趟:
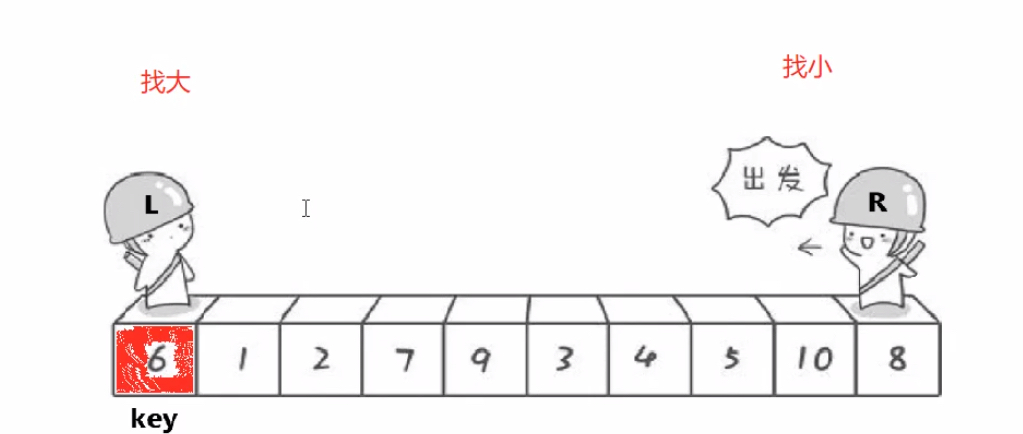
(一般)以第一个值为key,通过一系列操作让比它大的值全在其右边,比它小的都在左边
操作方法:定义两个指针left、right,left找大right找小,当找到了2个值以后,交换两个位置的元素;这样操作到left、right相遇,然后把begin位置的key值和left位置的元素交换
此时key值已经排序完成了,因为其左边都是较小值,右边都是较大值
int left = begin, right = end;int keyi = begin;while (left < right)//相等时结束循环{while (left < right && a[right] >= a[keyi])right--;//left不能大于rightwhile (left < right && a[left] <= a[keyi]) left++;//必须要先走右指针,再走左指针Swap(&a[left], &a[right]);}Swap(&a[keyi], &a[left]); 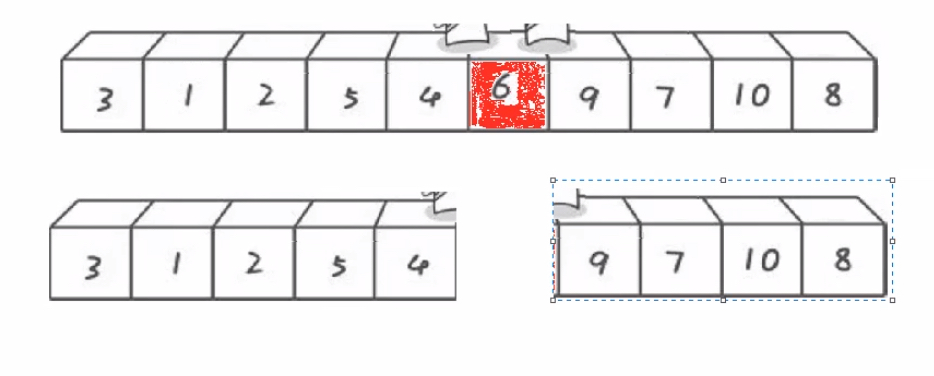
整体:
因为key已经排序完了,所以只需要对key的左右区间分别排序即可;对其左右区间分别再次进行快排,一整个问题可以由无数个子问题组成,不难想到使用递归实现
递归出口:begin >= end
如图,此时上一步是 begin = 0,end = 1,left(keyi) = 1;进入到递归调用函数以后,往左递归是(a,0,0) -> 一个单值,往右递归是(a,2,1) -> 不存在值
void QuickSort(int* a, int begin, int end)
{ if (begin >= end) return;int left = begin, right = end;int keyi = begin;while (left < right)//相等时结束循环{while (left < right && a[right] >= a[keyi])right--;//left不能大于rightwhile (left < right && a[left] <= a[keyi]) left++;//必须要先走右指针,再走左指针Swap(&a[left], &a[right]);}Swap(&a[keyi], &a[left]);QuickSort(a, begin, left - 1);QuickSort(a, left + 1, end);
}代码优化:
优化1:三数取中
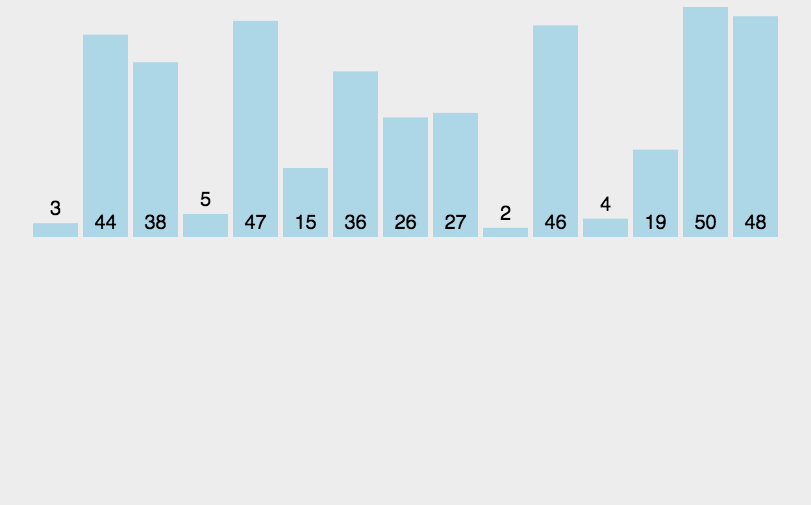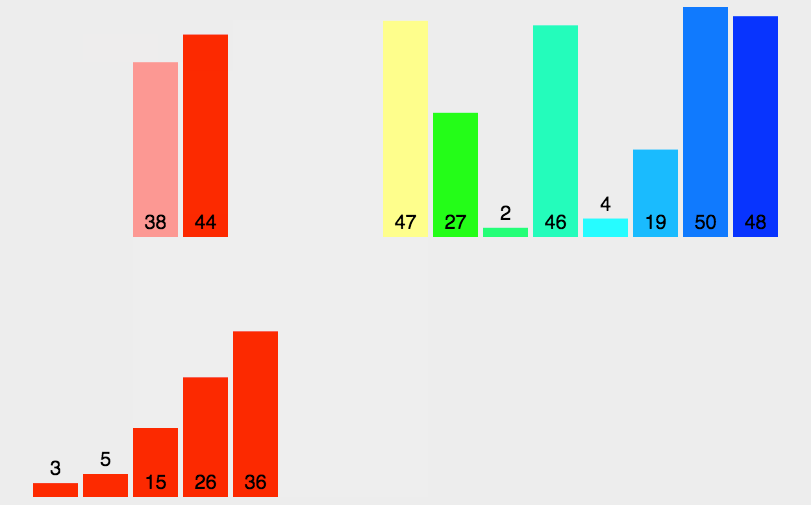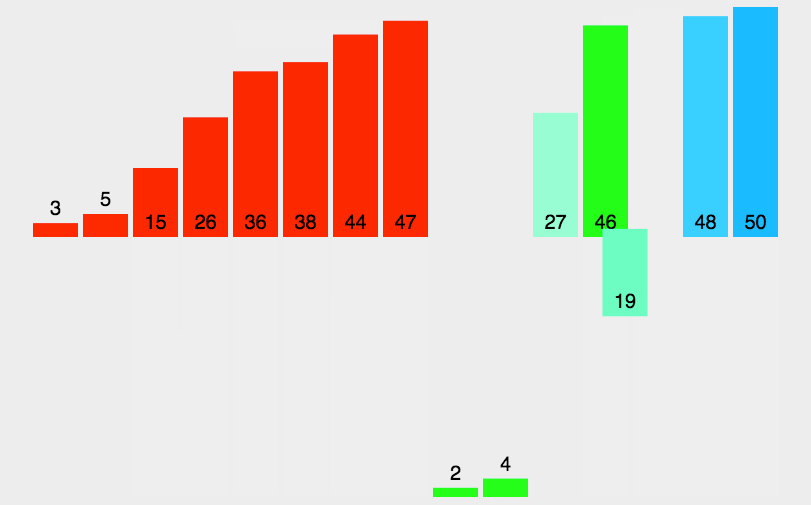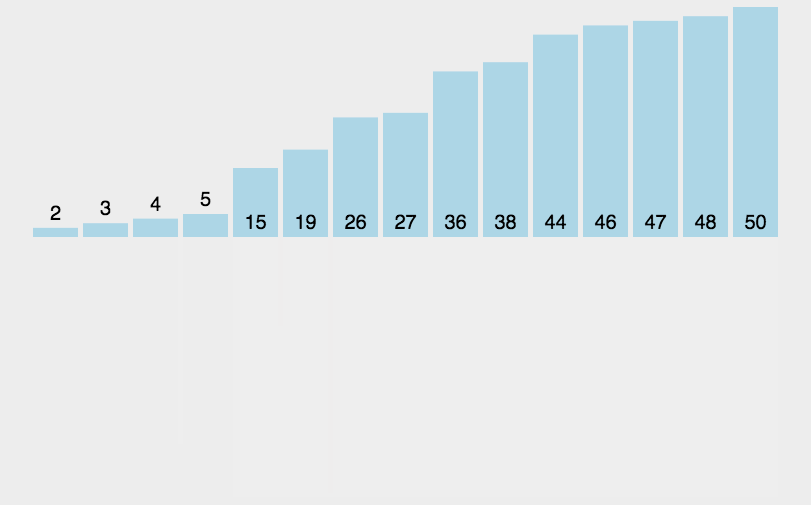
如上图,对于有序的数组,key值永远都取整个区间的最开头一个;(如果是升序)right会直接往左移动到key值位置,因此第一次的循环为N次;
接下来左区间没有东西,往右区间走,又是以开头值为key值,循环N-1次;然后左边区间没有东西(区间begin = 1 ,此处不是看数组来判断的),右边区间又是以开头值为key值……
整体时间复杂度会达到惊人的"N + (N - 1) + …… + 2 + 1 = O(N^2) ,
同时因为每次函数递归调用都需要开辟一个函数栈帧,N个数据的有序数组就得开辟N个栈帧;debug版本(栈帧带着调试信息)下,100000个栈帧就会栈溢出
因此我们可以通过在begin end mid 三个位置中找中间大小的数据,把他作为key值来解决这个问题(数组有序时,key值作为中间大小,能够左右区间都有数据去快排)
优化2:小区间优化
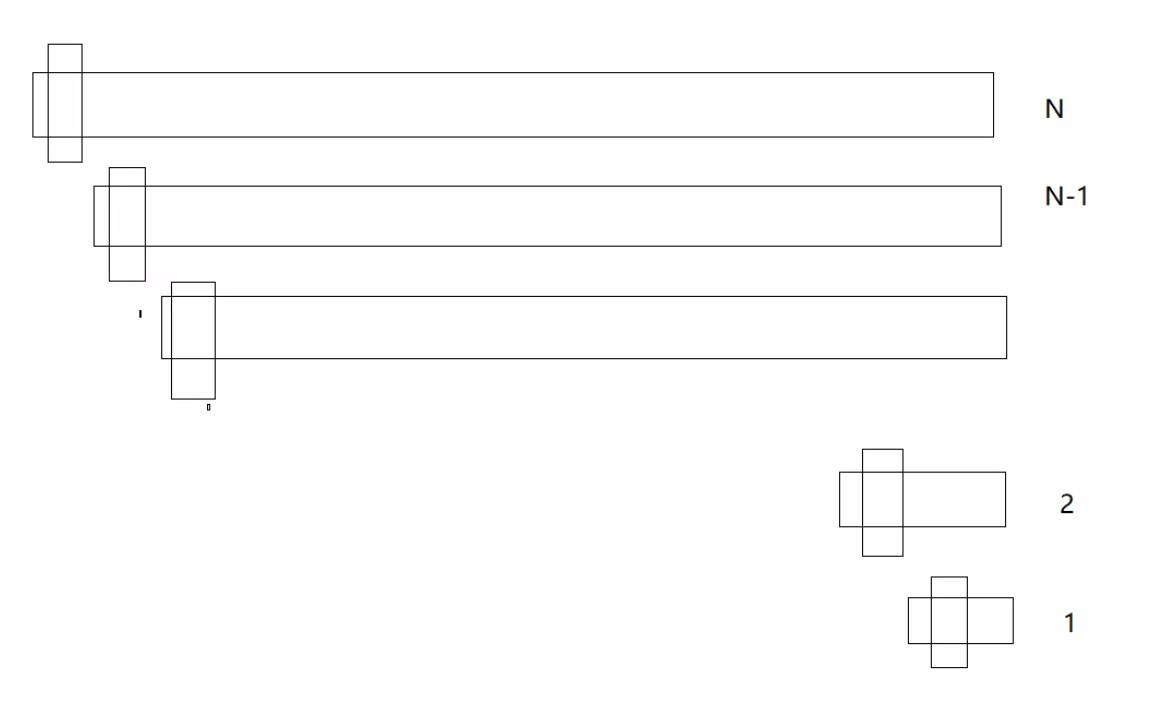
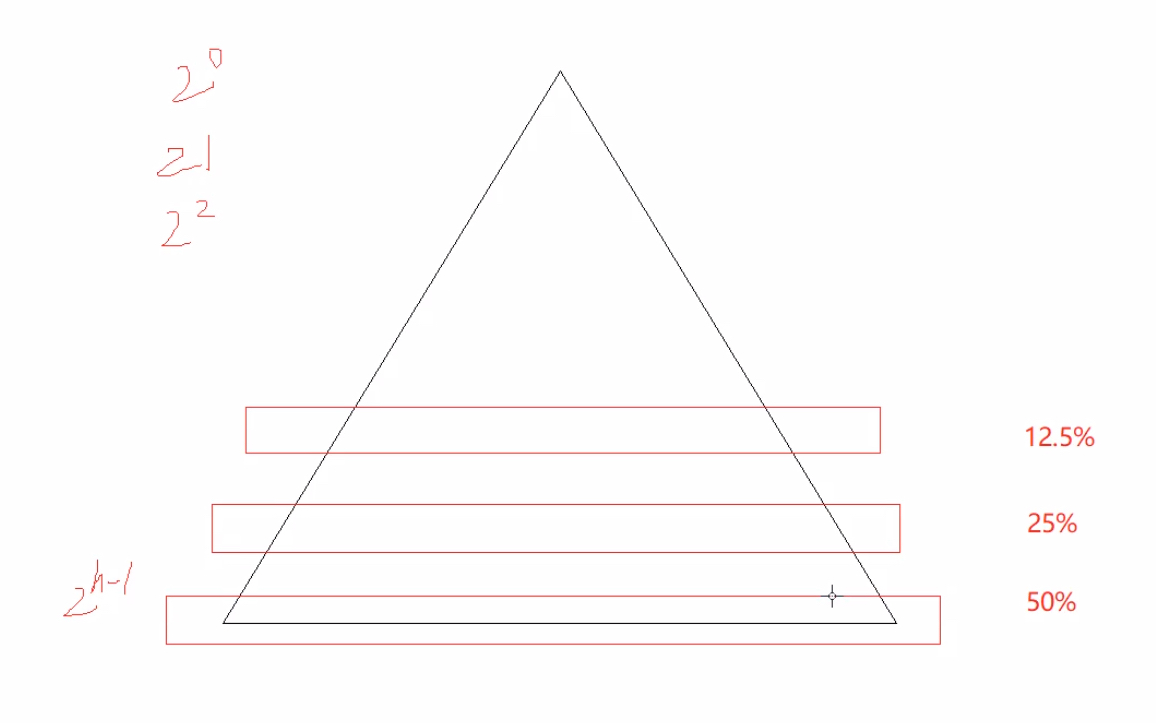
假设每次对某一个区间快速排序完,key都落在了中间位置,那我们可以把函数递归调用看作是一棵完全二叉树在进行先序遍历(当中key值为父节点,左右区间为父节点的左右子树)
如下图,根据完全二叉树的特点,最后一层根节点占到了所有节点的50%,倒数第二层占了25%;由于倒数几层的递归调用开销很大,因此最后几层我们可以不使用快速排序,改用别的排序方法
希尔排序主要用来排大量数据,冒泡快速太拉了,堆排还需要创建堆然后才能排序(每个区间都要创建堆,时间开销比较大),归并排序也得要递归调用,所以插入排序是最好的选择(c++sort函数用的就是插入排序+快排)
 三数取中代码:
三数取中代码:
int GetMid(int* a, int left, int right)
{int midi = (right - left) / 2;if (a[left] < a[midi]){if (a[midi] < a[right]) return midi;else if (a[left] < a[right]) return right;else return left;}else //a[left] > a[midi]{if (a[midi] > a[right]) return midi;else if (a[left] < a[right]) return left;else return right;}
}void QuickSort(int* a, int begin, int end)
{ ……;int midi = GetMid(a, begin, end);Swap(&a[begin], &a[midi]); //key值一定要放在最开头/最末尾的位置……;
}
小区间优化代码:
if ((end - begin + 1) <= 10) InsertSort(a + begin, end - begin + 1); 只要递归到某一个区间,区间内数据量小于等于10,就停止快排使用插入排序
如果传参传的是a+4,那么在InsertSort函数里,a[0](函数里逻辑上的数组) = a[4](实际存储空间里的数组)
hoare法疑问解答:
疑问1:为什么key值一定要放在区间头/尾?
如果key放在中间位置,前面有值,那么有可能left、right在key值前面相遇,本来应该放在key值左边的元素现在放到key值右边了,肯定会出问题
疑问2:为什么key放在区间头,一定要右指针先移动呢?
key值由于放在头部,因此在左右指针相遇后,相遇位置处的值需要小于key值,这样才能保证key左边都是比它小的,右边都是比它大的
右指针是专门去找小的指针,一般性会有以下3种情况:
1.right找到小的以后,left不断找大,一直没找到直到和right相遇 -> 相遇位置值比key小
2.left、right位置的值已经交换过数对,right不断找小一直没找到,与left相遇后由于前一次left、right(新一次找小开始的位置)的交换,当前left所指向的值依旧小于key值
3.left一次也没动过,right不断找小,一直没找到直到与left相遇,此时相当于key和key自己进行了一次位置交换
记忆方法:左边key右边先走,右边key左边先走
2.快速排序(挖坑法)
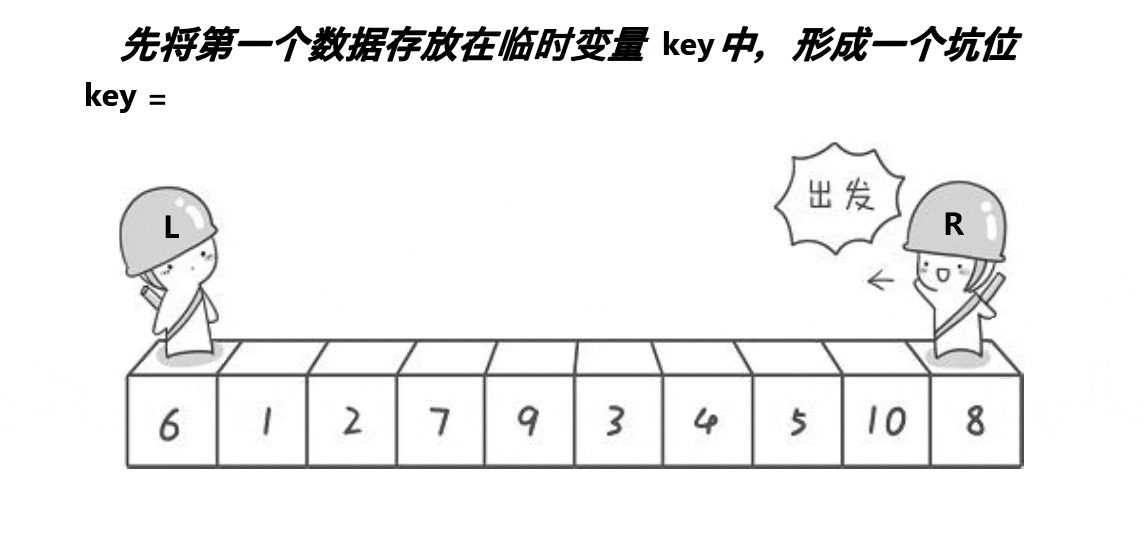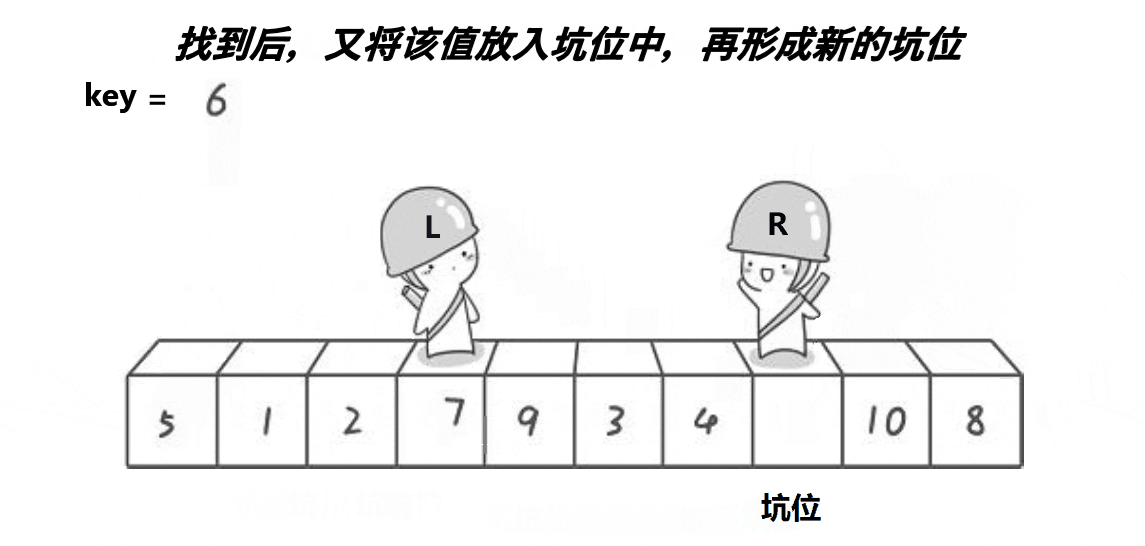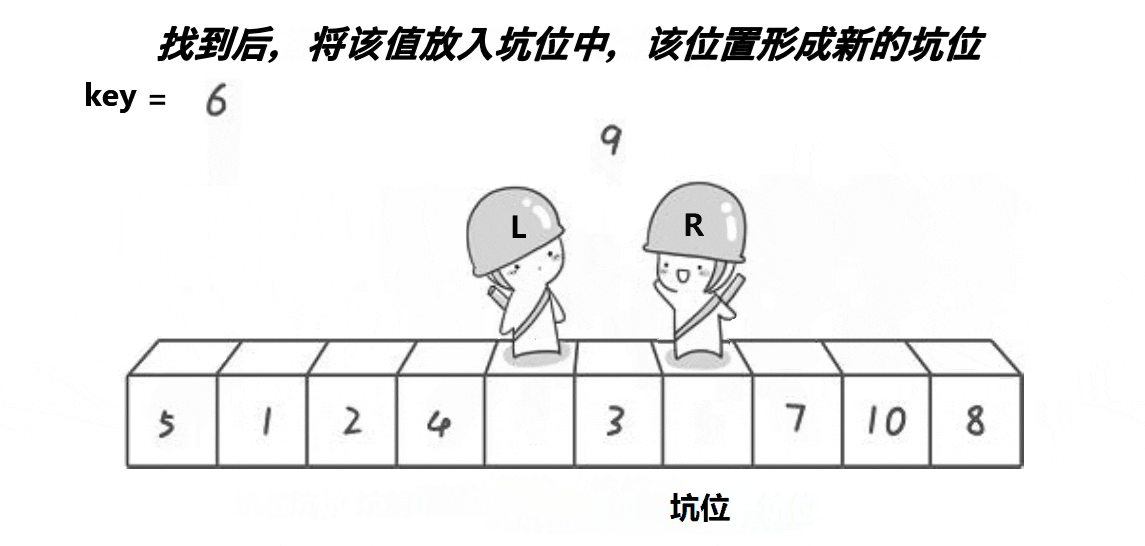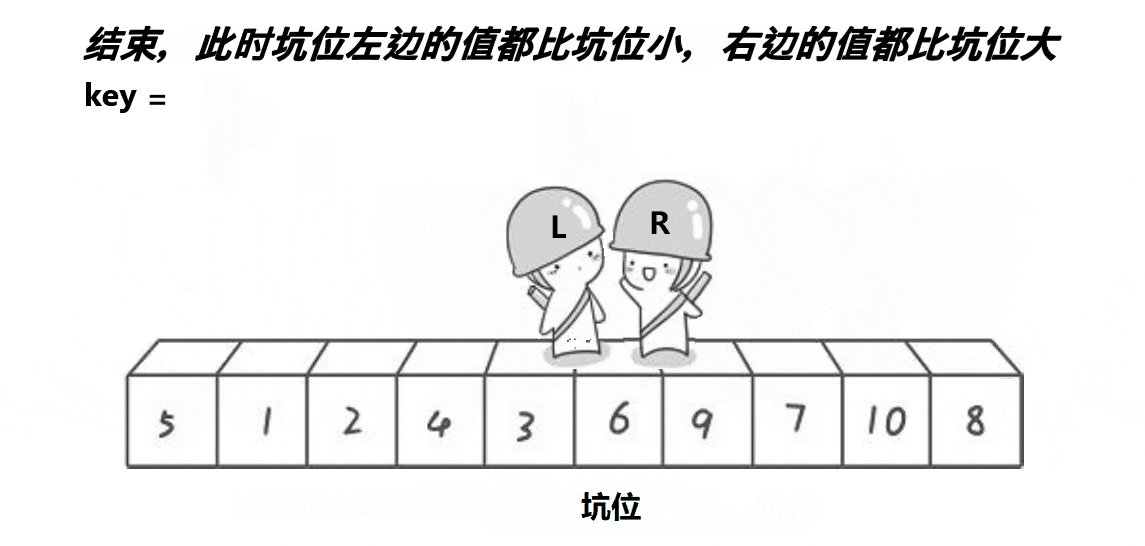
没有效率提升,但很多hoare法带来的疑问不需要分析了,因此比较好理解
3.快速排序(前后指针法)
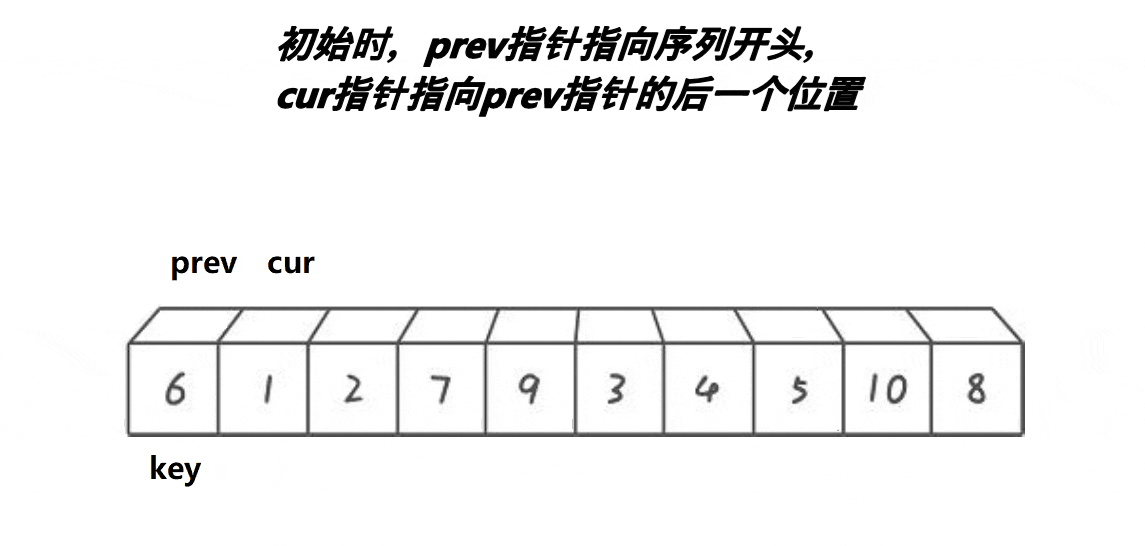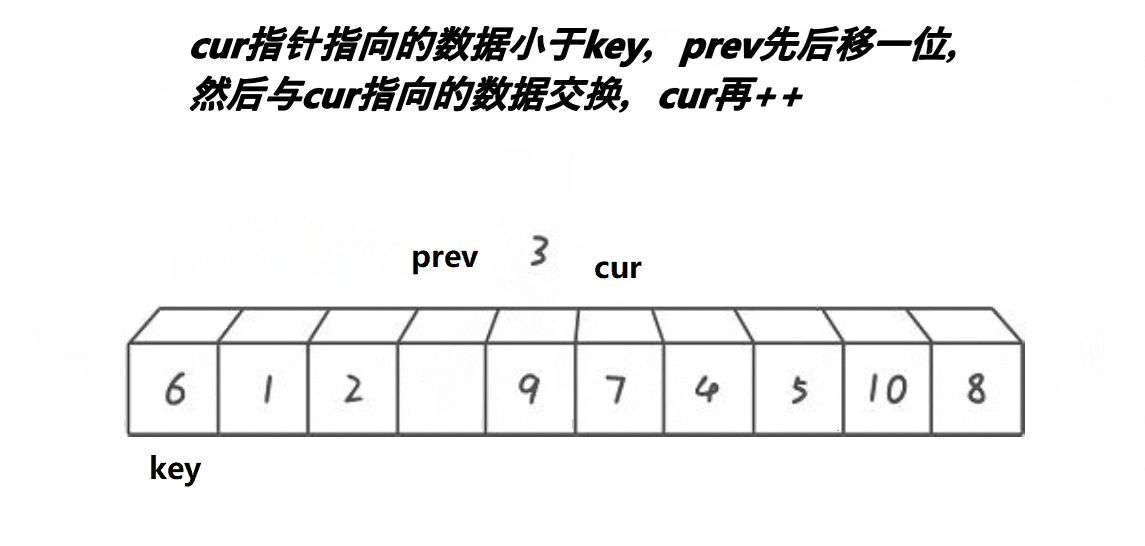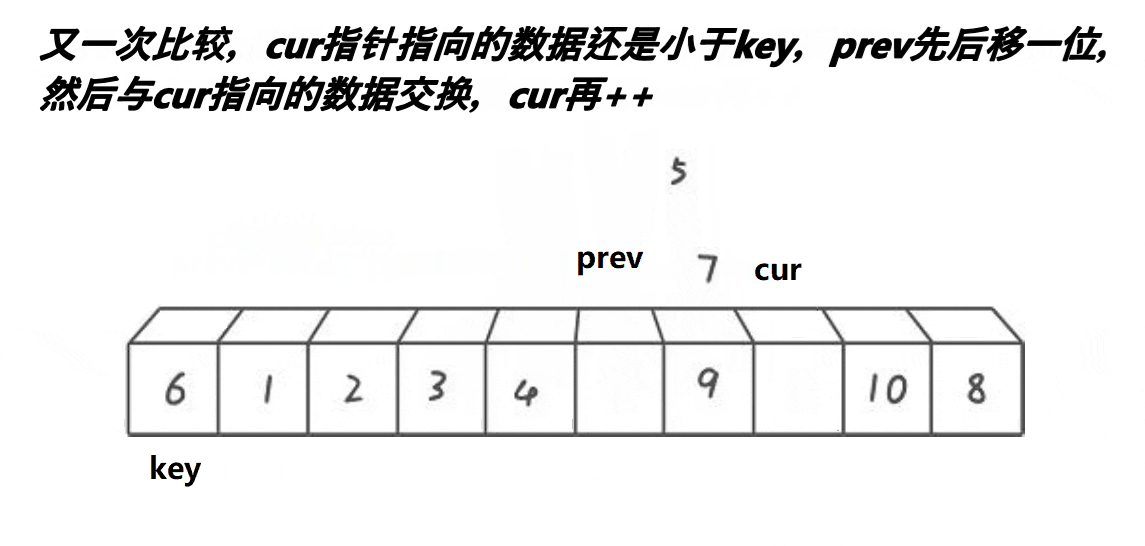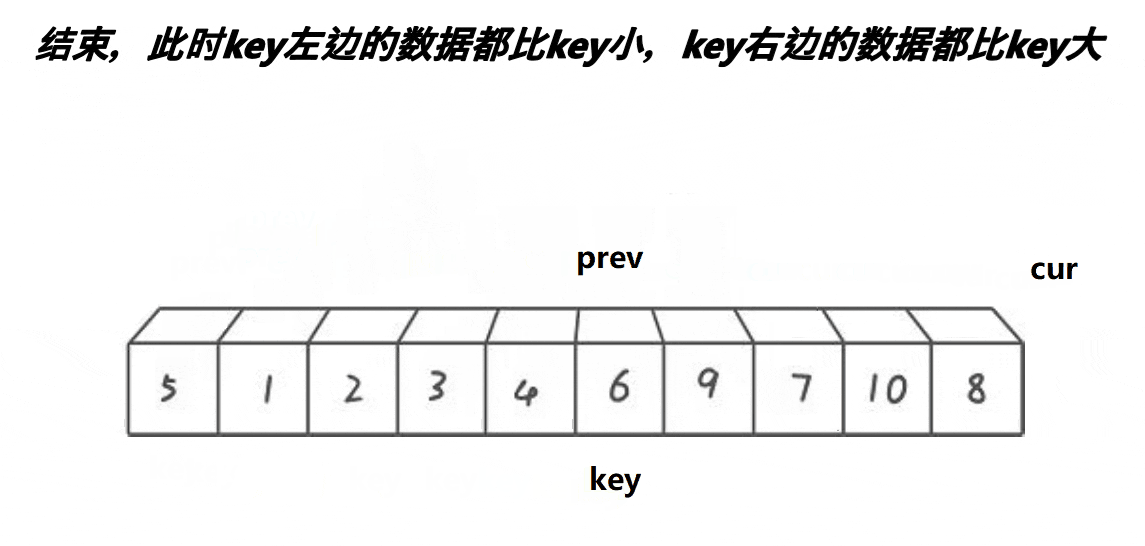
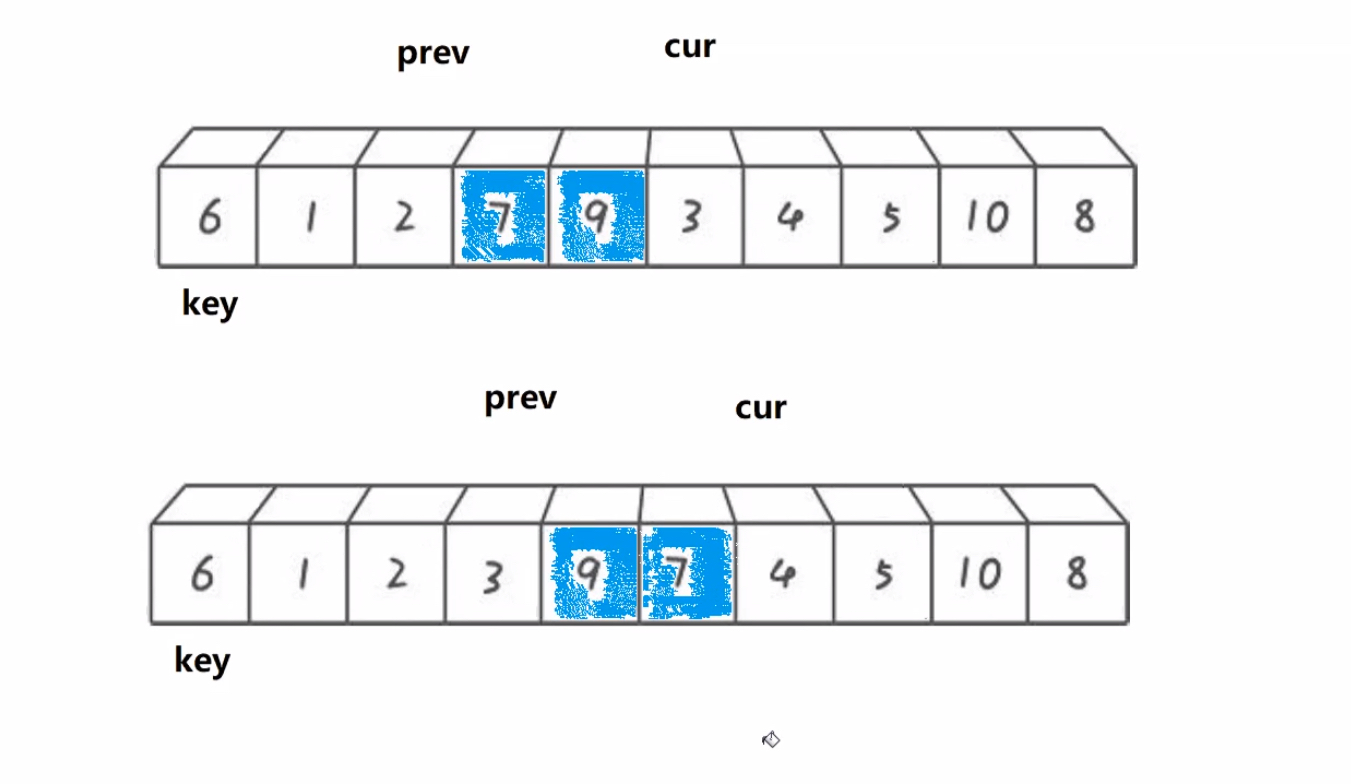
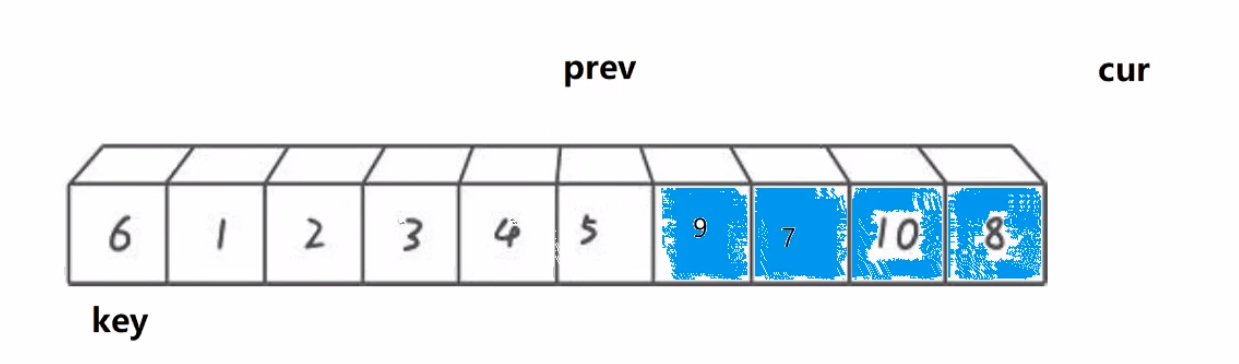
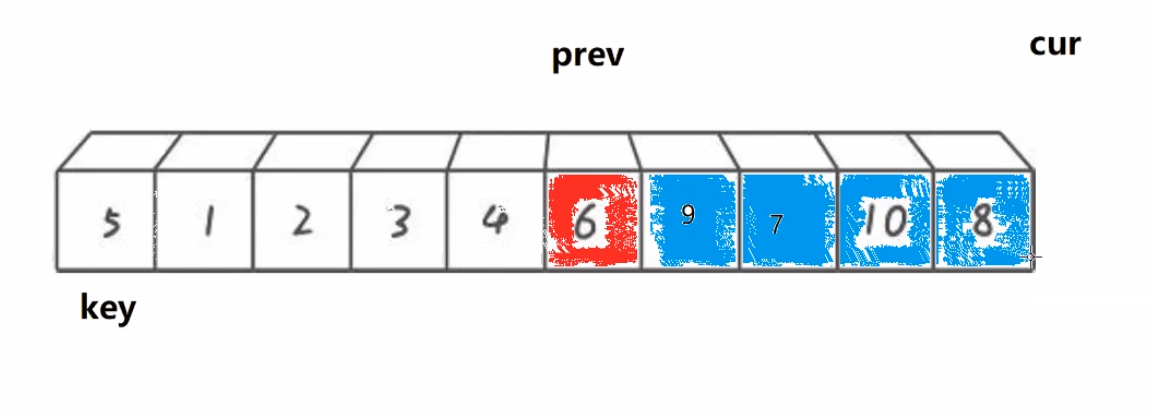
1.搞一个prev指针,再搞一个cur指针,初始都在begin位置
2.cur找大(比key大),cur和prev同步向后走,直到cur找到大
3.cur从找大变成找小,大的cur往后走prev不动(由于每次肯定cur先走,所以prev的限制是比较容易的),找到小的让prev先++,然后进行位置交换,此时就类似于把大于key的值翻滚往后移动
4.cur遍历完数组,交换prev和keyi位置元素
如果初始化时cur = begin + 1,那么就用后置++特性,自己和自己交换也可以
int prev = begin, cur = begin ;int keyi = begin;while (cur <= end){if (a[cur] < a[keyi] && ++prev != cur) Swap(&a[prev], &a[cur]);cur++;}Swap(&a[prev], &a[keyi]);
性能分析:
时间复杂度:O(NlogN),总共有logN层,每层需要遍历N个数
空间复杂度:O(logN),需要开辟logN个栈帧
全部代码(递归版):
int PartSort1(int* a, int begin, int end)
{int left = begin, right = end;int keyi = begin;while (left < right)//相等时结束循环{while (left < right && a[right] >= a[keyi])right--;//left不能大于rightwhile (left < right && a[left] <= a[keyi]) left++;//必须要先走右指针,再走左指针Swap(&a[left], &a[right]);}Swap(&a[keyi], &a[left]);return left;
}int PartSort2(int* a, int begin, int end)
{int prev = begin, cur = begin ;int keyi = begin;while (cur <= end){if (a[cur] < a[keyi] && ++prev != cur) Swap(&a[prev], &a[cur]);cur++;}Swap(&a[prev], &a[keyi]);return prev;
}void QuickSort(int* a, int begin, int end)
{if (begin >= end) return;int midi = GetMid(a, begin, end);Swap(&a[begin], &a[midi]); //key值一定要放在最开头/最末尾的位置if ((end - begin + 1) <= 10) InsertSort(a + begin, end - begin + 1);//hoare法int left = PartSort1(a, begin, end);//前后指针法//int left = PartSort2(a, begin, end);QuickSort(a, begin, left - 1);QuickSort(a, left + 1, end);}4.快速排序(非递归)
非递归一般使用栈or队列来完成
每次递归最重要的就是区间的起始下标与终止下标
所以我们可以:循环没走一次,取栈顶空间,单趟排序然后左右子区间的起止下标入栈[begin, keyi-1] keyi [keyi+1, end] 左右区间后进先出,所以begin如果要先出就得插入时后插入
typedef struct Stack
{int* a; //动态开辟int top; //栈顶int capacity; //可容纳空间
}st;void Stinit(st* pst)
{assert(pst);pst->a = NULL;pst->capacity = 0;pst->top = -1;
}
void Stdestory(st* pst)
{assert(pst);free(pst->a);pst->a = NULL;pst->capacity = 0;pst->top = -1;
}
void Stpush(st* pst, int x)
{assert(pst);//扩容if (pst->top + 1 == pst->capacity){int newcapacity = pst->capacity == 0 ? 4 : pst->capacity * 2;int* tmp = (int*)realloc(pst->a, sizeof(int) * newcapacity);if (tmp == NULL){perror("realloc fail");return;}pst->a = tmp;pst->capacity = newcapacity;}pst->a[++pst->top] = x;
}
void Stpop(st* pst) //用函数进行封装,易于管理与理解
{assert(pst);pst->top--;
}
int Sttop(st* pst)
{assert(pst);assert(pst->top >= 0);return pst->a[pst->top];
}
bool Stempty(st* pst)
{assert(pst);return pst->top == -1;
}
int Stsize(st* pst)
{assert(pst);return ++pst->top;
}void QuickSortNON(int* a, int begin, int end)//非递归写法
{st s;Stinit(&s);Stpush(&s, end);Stpush(&s, begin);while (!Stempty(&s)){int left = Sttop(&s);Stpop(&s);int right = Sttop(&s);Stpop(&s);//区间下标的获取int keyi = PartSort2(a, left, right);// [begin, keyi-1] keyi [keyi+1, end]if (keyi + 1 < right)//放入右区间的起止下标{Stpush(&s, right);Stpush(&s, keyi + 1);}if (left < keyi - 1)//放入左区间的起止下标{Stpush(&s, keyi - 1);Stpush(&s, left);}}
}非递归就是从dfs变成了bfs
因为非递归不需要创建函数栈帧,所以没有栈溢出风险;同时栈、队列这类数据结构,空间开辟在堆区,在4G内存中堆区大小为2GB,因此空间大小可以支持更多的数据进行排序
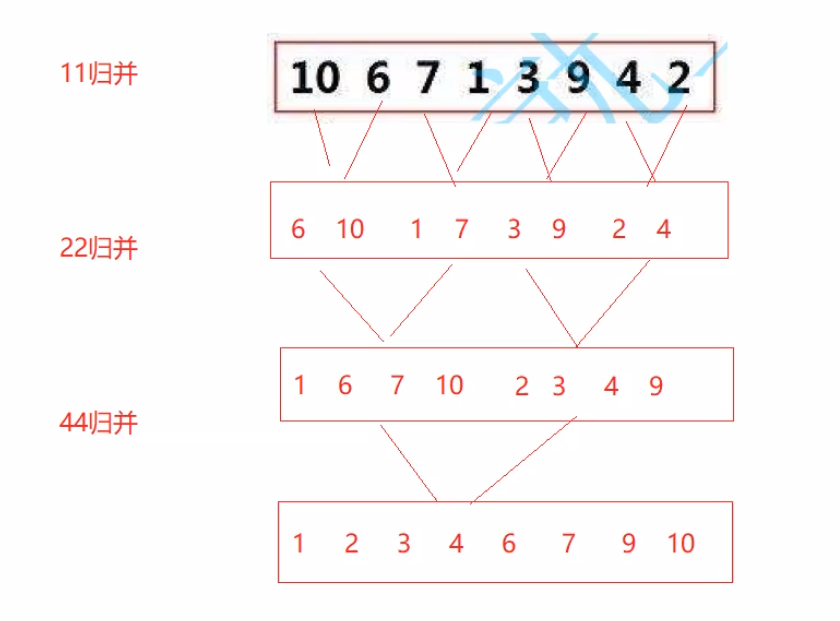
5.归并排序
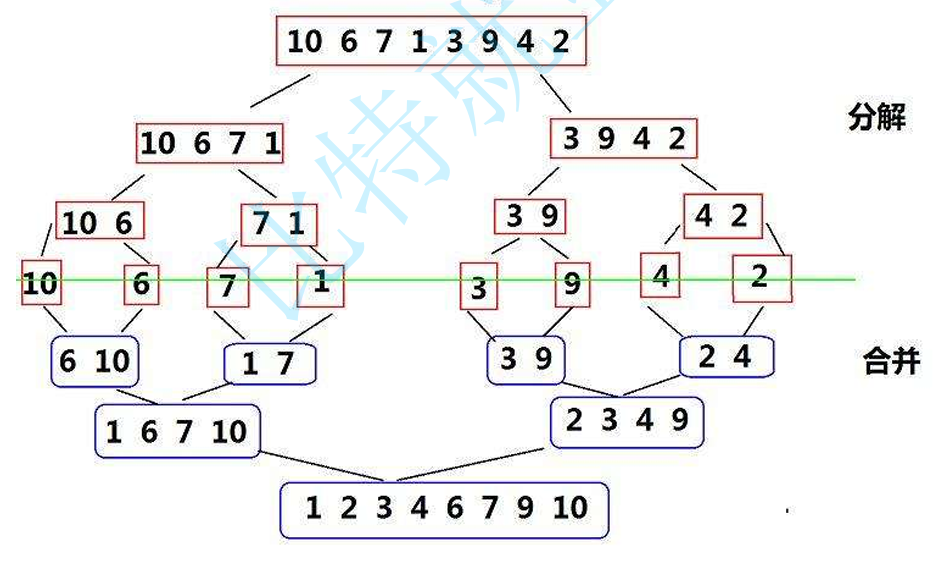
1.把数组平分成两块,然后对两块分别再平分
2.分到不可再分,开始归
3.归时进行小区间的排序,小区间合并成大区间以后,再对大区间进行排序,以此类推……
4.需要创建一个temp数组进行排序(例如2个数的区间,小的先放进temp,再放大的,自然排序完成了;大的区间,因为左右区间都有序了,所以比较放入temp时也是比较容易的)
5.平分成一个个小区间可以通过递归来实现(子问题是大区间平分成小区间,然后归并成大区间)
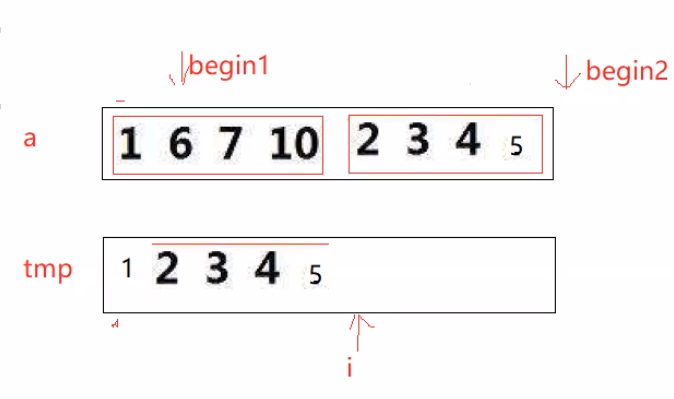
void _MergeSort(int* a, int* temp, int begin, int end)
{//分->exit//递归出口理由同快排if (begin >= end) return;//分->initint midi = (begin + end) / 2;//二分//分->r&t_MergeSort(a, temp, begin, midi);_MergeSort(a, temp, midi+1, end);//归并+排序int begin1 = begin, end1 = midi;//左区间int begin2 = midi + 1, end2 = end;//右区间int i = 0;//temp数组下标从0开始while (begin1 <= end1 && begin2 <= end2)//左右区间都还有值,直到一个没有值推出循环{if (a[begin1] < a[begin2]) temp[i++] = a[begin1++];else temp[i++] = a[begin2++];}while (begin1 <= end1) temp[i++] = a[begin1++];while (begin2 <= end2) temp[i++] = a[begin2++];memcpy(a + begin, temp, (end - begin + 1) * sizeof(int));
}void MergeSort(int* a, int n)
{int* temp = (int*)malloc(n * sizeof(int));if (!temp){perror("malloc error");return;}_MergeSort(a, temp, 0, n - 1);free(temp);temp = NULL;
}代码重点解释:
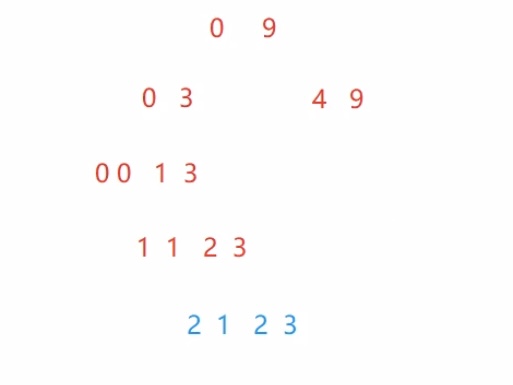
[begin,midi-1][midi,end]这样来区间划分会导致死循环(如下图1)
最后一层{2,3}的右区间会不断形成{2,3},a[midi] = 2 a[end] = 3
while (begin1 <= end1) temp[i++] = a[begin1++];
while (begin2 <= end2) temp[i++] = a[begin2++];根据循环退出条件,此时肯定还有一个区间有值,把剩下来没有放进(具体如下图2)
memcpy(a + begin, temp, (end - begin + 1) * sizeof(int));
将结果放入原数组(原数组需要从begin下标处开始覆盖,temp每次新值会覆盖旧值,所以可以多次使用)
性能分析:
时间复杂度:N*logN
某一层假设有4个小区间,每个小区间都遍历一遍相当于数组遍历了一边,时间复杂度为 N
递归看成完全二叉树,总共是进行了 logN 次区间遍历,因此时间复杂度为nlogn
空间复杂度:N
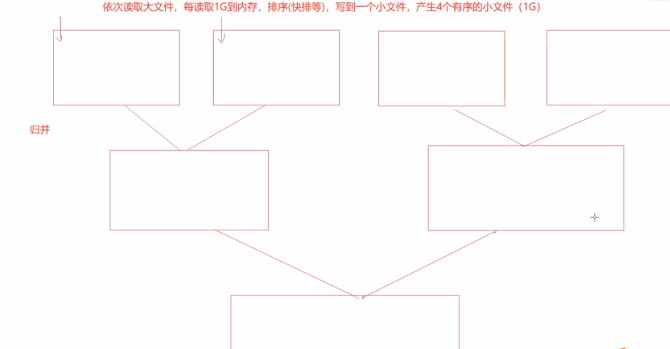
归并排序是一种外排序
假设只有1G内存,把4G的大文件拆分成4个1G的小文件,对4个小文件分别进行排序(用更快的,例如希尔)
然后再对4个小文件使用归并排序,归并成一个大文件,4G的数据就有序了
能够通过小内存来处理大数据的,我们一般称为外排序(可以理解成用内存来完成磁盘的活)
6.归并排序(非递归)
归并的递归不使用栈和队列这类数据结构
快排是操作+左右递归 -> 先序遍历
归并是左右递归+操作 -> 后序遍历
难以通过栈来实现后序遍历,因为后序遍历就决定了得先把下标依次全都放进栈,然后才能操作,使用栈无法实现归并的操作
因此我们可以使用希尔排序的思想,将数据之间看作是多个区间对,例如4个数的数组: [0,1][2,3] -> [0,0][1,1] [2.2][3.3] 从右往左,先是两个数一块排,再是4个数一块排
因此我们可以用到gap作为区间值的距离
[i,i+gap-1][i+gap,i+2*gap-1] 数组下标从0开始算,所以区间终止位置下标需要-1
其余思想与递归实现相同
void MergeSortNON(int* a, int n)
{int* temp = (int*)malloc(n * sizeof(int));if (!temp){perror("malloc error");return;}int gap = 1;while (gap < n){for (int i = 0;i < n;i += 2 * gap){int begin1 = i, end1 = i + gap - 1;//左区间int begin2 = i + gap, end2 = i + 2 * gap - 1;//右区间int j = 0;//temp数组下标从0开始while (begin1 <= end1 && begin2 <= end2)//左右区间都还有值,直到一个没有值推出循环{if (a[begin1] < a[begin2]) temp[j++] = a[begin1++];else temp[j++] = a[begin2++];}while (begin1 <= end1) temp[j++] = a[begin1++];while (begin2 <= end2) temp[j++] = a[begin2++];memcpy(a + i, temp, (end2 - i + 1) * sizeof(int));//这边i不能用begin,begin已经被修改掉了}gap *= 2;}free(temp);temp = NULL;
}当数组的数据不是2的倍数时,有可能会导致数组越界,以下是数组越界的三种情况:
 假设有一个有10个数据的数组,归并排序时会出现以下几个越界:
假设有一个有10个数据的数组,归并排序时会出现以下几个越界:
 如上图所示,对应了错误2、错误3 [8,9][10,11] & [8,11][12,15]
如上图所示,对应了错误2、错误3 [8,9][10,11] & [8,11][12,15]
此时,因为[8,9]区间的值通过前一步的操作已经有序了,所以可以直接结束本次循环(即不用归并);只有begin1没有越界or第二组越界,end1越界begin2必越界,所以可以放在一个判断语句里判断 -> 不需要归并了,用break就好不用continue,因为越界肯定发生在最后一组区间对上
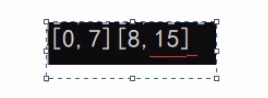
如上图所示,对应了错误1
此时[0,7][8,9]需要进行归并,所以我们可以手动将 end2 赋为 n-1
全部代码:
void MergeSortNON(int* a, int n)
{int* temp = (int*)malloc(n * sizeof(int));if (!temp){perror("malloc error");return;}int gap = 1;while (gap < n){for (int i = 0;i < n;i += 2 * gap){int begin1 = i, end1 = i + gap - 1;//左区间int begin2 = i + gap, end2 = i + 2 * gap - 1;//右区间if (begin2 >= n) break;if (end2 >= n) end2 = n - 1;int j = 0;//temp数组下标从0开始while (begin1 <= end1 && begin2 <= end2)//左右区间都还有值,直到一个没有值推出循环{if (a[begin1] < a[begin2]) temp[j++] = a[begin1++];else temp[j++] = a[begin2++];}//根据循环退出条件,此时肯定还有一个区间有值;把剩下来没有放进(图)while (begin1 <= end1) temp[j++] = a[begin1++];while (begin2 <= end2) temp[j++] = a[begin2++];memcpy(a + i, temp, (end2 - i + 1) * sizeof(int));//这边i不能用begin,begin已经被修改掉了}gap *= 2;}free(temp);temp = NULL;
}7.计数排序(非比较排序)

1.搞一个count数组
2.count数组下标对应的就是原数组中某一个元素,count数组某个下标所对应的元素大小即原数组中某一元素个数
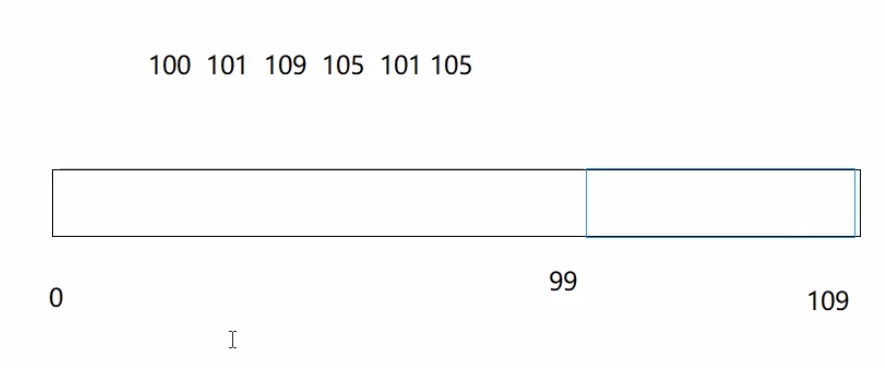
3.原数组里的值都比较大的话,可以通过 count[a[i]-min] 来优化 min为原数组中的最小元素(图)
4. 3 9 100 105 这个数组依旧可以完成排序,min = 3 max = 105 range = 102,105->[102] 100->[97] 9->[6] 3->[0]
5.负数range范围能概括到,并且i+min可以减到负数,因此负数也可以用该办法进行排序
void CountSort(int* a, int n)
{int min = a[0], max = a[0];for (int i = 1;i < n;i++){if (a[i] < min) min = a[i];if (a[i] > max) max = a[i];}int range = max - min + 1;int* count = (int*)calloc(range, sizeof(int));if (!count){perror("calloc error");return;}//统计出现次数for (int i = 0;i < n;i++) count[a[i] - min]++;//放到原数组里int j = 0;for (int i = 0;i < range;i++){while (count[i]--) a[j++] = i + min;}free(count);count = NULL;
}calloc(range, sizeof(int))是带初始化的malloc,相当于malloc + memset(count, 0, range * sizeof(int))
性能分析:
时间复杂度:range + N (range是对count数组遍历,原数组N个数,因此还需要 +N )
空间复杂度:range
只适合整数/数据范围比较集中(相当于用空间换时间)
8.排序稳定性

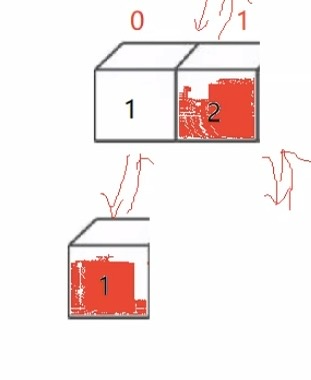
稳定性关注的是相同值排序以后,相同值的相对顺序是否有发生变化
例如上图的2个5,红前蓝后经过多次排序以后,依然还是红前蓝后,说明是稳定的

为什么需要去判断稳定性呢?
在实践时,一般都是对结构体进行排序;假设有张三、李四两个人的成绩结构体(两人的成绩相同),并且要求张三信息必须要在李四前面,如果不具备稳定性那么张三这条信息就放在李四后了,因此需要去考虑稳定性
插入排序:稳定(相等时不挪动,因此相对顺序没有变)
希尔排序:不稳定(分组不同导致的)
选择排序:不稳定(6 6 1 1 9 7 ,min = 1 begin=0 ,a[0] 和 a[2] 交换位置以后,放在数组首部的元素6失去了稳定性)
冒泡排序:稳定(相等时不交换位置)
快速排序:不稳定(只要left、right下标2值交换位置,就有可能打破原有的相对顺序)
归并排序:稳定(相同值在不同区间,通过a[begin1]<=a[begin2]把a[begin1]放进temp数组即可保证稳定;相同值在相同区间,是通过前面归并的操作到了当前这一步的,肯定稳定)堆排序:不稳定(相同值在不同子树,向上调整建堆时会破坏相对顺序)
相关文章:
)
排序复习/下(C语言版)
目录 1.快速排序(hoare法) 单趟: 整体: 代码优化: 编辑三数取中代码: 小区间优化代码: hoare法疑问解答: 2.快速排序(挖坑法) 3.快速排序&#x…...

Vue百日学习计划Day33-35天详细计划-Gemini版
总目标: 在 Day 33-35 理解 Vue 组件从创建到销毁的完整生命周期,熟练掌握 Composition API 中主要的生命周期钩子,并知道在不同阶段执行哪些操作。 所需资源: Vue 3 官方文档 (生命周期钩子): https://cn.vuejs.org/guide/essentials/lifecycle.html你…...

Apidog MCP服务器,连接API规范和AI编码助手的桥梁
#作者:曹付江 文章目录 1.了解 MCP2.什么是 Apidog MCP 服务器?3.Apidog MCP 服务器如何工作4.利用人工智能改变开发工作流程5.设置 Apidog MCP 服务器: 分步指南5.高级功能和提示5.1 使用 OpenAPI 规范5.2.多个项目配置5.3.安全最佳实践5.4…...

统计客户端使用情况,使用es存储数据,实现去重以及计数
这篇文件的重点在tshark、filebeat、和logstash。 需求:统计客户使用的客户端版本 实现工具:tshark 1.10.14,filebeat 8.17.0,logstash 8.17.0,elasticsearch 8.17.0,kibana 8.17.0 总体设计:…...

Git基础面试题
git的rm命令与系统的rm命令有什么区别 git rm 和系统的 rm (在 Windows 上是 del) 命令都用于删除文件,但它们在 Git 仓库的上下文中作用有所不同: 系统 rm (或 del) 命令: 作用: 直接从文件系统中删除文件。Git 的感知ÿ…...

conda 的常用命令
好的,下面为你介绍conda的常用命令: 环境管理 # 创建新环境 conda create -n env_name python3.8# 激活环境 conda activate env_name# 查看所有环境 conda env list# 复制环境 conda create -n new_env --clone old_env# 删除环境 conda remove -n en…...

PLC双人舞:profinet转ethernet ip网关奏响施耐德与AB的协奏曲
PLC双人舞:ethernet ip转profinet网关奏响施耐德与AB的协奏曲 案例分析:施耐德PLC与AB PLC的互联互通 在现代工业自动化中,设备之间的互联互通至关重要。本案例旨在展示如何通过北京倍讯科技的EtherNet/IP转Modbus网关,将施耐德P…...

百度OCR:证件识别
目录 一、编写目的 二、准备工作 2.1 OCR密钥 三、代码实现 3.1 配置文件 3.2 请求接收封装 3.3 请求响应封装 3.4 服务类参数初始化 3.5 服务类实现 3.6 解析结果 3.7 定义Web接口 四 测试效果 五、总结 欢迎来到盹猫🐱的博客 本篇文章主要介绍了 [百…...

纯前端实现图文识别 OCR
Tesseract.js Tesseract.js 是一个基于 Google Tesseract OCR 引擎的 JavaScript 库,利用 WebAssembly 技术将的 OCR 引擎带到了浏览器中。它完全运行在客户端,无需依赖服务器,适合处理中小型图片的文字识别。 基本使用 以下示例展示了如何…...

2025.05.01【Barplot】柱状图的多样性绘制
Custom color A few examples showing how to custom barplot color. Horizontal barchart It makes sense to make your barchart horizontal: group labels are now much easier to read 文章目录 Custom colorHorizontal barchart 探索Barplot的奥秘Barplot基础什么是Barp…...

在资源受限环境下,移动端如何实现流畅动画?如何在内存、CPU、GPU、网络等多种限制条件下,依然保持动画高帧率、低延迟、不卡顿?
在日常生活中,移动设备已经成为不可或缺的工具。从社交、购物到游戏、教育,几乎所有的应用场景都依赖于移动终端的计算和显示能力。然而,随着用户体验的不断提升需求,动画成为了界面交互中不可忽视的一环。动画不仅提升了视觉吸引…...

HJ10 字符个数统计【牛客网】
文章目录 零、原题链接一、题目描述二、测试用例三、解题思路四、参考代码 零、原题链接 HJ10 字符个数统计 一、题目描述 二、测试用例 三、解题思路 基本思路: 建立字符串的散列表,然后统计不同字符个数具体思路: 遍历字符串的字…...

关键点检测算法-RTMPose
一、网络框架(top-down模式) 二、各部分内容 1、骨干网络 对于网络而言,CXPset太大,可以换成starnet 2、一个卷积层 7x7的卷积核对性能提升最大 3、一个全连接层 将一维关键点表示扩展到由超参数控制的所需维度。 4、一个用…...

云原生安全:错误策略S3存储桶ACL设置为Everyone:FullControl
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 ——从基础到实践的深度解析 1. 基础概念 S3存储桶与ACL Amazon S3(Simple Storage Service)是AWS提供的对象存储服务,支持存储和检索任意规模的数据。ACL(访问控制列表…...
)
Axure疑难杂症:垂直菜单展开与收回(4大核心问题与专家级解决方案)
亲爱的小伙伴,在您浏览之前,烦请关注一下,在此深表感谢!如有帮助请订阅专栏! Axure产品经理精品视频课已登录CSDN可点击学习https://edu.csdn.net/course/detail/40420 课程主题:垂直菜单展开与收回 主要内容:超长菜单实现、展开与收回bug解释、Axure9版本限制等问题解…...
)
图漾相机错误码解析(待补充)
文章目录 1.相机错误码汇总2.常见报错码2.1 -1001报错2.1.1 没有找到相机2.1.2 SDK没有进行初始化 2.2 -1005报错2.2.1 跨网段打开相机2.2.2 旧版本SDK在软触发失败后提示的报错2.2.3 相机初始化上电时报错2.2.4 USB相机被占用 2.3 -1009报错2.3.1 相机本身不支持改属性 2.4 -1…...

SpringBoot 中文转拼音 Pinyin4j库 拼音转换 单据管理 客户管理
介绍 在客户管理系统中部分客户的名字会有生僻字为了沟通时候不叫错客户的名称,因此决定将客户名称的拼音一起返回给前端,也可以直接交给前端去处理。这里介绍后端的做法 Pinyin4j 是一个用于将汉字转换为拼音的 Java 库。在需要对中文文本进行拼音转换…...

使用 Whisper 生成视频字幕:从提取音频到批量处理
生成视频字幕是许多视频处理任务的核心需求。本文将指导你使用 OpenAI 的 Whisper 模型为视频文件(如电视剧《Normal People》或电影《花样年华》)生成字幕(SRT 格式)。我们将从提取音频开始,逐步实现字幕生成…...

Kotlin Compose Button 实现长按监听并实现动画效果
想要实现长按按钮开始录音,松开发送的功能。发现 Button 这个控件如果去监听这些按下,松开,长按等事件,发现是不会触发的,究其原因是 Button 已经提前消耗了这些事件所以导致,这些监听无法被触发。因此为了…...
)
SQL练习——(15/81)
目录 1.计算次日留存率 2.多条件查询 方法1:子查询 方法2:窗口函数实现 3.条件查询——自连接相关 1.计算次日留存率 550. 游戏玩法分析 IV - 力扣(LeetCode) 错误查询1:(没有考虑从首次登录日期开始…...

数据中心 智慧机房解决方案
该文档介绍数据中心智慧机房解决方案,涵盖模块化数据中心(机柜式、微模块),具备低成本快速部署、标准化建设等特点;监控管理系统(DCIM)可实现设施、资产、容量、能效管理;节能解决方案含精密空调节能控制柜,节能率高达 30%;还有7X24 小时云值守运维服务。方案亮点包括…...

网络-MOXA设备基本操作
修改本机IP和网络设备同网段,输入设备IP地址进入登录界面,交换机没有密码,路由器密码为moxa 修改设备IP地址 交换机 路由器 环网 启用Turbo Ring协议:在设备的网络管理界面中,找到环网配置选项,启用Turb…...

Docker构建 Dify 应用定时任务助手
概述 Dify 定时任务管理工具是一个基于 GitHub Actions 的自动化解决方案,用于实现 Dify Workflow 的定时执行和状态监控。无需再为缺乏定时任务支持而感到困扰,本工具可以帮助设置自动执行任务并获取实时通知,优化你的工作效率。 注意&…...

前端测试策略:单元测试到 E2E 测试
引言 在现代前端开发中,测试已成为确保应用质量和可靠性的关键环节。随着前端应用复杂度的不断提高,仅依靠手动测试已经远远不够。一个全面的前端测试策略应该包含多个层次的测试,从最小粒度的单元测试到模拟真实用户行为的端到端(E2E)测试。…...

Web漏洞扫描服务的特点与优势:守护数字时代的安全防线
在数字化浪潮中,Web应用程序的安全性已成为企业业务连续性和用户信任的核心要素。随着网络攻击手段的不断升级,Web漏洞扫描服务作为一种主动防御工具,逐渐成为企业安全体系的标配。本文将从特点与优势两方面,解析其价值与应用场景…...

大中型水闸安全监测系统解决方案
一、系统概述 水闸是重要的水利基础设施,具有防洪、挡潮、排涝、灌溉、供水、生态、航运和水力发电等综合功能,在国家水网构建、支撑经济社会高质量发展等方面具有十分重要的作用。我国水闸工程面广量大,据2021年统计数据,我国已建…...

紫光同创FPGA实现AD9238数据采集转UDP网络传输,分享PDS工程源码和技术支持和QT上位机
目录 1、前言工程概述免责声明 2、相关方案推荐我已有的所有工程源码总目录----方便你快速找到自己喜欢的项目紫光同创FPGA相关方案推荐我这里已有的以太网方案本方案在Xilinx系列FPGA的应用方案 3、设计思路框架工程设计原理框图AD输入源AD9238数据采集AD9238数据缓存控制模块…...

ffmpeg 把一个视频复制3次
1. 起因, 目的: 前面我写过,使用 python 把一个视频复制3次但是速度太慢了,我想试试看能否改进。而且我想换一种新的视频处理思路,并试试看速度如何。 2. 先看效果 效果就是能行,而且速度也快。 3. 过程: 代码 1…...

仿腾讯会议——添加音频
1、实现开启或关闭音频 2、 定义信号 3、实现开始暂停音频 4、实现信号槽连接 5、回收资源 6、初始化音频视频 7、 完成为每个人创建播放音频的对象 8、发送音频 使用的是对象ba,这样跨线程不会立刻回收,如果使用引用,跨线程会被直接回收掉&a…...

从零训练一个大模型:DeepSeek 的技术路线与实践
从零训练一个大模型:DeepSeek 的技术路线与实践 系统化学习人工智能网站(收藏):https://www.captainbed.cn/flu 文章目录 从零训练一个大模型:DeepSeek 的技术路线与实践摘要引言技术路线对比1. 模型架构:…...

interface接口和defer场景分析
接口 接口这里主要两点: 设计业务结构时采用依赖倒转:业务层向下依赖抽象层,实现层向上依赖抽象层。 相比于之前: 之后: 注意struct中嵌套interface和不嵌套interface的区别: type Myinterface interfac…...
)
【数据结构篇】排序1(插入排序与选择排序)
注:本文以排升序为例 常见的排序算法: 目录: 一 直接插入排序: 1.1 基本思想: 1.2 代码: 1.3 复杂度: 二 希尔排序(直接插入排序的优化): 2.1 基本思想…...

FastAPI自定义异常处理:优雅转换Pydantic校验错误
FastAPI自定义异常处理:优雅转换Pydantic校验错误 背景需求 当使用FastAPI开发API服务时,Pydantic的自动校验异常默认会返回如下格式的422响应: {"detail": [{"type": "missing","loc": ["body", "user", &…...

C++--内存管理
内存管理 1. C/C内存分布 在C语言阶段,常说局部变量存储在栈区,动态内存中的数据存储在堆区,静态变量存储在静态区(数据段),常量存储在常量区(代码段),其实这里所说的栈…...

YOLOV3 深度解析:目标检测的高效利器
在计算机视觉领域,目标检测一直是一个重要且热门的研究方向,广泛应用于安防监控、自动驾驶、机器人视觉等诸多场景。YOLO(You Only Look Once)系列算法凭借其出色的实时性和较高的检测精度,在目标检测领域占据着重要地…...

select * from 按时间倒序排序
在SQL中,如果你想要根据时间字段来倒序排序查询结果,你可以使用ORDER BY子句,并结合DESC关键字来实现这个目的。这里有几个常见的场景和示例,假设我们有一个表events,里面包含一个时间戳字段event_time。 示例1&#…...

数据结构-DAY06
一、树的概念 1.链表是数的一部分(斜树) 2.树的查找速度很快 3.层序:前序:根左右 中序:左根右 后序: 左右根 4.树的存储:顺序结构,链式结构 5.特点: 1…...
)
JavaWeb:SpringBoot处理全局异常(RestControllerAdvice)
问题 GlobalExceptionHandler 小结...

免费私有化部署! PawSQL社区版,超越EverSQL的企业级SQL优化工具面向个人开发者开放使用了
1. 概览 1.1 快速了解 PawSQL PawSQL是专注于数据库性能优化的企业级工具,解决方案覆盖SQL开发、测试、运维的整个流程,提供智能SQL审核、查询重写优化及自动化巡检功能,支持MySQL、PostgreSQL、Oracle、SQL Server等主流数据库及达梦、金仓…...

buuctf RSA之旅
BUUCTF-RSA的成长之路 rsarsaRSA1RSA3RSA2RSARSAROLLDangerous RSA[GUET-CTF2019]BabyRSArsa2RSA5[NCTF2019]childRSA[HDCTF2019]bbbbbbrsaRSA4[BJDCTF2020]rsa_output[BJDCTF2020]RSA[WUSTCTF2020]babyrsa[ACTF新生赛2020]crypto-rsa0[ACTF新生赛2020]crypto-rsa3[GWCTF 2019]…...
javascript与Node.js)
javascript 编程基础(2)javascript与Node.js
文章目录 一、Node.js 与 JavaScript1、基本概念1.1、JavaScript:动态脚本语言1.2、Node.js:JavaScript 运行时环境 2、核心区别3、执行环境差异3.1、浏览器中的JavaScript3.2、Node.js中的JavaScript 4、共同点5、为什么需要Node.js? 一、No…...

IDEA+AI 深度融合:重构高效开发的未来模式
在 Java 开发领域,IntelliJ IDEA(以下简称 IDEA)作为最受欢迎的集成开发环境之一,一直是开发者的得力工具。而飞算 JavaAI 凭借强大的人工智能技术,为 Java 开发带来了全新的效率提升可能。当 IDEA 与飞算 JavaAI 深度…...

深度学习中常见损失函数激活函数
损失函数 一、分类任务损失函数 二、回归任务损失函数 三、生成对抗网络(GAN)损失函数 四、其他专用损失函数 五、损失函数选择原则 任务类型:分类用交叉熵,回归用MSE/MAE。 数据分布:类别不平衡时选择Focal Loss或…...

入职软件开发与实施工程师了后........
时隔几个月没有创作的我又回来了,这几个月很忙,我一直在找工作,在自考(顺便还处理了一下分手的事),到处奔波,心力交瘁。可能我骨子里比较傲吧。我不愿意着急谋生,做我不愿意做的普通…...
)
告别Spring AI!我的Java轻量AI框架实践(支持多模型接入|注解式MCP架构|附开源地址)
~犬📰余~ “我欲贱而贵,愚而智,贫而富,可乎? 曰:其唯学乎” 1. 开发初衷 \quad 大家好,我是犬余,之前,为了体验一下MCP架构的JAVA实现,犬余使用了Spring AI框…...

【软考-架构】15、软件架构的演化和维护
✨资料&文章更新✨ GitHub地址:https://github.com/tyronczt/system_architect 文章目录 软件架构演化和定义面向对象软件架构演化软件架构演化方式的分类软件架构演化原则软件架构演化评估方法大型网站架构演化软件架构维护 软件架构演化和定义 软件架构生命周…...

编译Qt5.15.16并启用pdf模块
编译Qt5.15.16并启用pdf模块 标题1.目录设置 -q-bulid –qt-everywhere-src-5.15.16 –bulid cd bulid 必须,否则会提示Project ERROR: You cannot configure qt separately within a top-level build. create .qmake.stash and .qmake.super in build folder …...

spring中的EnvironmentPostProcessor接口详解
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站 EnvironmentPostProcessor 是 Spring Boot 提供的一个关键扩展接口,允许开发者在 Spring 应用环境初始化后、应用上下文创建前&…...

自学嵌入式 day20-数据结构 链表
注:gdb调试工具用法 3.链表的常规操作 (6)尾部插入 int InsertTailLinkList(LinkList* ll, DATATYPE* data) { if (IsEmptyLinkList(ll))//判断链表是否为空 { return InsertHeadLinkList(ll, data); } else { …...
)
Java设计模式之外观模式:从入门到精通(保姆级教程)
外观模式是结构型设计模式中非常实用的一种,它为复杂的子系统提供了一个统一的简化接口。本文将全面深入地剖析外观模式,从基础概念到高级应用,通过丰富的代码示例、图表和日常生活类比,帮助您彻底掌握这一模式。 一、外观模式基础概念 1.1 什么是外观模式? 外观模式(…...