论文学习_Precise and Accurate Patch Presence Test for Binaries
摘要:打补丁是应对软件漏洞的主要手段,及时将补丁应用到所有受影响的软件上至关重要,然而这一点在实际中常常难以做到,研究背景。因此,准确检测安全补丁是否已被集成进软件发行版本的能力,对于防御者和攻击者而言都极为关键,研究意义。FIBER 正是基于此需求而提出的自动化系统,它的设计灵感来自人类分析者的行为模式——通常只检查代码中局部且有限的区域,核心思想。该系统首先会对开源安全补丁进行深入解析与分析,然后生成高度精细的二进制签名,这些签名能够精准反映补丁引入的关键语法和语义变化,并可用于在目标二进制文件中进行匹配搜索。与以往的方法相比,FIBER 更加策略性地利用源代码层面的信息,专注于补丁的局部改动和最小上下文,而非整个函数或文件的对比。在评估方面,研究者选取了107个真实的安全补丁和来自三个主流厂商的8个Android内核镜像进行系统测试,结果显示FIBER平均检测准确率达到94%,且未出现误报情况。
引言
近年来,新发现的安全漏洞数量迅速上升,给各类软件系统及终端用户带来了严重威胁。虽然打补丁是应对漏洞的主要手段,但要确保安全补丁能够在短时间内被传播到众多受影响的软件发行版中,尤其是在拥有多个并行开发分支(如上游与下游)的庞大项目中,仍面临极大挑战。这一困难主要源于现代软件工程实践中广泛存在的代码重用现象。因此,具备检测某个特定安全补丁是否已被应用于某一软件发行版本的能力,对于防御方和攻击方来说都显得尤为重要。研究背景
为了更清晰地展开论述,有必要将“补丁存在性检测”与更通用的“漏洞搜索”在目标和范围上加以区分。补丁检测顾名思义,是在已知补丁内容及其影响函数的前提下,用于判断某个未知目标中是否已经应用了特定补丁,openssl中的heartbleed漏洞是否已在tls1_process_heartbeat()函数中被修复。相比之下,漏洞搜索则不预设目标函数的信息,而是更广泛地查找与已知漏洞函数相似的所有代码片段或函数,在某个软件发行版本中,哪些函数与存在漏洞的tls1_process_heartbeat()函数相似。当前研究聚焦于更具针对性的补丁存在性检测问题,其核心目标是提供精准、明确的判断结果。在这一前提下,学界对这两个方向分别进行了探索:
Source to sourve:完全在源代码层面进行,在近年来的相关工作中,通常还假设可获取与特定漏洞相关的补丁信息。
Binary to binary:不依赖任何源代码,因此所有比对工作均基于二进制层面的特征进行。这类方法也不要求掌握与补丁相关的任何信息,例如哪些二进制指令与补丁内容有关。
在该研究中,提出了一种介于上述两类方法之间的新范式——source to binary方式,其设立基于以下几点观察。首先,开源已成为当今计算领域的发展趋势,越来越多的软件以开源形式发布,并保留了完整的提交记录和补丁历史(例如托管在 GitHub 上)。事实上,即便是许多仅基于二进制的漏洞搜索研究,也普遍涵盖了如 Linux 和 OpenSSL 这类软件。其次,许多开源代码或组件在闭源软件中被广泛复用,例如用于物联网固件中的各类库或基于 Linux 的内核。这一变化至关重要,使得研究者能够借助源代码层面的信息优势,用以指导对二进制中补丁存在性的检测。原来是他们首先提出source to binary
遗憾的是,现有与之相关的仅基于二进制的漏洞搜索方法在转用于精确的补丁存在性检测时,往往缺失了关键的一环。由于其搜索范围极其广泛,这类方法通常不得不依赖基于相似度的模糊匹配策略,以提高处理速度,但这类策略本质上难以保证准确性。因此,大多数现有方案往往是以整个函数为单位进行比对。然而,现实中安全补丁往往仅涉及细微而局部的改动,这使得基于相似度的方法难以有效区分已打补丁与未打补丁的版本。
补丁或者说是漏洞往往仅涉及细微而局部的改动
为弥补上述缺失环节,该研究提出了FIBER系统,作为现有相似度基础漏洞搜索方法的有力补充,并将其扩展至能够实现精确补丁存在性检测的新阶段。FIBER的核心在于解决一个关键技术问题:如何生成能够准确反映源代码层补丁特征的二进制签名?对此,系统采用了两个主要步骤:首先,借鉴人类分析者的典型行为方式,从补丁中挑选出最具代表性、最适合作为签名的部分;其次,在签名生成过程中尽可能保留源代码层的丰富信息,不仅涵盖补丁本身,也包括其所在函数的整体上下文。根据源码生成二进制补丁(漏洞)代码签名
相关工作
面向源码的漏洞检测:许多工作致力于在同一软件版本内部或不同发行版之间查找代码克隆,其总体目标是定位与已知漏洞代码相似的代码片段——这一通用目标也可被转化为补丁存在性检测任务。由于漏洞搜索通常不限定在单一函数范围内,而是在大型软件中面对可能上百万行代码的搜索空间,因此在可扩展性的考虑下,这类方法通常采用某种形式的相似度匹配机制,基于源代码提取的特征进行比对,这些特征包括字符串、标记序列以及语法解析树等。然而,这种方法在判断匹配代码是否已被打补丁方面存在困难,原因在于补丁前后的代码版本可能非常相似,尤其当安全补丁仅涉及细微改动时更是如此。
面向二进制的漏洞检测:由于缺乏源代码信息(如变量类型和名称),这类方法通常依赖其他替代特征,例如代码的结构特征来进行比对。由于 binary to binary 的漏洞搜索方法无法依赖符号表,它们往往需要检查目标程序中的每一个函数,即使只是为了对某个特定函数进行精确的补丁存在性检测。例如,在给定一个含有漏洞的函数的情况下,像 Genius 和 Gemini 这类工具实际上是要在整个目标二进制文件中检索所有函数,以寻找同样受影响的函数。出于对可扩展性的考虑,这些方法的特征提取和比对策略更侧重于速度而非精度。像 BinDiff 和 BinSlayer 会通过控制流图之间的同构关系来判断相似性;更先进的方法如 Genius 和 Gemini 则从控制流图中提取特征表示,并将其编码为高维数值向量,即图嵌入,从而显著加快匹配过程。然而,面对庞大的搜索空间,那些基于语义、具备更高精度的方案普遍被认为难以扩展。例如,有研究通过比较基本块的输入/输出对来匹配相似的目标代码块,而 BinHunt 和 iBinHunt 则采用符号执行和定理验证器,以形式化手段确认基本块级别的语义等价关系。无论是面向源码还是面向二进制,目前的方法为了实现精度和效率的平衡,无法实现细粒度的补丁(漏洞)检测
FIBER 所处的位置颇具独特性,它能够利用源代码层的信息来回答一个更具体的问题——目标二进制中,某个明确受影响的函数是否已经打了补丁。据了解,迄今只有 Pewny 等人的研究提出可以借助源代码层的补丁信息来生成更细粒度的签名用于漏洞搜索,尽管该工作并未提供具体的实现或评估。然而,其研究重点依然停留在漏洞搜索,而非补丁存在性检测,这意味着其方法依旧是在整个目标二进制中查找相似的(已或未补丁的)代码片段,这种模糊的方式难以直接而准确地回答补丁是否存在的问题。FIBER从源码中提取二进制部分
内容概述
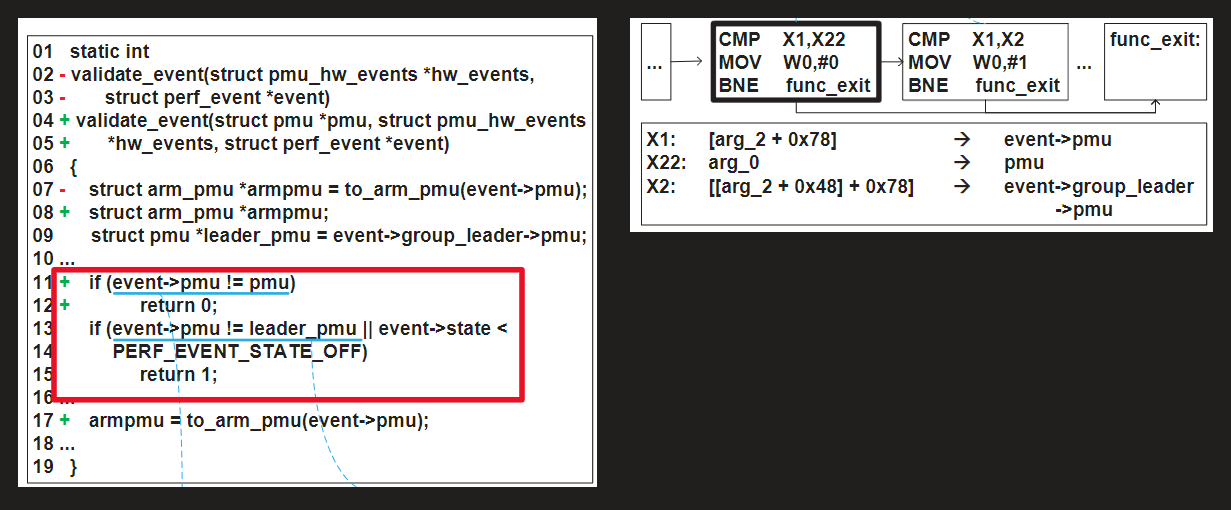
Motivation Example:以CVE-2015-8955这一Linux内核漏洞的安全补丁为例,通过这个案例可以直观展示检测补丁是否存在于目标二进制中的具体步骤。该补丁内容如图1所示。若要判断该补丁是否已应用于某个目标二进制,通常会自然地遵循以下几个步骤展开操作:
-
代码段选择:在补丁检测的流程中,首要步骤是选取一个变更位置,即一段被修改的语句序列。整体来看,该补丁包含多个改动点,但并非所有变更都适合作为判断补丁是否存在的依据。其中,第11行新增的 if 语句不仅引入了控制流结构的变化,还涉及了新增函数参数的使用,具有明显的语义特征。因此,将第11行作为判断补丁是否已应用的标志,更具代表性和可行性。
-
粗粒度匹配:在确定从目标二进制中的函数内查找第11行对应的代码,通常会从匹配控制流图(CFG)结构入手,因为这种方式相对快速且实现简单。类似的操作也可以在源代码层面进行。具体来说,条件语句中的 if 通常会对应一个拥有两个后继节点的基本块(出度为2的基本块),此外由于 if 语句中存在函数返回的操作因此基本块中应有一个后继节点指向函数的结束部分。在图1中展示了一个从已打补丁的Android内核镜像中生成的部分CFG,可以看到,加粗的基本块及其右侧的基本块都符合上述特征。
-
细粒度匹配:在仅有有限二进制信息的条件下,就需要设法将二进制指令映射回源代码中的语句。这一过程对人工分析而言通常十分耗时,因为分析者需要弄清楚某个寄存器或内存位置具体对应源代码中的哪个变量。以图1中的示例为例,分析者需要检查候选基本块中“cmp”指令所使用的寄存器,具体做法是回溯这些寄存器的来源(图1底部列出了相关信息)。通过这种方式,最终可以识别出两个“cmp”指令之间的差异,并准确判断出加粗的基本块正是对应源代码第11行的位置。
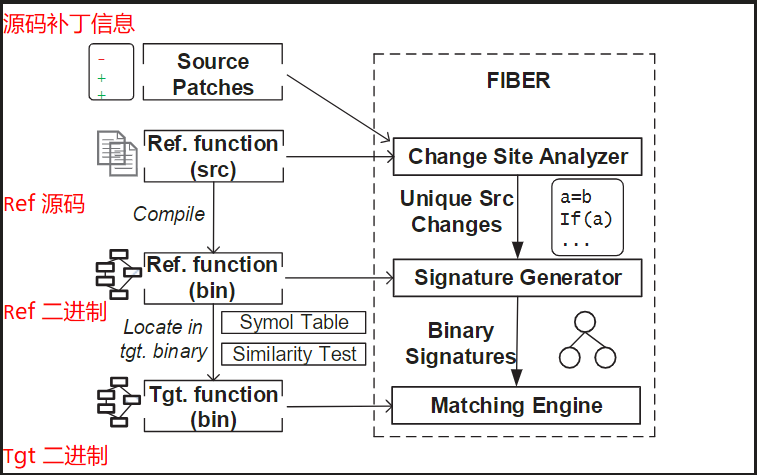
系统架构:系统由代码段选择模块、签名生成模块以及补丁匹配模块三部分组成:
- 代码段选择模块通过细致分析每个变更点及其对应的参考函数,从中筛选出最具代表性、唯一性和可匹配性的源代码改动;
- 签名生成模块通过二进制符号执行,在信息丢失的编译背景下实现源代码变更位置向二进制签名的映射,实现源码与二进制之间桥梁的搭建。
- 补丁匹配模块通过符号表定位目标函数后,先以局部控制流图拓扑进行快速语法匹配,再借助符号执行完成语义匹配,从而实现源代码签名在目标二进制中的精确搜索。
系统设计
签名用于表征补丁的核心内容。理想的签名通常需满足两个基本标准:(1)唯一性。签名应仅存在于补丁相关位置,若在补丁前后版本中都能找到该签名,便失去了对补丁的唯一标识性。因此,签名不宜过于简单,以免在与补丁无关的代码中也频繁出现;(2)稳定性。签名应对代码库的正常演进具有一定鲁棒性,例如由于版本差异,目标函数在结构上可能已与参考函数不同,因此签名也不宜过于复杂,避免因涉及过多源代码行而在目标中因细微无关变动产生误判,从而降低匹配准确性。
可以看出,前述两个看似矛盾的要求在签名生成中实际需要精巧的平衡,后续内容将对此展开具体说明。归根结底,关键在于从补丁中选取一个既具有唯一性、又有望在二进制层生成有效签名的源代码变更点。对这一任务有利的是,参考函数与目标函数之间通常在变量层的语义上具有高度一致性。假设两个版本均已打补丁,那么诸如“变量是如何被赋值与解引用的”以及“条件语句是如何构造的”等语义行为应基本一致。二进制签名所要做的,就是尽可能携带这些关键信息,从而还原出源代码中的语义特征。签名需要满足的两大特性
代码段选择模块
代码段发现:补丁可能涉及代码的新增或删除,因此我们既可以依据补丁未被应用(即删除行仍然存在)来判断,也可以依据补丁已被应用(即新增行出现)来识别。为便于讨论,这里以补丁已应用为前提,将签名生成聚焦于新增的代码行;若反向操作,思路也基本一致。整体策略是从一条新增语句出发,视情况逐步扩展。在处理每一条新增语句时,通常会依照以下步骤展开:
- 唯一性测试:某条语句必须仅出现在补丁新增的代码行中,而不能出现在其他位置(例如未打补丁的代码库中)。为实现这一目标,可采用基于词法分析器的简单标记序列匹配方法。需要特别指出的是,这一唯一性检测不仅关注语法层面的标记信息,还隐含了与语义相关的特征。例如,图1中第11行的源代码签名就体现了一个特定的语义关系——第一个函数参数被用于与最后一个参数的某个字段进行比较,这种语义结构本身具有唯一性,也是我们在生成二进制签名时必须保留的关键要素。
- 上下文补充:为解决单条语句无法满足唯一性要求的情况,系统会将该语句在控制流层面上的相邻语句作为潜在的上下文进行考虑。这种“相邻”关系是双向的,例如一个“if”语句通常对应两个后继分支,二者都可视为其上下文,因此可能存在多个可选的上下文语句。具体操作上,会以渐进式的方式逐步扩展上下文范围,例如当一条上下文语句仍不足以实现唯一性时,就尝试引入两条。
- 细粒度检测:旨在识别补丁中同一语句或源代码行内的具体改动。通常,补丁以源代码行的增删形式呈现,即便只对一行中的部分内容进行了修改,也会在补丁中显示为一行被删除、一行被新增。为避免将无关内容纳入签名从而导致签名冗长,系统会通过对比相邻的新增与删除行,精确定位实际改动的部分。举例来说,如果一个函数调用语句中仅修改了某一个参数,那么在匹配过程中,完全可以忽略其他未变的参数,从而降低干扰,提高签名的“稳定性”。
- 类型信息过滤:类型信息在源代码语句中同样扮演着重要角色,因为它直接影响后续二进制签名的生成与匹配过程。从理论上讲,可以为参考二进制中的每个变量(即寄存器或内存位置)标注其对应的类型,并在匹配时确保目标二进制中推断出的类型保持一致。然而,类型匹配有时并不足以唯一确定一个签名。一个典型的特殊情况是常量字符串,其通常以静态形式存储在固定内存地址中。如果某个补丁唯一的改动就是修改了该字符串的内容,那么在进行签名生成与匹配时,就必须解引用对应的
char*指针,获取实际的字符串内容。否则,生成的签名将只包含一个常量指针地址,而该地址在不同二进制版本中可能有所不同。即便目标中该指针的类型依然是char*,也无法据此判断其是否属于已打补丁或未打补丁的版本。在后续的案例分析中也会提供这类实际示例。
代码段排序:在前述步骤中,一个补丁可能对应多个具有唯一性的源代码变更候选项,而在实际应用中,只要其中一个变更存在,通常就已足以表明补丁已被应用。此外,不同的源代码变更在生成二进制签名时的适用性也存在差异。FIBER 的做法是先对所有候选变更进行排序,并选取排名靠前的若干项(Top N)用于后续的签名转换。排序依据主要参考三个因素,按重要性由低到高排列:
- 语句与函数入口之间的距离是一个重要考量因素。源代码签名中语句距离函数入口越近,签名生成过程通常就越高效,这与系统内部的具体实现机制有关。
- 函数体积的大小也是一个关键考量因素。如果源代码签名位于一个较小的函数中,匹配引擎将更具优势,因为搜索空间更小,受到无关代码干扰的可能性也更低,同时匹配过程的执行速度也会更快。值得注意的是,相较于前述“语句与函数入口的距离”,这一因素更为重要,因为签名生成只需执行一次,而匹配过程可能会在多个目标二进制上重复进行。
- 变更所涉及的语句类型同样具有重要影响。如果变更涉及结构性或控制流相关的语句(例如“if”语句),那么在匹配时可以快速将搜索范围缩小至结构上相似的候选区域,从而加快匹配速度。更关键的是,这类变更对二进制签名的稳定性也有积极作用。与函数调用等语句不同,结构性改动通常不会因编译器选项变化(如函数内联)而发生变化,因此在不同版本或编译配置下表现得更加稳健。
签名生成模块
二进制签名生成:借助调试信息,可以将源代码行映射到对应的二进制指令位置,从而完成初步定位。随后,会基于这些指令构建一个局部控制流图(CFG),该图包含所有相关指令所在的节点。如果这些节点本身已经互相连通,构建过程将非常直接;但若存在断裂,还需引入一些补充节点以形成一个连通的局部CFG,这本质上属于Steiner树问题。在实际操作中,可利用 NetworkX 包中实现的近似 Steiner 树算法来完成该任务。这样的局部CFG结构能够较好地反映源代码变更的控制流特征。相较于整个函数级别的CFG,局部CFG更能抵抗不同编译器选项和架构所带来的影响,因为它排除了无关代码。然而,即便如此,编译配置本身仍可能对签名造成影响。因此,理想情况下应确保参考内核与目标内核使用相同的编译配置。具体操作中,会采用一种主动探测方法来识别目标内核的编译配置。识别并整理与源代码变更相关的二进制指令,根指令签名
理论上,前述局部控制流图中识别出的所有指令都可以作为二进制签名的一部分,但在实际应用中,这并非理想做法。事实上,只有其中一部分指令真正体现了核心行为和数据流语义,这类指令被称为“根指令”。二进制签名中包含的指令越多,签名就越具体,也越不具备“稳定性”。例如,编译器可能会插入一些中间指令来释放寄存器(如将其值暂存到内存中),如果这些无关指令也被纳入签名,就可能导致在目标二进制中无法成功匹配。以图3中的两条源代码语句为例,第一条赋值语句在编译后生成了3条二进制指令,但仅捕获最后一条指令就足以表达其语义,因为通过数据流分析可知,X1 等于 X0 加上 0x4,因此前两条指令可以被安全忽略。类似地,第二条语句对应的第03和04号指令已充分表达其语义,因为前面的00至02号指令的输出将在后续由其他指令消耗,不影响关键语义的提取。
简单来说,“根指令”被定义为数据流链中的末尾指令,即那些其输出数据不会再被后续指令继续传递的指令,同时还包括一些用于补全源代码语义的辅助指令。例如,在这种定义下,cmp 指令可视为根指令,但为了完整表达其条件判断语义,还需补充紧随其后的条件跳转指令。再如函数调用的场景中,根指令通常包括用于传递参数的 push 指令(以 x86 架构为例,每条 push 指令在各自的数据流链中构成末尾节点),以及最终的 call 指令,以完整体现函数调用的语义结构。从局部控制流图中提取根指令,局部控制流图
需要注意的是,即便面对相同的源代码语句,不同编译器或编译优化策略仍可能生成略有差异的根指令。为了提升签名匹配的适应性,系统在处理时会将类型相同的根指令视为等价,借此实现根指令的标准化。在表1中展示了多个源代码变更可能对应的不同指令类型示例。例如,在处理某条赋值语句时,编译器可能选择使用位运算代替乘法操作,从而生成不同的底层指令序列。
接下来,需要对根指令进行充分标注,使其能够唯一对应到具体的源代码变更——这些标注内容即构成二进制签名。基于前文第4.1节中的观察,既然目标函数与参考函数本质上是同一函数的不同版本,它们在变量层面的语义应当保持一致,因此,关键就在于将根指令中的操作数(如寄存器或内存地址)映射回其对应的源代码变量。只要目标函数确实应用了补丁,那么这些操作数所涉及的变量应与参考函数中看到的一致。因此,我们的任务就是确保生成的二进制签名能够完整保留这类语义信息。为实现这一目标,系统会为每个操作数计算其对应的全函数级语义表达式,直到其在根指令处的使用位置为止。如图1所示,这些表达式以抽象语法树(AST)的形式呈现,本质上是一种符合图4中记号定义的语义表达结构。语义表达式
二进制签名验证:尽管在源代码变更选择阶段已尽力保证其唯一性与稳定性,但由于在转化为二进制签名过程中不可避免的信息损失,仍需对生成的候选二进制签名进行进一步验证,以确保其仍符合预期要求。(1)唯一性方面:针对每个补丁,会分别准备对应的已打补丁和未打补丁版本的参考二进制文件,并利用匹配引擎(详见第4.4节)将所生成的二进制签名与它们进行比对。若某个签名基于已打补丁的代码生成,只有在未打补丁的参考版本中无法找到匹配项时,才被视为具备唯一性。即便如此,在参考的已打补丁二进制中,该签名仍可能存在多个匹配项(尽管这种情况较少见),此时会将匹配次数作为辅助信息记录下来。今后在真实环境中用于检测目标二进制时,只有当匹配次数不少于先前记录的值,才能判断该补丁确实存在于目标中。(2)稳定性方面:此前在第4.2节中所做的努力,即尽可能缩小源代码变更范围,也有助于增强所生成二进制签名的稳定性,因为源变更的规模与对应签名的复杂度密切相关。此外,如果有更多真实数据可用,还可以准备多个版本的已打补丁和未打补丁的函数二进制文件,并将候选签名在这些版本间进行交叉验证,以进一步筛选出那些在所有已打补丁版本中均存在、而在所有未打补丁版本中均不存在的高度稳定签名。
补丁匹配模块
粗粒度匹配:这一阶段属于快速匹配流程,旨在借助一些易于提取的特征对二进制签名进行初步比对:
- 控制流图(CFG)结构是其中一项关键特征,因为二进制签名本质上就是函数控制流图中的一个子图。除非签名仅位于单个基本块内(例如某条赋值语句所对应的签名),否则该步骤通常能够提供有效的匹配线索。
- 基本块的出口类型也是一种可用于快速比对的特征。通常情况下,每个基本块的出口可分为两类:无条件跳转和条件跳转。其中,无条件跳转在大多数指令集架构(ISA)中又可细分为函数调用、返回以及其他常规的控制流转移。因此,不同基本块可以通过其出口类型实现高效对比。
- 根指令类型也是用于快速比对的重要特征,系统会分析签名中的每个基本块,并确定其对应的根指令集合。通过这些指令的类型,可以高效对比两个基本块是否相似。为此,需要先为目标函数二进制中的每个基本块构建数据流图,虽然这一操作相较前几步计算开销更高,但整体仍在可控范围内。
借助上述特征,可以在目标函数中迅速缩小搜索范围。如果在这一阶段未能找到任何匹配项,基本即可判断该签名在目标二进制中不存在;反之,若发现候选匹配点,则仍需对每一个候选项进行更精确的比对分析,以确保匹配结果的准确性。
细粒度匹配:在这一阶段,系统利用生成的标注信息,对两组根指令进行精确匹配。核心任务是比对它们各自关联的语义表达式(即语义公式),以判断是否在语义层面实现了一致的功能逻辑。
为了完成语义层的比对,首先需要为所有候选匹配的根指令生成对应的语义公式。若签名中的所有根指令公式在候选根指令中均能找到匹配项,即可认为两者在语义上是等价的,即它们可映射至相同的源代码语句。对于公式之间的比对,本质上是两个抽象语法树(AST)的比较,已有一些方法通过计算树编辑距离来生成相似度评分;然而,FIBER 的目标并非输出一个相似度分数,而是要给出明确的匹配判断。
另一种方式是使用定理证明器验证两个公式的语义等价性,这种方式虽然最为精确,但计算开销极大,难以应用于实际大规模场景。因此,FIBER 采取了一种折中方案。根据观察,语义公式表达的是依赖关系,也就是指令之间的执行顺序,在保持语义不变的前提下,其结构通常不会发生变动(如评估所示),例如表达式 (a + b) * 2 不会变成 a * 2 + b * 2。此外,借助对公式中基本元素的标准化处理,匹配过程还具备一定的抗干扰能力。具体操作中,通过递归地比对AST中的操作符与操作数来完成匹配,同时允许适当的灵活性,例如对可交换的运算符,操作数的顺序不作严格要求。在比对前,系统还会通过 Z3 求解器对AST进行简化处理,以提升匹配效率与准确性。
相关文章:

论文学习_Precise and Accurate Patch Presence Test for Binaries
摘要:打补丁是应对软件漏洞的主要手段,及时将补丁应用到所有受影响的软件上至关重要,然而这一点在实际中常常难以做到,研究背景。因此,准确检测安全补丁是否已被集成进软件发行版本的能力,对于防御者和攻击…...

ubuntu服务器版启动卡在start job is running for wait for...to be Configured
目录 前言 一、原因分析 二、解决方法 总结 前言 当 Ubuntu 服务器启动时,系统会显示类似 “start job is running for wait for Network to be Configured” 或 “start job is running for wait for Plymouth Boot Screen Service” 等提示信息,并且…...

国产数据库工具突围:SQLynx如何解决Navicat的三大痛点?深度体验报告
引言:Navicat的"中国困境" 当开发者面对达梦数据库的存储过程调试,或是在人大金仓中处理复杂查询时,Navicat突然变得力不从心——这不是个例。 真实痛点:某政务系统迁移至OceanBase后,开发团队发现Navicat无…...

牛客网NC21994:分钟计算
牛客网NC21994:分钟计算 📝 题目描述 输入格式 输入两行,每行包含两个整数,分别表示小时和分钟第一行表示起始时间,第二行表示结束时间 输出格式 输出一个整数,表示两个时间点之间的分钟数 示例 输入…...

全球宠物经济新周期下的亚马逊跨境采购策略革新——宠物用品赛道成本优化三维路径
在全球"孤独经济"与"银发经济"双轮驱动下,宠物用品市场正经历结构性增长。Euromonitor数据显示,2023年全球市场规模突破1520亿美元,其中中国供应链贡献度达38%,跨境电商出口增速连续三年超25%。在亚马逊流量红…...

Tomcat多应用部署与静态资源路径问题全解指南
🧑 博主简介:CSDN博客专家、CSDN平台优质创作者,高级开发工程师,数学专业,10年以上C/C, C#, Java等多种编程语言开发经验,拥有高级工程师证书;擅长C/C、C#等开发语言,熟悉Java常用开…...

128.在 Vue 3 中使用 OpenLayers 实现绘制矩形截图并保存地图区域
📌 本文将介绍如何在 Vue 3 中使用 OpenLayers 实现: 1)用户可在地图上绘制矩形; 2)自动截取该区域地图为图片; 3)一键保存为本地 PNG 图片。 ✨效果如下图所示 🧠一、前言 在地图类…...

使用 163 邮箱实现 Spring Boot 邮箱验证码登录
使用 163 邮箱实现 Spring Boot 邮箱验证码登录 本文将详细介绍如何使用网易 163 邮箱作为 SMTP 邮件服务器,实现 Spring Boot 项目中的邮件验证码发送功能,并解决常见配置报错问题。 一、为什么需要邮箱授权码? 出于安全考虑,大…...

python处理异常,JSON
异常处理 #异常处理 # 在连接MySQL数据库的过程中,如果不能有效地处理异常,则异常信息过于复杂,对用户不友好,暴露过多的敏感信息 # 所以,在真实的生产环境中, 程序必须有效地处理和控制异常,按…...

原生微信小程序 textarea组件placeholder无法换行的问题解决办法
【问题描述】 微信小程序原生代码,使用文本域,placeholder使用\n 没有效果,网上找了一堆方案说使用 也没有效果 最后在一个前端大佬博客,找到解决办法,CSS设置word-wrap: break-word; white-space: pre-line; 【解决办…...

毕设设计 | 管理系统图例
文章目录 环素1. 登录、注册2. 菜单管理 环素 1. 登录、注册 2. 菜单管理 公告通知 订单管理 会员管理 奖品管理 新增、编辑模块...

激光雷达视觉定位是3D视觉定位吗?
激光雷达视觉定位通常被归类为3D视觉定位,但具体来说,它是融合了激光雷达(LiDAR)数据和视觉(图像)数据的多模态3D定位方法。我们可以从几个角度来理解这点: 为什么说它属于3D视觉定位ÿ…...

每周靶点:NY-ESO-1、GPC3、IL27分享
本期精选了《自身免疫性癌抗原NY-ESO-1》《肝细胞癌标记物GPC3》《白细胞介素IL27》三篇文章。以下为各研究内容的概述: 自身免疫性癌抗原NY-ESO-1 NY-ESO-1是一种自身免疫性癌抗原,也称为CTA1B(CTAG1B),由主要组织相…...

Maven 插件参数注入与Mojo开发详解
🧑 博主简介:CSDN博客专家,历代文学网(PC端可以访问:https://literature.sinhy.com/#/?__c1000,移动端可微信小程序搜索“历代文学”)总架构师,15年工作经验,精通Java编…...

Java详解RabbitMQ工作模式之发布订阅模式
目录 一、发布订阅模式简介二、发布订阅模式的工作原理2.1 核心组件2.2 工作流程 三、代码示例3.1 生产者代码3.2 消费者代码 四、实际应用场景五、注意事项六、总结 在分布式系统中,消息队列作为异步通信的桥梁,扮演着至关重要的角色。而 RabbitMQ&…...

UR5e机器人Matlab仿真
在 MATLAB 中使用 UR5e 机器人模型进行仿真和控制,通常需要结合机器人系统工具箱(Robotics System Toolbox) UR5e loadrobot("universalUR5e","DataFormat","column"); UR5e.Gravity [0 0 -9.81]; % 保存机器…...

[ctfshow web入门] web75
信息收集 scandir被禁用了 解题 cforeach(new DirectoryIterator("glob:///*") as $a){echo($a->__toString(). ); } ob_flush();cif ( $a opendir("glob:///*") ) {while ( ($file readdir($a)) ! false ) {echo $file."<br>";}c…...
)
论文中表格跨页该怎么整(如何给跨页表格添加标题和表头)
标题:光标移动到第一行表格,然后快捷键;ctrl shirft enter,就会发现第二页多了一行,再把标题复制张贴过来即可 表头: 光标移动到第一行表格,鼠标右键 选择插入 再选择在上方插入行,然后手动添加…...

day26 Python 自定义函数
目录 一、函数的基本定义 示例 1:不带参数的函数 示例 2:查看文档字符串 二、带参数的函数 示例 3:带一个参数的函数 示例 4:带多个参数的函数 三、带返回值的函数 示例 5:计算两个数的和并返回结果 示例 6&am…...

洛谷P4907题解
题目传送门 题意: 扑克牌的部分牌被移除,需从剩牌中选 4 个区间,每个区间的牌都是同一花色且点数连续。如果不可选,输出最少需添加几张牌才能满足要求。 思路: 暴力和剪枝。 暴力:按照题意模拟ÿ…...

【MyBatis插件】PageHelper 分页
前言 在开发 Web 应用时,我们经常需要处理海量数据的展示问题。例如,在一个电商平台上,商品列表可能有成千上万条数据。如果我们一次性将所有数据返回给前端,不仅会导致页面加载缓慢,还会对数据库造成巨大压力。为了解…...

AI数字人融合VR全景:从技术突破到可信场景落地
摘要 本文深度解析AI数字人与VR全景技术融合的技术架构,结合故宫博物院、西门子、强生等真实行业案例,揭示技术落地的关键路径与量化价值。通过具体技术参数、实施细节及权威机构数据,构建可信的技术应用图景,为开发者提供可复用…...

机器学习——朴素贝叶斯练习题
一、 使用鸢尾花数据训练多项式朴素贝叶斯模型,并评估模型 代码展示: from sklearn.datasets import load_iris from sklearn.metrics import accuracy_score from sklearn.model_selection import train_test_split from sklearn.naive_bayes impor…...

【爬虫】DrissionPage-3
安装:4.1最新版本 pip install drissionpage --upgrade 官方文档:🛰️ 连接浏览器 | DrissionPage官网 1 Chromium对象 Chromium对象用于连接和管理浏览器。标签页的开关和获取、整体运行参数配置、浏览器信息获取等都由它进行。 1.1 默认…...

网络爬虫学习之httpx的使用
开篇 本文整理自《Python3 网络爬虫实战》,主要是httpx的使用。 笔记整理 使用urllib库requests库的使用,已经可以爬取绝大多数网站的数据,但对于某些网站依然无能为力。 这是因为这些网站强制使用HTTP/2.0协议访问,这时urllib和r…...

TASK02【Datawhale 组队学习】使用 LLM API 开发应用
文章目录 system prompt 和 user prompt高效prompt:用清晰、详尽的语言表达 Prompt原则一:清晰,具体的指令分隔符寻求结构化的输出要求模型检查是否满足条件提供少量示例 "Few-shot" prompting 原则二,给模型时间去思考…...
)
黑马k8s(七)
1.Pod介绍 查看版本: 查看类型,这里加s跟不加s没啥区别,可加可不加 2.Pod基本配置 3.镜像拉去策略 本地没有这个镜像,策略是Never,启动失败 查看拉去策略: 更改拉去策略: 4.启动命令 运行的是nginx、busv…...

【FMC216】基于 VITA57.1 的 2 路 TLK2711 发送、2 路 TLK2711 接收 FMC 子卡模块
产品概述 FMC216 是一款基于 VITA57.1 标准规范的 2 路 TLK2711 接收、2 路 TLK2711 发送 FMC 子卡模块。该板卡支持 2 路 TLK2711 数据的收发,支持线速率 1.6Gbps,经过 TLK2711 高速串行收发器,可以将 1.6Gbps 的高速串行数据解串为 16 位并…...

如何在Edge浏览器里-安装梦精灵AI提示词管理工具
方案一(应用中心安装-推荐): 梦精灵 跨平台AI提示词管理工具 - Microsoft Edge AddonsMake Microsoft Edge your own with extensions that help you personalize the browser and be more productive.https://microsoftedge.microsoft.com…...

Ubuntu shell指定conda的python环境启动脚本
Ubuntu shell指定conda的python环境启动脚本。 通过指令,获取目前系统的conda虚拟python环境 conda info -e 如下图所示,为我自己电脑的python环境 # conda environments: # base * /home/ubuntu/miniconda3 kitti …...

深入理解无监督学习与K-means聚类算法:原理与实践
一、无监督学习概述 无监督学习(Unsupervised Learning)是机器学习的重要分支之一,与有监督学习不同,它不需要预先标记的训练数据。在无监督学习中,计算机仅根据样本的特征或样本间的相关性,从数据中自动发现隐藏的模式或结构。 …...

单片机-STM32部分:16、Git工具使用
Docshttps://x509p6c8to.feishu.cn/wiki/Pftrw3Z6niRlewkurnyctyw1nQx 使用Git管理本地仓库的好处是,可以知道自己每次修改了哪些内容,随时进行版本切换。 待完善。...

扬州卓韵酒店用品:优质洗浴用品,提升酒店满意度与品牌形象
在酒店提供的服务里,沐浴用品占据了非常重要的地位,其质量与种类直接关系到客人洗澡时的感受。好的沐浴用品能让客人洗澡时感到舒心和快乐,反之,质量不好的用品可能会影响客人整个住宿期间的愉悦心情。挑选恰当的洗浴用品不仅能够…...

Coze 实战教程 | 10 分钟打造你的AI 助手
> 文章中的 xxx 自行替换,文章被屏蔽了。 📱 想让你的xxx具备 AI 对话能力?本篇将手把手教你,如何用 Coze 平台快速构建一个能与用户自然交流、自动回复提问的 xxx助手,零代码、超高效! 📌…...

使用 frp 实现内网穿透:从基础到进阶
在日常开发中,我们经常会遇到需要将本地服务暴露给外部用户的情况,比如测试同学需要临时测试一个本地开发的 Web 服务,或者希望在出差时远程访问家里的 NAS。这些需求的核心问题都是如何实现内网穿透。 一、为什么选择 frp? 经过…...

redis中key的过期和淘汰
一、过期(redis主动删除) 设置了ttl过期时间的key,在ttl时间到的时候redis会删除过期的key。但是redis是惰性过期。惰性过期:redis并不会立即删除过期的key,而是会在获取key的时候判断key是否过期,如果发现…...

鸿蒙OSUniApp制作多选框与单选框组件#三方框架 #Uniapp
使用UniApp制作多选框与单选框组件 前言 在移动端应用开发中,表单元素是用户交互的重要组成部分。尤其是多选框(Checkbox)和单选框(Radio),它们几乎存在于每一个需要用户做出选择的场景中。虽然UniApp提供…...

和为target问题汇总
文章目录 习题题型1377.组合总和 IV 题型2494.目标和 和为target的问题,可以有很多种问题的形式的考察,当然,及时的总结与回顾有利于我们熟练掌握这些知识! 题型1 爬楼梯问题,是对于转移步伐有规定,在不同…...
)
Ubuntu使用Docker搭建SonarQube企业版(含破解方法)
目录 Ubuntu使用Docker搭建SonarQube企业版(含破解方法)SonarQube介绍安装Docker安装PostgreSQL容器Docker安装SonarQube容器SonarQube汉化插件安装 破解生成license配置agent 使用 Ubuntu使用Docker搭建SonarQube企业版(含破解方法ÿ…...

牛客网 NC22167: 多组数据a+b
牛客网 NC22167: 多组数据ab 题目分析 这道题目来自牛客网(题号:NC22167),要求我们计算两个整数a和b的和。乍看简单,但有以下特殊点需要注意: 输入包含多组测试数据每组输入两个整数当两个整数都为0时表示…...

EdgeShard:通过协作边缘计算实现高效的 LLM 推理
(2024-05-23) EdgeShard: Efficient LLM Inference via Collaborative Edge Computing (EdgeShard:通过协作边缘计算实现高效的 LLM 推理) 作者: Mingjin Zhang; Jiannong Cao; Xiaoming Shen; Zeyang Cui;期刊: (发表日期: 2024-05-23)期刊分区:本地链接: Zhang 等 - 2024 …...

π0: A Vision-Language-Action Flow Model for General Robot Control
TL;DR 2024 年 Physical Intelligence 发布的 VLA 模型 π0,基于 transformer 流匹配(flow matching)架构,当前开源领域最强的 VLA 模型之一。 Paper name π0: A Vision-Language-Action Flow Model for General Robot Contr…...

RabbitMQ高级篇-MQ的可靠性
目录 MQ的可靠性 1.如何设置数据持久化 1.1.交换机持久化 1.2.队列持久化 1.3.消息持久化 2.消息持久化 队列持久化: 消息持久化: 3.非消息持久化 非持久化队列: 非持久化消息: 4.消息的存储机制 4.1持久化消息&…...

4、前后端联调文生文、文生图事件
4、前后端联调文生文、文生图事件 原文地址 1、底部【发送按钮】事件触发调用后端AI程序逻辑 <!-- 前端模板如下: --> <!DOCTYPE html> <html><head><meta charset"utf-8"><title>小薛博客LLM大模型实战</title><me…...

深度学习中的提示词优化:梯度下降全解析
深度学习中的提示词优化:梯度下降全解析 在您的代码中,提示词的更新方向是通过梯度下降算法确定的,这是深度学习中最基本的优化方法。 一、梯度下降与更新方向 1. 核心公式 对于可训练参数 θ \theta θ(这里是提示词嵌入向量),梯度下降的更新公式为:...

Midjourney 最佳创作思路与实战技巧深度解析【附提示词与学习资料包下载】
引言 在人工智能图像生成领域,Midjourney 凭借其强大的艺术表现力和灵活的创作模式,已成为设计师、艺术家和创意工作者的核心工具。作为 CSDN 博主 “小正太浩二”,我将结合多年实战经验,系统分享 Midjourney 的创作方法论&#x…...

【数字图像处理】半开卷复习提纲
1:要求 2张A4纸以内,正反面均可写 (不过博主由于墨水浸到背面了,采用了把2张单面通过双面胶粘起来的方法,结果考前半个小时都在用这个难用的双面胶。。。) 2:提纲内容 3:提示 考的…...

交通运输与能源融合发展——光储充在交通上的应用完整解决方案
在全球积极应对气候变化、推动可持续发展的大背景下,交通运输与能源领域的融合发展成为关键趋势。近日,交通运输部等十部门联合发布的《关于推动交通运输与能源融合发展的指导意见》,为这两个重要行业的协同前行指明了清晰的方向,…...

API 接口开放平台 Crabc 3.2 发布
2025 年 5 月 15 日,API 接口开放平台 Crabc 3.2 发布。 Crabc 是一款 API 接口开发平台、企业级接口管理和 SQL2API 平台。它支持动态数据源、动态 SQL 和标签,能接入多种 SQL 或 NoSQL 数据源,包括 MySQL、Oracle、达梦、TiDB、Hive、ES 和…...
(SpringBoot Thymeleaf)+文档)
基于智能推荐的就业平台的设计与实现(招聘系统)(SpringBoot Thymeleaf)+文档
💗博主介绍💗:✌在职Java研发工程师、专注于程序设计、源码分享、技术交流、专注于Java技术领域和毕业设计✌ 温馨提示:文末有 CSDN 平台官方提供的老师 Wechat / QQ 名片 :) Java精品实战案例《700套》 2025最新毕业设计选题推荐…...