C++_数据结构_哈希表(hash)实现
✨✨ 欢迎大家来到小伞的大讲堂✨✨
🎈🎈养成好习惯,先赞后看哦~🎈🎈
所属专栏:C++学习
小伞的主页:xiaosan_blog制作不易!点个赞吧!!谢谢喵!!!

1.哈希概念
1.1 直接链址法
387. 字符串中的第一个唯一字符 - 力扣(LeetCode)
这是一种空间换时间的一种方式,假如开辟无限大的空间,查找一个数为O(n),而插入则是O(1);
class Solution {
public:int firstUniqChar(string s) {int count[26] = {0};//哈希映射// 统计次数for (auto ch : s) {count[ch - 'a']++;}//第一次存入值for (size_t i = 0; i < s.size(); ++i) {if (count[s[i] - 'a'] == 1)return i;}//第二次查找return -1;}
};1.2 哈希冲突
1.3 哈希因子
假设哈希表中已经映射存储了N个值,哈希表的大小为M,那么负载因⼦ = M/N,负载因⼦有些地方也翻译为载荷因⼦/装载因⼦等,他的英文为load factor。负载因⼦越大,哈希冲突的概率越高,空间利用率越高;负载因子越小,哈希冲突的概率越低,空间利用率越低;
1.4 哈希函数
1.4.1 除法散列法/除留余数法
1.4.2 乘法散列法
1.4.3 全域散列法
1.4.4 其他方法
1.平方取中法
假设关键码为1234,对它平方就是1522756,抽取中间的3位227作为哈希地址; 再比如关键码为4321,对它平方就是18671041,抽取中间的3位671(或710)作为哈希地址。
平方取中法比较适合:不知道关键码的分布,而位数又不是很大的情况
2.折叠法
关键码从左到右分割成位数相等的几部分(最后一部分位数可以短些),然后将这几部分叠加求和,并按散列表表长,取后几位作为散列地址。
折叠法适合事先不需要知道关键码的分布且位数比较多的情况
3.随机数法
选择一个随机函数,取关键字的随机函数值为它的哈希地址,即H(key) = random(key),其中 random为随机数函数。
通常应用于关键字长度不等时采用此法
4.数学分析法
设有n个d位数,每一位可能有r种不同的符号,这r种不同的符号在各位上出现的频率不一定相同,可能在某些位上分布比较均匀,每种符号出现的机会均等,在某些位上分布不均匀,只有某几种符号经常出现。此时可根据散列表的大小,选择其中各种符号分布均匀的若干位作为散列地址。
比如:假设要存储某家公司员工登记表,如果用手机号作为关键字,那么极有可能前7位都是 相同的,那么我们可以选择后面的4位作为散列地址,如果这样的抽取工作还容易出现冲突,还可以对抽取出来的数字进行反转(如1234改成4321)、右环移位(如1234改成4123)、左环移位、前两数与后两数叠加(如1234改成12+34=46)等方法。
数字分析法通常适合处理关键字位数比较大的情况,如果事先知道关键字的分布且关键字的 若干位分布较均匀的情况
1.5 处理哈希冲突
哈希表无论选择什么方法都会产生哈希冲突,那如何解决冲突呢?主要有两个方法,开放定址法和链地址法
1.5.1 开放定址法概念
1.线性探测
1.从发⽣冲突的位置开始,依次线性向后探测,直到寻找到下⼀个没有存储数据的位置为⽌,如果⾛到哈希表尾,则回绕到哈希表头的位置。2.h(key) = hash0 = key % M, hash0位置冲突了,则线性探测公式为:hc(key,i) = hashi = (hash0 + i) % M, i = {1, 2, 3, ..., M − 1}, 因为负载因⼦⼩于1, 则最多探测M-1次,⼀定能找到⼀个存储key的位置。3.线性探测的⽐较简单且容易实现,线性探测的问题假设,hash0位置连续冲突,hash0,hash1, hash2位置已经存储数据了,后续映射到hash0,hash1,hash2,hash3的值都会争夺hash3位置,这种现象叫做群集/堆积。下⾯的⼆次探测可以⼀定程度改善这个问题。

| h(19) = 8,h(30) = 8,h(5) = 5,h(36) = 3,h(13) = 2,h(20) = 9,h(21) =10,h(12) = 1 |

2.二次探测
1.从发生冲突的位置开始,依次左右按二次方跳跃式探测,直到寻找到下一个没有存储数据的位置为止,如果往右走到哈希表尾,则回绕到哈希表头的位置;如果往左走到哈希表头,则回绕到哈希表尾的位置;
2.h(key) = hash0 = key % M,hash0位置冲突了,则二次探测公式为:
hc(key, i) = hashi = (hash0 ± i^2) % M, i = {1, 2, 3, ... ,M/2 }
3.二次探测当 hashi = (hash0 - i^2)%M 时,当hashi<0时,需要hashi += M
例:下面演示{19,30,52,63,11,22}等这一组值映射到M=11的表中。

h(19) = 8, h(30) = 8, h(52) = 8, h(63) = 8, h(11) = 0, h(22) = 0

3.双重散列
1.第一个哈希函数计算出的值发生冲突,使用第二个哈希函数计算出一个跟key相关的偏移量值,不断往后探测,直到寻找到下一个没有存储数据的位置为止。
2.h1(key) = hash0 = key % M, hash0位置冲突了,则双重探测公式为:
hc(key, i) = hashi = (hash0 + i ∗ h2(key)) % M, i = {1, 2, 3,... ,M/2 }
3.要求h2(key)<M且h2(key)和M互为质数,有两种简单的取值方法:1、当M为2整数幂时,h2(key)从[0,M-1]任选一个奇数;2、当M为质数时,h2(key)=key%(M-1)+1
4.保证h2(key)与M互质是因为根据固定的偏移量所寻址的所有位置将形成一个群,若最大公约数p=gcd(M,h(key))>1,那么所能寻址的位置的个数为M/FV,使得对于一个关键字来说无法充分利用整个散列表。举例来说,若初始探查位置为1,偏移量为3,整个散列表大小为12,那么所能寻址的位置为{1,4,7,10},寻址个数为12/gcd(12,3)=4
例:下面演示{19,30,52,74}等这一组值映射到M=11的表中,设h2(key)=key%10+1

1.5.1.1 开放定址法
开放定址法在实践中,不如下面讲的链地址法,因为开放定址法解决冲突不管使用哪种方法,占用的都是哈希表中的空间,始终存在互相影响的问题。所以开放定址法,我们简单选择线性探测实现即可。
开放定址法的哈希表结构
enum State {EXIST,EMPTY,DELETE }; template<class K, class V> struct HashData {pair<K, V> _kv;State _state = EMPTY; }; template<class K, class V> class HashTable {private :vector<HashData<K, V>> _tables;size_t _n = 0; // 表中存储数据个数 };
要注意的是这里需要给每个存储值的位置加一个状态标识,否则删除一些值以后,会影响后面冲突的值的查找。如下图,我们删除30,会导致查找20失败,当我们给每个位置加一个状态标识
{EXIST,EMPTY,DELETE},删除30就可以不用删除值,而是把状态改为DELETE,那么查找20
时是遇到EMPTY才能,就可以找到20。
| h(19) = 8,h(30) = 8,h(5) = 5,h(36) = 3,h(13) = 2,h(20) = 9,h(21) =10,h(12) = 1 |


扩容
这里我们哈希表负载因子控制在0.7,当负载因子到0.7以后我们就需要扩容了,我们还是按照2倍扩容,但是同时我们要保持哈希表大小是一个质数,第一个是质数,2倍后就不是质数了。那么如何解决了,一种方案就是上面1.4.1除法散列中我们讲的JavaHashMap的使用2的整数幂,但是计算时不能直接取模的改进方法。另外一种方案是sgi版本的哈希表使用的方法,给了一个近似2倍的质数表,每次去质数表获取扩容后的大小。
inline unsigned long __stl_next_prime(unsigned long n){// Note: assumes long is at least 32 bits.//采用质数开辟空间,减小哈希冲突static const int __stl_num_primes = 28;static const unsigned long __stl_prime_list[__stl_num_primes] ={ 53, 97, 193, 389, 769,1543, 3079, 6151, 12289, 24593,49157, 98317, 196613, 393241, 786433,1572869, 3145739, 6291469, 12582917, 25165843,50331653, 100663319, 201326611, 402653189, 805306457,1610612741, 3221225473, 4294967291};const unsigned long* first = __stl_prime_list;const unsigned long* last = __stl_prime_list +__stl_num_primes;const unsigned long* pos = lower_bound(first, last, n);return pos == last ? *(last - 1) : *pos;//三目表达式}
key不能取模的问题
当key是string/Date等类型时,key不能取模,那么我们需要给HashTable增加一个仿函数,这个仿函数支持把key转换成一个可以取模的整形,如果key可以转换为整形并且不容易冲突,那么这个仿函数就用默认参数即可,如果这个Key不能转换为整形,我们就需要自已实现一个仿函数传给这个参数,实现这个仿函数的要求就是尽量key的每值都参与到计算中,让不同的key转换出的整形值不同。string做哈希表的key非常常见,所以我们可以考虑把string特化一下。
struct HashFunc
{size_t operator()(const K& key){return (size_t)key;}
};
//特化
template<>
struct HashFunc<string>
{// 字符串转换成整形,可以把字符ascii码相加即可// 但是直接相加的话,类似"abcd"和"bcad"这样的字符串计算出是相同的// 这⾥我们使⽤BKDR哈希的思路,⽤上次的计算结果去乘以⼀个质数,这个质数⼀般去31, 131等效果会⽐较好size_t operator()(const string& key){size_t hash = 0;for (auto e : key){hash *= 131;hash += e;}return hash;}
};template<class K, class V, class Hash = HashFunc<K>>
class HashTable
{
public:
private:vector<HashData<K, V>> _tables;size_t _n = 0; // 表中存储数据个数
}完整代码
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
#include<vector>
using namespace std;
template<class K>
struct HashFunc
{size_t operator()(const K& key){return (size_t)key;}
};
template<>
struct HashFunc<string>
{// 字符串转换成整形,可以把字符ascii码相加即可// 但是直接相加的话,类似"abcd"和"bcad"这样的字符串计算出是相同的// 这⾥我们使⽤BKDR哈希的思路,⽤上次的计算结果去乘以⼀个质数,这个质数⼀般去31, 131等效果会⽐较好size_t operator()(const string& key){size_t hash = 0;for (auto e : key){hash *= 131;hash += e;}return hash;}
};namespace open_address
{enum State{EXIST,EMPTY,DELETE};template<class K, class V>struct HashData{pair<K, V> _kv;State _state = EMPTY;};template<class K, class V, class Hash = HashFunc<K>>class HashTable{public :inline unsigned long __stl_next_prime(unsigned long n){// Note: assumes long is at least 32 bits.static const int __stl_num_primes = 28;static const unsigned long __stl_prime_list[__stl_num_primes] ={ 53, 97, 193, 389, 769,1543, 3079, 6151, 12289, 24593,49157, 98317, 196613, 393241, 786433,1572869, 3145739, 6291469, 12582917, 25165843,50331653, 100663319, 201326611, 402653189, 805306457,1610612741, 3221225473, 4294967291};const unsigned long* first = __stl_prime_list;const unsigned long* last = __stl_prime_list +__stl_num_primes;const unsigned long* pos = lower_bound(first, last, n);return pos == last ? *(last - 1) : *pos;} HashTable(){_tables.resize(__stl_next_prime(0));} bool Insert(const pair<K, V>& kv){if (Find(kv.first))return false;// 负载因⼦⼤于0.7就扩容if (_n * 10 / _tables.size() >= 7){// 这⾥利⽤类似深拷⻉现代写法的思想插⼊后交换解决HashTable<K, V, Hash> newHT;newHT._tables.resize(__stl_next_prime(_tables.size() + 1));for (size_t i = 0; i < _tables.size(); i++){if (_tables[i]._state == EXIST){newHT.Insert(_tables[i]._kv);}} _tables.swap(newHT._tables);} Hash hash;size_t hash0 = hash(kv.first) % _tables.size();size_t hashi = hash0;size_t i = 1;while (_tables[hashi]._state == EXIST){// 线性探测hashi = (hash0 + i) % _tables.size();// ⼆次探测就变成 +- i^2++i;} _tables[hashi]._kv = kv;_tables[hashi]._state = EXIST;++_n;return true;} HashData<K, V>* Find(const K& key){Hash hash;size_t hash0 = hash(key) % _tables.size();size_t hashi = hash0;size_t i = 1;while (_tables[hashi]._state != EMPTY){if (_tables[hashi]._state == EXIST&& _tables[hashi]._kv.first == key){return &_tables[hashi];} // 线性探测hashi = (hash0 + i) % _tables.size();++i;}return nullptr;} bool Erase(const K& key){HashData<K, V>* ret = Find(key);if (ret == nullptr){return false;} else{ret->_state = DELETE;--_n;return true;}}private:vector<HashData<K, V>> _tables;size_t _n = 0; // 表中存储数据个数};
}开放定址法中所有的元素都放到哈希表里,链地址法中所有的数据不再直接存储在哈希表中,哈希表中存储一个指针,没有数据映射这个位置时,这个指针为空,有多个数据映射到这个位置时,我们把这些冲突的数据链接成一个链表,挂在哈希表这个位置下面,链地址法也叫做拉链法或者哈希桶。
1.5.2链地址法
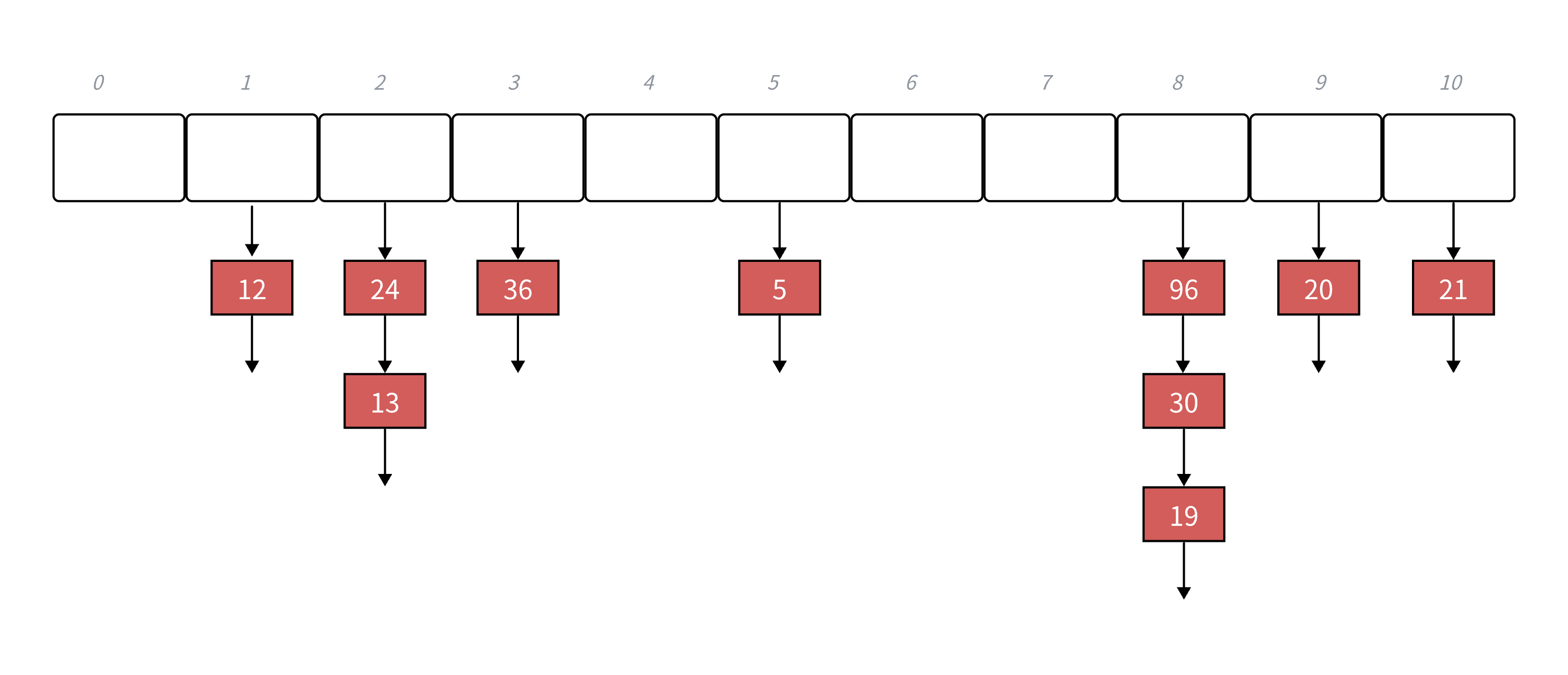
下面演示{19,30,5,36,13,20,21,12,24,96}等这一组值映射到M=11的表中。

| h(19) = 8,h(30) = 8,h(5) = 5,h(36) = 3,h(13) = 2,h(20) = 9 h(21) =10,h(12) = 1,h(24) = 2,h(96) = 88 |
扩容
开放定址法负载因子必须小于1,链地址法的负载因子就没有限制了,可以大于1。负载因子越大,哈希冲突的概率越高,空间利用率越高;负载因子越小,哈希冲突的概率越低,空间利用率越低;st中unordered_xxx的最大负载因子基本控制在1,大于1就扩容,我们下面实现也使用这个方式。
极端场景
如果极端场景下,某个桶特别长怎么办?其实我们可以考虑使用全域散列法,这样就不容易被针对
了。但是假设不是被针对了,用了全域散列法,但是偶然情况下,某个桶很长,查找效率很低怎么
办?这里在Java8的HashMap中当桶的长度超过一定阀值(8)时就把链表转换成红黑树。一般情况下,不断扩容,单个桶很长的场景还是比较少的。
代码实现
namespace hash_bucket
{template<class K, class V>struct HashNode{pair<K, V> _kv;HashNode<K, V>* _next;HashNode(const pair<K, V>& kv):_kv(kv), _next(nullptr){}};template<class K, class V, class Hash = HashFunc<K>>class HashTable{typedef HashNode<K, V> Node;inline unsigned long __stl_next_prime(unsigned long n){static const int __stl_num_primes = 28;static const unsigned long __stl_prime_list[__stl_num_primes] ={53, 97, 193, 389, 769,1543, 3079, 6151, 12289, 24593,49157, 98317, 196613, 393241, 786433,1572869, 3145739, 6291469, 12582917, 25165843,50331653, 100663319, 201326611, 402653189, 805306457,1610612741, 3221225473, 4294967291};const unsigned long* first = __stl_prime_list;const unsigned long* last = __stl_prime_list +__stl_num_primes;const unsigned long* pos = lower_bound(first, last, n);return pos == last ? *(last - 1) : *pos;}public:HashTable(){_tables.resize(__stl_next_prime(0), nullptr);} // 拷⻉构造和赋值拷⻉需要实现深拷⻉,有兴趣的同学可以⾃⾏实现~HashTable(){// 依次把每个桶释放for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;delete cur;cur = next;} _tables[i] = nullptr;}} bool Insert(const pair<K, V>& kv){Hash hs;size_t hashi = hs(kv.first) % _tables.size();// 负载因⼦==1扩容if (_n == _tables.size()){/*HashTable<K, V> newHT;newHT._tables.resize(__stl_next_prime(_tables.size()+1);for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while(cur){newHT.Insert(cur->_kv);cur = cur->_next;}} _tables.swap(newHT._tables);*/// 这⾥如果使⽤上⾯的⽅法,扩容时创建新的结点,后⾯还要使用就结点,浪费了// 下⾯的⽅法,直接移动旧表的结点到新表,效率更好vector<Node*>newtables(__stl_next_prime(_tables.size() + 1), nullptr);for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;// 旧表中节点,挪动新表重新映射的位置size_t hashi = hs(cur->_kv.first) %newtables.size();// 头插到新表cur->_next = newtables[hashi];newtables[hashi] = cur;cur = next;} _tables[i] = nullptr;} _tables.swap(newtables);} // 头插Node * newnode = new Node(kv);newnode->_next = _tables[hashi];_tables[hashi] = newnode;++_n;return true;} Node* Find(const K& key){Hash hs;size_t hashi = hs(key) % _tables.size();Node* cur = _tables[hashi];while (cur){if (cur->_kv.first == key){return cur;} cur = cur->_next;} return nullptr;}bool Erase(const K& key){Hash hs;size_t hashi = hs(key) % _tables.size();Node* prev = nullptr;Node* cur = _tables[hashi];while (cur){if (cur->_kv.first == key){if (prev == nullptr){_tables[hashi] = cur->_next;} else{prev->_next = cur->_next;} delete cur;--_n;return true;} prev = cur;cur = cur->_next;} return false;}
private:vector<Node*> _tables; // 指针数组size_t _n = 0; // 表中存储数据个数
};
}相关文章:
实现)
C++_数据结构_哈希表(hash)实现
✨✨ 欢迎大家来到小伞的大讲堂✨✨ 🎈🎈养成好习惯,先赞后看哦~🎈🎈 所属专栏:C学习 小伞的主页:xiaosan_blog 制作不易!点个赞吧!!谢谢喵!&…...

elasticsearch kibana ik 各版本下载
https://release.infinilabs.com/analysis-ik/stable/或者 https://github.com/infinilabs/analysis-ik/releases...

Uniapp 与 Uniapp X 对比:新手上手指南及迁移到 Uniapp X 的注意事项
文章目录 前言一、Uniapp 与 Uniapp X 核心区别二、Uniapp X 的核心优势三、新手学习 Uniapp X 必备技能栈3.1 基础技能要求3.2 平台相关知识3.3 工具链掌握 四、从 Uniapp 迁移到 Uniapp X 的注意事项4.1 语法转换:4.2 组件替换:4.3 状态管理࿱…...

SQL性能分析
查看数据库操作频次 使用SHOW GLOBAL STATUS LIKE Com_______; 指令,能查看当前数据库的INSERT、UPDATE、DELETE、SELECT访问频次 。若以查询为主,需重点优化查询相关性能,如索引;若以增删改为主,可考虑事务处理、批量…...

CANoe测试应用案例之A2L
写在前面 本系列文章主要讲解CANoe测试应用案例之A2L的相关知识,希望能帮助更多的同学认识和了解CANoe测试。 若有相关问题,欢迎评论沟通,共同进步。(*^▽^*) CANoe Option AMD/XCP支持加载A2L到CANoe中,方便ECU内部变量在功能验…...

H2数据库源码学习+debug, 数据库 sql、数据库引擎、数据库存储从此不再神秘
一、源码结构概览 H2源码采用标准Maven结构,核心模块在src/main/org/h2目录下: ├── command/ # SQL解析与执行 ├── engine/ # 数据库引擎核心(会话、事务) ├── table/ # 表结构定义与操作 ├── index/ # 索引实现&am…...

PopSQL:一个支持团队协作的SQL开发工具
PopSQL 是一款专为团队协作设计的现代化 SQL 编辑器,通过通团队过协作编写 SQL 查询、交互式可视化以及共享结果提升数据分析和管理效率。 PopSQL 提供了基于 Web 的在线平台以及跨系统(Windows、macOS、Linux)的桌面应用,包括免费…...

tomcat查看状态页及调优信息
准备工作 先准备一台已经安装好tomcat的虚拟机,tomcat默认是状态页是默认被禁用的 1.添加授权用户 vim /usr/local/tomcat/conf/tomcat-users.xml22 <role rolename"manager-gui"/>23 <user username"admin" password"tomcat&q…...

贝塞尔曲线原理
文章目录 一、 低阶贝塞尔曲线1.一阶贝塞尔曲线2. 二阶贝塞尔曲线3. 三阶贝塞尔曲线 一、 低阶贝塞尔曲线 1.一阶贝塞尔曲线 如下图所示, P 0 P_0 P0, P 1 P_1 P1 是平面中的两点,则 B ( t ) B ( t ) B(t) 代表平面中的一段线段。…...

【MYSQL】笔记
📚 博主的专栏 🐧 Linux | 🖥️ C | 📊 数据结构 | 💡C 算法 | 🅒 C 语言 | 🌐 计算机网络 在ubuntu中,改配置文件: sudo nano /etc/mysql/mysql.conf.d/mysq…...

构建 TypoView:一个富文本样式预览工具的全流程记录
我正在参加CodeBuddy「首席试玩官」内容创作大赛,本文所使用的 CodeBuddy 免费下载链接:腾讯云代码助手 CodeBuddy - AI 时代的智能编程伙伴 在一次和 CodeBuddy 的日常交流中,我提出了一个构想:能不能帮我从零构建一个富文本样式…...

使用conda创建python虚拟环境,并自定义路径
创建虚拟环境 conda create --prefixE:/ai-tools/Luoxuejiao/envs/Luo24 python3.8 此时虚拟环境没有名字,只有路径,下面将名字添加到配置中: conda config --append envs_dirs E:/ai-tools/Luoxuejiao/envs/...

【自然语言处理与大模型】向量数据库技术
向量数据库,是专门为向量检索设计的中间件! 高效存储、快速检索和管理高纬度向量数据的系统称为向量数据库 一、向量数据库是什么有什么用? 向量数据库是一种专门用于高效存储和检索高维向量数据的系统。它通过嵌入模型将各类非结构化数据&am…...
:隐藏的性能杀手与高并发优化实战)
Java中的伪共享(False Sharing):隐藏的性能杀手与高并发优化实战
引言 在高性能Java应用中,开发者通常会关注锁竞争、GC频率等显性问题,但一个更隐蔽的陷阱——伪共享(False Sharing)——却可能让精心设计的并发代码性能骤降50%以上。伪共享是由CPU缓存架构引发的底层问题,常见于多…...

【数据结构】2-3-3单链表的查找
数据结构知识点合集 知识点 单链表的按位查找 GetElem(L,i):按位查找操作。获取表L中第i个位置的元素的值。 /*查找L中的第i个节点并返回*/ LNode *GetElm(LinkList L,int i) { /*位置不合法返回NULL*/ if(i<0) return NULL; /*p指向当前节…...
)
从0开始学linux韦东山教程第四章问题小结(1)
本人从0开始学习linux,使用的是韦东山的教程,在跟着课程学习的情况下的所遇到的问题的总结,理论虽枯燥但是是基础。说实在的越看视频越感觉他讲的有点乱后续将以他的新版PDF手册为中心,视频作为辅助理解的工具。参考手册为嵌入式Linux应用开发…...

TYUT-企业级开发教程-第三章
JAVAWEB的三大组件 在 Spring Boot 项目中,会自动将 Spring 容器中的 Servlet 、 Filter 、 Listener 实例注册为 Web 服务器中对应的组件。因此,可以将自定义的 Java Web 三大组件作为 Bean 添加到 Spring 容器中,以实现组件的注册。使用 S…...

【数据结构】2-3-2 单链表的插入删除
数据结构知识点合集 知识点 按位序插入带头节点链表 ListInsert(&L,i,e):插入操作。在表L中的第i个位置上插入指定元素e;找到第 i-1 个结点,将新结点插入其后 。 /*在带头节点的单链表L的第i个位置插入元素e*/ bool ListInsert(LinkList …...

spark-配置yarn模式
1.上传并解压spark-3.1.1-bin-hadoop3.2.tgz (/opt/software) 解压的命令是:tar -zxvf spark-3.3.1-bin-hadoop3.tgz -C /opt/module (cd /opt/software 进入software) 2.重命名 解压之后的目录为spark-yarn(原为spark-3.1.1-…...

鸿蒙系统电脑:开启智能办公新时代
鸿蒙系统电脑:开启智能办公新时代 引言 2025 年 5 月 8 日,华为正式推出了鸿蒙系统电脑,这款具有里程碑意义的产品,不仅彰显了华为在智能设备领域的创新实力,也为用户带来了全新的智能办公体验。在数字化转型加速的背…...

Ubuntu---omg又出bug了
自用遇到问题的合集 250518——桌面文件突然消失 ANS:参考博文...

COCO数据集神经网络性能现状2025.5.18
根据当前搜索结果,截至2025年5月,COCO数据集上性能最佳的神经网络模型及其关键参数如下: 1. D-FINE(中科大团队) 性能参数: 在COCO数据集上以78 FPS的速度实现了59.3%的平均精度(AP࿰…...

elementplus menu 设置 activeindex
<el-menu:default-active"defaultActive"> 更改当前激活的 index 可以 绑定:default-active"defaultActive" 改变 defaultActive 值 即会改变 index 但不会改变路径 watch(() > route.fullPath,(newPath: string) > {defaultActive.value…...

张 心理问题的分类以及解决流程
心理问题的分类以及解决流程 目录 心理问题的分类以及解决流程心理问题的分类**一、心理问题的分类与层次****1. 一般心理问题****2. 严重心理问题****3. 神经症性心理问题(神经症)****4. 精神障碍**轻度问题以心理咨询==判断:时间(3个月,1年,大于1年=神经质),社会功能(…...

网页 H5 微应用接入钉钉自动登录
ℹ️关于云审批 云审批(cloud approve) ,一款专为小微企业打造,支持多租户的在线审批神器。它简化了申请和审批流程,让您随时随地通过手机或电脑完成请款操作。员工一键提交申请,审批者即时响应,…...

接口——类比摄像
最近迷上了买相机,大疆Pocket、Insta Go3、大疆Mini3、佳能50D、vivo徕卡人像大师(狗头),在买配件的时候,发现1/4螺口简直是神中之神,这个万能接口让我想到计算机设计中的接口,遂有此篇—— 接…...

java每日精进 5.18【文件存储】
1.文件存储思路 支持将文件上传到三类存储器: 兼容 S3 协议的对象存储:支持 MinIO、腾讯云 COS、七牛云 Kodo、华为云 OBS、亚马逊 S3 等等。磁盘存储:本地、FTP 服务器、SFTP 服务器。数据库存储:MySQL、Oracle、PostgreSQL、S…...

LeetCode 394. 字符串解码详解:Java栈实现与逐行解析
文章目录 1. 问题描述2. 解决思路核心问题栈的应用遍历逻辑 3. 完整代码实现4. 关键代码解析处理右括号 ]处理嵌套的示例 5. 复杂度分析6. 总结 1. 问题描述 给定一个经过编码的字符串,要求将其解码为原始字符串。编码规则为 k[encoded_string],表示方括…...

基于STC89C52的红外遥控的电子密码锁设计与实现
一、引言 电子密码锁作为一种安全便捷的门禁系统,广泛应用于家庭、办公室等场景。结合红外遥控功能,可实现远程控制开锁,提升使用灵活性。本文基于 STC89C52 单片机,设计一种兼具密码输入和红外遥控的电子密码锁系统,详细阐述硬件选型、电路连接及软件实现方案。 二、硬…...
—— 数据结构优化)
Android 性能优化入门(一)—— 数据结构优化
1、概述 一款 app 除了要有令人惊叹的功能和令人发指交互之外,在性能上也应该追求丝滑的要求,这样才能更好地提高用户体验: 优化目的性能指标优化的方向更快流畅性启动速度页面显示速度(显示和切换)响应速度更稳定稳定性避免出现 应用崩溃&…...

深入理解Docker和K8S
深入理解Docker和K8S Docker 是大型架构的必备技能,也是云原生核心。Docker 容器化作为一种轻量级的虚拟化技术,其核心思想:将应用程序及其所有依赖项打包在一起,形成一个可移植的单元。 容器的本质是进程: 容器是在…...

5.18本日总结
一、英语 复习list3list28 二、数学 学习14讲部分内容,1000题13讲部分 三、408 学习计网5.3剩余内容 四、总结 计网TCP内容比较重要,连接过程等要时常复习;高数学到二重积分对定积分的计算相关方法有所遗忘,需要加强巩固。…...

muduo库TcpServer模块详解
Muduo库核心模块——TcpServer Muduo库的TcpServer模块是一个基于Reactor模式的高性能TCP服务端实现,负责管理监听端口、接受新连接、分发IO事件及处理连接生命周期。 一、核心组件与职责 Acceptor 监听指定端口,接受新连接,通过epoll监听l…...

深入理解 OpenCV 的 DNN 模块:从基础到实践
在计算机视觉领域蓬勃发展的当下,深度学习模型的广泛应用推动着技术的不断革新。OpenCV 作为一款强大且开源的计算机视觉库,其 DNN(Deep Neural Network)模块为深度学习模型的落地应用提供了高效便捷的解决方案。本文将以理论为核…...

MyBatis 延迟加载与缓存
一、延迟加载策略:按需加载,优化性能 1. 延迟加载 vs 立即加载:核心区别 立即加载:主查询(如查询用户)执行时,主动关联加载关联数据(如用户的所有账号)。 场景…...

6.2.2邻接表法-图的存储
知识总览: 为什么要用邻接表 因为邻接矩阵的空间复杂度高(O(n)),且不适合边少的稀疏图,所以有了邻接表 用代码表示顶点、图 声明顶点图信息 声明顶点用一维数组存储各个顶点的信息,一维数组字段包括2个,每个顶点的…...

【甲方安全建设】拉取镜像执行漏洞扫描教程
文章目录 前置知识镜像(Docker Image)是什么?镜像的 tag(标签)查看本地已有镜像的 tag查看远程仓库的所有 tag构建镜像与拉取镜像的区别正文安装docker拉取待扫描镜像安装 veinmind-runner 镜像下载 veinmind-runner 平行容器启动脚本快速扫描本地镜像/容器6. 生成 报告前…...

第四天的尝试
目录 一、每日一言 二、练习题 三、效果展示 四、下次题目 五、总结 一、每日一言 很抱歉的说一下,我昨天看白色巨塔电视剧,看的入迷了,同时也看出一些道理,学到东西; 但是把昨天的写事情给忘记了,今天…...

大数据场景下数据导出的架构演进与EasyExcel实战方案
一、引言:数据导出的演进驱动力 在数字化时代,数据导出功能已成为企业数据服务的基础能力。随着数据规模从GB级向TB级甚至PB级发展,传统导出方案面临三大核心挑战: 数据规模爆炸:单次导出数据量从万级到亿级的增长…...

svn: E170013 和 svn: E120171 的问题
在 Deepin23 上尝试用 svn 连接我的 Visual SVN 服务器,得到如下错误信息, > svn: E170013: Unable to connect to a repository at URL https://my.com/svn/mysource/branch_4.2.x > svn: E120171: 执行上下文错误: An error occurred during SSL…...

Limesurvay系统“48核心92GB服务器”优化方案
1、Redis maxmemory 16GB # 限制Redis内存(预留足够空间给其他服务) maxmemory-policy volatile-lru # 自动淘汰旧会话(仅对带TTL的键) save 300 100 # 仅保留一个条件减少阻塞 stop-writes-on-bgsave-error no #…...

DockerFile实战
背景 在上一篇文章中,我们对DockerFile有了一个较为深刻的认识,那么这篇文章,我将会向你展示如何自定义一个镜像并且在docker上运行。 一、基础指令 指令技术说明生产环境最佳实践典型错误示例FROM- 必须作为Dockerfile第一条指令 - 推…...
)
【Linux】简易版Shell实现(附源码)
🌟🌟作者主页:ephemerals__ 🌟🌟所属专栏:Linux 前言 之前我们学习了Linux的进程概念以及进程控制相关接口: 【Linux】进程控制-CSDN博客 本篇文章,我们将一起踏上一段有趣的旅程&a…...

MATLAB安装常见问题解决方案
目前新版本的matlab安装往往需要十几G的本地安装容量,例如matlab2022b、matlab2023b, 首先就是要保证本地硬盘空间足够大,如果没有足够的本地内存空间,那么可以尝试释放本地硬盘空间,或者安装所需内存空间较小的旧版本的matlab&am…...

在 Vue 中插入 B 站视频
前言 在 Vue 项目中,有时我们需要嵌入 B 站视频来丰富页面内容,为用户提供更直观的信息展示。本文将详细介绍在 Vue 中插入 B 站视频的多种方法。 使用<iframe>标签直接嵌入,<iframe>标签是一种简单直接的方式,可将 B 站视频嵌…...

【深度学习】#12 计算机视觉
主要参考学习资料: 《动手学深度学习》阿斯顿张 等 著 【动手学深度学习 PyTorch版】哔哩哔哩跟李沐学AI 目录 目标检测锚框交并比(IoU)锚框标注真实边界框分配偏移量计算损失函数 非极大值抑制预测 多尺度目标检测单发多框检测(S…...

QT学习3
QT项目视图 1、List View清单视图 private:QListView *listview1; private slots:void slotClickedFunc(const QModelIndex &index); #include "widget.h" #include "ui_widget.h"#include <QStringListModel>//字符串列表模型 #include <QS…...
)
Vue 3 动态 ref 的使用方式(表格)
一、问题描述 先给大家简单介绍一下问题背景。我正在开发的项目中,有一个表格组件,其中一列是分镜描述,需要支持视频上传功能。用户可以为每一行的分镜描述上传对应的视频示例。然而,在实现过程中,出现了一个严重的问…...
)
FAST-DDS源码分析PDP(一)
准备开一个FAST-DDS源码分析系列,源码版本FAST-DDS 1.1.0版本。 FAST-DDS这种网络中间件是非常复杂的,所以前期先去分析每个类的作用是什么,然后在结合RTPS DOC,FAST-DDS DEMO,以及FAST-DDS的doc去串起来逻辑。 Builtin Discovery…...
深度对比及鸿蒙生态适配解析)
Flutter与Kotlin Multiplatform(KMP)深度对比及鸿蒙生态适配解析
Flutter 与 Kotlin Multiplatform(KMP)深度对比及鸿蒙生态适配解析 在跨平台开发领域,Flutter 与 Kotlin Multiplatform(KMP)代表了两种不同的技术路线:前者以 “统一 UI 体验” 为核心,后者以…...