《Python星球日记》 第94天:走近自动化训练平台
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
目录
- 一、自动化训练平台简介
- 1. Kubeflow Pipelines
- 2. TensorFlow Extended (TFX)
- 二、自动化训练流程
- 1. 数据预处理
- 2. 模型训练
- 3. 评估与部署
- 三、构建简单自动化训练流水线
- 1. 环境准备
- 2. 流水线组件定义
- 3. 数据处理模块
- 4. 模型训练模块
- 5. 构建完整流水线
- 6. 执行流水线
- 四、自动化训练平台的优势与挑战
- 1. 自动化训练的优势
- 2. 实施挑战与解决方案
- 五、结语与展望
👋 专栏介绍: Python星球日记专栏介绍(持续更新ing)
✅ 上一篇: 《Python星球日记》 第93天:MLOps 入门
欢迎回到Python星球🪐日记!今天是我们旅程的第94天。
一、自动化训练平台简介
在机器学习和深度学习项目中,从数据准备到模型部署的流程通常包含多个复杂环节。随着项目规模扩大,手动管理这些流程变得困难且容易出错。自动化训练平台就是为了解决这一问题而生的强大工具,它能帮助我们自动化整个机器学习工作流程,提高效率和可靠性。
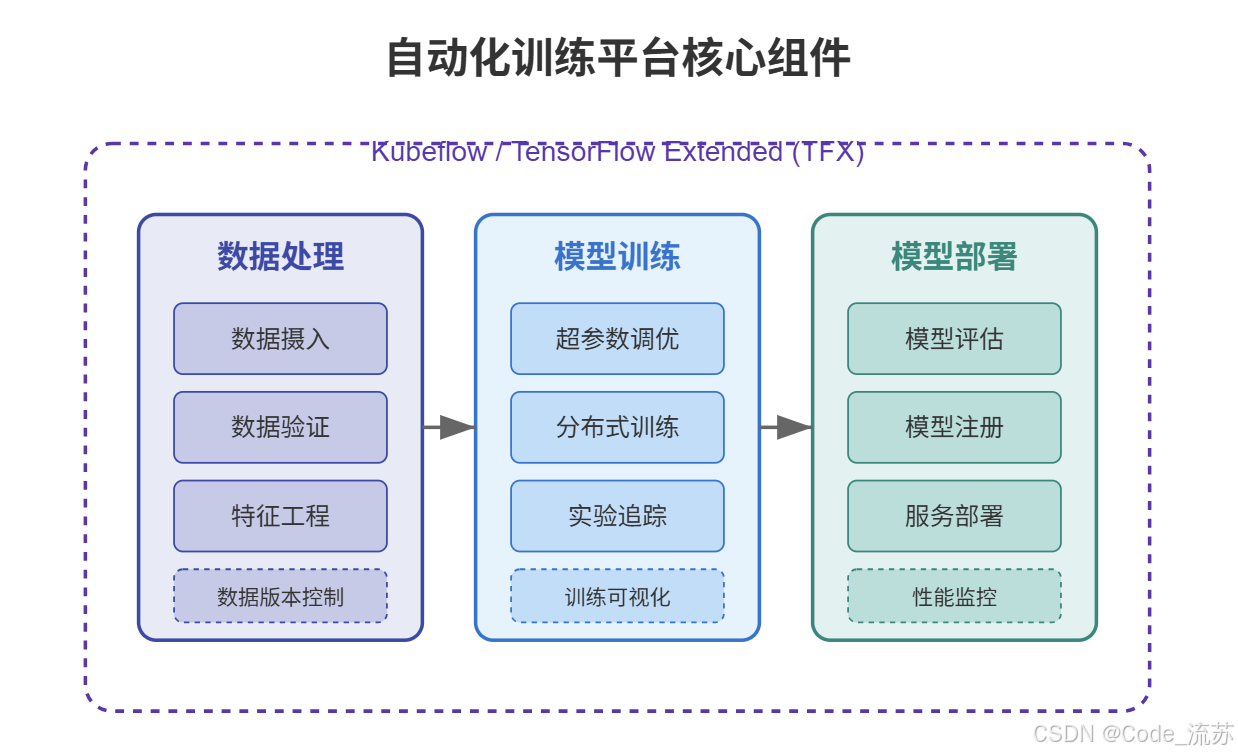
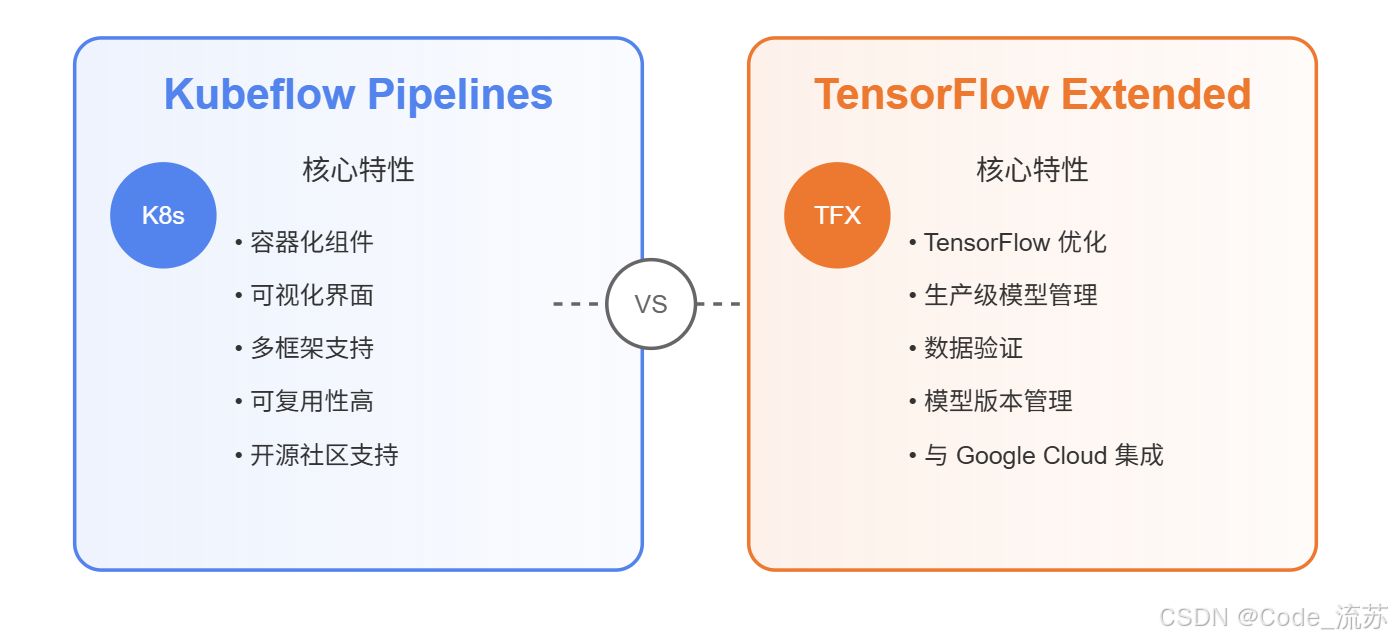
1. Kubeflow Pipelines
Kubeflow Pipelines 是基于 Kubernetes 的端到端机器学习工作流编排工具,它允许数据科学家构建和自动化可重复的机器学习工作流。
图片来源:Kubeflow Pipelines官方
Kubeflow Pipelines 的核心优势:
- 可复现性:将整个工作流定义为代码,确保实验可以精确复现
- 可组合性:将复杂流程拆分为可重用组件
- 可视化:提供直观的界面监控和管理工作流
- 可扩展性:无缝扩展到大规模数据和模型处理
2. TensorFlow Extended (TFX)
TensorFlow Extended (TFX) 是 Google 开发的端到端平台,用于部署生产级机器学习流水线。它专为 TensorFlow 模型优化,但也支持其他框架。
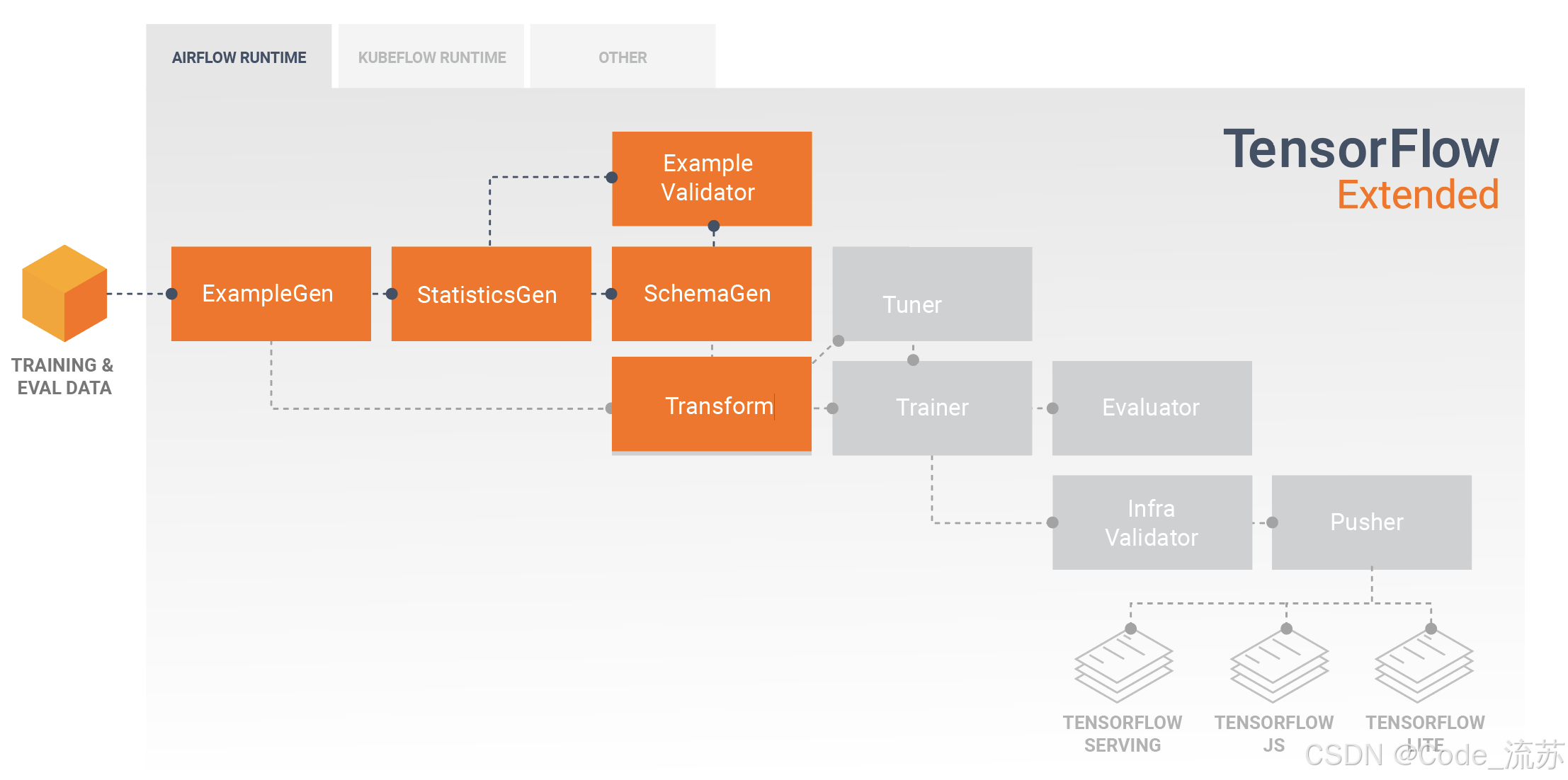
图片来源:TensorFlow Extended官方
TFX 的主要特点:
- 全生命周期管理:覆盖从数据摄入到模型服务的所有阶段
- 强大的验证机制:自动验证数据和模型质量
- 模型版本控制:追踪和管理不同版本的模型
- 与 Google Cloud 深度集成:可以利用 Google 云平台的强大功能
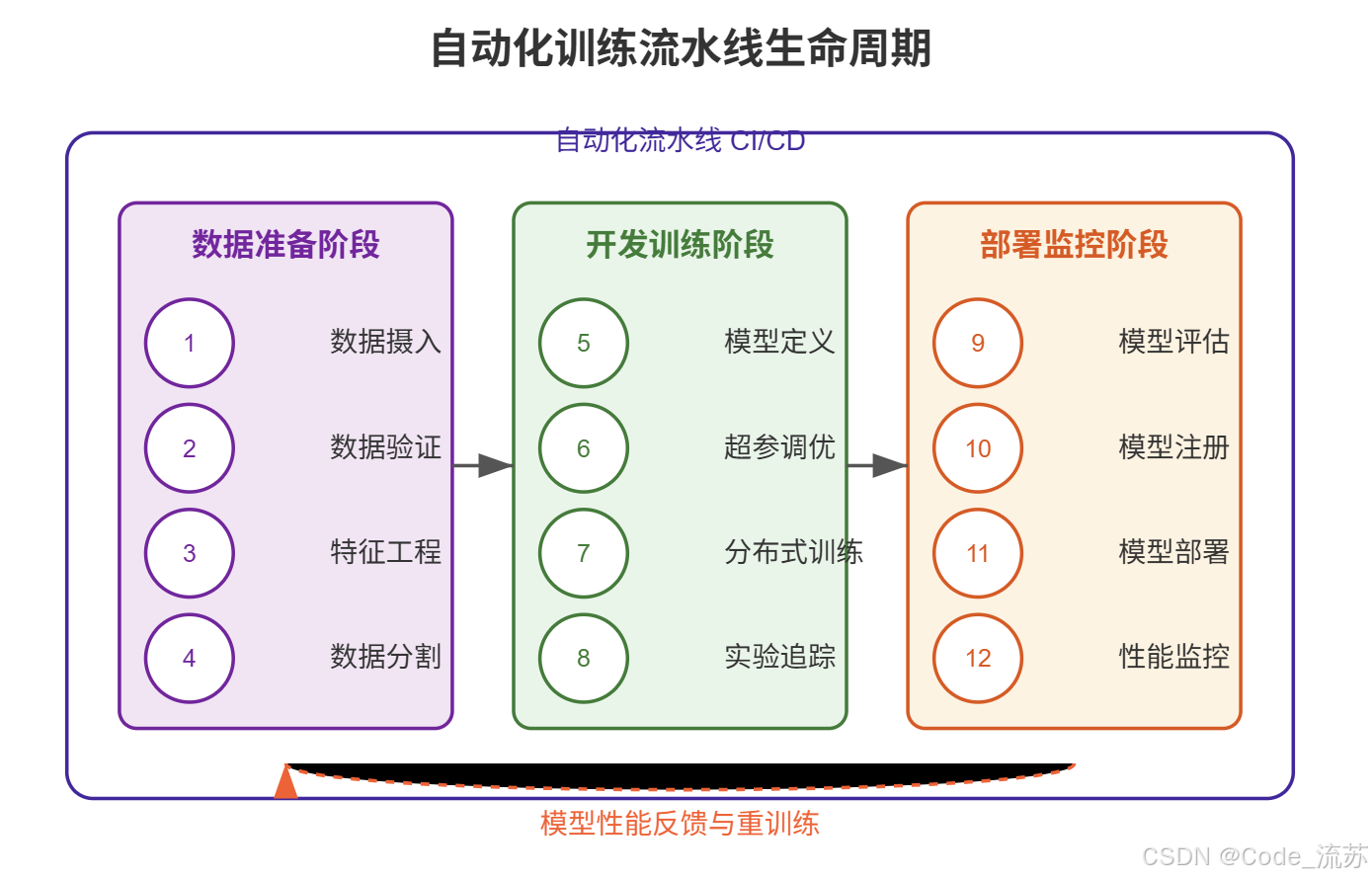
二、自动化训练流程
机器学习项目的自动化流程通常包含多个关键阶段,每个阶段都有特定的任务和目标。理解这些阶段对于构建有效的自动化流水线至关重要。
1. 数据预处理
数据预处理是任何机器学习流水线的第一个关键步骤,它解决了数据质量和格式的问题:
- 数据验证:确保数据符合预期的模式和分布
- 数据清洗:处理缺失值、异常值和重复记录
- 特征工程:创建、选择和转换特征以提高模型性能
- 数据拆分:将数据划分为训练集、验证集和测试集
在自动化流水线中,这些步骤被编码为可重用组件,能够一致地处理新数据。
2. 模型训练
模型训练阶段涉及选择和优化算法以从数据中学习模式:
- 超参数调优:自动化搜索最佳模型参数
- 训练监控:跟踪损失函数、准确率等指标
- 分布式训练:利用多个计算资源加速训练过程
- 实验追踪:记录每次训练运行的所有相关信息
自动化平台允许设置触发器来启动新的训练作业,例如当新数据到达或按照预定的时间表。
3. 评估与部署
训练完成后,模型需要经过彻底评估并准备部署:
- 模型评估:在测试数据上评估性能指标
- A/B测试:对比新模型与当前生产模型
- 模型注册:将经过批准的模型添加到模型注册表
- 模型服务:打包和部署模型用于推理
- 监控:跟踪生产环境中的模型性能
自动化平台确保这些步骤以可重复和可靠的方式执行,减少了手动干预的需要。
三、构建简单自动化训练流水线
现在让我们通过实际代码示例来了解如何构建一个简单的自动化训练流水线。我们将使用 TFX 框架来实现一个基础的流水线,适合初学者理解和扩展。
1. 环境准备
首先,我们需要安装必要的包和依赖:
# 安装TFX
!pip install tfx
# 安装相关依赖
!pip install tensorflow==2.12.0
!pip install apache-beam
2. 流水线组件定义
TFX 流水线由多个组件组成,每个组件负责特定的任务。下面我们定义一个简单的流水线,包含数据摄入、验证、预处理、训练和评估组件:
import tensorflow as tf
import tensorflow_model_analysis as tfma
from tfx import v1 as tfx
from tfx.components import (CsvExampleGen, # 数据摄入StatisticsGen, # 数据统计SchemaGen, # 数据模式生成ExampleValidator, # 数据验证Transform, # 特征转换Trainer, # 模型训练Evaluator, # 模型评估Pusher # 模型部署
)
from tfx.orchestration import pipeline
from tfx.orchestration.local.local_dag_runner import LocalDagRunner
3. 数据处理模块
接下来,我们需要创建预处理模块,定义如何转换原始特征:
# 创建 preprocessing_fn.py 文件
def preprocessing_fn(inputs):"""预处理函数:定义特征工程逻辑Args:inputs: 包含特征的字典Returns:转换后的特征字典"""# 获取输入特征features = {}# 对数值特征进行标准化for feature_name in ['feature1', 'feature2', 'feature3']:features[feature_name] = tf.feature_column.numeric_column(feature_name, normalizer_fn=lambda x: (x - mean) / stddev)# 对类别特征进行独热编码for feature_name in ['category1', 'category2']:features[feature_name] = tf.feature_column.categorical_column_with_vocabulary_list(feature_name, vocabulary_list=vocabulary_dict[feature_name])return features
4. 模型训练模块
我们还需要定义模型训练逻辑:
# 创建 trainer.py 文件
def run_fn(fn_args):"""训练函数:定义模型架构和训练逻辑Args:fn_args: 包含训练所需参数的对象"""# 加载转换后的数据tf_transform_output = tft.TFTransformOutput(fn_args.transform_output)train_dataset = input_fn(fn_args.train_files, tf_transform_output)eval_dataset = input_fn(fn_args.eval_files, tf_transform_output)# 构建模型model = tf.keras.Sequential([tf.keras.layers.Dense(64, activation='relu'),tf.keras.layers.Dense(32, activation='relu'),tf.keras.layers.Dense(1) # 根据任务类型调整输出层])# 编译模型model.compile(optimizer='adam',loss='mse', # 根据任务类型选择损失函数metrics=['mae'])# 训练模型model.fit(train_dataset,epochs=10,validation_data=eval_dataset)# 保存模型model.save(fn_args.serving_model_dir, save_format='tf')
5. 构建完整流水线
最后,我们将所有组件组合成一个完整的流水线:
def create_pipeline(pipeline_name,pipeline_root,data_root,module_file,serving_model_dir,metadata_path
):"""创建完整的TFX流水线Args:pipeline_name: 流水线名称pipeline_root: 流水线根目录data_root: 数据根目录module_file: 包含预处理和训练函数的模块serving_model_dir: 模型部署目录metadata_path: 元数据存储路径Returns:构建好的流水线"""# 1. 数据摄入组件example_gen = CsvExampleGen(input_base=data_root)# 2. 数据统计组件statistics_gen = StatisticsGen(examples=example_gen.outputs['examples'])# 3. 模式推断组件schema_gen = SchemaGen(statistics=statistics_gen.outputs['statistics'])# 4. 数据验证组件example_validator = ExampleValidator(statistics=statistics_gen.outputs['statistics'],schema=schema_gen.outputs['schema'])# 5. 特征转换组件transform = Transform(examples=example_gen.outputs['examples'],schema=schema_gen.outputs['schema'],module_file=module_file # 包含预处理函数的文件)# 6. 模型训练组件trainer = Trainer(module_file=module_file, # 包含训练函数的文件examples=transform.outputs['transformed_examples'],transform_graph=transform.outputs['transform_graph'],schema=schema_gen.outputs['schema'],train_args=tfx.proto.TrainArgs(num_steps=1000),eval_args=tfx.proto.EvalArgs(num_steps=500))# 7. 模型评估组件eval_config = tfma.EvalConfig(model_specs=[tfma.ModelSpec(label_key='target')],metrics_specs=[tfma.MetricsSpec(metrics=[tfma.MetricConfig(class_name='MeanSquaredError'),tfma.MetricConfig(class_name='MeanAbsoluteError')])],slicing_specs=[tfma.SlicingSpec()])evaluator = Evaluator(examples=example_gen.outputs['examples'],model=trainer.outputs['model'],eval_config=eval_config)# 8. 模型部署组件pusher = Pusher(model=trainer.outputs['model'],model_blessing=evaluator.outputs['blessing'],push_destination=tfx.proto.PushDestination(filesystem=tfx.proto.PushDestination.Filesystem(base_directory=serving_model_dir)))# 构建流水线components = [example_gen,statistics_gen,schema_gen,example_validator,transform,trainer,evaluator,pusher]return pipeline.Pipeline(pipeline_name=pipeline_name,pipeline_root=pipeline_root,components=components,metadata_connection_config=tfx.orchestration.metadata.sqlite_metadata_connection_config(metadata_path))
6. 执行流水线
最后一步是配置和执行流水线:
# 定义路径和配置
PIPELINE_NAME = "my_automl_pipeline"
PIPELINE_ROOT = "pipeline_output"
DATA_ROOT = "data/my_dataset"
MODULE_FILE = "my_pipeline_modules.py" # 包含预处理和训练函数的文件
SERVING_MODEL_DIR = "serving_model"
METADATA_PATH = "metadata.db"# 构建流水线
my_pipeline = create_pipeline(pipeline_name=PIPELINE_NAME,pipeline_root=PIPELINE_ROOT,data_root=DATA_ROOT,module_file=MODULE_FILE,serving_model_dir=SERVING_MODEL_DIR,metadata_path=METADATA_PATH
)# 执行流水线
LocalDagRunner().run(my_pipeline)
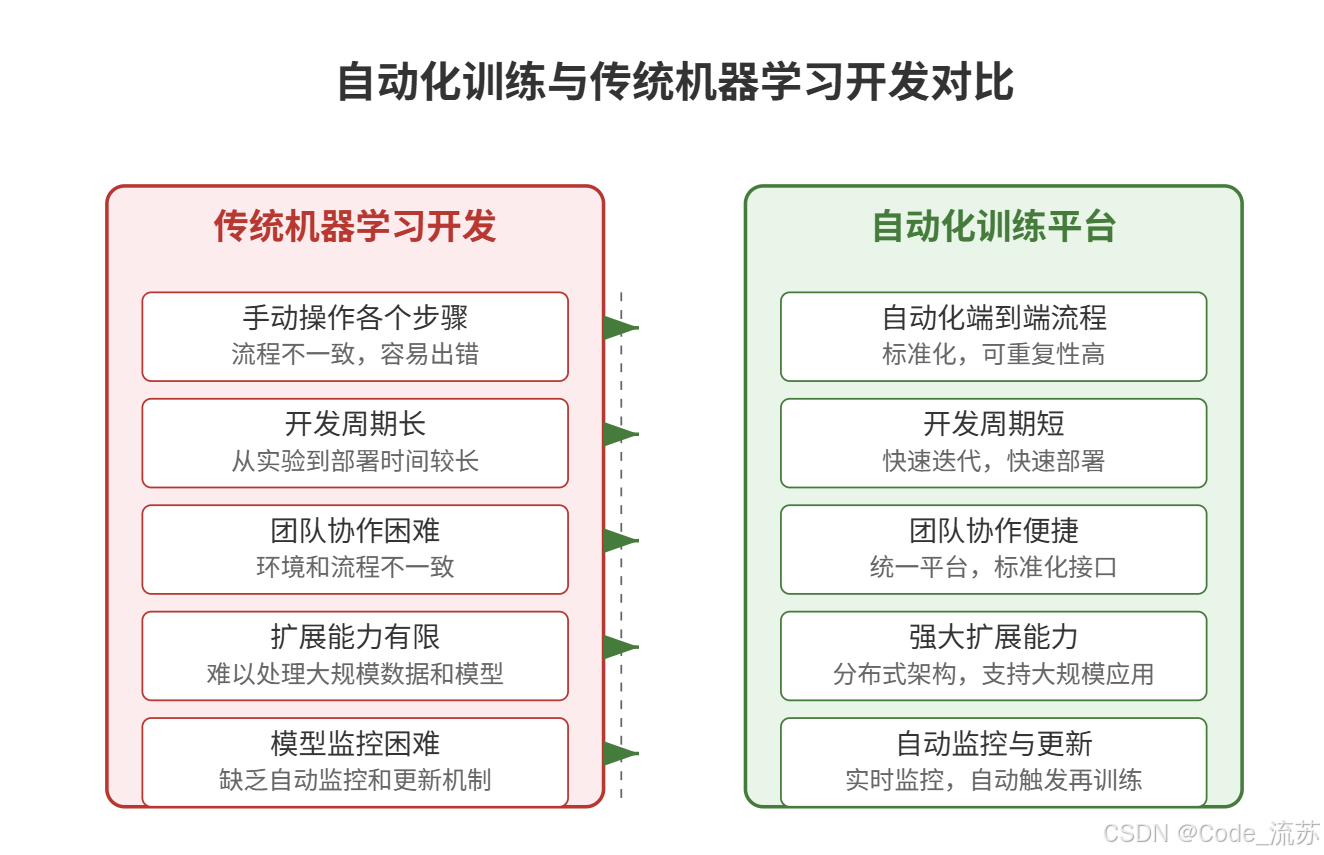
四、自动化训练平台的优势与挑战
1. 自动化训练的优势
自动化训练平台为机器学习项目带来了许多显著优势:
| 优势 | 描述 |
|---|---|
| 可重复性 | 流水线确保每次运行都遵循相同的流程,消除手动操作的不一致性 |
| 可追溯性 | 自动记录每次运行的所有步骤、参数和结果,便于审计和调试 |
| 效率提升 | 自动化重复任务,解放数据科学家专注于更有价值的工作 |
| 协作改进 | 标准化流程使团队成员更容易理解和贡献代码 |
| 扩展能力 | 能够处理更大规模的数据和更复杂的模型 |
| 快速迭代 | 缩短从实验到生产的时间,加速模型开发周期 |
2. 实施挑战与解决方案
尽管自动化训练平台带来了巨大好处,但实施过程中也会面临一些挑战:
-
学习曲线陡峭:Kubeflow和TFX等平台需要时间掌握
解决方案:从简单流水线开始,逐步增加复杂性;利用官方教程和示例
-
环境配置复杂:设置和维护基础设施可能很困难
解决方案:考虑使用托管服务如Google Cloud AI Platform或AWS SageMaker
-
版本兼容性问题:依赖项和框架版本冲突常见
解决方案:使用容器化技术如Docker隔离环境;详细记录依赖版本
-
调试困难:分布式流水线的错误可能难以诊断
解决方案:实现全面的日志记录;分阶段测试流水线组件
五、结语与展望
自动化训练平台正在彻底改变机器学习项目的开发和部署方式。通过将复杂的工作流程自动化,数据科学家可以专注于创造性工作,而不是繁琐的手动任务。
随着技术的发展,我们可以期待自动化平台变得更加易用、功能更强大。AutoML和低代码/无代码解决方案的兴起将进一步降低构建自动化流水线的门槛,使更多人能够参与到AI应用开发中。
今天我们学习了自动化训练平台的基础知识,包括Kubeflow Pipelines和TFX的介绍,以及如何构建一个简单的自动化流水线。在未来的章节中,我们将深入探讨更复杂的自动化训练场景和高级技术。
思考问题:你能想到在你当前的机器学习项目中,哪些环节最适合自动化?自动化这些环节可能会带来哪些好处和挑战?
祝你学习愉快,勇敢的Python星球探索者!👨🚀🌠
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
如果你对今天的内容有任何问题,或者想分享你的学习心得,欢迎在评论区留言讨论!
相关文章:

《Python星球日记》 第94天:走近自动化训练平台
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 一、自动化训练平台简介1. Kubeflow Pipelines2. TensorFlow Extended (TFX) 二…...

MetaMask安装及使用-使用水龙头获取测试币的坑?
常见的异常有: 1.unable to request drip, please try again later. 2.You must hold at least 1 LINK on Ethereum Mainnet to request native tokens. 3.The address provided does not have sufficient historical activity or balance on the Ethereum Mainne…...

软件架构之--论微服务的开发方法1
论微服务的开发方法1 摘要 2023年 2月,本人所在集团公司承接了长三角地区某省渔船图纸电子化审查系统项目开发,该项目旨在为长三角地区渔船建造设计院、以及渔船图纸审查机构提供一个便捷的渔船图纸电子化审查服务平台。在此项目中,我作为项目组成员参与项目的建设工作,并…...

SOLID 面对象设计的五大基本原则
SOLID 原则的价值 原则核心价值解决的问题SRP职责分离,提高内聚性代码臃肿、牵一发而动全身OCP通过扩展而非修改实现变化频繁修改现有代码导致的风险LSP确保子类行为的一致性继承滥用导致的系统不稳定ISP定制化接口,避免依赖冗余接口过大导致的实现负担…...

游戏引擎学习第293天:移动Familiars
回顾并为今天的内容定下基调 我们正在做一款完整的游戏,今天的重点是“移动模式”的正式化处理。目前虽然移动机制大致能运作,但写法相对粗糙,不够严谨,我们希望将其清理得更规范,更可靠一点。 目前脑逻辑࿰…...

《沙尘暴》观影记:当家庭成为人性的修罗场
起初点开《沙尘暴》,不过是想在碎片时间里寻个消遣,毕竟短剧的篇幅显得轻松无负担。未曾想,这看似简短的故事却如一场裹挟着砂砾的风暴,在心底掀起层层涟漪,让我忍不住在家庭教育、人性幽微处反复踱步沉思。 一、风暴眼…...

牛客网NC21989:牛牛学取余
牛客网NC21989:牛牛学取余 📝 题目描述 ⏱️ 限制条件 时间限制:C/C/Rust/Pascal 1秒,其他语言2秒空间限制:C/C/Rust/Pascal 32 M,其他语言64 M输入范围:两个整数,在int范围内 📥…...

王者荣耀游戏测试场景题
如何测试一个新英雄:方法论与实践维度 测试一个新英雄不仅仅是“打打打”,而是一套完整的测试流程,包括设计文档验证、功能验证、数值验证、性能验证、交互验证等。可以从以下多个角度展开: 🔍 1. 方法论维度 ✅ 测试…...
)
Spring Boot 与 RabbitMQ 的深度集成实践(二)
集成步骤详解 配置 RabbitMQ 连接信息 在 Spring Boot 项目中,通常在application.properties或application.yml文件中配置 RabbitMQ 的连接信息。以application.yml为例,配置如下: spring: rabbitmq: host: localhost port: 5672 usern…...

医疗信息系统安全防护体系的深度构建与理论实践融合
一、医疗数据访问系统的安全挑战与理论基础 1.1 系统架构安全需求分析 在医疗信息系统中,基于身份标识的信息查询功能通常采用分层架构设计,包括表现层、应用层和数据层。根据ISO/IEC 27001信息安全管理体系要求,此类系统需满足数据保密性…...
)
多模态大语言模型arxiv论文略读(八十)
## MMWorld: Towards Multi-discipline Multi-faceted World Model Evaluation in Videos ➡️ 论文标题:MMWorld: Towards Multi-discipline Multi-faceted World Model Evaluation in Videos ➡️ 论文作者:Xuehai He, Weixi Feng, Kaizhi Zheng, Yuji…...

FFmpeg:多媒体处理的终极利器
FFmpeg详细介绍 1. 定义与基本概述 FFmpeg是一套开源的跨平台多媒体处理工具集,最初由法国程序员Fabrice Bellard于2000年开发,其名称源自“Fast Forward MPEG”,体现了其高效处理MPEG格式的能力。它不仅是命令行工具,还包含多个库和开发套件,支持视频转码、剪辑、合并、…...

【Leetcode】取余/2的幂次方
给定一个非负整数 num,反复将各个位上的数字相加,直到结果为一位数。返回这个结果。 示例 1: 输入: num 38 输出: 2 解释: 各位相加的过程为: 38 --> 3 8 --> 11 11 --> 1 1 --> 2 由于 2 是一位数,所以返回 2。 …...

程序代码篇---ESP32的数据采集
文章目录 前言 前言 本文简单介绍了ESP32可以怎样采集数据。...
:虚拟机体系结构风格)
系统架构设计(十三):虚拟机体系结构风格
概念 虚拟机(Virtual Machine)体系结构风格,是指将整个系统抽象为一台“虚拟机”,通过解释或模拟的方式运行应用程序。 它本质上提供了一种“平台中立”的运行环境,典型代表就是 Java 虚拟机(JVM…...

lvs-dr部署
实验准备: 准备4台设备,1台作为客户机,3台作为服务器,服务器中1台作为调度器,2台作为后端真实访问服务器。并关闭所有防火墙与核心防护。 systemctl stop firewalld setenforce 0 实验开始 调度器配置 yum -y ins…...

数据库blog2_数据结构与效率
🌿计算机中的数据————存储结构与逻辑结构 🍂存储结构(物理结构) 定义:存储结构是指数据在计算机存储器中的实际存储方式,由计算机硬件特性决定。它涉及到数据的物理位置和存储顺序。存储结构直接影响数…...

聊天室项目总结
已实现的功能点: 存在的问题: 1.没有实现有含金量的创新功能点 2.太过于依赖工具,不喜欢自己看文章总结对知其然而不知其所以然,自己的理解比较少,懒于去思考 3.太过于依赖他人,自己的想法有点少&#x…...

数据结构:二叉树一文详解
数据结构:二叉树一文详解 前言一、二叉树的基本概念与结构特性1.1 二叉树的定义1.2 二叉树的特殊类型1.3 二叉树的性质 二、二叉树的遍历方式2.1 前序遍历(Pre-order Traversal)2.2 中序遍历(In-order Traversal)2.3 后序遍历&…...
---java版)
2025年- H28-Lc136- 24.两两交换链表中的节点(链表)---java版
1.题目描述 2.思路 cur指针要先放在虚拟头节点,才能去操作第一个数和第二个数 先判断偶数个节点,再判断奇数个节点,否则会犯空指针异常。 (1)如果节点是偶数个节点,只要满足curr.nextnull,就说…...

ubuntu18.04通过cuda_11.3_xxx.run安装失败,电脑黑屏解决办法
项目场景: ubuntu18.04跑DG-SLAM相关代码,安装lietorch包报错,需要用到GPU。 问题描述 跑代码需要cuda11.3,系统里面有另外一个版本,运行cuda_11.3_xxx.run,同时也选择了driver,安装成功后&am…...

Linux之基础IO
目录 一、理解 "文件" 1.1、狭义理解 1.2、广义理解 1.3、文件操作的归类认知 1.4、系统角度 二、回顾C语言接口 2.1、打开文件 2.2、写文件 2.3、读文件 2.4、stdin & stdout & stderr 2.6、打开文件的方式 三、系统文件I/O 3.1、一种传递标志…...

上位机知识篇---涂鸦智能云平台
文章目录 前言 前言 本文简单介绍了涂鸦智能云平台。...

InfluxDB 3 Core + Java 11 + Spring Boot:打造高效物联网数据平台
一、 引言:为什么选择InfluxDB 3? 项目背景: 在我们的隧道风机监控系统中,实时数据的采集、存储和高效查询是至关重要的核心需求。风机运行产生的振动、倾角、电流、温度等参数是典型的时序数据,具有高并发写入、数据…...
:容器网络接口 CNI)
Kubernetes控制平面组件:Kubelet详解(七):容器网络接口 CNI
云原生学习路线导航页(持续更新中) kubernetes学习系列快捷链接 Kubernetes架构原则和对象设计(一)Kubernetes架构原则和对象设计(二)Kubernetes架构原则和对象设计(三)Kubernetes控…...

Pandas 构建并评价聚类模型② 第六章
构建并评价聚类模型 构建并评价聚类模型一、数据读取与准备(代码6 - 6部分)结果代码解析 二、Kmeans聚类(代码6 - 6部分)结果代码解析 三、数据降维可视化(代码6 - 6部分)结果代码解析 四、FMI评价…...

【simulink】IEEE33节点系统潮流分析模型
目录 主要内容 程序内容 2.1 33节点simulink模型一览 2.2 节点模型图 下载链接 主要内容 该仿真采用simulink模型对33节点网络进行模拟仿真,在simulink模型中定义了33节点系统的电阻、电抗、节点连接关系等参数,通过控制块来实现信号连接关系&…...

彻底解决docker代理配置与无法拉取镜像问题
为什么会有这篇文章? 博主在去年为部署dify研究了docker,最后也是成功部署,但是因为众所周知的原因,卡ziji脖子 ,所以期间遇到各种网络问题的报错,好在最后解决了. 但时隔一年,博主最近因为学习原因又一次使用docker,原本解决的问题却又没来由的出现,且和之前有很多不同(有时…...

Linux 安装 Unreal Engine
需要对在unreal engine官网进行绑定github账号,然后到unreal engine github仓库中进行下载对应的版本,并进行安装unreal engine官网 github地址...

tensorflow图像分类预测
tensorflow图像分类预测 CPU版本和GPU版本二选一 CPU版本 pip -m install --upgrade pippip install matplotlib pillow scikit-learnpip install tensorflow-intel2.18.0GPU版本 工具 miniconda 升级依赖库 conda update --all创建目录 mkdir gpu-tf进入目录 cd gpu-tf创建虚…...

C++数组详解:一维和多维数组的定义、初始化、访问与遍历
1. 引言 数组是C中最基础的数据结构之一,用于存储相同类型的元素的集合。它提供了高效的内存访问方式,适用于需要快速查找和遍历数据的场景。本文将全面介绍: 一维数组的定义、初始化与遍历多维数组(如二维数组)的定…...

linux下编写shell脚本一键编译源码
0 前言 进行linux应用层编程时,经常会使用重复的命令对源码进行编译,然后把编译生成的可执行文件拷贝到工作目录,操作非常繁琐且容易出错。本文编写一个简单的shell脚本一键编译源码。 1 linux下编写shell脚本一键编译源码 shell脚本如下&…...
)
安卓端互动娱乐房卡系统调试实录:从UI到协议的万字深拆(第一章)
前言:调房卡,不如修空调(但更费脑) 老实说,拿到这套安卓端互动组件源码的时候,我内心是拒绝的。不是因为它不好,而是太好了,目录规整、界面精美、逻辑还算清晰,唯一的问…...

【通用大模型】Serper API 详解:搜索引擎数据获取的核心工具
Serper API 详解:搜索引擎数据获取的核心工具 一、Serper API 的定义与核心功能二、技术架构与核心优势2.1 技术实现原理2.2 对比传统方案的突破性优势 三、典型应用场景与代码示例3.1 SEO 监控系统3.2 竞品广告分析 四、使用成本与配额策略五、开发者注意事项六、替…...

宝塔面板屏蔽垃圾搜索引擎蜘蛛和扫描工具的办法
首先进入宝塔面板,文件管理进入/www/server/nginx/conf目录,新建空白文件kill_bot.conf。然后将以下代码保存到当前文件中。 #禁止垃圾搜索引擎蜘蛛抓取if ($http_user_agent ~* "CheckMarkNetwork|Synapse|Nimbostratus-Bot|Dark|scraper|LMAO|Ha…...

【低成本STM32的T-BOX开发实战:高可靠的车联网解决方案】
基于STM32的车辆远程通信终端(T-BOX)开发实战:低成本高可靠的车联网解决方案 目录 引言:为什么需要T-BOX?系统总体设计:T-BOX的架构与核心功能硬件设计:STM32主控与关键模块解析 STM32F105VCT6…...

聚类算法K-means和Dbscan的对比
K-means和DBSCAN_dbscan和kmeans的区别-CSDN博客...

mysql的高可用
1. 环境准备 2台MySQL服务器(node1: 192.168.1.101,node2: 192.168.1.102)2台HAProxy Keepalived服务器(haproxy1: 192.168.1.103,haproxy2: 192.168.1.104)虚拟IP(VIP: 192.168.1.100&#x…...

vue3 elementplus tabs切换实现
Tabs 标签页 | Element Plus <template><!-- editableTabsValue 是当前tab 的 name --><el-tabsv-model"editableTabsValue"type"border-card"editableedit"handleTabsEdit"><!-- 这个是标签面板 面板数据 遍历 editableT…...
)
printf在c语言中代表什么(非常详细)
在C语言中,有三个函数可以用来向控制台(可以理解为显示器或者屏幕)输出数据,它们分别是: 输出函数说明用法演示puts()只能输出字符串,并且输出结束后会自动换行puts("C language is great");put…...

Linux梦开始的地方
1.概率 经过C语言,数据结构,C的学习我们现在要开始学习Linux的学习了。我们学习Linux是从四部分来进行的: 1.Linux初识,Linux环境,Linux指令,Linux开发环境。 2.Linux系统。 3.Linux网络 4.MySQL Lin…...

关于机器学习的实际案例
以下是一些机器学习的实际案例: 营销与销售领域 - 推荐引擎:亚马逊、网飞等网站根据用户的品味、浏览历史和购物车历史进行推荐。 - 个性化营销:营销人员使用机器学习联系将产品留在购物车或退出网站的用户,根据客户兴趣定制营销…...
:切换docker运行时为containerd)
Kubernetes控制平面组件:Kubelet详解(五):切换docker运行时为containerd
云原生学习路线导航页(持续更新中) kubernetes学习系列快捷链接 Kubernetes架构原则和对象设计(一)Kubernetes架构原则和对象设计(二)Kubernetes架构原则和对象设计(三)Kubernetes控…...

<前端小白> 前端网页知识点总结
HTML 标签 1. 标题标签 h1到h6 2. 段落标签 p 3. 换行 br 水平线 hr 4. 加粗 strong 倾斜 em 下划线 ins 删除 del 5. 图像标签 img src-图像的位置 alt- 图片加载失败显示的文字 替换文本 title--- 鼠标放到图片上显示的文字 提示…...

【Linux驱动】Linux 按键驱动开发指南
Linux 按键驱动开发指南 1、按键驱动开发基础 1.1. 按键驱动类型 Linux下的按键驱动主要有两种实现方式: 输入子系统驱动:最常用,通过input子系统上报按键事件 字符设备驱动:较少用,需要自己实现文件操作接口 1.…...

AI日报 - 2025年05月19日
🌟 今日概览 (60秒速览) ▎🤖 大模型前沿 | GPT-5传闻再起,将基于全新模型构建,与GPT-4彻底分离;Claude 3.7 Sonnet系统提示泄露,揭示其主动引导对话、多语言支持及安全新特性;研究指出直接复用…...

BUUCTF——ReadlezPHP
BUUCTF——ReadlezPHP 进入靶场 看了看框架和源码信息 没有什么可以利用的地方 爆破一下目录看看 结果只出来个index.php 看了一下Findsomthing 报了个路径 /time.php?source拼接访问一下 出了个php代码 <?php #error_reporting(0); class HelloPhp {public $a;pub…...

java集合相关的api-总结
简介 集合是存储数据的容器,集合相关的API提供了不同的数据结构,来满足不同的需求。这里是对常见集合API的使用场景和相关源码的一个总结,在实际开发中,如果不知道该选择什么集合,这篇文章也许可以参考一下。 集合相…...

FloodFill算法:洪水般的图像处理艺术
简单来说就是一场洪水(雨水)会把低洼的地方淹没 也就是一道题,你要找出所有为负数的连通块,对角线不能连通,所以上述图有两个 其实也很简单,就是你扫描的过程,发现一个负数,就以这…...
)
【开源分享】健康饮食管理系统(双端+论文)
💻技术栈 前后端分离项目,PC双端(管理端用户端) 后端:Javaspringboot 前端:vue 数据库:mysql 💡运行效果图 1. 管理端: 2. 用户端: 📕源码获…...