机器学习 KNN算法
KNN算法
- 1. sklearn机器学习概述
- 2. KNN算法-分类
- 1 样本距离判断
- 2 KNN 算法原理
- 3 KNN缺点
- 4 API
- 5 sklearn 实现KNN示例
- 6 模型保存与加载
- 葡萄酒(load_wine)数据集KNN算法
- (1)wine.feature_names:
- (2)wine.target_names
- (3)KNN算法实现
1. sklearn机器学习概述
获取数据、数据处理、特征工程后,就可以交给预估器进行机器学习,流程和常用API如下。
1.实例化预估器(估计器)对象(estimator), 预估器对象很多,都是estimator的子类(1)用于分类的预估器sklearn.neighbors.KNeighborsClassifier k-近邻sklearn.naive_bayes.MultinomialNB 贝叶斯sklearn.linear_model.LogisticRegressioon 逻辑回归sklearn.tree.DecisionTreeClassifier 决策树sklearn.ensemble.RandomForestClassifier 随机森林(2)用于回归的预估器sklearn.linear_model.LinearRegression线性回归sklearn.linear_model.Ridge岭回归(3)用于无监督学习的预估器sklearn.cluster.KMeans 聚类
2.进行训练,训练结束后生成模型estimator.fit(x_train, y_train)
3.模型评估(1)方式1,直接对比y_predict = estimator.predict(x_test)y_test == y_predict(2)方式2, 计算准确率accuracy = estimator.score(x_test, y_test)
4.使用模型(预测)
y_predict = estimator.predict(x_true)
2. KNN算法-分类
1 样本距离判断
明可夫斯基距离欧式距离,明可夫斯基距离的特殊情况 (平方和开根号)曼哈顿距离,明可夫斯基距离的特殊情况 (绝对值之和)
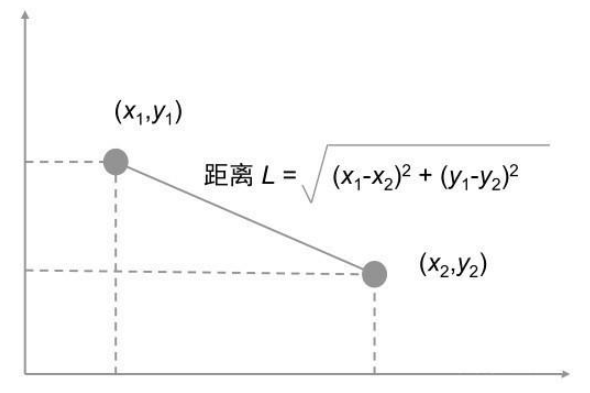
两个样本的距离公式可以通过如下公式进行计算,又称为欧式距离。
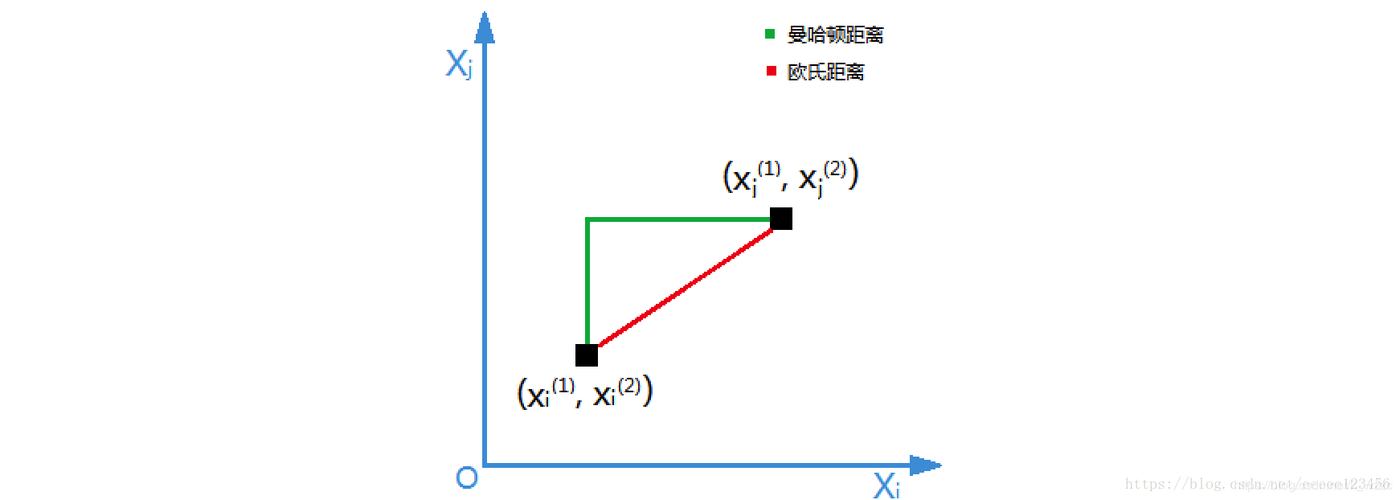
(1)欧式距离
2)曼哈顿距离
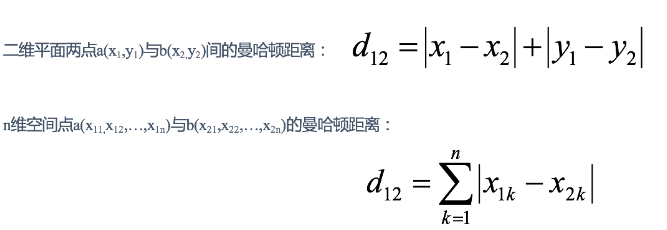
(3)其他距离公式





2 KNN 算法原理
K-近邻算法(K-Nearest Neighbors,简称KNN),根据K个邻居样本的类别来判断当前样本的类别;
如果一个样本在特征空间中的 k个最相似(最邻近)样本中的大多数属于某个类别,则该类本也属于这个类别
比如: 有10000个样本,选出7个到样本A的距离最近的,然后这7个样本中假设:类别1有2个,类别2有3个,类别3有2个.那么就认为A样本属于类别2,因为它的7个邻居中 类别2最多(近朱者赤近墨者黑)
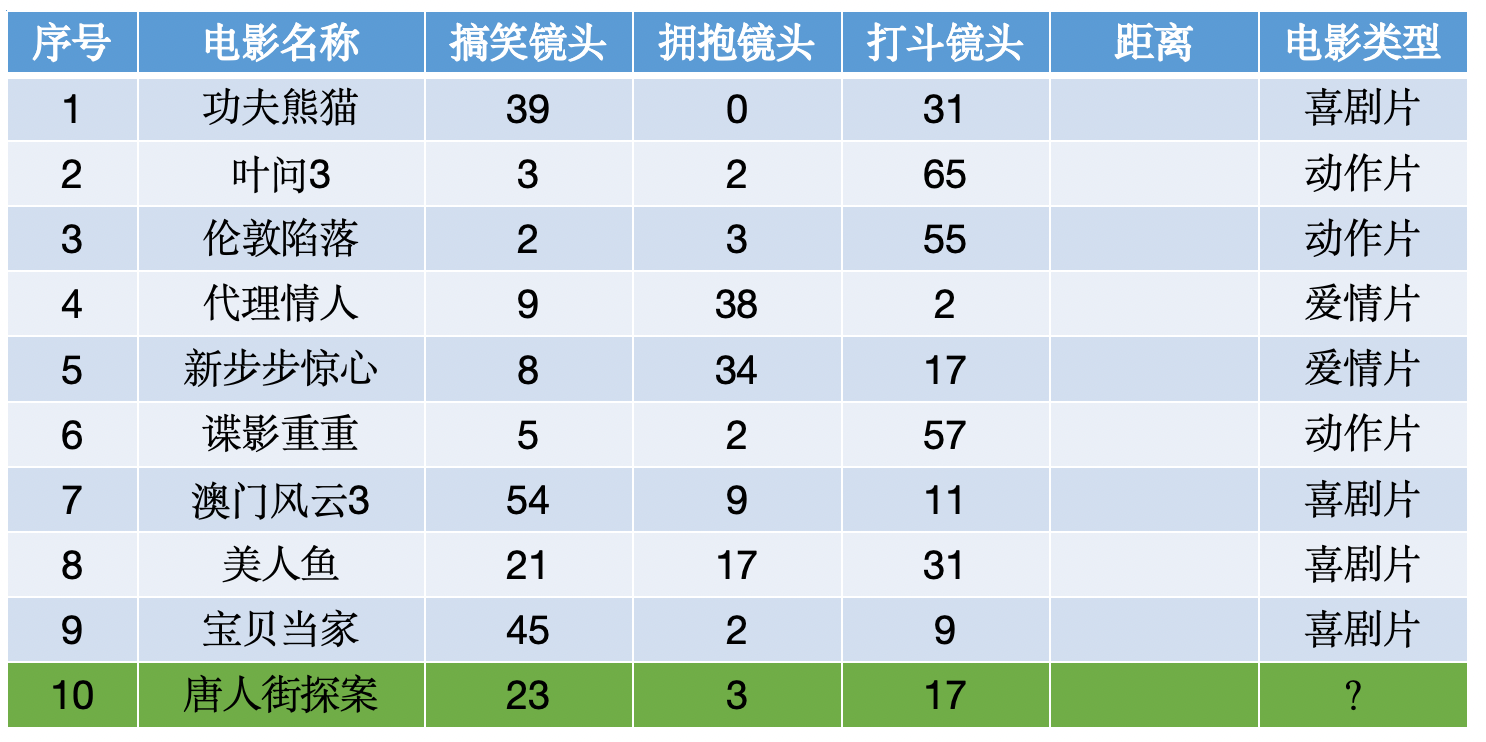
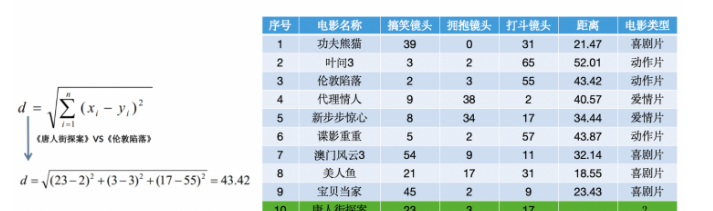
使用KNN算法预测《唐人街探案》电影属于哪种类型?分别计算每个电影和预测电影的距离然后求解:
3 KNN缺点
缺点:
-(1) 对于大规模数据集,计算量大,因为需要计算测试样本与所有训练样本的距离。
- (2)对于高维数据,距离度量可能变得不那么有意义,这就是所谓的“维度灾难”
- (3)需要选择合适的k值和距离度量,这可能需要一些实验和调整
- (4)如果k值取太小会导致噪声影响,k值为1是只会由与测试值最近的决定,k值取大了就会导致维度灾难,k值取值为训练特征总数时,就会导致有训练集中数量多的决定预测值
4 API
class sklearn.neighbors.KNeighborsClassifier(n_neighbors=5, algorithm=‘auto’)
参数:
(1)n_neighbors:
int, default=5, 默认情况下用于kneighbors查询的近邻数,就是K
(2)algorithm:
{‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’}, default=’auto’。找到近邻的方式,注意不是计算距离 的方式,与机器学习算法没有什么关系,开发中请使用默认值’auto’
方法:
(1) fit(x, y)
使用X作为训练数据和y作为目标数据
(2) predict(X) 预测提供的数据,得到预测数据
5 sklearn 实现KNN示例
用KNN算法对鸢尾花进行分类
# 引入KNN算法的库
from sklearn.neighbors import KNeighborsClassifier
# 引入鸢尾花数据集
from sklearn.datasets import load_iris
# 引入划分数据集库
from sklearn.model_selection import train_test_split
# 引入标准化库
from sklearn.preprocessing import StandardScaler# 获取鸢尾花数据集的特征值和目标值
x,y=load_iris(return_X_y=True)#return_X_y:表示只返回特征值和目标值
# 训练集划分
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2,shuffle=True,random_state=22)
# 训练集和测试集标准化
scaler=StandardScaler()
x_train=scaler.fit_transform(x_train)#可以获取标准化后的的信息
x_test=scaler.transform(x_test)#使用x_trian的均值和方差
# 建立KNN算法模型
model=KNeighborsClassifier(n_neighbors=5)
# 模型训练
model.fit(x_train,y_train)
#模型评估
score=model.score(x_test,y_test)
print(score)
#模型预测
y_pred=model.predict(x_test)
print(y_pred)
print(y_test)
'''
0.9333333333333333
[0 2 1 2 1 1 1 1 1 0 2 1 2 2 0 2 1 1 1 1 0 2 0 1 2 0 2 2 2 2]
[0 2 1 2 1 1 1 2 1 0 2 1 2 2 0 2 1 1 2 1 0 2 0 1 2 0 2 2 2 2]
'''
#推理模型(生产)
x_new=[[5.1,2.5,4.4,1.3],[5,4.2,1.2,4.2],[2.3,4.5,1.2,3.2],[2.75,2.3,1.2,4.5]]
x_new=scaler.transform(x_new)
y_new=model.predict(x_new)
print(y_new)
# [1 2 0 2]
步骤:
- (1)加载数据集
- (2)划分数据集
- (3)数据集标准化
- (4)模型训练
- (5)模型预测与模型评估
- (6)推理模型(生产)
注意: - (1)一般对模型进行训练时都要现将数据集进行划分
- (2)进行标准化时训练集fit,transform,fit_transform都可以用,但测试集只能能用transform,原因是fit,fit_transform可以将进行标准化的数据的信息(如均值和方差)计算出来,而我们测试时使用的是训练的信息才能得到真实的值
6 模型保存与加载
import joblib
保存模型
joblib.dump(estimator, “my_ridge.pkl”)
加载模型
estimator = joblib.load(“my_ridge.pkl”)
#使用模型预测
y_test=estimator.predict([[0.4,0.2,0.4,0.7]])
print(y_test)
代码如下:
# 引入KNN算法的库
from sklearn.neighbors import KNeighborsClassifier
# 引入鸢尾花数据集
from sklearn.datasets import load_iris
# 引入划分数据集库
from sklearn.model_selection import train_test_split
# 引入标准化库
from sklearn.preprocessing import StandardScaler
import joblib
def train():# 获取鸢尾花数据集的特征值和目标值x,y=load_iris(return_X_y=True)#return_X_y:表示只返回特征值和目标值# 训练集划分x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2,shuffle=True,random_state=22)# 训练集和测试集标准化scaler=StandardScaler()x_train=scaler.fit_transform(x_train)#可以获取标准化后的的信息x_test=scaler.transform(x_test)#使用x_trian的均值和方差# 建立KNN算法模型model=KNeighborsClassifier(n_neighbors=5)# 模型训练model.fit(x_train,y_train)#模型评估score=model.score(x_test,y_test)print(score)#模型预测y_pred=model.predict(x_test)print(y_pred)print(y_test)'''0.9333333333333333[0 2 1 2 1 1 1 1 1 0 2 1 2 2 0 2 1 1 1 1 0 2 0 1 2 0 2 2 2 2][0 2 1 2 1 1 1 2 1 0 2 1 2 2 0 2 1 1 2 1 0 2 0 1 2 0 2 2 2 2]'''# 模型保存joblib.dump(model,"./src/model/knn.pkl")joblib.dump(scaler,"./src/model/knn_scaler.pkl")def detect():#模型加载model=joblib.load("./src/model/knn.pkl")scaler=joblib.load("./src/model/knn_scaler.pkl")#推理模型(生产)x_new=[[5.1,2.5,4.4,1.3],[5,4.2,1.2,4.2],[2.3,4.5,1.2,3.2],[2.75,2.3,1.2,4.5]]x_new=scaler.transform(x_new)y_new=model.predict(x_new)print(y_new)# [1 2 0 2]
if __name__=="__main__":train()detect()
葡萄酒(load_wine)数据集KNN算法
(1)wine.feature_names:
[‘alcohol’, ‘malic_acid’, ‘ash’, ‘alcalinity_of_ash’, ‘magnesium’, ‘total_phenols’, ‘flavanoids’, ‘nonflavanoid_phenols’,‘proanthocyanins’, ‘color_intensity’, ‘hue’, ‘od280/od315_of_diluted_wines’, ‘proline’]
以下是这些葡萄酒相关术语的翻译及简要说明:
alcohol - 酒精(葡萄酒中的酒精含量)
malic_acid - 苹果酸(葡萄酒中的天然有机酸)
ash - 灰分(燃烧后残留的无机物含量)
alcalinity_of_ash - 灰分碱度(灰分的碱性程度)
magnesium - 镁(矿物质含量)
total_phenols - 总酚(影响风味和抗氧化性的化合物)
flavanoids - 黄酮类化合物(多酚类物质,与颜色和健康益处相关)
nonflavanoid_phenols - 非黄酮酚(其他酚类物质)
proanthocyanins - 原花青素(缩合单宁,影响口感)
color_intensity - 颜色强度(葡萄酒色泽的深浅)
hue - 色调(颜色的类型,如红/紫/棕等)
od280/od315_of_diluted_wines - 稀释葡萄酒的OD280/OD315值(紫外吸光度比值,反映酚类物质浓度)
proline - 脯氨酸(氨基酸,与葡萄酒的氮代谢相关)
(2)wine.target_names
[‘class_0’ ‘class_1’ ‘class_2’]
class_0
葡萄品种: Barbera(巴贝拉)
特点: 高酸度、低单宁,通常酿造果香浓郁的红葡萄酒。
class_1
葡萄品种: Barolo(巴罗洛,由 Nebbiolo 内比奥罗葡萄酿造)
特点: 高单宁、高酸度,酿造复杂、陈年潜力强的顶级红葡萄酒。
class_2
葡萄品种: Grignolino(格丽尼奥里诺)
特点: 轻酒体、高酸度,常酿造清新风格的红葡萄酒或桃红葡萄酒。
(3)KNN算法实现
# 引入KNN算法的库
from sklearn.neighbors import KNeighborsClassifier
# 引入葡萄酒数据集
from sklearn.datasets import load_wine
# 引入划分数据集库
from sklearn.model_selection import train_test_split
# 引入标准化库
from sklearn.preprocessing import StandardScaler
import joblib
def train():# wine=load_wine()x,y=load_wine(return_X_y=True)# print(x)print(x.shape)x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2,shuffle=True,random_state=22)print(x_train.shape)scaler=StandardScaler()x_train=scaler.fit_transform(x_train)x_test=scaler.transform(x_test)model=KNeighborsClassifier(n_neighbors=5)model.fit(x_train,y_train)y_pred=model.predict(x_test)print(y_pred)score=model.score(x_test,y_test)print(score)'''[1 2 2 2 0 1 0 1 2 1 1 1 0 0 2 0 0 0 2 2 0 1 2 1 1 2 0 1 2 2 1 1 2 1 0 2]
0.9166666666666666'''joblib.dump(model,"./src/model/knn_wine_model.pkl")joblib.dump(scaler,"./src/model/knn_wine_scaler.pkl")
def detect():model=joblib.load("./src/model/knn_wine_model.pkl")scaler=joblib.load("./src/model/knn_wine_scaler.pkl")x_new=[[1.2,4.5,2.3,1.2,2.3,2.6,1.2,0.3,0.2,0.5,1.2,1.4,2.3]]x_new=scaler.transform(x_new)y_new=model.predict(x_new)print(y_new)#[1]if __name__=="__main__":train()detect()相关文章:

机器学习 KNN算法
KNN算法 1. sklearn机器学习概述2. KNN算法-分类1 样本距离判断2 KNN 算法原理3 KNN缺点4 API5 sklearn 实现KNN示例6 模型保存与加载葡萄酒(load_wine)数据集KNN算法(1)wine.feature_names:(2)wine.target_names(3)KNN算法实现 1. sklearn机器学习概述 获取数据、数据处理、特…...

强化学习赋能医疗大模型:构建闭环检索-反馈-优化系统提升推理能力
引言 人工智能技术在医疗领域的应用正经历前所未有的发展,特别是在大型语言模型(LLMs)技术的推动下,医疗大模型(Medical Large Models)展现出巨大的潜力。这些模型不仅能够理解复杂的医学术语和概念,还能通过自然语言与用户交互,为医疗专业人士和患者提供有价值的信息和建…...

深入解析Spring Boot与JUnit 5的集成测试实践
深入解析Spring Boot与JUnit 5的集成测试实践 引言 在现代软件开发中,测试是确保代码质量和功能正确性的关键环节。Spring Boot作为目前最流行的Java Web框架之一,提供了强大的支持来简化测试流程。而JUnit 5作为最新的JUnit版本,引入了许多…...

哈希的原理、实现
目录 引言 一、哈希概念 二、哈希函数 三、哈希冲突解决方法 四、unordered系列关联式容器(以unordered_map为例) 五、哈希的应用 完整代码 六、总结 引言 在计算机科学领域,哈希是一种非常重要的数据结构和算法思想,广…...

端口443在git bash向github推送时的步骤
端口443在git bash向github推送时的步骤 你的环境可能因防火墙限制无法使用默认的 SSH 端口(22),因此需要改用 SSH over HTTPS(端口 443) 进行 Git 推送。 github与git bash绑定问题详见博主先前写过的参考博文&#…...

Ankr:Web3基础设施的革新者
在Web3技术蓬勃发展的今天,去中心化基础设施的重要性日益凸显。Ankr作为这一领域的佼佼者,凭借其强大的分布式云计算能力和创新的技术解决方案,正在成为推动Web3发展的关键力量。本文将深入探讨Ankr的技术亮点、应用场景以及其在区块链生态中…...

配置git从公网能访问-基于frp
git从公网能访问 一个小小的疏忽带来了一下午上午的工作量起因与上下文与结论主要收获1。公网主机的防火墙需要至少三条3。gitlab的http端口和ssh端口,需要分为两个3。不要用nginx来解析二级域名 测试指令最终的成功的指令是: 用到的指令ssh1. 生成 SSH …...

HarmonyOS:重构万物互联时代的操作系统范式
HarmonyOS:重构万物互联时代的操作系统范式 引言:操作系统的新纪元 在数字化转型的深水区,操作系统作为数字世界的基石正在经历前所未有的变革。当全球科技巨头还在移动终端操作系统领域激烈角逐时,华为推出的HarmonyOS以分布式…...

告别“知识孤岛”:RAG赋能网络安全运营
一、背景 在网络安全运营工作中,我们积累了大量的内部知识内容,涵盖了威胁情报、事件响应流程、安全策略、合规性要求等多个方面。然而,这些知识虽然数量庞大、内容丰富,却因形式多样、结构分散,难以让每一位成员真正…...

A级、B级弱电机房数据中心建设运营汇报方案
该方案围绕A 级、B 级弱电机房数据中心建设与运营展开,依据《数据中心设计规范》等标准,施工范围涵盖 10 类机房及配套设施,采用专业化施工团队与物资调配体系,强调标签规范、线缆隐藏等细节管理。运营阶段建立三方协同运维模式,针对三级故障制定30 分钟至 1 小时响应机制…...
)
C 语言学习笔记(数组)
C 语言基础:第 08天笔记 内容提要 数组 排序算法:冒泡排序二维数组字符数组 数组 冒泡排序 排序思想(向前冒泡): 一次排好一个数,针对n个数,最差情况需要n - 1次就可以排好每次排序假定第一…...
openjdk17 c++源码垃圾回收安全点信号函数处理线程阻塞)
jvm安全点(二)openjdk17 c++源码垃圾回收安全点信号函数处理线程阻塞
1. 信号处理与桩代码(Stub) 当线程访问安全点轮询页(Polling Page)时: 触发 SIGSEGV 信号:访问只读的轮询页会引发 SIGSEGV 异常。信号处理函数:pd_hotspot_signal_handl…...

uni-app 开发HarmonyOS的鸿蒙影视项目分享:从实战案例到开源后台
最近,HBuilderX 新版本发布,带来了令人兴奋的消息——uni-app 现在支持 Harmony Next 平台的 App 开发。这对于开发者来说无疑是一个巨大的福音,意味着使用熟悉的 Vue 3 语法和开发框架,就可以为鸿蒙生态贡献自己的力量。 前言 作…...

【赵渝强老师】在PostgreSQL中访问Oracle
在PostgreSQL数据库中,oracle_fdw是PostgreSQL数据库支持的外部扩展。通过使用oracle_fdw扩展可以读取到Oracle数据库中的数据。它是一种非常方便且常见的PostgreSQL与Oracle的同步数据的方法。使用oracle_fdw扩展需要依赖Oracle的Instance Client环境。 视频讲解如…...
)
板凳-------Mysql cookbook学习 (二)
生成一个包含cookbook数据库中的表备份的名为backup.sql的dump文件。 sql C:\Users\lenovo>mysqldump -u root -p --default-character-setutf8mb4 cookbook > D:\sql\Mysql_learning\backup.sql mysqldump 不是内部或外部命令,也不是可运行的程序 或批处理文…...

sudo apt update是什么意思呢?
非常好的问题! ✅ sudo apt update 是什么意思? 它的作用是: 更新你的 Ubuntu 系统中软件列表的信息(但不安装软件) 就像你每天先去超市了解今天上架了哪些新商品(只是“查看”而不是“买”)&a…...

.NET Core 中 Swagger 配置详解:常用配置与实战技巧
随着微服务架构和 RESTful API 的广泛应用,API 文档的管理和自动化生成成为了开发中的重要部分。Swagger(现为 OpenAPI)是一款功能强大的工具,它可以自动生成 API 文档,并提供交互式 UI,帮助开发者、测试人…...

spring cache使用指南
Spring cache Spring Cache 是一个框架,实现了基于注解的缓存功能,只需要简单地加一个注解,就能实现缓存功能。 Spring Cache 提供了一层抽象,底层可以切换不同的缓存实现。 例如:EHCache,Caffeine,Redi…...

9.DMA
目录 DMA —为 CPU 减负 DMA 的简介和使用场景 DMA 的例子讲解 STM32 的 DMA 框图和主要特性 编辑 DMA 的通道的对应通道外设 – DMA 和哪些外设使用 编辑编辑ADC_DR 寄存器地址的计算 常见的数据滤波方法 ADCDMA 的编程 DMA —为 CPU 减负 DMA 的简介和使用场…...

Python自学笔记3 常见运算符
常用运算符 加减法 python的自动数据类型转换 整形转为浮点型 实数转为复数 数字类型不能和浮点数类型相加减 乘除法 数据转换基本同加减法, 但字符串可以和整数相加减,作用是字符串的自我复制 反斜杠 成员运算符 判断一个元素是不是一个序列的成员…...

【C/C++】C++中constexpr与const的深度对比
文章目录 C中constexpr与const的深度对比1. 编译期确定性2. 更严格的优化保证3. 适用范围更广4. 类型安全与错误检查5. 现代 C 的演进方向何时使用 const?constexpr应用场景1. 配置常量与全局参数2. 数据验证与业务规则检查3. 数学计算与业务逻辑优化4. 模板元编程与…...

劳特巴赫trace32负载率测试
按照下图步骤点击即可...

牛客OJ在线编程常见输入输出练习--Java版
目录 一、链接 二、题目 一、链接 牛客输入输出链接:牛客网 - 找工作神器|笔试题库|面试经验|实习招聘内推,求职就业一站解决_牛客网 二、题目 1.只有输出 public class Main {public static void main(String[] args) {System.out.println("H…...

STM32 | FreeRTOS 递归信号量
递归信号量 一、概述 互斥量的使用比较单一,因为它是信号量的一种,并且它是以锁的形式存在。在初始化的时候,互斥量处于开锁的状态,而被任务持有的时候则立刻转为闭锁的状态。 递归类型的互斥量可以被拥有者重复获取。拥有互斥量…...

STM32 | 软件定时器
01 一、概述 软件定时器是用程序模拟出来的定时器,可以由一个硬件定时器模拟出成千上万个软件定时器,这样程序在需要使用较多定时器的时候就不会受限于硬件资源的不足,这是软件定时器的一个优点,即数量不受限制。但由于软件定…...

2025年EB SCI2区TOP,多策略改进黑翅鸢算法MBKA+空调系统RC参数辨识与负载聚合分析,深度解析+性能实测
目录 1.摘要2.黑翅鸢优化算法BKA原理3.改进策略4.结果展示5.参考文献6.代码获取7.读者交流 1.摘要 随着空调负载在电力系统中所占比例的不断上升,其作为需求响应资源的潜力日益凸显。然而,由于建筑环境和用户行为的变化,空调负载具有异质性和…...

互联网大厂Java面试:从Spring到微服务的全面探讨
文章简述 本文模拟了一个互联网大厂Java求职者的面试场景,涵盖了Java核心语言与平台、构建工具、Web框架、微服务与云原生等多个技术栈。通过面试问答的形式,展示了在真实业务场景下如何应用这些技术点,帮助初学者理解和学习。 场景介绍 在…...
--playwright浏览器自动化)
Python爬虫之路(14)--playwright浏览器自动化
playwright 前言 你有没有在用 Selenium 抓网页的时候,体验过那种「明明点了按钮,它却装死不动」的痛苦?或者那种「刚加载完页面,它又刷新了」的抓狂?别担心,你不是一个人——那是 Selenium 在和现代前…...

Elasticsearch Fetch阶段面试题
Elasticsearch Fetch阶段面试题 🚀 目录 基础原理性能优化错误排查场景设计底层机制总结基础原理 🔍 面试题1:基础原理 题目: 请描述Elasticsearch分布式搜索中Query阶段和Fetch阶段的工作流程,为什么需要将搜索过程拆分为这两个阶段? 👉 点击查看答案 查询流程…...

RAGFlow Arbitrary Account Takeover Vulnerability
文章目录 RAGFlowVulnerability Description[1]Vulnerability Steps[2]Vulnerability Steps[3]Vulnerability Steps RAGFlow RAGFlow is an open-source RAG (Retrieval-Augmented Generation) engine developed by Infiniflow, focused on deep document understanding and d…...

框架之下再看HTTP请求对接后端method
在当今的软件开发领域,各类框架涌现,极大地提升了开发效率。以 Java 开发为例,Spring 框架不断演进,Spring Boot 更是简化到只需引入 Maven 包,添加诸如SpringBootApplication、RestController等注解,就能轻…...

机器学习中的过拟合及示例
文章目录 机器学习中的过拟合及示例1. 过拟合的定义2. 过拟合的常见例子例1:图像分类中的过拟合例2:回归任务中的过拟合例3:自然语言处理(NLP)中的过拟合 3. Python代码示例:过拟合的直观演示示例1…...

机器学习-人与机器生数据的区分模型测试 -数据筛选
内容继续机器学习-人与机器生数据的区分模型测试 使用随机森林的弱学习树来筛选相对稳定的特征数据 # 随机森林筛选特征 X data.drop([city, target], axis1) # 去除修改前的城市名称列和目标变量列 y data[target] X_train, X_test, y_train, y_test train_test_split(X…...

第9讲、深入理解Scaled Dot-Product Attention
Scaled Dot-Product Attention是Transformer架构的核心组件,也是现代深度学习中最重要的注意力机制之一。本文将从原理、实现和应用三个方面深入剖析这一机制。 1. 基本原理 Scaled Dot-Product Attention的本质是一种加权求和机制,通过计算查询(Query…...

无监督学习在医疗AI领域的前沿:多模态整合、疾病亚型发现与异常检测
引言 人工智能技术在医疗领域的应用正经历着从辅助决策向深度赋能的转变。无监督学习作为人工智能的核心范式之一,因其无需大量标注数据、能够自动发现数据内在规律的特性,在医疗AI领域展现出独特优势。尤其在2025年,无监督学习技术在医疗AI应用中呈现出多模态整合、疾病亚…...

PostgreSQL内幕剖析——结构与架构
大家好,这里是失踪人口bang__bang_,从今天开始持续更新PostgreSQL内幕相关内容,让我们一起了解学习吧✊! 目录 1️⃣ DB集群、数据库、表 🍙 数据库集群的逻辑结构 🍙 数据库集群的物理结构 &am…...

架构师论文《论模型驱动架构软件开发方法及其应用》
摘要 在当前的软件开发领域,模型驱动架构(MDA)作为一种重要的开发方法,强调通过抽象化模型指导系统设计与实现,能够有效提升开发效率并降低复杂性。本文结合笔者参与的某医疗信息管理系统的开发实践,探讨MD…...

当硅基存在成为人性延伸的注脚:论情感科技重构社会联结的可能性
在东京大学机器人实验室的档案室里,保存着一份泛黄的二战时期设计图——1943年日本陆军省秘密研发的“慰安妇替代品”草图。这个诞生于战争阴霾的金属躯体,与2025年上海进博会上展出的MetaBox AI伴侣形成时空对话:当人类将情感需求投射于硅基…...

最小二乘法拟合直线,用线性回归法、梯度下降法实现
参考笔记: 最小二乘法拟合直线,多个方法实现-CSDN博客 一文让你彻底搞懂最小二乘法(超详细推导)-CSDN博客 目录 1.问题引入 2.线性回归法 2.1 模型假设 2.2 定义误差函数 2.3 求偏导并解方程 2.4 案例实例 2.4.1 手工计算…...

机器学习 day04
文章目录 前言一、线性回归的基本概念二、损失函数三、最小二乘法 前言 通过今天的学习,我掌握了机器学习中的线性回归的相关基本概念,包括损失函数的概念,最小二乘法的理论与算法实现。 一、线性回归的基本概念 要理解什么是线性回归&…...

数据分析_Python
1 分析内容 1.1 数据的整体概述 提供数据集的基本信息,包括数据量、时间跨度、地理范围和主要字段. import pandas as pd# 创建示例数据 data {姓名: [张三, 李四, 王五, 赵六, 钱七, 孙八, 周九, 吴十],年龄: [25, 30, 35, 40, 45, 50, 55, 60],性别: [男, 男, 女, 女, 男,…...
:移情阶段的深度潜入——从用户生活到产品渗透的全链路解析)
精益数据分析(63/126):移情阶段的深度潜入——从用户生活到产品渗透的全链路解析
精益数据分析(63/126):移情阶段的深度潜入——从用户生活到产品渗透的全链路解析 在创业的移情阶段,成功的关键不仅在于发现用户的表面需求,更在于深入潜入用户的日常生活,理解其行为背后的真实动机与场景…...
聚合查询(上))
【MySQL】第五弹——表的CRUD进阶(三)聚合查询(上)
文章目录 🌅聚合函数🌊1.COUNT();统计所有行🌊2. SUM(列名); 求和🌊3. AVG() 求平均🌊4. MAX(),MIIN() 🌅分组查询🌊GROUP BY 子句🌊HAVING 🌅联合查询🌊联合…...

英语学习5.16
recede 【动词】 👉 关键词:后退、减弱、退去 ✅ 释义: 后退,远离 指物体逐渐远离、移开或变得不明显,常用于描述水面、声音、军队、头发线等的“退却”或“后移”。 如:The floodwaters receded.&#x…...

创建react工程并集成tailwindcss
1. 创建工程 npm create vite admin --template react 2.集成tailwndcss 打开官网跟着操作一下就行。 Installing Tailwind CSS with Vite - Tailwind CSS...
赛项竞赛样题)
2025 年九江市第二十三届中职学校技能大赛 (网络安全)赛项竞赛样题
2025 年九江市第二十三届中职学校技能大赛 (网络安全)赛项竞赛样题 (二)A 模块基础设施设置/安全加固(200 分)A-1 任务一登录安全加固(Windows,Linux)A-2 任务二 Nginx 安全策略&…...

STM32IIC实战-OLED模板
STM32IIC实战-OLED模板 一,SSD1306 控制芯片1, 主要特性2,I2C 通信协议3, 显示原理4, 控制流程5, 开发思路 二,HAL I2C API 解析I2C 相关 API1,2,3,4…...

BMVC2023 | 多样化高层特征以提升对抗迁移性
Diversifying the High-level Features for better Adversarial Transferability 摘要-Abstract引言-Introduction相关工作-Related Work方法-Methodology实验-Experiments结论-Conclusion 论文链接 GitHub链接 本文 “Diversifying the High-level Features for better Adve…...

C++ deque双端队列、deque对象创建、deque赋值操作
在deque中,front()是头部元素,back()指的是尾部元素。begin()是指向头部的迭代器,end()是指向尾部的下一个元素的迭代器。 push_front 头部进行插入 pop_front 尾部进行删除 push_back 尾部进行插入 pop_back 尾部进行删除 deque如果同时…...
 不同先验代表算法整理2)
【论文阅读】人脸修复(face restoration ) 不同先验代表算法整理2
文章目录 一、前述二、不同的先验及代表性论文2.1 几何先验(Geometric Prior)2.2 生成式先验(Generative Prior)2.3 codebook先验(Vector Quantized Codebook Prior)2.4 扩散先验 (Diffusion Pr…...