AI在网络安全中的应用之钓鱼邮件检测
0x01 前言
为什么写这个呢,源自于我之前在某教培网站留了信息,不出意外的个人信息泄露的飞快,邮箱开始疯狂收到垃圾邮件甚至钓鱼邮件,看着每天的拦截消息,就在想这个拦截机制挺好玩的,拦截器是怎么知道是不是正常邮件呢,结合现在AI有些爆火,于是就学习一下。
此处也建议大家尽量不要去在网站上留个人信息,最好去找一些有实体公司的中介或者机构,网上的大部分都是第三方平台,他们收到信息就会推到所有合作的机构手里,个人信息就满天飞啦~啦~啦~
0x02 先来思考
我们如何判断一封邮件是钓鱼邮件还是正常邮件呢?像这种
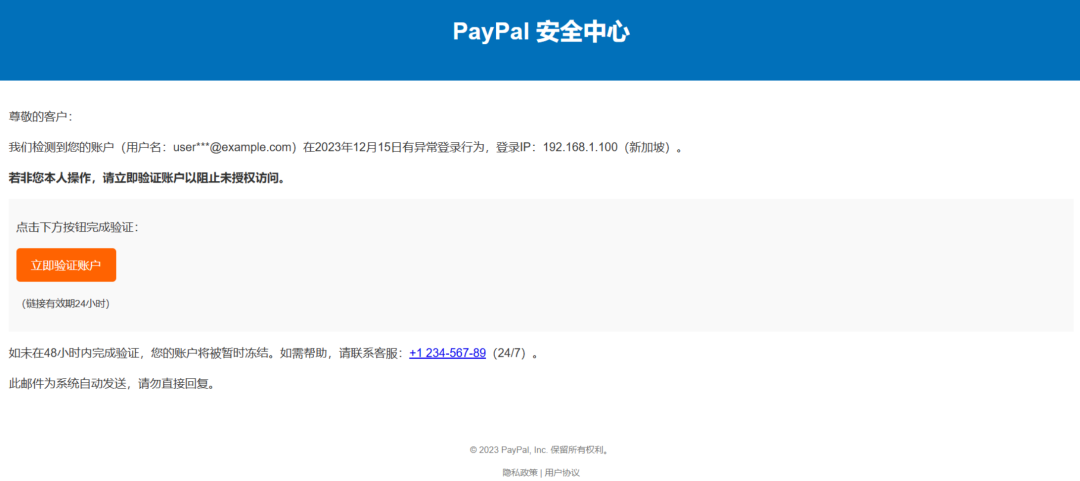
那么我们可以从邮件内容看出来,钓鱼邮件的内容通常是用一两句我们认为比较重要的提示信息+诱导点击链接。 但是,只要出现特征点就一定是吗,当然不是。比如这种就是正常邮件:
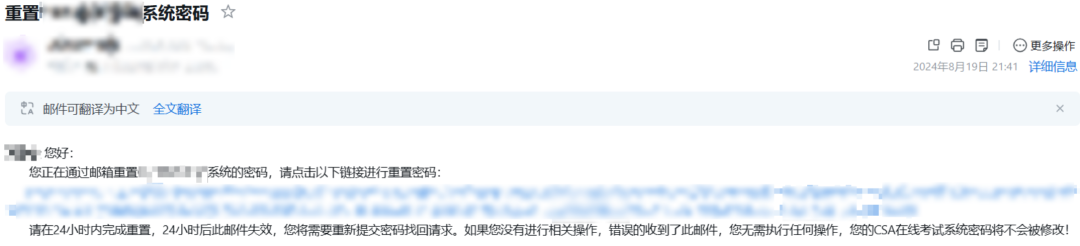
所以此时就要引出神秘的三人组:权重、激活函数、阈值
0x03 神秘三幻神:权重、激活函数、阈值
权重:表示特征点重要程度,就像比如当我们看到“bo彩”就会知道这一定不是什么好内容。
激活函数:作用是将加权信号转换为输出信号。人话就是把一堆特征点算出来的值通过线代求和的方式变成一个值。
阈值:通过激活函数出来的值如果大于阈值,则输出为aaa,否则输出为bbb。 这样经过权重的加持下,就可以友好的避免了误伤,文字有点难理解了,那我们就看个表
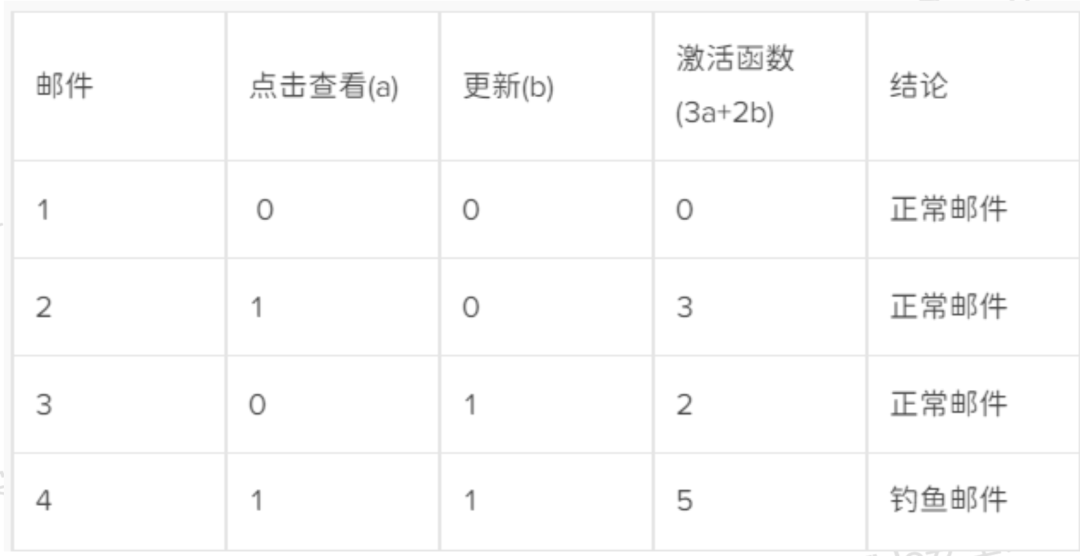
可以看到,我们给予"点击查看"的权重为3,"更新"为2,而这,就组成了激活函数y=3a+2b,当计算值为5的时候达到阈值,判断为钓鱼邮件。 那么一个新的问题,现在的钓鱼手段层出不穷,对于特征点的权重和阈值也需要实时更新才可以,这里就要提到AI在网络安全领域里的第一个例子-感知机
0x04 感知机
何为感知机?
感知机是模仿人类神经元的一个二分类模型,将输入值做线性代数运算求和,并在达到一定值时激活函数从而得出结论。就像人类,看到红色的软妹币大脑就会刺激我们开心,但是打开看到的是印着玉皇大帝的时候又会刺激我们做出愤恨的情绪一样。 那感知机如何做到实时更新的能力呢?他的运转过程大概如下: 1、将权重初始化为预订值,通常为0 2、计算每个训练样本x,并输出y(结论) 3、根据样本中预设的y与输出的y之间的差距更新权重
用感知机实现一下嘞
理论结束,开始实践。首先解决输入样本的问题,这次先做简单的样本尝试一下,特征点就采用“点击查看”和“更新”并预设邮件类型和特征点出现次数搞个一百来行(其实ai生成一下也行)。
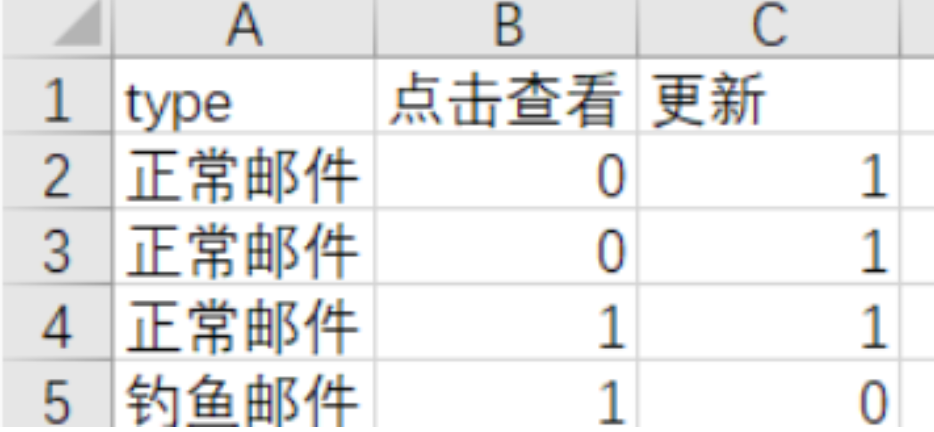
输入样本搞定,然后使用pandas库的DataFrame提供文件加载能力,iloc函数提供数据提取能力,使用numpy库提供数学运算能力
import pandas as pd
import numpy as np
df = pd.read_csv('heihei.csv', encoding='gbk')# 读取数据集,注意文件路径是否正确,并指定正确的编码格式
y = df.iloc[:, 0].values
y = np.where(y == '钓鱼邮件', -1, 1) # 此处的where函数由numpy提供,用于将类别转换成-1和+1
X = df.iloc[:, [1, 2]].values# 获取特征列(假设第2和第3列为特征)
人工智能嘛必须得训练一下
设定用来训练和预测的数据范围,这里为了看最终效果强制73分了,其实可以随机取70%做训练集。
split_index = int(len(X) * 0.7)# 取前70%为训练集
X_train, X_test = X[:split_index], X[split_index:]
y_train, y_test = y[:split_index], y[split_index:]
#随机取可以用:X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
输入都完事了,开始实例化感知机,使用scikit-learn库提供感知机模型,给予他最大迭代次数70,学习率0.1,并初始化权重,看他经过训练最终权重会发生怎样的变化。
# 创建感知机实例,使用SGDClassifier模拟感知机行为
p = SGDClassifier(loss='perceptron', max_iter=70, eta0=1.0, learning_rate='constant', random_state=0)
#初始化权重
p.coef_ = np.zeros((1, X_train.shape[1]))
p.intercept_ = np.zeros(1)
# 训练模型
p.fit(X_train, y_train)
使用predict()方法预估值
y_pred = p.predict(X_test)
打印数据看看结果

可以看到结果正确率八成以上,并且权重完成了更新。
意犹未尽,继续思考
刚才说,这其实就是一个二分类模型,说白了就是把所有样本化成坐标然后一分为二,一半是钓鱼邮件、一半是正常邮件,用刚才的例子画成图:
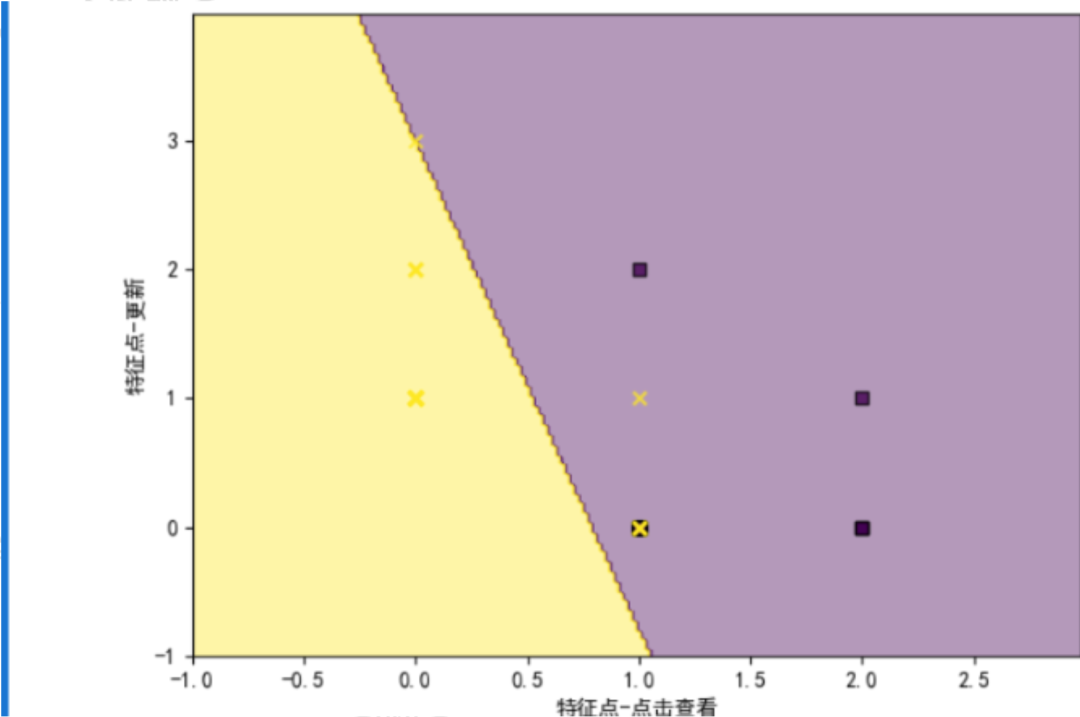
这就有一个局限性,如果点变多了,可能无法找到可以一分为二的地方,就会产生无限震荡(挂了),且这是我提前预设好了特征点,而现在随着技术进步,显然已经不实用了,他应该可以自己从邮件里找到特征点,那么怎么才能解决这一堆的问题呢?
0x05 感知机究极进化
朴素贝叶斯
先看下贝叶斯公式
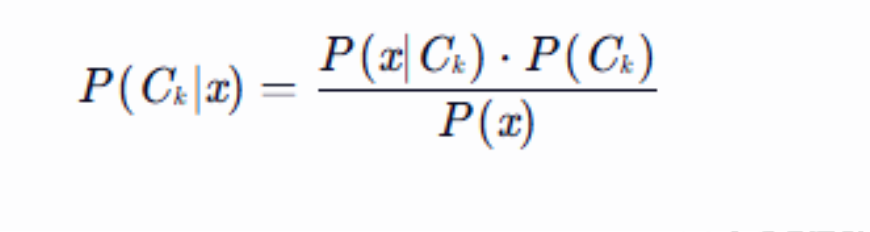
-
P(Ck∣x):数据点 x 属于类别 Ck 的概率。
-
P(x∣Ck):在类别 Ck 下,数据点 x 出现的概率。
-
P(Ck):类别 Ck 的先验概率(即该类别在数据中的占比)。
-
P(x):数据点 x 的概率(可忽略,因为对所有类别相同)。 嗯。。把数学基础还给老师了。。。。还是用个例子说下
用相亲交友软件,假设坏人主页的常见词汇:“深夜”“寂寞”“约我”等,而正常用户中常见词汇:“读书”“认真”“吃苦”等。假设 **先验概率P(Ck)**:坏人占比:70%(即 P(坏人)=0.7)。正常用户占比:30%(即 P(正常)=0.3)。
条件概率:在坏人中,“寂寞”出现的概率:80%(即 P(寂寞∣坏人)=0.8)。在正常用户中,“寂寞”出现的概率:10%(即 P(寂寞∣正常)=0.1)。其他词汇的概率类似计算。 当再出现一个用户写有”寂寞”“约我”“认真”这个词时,
预测坏人的概率就是: P(坏人|账号)=P(坏人)xP(寂寞|坏人)xP(约我|坏人)xP(认真|坏人)=0.7x0.8x0.7x0.2=0.0784,
预测正常用户的概率时: P(正常用户|账号)=P(正常用户)xP(寂寞|正常用户)xP(约我|正常用户)xP(认真|正常用户)=0.3x0.1x0.1x0.6=0.0018, 那么这个账号大概率就是坏人。
而朴素贝叶斯算法,可以动态识别钓鱼邮件中的可以关键字,加上贝叶斯公式的原理,做到动态识别,精准分析。
朴素贝叶斯钓鱼邮件检测器的实现
理论结束,实践开始,首先还是要解决样本问题,这次,我们只需要做出样本的分类和内容就行,大概长这样:

# 导入必要的库
import matplotlib.pyplot as plt # 用于绘图
import csv # 用于处理CSV文件
from textblob import TextBlob # 用于自然语言处理
import pandas as pd # 数据处理库
import sklearn # 机器学习库
import numpy as np # 数值计算库
import nltk # 自然语言工具包
# 加载数据集,指定正确的编码格式
sms = pd.read_csv('yangben.csv', sep=',', names=["type", "text"], encoding='gbk') # 读取CSV文件
# 数据集划分:将数据分为训练集和测试集
text_train, text_test, type_train, type_test = train_test_split(sms['text'], sms['type'], test_size=0.3, random_state=42)
使用sklearn.naive_bayes中的MultinomialNB实现一个基于贝叶斯的分类器
from sklearn.naive_bayes import MultinomialNB # 多项式朴素贝叶斯分类器
spam_detector = MultinomialNB().fit(sms_tfidf, type_train)# 模型训练:使用多项式朴素贝叶斯分类器训练模型
使用 sklearn.feature_extraction.text 中的 CountVectorizer为为文本中每个识别词标记一个数字,并使用get_lemmas提取
bow = CountVectorizer(analyzer=get_lemmas).fit(text_train) # 使用词袋模型提取特征
sms_bow = bow.transform(text_train) # 将训练文本转换为词袋表示
from sklearn.feature_extraction.text import CountVectorizer, TfidfTransformer # 文本向量化工具
from defs import get_tokens, get_lemmas # 获取分词和词形还原的函数
因为邮件有长有短,文件中出现过多词会影响计算,就需要使用scikit-learn 中的TfidfTransformer() 将词频计数转换为 TF-IDF (Term Frequency-Inverse Document Frequency) 值,从而把词频归一化并加权。
TF (Term Frequency):词频f(t,d),表示一个词在文档中出现的频率归一化(Normalization):tf(t,d) = f(t,d) / sqrt(sum(f(t,d)^2 for all t in d)),使不同特征在同一尺度上,便于比较和机器学习算法处理 IDF (Inverse Document Frequency):idf(t) = log((n + 1) / (df(t) + 1)) + 1逆文档频率,衡量一个词的普遍重要性 TF-IDF 计算:tfidf(t,d) = tf(t,d) * idf(t)TF-IDF 计算:tfidf(t,d) = tf(t,d) * idf(t)
tfidf = TfidfTransformer().fit(sms_bow) # 计算TF-IDF权重
sms_tfidf = tfidf.transform(sms_bow) # 将词袋表示转换为TF-IDF表示
然后先预测一行数据,如第45行为例子,看是否正确



没啥毛病,开始完整预测测试集
# 对测试集进行特征提取和预测
text_test_bow = bow.transform(text_test)
text_test_tfidf = tfidf.transform(text_test_bow)
predictions = spam_detector.predict(text_test_tfidf)
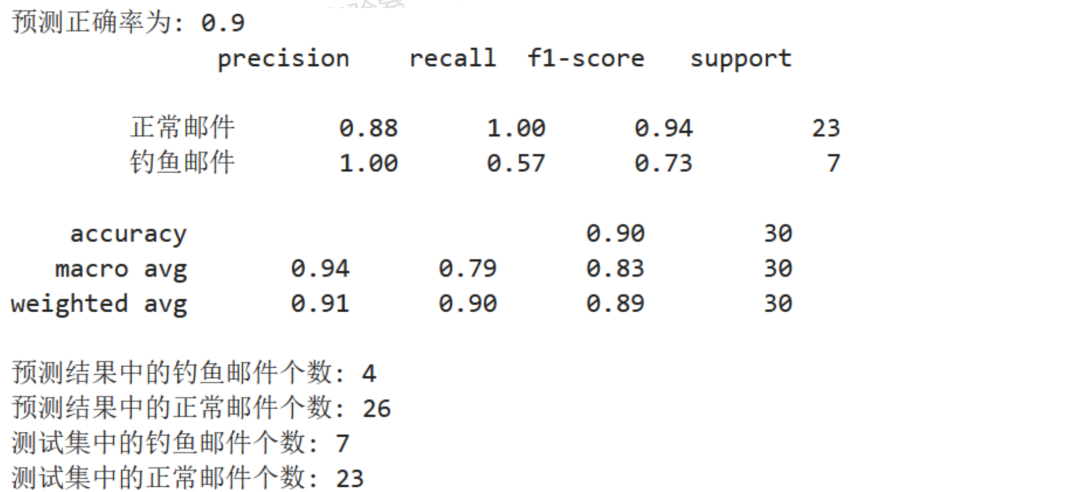
参数解释: precision(精确率):钓鱼邮件样本7个,预测到4个,4个均是钓鱼邮件,精确率100% recall(召回率):钓鱼邮件样本7个,预测到4个,召回率57% f1-score(调和平均值):F1 = 2 × (1.0 × 0.57) / (1.0 + 0.57)=0.73 support(支持):样本数量 Macro Avg (宏平均):对每个类别的精确率、召回率和F1分数取平均值 Weighted Avg (加权平均):对每个类别的精确率、召回率和F1分数按支持度加权取平均值。
可以看到最终准确率也是高达9成。
0x06 总结
钓鱼邮件攻击手段日益复杂,传统规则检测已不足以应对。未来需结合AI检测、用户教育、企业安全策略等多层防御,才能有效降低风险。机器学习(如BERT、异常检测)在钓鱼邮件识别中表现优异,但仍需不断优化以应对新型攻击手法并且我们自身也需要不断提高安全意识。
相关文章:

AI在网络安全中的应用之钓鱼邮件检测
0x01 前言 为什么写这个呢,源自于我之前在某教培网站留了信息,不出意外的个人信息泄露的飞快,邮箱开始疯狂收到垃圾邮件甚至钓鱼邮件,看着每天的拦截消息,就在想这个拦截机制挺好玩的,拦截器是怎么知道是不…...

游戏引擎学习第294天:增加手套
准备战斗 我们正在进行的是第294天的开发,目前暂时没有特别确定要做的内容,但我们决定继续研究移动模式相关的部分。虽然一些小型实体系统已经在运行,但并不确定最终效果如何。 今天我们决定实现一个全新的功能:战斗系统。这是游…...
)
[架构之美]从PDMan一键生成数据库设计文档:Word导出全流程详解(二十)
[架构之美]从PDMan一键生成数据库设计文档:Word导出全流程详解(二十) 一、痛点 你是否经历过这些场景? 数据库字段频繁变更,维护文档耗时费力用Excel维护表结构,版本混乱难以追溯手动编写Word文档&#…...

5个开源MCP服务器:扩展AI助手能力,高效处理日常工作
AI大语言模型(如Claude、GPT)尽管强大,但其原生形态仅限于文本对话,无法直接与外部世界交互。这一局限严重制约了AI在实际应用场景中的价值发挥 - 无法主动获取实时数据、无法操作外部系统、无法访问用户私有资源。 MCPÿ…...

服务器的基础知识
什么是服务器 配置牛、运行稳、价格感人的高级计算机,家用电脑不能比拟的。 服务器的组成:电源、raid卡、网卡、内存、cpu、主板、风扇、硬盘。 服务器的分类 按计算能力分类 超级计算机 小型机AIX x86服务器(服务器cpu架构) …...
- 本地部署(前后端))
bisheng系列(二)- 本地部署(前后端)
一、导读 环境:Ubuntu 24.04、open Euler 23.03、Windows 11、WSL 2、Python 3.10 、bisheng 1.1.1 背景:需要bisheng二开商用,故而此处进行本地部署,便于后期调试开发 时间:20250519 说明:bisheng前后…...

华为ODgolang后端一面面经
MySQL死锁是怎么产生的? 假如有一条SQL语句执行了非常久,你会怎么优化呢? explain 索引什么情况下会失效? InnoDB和MyISAM引擎的区别是什么? 为什么是三次握手 避免历史连接 同步双方初始序列号避免资源浪费 为什么…...

UE5 GAS框架解析内部数据处理机制——服务器与客户端
当, gas通过点击鼠标光标触发事件时,内部的处理机制。 当通过点击事件,命中中目标时, 可获取到对应的TargetData 目标数据。处理相应的操作。 仅有本地的客户端的情况下。命中并不会有什么异常。 当存在服务器时, 服…...

《打造第二大脑》
序 第二大脑,前景无限 2025/05/08 发表想法 是的说的太对了,关键是之前自己一直在找如何能避免出现此问题的方法,今天终于看到了本书所讲的的内容 原文:我们耗费了无数的时间阅读、倾听和观摩他人提供的处世原则、思考方式以及生活…...

Word2Vec详解
目录 Word2Vec 一、Word2Vec 模型架构 (一)Word2Vec 的核心理念 (二)Word2Vec 的两种架构 (三)负采样与层次 Softmax (四)Word2Vec 的优势与局限 二、Word2Vec 预训练及数据集…...

[特殊字符] Word2Vec:将词映射到高维空间,它到底能解决什么问题?
一、在 Word2Vec 之前,我们怎么处理语言? 在 Word2Vec 出现之前,自然语言处理更多是“工程方法”,例如字符串匹配、关键词提取、正则规则...。但这些表示通常缺乏语义,词与词之间看不出任何联系以及非常浅显。当然,技术没有好坏,只有适合的场景。例如: 关键词匹配非常…...

anythingLLM支持本地大模型嵌入知识库后进行api调用
anythingLLM 可以使用本地大模型,并且可以嵌入知识库(Knowledge Base),通过 API 调用该知识库。 ✅ 一、anythingLLM 的基本架构 anythingLLM 是一个支持多种本地大模型(如 LLaMA、Qwen、ChatGLM 等)的开…...

PHP 实现连续子数组的最大和、整数中1出现的次数
在编程面试和实际应用中,处理数组和整数的常见问题之一是求解连续子数组的最大和以及计算整数中1出现的次数。本文将详细介绍如何使用 PHP 实现这两个问题的解决方案。 连续子数组的最大和 连续子数组的最大和问题要求找到一个数组中的连续子数组,使得…...

面试题之进程 PID 分配与回收算法:从理论到 Linux 内核实现
总结: 在操作系统中,进程 PID(Process Identifier)的分配与回收是核心功能之一。本文深入剖析了三种主流算法:位图法、空闲链表法和位图 哈希表组合法,并结合 Linux 内核源码探讨其优化思路。通过时间复杂…...

Pyro:基于PyTorch的概率编程框架
Pyro:基于PyTorch的概率编程框架 **Pyro:基于PyTorch的概率编程框架**基础讲解**一、Pyro核心模块****1. 入门与基础原语****2. 推理算法****3. 概率分布与变换****4. 神经网络与优化****5. 效应处理与工具库** **二、扩展应用与社区贡献****1. 特定领域…...

API Gateway REST API 集成 S3 服务自定义 404 页面
需求分析 使用 API Gateway REST API 可以直接使用 S3 作为后端集成对外提供可以访问的 API. 而当访问的 URL 中存在无效的桶, 或者不存在的对象时, API Gateway 默认回向客户端返回 200 状态码. 而实际上这并不是正确的响应, 本文将介绍如何自定义返回 404 错误页面. 基本功…...
)
02-前端Web开发(JS+Vue+Ajax)
介绍 在前面的课程中,我们已经学习了HTML、CSS的基础内容,我们知道HTML负责网页的结构,而CSS负责的是网页的表现。 而要想让网页具备一定的交互效果,具有一定的动作行为,还得通过JavaScript来实现。那今天,我们就来讲…...

visual studio code中的插件都是怎么开发的?用的什么编程语言?
目录 开发VS Code插件的编程语言 开发VS Code插件的步骤 学习资源 Visual Studio Code(VS Code)是一款流行的开源代码编辑器,由微软开发,支持多种编程语言。它的一个重要特性是可以通过插件(Extensions)来扩展其功能。这些插件可以增加新的语言支持、主题、调试器以及…...

python第30天
知识点回顾: 导入官方库的三种手段导入自定义库/模块的方式导入库/模块的核心逻辑:找到根目录(python解释器的目录和终端的目录不一致) 作业:自己新建几个不同路径文件尝试下如何导入 浙大疏锦行-CSDN博客 from lib.ut…...

【数据仓库面试题合集③】实时数仓建模思路与实践详解
实时数据仓库已经成为各大企业构建核心指标监控与业务实时洞察的基础能力。面试中,关于实时建模的题目频繁出现,尤其聚焦于建模思路、宽表设计、状态管理、乱序处理等方面。本文整理典型题目及答题思路,帮助你应对相关考察。 一、建模原则与数仓分层认知 1. 实时数仓与离线…...

kotlin Android AccessibilityService 无障碍入门
安卓的无障碍模式可以很好的进行自动化操作以帮助视障人士自动化完成一些任务。 无障碍可以做到,监听屏幕变化,朗读文本,定位以及操作控件等。 以下从配置到代码依次进行无障碍设置与教程。 一、配置 AndroidManifest.xml 无障碍是个服务…...
:最小可行化产品(MVP)的设计、验证与数据驱动迭代)
精益数据分析(69/126):最小可行化产品(MVP)的设计、验证与数据驱动迭代
精益数据分析(69/126):最小可行化产品(MVP)的设计、验证与数据驱动迭代 在创业旅程中,从需求洞察到产品落地的关键一跃是打造最小可行化产品(MVP)。今天,我们结合《精益…...

JVM频繁FullGC:面试通关“三部曲”心法
想象一下,你的Java应用程序是一个繁忙的工厂,JVM堆内存就是工厂的仓库和车间。垃圾收集(GC)就像工厂的清洁工,负责清理不再需要的废料(无用对象),腾出空间让新的生产(对象…...

Scala语言基础与函数式编程详解
Scala语言基础与函数式编程详解 本文系统梳理Scala语言基础、函数式编程核心、集合与迭代器、模式匹配、隐式机制、泛型与Spark实战,并对每个重要专业术语进行简明解释,配合实用记忆口诀与典型代码片段,助你高效学习和应用Scala。 目录 Scal…...

大语言模型 13 - 从0开始训练GPT 0.25B参数量 MiniMind2 补充 训练开销 训练步骤 知识蒸馏 LoRA等
写在前面 GPT(Generative Pre-trained Transformer)是目前最广泛应用的大语言模型架构之一,其强大的自然语言理解与生成能力背后,是一个庞大而精细的训练流程。本文将从宏观到微观,系统讲解GPT的训练过程,…...

【NLP】37. NLP中的众包
众包的智慧:当“无数人”帮你训练AI 当我们谈论构建大语言模型时,脑海中浮现的往往是服务器、GPU 和Transformer,而很少想到成千上万的普通人也在默默贡献力量。 这背后依赖的机制就是:众包(Crowdsourcing࿰…...

数据分析入门指南:从历史到实践
在信息爆炸的时代,数据分析已经成为各行各业不可或缺的技能,无论是商业决策、医疗研究,还是社会科学,数据分析都在其中扮演着关键角色。本文将带你深入了解数据分析的历史、定义、流程、数据来源与处理、常用工具,并通…...

大语言模型 12 - 从0开始训练GPT 0.25B参数量 MiniMind2 补充 训练开销 训练步骤 知识蒸馏 LoRA等
写在前面 GPT(Generative Pre-trained Transformer)是目前最广泛应用的大语言模型架构之一,其强大的自然语言理解与生成能力背后,是一个庞大而精细的训练流程。本文将从宏观到微观,系统讲解GPT的训练过程,…...
:数据透视表实战与解决方案验证——从问卷分析到产品落地的关键跨越)
精益数据分析(68/126):数据透视表实战与解决方案验证——从问卷分析到产品落地的关键跨越
精益数据分析(68/126):数据透视表实战与解决方案验证——从问卷分析到产品落地的关键跨越 在创业的移情阶段,通过问卷调查获取数据后,如何深入分析数据并验证解决方案的可行性?今天,我们结合《…...

Cursor 模型深度分析:区别、优缺点及适用场景
Cursor 模型深度分析:区别、优缺点及适用场景 在AI辅助编程领域,Cursor凭借其多模型架构和智能上下文感知能力,成为开发者提升效率的核心工具。不同模型在代码生成、逻辑推理、多模态处理等方面存在显著差异,本文将结合技术特性与…...

LightRAG 由入门到精通
LightRAG 由入门到精通 作者:王珂 邮箱:49186456qq.com 文章目录 LightRAG 由入门到精通简介一、LightRAG Server1.1 安装 LightRAG Server1.2 LightRAG Server 和 WebUI1.2.1 配置 LightRAG Server1.2.2 启动 LightRAG Server1.2.3 使用 Docker 加载 …...

【Spring Boot 整合 MongoDB 完整指南】
目录 Spring Boot 整合 MongoDB 完整指南1. 添加依赖2. 配置 MongoDB 连接application.properties 方式:application.yml 方式:3. 创建实体类(映射MongoDB中的文档,相当于MySQL的表)4. 创建 Repository 接口完成简单操作5. 使用 MongoTemplate 进行复杂操作6. 高级配置配置…...

prisma连接非关系型数据库mongodb并简单使用
prisma连接非关系型数据库如mongodb数据库并简单使用 安装 mongodbPrisma连接mongodb改造目录结构写一个model增查查多个查单个分页排序改改多个删单个多个最后代码进度安装 mongodb 社区版下载 副本集模式文档 可以百度下安装副本集模式,因为prisma要用事务。 如果你觉得安装…...
)
深度强化学习 | 基于SAC算法的移动机器人路径跟踪(附Pytorch实现)
目录 0 专栏介绍1 软性演员-评论家SAC算法2 基于SAC算法的路径跟踪2.1 SAC网络设计2.2 动作空间设计2.3 奖励函数设计 3 算法仿真 0 专栏介绍 本专栏以贝尔曼最优方程等数学原理为根基,结合PyTorch框架逐层拆解DRL的核心算法(如DQN、PPO、SAC)逻辑。针对机器人运动…...

VS中将控制台项目编程改为WINDOWS桌面程序
有时候因为误操作,建立了控制台项目,但是实际上想建立桌面程序。那么应该如何改过来呢? 一共要修改两个地方,修改步骤如下: 第一处修改地点: 将C/C下面的预处理器选项中,将原本的_CONSOLE修改…...

从API到UI:直播美颜SDK中的滤镜与贴纸功能开发与落地方案详解
时下,滤镜和贴纸功能,已经成为主播们展现个性、增强互动的“必备神器”。那么,这些功能背后的技术实现到底有多复杂?如何从API到UI构建一个流畅、灵活的美颜SDK呢?本文将从底层原理到前端实现,全面解析这两…...

vue3与springboot交互-前后分离【验证element-ui输入的内容】
系列文章目录 提示:帮帮志会陆续更新非常多的IT技术知识,希望分享的内容对您有用。本章分享的是node.js和vue的使用。前后每一小节的内容是存在的有:学习and理解的关联性。【帮帮志系列文章】:每个知识点,都是写出代码…...

VS2017编译librdkafka 2.1.0
VS2017编译librdkafka 2.1.0 本篇是 Windows系统编译Qt使用的kafka(librdkafka)系列中的其中一篇,编译librdkafka整体步骤大家可以参考: Windows系统编译Qt使用的kafka(librdkafka) 由于项目需要,使用kafka,故自己编译了一次,编译的过程,踩了太多的坑了,特写了本篇…...

DeepSeek 赋能数字孪生:重构虚实共生的智能未来图景
目录 一、数字孪生技术概述1.1 数字孪生的概念1.2 技术原理剖析1.3 应用领域与价值 二、DeepSeek 技术解读2.1 DeepSeek 的技术亮点2.2 与其他模型的对比优势 三、DeepSeek 赋能数字孪生3.1 高精度建模助力3.2 实时数据处理与分析3.3 智能分析与预测 四、实际案例解析4.1 垃圾焚…...

谷歌前CEO TED演讲解析:AI 红利的三年窗口期与行业重构
谷歌前CEO埃里克施密特在2025年TED演讲中提出的"AI红利仅剩3年窗口期"观点,揭示了AI技术从算力、需求到监管的全局性变革。以下是基于演讲内容及关联数据的深度分析: 谷歌前CEO TED演讲解析:AI红利的三年窗口期与行业重构 一、算…...

数据仓库面试题合集②】ETL 设计与调度策略详解
📌 面试官为什么爱问 ETL 与调度? ETL 与调度是数据链路的“输血管道”,它的设计直接决定了数据处理的稳定性、扩展性与时效性。面试中此类问题侧重考察: 数据流设计是否合理 对任务依赖与失败容错的认知 是否具备复杂调度 DAG 设计经验 是否理解增量/全量策略、分区机制…...

前端入职总结
负责的工作内容,遇到的问题,怎么解决, 技能组溢出 问题一:溢入溢出bug 互斥实现的核心逻辑 状态管理: selectedOverflowGroups:存储当前选中的溢出技能组ID(数字字符串数组) sel…...

易境通海外仓系统:一件代发全场景数字化解决方案
随着全球经济一体化和消费升级,一件代发业务的跨境电商市场规模持续增长。然而,一件代发的跨境运营也面临挑战,传统海外仓管理模式更因效率低下、协同困难成为业务扩张的瓶颈。 一、一件代发跨境运营痛点 1、多平台协同:卖家往往…...

C#接口的setter或getter的访问性限制
有时候只想对外提供getter,但是属性的赋值又必须是setter,此时,可以限制setter的访问性。例如,假设有一个自定义字典(MyDict)属性,该属性我只希望外部能够访问,但是设置必须在内部,则可提供如下…...
)
云计算与大数据进阶 | 26、解锁云架构核心:深度解析可扩展数据库的5大策略与挑战(下)
在数据库的世界里,面对数据如潮水般的增长难题,聪明的工程师早已准备了五大扩展方案来应对,它们就像五把钥匙,以破解着不同场景下的性能困局。 上回书云计算与大数据进阶 | 26、解锁云架构核心:深度解析可扩展数据库的…...

SID 2025上的天马,用“好屏”技术重构产业叙事
作为全球最具影响力的显示行业盛会,SID国际显示周不仅是技术比拼的舞台,更是未来产业方向的风向标。SID 2025上的技术密度与产业动态,再一次验证了这一定律。 Micro-LED、柔性OLED、裸眼3D、量子点、透明显示等新技术在SID 2025集中亮相&…...

深入理解 Hadoop 核心组件 Yarn:架构、配置与实战
一、Hadoop 三大件概述 Hadoop 作为大数据领域的基石,其核心由三大组件构成: HDFS(分布式文件系统):负责海量数据的分布式存储,通过数据分块和副本机制保障可靠性,是大数据存储的基础设施。 …...
)
Linux云计算训练营笔记day11(Linux CentOS7)
Linux云计算 云计算是一种服务,是通过互联网按需提供计算资源的服务模式 程序员写代码的,部署上线项目 买服务器(一台24小时不关机的电脑,为客户端提供服务) 20万 买更多的服务器 Linux(命令) windows(图形化) 就业岗位: 云计算工程师 li…...

2025年AI与网络安全的终极博弈:冲击、重构与生存法则
引言 2025年,生成式AI的推理速度突破每秒千万次,网络安全行业正经历前所未有的范式革命。攻击者用AI批量生成恶意代码,防御者用AI构建智能护盾,这场技术军备竞赛正重塑行业规则——60%的传统安全岗位面临转型,70%的防…...

Hadoop中 8020、9000、50070 端口用途的详细对比
Hadoop 端口用途对比教程 1. 端口用途总览 Hadoop 的核心服务(如 NameNode、DataNode、ResourceManager 等)通过不同的端口对外提供服务。不同版本中,部分端口号可能发生变化,尤其是 Hadoop 3.x 对部分默认端口进行了调整。 端口Hadoop 2.x (2.7.7)Hadoop 3.x (3.1.3)协议…...