Qwen3 - 0.6B与Bert文本分类实验:深度见解与性能剖析
Changelog
-
[25/04/28] 新增
Qwen3-0.6B在Ag_news数据集Zero-Shot的效果。新增Qwen3-0.6B线性层分类方法的效果。调整Bert训练参数(epoch、eval_steps),以实现更细致的观察,避免严重过拟合的情况。 -
TODO:
- 利用
Qwen3-0.6Bppl、zero-shot筛选难样本,观察Qwen3-0.6B(SFT分类)在不同数据量级,不同数据难度情况下的性能变化。 ppl筛选出的难样本对Qwen33-0.6B(SFT分类)Qwen3-0.6B(线性层分类)影响是否具有同质性。- 不同尺寸模型
Think与No Think状态下Zero-Shot能力变化。 - 使用大模型蒸馏
Think数据,观察Think和No Think模式下对Qwen3-0.6B(SFT分类)性能的影响。 - 测试其他难开源分类数据集(更多分类数、多语言、长样本)。
- 利用
前言
最近在知乎上刷到一个很有意思的提问Qwen3-0.6B这种小模型有什么实际意义和用途。查看了所有回答,有人提到小尺寸模型在边缘设备场景中的优势(低延迟)、也有人提出小模型只是为了开放给其他研究者验证scaling law(Qwen2.5系列丰富的模型尺寸为开源社区验证方法有效性提供了基础)、还有人说4B、7B的Few-Shot效果就已经很好了甚至直接调用更大的LLM也能很好的解决问题。让我比较感兴趣的是有大佬提出小模型在向量搜索、命名实体识别(NER)和文本分类领域中很能打,而另一个被拿来对比的就是Bert模型。在中文文本分类中,若对TextCNN、FastText效果不满意,可能会尝试Bert系列及其变种(RoBerta等)。但以中文语料为主的类Encoder-Only架构模型其实并不多(近期发布的ModernBERT,也是以英文和Code语料为主),中文文本分类还是大量使用bert-base-chinese为基础模型进行微调,而距Bert发布已经过去了6年。Decoder-Only架构的LLM能在文本分类中击败参数量更小的Bert吗?所以我准备做一个实验来验证一下。
不想看实验细节的,可以直接看最后的结论和实验局限性部分。
实验设置
- GPU:RTX 3090(24G)
- 模型配置:
| 模型 | 参数量 | 训练方式 |
|---|---|---|
| google-bert/bert-base-cased | 0.1B | 添加线性层,输出维度为分类数 |
| Qwen/Qwen3-0.6B | 0.6B | 构造Prompt,SFT |
- 数据集配置:fancyzhx/ag_news,分类数为4,分别为World(0)、Sports(1)、Business(2)、Sci/Tech(3)。训练样本数120000,测试样本数7600,样本数量绝对均衡。数据集展示:
{"text": "New iPad released Just like every other September, this one is no different. Apple is planning to release a bigger, heavier, fatter iPad that...""label": 3
}
- 选择该数据集是在
Paper with code的Text Classification类中看到的榜单,并且该数据集元素基本上不超过510个token(以Bert Tokenizer计算)。因为Bert的最大输入长度是510个token,超过会进行截断,保留前510个token,所以为了进行公平的比较,尽量避免截断。 - 因为是多分类任务,我们以模型在测试集上的F1指标为标准,F1值越高,模型效果越好。
Bert训练细节
Bert的训练比较简单,将文本使用Tokenizer转换成input_ids后,使用Trainer进行正常训练即可。训练参数(若未单独指出,则代表使用Trainer默认值):
| 参数名称 | 值 |
|---|---|
| lr_scheduler_type(学习率衰减策略) | cosine |
| learning_rate(学习率) | 1.0e-5 |
| per_device_train_batch_size(训练batch_size) | 64 |
| gradient_accumulation_steps(梯度累积) | 1 |
| per_device_eval_batch_size(验证batch_size) | 256 |
| num_train_epochs(epoch) | 3 |
| weight_decay | 1e-6 |
| eval_steps(验证频率) | 0.05 |
- 训练过程中模型对测试集的指标变化:
| Step | Training Loss | Validation Loss | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|---|---|
| 282 | 0.274700 | 0.263394 | 0.909737 | 0.910311 | 0.909737 | 0.909676 |
| 564 | 0.207800 | 0.222230 | 0.922237 | 0.922701 | 0.922237 | 0.922246 |
| 846 | 0.199600 | 0.204222 | 0.931579 | 0.932552 | 0.931579 | 0.931510 |
| 1128 | 0.215600 | 0.191824 | 0.934605 | 0.935274 | 0.934605 | 0.934737 |
| 1410 | 0.190500 | 0.192846 | 0.932763 | 0.934421 | 0.932763 | 0.932937 |
| 1692 | 0.193300 | 0.180665 | 0.937895 | 0.938941 | 0.937895 | 0.937849 |
| 1974 | 0.143000 | 0.180497 | 0.940526 | 0.940945 | 0.940526 | 0.940636 |
| 2256 | 0.141500 | 0.177630 | 0.941711 | 0.941988 | 0.941711 | 0.941644 |
| 2538 | 0.147100 | 0.173602 | 0.943947 | 0.944022 | 0.943947 | 0.943908 |
| 2820 | 0.131600 | 0.176895 | 0.940658 | 0.941790 | 0.940658 | 0.940683 |
| 3102 | 0.152800 | 0.170928 | 0.945000 | 0.945140 | 0.945000 | 0.944925 |
| 3384 | 0.140000 | 0.169215 | 0.944474 | 0.944766 | 0.944474 | 0.944399 |
| 3666 | 0.149900 | 0.168865 | 0.944474 | 0.944538 | 0.944474 | 0.944483 |
| 3948 | 0.112000 | 0.172459 | 0.946184 | 0.946142 | 0.946184 | 0.946159 |
| 4230 | 0.124000 | 0.172826 | 0.945000 | 0.945254 | 0.945000 | 0.944924 |
| 4512 | 0.122300 | 0.171583 | 0.944737 | 0.944925 | 0.944737 | 0.944708 |
| 4794 | 0.104400 | 0.171969 | 0.944868 | 0.945059 | 0.944868 | 0.944854 |
| 5076 | 0.117500 | 0.171504 | 0.945395 | 0.945502 | 0.945395 | 0.945363 |
| 5358 | 0.099800 | 0.171761 | 0.945263 | 0.945510 | 0.945263 | 0.945232 |
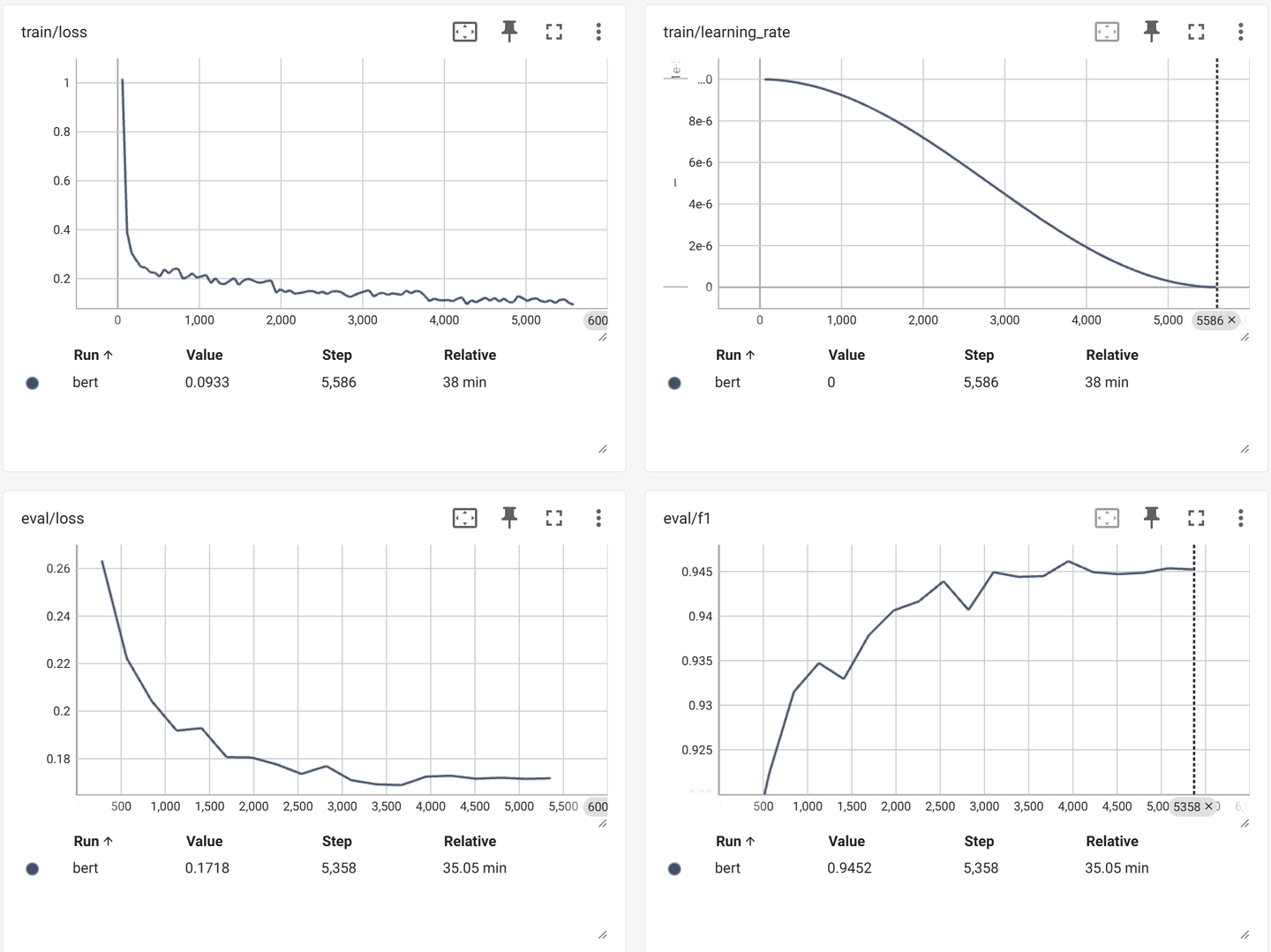
- 可以看到
Bert在测试集上最好结果是:0.945
Qwen3训练细节
- 使用
Qwen3训练文本分类模型有2种方法。第1种是修改模型架构,将模型最后一层替换为输出维度为分类数的线性层。第2种是构造Prompt,以选择题的方式创建问答对,然后进行SFT训练。
线性层分类
- 与微调Bert类似,将文本使用
Tokenizer转换成input_ids后,使用Trainer进行正常训练。训练参数(若未单独指出,则代表使用Trainer默认值):
| 参数名称 | 值 |
|---|---|
| lr_scheduler_type(学习率衰减策略) | cosine |
| learning_rate(学习率) | 1.0e-5 |
| per_device_train_batch_size(训练batch_size) | 8 |
| gradient_accumulation_steps(梯度累积) | 8 |
| per_device_eval_batch_size(验证batch_size) | 16 |
| num_train_epochs(epoch) | 1 |
| weight_decay | 1.0e-6 |
| eval_steps(验证频率) | 0.05 |
- 训练过程中模型对测试集的指标变化:
| Step | Training Loss | Validation Loss | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|---|---|
| 94 | 0.281800 | 0.243619 | 0.918158 | 0.918180 | 0.918158 | 0.917893 |
| 188 | 0.224100 | 0.220015 | 0.924211 | 0.925216 | 0.924211 | 0.924289 |
| 282 | 0.197700 | 0.236405 | 0.919211 | 0.920127 | 0.919211 | 0.919257 |
| 376 | 0.182800 | 0.243235 | 0.920132 | 0.925368 | 0.920132 | 0.919136 |
| 470 | 0.191500 | 0.207864 | 0.928289 | 0.929563 | 0.928289 | 0.928304 |
| 564 | 0.208400 | 0.192414 | 0.935658 | 0.935668 | 0.935658 | 0.935647 |
| 658 | 0.201900 | 0.191506 | 0.938553 | 0.938695 | 0.938553 | 0.938607 |
| 752 | 0.191900 | 0.179849 | 0.937500 | 0.937417 | 0.937500 | 0.937378 |
| 846 | 0.156100 | 0.177319 | 0.938684 | 0.938983 | 0.938684 | 0.938653 |
| 940 | 0.159900 | 0.177048 | 0.938289 | 0.939433 | 0.938289 | 0.938175 |
| 1034 | 0.159100 | 0.172280 | 0.943553 | 0.943725 | 0.943553 | 0.943455 |
| 1128 | 0.117000 | 0.168742 | 0.943026 | 0.942911 | 0.943026 | 0.942949 |
| 1222 | 0.151500 | 0.164628 | 0.943421 | 0.944371 | 0.943421 | 0.943503 |
| 1316 | 0.143600 | 0.158676 | 0.945921 | 0.946856 | 0.945921 | 0.945965 |
| 1410 | 0.183200 | 0.154356 | 0.946184 | 0.946708 | 0.946184 | 0.946221 |
| 1504 | 0.159400 | 0.153549 | 0.947763 | 0.947847 | 0.947763 | 0.947771 |
| 1598 | 0.147100 | 0.152530 | 0.948553 | 0.948609 | 0.948553 | 0.948539 |
| 1692 | 0.161400 | 0.151299 | 0.949079 | 0.949216 | 0.949079 | 0.949029 |
| 1786 | 0.150500 | 0.151270 | 0.948421 | 0.948572 | 0.948421 | 0.948363 |
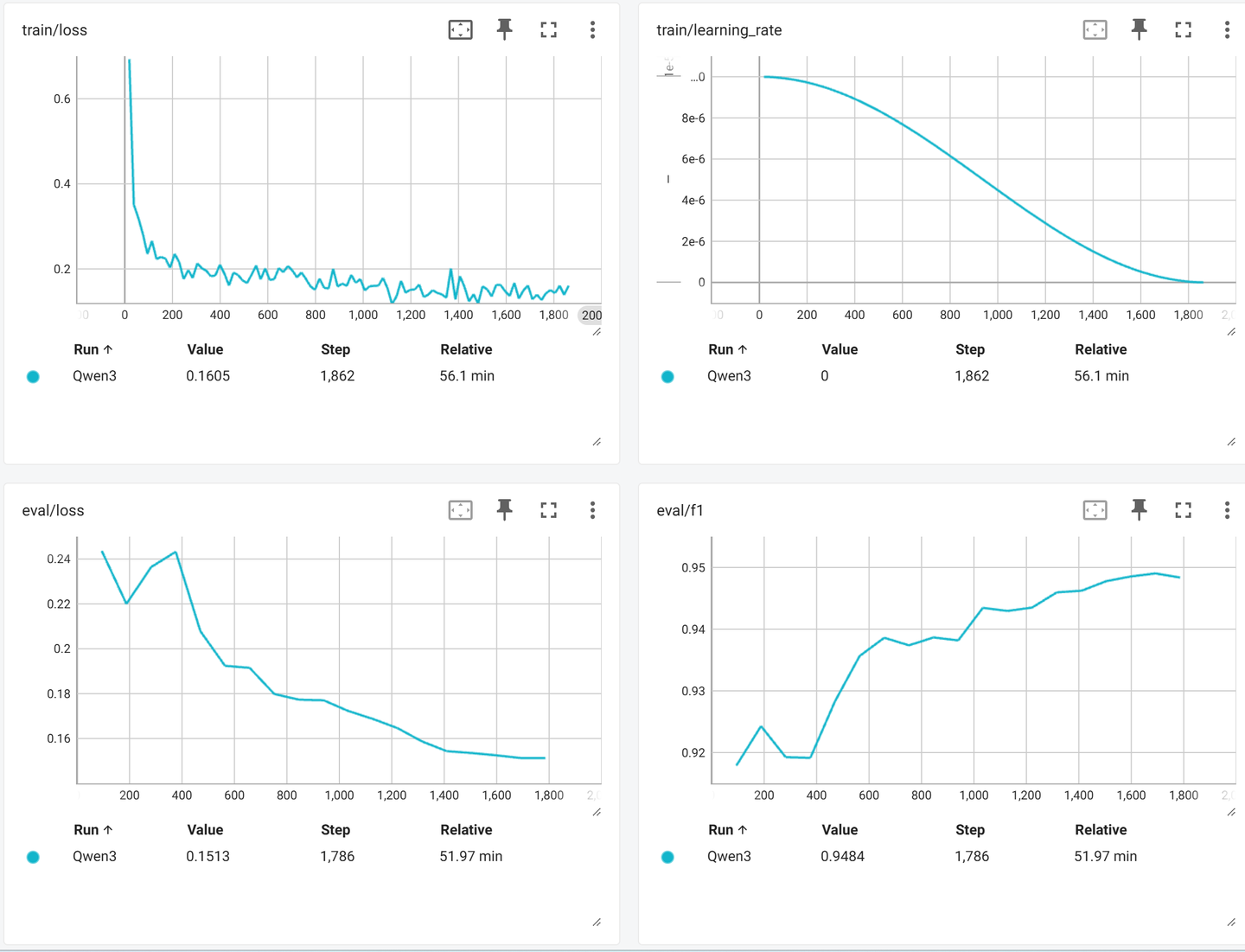
- 可以看到使用线性层分类的Qwen3-0.6B在测试集上最好结果是:0.949
SFT分类
- 我们先基于数据集写一个选择题形式的Prompt,Prompt模板为:
prompt = """Please read the following news article and determine its category from the options below.Article:
{news_article}Question: What is the most appropriate category for this news article?
A. World
B. Sports
C. Business
D. Science/TechnologyAnswer:/no_think"""answer = "<think>\n\n</think>\n\n{answer_text}"
news_article为新闻文本,answer_text表示标签。- 先测试一下Qwen3-0.6B在测试集上思考和非思考模式下的
zero-shot能力(准确率)。为获得稳定的结果,非思考模式使用手动拼接选项计算ppl,ppl最低的选项为模型答案。思考模式取<think>...</think>后的第一个选项。结果如下:
| 模型 | 思考 | 非思考 |
|---|---|---|
| Qwen3-0.6B | 0.7997 | 0.7898 |
- 训练框架使用
LLama Factory,Prompt模板与上文一致。 - 因为
Qwen3为混合推理模型,所以对非推理问答对要在模板最后加上/no_think标识符(以避免失去推理能力),并且回答要在前面加上<think>\n\n</think>\n\n。 - 按照LLama Factory SFT训练数据的格式要求组织数据,如:
{'instruction': "Please read the following news article and determine its category from the options below.\n\nArticle:\nWall St. Bears Claw Back Into the Black (Reuters) Reuters - Short-sellers, Wall Street's dwindling\\band of ultra-cynics, are seeing green again.\n\nQuestion: What is the most appropriate category for this news article?\nA. World\nB. Sports\nC. Business\nD. Science/Technology\n\nAnswer:/no_think",'output': '<think>\n\n</think>\n\nC'
}
- 训练参数配置文件:
### model
model_name_or_path: model/Qwen3-0.6B### method
stage: sft
do_train: true
finetuning_type: full### dataset
dataset: agnews_train
template: qwen3
cutoff_len: 512overwrite_cache: true
preprocessing_num_workers: 8### output
output_dir: Qwen3-0.6B-Agnews
save_strategy: steps
logging_strategy: steps
logging_steps: 0.01
save_steps: 0.2
plot_loss: true
report_to: tensorboard
overwrite_output_dir: true### train
per_device_train_batch_size: 12
gradient_accumulation_steps: 8
learning_rate: 1.2e-5
warmup_ratio: 0.01
num_train_epochs: 1
lr_scheduler_type: cosine
bf16: true
- 因为
Bert在训练2个epoch后就出现了严重的过拟合,所以对Qwen3模型,只训练1个epoch,每0.2个epoch保存一个检查点。 - 训练过程中模型对测试集的指标变化(训练结束后加载检查点对测试集进行推理,注意!为保证推理结果稳定,我们选择选项ppl低的作为预测结果):
| Step | Training Loss | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|---|
| 250 | 0.026 | 0.912 | 0.917 | 0.912 | 0.912 |
| 500 | 0.027 | 0.924 | 0.924 | 0.924 | 0.924 |
| 750 | 0.022 | 0.937 | 0.937 | 0.937 | 0.937 |
| 1000 | 0.022 | 0.941 | 0.941 | 0.941 | 0.941 |
| 1250 | 0.023 | 0.940 | 0.940 | 0.940 | 0.940 |
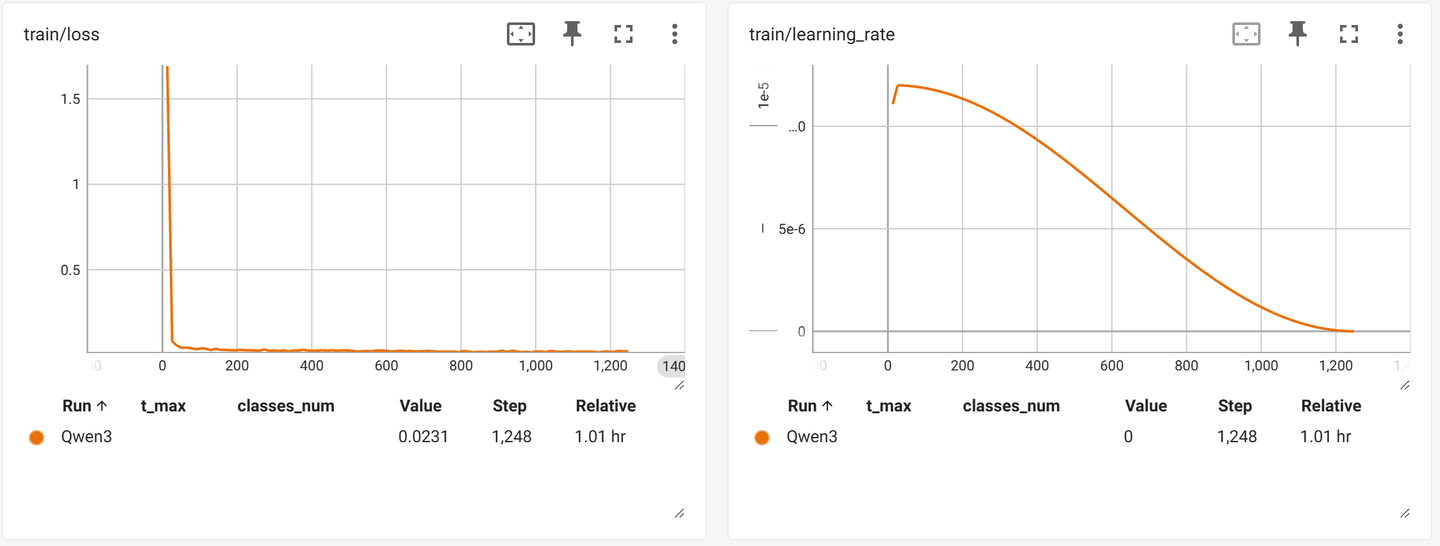
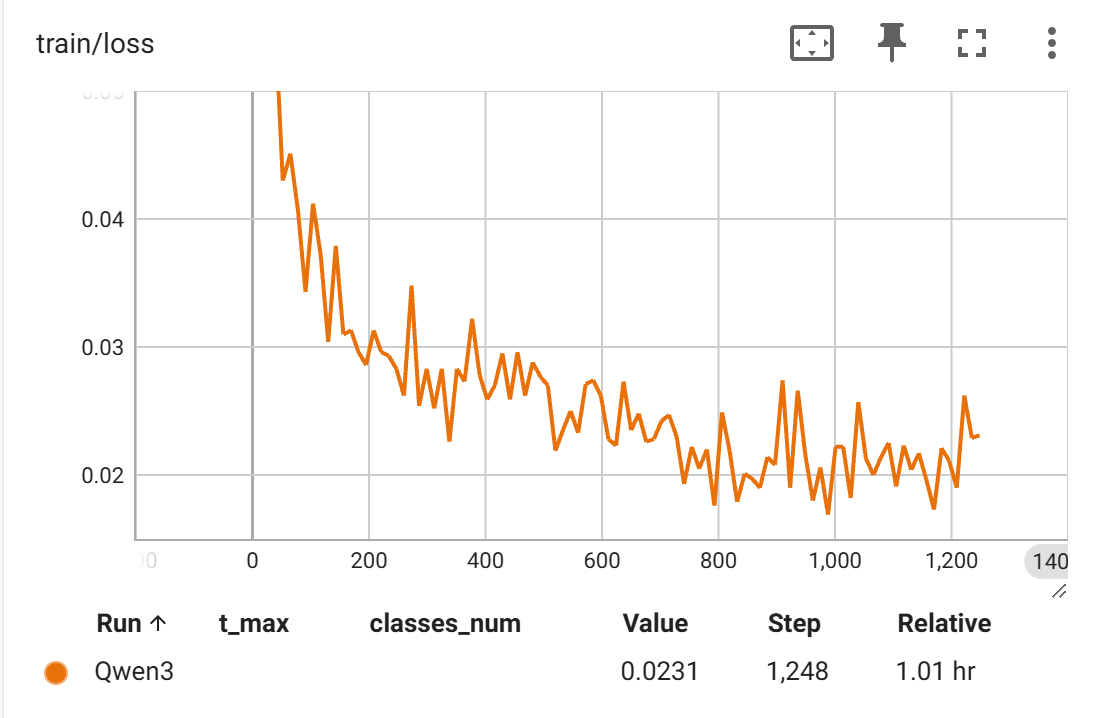
- 可以看到
Qwen3-0.6B模型Loss在一开始就急速下降,然后开始抖动的缓慢下降,如下图(纵轴范围调整0.05~0.015)。在测试集上最好结果是:0.941。
Bert和Qwen3-0.6B训练耗时
| 模型 | Epoch | 训练耗时 | 推理耗时 | 总耗时 |
|---|---|---|---|---|
| Bert | 3 | 35 min | - | 0.58 h |
| Qwen3-0.6B(线性层分类) | 1 | 52 min | - | 0.86 h |
| Qwen3-0.6B(SFT分类) | 1 | 62 min | 30 min | 1.5 h |
Bert和Qwen3-0.6B RPS测试
- 为测试
Bert和Qwen3-0.6B是否满足实时业务场景,对微调后的Bert和Qwen3-0.6B进行RPS测试,GPU为RTX 3090(24G):
| 模型 | 推理引擎 | 最大输出Token数 | RPS |
|---|---|---|---|
| Bert | HF | - | 60.3 |
| Qwen3-0.6B(SFT分类) | HF | 8 | 13.2 |
| Qwen3-0.6B(SFT分类) | VLLM | 8 | 27.1 |
| Qwen3-0.6B(线性层分类) | HF | - | 38.1 |
结论
- 在
Ag_new数据集上,各模型效果:Qwen3-0.6B(线性层分类)>Bert>Qwen3-0.6B(SFT分类)>Qwen3-0.6B(Think Zero-Shot)>Qwen3-0.6B(No Think Zero-Shot)。 - 各模型训练推理耗时:
Qwen3-0.6B(SFT分类)>Bert>Qwen3-0.6B(线性层分类)。 - 各模型
RPS:Bert>Qwen3-0.6B(线性层分类) >Qwen3-0.6B(SFT分类)。 Think模式下的Qwen3-0.6B比No Think模式下的Qwen3-0.6B准确率仅高出1%,推理时间比No Think慢20倍(HF推理引擎,Batch推理)。- 在训练
Qwen3-0.6B(线性层分类)时,Loss在前期有点抖动,或许微调一下学习率预热比率会对最终结果有微弱正向效果。
实验局限性
- 未实验在
Think模式下Qwen3-0.6B的效果(使用GRPO直接训练0.6B的模型估计是不太行的,可能还是先使用较大的模型蒸馏出Think数据,然后再进行SFT。或者先拿出一部分数据做SFT,然后再进行GRPO训练(冷启动))。 - 未考虑到长序列文本如
token数(以Bert Tokenizer为标准)超过1024的文本。 - 也许因为
AgNews分类任务比较简单,其实不管是Bert还是Qwen3-0.6B在F1超过0.94的情况下,都是可用的状态。Bert(F1:0.945)和Qwen3-0.6B线性层分类(F1:0.949)的差距并不明显。如果大家有更好的开源数据集可以用于测试,也欢迎提出。 - 未测试两模型在中文文本分类任务中的表现。
来源:https://zhuanlan.zhihu.com/p/1906768058745349565?share_code=KPTadtlbij0m&utm_psn=1907715099319312567
相关文章:

Qwen3 - 0.6B与Bert文本分类实验:深度见解与性能剖析
Changelog [25/04/28] 新增Qwen3-0.6B在Ag_news数据集Zero-Shot的效果。新增Qwen3-0.6B线性层分类方法的效果。调整Bert训练参数(epoch、eval_steps),以实现更细致的观察,避免严重过拟合的情况。 TODO: 利用Qwen3-0.6…...

Oracle 的 PGA_AGGREGATE_LIMIT 参数
Oracle 的 PGA_AGGREGATE_LIMIT 参数 基本概念 PGA_AGGREGATE_LIMIT 是 Oracle 数据库 12c 引入的一个重要内存管理参数,用于限制所有服务器进程使用的 PGA(Program Global Area)内存总量。 参数作用 硬性限制:设置 PGA 内存使…...

# idea 中如何将 java 项目打包成 jar 包?
idea 中如何将 java 项目打包成 jar 包? 例如如何将项目dzs168-dashboard-generate打包成 dzs168-dashboard-generate.jar 1、打开项目结构 Project Structure 在IDEA的顶部菜单栏中选择【File】,然后选择【Project Structure】(或者使用快…...
深度解析)
JVM(Java 虚拟机)深度解析
JVM(Java 虚拟机)深度解析 作为 Java 生态系统的核心,JVM(Java Virtual Machine)是 Java 语言 "一次编写,到处运行" 的关键。它不仅是 Java 程序的运行环境,更是一个复杂的系统软件&…...
:拼数)
算法题(150):拼数
审题: 本题需要我们将数组中的数据经过排序,使得他们拼接后得到的数是所有拼接方案中最大的 思路: 方法一:排序贪心 贪心策略1:直接排序 如果我们直接按照数组数据的字典序进行排序,会导致部分情况出错 eg&…...

怎么样进行定性分析
本文章将教会你如何对实验结果进行定性分析,其需要一定的论文基础,文末有论文撰写小技巧,不想看基础原理的人可以直接调到文章末尾。 一、什么是定性分析 定性分析是一种在众多领域广泛应用的研究方法,它致力于对事物的性质、特…...

RLᵛ_ Better Test-Time Scaling by Unifying LLM Reasoners With Verifiers
RLᵛ: Better Test-Time Scaling by Unifying LLM Reasoners With Verifiers 在人工智能领域,大语言模型(LLM)的推理能力提升一直是研究热点。今天要解读的论文提出了一种全新的强化学习框架RLᵛ,通过融合推理与验证能力…...
)
关于百度地图JSAPI自定义标注的图标显示不完整的问题(其实只是因为图片尺寸问题)
下载了几个阿里矢量图标库里的图标作为百度地图的自定义图标,结果百度地图显示的图标一直不完整。下载的PNG图标已经被正常引入到前端代码,anchor也设置为了图标底部中心,结果还是显示不完整。 if (iconUrl) {const icon new mapClass.Icon(…...

海思22AP70集超强算力、4K60编解码与多元特性于一体的智能SoC可替代3559V200、3516AV300、3556A
嘿,朋友们!在这个对视觉效果有着极致追求的时代,海思半导体带着满满的诚意,为大家呈上一款堪称惊艳的专业超高清智能网络录像机SoC——22AP70,它就像一颗闪耀的科技新星,即将在各个领域掀起一场视觉革命&am…...

网络协议之一根网线就能连接两台电脑?
写在前面 ~~~~ 如果有两台电脑,通过一根网线可以实现网络互通吗?三台电脑呢?N台电脑呢?本文就以此作为主线来看下吧! 1:正文 ~~~~ 如标题,一根网线就能连接两台电脑?答案是肯定的&a…...

为 Windows 和 Ubuntu 中设定代理服务器的详细方法
有时下载大模型总是下载不出来,要配置代理才行 一、Windows代理设置 ① 系统全局代理设置 打开【设置】→【网络和Internet】→【代理】。 在【手动设置代理】下,打开开关,输入: 地址:10.10.10.215 端口:…...

cmd里可以使用npm,vscode里使用npm 报错
cmd里可以使用npm,vscode里使用npm 报错 报错提示原因解决方法 报错提示 npm : 无法加载文件 C:\Program Files\nodejs\npm.ps1,因为在此系 统上禁止运行脚本。有关详细信息,请参阅 https:/go.microsoft.com/ fwlink/?LinkID135170 中的 about_Executi…...

MySQL数据库基础 -- SQL 语句的分类,存储引擎
目录 1. 什么是数据库 2. 基本使用 2.1 进入 mysql 2.2 服务器、数据库以及表的关系 2.3 使用案例 2.4 数据逻辑存储 3. SQL 语句分类 4. 存储引擎 4.1 查看存储引擎 4.2 存储引擎的对比 1. 什么是数据库 安装完 MySQL 之后,会有 mysql 和 mysqld。 MySQL …...

设置windows10同时多用户登录方法
RDP wrapper 的版本更新停止在2017年, 找到网上其它大神更新的软件, 参考:RDPWrap v1.8.9.9 (Windows家庭版开启远程桌面、Server解除远程数量限制) - 吾爱破解 - 52pojie.cn 我的需求是在离线环境中布置,方法是&…...

【hive】hive内存dump导出hprof文件
使用jmap -dump:live,formatb,file命令 hive-metastore-heap-eval.sh文件 # if want hiveserver2 ,should grep "org.apache.hive.service.server.HiveServer2" # get pid pidps -ef | grep "org.apache.hadoop.hive.metastore.HiveMetaStore" | grep &qu…...

专题讨论3:基于图的基本原理实现走迷宫问题
问题描述 迷宫通常以二维矩阵形式呈现,矩阵中的元素用 0 和 1 表示,其中 0 代表通路,1 代表墙壁 。存在特定的起点和终点坐标,目标是从起点出发,寻找一条能够到达终点的路径。 实现思路 将迷宫中的每个可通行单元格…...

Linux基础第四天
系统之间文件共享 想要实现两个不同的系统之间实现文件共享,最简单的一种方案就是设置VMware软件的共享文件夹,利用共享文件夹可以实现linux系统和windows系统之间的文件共享,这样就可以实现在windows系统上编辑程序,然后在linux系…...

eNSP中单臂路由器配置完整实验及命令解释
单臂路由器(Router on a Stick)是一种通过单个物理接口处理多个VLAN间路由的解决方案 单臂路由器通过以下方式工作: 交换机端口配置为Trunk模式,允许多个VLAN流量通过路由器子接口为每个VLAN创建虚拟接口每个子接口配置对应VLAN…...

TeaType 奶茶性格占卜机开发记录:一场俏皮的 UniApp 单页奇遇
我正在参加CodeBuddy「首席试玩官」内容创作大赛,本文所使用的 CodeBuddy 免费下载链接:腾讯云代码助手 CodeBuddy - AI 时代的智能编程伙伴 最近我突发奇想,想用 UniApp 做一个轻松又俏皮的小工具,叫做「TeaType 奶茶性格占卜机」…...

AI神经网络降噪 vs 传统单/双麦克风降噪的核心优势对比
1. 降噪原理的本质差异 对比维度传统单/双麦克风降噪AI神经网络降噪技术基础基于固定规则的信号处理(如谱减法、维纳滤波)基于深度学习的动态建模(DNN/CNN/Transformer)噪声样本依赖预设有限噪声类型训练数据覆盖数十万种真实环境…...

【Nginx学习笔记】:Fastapi服务部署单机Nginx配置说明
服务部署单机Nginx配置说明 服务.conf配置文件: upstream asr_backend {server 127.0.0.1:8010; }server {listen 80;server_name your_domain.com;location / {proxy_pass http://localhost:8000;proxy_set_header Host $host;proxy_set_header X-Real-IP $remot…...

JAVA Web 期末速成
一、专业术语及名词 1. Web 的特点 定义:web 是分布在全世界,基于 HTTP 通信协议,存储在 Web 服务器中的所有相互链接的超文本集 Web 是一种分布式超媒体系统Web 是多媒体化 和 易于导航的Web 与平台无关Web 是动态、交互的 2. TCP/IP 结…...

iOS:重新定义移动交互,引领智能生活新潮流
在当今智能手机与移动设备充斥的时代,操作系统作为其 “灵魂”,掌控着用户体验的方方面面。iOS 系统,这一由苹果公司精心雕琢的杰作,自诞生起便以独特魅力与卓越性能,在移动操作系统领域独树一帜,深刻影响着…...

LabVIEW数据库使用说明
介绍LabVIEW如何在数据库中插入记录以及执行 SQL 查询,适用于对数据库进行数据管理和操作的场景。借助 Database Connectivity Toolkit,可便捷地与指定数据库交互。 各 VI 功能详述 左侧 VI 功能概述:实现向数据库表中插入数据的操作。当输入…...

Linux多进程 写时拷贝 物理地址和逻辑地址
如果不采用写时拷贝技术 直接fork子进程 会发生什么? 如上图所示 橙色为父进程所占内存空间 绿色为子进程所占内存空间。 如果子进程只是需要做出一点点和父进程不一样的 其余和父进程均为相同 第一 就会出现复制开销比较大;第二占用内存空间 所以 …...

在 CentOS 7.9 上部署 node_exporter 并接入 Prometheus + Grafana 实现主机监控
文章目录 在 CentOS 7.9 上部署 node_exporter 并接入 Prometheus Grafana 实现主机监控环境说明node_exporter 安装与配置下载并解压 node_exporter创建 Systemd 启动服务验证服务状态验证端口监听 Prometheus 配置 node_exporter 监控项修改 prometheus.yml重新加载 Prometh…...
技术)
Java 反射(Reflection)技术
反射是 Java 提供的一种强大机制,允许程序在运行时(Runtime)动态地获取类的信息、操作类的属性和方法。这种能力使得 Java 程序可以突破编译时的限制,实现更灵活的设计。 一、反射的核心概念 1. 什么是反射 反射是指在程序运行…...
)
【SpringBoot】从零开始全面解析SpringMVC (三)
本篇博客给大家带来的是SpringBoot的知识点, 本篇是SpringBoot入门, 介绍SpringMVC相关知识. 🐎文章专栏: JavaEE进阶 🚀若有问题 评论区见 ❤ 欢迎大家点赞 评论 收藏 分享 如果你不知道分享给谁,那就分享给薯条. 你们的支持是我不断创作的动力 . 王子,…...

DeerFlow安装配置及使用案例
DeerFlow安装配置及使用案例 简介 DeerFlow项目由字节跳动技术团队发起和主导开发,作为一个开源深度研究框架,于2025年年初正式开源。该项目基于LangStack生态,构建于LangChain与LangGraph的开源技术栈之上,充分利用语言模型…...

吉林省建筑工程专业技术人员职称评审实施办法
吉林省人力资源和社会保障厅 吉林省建筑工程专业技术人员职称评审实施办法 吉林省建筑工程技术人才之技术员评审条件 吉林省建筑工程技术人才之助理工程师评审条件 吉林省建筑工程技术人才之工程师评审条件 吉林省建筑工程技术人才之高级工程师评审条件 吉林省建筑工程技术人才…...

React组件开发流程-03.1
此章先以一个完整的例子来全面了解下React组件开发的流程,主要是以代码为主,在不同的章节中会把重点标出来,要完成的例子如下,也可从官网中找到。 React组件开发流程 这只是一个通用流程,在熟悉后不需要完全遵从。 …...

Vue 中 v-model 的三种使用方式对比与实践
在 Vue 3 中,v-model 是组件双向数据绑定的核心特性。随着 Vue 的版本演进,v-model 的使用方式也在不断优化。本文将基于您提供的代码示例,详细分析三种不同的 v-model 实现方式:基础用法、useVModel Hook(vueuse/core…...

Adminer:一个基于Web的轻量级数据库管理工具
Adminer 是一个由单个 PHP 文件实现的免费数据库管理工具,支持 MySQL、MariaDB、PostgreSQL、CockroachDB、SQLite、SQL Server、Oracle、Elasticsearch、SimpleDB、MongoDB、Firebird、Clickhouse 等数据库。 Adminer 支持的主要功能如下: 连接数据库服…...

Linux笔记---内核态与用户态
用户态(User Mode) 权限级别:较低,限制应用程序直接访问硬件或关键系统资源。 适用场景:普通应用程序的运行环境。 限制:无法执行特权指令(如操作I/O端口、修改内存管理单元配置等)…...

MFC 编程中 OnInitDialog 函数
核心作用 对话框初始化入口 :创建完成后第一个执行的函数。是对话框的起点。控件操作安全期 :此时所有控件已创建完成。可以安全地进行控件的初始化、属性设置等操作。界面布局最佳时机 :窗口显示前完成初始化设置。可以进行布局调整、数据初…...

Java高频面试之并发编程-18
hello啊,各位观众姥爷们!!!本baby今天又来报道了!哈哈哈哈哈嗝🐶 面试官:详细说说synchronized synchronized 是 Java 中实现线程同步的核心关键字,用于解决多线程环境下的资源竞争…...

深入探究AKS Workload Identity
Azure Kubernetes 服务 (AKS) 提供了一项名为 Workload Identity 的强大功能,它可以增强安全性并简化在 Kubernetes 集群中运行的应用程序的身份验证。以下是 Workload Identity 在 AKS 环境中的工作原理概述: AKS 中的 Workload Identity 允许 Pod 无需…...

【MySQL基础】MySQL基础:MySQL基本操作与架构
MySQL学习: https://blog.csdn.net/2301_80220607/category_12971838.html?spm1001.2014.3001.5482 前言: 这里是MySQL学习的第一篇,本篇主要是讲解一些MySQL的基础操作,但这并不是重点,本篇我们主要是要理解MySQL…...

【线下沙龙】NineData x Apache Doris x 阿里云联合举办数据库技术Meetup,5月24日深圳见!
5月24日下午,NineData 将联合 Apache Doris、阿里云一起,在深圳举办数据库技术Meetup。本次技术沙龙聚焦「数据实时分析」与「数据同步迁移」 两大核心领域,针对企业数据战略中的痛点,特邀行业资深技术大咖,结合多年技…...

【Unity网络编程知识】Unity的 UnityWebRequest相关类学习
1、UnityWebRequest类介绍 UnityWebRequest是一个unity提供的一个模块化的系统类,用于构成HTTP请求和处理HTTP响应,它主要目标是让unity游戏和Web服务端进行交互,它将之前WWW的相关功能都集成在了其中,所以新版本中都建议使用unit…...

STM32实战指南——DHT11温湿度传感器驱动开发与避坑指南
知识点1【DHT11的概述】 1、概述 DHT是一款温湿度一体化的数字传感器(无需AD转换)。 2、驱动方式 通过单片机等微处理器简单的电路连接就能实时采集本地湿度和温度。DHT11与单片机之间采用单总线进行通信,仅需要一个IO口。 相对于单片机…...

SVG 与 Canvas 技术调研对比
在 画布 中进行 大量矩形框绘制 时,SVG 和 Canvas 都是可行的技术方案,但它们适用于不同的场景,技术特性也有明显区别。下面我从性能、灵活性、可维护性、适用场景等方面做一个系统性的对比,帮助你做出更合适的选择。 ᾞ…...

Ubuntu 远程桌面配置指南
概述: 本文主要介绍在Ubuntu 22.04中通过VNC实现远程连接的方法。首先需安装图形化界面和VNC工具x11vnc,设置开机启动服务;然后在Windows客户端用VNC Viewer通过局域网IP和端口5900连接。 总结: 一、VNC配置与安装 安装图形化界面 在Ubuntu 22.04中需先安装: sudo apt …...

146. LRU 缓存
一、题目 二、思路 题目要求 O(1) 的平均时间复杂度运行 -> 使用Map空间换时间 Map<Integer, Node>Map 通过 key 直接找到对应节点 getNode(key) -> Node记得只要查过该节点之后就应该把该节点放到最前面 pushFront(Node)put 元素后,在map中添加&…...

微信学习之导航功能
先看这个功能的效果: 然后开始学习吧。 一、我们这里用的是vant的Grid控件,首先我们导入: { "usingComponents": {"van-search": "vant/weapp/search/index","my-swiper":"../../components…...
不存在(APP))
MySQL替换瀚高数据库报错: TO_DAYS()不存在(APP)
文章目录 环境症状问题原因解决方案报错编码 环境 系统平台:中标麒麟(海光)7,中标麒麟(飞腾)7 版本:4.5 症状 MySQL替换为瀚高数据库进行应用系统适配报错:TO_DAYS()不…...

FPGA:高速接口JESD204B以及FPGA实现
本文将先介绍JESD204B高速接口的基本概念和特性,然后详细说明如何基于Xilinx Kintex-7系列FPGA实现JESD204B高速接口。 一、JESD204B高速接口介绍 JESD204B是由JEDEC(固态技术协会)制定的一种高速串行通信标准,主要用于数据转换器…...

HarmonyOS Navigation组件深度解析与应用实践
HarmonyOS Navigation组件深度解析与应用实践 一、组件架构与核心能力 HarmonyOS Navigation组件作为路由导航的根视图容器,采用三层架构设计: 标题层:支持主副标题配置,提供Mini/Free/Full三种显示模式内容层:默认…...

C#中的ThreadStart委托
ThreadStart 委托: ThreadStart 是 .NET 中的一个内置委托类型,表示无参数且无返回值的方法。其定义如下: public delegate void ThreadStart(); 通常用于定义线程的入口方法。 List<ThreadStart>: 这是一个泛型集合&…...

Spring boot 集成 Knife4j
knife4j官网:https://doc.xiaominfo.com/docs/quick-start 1. 引入Knife4j相关依赖 <!-- knife4j--> <dependency><groupId>com.github.xiaoymin</groupId><artifactId>knife4j-spring-boot-starter</artifactId><version…...