基于策略的强化学习方法之近端策略优化(PPO)深度解析
PPO(Proximal Policy Optimization)是一种基于策略梯度的强化学习算法,旨在通过限制策略更新幅度来提升训练稳定性。传统策略梯度方法(如REINFORCE)直接优化策略参数,但易因更新步长过大导致性能震荡或崩溃。PPO通过引入近端策略优化目标函数和截断技巧(Clipping Trick)替代TRPO的信任区域约束,约束新旧策略之间的差异,避免策略突变,既保持了策略更新的稳定性,又显著降低了计算成本。其核心思想是:在保证策略改进的同时,限制策略更新的幅度。
前文基础:
(1)基于值函数的强化学习算法之Q-Learning详解:基于值函数的强化学习算法之Q-Learning详解_网格世界q值-CSDN博客
(2)基于值函数的强化学习算法之SARSA详解:基于值函数的强化学习算法之SARSA详解_sarsa算法流程-CSDN博客
(3)基于值函数的强化学习算法之深度Q网络(DQN)详解:基于值函数的强化学习算法之深度Q网络(DQN)详解_dqn算法对传统q-learning算法进行了改进,使用了神经网络(结构可以自行设计)对acti-CSDN博客(4)基于策略的强化学习方法之策略梯度(Policy Gradient)详解:基于策略的强化学习方法之策略梯度(Policy Gradient)详解-CSDN博客
一、理论基础
(一)强化学习与策略梯度方法概述
1. 强化学习基本框架
强化学习(Reinforcement Learning, RL)旨在解决智能体与环境交互过程中的序列决策问题。其核心要素包括:
(1)环境(Environment):用马尔可夫决策过程(MDP)建模,状态空间S,动作空间A,转移概率p(s′|s,a),奖励函数r(s,a,s′)。马尔可夫决策过程(MDP)示例图:
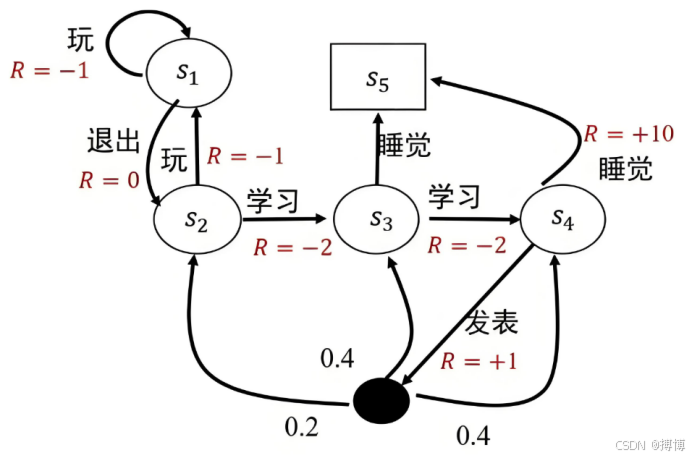
(2)智能体(Agent):通过策略π(a|s)选择动作,目标是最大化长期累积奖励的期望,即回报![]() 的期望,其中γ∈[0,1]为折扣因子。
的期望,其中γ∈[0,1]为折扣因子。
回报公式说明:回报是智能体从时刻t开始的未来累积奖励,通过折扣因子γ对远期奖励进行衰减,体现“即时奖励比远期奖励更重要”的特性。γ=0时仅考虑即时奖励,γ=1时等同蒙特卡洛回报(无折扣)。引入折扣因子可确保无限序列的期望收敛,便于数学处理。
(3)价值函数:状态价值函数![]() ,动作价值函数
,动作价值函数![]() 。
。
状态价值函数说明:表示在策略π下,从状态s出发的期望回报,是评估策略长期性能的核心指标。满足贝尔曼方程:![]() ,体现递归性质。
,体现递归性质。
动作价值函数说明:表示在策略π下,从状态s执行动作a后的期望回报,用于比较不同动作的优劣。与状态价值函数的关系:![]() ,即状态价值是动作价值的策略期望。
,即状态价值是动作价值的策略期望。
以下是强化学习核心三要素之间的关系:
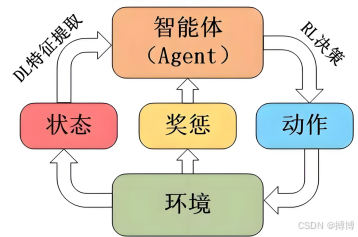
强化学习基本框架如下:
2. 策略梯度方法核心思想
策略梯度方法直接对策略进行参数化(θ为参数),通过优化目标函数提升策略性能。常见目标函数
包括:
(1)初始价值(Start Value):![]() ,对应从初始状态出发的期望回报。
,对应从初始状态出发的期望回报。
(2)平均价值(Average Value):![]() ,其中
,其中为策略π下的状态分布。
(3)平均奖励(Average Reward):![]() ,适用于无限horizon问题。
,适用于无限horizon问题。
策略梯度定理表明,在参数θ下的目标函数的梯度可表示为:
![]()
该公式揭示了策略优化的本质:通过提升高价值动作的选择概率,降低低价值动作的选择概率。
(二)近端策略优化(PPO)的提出背景
1. 传统策略梯度方法的局限性
(1)高方差问题:直接使用θ参数下的动作价值函数作为优势估计会引入较大方差,通常用优势函数
![]() 替代,以减少基线(Baseline)以上的波动。
替代,以减少基线(Baseline)以上的波动。
(2)样本效率低:策略更新后需重新收集数据,导致离线策略(Off-Policy)方法难以直接应用。
2. 信任区域策略优化(TRPO)的改进与不足
TRPO 通过引入信任区域(Trust Region)约束,确保策略更新不会导致性能大幅下降。其优化目标为:
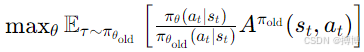
约束条件为:
![]()
TRPO通过共轭梯度法求解带约束的优化问题,保证了单调改进,但计算复杂度高(需计算Hessian矩阵),工程实现难度大。
3. PPO的核心创新
PPO通过近端策略优化目标函数和截断技巧(Clipping Trick)替代TRPO的信任区域约束,既保持了策略更新的稳定性,又显著降低了计算成本。其核心思想是:在策略更新时,限制新旧策略的概率比值在合理范围内,避免过大的策略变化。
二、数学基础
(一)策略梯度与重要性采样
先对公式关联关系进行说明:
(1)策略梯度定理是所有策略优化方法的基石,引出了优势函数的核心作用。
(2)重要性采样使离线策略优化成为可能,是PPO复用旧样本的理论基础。
(3)GAE通过加权求和优化优势估计,提升了策略梯度的估计精度,直接影响PPO目标函数的有效性。
(4)TRPO的信任区域思想通过PPO的截断技巧近似实现,平衡了优化效率与稳定性。
(5)梯度裁剪、归一化从数学层面解决了优化过程中的数值稳定性问题,确保理论公式在实际训练中有效落地。
1. 策略梯度推导
目标函数:
![]()
梯度推导:
(1)对目标函数求导,利用期望的线性性质和链式法则:
![]()
其中,表示轨迹,
是策略的对数概率,其梯度指示策略参数变化对动作概率的影响方向。
(2)引入价值函数作为基线(Baseline),消去常数项以减少方差
![]()
其中,![]() 为差分误差(TD Error),等价于优势函数
为差分误差(TD Error),等价于优势函数。
(3)代入后化简得策略梯度定理,因此,在θ参数下的策略梯度可简化为:
![]()
物理意义:策略梯度是优势函数与策略对数梯度的期望,表明应增加高优势动作的概率,降低低优势动作的概率。
2. 重要性采样(Importance Sampling)
在离线策略优化中,利用旧策略收集的数据训练新策略
,需通过重要性采样权重校正分布差异:
![]()
重要性采样权重的说明:用于离线策略优化,校正旧策略
与新策略
的分布差异。权重是轨迹中各动作概率比值的累积乘积,反映新旧策略生成该轨迹的相对概率。
则离线策略梯度可表示为:
![]()
通过重要性采样,可利用旧策略收集的数据优化新策略,避免频繁交互环境,提升样本效率。但权重可能导致高方差,需通过优势函数归一化或截断技巧缓解。
(二)优势函数估计与广义优势估计(GAE)
1. 优势函数的作用
优势函数表示动作a在状态s下相对于平均动作的优劣,其估计精度直接影响策略更新的稳定性。若直接使用蒙特卡洛回报
作为优势估计,方差较高;若使用TD误差
,偏差较高。
2. 广义优势估计(GAE)
GAE通过引入参数λ∈[0,1]平衡偏差与方差,其递归公式为:
![]()
其中,![]() 。表示当前状态价值估计与下一状态价值估计的差异,是单步引导(Bootstrapping)的结果。低方差但有偏差(依赖价值函数估计精度)。当λ=0时,退化为TD误差,等价于单步优势估计(低方差,高偏差);当λ=1时,等价于蒙特卡洛优势估计(无偏差,高方差),通常取λ∈[0.9, 0.99]平衡偏差与方差。将GAE递归公式展开,等价于加权求和,因此,GAE的优势估计可表示为:
。表示当前状态价值估计与下一状态价值估计的差异,是单步引导(Bootstrapping)的结果。低方差但有偏差(依赖价值函数估计精度)。当λ=0时,退化为TD误差,等价于单步优势估计(低方差,高偏差);当λ=1时,等价于蒙特卡洛优势估计(无偏差,高方差),通常取λ∈[0.9, 0.99]平衡偏差与方差。将GAE递归公式展开,等价于加权求和,因此,GAE的优势估计可表示为:
![]()
该估计具有较低的方差和较好的计算效率,是PPO的关键技术之一。
补充:蒙特卡洛优势:
![]()
直接使用实际回报减去状态价值,无偏差但方差高(需完整轨迹)。
(三)PPO目标函数推导
1. 原始目标函数与截断思想
PPO的优化目标基于重要性采样的策略梯度,结合截断技巧防止策略更新幅度过大。定义概率比值:
![]()
概率比值用于衡量新旧策略在相同状态下选择相同动作的概率变化,表示新策略更倾向于该动作,反之则更抑制。
则截断目标函数为:
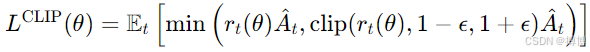
其中,clip(·,l,u)为截断函数,将概率比值限制在[1−ϵ,1+ϵ]范围内。截断目标函数的推导逻辑:
(1)当优势函数时(高价值动作),鼓励
增大以提升动作概率,但不超过1+ϵ,避免过度偏离旧策略;
(2)当时(低价值动作),限制
减小以降低动作概率,但不低于1−ϵ,从而避免策略更新过于激进;
(3)clip函数形成 “安全区间”,确保策略更新在旧策略的“近端”范围内,类似TRPO的信任区域约束。
2. 包含价值函数的联合优化目标
为同时优化价值函数,PPO引入价值损失,并通过熵正则项
增强探索性,最终联合目标函数为:
![]()
其中,各分量作用:
(1):策略优化的核心项,平衡性能提升与稳定性。
(2):价值损失通常采用均方误差(MSE),提升优势估计精度(优势估计为:
![]() ):
):
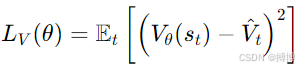
为目标价值,可通过GAE计算的回报
![]() 得到。
得到。
(3)熵正则项![]() ,鼓励策略探索,用于防止策略过早收敛到确定性策略。
,鼓励策略探索,用于防止策略过早收敛到确定性策略。
3. PPO与TRPO的理论关联
TRPO通过KL散度约束确保策略更新在信任区域内,而PPO通过截断概率比值间接实现类似约束。理论上,当ϵ较小时,PPO的截断操作近似于TRPO的信任区域约束,但计算复杂度显著降低。
(1)TRPO约束条件:
![]()
解析:通过KL散度约束新旧策略的分布差异,确保策略更新在“信任区域”内,理论上保证性能单调提升。需计算二阶导数(Hessian 矩阵),计算复杂度高。
(2)PPO的近似性:当ϵ较小时,截断操作近似于KL散度约束。例如,若![]() ,则对数概率差异
,则对数概率差异![]() ,根据泰勒展开:
,根据泰勒展开:
![]()
即ϵ间接控制了KL散度的上界,实现与TRPO类似的稳定性保证,但无需显式计算KL散度。
三、网络结构
(一)Actor-Critic 架构
1. 网络组成
PPO采用Actor-Critic架构(策略+价值学习),包含两个神经网络:
(1)Actor策略网络:输入状态s,输出动作概率分布,对于离散动作空间通常使用Softmax层,连续空间则使用高斯分布(输出均值和标准差)。
(2)Critic价值网络:输入状态s,输出价值估计,通常为全连接网络,输出标量值。
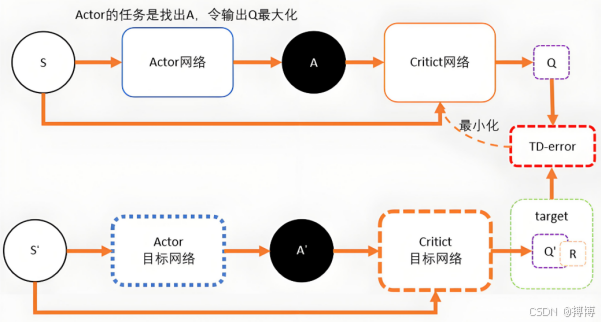
2. 共享特征提取层
为提高样本效率,Actor和Critic网络通常共享前几层卷积层(图像输入)或全连接层(状态为向量时),仅在输出层分支为策略输出和价值输出。例如,对于Atari游戏,共享卷积层提取视觉特征,Actor输出各动作概率,Critic输出价值估计。
(二)执行流程图
PPO执行流程:
初始化策略网络π_old和π_new,价值网络V,优化器
for 每个训练周期:
1. 数据收集阶段:
用π_old与环境交互,收集轨迹D = {(s_t, a_t, r_t, s_{t+1})}
计算优势估计Â_t和目标价值Ŕ_t(使用GAE)
2. 策略更新阶段:
将D输入π_new,计算概率比值r_t = π_new(a_t|s_t)/π_old(a_t|s_t)
计算截断目标函数L_CLIP = min(r_t*Â_t, clip(r_t, 1-ε, 1+ε)*Â_t)
计算熵损失L_ent = -E[log π_new(a_t|s_t)]
总策略损失L_pi = -E[L_CLIP + c2*L_ent]
反向传播更新π_new参数
重复K次更新(通常K=3-10)
3. 价值网络更新阶段:
计算价值损失L_v = MSE(V(s_t), Ŕ_t)
反向传播更新V参数
4. 同步策略网络:
π_old = π_new
end for
(三)关键组件细节
1. 经验回放与批量处理
PPO通常不使用大规模经验回放缓冲区(因策略更新需保证数据来自相近策略),而是将每个周期收集的轨迹分割为多个小批量(Mini-Batch),在每个小批量上进行多次更新,以模拟SGD的效果,减少内存占用。
2. 优势归一化
为稳定训练,通常对优势估计进行归一化处理,使其均值为0,标准差为1:
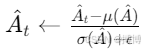
其中ϵ为极小值防止除零。
3. 动作空间处理
(1)离散动作空间:Actor网络输出各动作的logits,经Softmax得到概率分布,采样时根据概率选择动作。
(2)连续动作空间:Actor网络输出动作均值μ和对数标准差,动作通过
采样,其中
。
四、工程化实现技术
(一)优化技巧
1. 梯度裁剪(Gradient Clipping)
为防止梯度爆炸,对策略梯度和价值梯度进行范数裁剪:
![]()
前者为值裁剪,后者为范数裁剪,实际中范数裁剪更常用。
解析:将梯度范数限制在c以内,防止梯度爆炸(如||g||过大时,梯度方向不变但幅值缩放)。数学上保证优化过程的稳定性,避免参数更新步长过大导致振荡。
优势归一化:
![]()
解析:将优势估计标准化为均值 0、标准差1的分布,避免不同批次数据的尺度差异影响训练。减少梯度方差,加速收敛,尤其在多环境并行训练时效果显著。
2. 学习率衰减
采用线性衰减或指数衰减学习率,提升训练后期的稳定性。例如,线性衰减公式为:
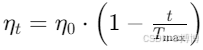
其中t为当前训练步数,为总步数。
3. 参数初始化
使用正交初始化(Orthogonal Initialization)对网络权重进行初始化,激活函数通常选择 ReLU或Tanh。例如,Actor网络的输出层权重初始化为0.01,以避免初始策略过于确定。
(二)并行训练与样本效率提升
1. 向量化环境(Vectorized Environment)
通过并行运行多个环境实例(如使用SubprocVecEnv),同时收集多条轨迹,减少CPU空闲时间。例如,在Python中使用gym.vector库创建向量化环境:
python代码:
from gym.vector import SyncVectorEnvenv = SyncVectorEnv([lambda: gym.make("CartPole-v1") for _ in range(8)])2. 异步策略更新(Asynchronous Update)
在分布式架构中,多个工作节点(Worker)并行收集数据,参数服务器(Parameter Server)汇总梯度并更新全局模型。该方法可显著提升样本采集速度,但需注意策略过时(Staleness)问题。
(三)部署与泛化能力增强
1. 环境归一化
对状态输入进行归一化处理,如减去均值、除以标准差,可提升模型泛化能力。通常维护一个运行均值和方差,在训练过程中动态更新:
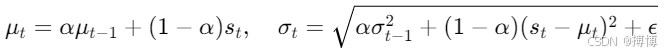
2. 多任务学习与迁移学习
通过预训练模型在相似任务上的参数,初始化目标任务的网络,可加速收敛。例如,在机器人控制中,先在仿真环境中训练PPO模型,再通过域随机化(Domain Randomization)迁移到真实环境。
五、Python 完整示例(以 CartPole 为例)
(一)环境配置与依赖安装
python代码:
import gymimport torchimport torch.nn as nnimport torch.optim as optimfrom torch.distributions import Categoricalimport numpy as np# 超参数LR = 3e-4GAMMA = 0.99EPS_CLIP = 0.2K_EPOCHS = 4UPDATE_INTERVAL = 2000ENTROPY_COEF = 0.01VALUE_COEF = 0.5(二)Actor-Critic网络定义
python代码:
class ActorCritic(nn.Module):def __init__(self, state_dim, action_dim):super(ActorCritic, self).__init__()self.common = nn.Sequential(nn.Linear(state_dim, 64),nn.ReLU(),nn.Linear(64, 64),nn.ReLU())self.actor = nn.Linear(64, action_dim)self.critic = nn.Linear(64, 1)def forward(self, state):x = self.common(state)action_logits = self.actor(x)value = self.critic(x)return action_logits, valuedef act(self, state):state = torch.from_numpy(state).float().unsqueeze(0)action_logits, _ = self.forward(state)dist = Categorical(logits=action_logits)action = dist.sample()return action.item(), dist.log_prob(action)(三)PPO算法实现
python代码:
class PPO:def __init__(self, state_dim, action_dim):self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")self.policy = ActorCritic(state_dim, action_dim).to(self.device)self.optimizer = optim.Adam(self.policy.parameters(), lr=LR)self.MseLoss = nn.MSELoss()def select_action(self, state):with torch.no_grad():action, log_prob = self.policy.act(state)return action, log_probdef update(self, transitions):states, actions, log_probs_old, rewards, next_states, dones = zip(*transitions)# 预计算优势函数和目标价值,避免在训练循环中重复计算states_tensor = torch.FloatTensor(states).to(self.device)next_states_tensor = torch.FloatTensor(next_states).to(self.device)# 计算优势函数和目标价值(使用GAE)with torch.no_grad():values = self.policy.forward(states_tensor)[1].squeeze()next_values = self.policy.forward(next_states_tensor)[1].squeeze()rewards_tensor = torch.FloatTensor(rewards).to(self.device)dones_tensor = torch.FloatTensor(dones).to(self.device)deltas = rewards_tensor + GAMMA * next_values * (1 - dones_tensor) - valuesadvantages = self.gae(deltas, values, next_values, dones_tensor)returns = values + advantages# 标准化优势函数advantages = (advantages - advantages.mean()) / (advantages.std() + 1e-8)# 将数据转换为张量并移动到设备actions_tensor = torch.LongTensor(actions).to(self.device)log_probs_old_tensor = torch.FloatTensor(log_probs_old).to(self.device)# PPO更新 - 每次迭代重新计算损失for _ in range(K_EPOCHS):# 重新计算当前策略下的动作概率和价值估计action_logits, values_pred = self.policy.forward(states_tensor)dist = Categorical(logits=action_logits)log_probs = dist.log_prob(actions_tensor)entropy = dist.entropy().mean()# 计算概率比值和截断目标ratios = torch.exp(log_probs - log_probs_old_tensor)surr1 = ratios * advantagessurr2 = torch.clamp(ratios, 1-EPS_CLIP, 1+EPS_CLIP) * advantagespolicy_loss = -torch.min(surr1, surr2).mean()value_loss = self.MseLoss(values_pred.squeeze(), returns)total_loss = policy_loss + VALUE_COEF * value_loss - ENTROPY_COEF * entropyself.optimizer.zero_grad()total_loss.backward()nn.utils.clip_grad_norm_(self.policy.parameters(), 0.5) # 梯度裁剪self.optimizer.step()def gae(self, deltas, values, next_values, dones):advantages = torch.zeros_like(deltas)running_advantage = 0for t in reversed(range(len(deltas))):running_advantage = deltas[t] + GAMMA * 0.95 * running_advantage * (1 - dones[t])advantages[t] = running_advantagereturn advantages(四)训练与测试流程
python代码:
def train():env = gym.make("CartPole-v1")state_dim = env.observation_space.shape[0]action_dim = env.action_space.nppo = PPO(state_dim, action_dim)print("开始训练...")running_reward = 0transitions = []for step in range(1, 1000001):state, _ = env.reset()episode_reward = 0while True:action, log_prob = ppo.select_action(state)next_state, reward, terminated, truncated, _ = env.step(action)done = terminated or truncated # 合并终止和截断标志transitions.append((state, action, log_prob, reward, next_state, done))episode_reward += rewardstate = next_stateif len(transitions) >= UPDATE_INTERVAL or done:ppo.update(transitions)transitions = []if done:running_reward = 0.99 * running_reward + 0.01 * episode_reward if running_reward != 0 else episode_rewardprint(f"Step: {step}, Reward: {episode_reward:.2f}, Running Reward: {running_reward:.2f}")break# 训练完成后保存模型torch.save(ppo.policy.state_dict(), "ppo_cartpole.pth") # 修改:使用实例变量ppoenv.close()return ppo # 返回训练好的模型实例def test():env = gym.make("CartPole-v1", render_mode="human")state_dim = env.observation_space.shape[0]action_dim = env.action_space.nppo = PPO(state_dim, action_dim)ppo.policy.load_state_dict(torch.load("ppo_cartpole.pth"))state, _ = env.reset()while True:action, _ = ppo.select_action(state)state, reward, terminated, truncated, _ = env.step(action)done = terminated or truncatedenv.render()if done:breakenv.close()if __name__ == "__main__":trained_ppo = train() # 保存训练好的模型实例test()要执行的步骤次数在train()函数中修改,当前默认是1000000次,会很久。训练过程如下:
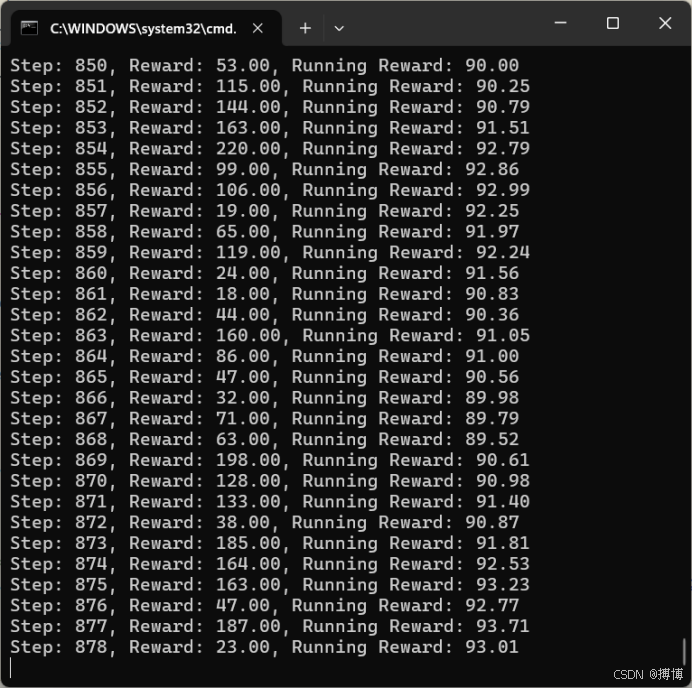
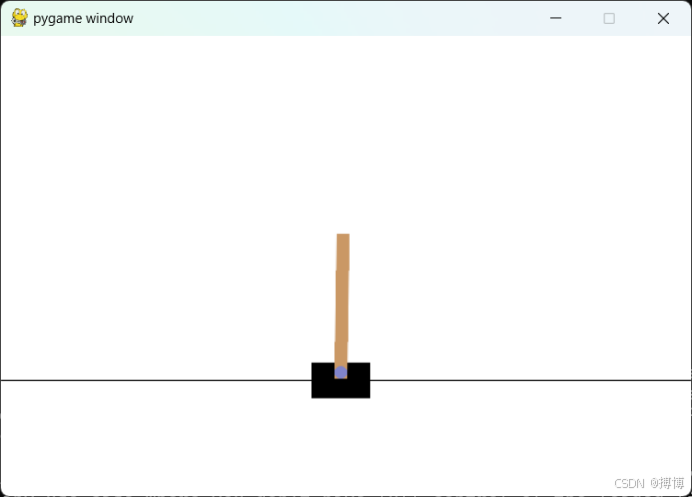
效果如下:
六、总结与扩展
(一)PPO的优缺点分析
1.优点:
(1)稳定性强:通过截断技巧有效控制策略更新幅度,避免性能骤降。
(2)样本效率高:支持离线策略优化,可重复利用旧样本。
(3)工程友好:无需复杂的二阶导数计算,易于实现和调试。
2.缺点:
(1)超参数敏感:ϵ、K_EPOCHS等参数需仔细调整。
(2)连续动作空间处理:需额外设计动作分布(如高斯分布),收敛速度可能慢于离散空间。
(二)扩展方向
1. 连续动作空间优化
对于机器人控制等连续动作场景,可将Actor网络改为输出高斯分布的均值和标准差,并使用Tanh激活函数限制动作范围。此时,概率比值计算需考虑动作空间的雅可比行列式(Jacobian Determinant)。
2. 多智能体强化学习
将PPO扩展至多智能体场景(如MADDPG),需引入全局状态或联合动作空间,并设计通信机制或集中式评论家(Centralized Critic)。
3. 与模仿学习结合
通过逆强化学习(IRL)从专家数据中学习奖励函数,结合PPO进行策略优化,可提升在复杂环境中的表现。
(三)理论延伸:PPO 的收敛性分析
尽管 PPO未严格证明全局收敛性,但其通过截断操作保证了每次更新的单调改进(在理想情况下)。研究表明,当学习率足够小且截断参数ϵ适当,PPO可收敛到局部最优策略,其性能接近TRPO但计算成本更低。
全文总结:
PPO通过理论创新(截断目标函数)和工程优化(梯度裁剪、批量更新),成为当前最流行的策略梯度方法之一。其数学基础融合了策略梯度、重要性采样和信任区域思想,网络结构基于Actor-Critic架构,工程实现中通过多种技巧提升稳定性和样本效率。通过上述深度解析,读者可全面掌握PPO的核心原理与实践方法,并能根据具体场景进行扩展应用。
相关文章:
深度解析)
基于策略的强化学习方法之近端策略优化(PPO)深度解析
PPO(Proximal Policy Optimization)是一种基于策略梯度的强化学习算法,旨在通过限制策略更新幅度来提升训练稳定性。传统策略梯度方法(如REINFORCE)直接优化策略参数,但易因更新步长过大导致性能震荡或崩溃…...

前端图形渲染 html+css、canvas、svg和webgl绘制详解,各个应用场景及其区别
在前端开发中,HTMLCSS、Canvas、SVG 和 WebGL 是实现图形渲染的四种常见技术。它们各自具有不同的特点和适用场景。以下是对这四种技术的详细解析: 1. HTML CSS 特点: 主要用于构建网页的结构和样式。通过 CSS 可以实现简单的图形效果&am…...

《Navicat之外的新选择:实测支持国产数据库的SQLynx核心功能解析》
数据库工具生态的新变量 在数据库管理工具领域,Navicat长期占据开发者心智。但随着国产数据库崛起和技术信创需求,开发者对工具的兼容性、轻量化和本土化适配提出了更高要求。近期体验了一款名为SQLynx的国产数据库管理工具(麦聪旗下产品&am…...

Elasticsearch 快速入门指南
1. Elasticsearch 简介 Elasticsearch 是一个基于 Lucene 的开源分布式搜索和分析引擎,由 Elastic 公司开发。它具有以下特点: 分布式:可以轻松扩展到数百台服务器,处理 PB 级数据实时性:数据一旦被索引,…...

解决Mawell1.29.2启动SQLException: You have an error in your SQL syntax问题
问题背景 此前在openEuler24.03 LTS环境下的Hive使用了MySQL8.4.2,在此环境下再安装并启动Maxwell1.29.2时出现如下问题 [ERROR] Maxwell: SQLException: You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version f…...

【Conda】环境应用至JupyterLab
目录 ✅ 步骤一:激活你的 conda 虚拟环境 ✅ 步骤二:安装 ipykernel(如果尚未安装) ✅ 步骤三:将环境注册为 Jupyter 内核 ✅ 步骤四:启动 JupyterLab 并选择内核 🧼 可选:删除…...

英语六级听力
试卷结构考试内容数量听力理解长对话8*7.1分听力篇章7*7.1分讲话/报道/讲座10*14.2分考点分析 A. 理解明示的信息 理解主旨大意听懂重要信息或特定的细节理解说话人明确表达的观点、态度等B. 理解隐含的信息 推论隐含的意义判断话语的交际功能推断说话人的观点、态度等C. 运用…...

视差计算,求指导
通过SGBM算法算出来的视差图,照片是3072*3072的, numDisparities是112,bloksize是7 不知道怎么调整了,求指导...

各个历史版本mysql/tomcat/Redis/Jdk/Apache/gitlab下载地址
mysql 各版本下载地址: https://downloads.mysql.com/archives/community/ **************************************************************** tomcat 各版本下载地址: https://archive.apache.org/dist/tomcat/ ********************************…...

【Redis】压缩列表
目录 1、背景2、压缩列表【1】底层结构【2】特性【3】优缺点 1、背景 ziplist(压缩列表)是redis中一种特殊编码的双向链表数据结构,主要用于存储小型列表和哈希表。它通过紧凑的内存布局和特殊的编码方式来节省内存空间。 2、压缩列表 【1…...
)
计算机网络--第一章(上)
目录 1.计算机网络的概念 2.计算机网络的组成、功能 3.交换 3.1 电路交换 3.2 报文交换 3.3 分组交换 3.4 虚拟电路交换 4.交换的性能分析 4.1 电路交换 4.2 报文交换 4.3 分组交换 4.4 总结 5.计算机网络的分类 5.1 分布范围分类 5.2 传输技术分类 5.3 拓扑结…...
)
hbit资产收集工具Docker(笔记版)
1. 安装 Docker 在 Kali 系统中,首先更新软件源,并安装 Docker apt-get update && apt-get upgrade && apt-get dist-upgrade apt-get install docker.io docker-compose安装完成后,使用 docker -v 命令验证安装是否成功。…...

套路化编程:C# winform ListView 自定义排序
初级代码游戏的专栏介绍与文章目录-CSDN博客 我的github:codetoys,所有代码都将会位于ctfc库中。已经放入库中我会指出在库中的位置。 这些代码大部分以Linux为目标但部分代码是纯C的,可以在任何平台上使用。 源码指引:github源…...

CSS3 变形
一、CSS3变形(Transform)是一些效果的集合,有以下几种: 平移(Translate):元素沿水平或垂直方向移动。旋转(Rotate):元素绕某点旋转一定的角度。缩放…...

【python基础知识】Day26 函数
一、函数的定义 函数是一段具有特定功能的、可重用的语句组,用函数名来表示。在需要使用函数时,通过函数名进行调用。函数也可以看作一段具有名字的子程序,可以在需要使用它的地方进行调用执行,不需要在每个执行的地方重复编写这些…...

C#中Action的用法
Action 是 C# 中委托的一种,用于封装无返回值的方法。它引用的方法不能有返回值,但可以有零个或多个参数。相比delegate委托,Action 委托的优点是不必显式定义封装无参数过程的委托,使代码更加简洁和易读。 1、delegate-委托 先…...
IOS CSS3 right transformX 动画卡顿 回弹
卡片从右往左滑动,在同时变换 width height right transformX的时候 在某些IPhone机型上 会有卡顿,在Chrome和Android等很多机型都是OK的,包括我的iphone 14 pro max. IOS 18.2 也是好的。但是,新的iPhone16 也会卡,会…...

ruskal 最小生成树算法
https://www.lanqiao.cn/problems/17138/learning/ 并查集ruskal 最小生成树算法 Kruskal 算法是一种用于在加权无向连通图中寻找最小生成树(MST)的经典算法。其核心思想是基于贪心策略,通过按边权从小到大排序并逐步选择边,确保…...

多系统环境下,如何构建高效的主数据管理体系?
企业信息化建设步伐不断加快,各类业务系统如雨后春笋般涌现,如ERP、CRM、SCM、MES等等。然而,系统繁多也带来了一个棘手的问题:数据孤岛。各系统间数据标准不一、信息不流通、口径不统一,导致企业主数据(如…...

Linux515 rsync定时备份
凌晨1时三分进行备份 源码 code: code指定文件夹定时备份rsync到备份机指定文件夹 一.环境配置(code,backup) 1.关闭防火墙 设置selinux相关为0 setenforce 0 /etc/selinux/config SELINUXdisable 分别配置 2.设置主机名 3.配置ip地址(…...

Claude官方63组提示词模板全解析:从工作到生活的AI应用指南
在当今AI技术飞速发展的时代,大模型如ChatGPT、Claude等已成为我们工作和生活中不可或缺的助手。然而,许多用户发现同样的AI工具在不同人手中能产生截然不同的效果——关键在于提示词(Prompt)的质量。 提示词是与AI沟通的桥梁,好的提示词能…...

C#中的typeof操作符与Type类型:揭秘.NET反射的基础
引言 在C#编程中,反射(Reflection)是一种强大的机制,它允许我们在运行时检查和操作类型、方法、属性等程序元素。而这种反射能力的核心就是typeof操作符和System.Type类。当我们希望动态加载程序集、创建对象实例、调用方法&…...

鸿蒙OSUniApp 实现的表单验证与提交功能#三方框架 #Uniapp
UniApp 实现的表单验证与提交功能 前言 在移动端应用开发中,表单是用户与应用交互的重要媒介。一个好的表单不仅布局合理、使用方便,还应该具备完善的验证与提交功能,以确保用户输入的数据准确无误。本文将分享如何在 UniApp 中实现表单验证…...

开源的跨语言GUI元素理解8B大模型:AgentCPM-GUI
一、模型概述 AgentCPM-GUI 是由清华大学自然语言处理实验室 (THUNLP) 和 ModelBest 联合开发的开源大模型。该模型基于 MiniCPM-V 架构,拥有 80 亿参数规模,是一个能够直接在终端设备上运行的轻量化智能体。它创新性地将多模态输入与 GUI 操作相结合&a…...

Function Calling
在介绍Function Calling之前我们先了解一个概念,接口。 接口 两种常见接口: 人机交互接口,User Interface,简称 UI应用程序编程接口,Application Programming Interface,简称 API接口能「通」的关键,是两边都要遵守约定。 人要按照 UI 的设计来操作。UI 的设计要符合人…...

星巴克中国要卖在高点
9%能否救70%的急? 作者|古廿 编辑|文昌龙 星巴克中国刚刚回暖,总部出售的计划再次提上日程。 5月15日,外媒又适时放出消息:星巴克将开始出售其在中国的股份。消息人士称,星巴克本周通过一位财务顾问向几位潜在投资…...

Docker实现MySQL数据库主从复制
一、拉取数据库镜像 docker pull mysql:5.7二、创建两个数据库(一主一从模式) mysql01(主) 1.docker run -d -p 3310:3306 -v /root/mysql/node-1/init:/docker-entrypoinit-initdb.d -v /root/mysql/node-1/config:/etc/mysql/conf.d -v /root/mysq…...

【物联网】基于树莓派的物联网开发【4】——WIFI+SSH远程登录树莓派
使用背景 没有有线网络,无屏幕如何远程登录?程序猫教大家如何通过电脑wifi热点的方式连接树莓派,ssh连接访问树莓派,包括putty开源远程工具进行连接,VNC远程桌面显示。 注:新手建议买一个树莓派配置的显示…...

CentOS7 OpenSSL升级1.1.1w
1.安装依赖 # openssl-3.4.0需要perl-IPC-Cmd perl-Data-Dumper yum -y install gcc* yum -y install perl-IPC-Cmd perl-Data-Dumper 2.备份、卸载旧OpenSSL 查找安装目录并备份 # whereis openssl openssl: /usr/bin/openssl /usr/lib64/openssl /usr/share/man/man1/op…...

高精度降压稳压技术在现代工业自动化中的应用
一、引言 在现代工业自动化的浪潮中,电源管理技术犹如隐藏在精密机械背后的智囊,虽不直接参与生产流程的逻辑决策,却是保障各类自动化设备稳定、高效运行的基石。高精度降压稳压技术,作为电源管理领域的核心分支,聚焦…...
#三方框架 #Uniapp)
鸿蒙OSUniApp制作动态筛选功能的列表组件(鸿蒙系统适配版)#三方框架 #Uniapp
使用UniApp制作动态筛选功能的列表组件(鸿蒙系统适配版) 前言 随着移动应用的普及,用户对应用内容检索和筛选的需求也越来越高。在开发跨平台应用时,动态筛选功能已成为提升用户体验的重要组成部分。本文将详细介绍如何使用UniA…...

Qt中控件的Viewport作用
在Qt中,viewport是控件中用于显示内容的一个概念区域,它在可滚动控件中尤为重要。以下是viewport的主要作用和特点: 主要作用 内容显示区域:viewport定义了控件中实际可见的部分,所有内容都在这个区域内显示。 滚动机…...

论文学习_Precise and Accurate Patch Presence Test for Binaries
摘要:打补丁是应对软件漏洞的主要手段,及时将补丁应用到所有受影响的软件上至关重要,然而这一点在实际中常常难以做到,研究背景。因此,准确检测安全补丁是否已被集成进软件发行版本的能力,对于防御者和攻击…...

ubuntu服务器版启动卡在start job is running for wait for...to be Configured
目录 前言 一、原因分析 二、解决方法 总结 前言 当 Ubuntu 服务器启动时,系统会显示类似 “start job is running for wait for Network to be Configured” 或 “start job is running for wait for Plymouth Boot Screen Service” 等提示信息,并且…...

国产数据库工具突围:SQLynx如何解决Navicat的三大痛点?深度体验报告
引言:Navicat的"中国困境" 当开发者面对达梦数据库的存储过程调试,或是在人大金仓中处理复杂查询时,Navicat突然变得力不从心——这不是个例。 真实痛点:某政务系统迁移至OceanBase后,开发团队发现Navicat无…...

牛客网NC21994:分钟计算
牛客网NC21994:分钟计算 📝 题目描述 输入格式 输入两行,每行包含两个整数,分别表示小时和分钟第一行表示起始时间,第二行表示结束时间 输出格式 输出一个整数,表示两个时间点之间的分钟数 示例 输入…...

全球宠物经济新周期下的亚马逊跨境采购策略革新——宠物用品赛道成本优化三维路径
在全球"孤独经济"与"银发经济"双轮驱动下,宠物用品市场正经历结构性增长。Euromonitor数据显示,2023年全球市场规模突破1520亿美元,其中中国供应链贡献度达38%,跨境电商出口增速连续三年超25%。在亚马逊流量红…...

Tomcat多应用部署与静态资源路径问题全解指南
🧑 博主简介:CSDN博客专家、CSDN平台优质创作者,高级开发工程师,数学专业,10年以上C/C, C#, Java等多种编程语言开发经验,拥有高级工程师证书;擅长C/C、C#等开发语言,熟悉Java常用开…...

128.在 Vue 3 中使用 OpenLayers 实现绘制矩形截图并保存地图区域
📌 本文将介绍如何在 Vue 3 中使用 OpenLayers 实现: 1)用户可在地图上绘制矩形; 2)自动截取该区域地图为图片; 3)一键保存为本地 PNG 图片。 ✨效果如下图所示 🧠一、前言 在地图类…...

使用 163 邮箱实现 Spring Boot 邮箱验证码登录
使用 163 邮箱实现 Spring Boot 邮箱验证码登录 本文将详细介绍如何使用网易 163 邮箱作为 SMTP 邮件服务器,实现 Spring Boot 项目中的邮件验证码发送功能,并解决常见配置报错问题。 一、为什么需要邮箱授权码? 出于安全考虑,大…...

python处理异常,JSON
异常处理 #异常处理 # 在连接MySQL数据库的过程中,如果不能有效地处理异常,则异常信息过于复杂,对用户不友好,暴露过多的敏感信息 # 所以,在真实的生产环境中, 程序必须有效地处理和控制异常,按…...

原生微信小程序 textarea组件placeholder无法换行的问题解决办法
【问题描述】 微信小程序原生代码,使用文本域,placeholder使用\n 没有效果,网上找了一堆方案说使用 也没有效果 最后在一个前端大佬博客,找到解决办法,CSS设置word-wrap: break-word; white-space: pre-line; 【解决办…...

毕设设计 | 管理系统图例
文章目录 环素1. 登录、注册2. 菜单管理 环素 1. 登录、注册 2. 菜单管理 公告通知 订单管理 会员管理 奖品管理 新增、编辑模块...

激光雷达视觉定位是3D视觉定位吗?
激光雷达视觉定位通常被归类为3D视觉定位,但具体来说,它是融合了激光雷达(LiDAR)数据和视觉(图像)数据的多模态3D定位方法。我们可以从几个角度来理解这点: 为什么说它属于3D视觉定位ÿ…...

每周靶点:NY-ESO-1、GPC3、IL27分享
本期精选了《自身免疫性癌抗原NY-ESO-1》《肝细胞癌标记物GPC3》《白细胞介素IL27》三篇文章。以下为各研究内容的概述: 自身免疫性癌抗原NY-ESO-1 NY-ESO-1是一种自身免疫性癌抗原,也称为CTA1B(CTAG1B),由主要组织相…...

Maven 插件参数注入与Mojo开发详解
🧑 博主简介:CSDN博客专家,历代文学网(PC端可以访问:https://literature.sinhy.com/#/?__c1000,移动端可微信小程序搜索“历代文学”)总架构师,15年工作经验,精通Java编…...

Java详解RabbitMQ工作模式之发布订阅模式
目录 一、发布订阅模式简介二、发布订阅模式的工作原理2.1 核心组件2.2 工作流程 三、代码示例3.1 生产者代码3.2 消费者代码 四、实际应用场景五、注意事项六、总结 在分布式系统中,消息队列作为异步通信的桥梁,扮演着至关重要的角色。而 RabbitMQ&…...

UR5e机器人Matlab仿真
在 MATLAB 中使用 UR5e 机器人模型进行仿真和控制,通常需要结合机器人系统工具箱(Robotics System Toolbox) UR5e loadrobot("universalUR5e","DataFormat","column"); UR5e.Gravity [0 0 -9.81]; % 保存机器…...

[ctfshow web入门] web75
信息收集 scandir被禁用了 解题 cforeach(new DirectoryIterator("glob:///*") as $a){echo($a->__toString(). ); } ob_flush();cif ( $a opendir("glob:///*") ) {while ( ($file readdir($a)) ! false ) {echo $file."<br>";}c…...
)
论文中表格跨页该怎么整(如何给跨页表格添加标题和表头)
标题:光标移动到第一行表格,然后快捷键;ctrl shirft enter,就会发现第二页多了一行,再把标题复制张贴过来即可 表头: 光标移动到第一行表格,鼠标右键 选择插入 再选择在上方插入行,然后手动添加…...