从0到1吃透卷积神经网络(CNN):原理与实战全解析
一、开篇:CNN 在 AI 领域的地位
在当今人工智能(AI)飞速发展的时代,卷积神经网络(Convolutional Neural Network,简称 CNN)无疑是深度学习领域中最为耀眼的明星之一 。它就像是 AI 世界里的超级 “侦察兵”,在众多复杂的任务中发挥着至关重要的作用,尤其是在图像识别、目标检测、语义分割等计算机视觉领域,更是大放异彩。
当你打开手机相册,利用图像搜索功能快速找到特定照片时,背后很可能是 CNN 在助力;当自动驾驶汽车在道路上准确识别交通标志、行人以及其他车辆,从而安全行驶时,CNN 功不可没;在医疗领域,CNN 能够帮助医生从 X 光、CT 等医学影像中精准检测疾病,为患者的诊断和治疗提供有力支持 。这些令人惊叹的应用场景,都离不开卷积神经网络强大的能力。那么,CNN 究竟是如何做到这一切的呢?它的内部工作原理又隐藏着怎样的奥秘?接下来,就让我们一起深入探索卷积神经网络的奇妙世界。
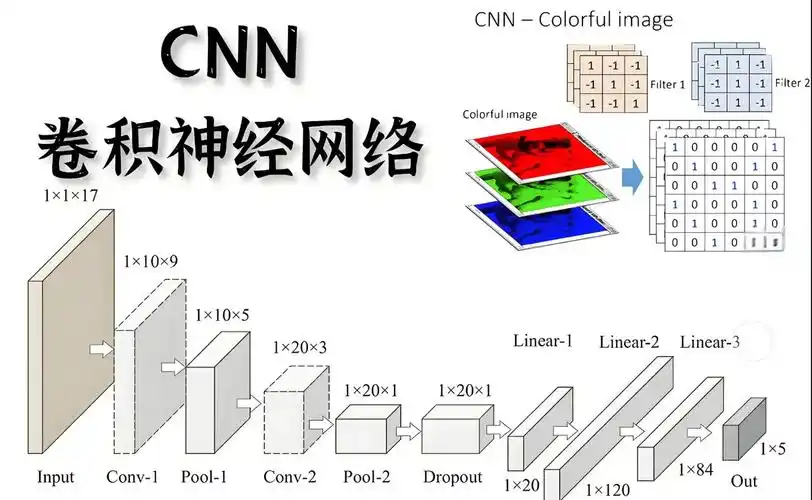
二、CNN 基础概念快速入门
2.1 定义与特点
卷积神经网络(Convolutional Neural Network,CNN)是一种专门为处理具有网格结构数据(如图像、音频)而设计的深度学习模型 ,是深度学习的代表算法之一。它通过卷积层中的卷积核与输入数据进行卷积操作,自动提取数据中的特征 。与传统神经网络相比,CNN 具有以下几个显著特点:
- 局部连接:在传统神经网络中,神经元之间是全连接的,这意味着每个神经元都与下一层的所有神经元相连,参数数量巨大,计算复杂度高。而 CNN 的卷积层中,每个神经元仅与输入数据的一个局部区域相连,例如在处理图像时,一个神经元只感受图像中的一个小区域(如 3x3 的像素区域),这种局部连接的方式大大减少了参数数量,降低了计算量 。比如,对于一张 100x100 像素的图像,如果使用全连接层,假设下一层有 100 个神经元,那么仅这一层的参数数量就达到 100x100x100 = 100 万;而采用 3x3 的卷积核进行局部连接,参数数量仅为 3x3 = 9,极大地减少了计算负担。
- 权值共享:同一个卷积核在整个输入数据上滑动进行卷积操作,其权重(权值)在不同位置是共享的。这一特性使得 CNN 在处理图像时,能够对不同位置的相同特征进行提取,而无需为每个位置学习一套独立的参数 。例如,在识别图像中的边缘特征时,无论边缘出现在图像的哪个位置,同一个边缘检测卷积核都能发挥作用,这不仅进一步减少了参数数量,还提高了模型的泛化能力 。如果没有权值共享,对于每个可能出现边缘的位置都需要单独的参数来检测,参数数量将呈指数级增长。
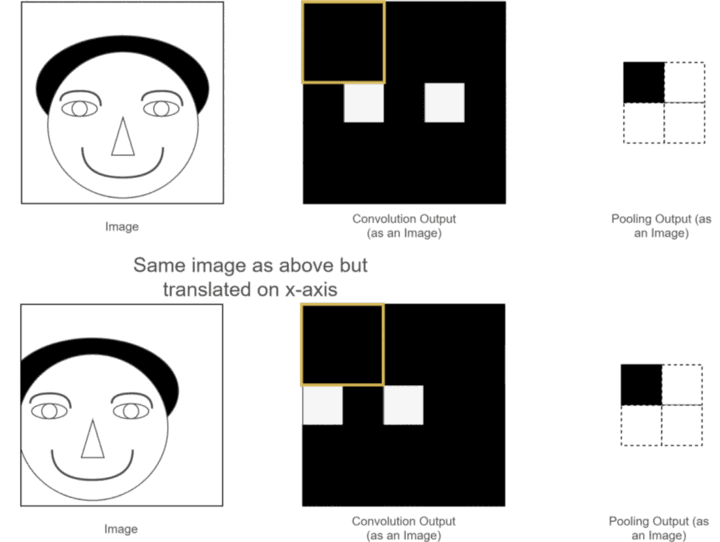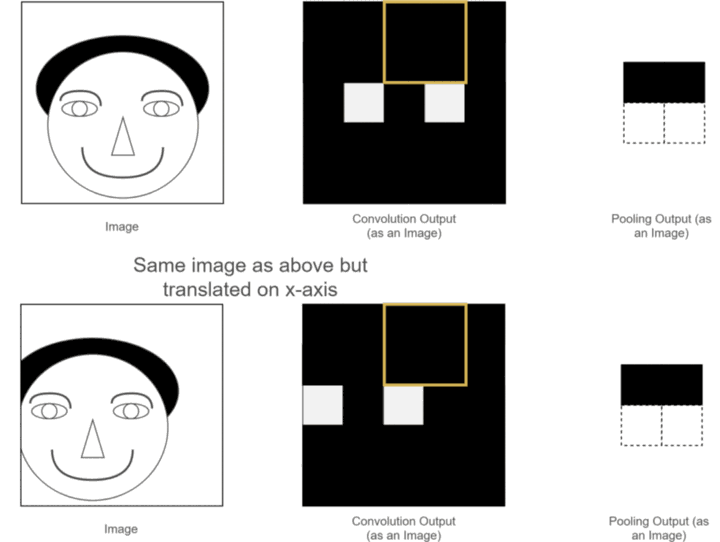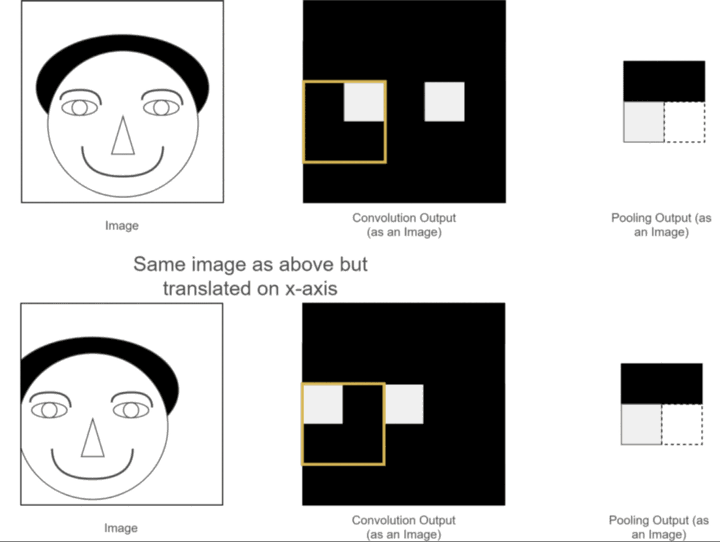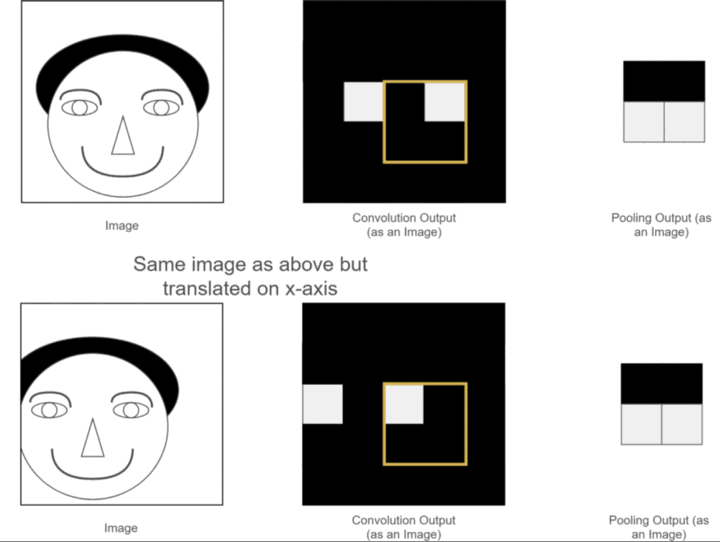
- 平移不变性:由于权值共享和局部连接的特性,CNN 对输入数据的平移具有不变性。也就是说,当图像中的物体发生平移时,CNN 提取到的特征不会发生改变,模型依然能够正确识别 。比如,一张猫的图像,无论猫在图像中是靠左还是靠右,CNN 都能提取到猫的关键特征,从而准确判断图像类别 。这种平移不变性使得 CNN 在图像识别任务中表现出色,能够适应不同位置的物体识别。
2.2 应用领域概览
CNN 凭借其强大的特征提取能力和对复杂数据的处理能力,在众多领域得到了广泛应用:
- 图像分类:这是 CNN 应用最为广泛的领域之一。CNN 可以自动学习图像中的特征,将图像分类到预定义的类别中,如识别手写数字、区分动物种类、判断交通标志等 。例如,在 MNIST 手写数字数据集上,CNN 能够达到非常高的准确率,将手写数字准确分类为 0 - 9 中的某一个数字 ;在 CIFAR - 10 数据集上,CNN 也能对飞机、汽车、鸟类等 10 类不同的物体图像进行有效分类。
- 目标检测:不仅要识别图像中的物体类别,还要确定物体在图像中的位置。CNN 通过滑动窗口、区域提议等方法,结合分类和回归任务,能够在图像中检测出多个目标,并标注出它们的边界框和类别 。在智能安防领域,CNN 可以实时检测监控视频中的人物、车辆等目标;在自动驾驶中,CNN 能够检测道路上的行人、车辆、交通标志等,为车辆的行驶决策提供重要依据 。像 Faster R - CNN、YOLO 等经典的目标检测算法都是基于 CNN 实现的。
- 图像分割:将图像中的不同物体或区域进行精确分割,为每个像素点分配所属的类别标签 。医学图像分析中,CNN 可以对 X 光、CT 等医学影像进行分割,帮助医生准确识别病变区域;在遥感图像领域,CNN 能够对土地利用类型、建筑物等进行分割 。U - Net 等网络结构在图像分割任务中表现卓越,能够实现高精度的图像分割。
- 语音识别:将语音信号转换为文本或命令。CNN 可以处理语音的时域和频域特征,学习语音中的模式和规律,实现语音识别 。常见的语音助手,如 Siri、小爱同学等,背后都可能运用了 CNN 技术来提高语音识别的准确率,实现人机自然交互 。通过对大量语音数据的训练,CNN 能够准确识别不同人的语音、不同口音的语音以及各种复杂环境下的语音。
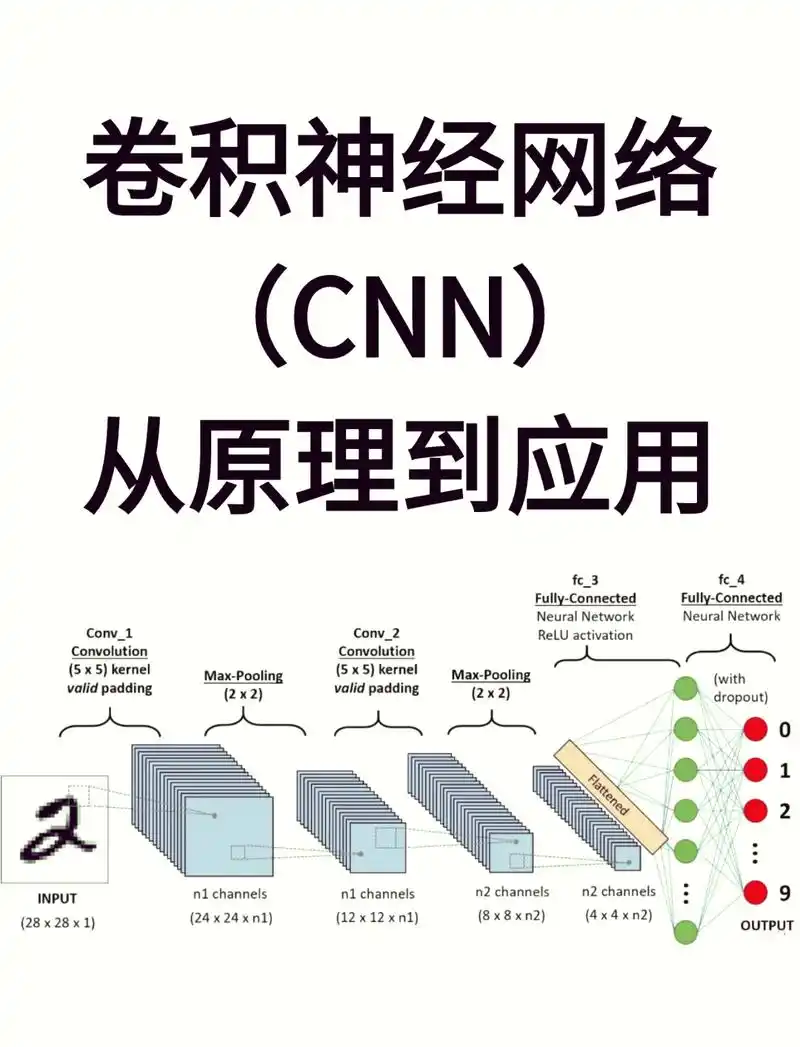
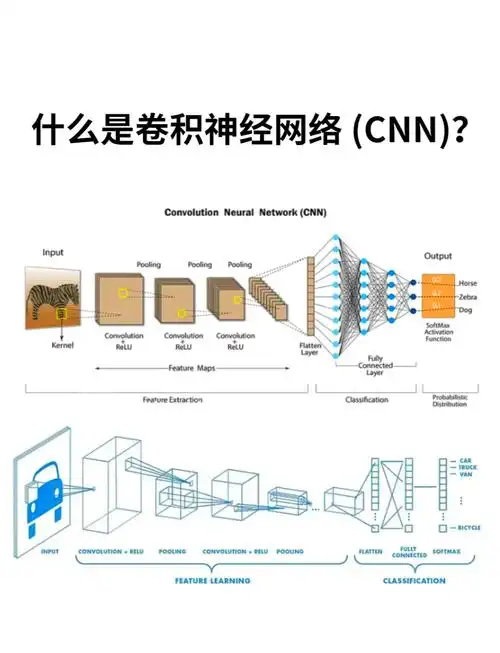
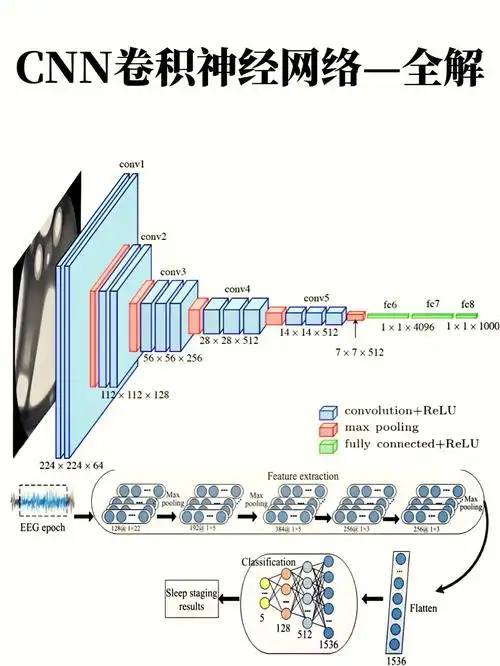
三、CNN 结构原理深度剖析
3.1 输入层:数据的起点
输入层是 CNN 处理数据的入口,它的主要作用是接收原始数据,并将其转换为适合后续层处理的格式 。对于图像数据而言,通常以多维数组的形式输入,比如常见的 RGB 彩色图像,其维度为 [高度,宽度,通道数],其中通道数为 3,分别对应红、绿、蓝三个颜色通道;灰度图像的通道数则为 1 。假设我们有一张尺寸为 224x224 的 RGB 图像,那么它在输入层的形状就是 [224, 224, 3]。
在数据进入后续层之前,往往需要进行一些预处理操作 。去均值操作是将图像中每个像素点的 RGB 值减去数据集的均值,这样可以使数据的中心分布在原点附近,有助于模型的收敛。归一化操作则是将像素值的范围缩放到特定区间,如 [0, 1] 或 [-1, 1],减少不同特征之间的尺度差异对模型训练的影响 。对于一张像素值范围在 0 - 255 的图像,将其每个像素值除以 255,就可以将其归一化到 [0, 1] 区间 。这些预处理步骤虽然看似简单,但对于提升模型的性能和稳定性至关重要。
3.2 卷积层:特征提取的核心
卷积层是 CNN 的核心组成部分,承担着特征提取的关键任务。它通过卷积核与输入数据的卷积操作,从原始数据中提取出各种有价值的特征 。
3.2.1 卷积操作详解
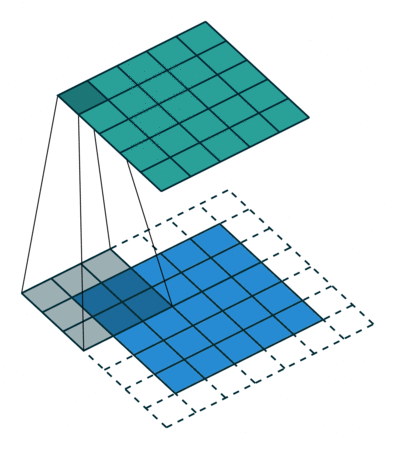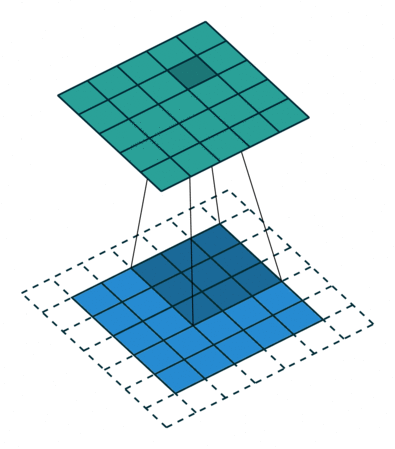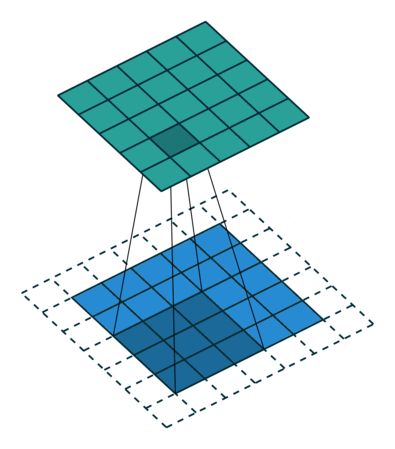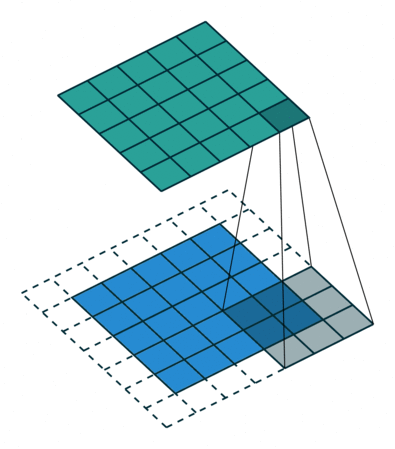
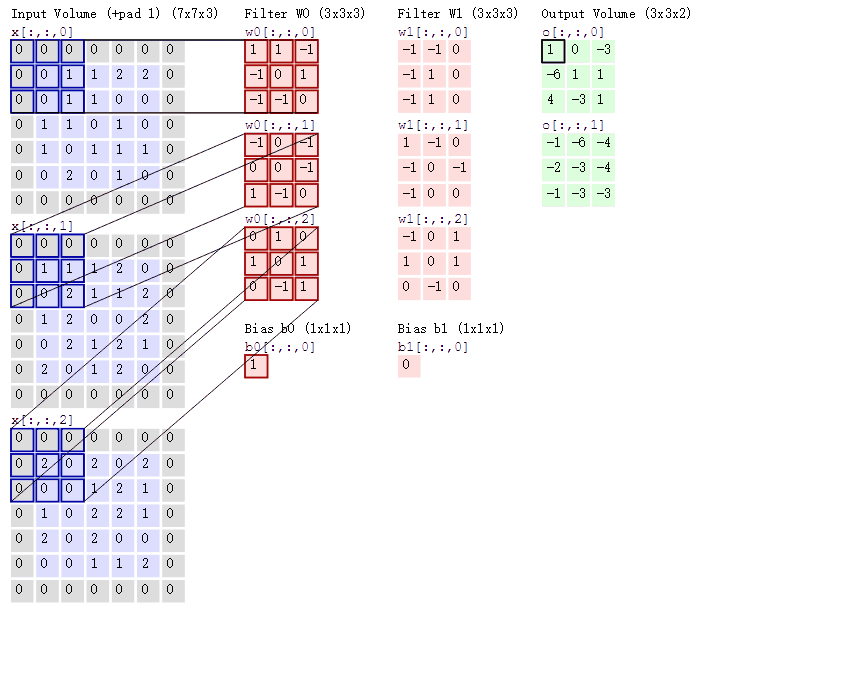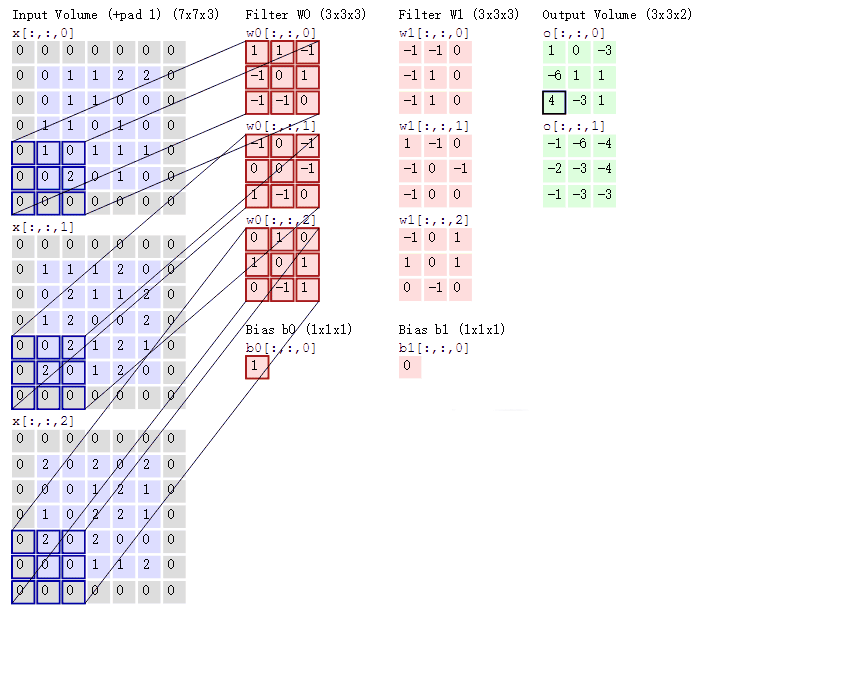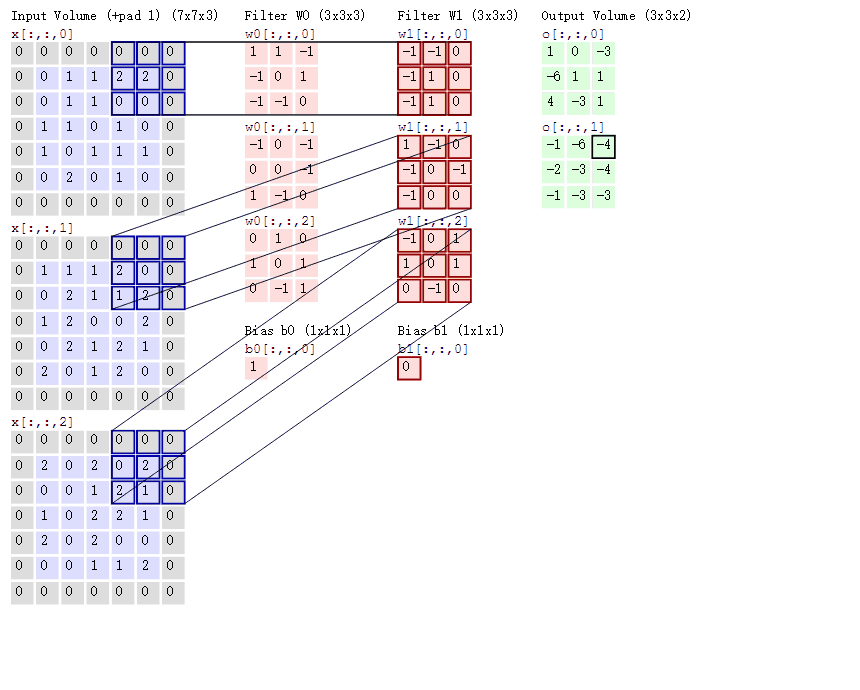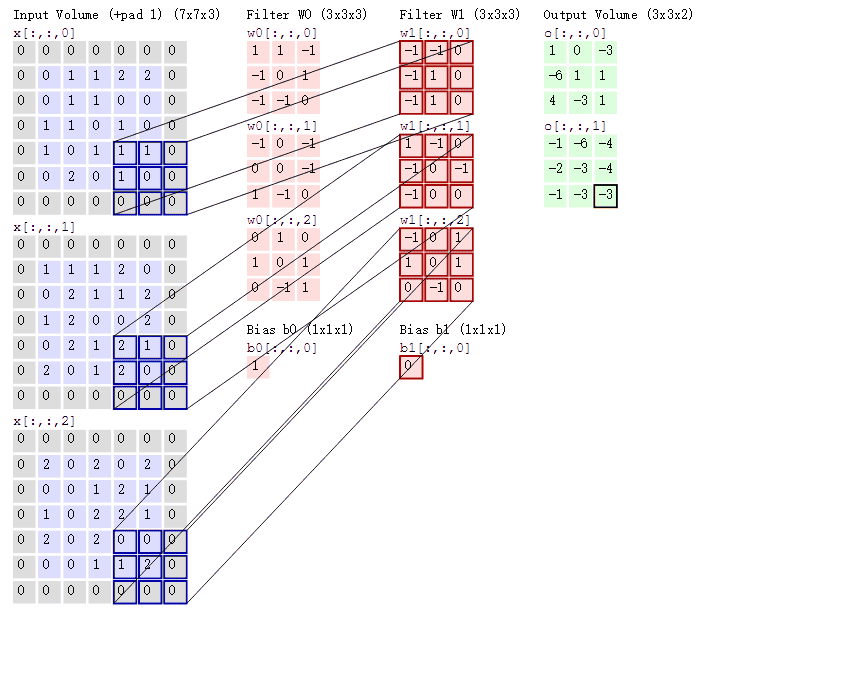
卷积操作的本质是一种数学运算,它通过卷积核在输入数据上的滑动,对局部区域的像素进行加权求和,从而生成新的特征图 。为了更直观地理解这个过程,我们来看下面这张示意图:
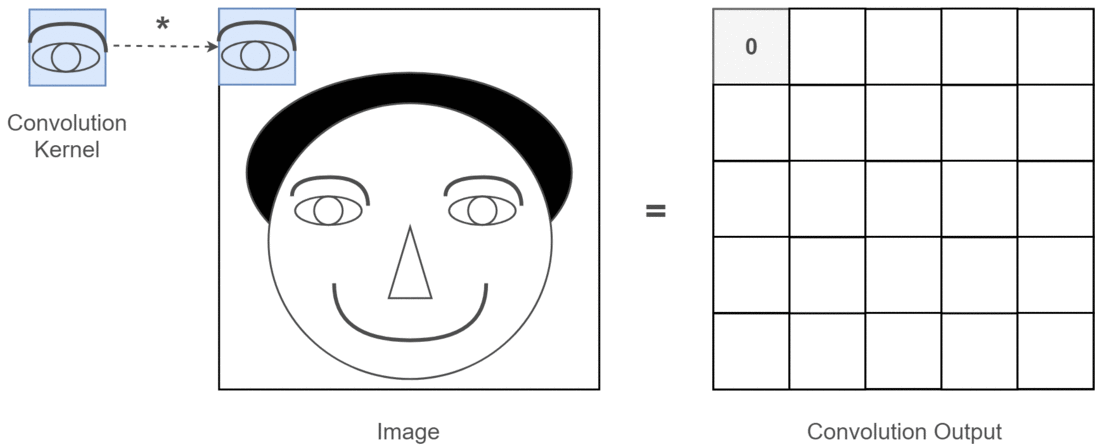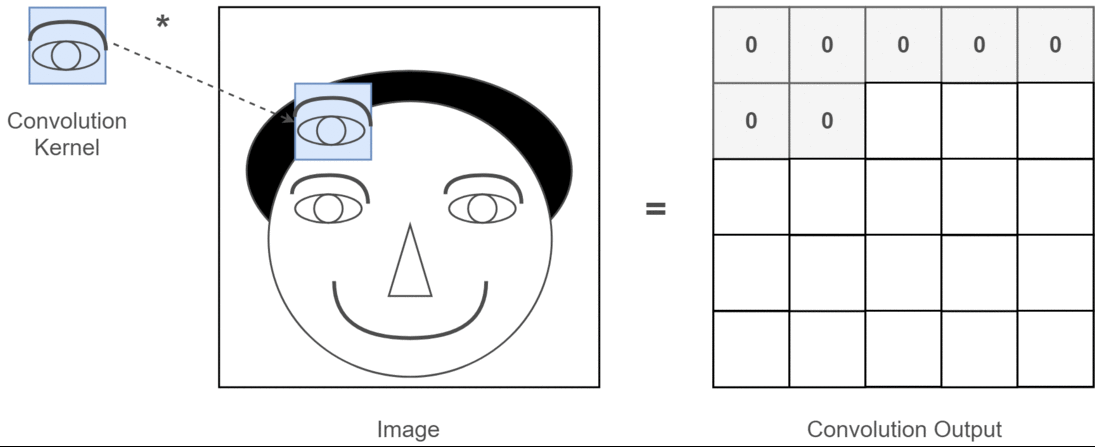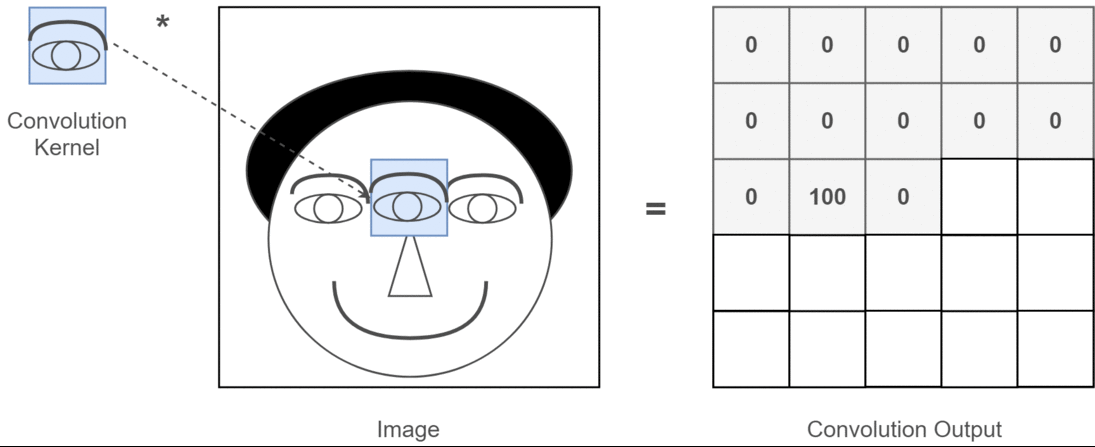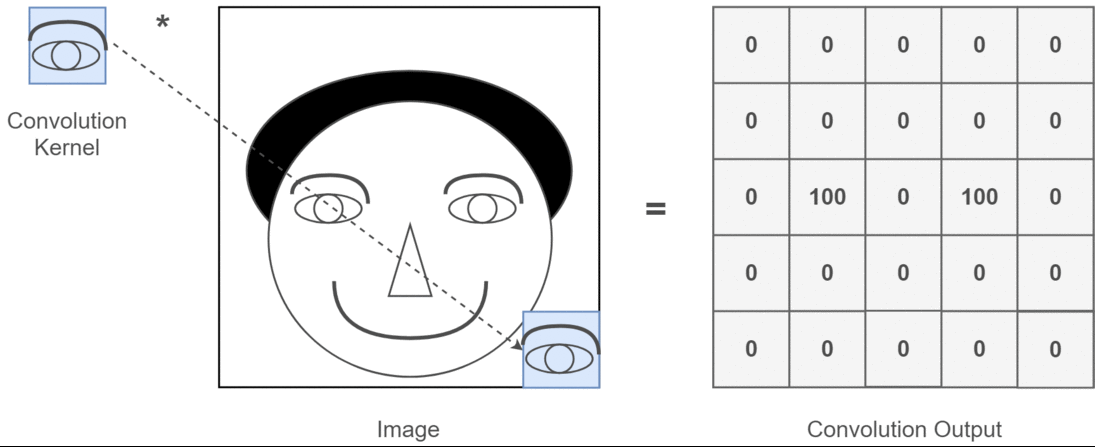
假设输入数据是一个 5x5 的二维矩阵,卷积核是一个 3x3 的矩阵 。在进行卷积时,卷积核从输入数据的左上角开始,依次与对应的 3x3 区域的元素进行对应位置相乘,然后将乘积结果相加,得到输出特征图中对应位置的一个值 。如上图中,卷积核与输入数据左上角 3x3 区域的计算过程为:(1x1 + 2x0 + 3x1 + 0x0 + 1x1 + 2x0 + 1x1 + 2x0 + 3x1) = 10,这个 10 就是输出特征图左上角的值 。接着,卷积核按照设定的步长(这里假设步长为 1)向右滑动一个位置,重复上述计算过程,直到遍历完整个输入数据,从而得到完整的输出特征图 。如果将这个过程制作成动画,会更清晰地看到卷积核是如何在输入数据上滑动并计算的,就像一个探测器在图像上扫描,寻找特定的模式和特征 。在实际的图像卷积中,输入数据通常是三维的(包含通道维度),卷积核也相应地是三维的,但基本原理与上述二维示例一致,只是在计算时需要对每个通道分别进行卷积操作,然后将结果进行叠加 。
3.2.2 卷积核参数解读
- 卷积核大小:指卷积核的宽度和高度,常见的有 3x3、5x5、7x7 等 。较小的卷积核(如 3x3)能够提取局部的细节特征,计算量相对较小,并且可以通过多层小卷积核的堆叠来增加感受野,同时引入更多的非线性变换 。在 VGG 网络中,就大量使用了 3x3 的卷积核,通过多个 3x3 卷积核的堆叠来替代大卷积核,既减少了参数数量,又提高了模型的表达能力 。而较大的卷积核(如 7x7)可以一次捕捉更大范围的特征,但计算量较大,参数也更多,通常在网络的较浅层用于快速提取一些全局特征 。在 AlexNet 中,第一层就使用了 11x11 的大卷积核,用于快速提取图像中的显著特征 。
- 步长:卷积核在输入数据上滑动时每次移动的像素数 。步长为 1 时,卷积核逐像素滑动,能够保留更多的细节信息,输出特征图的尺寸相对较大;步长为 2 时,卷积核每次移动 2 个像素,输出特征图的尺寸会减半,计算量也相应减少,但可能会丢失一些细节 。在目标检测任务中,为了快速缩小特征图尺寸,减少计算量,常常会使用步长为 2 的卷积操作 。步长大于 2 的情况相对较少使用,因为可能会丢失过多的信息,但在某些对计算效率要求极高的场景下,也会被采用 。
- 填充:在输入数据的边缘添加额外的像素,通常是填充 0,目的是控制输出特征图的大小,避免在卷积过程中由于卷积核无法完全覆盖边缘区域而导致边缘信息丢失 。当填充为 0 时,输出特征图的尺寸会小于输入数据;当填充值合适时,可以使输出特征图的尺寸与输入数据相同 。对于一个 6x6 的输入数据,使用 3x3 的卷积核,步长为 1,若不进行填充,输出特征图的尺寸为 4x4;若填充 1 圈(即填充值为 1),输出特征图的尺寸则为 6x6 。
- 输入 / 输出通道数:输入通道数与输入数据的通道数一致,如 RGB 图像的输入通道数为 3 。输出通道数则表示卷积层输出的特征图的数量,每个输出通道对应一个不同的卷积核,每个卷积核学习到的特征不同 。在一个卷积层中设置 64 个输出通道,就意味着有 64 个不同的卷积核在对输入数据进行特征提取,每个卷积核提取到的特征图都包含了输入数据的不同方面的信息,这些特征图共同构成了该卷积层的输出 。
3.3 激活函数:引入非线性
在卷积层提取到线性特征后,激活函数的作用就凸显出来了。它为神经网络引入了非线性因素,使得模型能够学习和表示更加复杂的函数关系,大大增强了模型的表达能力 。如果没有激活函数,无论神经网络有多少层,其输出都只是输入的线性组合,这就相当于只有一个隐藏层的神经网络,无法处理复杂的任务 。
常见的激活函数有 ReLU(Rectified Linear Unit)、Sigmoid、Tanh(双曲正切)等 :
- ReLU:数学表达式为\(f(x) = max(0, x)\),即当\(x\)大于 0 时,输出为\(x\);当\(x\)小于等于 0 时,输出为 0 。它的优点十分显著,计算简单,收敛速度快,能够有效缓解梯度消失问题 。在深层神经网络中,使用 ReLU 作为激活函数,训练速度比使用 Sigmoid 等函数快很多 。但它也存在一些缺点,当\(x\)小于 0 时,神经元会处于 “死亡” 状态,即梯度为 0,在训练过程中无法更新参数 。如果学习率设置不当,可能会导致大量神经元死亡,从而影响模型性能 。为了解决这个问题,出现了一些 ReLU 的变体,如 Leaky ReLU,它在\(x\)小于 0 时,会给予一个很小的非零梯度,避免神经元完全死亡 。
- Sigmoid:公式为\(f(x) = \frac{1}{1 + e^{-x}}\),它将输入值映射到 (0, 1) 区间 。Sigmoid 函数在早期的神经网络中应用广泛,其输出可以看作是概率值,在二分类任务的输出层经常使用 。它存在严重的梯度消失问题,当输入值较大或较小时,函数处于饱和区,梯度接近 0,导致在反向传播过程中,参数更新缓慢甚至无法更新 。Sigmoid 函数的输出不是以 0 为中心的,这会导致后续网络层的输入数据分布出现偏移,影响梯度下降的效率 。
- Tanh:表达式为\(f(x) = \frac{e^{x} - e^{-x}}{e^{x} + e^{-x}}\),输出范围是 (-1, 1),是以 0 为中心的 。与 Sigmoid 相比,Tanh 的收敛速度更快,在循环神经网络(RNN)中表现较好 。它同样存在梯度消失问题,在深层网络中,随着层数的增加,梯度会逐渐变小,不利于模型的训练 。
3.4 池化层:降维与抗过拟合
池化层位于卷积层之后,主要作用是对特征图进行降维处理,减少数据量和计算量,同时在一定程度上防止过拟合,提高模型的泛化能力 。
3.4.1 最大池化与平均池化
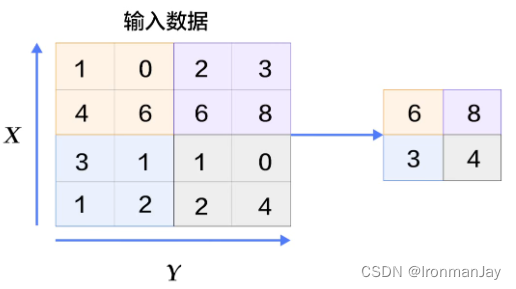
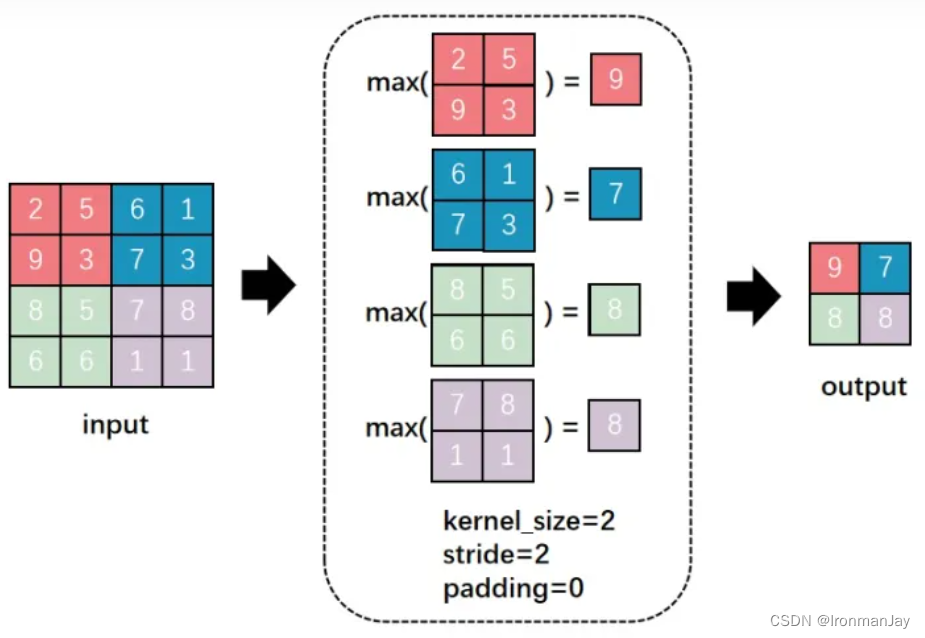
- 最大池化:操作方式是将特征图划分为一个个固定大小的池化窗口(如 2x2、3x3),在每个窗口内选取最大值作为输出 。对于一个 4x4 的特征图,使用 2x2 的池化窗口,步长为 2,第一个池化窗口包含左上角的 2x2 区域,其中最大值为 9,那么这个 9 就是输出特征图左上角的值 。依次对整个特征图进行这样的操作,就可以得到降维后的输出 。最大池化能够保留特征图中的显著特征,因为它选取的是每个区域内的最大值,这些最大值往往代表了图像中最突出的特征,对于图像中的小位移和变形具有一定的鲁棒性 。在图像识别中,即使物体在图像中的位置有轻微变化,最大池化也能提取到关键特征 。
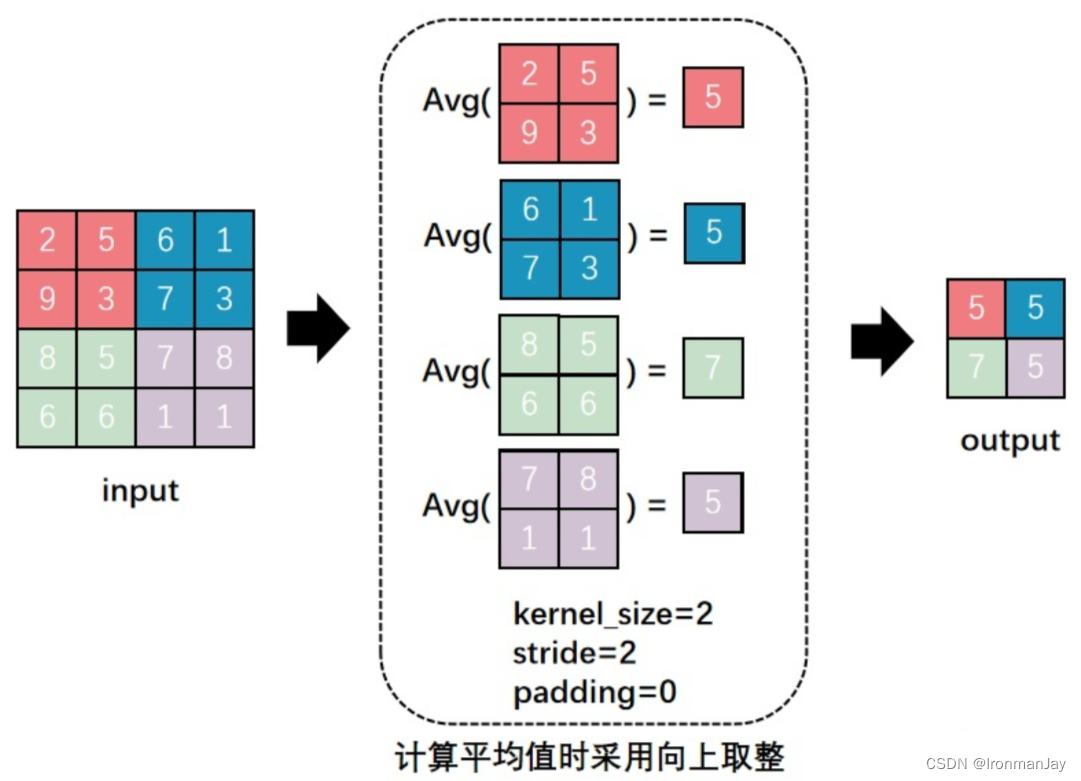
- 平均池化:则是计算每个池化窗口内所有元素的平均值作为输出 。同样以 4x4 的特征图和 2x2 的池化窗口为例,第一个池化窗口内元素的平均值为 (1 + 2 + 4 + 5) / 4 = 3,这个 3 就是输出特征图左上角的值 。平均池化可以平滑特征图,减少噪声的影响,但相比最大池化,它可能会丢失一些重要的细节信息 。在一些对图像细节要求不高,更注重整体特征的任务中,平均池化可能会有较好的表现 。
3.4.2 池化的作用
- 减少参数:通过降低特征图的尺寸,减少了后续全连接层的参数数量 。假设一个特征图的尺寸为 100x100,经过 2x2 的最大池化(步长为 2)后,尺寸变为 50x50,这样在与全连接层连接时,参数数量会大幅减少,从而降低了模型的复杂度和计算量 。
- 降低计算量:较小的特征图在后续的计算中,无论是与其他层的运算还是参数更新,计算量都会相应减少,提高了模型的训练和推理速度 。在实时性要求较高的应用中,如自动驾驶的实时目标检测,减少计算量可以使模型更快地做出决策 。
- 防止过拟合:池化层通过对特征进行聚合,使得模型对特征的具体位置不那么敏感,从而增强了模型的泛化能力,降低了过拟合的风险 。它相当于为模型增加了一种先验知识,即图像中的重要特征在不同位置出现时都应该被识别,而不仅仅是在特定的精确位置 。
3.5 全连接层:整合特征与分类
全连接层位于 CNN 的末端,它的主要任务是将前面卷积层和池化层提取到的局部特征进行整合,形成一个全局的特征表示,然后将其映射到最终的输出类别上,用于分类或回归任务 。
在经过一系列的卷积和池化操作后,特征图被转换为了一个一维的特征向量 。全连接层中的每个神经元都与上一层的所有神经元相连,通过权重矩阵和偏置项对输入的特征向量进行线性变换 。假设上一层输出的特征向量长度为 1000,全连接层有 10 个神经元,那么就会有一个 10x1000 的权重矩阵,将特征向量与权重矩阵相乘,再加上偏置项,得到一个长度为 10 的输出向量 。这个输出向量经过激活函数(如 Softmax 用于分类任务)的处理后,就可以得到每个类别的预测概率 。在一个图像分类任务中,全连接层将前面提取到的图像特征进行综合分析,判断图像属于不同类别的可能性,最终输出图像属于每个类别的概率,概率最大的类别就是模型的预测结果 。全连接层的参数数量通常较多,在训练过程中需要大量的计算资源,同时也容易出现过拟合,因此常常会结合 Dropout 等正则化技术来防止过拟合 。
3.6 输出层:任务的终点
输出层是 CNN 模型的最后一层,它的形式和作用取决于具体的任务 。
- 分类任务:最常用的输出层形式是使用 Softmax 激活函数 。Softmax 函数将全连接层输出的数值转换为概率分布,使得所有类别的概率之和为 1 。对于一个 10 分类的图像识别任务,输出层有 10 个神经元,每个神经元的输出表示图像属于对应类别的概率 。如果第一个神经元的输出为 0.8,第二个神经元的输出为 0.1,以此类推,那么模型认为图像属于第一个类别的概率最高,即预测图像为第一个类别 。
- 回归任务:输出层通常只包含一个神经元,且不使用激活函数(或使用线性激活函数),直接输出一个连续的数值 。在预测房价的任务中,输出层的神经元输出的数值就是预测的房价 。此时,模型的损失函数通常采用均方误差(MSE)等回归损失函数,用于衡量预测值与真实值之间的差异,通过最小化损失函数来调整模型的参数 。
四、CNN 前向传播与反向传播原理
4.1 前向传播:信息的流动
前向传播是 CNN 处理数据的正向过程,数据从输入层开始,依次经过卷积层、激活函数层、池化层和全连接层等,最终在输出层得到预测结果 。这一过程就像是一条生产线,数据在各个环节中逐步被加工和处理,从原始的输入逐渐转化为有价值的输出 。
当一张图像作为输入数据进入 CNN 时,首先在输入层进行预处理,如归一化、去均值等操作,使其符合后续层的处理要求 。接着,数据进入卷积层,卷积核在输入数据上滑动进行卷积操作,提取出各种局部特征,生成特征图 。假设有一个 3x3 的卷积核在一张 6x6 的图像上进行卷积,步长为 1,填充为 0,经过卷积操作后,会得到一个 4x4 的特征图,这个特征图中每个元素都包含了原始图像局部区域的特征信息 。
特征图经过卷积层提取后,会进入激活函数层 。以 ReLU 激活函数为例,它会对特征图中的每个元素进行处理,将小于 0 的值置为 0,大于 0 的值保持不变,从而为模型引入非线性因素 。这样处理后的特征图能够表达更加复杂的函数关系,增强模型的学习能力 。
随后,激活函数处理后的特征图进入池化层 。如果采用 2x2 的最大池化窗口,步长为 2,对前面得到的 4x4 特征图进行池化操作,会得到一个 2x2 的池化结果 。池化层通过对特征图进行降维,减少了数据量和计算量,同时在一定程度上增强了模型对图像中物体位置变化的鲁棒性 。
经过多次卷积、激活和池化操作后,数据会进入全连接层 。全连接层将前面得到的特征图展平为一维向量,并通过权重矩阵和偏置项进行线性变换,将其映射到最终的输出空间 。如果是一个 10 分类的任务,全连接层的输出维度通常为 10,每个维度代表了图像属于对应类别的得分 。
最后,全连接层的输出进入输出层 。在分类任务中,输出层一般使用 Softmax 激活函数,将得分转换为概率分布,得到图像属于各个类别的概率 。概率最大的类别就是模型对输入图像的预测类别 。
4.2 反向传播:参数的优化
反向传播是 CNN 训练过程中的关键环节,其目的是通过计算损失函数对网络参数(如卷积核权重、全连接层权重等)的梯度,来更新这些参数,使得模型的预测结果与真实标签之间的差距(即损失函数值)不断减小,从而优化模型的性能 。
在反向传播过程中,首先需要计算损失函数 。在分类任务中,常用的损失函数是交叉熵损失函数,它能够衡量模型预测的概率分布与真实标签之间的差异 。对于一个样本,其交叉熵损失的计算公式为\(L = -\\sum_{i=1}^{C}y_{i}\\log(\\hat{y}_{i})\),其中\(y_{i}\)是真实标签中第\(i\)类的概率(通常为 0 或 1),\(\\hat{y}_{i}\)是模型预测的第\(i\)类的概率,\(C\)是类别总数 。通过对所有样本的损失进行求和并取平均,就得到了整个训练批次的损失值 。
计算出损失函数后,接下来利用链式法则从输出层开始,逐层向前计算损失函数对各层参数的梯度 。以全连接层为例,假设全连接层的输入为\(X\),权重矩阵为\(W\),偏置为\(b\),输出为\(Y\),激活函数为\(f\) 。首先计算损失函数对输出\(Y\)的梯度\(\\frac{\\partial L}{\\partial Y}\),然后根据链式法则计算对权重\(W\)的梯度\(\\frac{\\partial L}{\\partial W} = \\frac{\\partial L}{\\partial Y}X^{T}\),以及对偏置\(b\)的梯度\(\\frac{\\partial L}{\\partial b} = \\frac{\\partial L}{\\partial Y}\) 。
对于卷积层,计算梯度的过程相对复杂一些 。它需要将梯度与输入特征图进行卷积操作,以得到对卷积核权重的梯度 。同时,还需要将梯度传播给下一层(即更靠近输入层的层),这通常通过转置卷积操作实现 。转置卷积可以看作是卷积操作的逆过程,用于上采样特征图,将梯度正确地传播回前一层 。
在池化层反向传播时,对于最大池化,梯度只传递给产生最大值的神经元,因为在正向过程中只有最大值被保留,其他位置的信息被丢弃;对于平均池化,梯度会平均分配给池化窗口内的所有神经元 。
计算得到各层参数的梯度后,就可以使用优化算法(如随机梯度下降 SGD、Adam 等)来更新参数 。以随机梯度下降为例,其参数更新公式为\(W = W - \\eta\\frac{\\partial L}{\\partial W}\),\(b = b - \\eta\\frac{\\partial L}{\\partial b}\),其中\(\\eta\)是学习率,控制着参数更新的步长 。通过不断地重复前向传播、计算损失、反向传播和参数更新的过程,模型的参数会逐渐调整到最优值,使得模型在训练集上的损失不断降低,在测试集上的性能不断提高 。
五、经典 CNN 模型案例分析
5.1 LeNet - 5:CNN 的开山之作
LeNet - 5 由 Yann LeCun 于 1998 年提出,是卷积神经网络发展历程中的开山之作,它的出现为后续 CNN 的发展奠定了坚实的基础,就像一座灯塔,照亮了深度学习在图像识别领域的探索之路 。在当时,手写数字识别是一个极具挑战性的任务,LeNet - 5 的诞生为解决这个问题提供了全新的思路和方法 。
LeNet - 5 的网络结构相对简洁,但却包含了 CNN 的基本组件 。它的输入是 32x32 像素的手写数字图像,经过一系列的卷积、池化和全连接层的处理,最终输出 10 个类别(对应数字 0 - 9)的预测结果 。具体结构如下:
- 卷积层 C1:使用 6 个 5x5 大小的卷积核,步长为 1,无填充 。经过卷积操作后,输出 6 个 28x28 大小的特征图 。这一层的作用是提取图像中的低级特征,如边缘、线条等 。可以将这些卷积核想象成不同的探测器,每个探测器在图像上滑动,寻找特定的模式 。
- 池化层 S2:采用 2x2 大小的池化窗口,步长为 2 的平均池化操作 。输出 6 个 14x14 大小的特征图 。池化层通过对特征图进行下采样,减少数据量,同时在一定程度上增强模型对图像中物体位置变化的鲁棒性 。就像是对图像进行了一次 “压缩”,保留了主要的特征信息 。
- 卷积层 C3:使用 16 个 5x5 大小的卷积核,步长为 1,无填充 。输出 16 个 10x10 大小的特征图 。这一层进一步提取更复杂的特征,通过不同卷积核的组合,学习到图像中更高级的特征表示 。
- 池化层 S4:同样采用 2x2 大小的池化窗口,步长为 2 的平均池化 。输出 16 个 5x5 大小的特征图 。再次对特征图进行降维,减少计算量 。
- 卷积层 C5:使用 120 个 5x5 大小的卷积核,步长为 1,无填充 。由于输入的 5x5 特征图与卷积核大小相同,经过卷积后,输出 120 个 1x1 大小的特征图,这一层也可看作是全连接层 。它将前面提取到的特征进行了整合,形成了一个更紧凑的特征表示 。
- 全连接层 F6:包含 84 个神经元,与 C5 层的 120 个特征图全连接 。对特征进行进一步的处理和映射,为最终的分类做准备 。
- 输出层:采用 Softmax 激活函数,输出 10 个类别(对应数字 0 - 9)的概率分布 。模型根据概率最大的类别来预测输入图像中的手写数字 。
在手写数字识别任务中,LeNet - 5 展现出了卓越的性能 。它通过卷积层的局部连接和权值共享机制,有效地提取了手写数字的关键特征,同时池化层的降维操作减少了计算量,提高了模型的泛化能力 。在 MNIST 手写数字数据集上,LeNet - 5 能够达到很高的准确率,将手写数字准确分类为 0 - 9 中的某一个数字 。这一成果不仅证明了 CNN 在图像识别任务中的有效性,也为后续研究人员提供了宝贵的经验和借鉴,激励着他们不断探索和改进 CNN 的结构与算法 。
5.2 AlexNet:开启深度学习新时代
AlexNet 由 Alex Krizhevsky 等人于 2012 年提出,它在当年的 ImageNet 大规模视觉识别挑战赛(ILSVRC)中以巨大优势夺冠,其 top - 5 错误率比第二名低了 10.9 个百分点,这一成绩震惊了学术界和工业界,也标志着深度学习在计算机视觉领域的崛起,开启了深度学习的新时代 。在此之前,传统的机器学习方法在图像识别任务中面临着诸多挑战,而 AlexNet 的出现打破了这一僵局,为图像识别技术带来了革命性的突破 。
AlexNet 的网络结构在当时具有创新性和先进性 ,它包含 5 个卷积层和 3 个全连接层,具体结构如下:
- 输入层:输入为 224x224x3 的 RGB 图像 。
- 卷积层 Conv1:使用 96 个 11x11 大小的卷积核,步长为 4,填充为 2 。输出 96 个 55x55 大小的特征图 。这一层通过大卷积核快速提取图像中的显著特征,感受野较大,能够捕捉到图像中较大范围的信息 。
- 池化层 MaxPool1:采用 3x3 大小的池化窗口,步长为 2 的最大池化操作 。输出 96 个 27x27 大小的特征图 。通过最大池化,保留了每个区域内的最大值,即最显著的特征,同时减少了数据量 。
- 卷积层 Conv2:使用 256 个 5x5 大小的卷积核,步长为 1,填充为 2 。输出 256 个 27x27 大小的特征图 。进一步提取更精细的特征,增加了特征的多样性 。
- 池化层 MaxPool2:同样采用 3x3 大小的池化窗口,步长为 2 的最大池化 。输出 256 个 13x13 大小的特征图 。再次对特征图进行降维,减少计算量 。
- 卷积层 Conv3:使用 384 个 3x3 大小的卷积核,步长为 1,填充为 1 。输出 384 个 13x13 大小的特征图 。通过多个小卷积核的堆叠,增加了网络的非线性和表达能力 。
- 卷积层 Conv4:使用 384 个 3x3 大小的卷积核,步长为 1,填充为 1 。输出 384 个 13x13 大小的特征图 。继续提取更高级的特征 。
- 卷积层 Conv5:使用 256 个 3x3 大小的卷积核,步长为 1,填充为 1 。输出 256 个 13x13 大小的特征图 。对特征进行进一步的细化和整合 。
- 池化层 MaxPool3:采用 3x3 大小的池化窗口,步长为 2 的最大池化 。输出 256 个 6x6 大小的特征图 。
- 全连接层 FC6:将池化后的特征图展平为一维向量,与 4096 个神经元全连接 。对特征进行综合处理,形成更抽象的特征表示 。
- 全连接层 FC7:包含 4096 个神经元,与 FC6 层全连接 。进一步对特征进行映射和变换 。
- 输出层 FC8:采用 Softmax 激活函数,输出 1000 个类别的概率分布 。用于图像分类任务,判断图像属于 1000 个类别中的哪一类 。
AlexNet 的创新点众多,对深度学习的发展产生了深远的影响:
- ReLU 激活函数:采用 ReLU(Rectified Linear Unit)作为激活函数,解决了 Sigmoid 函数在网络较深时出现的梯度消失问题 。ReLU 函数的计算简单,收敛速度快,使得模型的训练更加高效 。在 AlexNet 之前,Sigmoid 函数是常用的激活函数,但由于其在输入值较大或较小时,梯度接近 0,导致在反向传播过程中,参数更新缓慢甚至无法更新 。而 ReLU 函数在正半轴的梯度恒为 1,能够有效避免梯度消失问题,大大提高了模型的训练速度和性能 。
- Dropout 技术:在全连接层中使用了 Dropout 技术,以 0.5 的概率随机失活一些神经元,有效防止了过拟合 。全连接层的参数数量通常较多,容易出现过拟合现象 。Dropout 技术通过在训练过程中随机丢弃一些神经元,使得模型在训练时不能依赖于某些特定的神经元,从而增强了模型的泛化能力 。这就像是在训练过程中,让模型不断学习不同的 “技能”,避免过度依赖某一种 “技能”,提高了模型的适应性 。
- 重叠最大池化:全部使用最大池化,避免了平均池化的模糊化效果 。并且提出让步长比池化核的尺寸小,这样池化层的输出之间会有重叠和覆盖,提升了特征的丰富性 。传统的平均池化会对池化窗口内的所有元素进行平均计算,可能会丢失一些重要的细节信息 。而最大池化只保留每个区域内的最大值,能够更好地保留显著特征 。通过设置较小的步长,使得池化后的特征图之间有重叠,增加了特征的多样性和丰富性 。
- 数据增强:采用了多种数据增强方法,如随机裁剪、水平翻转等,增加了训练数据的多样性,提高了模型的泛化能力 。在深度学习中,数据量的多少对模型的性能有很大影响 。通过数据增强,可以在不增加实际数据量的情况下,生成更多不同的训练样本,让模型学习到更多的特征和变化,从而提高模型的泛化能力,使其能够更好地适应不同的测试数据 。
AlexNet 的成功,不仅证明了深度卷积神经网络在大规模图像识别任务中的有效性,还为后续深度学习模型的发展提供了重要的参考和启示 。它激发了研究人员对深度学习的浓厚兴趣,推动了深度学习在各个领域的广泛应用和快速发展 。此后,各种基于 CNN 的模型不断涌现,性能也不断提升,深度学习逐渐成为人工智能领域的核心技术之一 。
5.3 VGG:加深网络结构的探索
VGG(Visual Geometry Group)网络由牛津大学的 Visual Geometry Group 于 2014 年提出,它在 ILSVRC 2014 图像分类任务中获得了第二名的优异成绩 。VGG 的主要贡献在于通过对网络结构的深入探索,证明了增加网络深度能够在一定程度上提升模型的性能,为 CNN 的发展开辟了新的道路 。
VGG 网络的结构简洁且规整,它主要由卷积层和池化层堆叠而成,最后接几个全连接层 。VGG 有多个版本,其中比较著名的是 VGG16 和 VGG19,分别包含 16 个和 19 个权重层 。以 VGG16 为例,其结构如下:
- 输入层:输入为 224x224x3 的 RGB 图像 。
- 卷积层组 1:包含两个卷积层,每个卷积层都使用 64 个 3x3 大小的卷积核,步长为 1,填充为 1 。经过这两个卷积层后,输出 64 个 224x224 大小的特征图 。这一层组通过多个小卷积核的堆叠,增加了网络的非线性,能够提取到更丰富的低级特征 。
- 池化层 1:采用 2x2 大小的池化窗口,步长为 2 的最大池化操作 。输出 64 个 112x112 大小的特征图 。对特征图进行降维,减少数据量 。
- 卷积层组 2:包含两个卷积层,每个卷积层都使用 128 个 3x3 大小的卷积核,步长为 1,填充为 1 。输出 128 个 112x112 大小的特征图 。进一步提取更高级的特征 。
- 池化层 2:同样采用 2x2 大小的池化窗口,步长为 2 的最大池化 。输出 128 个 56x56 大小的特征图 。
- 卷积层组 3:包含三个卷积层,每个卷积层都使用 256 个 3x3 大小的卷积核,步长为 1,填充为 1 。输出 256 个 56x56 大小的特征图 。通过更多的卷积层,学习到更复杂的特征 。
- 池化层 3:采用 2x2 大小的池化窗口,步长为 2 的最大池化 。输出 256 个 28x28 大小的特征图 。
- 卷积层组 4:包含三个卷积层,每个卷积层都使用 512 个 3x3 大小的卷积核,步长为 1,填充为 1 。输出 512 个 28x28 大小的特征图 。继续加深网络,提取更抽象的特征 。
- 池化层 4:采用 2x2 大小的池化窗口,步长为 2 的最大池化 。输出 512 个 14x14 大小的特征图 。
- 卷积层组 5:包含三个卷积层,每个卷积层都使用 512 个 3x3 大小的卷积核,步长为 1,填充为 1 。输出 512 个 14x14 大小的特征图 。对特征进行最后的细化和整合 。
- 池化层 5:采用 2x2 大小的池化窗口,步长为 2 的最大池化 。输出 512 个 7x7 大小的特征图 。
- 全连接层 FC6:将池化后的特征图展平为一维向量,与 4096 个神经元全连接 。对特征进行综合处理,形成更抽象的特征表示 。
- 全连接层 FC7:包含 4096 个神经元,与 FC6 层全连接 。进一步对特征进行映射和变换 。
- 输出层 FC8:采用 Softmax 激活函数,输出 1000 个类别的概率分布 。用于图像分类任务 。
VGG 通过加深结构提升性能的原理主要体现在以下几个方面:
- 小卷积核的堆叠:VGG 全部使用 3x3 的小卷积核,通过多个小卷积核的堆叠来替代大卷积核 。两个 3x3 的卷积核堆叠相当于一个 5x5 的卷积核的感受野,但参数数量却减少了 。一个 5x5 卷积核的参数数量为 5x5 = 25,而两个 3x3 卷积核的参数数量为 2x3x3 = 18 。这样不仅减少了参数数量,降低了计算量,还增加了网络的非线性,因为每经过一个卷积层都会进行一次非线性激活函数的运算,从而提高了模型的表达能力 。
- 加深网络层次:随着网络层数的增加,模型能够学习到更高级、更抽象的特征 。浅层的卷积层主要提取图像的边缘、纹理等低级特征,而深层的卷积层则能够学习到物体的整体形状、结构等高级特征 。通过不断加深网络,VGG 能够对图像进行更深入的特征提取和分析,从而提升了在图像分类任务中的表现 。
在图像分类任务中,VGG 表现出色 。它凭借其深度的网络结构和规整的设计,能够有效地提取图像的特征,对各种不同类别的图像进行准确分类 。虽然 VGG 的参数量较大,计算成本较高,但它在图像特征提取和迁移学习等方面具有重要的应用价值,许多后续的研究都基于 VGG 进行改进和拓展 。例如,在迁移学习中,VGG 预训练模型可以作为特征提取器,将其在大规模图像数据集上学习到的特征应用到其他相关的图像任务中,能够显著提升模型的性能 。
5.4 GoogLeNet:Inception 模块的创新
GoogLeNet 由谷歌团队于 2014 年提出,在当年的 ImageNet 大规模视觉识别挑战赛(ILSVRC)中夺得冠军,它的出现为卷积神经网络的发展带来了新的思路和方法 。GoogLeNet 的核心创新点在于引入了 Inception 模块,通过对网络结构的巧妙设计,在提高模型性能的同时,有效地控制了计算量和参数数量 。
Inception 模块的设计思路独特而精妙 。在传统的 CNN 中,选择合适大小的卷积核一直是一个难题 。信息分布更全局性的图像偏好较大的卷积核,能够捕捉到更大范围的特征;而信息分布比较局部的图像则偏好较小的卷积核,能够提取更精细的细节 。为了解决这个问题,Inception 模块采用了并行的方式,在同一层级上同时使用不同大小的卷积核(1x1、3x3、5x5)以及最大池化操作,然后将这些操作的结果拼接在一起 。这样,网络可以自动学习不同尺度的特征,而无需人为地选择特定大小的卷积核 。
具体来说,Inception 模块包含以下几个部分:
- 1x1 卷积层:在 Inception 模块中,1x1 卷积层起到了至关重要的作用 。它不仅可以对输入特征图进行降维,减少后续卷积层的计算量,还能够增加网络的非线性 。当输入特征图的通道数较多时,直接使用 3x3 或 5x5 的卷积核进行卷积操作,计算量会非常大 。通过在 3x3 和 5x5 卷积层之前添加 1x1 卷积层,先对通道数进行压缩,再进行后续的卷积操作,能够显著降低计算成本 。1x1 卷积核的参数量和计算量都相对较小,通过 1x1 卷积对特征图进行线性变换,再经过激活函数,能够增加网络的非线性表达能力 。
- 3x3 卷积层:用于提取中等尺度的特征,感受野适中,能够捕捉到图像中一些局部的结构和模式 。
- 5x5 卷积层:感受野较大,可以提取图像中的全局特征和更宏观的结构信息 。但由于 5x5 卷积核的计算量较大,在 Inception 模块中,通常会在其前面添加 1x1 卷积层进行降维,以减少计算负担 。
- 最大池化层
六、CNN 在实战中的应用与实现
6.1 图像分类实战
在图像分类领域,CIFAR - 10 数据集是一个常用的基准数据集,它包含 10 个不同类别的 60000 张彩色图像,每张图像的尺寸为 32x32 像素。接下来,我们将详细介绍使用 CNN 对 CIFAR - 10 数据集进行图像分类的完整流程 。
首先是数据预处理阶段 。由于原始图像的像素值范围是 0 - 255,为了加快模型的训练速度并提高性能,我们需要对数据进行归一化处理,将像素值缩放到 0 - 1 之间,可使用以下代码实现:
from tensorflow.keras.datasets import cifar10
import numpy as np# 加载CIFAR - 10数据集
(train_images, train_labels), (test_images, test_labels) = cifar10.load_data()# 归一化
train_images = train_images / 255.0
test_images = test_images / 255.0此外,为了增加数据的多样性,减少过拟合,我们还可以采用数据增强技术,如随机旋转、翻转、裁剪等 。使用torchvision库进行数据增强的示例代码如下:
import torchvision.transforms as transformstransform = transforms.Compose([transforms.RandomRotation(10), # 随机旋转10度transforms.RandomHorizontalFlip(), # 随机水平翻转transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])train_dataset = torchvision.datasets.CIFAR10(root='./data', train=True,download=True, transform=transform)接下来是模型搭建 。我们构建一个简单的 CNN 模型,包含多个卷积层、池化层和全连接层 :
from tensorflow.keras import models, layersmodel = models.Sequential([layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)),layers.MaxPooling2D((2, 2)),layers.Conv2D(64, (3, 3), activation='relu'),layers.MaxPooling2D((2, 2)),layers.Conv2D(64, (3, 3), activation='relu'),layers.Flatten(),layers.Dense(64, activation='relu'),layers.Dense(10, activation='softmax')])在这个模型中,首先通过Conv2D层进行卷积操作,提取图像特征,ReLU作为激活函数引入非线性 。然后使用MaxPooling2D层进行最大池化,降低特征图的空间维度 。接着再次进行卷积和池化操作,进一步提取高级特征 。最后通过Flatten层将多维特征图展平为一维向量,再经过两个Dense全连接层,将特征映射到 10 个类别上,使用Softmax激活函数输出每个类别的概率 。
模型搭建完成后,需要对其进行编译,指定损失函数、优化器和评估指标 :
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])这里使用adam优化器来更新模型的权重,sparse_categorical_crossentropy作为损失函数,用于衡量模型预测结果与真实标签之间的差异,accuracy作为评估指标,用于监控模型在训练过程中的准确率 。
一切准备就绪后,就可以开始训练模型了 :
history = model.fit(train_images, train_labels, epochs=10,validation_data=(test_images, test_labels))在训练过程中,模型会根据损失函数的反馈不断调整参数,以提高在训练集和验证集上的性能 。这里设置训练轮数为 10,在每一轮训练中,模型会对训练数据进行一次完整的遍历,并在验证集上评估性能 。
训练完成后,我们需要评估模型在测试集上的性能 :
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)print('\n测试准确率:', test_acc)通过evaluate方法,我们可以得到模型在测试集上的损失值和准确率,从而了解模型的泛化能力 。
6.2 目标检测实战
以 Faster R - CNN 算法为例,展示如何利用 CNN 实现目标检测 。目标检测不仅要识别图像中的物体类别,还要确定物体在图像中的位置,Faster R - CNN 通过区域提议网络(RPN)生成候选框,并结合卷积神经网络进行物体分类和位置回归,能够高效地完成目标检测任务 。
首先是数据集标注 。常用的目标检测数据集有 PASCAL VOC 和 COCO 等 。在使用这些数据集之前,需要对图像中的目标物体进行标注,标注信息包括物体的类别和边界框的坐标 。标注工具如 LabelImg 可以帮助我们方便地进行标注 。标注完成后,数据通常会以特定的格式保存,如 PASCAL VOC 数据集使用 XML 格式存储标注信息,COCO 数据集使用 JSON 格式 。以下是 PASCAL VOC 数据集中一个标注文件的示例:
<annotation><folder>VOC2007</folder><filename>000001.jpg</filename><size><width>500</width><height>333</height><depth>3</depth></size><object><name>person</name><bndbox><xmin>100</xmin><ymin>150</ymin><xmax>200</xmax><ymax>250</ymax></bndbox></object></annotation>这个标注文件表示图像中存在一个类别为 “person” 的物体,其边界框的左上角坐标为 (100, 150),右下角坐标为 (200, 250) 。
接下来是模型训练 。Faster R - CNN 的模型结构主要包括卷积层、RPN 层、ROI 池化层和分类回归层 。在训练之前,需要对数据进行预处理,包括图像的缩放、归一化等操作,以适应模型的输入要求 。以下是使用 PyTorch 实现 Faster R - CNN 模型训练的部分代码:
import torchimport torchvisionfrom torchvision.models.detection import fasterrcnn_resnet50_fpnfrom torchvision.transforms import functional as F# 加载数据集train_dataset = torchvision.datasets.VOCDetection(root='./VOCdevkit', year='2007',image_set='train', download=True,transforms=lambda x, y: (F.to_tensor(x), y))train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=2,shuffle=True, num_workers=4)# 初始化模型model = fasterrcnn_resnet50_fpn(pretrained=True)device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')model.to(device)# 定义优化器optimizer = torch.optim.SGD(model.parameters(), lr=0.005,momentum=0.9, weight_decay=0.0005)# 训练模型for epoch in range(10):model.train()for images, targets in train_loader:images = list(image.to(device) for image in images)targets = [{k: v.to(device) for k, v in t.items()} for t in targets]loss_dict = model(images, targets)losses = sum(loss for loss in loss_dict.values())optimizer.zero_grad()losses.backward()optimizer.step()print(f'Epoch {epoch + 1}, Loss: {losses.item()}')在这段代码中,首先加载 PASCAL VOC 2007 数据集的训练集,并对图像进行了转换为张量的预处理 。然后初始化了基于 ResNet50 和 FPN 的 Faster R - CNN 模型,并将其移动到 GPU 上(如果可用) 。接着定义了随机梯度下降(SGD)优化器,设置了学习率、动量和权重衰减等参数 。在训练过程中,模型在每个 epoch 中对训练数据进行迭代,计算损失并进行反向传播和参数更新 。
模型训练完成后,就可以进行目标检测并可视化检测结果了 。以下是使用训练好的模型进行预测并可视化的代码:
import cv2
import numpy as npfrom torchvision.utils import draw_bounding_boxesmodel.eval()image_path = 'test_image.jpg'image = cv2.imread(image_path)image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)image_tensor = F.to_tensor(image).unsqueeze(0).to(device)with torch.no_grad():predictions = model(image_tensor)boxes = predictions[0]['boxes'].cpu().numpy()labels = predictions[0]['labels'].cpu().numpy()scores = predictions[0]['scores'].cpu().numpy()# 过滤掉得分较低的检测结果threshold = 0.5keep_indices = scores > thresholdboxes = boxes[keep_indices]labels = labels[keep_indices]image_with_boxes = draw_bounding_boxes(torch.from_numpy(image.transpose(2, 0, 1)),boxes=torch.from_numpy(boxes),labels=[train_dataset.class_names[label] for label in labels],colors='red')image_with_boxes = np.transpose(image_with_boxes.numpy(), (1, 2, 0)).astype(np.uint8)image_with_boxes = cv2.cvtColor(image_with_boxes, cv2.COLOR_RGB2BGR)cv2.imshow('Detected Objects', image_with_boxes)cv2.waitKey(0)cv2.destroyAllWindows()这段代码首先读取一张测试图像,将其转换为张量并输入到模型中进行预测 。然后从预测结果中提取边界框、标签和得分,过滤掉得分低于阈值的检测结果 。最后使用torchvision的draw_bounding_boxes函数在图像上绘制边界框,并显示检测结果 。
6.3 图像分割实战
基于 U - Net 网络结构进行图像分割 。U - Net 是一种专为医学图像分割而设计的卷积神经网络架构,其 U 型结构和跳跃连接使其能够有效地利用上下文信息和细节信息,在图像分割任务中表现出色 。
以医学图像分割为例,假设我们有一个包含医学图像及其对应分割掩码的数据集 。首先进行数据预处理,包括图像的缩放、归一化以及将掩码转换为合适的格式 。以下是使用 Python 和numpy进行数据预处理的示例代码:
import osimport cv2import numpy as npfrom sklearn.model_selection import train_test_split# 数据集路径images_path ='medical_images'masks_path ='medical_masks'# 图像尺寸IMG_WIDTH = 256IMG_HEIGHT = 256# 读取图像和掩码images = []masks = []for filename in os.listdir(images_path):image = cv2.imread(os.path.join(images_path, filename))image = cv2.resize(image, (IMG_WIDTH, IMG_HEIGHT))image = image / 255.0images.append(image)for filename in os.listdir(masks_path):mask = cv2.imread(os.path.join(masks_path, filename), cv2.IMREAD_GRAYSCALE)mask = cv2.resize(mask, (IMG_WIDTH, IMG_HEIGHT))mask = mask / 255.0mask = np.expand_dims(mask, axis=-1)masks.append(mask)images = np.array(images)masks = np.array(masks)# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(images, masks, test_size=0.2, random_state=42)在这段代码中,首先遍历图像和掩码文件夹,读取图像和掩码文件,并将其调整为指定大小,进行归一化处理 。然后将掩码扩展一个维度,以适应模型的输入要求 。最后使用train_test_split函数将数据集划分为训练集和测试集 。
接下来搭建 U - Net 模型 :
from tensorflow.keras.models import Modelfrom tensorflow.keras.layers import Input, Conv2D, MaxPooling2D, UpSampling2D, concatenatedef build_unet():inputs = Input((IMG_HEIGHT, IMG_WIDTH, 3))# 编码器conv1 = Conv2D(64, 3, activation='relu', padding='same')(inputs)conv1 = Conv2D(64, 3, activation='relu', padding='same')(conv1)pool1 = MaxPooling2D(pool_size=(2, 2))(conv1)conv2 = Conv2D(128, 3, activation='relu', padding='same')(pool1)conv2 = Conv2D(128, 3, activation='relu', padding='same')(conv2)pool2 = MaxPooling2D(pool_size=(2, 2))(conv2)conv3 = Conv2D(256, 3, activation='relu', padding='same')(pool2)conv3 = Conv2D(256, 3, activation='relu', padding='same')(conv3)pool3 = MaxPooling2D(pool_size=(2, 2))(conv3)conv4 = Conv2D(512, 3, activation='relu', padding='same')(pool3)conv4 = Conv2D(512, 3, activation='relu', padding='same')(conv4)pool4 = MaxPooling2D(pool_size=(2, 2))(conv4)# 瓶颈层conv5 = Conv2D(1024, 3, activation='relu', padding='same')(pool4)conv5 = Conv2D(1024, 3, activation='relu', padding='same')(conv5)# 解码器up6 = UpSampling2D(size=(2, 2))(conv5)up6 = concatenate([up6, conv4], axis=-1)conv6 = Conv2D(512, 3, activation='relu', padding='same')(up6)conv6 = Conv2D(512, 3, activation='relu', padding='same')(conv6)up7 = UpSampling2D(size=(2, 2))(conv6)up7 = concatenate([up7, conv3], axis=-1)conv7 = Conv2D(256, 3, activation='relu', padding='same')(up7)conv7 = Conv2D(256, 3, activation='relu', padding='same')(conv7)up8 = UpSampling2D(size=(2, 2))(conv7)up8 = concatenate([up8, conv2], axis=-1)conv8 = Conv2D(128, 3, activation='relu', padding='same')(up8)conv8 = Conv2D(128, 3, activation='relu', padding='same')(conv8)up9 = UpSampling2D(size=(2, 2))(conv8)up9 = concatenate([up9, conv1], axis=-1)conv9 = Conv2D(64, 3, activation='relu', padding='same')(up9)conv9 = Conv2D(64, 3, activation='relu', padding='same')(conv9)outputs = Conv2D(1, 1, activation='sigmoid')(conv9)model = Model(inputs=[inputs], outputs=[outputs])model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])return modelmodel = build_unet()在这个 U - Net 模型中,编码器部分通过多个卷积层和最大池化层逐步降低图像的空间分辨率,增加特征通道数,提取图像的高级特征 。瓶颈层是模型中最深的层,进一步提取抽象特征 。解码器部分通过上采样和跳跃连接,将编码器中提取的特征与上采样后的特征进行融合,逐步恢复图像的空间分辨率,最终输出与输入图像大小相同的分割掩码 。模型使用adam优化器和binary_crossentropy损失函数进行编译 。
模型训练:
history = model.fit(X_train, y_train, batch_size=16, epochs=10, validation_data=(X_test, y_test))这里设置训练的批次大小为 16,训练轮数为 10,并使用测试集作为验证数据 。在训练过程中,模型会根据损失函数的反馈不断调整参数,以提高在训练集和验证集上的性能 。
训练完成后,我们可以使用测试集对模型进行评估,并可视化分割结果 。常用的评价指标有交并比(IoU)、Dice 系数等 。以下是计算 IoU 和可视化分割结果的代码:
import matplotlib.pyplot as pltdef calculate_iou七、CNN的发展趋势与挑战
7.1 发展趋势
随着深度学习领域的不断发展,CNN也在持续演进,展现出一些令人瞩目的发展趋势。
一方面,CNN与其他技术的融合成为研究热点 。与Transformer的融合是当前的一个重要方向 。Transformer最初在自然语言处理领域取得巨大成功,其基于自注意力机制,能够有效捕捉长距离依赖关系 。而CNN擅长提取局部特征 。将两者结合,可以充分发挥各自的优势 。如Vision Transformer(ViT)将图像划分为补丁并作为序列输入Transformer进行处理,在大规模图像分类任务中表现出色 。一些研究提出的混合模型,在卷积层之后引入Transformer模块,利用Transformer对卷积层提取的局部特征进行全局建模,进一步提升了模型在复杂视觉任务中的性能 。在目标检测任务中,通过结合CNN和Transformer,能够更准确地检测出小目标和遮挡目标 。
CNN与强化学习的融合也展现出广阔的应用前景 。强化学习通过智能体与环境的交互,以最大化奖励为目标进行学习 。将CNN强大的感知能力与强化学习的决策能力相结合,可以解决许多复杂的实际问题 。在自动驾驶领域,基于CNN的感知模块可以实时识别道路场景中的各种目标,如行人、车辆、交通标志等,而强化学习模块则根据这些感知信息,做出合理的驾驶决策,如加速、减速、转弯等,实现自动驾驶的智能控制 。在机器人控制中,CNN用于感知周围环境,强化学习则帮助机器人根据感知结果做出最优的动作决策,完成复杂的任务,如在未知环境中自主导航、操作物体等 。
另一方面,CNN在新兴领域的应用不断拓展 。在医学影像分析领域,CNN的应用越来越深入 。它可以帮助医生更准确地诊断疾病,如通过对X光、CT、MRI等医学影像的分析,检测出肿瘤、病变等异常情况 。利用CNN对肺部CT影像进行分析,能够快速、准确地检测出新冠肺炎患者的肺部病变特征,为疫情防控和患者治疗提供有力支持 。CNN还可以用于医学图像的分割,将医学影像中的不同组织和器官进行精确分割,辅助医生进行疾病诊断和手术规划 。
在遥感图像分析领域,CNN同样发挥着重要作用 。随着遥感技术的发展,获取的遥感图像数据量越来越大,利用CNN可以实现对遥感图像的自动分类、目标检测和变化检测等任务 。通过CNN可以对高分辨率遥感图像中的建筑物、道路、植被等进行分类,为城市规划、土地利用监测等提供数据支持 。在环境监测中,CNN可以检测遥感图像中的森林火灾、水体污染等环境变化,及时发现环境问题并采取相应措施 。
7.2 面临的挑战
尽管CNN取得了巨大的成功,但在实际应用中仍然面临一些挑战。
计算资源需求是一个重要问题 。CNN通常包含大量的参数和复杂的计算操作,训练和部署过程需要消耗大量的计算资源,如GPU等 。在训练大规模的CNN模型时,需要花费数天甚至数周的时间,这不仅增加了研发成本,也限制了模型的应用范围 。对于一些资源受限的设备,如移动设备、嵌入式设备等,难以部署复杂的CNN模型 。为了解决这个问题,研究人员提出了一系列优化方法,如模型压缩技术,包括剪枝、量化和知识蒸馏等 。剪枝通过去除模型中不重要的连接或神经元,减少模型的参数数量;量化将模型中的参数和计算过程进行量化,使用低精度的数据类型(如8位整数)代替高精度的数据类型(如32位浮点数),降低计算复杂度;知识蒸馏则是将大模型学到的知识传递给小模型,使小模型在保持性能的同时,减小模型规模 。
可解释性也是CNN面临的一大挑战 。CNN是一种黑盒模型,其决策过程难以理解和解释 。在一些关键应用领域,如医疗诊断、金融风险评估等,模型的可解释性至关重要 。医生在使用CNN进行疾病诊断时,不仅需要知道诊断结果,还需要了解模型是如何做出判断的,以便对结果进行验证和评估 。为了提高CNN的可解释性,研究人员提出了多种方法 。可视化技术可以将CNN学习到的特征或决策过程以可视化的方式呈现出来,帮助人们理解模型的行为 。通过热力图可以展示图像中哪些区域对模型的决策起到了关键作用;通过特征可视化可以观察不同层的卷积核学习到的特征模式 。还可以使用一些解释性模型,如LIME(Local Interpretable Model - agnostic Explanations)和SHAP(SHapley Additive exPlanations)等,为CNN的预测结果提供解释 。
数据依赖性是CNN的另一个挑战 。CNN需要大量的标注数据进行训练,标注数据的质量和数量直接影响模型的性能 。获取和标注大规模的数据往往需要耗费大量的人力、物力和时间 。在一些特定领域,如医学、天文学等,数据的获取和标注更加困难,因为这些领域的数据通常需要专业知识和设备 。数据的不平衡问题也会影响CNN的性能,当训练数据中不同类别的样本数量差异较大时,模型容易偏向于样本数量较多的类别,导致对样本数量较少类别的识别能力下降 。为了解决数据依赖性问题,研究人员提出了数据增强、迁移学习和半监督学习等方法 。数据增强通过对原始数据进行变换,如旋转、翻转、裁剪等,生成更多的训练样本,增加数据的多样性;迁移学习利用在其他相关任务或数据集上预训练的模型,将其学习到的知识迁移到目标任务中,减少对大规模标注数据的需求;半监督学习则结合少量的标注数据和大量的未标注数据进行训练,通过利用未标注数据中的信息来提升模型的性能 。
八、总结与展望
卷积神经网络作为深度学习领域的核心技术之一,凭借其独特的结构和强大的特征提取能力,在众多领域取得了令人瞩目的成就 。通过对CNN原理的深入剖析,我们了解了它如何通过卷积层、激活函数层、池化层、全连接层等组件,从输入数据中自动学习和提取特征,实现高效的分类、检测和分割等任务 。
从经典的LeNet - 5到开启深度学习新时代的AlexNet,再到不断探索网络深度的VGG以及引入创新Inception模块的GoogLeNet,每一个经典模型都代表了CNN发展的一个重要阶段,它们的出现推动了CNN技术的不断进步和创新 。在实战应用中,我们看到了CNN在图像分类、目标检测和图像分割等任务中的出色表现,通过实际案例的实现,我们更加深入地理解了如何将理论知识应用到实际问题的解决中 。
展望未来,CNN的发展前景依然广阔 。随着与其他技术的不断融合以及在新兴领域的持续拓展,CNN有望在更多复杂任务和应用场景中发挥重要作用 。尽管CNN面临着计算资源需求高、可解释性差和数据依赖性强等挑战,但研究人员正在积极探索各种解决方案,相信在未来,这些问题将逐步得到解决 。
如果你对深度学习和卷积神经网络感兴趣,希望你能继续深入学习和探索 。不断尝试新的算法、模型和应用场景,将CNN技术应用到更多实际问题中,为人工智能的发展贡献自己的力量 。在这个充满机遇和挑战的领域里,相信你会有更多的发现和收获 。
Python相关文章推荐:
1、Python详细安装教程(大妈看了都会)
2、02-pycharm详细安装教程(大妈看了都会)
3、如何系统地自学Python?
4、Alibaba Cloud Linux 3.2104 LTS 64位 怎么安装python3.10.12和pip3.10
5、职场新技能:Python数据分析,你掌握了吗?
6、Python爬虫图片:从入门到精通
7、Python+Pycharm详细安装教程(大妈看了都会)
人工智能基础Python串联文章:
1、Python小白的蜕变之旅:从环境搭建到代码规范(1/10)
2、Python面向对象编程实战:从类定义到高级特性的进阶之旅(2/10)
3、Python 异常处理与文件 IO 操作:构建健壮的数据处理体系(3/10)
4、从0到1:用Lask/Django框架搭建个人博客系统(4/10)
5、Python 数据分析与可视化:开启数据洞察之旅(5/10)
6、Python 自动化脚本开发秘籍:从入门到实战进阶(6/10)
7、Python并发编程:开启性能优化的大门(7/10)
8、从0到1:Python机器学习实战全攻略(8/10)
9、解锁Python TDD:从理论到实战的高效编程之道(9/10)
10、从0到1:Python项目部署与运维全攻略(10/10)
素材来源:
1、卷积神经网络(CNN)详细介绍及其原理详解
2、百度百科:CNN
相关文章:
:原理与实战全解析)
从0到1吃透卷积神经网络(CNN):原理与实战全解析
一、开篇:CNN 在 AI 领域的地位 在当今人工智能(AI)飞速发展的时代,卷积神经网络(Convolutional Neural Network,简称 CNN)无疑是深度学习领域中最为耀眼的明星之一 。它就像是 AI 世界里的超级…...
和条件随机场(CRF)的模型)
建一个结合双向长短期记忆网络(BiLSTM)和条件随机场(CRF)的模型
构建一个结合双向长短期记忆网络(BiLSTM)和条件随机场(CRF)的模型,通常用于序列标注任务,如命名实体识别(NER)、词性标注(POS Tagging)等。下面我将通过口述的…...

mvc-ioc实现
IOC 1)耦合/依赖 依赖,是谁离不开谁 就比如上诉的Controller层必须依赖于Service层,Service层依赖于Dao 在软件系统中,层与层之间存在依赖。我们称之为耦合 我们系统架构或者设计的一个原则是ÿ…...
)
符合Python风格的对象(再谈向量类)
再谈向量类 为了说明用于生成对象表示形式的众多方法,我们将使用一个 Vector2d 类,它与第 1 章中的类似。这一节和接下来的几节会不断实 现这个类。我们期望 Vector2d 实例具有的基本行为如示例 9-1 所示。 示例 9-1 Vector2d 实例有多种表示形式 &g…...

4.1.8文件共享
知识总览 基于索引节点的共享方式(硬链接): 让不同用户的文件目录项指向同一个文件的索引节点 用户1创建文件1,并让文件目录项aaa指向了文件1,这个文件对应了一个索引节点,这个索引节点 包含了文件的物理地址和文件的其他属性信…...

[LevelDB]LevelDB版本管理的黑魔法-为什么能在不锁表的情况下管理数据?
文章摘要 LevelDB的日志管理系统是怎么通过双链表来进行数据管理为什么LevelDB能够在不锁表的情况下进行日志新增 适用人群: 对版本管理机制有开发诉求,并且希望参考LevelDB的版本开发机制。数据库相关从业者的专业人士。计算机狂热爱好者,对计算机的…...

普通用户的服务器连接与模型部署相关记录
普通用户的服务器连接与模型部署相关记录 一、从登录到使用自己的conda 1.账号登陆: ssh xxx172.31.226.236 2.下载与安装conda: 下载conda: wget -c https://repo.anaconda.com/archive/Anaconda3-2023.03-1-Linux-x86_64.sh 安装con…...

WebSocket解决方案的一些细节阐述
今天我们来看看WebSocket解决方案的一些细节问题: 实际上,集成WebSocket的方法都有相关的工程挑战,这可能会影响项目成本和交付期限。在最简单的层面上,构建 WebSocket 解决方案似乎是添加接收实时更新功能的前进方向。但是&…...

架构思维:构建高并发扣减服务_分布式无主架构
文章目录 Pre无主架构的任务简单实现分布式无主架构 设计和实现扣减中的返还什么是扣减的返还返还实现原则原则一:扣减完成才能返还原则二:一次扣减可以多次返还原则三:返还的总数量要小于等于原始扣减的数量原则四:返还要保证幂等…...
详解)
C++函数基础:定义与调用函数,参数传递(值传递、引用传递)详解
1. 引言 函数是C编程中的核心概念之一,它允许我们将代码模块化,提高代码的可读性、复用性和可维护性。本文将深入探讨: 函数的定义与调用参数传递方式(值传递 vs 引用传递)应用场景与最佳实践 2. 函数的定义与调用 …...

深入解析Python中的Vector2d类:从基础实现到特殊方法的应用
引言 在Python面向对象编程中,特殊方法(或称魔术方法)是实现对象丰富行为的关键。本文将以Vector2d类为例,详细讲解如何通过特殊方法为自定义类添加多种表示形式和操作能力。 Vector2d类的基本行为 Vector2d类是一个二维向量类…...
网络安全防护系统)
【25软考网工】第六章(7)网络安全防护系统
博客主页:christine-rr-CSDN博客 专栏主页:软考中级网络工程师笔记 大家好,我是christine-rr !目前《软考中级网络工程师》专栏已经更新三十多篇文章了,每篇笔记都包含详细的知识点,希望能帮助到你&#x…...

Mac下载bilibili视频
安装 安装 yt-dlp brew install yt-dlp安装FFmpeg 用于合并音视频流、转码等操作 brew install ffmpeg使用 下载单个视频 查看可用格式 yt-dlp -F --cookies-from-browser chrome "https://www.bilibili.com/video/BV15B4y1G7F3?spm_id_from333.788.recommend_more_vid…...
)
6个月Python学习计划:从入门到AI实战(前端开发者进阶指南)
作者:一名前端开发者的进阶日志 计划时长:6个月 每日学习时间:2小时 覆盖方向:Python基础、爬虫开发、数据分析、后端开发、人工智能、深度学习 📌 目录 学习目标总览每日时间分配建议第1月:Python基础与编…...

批量处理 Office 文档 高画质提取图片、视频、音频素材助手
各位办公小能手们!你们有没有遇到过想从 Office 文档里提取图片、音频和视频,却又搞得焦头烂额的情况?今天就给大家介绍一款超厉害的工具——OfficeImagesExtractor! 这货的核心功能那可真是杠杠的!首先是高画质提取&a…...

【甲方安全建设】Python 项目静态扫描工具 Bandit 安装使用详细教程
文章目录 一、工具简介二、工具特点1.聚焦安全漏洞检测2.灵活的扫描配置3.多场景适配4.轻量且社区活跃三、安装步骤四、使用方法场景1:扫描单个Python文件场景2:递归扫描整个项目目录五、结果解读六、总结一、工具简介 Bandit 是由Python官方推荐的静态代码分析工具(SAST)…...

【推荐】新准则下对照会计报表172个会计科目解释
序号 科目名称 对应的会计报表项目 序号 科目名称 对应的会计报表项目 一、资产类 二、负债类 1 1001 库存现金 货币资金 103 2001 短期借款 短期借款 2 1002 银行存款 货币资金 104 2101 交易性金融负债 易性金融负债 3 1012 其他货币资…...

IntelliJ IDEA设置编码集
在IntelliJ IDEA中设置Properties文件的编码格式,主要涉及以下步骤和注意事项: 1. 全局和项目编码设置 打开设置界面:File -> Settings -> Editor -> File Encodings。在Global Encoding和Project Encoding下拉菜单中均选择UT…...

类魔方 :多变组合,灵活复用
文章目录 一、类的基础1. 类的基本结构与语法1. 类的定义与实例化2. 成员变量(属性)3. 构造函数(Constructor)4. 成员方法 2. 访问修饰符1. 基本访问规则2. 子类对父类方法的重写3. 构造函数的访问修饰符4. 参数属性与继承总结 3.…...

支持多方式拼接图片的软件
软件介绍 本文介绍一款名为 PicMerger 的图片拼接软件。 拼接亮点 PicMerger 这款软件最大的亮点在于,它能够将不同分辨率的图片完美地拼接在一起。拼接时会自动以分辨率最小的图片为标准,操作十分方便。 拼接方式与设置 该软件支持横向和纵向的拼接…...

Qt音视频开发过程中一个疑难杂症的解决方法/ffmpeg中采集本地音频设备无法触发超时回调
一、前言 最近在做实时音视频通话的项目中,遇到一个神奇的问题,那就是用ffmpeg采集本地音频设备,当音频设备拔掉后,采集过程会卡死在av_read_frame函数中,尽管设置了超时时间,也设置了超时回调interrupt_c…...

Android studio Could not move temporary workspace
Android studio Could not move temporary workspace 在Window上运行AS出现Could not move temporary workspace报错方法一(有效)方法二方法三方法四总结 在Window上运行AS出现Could not move temporary workspace报错 Could not move temporary workspa…...
?)
深度估计中为什么需要已知相机基线(known camera baseline)?
在计算机视觉和立体视觉的上下文中,“已知相机基线”(known camera baseline)的解释 1. 相机基线的定义 相机基线是指两个相机中心之间的距离。在立体视觉系统中,通常有两个相机(或一个相机在不同位置拍摄两张图像&a…...

Spring Cloud 技术实战
Spring Cloud 简介 Spring Cloud 是基于 Spring Boot 构建的微服务框架,提供了一套完整的微服务解决方案。它利用 Spring Boot 的开发便利性,并通过各种组件简化分布式系统的开发。 核心组件 Spring Cloud Netflix Eureka: 服务注册与发现Spring Clou…...

《云端共生体:Flutter与AR Cloud如何改写社交交互规则》
当Flutter遇上AR Cloud,一场关于社交应用跨设备增强现实内容共享与协作的变革正在悄然发生。 Flutter是谷歌推出的一款开源UI软件开发工具包,其最大的优势在于能够实现一套代码,多平台部署,涵盖iOS、Android、Web、Windows、macO…...

【数据结构】1-3 算法的时间复杂度
数据结构知识点合集:数据结构与算法 • 知识点 • 时间复杂度的定义 1、算法时间复杂度 事前预估算法时间开销T(n)与问题规模 n 的关系(T 表示 “time”) 2、语句频度 算法中语句的执行次数 对于以上算法,语句频度:…...

Science Robotics 封面论文:基于形态学开放式参数化的仿人灵巧手设计用于具身操作
人形机械手具有无与伦比的多功能性和精细运动技能,使其能够精确、有力和稳健地执行各种任务。在古生物学记录和动物王国中,我们看到了各种各样的替代手和驱动设计。了解形态学设计空间和由此产生的涌现行为不仅可以帮助我们理解灵巧的作用及其演变&#…...

Vue百日学习计划Day24-28天详细计划-Gemini版
总目标: 在 Day 24-27 熟练掌握 Vue.js 的各种模板语法,包括文本插值、属性绑定、条件渲染、列表渲染、事件处理和表单绑定,并能结合使用修饰符。 所需资源: Vue 3 官方文档 (模板语法): https://cn.vuejs.org/guide/essentials/template-syntax.htmlVu…...
实现)
C++_数据结构_哈希表(hash)实现
✨✨ 欢迎大家来到小伞的大讲堂✨✨ 🎈🎈养成好习惯,先赞后看哦~🎈🎈 所属专栏:C学习 小伞的主页:xiaosan_blog 制作不易!点个赞吧!!谢谢喵!&…...

elasticsearch kibana ik 各版本下载
https://release.infinilabs.com/analysis-ik/stable/或者 https://github.com/infinilabs/analysis-ik/releases...

Uniapp 与 Uniapp X 对比:新手上手指南及迁移到 Uniapp X 的注意事项
文章目录 前言一、Uniapp 与 Uniapp X 核心区别二、Uniapp X 的核心优势三、新手学习 Uniapp X 必备技能栈3.1 基础技能要求3.2 平台相关知识3.3 工具链掌握 四、从 Uniapp 迁移到 Uniapp X 的注意事项4.1 语法转换:4.2 组件替换:4.3 状态管理࿱…...

SQL性能分析
查看数据库操作频次 使用SHOW GLOBAL STATUS LIKE Com_______; 指令,能查看当前数据库的INSERT、UPDATE、DELETE、SELECT访问频次 。若以查询为主,需重点优化查询相关性能,如索引;若以增删改为主,可考虑事务处理、批量…...

CANoe测试应用案例之A2L
写在前面 本系列文章主要讲解CANoe测试应用案例之A2L的相关知识,希望能帮助更多的同学认识和了解CANoe测试。 若有相关问题,欢迎评论沟通,共同进步。(*^▽^*) CANoe Option AMD/XCP支持加载A2L到CANoe中,方便ECU内部变量在功能验…...

H2数据库源码学习+debug, 数据库 sql、数据库引擎、数据库存储从此不再神秘
一、源码结构概览 H2源码采用标准Maven结构,核心模块在src/main/org/h2目录下: ├── command/ # SQL解析与执行 ├── engine/ # 数据库引擎核心(会话、事务) ├── table/ # 表结构定义与操作 ├── index/ # 索引实现&am…...

PopSQL:一个支持团队协作的SQL开发工具
PopSQL 是一款专为团队协作设计的现代化 SQL 编辑器,通过通团队过协作编写 SQL 查询、交互式可视化以及共享结果提升数据分析和管理效率。 PopSQL 提供了基于 Web 的在线平台以及跨系统(Windows、macOS、Linux)的桌面应用,包括免费…...

tomcat查看状态页及调优信息
准备工作 先准备一台已经安装好tomcat的虚拟机,tomcat默认是状态页是默认被禁用的 1.添加授权用户 vim /usr/local/tomcat/conf/tomcat-users.xml22 <role rolename"manager-gui"/>23 <user username"admin" password"tomcat&q…...

贝塞尔曲线原理
文章目录 一、 低阶贝塞尔曲线1.一阶贝塞尔曲线2. 二阶贝塞尔曲线3. 三阶贝塞尔曲线 一、 低阶贝塞尔曲线 1.一阶贝塞尔曲线 如下图所示, P 0 P_0 P0, P 1 P_1 P1 是平面中的两点,则 B ( t ) B ( t ) B(t) 代表平面中的一段线段。…...

【MYSQL】笔记
📚 博主的专栏 🐧 Linux | 🖥️ C | 📊 数据结构 | 💡C 算法 | 🅒 C 语言 | 🌐 计算机网络 在ubuntu中,改配置文件: sudo nano /etc/mysql/mysql.conf.d/mysq…...

构建 TypoView:一个富文本样式预览工具的全流程记录
我正在参加CodeBuddy「首席试玩官」内容创作大赛,本文所使用的 CodeBuddy 免费下载链接:腾讯云代码助手 CodeBuddy - AI 时代的智能编程伙伴 在一次和 CodeBuddy 的日常交流中,我提出了一个构想:能不能帮我从零构建一个富文本样式…...

使用conda创建python虚拟环境,并自定义路径
创建虚拟环境 conda create --prefixE:/ai-tools/Luoxuejiao/envs/Luo24 python3.8 此时虚拟环境没有名字,只有路径,下面将名字添加到配置中: conda config --append envs_dirs E:/ai-tools/Luoxuejiao/envs/...

【自然语言处理与大模型】向量数据库技术
向量数据库,是专门为向量检索设计的中间件! 高效存储、快速检索和管理高纬度向量数据的系统称为向量数据库 一、向量数据库是什么有什么用? 向量数据库是一种专门用于高效存储和检索高维向量数据的系统。它通过嵌入模型将各类非结构化数据&am…...
:隐藏的性能杀手与高并发优化实战)
Java中的伪共享(False Sharing):隐藏的性能杀手与高并发优化实战
引言 在高性能Java应用中,开发者通常会关注锁竞争、GC频率等显性问题,但一个更隐蔽的陷阱——伪共享(False Sharing)——却可能让精心设计的并发代码性能骤降50%以上。伪共享是由CPU缓存架构引发的底层问题,常见于多…...

【数据结构】2-3-3单链表的查找
数据结构知识点合集 知识点 单链表的按位查找 GetElem(L,i):按位查找操作。获取表L中第i个位置的元素的值。 /*查找L中的第i个节点并返回*/ LNode *GetElm(LinkList L,int i) { /*位置不合法返回NULL*/ if(i<0) return NULL; /*p指向当前节…...
)
从0开始学linux韦东山教程第四章问题小结(1)
本人从0开始学习linux,使用的是韦东山的教程,在跟着课程学习的情况下的所遇到的问题的总结,理论虽枯燥但是是基础。说实在的越看视频越感觉他讲的有点乱后续将以他的新版PDF手册为中心,视频作为辅助理解的工具。参考手册为嵌入式Linux应用开发…...

TYUT-企业级开发教程-第三章
JAVAWEB的三大组件 在 Spring Boot 项目中,会自动将 Spring 容器中的 Servlet 、 Filter 、 Listener 实例注册为 Web 服务器中对应的组件。因此,可以将自定义的 Java Web 三大组件作为 Bean 添加到 Spring 容器中,以实现组件的注册。使用 S…...

【数据结构】2-3-2 单链表的插入删除
数据结构知识点合集 知识点 按位序插入带头节点链表 ListInsert(&L,i,e):插入操作。在表L中的第i个位置上插入指定元素e;找到第 i-1 个结点,将新结点插入其后 。 /*在带头节点的单链表L的第i个位置插入元素e*/ bool ListInsert(LinkList …...

spark-配置yarn模式
1.上传并解压spark-3.1.1-bin-hadoop3.2.tgz (/opt/software) 解压的命令是:tar -zxvf spark-3.3.1-bin-hadoop3.tgz -C /opt/module (cd /opt/software 进入software) 2.重命名 解压之后的目录为spark-yarn(原为spark-3.1.1-…...

鸿蒙系统电脑:开启智能办公新时代
鸿蒙系统电脑:开启智能办公新时代 引言 2025 年 5 月 8 日,华为正式推出了鸿蒙系统电脑,这款具有里程碑意义的产品,不仅彰显了华为在智能设备领域的创新实力,也为用户带来了全新的智能办公体验。在数字化转型加速的背…...

Ubuntu---omg又出bug了
自用遇到问题的合集 250518——桌面文件突然消失 ANS:参考博文...

COCO数据集神经网络性能现状2025.5.18
根据当前搜索结果,截至2025年5月,COCO数据集上性能最佳的神经网络模型及其关键参数如下: 1. D-FINE(中科大团队) 性能参数: 在COCO数据集上以78 FPS的速度实现了59.3%的平均精度(AP࿰…...