【C++】18.二叉搜索树
由于map和set的底层是红黑树,同时后面要讲的AVL树(高度平衡二叉搜索树),为了方便理解,我们先来讲解二叉搜索树,因为红黑树和AVL树都是在二叉搜索树的前提下实现的
在之前的C语言数据结构章节中,我们讲过二叉树,这次就来认识一下二叉搜索树
1. 二叉搜索树的概念
二叉搜索树又称二叉排序树,它或者是一棵空树,或者是具有以下性质的二叉树:
• 若它的左子树不为空,则左子树上所有结点的值都小于等于根结点的值
• 若它的右子树不为空,则右子树上所有结点的值都大于等于根结点的值
• 它的左右子树也分别为二叉搜索树
• 二叉搜索树中可以支持插入相等的值,也可以不支持插入相等的值,具体看使用场景定义,后续我们学习map/set/multimap/multiset系列容器底层就是二叉搜索树,其中map/set不支持插入相等值,multimap/multiset支持插入相等值
2. 二叉搜索树的性能分析
最优情况下,二叉搜索树为完全二叉树(或者接近完全二叉树),其高度为: log2 N
最差情况下,二叉搜索树退化为单支树(或者类似单支),其高度为: N
所以综合而言二叉搜索树增删查改时间复杂度为: O(N)
那么这样的效率显然是无法满足我们需求的,我们后续章节需要继续讲解二叉搜索树的变形,平衡二叉搜索树AVL树和红黑树,才能适用于我们在内存中存储和搜索数据。
另外需要说明的是,二分查找也可以实现 O(log2 N) 级别的查找效率,但是二分查找有两大缺陷:
1. 需要存储在支持下标随机访问的结构中,并且有序。
2. 插入和删除数据效率很低,因为存储在下标随机访问的结构中,插入和删除数据一般需要挪动数据。
这里也就体现出了平衡二叉搜索树的价值
3. 二叉搜索树的实现
template<class K>
struct BSTreeNode
{BSTreeNode(const K& key):_key(key),_left(nullptr),_right(nullptr){}K _key;BSTreeNode<K>* _left;BSTreeNode<K>* _right;
};template<class K>
class BSTree
{//typedef BSTreeNode<K> Node;using Node = BSTreeNode<K>;
public:
private:Node* _root = nullptr;
};首先我们要管理每个节点的数据以及它的左右孩子,所以我们先封装一个树节点类,用来管理节点的数据和左右孩子,其次我们要把每个树节点统一管理,所以还需要再封装一个树类,用来管理所有节点。
BSTreeNode:
这里我们模板参数使用K(表示key的意思),模板参数并不是只能是T
和之前list一样,只需要写构造,原因如下:
I. 节点类的核心需求
二叉搜索树的节点通常需要强制初始化关键值(如节点的值 val),并将子节点指针(left 和 right)初始化为空。
通过定义带参数的构造函数,可以确保:
-
值必须显式初始化:节点必须有值,不能存在未初始化的节点。
-
子节点指针默认置空:左右子节点指针默认初始化为
nullptr,避免野指针问题。
II. C++ 构造函数规则
-
默认构造函数:如果用户没有定义任何构造函数,编译器会生成一个默认构造函数。但如果用户定义了带参数的构造函数,编译器不再生成默认构造函数。此时若尝试无参创建对象会报错,符合“节点必须有值”的逻辑。
-
拷贝构造函数:若未显式定义,编译器会生成一个浅拷贝构造函数。对于树节点来说,浅拷贝通常是危险的(可能导致重复释放同一内存),但二叉搜索树的操作一般通过指针传递节点,不涉及拷贝节点对象本身,因此可以暂时忽略拷贝构造函数的需求。若需要更严格的控制,可显式删除拷贝构造函数。
III. 为什么其他构造函数可以不写?
-
默认构造函数:
已通过带参构造函数禁用,确保节点必须有初始值。 -
拷贝构造函数:
树节点通常通过指针操作,不需要拷贝节点对象。若需要复制整棵树(深拷贝),应在树结构中实现,而非节点类中。 -
移动构造函数:
对于简单的值类型(如int和指针),默认生成的移动操作已足够。 -
析构函数:
节点类的子节点指针是“原始指针”,但二叉搜索树的释放通常由树结构统一管理(如递归删除子树),因此节点类可以不显式定义析构函数。
BSTree:
我们先将BSTreeNode<K>类型typedef一下(类型太长了不好写),但是我们这里使用using,在现阶段using和typedef功能是一样的,具体差异后面章节会讲,不过using取别名的用法有点不一样;由于我们要管理树,将所有节点联系起来,所以我们可以提供一个指向根节点的指针_root作为成员变量,方便我们管理
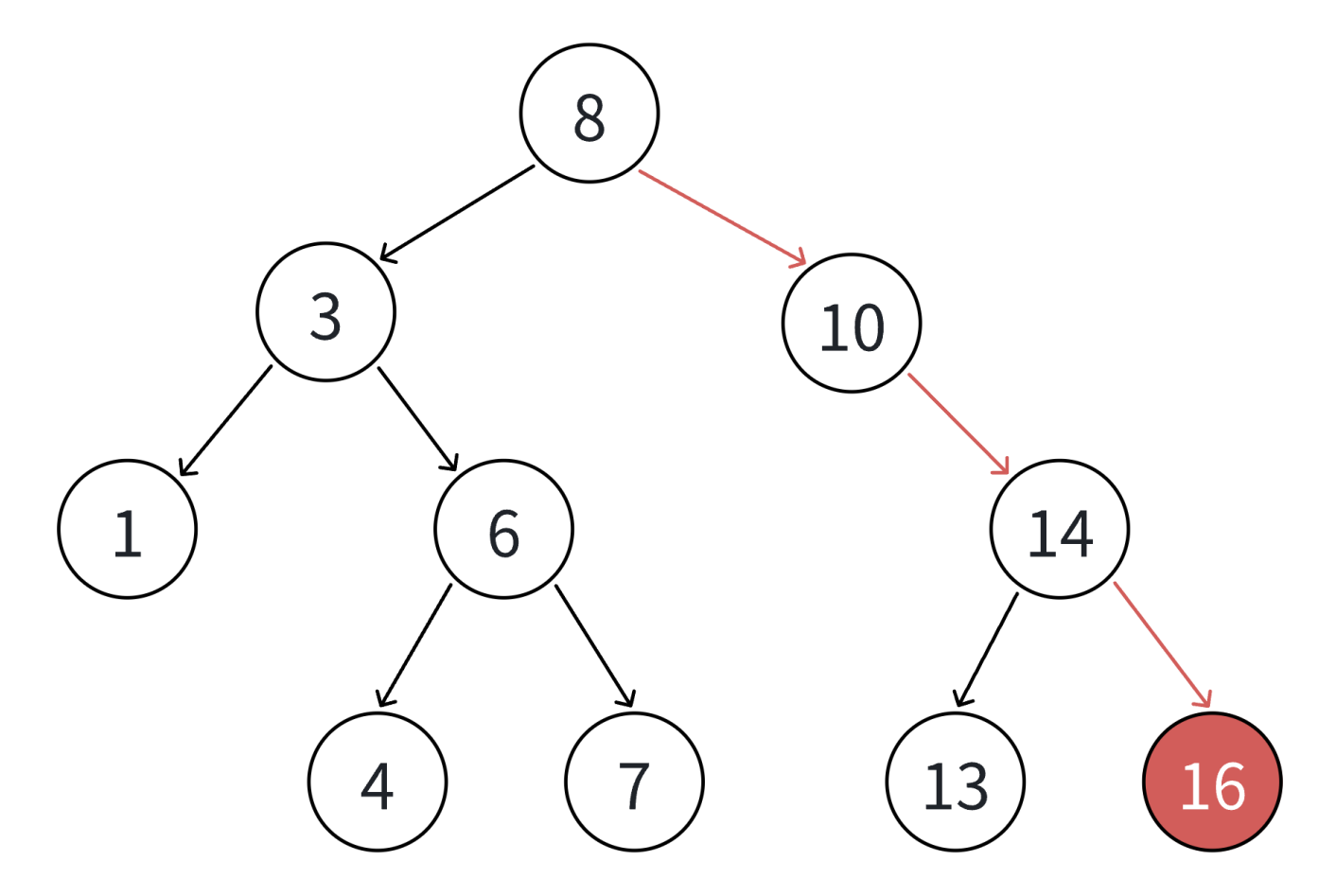
3.1 二叉搜索树的插入
插入的具体过程如下:
1. 树为空,则直接新增结点,赋值给root指针
2. 树不空,按二叉搜索树性质,插入值比当前结点大往右走,插入值比当前结点小往左走,找到空位置,插入新结点。
3. 如果支持插入相等的值,插入值跟当前结点相等的值可以往右走,也可以往左走,找到空位置,插入新结点。(要注意的是要保持逻辑一致性,插入相等的值不要一会往右走,一会往左走)
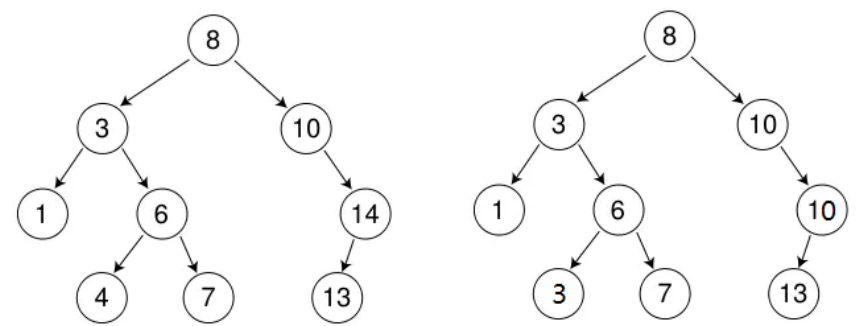
int a[] = { 8 , 3 , 1 , 10 , 6 , 4 , 7 , 14 , 13 };
以这组数据为例来画图演示一下:
插入不相等的值
插入相等的值
代码实现:
代码实现分别可以用递归和非递归两种方法来实现,这里我们采用非递归,递归太深的情况会栈溢出,同时我们这里默认不允许插入相等的值。
第一步:处理空树的特殊情况
-
若树为空(
_root == nullptr),直接创建根节点并初始化值为key,返回true表示插入成功。if (_root == nullptr) {_root = new Node(key);return true; }
第二步:查找插入位置
-
初始化指针:
-
parent记录当前节点的父节点(初始为nullptr)。 -
cur从根节点_root开始遍历。
Node* parent = nullptr; Node* cur = _root; -
-
循环遍历树:
-
若
key大于当前节点的值,向右子树移动。 -
若
key小于当前节点的值,向左子树移动。 -
若遇到重复值(
key已存在),返回false表示插入失败。
while (cur) {if (cur->_key < key) {parent = cur;cur = cur->_right;} else if (cur->_key > key) {parent = cur;cur = cur->_left;} else {return false; // 重复值,插入失败} } -
第三步:创建新节点并链接到父节点
-
创建新节点:
循环结束后,cur指向nullptr,此时parent是待插入位置的父节点。创建新节点cur。cur = new Node(key); -
确定插入方向:
根据key与父节点值的比较结果,将新节点链接为父节点的左子节点或右子节点。if (parent->_key < key) {parent->_right = cur; // 插入右子树 } else {parent->_left = cur; // 插入左子树 }
代码如下:
bool Insert(const K& key)
{if (_root == nullptr){_root = new Node(key);return true;}Node* parent = nullptr;Node* cur = _root;while (cur){if (cur->_key < key){parent = cur;cur = cur->_right;}else if (cur->_key > key){parent = cur;cur = cur->_left;}else{return false;}}cur = new Node(key);if (parent->_key < key){parent->_right = cur;}else{parent->_left = cur;}return true;
}如果想要允许插入相等的值,只需要在第二步插入位置时,判断条件修改一下为cur->_key <= key或者cur->_key >= key,然后去掉else语句——遇到重复值(key 已存在),返回 false 表示插入失败。
3.2 打印测试
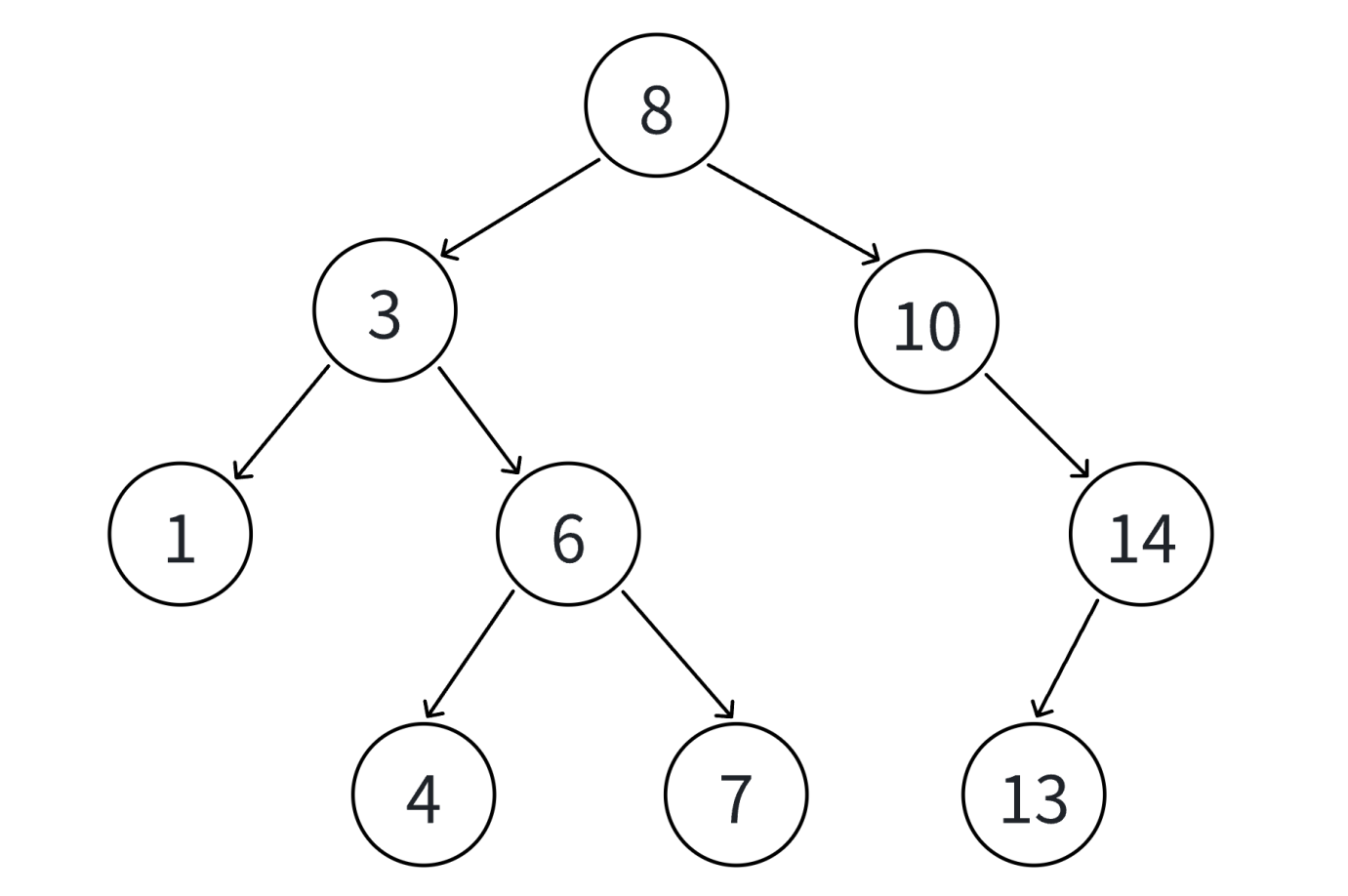
这里我们采用中序遍历的方式,将数据打印出来
void InOrder(Node* root)
{if (root == nullptr) return;InOrder(root->_left);cout << root->_key << " ";InOrder(root->_right);
}使用上面图示数据模拟:
void Test()
{int a[] = { 8,3,1,10,6,4,7,14,13 };BSTree<int> t;for (auto x : a){t.Insert(x);}t.InOrder(_root);
}显然这么写是错的,编译一下可以看到
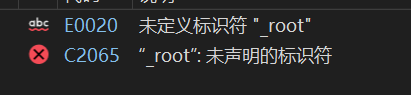
我们知道_root是私有成员变量,在类外我们是访问不了的,但是我们中序遍历需要传根节点指针,那应该怎么办呢?
我们可以实现一个类外可以访问的访问根节点的成员函数GetRoot(),但是这么写不太好,我们可以这么写
public:void InOrder(){_InOrder(_root);cout << endl;}
private:void _InOrder(Node* root){if (root == nullptr) return;_InOrder(root->_left);cout << root->_key << " ";_InOrder(root->_right);}我们直接将中序遍历私有,然后在公有下把中序遍历封装在另一个函数中,这样我们就可以在类外无参的使用中序遍历
运行结果:

3.3 二叉搜索树的查找
1. 从根开始比较,查找x,x比根的值大则往右边走查找,x比根值小则往左边走查找。
2. 最多查找高度次,走到空,还没找到,这个值不存在。
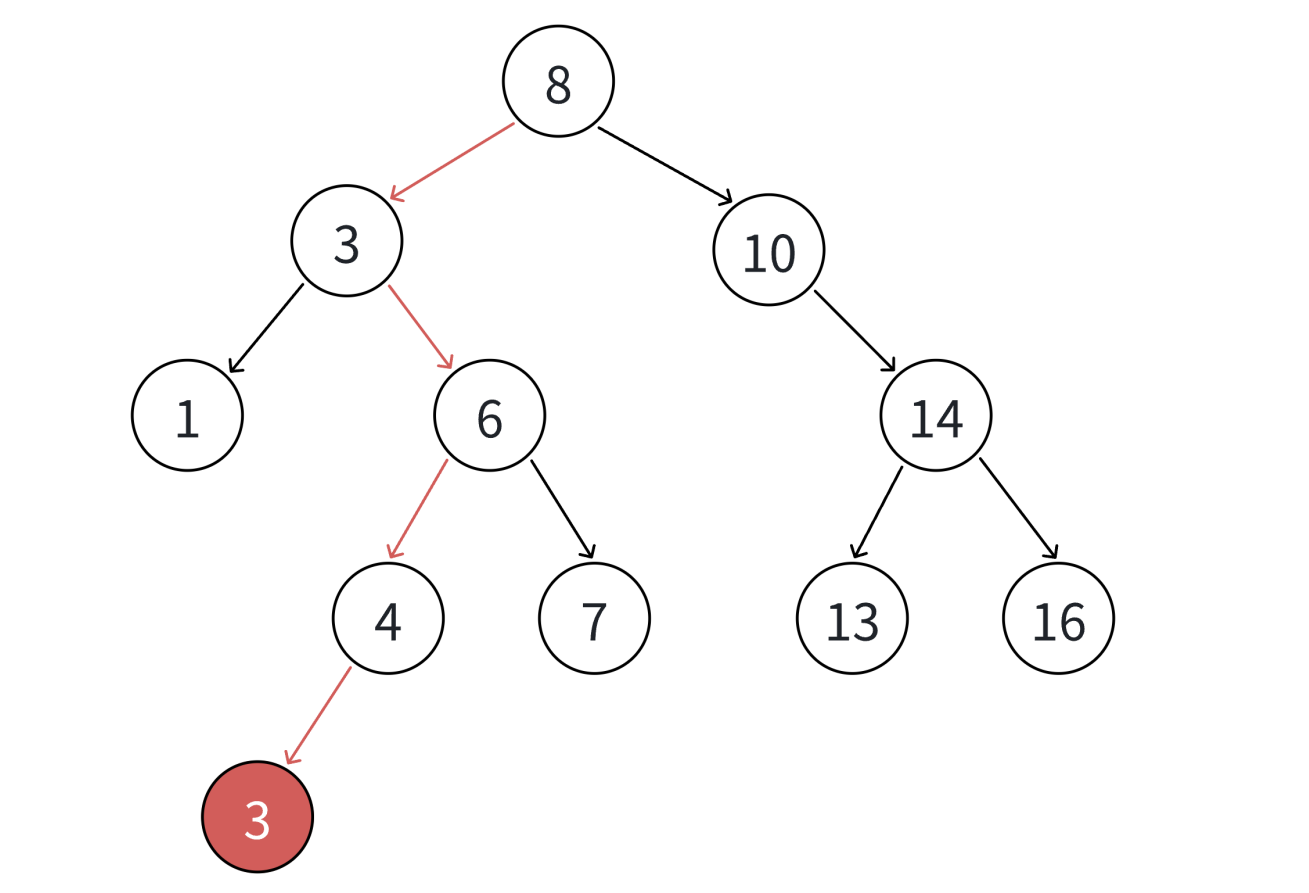
3. 如果不支持插入相等的值,找到x即可返回
4. 如果支持插入相等的值,意味着有多个x存在,一般要求查找中序的第一个x。如下图,查找3,要找到1的右孩子的那个3返回
代码实现:
查找非常简单,和插入的思路一样
bool Find(const K& key)
{Node* cur = _root;while (cur){if (cur->_key < key){cur = cur->_right;}else if (cur->_key > key){cur = cur->_left;}else{return true;//找到了}}//没找到return false;
}3.4 二叉搜索树的删除
首先查找元素是否在二叉搜索树中,如果不存在,则返回false。
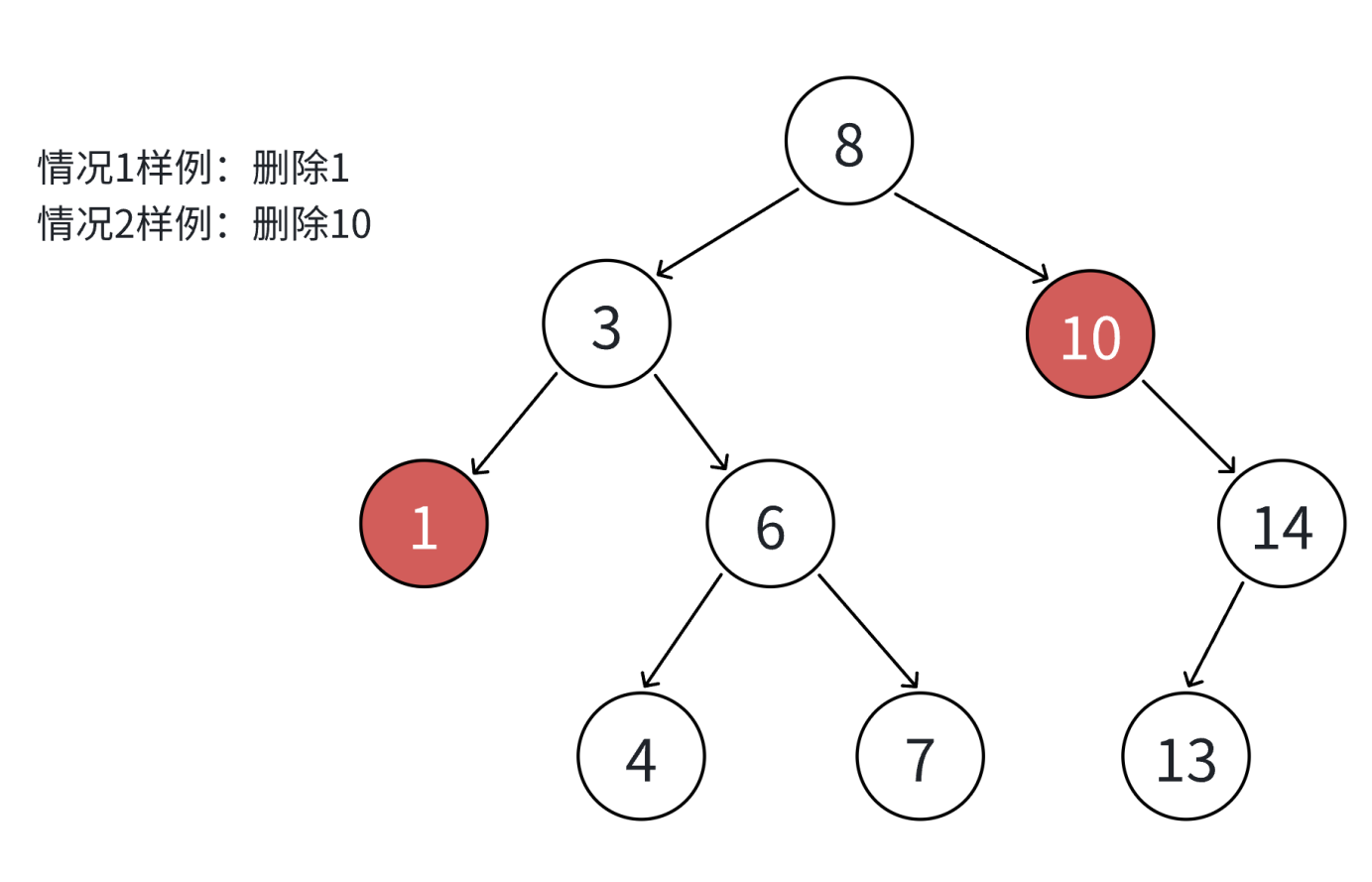
如果查找元素存在则分以下四种情况分别处理:(假设要删除的结点为N)
1. 要删除的结点N左右孩子均为空
2. 要删除的结点N左孩子为空,右孩子结点不为空
3. 要删除的结点N右孩子为空,左孩子结点不为空
4. 要删除的结点N左右孩子结点均不为空
对应以上四种情况的解决方案:
1. 把N结点的父亲对应孩子指针指向空,直接删除N结点(情况1可以当成2或者3处理,效果是一样的)
2. 把N结点的父亲对应孩子指针指向N的右孩子,直接删除N结点
3. 把N结点的父亲对应孩子指针指向N的左孩子,直接删除N结点
4. 无法直接删除N结点,因为N的两个孩子无处安放,只能用替换法删除。找N左子树的值最大结点R(最右结点)或者N右子树的值最小结点R(最左结点)替代N,因为这两个结点中任意一个,放到N的位置,都满足二叉搜索树的规则。替代N的意思就是N和R的两个结点的值交换,转而变成删除R结点,R结点符合情况2或情况3,可以直接删除。
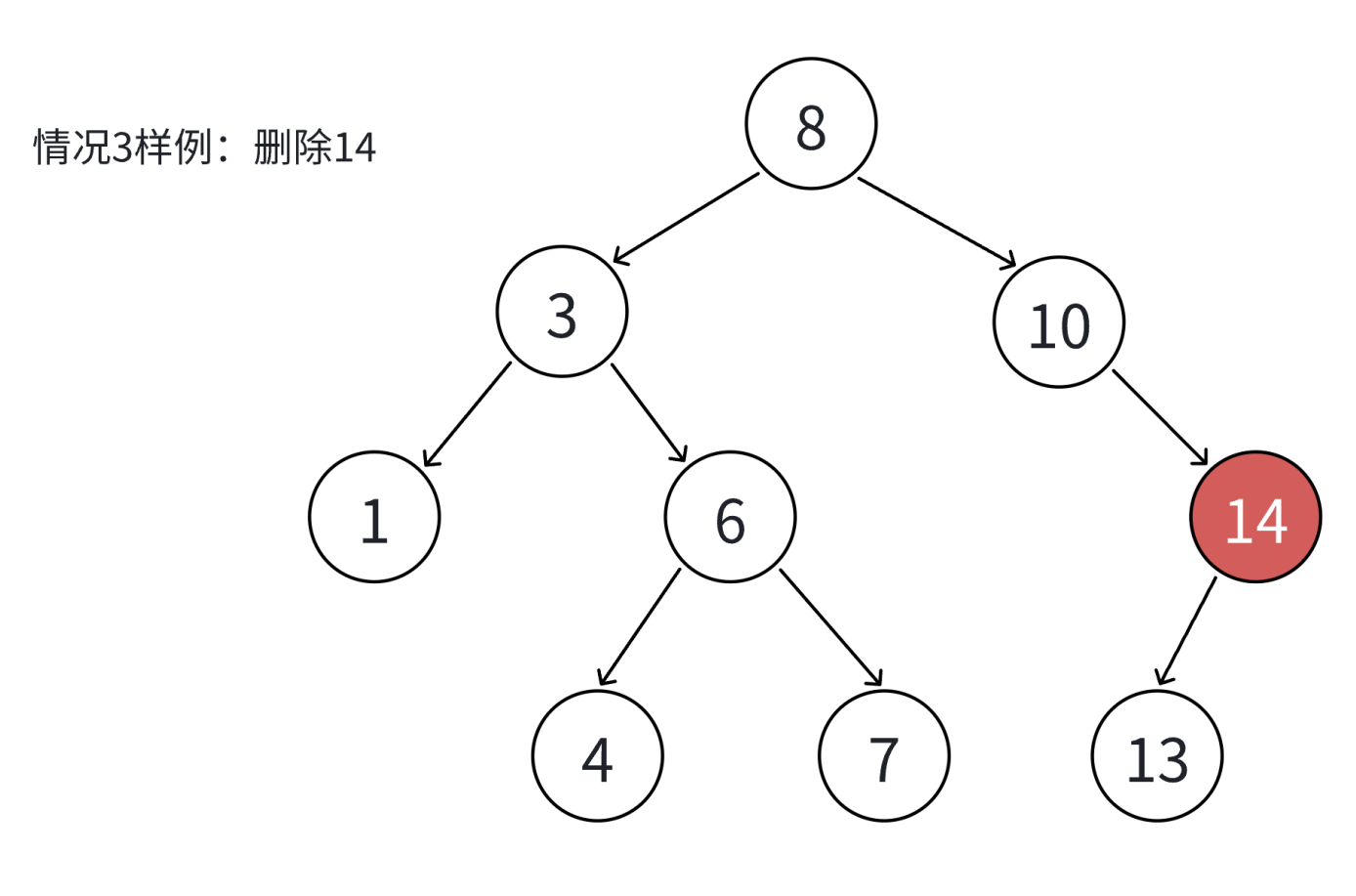
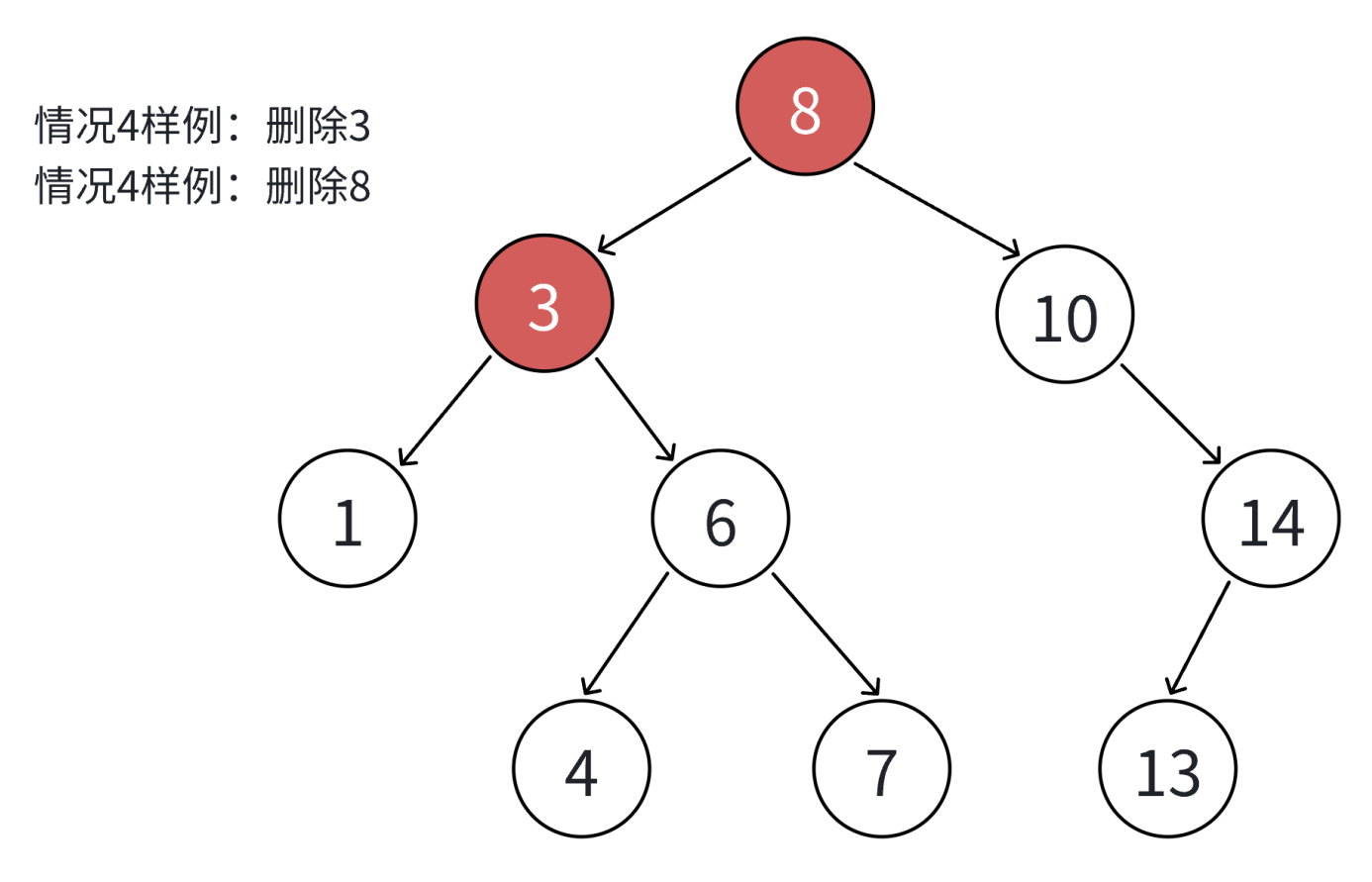
代码实现:
第1步. 查找待删除节点
-
初始化指针:
parent记录当前节点的父节点(初始为nullptr),cur从根节点_root开始遍历。 -
遍历搜索:
根据key与当前节点值的比较,向左或向右子树移动,直到找到目标节点或遍历结束。while (cur) {if (cur->_key < key) { ... } // 向右子树移动else if (cur->_key > key) { ... } // 向左子树移动else { ... } // 找到目标节点,进入删除逻辑 } -
未找到处理:
若遍历结束未找到key,返回false表示删除失败。
第2步. 根据子节点情况删除节点
(1) 左子节点为空(或右子节点为空)
-
直接替换:
-
若左子节点为空,用右子节点
cur->_right替代当前节点。 -
若右子节点为空,用左子节点
cur->_left替代当前节点。
-
-
处理根节点:
若删除的是根节点(cur == _root),直接更新_root为对应的子节点。 -
链接父节点:
根据cur是父节点的左/右子节点,更新父节点的指针指向cur的子节点。// 左子节点为空的情况 if (cur->_left == nullptr) {if (cur == _root) {_root = cur->_right; // 更新根节点} else {if (parent->_right == cur) {parent->_right = cur->_right;} else {parent->_left = cur->_right;}}delete cur; }
(2) 左右子节点均存在
-
替换法删除:
-
找到右子树的最小节点:从
cur->_right出发,循环找到最左侧节点replace(即右子树的最小节点)。 -
替换值:将
replace->_key赋值给cur->_key。 -
删除替换节点:
-
若
replace是其父节点的左子节点,将父节点的左指针指向replace的右子节点。 -
若
replace是其父节点的右子节点(即右子树没有左子节点),将父节点的右指针指向replace的右子节点。 -
删除
replace节点。
-
else {// 找右子树的最小节点Node* replaceParent = cur;Node* replace = cur->_right;while (replace->_left) {replaceParent = replace;replace = replace->_left;}// 替换值cur->_key = replace->_key;// 删除替换节点if (replace == replaceParent->_left) {replaceParent->_left = replace->_right;} else {replaceParent->_right = replace->_right;}delete replace; } -
第3步. 返回结果
-
删除成功:
在找到并删除节点后,立即返回true。 -
删除失败:
若循环结束未找到节点,返回false。
总结步骤
-
查找目标节点:遍历树找到待删除节点。
-
处理删除逻辑:
-
单子节点:直接用子节点替换,更新父节点或根节点指针。
-
双子节点:替换法删除(右子树最小节点),调整指针关系。
-
-
释放内存:删除节点并返回操作结果。
代码如下:
bool Erase(const K& key)
{Node* parent = nullptr;Node* cur = _root;while (cur){if (cur->_key < key){parent = cur;cur = cur->_right;}else if (cur->_key > key){parent = cur;cur = cur->_left;}else{// 找到了删除if (cur->_left == nullptr) // 左孩子为空{if (cur == _root){_root = cur->_right;}else{if (parent->_right == cur){// 此时cur->_key > parent->_keyparent->_right = cur->_right;}else //parent->_left == cur{// 此时cur->_key < parent->_keyparent->_left = cur->_right;}}delete cur;}else if (cur->_right == nullptr) // 右孩子为空{if (cur == _root){_root = cur->_left;}else{if (parent->_right == cur){// 此时cur->_key > parent->_keyparent->_right = cur->_left;}else //parent->_left == cur{// 此时cur->_key < parent->_keyparent->_left = cur->_left;}}delete cur;}else // 两个孩子都不为空{// 替换法删除节点——右子树最小节点替换Node* replaceParent = cur;// 要考虑删除根节点时,不能置为nullptrNode* replace = cur->_right;while (replace->_left){replaceParent = replace;replace = replace->_left;}cur->_key = replace->_key;if (replace == replaceParent->_left){replaceParent->_left = replace->_right;}else //replace == replaceParent->_right{// 此时第一个右孩子就是右子树最小节点replaceParent->_right = replace->_right;}delete replace;}//成功删除return true;}}//没找到,删除失败return false;
}4. 二叉搜索树key和key/value使用场景
4.1 key搜索场景:
只有key作为关键码,结构中只需要存储key即可,关键码即为需要搜索到的值,搜索场景只需要判断key在不在。key的搜索场景实现的二叉树搜索树支持增删查,但是不支持修改,修改key破坏搜索树结构了。
场景1:小区无人值守车库,小区车库买了车位的业主车才能进小区,那么物业会把买了车位的业主的车牌号录入后台系统,车辆进入时扫描车牌在不在系统中,在则抬杆,不在则提示非本小区车辆,无法进入。
场景2:检查一篇英文章单词拼写是否正确,将词库中所有单词放入二叉搜索树,读取文章中的单 词,查找是否在二叉搜索树中,不在则波浪线标红提示

4.2 key/value搜索场景:
每一个关键码key,都有与之对应的值value,即<key, value>,value可以是任意类型对象。树的结构中(结点)除了需要存储key还要存储对应的value,增/删/查还是以key为关键字走二叉搜索树的规则进行比较,可以快速查找到key对应的value。key/value的搜索场景实现的二叉树搜索树支持修改,但是不支持修改key,修改key破坏搜索树性质了,可以修改value。
I. 键(Key)与值(Value)的定义
-
键(Key)
键是用于唯一标识数据的标识符。它类似于字典中的“词条”,用于快速查找、插入或删除对应的值。-
特性:唯一性(在同一个容器中,键不能重复)、可比较性(必须支持比较或哈希操作)。
-
示例:学号、身份证号、用户名等。
-
-
值(Value)
值是与键关联的实际数据。它可以是任意类型,存储具体的业务信息。-
特性:允许重复、无特殊约束(除非业务需要)。
-
示例:学生成绩、用户详细信息、缓存的数据等。
-
II. 键与值的核心差异
| 特性 | 键(Key) | 值(Value) |
|---|---|---|
| 唯一性 | 必须唯一 | 可以重复 |
| 作用 | 快速定位数据 | 存储实际数据 |
| 约束 | 必须可比较或可哈希 | 无特殊约束(类型灵活) |
| 修改性 | 通常不可修改(需删除后重新插入) | 可直接修改 |
场景1:简单中英互译字典,树的结构中(结点)存储key(英文)和vlaue(中文),搜索时输入英文,则同时查找到了英文对应的中文。
场景2:商场五日值守车库,入口进场时扫描车牌,记录车牌和入场时间,出口离场时,扫描车牌,查找入场时间,用当前时间-入场时间计算出停车时长,计算出停车费用,缴费后抬杆,车辆离场。
场景3:统计一篇文章中单词出现的次数,读取一个单词,查找单词是否存在,不存在这个单词说明第一次出现,(单词,1),单词存在,则++单词对应的次数。
代码实现:
我们只需要在之前二叉搜索树的增删查代码的基础上简单修改即可,增加一个模板参数V,此时我们节点中存储的数据就是键值对<key, value>,所以在树节点类中需要新增一个V类型的成员变量,同时构造函数中也需要增加一个V类型的形参
Insert: 只需增加一个V类型的形参,因为在插入新的树节点时,要new一个<key, value>类型的树节点,其余操作不需要改变
Find:只需要查找键,修改返回值,我们返回树节点,就可以通过树节点得到里面的值
Erase:不需要修改
namespace key_value
{template<class K, class V>struct BSTreeNode{BSTreeNode(const K& key, const V& value):_key(key),_value(value), _left(nullptr), _right(nullptr){}// 不写默认构造函数、拷贝构造函数等// 编译器会自动禁用默认构造函数(因为用户已定义其他构造函数)// 若需要禁用拷贝,可显式删除K _key;V _value;BSTreeNode<K, V>* _left;BSTreeNode<K, V>* _right;};template<class K, class V>class BSTree{//typedef BSTreeNode<K> Node;using Node = BSTreeNode<K, V>;public:bool Insert(const K& key, const V& value){if (_root == nullptr){_root = new Node(key, value);return true;}Node* parent = nullptr;Node* cur = _root;while (cur){if (cur->_key < key){parent = cur;cur = cur->_right;}else if (cur->_key > key){parent = cur;cur = cur->_left;}else{return false; //重复值插入失败}}cur = new Node(key, value);if (parent->_key < key){parent->_right = cur;}else{parent->_left = cur;}return true;}Node* Find(const K& key){Node* cur = _root;while (cur){if (cur->_key < key){cur = cur->_right;}else if (cur->_key > key){cur = cur->_left;}else{return cur;//找到了}}//没找到return nullptr;}bool Erase(const K& key){Node* parent = nullptr;Node* cur = _root;while (cur){if (cur->_key < key){parent = cur;cur = cur->_right;}else if (cur->_key > key){parent = cur;cur = cur->_left;}else{// 找到了删除if (cur->_left == nullptr) // 左孩子为空{if (cur == _root){_root = cur->_right;}else{if (parent->_right == cur){// 此时cur->_key > parent->_keyparent->_right = cur->_right;}else //parent->_left == cur{// 此时cur->_key < parent->_keyparent->_left = cur->_right;}}delete cur;}else if (cur->_right == nullptr) // 右孩子为空{if (cur == _root){_root = cur->_left;}else{if (parent->_right == cur){// 此时cur->_key > parent->_keyparent->_right = cur->_left;}else //parent->_left == cur{// 此时cur->_key < parent->_keyparent->_left = cur->_left;}}delete cur;}else // 两个孩子都不为空{// 替换法删除节点——右子树最小节点替换Node* replaceParent = cur;// 要考虑删除根节点时,不能置为nullptrNode* replace = cur->_right;while (replace->_left){replaceParent = replace;replace = replace->_left;}cur->_key = replace->_key;if (replace == replaceParent->_left){replaceParent->_left = replace->_right;}else //replace == replaceParent->_right{// 此时第一个右孩子就是右子树最小节点replaceParent->_right = replace->_right;}delete replace;}//成功删除return true;}}//没找到,删除失败return false;}void InOrder(){_InOrder(_root);cout << endl;}private:void _InOrder(Node* root){if (root == nullptr) return;_InOrder(root->_left);cout << root->_key << ":" << root->_value << endl;_InOrder(root->_right);}private:Node* _root = nullptr;};}我们这里还要显式实现一下拷贝构造和析构,因为这里需要深拷贝资源,且在析构时要把每个new出来的树节点都要释放掉。
拷贝构造:
通过调用 Copy(t._root),复制原树 t 的根节点,并将新树的根节点 _root 指向复制后的根节点。
因为拷贝构造没有返回值,独立函数 Copy 将递归逻辑封装为一个“黑盒”,只需关注输入(原树的根节点)和输出(新树的根节点),同时:
-
Copy函数通常设为私有,因为它是类内部的实现细节,外部无需知道如何复制一棵树。 -
隐藏实现细节,避免用户误用,同时提高类的封装性。
BSTree(const BSTree& t){_root = Copy(t._root);}
private:Node* Copy(Node* root){if (root == nullptr) return nullptr;Node* newNode = new Node(root->_key, root->_value);newNode->_left = Copy(root->_left);newNode->_right = Copy(root->_right);return newNode;}构造函数:
当我们自己显式定义了拷贝构造函数时,编译器就不会自动生成默认的无参构造函数
这样的话我们的根节点_root就不能实现初始化了,所以我们这里可以手动实现,也可以强制编译器生成默认构造
手动实现:
BSTree() {}强制编译器生成:
BSTree() = default;//C++11起赋值重载:
BSTree& operator=(BSTree tmp)
{swap(tmp._root, _root);return *this;
}这里直接使用现代写法来实现
析构函数:
~BSTree(){Destroy(_root);_root = nullptr;}
private:void Destroy(Node* root){if (root == nullptr) return;Destroy(root->_left);Destroy(root->_right);delete root;}这里和拷贝构造一样,封装一个Destroy()函数,递归销毁每个树节点
模拟测试一下场景1:
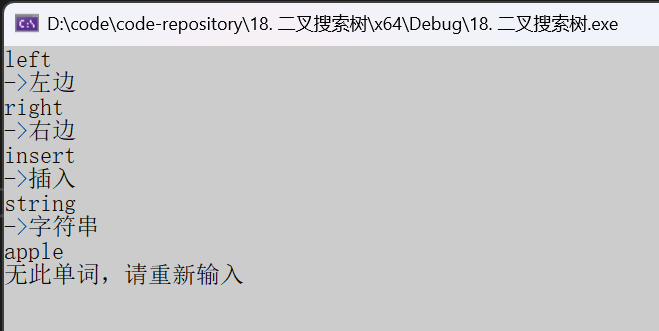
void test1()
{BSTree<string, string> dict;dict.Insert("left", "左边");dict.Insert("right", "右边");dict.Insert("insert", "插入");dict.Insert("string", "字符串");string str;while (cin >> str){auto ret = dict.Find(str);if (ret){cout << "->" << ret->_value << endl;}else{cout << "无此单词,请重新输入" << endl;}}
}运行结果:
模拟测试一下场景3:
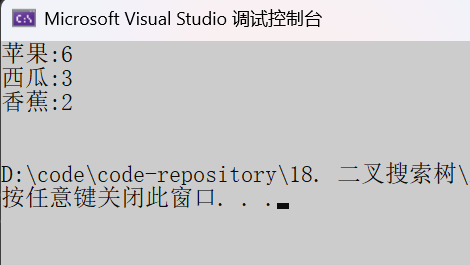
void test2()
{string arr[] = { "苹果", "西瓜", "苹果", "西瓜", "苹果", "苹果", "西瓜", "苹果", "香蕉", "苹果", "香蕉" };BSTree<string, int> countTree;for (const auto& str : arr){// 先查找水果在不在搜索树中// 1、不在,说明水果第一次出现,则插入<水果, 1>// 2、在,则查找到的结点中水果对应的次数++//BSTreeNode<string, int>* ret = countTree.Find(str);auto ret = countTree.Find(str);if (ret == NULL){countTree.Insert(str, 1);}else{ret->_value++;}}countTree.InOrder();
}运行结果:
代码:
namespace key
{template<class K>struct BSTreeNode{BSTreeNode(const K& key):_key(key), _left(nullptr), _right(nullptr){}// 不写默认构造函数、拷贝构造函数等// 编译器会自动禁用默认构造函数(因为用户已定义其他构造函数)// 若需要禁用拷贝,可显式删除:// BSTreeNode(const BSTreeNode<K>&) = delete;// BSTreeNode& operator=(const BSTreeNode<K>&) = delete;K _key;BSTreeNode<K>* _left;BSTreeNode<K>* _right;};template<class K>class BSTree{//typedef BSTreeNode<K> Node;using Node = BSTreeNode<K>;public:bool Insert(const K& key){if (_root == nullptr){_root = new Node(key);return true;}Node* parent = nullptr;Node* cur = _root;while (cur){if (cur->_key < key){parent = cur;cur = cur->_right;}else if (cur->_key > key){parent = cur;cur = cur->_left;}else{return false; //重复值插入失败}}cur = new Node(key);if (parent->_key < key){parent->_right = cur;}else{parent->_left = cur;}return true;}bool Find(const K& key){Node* cur = _root;while (cur){if (cur->_key < key){cur = cur->_right;}else if (cur->_key > key){cur = cur->_left;}else{return true;//找到了}}//没找到return false;}bool Erase(const K& key){Node* parent = nullptr;Node* cur = _root;while (cur){if (cur->_key < key){parent = cur;cur = cur->_right;}else if (cur->_key > key){parent = cur;cur = cur->_left;}else{// 找到了删除if (cur->_left == nullptr) // 左孩子为空{if (cur == _root){_root = cur->_right;}else{if (parent->_right == cur){// 此时cur->_key > parent->_keyparent->_right = cur->_right;}else //parent->_left == cur{// 此时cur->_key < parent->_keyparent->_left = cur->_right;}}delete cur;}else if (cur->_right == nullptr) // 右孩子为空{if (cur == _root){_root = cur->_left;}else{if (parent->_right == cur){// 此时cur->_key > parent->_keyparent->_right = cur->_left;}else //parent->_left == cur{// 此时cur->_key < parent->_keyparent->_left = cur->_left;}}delete cur;}else // 两个孩子都不为空{// 替换法删除节点——右子树最小节点替换Node* replaceParent = cur;// 要考虑删除根节点时,不能置为nullptrNode* replace = cur->_right;while (replace->_left){replaceParent = replace;replace = replace->_left;}cur->_key = replace->_key;if (replace == replaceParent->_left){replaceParent->_left = replace->_right;}else //replace == replaceParent->_right{// 此时第一个右孩子就是右子树最小节点replaceParent->_right = replace->_right;}delete replace;}//成功删除return true;}}//没找到,删除失败return false;}void InOrder(){_InOrder(_root);cout << endl;}private:void _InOrder(Node* root){if (root == nullptr) return;_InOrder(root->_left);cout << root->_key << " ";_InOrder(root->_right);}private:Node* _root = nullptr;};void Test(){int a[] = { 8,3,1,10,6,4,7,14,13 };BSTree<int> t;for (auto x : a){t.Insert(x);}t.InOrder();for (auto x : a){t.Erase(x);t.InOrder();}}
}namespace key_value
{template<class K, class V>struct BSTreeNode{BSTreeNode(const K& key, const V& value):_key(key),_value(value), _left(nullptr), _right(nullptr){}// 不写默认构造函数、拷贝构造函数等// 编译器会自动禁用默认构造函数(因为用户已定义其他构造函数)// 若需要禁用拷贝,可显式删除K _key;V _value;BSTreeNode<K, V>* _left;BSTreeNode<K, V>* _right;};template<class K, class V>class BSTree{//typedef BSTreeNode<K> Node;using Node = BSTreeNode<K, V>;public://BSTree() {}BSTree() = default;//C++11起BSTree(const BSTree& t){_root = Copy(t._root);}BSTree& operator=(BSTree tmp){swap(tmp._root, _root);return *this;}~BSTree(){Destroy(_root);_root = nullptr;}bool Insert(const K& key, const V& value){if (_root == nullptr){_root = new Node(key, value);return true;}Node* parent = nullptr;Node* cur = _root;while (cur){if (cur->_key < key){parent = cur;cur = cur->_right;}else if (cur->_key > key){parent = cur;cur = cur->_left;}else{return false; //重复值插入失败}}cur = new Node(key, value);if (parent->_key < key){parent->_right = cur;}else{parent->_left = cur;}return true;}Node* Find(const K& key){Node* cur = _root;while (cur){if (cur->_key < key){cur = cur->_right;}else if (cur->_key > key){cur = cur->_left;}else{return cur;//找到了}}//没找到return nullptr;}bool Erase(const K& key){Node* parent = nullptr;Node* cur = _root;while (cur){if (cur->_key < key){parent = cur;cur = cur->_right;}else if (cur->_key > key){parent = cur;cur = cur->_left;}else{// 找到了删除if (cur->_left == nullptr) // 左孩子为空{if (cur == _root){_root = cur->_right;}else{if (parent->_right == cur){// 此时cur->_key > parent->_keyparent->_right = cur->_right;}else //parent->_left == cur{// 此时cur->_key < parent->_keyparent->_left = cur->_right;}}delete cur;}else if (cur->_right == nullptr) // 右孩子为空{if (cur == _root){_root = cur->_left;}else{if (parent->_right == cur){// 此时cur->_key > parent->_keyparent->_right = cur->_left;}else //parent->_left == cur{// 此时cur->_key < parent->_keyparent->_left = cur->_left;}}delete cur;}else // 两个孩子都不为空{// 替换法删除节点——右子树最小节点替换Node* replaceParent = cur;// 要考虑删除根节点时,不能置为nullptrNode* replace = cur->_right;while (replace->_left){replaceParent = replace;replace = replace->_left;}cur->_key = replace->_key;if (replace == replaceParent->_left){replaceParent->_left = replace->_right;}else //replace == replaceParent->_right{// 此时第一个右孩子就是右子树最小节点replaceParent->_right = replace->_right;}delete replace;}//成功删除return true;}}//没找到,删除失败return false;}void InOrder(){_InOrder(_root);cout << endl;}private:void Destroy(Node* root){if (root == nullptr) return;Destroy(root->_left);Destroy(root->_right);delete root;}Node* Copy(Node* root){if (root == nullptr) return nullptr;Node* newNode = new Node(root->_key, root->_value);newNode->_left = Copy(root->_left);newNode->_right = Copy(root->_right);return newNode;}void _InOrder(Node* root){if (root == nullptr) return;_InOrder(root->_left);cout << root->_key << ":" << root->_value << endl;_InOrder(root->_right);}private:Node* _root = nullptr;};void test1(){BSTree<string, string> dict;dict.Insert("left", "左边");dict.Insert("right", "右边");dict.Insert("insert", "插入");dict.Insert("string", "字符串");string str;while (cin >> str){auto ret = dict.Find(str);if (ret){cout << "->" << ret->_value << endl;}else{cout << "无此单词,请重新输入" << endl;}}}void test2(){string arr[] = { "苹果", "西瓜", "苹果", "西瓜", "苹果", "苹果", "西瓜", "苹果", "香蕉", "苹果", "香蕉" };BSTree<string, int> countTree;for (const auto& str : arr){// 先查找水果在不在搜索树中// 1、不在,说明水果第一次出现,则插入<水果, 1>// 2、在,则查找到的结点中水果对应的次数++//BSTreeNode<string, int>* ret = countTree.Find(str);auto ret = countTree.Find(str);if (ret == NULL){countTree.Insert(str, 1);}else{ret->_value++;}}countTree.InOrder();}
}相关文章:

【C++】18.二叉搜索树
由于map和set的底层是红黑树,同时后面要讲的AVL树(高度平衡二叉搜索树),为了方便理解,我们先来讲解二叉搜索树,因为红黑树和AVL树都是在二叉搜索树的前提下实现的 在之前的C语言数据结构章节中,我们讲过二叉树&#x…...

刘家祎双剧收官见证蜕变,诠释多面人生
近期,两部风格迥异的剧集迎来收官时刻,而青年演员刘家祎在《我家的医生》与《无尽的尽头》中的精彩演绎,无疑成为观众热议的焦点。从温暖治愈的医疗日常到冷峻深刻的少年救赎,他以极具张力的表演,展现出令人惊叹的可塑…...

python + streamlink 下载 vimeo 短视频
1. 起因, 目的: 看到一个视频,很喜欢,想下载。https://player.vimeo.com/video/937787642 2. 先看效果 能下载。 3. 过程: 因为我自己没头绪。先看一下别人的例子, 问一下 ai 或是 google问了几个来回,原来是流式…...

18-总线IIC
一、IIC 1、IIC概述 I2C(IIC,Inter-Integrated Circuit),两线式串行总线,由PHILIPS(飞利浦)公司开发用于连接微控制器及其外围设备。 它是由数据线SDA和时钟SCL构成的串行总线,可发送和接收数据。在CPU与被控IC之间、IC与IC之间…...

【深度学习-Day 12】从零认识神经网络:感知器原理、实现与局限性深度剖析
Langchain系列文章目录 01-玩转LangChain:从模型调用到Prompt模板与输出解析的完整指南 02-玩转 LangChain Memory 模块:四种记忆类型详解及应用场景全覆盖 03-全面掌握 LangChain:从核心链条构建到动态任务分配的实战指南 04-玩转 LangChai…...

力扣HOT100之二叉树:98. 验证二叉搜索树
这道题之前也刷过,自己做了一遍,发现卡在了第70多个样例,才发现自己没有利用二叉搜索树的性质,但凡涉及到二叉搜索树,应该首先考虑中序遍历!!! 被卡住的测试样例是这样的:…...
)
vector(c++)
前言 正式进入学习STL的第一步就是vector容器, vector是一种用于存储可变大小数组的序列容器,就像数组一样,vector也采用的连续存储空间来存储元素。本质上讲,vector使用动态分配数组来存储它的元素。底层是一个顺序表。本文介绍…...
)
CAPL Class: TcpSocket (此类用于实现 TCP 网络通信 )
目录 Class: TcpSocketacceptopenclosebindconnectgetLastSocketErrorgetLastSocketErrorAsStringlistenreceivesendsetSocketOptionshutdown函数调用的基本流程服务器端的基本流程客户端的基本流程Class: TcpSocket学习笔记。来自CANoe帮助文档。 Class: TcpSocket accept /…...

C语言:gcc 如何调用 Win32 打开文件对话框 ?
在 Windows 平台上使用 gcc 调用原生 Win32 API 实现文件打开对话框是可行的,但需要直接使用 Win32 的 GetOpenFileName 函数(位于 commdlg.h 头文件,依赖 comdlg32.lib 库)。以下是完整实现步骤和代码示例: 编写 file…...

OpenHarmony:开源操作系统重塑产业数字化底座
OpenHarmony:开源操作系统重塑产业数字化底座 引言:当操作系统成为数字公共品 在万物智联时代,操作系统不再是科技巨头的专属领地。华为捐赠的OpenHarmony项目,正以开源协作模式重构操作系统产业格局。这个脱胎于商业版本的开源…...

线程同步学习
概念 有A、B、C三个线程,A线程负责输入数据,B线程负责处理数据、C线程负责输出数据,这三个线程之间就存在着同步关系,即A必须先执行,B次之,C最后执行,否则不能得到正确的结果。 那么所谓线程同…...

十二、Hive 函数
作者:IvanCodes 日期:2025年5月17日 专栏:Hive教程 在数据处理的广阔天地中,我们常常需要对数据进行转换、计算、清洗或提取特定信息。Hive 提供了强大的内置运算符和丰富的内置函数库,它们就像魔法师手中的魔法棒&…...

DeepSeek 赋能社会科学:解锁研究新范式
目录 一、DeepSeek:大语言模型中的新力量1.1 DeepSeek 技术亮点1.2 与其他模型对比 二、DeepSeek 在社会科学研究中的应用领域2.1 经济学研究2.2 社会学研究2.3 历史学研究2.4 法学研究 三、DeepSeek 应用案例深度剖析3.1 案例一:社会学研究中社会舆情分…...

java函数内的变量问题
public class VendingMachine {//设计一个类叫做VendingMachine,用这个类制造一个对象vmint price 80;int balance;//三个属性int total;void showprompt(){System.out.println("Welcome");}void insertmoney(int amount){balance balance amount;}void showBalan…...

docker部署第一个Go项目
1.前期准备 目录结构 main.go package mainimport ("fmt""github.com/gin-gonic/gin""net/http" )func main() {fmt.Println("\n .::::.\n .::::::::.\n :::::::::::\n …...

【读代码】端到端多模态语言模型Ultravox深度解析
一、项目基本介绍 Ultravox是由Fixie AI团队开发的开源多模态大语言模型,专注于实现音频-文本的端到端实时交互。项目基于Llama 3、Mistral等开源模型,通过创新的跨模态投影架构,绕过了传统语音识别(ASR)的中间步骤,可直接将音频特征映射到语言模型的高维空间。 核心优…...

管理前端项目依赖版本冲突导致启动失败的问题的解决办法
管理前端项目依赖版本冲突导致启动失败的问题,可按照以下步骤系统解决: 1. 定位冲突来源 查看错误日志:启动失败时的控制台报错通常会指出具体模块或版本问题,例如 Module not found 或 TypeError。检查依赖树:npm l…...

北京市工程技术人才职称评价基本标准条件解读
北京市工程技术人才职称评价基本标准条件 北京市工程技术人才之技术员 北京市工程技术人才之助理工程师 北京市工程技术人才之工程师 北京市工程技术人才之高级工程师 北京市工程技术人才之高级工程师(破格) 北京市工程技术人才之正高级工程师 北京市工程…...

MUSE Pi Pro 开发板 Imagination GPU 利用 OpenCL 测试
视频讲解: MUSE Pi Pro 开发板 Imagination GPU 利用 OpenCL 测试 继续玩MUSE Pi Pro,今天看下比较关注的gpu这块,从opencl看起,安装clinfo指令 sudo apt install clinfo 可以看到这颗GPU是Imagination的 一般嵌入式中gpu都和hos…...

Mysql数据库之集群进阶
一、日志管理 5.7版本自定义路径时的文件需要自己提前创建好文件,不会自动创建,否则启动mysql会报错 错误日志 rpm包(yum) /var/log/mysql.log 默认错误日志 ###查询日志路径 [rootdb01 ~]# mysqladmin -uroot -pEgon123 variables | grep -w log_e…...

JavaScript防抖与节流全解析
文章目录 前言:为什么需要防抖和节流基本概念与区别防抖(Debounce)节流(Throttle)关键区别防抖(Debounce)详解1. 基本防抖函数实现2. 防抖函数的使用3. 防抖函数的工作流程4. 防抖函数进阶 - 立即执行选项节流(Throttle)详解1. 基本节流函数实现时间戳法(第一次会立即执行)定…...
)
大模型学习:Deepseek+dify零成本部署本地运行实用教程(超级详细!建议收藏)
文章目录 大模型学习:Deepseekdify零成本部署本地运行实用教程(超级详细!建议收藏)一、Dify是什么二、Dify的安装部署1. 官网体验2. 本地部署2.1 linux环境下的Docker安装2.2 Windows环境下安装部署DockerDeskTop2.3启用虚拟机平台…...

在RK3588上使用NCNN和Vulkan加速ResNet50推理全流程
在RK3588上使用NCNN和Vulkan加速ResNet50推理全流程 前言:为什么需要关注移动端AI推理一、环境准备与框架编译1.1 获取NCNN源码1.2 安装必要依赖1.3 编译NCNN二、模型导出与转换2.1 生成ONNX模型2.2 转换NCNN格式三、模型量化加速3.1 生成校准数据3.2 执行量化操作四、性能测试…...

Web安全基础:深度解析与实战指南
一、Web安全体系架构的全面剖析 1.1 分层防御模型(Defense in Depth) 1.1.1 网络层防护 防火墙技术: 状态检测防火墙(SPI):基于连接状态跟踪,阻断非法会话(如SYN Flood攻击)下一代防火墙(NGFW):集成IPS、AV、URL过滤(如Palo Alto PA-5400系列)配置示例…...

Uniapp开发鸿蒙应用时如何运行和调试项目
经过前几天的分享,大家应该应该对uniapp开发鸿蒙应用的开发语法有了一定的了解,可以进行一些简单的应用开发,今天分享一下在使用uniapp开发鸿蒙应用时怎么运行到鸿蒙设备,并且在开发中怎么调试程序。 运行 Uniapp项目支持运行到…...
核心函数和关键要点)
Python海龟绘图(Turtle Graphics)核心函数和关键要点
以下是Python海龟绘图(Turtle Graphics)的核心函数和关键要点整理: 一、画布设置 函数/方法说明参数说明备注turtle.setup(width, height, x, y)设置画布尺寸和位置width宽度,height高度,x/y窗口左上角坐标默认尺寸80…...

如何在Cursor中高效使用MCP协议
1、Cursor介绍 Cursor是一个功能强大的开发工具,内置了聊天助手、代码自动补全和调试工具,能够与多种外部工具和服务(如数据库、文件系统、浏览器等)进行深度集成。借助MCP(Multiverse Communication Protocol&#x…...

典籍知识问答模块AI问答bug修改
一、修改流式数据处理问题 1.问题描述:由于传来的数据形式如下: event:START data:350 data:< data:t data:h data:i data:n data:k data:> data: data: data: data: data:嗯 data:, 导致需要修改获取正常的当前信息id并更…...

Redis 发布订阅模式深度解析:原理、应用与实践
在现代分布式系统架构中,实时消息传递机制扮演着至关重要的角色。Redis 作为一款高性能的内存数据库,其内置的发布订阅(Pub/Sub)功能提供了一种轻量级、高效的消息通信方案。本文将全面剖析 Redis 发布订阅模式,从其基本概念、工作原理到实际…...
)
通义千问-langchain使用构建(三)
目录 序言docker 部署xinference1WSL环境docker安装2拉取镜像运行容器3使用的界面 本地跑chatchat1rag踩坑2使用的界面2.1配置个前置条件然后对话2.2rag对话 结论 序言 在前两天的基础上,将xinference调整为wsl环境,docker部署。 然后langchain chatcha…...

c++ 仿函数
示例代码: void testFunctor() {using Sum struct MyStruct {int operator() (int a, int b) const { // 重载()运算符return a b;}};Sum sum;std::cout << sum(9528, -1) << std::endl; } 打印: 仿函数意思是&am…...

hyper-v 虚拟机怎么克隆一台一样的虚拟机?
环境: hyper-v Win10专业版 问题描述: hyper-v 虚拟机怎么克隆一台一样的虚拟机? 解决方案: 以下是在 Hyper-V 中克隆虚拟机的几种方法: 方法一:使用导出和导入功能 导出虚拟机: 打开 H…...

操作系统:os概述
操作系统:OS概述 程序、进程与线程无极二级目录三级目录 程序、进程与线程 指令执行需要那些条件?CPU内存 需要数据和 无极 二级目录 三级目录...

【技巧】GoogleChrome浏览器开发者模式查看dify接口
回到目录 GoogleChrome浏览器开发者模式查看dify接口 1.搭建本地dify开发环境 参考 《 win10的wsl环境下调试dify的api后端服务(20250511发布)》 2.打开dify首页,进入开发者模式,Network页 勾选 Preserve log [图1] 3.填好用户名和密码,…...
Ocean: Object-aware Anchor-free Tracking
领域:Object tracking It aims to infer the location of an arbitrary target in a video sequence, given only its location in the first frame 问题/现象: Anchor-based Siamese trackers have achieved remarkable advancements in accuracy, yet…...

java中的循环结构
文章目录 流程控制顺序结构if单选择结构if双选择结构if多选择结构嵌套的if结构switch多选择结构 循环结构while循环do...while循环 for循环增强for循环 break continue练习案例 流程控制 顺序结构 java的基本结果就是顺序结构,除非特别指明,否则就按照…...

数学复习笔记 16
前言 例题真是经典。 background music 《青春不一样》 2.28 算一个行列式,算出来行列式不等于零,这表示矩阵式可逆的。但是这个算的秩是复合的,感觉没啥好办法了,我直接硬算了,之后再看解析积累好的方法。算矩阵…...
)
PySide6 GUI 学习笔记——常用类及控件使用方法(常用类颜色QColor)
文章目录 一、概述二、核心功能三、常用函数及方法四、代码示例五、注意事项 一、概述 QColor 是用于处理颜色的类,支持 RGB、HSV、HSL、CMYK 等多种颜色模型,提供颜色创建、转换、分量操作及格式转换功能。支持透明度设置,可通过颜色名称或…...

【Closure-Hayd】
RNA序列本身存在结构上的物理信息,因此可以利用文献提供的相关方法来对RNA序列的物理特征进行更加细致的提取。 几何向量编码(GVP模块)借鉴Rhodesign模型中的GVP(Geometric Vector Perceptron)模块,将每个…...

MySQL高可用架构
一、读写分离在高可用架构中的核心作用 1.读写分离与高可用的协同价值 在MySQL高可用架构中,读写分离不仅是性能优化的手段,更是提升系统容错能力的关键策略。通过将写操作(INSERT、UPDATE、DELETE) 集中到主节点,读…...
)
粒子群算法(PSO算法)
粒子群算法概述 1.粒子群优化算法(Particle Swarm Optimization,简称PSO)。粒子群优化算法是在1995年由Kennedy博士和Eberhart博士一起提出的,它源于对鸟群捕食行为的研究。 2.基本核心是利用群体中的个体对信息的共享从而使得整…...

信道编码技术介绍
信息与通信系统中的编码有4 种形式:信源编码、信道编码、密码编码和多址编码。 其中信道编码的作用是对信源经过压缩后的数据加一定数量受到控制的冗余,使得数据在传输中或接收中发生的差错可以被纠正或被发现,从而可以正确恢复出原始数据信息…...
)
JavaScript【4】数组和其他内置对象(API)
1.数组: 1.概述: js中数组可理解为一个存储数据的容器,但与java中的数组不太一样;js中的数组更像java中的集合,因为此集合在创建的时候,不需要定义数组长度,它可以实现动态扩容;js中的数组存储元素时,可以存储任意类型的元素,而java中的数组一旦创建后,就只能存储定义类型的元…...
)
【背包dp-----分组背包】------(标准的分组背包【可以不装满的 最大价值】)
通天之分组背包 题目链接 题目描述 自 01 01 01 背包问世之后,小 A 对此深感兴趣。一天,小 A 去远游,却发现他的背包不同于 01 01 01 背包,他的物品大致可分为 k k k 组,每组中的物品相互冲突,现在&a…...

docker-compose——安装mongo
编写docker-compose.yml version : 3.8services:zaomeng-mongodb:container_name: zaomeng-mongodbimage: mongo:latestrestart: alwaysports:- 27017:27017environment:- MONGO_INITDB_ROOT_USERNAMEroot- MONGO_INITDB_ROOT_PASSWORDpssw0rdvolumes:- ./mongodb/data:/data/…...

day 28
类 一个常见的类的定义包括了: 1. 关键字class 2. 类名 3. 语法固定符号冒号(:) 4. 一个初始化函数__init__(self) Pass占位符和缩进 Python 通过缩进来定义代码块的结构。当解释器遇到像 def, class, if, for 这样的语句,并且后面跟着冒号 : 时&…...

JavaScript入门【1】概述
1.JavaScript是什么? <font style"color:rgb(38,38,38);">Javascript (简称“JS”)是⼀种直译式脚本语⾔,⼀段脚本其实就是⼀系列指令,计算机通过这些指令来达成⽬标。它⼜是⼀种动态类型的编程语⾔。JS⽤来在⽹…...

MySQL 中 JOIN 和子查询的区别与使用场景
目录 一、JOIN:表连接1.1 INNER JOIN:内连接1.2 LEFT JOIN:左连接1.3 RIGHT JOIN:右连接1.4 FULL JOIN:全连接二、子查询:嵌套查询2.1 WHERE 子句中的子查询2.2 FROM 子句中的子查询2.3 SELECT 子句中的子查询三、JOIN 和子查询的区别3.1 功能差异3.2 性能差异3.3 使用场…...

DeepSeek 大模型部署全指南:常见问题、优化策略与实战解决方案
DeepSeek 作为当前最热门的开源大模型之一,其强大的语义理解和生成能力吸引了大量开发者和企业关注。然而在实际部署过程中,无论是本地运行还是云端服务,用户往往会遇到各种技术挑战。本文将全面剖析 DeepSeek 部署中的常见问题,提…...
Python 3.11详细图文安装教程)
Python 3.11详细安装步骤(包含安装包)Python 3.11详细图文安装教程
文章目录 前言Python 3.11介绍Python 3.11安装包下载Python 3.11安装步骤 前言 作为当前最热门的编程语言之一,Python 3.11 不仅拥有简洁优雅的语法,还在性能上实现了飞跃,代码运行速度提升显著。无论是初入编程的小白,还是经验丰…...