25、DeepSeek-R1论文笔记
DeepSeek-R1论文笔记
- 1、研究背景与核心目标
- 2、核心模型与技术路线
- 3、蒸馏技术与小模型优化
- 4、训练过程简介
- 5、COT思维链(Chain of Thought)
- 6、强化学习算法(GRPO)
- 7、冷启动
- **1. 冷启动的目的**
- **2. 冷启动的实现步骤**
- **3. 冷启动的作用**
- **典型应用场景**
- 汇总
- 一、核心模型与技术路线
- 二、蒸馏技术与小模型优化
- 三、实验与性能对比
- 四、研究贡献与开源
- 五、局限与未来方向
- 关键问题
- 1. **DeepSeek-R1与DeepSeek-R1-Zero的核心区别是什么?**
- 2. **蒸馏技术在DeepSeek-R1研究中的核心价值是什么?**
- 3. **DeepSeek-R1在数学推理任务上的性能如何超越同类模型?**
DeepSeek-R1
• 标题:DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
• 时间:2025年1月
• 链接:arXiv:2501.12948
• 突破:基于DeepSeek-V3-Base,通过多阶段强化学习训练(RL)显著提升逻辑推理能力,支持思维链(CoT)和过程透明化输出。
1、研究背景与核心目标
-
大语言模型的推理能力提升
近年来,LLM在推理任务上的性能提升显著,OpenAI的o1系列通过思维链(CoT)扩展实现了数学、编码等任务的突破,但如何通过高效方法激发模型的推理能力仍需探索。- 传统方法依赖大量监督数据,而本文探索**纯强化学习(RL)**路径,无需监督微调(SFT)即可提升推理能力。
-
核心目标
- 验证纯RL能否驱动LLM自然涌现推理能力(如自我验证、长链推理)。
- 解决纯RL模型的局限性(如语言混合、可读性差),通过多阶段训练提升实用性。
- 将大模型推理能力迁移至小模型,推动模型轻量化。
2、核心模型与技术路线
-
DeepSeek-R1-Zero
- 纯强化学习训练:基于DeepSeek-V3-Base,使用GRPO算法,无监督微调(SFT),通过规则奖励(准确性+格式)引导推理过程。
- 能力涌现:自然发展出自我验证、反思、长链推理(CoT)等行为,AIME 2024 Pass@1从15.6%提升至71.0%,多数投票达86.7%,接近OpenAI-o1-0912。
- 局限性:语言混合、可读性差,需进一步优化。
-
DeepSeek-R1
- 多阶段训练:
- 冷启动阶段:使用数千条长CoT数据微调,提升可读性和初始推理能力。
- 推理导向RL:引入语言一致性奖励,解决语言混合问题。
- 拒绝采样与SFT:收集60万推理数据+20万非推理数据(写作、事实QA等),优化通用能力。
- 全场景RL:结合规则奖励(推理任务)和神经奖励(通用任务),对齐人类偏好。
- 性能突破:AIME 2024 Pass@1 79.8%(超越o1-1217的79.2%),MATH-500 97.3%(对标o1-1217的96.4%),Codeforces评级2029(超越96.3%人类选手)。
- 多阶段训练:
3、蒸馏技术与小模型优化
- 蒸馏策略:以DeepSeek-R1为教师模型,生成80万训练数据,微调Qwen和Llama系列模型,仅用SFT阶段(无RL)。
- 关键成果:
- 14B蒸馏模型:AIME 2024 Pass@1 69.7%,远超QwQ-32B-Preview的50.0%。
- 32B/70B模型:MATH-500 94.3%、LiveCodeBench 57.2%,刷新密集模型推理性能纪录。
4、训练过程简介
zero:cot+grpo
R1:冷启动+cot+grpo


5、COT思维链(Chain of Thought)
COT详细原理参考:CoT论文笔记
2022 年 Google 论文《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》中首次提出,通过让大模型逐步参与将一个复杂问题分解为一步一步的子问题并依次进行求解的过程可以显著提升大模型的性能。而这些推理的中间步骤就被称为思维链(Chain of Thought)。
思维链提示(CoT Prompting),在少样本提示中加入自然语言推理步骤(如“先计算…再相加…”),将问题分解为中间步骤,引导模型生成连贯推理路径。
-
示例:标准提示仅给“问题-答案”,思维链提示增加“问题-推理步骤-答案”(如)。
-
区别于传统的 Prompt 从输入直接到输出的映射 <input——>output> 的方式,CoT 完成了从输入到思维链再到输出的映射,即 <input——>reasoning chain——>output>。如果将使用 CoT 的 Prompt 进行分解,可以更加详细的观察到 CoT 的工作流程。
-
示例对比(传统 vs. CoT)
-
传统提示
问题:1个书架有3层,每层放5本书,共有多少本书? 答案:15本 -
CoT 提示
问题:1个书架有3层,每层放5本书,共有多少本书? 推理: 1. 每层5本书,3层的总书数 = 5 × 3 2. 5 × 3 = 15 答案:15本
-
关键类型
-
零样本思维链(Zero-Shot CoT)
无需示例,仅通过提示词(如“请分步骤思考”)触发模型生成思维链。适用于快速引导模型进行推理。 -
少样本思维链(Few-Shot CoT)
提供少量带思维链的示例,让模型模仿示例结构进行推理。例如,先给出几个问题及其分解步骤,再让模型处理新问题。

如图所示,一个完整的包含 CoT 的 Prompt 往往由指令(Instruction),逻辑依据(Rationale),示例(Exemplars)三部分组成。一般而言指令用于描述问题并且告知大模型的输出格式,逻辑依据即指 CoT 的中间推理过程,可以包含问题的解决方案、中间推理步骤以及与问题相关的任何外部知识,而示例则指以少样本的方式为大模型提供输入输出对的基本格式,每一个示例都包含:问题,推理过程与答案。
以是否包含示例为区分,可以将 CoT 分为 Zero-Shot-CoT 与 Few-Shot-CoT,在上图中,Zero-Shot-CoT 不添加示例而仅仅在指令中添加一行经典的“Let’s think step by step”,就可以“唤醒”大模型的推理能力。而 Few-Shot-Cot 则在示例中详细描述了“解题步骤”,让大模型照猫画虎得到推理能力。
提示词工程框架( 链式提示Chain):其他提示词工程框架,思维链CoT主要是线性的,多个推理步骤连成一个链条。在思维链基础上,又衍生出ToT、GoT、PoT等多种推理模式。这些和CoT一样都属于提示词工程的范畴。CoT、ToT、GoT、PoT等提示词工程框架大幅提升了大模型的推理能力,让我们能够使用大模型解决更多复杂问题,提升了大模型的可解释性和可控性,为大模型应用的拓展奠定了基础。
参考:
https://blog.csdn.net/kaka0722ww/article/details/147950677
https://www.zhihu.com/tardis/zm/art/670907685?source_id=1005
6、强化学习算法(GRPO)
详细GRPO原理参考:DeepSeekMath论文笔记
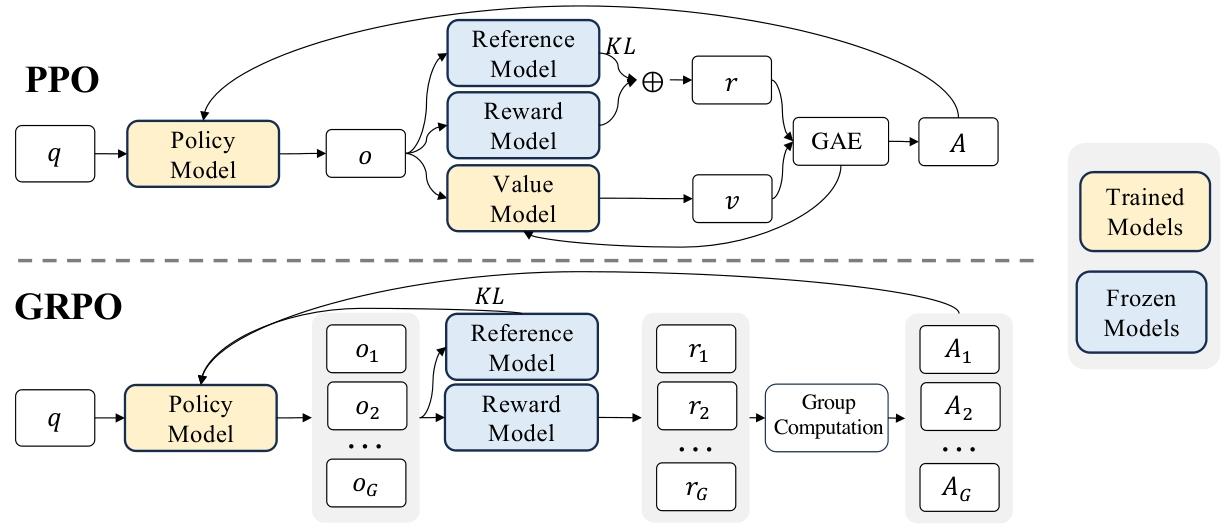
2.2.1 强化学习算法
群组相对策略优化 为降低强化学习的训练成本,我们采用群组相对策略优化(GRPO)算法(Shao等人,2024)。该算法无需与策略模型规模相当的评论家模型,而是通过群组分数估计基线。具体来说,对于每个问题𝑞,GRPO从旧策略𝜋𝜃𝑜𝑙𝑑中采样一组输出{𝑜1, 𝑜2, · · · , 𝑜𝐺},然后通过最大化以下目标函数优化策略模型𝜋𝜃:
J GRPO ( θ ) = E [ q ∼ P ( Q ) , { o i } i = 1 G ∼ π θ old ( O ∣ q ) ] 1 G ∑ i = 1 G ( min ( π θ ( o i ∣ q ) π θ old ( o i ∣ q ) A i , clip ( π θ ( o i ∣ q ) π θ old ( o i ∣ q ) , 1 − ε , 1 + ε ) A i ) − β D KL ( π θ ∣ ∣ π ref ) ) , ( 1 ) J_{\text{GRPO}}(\theta) = \mathbb{E}\left[ q \sim P(Q), \{o_i\}_{i=1}^G \sim \pi_{\theta^{\text{old}}}(O|q) \right] \frac{1}{G} \sum_{i=1}^G \left( \min\left( \frac{\pi_\theta(o_i|q)}{\pi_{\theta^{\text{old}}}(o_i|q)} A_i, \text{clip}\left( \frac{\pi_\theta(o_i|q)}{\pi_{\theta^{\text{old}}}(o_i|q)}, 1 - \varepsilon, 1 + \varepsilon \right) A_i \right) - \beta D_{\text{KL}}(\pi_\theta || \pi_{\text{ref}}) \right), \quad (1) JGRPO(θ)=E[q∼P(Q),{oi}i=1G∼πθold(O∣q)]G1i=1∑G(min(πθold(oi∣q)πθ(oi∣q)Ai,clip(πθold(oi∣q)πθ(oi∣q),1−ε,1+ε)Ai)−βDKL(πθ∣∣πref)),(1)
D KL ( π θ ∣ ∣ π ref ) = π ref ( o i ∣ q ) ( π θ ( o i ∣ q ) π ref ( o i ∣ q ) − log π θ ( o i ∣ q ) π ref ( o i ∣ q ) − 1 ) , ( 2 ) D_{\text{KL}}(\pi_\theta || \pi_{\text{ref}}) = \pi_{\text{ref}}(o_i|q) \left( \frac{\pi_\theta(o_i|q)}{\pi_{\text{ref}}(o_i|q)} - \log \frac{\pi_\theta(o_i|q)}{\pi_{\text{ref}}(o_i|q)} - 1 \right), \quad (2) DKL(πθ∣∣πref)=πref(oi∣q)(πref(oi∣q)πθ(oi∣q)−logπref(oi∣q)πθ(oi∣q)−1),(2)
其中,𝜀和𝛽为超参数,𝐴𝑖为优势函数,通过每组输出对应的奖励集合{𝑟1, 𝑟2, . . . , 𝑟𝐺}计算得到:
A i = r i − mean ( { r 1 , r 2 , ⋅ ⋅ ⋅ , r G } ) std ( { r 1 , r 2 , ⋅ ⋅ ⋅ , r G } ) . ( 3 ) A_i = \frac{r_i - \text{mean}(\{r_1, r_2, · · · , r_G\})}{\text{std}(\{r_1, r_2, · · · , r_G\})}. \quad (3) Ai=std({r1,r2,⋅⋅⋅,rG})ri−mean({r1,r2,⋅⋅⋅,rG}).(3)


7、冷启动


冷启动(Cold Start)
在DeepSeek-R1的训练流程中,冷启动是一个关键阶段,旨在通过少量高质量数据为模型提供初步的推理能力,为后续强化学习(RL)奠定基础。以下是其核心内容:
AI 冷启动是指人工智能系统在初始阶段因缺乏足够数据或历史信息导致的性能瓶颈问题,常见于推荐系统、大模型训练、提示词优化等场景。以下是基于多领域研究的综合解析:
AI模型训练的冷启动问题
-
数据匮乏的挑战
• 问题:模型初期因数据不足导致推理能力弱,生成结果混乱或重复。
• 解决方案:
• 冷启动数据(Cold-start Data):
◦ 高质量微调:用少量人工筛选的推理数据(如数学题详细步骤)对模型进行初步训练,提供“入门指南”。
◦ 数据来源:从大型模型生成(如ChatGPT)、现有模型输出筛选、人工优化等方式获取。 -
多阶段训练策略
• 阶段1:冷启动微调:用冷启动数据优化模型基础推理能力,提升生成结果的可读性和逻辑性。
• 阶段2:强化学习(RL):通过奖励机制(如答案准确度、格式规范性)动态调整模型参数,优化推理策略。
• 阶段3:多场景优化:结合拒绝采样(筛选高质量输出)和监督微调(SFT),扩展模型在专业领域(如金融、医学)的适用性。
三、提示词与上下文冷启动
-
提示词冷启动策略
• 知识初始化:利用领域知识库初始化模型参数,指导模型生成更符合任务需求的回答。
• 动态调整:根据模型表现实时调整学习率和任务权重,例如在复杂任务中增加上下文信息权重。 -
上下文信息利用
• 时间/场景适配:结合用户当前环境(如工作日早晨推荐新闻,周末推荐娱乐内容)提升推荐相关性。
• 多模态数据融合:整合文本、图像、社交网络等多源数据,丰富冷启动阶段的特征提取。
1. 冷启动的目的
• 解决DeepSeek-R1-Zero的局限性:
直接从基础模型启动RL(如DeepSeek-R1-Zero)会导致生成内容可读性差、语言混杂(如中英文混合)。
• 引导模型生成结构化推理链:
通过冷启动数据,教会模型以“思考过程→答案”的格式输出,提升可读性和逻辑性。
2. 冷启动的实现步骤
(1) 数据收集
• 来源:
• 模型生成:用基础模型(DeepSeek-V3-Base)通过few-shot提示生成长链推理(CoT)数据。
• 人工修正:对模型生成的答案进行筛选和润色,确保可读性。
• 外部数据:少量开源数学、编程问题的高质量解答。
• 格式要求:
强制要求模型将推理过程放在<reasoning>标签内,答案放在<answer>标签内,例如:
<reasoning>设方程√(a−√(a+x))=x,首先平方两边...</reasoning>
<answer>\boxed{2a-1}</answer>
(2) 监督微调(SFT)
• 数据规模:数千条(远少于传统SFT的百万级数据)。
• 训练目标:让模型学会:
• 生成清晰的推理步骤。
• 遵守指定输出格式。
• 避免语言混杂(如中英文混合)。
3. 冷启动的作用
• 提升可读性:
通过结构化标签和人工修正,生成内容更符合人类阅读习惯。
• 加速RL收敛:
冷启动后的模型已具备基础推理能力,RL阶段更易优化策略。
• 缓解语言混合问题:
强制输出格式和语言一致性奖励(如中文或英文占比)减少混杂。
典型应用场景
-
推荐系统
- 新用户注册时,通过引导式问卷(主动学习)或热门内容(规则策略)完成冷启动,随后逐步切换至个性化推荐。
- 案例:TikTok对新用户先推送泛领域热门视频,再根据前几个视频的互动数据快速建模兴趣标签。
-
自然语言处理(NLP)
- 新领域对话系统冷启动:用预训练语言模型(如LLaMA)结合少量领域数据微调,快速适应垂直场景(如法律咨询、金融客服)。
-
计算机视觉(CV)
- 新类别图像识别:通过迁移学习加载ImageNet预训练模型,再用少量新类别样本微调,解决“新物体冷启动”问题。
-
医疗AI
- 罕见病诊断冷启动:利用元学习快速适配新病例,或通过合成医学影像数据增强模型泛化能力。
汇总
一、核心模型与技术路线
-
DeepSeek-R1-Zero
- 纯强化学习训练:基于DeepSeek-V3-Base,使用GRPO算法,无监督微调(SFT),通过规则奖励(准确性+格式)引导推理过程。
- 能力涌现:自然发展出自我验证、反思、长链推理(CoT)等行为,AIME 2024 Pass@1从15.6%提升至71.0%,多数投票达86.7%,接近OpenAI-o1-0912。
- 局限性:语言混合、可读性差,需进一步优化。
-
DeepSeek-R1
- 多阶段训练:
- 冷启动阶段:使用数千条长CoT数据微调,提升可读性和初始推理能力。
- 推理导向RL:引入语言一致性奖励,解决语言混合问题。
- 拒绝采样与SFT:收集60万推理数据+20万非推理数据(写作、事实QA等),优化通用能力。
- 全场景RL:结合规则奖励(推理任务)和神经奖励(通用任务),对齐人类偏好。
- 性能突破:AIME 2024 Pass@1 79.8%(超越o1-1217的79.2%),MATH-500 97.3%(对标o1-1217的96.4%),Codeforces评级2029(超越96.3%人类选手)。
- 多阶段训练:
二、蒸馏技术与小模型优化
- 蒸馏策略:以DeepSeek-R1为教师模型,生成80万训练数据,微调Qwen和Llama系列模型,仅用SFT阶段(无RL)。
- 关键成果:
- 14B蒸馏模型:AIME 2024 Pass@1 69.7%,远超QwQ-32B-Preview的50.0%。
- 32B/70B模型:MATH-500 94.3%、LiveCodeBench 57.2%,刷新密集模型推理性能纪录。
三、实验与性能对比
| 任务/模型 | DeepSeek-R1 | OpenAI-o1-1217 | DeepSeek-R1-Zero | DeepSeek-V3 |
|---|---|---|---|---|
| AIME 2024 (Pass@1) | 79.8% | 79.2% | 71.0% | 39.2% |
| MATH-500 (Pass@1) | 97.3% | 96.4% | 86.7% | 90.2% |
| Codeforces (评级) | 2029 | - | 1444 | 1134 |
| MMLU (Pass@1) | 90.8% | 91.8% | - | 88.5% |
四、研究贡献与开源
- 方法论创新:
- 首次证明纯RL可激发LLM推理能力,无需监督微调(SFT)。
- 提出“冷启动数据+多阶段RL”框架,平衡推理能力与用户友好性。
- 开源资源:
- 开放DeepSeek-R1/Zero及6个蒸馏模型(1.5B、7B、8B、14B、32B、70B),基于Qwen和Llama。
五、局限与未来方向
- 当前局限:
- 语言混合问题(中英文混杂),多语言支持不足。
- 工程任务(如代码生成)数据有限,性能待提升。
- 对提示格式敏感,少样本提示可能降低性能。
- 未来方向:
- 探索长CoT在函数调用、多轮对话中的应用。
- 优化多语言一致性,解决非中英查询的推理语言偏好问题。
- 引入异步评估,提升软件任务的RL训练效率。
关键问题
1. DeepSeek-R1与DeepSeek-R1-Zero的核心区别是什么?
答案:DeepSeek-R1-Zero采用纯强化学习训练,无需监督微调(SFT),依赖规则奖励自然涌现推理能力,但存在语言混合和可读性问题;DeepSeek-R1在此基础上引入冷启动数据(数千条长CoT示例)进行初始微调,并通过多阶段训练(SFT+RL交替)优化可读性、语言一致性和通用能力,最终性能更接近OpenAI-o1-1217。
2. 蒸馏技术在DeepSeek-R1研究中的核心价值是什么?
答案:蒸馏技术将大模型的推理模式迁移至小模型,使小模型在保持高效的同时获得强大推理能力。例如,DeepSeek-R1-Distill-Qwen-14B在AIME 2024上的Pass@1为69.7%,远超同规模的QwQ-32B-Preview(50.0%);32B蒸馏模型在MATH-500上达94.3%,接近o1-mini的90.0%。该技术证明大模型推理模式对小模型优化至关重要,且蒸馏比直接对小模型进行RL更高效经济。
3. DeepSeek-R1在数学推理任务上的性能如何超越同类模型?
答案:DeepSeek-R1在AIME 2024上的Pass@1为79.8%,略超OpenAI-o1-1217的79.2%;MATH-500达97.3%,与o1-1217持平(96.4%)。其优势源于强化学习对长链推理的优化(如自动扩展思考步骤、自我验证),以及冷启动数据和多阶段训练对推理过程可读性和准确性的提升。此外,规则奖励模型确保了数学问题答案的格式正确性(如公式框输出),减少了因格式错误导致的失分。
相关文章:

25、DeepSeek-R1论文笔记
DeepSeek-R1论文笔记 1、研究背景与核心目标2、核心模型与技术路线3、蒸馏技术与小模型优化4、训练过程简介5、COT思维链(Chain of Thought)6、强化学习算法(GRPO)7、冷启动**1. 冷启动的目的****2. 冷启动的实现步骤****3. 冷启动…...

CodeBuddy 打造响应式测试平台:ScreenLab 的诞生记
我正在参加CodeBuddy「首席试玩官」内容创作大赛,本文所使用的 CodeBuddy 免费下载链接:腾讯云代码助手 CodeBuddy - AI 时代的智能编程伙伴 开发工具:CodeBuddy(AI 代码伙伴) 技术栈:Vue3 Vite 原生 CSS…...

STM32实战指南:SG90舵机控制原理与代码详解
知识点1【SG90的简述】 SG90是一款微型舵机(Micro Servo),由TowerPro等厂商提供,广泛用于机器人,舵机云台,舵机控制教学等项目中。 1、基本参数 2、工作原理 SG90内部有电机,齿轮组ÿ…...
)
基于Spring Boot和Vue的在线考试系统架构设计与实现(源码+论文+部署讲解等)
源码项目获取联系 请文末卡片dd我获取更详细的演示视频 系统介绍 基于Spring Boot和Vue的在线考试系统。为学生和教师/管理员提供一个高效、便捷的在线学习、考试及管理平台。系统采用前后端分离的架构,后端基于成熟稳定的Spring Boot框架,负责数据处理…...
:nuttx 编译)
开源RTOS(实时操作系统):nuttx 编译
开源RTOS(实时操作系统):nuttx 编译 手册:Installing — NuttX latest documentation 源码:GitHub - apache/nuttx: Apache NuttX is a mature, real-time embedded operating system (RTOS) Installing The fir…...

C++学习:六个月从基础到就业——C++11/14:decltype关键字
C学习:六个月从基础到就业——C11/14:decltype关键字 本文是我C学习之旅系列的第四十二篇技术文章,也是第三阶段"现代C特性"的第四篇,主要介绍C11/14中的decltype关键字。查看完整系列目录了解更多内容。 引言 在现代C…...
及字母表的工具(分享))
【51】快速获取数码管段选表(含小数点)及字母表的工具(分享)
1 介绍 1.1 画面 1.2 用法 输入IO口和段码字母的映射关系,比如这里e4d5dp2,指的是bit4是e段,bit5是d段,bit2是小数点dp段。 然后选择有效电平(1表示亮 or 0表示亮)。 点击生成段码配置,即可得到…...
基本总结回顾120)
高频面试题(含笔试高频算法整理)基本总结回顾120
干货分享,感谢您的阅读! (暂存篇---后续会删除,完整版和持续更新见高频面试题基本总结回顾(含笔试高频算法整理)) 备注:引用请标注出处,同时存在的问题请在相关博客留言…...

5月17日
这几天不知道为啥没更新。可能是玩得太疯了。或者是考试有点集中?? 线性代数开课了,英语昨天完成了debate 昨天中午debate结束我们就出去玩了,去的那里时光民俗,别墅很好,770平米,但是缺点是可…...
WiFi 抓包环境配置教程)
摩方 12 代 N200 迷你主机(Ubuntu 系统)WiFi 抓包环境配置教程
摩方12代N200迷你主机标配 Intel AX201无线网卡,支持 WiFi 6 协议(802.11ax)及蓝牙5.2。此网卡兼容主流抓包工具,但需注意: 驱动兼容性:Ubuntu 20.04及以上内核版本(5.4)默认支持AX2…...

从零开始:使用 PyTorch 构建深度学习网络
从零开始:使用 PyTorch 构建深度学习网络 目录 PyTorch 简介环境配置PyTorch 基础构建神经网络训练模型评估与测试案例实战:手写数字识别进阶技巧常见问题解答 PyTorch 简介 PyTorch 是一个开源的深度学习框架,由 Facebook(现…...

应用层自定义协议与序列化
应用层自定义协议与序列化 应用层协议网络版计算器序列化和反序列化序列化反序列化 重新理解read、write、recv、send和TCP为什么支持全双工代码结构Jsoncpp特性安装序列化使用Json::Value的toStyledString方法使用Json::StreamWriter使用Json::FastWriter 反序列化使用Json::R…...

2025春训第二十场
问题 B: 狗是啥呀 题目描述 在神秘的地狱深处,有着一种神秘的犬类生物,据传这种生物长了x个脑袋,并且具有强大的生命力。由于见过它的人全都下落不明,至今没有人知道它的真面目。 一位勇士为了斩杀这奇怪的生物,来到地…...

分糖果--思维+while判断
1.从左到右只考虑右边一遍,再从右到左考虑左边一遍,相当于左右考虑了 2.然后关键是1遍不一定行,while循环直到成功 https://www.luogu.com.cn/problem/B4091 #include<bits/stdc.h> using namespace std; #define N 100011 typedef …...

[system-design] ByteByteGo_Note Summary
目录 通信协议 REST API 与 GraphQL gRPC 如何工作? 什么是Webhook? 如何提高应用程序接口的性能? HTTP 1.0 -> HTTP 1.1 -> HTTP 2.0 -> HTTP 3.0 (QUIC) SOAP vs REST vs GraphQL vs RPC 代码优先与应用程序接口优先 HTT…...
)
Flask项目实践:构建功能完善的博客系统(含评论与标签功能)
引言 在Python Web开发领域,Flask以其轻量级、灵活性和易用性赢得了众多开发者的青睐。本文将带您从零开始构建一个功能完善的博客系统,包含文章发布、评论互动和标签分类等核心功能。通过这个实战项目,您不仅能掌握Flask的核心技术…...

Python爬虫实战:获取1688商品信息
在电商领域,获取1688商品信息对于市场分析、竞品研究、用户体验优化等至关重要。1688作为国内领先的B2B电商平台,提供了丰富的商品资源。通过Python爬虫技术,我们可以高效地获取1688商品的详细信息,包括商品名称、价格、图片、描述…...

Canva 推出自有应用生成器以与 Bolt 和 Lovable 竞争
AI 目前是一个巨大的市场,每个人都想从中分一杯羹。 即使是 Canva,这个以拖放图形设计而闻名的流行设计平台,也在其 Canva Create 2025 活动中发布了自己版本的代码生成器,加入了 AI 竞赛。 但为什么一个以设计为先的平台会提供代码生成工具呢? 乍看之下,这似乎有些不…...

多平台屏幕江湖生存指南
UniApp 屏幕适配大师:多平台屏幕江湖生存指南 屏幕江湖:尺寸混战 屏幕适配就像是应对不同体型的客人:从迷你的手机屏,到标准的平板,再到巨大的电视屏幕,你的应用必须有如武林高手般的适应力。 ┌──────────────────────────────────…...
)
BootCDN介绍(Bootstrap主导的前端开源项目免费CDN加速服务)
文章目录 BootCDN前端开源项目CDN加速服务全解析什么是BootCDN技术原理与架构CDN技术基础BootCDN架构特点1. 全球分布式节点网络2. 智能DNS解析系统3. 高效缓存管理机制4. 自动同步更新机制5. HTTPS和HTTP/2协议支持 BootCDN的核心优势速度与稳定性开源免费资源丰富度技术规范遵…...

LeetCode 153. 寻找旋转排序数组中的最小值:二分查找法详解及高频疑问解析
文章目录 问题描述算法思路:二分查找法关键步骤 代码实现代码解释高频疑问解答1. 为什么循环条件是 left < right 而不是 left < right?2. 为什么比较 nums[mid] > nums[right] 而不是 nums[left] < nums[mid]?3. 为什么 right …...

刷leetcodehot100返航版--二叉树
二叉树理论基础 二叉树的种类 满二叉树和完全二叉树,二叉树搜索树 满二叉树 如果一棵二叉树只有度为0的结点和度为2的结点,并且度为0的结点在同一层上,则这棵二叉树为满二叉树。 节点个数2^n-1【n为树的深度】 完全二叉树 在完全二叉树…...

「Mac畅玩AIGC与多模态41」开发篇36 - 用 ArkTS 构建聚合搜索前端页面
一、概述 本篇基于上一节 Python 实现的双通道搜索服务(聚合 SearxNG 本地知识库),构建一个完整的 HarmonyOS ArkTS 前端页面。用户可在输入框中输入关键词,实时查询本地服务 http://localhost:5001/search?q...,返…...
:封装、信号量与环形队列)
【LINUX操作系统】生产者消费者模型(下):封装、信号量与环形队列
1.封装、完善基于阻塞队列的productor-consumer module 前文中我们封装了自己的Mutex 【LINUX操作系统】线程同步与互斥-CSDN博客 按照老规矩,现在我们对同步与互斥的理解更进一步了,现在把这种面向过程的语言封装成面向对象的写法 1.1 封装条件变量 #p…...

项目管理学习-CSPM-4考试总结
前言 经过两个月左右时间的学习,今天(2025年5月17日)参加了CSPM-4的考试,仿佛回到了2011年参加软考高项的时候。中午12点考完出来后,手都是酸酸的。不过整体感觉还可以,和预想的差不多。CSPM-4的考试一共有…...

自己手写tomcat项目
一:Servlet的原理 在Servlet(接口中)有: 1.init():初始化servlet 2.getServletConfig():获取当前servlet的配置信息 3.service():服务器(在HttpServlet中实现,目的是为了更好的匹配http的请求方式) 4.g…...
)
C语言—再学习(结构体)
一、建立结构体 用户自己建立由不同类型数据组成的组合型的数据结构,它称为结构体。 struct Student { int num; //学号char name[20]; //名字为字符串char sex; //性别int age; //年纪float score; //分数char addr[30]; 地址为字符…...

SpringBoot--自动配置原理详解
为什么要学习自动配置原理? 原因:在实际开发中,我们经常会定义一些公共的组件,提供各个团队来使用,为了使用方便,我们经常会将公共的组件自定义成starter,如果想自定义starter,必须…...

MiInsertPageInFreeList函数分析和MmFreePagesByColor数组的关系
第一部分: Color MI_GET_COLOR_FROM_LIST_ENTRY(PageFrameIndex, Pfn1); ColorHead &MmFreePagesByColor[ListName][Color]; 第二部分: #define MI_GET_COLOR_FROM_LIST_ENTRY(index,pfn) \ ((ULONG)(((pfn)->…...

Windows/MacOS WebStorm/IDEA 中开发 Uni-App 配置
文章目录 前言1. 安装 HBuilder X2. WebStorm/IDEA 安装 Uniapp Tool 插件3. 配置 Uniapp Tool 插件4. 运行 Uni-App 项目 前言 前端开发人员对 WebStorm 一定不陌生,但有时需要开发 Uni-App 的需求,就必须要采用 HBuilder X,如果不习惯 HBu…...

redisson分布式锁实现原理归纳总结
Redisson 分布式锁的实现原理主要依赖于 Redis 的 Hash 数据结构、Lua 脚本、发布订阅机制以及看门狗(Watchdog)机制,以下是核心要点总结: 1. 核心原理 • 互斥性与可重入性: 通过 Redis 的 Hash 数据结构保存锁的持…...

Ubuntu 添加系统调用
实验内容 通过内核编译法添加一个不用传递参数的系统调用,其功能可自定义。 (1)添加系统调用号,系统会根据这个号找到syscall_table中的相应表项。具体做法是在syscall_64.tbl文件中添加系统调用号和调用函数的对应关系。 &#…...

Olib 2.2.0 | 免费开源软件,无需注册登录即可从ZLibrary下载多语言电子书
Olib是一款专为书籍爱好者设计的免费开源软件,它允许用户无需注册或登录即可从ZLibrary高速下载各种语言的电子书。该软件支持上百种语言的电子书下载,非常适合需要多语言资源的读者和研究人员使用。Olib的操作界面非常直观,使得书籍的搜索与…...

c++动态链接库
1. 生成动态链接库 首先实现一个动态链接库的代码 // example.cpp #include <iostream> void sayHello() {std::cout << "Hello from shared library!" << std::endl; }int add(int a, int b) {return a b; }// example.h #pragma once void sa…...

HelloWorld
HelloWorld 新建一个java文件 文件后缀名为 .javahello.java【注意】系统可能没有显示文件后缀名,我们需要手动打开 编写代码 public class hello {public static void main(String[] args) {System.out.print(Hello,World)} }编译 javac java文件,会生…...

SVGPlay:一次 CodeBuddy 主动构建的动画工具之旅
我正在参加CodeBuddy「首席试玩官」内容创作大赛,本文所使用的 CodeBuddy 免费下载链接:腾讯云代码助手 CodeBuddy - AI 时代的智能编程伙伴 背景与想法 我一直对 SVG 图标的动画处理有浓厚兴趣,特别是描边、渐变、交互等效果能为图标增添许…...

SLAM定位常用地图对比示例
序号 地图类型 概述 1 格栅地图 将现实环境栅格化,每一个栅格用 0 和 1 分别表示空闲和占据状态,初始化为未知状态 0.5 2 特征地图 以点、线、面等几何特征来描绘周围环境,将采集的信息进行筛选和提取得到关键几何特征 3 拓扑地图 将重要部分抽象为地图,使用简单的图形表示…...
和 episodes(回合))
强化学习中,frames(帧)和 episodes(回合)
在强化学习中,frames(帧)和 episodes(回合)是两个不同的概念: 1. 定义差异 Frame(帧): 表示智能体与环境交互的单个时间步(step),例如…...

HCIP第六次作业
一、拓扑图 二、需求 1、使用PreVal策略,确保R4通过R2到达192.168.10.0/24 2、使用AS_Path策略,确保R4通过R3到达192.168.11.0/24 3、配置MED策略,确保R4通过R3到达192.168.12.0/24 4、使用Local Preference策略,确保R1通过R2…...
基本总结回顾110)
高频面试题(含笔试高频算法整理)基本总结回顾110
干货分享,感谢您的阅读! (暂存篇---后续会删除,完整版和持续更新见高频面试题基本总结回顾(含笔试高频算法整理)) 备注:引用请标注出处,同时存在的问题请在相关博客留言…...

数据湖与数据仓库融合:Hudi、Iceberg、Delta Lake 实践对比
在实时与离线一体化的今天,数据湖与数据仓库边界不断融合,越来越多企业选用如 Hudi、Iceberg、Delta Lake 等开源方案实现统一的数据存储、计算、分析平台。本篇将围绕以下关键点,展开实战对比与解决方案分享: ✅ 实时写入能力 ✅ ACID 保证 ✅ 增量数据处理能力 ✅ 流批一…...

OGG 更新表频繁导致进程中断,见鬼了?非也!
大家好,这里是 DBA学习之路,专注于提升数据库运维效率。 目录 前言问题描述问题分析解决方案后续 前言 最近几周一直遇到一个 OGG 问题,有一张表已更新就会中断 OGG 同步进程,本文记录一下分析过程以及解决方案。 问题描述 昨天…...

C++学习-入门到精通-【7】类的深入剖析
C学习-入门到精通-【7】类的深入剖析 类的深入剖析 C学习-入门到精通-【7】类的深入剖析一、Time类的实例研究二、组成和继承三、类的作用域和类成员的访问类作用域和块作用域圆点成员选择运算符(.)和箭头成员选择运算符(->)访问函数和工具函数 四、具有默认实参的构造函数重…...

非易失性存储技术综合对比:EEPROM、NVRAM、NOR Flash、NAND Flash和SD卡
非易失性存储技术综合对比:EEPROM、NVRAM、NOR Flash、NAND Flash和SD卡 读写性能对比 存储类型读取速度写入速度随机访问能力最小操作单位NVRAM极快(~10ns)极快(~10ns)极优(字节级)字节EEPROM中等(~100ns)慢(~5ms/字节)优(字节级)字节NOR Flash快(~50ns)慢(~5ms/…...

数字化转型- 数字化转型路线和推进
数字化转型三个阶段 百度百科给出的企业的数字化转型包括信息化、数字化、数智化三个阶段 信息化是将企业在生产经营过程中产生的业务信息进行记录、储存和管理,通过电子终端呈现,便于信息的传播与沟通。数字化通过打通各个系统的互联互通,…...
)
ARM (Attention Refinement Module)
ARM模块【来源于BiSeNet】:细化特征图的注意力,增强重要特征并抑制不重要的特征。 Attention Refinement Module (ARM) 详解 ARM (Attention Refinement Module) 是 BiSeNet 中用于增强特征表示的关键模块,它通过注意力机制来细化特征图&…...
)
符合Python风格的对象(对象表示形式)
对象表示形式 每门面向对象的语言至少都有一种获取对象的字符串表示形式的标准方 式。Python 提供了两种方式。 repr() 以便于开发者理解的方式返回对象的字符串表示形式。str() 以便于用户理解的方式返回对象的字符串表示形式。 正如你所知,我们要实现_…...

AtCoder AT_abc406_c [ABC406C] ~
前言 除了 A 题,唯一一道一遍过的题。 题目大意 我们定义满足以下所有条件的一个长度为 N N N 的序列 A ( A 1 , A 2 , … , A N ) A(A_1,A_2,\dots,A_N) A(A1,A2,…,AN) 为波浪序列: N ≥ 4 N\ge4 N≥4(其实满足后面就必须满足这…...

多指标组合策略
该策略(MultiConditionStrategy)是一种基于多种技术指标和市场条件的交易策略。它通过综合考虑多个条件来生成交易信号,从而决定买入或卖出的时机。 以下是对该策略的详细分析: 交易逻辑思路 1. 条件1:星期几和价格变化判断 - 该条件根据当前日期是星期几以及价格的变化…...

系统架构-大数据架构设计
基础介绍 三大挑战: 如何处理非结构化和半结构化数据如何探索大数据复杂性、不确定性特征描述的刻画方法及大数据的系统建模数据异构性与决策异构性的关系对大数据知识发现与管理决策的影响 架构特征: 鲁棒性(稳定性)和容错性…...