RNope:结合 RoPE 和 NoPE 的长文本建模架构
TL;DR
- 2025 年 Cohere 提出的一种高效且强大的长上下文建模架构——RNope-SWA。通过系统分析注意力模式、位置编码机制与训练策略,该架构不仅在长上下文任务上取得了当前最优的表现,还在短上下文任务和训练/推理效率方面实现了良好平衡。
Paper name
Rope to Nope and Back Again: A New Hybrid Attention Strategy
Paper Reading Note
Paper URL:
- https://arxiv.org/pdf/2501.18795
Introduction
背景
- 现有的基于 RoPE 的方法在处理进一步扩展的上下文长度时表现出一定的性能局限。
- Query-Key Normalization(QK-Norm)被提出用于改善训练稳定性,该方法在计算注意力前对查询-键向量在头维度上进行归一化处理。虽然 QK-Norm 缓解了训练过程中的数值不稳定性并被广泛采用,但它可能削弱模型的长上下文建模能力。
- “无位置嵌入”(NoPE)的提出,认为移除显式的位置嵌入、仅依赖因果掩码带来的隐式位置信息,反而可能提升长上下文的表现。
本文方案
- 首先分析不同注意力机制(包括 NoPE 和 QK-Norm)在训练至 7500 亿 token 后的注意力模式及其对长上下文性能的影响
- 提出了一种结合 RoPE 和 NoPE 的新架构——RNoPE 。该架构不仅在长上下文任务上超越了传统的基于 RoPE 的 Transformer 模型,同时在较短上下文需求的基准测试中也表现出具有竞争力的性能。
Methods
实验配置
-
模型架构,参数总量为80亿(包括词嵌入参数)
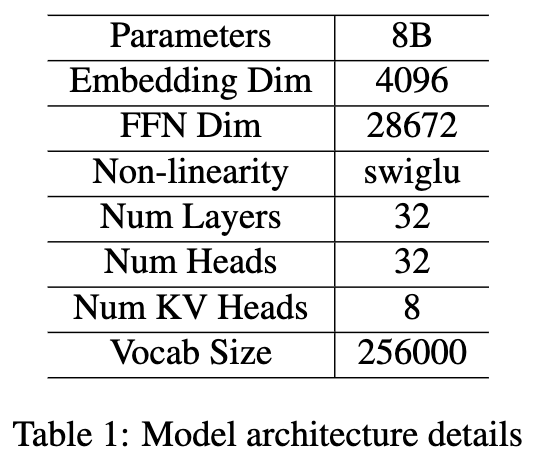
-
模型训练分为两个阶段:预训练阶段和监督微调(SFT)阶段。
- 在进行长上下文评估时,SFT阶段是必要的,因为它可以降低长上下文任务中的方差,并使仅通过预训练无法显现的长上下文能力得以展现
-
测试的三种模型变体如下:
- RoPE 模型 :该变体使用旋转位置嵌入(Rotary Position Embedding, RoPE)来编码位置信息。在预训练阶段,RoPE 参数 θ 设置为10,000;在随后的SFT阶段,θ 被提升至200万,以适应更长的上下文长度。该变体作为基线模型,其架构与大多数现有模型相似。
- QK-Norm 模型 :在执行RoPE中的角度旋转之前,对查询向量和键向量分别应用层归一化(Layer Normalization)。除归一化操作外,其他超参数(包括θ值和训练方法)均与RoPE变体保持一致。
- NoPE 模型 :已有研究表明,不使用位置嵌入(NoPE)的Transformer变体在长上下文任务中仍可有效运行。然而,这些模型在训练序列长度内的困惑度(perplexity)和下游任务表现通常较差。在我们的研究中,NoPE变体未使用QK-Norm,其余训练方法与上述两种变体相同。
评估与注意力分析
- RoPE 和 QK-Norm 变体在标准基准上的表现相当,而 NoPE 变体则相对落后,这与先前研究结果一致
- 在长上下文评估中,QK-Norm 表现最差,尽管它在其他能力上表现尚可
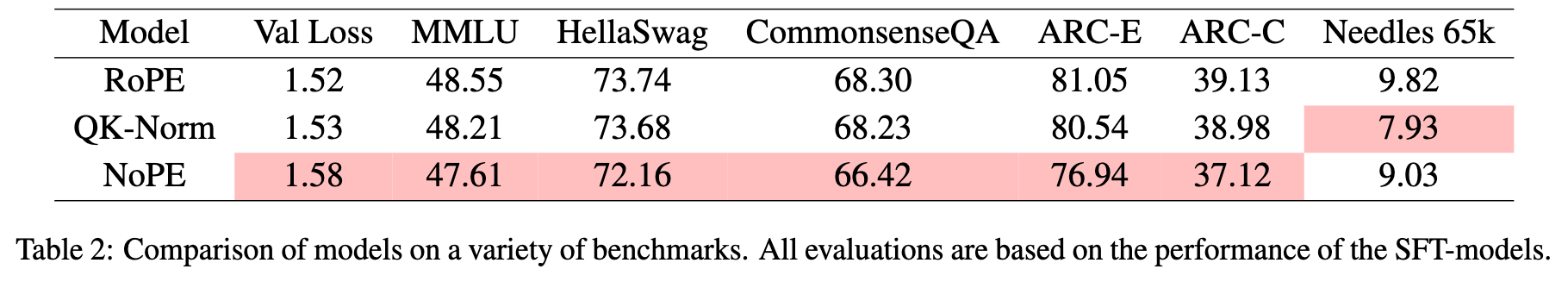
注意力模式分析
- 为了探究不同架构的影响,对各模型内部的注意力模式进行了分析
- 继续使用 NIAH 任务,将上下文划分为四个部分
- 前10个token(begin)
- 针句token(needle)
- 一般上下文token(context)
- 问题/补全token(qc)
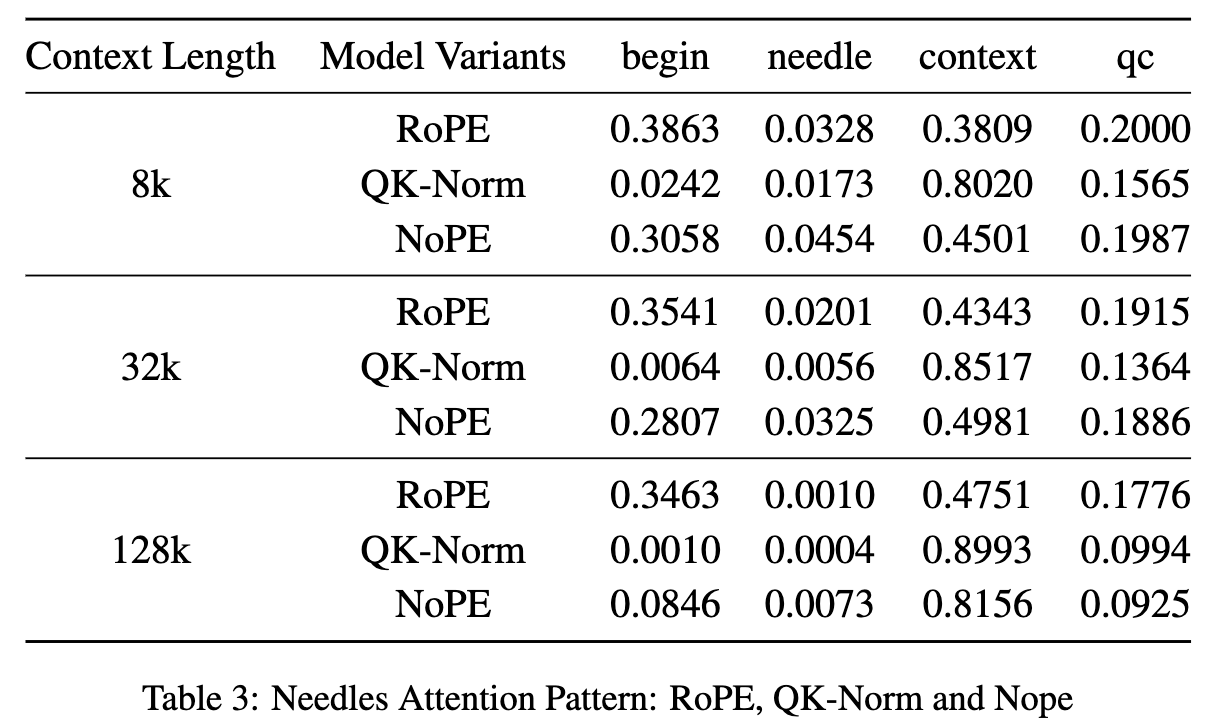
- 对于每个模型,我们首先计算“qc”查询token与所有四个段落的键token之间的注意力分数。注意力分数在每个段内进行求和,然后在所有注意力头和层之间进行聚合,以获得每个段的平均注意力分数。这些分数进一步在多个样本上按序列长度(8000、32000、128000 token)进行平均。我们称这一指标为“注意力质量”(attention mass),结果见表3。
- 随着序列长度增加,所有变体在“针”token上的注意力质量都在下降,表明相关信息的检索难度随上下文增长而增大。
- 在同一上下文长度下,NoPE 变体对“针”的注意力质量最高,其次是 RoPE,而 QK-Norm 最低。
- QK-Norm 在 “开头token” 上的注意力质量极低,而在“噪声上下文”上的注意力质量较高,这与其在 NIAH 任务中相对较差的表现一致。QK-Norm 中的归一化操作削弱了 Query 与 Key 向量点积中的幅度信息,导致注意力 logit 更接近且分布更平坦。
混合模型(Hybrid Model)
提出了一种结合 RoPE 和 NoPE 的新架构——RNoPE,以融合两种方法的优势。将两者结合有望在保持长上下文能力的同时提升整体性能。
- NoPE 能够通过向量相似性实现高效的信息检索
- RoPE 则能够显式建模位置信息和“最近性偏置”(recency bias)
实现方式:在模型中交替使用 NoPE 层和 RoPE 层:在一个层中应用 NoPE,在下一层中应用 RoPE
RNoPE 训练与评估
- 预训练阶段 RoPE 参数 θ 统一设为 10,000。随后我们进行多轮微调,分别尝试了不同的 θ 值:10,000、100,000、200万和400万,以评估不同配置下的模型表现。
- 将该变体称为 RNoPE 变体 ,并根据 SFT 阶段使用的 θ 值分别命名为:
- RNoPE-10k(θ = 10,000)
- RNoPE-100k(θ = 100,000)
- RNoPE-2M(θ = 2,000,000)
- RNoPE-4M(θ = 4,000,000)
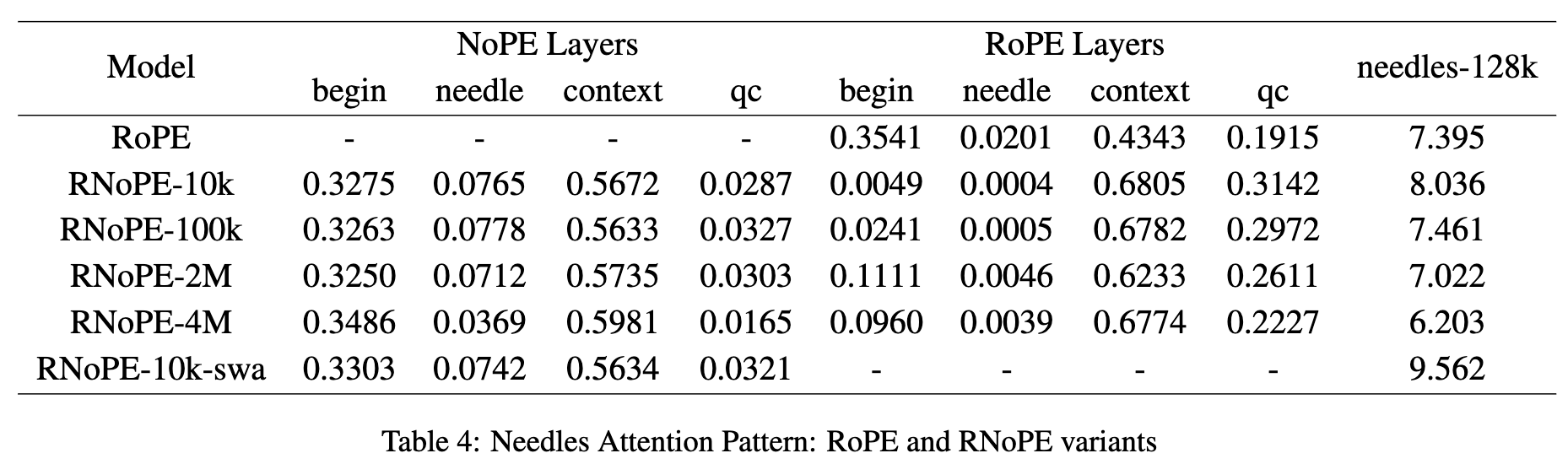
在序列长度为 128,000 的 NIAH 任务上报告针句得分,并计算各变体的注意力质量(attention mass),结果见表4。注意力质量分别对所有 RoPE 层和 NoPE 层进行聚合。
- 随着 SFT 阶段 RoPE 参数 θ 的增加,模型的长上下文能力反而下降。这与之前纯 RoPE 模型中的观察相矛盾:在那些模型中,更大的 θ 值通常有助于提升长上下文性能,并扩展注意力机制的有效感受野
- NoPE 层的表现
- 表现出强大的信息检索能力,表现为在针句 token 上注意力质量显著增强
- 在开头 token 上出现明显的 attention sink 现象
- 相较于纯 RoPE 或纯 NoPE 模型,其 recency bias 更弱
- RoPE 层的表现
- 检索能力极弱,针句和开头 token 的注意力质量都很低。
- 几乎没有 attention sink 现象。
- 却展现出比纯 RoPE 模型更强的 recency bias。
- 不同 θ 值的影响 :
- 随着 θ 增大,RoPE 层的 recency bias 减弱,表现为对 qc token 的注意力质量下降。
- 这与已有研究一致:增大 θ 会扩展注意力机制的有效感受野,使注意力分布更平坦
- RoPE 层感受野的扩大引入了噪声,干扰了后续 NoPE 层进行相似度计算和信息检索的能力,最终导致针句得分下降。
【结论】
- NoPE 与 RoPE 层的组合具有协同优势 :
- NoPE 层擅长全局信息检索;
- RoPE 层则因具备 recency bias 而适合处理局部上下文信息。
改进方案:RNoPE-10k-swa
基于上述洞察,我们提出了一个新的变体:RNoPE-10k-swa ,其中 “swa” 表示滑动窗口注意力(Sliding Window Attention)。
-
具体做法是:
- 对 RoPE 层设置硬性的注意力窗口大小(设为 8,192),从而限制其有效注意力范围;
- 同时保留 NoPE 层的全注意力机制,用于长上下文信息检索;
- 其他训练参数与 RNoPE-10k 保持一致,包括 θ 值不变。
-
变体取得了显著改进:
- 在 128,000 token 长度下的 NIAH 得分达到 9.562 ,明显优于基线模型和原始 RNoPE-10k;
- NoPE 层展现出结构清晰的注意力模式,表明其具备强大的长上下文检索能力。
模型架构
- 在 Command R+ 架构 (Cohere For AI, 2024)的基础上进行了以下关键架构设计选择:
- 移除 QK-Norm 组件 :由于其注意力模式不佳,严重影响长上下文性能,因此我们决定不再使用 Query-Key Normalization。
- 引入全注意力范围的 NoPE 层 :通过在部分层中使用无位置嵌入(NoPE)机制,增强模型对长距离信息的检索能力。
- 对 RoPE 层应用滑动窗口机制 :设置 RoPE 层的滑动窗口大小为 4,096,利用 RoPE 固有的“最近性偏置”(recency bias),提升模型在中短上下文范围内的表现。
- 全注意力层与滑动窗口层交错比例为 1:3
Experiments
标准基准任务
-
RNope-SWA 在长上下文任务上显著优于基线模型,同时在短上下文任务中也保持竞争力 ,实现了效率与性能之间的良好平衡。
- 在 MMLU 上提升 +2.0%,在 GSM8k 上提升 +1.8%;

- 在 MMLU 上提升 +2.0%,在 GSM8k 上提升 +1.8%;
-
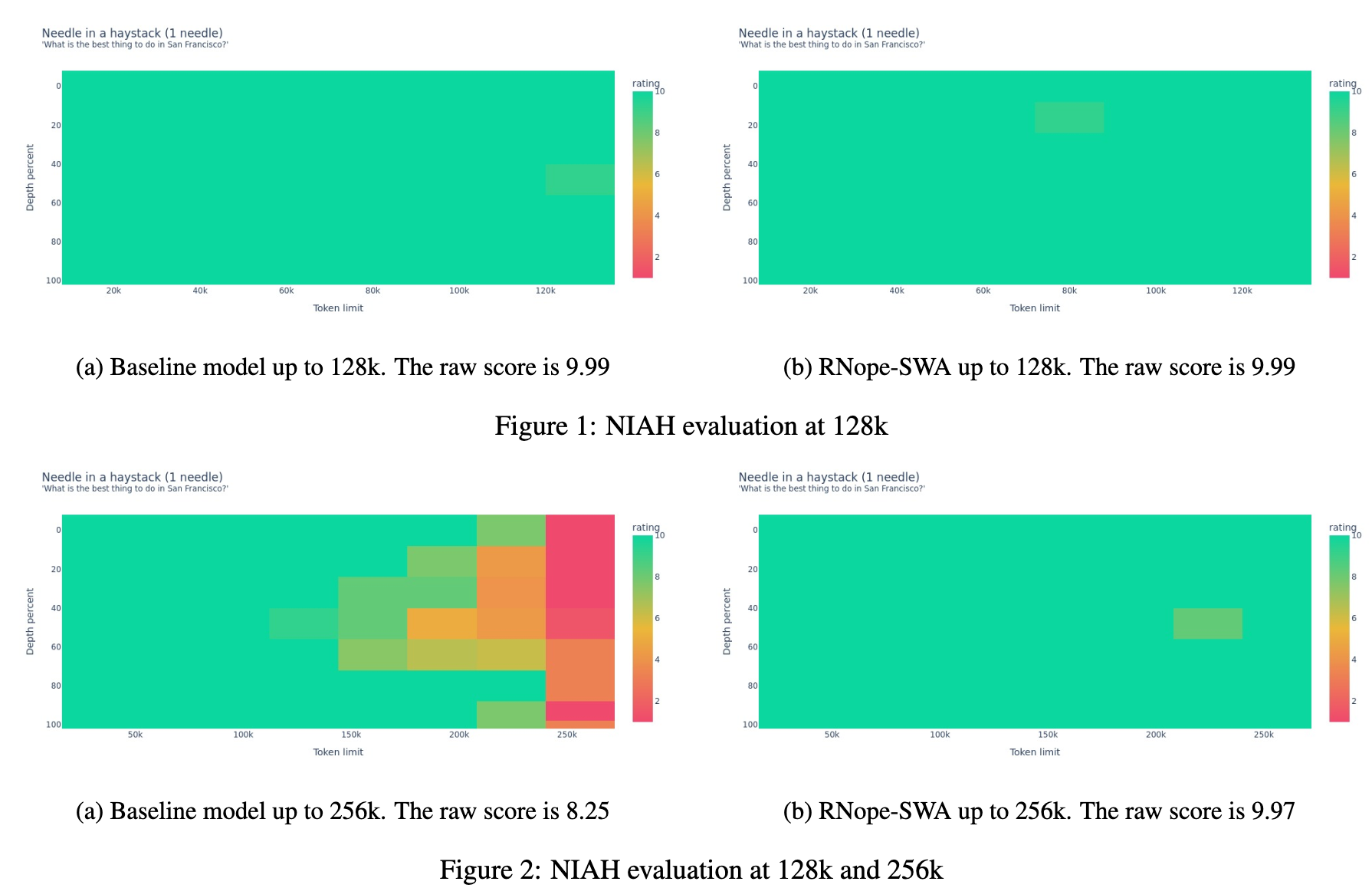
长文本下的检索能力, NIAH 任务(Needles-in-a-Haystack)
- 虽然两个模型在训练见过的上下文长度内都能接近满分,但 RNope-SWA 具有更强的外推能力
- 在 256k 上下文长度下,RNope-SWA 几乎没有性能下降,而 Baseline 即使使用了 θ=8,000,000 的 RoPE 参数,也表现出显著的性能退化
Ruler 基准任务(检索与问答)
Ruler 是比 NIAH 更具挑战性的任务集合,包含多查询/键/值设置、长上下文问答等;
- Baseline 在超过 64k 的上下文长度后性能急剧下降
- 在 8k 到 256k 的变化中:
- 检索任务得分从 96.6 降至 57.1(下降约 41%)
- 问答任务得分从 53.5 降至 30.0(下降约 44%)
- 在 8k 到 256k 的变化中:
- 而 RNope-SWA 分别仅下降 22.1% 和 23.4% ,表现更稳定。

训练与推理效率分析
- 训练阶段:
- 设滑动窗口大小为 S,完整上下文长度为 L;
- 75% 的层现在使用 O(SL) 复杂度计算,而非传统 O(L²);
- 使用 Flash Attention 和序列并行技术(sequence-parallel):
- 在 64k 上下文长度下,训练吞吐量提升约 50%;
- 在 128k 上下文长度下,提升近 2 倍。
- 推理阶段:
- 理论上,KV 缓存最多可节省 75%;
- 实测结果:
- 使用 132k 输入 token、96 输出 token 时,端到端延迟降低约 44%;
- 使用 990k 输入 token、8 输出 token 时,延迟降低近 70%;
Conclusion
- 提出了 RNope-SWA ,一种结合 NoPE 与 RoPE 的混合注意力架构,通过交错使用全注意力与滑动窗口机制,在保持高性能的同时大幅提升训练与推理效率。
相关文章:

RNope:结合 RoPE 和 NoPE 的长文本建模架构
TL;DR 2025 年 Cohere 提出的一种高效且强大的长上下文建模架构——RNope-SWA。通过系统分析注意力模式、位置编码机制与训练策略,该架构不仅在长上下文任务上取得了当前最优的表现,还在短上下文任务和训练/推理效率方面实现了良好平衡。 Paper name …...

22、能源监控与优化 - 数据中心模拟 - /能源管理组件/data-center-energy-monitoring
76个工业组件库示例汇总 能源监控与优化组件 - 数据中心模拟 1. 组件概述 本组件旨在模拟一个典型数据中心的能源消耗情况,并提供实时的监控数据和基本的优化建议/警报功能。用户可以通过界面直观地了解数据中心总体功耗、PUE (电源使用效率)、各部分能耗构成、机…...
)
docker学习与使用(概念、镜像、容器、数据卷、dockerfile等)
文章目录 前言引入docker 简介docker的应用场景docker的虚拟化技术VS虚拟机docker的优点docker架构Docker仓库Docker镜像linux操作系统的大致组成部分 Docker容器 docker安装与启动校验版本移除旧的版本安装依赖工具设置软件源安装docker验证 配置镜像加速器docker服务相关命令…...

突围“百机大战”,云轴科技ZStack智塔获IDC中国AI大模型一体机推荐品牌
随着DeepSeek在今年年初火爆全球,AI大模型市场的“百模大战”已迅速燃向AI一体机市场形成“百机大战”。近日,国际数据公司(IDC)发布的《中国AI大模型一体机市场分析与品牌推荐2025》报告显示,当前中国市场有100多家厂…...

Python-homework
1.if_name_main的含义,why? 假设有一个文件 module.py,内容如下: def greet():print("Hello from module!")if __name__ __main__:print("This is the main script.")greet()如果直接执行 module.py: pyt…...
)
内核性能测试(60s不丢包性能)
以xGAP-200-SE7K-L(双口10G)在飞腾D2000上为例(单通道最高性能约2.8Gbps) 单口测试 0口: tcp: taskset -c 4 iperf -c 1.1.1.1 -i 1 -t 60 -p 60001 taskset -c 4 iperf -s -i 1 -p 60001 udp: taskse…...

解决LeetCode 47. 全排列 II 问题的正确姿势:深入分析剪枝与状态跟踪
文章目录 问题描述常见错误代码与问题分析错误代码示例错误分析 正确解决方案修正后的代码关键修正点 核心逻辑详解1. 为何使用 boolean[] used 而非 HashSet?2. 剪枝条件 !used[i - 1] 的作用 场景对比:何时用数组?何时用哈希表?…...

面向SDV的在环测试深度解析——仿真中间件SIL KIT应用篇
1.引言 在汽车行业向软件定义汽车(SDV)转型的过程中,传统硬件在环(HIL)测试方案因难以适应新的技术架构与需求,其局限性日益凸显。传统HIL对硬件依赖性强,扩展性差,更换ECU或传感器…...

03算法学习_977、有序数组的平方
03算法学习_977、有序数组的平方 03算法学习_977、有序数组的平方题目描述:个人代码:学习思路:移除元素第一种写法:暴力解法题解关键点: 移除元素第二种写法:双指针法(快慢指针)题解…...
)
AWS Elastic Beanstalk控制台部署Spring极简工程(LB版)
问题 之前文章《AWS Elastic Beanstalk控制台部署Spring极简工程》,是最简单的eb设置,里面没有负载均衡器的配置,这次,我需要尝试创建一个有LB的eb部署。 步骤 配置eb 打开eb网页开始创建应用程序,如下图ÿ…...

前端JSON序列化中的隐形杀手:精度丢失全解析与实战解决方案
当你在电商平台看到订单ID从 “1298035313029456899” 变成 “1298035313029456900”,或者在金融系统中发现账户余额 100.01 元变成了 100.00999999999999 元时,这很可能遭遇了前端开发中最隐蔽的陷阱之一 —— JSON序列化精度丢失。本文将深入解析这一问…...

防篡改小工具监测被该文件
核心功能模块 哈希计算模块:通过 SHA-256 算法计算文件的哈希值,用于唯一标识文件内容。基线构建模块:遍历指定目录下的所有文件,计算哈希值并保存到 JSON 文件中,形成初始基线。文件监控模块:使用 watchd…...
)
【四川省专升本计算机基础】第二章 计算机软硬件基础(1)
【四川省专升本计算机基础】第二章 计算机软硬件基础(1) 2.1 计算机系统组成 计算机系统分为硬件系统和软件系统,其详细分类如下图所示: 计算机硬件是由电子、机械和光电原件组成的各种设备和部件的总称。是计算机运行的物质基础。 计算机软件是运行的各种程序、文档和…...

质量管理工程师面试总结
今天闲着无聊参加了学校招聘会的一家双选会企业,以下是面试的过程。 此次面试采用的是一对多的形式。(此次三个求职者,一个面试官) 面试官:开始你们每个人先做个自我介绍吧。 哈哈哈哈哈哈哈哈,其实我们…...

【沉浸式求职学习day41】【Servlet】
沉浸式求职学习 Servlet1.Servlet简介2.HelloServletServlet原理 3.ServletContext共享数据拿到初始化信息请求转发读取资源文件 Servlet 1.Servlet简介 Servlet就是sun公司开发动态web的一门技术。 Sun在这些API中提供一个接口叫做:Servlet,如果你想开…...

Java 多线程基础:Thread 类核心用法详解
一、线程创建 1. 继承 Thread 类(传统写法) class MyThread extends Thread { Override public void run() { System.out.println("线程执行"); } } // 使用示例 MyThread t new MyThread(); t.start(); 缺点:Java 单…...

时频分析的应用—外部信号的显影和定点清除
上面的图样是一张时频图,横坐标是时间,纵坐标是频率,颜色标志着主要的干扰源。50Hz工频谐波。 这类信号在数据分析领域往往是需要过滤掉的杂波。因为这类信号足够强,所以他会在频域弥漫为一组同样特征的谐波信号,比如…...

目标检测指标计算
mAP(mean Average Precision) 概述 预备参数:类别数,IoU阈值;根据模型输出的置信度分数,将所有预测框按从高到低排序;根据IoU是否超过阈值,判断每个预测框是 T P I o U TP_{IoU} T…...

独立开发者利用AI工具快速制作产品MVP
在当今快速发展的科技时代,独立开发者面临着前所未有的机遇与挑战。曾经需要花费数天甚至数周才能完成的产品MVP(Minimum Viable Product,最小可行性产品),如今借助强大的AI工具,可以在短短1小时内实现。 …...

YOLOv3深度解析:多尺度特征融合与实时检测的里程碑
一、YOLOv3的诞生:继承与突破的起点 YOLOv3作为YOLO系列的第三代算法,于2018年由Joseph Redmon等人提出。它在YOLOv2的基础上,针对小目标检测精度低、多类别标签预测受限等问题进行了系统性改进。通过引入多尺度特征图检测、残差网络架构和独…...

MATLAB中的概率分布生成:从理论到实践
MATLAB中的概率分布生成:从理论到实践 引言 MATLAB作为一款强大的科学计算软件,在统计分析、数据模拟和概率建模方面提供了丰富的功能。本文将介绍如何使用MATLAB生成各种常见的概率分布,包括均匀分布、正态分布、泊松分布等,并…...

今日积累:若依框架配置QQ邮箱,来发邮件,注册账号使用
QQ邮箱SMTP服务器设置 首先,我们需要了解QQ邮箱的SMTP服务器地址。对于QQ邮箱,SMTP服务器地址通常是smtp.qq.com。这个地址适用于所有使用QQ邮箱发送邮件的客户端。 QQ邮箱SMTP端口设置 QQ邮箱提供了两种加密方式:SSL和STARTTLS。根据您选…...

MySQL高效开发规范
1.基础规范 数据库字符集默认使用utf8mb4,兼容utf8,并支持存储emoji表情等四字节内容 禁止在线上生产环境做数据库压力测试 禁止从测试、开发环境、本机直连线上生产数据库 禁止在数据库中存储明文密码 禁止在数据库中存储图片、文件等大数据 …...
)
MySQL基础面试通关秘籍(附高频考点解析)
文章目录 一、事务篇(必考重点)1.1 事务四大特性(ACID)1.2 事务实战技巧 二、索引优化大法2.1 索引类型全家福2.2 EXPLAIN命令实战 三、存储引擎选型指南3.1 InnoDB vs MyISAM 终极对决 四、SQL优化实战手册4.1 慢查询七宗罪4.2 分…...
)
信贷风控笔记5——风控贷中策略笔记(面试准备13)
1.划分贷前贷中的标准:授信通过 2.框架:贷中风险管理:用信审批/贷中风险预警 存量客户运营:不仅考虑风险,还要考虑客户需求、体验等因素,通过精细化的客户分层和差异化的权益调整方式ÿ…...

第五章:Linux用户管理
Linux系统中超级用户是root,通过超级用户root可以创建其它的普通用户,Linux是一个支持多用户的操作系统。在实际使用中,一般会分配给开发人员专属的账户,这个账户只拥有部分权限,如果权限太高,操作的范围过…...

低空态势感知:基于AI的DAA技术是低空飞行的重要安全保障-机载端地面端
低空态势感知:基于AI的DAA技术是低空飞行的重要安全保障-机载端&地面端 目前空中已经有大量无人机和其他飞机,未来几年还会有空中出租车。目前,美国每年平均发生 15 到 25 起空中相撞事故。 检测和避免 (DAA) 检测和避免 (DAA) 技术可…...

Web服务器怎么压测?可用什么软件?
针对Web服务器的压力测试,需要系统性地模拟真实用户请求,评估服务器在高并发场景下的性能表现(如吞吐量、响应时间、错误率等)。以下是完整的压测方案和工具选型指南: 一、压测核心指标 指标类型关键指标健康阈值参考并发能力最大支持并发用户数(Concurrency)错误率<…...

IntelliJ IDEA克隆项目失败的解决方法
IntelliJ IDEA克隆项目失败。 咨询AI后,在它建议下,在Windows PowerShell中执行语句,成功克隆。 操作流程如下; 1. 检查网络连接 确保你的网络连接稳定,尝试更换网络环境或使用有线连接代替无线连接。 2. 删除项目 …...

云存储最佳实践
大家好,我是Petter Guo 对Coding充满热情的🐂🐎,坚信实操出真知。在这里,你将听到最真实的经验分享,绝不贩卖焦虑,只提供积极向上的硬核干货,助你一路前行! 如果对你有帮助, 请点赞…...

矫平机技术新维度:材料科学、数字孪生与零缺陷制造
矫平机技术正经历从"被动修正"到"主动预判"的范式革命。本文聚焦三大前沿方向,揭示如何通过跨学科融合实现金属板材加工的极限突破。 一、微观组织调控:材料科学与矫平工艺的量子纠缠 晶粒定向技术 通过矫平过程中的应变诱导取向&a…...

Dify中使用插件LocalAI配置模型供应商报错
服务器使用vllm运行大模型,今天在Dify中使用插件LocalAI配置模型供应商后,使用工作流的时候,报错:“Run failed: PluginInvokeError: {"args":{},"error_type":"ValueError","message":&…...

第二天的尝试
目录 一、每日一言 二、练习题 三、效果展示 四、下次题目 五、总结 一、每日一言 清晰的明白自己想要的是什么,培养兴趣也好,一定要有自己的一技之长。我们不说多优秀,但是如果父母需要我们出力,不要只有眼泪。 二、练习题 对…...

专业版降重指南:如何用Python批量替换同义词?自动化操作不香嘛?
还在手动一个个改词降重?👀 是兄弟就别再CtrlF了,来试试Python自动同义词替换批量降重法,简直是论文改写效率神器! 这篇我们来一波实操干货: 👉 如何用Python写出一个自动替换论文关键词的脚本…...

动态图标切换的艺术
动态图标切换的艺术 - Vue实战指南 图标切换的本质:状态与视觉的双重舞蹈 在前端开发中,图标切换就像我们日常生活中的换装游戏。想象一下,当你按下卧室的开关,灯泡从暗变亮;当你打开衣柜,选择不同场合的着装。图标切换的核心就是根据状态变化呈现不同的视觉效果。 方…...

最小二乘法:从房价预测到损失计算
以下通过一个简单例子说明 y = w x + b y = wx + b y=...
增加发送队列实现全双工通信)
C++ asio网络编程(7)增加发送队列实现全双工通信
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、数据节点设计二、封装发送接口介绍锁mutex和加锁工具lock_guard回调函数的实现为什么在回调函数中也要加锁修改读回调 总结 前言 前文介绍了通过智能指针实…...
】--字符分类函数,字符转换函数,strlen,strcpy,strcat函数的使用和模拟实现)
【C语言字符函数和字符串函数(一)】--字符分类函数,字符转换函数,strlen,strcpy,strcat函数的使用和模拟实现
目录 一.字符分类函数 1.1--字符分类函数的理解 1.2--字符分类函数的使用 二.字符转换函数 2.1--字符转换函数的理解 2.2--字符转换函数的使用 三.strlen的使用和模拟实现 3.1--strlen的使用演示 3.2--strlen的返回值 3.3--strlen的模拟实现 四.strcpy的使用和模拟实现…...

ADC深入——SNR、SFDR、ENOB等概念
目录 SNR(Spurious‑Free Dynamic Range 信噪比) ENOB(Effective Number Of Bits 有效位) SFDR(Spurious‑Free Dynamic Range) 感觉SNR和SFDR差不多?看看下图 输入带宽 混叠 带通采样/欠…...
)
逻辑回归(二分类)
一.逻辑回归的由来 逻辑回归不是一个回归的算法,不是用来做预测的,逻辑回归是一个分类的算法,那为什么不叫逻辑分类?因为逻辑回归算法是基于多元线性回归的算法(多元线性回归:yw0x0w1x1.....wnxn)。正因为…...

深入 Linux 内核:GPU Runtime Suspend 源码和工作流程全面分析
这是系列文章中第二篇,我们将分析完整的 Linux runtime suspend 操作流程,以 Vivante GPU 为例,展示开发者如何通过内核程序实现和调试 runtime PM 机制。 一、内核中的 Runtime PM 工作流程概览 当调用者执行: pm_runtime_put(dev);时&…...

深入理解 this 指向与作用域解析
引言 JavaScript 中的 this 关键字的灵活性既是强大特性也是常见困惑源。理解 this 的行为对于编写可维护的代码至关重要,但其动态特性也会让我们感到困惑。 与大多数编程语言不同,JavaScript 的 this 不指向函数本身,也不指向函数的词法作…...

c++20引入的三路比较操作符<=>
目录 一、简介 二、三向比较的返回类型 2.1 std::strong_ordering 2.2 std::weak_ordering 2.3 std::partial_ordering 三、对基础类型的支持 四、自动生成的比较运算符函数 4.1 std::rel_ops的作用 4.2 使用<> 五、兼容他旧代码 一、简介 c20引入了三路比较操…...
)
Spring框架(三)
目录 一、JDBC模板技术概述 1.1 什么是JDBC模板 二、JdbcTemplate使用实战 2.1 基础使用(手动创建对象) 2.2 使用Spring管理模板类 2.3 使用开源连接池(Druid) 三、模拟转账开发 3.1 基础实现 3.1.1 Service层 3.1.2 Da…...

CS016-4-unity ecs
【37】将系统转换为任务 Converting System to Job 【Unity6】使用DOTS制作RTS游戏|17小时完整版|CodeMonkey|【37】将系统转换为任务 Converting System to Job_哔哩哔哩_bilibili a. 将普通的方法,转化成job。第一个是写一个partial struct xxx;第二…...
——PROJECT#1-BufferPoolManager-Task#2)
CMU-15445(4)——PROJECT#1-BufferPoolManager-Task#2
PROJECT#1-BufferPoolManager Task #2 - Disk Scheduler 在前一节我实现了 TASK1 并通过了测试,在本节中,我将逐步实现 TASK2。 如上图,Page Table(页表)通过哈希表实现,用于跟踪当前存在于内存中的页&am…...
(The Probability Lifesaver)(P10): 生日概率问题.)
[原创](计算机数学)(The Probability Lifesaver)(P10): 生日概率问题.
[作者] 常用网名: 猪头三 出生日期: 1981.XX.XX 企鹅交流: 643439947 个人网站: 80x86汇编小站 编程生涯: 2001年~至今[共24年] 职业生涯: 22年 开发语言: C/C++、80x86ASM、Object Pascal、Objective-C、C#、R、Python、PHP、Perl、 开发工具: Visual Studio、Delphi、XCode、…...

计算机组成原理——数据的表示
2.1数据的表示 整理自Beokayy_ 1.进制转换 十六进制与二进制的转换 一位十六进制等于四位二进制 四位二进制等于一位十六进制 0x173A4C0001 0111 0011 1010 0100 1100 十六进制与十进制的转换 十六转十:每一位数字乘以相应的16的幂再相加 十转十六:…...
)
源码:处理文件格式和字符集的相关代码(3-3)
总入口:源码:处理文件格式和字符集的相关代码(3-1)-CSDN博客 目录 六、预览(正确显示文本文件) 6.1 总体逻辑 6.2 二进制显示 6.3 文本显示 六、预览(正确显示文本文件) 6.1 总…...

Spring MVC 对 JavaWeb 的优化:从核心组件到注解
Spring MVC 功能组件与注解对 JavaWeb 的优化 文章介绍: SpringMVC对比JavaWeb优势,Spring MVC 通过引入功能组件和注解,从多个维度对传统 JavaWeb 开发进行了优化,显著提升了开发效率和代码可维护性。以下是关键优化点的详细对…...