从专家编码到神经网络学习:DTM 的符号操作新范式
1st author: Paul Soulos
paper: Differentiable Tree Operations Promote Compositional Generalization ICML 2023
code: psoulos/dtm: Differentiable Tree Machine
1. 问题与思路
现代深度学习在连续向量空间中取得了巨大成功,然而在处理具有显式结构(Structure),尤其是离散(Discrete) 符号结构的任务时,例如程序合成、逻辑推理、自然语言的句法和语义结构,其组合泛化(Compositional Generalization) 能力常常捉襟见肘。传统的符号系统(GOFAI)天然具备结构处理和组合泛化能力,但其离散性导致难以与基于梯度的端到端学习框架兼容。这篇论文正是试图弥合这一裂痕,其关键是:如何在连续向量空间中实现可微(Differentiable) 的、结构感知(Structure-aware) 的符号操作,从而赋予神经网络强大的组合泛化能力。
1.1. 问题:结构操作的“不可微”
考虑对树结构进行操作的任务,比如句法树转换、逻辑形式生成。这些任务本质上是应用一系列离散的、符号性的树操作(如 Lisp 中的 car, cdr, cons)来转换结构。问题在于,这些离散操作在数学上通常是不可微的,这意味着我们无法直接通过梯度下降来学习执行这些操作的序列或策略。现有的神经网络模型,即使是 Tree-based Transformer 或 LSTM,虽然能编码树结构,但其内部的处理(通常是黑箱的非线性变换)仍然难以显式地执行或学习离散的结构操作序列,导致在面对训练中未见的结构组合时泛化能力差。

car,cdr,cons是 Lisp 对列表的三种操作, 其使用嵌套列表存储树.car表示取左子树,cdr表示取右子树,cons表示创建新树。Fiugre 2 是三个操作的例子, 被操作的是图片中间以 ‘NP’ 为根的一颗句法分析树。
1.2. 思路:重定义操作为可微操作
这篇论文的独特之处在于,它并没有试图去“软化”离散操作本身,而是将离散的符号结构及其操作整体嵌入到一个连续的向量空间中,并在这个空间中定义出与原离散操作等价的可微线性变换。具体来说,他们使用了 张量积表示 (Tensor Product Representation, TPR) 来编码树结构。
TPR 的核心思想是将一个结构分解为角色 (Roles) 和填充物 (Fillers) 的绑定。对于树结构而言,一个节点的位置可以看作一个“角色”,该节点的标签或子结构则是这个“填充物”。一个完整的树结构 T T T 被表示为所有 “角色-填充物” 对的张量积之和:
T = ∑ i f i ⊗ r i T = \sum_i f_i \otimes r_i T=i∑fi⊗ri
其中 f i f_i fi 是第 i i i 个位置的填充物(例如,词汇的向量表示), r i r_i ri 是第 i i i 个位置的角色(表示该位置在树中的结构信息向量)。 ⊗ \otimes ⊗ 是张量积运算。
例如 f 011 f_{011} f011 是从根节点开始以"左右右"路径到达节点的填充物向量 (0表示左, 1表示右),下标从左往右读。 f ϵ f_\epsilon fϵ 表示根节点。
关键来了:如果在向量空间中精心设计角色向量 r i r_i ri,就可以将 car, cdr, cons 这些离散的树操作转化为对这个 TPR 向量 T T T 的线性变换。
2. 可微树操作
2.1. 定义可微操作
关于张量积与张量积表示 TPR的解释可以看这篇文章: 张量积表示 (Tensor Product Representation, TPR)-CSDN博客
我们聚焦于二叉树 ( b = 2 b=2 b=2)。假设树的最大深度为 D D D。树中可能的节点位置总数 N = ( 2 D + 1 − 1 ) / ( 2 − 1 ) = 2 D + 1 − 1 N = (2^{D+1} - 1) / (2-1) = 2^{D+1} - 1 N=(2D+1−1)/(2−1)=2D+1−1。我们可以生成一组 N N N 个标准正交 (Orthonormal) 的角色向量 r i ∈ R d r r_i \in \mathbb{R}^{d_r} ri∈Rdr,其中 d r = N d_r = N dr=N。
对于一个树 T = ∑ i = 1 N f i ⊗ r i T = \sum_{i=1}^N f_i \otimes r_i T=∑i=1Nfi⊗ri,其中 f i f_i fi 是填充物向量。由于角色向量是标准正交的,我们可以通过内积恢复任何位置的填充物: f i = ⟨ T , r i ⟩ f_i = \langle T, r_i \rangle fi=⟨T,ri⟩。或者更一般地,通过与角色向量 r i r_i ri 的对偶空间操作来实现 ( 论文中使用矩阵乘法 T r i Tr_i Tri,如果将 T T T 看作一个高阶张量,这等价于在角色维度上与 r i r_i ri 做张量的收缩)。
现在,如何用矩阵操作实现 car, cdr, cons?
论文中给出了基于角色向量的线性变换矩阵。考虑 car 操作,它提取根节点的左子树。这需要将左子树中的每个节点的“角色”向上移动一层。cdr 类似,提取右子树。cons 则根据两个子树构建一个新的父节点树。
定义矩阵 D c D_c Dc 和 E c E_c Ec:
D c D_c Dc 矩阵用于提取第 c c c 个孩子( c = 0 c=0 c=0 为左孩子 car, c = 1 c=1 c=1 为右孩子 cdr),并将其子树的角色向上提升一层。
E c E_c Ec 矩阵用于将一个子树的角色向下推一层,以便将其作为新树的第 c c c 个孩子。
形式上,对于角色空间中的操作,这些矩阵定义为:
D c = I F ⊗ ∑ x ∈ P r x r c x ⊤ E c = I F ⊗ ∑ x ∈ P r c x r x ⊤ D_c = I_F \otimes \sum_{x \in P} r_x r_{cx}^\top\\ E_c = I_F \otimes \sum_{x \in P} r_{cx} r_x^\top Dc=IF⊗x∈P∑rxrcx⊤Ec=IF⊗x∈P∑rcxrx⊤
其中 I F I_F IF 是填充物空间 F F F 上的单位矩阵, P = { r x ∥ ∣ x ∣ < D } P=\{r_x\|\:|x|<D\} P={rx∥∣x∣<D} 是所有深度小于 D D D 的路径对应的角色集合, r x r_x rx 是路径 x x x 的角色向量, r c x r_{cx} rcx 是在路径 x x x 前面加上 c c c 形成新路径的角色向量。这两个公式不太好理解, 可以看下一小节的例子。
这样,可微的 car , cdr 和 cons 操作(将 T 0 T_0 T0 作为左子树, T 1 T_1 T1 作为右子树)可以表示为对 TPR 向量 T T T 的矩阵操作:
car ( T ) = D 0 T cdr ( T ) = D 1 T cons ( T 0 , T 1 ) = E 0 T 0 + E 1 T 1 \text{car}(T) = D_0 T\\ \text{cdr}(T) = D_1 T\\ \text{cons}(T_0, T_1) = E_0 T_0 + E_1 T_1 car(T)=D0Tcdr(T)=D1Tcons(T0,T1)=E0T0+E1T1
注意,cons 还需要指定新创建的根节点的填充物 s s s。也就是将 s ⊗ r r o o t s \otimes r_{root} s⊗rroot 加入到结果中 ( r r o o t r_{root} rroot 是根节点的角色向量)。
所以,在向量空间中,这些原本离散的树操作,就变成了 TPR 向量上的线性变换。整个 DTM 模型的核心操作步骤,就是对输入的 TPR 树进行这些可微的线性操作,并根据学习到的权重进行线性组合。
2.2. 以 cdr 操作为例

如上图, T ′ = car ( T ) T'=\text{car}(T) T′=car(T), 其中 T T T 的 P = { r x ∥ ∣ x ∣ < 3 } = { r ϵ , r 0 , r 1 } P=\{r_x\|\:|x|<3\}=\{r_\epsilon,r_0,r_1\} P={rx∥∣x∣<3}={rϵ,r0,r1}, 我们的目的是: 将节点 B 的位置 r 0 → r ϵ r_0\to r_\epsilon r0→rϵ, 节点 D 的位置 r 00 → r 0 r_{00}\to r_0 r00→r0, 节点 B 的位置 r 01 → r 1 r_{01}\to r_1 r01→r1.
car ( T ) = D 0 T = ( I F ⊗ ∑ x ∈ P r x r c x ⊤ ) ( ∑ i f i ⊗ r i ) = ( I F ⊗ ( ( r ϵ r 0 ϵ ⊤ ) + ( r 0 r 00 ⊤ ) + ( r 1 r 01 ⊤ ) ) ⏟ let = R ) ( ∑ i f i ⊗ r i ) = ( I F ⊗ R ) ( ( f ϵ ⊗ r ϵ ) + ( f 0 ⊗ r 0 ) + ( f 1 ⊗ r 1 ) + ( f 00 ⊗ r 00 ) + ( f 01 ⊗ r 01 ) + ( f 10 ⊗ r 10 ) ) = ( I F ⊗ R ) ( f ϵ ⊗ r ϵ ) + ( I F ⊗ R ) ( f 0 ⊗ r 0 ) + ⋯ + ( I F ⊗ R ) ( f 10 ⊗ r 10 ) = ( I F f ϵ ) ⊗ ( R r ϵ ) + ( I F f 0 ) ⊗ ( R r 0 ) + ⋯ + ( I F f 10 ) ⊗ ( R r 10 ) = f ϵ ⊗ ( [ ( r ϵ r 0 ϵ ⊤ ) + ( r 0 r 00 ⊤ ) + ( r 1 r 01 ⊤ ) ] r ϵ ) + ⋯ + f 10 ⊗ ( [ ( r ϵ r 0 ϵ ⊤ ) + ( r 0 r 00 ⊤ ) + ( r 1 r 01 ⊤ ) ] r 10 ) = 0 + f 0 ⊗ ( r ϵ r 0 ϵ ⊤ r 0 ) + 0 + f 00 ⊗ ( r 0 r 00 ⊤ r 00 ) + f 01 ⊗ ( r 1 r 01 ⊤ r 01 ) + 0 = f 0 ⊗ r ϵ + f 00 ⊗ r 0 + f 01 ⊗ r 1 \begin{align} \text{car}(T)&=D_0T\\ &= \bigg( I_F \otimes \sum_{x \in P} r_x r_{cx}^\top \bigg)\bigg (\sum_i f_i \otimes r_i \bigg)\\ &= \bigg( I_F \otimes \underbrace{\big((r_\epsilon r_{0\epsilon}^\top)+(r_0 r_{00}^\top)+(r_1 r_{01}^\top)\big)}_{\text{let}=R} \bigg)\bigg (\sum_i f_i \otimes r_i \bigg) \\ &= \left (I_F \otimes R\right )\big( (f_{\epsilon}\otimes r_\epsilon)+(f_0\otimes r_0)+(f_1\otimes r_1)+(f_{00}\otimes r_{00})+(f_{01}\otimes r_{01})+(f_{10}\otimes r_{10})\big)\\ &= (I_F \otimes R) (f_{\epsilon}\otimes r_\epsilon)+(I_F \otimes R) (f_{0}\otimes r_0)+\dots+(I_F \otimes R)(f_{10}\otimes r_{10})\\ &= (I_Ff_\epsilon)\otimes (Rr_\epsilon)+(I_Ff_0)\otimes (Rr_0)+\dots+(I_Ff_{10})\otimes (Rr_{10})\\ &= f_\epsilon\otimes (\textcolor{green}{\big[(r_\epsilon r_{0\epsilon}^\top)+(r_0 r_{00}^\top)+(r_1 r_{01}^\top)\big]}r_\epsilon)+\dots+f_{10}\otimes (\textcolor{green}{\big[(r_\epsilon r_{0\epsilon}^\top)+(r_0 r_{00}^\top)+(r_1 r_{01}^\top)\big]}r_{10})\\ &= 0+f_0\otimes (r_\epsilon r_{0\epsilon}^\top r_0)+0+f_{00}\otimes (r_0 r_{00}^\top r_{00})+f_{01}\otimes (r_1 r_{01}^\top r_{01})+0\\ &= f_0\otimes r_\epsilon+f_{00}\otimes r_0+f_{01}\otimes r_1\\ \end{align} car(T)=D0T=(IF⊗x∈P∑rxrcx⊤)(i∑fi⊗ri)=(IF⊗let=R ((rϵr0ϵ⊤)+(r0r00⊤)+(r1r01⊤)))(i∑fi⊗ri)=(IF⊗R)((fϵ⊗rϵ)+(f0⊗r0)+(f1⊗r1)+(f00⊗r00)+(f01⊗r01)+(f10⊗r10))=(IF⊗R)(fϵ⊗rϵ)+(IF⊗R)(f0⊗r0)+⋯+(IF⊗R)(f10⊗r10)=(IFfϵ)⊗(Rrϵ)+(IFf0)⊗(Rr0)+⋯+(IFf10)⊗(Rr10)=fϵ⊗([(rϵr0ϵ⊤)+(r0r00⊤)+(r1r01⊤)]rϵ)+⋯+f10⊗([(rϵr0ϵ⊤)+(r0r00⊤)+(r1r01⊤)]r10)=0+f0⊗(rϵr0ϵ⊤r0)+0+f00⊗(r0r00⊤r00)+f01⊗(r1r01⊤r01)+0=f0⊗rϵ+f00⊗r0+f01⊗r1
上方推导过程中:
- 第 4 到第 5 步, 使用了线性性质的分配律. A ( B + C ) = A B + C D A(B+C)=AB+CD A(B+C)=AB+CD.
- 第 5 到 第 6步, 使用了张量积性质, ( A ⊗ B ) ( v ⊗ w ) = ( A v ) ⊗ ( B w ) (A\otimes B)(v\otimes w)=(Av)\otimes(Bw) (A⊗B)(v⊗w)=(Av)⊗(Bw).
- 第 7 步中, 由于 r i r_i ri 正交, 则 r i ⊤ r i = 1 , r i ⊤ r ≠ i = 0 r_i^\top r_i = 1, r_i^\top r_{\neq i} = 0 ri⊤ri=1,ri⊤r=i=0.
- r x r c x ⊤ r_x r_{cx}^\top rxrcx⊤: 这是一个外积,得到一个矩阵。当这个矩阵作用于一个角色向量 r y r_y ry 时,如果 y = c x y = cx y=cx,结果是 r x r_x rx;否则结果是零向量(因为角色向量是正交的)。这实现了一个“将子节点位置的角色映射到父节点位置的角色”的操作。
- ∑ x ∈ P r x r c x ⊤ \sum_{x \in P} r_x r_{cx}^\top ∑x∈Prxrcx⊤: 这个求和构建了一个总的矩阵,它将所有可能的“子节点位置 c x cx cx 的角色”映射到对应的“父节点位置 x x x 的角色”。
I F ⊗ ( ∑ x ∈ P r x r c x ⊤ ) I_F \otimes (\sum_{x \in P} r_x r_{cx}^\top) IF⊗(∑x∈Prxrcx⊤)整个算子 D c D_c Dc 作用于一个树的 TPR 表示 T = ∑ i f i ⊗ r i T = \sum_{i} f_i \otimes r_i T=∑ifi⊗ri 时,由于张量积的性质 ( A ⊗ B ) ( v ⊗ w ) = ( A v ) ⊗ ( B w ) (A \otimes B)(v \otimes w) = (Av) \otimes (Bw) (A⊗B)(v⊗w)=(Av)⊗(Bw),它会独立地作用于填充物向量和角色向量。 I F I_F IF 作用于 f i f_i fi 保持不变,$ (\sum r_x r_{cx}^\top)$ 作用于 r i r_i ri。如果 r i r_i ri 是某个 r c x r_{cx} rcx,它就会被映射到 r x r_x rx;如果 r i r_i ri 是其他角色,它会被映射到零向量。
3. DTM 架构与运作机制
基于上一部分提到的向量空间中的可微树操作,论文构建了可微树机器(Differentiable Tree Machine, DTM) 这一架构。DTM 的核心思想是,将离散的符号操作逻辑与连续的神经网络决策过程解耦。
3.1. DTM 架构
DTM 主要由三个核心组件构成(如论文 Figure 1 所示):
- 神经树 Agent (Neural Tree Agent): 一个学习组件,负责在每一步决策要执行什么操作 (car, cdr, cons) 以及操作作用在记忆中的哪些树上。
- 可微树解释器 (Differentiable Tree Interpreter): 非学习组件,根据神经树 Agent 的指令,执行上一节描述的、预定义的可微线性树操作。
- 树记忆 (Tree Memory): 一个外部记忆单元,用于存储中间计算过程中产生的树的 TPR 表示。
DTM 是个很有意思的设计:将复杂的、黑箱的非线性学习能力被封装在神经树 Agent 中,而对树结构的显式、结构感知操作则通过可微树解释器以透明、可微的方式实现。
3.1.1. 神经树 Agent
神经树 Agent 是 DTM 中唯一包含可学习参数的部分。它被实现为一个标准的 Transformer 层(包含多头自注意力、前馈网络等)。
在每个计算步骤(timestep l l l),神经树 Agent (Neural Tree Agent) 会接收一个输入序列。这个序列包括以下编码:
- 操作编码 (Operation Encoding)
- 根符号编码 (Root Symbol Encoding)
- 树记忆 (Tree Memory) 中所有树的编码。被读取时,会从 TPR 维度 d t p r d_{tpr} dtpr 被压缩到 Transformer 输入维度 d m o d e l d_{model} dmodel,这通过一个可学习的线性变换 W s h r i n k ∈ R d t p r × d m o d e l W_{shrink}\in\mathbb{R}^{d_{tpr}\times d_{model}} Wshrink∈Rdtpr×dmodel 实现。
Transformer 的输入序列长度会随着每个步骤的进行而增长,每一步包含前一步骤新产生的树的编码 (如论文 Fiuger 4)。
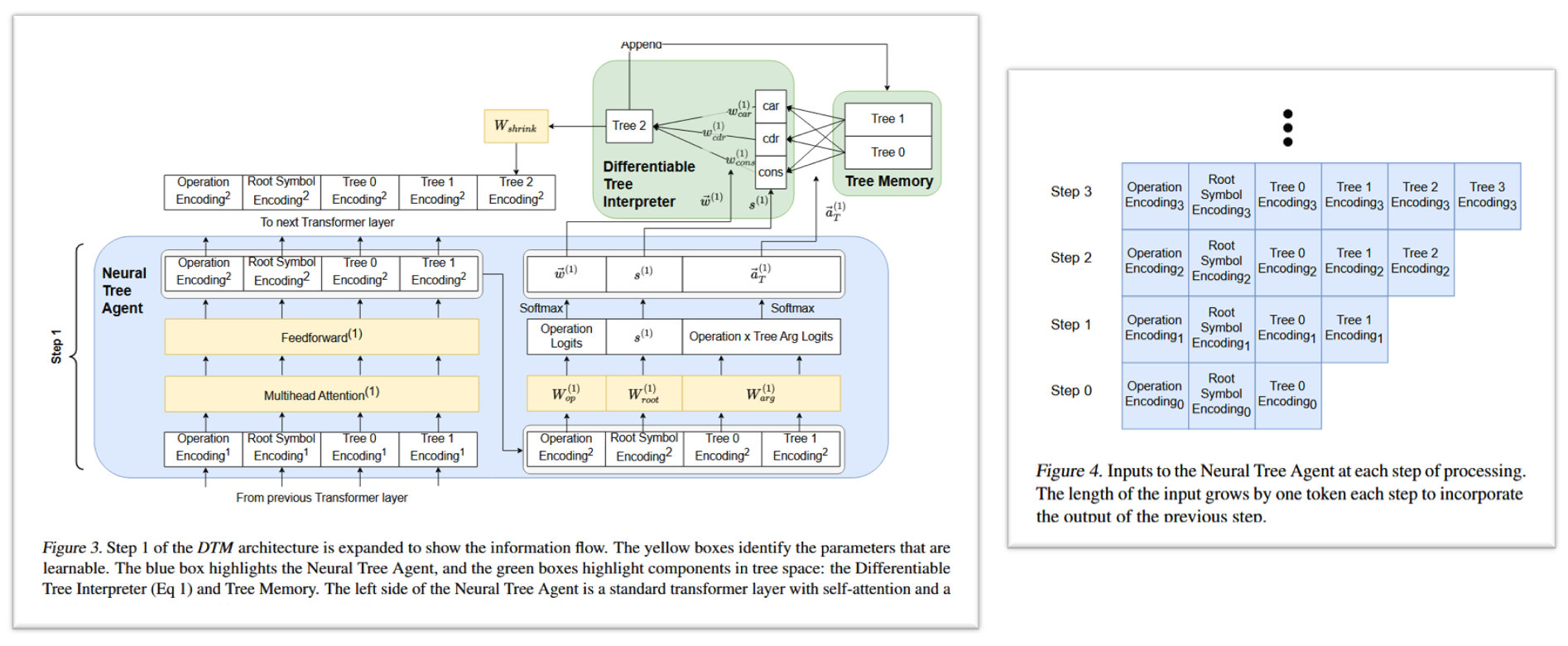
在每个计算步骤 l l l,神经树 Agent 的输出被用来做以下决策:
-
操作选择 ( w ( l ) w^{(l)} w(l)): 决定 car, cdr, cons 三种操作各自的权重。通过将一个特殊 token 的输出投影到 3 维向量,再经过 softmax 得到 w ⃗ ( l ) = ( w c a r ( l ) , w c d r ( l ) , w c o n s ( l ) ) \vec{w}^{(l)} = (w_{car}^{(l)}, w_{cdr}^{(l)}, w_{cons}^{(l)}) w(l)=(wcar(l),wcdr(l),wcons(l)),其中 ∑ w i ( l ) = 1 \sum w_i^{(l)} = 1 ∑wi(l)=1。
-
参数选择 ( a T ( l ) a_T^{(l)} aT(l)): 决定每种操作的输入应该“读取”记忆中的哪些树,以及它们的权重。例如,对于 car 操作,它需要一个被操作树 T c a r ( l ) T_{car}^{(l)} Tcar(l) (输入树)。神经树 Agent 会为记忆中的每一棵树计算一个权重,然后通过 softmax 归一化。最终 T c a r ( l ) T_{car}^{(l)} Tcar(l) 是记忆中所有树的加权和 (blended tree)。Cons 操作需要两个输入树 T c o n s 0 ( l ) T_{cons0}^{(l)} Tcons0(l) 和 T c o n s 1 ( l ) T_{cons1}^{(l)} Tcons1(l),同样通过加权求和获得。这组用于选择参数的权重记为 a ⃗ T ( l ) \vec{a}_{T}^{(l)} aT(l)。
-
新根符号选择 ( s ( l ) s^{(l)} s(l)): 如果 w ( l ) w^{(l)} w(l) 选择了 cons 操作,还需要确定新创建的根节点的符号。神经树 Agent 通过另一个特殊 token 的输出预测一个符号向量 s ( l ) s^{(l)} s(l)。
这 3 个输出是 Transformer 最后一层通过三个线性投影 W o p ∈ R d m o d e l × 3 ; W r o o t ∈ R d m o d e l × d s y m b o l ; W a r a ∈ R d m o d e l × 4 W_{op}\in\mathbb{R}^{d_{model}\times3};\ W_{root}\in\mathbb{R}^{d_{model}\times d_{symbol}};\ W_{ara}\in\mathbb{R}^{d_{model}\times4} Wop∈Rdmodel×3; Wroot∈Rdmodel×dsymbol; Wara∈Rdmodel×4 得到 ( Figure 3 蓝块的右侧)。
值得注意的是,Agent 的这些选择(操作权重 w ( l ) w^{(l)} w(l) 和参数权重 a T ( l ) a_T^{(l)} aT(l))都是通过 softmax 产生的软选择(Soft Selection),这意味着在训练初期,DTM 会在不同的操作和不同的输入树之间进行“混合”(blending)。论文的实验表明,这种混合对于学习至关重要,尽管在训练收敛后,权重通常会趋向于 one-hot 分布,退化为离散的操作序列。
3.1.2. 树记忆
树记忆是一个简单的外部存储,按顺序存放每个计算步骤产生的 TPR 树。在步骤 l l l 计算时,步骤 0 0 0 到 l − 1 l-1 l−1 生成的所有树都在记忆中,可以被神经树 Agent 读取并作为操作的参数。新的计算结果会被写入下一个可用的记忆槽位。我们用 M ( l − 1 ) \mathcal{M}^{(l-1)} M(l−1) 表示在步骤 l l l 时被操作的记忆树。
3.1.3. 可微树解释器
将神经树 Agent 的决策 (输出) 与可微树解释器结合,(可微树解释器就是一个预定义的公式, 以产生输出 O O O), DTM 的单步计算可以描述如下:
在计算步骤 l l l,神经树 Agent 根据记忆中的树(TPR 向量集合 M ( l − 1 ) \mathcal{M}^{(l-1)} M(l−1))计算出操作权重 w ⃗ ( l ) \vec{w}^{(l)} w(l)、参数选择权重 a ⃗ T ( l ) \vec{a}_{T}^{(l)} aT(l) 以及新的根符号 s ( l ) s^{(l)} s(l)。
参数选择权重 a ⃗ ∗ T ( l ) \vec{a}*{T}^{(l)} a∗T(l) 定义了每种操作的输入树。假设记忆中有 K K K 棵树 M 1 , … , M K M_1, \dots, M_K M1,…,MK,则:
T c a r ( l ) = ∑ k = 1 K a c a r , k ( l ) M k T c d r ( l ) = ∑ k = 1 K a c d r , k ( l ) M k T c o n s 0 ( l ) = ∑ k = 1 K a c o n s 0 , k ( l ) M k ; T c o n s 1 ( l ) = ∑ k = 1 K a c o n s 1 , k ( l ) M k T_{car}^{(l)} = \sum_{k=1}^K a_{car,k}^{(l)} M_k\\ T_{cdr}^{(l)} = \sum_{k=1}^K a_{cdr,k}^{(l)} M_k\\ T_{cons0}^{(l)} = \sum_{k=1}^K a_{cons0,k}^{(l)} M_k;\ \ T_{cons1}^{(l)} = \sum_{k=1}^K a_{cons1,k}^{(l)} M_k Tcar(l)=k=1∑Kacar,k(l)MkTcdr(l)=k=1∑Kacdr,k(l)MkTcons0(l)=k=1∑Kacons0,k(l)Mk; Tcons1(l)=k=1∑Kacons1,k(l)Mk
然后,可微树解释器根据操作权重 w ⃗ ( l ) \vec{w}^{(l)} w(l) 对这些输入树应用对应的可微操作,并进行加权求和,得到本步骤的输出树 O ( l ) O^{(l)} O(l) 的 TPR 表示:
O ( l ) = w c a r ( l ) car ( T c a r ( l ) ) + w c d r ( l ) cdr ( T c d r ( l ) ) + w c o n s ( l ) ( cons ( T c o n s 0 ( l ) , T c o n s 1 ( l ) ) + s ( l ) ⊗ r r o o t ) O^{(l)} = w_{car}^{(l)} \text{car}(T_{car}^{(l)}) + w_{cdr}^{(l)} \text{cdr}(T_{cdr}^{(l)}) + w_{cons}^{(l)} \big(\text{cons}(T_{cons0}^{(l)}, T_{cons1}^{(l)}) + s^{(l)} \otimes r_{root}\big) O(l)=wcar(l)car(Tcar(l))+wcdr(l)cdr(Tcdr(l))+wcons(l)(cons(Tcons0(l),Tcons1(l))+s(l)⊗rroot)
最后,这个输出 TPR 向量 O ( l ) O^{(l)} O(l) 被写入树记忆的下一个顺序槽位,成为下一步计算的可用输入之一。整个过程持续固定的步数 L L L。最终,最后一步产生的树 O ( L ) O^{(L)} O(L) 被视为模型的预测输出树。
3.2. 端到端训练
DTM 是一个完全可微的模型,因此可以通过标准的反向传播进行端到端的训练。损失函数定义为预测输出树与目标树之间的均方误差(MSE)。具体来说,是对预测树和目标树中每个节点位置上的符号(填充物向量)计算 MSE。同时,对预测树中目标树为空的位置上的非零填充物进行 L2 惩罚,鼓励生成稀疏、明确的树结构。
L ( T p r e d , T t a r g e t ) = ∑ i ∈ Nodes ∥ recover ( T p r e d , r i ) − recover ( T t a r g e t , r i ) ∥ 2 + λ ∑ i : target node i is empty ∥ recover ( T p r e d , r i ) ∥ 2 \mathcal{L}(T_{pred}, T_{target}) = \sum_{i \in \text{Nodes}} \left\| \text{recover}(T_{pred}, r_i) - \text{recover}(T_{target}, r_i) \right\|^2 + \lambda \sum_{i: \text{target node } i \text{ is empty}} \left\| \text{recover}(T_{pred}, r_i) \right\|^2 L(Tpred,Ttarget)=i∈Nodes∑∥recover(Tpred,ri)−recover(Ttarget,ri)∥2+λi:target node i is empty∑∥recover(Tpred,ri)∥2
其中 recover ( T , r i ) \text{recover}(T, r_i) recover(T,ri) 是从 TPR 向量 T T T 中恢复位置 i i i 的填充物向量的操作(例如 T r i Tr_i Tri), λ \lambda λ 是惩罚系数。
T t a r g e t T_{target} Ttarget 是目标树(target tree),它来自用于训练模型的数据集。
例如,在 Active ↔ \leftrightarrow ↔ Logical (主动语态转逻辑形式) 任务中,数据集包含源树和对应的目标树。以下是一个来自数据集的例子:

这两个树的转变是从句法结构树 (Syntactic Tree) 到 逻辑形式树 (Logical Form Tree) 的转变。
- Source Tree (句法结构树): 它展示了句子的语法结构,即单词如何组成短语,短语如何组成句子。它反映了句子的表面结构。
S: 表示句子 (Sentence)NP: 表示名词短语 (Noun Phrase)VP: 表示动词短语 (Verb Phrase)DET: 表示限定词 (Determiner)AP: 表示形容词短语 (Adjective Phrase)N: 表示名词 (Noun)V: 表示动词 (Verb)ADJ: 表示形容词 (Adjective)- 树的结构显示了短语的层级关系,例如
( NP ( DET some ) ( AP ( N crocodile ) ) )表示 “some crocodile” 是一个名词短语,其中 “some” 是限定词,“crocodile” 是名词,而 “crocodile” 又被看作是一个形容词短语的头部 (在某些语法标注约定中可能会有这样的表示方式)。- Target Tree (逻辑形式树): 它试图表示句子的语义或意义结构。它关注句子中主要动词及其论元(Arguments),也就是谁做了什么,对谁做了什么。它反映了句子的深层结构或逻辑意义。
LF: 表示逻辑形式 (Logical Form)V: 表示动词 (这里是句子的主要动词)ARGS: 表示论元 (Arguments),也就是动词作用的对象或参与者。- 树的结构显示了动词 “washed” 是逻辑形式的核心,而它的论元是两个名词短语:
( NP ( DET some ) ( AP ( N crocodile ) ) )和( NP ( DET our ) ( AP ( ADJ happy ) ( AP ( ADJ thin ) ( AP ( N donkey ) ) ) ) ) )。这表示 “washed” 这个动作发生在 “some crocodile” 和 “our happy thin donkey” 之间。这种转变是从关注句子的表面语法结构到关注句子的语义关系的抽象过程。
在这个例子中, T t a r g e t T_{target} Ttarget 就是上述的 Target Tree。模型训练的目标是使预测树 T p r e d T_{pred} Tpred 尽可能接近这个目标树 T t a r g e t T_{target} Ttarget。损失函数衡量了预测树在每个节点上与目标树的差异,并惩罚了在目标树中为空但在预测树中被填充的节点。
通过最小化这个损失,神经树 Agent 学会选择合适的操作和参数,从而引导可微树解释器执行一系列有效的树转换步骤,最终生成目标树。这种设计巧妙地结合了神经网络的灵活性和符号操作的结构性。
4. 实验验证
实验是检验模型优劣的唯一标准。这篇论文设计了一系列合成的树到树转换任务,尤其侧重考察模型在分布外(Out-of-Distribution, OOD) 的组合泛化能力。
4.1. 实验结果
论文在合成数据集(Basic Sentence Transforms)上评估了 DTM 与多种基线模型,包括 Transformer、LSTM 及其树结构变体 (Tree2Tree LSTM, Tree Transformer)。这些任务包括根据 Lisp 操作符序列转换树 (CAR-CDR-SEQ),以及主动语态 / 被动语态到逻辑形式的转换 (ACTIVE↔LOGICAL, PASSIVE↔LOGICAL, ACTIVE & PASSIVE→LOGICAL)。数据集精心构造了 OOD 词汇 ( 未见过的词汇出现在训练过的结构位置 ) 和 OOD 结构 ( 未见过的结构组合,例如更深的树或新的子结构组合 ) 划分。
实验结果令人瞩目:在大多数任务的 OOD 词汇和 OOD 结构测试集上,DTM 都取得了接近 100% 的准确率。相比之下,所有基线模型在 OOD 结构泛化上表现惨淡,准确率普遍低于 30%,在一些语言转换任务上甚至接近 0%。
这有力地证明了 DTM 在处理结构化数据的组合泛化方面具有显著优势。其关键在于,DTM 学习的是如何组合基本的可微结构操作,而不是仅仅学习输入和输出序列或树结构的关联模式。这种学习策略使其能够推广到由已知元素组成但以新方式组合的结构。
4.2. 消融实验
为了理解 DTM 成功的原因,论文进行了一些关键的消融实验:
- 预定义操作 vs. 学习操作: 如果不使用预定义的、基于 TPR 的可微 car, cdr, cons 操作,而是让神经树 Agent 去学习这些结构转换矩阵 D c , E c D_c, E_c Dc,Ec,模型在 OOD 结构泛化上的性能急剧下降。这证明了预定义结构化可微操作的必要性。这些预定义操作提供了正确的归纳偏置,确保了模型学习到的是真正的结构转换逻辑,而不是对特定训练结构的记忆。
- 混合 vs. 离散选择: 前面提到,神经树 Agent 使用 softmax 进行软选择。如果强制使用 Gumbel-Softmax 使选择在训练初期就变得离散,DTM 的性能会完全崩溃。这反直觉地表明,训练初期的连续混合(Blending) 是必要的。它可能允许模型在不同操作和输入树之间进行探索,构建平滑的损失面,从而更容易找到有效的操作序列。最终收敛时,选择趋于离散,恢复了程序的解释性。
这两个消融实验从机制上解释了 DTM 成功的两个策略:提供正确的结构性“积木”(预定义操作)和采用有效的学习策略(训练中的混合)。
4.3. 可解释性
DTM 的另一个重要优势是其可解释性(Interpretability) 。由于最终模型的操作选择权重趋于 one-hot,我们可以将 DTM 的推理过程解释为一系列离散的树操作序列,就像一个程序。
例如,在 CAR-CDR-SEQ 任务中,模型学习到如何根据输入的 Lisp 操作符 token 转化为执行相应的 car/cdr 序列。在语言转换任务中,可以追踪每一步记忆中树的变化以及应用的具体操作。论文中给出了逻辑形式到被动语态转换的例子(论文 Figure 5),清晰地展示了输入树如何通过一系列 car, cdr, cons 操作逐步转换为输出树。

更有趣的是,论文通过追踪这个“程序”执行流,发现了模型emergent operation。在 PASSIVE↔LOGICAL 任务中,目标树需要插入源树中不存在的词(如 “was” 和 “by”)。car, cdr, cons 本身并不能直接插入新节点。但模型学会了一个技巧:通过对一个单子节点树执行 car 得到一个空树(empty tree) 的 TPR 表示,然后将这个空树作为 cons 的子树,并提供新的填充物作为根节点,从而有效地“插入”了一个新节点(如插入 “was”)。这种从基本操作中组合出更复杂行为的能力,以及能够通过追踪中间步骤来发现这种行为,是 DTM 可解释性的体现。
5. 总结/局限/展望
-
论文的核心思想是将传统的、离散的符号操作(例如树操作)通过张量积表示(TPR)嵌入到一个连续且可微的空间中。这样做并非仅仅是让操作本身连续化,并进一步使得神经网络能够通过基于梯度的学习方法,学会如何智能地组合和应用这些(现在是可微的)符号操作序列,从而学习到解决特定问题的“算法”或“程序”。
这与传统的符号主义方法形成对比,后者通常需要人工专家来设计和编码操作序列(即算法)。DTM 中的神经树代理正是负责学习这个“操纵符号操作”的“算法”。
-
DTM 的架构可以被形象地理解为给神经网络提供了一个包含特定“符号表示”(TPR编码的树)和“符号操作”(car, cdr, cons 的可微实现)的工具箱。神经网络(神经树代理)的任务就是通过学习,掌握如何有效地使用这个工具箱中的工具(选择合适的操作、作用于记忆中的树)来将输入的树转换成目标的树,从而解决任务。通过在大规模数据上训练,神经网络学会了使用这些基本工具来构建更复杂的结构转换过程。
局限
论文很类似神经图灵机 (Neural Turing Machine, NTM) 模仿图灵机一样,通过引入一个有意的结构偏置,带来了可解释性和泛化能力的优势,但也可能限制了模型能够解决的问题范围和学习到的算法的类型。论文最后也提到了这一点,例如当前模型局限于树结构输入输出、共享词汇表以及预设的最大树深度等,并提出未来可以探索其他树函数或数据结构。
论文中使用的 car, cdr, cons 操作是基于 Lisp 语言的基础操作,并且 TPR 表示的设计也针对二叉树结构。这些工具是基于对符号操作和树结构的理解而人为定义的。虽然这些操作被证明在论文研究的任务上非常有效,特别是在组合泛化方面,但它们可能不足以表达或高效地执行所有可能的树操作或更广义的符号操作。
相关文章:

从专家编码到神经网络学习:DTM 的符号操作新范式
1st author: Paul Soulos paper: Differentiable Tree Operations Promote Compositional Generalization ICML 2023 code: psoulos/dtm: Differentiable Tree Machine 1. 问题与思路 现代深度学习在连续向量空间中取得了巨大成功,然而在处理具有显式结构&#x…...

江协科技GPIO输入输出hal库实现
首先先介绍一下GPIO在hal库里面的函数 GPIOhal库函数介绍 GPIO在hal库里面有两个文件,一个hal_gpio.h一个hal_gpio_ex.h 第一个文件主要存放的就是hal库里面对gpio的相关函数以及GPIO配置的结构体,还有hal库与标准库的一大区别回调函数。以及一些对gp…...
)
软件设计师教程—— 第二章 程序设计语言基础知识(上)
前言 在竞争激烈的就业市场中,证书是大学生求职的重要加分项。中级软件设计师证书专业性强、认可度高,是计算机相关专业学生考证的热门选择,既能检验专业知识,又有助于职业发展。本教程将聚焦核心重点,以点带面构建知…...

Java 快速转 C# 教程
以下是一个针对 Java 开发者快速转向 C# 的简明教程,重点对比 Java 与 C# 的异同,帮助你快速上手。 项目结构: .sln :解决方案文件,管理多个项目之间的依赖关系。.csproj :项目文件,定义目标框…...
)
Linux面试题集合(5)
把文件1的内容追加到文件2 cat 文件1>>文件2 把文件1和文件2合并成文件3 cat 文件1 文件2>文件3 使用less查看文件时,搜寻ab字符 /ab 用more和less如何查看文件 more: CtrlF -- 向下滚动一屏 CtrlB -- 返回上一屏 f -- 向下翻屏 b -- 向上翻屏 …...

OpenCV 光流估计:从原理到实战
在计算机视觉领域,光流估计(Optical Flow Estimation)是一项至关重要的技术,它能够通过分析视频序列中图像像素的运动信息,捕捉物体和相机的运动情况。OpenCV 作为强大的计算机视觉库,为我们提供了高效实现…...

星火杯大模型应用创新赛学习笔记——datawhale
背景——赛事任务 聚焦大学生真实应用场景,围绕阅读、写作、搜索、聊天、问答等方向,聚焦口语学习、面试招聘、论文写作、学习笔记等一个或多个细分应用场景,完成具有创新性、实用性的应用方案,呈现可演示、可落地、具备商业价值…...

Ulyssess Ring Attention
https://zhuanlan.zhihu.com/p/689067888https://zhuanlan.zhihu.com/p/689067888DeepSpeed Ulysess:切分Q、K、V序列维度,核心卖点保持通信复杂度低,和GPU数无关,和序列长度呈线性关系。 Ring-Attention:切分Q、K、V序…...
)
c++重要知识点汇总(不定期更新)
前言 真心希望各位dalao点赞收藏~ 树状数组 作用:高效求出区间前缀和,允许进行修改操作。 举个栗子: 刚开始有8项,分别为1-8。 首先构建二叉树: 1-8/ |/ |/ |/ |/ |1-4 5-8/ | / |/ | / |1-…...

重排序模型解读 mxbai-rerank-base-v2 强大的重排序模型
mxbai-rerank-base-v2 强大的重排序模型 模型介绍benchmark综合评价安装 模型介绍 mxbai-rerank-base-v2 是 Mixedbread 提供的一个强大的重排序模型,旨在提高搜索相关性。该模型支持多语言,特别是在英语和中文方面表现出色。它还支持代码和 SQL 排序&a…...

电子电路:到底该怎么理解电容器的“通交流阻直流”?
电容器“通交流,阻直流”的特性源于其对不同频率电信号的响应差异,具体可通过以下步骤理解: 一、电容器的基本结构与充放电机制 结构:由两个导体极板(如金属)和中间的绝缘介质组成。充放电过程:…...

售前工作.工作流程和工具
第一部分 售前解决方案及技术建议书的制作 售前解决方案编写的标准操作步骤SOP: 售前解决方案写作方法_哔哩哔哩_bilibili 第二部分 投标过程关键活动--商务标技术方案 1. 按项目管理--售前销售项目立项 销售活动和销售线索的跟踪流程和工具 1)拿到标书ÿ…...

ORACLE数据库实例报错ORA-00470: LGWR process terminated with error宕机问题分析报告
服务概述 10月21号03:22分,BOSS数据库实例发生异常宕机;工程师及时响应此问题并对此故障原因进行分析及相关建议,详细的故障情况及相关日志、TRACE文件的分析及总结、建议,请参阅本文档。 hzboss数据库实例宕机分析 4.1 数据库层面日志的分…...
)
深度学习---知识蒸馏(Knowledge Distillation, KD)
一、知识蒸馏的本质与起源 定义: 知识蒸馏是一种模型压缩与迁移技术,通过将复杂高性能的教师模型(Teacher Model)所学的“知识”迁移到轻量级的学生模型(Student Model),使学生模型在参数量和计…...

AI日报 - 2024年5月17日
🌟 今日概览 (60秒速览) ▎🤖 大模型前沿 | OpenAI推出自主编码代理Codex;Google DeepMind发布Gemini驱动的编码代理AlphaEvolve,能设计先进算法;Meta旗舰AI模型Llama 4 Behemoth发布推迟。 Codex能并行处理多任务&…...

OAuth2.0
OAuth2.0 1. 什么是OAuth2.02.OAuth2.0的应用场景3. OAuth2.0基本概念4. 经典OAuth2.0认证流程5. 四种授权模式5.1 授权码模式(Authorization Code Grant)5.2 隐式授权(Implicit Grant)5.3 密码模式(Resource Owner Pa…...

deepin v23.1 音量自动静音问题解决
有的机器上会有音量自动静音问题, 如果你的电脑上也遇到, 这个问题是 Linux 内核的原因, ubuntu上也可能会遇到相同问题(比如你升级了最新内核6.14), 而我测试得6.8.0的内核是不会自动静音的. Index of /mainline 到上面这个链接(linux 内核的官方链接)下载6.8.0的内核, s…...

Spring Security 集成指南:避免 CORS 跨域问题
Spring Security 集成指南:避免 CORS 跨域问题 在现代 Web 应用开发中,前后端分离架构已成为主流。当我们使用 Spring Security 保护后端 API 时,经常会遇到跨域资源共享(CORS)问题。这篇文章将详细解析 Spring Secur…...

stack和queue简单模拟实现
stackreverse_iteratorqueuepriority_queue仿函数具体代码 stack Stacks are a type of container adaptor, specifically designed to operate in a LIFO context (last-in first-out), where elements are inserted and extracted only from one end of the container. 上述描…...
)
2.单链表两数相加(java)
题目描述: 分析: 1.首先创建一个虚拟节点 ListNode dummy new ListNode(-1);再创建一个节点来保存虚拟节点,因为使用虚拟节点来移动,如果不保存,最后就会丢失。保存虚拟节点:ListNode pdummy; 2.进位标志…...

JDBC 的编写步骤及原理详解
一、JDBC 简介 JDBC(Java DataBase Connectivity)即 Java 数据库连接,是 Java 语言用于操作数据库的一套 API。它为多种关系数据库提供了统一的访问方式,允许 Java 程序与不同类型的数据库(如 MySQL、Oracle、SQL Ser…...

AIStarter Windows 版本迎来重磅更新!模型插件工作流上线,支持 Ollama / ComfyUI 等多平台本地部署模型统一管理
如果你正在使用 AIStarter 工具进行本地 AI 模型部署 ,那么这条消息对你来说非常重要! 在最新推出的 AIStarter Windows 正式版更新中 ,官方对整个平台进行了功能重构和性能优化,尤其是新增了「模型插件工作流 」功能,…...

卸载和安装JDK
文章目录 卸载JDK安装JDK 卸载JDK 删除java的安装目录删除JAVA_HOME删除path下关于java的目录在cmd命令提示符中输入 java -version 安装JDK 浏览器搜索JDK8 下载电脑对应版本 双击安装JDK 记住安装的路径 配置环境变量 我的电脑 -> 右键 -> 属性 新建系统环境变量…...

【蓝桥杯省赛真题51】python石头运输 第十五届蓝桥杯青少组Python编程省赛真题解析
python石头运输 第十五届蓝桥杯青少年组python比赛省赛真题详细解析 博主推荐 所有考级比赛学习相关资料合集【推荐收藏】1、Python比赛 信息素养大赛Python编程挑战赛 蓝桥杯python选拔赛真题详解 <...

USRP 射频信号 采集 回放 系统
USRP 射频信号采集回放系统 也可以叫做: 利用宽带RF录制和回放系统实现6G技术研究超宽带射频信号采集回放系统使用NI USRP平台实现射频信号录制和回放操作演示USRP也能实现多通道宽带信号流盘回放了! 对于最简单的实现方法就是使用LabVIEW进行实现 采…...
产品体验报告)
产品经理入门(2)产品体验报告
产品体验报告大纲:重点在产品体验——优点。 1.产品概括 可以从各大平台搜产品介绍。 2.市场分析 按照产品方向分析各个指标——包括有效使用时间,市场规模等。 3. 用户分析——对用户通过各项指标画像。 4.产品体验——对各项功能与设计的体验。 5.报告总结...

区块链基本理解
文章目录 前言一、什么是分布式账本(DLT)二、什么是P2P网络?二、共识算法三、密码算法前言 区块链是由一个一个数据块组成的链条,按照时间顺序将数据块逐一链接,通过哈希指针链接,所有的数据块共同维护一份分布式账本(DLT),每个节点(可以理解为一个玩家,一台计算机)都拥…...

数字万用表与指针万用表使用方法及注意事项
在电子测量领域,万用表是极为常用的工具,数字万用表和指针万用表各具特点。熟练掌握它们的使用方法与注意事项,能确保测量的准确性与安全性。下面为您详细介绍: 一 、数字万用表按钮功能 > 进入及退出手动量程模式 每 按 […...

C语言查漏补缺
1、数组初始化时,例如char arr[5] "abcde",因为字符串中有6个字符,即末尾还有个结束符,但是数组容量为5,所以仅接纳5个字符,末尾的结束符不会被接纳,故而这样的字符数组在直接输出时…...

【JDBC】JDBC常见错误处理方法及驱动的加载
MySQL8中数据库连接的四个参数有两个发生了变化 String driver "com.mysql.cj.jdbc.Driver"; String url "jdbc:mysql://127.0.0.1:3306/mydb?useSSLfalse&useUnicodetrue&characterEncodingutf8&serverTimezoneAsia/Shanghai"; 或者Strin…...

从紫光集团看基本财务分析
PE 46PE 代表投资人对他的期望是它的业绩至少要增长50%才算及格。 但实际业绩 一年不如一年. 所以,这个PE 应该是 业绩倒退了,但是市值还没有掉下去,导致运算的结果处在高PE阶段。 那么随着股价的下跌,这个数字会慢慢变小。 当然…...

软件调试纵横谈-17-win32堆的调试支持
17.Win32堆的调试支持_哔哩哔哩_bilibili 继续边看录像边做实验。 堆上的内存时用size表达的,组成一个链表。 创建一个FreCheck应用 上次看heap,直接使用下载的文件,本次要做实验了,就需要自己动手,搞个VC proje…...

CANoe CAPL TCP DoIP通信问题
目录 问题Class: TcpSocketdemo示例client注释掉配置TCP/IP stack改demo代码过滤IP,与需要的IP建立连接问题 使用CANoe进行DoIP通信时,如果是标准的DoIP节点,可以使用DoIP相关函数进行通信。 以下两篇文章是按照此方式实现的。 十六、DoIP诊断通信 1 (专栏:从零开始搭建…...

理解 plank 自动生成的 copyWithBlock: 方法
当你使用 plank 命令自动生成一个类时 ./plank --objc_class_prefix=PUG --no_runtime --no_recursive user.json分析 在 JSON 目录下, 执行如上命令后, 生成的 PUGUser 对象, 会自带 copyWithBlock: 方法, 这个方法是用来做什么的 ? copyWithBlock: (注意末尾有一个冒号,因…...
FreeCAD源码分析: Transaction实现原理
本文阐述FreeCAD中Transaction的实现原理。 注1:限于研究水平,分析难免不当,欢迎批评指正。 注2:文章内容会不定期更新。 一、概念 Ref. from What is a Transaction? A transaction is a group of operations that have the f…...

黑马点评-用户登录
文章目录 用户登录发送短信验证码注册/登录校验登录 用户登录 发送短信验证码 public Result sendCode(String phone, HttpSession session) {// 1.校验手机号if (RegexUtils.isPhoneInvalid(phone)) {// 2.如果不符合,返回错误信息return Result.fail("手机…...

OpenAI新发布Codex的全面解析
一 . 介绍 人工智能技术的飞速发展正在重塑各行各业的运作方式,特别是在软件工程领域。随着生成式AI模型能力的不断提升,代码生成与软件开发领域正经历一场前所未有的变革。OpenAI作为人工智能领域的领军企业,其每一次技术突破都备受全球科技…...

【AI算法工程师面试指北】ResNet为什么用avgpool结构?
在ResNet(残差网络)中,最后使用平均池化(AvgPool)结构主要有以下几个关键原因,这些设计与网络的效率、性能和泛化能力密切相关: 1. 减少参数与计算量,避免过拟合 替代全连接层的冗…...

单调栈和单调队列
一、单调栈 1、使用场景 解决元素左 / 右侧第一个比他大 / 小的数字。 2、原理解释 用栈解决,目标是栈顶存储答案。 以元素左侧第一个比他小为例: (1)遍历顺序一定是从左向右。 (2)由于栈顶一定是答…...
)
DeepSeek-R1 Supervised finetuning and reinforcement learning (SFT + RL)
DeepSeek-R1Supervised finetuning and reinforcement learning (SFT RL) 好啊,我们今天的直播会非常透彻的跟大家系统性的分享一下整个agents AI就大模型智能体系统和应用程序。我们在做开发的时候,或者实际做企业级的产品落地的时候,你必…...

【部署】读取excel批量导入dify的QA知识库
回到目录 【部署】读取excel批量导入dify的QA知识库 0. 背景 dify的知识库支持QA模式,分段效果不算太理想,在我们的项目里面,手工编辑高质量QA文档,没有办法批量导入系统。 项目dify_import,支持读取excel文件批量导…...

Scanner对象
文章目录 Scanner对象基本语法使用next()接受使用nextLine()接受小案例总结 Scanner对象 java给我们提供了一个工具类,我们可以获取用户的输入 java.util.Scanner是java5的新特性,我们可以通过Scanner类来获取用户的输入 基本语法 Scanner s new Sc…...

Java 面向对象详解和JVM底层内存分析
先关注、点赞再看、人生灿烂!!!(谢谢) 神速熟悉面向对象 表格结构和类结构 我们在现实生活中,思考问题、发现问题、处理问题,往往都会用“表格”作为工具。实际上,“表格思维”就是…...

PIC16F18877 ADC 代码
这段代码是为PIC16F18877微控制器设计的嵌入式系统程序,主要实现了LCD显示屏控制、DHT11温湿度传感器数据采集和ADC模拟量读取三大功能。程序通过配置32MHz内部时钟源初始化系统,使用4位数据总线驱动LCD显示模块,定时读取DHT11传感器获取温湿度数据并校验,同时通过ADC通道采…...

Visual Studio2022跨平台Avalonia开发搭建
由于我已经下载并安装了 VS2022版本,这里就跳过不做阐述。 1.安装 Visual Studio 2022 安装时工作负荷Tab页勾选 “.NET 桌面开发” 和“Visual Studio扩展开发” ,这里由于不是用的微软的MAUI,所以不用选择其他的来支持跨平台开发&a…...

灵光一现的问题和常见错误1
拷贝构造函数显式写,编译器还会自动生成默认构造函数吗,还有什么函数会出现这种问题 在C中,当类显式定义某些特殊成员函数时,编译器可能不再自动生成其他相关函数。以下是详细分析: I. 显式定义拷贝构造函数对默认构造…...
-变量)
React学习(二)-变量
也是很无聊,竟然写这玩意,毕竟不是学术研究,普通工作没那么多概念性东西,会用就行╮(╯▽╰)╭ 在React中,变量是用于存储和管理数据的基本单位。根据其用途和生命周期,React中的变量可以分为以下几类: 1. 状态变量(State) 用途:用于存储组件的内部状态,状态变化会触…...
)
我的世界模组开发——特征(2)
原版代码 AbstractHugeMushroomFeature 以下是对AbstractHugeMushroomFeature类代码的逐段解析,结合Minecraft游戏机制和蘑菇形态学特征进行说明: 1. 类定义与继承关系 public abstract class AbstractHugeMushroomFeature extends Feature<HugeMushroomFeatureConfigu…...
)
中国30米年度土地覆盖数据集及其动态变化(1985-2022年)
中文名称 中国30米年度土地覆盖数据集及其动态变化(1985-2022年) 英文名称:The 30 m annual land cover datasets and its dynamics in China from 1985 to 2022 CSTR:11738.11.NCDC.ZENODO.DB3943.2023 DOI 10.5281/zenodo.8176941 数据共享方式:…...

2000 元以下罕见的真三色光源投影仪:雷克赛恩Cyber Pro1重新定义入门级投影体验
当性价比遇上技术瓶颈 在 2000元以下的1080P投影仪,单LCD 技术长期主导。而三色光源的DLP和3LCD真1080P都在4000元以上。 单LCD投影为纯白光光源,依赖CF滤光膜导致光效低下,普遍存在" 色彩失真 " 等问题。数据显示,该价…...