TASK03【Datawhale 组队学习】搭建向量知识库
文章目录
- 向量及向量知识库
- 词向量与向量
- 向量数据库
- 数据处理
- 数据清洗
- 文档分割
- 搭建并使用向量数据库
向量及向量知识库
词向量与向量
词向量(word embedding)是一种以单词为单位将每个单词转化为实数向量的技术。词向量背后的主要想理念是相似或相关的对象在向量空间中的距离应该很近。
词向量实际上是将单词转化为固定的静态的向量,虽然可以在一定程度上捕捉并表达文本中的语义信息,但忽略了单词在不同语境中的意思会受到影响这一现实。
通用文本向量(单位:文本):RAG应用中使用的向量技术一般为通用文本向量(Universal text embedding),该技术可以对一定范围内任意长度的文本进行向量化,输出的向量会捕捉更多的语义信息。
在RAG(Retrieval Augmented Generation,检索增强生成)方面向量的优势主要有两点:
- 向量比文字更适合检索。可以通过计算问题与数据库中数据的点积、余弦距离、欧几里得距离等指标,直接获取问题与数据在语义层面上的相似度;
- 向量比其它媒介的综合信息能力更强,当传统数据库存储文字、声音、图像、视频等多种媒介时,很难去将上述多种媒介构建起关联与跨模态的查询方法;但是向量却可以通过多种向量模型将多种数据映射成统一的向量形式。
在搭建 RAG 系统时,我们往往可以通过使用向量模型来构建向量,我们可以选择:
- 使用各个公司的 Embedding API;
- 在本地使用向量模型将数据构建为向量。
向量数据库
向量数据库(每个向量代表一个数据项)是用于高效计算和管理大量向量数据的解决方案。向量数据库是一种专门用于存储和检索向量数据(embedding)的数据库系统。它与传统的基于关系模型的数据库不同,它主要关注的是向量数据的特性和相似性。
向量数据库中的数据以向量作为基本单位,对向量进行存储、处理及检索。当处理大量甚至海量的向量数据时,向量数据库索引和查询算法的效率明显高于传统数据库。
- Chroma(功能相对简单且不支持GPU加速,适合初学者使用。
- Weaviate 支持相似度搜索和最大边际相关性搜索外还可以支持结合多种搜索算法(基于词法搜索、向量搜索)的混合搜索
- Qdrant 有极高的检索效率和RPS支持本地运行、部署在本地服务器及Qdrant云三种部署模式
_ = load_dotenv(find_dotenv())from zhipuai import ZhipuAI
def zhipu_embedding(text: str):api_key = os.environ['ZHIPUAI_API_KEY']client = ZhipuAI(api_key=api_key)response = client.embeddings.create(model="embedding-3",input=text,)return responsetext = '要生成 embedding 的输入文本,字符串形式。'
response = zhipu_embedding(text=text)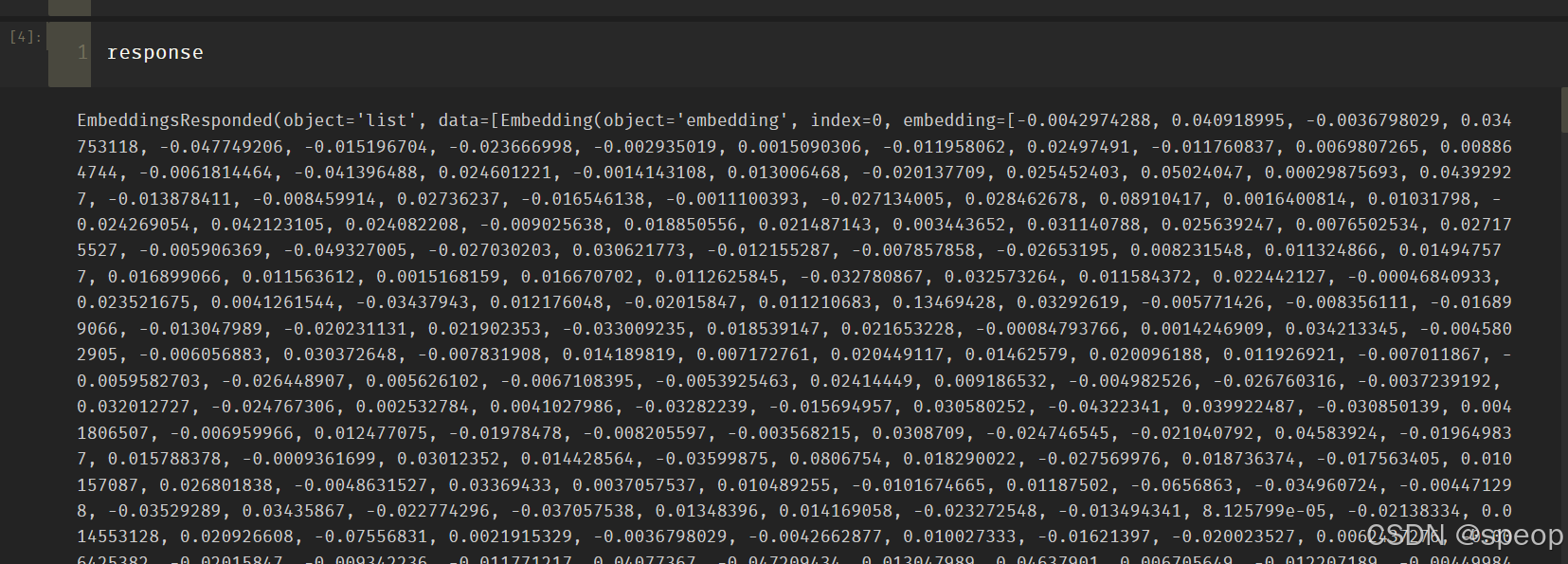
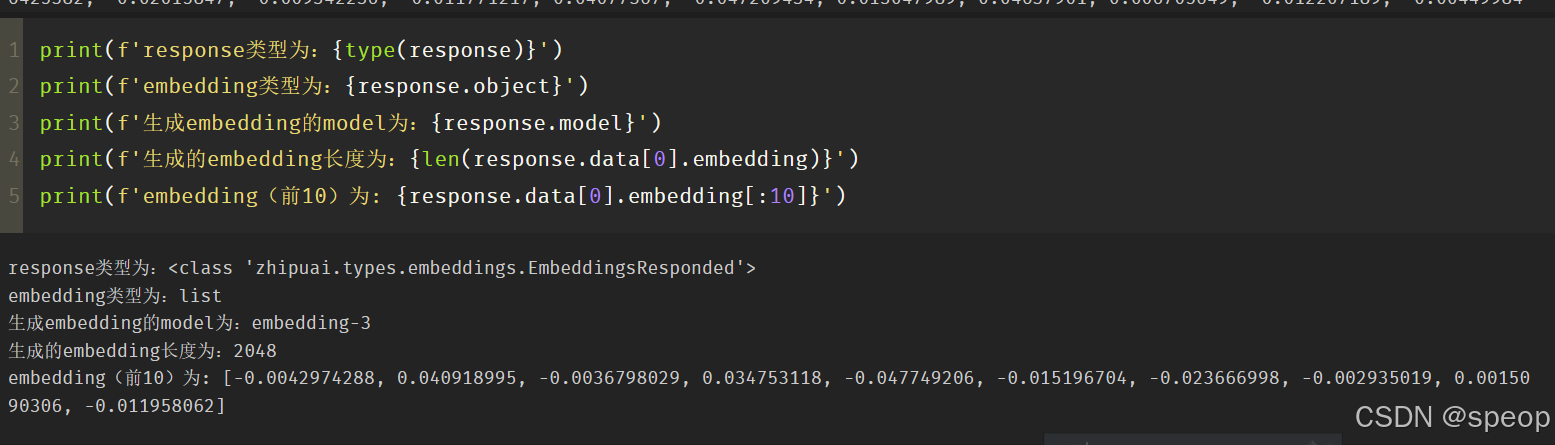
print(f'response类型为:{type(response)}')
print(f'embedding类型为:{response.object}')
print(f'生成embedding的model为:{response.model}')
print(f'生成的embedding长度为:{len(response.data[0].embedding)}')
print(f'embedding(前10)为: {response.data[0].embedding[:10]}')
数据处理
pdf读取:使用langchain的PyMuPDFLoader读取知识库的pdf,结果会包含 PDF 及其页面的详细元数据,并且每页返回一个文档。
from langchain_community.document_loaders import PyMuPDFLoader
# 创建一个 PyMuPDFLoader Class 实例,输入为待加载的 pdf 文档路径
loader = PyMuPDFLoader("./pumpkin_book.pdf")
# 调用 PyMuPDFLoader Class 的函数 load 对 pdf 文件进行加载
pdf_pages = loader.load()
print(f"载入后的变量类型为:{type(pdf_pages)},", f"该 PDF 一共包含 {len(pdf_pages)} 页")
markdown读取:
from langchain_community.document_loaders.markdown import UnstructuredMarkdownLoader
loader = UnstructuredMarkdownLoader("./1. 简介.md")
md_pages = loader.load()
page 中的每一元素为一个文档,变量类型为 langchain_core.documents.base.Document, 文档变量类型包含两个属性
- page_content 包含该文档的内容。
- meta_data 为文档相关的描述性数据。
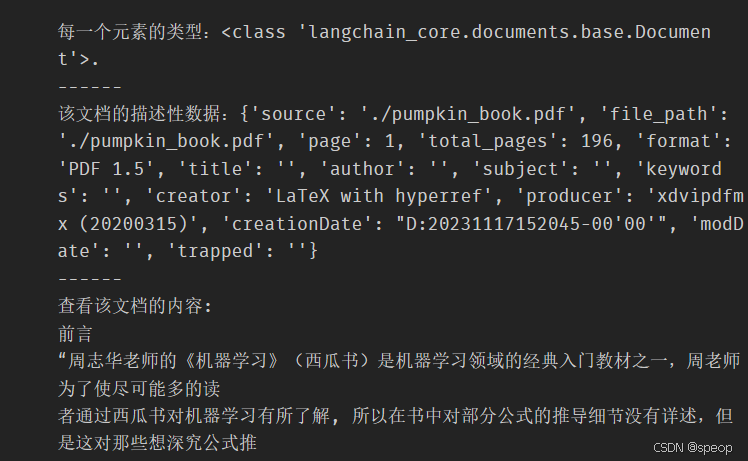
pdf_page = pdf_pages[1]
print(f"每一个元素的类型:{type(pdf_page)}.", f"该文档的描述性数据:{pdf_page.metadata}", f"查看该文档的内容:\n{pdf_page.page_content}", sep="\n------\n")
数据清洗
按照原文的分行添加了换行符\n,也在原本两个符号中间插入了\n
pattern = re.compile(r'[^\u4e00-\u9fff](\n)[^\u4e00-\u9fff]', re.DOTALL)
pdf_page.page_content = re.sub(pattern, lambda match: match.group(0).replace('\n', ''), pdf_page.page_content)
print(pdf_page.page_content)
pdf_page.page_content = pdf_page.page_content.replace('•', '')
pdf_page.page_content = pdf_page.page_content.replace(' ', '')
print(pdf_page.page_content)
md_page.page_content = md_page.page_content.replace('\n\n', '\n')
print(md_page.page_content)文档分割
单个文档的长度往往会超过模型支持的上下文,导致检索得到的知识太长超出模型的处理能力,因此,在构建向量知识库的过程中,我们往往需要对文档进行分割,将单个文档按长度或者按固定的规则分割成若干个 chunk,然后将每个 chunk 转化为词向量,存储到向量数据库中。
在检索时,我们会以 chunk 作为检索的元单位,也就是每一次检索到 k 个 chunk 作为模型可以参考来回答用户问题的知识,这个 k 是我们可以自由设定的。
Langchain 中文本分割器都根据 chunk_size (块大小)和 chunk_overlap (块与块之间的重叠大小)进行分割。
- chunk_size 指每个块包含的字符或 Token (如单词、句子等)的数量
- chunk_overlap 指两个块之间共享的字符数量,用于保持上下文的连贯性,避免分割丢失上下文信息
Langchain 提供多种文档分割方式,区别在怎么确定块与块之间的边界、块由哪些字符/token组成、以及如何测量块大小
- RecursiveCharacterTextSplitter(): 按字符串分割文本,递归地尝试按不同的分隔符进行分割文本。
- CharacterTextSplitter(): 按字符来分割文本。
- MarkdownHeaderTextSplitter(): 基于指定的标题来分割markdown 文件。
- TokenTextSplitter(): 按token来分割文本。
- SentenceTransformersTokenTextSplitter(): 按token来分割文本
- Language(): 用于 CPP、Python、Ruby、Markdown 等。
- NLTKTextSplitter(): 使用 NLTK(自然语言工具包)按句子分割文本。
- SpacyTextSplitter(): 使用 Spacy按句子的切割文本。
'''
* RecursiveCharacterTextSplitter 递归字符文本分割
RecursiveCharacterTextSplitter 将按不同的字符递归地分割(按照这个优先级["\n\n", "\n", " ", ""]),这样就能尽量把所有和语义相关的内容尽可能长时间地保留在同一位置
RecursiveCharacterTextSplitter需要关注的是4个参数:* separators - 分隔符字符串数组
* chunk_size - 每个文档的字符数量限制
* chunk_overlap - 两份文档重叠区域的长度
* length_function - 长度计算函数
'''
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 知识库中单段文本长度
CHUNK_SIZE = 500
# 知识库中相邻文本重合长度
OVERLAP_SIZE = 50
# 使用递归字符文本分割器
text_splitter = RecursiveCharacterTextSplitter(chunk_size=CHUNK_SIZE,chunk_overlap=OVERLAP_SIZE
)
text_splitter.split_text(pdf_page.page_content[0:1000])
split_docs = text_splitter.split_documents(pdf_pages)
print(f"切分后的文件数量:{len(split_docs)}")
print(f"切分后的字符数(可以用来大致评估 token 数):{sum([len(doc.page_content) for doc in split_docs])}")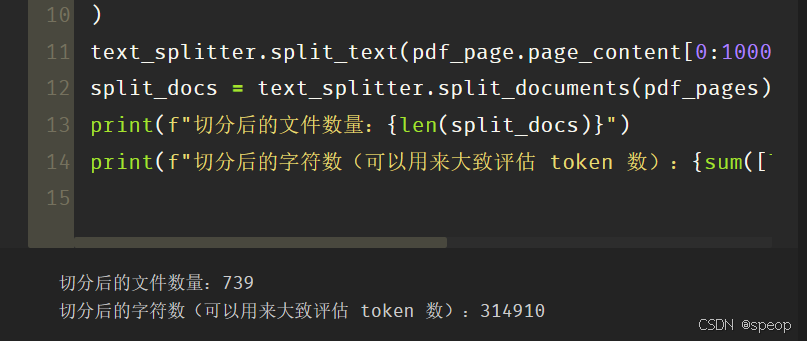
搭建并使用向量数据库
import os
from dotenv import load_dotenv, find_dotenv
# 获取folder_path下所有文件路径,储存在file_paths里
file_paths = []
folder_path = '../../data_base/knowledge_db'
for root, dirs, files in os.walk(folder_path):for file in files:file_path = os.path.join(root, file)file_paths.append(file_path)
print(file_paths[:3])
from langchain_community.document_loaders import PyMuPDFLoader
from langchain_community.document_loaders import UnstructuredMarkdownLoader
# 遍历文件路径并把实例化的loader存放在loaders里
loaders = []
for file_path in file_paths:file_type = file_path.split('.')[-1]if file_type == 'pdf':loaders.append(PyMuPDFLoader(file_path))elif file_type == 'md':loaders.append(UnstructuredMarkdownLoader(file_path))
# 下载文件并存储到text
texts = []
for loader in loaders: texts.extend(loader.load())
#载入后的变量类型为langchain_core.documents.base.Document, 文档变量类型同样包含两个属性
#page_content 包含该文档的内容。
#meta_data 为文档相关的描述性数据。
text = texts[1]
print(f"每一个元素的类型:{type(text)}.", f"该文档的描述性数据:{text.metadata}", f"查看该文档的内容:\n{text.page_content[0:]}", sep="\n------\n")
相关文章:

TASK03【Datawhale 组队学习】搭建向量知识库
文章目录 向量及向量知识库词向量与向量向量数据库 数据处理数据清洗文档分割 搭建并使用向量数据库 向量及向量知识库 词向量与向量 词向量(word embedding)是一种以单词为单位将每个单词转化为实数向量的技术。词向量背后的主要想理念是相似或相关的…...

ProfibusDP转ModbusRTU的实用攻略
ProfibusDP转ModbusRTU的实用攻略 在工业自动化领域中,Profibus DP和Modbus RTU是两种常见的通信协议。 Profibus DP是一种广泛应用于过程控制和工厂自动化的现场总线标准,具有高实时性和可靠性。 而Modbus RTU则是一种串行通信协议,常用于…...

基于开源AI智能名片链动2+1模式S2B2C商城小程序源码的去中心化商业扩散研究
摘要:本文探讨在去中心化商业趋势下,开源AI智能名片链动21模式S2B2C商城小程序源码如何助力企业挖掘数据价值、打破信息孤岛,实现商业高效扩散。通过分析该技术组合的架构与功能,结合实际案例,揭示其在用户关系拓展、流…...

iOS 工厂模式
iOS 工厂模式 文章目录 iOS 工厂模式前言工厂模式简单工厂案例场景分析苹果类优点缺点 小结 工厂模式客户端调用**优点****缺点** 抽象工厂模式三个模式对比 前言 笔者之前学习了有关于设计模式的六大原则,之前简单了解过这个工厂模式,今天主要是重新学习一下这个模式,正式系统…...

LaTeX OCR - 数学公式识别系统
文章目录 一、关于 LaTeX OCR1、项目概览架构图2、相关链接资源3、功能特性 二、安装配置基础环境要求Linux 安装Mac 安装 三、使用指南1、快速训练(小数据集)2、完整训练(大数据集) 四、可视化功能训练过程可视化预测过程可视化 …...

Go 语言即时通讯系统开发日志-日志day2-5:架构设计与日志封装
Go语言即时通讯系统开发日志day2 计划:学习go中MySQL,Redis的使用,使用MySQL和Redis完成一个单聊demo。 总结:现在每天下午用来开发这个项目,如果有课的话可能学习时间只有3-4个小时,再加上今天的学习效率不…...

@JsonProperty和@JSONField 使用
JsonProperty和JSONField注解的区别 1.底层框架不同 JsonProperty 是Jackson实现的 JSONField 是fastjson实现的 2.用法不同 (1)bean序列化为Json: JsonProperty: ObjectMapper().writeValueAsString(Object value) JSONField&…...

从代码学习深度学习 - 近似训练 PyTorch版
文章目录 前言负采样 (Negative Sampling)层序Softmax (Hierarchical Softmax)代码示例总结前言 在自然语言处理(NLP)领域,词嵌入(Word Embeddings)技术如Word2Vec(包括Skip-gram和CBOW模型)已经成为一项基础且强大的工具。它们能够将词语映射到低维稠密向量空间,使得…...

代码上传gitte仓库
把代码push上去就行...
:解释器风格)
系统架构设计(十四):解释器风格
概念 解释器风格是一种将程序的每个语句逐条读取并解释执行的体系结构风格。程序在运行时不会先被编译为机器码,而是动态地由解释器分析并执行其语义。 典型应用:Python 解释器、JavaScript 引擎、Bash Shell、SQL 引擎。 组成结构 解释器风格系统的…...

掌握LINQ:查询语法与方法语法全解析
文章目录 引言1. 查询语法 vs 方法语法1.1 查询语法 (Query Syntax)1.2 方法语法 (Method Syntax)1.3 两种语法的比较 2. 基本的 LINQ 查询结构2.1 数据源2.2 查询操作2.3 查询执行 3. 查询表达式中的关键字3.1 基本关键字fromwhereselectorderbygroup byjoin 3.2 其他常用关键…...

Go 后端中双 token 的实现模板
下面是一个典型的 Go 后端双 Token 认证机制 实现模板,使用 Gin 框架 JWT Redis,结构清晰、可拓展,适合实战开发。 项目结构建议 /utils├── jwt.go // Access & Refresh token 的生成和解析├── claims.go // 从请求…...

GESP编程能力等级认证C++3级1-数组1
1 GESP编程能力等级认证C3级 1.1 GESP简介 GESP是CCF 编程能力等级认证的简称,它为青少年计算机和编程学习者提供学业能力验证的规则和平台。GESP 覆盖中小学阶段,符合年龄条件的青少年均可参加认证。 1.2 GESP的分级 C 编程测试划分为一至八级&…...

FreeRTOS “探究任务调度机制魅力”
引入 现如今随着单片机的资源越来越多,主频越来越高,在面临更复杂的功能实现以及对MCU性能的充分压榨,会RTOS已经成为一个必要的技能,新手刚开始学习的时候就很好奇“为什么代码可以放到两个循环里同时运行?”。接下来…...

BGP策略实验练习
要求: 1、使用PreVal策略,确保R4通过R2到达192.168.10.0/24 2、使用AS_Path策略,确保R4通过R3到达192.168.11.0/24 3、配置MED策略,确保R4到达R3到达192.168.11.0/24 4、使用Local Preference策略,确保R1通过R2到达192…...

Office 中 VBE 的共同特点与区别
1. Excel VBE 核心对象 #mermaid-svg-IklDO11Hu656bdGS {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-IklDO11Hu656bdGS .error-icon{fill:#552222;}#mermaid-svg-IklDO11Hu656bdGS .error-text{fill:#552222;stro…...
)
Linux虚拟文件系统(1)
1 虚拟文件系统(VFS) 虚拟文件系统(Virtual File System, VFS)作为内核的子系统。,它为用户空间的应用程序提供了一个统一的文件系统接口。通过VFS,不同的文件系统可以共存于同一个操作系统中,…...

目标检测评估指标mAP详解:原理与代码
目标检测评估指标mAP详解:原理与代码 目标检测评估指标mAP详解:原理与代码一、前言:为什么需要mAP?二、核心概念解析2.1 PR曲线(Precision-Recall Curve)2.2 AP计算原理 三、代码实现详解3.1 核心函数ap_pe…...
)
Linux干货(六)
前言 从B站黑马程序员Linux课程摘选的学习干货,新手友好!若有侵权,会第一时间处理。 目录 前言 1.环境变量 1.环境变量的定义 2.env命令的作用 3.$符号的作用 4.PATH的定义和作用 5.修改环境变量的方法 1.临时生效 2.永久生效 2.…...
)
字符串相乘(43)
43. 字符串相乘 - 力扣(LeetCode) 解法: class Solution { public:string multiply(string num1, string num2) {string res "0";for (int i 0; i < num2.size(); i) {string str multiplyOneNum(num1, num2[num2.size() -…...

【Vue篇】数据秘语:从watch源码看响应式宇宙的蝴蝶效应
目录 引言 一、watch侦听器(监视器) 1.作用: 2.语法: 3.侦听器代码准备 4. 配置项 5.总结 二、翻译案例-代码实现 1.需求 2.代码实现 三、综合案例——购物车案例 1. 需求 2. 代码 引言 💬 欢迎讨论&#…...
lcd屏显示文字与照片)
esp32课设记录(二)lcd屏显示文字与照片
取模软件链接: 链接: 百度网盘 请输入提取码 提取码: 1234 课设要求如图所示,因此需要在esp32显示文字和照片。在上个文章中我已经写了按键相关内容。这篇主要描述怎么显示文字和照片。我使用的是ESP-IDF库。 本项目使用的是基于ST7789驱动芯片的LCD屏幕…...

Open CASCADE学习|几何体切片处理:OpenMP与OSD_Parallel并行方案深度解析
在三维建模与仿真领域,几何体切片处理是CAE前处理、3D打印路径规划、医学影像分析等场景的关键技术。其核心目标是将三维模型沿特定方向离散为二维截面集合,便于后续分析或制造。OpenCASCADE作为开源几何内核,提供高效的布尔运算与几何算法&a…...
)
【Android】从Choreographer到UI渲染(二)
【Android】从Choreographer到UI渲染(二) Google 在 2012 年推出的 Project Butter(黄油计划)是 Android 系统发展史上的重要里程碑,旨在解决长期存在的 UI 卡顿、响应延迟等问题,提升用户体验。 在 Androi…...
)
板凳-------Mysql cookbook学习 (三)
1.22 使长输出行更具可读性 mysql> show full columns from limbs; ------------------------------------------------------------------------------------------------------------- | Field | Type | Collation | Null | Key | Default | Extra | Pri…...

济南国网数字化培训班学习笔记-第三组-2-电力通信光缆网认知
电力通信光缆网认知 光缆网架构现状 基础底座 电路系统是高度复杂,实时性、安全性、可靠性要求极高的巨系统,必须建设专用通信网 相伴相生 电力系统是由发电、输电、变电、配电、用电等一次设施,及保障其正常运行的保护、自动化、通信等…...

黑灰产业链深度解析
黑灰产业链深度解析 大家好,欢迎来到「黑产档案」。本频道专注于反诈教育宣传,通过深度拆解黑灰产业链的运作逻辑,帮助公众识别骗局、规避风险。本节课将聚焦产业链的核心环节,揭示其背后的灰色生态。 一、黑灰产的定义与范畴 要…...

golang选项设计模式
选项设计模式 有时候一个函数会有很多参数,为了方便函数的使用,我们会给希望给一些参数设定默认值,调用时只需要传与默认值不同的参数即可,类似于 python 里面的默认参数和字典参数,虽然 golang 里面既没有默认参数也…...

方案精读:104页DeepSeek金融银行核算流程场景部署建设方案【附全文阅读】
DeepSeek,金融银行核算流程的革新方案! 这份方案专为金融银行从业者打造,旨在解决传统核算流程的难题。当下,金融银行核算面临效率低、错误率高、合规压力大等挑战,DeepSeek 方案正是应对之策。 该方案运用人工智能和大数据技术,实现数据采集、清洗自动化,智能核算对账,…...

【MySQL】02.数据库基础
1. 数据库的引入 之前存储数据用文件就可以了,为什么还要弄个数据库? 文件存储存在安全性问题,文件不利于数据查询和管理,文件不利于存储海量数据,文件在程序中控制不方便。而为了解决上述问题,专家们设计出更加利于…...

STM32项目实战:ADC采集
STM32F103C8T6的ADC配置。PB0对应的是ADC1的通道8。在标准库中,需要初始化ADC,设置通道,时钟,转换模式等。需要配置GPIOB的第0脚为模拟输入模式,然后配置ADC1的通道8,设置转换周期和触发方式。 接下来是I2C…...

《AI语音模型:MiniMax Speech-02》
开场:AI 语音界的震撼弹 在 AI 语音技术的激烈竞争赛道上,MiniMax Speech - 02 的出现宛如一颗震撼弹,瞬间引爆了整个行业。不久前,一则消息在全球 AI 领域引起轩然大波:MiniMax 的新一代语音大模型 Speech - 02&#…...

基于LabVIEW的双音多频系统设计
目录 1 系统设计概述 双音多频(Dual-Tone Multi-Frequency, DTMF)信号是一种广泛应用于电话系统中的音频信号,通过不同的频率组合表示不同的按键。每个按键对应两个频率,一个低频和一个高频,共同组成独特的信号。在虚拟仪器技术快速发展的背景下,利用LabVIEW等图形化编程…...

快速生成角色背景设定:基于Next.js的AI辅助工具开发实践
引言 在游戏开发、小说创作和角色扮演(RP)中,角色背景设定(Headcanon)的构建往往耗时耗力。传统方法依赖手动编写,容易陷入思维定式。本文将分享如何利用Next.js和Tailwind CSS开发一个高效的AI角色设定生…...

轻量级视频剪辑方案:FFmpeg图形化工具体验
FFmpeg小白助手是基于开源FFmpeg开发的本地化视频处理软件,采用绿色免安装设计,解压后即可直接运行。该工具主要面向普通用户的日常音视频处理需求,通过简洁的图形界面降低了FFmpeg的使用门槛。 功能特性 基础编辑功能 格式转换:…...

主成分分析的应用之sklearn.decomposition模块的PCA函数
主成分分析的应用之sklearn.decomposition模块的PCA函数 一、模型建立整体步骤 二、数据 2297.86 589.62 474.74 164.19 290.91 626.21 295.20 199.03 2262.19 571.69 461.25 185.90 337.83 604.78 354.66 198.96 2303.29 589.99 516.21 236.55 403.92 730.05 438.41 225.80 …...

Java基于数组的阻塞队列实现详解
在多线程编程中,阻塞队列是一种非常有用的工具,它可以在生产者和消费者之间提供一个缓冲区,使得生产者可以往队列中添加数据,而消费者可以从队列中取出数据。当队列满时,生产者会被阻塞直到有空间可用;当队…...

ngx_http_random_index_module 模块概述
一、使用场景 随机内容分发 当同一目录下存放多份等价内容(如多张轮播图、不同版本静态页面等)时,可通过随机索引实现负载均衡或流量分散。A/B 测试 通过目录请求自动随机分配用户到不同测试组,无需后端逻辑参与。动态“首页”选…...

你引入的lodash充分利用了吗?
#开发中,发现自己只有cloneDeep的时候才想起来用这个库的便利,搜索了项目内代码,发现大家基本也是这样,其实我们错过了很多好东西# cloneDeep 深拷贝 var objects [{ a: 1 }, { b: 2 }];var deep _.cloneDeep(objects); conso…...

Python爬虫基础
本篇内容中,我们主要分享一些爬虫的前置知识,主要知识点有: 爬虫的概念和作用爬虫的流程【重要】http相关的复习 http和https概念和区别浏览器访问一个网址的过程爬虫中常用的请求头、响应头常见的响应状态码 浏览器自带开发者工具的使用 爬…...

飞帆控件:on_post_get 接口配置
在网页中写一个接口是很基础的要求。 今天我们介绍一个工具,不用写代码,配置即可。 先上链接: on_post_gethttps://fvi.cn/798来看看控件的配置: 使用这个控件,在网页中写 post/get 接口可以告别代码。或许能做到初…...
:)
C++笔试题(金山科技新未来训练营):
题目分布: 17道单选(每题3分)3道多选题(全对3分,部分对1分)2道编程题(每一道20分)。 不过题目太多,就记得一部分了: 单选题: static变量的初始…...
)
Selenium-Java版(css表达式)
css表达式 前言 根据 tag名、id、class 选择元素 tag名 #id .class 选择子元素和后代元素 定义 语法 根据属性选择 验证CSS Selector 组选择 按次序选择子节点 父元素的第n个子节点 父元素的倒数第n个子节点 父元素的第几个某类型的子节点 父元素的…...

19. 结合Selenium和YAML对页面实例化PO对象改造
19. 结合Selenium和YAML对页面实例化PO对象改造 一、架构升级核心思路 1.1 改造核心目标 # 原始PO模式:显式定义元素定位 username (id, ctl00_MainContent_username)# 改造后PO模式:动态属性访问 self.username.send_keys(Tester) # 自动触发元素定…...

MySQL——5、基本查询
表的增删改查 1、Create1.1、单行数据全列插入1.2、多行数据指定列插入1.3、插入否则更新1.4、替换 2、Retrieve2.1、select列2.2、where条件2.3、结果排序2.4、筛选分页结果 3、Update4、Delete4.1、删除数据4.2、截断表 5、插入查询结果6、聚合函数7、group by子句的使用8、实…...

ngx_http_referer_module 模块概述
一、使用场景 防盗链 仅允许本站或特定域名的页面直接引用图片、视频等资源,拒绝第三方网站直接嵌入。流量控制 阻止来自社交媒体、搜索引擎或未知来源的大量自动化抓取。安全审计 简易记录并过滤可疑 Referer,以减少非法请求。 注意 Referer 头可被伪造…...

Go语言--语法基础5--基本数据类型--类型转换
Go 编程语言中 if 条件语句的语法如下: 1、基本形式 if 布尔表达式 { /* 在布尔表达式为 true 时执行 */ } If 在布尔表达式为 true 时,其后紧跟的语句块执行,如果为 false 则 不执行。 package main import "fmt" …...
)
用golang实现二叉搜索树(BST)
目录 一、概念、性质二、二叉搜索树的实现1. 结构2. 查找3. 插入4. 删除5. 中序遍历 中序前驱/后继结点 一、概念、性质 二叉搜索树(Binary Search Tree),简写BST,又称为二叉查找树 它满足: 空树是一颗二叉搜索树对…...

基于FPGA的电子万年历系统开发,包含各模块testbench
目录 1.课题概述 2.系统仿真结果 3.核心程序与模型 4.系统原理简介 5.完整工程文件 1.课题概述 基于FPGA的电子万年历系统开发,包含各模块testbench。主要包含以下核心模块: 时钟控制模块:提供系统基准时钟和计时功能。 日历计算模块:…...

上位机知识篇---Web
文章目录 前言 前言 本文简单介绍了Web。...