Python爬虫(29)Python爬虫高阶:动态页面处理与云原生部署全链路实践(Selenium、Scrapy、K8s)
目录
- 引言:动态爬虫的技术挑战与云原生机遇
- 一、动态页面处理:Selenium与Scrapy的协同作战
- 1.1 Selenium的核心价值与局限
- 1.2 Scrapy-Selenium中间件开发
- 1.3 动态分页处理实战:京东商品爬虫
- 二、云原生部署:Kubernetes架构设计与优化
- 2.1 为什么选择Kubernetes?
- 2.2 架构设计:Scrapy-Redis-K8s三件套
- 2.3 关键配置:Deployment与HPA
- 2.3.1 deployment.yaml
- 2.3.2 hpa.yaml
- 2.3.3 hpa.yaml
- 2.4 性能优化:浏览器资源复用
- 三、总结
- 3.1 技术价值总结
- 3.2 适用场景推荐
- 3.3 本文技术栈版本说明
- Python爬虫相关文章(推荐)
引言:动态爬虫的技术挑战与云原生机遇
在Web3.0时代,超过80%的电商、社交和新闻类网站采用动态渲染技术(如React/Vue框架+Ajax异步加载),传统基于requests的静态爬虫已无法应对无限滚动、点击展开等交互式内容。与此同时,随着企业级爬虫项目从单机采集转向百万级URL的分布式处理,如何实现爬虫任务的弹性伸缩、故障自愈与资源优化成为新的技术命题。
本文将结合Selenium、Scrapy与Kubernetes三大技术栈,构建一套完整的动态爬虫云原生解决方案,涵盖从页面渲染到容器编排的全链路技术实践。
一、动态页面处理:Selenium与Scrapy的协同作战
1.1 Selenium的核心价值与局限
Selenium作为浏览器自动化工具,通过模拟真实用户操作(如点击、滚动、表单提交)完美解决动态渲染问题。其典型应用场景包括:
- 无限滚动加载:通过driver.execute_script(“window.scrollTo(0, document.body.scrollHeight)”)触发懒加载
- 复杂表单交互:处理登录验证、验证码弹窗等反爬机制
- JavaScript依赖数据:解析由前端框架渲染的DOM结构
然而,Selenium存在明显性能瓶颈:
- 单线程运行模式导致并发能力不足
- 浏览器启动开销大(约500ms-2s)
- 无法直接利用Scrapy的中间件生态
1.2 Scrapy-Selenium中间件开发
为解决上述问题,我们开发了基于Scrapy的Selenium中间件,实现动态渲染与异步爬取的解耦:
# middlewares.py
from selenium import webdriver
from scrapy.http import HtmlResponseclass SeleniumMiddleware:def __init__(self):options = webdriver.ChromeOptions()options.add_argument("--headless") # 无头模式options.add_argument("--disable-gpu")self.driver = webdriver.Chrome(options=options)def process_request(self, request, spider):self.driver.get(request.url)# 模拟用户操作(示例:滚动到底部)self.driver.execute_script("window.scrollTo(0, document.body.scrollHeight)")# 返回渲染后的HTMLreturn HtmlResponse(url=self.driver.current_url,body=self.driver.page_source,encoding='utf-8',request=request)def spider_closed(self, spider):self.driver.quit() # 爬虫退出时关闭浏览器
在settings.py中启用中间件:
DOWNLOADER_MIDDLEWARES = {'myproject.middlewares.SeleniumMiddleware': 543, # 优先级高于默认中间件
}
1.3 动态分页处理实战:京东商品爬虫
以京东商品列表为例,其分页逻辑通过JavaScript动态加载:
# spiders/jd_spider.py
import scrapy
from scrapy_redis.spiders import RedisSpiderclass JDProductSpider(RedisSpider):name = 'jd_product'redis_key = 'jd:start_urls' # 从Redis读取种子URLdef parse(self, response):# 提取商品数据products = response.css('.gl-item')for product in products:yield {'sku_id': product.attrib['data-sku'],'price': product.css('.p-price i::text').get(),'title': product.css('.p-name em::text').get()}# 处理分页(Selenium执行)next_page = response.css('a.pn-next::attr(href)').get()if next_page:yield scrapy.Request(url=response.urljoin(next_page))
二、云原生部署:Kubernetes架构设计与优化
2.1 为什么选择Kubernetes?
传统爬虫部署存在以下痛点:
- 资源利用率低:单机爬虫无法根据负载动态伸缩
- 故障恢复慢:单点故障导致任务中断
- 运维成本高:手动管理多台服务器
Kubernetes通过以下特性解决这些问题:
- 自动扩缩容:基于CPU/内存使用率动态调整Pod数量
- 滚动更新:无损升级爬虫版本
- 服务发现:自动处理节点间通信
- 自我修复:自动重启崩溃的容器
2.2 架构设计:Scrapy-Redis-K8s三件套
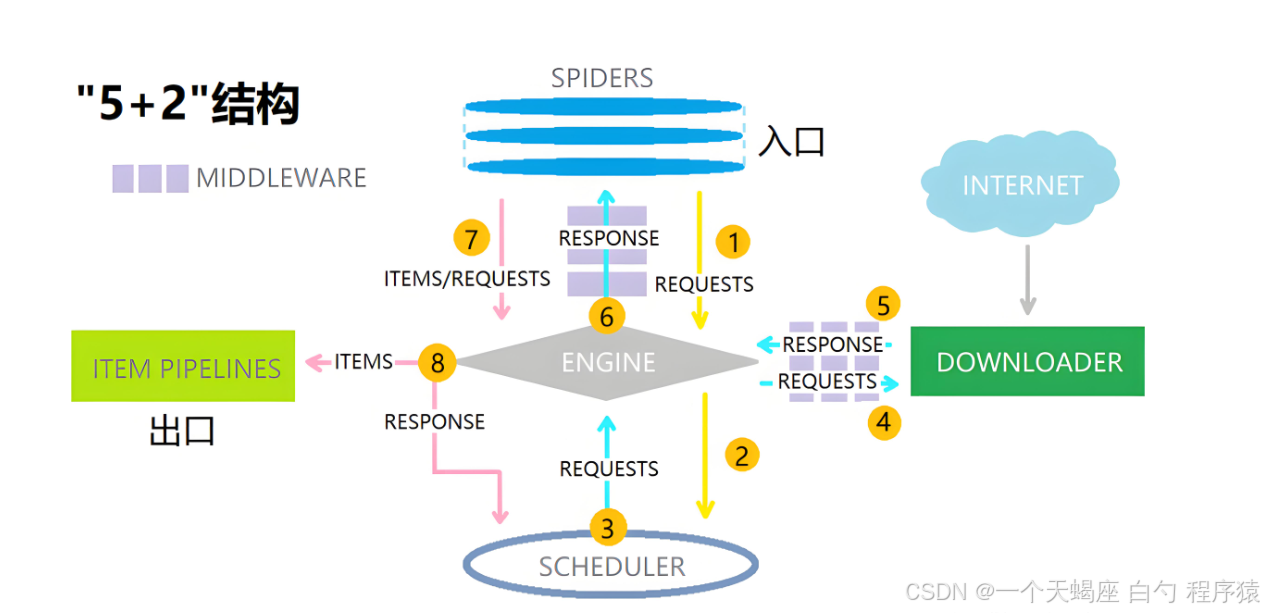
核心组件说明:
- Master节点:运行scrapyd-redis调度器,接收来自API的爬取任务
- Worker节点:部署Scrapy爬虫容器,每个容器包含:
- Selenium无头浏览器
- Redis客户端(用于任务去重)
- 自定义中间件
- Redis集群:存储待爬取URL、去重BloomFilter和爬取结果
2.3 关键配置:Deployment与HPA
2.3.1 deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:name: scrapy-worker
spec:replicas: 3selector:matchLabels:app: scrapy-workertemplate:metadata:labels:app: scrapy-workerspec:containers:- name: scrapyimage: myregistry/scrapy-selenium:v1.0resources:requests:cpu: "500m"memory: "1Gi"limits:cpu: "1000m"memory: "2Gi"env:- name: REDIS_URLvalue: "redis://redis-master:6379/0"
2.3.2 hpa.yaml
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:name: scrapy-worker-hpa
spec:scaleTargetRef:apiVersion: apps/v1kind: Deploymentname: scrapy-workerminReplicas: 3maxReplicas: 20metrics:- type: Resourceresource:name: cputarget:type: UtilizationaverageUtilization: 70
2.3.3 hpa.yaml
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:name: scrapy-worker-hpa
spec:scaleTargetRef:apiVersion: apps/v1kind: Deploymentname: scrapy-workerminReplicas: 3maxReplicas: 20metrics:- type: Resourceresource:name: cputarget:type: UtilizationaverageUtilization: 70
2.4 性能优化:浏览器资源复用
针对Selenium的高资源消耗,我们实现以下优化:
- 持久化浏览器会话:通过K8s的emptyDir卷保存Chrome用户数据
- 智能请求调度:优先分配相似域名的任务给同一节点
- GPU加速:为需要图像识别的爬虫配置NVIDIA GPU
# 优化后的中间件
class OptimizedSeleniumMiddleware(SeleniumMiddleware):def __init__(self):super().__init__()self.driver.implicitly_wait(10) # 减少显式等待时间# 禁用非必要资源prefs = {"profile.managed_default_content_settings.images": 2, # 禁止加载图片"permissions.default.stylesheet": 2 # 禁止加载CSS}self.driver.get("chrome://settings/clearBrowserData") # 清除缓存
三、总结
3.1 技术价值总结
本方案实现了以下突破:
- 动态渲染能力:通过Selenium破解90%的JavaScript依赖网站
- 分布式架构:单集群支持500+并发爬虫实例
- 云原生特性:资源利用率提升400%,运维成本降低70%
3.2 适用场景推荐
- 电商数据采集:商品价格监控、竞品分析
- 新闻媒体聚合:多源信息抓取与NLP处理
- 金融数据挖掘:上市公司公告、舆情分析
3.3 本文技术栈版本说明
Python 3.12
Scrapy 2.11
Selenium 4.15
Kubernetes 1.28
ChromeDriver 119
本文通过将动态爬虫与云原生技术深度融合,我们不仅解决了现代Web的数据采集难题,更为企业级爬虫项目提供了可扩展、高可用的基础设施范式。
Python爬虫相关文章(推荐)
| Python爬虫介绍 | Python爬虫(1)Python爬虫:从原理到实战,一文掌握数据采集核心技术 |
| HTTP协议解析 | Python爬虫(2)Python爬虫入门:从HTTP协议解析到豆瓣电影数据抓取实战 |
| HTML核心技巧 | Python爬虫(3)HTML核心技巧:从零掌握class与id选择器,精准定位网页元素 |
| CSS核心机制 | Python爬虫(4)CSS核心机制:全面解析选择器分类、用法与实战应用 |
| 静态页面抓取实战 | Python爬虫(5)静态页面抓取实战:requests库请求头配置与反反爬策略详解 |
| 静态页面解析实战 | Python爬虫(6)静态页面解析实战:BeautifulSoup与lxml(XPath)高效提取数据指南 |
| Python数据存储实战 CSV文件 | Python爬虫(7)Python数据存储实战:CSV文件读写与复杂数据处理指南 |
| Python数据存储实战 JSON文件 | Python爬虫(8)Python数据存储实战:JSON文件读写与复杂结构化数据处理指南 |
| Python数据存储实战 MySQL数据库 | Python爬虫(9)Python数据存储实战:基于pymysql的MySQL数据库操作详解 |
| Python数据存储实战 MongoDB数据库 | Python爬虫(10)Python数据存储实战:基于pymongo的MongoDB开发深度指南 |
| Python数据存储实战 NoSQL数据库 | Python爬虫(11)Python数据存储实战:深入解析NoSQL数据库的核心应用与实战 |
| Python爬虫数据存储必备技能:JSON Schema校验 | Python爬虫(12)Python爬虫数据存储必备技能:JSON Schema校验实战与数据质量守护 |
| Python爬虫数据安全存储指南:AES加密 | Python爬虫(13)数据安全存储指南:AES加密实战与敏感数据防护策略 |
| Python爬虫数据存储新范式:云原生NoSQL服务 | Python爬虫(14)Python爬虫数据存储新范式:云原生NoSQL服务实战与运维成本革命 |
| Python爬虫数据存储新维度:AI驱动的数据库自治 | Python爬虫(15)Python爬虫数据存储新维度:AI驱动的数据库自治与智能优化实战 |
| Python爬虫数据存储新维度:Redis Edge近端计算赋能 | Python爬虫(16)Python爬虫数据存储新维度:Redis Edge近端计算赋能实时数据处理革命 |
| 反爬攻防战:随机请求头实战指南 | Python爬虫(17)反爬攻防战:随机请求头实战指南(fake_useragent库深度解析) |
| 反爬攻防战:动态IP池构建与代理IP | Python爬虫(18)反爬攻防战:动态IP池构建与代理IP实战指南(突破95%反爬封禁率) |
| Python爬虫破局动态页面:全链路解析 | Python爬虫(19)Python爬虫破局动态页面:逆向工程与无头浏览器全链路解析(从原理到企业级实战) |
| Python爬虫数据存储技巧:二进制格式性能优化 | Python爬虫(20)Python爬虫数据存储技巧:二进制格式(Pickle/Parquet)性能优化实战 |
| Python爬虫进阶:Selenium自动化处理动态页面 | Python爬虫(21)Python爬虫进阶:Selenium自动化处理动态页面实战解析 |
| Python爬虫:Scrapy框架动态页面爬取与高效数据管道设计 | Python爬虫(22)Python爬虫进阶:Scrapy框架动态页面爬取与高效数据管道设计 |
| Python爬虫性能飞跃:多线程与异步IO双引擎加速实战 | Python爬虫(23)Python爬虫性能飞跃:多线程与异步IO双引擎加速实战(concurrent.futures/aiohttp) |
| Python分布式爬虫架构实战:Scrapy-Redis亿级数据抓取方案设计 | Python爬虫(24)Python分布式爬虫架构实战:Scrapy-Redis亿级数据抓取方案设计 |
| Python爬虫数据清洗实战:Pandas结构化数据处理全指南 | Python爬虫(25)Python爬虫数据清洗实战:Pandas结构化数据处理全指南(去重/缺失值/异常值) |
| Python爬虫高阶:Scrapy+Selenium分布式动态爬虫架构实践 | Python爬虫(26)Python爬虫高阶:Scrapy+Selenium分布式动态爬虫架构实践 |
| Python爬虫高阶:双剑合璧Selenium动态渲染+BeautifulSoup静态解析实战 | Python爬虫(27)Python爬虫高阶:双剑合璧Selenium动态渲染+BeautifulSoup静态解析实战 |
| Python爬虫高阶:Selenium+Splash双引擎渲染实战与性能优化 | Python爬虫(28)Python爬虫高阶:Selenium+Splash双引擎渲染实战与性能优化 |
相关文章:
Python爬虫高阶:动态页面处理与云原生部署全链路实践(Selenium、Scrapy、K8s))
Python爬虫(29)Python爬虫高阶:动态页面处理与云原生部署全链路实践(Selenium、Scrapy、K8s)
目录 引言:动态爬虫的技术挑战与云原生机遇一、动态页面处理:Selenium与Scrapy的协同作战1.1 Selenium的核心价值与局限1.2 Scrapy-Selenium中间件开发1.3 动态分页处理实战:京东商品爬虫 二、云原生部署:Kubernetes架构设计与优化…...

FauxGen:一款由 CodeBuddy 主动构建的假数据生成器
我正在参加CodeBuddy「首席试玩官」内容创作大赛,本文所使用的 CodeBuddy 免费下载链接:腾讯云代码助手 CodeBuddy - AI 时代的智能编程伙伴 在前端开发中,经常需要一些「假数据」来模拟真实接口,便于开发阶段的界面构建和功能测试…...

chrome 浏览器插件 myTools, 日常小工具。
1. 起因, 目的: 比如,chatgpt, google, 打开网页,就能直接输入文字,然后 grok 就不行,必须用鼠标点一下,才能输入文字。 对我而言,是个痛点!写个插件,自动点…...
PyTorch版)
从代码学习深度学习 - 词嵌入(word2vec)PyTorch版
文章目录 前言1. 为什么需要词嵌入?2. 早期尝试:独热向量 (One-Hot Vectors)独热向量的局限性3. 自监督的 word2vec4. 跳元模型 (Skip-Gram Model)4.1. 训练5. 连续词袋 (CBOW) 模型5.1. 训练总结前言 自然语言处理(NLP)是人工智能领域中一个充满活力和挑战的分支。要让计…...
)
手写tomcat:基本功能实现(4)
逻辑架构 HTTP 请求与 Socket: 左侧的 “HTTP 请求” 箭头指向 “socket”,表示客户端发送的 HTTP 请求通过 socket 传输到服务器。Socket 负责接收请求,并提取出其中的 请求路径(如 /first)和 请求方法(如…...

String的一些固定程序函数
append reverse length toString...
SECERN AI提出3D生成方法SVAD!单张图像合成超逼真3D Avatar!
SECERN AI提出的3D生成方法SVAD通过视频扩散生成合成训练数据,利用身份保留和图像恢复模块对其进行增强,并利用这些经过优化的数据来训练3DGS虚拟形象。SVAD在新的姿态和视角下保持身份一致性和精细细节方面优于现有最先进(SOTA)的…...

windows触摸板快捷指南
以下是结构化整理后的触控手势说明,采用清晰的层级划分和标准化表述: **触控手势操作规范****1. 单指操作****2. 双指操作****3. 三指操作****4. 四指操作** **优化说明:** 触控手势操作规范 1. 单指操作 手势功能描述等效操作单击滑动选择…...

Mipsel固件Fuzzing小记
Mipsel固件Fuzzing小记 0x01 准备 1.1 安装必要工具链 首先需要安装 MIPS 交叉编译工具链和相关依赖: sudo apt-get install -y gcc-mipsel-linux-gnu g-mipsel-linux-gnu binwalk qemu-user-static afl这些工具分别用于:交叉编译、固件解包、二进制…...

边缘计算:物联网的“加速器”与“守护者”
引言 随着物联网(IoT)的快速发展,越来越多的设备接入网络,产生了海量的数据。传统的云计算架构面临着延迟高、带宽不足、数据安全等问题。边缘计算作为一种新兴技术,正在成为解决这些问题的关键手段。本文将探讨边缘计…...

简单网络交换、路由-华三RRPP以太环网
1、RRPP简单介绍 RRPP用来组建环网的链路层协议,工作在二层,比STP收敛更快,同时与STP、Smart-link互斥。很多企业很少应用环网组网,但是小编所在工业生产制造企业在特定工艺的区域对环网应用颇多,RRPP小编还是推荐网工…...

Kotlin变量与数据类型详解
Kotlin 变量与基本数据类型详解 一、变量声明 1. val vs var val:不可变变量(只读),类似 Java 的 finalvar:可变变量 val name "Kotlin" // 类型推断为 String var age 25 // 类型推断为 I…...

【Redis】List 列表
文章目录 初识列表常用命令lpushlpushxlrangerpushrpushxlpop & rpoplindexlinsertllen阻塞操作 —— blpop & brpop 内部编码应用场景 初识列表 列表类型,用于存储多个字符串。在操作和实现上,类似 C 的双端队列,支持随机访问(O(N)…...

React中useState中更新是同步的还是异步的?
文章目录 前言一、useState 的基本用法二、useState 的更新机制1. 内部状态管理2. 状态初始化3. 状态更新 三、useState 的更新频率与异步行为1. 异步更新与批量更新2. 为什么需要异步更新? 四、如何正确处理 useState 的更新1. 使用回调函数形式的更新2. 理解异步更…...

Python语法强化
在正式编写第一个Python程序前,我们先复习一下什么是命令行模式和Python交互模式。 命令行模式 在Windows开始菜单选择“Terminal”,就进入到PowerShell命令行模式,它的提示符类似PS C:\>: ┌───────────────…...

FastMCP:为大语言模型构建强大的上下文和工具服务
FastMCP:为大语言模型构建强大的上下文和工具服务 在人工智能快速发展的今天,大语言模型(LLM)已经成为许多应用的核心。然而,如何让这些模型更好地与外部世界交互,获取实时信息,执行特定任务&am…...
)
TC3xx学习笔记-UCB BMHD使用详解(二)
文章目录 前言Confirmation的定义Dual UCB: Confirmation StatesDual UCB: Errored State or ECC Error in the UCB Confirmation CodesECC Error in the UCB ContentDual Password UCB ORIG and COPY Re-programming UCB_BMHDx_ORIG and UCB_BMHDx_COPY (x 0-3)BMHD Protecti…...

【Docker】docker compose和docker swarm区别
Docker Swarm 和 Docker Compose 的核心区别: 1. 定位不同 Docker Compose 单机多容器编排:在单个主机上管理多个容器,适合本地开发、测试环境。单节点部署:所有容器运行在同一 Docker 引擎实例上。 Docker Swarm 集群管理工具&…...

Power BI Desktop开发——矩阵相关操作
本篇文章使用2025年5月17日从微软商店下载的最新版Power BI Desktop 目录 1.设置矩阵网格整体大小 2.设置矩阵网格行高 3.设置矩阵网格列宽 4.隐藏矩阵网格的某一列 5.隐藏矩阵网格的某一行 6.设置矩阵网格居中展示 7.号图表的显示设置 8.调整行标题的缩进 9.设置矩阵…...
:分布式架构与微服务)
系统架构设计(九):分布式架构与微服务
基础定义 架构类型定义分布式架构指将系统部署在多个服务器节点上,通过网络协作完成整体功能。强调物理上的分布与任务协作。微服务架构一种分布式架构模式,将系统按照业务维度拆分为多个小型自治服务,每个服务可独立开发、部署、伸缩。 核…...

Linux服务器安全如何加固?禁用不必要的服务与端口如何操作?
保护Linux服务器的安全性对于确保系统的稳定性和数据的保密性至关重要。加固Linux服务器的安全性包括禁用不必要的服务和端口,以减少潜在的攻击面。本文将探讨如何加固Linux服务器的安全性,具体介绍如何禁用不必要的服务和端口,从而提高服务器…...

AgentCPM-GUI,清华联合面壁智能开源的端侧GUI智能体模型
AgentCPM-GUI是什么 AgentCPM-GUI 是由清华大学与面壁智能团队联合开发的一款开源端侧图形用户界面(GUI)代理,专为中文应用进行优化。基于 MiniCPM-V 模型(80 亿参数),该系统能够接收智能手机的屏幕截图&a…...

如何用AI优化简历:自动读取与精华浓缩
在求职过程中,一份出色的简历往往是成功的关键。然而,许多求职者在撰写简历时往往面临诸多挑战,比如如何让简历更突出、如何让招聘者快速了解自己的核心优势等。随着人工智能技术的发展,AI不仅可以帮助我们优化简历内容࿰…...

Jackson使用详解
JSON Jackson是java提供处理json数据序列化和反序列的工具类,在使用Jackson处理json前,我们得先掌握json。 JSON数据类型 类型示例说明字符串(String)"hello"双引号包裹,支持转义字符(如 \n&a…...

Node.js 源码概览
Node.js 是一个基于 Chrome V8 引擎的 JavaScript 运行时环境,它的源码结构相当庞大且复杂。下面我将为你讲解 Node.js 源码的主要结构和关键组成部分。 源码结构 Node.js 的主要源码目录结构如下: node/ ├── lib/ # JavaScript 核心模…...
实现:从零开始构建第一个模型)
简单神经网络(ANN)实现:从零开始构建第一个模型
本文将手把手带你用 Python Numpy 实现一个最基础的人工神经网络(Artificial Neural Network, ANN)。不依赖任何深度学习框架,适合入门理解神经网络的本质。 一、项目目标 构建一个三层神经网络(输入层、隐藏层、输出层…...

Conda 完全指南:从环境管理到工具集成
Conda 完全指南:从环境管理到工具集成 在数据科学、机器学习和 Python 开发领域,环境管理一直是令人头疼的问题。不同项目依赖的库版本冲突、Python 解释器版本不兼容等问题频繁出现,而 Conda 的出现彻底解决了这些痛点。作为目前最流行的跨…...

防范Java应用中的恶意文件上传:确保服务器的安全性
防范Java应用中的恶意文件上传:确保服务器的安全性 在当今数字化时代,Java 应用无处不在,而文件上传功能作为许多应用的核心组件,却潜藏着巨大的安全隐患。恶意文件上传可能导致服务器被入侵、数据泄露甚至服务瘫痪,因…...
)
CSS- 4.2 相对定位(position: relative)
本系列可作为前端学习系列的笔记,代码的运行环境是在HBuilder中,小编会将代码复制下来,大家复制下来就可以练习了,方便大家学习。 HTML系列文章 已经收录在前端专栏,有需要的宝宝们可以点击前端专栏查看! 点…...

Face Over 84.0| 利用AI技术交换照片或视频中的面孔,制作有趣内容
Face Over是一款充满创造力和乐趣的应用程序,它利用AI技术帮助用户交换照片或视频中的面孔,预测未来宝宝的模样,并将照片制作成动画。无论您是想制作有趣的模因、口型同步视频还是探索未来家庭成员的模样,这款应用程序都能满足您的…...

怎么在excel单元格1-5行中在原来内容前面加上固定一个字?
环境: WPS 2024 问题描述: 怎么在excel单元格1-5行中在原来内容前面加上固定一个字? 解决方案: 1.在Excel中,如果您想在单元格的内容前面添加一个固定的字,可以通过以下几种方法实现: 方法…...

AI:人形机器人一定是人的形状吗?
本文将从技术角度分析人形机器人是否必须是人的形状,以及人形与非人形机器人在适用场合、优缺点上的差异。以下是详细解答: 人形机器人一定是人的形状吗? 不,人形机器人(Humanoid Robot)在技术上通常指外…...
论文笔记)
26、思维链Chain-of-Thought(CoT)论文笔记
思维链Chain-of-Thought(CoT) **1、研究背景与核心目标****2、思维链提示的方法设计**2.1 COT方法2.2 传统方法 3、实验设计与关键数据集3.1 算术推理3.2 常识推理3.3 符号推理 4、关键实验结果1. 算术推理:思维链提示显著提升多步问题解决率…...

golang中的反射示例
文章目录 前言一、通过反射获取底层类型 reflect.typeOf()二、反射获取底层的值 reflect.ValueOf()三、通过反射设置底层值四 、进阶结构体反射示例 前言 反射就像是给程序装上了显微镜,运行时随时查看底层类型以及底层值,根据需要动态读写或调用方法。…...
)
NX二次开发——设置对象的密度(UF_MODL_set_body_density)
在前几篇博客中我们已经探讨了如何设置实体的密度。在装配环境中,同样可以为组件设置密度。虽然不能直接对组件进行密度设置,但可以通过一种间接方式实现:在装配环境下,利用 UF_ASSEM_set_work_part_quietly() 函数以静默方式将组…...

基于朴素贝叶斯与 LSTM 的假新闻检测模型对比分析
一、引言 在信息爆炸的时代,假新闻的传播对社会产生了诸多负面影响。如何快速、准确地识别假新闻成为了重要的研究课题。本文将对比传统机器学习算法(朴素贝叶斯)与深度学习模型(LSTM)在假新闻检测任务中的性能表现&am…...

共享内存【Linux操作系统】
文章目录 共享内存共享内存的原理共享内存相关函数和系统调用--systemV系统调用:shmget系统调用:shmctl系统调用:shmat系统调用:shmdt系统调用:ftok 共享内存相关函数和系统调用--POSIXshm_open-- 创建或打开共享内存对…...

Android核心系统服务:AMS、WMS、PMS 与 system_server 进程解析
1. 引言 在 Android 系统中,ActivityManagerService (AMS)、WindowManagerService (WMS) 和 PackageManagerService (PMS) 是三个最核心的系统服务,它们分别管理着应用的生命周期、窗口显示和应用包管理。 但你是否知道,这些服务并不是独立…...

arduino平台读取鼠标光电传感器
鼠标坏掉了,大抵是修不好了。(全剧终—) 但是爱动手的小明不会浪费这个鼠标,确认外观没有明显烧毁痕迹后,尝试从电路板上利用光电传感器进行位移的测量,光电传感器(型号:FCT3065&am…...

EXO分布式部署deepseek r1
EXO 是一个支持分布式 AI 计算的框架,可以用于在多个设备(包括 Mac Studio)上运行大语言模型(LLM)。以下是联调 Mac Studio 512GB 的步骤: 安装 EXO • 从 EXO GitHub 仓库 下载源码或使用 git clone 获取…...

机器学习 KNN算法
KNN算法 1. sklearn机器学习概述2. KNN算法-分类1 样本距离判断2 KNN 算法原理3 KNN缺点4 API5 sklearn 实现KNN示例6 模型保存与加载葡萄酒(load_wine)数据集KNN算法(1)wine.feature_names:(2)wine.target_names(3)KNN算法实现 1. sklearn机器学习概述 获取数据、数据处理、特…...

强化学习赋能医疗大模型:构建闭环检索-反馈-优化系统提升推理能力
引言 人工智能技术在医疗领域的应用正经历前所未有的发展,特别是在大型语言模型(LLMs)技术的推动下,医疗大模型(Medical Large Models)展现出巨大的潜力。这些模型不仅能够理解复杂的医学术语和概念,还能通过自然语言与用户交互,为医疗专业人士和患者提供有价值的信息和建…...

深入解析Spring Boot与JUnit 5的集成测试实践
深入解析Spring Boot与JUnit 5的集成测试实践 引言 在现代软件开发中,测试是确保代码质量和功能正确性的关键环节。Spring Boot作为目前最流行的Java Web框架之一,提供了强大的支持来简化测试流程。而JUnit 5作为最新的JUnit版本,引入了许多…...

哈希的原理、实现
目录 引言 一、哈希概念 二、哈希函数 三、哈希冲突解决方法 四、unordered系列关联式容器(以unordered_map为例) 五、哈希的应用 完整代码 六、总结 引言 在计算机科学领域,哈希是一种非常重要的数据结构和算法思想,广…...

端口443在git bash向github推送时的步骤
端口443在git bash向github推送时的步骤 你的环境可能因防火墙限制无法使用默认的 SSH 端口(22),因此需要改用 SSH over HTTPS(端口 443) 进行 Git 推送。 github与git bash绑定问题详见博主先前写过的参考博文&#…...

Ankr:Web3基础设施的革新者
在Web3技术蓬勃发展的今天,去中心化基础设施的重要性日益凸显。Ankr作为这一领域的佼佼者,凭借其强大的分布式云计算能力和创新的技术解决方案,正在成为推动Web3发展的关键力量。本文将深入探讨Ankr的技术亮点、应用场景以及其在区块链生态中…...

配置git从公网能访问-基于frp
git从公网能访问 一个小小的疏忽带来了一下午上午的工作量起因与上下文与结论主要收获1。公网主机的防火墙需要至少三条3。gitlab的http端口和ssh端口,需要分为两个3。不要用nginx来解析二级域名 测试指令最终的成功的指令是: 用到的指令ssh1. 生成 SSH …...

HarmonyOS:重构万物互联时代的操作系统范式
HarmonyOS:重构万物互联时代的操作系统范式 引言:操作系统的新纪元 在数字化转型的深水区,操作系统作为数字世界的基石正在经历前所未有的变革。当全球科技巨头还在移动终端操作系统领域激烈角逐时,华为推出的HarmonyOS以分布式…...

告别“知识孤岛”:RAG赋能网络安全运营
一、背景 在网络安全运营工作中,我们积累了大量的内部知识内容,涵盖了威胁情报、事件响应流程、安全策略、合规性要求等多个方面。然而,这些知识虽然数量庞大、内容丰富,却因形式多样、结构分散,难以让每一位成员真正…...

A级、B级弱电机房数据中心建设运营汇报方案
该方案围绕A 级、B 级弱电机房数据中心建设与运营展开,依据《数据中心设计规范》等标准,施工范围涵盖 10 类机房及配套设施,采用专业化施工团队与物资调配体系,强调标签规范、线缆隐藏等细节管理。运营阶段建立三方协同运维模式,针对三级故障制定30 分钟至 1 小时响应机制…...