Android 性能优化入门(一)—— 数据结构优化
1、概述
一款 app 除了要有令人惊叹的功能和令人发指交互之外,在性能上也应该追求丝滑的要求,这样才能更好地提高用户体验:
| 优化目的 | 性能指标 | 优化的方向 |
|---|---|---|
| 更快 | 流畅性 | 启动速度 页面显示速度(显示和切换) 响应速度 |
| 更稳定 | 稳定性 | 避免出现 应用崩溃(Crash) 避免出现 应用无响应(ANR) |
| 更省 | 资源节省性 | 内存大小 安装包大小 耗电量 网络流量 |
响应速度一项就主要取决于数据结构和算法。
2、ArrayList 与 LinkedList
ArrayList 里面是数组,get/set 速度快,但 add/remove 速度慢,因为数组是连续内存,访问某个元素可以根据首地址与偏移量计算出该元素的地址,从而快速访问到元素,但是添加/移除一个元素需要移动其它元素,故而速度慢。
研究下 add() 的源码,视频里的源码版本 add() 时,如果目标位置上已经存有元素,就会调用 System.arrayCopy() 把所有元素向后移一位,但是我看现在的版本底层实现又改了,不用 System.arrayCopy() 了。但不论怎样实现,你都要清除,添加、删除元素都会有性能损耗。
与 ArrayList 相对的是基于双向链表的 LinkedList,插入删除快,访问慢。
3、HashMap 存元素过程
HashMap 在 Android 源码中的实现以 api 26,即 Android 8.0 为界,分为两个版本:
- Android 8.0(api 26)之前,HashMap 通过 ArrayList + LinkedList 实现
- Android 8.0 开始,HashMap 通过数组 + 链表 + 红黑树实现
以下是 HashMap 的结构示意图:
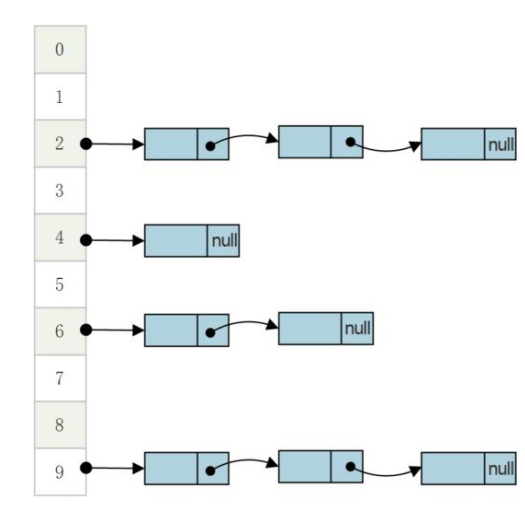
竖向排列的 0 ~ 9 是存放 key 的数组,数组存放一个链表,链表的每个节点都是 value。
首先来考虑一个问题,HashMap 中 key 与 value 的关系,是一对多、一对一还是多对一?结论是多对一,即一个 key 只能保存一个 value,如果对同一个 key put 不同的 value,那么原来的 value 会被覆盖;反之,多个 key 可以有同一个 value。
具体内容要看 put 的源码(使用 7.0 源码):
// 默认初始容量,必须是 2 的幂static final int DEFAULT_INITIAL_CAPACITY = 4;// 当表格未被填充时,可以共享的空表格实例static final HashMapEntry<?,?>[] EMPTY_TABLE = {};// HashMap 实体,可以根据需要调整大小。长度必须始终是 2 的幂transient HashMapEntry<K,V>[] table = (HashMapEntry<K,V>[]) EMPTY_TABLE;public V put(K key, V value) {// table 为空时创建一个 HashMapEntry 数组给它,这是延迟初始化if (table == EMPTY_TABLE) {inflateTable(threshold);}// 如果 key 为空,则将其加入 table[0] 这个链表中if (key == null)return putForNullKey(value);// 通过 key 计算出哈希值int hash = sun.misc.Hashing.singleWordWangJenkinsHash(key);// 哈希值与 HashMap 长度进行位运算(等价于取模运算)计算索引int i = indexFor(hash, table.length);// table[i] 是 i 位置的链表头,for 循环就是从头遍历这个链表for (HashMapEntry<K,V> e = table[i]; e != null; e = e.next) {Object k;// 寻找哈希值相同并且 key 也相同的节点,把新的 value 存进该节点if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {V oldValue = e.value;e.value = value;e.recordAccess(this);return oldValue;}}// key 尚未存入 HashMap,通过 addEntry() 将新的 key-value 加入modCount++;addEntry(hash, key, value, i);return null;}
从 put() 中能看出最明显的一点是:哈希表不是在 HashMap 的构造方法中初始化的,而是在 put() 时才初始化,这是一种通过延迟加载节约内存的方式,因为 HashMap 很大。
下面按照 put() 的代码顺序说明其中的部分细节。
3.1 table 初始化
当 table 是空表 EMPTY_TABLE 时,通过 inflateTable() 为 table 初始化:
// threshold = capacity * loadFactor,当 HashMap 中// 存储的元素个数大于 threshold 时就要对 HashMap 扩容。int threshold;// 默认为 0.75final float loadFactor = DEFAULT_LOAD_FACTOR;// 初始化 table 并计算出扩容阈值 thresholdprivate void inflateTable(int toSize) {// capacity 是比 toSize 大的最小的 2 的幂int capacity = roundUpToPowerOf2(toSize);// Android-changed: 替换此处对 Math.min() 的使用,因为该方法在运行时的// <clinit> 中调用,此时 Float.* 所需的本地库可能尚未加载float thresholdFloat = capacity * loadFactor;if (thresholdFloat > MAXIMUM_CAPACITY + 1) {thresholdFloat = MAXIMUM_CAPACITY + 1;}threshold = (int) thresholdFloat;table = new HashMapEntry[capacity];}
roundUpToPowerOf2()
roundUpToPowerOf2() 在不超过最大容量 MAXIMUM_CAPACITY = 1 << 30 的情况下,返回大于参数 number 的最小 2 的幂:
private static int roundUpToPowerOf2(int number) {// assert number >= 0 : "number must be non-negative";int rounded = number >= MAXIMUM_CAPACITY? MAXIMUM_CAPACITY: (rounded = Integer.highestOneBit(number)) != 0 ? (Integer.bitCount(number) > 1) ? rounded << 1 : rounded : 1;return rounded;}
Integer.highestOneBit()
Integer.highestOneBit() 是一个简单的位操作算法,它通过执行一系列的位移和按位或操作,将指定的值的所有位都设置为最高位之后的所有位都为 1。然后,通过将该值减去右移一位后的值(无符号右移)来保留最高位的 1,其他位都为 0:
/*** 返回一个 long 类型的值,其最多只有一个位为 1,该位位于指定* 的 i 值最高位(最左边)的一位。* 如果指定的值在其二进制的补码表示中没有一位为 1,即等于零,则返回零*/public static long highestOneBit(long i) {// long 是 64 为,而 i 右移了 63 位i |= (i >> 1);i |= (i >> 2);i |= (i >> 4);i |= (i >> 8);i |= (i >> 16);i |= (i >> 32);return i - (i >>> 1);}
例如 i = 10011010,最高位的 1 位于第 5 位(从右向左数)。经过方法的处理后,返回的值为 10000000。这个方法的用途包括找到一个数中的最高位,计算一个数的对数(以 2 为底),或者确定一个数是否是 2 的幂等等。
Integer.bitCount()
/*** 返回给定值二进制补码表示中的位数,有时这个函数被称为种群计数*/public static int bitCount(long i) {i = i - ((i >>> 1) & 0x5555555555555555L);i = (i & 0x3333333333333333L) + ((i >>> 2) & 0x3333333333333333L);i = (i + (i >>> 4)) & 0x0f0f0f0f0f0f0f0fL;i = i + (i >>> 8);i = i + (i >>> 16);i = i + (i >>> 32);return (int)i & 0x7f;}
3.2 存放 key 为 null 的元素
key 为 null 时通过 putForNullKey() 存入元素:
private V putForNullKey(V value) {// 遍历 table[0] 这个链表,如果有 key 为 null 的节点,则用新的 value 替换 oldValuefor (HashMapEntry<K,V> e = table[0]; e != null; e = e.next) {if (e.key == null) {V oldValue = e.value;e.value = value;e.recordAccess(this);return oldValue;}}// table[0] 目前没有 key = null 的节点,则创建并存入这个节点modCount++;addEntry(0, null, value, 0);return null;}
addEntry() :
// 添加 key = null 的元素时,hash 传 0、key 传 null、bucketIndex 传 0void addEntry(int hash, K key, V value, int bucketIndex) {// 超过扩容的阈值并且 table[bucketIndex] 链表不为空if ((size >= threshold) && (null != table[bucketIndex])) {// 扩容resize(2 * table.length);hash = (null != key) ? sun.misc.Hashing.singleWordWangJenkinsHash(key) : 0;// 通过哈希值和扩容后的长度,计算应该放在哪个链表中bucketIndex = indexFor(hash, table.length);}// 创建新的 HashMapEntrycreateEntry(hash, key, value, bucketIndex);}void createEntry(int hash, K key, V value, int bucketIndex) {// 让 e 指向 table[bucketIndex] 这个链表头HashMapEntry<K,V> e = table[bucketIndex];// 新创建的 HashMapEntry 的 next 指向 e,再赋值给 table[bucketIndex],// 相当于在链表头插入了这个新的 HashMapEntrytable[bucketIndex] = new HashMapEntry<>(hash, key, value, e);size++;}
HashMapEntry 的构造方法:
static class HashMapEntry<K,V> implements Map.Entry<K,V> {final K key;V value;// 链表HashMapEntry<K,V> next;int hash;// n 是原来的链表,让 next指向 n,就是在原链表的头插入了 thisHashMapEntry(int h, K k, V v, HashMapEntry<K,V> n) {value = v;next = n;key = k;hash = h;}}
3.3 计算 key 的哈希值
HashMap 使用 key 的 hashCode 值来确定 key 在内部数据结构中的存储位置。计算 key 的哈希值时可能会有装箱操作:
public static int singleWordWangJenkinsHash(Object k) {// k 是 Object 类型,那么可能是基本类型,也可能是引用类型int h = k.hashCode();h += (h << 15) ^ 0xffffcd7d;h ^= (h >>> 10);h += (h << 3);h ^= (h >>> 6);h += (h << 2) + (h << 14);return h ^ (h >>> 16);}
如果 k 是基本数据类型,不会发生装箱操作,但如果是引用数据类型,通常会将对象转换为 Integer、Long 或其他装箱类型,然后再调用其 hashCode() 来计算哈希值。这个装箱操作可能会对性能产生一定的影响,因此在需要高性能的场景下,可以考虑使用基本数据类型作为 key,以避免装箱操作带来的开销。
3.4 indexFor() 计算索引
计算索引的目的是为了找出新加入元素应该保存在哪个位置:
// h 是 key 的哈希值,length 是 HashMap 当前容量static int indexFor(int h, int length) {return h & (length-1);}
h & (length-1) 这个与运算,相当于 h % length 即对 length 求模。直接使用位运算的原因是其效率更高(所有的加减乘除的计算,最终都会转换成位的与或非运算,在将运算指令转换为字节码的过程中,位运算可能只有一条字节码,而数学计算因为存在转换,可能有多条字节码,显然使用一条字节码的位运算效率更高)。
3.5 保存新的值
通过 indexFor() 求出新值在 table 数组的下标后,就应该将其保存到数组中。数组的结构如下图:
table 数组的每一个元素都是一个链表,链表元素类型是 HashMapEntry,其内部有 next 指针指向链表中的下一个 HashMapEntry。
从图中能看出,存放新值涉及两种情况:
- 目标位置的链表不为空,且遍历时发现要操作的 key 所在的 HashMapEntry 已经在这个链表中,那么直接用新值覆盖老值
- 目标位置的链表为空,或者链表不为空但在遍历时并没有找到包含目标 key 的 HashMapEntry,那就只能新建一个 HashMapEntry 存入目标位置
这两种情况分别对应 put() 中的 for 循环和最后的 addEntry(),for 循环会在 key 匹配的 HashMapEntry 直接用新值替换老值,而 addEntry() 前面已经介绍过,它会使用“头插法”,在链表头插入新的 HashMapEntry。
为什么用链表保存 HashMapEntry 呢?一个 table[k] 中的链表有多个元素,是因为这些元素的 hashCode 计算出的 index 相同,也称哈希碰撞(冲突)。而这种“链表法”也正是解决哈希碰撞的一种方法,将相同 index 的元素存在链表中,那么在 get 某一个元素时,先计算出这个元素的 index,然后再去这个 index 的链表中遍历元素,找是否有 key 相同的元素。
3.6 扩容问题
最后我们来说说扩容问题。其实前面贴源码的时候出现过与扩容有关的常量和变量:
- HashMap 容量:在 8.0 之前的 HashMap 中,DEFAULT_INITIAL_CAPACITY = 4,而从 8.0 开始,DEFAULT_INITIAL_CAPACITY = 1 << 4,即 16 个。并且这个容量值必须是 2 的幂,如 16、32、64…
- 加载因子:默认值 DEFAULT_LOAD_FACTOR = 0.75f,这个 0.75 是谷歌测试结果,实际上论文中表述的是数学家认为 0.6 ~0.75 是最佳范围。
- 扩容的阈值:当 HashMap 中元素个数超过 threshold = DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR 时,对于默认值来说就是 4 * 0.75 = 3 个时,就要进行扩容
以下我们通过几个问题来了解扩容。
为什么要扩容?
HashMap 扩容的意义在于提升效率,那么 HashMap 何时效率最低呢?不是满载的时候,而是全部冲突时(所有元素全在 table[k] 的链表中,退化成单链表了)。
扩容会降低元素的冲突情况。因为扩容只是将 HashMap 的 length 翻倍,而通过 key 计算的 hashCode 没有变,由于索引等价于 hashCode % length,这样 HashMapEntry 的索引就会随之改变,很容易出现原本在同一个链表中的 HashMapEntry 在扩容后会分到不同链表的情况。
比如两个 key 的 hashCode 分别为 1 和 17,那么对于容量为 16 的 HashMap 而言,这两个 key 都会存在 table[1] 中。而假如将 HashMap 扩容到 32,那么这两个 key 就不会存在同一个 table 链表中了。这样就降低了哈希冲突的概率,从而提升了 HashMap 的效率。
为什么要尽量避免扩容
扩容后需要把已经在 HashMap 中的元素重新计算它在扩容后的新位置并将其移动到这个新位置上,所以扩容是 HashMap 中耗费性能的一个动作,应该尽量避免扩容。因此在 new HashMap() 时应该先评估哈希表中可能要存放的元素数量 count,在 new 时传 new HashMap(count/0.75+1)。传进来的这个数,会在内部被取成大于它的最小的 2 的整数幂,比如传进来 25 会转变成 32。
为什么要求 HashMap 的容量必须是 2 的幂?
也是为了减少哈希碰撞从而提升效率的一种方法,这需要从二进制的角度来看 hashCode & (length - 1) 这个求模公式。
假如我们的长度违背了必须是 2 的幂的法则,比如说是 10,那么 length - 1 就为 9,转换成二进制就是 1001。那么在与 hashCode 做与运算时,就只有最高位和最低位是有效的,中间两位由于是 0,无论 hashCode 这两位是什么运算完都是 0,这就增加了 hashCode 碰撞的几率。比如说 hashCode 为 001,101,111 运算完都是 0001,那么他们就都会去 table[1] 这个链表中。而 2 的整数次幂 -1 后的二进制全部都是1,在与 hashCode 做与运算时对应位置的结果要看 hashCode 那一位是什么(即 hashCode 的所有位置都是有效的运算位置),减少了 hashCode 冲突的情况,从而提高了效率。
HashMap 有什么缺点吗?
因为 HashMap 存储的元素数量到最大容量的 75% 时就会开始扩容,这是用空间换时间的做法;而这造成了空间的浪费,尤其是仅仅超出阈值 1 个时也要扩容 2 倍,这大大的浪费了空间。所以在 Android 中有一个解决方法就是使用 SparseArray。
4、SparseArray
使用 SparseArray 主要是为了节省空间,其内部将 key 和 value 分别保存在两个数组中:
private int[] mKeys;private Object[] mValues;
在 put() 时通过二分查找找到 key 在 mKeys[] 中的位置并存入(key 按照从小到大的顺序排列),如果需要移动元素就 arrayCopy() 移动。比如说找到 key 存入 mKeys[k],那么 value 就要存到 mValues[k] 这个位置。大致结构如图:
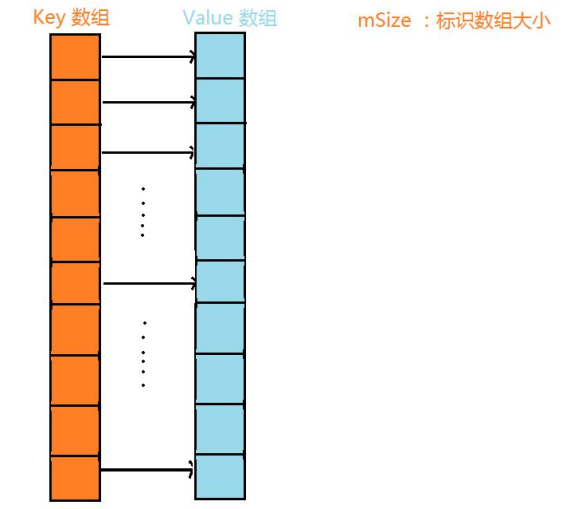
这样做的优点:
- 节约内存,不会有冲突了
- 速度上采用二分查找,也很快,删除时是给这个位置赋值为 DELETED,不发生位移,不会把后面的元素向前移,等到后面再插入元素时如果这个位置是 DELETED 就可以直接存放,不用把该位置后面的元素都向后移一位。
测试同样是长度为 10000 的 HashMap 和 SparseArray:
- put 10000 个元素,HashMap 用时 239ms,SparseArray 用时 44ms
- get 10000 个元素,HashMap 用时 43ms,SparseArray 用时 17ms
空间上 SparseArray 一定是比 HashMap 要节约空间的。
缺点是 key 只能是 int 类型的,解决方式是使用 ArrayMap(SimpleArrayMap),它是 HashMap 与 SparseArray 的结合体。
SimpleArrayMap 的 key 取的是 Object 的 hashCode,由于 hashCode 也是可能会发生冲突的,所以 SimpleArrayMap 也是需要解决哈希碰撞的,它的解决方式就是采用追加。意思是,比如通过 hashCode 算出某个 Object 应该存放的位置是 k,但是 keys[k] 已经有了元素,那么就逐一再检查 keys[k+1],keys[k+2]…直到有一个位置空闲,就把 Object 放在那个位置上。当元素满了之后也需要扩容(+1),发生 arraycopy 操作。
总结:实际上源码中使用的数据结构不断演进的过程,就是不断提升性能的过程。而性能提升,又分为空间和时间的优化。
相关文章:
—— 数据结构优化)
Android 性能优化入门(一)—— 数据结构优化
1、概述 一款 app 除了要有令人惊叹的功能和令人发指交互之外,在性能上也应该追求丝滑的要求,这样才能更好地提高用户体验: 优化目的性能指标优化的方向更快流畅性启动速度页面显示速度(显示和切换)响应速度更稳定稳定性避免出现 应用崩溃&…...

深入理解Docker和K8S
深入理解Docker和K8S Docker 是大型架构的必备技能,也是云原生核心。Docker 容器化作为一种轻量级的虚拟化技术,其核心思想:将应用程序及其所有依赖项打包在一起,形成一个可移植的单元。 容器的本质是进程: 容器是在…...

5.18本日总结
一、英语 复习list3list28 二、数学 学习14讲部分内容,1000题13讲部分 三、408 学习计网5.3剩余内容 四、总结 计网TCP内容比较重要,连接过程等要时常复习;高数学到二重积分对定积分的计算相关方法有所遗忘,需要加强巩固。…...

muduo库TcpServer模块详解
Muduo库核心模块——TcpServer Muduo库的TcpServer模块是一个基于Reactor模式的高性能TCP服务端实现,负责管理监听端口、接受新连接、分发IO事件及处理连接生命周期。 一、核心组件与职责 Acceptor 监听指定端口,接受新连接,通过epoll监听l…...

深入理解 OpenCV 的 DNN 模块:从基础到实践
在计算机视觉领域蓬勃发展的当下,深度学习模型的广泛应用推动着技术的不断革新。OpenCV 作为一款强大且开源的计算机视觉库,其 DNN(Deep Neural Network)模块为深度学习模型的落地应用提供了高效便捷的解决方案。本文将以理论为核…...

MyBatis 延迟加载与缓存
一、延迟加载策略:按需加载,优化性能 1. 延迟加载 vs 立即加载:核心区别 立即加载:主查询(如查询用户)执行时,主动关联加载关联数据(如用户的所有账号)。 场景…...

6.2.2邻接表法-图的存储
知识总览: 为什么要用邻接表 因为邻接矩阵的空间复杂度高(O(n)),且不适合边少的稀疏图,所以有了邻接表 用代码表示顶点、图 声明顶点图信息 声明顶点用一维数组存储各个顶点的信息,一维数组字段包括2个,每个顶点的…...

【甲方安全建设】拉取镜像执行漏洞扫描教程
文章目录 前置知识镜像(Docker Image)是什么?镜像的 tag(标签)查看本地已有镜像的 tag查看远程仓库的所有 tag构建镜像与拉取镜像的区别正文安装docker拉取待扫描镜像安装 veinmind-runner 镜像下载 veinmind-runner 平行容器启动脚本快速扫描本地镜像/容器6. 生成 报告前…...

第四天的尝试
目录 一、每日一言 二、练习题 三、效果展示 四、下次题目 五、总结 一、每日一言 很抱歉的说一下,我昨天看白色巨塔电视剧,看的入迷了,同时也看出一些道理,学到东西; 但是把昨天的写事情给忘记了,今天…...

大数据场景下数据导出的架构演进与EasyExcel实战方案
一、引言:数据导出的演进驱动力 在数字化时代,数据导出功能已成为企业数据服务的基础能力。随着数据规模从GB级向TB级甚至PB级发展,传统导出方案面临三大核心挑战: 数据规模爆炸:单次导出数据量从万级到亿级的增长…...

svn: E170013 和 svn: E120171 的问题
在 Deepin23 上尝试用 svn 连接我的 Visual SVN 服务器,得到如下错误信息, > svn: E170013: Unable to connect to a repository at URL https://my.com/svn/mysource/branch_4.2.x > svn: E120171: 执行上下文错误: An error occurred during SSL…...

Limesurvay系统“48核心92GB服务器”优化方案
1、Redis maxmemory 16GB # 限制Redis内存(预留足够空间给其他服务) maxmemory-policy volatile-lru # 自动淘汰旧会话(仅对带TTL的键) save 300 100 # 仅保留一个条件减少阻塞 stop-writes-on-bgsave-error no #…...

DockerFile实战
背景 在上一篇文章中,我们对DockerFile有了一个较为深刻的认识,那么这篇文章,我将会向你展示如何自定义一个镜像并且在docker上运行。 一、基础指令 指令技术说明生产环境最佳实践典型错误示例FROM- 必须作为Dockerfile第一条指令 - 推…...
)
【Linux】简易版Shell实现(附源码)
🌟🌟作者主页:ephemerals__ 🌟🌟所属专栏:Linux 前言 之前我们学习了Linux的进程概念以及进程控制相关接口: 【Linux】进程控制-CSDN博客 本篇文章,我们将一起踏上一段有趣的旅程&a…...

MATLAB安装常见问题解决方案
目前新版本的matlab安装往往需要十几G的本地安装容量,例如matlab2022b、matlab2023b, 首先就是要保证本地硬盘空间足够大,如果没有足够的本地内存空间,那么可以尝试释放本地硬盘空间,或者安装所需内存空间较小的旧版本的matlab&am…...

在 Vue 中插入 B 站视频
前言 在 Vue 项目中,有时我们需要嵌入 B 站视频来丰富页面内容,为用户提供更直观的信息展示。本文将详细介绍在 Vue 中插入 B 站视频的多种方法。 使用<iframe>标签直接嵌入,<iframe>标签是一种简单直接的方式,可将 B 站视频嵌…...

【深度学习】#12 计算机视觉
主要参考学习资料: 《动手学深度学习》阿斯顿张 等 著 【动手学深度学习 PyTorch版】哔哩哔哩跟李沐学AI 目录 目标检测锚框交并比(IoU)锚框标注真实边界框分配偏移量计算损失函数 非极大值抑制预测 多尺度目标检测单发多框检测(S…...

QT学习3
QT项目视图 1、List View清单视图 private:QListView *listview1; private slots:void slotClickedFunc(const QModelIndex &index); #include "widget.h" #include "ui_widget.h"#include <QStringListModel>//字符串列表模型 #include <QS…...
)
Vue 3 动态 ref 的使用方式(表格)
一、问题描述 先给大家简单介绍一下问题背景。我正在开发的项目中,有一个表格组件,其中一列是分镜描述,需要支持视频上传功能。用户可以为每一行的分镜描述上传对应的视频示例。然而,在实现过程中,出现了一个严重的问…...
)
FAST-DDS源码分析PDP(一)
准备开一个FAST-DDS源码分析系列,源码版本FAST-DDS 1.1.0版本。 FAST-DDS这种网络中间件是非常复杂的,所以前期先去分析每个类的作用是什么,然后在结合RTPS DOC,FAST-DDS DEMO,以及FAST-DDS的doc去串起来逻辑。 Builtin Discovery…...
深度对比及鸿蒙生态适配解析)
Flutter与Kotlin Multiplatform(KMP)深度对比及鸿蒙生态适配解析
Flutter 与 Kotlin Multiplatform(KMP)深度对比及鸿蒙生态适配解析 在跨平台开发领域,Flutter 与 Kotlin Multiplatform(KMP)代表了两种不同的技术路线:前者以 “统一 UI 体验” 为核心,后者以…...
)
深入了解linux系统—— 基础IO(上)
文件 在之前学习C语言文件操作时,我们了解过什么是文件,这里简单回顾一下: 文件存在磁盘中,文件有分为程序文件、数据文件;二进制文件和文本文件等。 详细描述见文章:文件操作——C语言 文件在磁盘里&a…...

C++ map multimap 容器:赋值、排序、大小与删除操作
概述 map和multimap是C STL中的关联容器,它们存储的是键值对(key-value pairs),并且会根据键(key)自动排序。两者的主要区别在于: map不允许重复的键multimap允许重复的键 本文将详细解析示例代码中涉及的map操作,包括赋值、排…...

EmuEdit
EmuEdit详解:统一多任务图像编辑的扩展性范式 引言:图像编辑的困境 近年来,扩散模型(Diffusion Models)在图像合成和编辑方面取得了巨大进展,如 Prompt-to-Prompt (P2P)、InstructPix2Pix、DiffEdit 等方法…...

Linux编译rpm包与deb包
注意: 本文内容于 2025-05-14 23:55:53 创建,可能不会在此平台上进行更新。如果您希望查看最新版本或更多相关内容,请访问原文地址:编译rpm包与deb包。感谢您的关注与支持! 近期在通过源码编译安装一些软件包时&#…...
)
GitHub 趋势日报 (2025年05月17日)
本日报由 TrendForge 系统生成 https://trendforge.devlive.org/ 🌐 本日报中的项目描述已自动翻译为中文 📈 今日整体趋势 Top 10 排名项目名称项目描述今日获星总星数语言1TapXWorld/ChinaTextbookPDF教材。⭐ 2471⭐ 22302Roff2public-apis/public-a…...

[创业之路-362]:企业战略管理案例分析-3-战略制定-华为使命、愿景、价值观的演变过程
一、华为使命、愿景、价值观的演变过程 1、创业初期(1987 - 1994 年):生存导向,文化萌芽 使命愿景雏形:1994年华为提出“10年之后,世界通信行业三分天下,华为将占一份”的宏伟梦想,…...
—— 内存优化)
Android 性能优化入门(二)—— 内存优化
1、概述 1.1 Java 对象的生命周期 各状态含义: 创建:分配内存空间并调用构造方法应用:使用中,处于被强引用持有(至少一个)的状态不可见:不被强引用持有,应用程序已经不再使用该对象…...
python爬虫--BeautifulSoup(bs4))
(5)python爬虫--BeautifulSoup(bs4)
文章目录 [TOC](文章目录) 前言一、安装bs4二、bs4的基础使用2.1 创建soup对象2.2 根据标签名查找节点2.3 根据函数来查找节点1. find函数2. find_all函数3. select函数 三、使用bs4获取节点信息3.1 获取节点内容3.2 获取节点的属性3.3 获取节点的属性值 四、测试练习 总结 前言…...

如何利用DeepSeek提升工作效率
1. 代码开发辅助 1.1 代码生成 根据需求描述生成代码框架 自动补全代码片段 生成单元测试用例 创建项目文档 1.2 代码优化 代码重构建议 性能优化方案 最佳实践推荐 设计模式应用 2. 问题诊断与解决 2.1 错误分析 编译错误解析 运行时错误诊断 内存泄漏检测 性…...

游戏引擎学习第292天:实现蛇
每次VLC 读取OSD 会有bug 修复一下 回顾并计划实现一种漂浮的移动方式,并制作一个贪吃蛇 虽然不完全记得之前具体计划,但感觉是想实现一个小蛇形生物,之前一直没来得及做。我们还打算让熟悉的伙伴能漂浮移动,所以今天会继续进行一…...

菱形继承原理
在C中,菱形继承的内存模型会因是否使用虚继承产生本质差异。我们通过具体示例说明两种场景的区别: 一、普通菱形继承的内存模型 class A { int a; }; class B : public A { int b; }; class C : public A { int c; }; class D : public B, public C { i…...

C++编程起步项目
员工信息管理系统 需求 Employee.h #pragma once#include<iostream> #include<string>using namespace std;class Employee { public:int id; // 编号string name; // 姓名string position; // 岗位int deptId; // 部门编号Employee();Employee(int id, string n…...

c++编写中遇见的错误
目录 一.获取动态数组的长度二.编译错误三、内存泄露 一.获取动态数组的长度 首先想到获取数组的长度的代码是: sizeof(arr) / sizeof(arr[0]);但是当将其使用到动态数组上时就会产生错误; int* help new int[3];for (int i 0; i < 3; i) {help[…...

股票数据源对接技术指南:印度尼西亚、印度、韩国
一、多国数据对接全景图 1. 核心数据领域对比 国家金融市场数据源宏观经济指标特色数据资源印度NSE/BSE实时行情RBI经济统计库UPI支付数据/GST税务记录印尼IDX交易所数据流BPS官方统计棕榈油产业数据/群岛物流信息韩国KRX综合指数KOSTAT国家统计K-POP消费趋势/半导体出口数据…...

常见面试题:Webpack的构建流程简单说一下。
文章目录 前言一、Webpack 的核心使命:模块化打包二、Webpack 构建流程详解三、构建流程的可视化演示项目结构构建流程图 四、构建流程中的关键技术点1. 依赖图的构建与优化2. 哈希与缓存策略3. 开发环境优化 五、简易版概括构建流程 总结 前言 在前端工程化中&…...

Elasticsearch基础篇-java程序通过RestClient操作es
目录 1.引入 2 初始化RestClient 1)引入es的RestHighLevelClient依赖: 2)因为SpringBoot默认的ES版本是7.17.10,所以我们需要覆盖默认的ES版本: 3)初始化RestHighLevelClient: 4)…...

SuperYOLO:多模态遥感图像中的超分辨率辅助目标检测之论文阅读
摘要 在遥感影像(RSI)中,准确且及时地检测包含数十像素的多尺度小目标仍具有挑战性。现有大多数方法主要通过设计复杂的深度神经网络来学习目标与背景的区分特征,常导致计算量过大。本文提出一种兼顾检测精度与计算代价的快速准确…...

k6学习k6学习k6学习k6学习k6学习k6学习
1.安装go 2.安装 xk6 (k6 扩展构建工具): go install go.k6.io/xk6/cmd/xk6latest3.构建自定义 k6 二进制文件(集成 faker 扩展): xk6 build --with github.com/gkarthiks/xk6-fakerlatest构建报错处理(代码拉取失败)࿱…...

ubuntu 安装mq
一、安装依赖 编译 Erlang 需要以下依赖库和工具: sudo apt update sudo apt install -y build-essential autoconf libncurses5-dev libssl-dev m4 unixodbc-dev libwxgtk3.0-gtk3-dev libgl1-mesa-dev libglu1-mesa-dev 二、解压源码包 tar -xzvf otp_src_21.…...

优化 Spring Boot 应用启动性能的实践指南
1. 引言 Spring Boot 以其“开箱即用”的特性深受开发者喜爱,但随着项目复杂度的增加,应用的启动时间也可能会变得较长。对于云原生、Serverless 等场景而言,快速启动是一个非常关键的指标。 2. 分析启动过程 2.1 启动阶段概述 Spring Boot 的启动流程主要包括以下几个阶…...

ubuntu18.04编译qt5.14.2源码
ubuntu18.04编译qt5.14.2源码 文章目录 ubuntu18.04编译qt5.14.2源码[toc]1 前言2 参考文档3 下载源码3.1 方法13.2 方法23.3 方法3 4 ubuntu编译qt源码4.1 环境准备4.2 设置交换分区大小4.3 编译源码4.4 添加环境变量4.5 验证编译结果4.6 编译帮助文档(qch…...

leetcodehot100刷题——排序算法总结
排序算法总结 冒泡排序介绍步骤(以升序排序为例)算法实现复杂度分析时间复杂度空间复杂度 是否为稳定排序:是稳定排序的定义 选择排序介绍步骤(以升序排序为例)算法实现复杂度分析时间复杂度空间复杂度 是否为稳定排序…...

多用途商务,电子产品发布,科技架构,智能手表交互等发布PPT模版20套一组分享
产品发布类PPT模版20套一组:产品发布PPT模版https://pan.quark.cn/s/25c8517b0be3 第一套PPT模版是一个总结用的PPT封面,背景浅灰色,有绿色叶片和花朵装饰,深绿色标题,多个适用场景和占位符。突出其清新自然的设计和商…...
---java版)
2025年- H29-Lc137- 19.删除链表的倒数第N个节点(快慢指针)---java版
1.题目描述 2.思路 快慢指针都在虚拟头节点,然后让快指针先走n1步,接下来,快慢指针以前移动,直到快指针指向null,慢指针指向被删节点的前一个节点。 3.代码实现 方法一:不带测试用例 /*** Definition …...

新电脑软件配置二:安装python,git, pycharm
安装python 地址 https://www.python.org/downloads/ 不是很懂为什么这么多版本 安装windows64位的 这里我是凭自己感觉装的了 然后cmd输入命令没有生效,先重启下? 重启之后再次验证 环境是成功的 之前是输入的python -version 命令输入错误 安装pyc…...

医学影像开发的开源生态与技术实践:从DCMTK到DICOMweb的全面探索
🧑 博主简介:CSDN博客专家、CSDN平台优质创作者,高级开发工程师,数学专业,10年以上C/C++, C#, Java等多种编程语言开发经验,拥有高级工程师证书;擅长C/C++、C#等开发语言,熟悉Java常用开发技术,能熟练应用常用数据库SQL server,Oracle,mysql,postgresql等进行开发应用…...

【HarmonyOS 5开发入门】DevEco Studio安装配置完全指南
⭐本期内容:【HarmonyOS4+NEXT】Button组件核心特性 🏆系列专栏:鸿蒙HarmonyOS:探索未来智能生态新纪元 文章目录 前言下载开发工具安装开发工具配置开发环境新建项目项目结构概述运行项目Preview预览模拟器运行 报错处…...

出现 Uncaught ReferenceError: process is not defined 错误
在浏览器环境中,process 对象是 Node.js 环境特有的,因此当你在浏览器中运行代码时,会出现 Uncaught ReferenceError: process is not defined 错误。这个错误是因为代码里使用了 process.env.BASE_URL,而浏览器环境下并没有 proc…...

如何实现RTSP和RTMP低至100-200ms的延迟:直播SDK的技术突破
在实时音视频传输中,低延迟是直播应用的核心技术要求之一。无论是在线教育、远程医疗,还是实时互动直播,延迟过大会影响用户体验,甚至导致应用无法正常使用。大牛直播SDK(SmartMediaKit)在RTSP和RTMP播放器…...