嵌入式学习笔记DAY23(树,哈希表)
一、树
1.树的概念
之前我们一直在谈的是一对一的线性结构,现实中,还存在很多一对多的情况需要处理,一对多的线性结构——树。

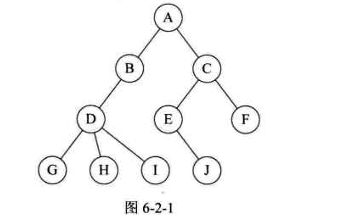
树的结点包括一个数据元素及若干指向其子树的分支,结点拥有的子树数称为结点的度。度为0的结点称为叶结点或者终端结点;度不为0的结点称为非终端结点或者分支节点。除根节点外,分支节点也称为内部节点树的度是树内各节点的度的最大值。

结点的关系:结点的子树的根称为该结点的孩子,相应地,该结点称为孩子的双亲。
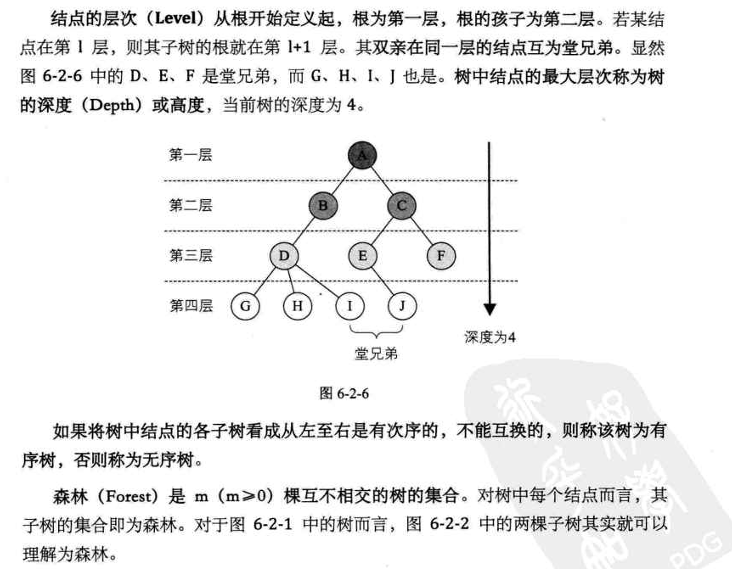
结点的层次:
2. 二叉树

二叉树的特点:
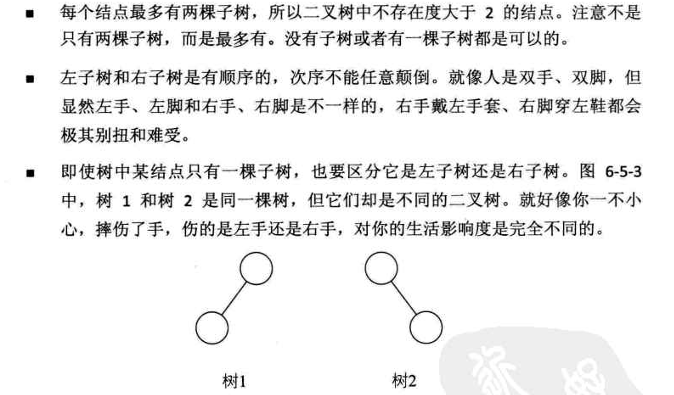
3. 特殊二叉树
- 斜树
- 满二叉树
- 完全二叉树

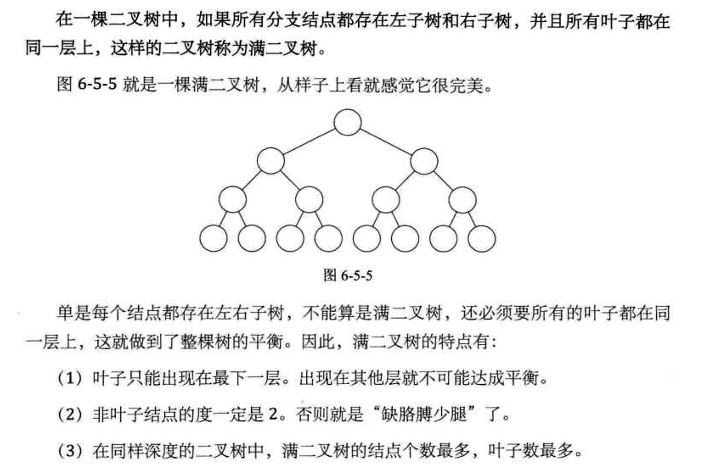
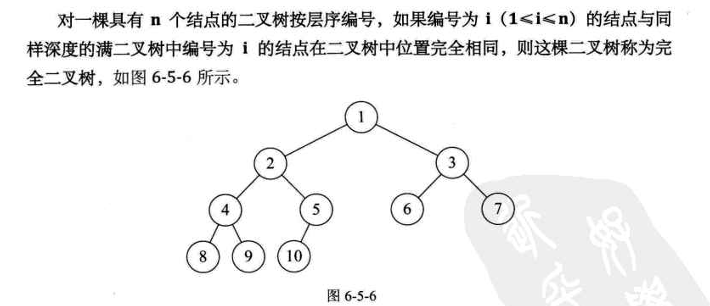
4. 树的存储结构
二叉树每个结点最多有两个孩子,所以为它设计一个数据域和两个指针域,我们称这样的链表叫做二叉链表:
![]()
其中data是数据域,Ichild和rchild都是指针域,分别存放指向左孩子和右孩子的指针。
5.树的基本操作
- 树的结构定义
typedef char DATATYPE; // 定义树节点存储的数据类型为字符
typedef struct _tree_node_
{DATATYPE data; // 节点存储的数据struct _tree_node_ *left, *right; // 左右子树指针
} TreeNode; // 二叉树节点结构// 创建二叉树(双星指针用于修改外部指针的值)
char data[]="abd#f###c#eg###"; // 带空节点标记的先序遍历序列
int ind = 0; // 全局索引,用于遍历数据数组
- 创建树
void CreateTree(TreeNode** root)
{char c = data[ind++]; // 读取当前字符并移动索引if('#' == c) // '#'表示空节点{*root = NULL; // 当前节点置空return;}else{*root = malloc(sizeof(TreeNode)); // 创建新节点if(NULL == *root){fprintf(stderr, "CreateTree malloc error");return;}(*root)->data = c; // 设置节点数据CreateTree(&(*root)->left); // 递归创建左子树CreateTree(&(*root)->right); // 递归创建右子树}
}- 树的三种遍历方式
// 前序遍历(根-左-右)
void PreOrderTraverse(TreeNode* root)
{if(NULL == root) // 空节点直接返回{return;}printf("%c", root->data); // 访问根节点PreOrderTraverse(root->left); // 递归遍历左子树PreOrderTraverse(root->right); // 递归遍历右子树
}
// 中序遍历(左-根-右)
void InOrderTraverse(TreeNode* root)
{if (root == NULL) return;InOrderTraverse(root->left);printf("%c", root->data);InOrderTraverse(root->right);
}// 后序遍历(左-右-根)
void PostOrderTraverse(TreeNode* root)
{if (root == NULL) return;PostOrderTraverse(root->left);PostOrderTraverse(root->right);printf("%c", root->data);
}
- 树的销毁
void DestroyTree(TreeNode* root)
{if (root == NULL) {return;}DestroyTree(root->left);DestroyTree(root->right);free(root);
}二、哈希表

关键逻辑说明(除留取余法):
哈希函数与冲突处理:
- 使用简单的取模运算作为哈希函数,可能导致较多冲突(如 12 和 24 对 12 取模均为 0)。
- 采用线性探测法处理冲突:当槽位被占时,依次尝试下一个槽位(
ind = (ind + 1) % tlen)。插入流程:
- 插入数据时,若遇到冲突(槽位非 - 1),持续探测直到找到空槽位(值为 - 1)。
- 示例中输出冲突信息,可观察线性探测过程(如 67%12=7,若槽位 7 被占,尝试 8、9...)。
查找流程:
- 从初始哈希值开始探测,若未找到则按顺序查找下一个槽位。
- 通过记录初始索引
old_ind,避免在满表时陷入无限循环。内存管理:
- 示例中未释放哈希表内存,实际使用中需在程序结束前调用
free释放hs->head和hs,避免内存泄漏。示例输出与分析
假设插入数据
array时的冲突过程如下(以 12 和 67 为例):
- 12%12=0:槽位 0 为空,直接插入。
- 67%12=7:槽位 7 为空,直接插入。
- 56%12=8:槽位 8 为空,直接插入。
- 16%12=4:槽位 4 为空,直接插入。
- 25%12=1:槽位 1 为空,直接插入。
- 37%12=1:槽位 1 已被 25 占用,探测 2→空,插入槽位 2。
- ...(其他数据类似,可能产生多次冲突)
查找 37 时,计算哈希值 1→探测 2,找到数据,返回槽位 2。
#include <stdio.h> // 标准输入输出
#include <stdlib.h> // 内存分配函数(malloc/free)
#include <string.h> // 字符串处理(此处未用到,但保留可能的扩展需求)// 定义数据类型别名(当前为整数,可修改为其他类型)
typedef int DATATYPE;// 哈希表结构体定义
typedef struct {DATATYPE* head; /**< 指向哈希表数组的指针,存储数据 */int tlen; /**< 哈希表的长度(数组大小) */
} HSTable;/*** @brief 创建哈希表并初始化* @param len 哈希表的长度(数组大小)* @return HSTable* 指向新创建的哈希表的指针,失败时返回NULL* @note 哈希表数组元素初始化为-1(假设-1表示空槽位)*/
HSTable* CreateHsTable(int len) {// 1. 分配哈希表结构体内存HSTable* hs = malloc(sizeof(HSTable));if (NULL == hs) {// 内存分配失败,输出错误信息到标准错误流fprintf(stderr, "CreateHsTable: 分配结构体内存失败\n");return NULL;}// 2. 分配哈希表数据数组内存hs->head = malloc(sizeof(DATATYPE) * len);if (NULL == hs->head) {// 数据数组分配失败,释放已分配的结构体内存fprintf(stderr, "CreateHsTable: 分配数据数组内存失败\n");free(hs); // 避免内存泄漏return NULL;}// 3. 初始化哈希表数组:所有槽位标记为-1(空)hs->tlen = len;int i = 0;for (i = 0; i < len; i++) {hs->head[i] = -1;}return hs;
}
/*** @brief 哈希函数:计算数据的哈希值(取模运算)* @param hs 哈希表指针(用于获取表长度)* @param data 待计算的数据源指针* @return int 哈希值(即数组索引)* @note 直接使用数据值对表长取模,简单但可能导致较多冲突*/
int HSFun(HSTable* hs, DATATYPE* data) {return *data % hs->tlen; // 例如:数据12对12取模得到0
}/*** @brief 向哈希表中插入数据(开放寻址法处理冲突,线性探测)* @param hs 哈希表指针* @param data 待插入的数据指针* @return int 0表示成功,其他值可扩展为错误码* @note 当槽位被占用时,逐个探测下一个槽位(线性探测)*/
int HSInsert(HSTable* hs, DATATYPE* data) {// 1. 计算初始哈希值int ind = HSFun(hs, data);// 2. 线性探测寻找空槽位while (hs->head[ind] != -1) {// 输出冲突信息(调试用)printf("冲突:位置 %d 已被占用,数据 %d 尝试下一个位置\n", ind, *data);// 移动到下一个槽位(取模实现循环探测)ind = (ind + 1) % hs->tlen;}// 3. 插入数据到空槽位hs->head[ind] = *data;return 0;
}/*** @brief 在哈希表中查找数据* @param hs 哈希表指针* @param data 待查找的数据指针* @return int 找到时返回数据所在槽位索引,-1表示未找到* @note 使用线性探测法遍历可能的槽位,避免陷入死循环*/
int HsSearch(HSTable* hs, DATATYPE* data) {// 1. 计算初始哈希值int ind = HSFun(hs, data);// 记录初始索引,用于判断是否绕表一周(避免死循环)int old_ind = ind;// 2. 线性探测查找数据while (hs->head[ind] != *data) {// 移动到下一个槽位ind = (ind + 1) % hs->tlen;// 若回到初始索引,说明未找到if (old_ind == ind) {return -1;}}return ind; // 返回找到的槽位索引
}int main(int argc, char** argv) {// 1. 创建长度为12的哈希表HSTable* hs = CreateHsTable(12);if (hs == NULL) {return 1; // 创建失败,退出程序}// 2. 测试数据数组int array[] = {12, 67, 56, 16, 25, 37, 22, 29, 15, 47, 48, 34};int i = 0;int array_len = sizeof(array) / sizeof(array[0]); // 计算数组长度(12)// 3. 插入数据到哈希表for (i = 0; i < array_len; i++) {HSInsert(hs, &array[i]);}// 4. 查找数据37int want_num = 37;int ret = HsSearch(hs, &want_num);// 5. 输出查找结果if (-1 == ret) {printf("未找到数据 %d\n", want_num);} else {printf("找到数据 %d,位于槽位 %d\n", hs->head[ret], ret);}// 6. 释放哈希表内存(示例中未实现,实际需添加)// free(hs->head);// free(hs);return 0;
}三、内核链表
1、Linux内核链表是一种数据结构,它在Linux内核编程中广泛使用,用于管理各种类
型的数据元素。链表由一系列节点组成,每个节点包含指向下一个节点和前一个节点的
指针。这种设计使得链表在插入和删除操作时非常高效,因为不需要移动其他元素。
2、链表的定义和初始化
(1)在Linux内核中,链表通过包含list_head结构体的方式在各种数据结构中实现。
(2)list_head结构体定义在<linux/list.h>头文件中,包含next和prev两个指针,分别指
向链表的下一个和前一个元素。要使用内核链表,首先需要包含这个头文件。
(3)初始化链表时,可以使用INIT_LIST_HEAD宏,它将链表的next和prev指针都指向
链表本身,形成一个循环链表。
内核链表是双向循环链表:
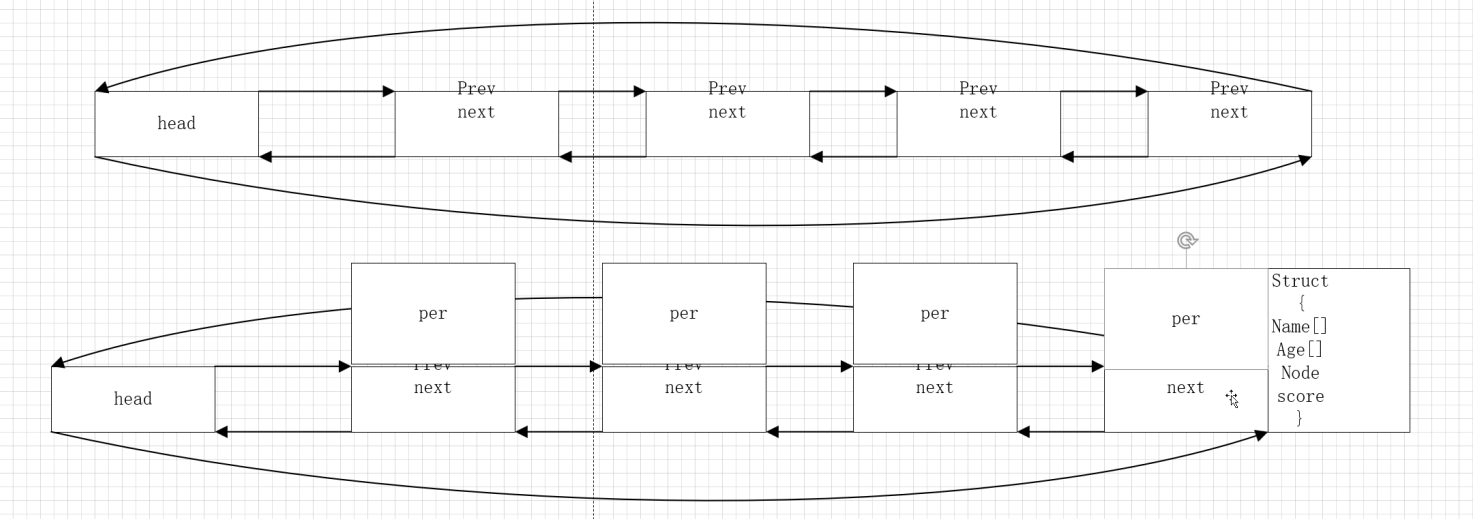
注:内部增删改查已经写好,将需要的内容组合到结构体中即可使用
(可通过www.kernel.org去下载内核)
3、内核链表的思想:普通链表与数据耦合性高,自己定义结构体,将数据放入;
(1)offset宏:传入结构体,成员,通过宏进入,计算node的偏移量是多少;
(2)contrainof宏:返回该类型指针的地址。
4、内核链表提供了一系列宏和函数来进行操作,如添加、删除和遍历节点:
(1)添加节点:使用list_add或list_add_tail函数可以在链表的头部或尾部添加新节点。
(2)删除节点:使用list_del函数可以从链表中删除节点。
(3)遍历链表:使用list_for_each或list_for_each_entry宏可以遍历链表中的每个元素。
5、注意事项在:使用内核链表时,需要注意几个重要的点:
(1)内存管理:当添加新节点到链表时,需要确保为节点分配了内存。同样,从链表
中删除节点时,需要释放节点占用的内存。
(2)同步:在多线程环境中操作链表时,可能需要使用锁来避免竞态条件。
(3)性能:虽然链表在插入和删除操作时非常高效,但在查找元素时可能需要遍历整
个链表,这可能会影响性能。
相关文章:
)
嵌入式学习笔记DAY23(树,哈希表)
一、树 1.树的概念 之前我们一直在谈的是一对一的线性结构,现实中,还存在很多一对多的情况需要处理,一对多的线性结构——树。 树的结点包括一个数据元素及若干指向其子树的分支,结点拥有的子树数称为结点的度。度为0的结点称为叶…...
大总结)
操作系统————五种页面置换算法(OPT,FIFO,LRU,NRU,加强版NRU)大总结
❤️❤️❤️算法1:最佳置换算法(OPT) 算法思想: 值得注意的是这是一种理想型算法,实际上并不可能实现,读者需要注意 下面我们来解析一下它的原理: 我们假设有三个内存块,对于页面…...
 线性表)
数据结构(二) 线性表
一. 线性表 1.定义 线性表是由n(n>0)个具有相同数据类型的数据元素构成的有限序列。其中,元素之间通过顺序关系排列,每个元素有且只有一个直接前驱和一个直接后继(除首尾元素外) 二.线性表的顺序表示(顺序表) 1.存储方式 使用连续的内存空间(数组)存储…...

TS04:高性能四通道自动灵敏度校准电容触摸传感器
在现代电子设备中,电容触摸传感器的应用越来越广泛,而高性能的传感器芯片是实现良好用户体验的关键。 TS04 四通道电容触摸传感器,凭借其自动灵敏度校准功能和多种特性,成为理想的解决方案。本文将简要介绍 TS04 的主要特性、功能…...

鸿蒙 系统-安全-程序访问控制-应用权限管控
Ability Kit 提供了一种允许应用访问系统资源(如:通讯录等)和系统能力(如:访问摄像头、麦克风等)的通用权限访问方式,来保护系统数据(包括用户个人数据)或功能࿰…...

ArcGIS Pro 3.4 二次开发 - 框架
环境:ArcGIS Pro SDK 3.4 .NET 8 文章目录 框架1 框架1.1 如何在 DockPane 可见或隐藏时订阅和取消订阅事件1.2 执行命令1.3 设置当前工具1.4 激活选项卡1.5 激活/停用状态 - 修改条件1.6 判断应用程序是否繁忙1.7 获取应用程序主窗口1.8 关闭 ArcGIS Pro1.9 获取 …...

打破传统仓库管理困局:WMS如何重构出入库全流程
引言 在制造业与零售业高速发展的今天,仓库管理仍普遍面临效率低、错发漏发频发、库存数据滞后等痛点。人工登记导致30%的错单率,货位混乱让拣货耗时增加50%,而账实不符引发的二次采购成本更吞噬着企业利润。如何突破传统管理桎梏࿱…...

npm 安装时 SSL 证书过期问题笔记
问题描述: npm error code CERT_HAS_EXPIRED npm error errno CERT_HAS_EXPIRED npm error request to https://registry.npm.taobao.org/axios failed, reason: certificate has expired 这表明当前配置的 npm 镜像源(淘宝镜像 https://registry.npm.taobao.org&…...

【大数据】MapReduce 编程-- PageRank--网页排名算法,用于衡量网页“重要性”-排序网页
PageRank 是 Google 创始人拉里佩奇(Larry Page)和谢尔盖布林(Sergey Brin)在 1998 年提出的一种网页排名算法,用于衡量网页“重要性”的一种方式。它是搜索引擎中用于排序网页的一种基础算法 一个网页越是被其他重要…...

Craw4AI:LLM友好的网页爬虫
GitHub:https://github.com/unclecode/crawl4ai 更多AI开源软件:发现分享好用的AI工具、AI开源软件、AI模型、AI变现 - 小众AI Crawl4AI旨在让网页爬取和数据提取变得简单而高效。无论构建复杂的 AI 应用程序还是增强大语言模型,Crawl4AI 都能…...

idea 安装飞算-javaAI 插件使用
文章目录 前言idea 安装飞算-javaAI 插件使用1. 介绍一下飞算-AI2. 安装使用 前言 如果您觉得有用的话,记得给博主点个赞,评论,收藏一键三连啊,写作不易啊^ _ ^。 而且听说点赞的人每天的运气都不会太差,实在白嫖的…...

Lombok
Lombok Lombok 是一个 Java 库,通过注解自动生成样板代码(如 Getter/Setter、构造函数等),从而简化开发。在你提供的代码中,AllArgsConstructor 就是一个 Lombok 注解。以下是 Lombok 常用注解及其作用的详细说明&…...

起点与破圈
写了多年代码,我为什么开始转向算法,直到如今投身于大模型领域? 作为一名拥有 10 年经验的开发者,我的职业路径几乎覆盖了技术发展的多个阶段。从最早使用 Flask/Django 开发网站,到后来构建大数据系统、设计服务器架…...

基于AI的Web数据管道,使用n8n、Scrapeless和Claude
引言 在当今数据驱动的环境中,组织需要高效的方法来提取、处理和分析网络内容。传统的网络抓取面临着诸多挑战:反机器人保护、复杂的JavaScript渲染以及持续的维护需求。此外,理解非结构化的网络数据则需要复杂的处理能力。 本指南演示了如…...

7GB显存如何部署bf16精度的DeepSeek-R1 70B大模型?
构建RAG混合开发---PythonAIJavaEEVue.js前端的实践-CSDN博客 服务容错治理框架resilience4j&sentinel基础应用---微服务的限流/熔断/降级解决方案-CSDN博客 conda管理python环境-CSDN博客 快速搭建对象存储服务 - Minio,并解决临时地址暴露ip、短链接请求改…...
)
初识函数------了解函数的定义、函数的参数、函数的返回值、说明文档的书写、函数的嵌套使用、变量的作用域(全局变量与局部变量)
文章目录 一、什么是函数?二、函数定义与调用2.1 基本语法2.2 示例演示 三、函数参数详解3.1 位置参数3.2 默认参数3.3 可变参数3.4 关键字参数 四、返回值与文档说明4.1 返回多个值4.2 编写文档字符串 五、函数嵌套与作用域5.1 嵌套函数示例5.2 变量作用域5.3 glob…...
)
Java常见API文档(下)
格式化的时间形式的常用模式对应关系如下: 空参构造创造simdateformate对象,默认格式 练习.按照指定格式展示 package kl002;import java.text.ParseException; import java.text.SimpleDateFormat; import java.util.Date;public class Date3 {publi…...

ubuntu 20.04 ping baidu.coom可以通,ping www.baidu.com不通 【DNS出现问题】解决方案
ping baidu.coom可以通,ping www.baidu.com不通【DNS出现问题】解决方案 检查IPV6是否有问题 # 1. 检查 IPv6 地址,记住网络接口的名称 ip -6 addr show# 2. 测试本地 IPv6,eth0换成自己的网络接口名称 ping6 ff02::1%eth0# 3. 检查路由 ip…...

Oracle 中 open_cursors 参数详解:原理、配置与性能测试
#Oracle #参数 # open_cursors #ORA-01000 在 Oracle 数据库的众多参数中,open_cursors是一个对应用程序性能和资源管理有着重要影响的参数。它直接关系到数据库与应用程序之间游标资源的使用与分配,合理配置open_cursors参数,能够避免应用程…...

线程调度与单例模式:wait、notify与懒汉模式解析
一.wait 和 notify(等待 和 通知) 引入 wait notify 就是为了能够从应用层面,干预到多个不同线程代码的执行顺序,可以让后执行的线程主动放弃被调度的机会,等先执行的线程完成后通知放弃调度的线程重新执行。 自助取…...
:LangChain向量存储)
AGI大模型(27):LangChain向量存储
1 安装依赖 使用一个简单的本地向量存储 FAISS,首先需要安装它 pip install faiss-cpu -i https://pypi.tuna.tsinghua.edu.cn/simple pip install langchain_community==0.3.7 -i https://pypi.tuna.tsinghua.edu.cn/simple 由于演示过程中用到了爬虫,需要安装依赖库,如…...

Qwen3 - 0.6B与Bert文本分类实验:深度见解与性能剖析
Changelog [25/04/28] 新增Qwen3-0.6B在Ag_news数据集Zero-Shot的效果。新增Qwen3-0.6B线性层分类方法的效果。调整Bert训练参数(epoch、eval_steps),以实现更细致的观察,避免严重过拟合的情况。 TODO: 利用Qwen3-0.6…...

Oracle 的 PGA_AGGREGATE_LIMIT 参数
Oracle 的 PGA_AGGREGATE_LIMIT 参数 基本概念 PGA_AGGREGATE_LIMIT 是 Oracle 数据库 12c 引入的一个重要内存管理参数,用于限制所有服务器进程使用的 PGA(Program Global Area)内存总量。 参数作用 硬性限制:设置 PGA 内存使…...

# idea 中如何将 java 项目打包成 jar 包?
idea 中如何将 java 项目打包成 jar 包? 例如如何将项目dzs168-dashboard-generate打包成 dzs168-dashboard-generate.jar 1、打开项目结构 Project Structure 在IDEA的顶部菜单栏中选择【File】,然后选择【Project Structure】(或者使用快…...
深度解析)
JVM(Java 虚拟机)深度解析
JVM(Java 虚拟机)深度解析 作为 Java 生态系统的核心,JVM(Java Virtual Machine)是 Java 语言 "一次编写,到处运行" 的关键。它不仅是 Java 程序的运行环境,更是一个复杂的系统软件&…...
:拼数)
算法题(150):拼数
审题: 本题需要我们将数组中的数据经过排序,使得他们拼接后得到的数是所有拼接方案中最大的 思路: 方法一:排序贪心 贪心策略1:直接排序 如果我们直接按照数组数据的字典序进行排序,会导致部分情况出错 eg&…...

怎么样进行定性分析
本文章将教会你如何对实验结果进行定性分析,其需要一定的论文基础,文末有论文撰写小技巧,不想看基础原理的人可以直接调到文章末尾。 一、什么是定性分析 定性分析是一种在众多领域广泛应用的研究方法,它致力于对事物的性质、特…...

RLᵛ_ Better Test-Time Scaling by Unifying LLM Reasoners With Verifiers
RLᵛ: Better Test-Time Scaling by Unifying LLM Reasoners With Verifiers 在人工智能领域,大语言模型(LLM)的推理能力提升一直是研究热点。今天要解读的论文提出了一种全新的强化学习框架RLᵛ,通过融合推理与验证能力…...
)
关于百度地图JSAPI自定义标注的图标显示不完整的问题(其实只是因为图片尺寸问题)
下载了几个阿里矢量图标库里的图标作为百度地图的自定义图标,结果百度地图显示的图标一直不完整。下载的PNG图标已经被正常引入到前端代码,anchor也设置为了图标底部中心,结果还是显示不完整。 if (iconUrl) {const icon new mapClass.Icon(…...

海思22AP70集超强算力、4K60编解码与多元特性于一体的智能SoC可替代3559V200、3516AV300、3556A
嘿,朋友们!在这个对视觉效果有着极致追求的时代,海思半导体带着满满的诚意,为大家呈上一款堪称惊艳的专业超高清智能网络录像机SoC——22AP70,它就像一颗闪耀的科技新星,即将在各个领域掀起一场视觉革命&am…...

网络协议之一根网线就能连接两台电脑?
写在前面 ~~~~ 如果有两台电脑,通过一根网线可以实现网络互通吗?三台电脑呢?N台电脑呢?本文就以此作为主线来看下吧! 1:正文 ~~~~ 如标题,一根网线就能连接两台电脑?答案是肯定的&a…...

为 Windows 和 Ubuntu 中设定代理服务器的详细方法
有时下载大模型总是下载不出来,要配置代理才行 一、Windows代理设置 ① 系统全局代理设置 打开【设置】→【网络和Internet】→【代理】。 在【手动设置代理】下,打开开关,输入: 地址:10.10.10.215 端口:…...

cmd里可以使用npm,vscode里使用npm 报错
cmd里可以使用npm,vscode里使用npm 报错 报错提示原因解决方法 报错提示 npm : 无法加载文件 C:\Program Files\nodejs\npm.ps1,因为在此系 统上禁止运行脚本。有关详细信息,请参阅 https:/go.microsoft.com/ fwlink/?LinkID135170 中的 about_Executi…...

MySQL数据库基础 -- SQL 语句的分类,存储引擎
目录 1. 什么是数据库 2. 基本使用 2.1 进入 mysql 2.2 服务器、数据库以及表的关系 2.3 使用案例 2.4 数据逻辑存储 3. SQL 语句分类 4. 存储引擎 4.1 查看存储引擎 4.2 存储引擎的对比 1. 什么是数据库 安装完 MySQL 之后,会有 mysql 和 mysqld。 MySQL …...

设置windows10同时多用户登录方法
RDP wrapper 的版本更新停止在2017年, 找到网上其它大神更新的软件, 参考:RDPWrap v1.8.9.9 (Windows家庭版开启远程桌面、Server解除远程数量限制) - 吾爱破解 - 52pojie.cn 我的需求是在离线环境中布置,方法是&…...

【hive】hive内存dump导出hprof文件
使用jmap -dump:live,formatb,file命令 hive-metastore-heap-eval.sh文件 # if want hiveserver2 ,should grep "org.apache.hive.service.server.HiveServer2" # get pid pidps -ef | grep "org.apache.hadoop.hive.metastore.HiveMetaStore" | grep &qu…...

专题讨论3:基于图的基本原理实现走迷宫问题
问题描述 迷宫通常以二维矩阵形式呈现,矩阵中的元素用 0 和 1 表示,其中 0 代表通路,1 代表墙壁 。存在特定的起点和终点坐标,目标是从起点出发,寻找一条能够到达终点的路径。 实现思路 将迷宫中的每个可通行单元格…...

Linux基础第四天
系统之间文件共享 想要实现两个不同的系统之间实现文件共享,最简单的一种方案就是设置VMware软件的共享文件夹,利用共享文件夹可以实现linux系统和windows系统之间的文件共享,这样就可以实现在windows系统上编辑程序,然后在linux系…...

eNSP中单臂路由器配置完整实验及命令解释
单臂路由器(Router on a Stick)是一种通过单个物理接口处理多个VLAN间路由的解决方案 单臂路由器通过以下方式工作: 交换机端口配置为Trunk模式,允许多个VLAN流量通过路由器子接口为每个VLAN创建虚拟接口每个子接口配置对应VLAN…...

TeaType 奶茶性格占卜机开发记录:一场俏皮的 UniApp 单页奇遇
我正在参加CodeBuddy「首席试玩官」内容创作大赛,本文所使用的 CodeBuddy 免费下载链接:腾讯云代码助手 CodeBuddy - AI 时代的智能编程伙伴 最近我突发奇想,想用 UniApp 做一个轻松又俏皮的小工具,叫做「TeaType 奶茶性格占卜机」…...

AI神经网络降噪 vs 传统单/双麦克风降噪的核心优势对比
1. 降噪原理的本质差异 对比维度传统单/双麦克风降噪AI神经网络降噪技术基础基于固定规则的信号处理(如谱减法、维纳滤波)基于深度学习的动态建模(DNN/CNN/Transformer)噪声样本依赖预设有限噪声类型训练数据覆盖数十万种真实环境…...

【Nginx学习笔记】:Fastapi服务部署单机Nginx配置说明
服务部署单机Nginx配置说明 服务.conf配置文件: upstream asr_backend {server 127.0.0.1:8010; }server {listen 80;server_name your_domain.com;location / {proxy_pass http://localhost:8000;proxy_set_header Host $host;proxy_set_header X-Real-IP $remot…...

JAVA Web 期末速成
一、专业术语及名词 1. Web 的特点 定义:web 是分布在全世界,基于 HTTP 通信协议,存储在 Web 服务器中的所有相互链接的超文本集 Web 是一种分布式超媒体系统Web 是多媒体化 和 易于导航的Web 与平台无关Web 是动态、交互的 2. TCP/IP 结…...

iOS:重新定义移动交互,引领智能生活新潮流
在当今智能手机与移动设备充斥的时代,操作系统作为其 “灵魂”,掌控着用户体验的方方面面。iOS 系统,这一由苹果公司精心雕琢的杰作,自诞生起便以独特魅力与卓越性能,在移动操作系统领域独树一帜,深刻影响着…...

LabVIEW数据库使用说明
介绍LabVIEW如何在数据库中插入记录以及执行 SQL 查询,适用于对数据库进行数据管理和操作的场景。借助 Database Connectivity Toolkit,可便捷地与指定数据库交互。 各 VI 功能详述 左侧 VI 功能概述:实现向数据库表中插入数据的操作。当输入…...

Linux多进程 写时拷贝 物理地址和逻辑地址
如果不采用写时拷贝技术 直接fork子进程 会发生什么? 如上图所示 橙色为父进程所占内存空间 绿色为子进程所占内存空间。 如果子进程只是需要做出一点点和父进程不一样的 其余和父进程均为相同 第一 就会出现复制开销比较大;第二占用内存空间 所以 …...

在 CentOS 7.9 上部署 node_exporter 并接入 Prometheus + Grafana 实现主机监控
文章目录 在 CentOS 7.9 上部署 node_exporter 并接入 Prometheus Grafana 实现主机监控环境说明node_exporter 安装与配置下载并解压 node_exporter创建 Systemd 启动服务验证服务状态验证端口监听 Prometheus 配置 node_exporter 监控项修改 prometheus.yml重新加载 Prometh…...
技术)
Java 反射(Reflection)技术
反射是 Java 提供的一种强大机制,允许程序在运行时(Runtime)动态地获取类的信息、操作类的属性和方法。这种能力使得 Java 程序可以突破编译时的限制,实现更灵活的设计。 一、反射的核心概念 1. 什么是反射 反射是指在程序运行…...
)
【SpringBoot】从零开始全面解析SpringMVC (三)
本篇博客给大家带来的是SpringBoot的知识点, 本篇是SpringBoot入门, 介绍SpringMVC相关知识. 🐎文章专栏: JavaEE进阶 🚀若有问题 评论区见 ❤ 欢迎大家点赞 评论 收藏 分享 如果你不知道分享给谁,那就分享给薯条. 你们的支持是我不断创作的动力 . 王子,…...

DeerFlow安装配置及使用案例
DeerFlow安装配置及使用案例 简介 DeerFlow项目由字节跳动技术团队发起和主导开发,作为一个开源深度研究框架,于2025年年初正式开源。该项目基于LangStack生态,构建于LangChain与LangGraph的开源技术栈之上,充分利用语言模型…...