机器学习 --- 模型选择与调优
机器学习 — 模型选择与调优
文章目录
- 机器学习 --- 模型选择与调优
- 一,交叉验证
- 1.1 保留交叉验证HoldOut
- 1.2 K-折交叉验证(K-fold)
- 1.3 分层k-折交叉验证Stratified k-fold
- 二,超参数搜索
- 三,鸢尾花数据集示例
- 四,现实世界数据集示例
一,交叉验证
1.1 保留交叉验证HoldOut
HoldOut Cross-validation(Train-Test Split)
在这种交叉验证技术中,整个数据集被随机地划分为训练集和验证集。根据经验法则,整个数据集的近70%被用作训练集,其余30%被用作验证集。也就是我们最常使用的,直接划分数据集的方法。
优点:很简单很容易执行。
缺点1:不适用于不平衡的数据集。假设我们有一个不平衡的数据集,有0类和1类。假设80%的数据属于 “0 “类,其余20%的数据属于 “1 “类。这种情况下,训练集的大小为80%,测试数据的大小为数据集的20%。可能发生的情况是,所有80%的 “0 “类数据都在训练集中,而所有 “1 “类数据都在测试集中。因此,我们的模型将不能很好地概括我们的测试数据,因为它之前没有见过 “1 “类的数据。
缺点2:一大块数据被剥夺了训练模型的机会。
在小数据集的情况下,有一部分数据将被保留下来用于测试模型,这些数据可能具有重要的特征,而我们的模型可能会因为没有在这些数据上进行训练而错过。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_splitiris = load_iris()
X = iris.data
y = iris.target#保留交叉验证HoldOut
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=22)print(y_test)[0 2 1 2 1 1 1 2 1 0 2 1 2 2 0 2 1 1 2 1 0 2 0 1 2 0 2 2 2 2]
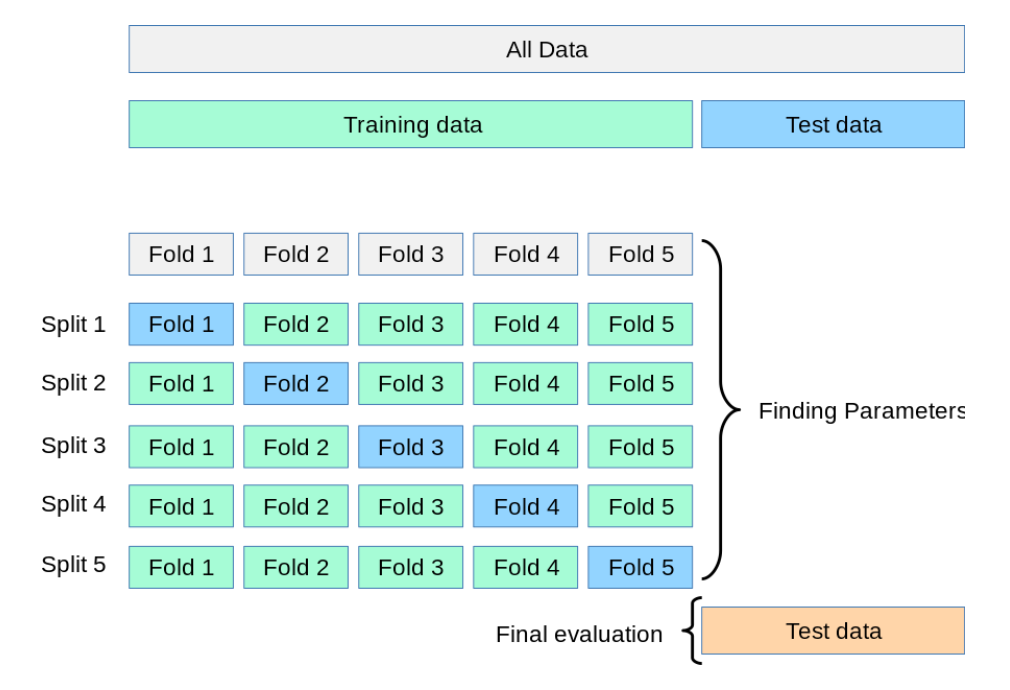
1.2 K-折交叉验证(K-fold)
K-fold Cross Validation,记为K-CV或K-fold)
K-Fold交叉验证技术中,整个数据集被划分为K个大小相同的部分。每个分区被称为 一个”Fold”。所以我们有K个部分,我们称之为K-Fold。一个Fold被用作验证集,其余的K-1个Fold被用作训练集。
该技术重复K次,直到每个Fold都被用作验证集,其余的作为训练集。
模型的最终准确度是通过取k个模型验证数据的平均准确度来计算的。
from sklearn.datasets import load_iris
from sklearn.model_selection import KFoldiris = load_iris()
x = iris.data
y = iris.target#k-Fold K折交叉验证
kf = KFold(n_splits=5)
index = kf.split(x,y)
for train_index,test_index in index:x_train,x_test = x[train_index],x[test_index]y_train,y_test = y[train_index],y[test_index]print(y_test)# print(next(index))
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1]
[1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1]
[1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2]
[2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2]
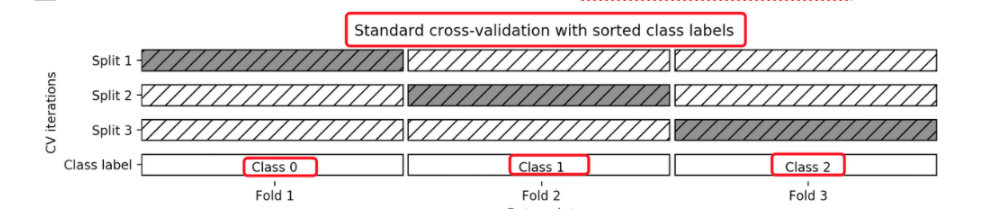
1.3 分层k-折交叉验证Stratified k-fold
Stratified k-fold cross validation,
K-折交叉验证的变种, 分层的意思是说在每一折中都保持着原始数据中各个类别的比例关系,比如说:原始数据有3类,比例为1:2:1,采用3折分层交叉验证,那么划分的3折中,每一折中的数据类别保持着1:2:1的比例,这样的验证结果更加可信。
from sklearn.datasets import load_iris
from sklearn.model_selection import StratifiedKFoldiris = load_iris()
x = iris.data
y = iris.target#k-Fold K折交叉验证
kf = StratifiedKFold(n_splits=5)
index = kf.split(x,y)
for train_index,test_index in index:x_train,x_test = x[train_index],x[test_index]y_train,y_test = y[train_index],y[test_index]print(y_test)break
print(next(index))
[0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2]
(array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 20, 21, 22,23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35,36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48,49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 70, 71,72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84,85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97,98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 120,121, 122, 123, 124, 125, 126, 127, 128, 129, 130, 131, 132, 133,134, 135, 136, 137, 138, 139, 140, 141, 142, 143, 144, 145, 146,147, 148, 149]), array([ 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 60, 61, 62,63, 64, 65, 66, 67, 68, 69, 110, 111, 112, 113, 114, 115,116, 117, 118, 119]))
二,超参数搜索
超参数搜索也叫网格搜索(Grid Search)
比如在KNN算法中,k是一个可以人为设置的参数,所以就是一个超参数。网格搜索能自动的帮助我们找到最好的超参数值。
class sklearn.model_selection.GridSearchCV(estimator, param_grid)说明:
同时进行交叉验证(CV)、和网格搜索(GridSearch),GridSearchCV实际上也是一个估计器(estimator),同时它有几个重要属性:best_params_ 最佳参数best_score_ 在训练集中的准确率best_estimator_ 最佳估计器cv_results_ 交叉验证过程描述best_index_最佳k在列表中的下标
参数:estimator: scikit-learn估计器实例param_grid:以参数名称(str)作为键,将参数设置列表尝试作为值的字典示例: {"n_neighbors": [1, 3, 5, 7, 9, 11]}cv: 确定交叉验证切分策略,值为:(1)None 默认5折(2)integer 设置多少折如果估计器是分类器,使用"分层k-折交叉验证(StratifiedKFold)"。在所有其他情况下,使用KFold。
三,鸢尾花数据集示例
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.preprocessing import StandardScaleriris = load_iris()
x,y = load_iris(return_X_y=True)
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2,random_state=22)knn_model = KNeighborsClassifier(n_neighbors=5)
model = GridSearchCV(knn_model,param_grid={"n_neighbors":[3,4,5,6,7,8,9,10]},cv=10)transfer=StandardScaler()
x_train=transfer. fit_transform(x_train)
x_test=transfer.transform(x_test)model.fit(x_train,y_train)print("最佳参数:",model.best_params_)
print("最佳结果:",model.best_score_)
print("模型结果:",model.best_estimator_)
y_pred=model.best_estimator_.predict([[1,2,3,4]])
print("预测结果:",y_pred)print("信息",model.cv_results_)
print("最佳下标",model.best_index_)
最佳参数: {'n_neighbors': 6}
最佳结果: 0.9833333333333332
模型结果: KNeighborsClassifier(n_neighbors=6)
预测结果: [2]
信息 {'mean_fit_time': array([3.00216675e-04, 7.20500946e-05, 6.69097900e-04, 3.50546837e-04,5.07640839e-04, 4.11176682e-04, 3.00264359e-04, 2.49981880e-04]), 'std_fit_time': array([0.00045859, 0.00019672, 0.00045004, 0.0004505 , 0.0005081 ,0.00050452, 0.00045866, 0.00040276]), 'mean_score_time': array([0.0015717 , 0.0016468 , 0.00132856, 0.00173099, 0.00160072,0.00148973, 0.00171149, 0.00175641]), 'std_score_time': array([0.0004462 , 0.00054278, 0.00045266, 0.00043214, 0.00049067,0.0004907 , 0.00044354, 0.00033344]), 'param_n_neighbors': masked_array(data=[3, 4, 5, 6, 7, 8, 9, 10],mask=[False, False, False, False, False, False, False, False],fill_value=999999), 'params': [{'n_neighbors': 3}, {'n_neighbors': 4}, {'n_neighbors': 5}, {'n_neighbors': 6}, {'n_neighbors': 7}, {'n_neighbors': 8}, {'n_neighbors': 9}, {'n_neighbors': 10}], 'split0_test_score': array([1., 1., 1., 1., 1., 1., 1., 1.]), 'split1_test_score': array([0.91666667, 1. , 1. , 1. , 1. ,1. , 0.91666667, 0.91666667]), 'split2_test_score': array([0.91666667, 1. , 1. , 1. , 1. ,1. , 1. , 1. ]), 'split3_test_score': array([0.91666667, 1. , 0.91666667, 1. , 0.91666667,0.91666667, 0.91666667, 0.91666667]), 'split4_test_score': array([1. , 0.91666667, 1. , 1. , 1. ,1. , 1. , 1. ]), 'split5_test_score': array([1. , 0.91666667, 1. , 1. , 1. ,1. , 1. , 1. ]), 'split6_test_score': array([0.91666667, 0.91666667, 0.91666667, 0.91666667, 0.91666667,0.91666667, 0.91666667, 0.91666667]), 'split7_test_score': array([0.83333333, 0.83333333, 0.91666667, 1. , 0.91666667,0.91666667, 0.91666667, 0.91666667]), 'split8_test_score': array([0.91666667, 0.83333333, 0.91666667, 0.91666667, 0.91666667,0.91666667, 0.91666667, 0.91666667]), 'split9_test_score': array([1., 1., 1., 1., 1., 1., 1., 1.]), 'mean_test_score': array([0.94166667, 0.94166667, 0.96666667, 0.98333333, 0.96666667,0.96666667, 0.95833333, 0.95833333]), 'std_test_score': array([0.05335937, 0.06508541, 0.04082483, 0.03333333, 0.04082483,0.04082483, 0.04166667, 0.04166667]), 'rank_test_score': array([7, 7, 2, 1, 2, 2, 5, 5])}
最佳下标 3
四,现实世界数据集示例
from sklearn.datasets import fetch_20newsgroups
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import GridSearchCVnews=fetch_20newsgroups(data_home="./src",subset="all")# 数据集划分
x_train,x_test,y_train,y_test = train_test_split(news.data,news.target,test_size=0.25,random_state=22)tfidf = TfidfVectorizer()
x_train = tfidf.fit_transform(x_train)
x_test = tfidf.transform(x_test)# 创建模型
knn_model = KNeighborsClassifier(n_neighbors=5)
# 进行超参数搜索
model = GridSearchCV(knn_model,param_grid={"n_neighbors":[3,4,5,6,7,8,9,10]},cv=10)
model.fit(x_train,y_train)# 模型评估
score = model.score(x_test,y_test)
print("准确率:",score)
print("最佳参数:",model.best_params_)
print("最佳结果:",model.best_score_)
准确率: 0.7871392190152802
最佳参数: {'n_neighbors': 3}
最佳结果: 0.7871105445394403
相关文章:

机器学习 --- 模型选择与调优
机器学习 — 模型选择与调优 文章目录 机器学习 --- 模型选择与调优一,交叉验证1.1 保留交叉验证HoldOut1.2 K-折交叉验证(K-fold)1.3 分层k-折交叉验证Stratified k-fold 二,超参数搜索三,鸢尾花数据集示例四,现实世界数据集示例…...

PostgreSQL pgrowlocks 扩展详解
一、简介 pgrowlocks 是 PostgreSQL 官方提供的扩展模块,用于查看指定表中每一行当前的行级锁(Row Lock)信息。它非常适用于: 并发冲突排查行级锁等待分析死锁前兆探测热点数据行分析 二、安装与启用 1. 安装前提(…...

Makefile 详解
Makefile 是一个用于自动化构建过程的脚本文件,主要用于管理源代码的编译和链接过程。它定义了项目中的依赖关系以及如何从源文件生成目标文件。 基本概念 Make:一个构建自动化工具,读取 Makefile 中的指令目标(Target):要生成的…...

IntelliJ IDEA 集成AI编程助手全解析:从Copilot到GPT-4o Mini的实践
目录 AI编程助手的演进与核心价值GitHub Copilot深度集成指南国产新星DeepSeek配置实战GPT-4o Mini低成本接入方案三大助手对比与场景适配企业级安全与本地化部署未来发展趋势与开发者启示1. AI编程助手的演进与核心价值 1.1 技术演进图谱 #mermaid-svg-LwYPrW2Y2Pqvqgf0 {fon…...

wps excel将表格输出pdf时所有列在一张纸上
记录:wps excel将表格输出pdf时所有列在一张纸上 1,调整缩放比例 2,将表格的所有铺满到这套虚线...

【开源Agent框架】OWL:面向现实任务自动化的多智能体协作框架深度解析
一、基本介绍 1.1 项目概述 OWL(Optimized Workforce Learning)是基于CAMEL-AI框架构建的创新型多智能体协作系统,旨在通过动态智能体交互实现复杂任务的自动化处理。项目在GAIA基准测试中以69.09的平均分位列开源框架榜首,展现了强大的任务处理能力。 技术特性矩阵: 多…...

120页WORD方案 | 2025企业数字化转型AI大模型数字底座项目设计方案
这份文档是一份关于企业数字化转型AI大模型数字底座项目的设计方案,涵盖了从项目概述、业务需求分析到技术架构设计等多个方面。它详细阐述了企业为何需要构建AI大模型底座,以及如何通过这一底座实现智能化决策支持、业务流程优化和客户体验提升。方案中…...

Vue3 本地环境 Vite 与生产环境 Nginx 反向代理配置方法汇总【反向代理篇】
文章目录 一、前言二、问题场景三、开发环境配置(Vite)四、生产环境配置(Nginx)4.1 初始错误配置4.2 正确配置方案4.3 配置解析4.4高级配置选项 五、常见问题排查六、开发环境 vs 生产环境对比七、总结 一、前言 在前后端分离架构…...

机器视觉对位手机中框点胶的应用
在手机制造的精密世界里,每一个环节都关乎着产品的最终品质,而手机中框点胶工艺更是其中关键一环。点胶不仅起到固定内部组件、增强结构强度的作用,还影响着手机的防水、防尘性能。然而,随着手机设计日益轻薄化、复杂化࿰…...

Elasticsearch性能调优全攻略:从日志分析到集群优化
#作者:猎人 文章目录 前言搜索慢查询日志索引慢写入日志性能调优之基本优化建议性能调优之索引写入性能优化提升es集群写入性能方法:性能调优之集群读性能优化性能调优之搜索性能优化性能调优之GC优化性能调优之路由优化性能调优之分片优化 前言 es里面…...

Electron 主进程中使用Worker来创建不同间隔的定时器实现过程
背景 目前主进程使用 timer.setInterval 来做间隔任务执行,但是总有用户反馈养号卡主不执行了,或者某个操作不执行了,为了排除主进程的运行造成 setInterval 阻塞可能,将 setInterval 单独处理,可以排除主进程对定时器…...

用户安全架构设计
一、主动踢出,被动踢出 二、密码设计策略:密码复杂度,密码安全检查,密码失效设计,账号锁定设计,密码存储和传输加密 三、密码找回策略:密保问题,下行短信验证码,上行短信…...

2025年黑客扫段攻击激增:如何构建智能防御体系保障业务安全?
引言 2025年,随着全球物联网设备突破500亿台,黑客利用自动化工具发起的扫段攻击(IP段扫描漏洞利用)已成为企业业务安全的最大威胁之一。单次攻击可覆盖数万个IP,精准定位未修复漏洞,导致数据泄露、服务瘫痪…...

基于大模型预测胃穿孔预测与围手术期管理系统技术方案
目录 1. 系统架构模块2. 关键算法实现2.1 术前预测模型(Transformer多模态融合)2.2 术中实时分析(在线学习LSTM)3. 模块流程图(Mermaid)3.1 数据预处理系统3.2 术前预测系统3.3 术中实时分析系统4. 技术验证模块4.1 模型可解释性验证4.2 边缘计算部署架构1. 系统架构模块…...
:简单的分布式)
Java转Go日记(三十六):简单的分布式
1.1.1. 简单的分布式server 目前分布式系统已经很流行了,一些开源框架也被广泛应用,如dubbo、Motan等。对于一个分布式服务,最基本的一项功能就是服务的注册和发现,而利用zk的EPHEMERAL节点则可以很方便的实现该功能。EPHEMERAL节…...

操作系统-进程与线程
操作系统 操作系统用来保护系统资源和提高稳定性的重要机制 文章目录 用户态和内核态为什么要区分状态? 进程管理进程,线程进程/线程切换进程的5种状态进程通信线程通讯进程调度算法 用户态和内核态 用户态 应用程序运行时所在的模式,权限受限…...

人体肢体渲染-一步几个脚印从头设计数字生命——仙盟创梦IDE
人体肢体动作数据集-太极拳 渲染代码 # 初始化Pygame pygame.init()# 设置窗口尺寸 WINDOW_WIDTH 800 WINDOW_HEIGHT 600 window pygame.display.set_mode((WINDOW_WIDTH, WINDOW_HEIGHT)) pygame.display.set_caption("动作回放")# 设置帧率 FPS 30 clock pyg…...

如何安全配置好CDN用于防止DDoS与Web攻击 ?
保护网站免受DDoS和Web攻击是至关重要的,CDN(内容分发网络)可以作为一种有效的防御工具。以下是一些安全配置CDN以防止DDoS和Web攻击的最佳实践: 1. 选择可靠的CDN提供商 安全功能: 选择拥有强大安全功能的CDN提供商…...

01-数据结构概述和时间空间复杂度
数据结构概述和时间空间复杂度 1. 什么是数据结构 数据结构(Data Structure)是计算机存储、组织数据的方式,指相互之间存在一种或多种特定关系的数据元素的集合。 2. 什么是算法 算法(Algorithm)就是定义良好的计算…...

【ArcGIS技巧】根据地块、界址点图层生成界址线
"农经权二轮延包我已经写的差不多了,需要的一些生成四至、分割地块的功能也分享了替代的插件。前面刚分享完界址点的生成,今天分享界址线的生成,有需要的自取,至此,基本可以用这些功能完成出成果工作。" 1、…...

PC:使用WinSCP密钥文件连接sftp服务器
1. 打开winscp工具,点击“标签页”->“新标签页” 2. 点击“高级"->“高级” 3. 点击"验证"->“选择密钥文件” 选择ppk文件,如果没有ppk文件选择pem文件,会自动生成ppk文件 点击确定 4. 输入要连接到的sftp服务器的…...

RedHat7 如何更换yum镜像源
RedHat7如何更换yum镜像源? # 删除系统自带 yum rpm -qa|grep -e yum -e python-urlgrabber |xargs rpm -e --nodeps# 下载yum与wget的rpm软件包 curl -O http://mirrors.aliyun.com/centos/7/os/x86_64/Packages/yum-3.4.3-168.el7.centos.noarch.rpm curl -O ht…...

k8s 1.10.26 一次containerd失败引发kubectl不可用问题
k8s 1.10.26 一次containerd失败引发kubectl不可用问题 开机k8s 1.10.26时,报以下错误 [rootmaster ~]# kubectl get no E0515 08:03:00.914894 7993 memcache.go:265] couldnt get current server API group list: Get "https://192.168.80.50:6443/api?…...

Qt信号槽机制与UI设计完全指南:从基础原理到实战应用
目录 前言一、信号槽1.1 传参1.2 Qt信号与槽的对应关系1.2.1一对多关系1.2.2 多对一关系 二、Designer三、Layout 布局3.1 基础用法3.2 打破布局3.3 贴合窗口3.4 伸展器(Spacer)3.5 嵌套布局 四、ui指针五、QWidget六、QLabel 标签使用指南总结 前言 本…...

微信小程序van-dialog确认验证失败时阻止对话框的关闭
使用官方(Vant Weapp - 轻量、可靠的小程序 UI 组件库)的before-close: wxml: <van-dialog use-slot title"名称" show"{{ show }}" show-cancel-button bind:cancel"onClose" bind:confirm"getBackInfo"…...

嵌入式学习--江科大51单片机day7
我们在听课的过程中,可能对老师讲的有疑问,或者有些自己的理解,我们可以去问豆包,包括在写博客的时候我也是,不断去问豆包保证思考的正确性。(有人感觉豆包很low啊,其实这些基础性的东西豆包一般…...

spark和hadoop之间的区别和联系
Spark和Hadoop的对比 1. 架构层面 Hadoop: HDFS(分布式文件系统):Hadoop的核心组件之一,用于存储大规模数据。它将数据分散存储在多个节点上,通过冗余存储(默认三副本)来保证数据…...

antd mobile 点击 TabBar 切换页面
switchRoute 函数,navigate 点击的 path import { Button, TabBar } from "antd-mobile"; import { useEffect } from "react"; import { Outlet, useNavigate } from "react-router-dom"; import { useDispatch } from "react…...

20250515让飞凌的OK3588-C的核心板在Linux R4下适配以太网RTL8211F-CG为4线百兆时的接线图
20250515让飞凌的OK3588-C的核心板在Linux R4下适配以太网RTL8211F-CG为4线百兆时的接线图 2025/5/15 20:19 缘起:以前做的网线找不到了,那就再来一条吧。 引脚定义要从头来过?还好找到了一条。 开干! 万用表一对/点,几…...

大语言模型 07 - 从0开始训练GPT 0.25B参数量 - MiniMind 实机训练 预训练 监督微调
写在前面 GPT(Generative Pre-trained Transformer)是目前最广泛应用的大语言模型架构之一,其强大的自然语言理解与生成能力背后,是一个庞大而精细的训练流程。本文将从宏观到微观,系统讲解GPT的训练过程,…...

【学习心得】WSL2安装Ubuntu22.04
为了使用Docker desktop,所以我的win10需要安装一下wsl并且下载一个Ubuntu。默认Windows10/11是自带wsl的,你在进行下面操作的时候可以升级一下wsl --update 1、管理员身份打开cmd,输入命令查询所有可以下载的Linux版本 # 查看有哪些 Linux 发…...

人工智能、深度学习、机器学习的联系与区别
定义 人工智能(AI - Artificial Intelligence) :是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。它旨在让计算机能够像人类一样思考、学习和决策,涉及到诸如计算机视觉、自然语言处理…...

基于互联网和LabVIEW的多通道数据采集系统仿真设计
标题:基于互联网和LabVIEW的多通道数据采集系统仿真设计 内容:1.摘要 在当今科技飞速发展的背景下,多通道数据采集在众多领域有着广泛需求。本研究的目的是设计一个基于互联网和LabVIEW的多通道数据采集系统仿真方案。采用互联网技术实现数据的远程传输与共享&…...

【Android】Android 实现一个依赖注入的注解
Android 实现一个依赖注入的注解 🎯 目标功能 自定义注解 Inject创建一个 Injector 类,用来扫描并注入对象支持 Activity 或其他类中的字段注入 🧩 步骤一:定义注解 import java.lang.annotation.ElementType; import java.lan…...

【Ansible基础】Ansible 核心组件深度解析:控制节点、受管节点、Inventory与Playbook
目录 1 Ansible架构概述 2 控制节点(Control Node)详解 2.1 控制节点定义与功能 2.2 控制节点配置文件 3 受管节点(Managed Node)详解 3.1 受管节点特点 3.2 受管节点准备工作 3.3 连接方式对比 4 Invento…...
(二))
数据库--处理模型(Processing Model)(二)
执行查询的方法有很多,接下来将介绍以更高效和更有效率的方式执行分析工作负载(在OLAP系统中)的不同技术,包括以下内容: 执行并行性(Execution Parallelism)执行引擎(Execution Engines)执行操作符输出(Execution Operator Output)中间数据表示(Intermediate Data …...

机器学习 day03
文章目录 前言一、特征降维1.特征选择2.主成分分析(PCA) 二、KNN算法三、模型的保存与加载 前言 通过今天的学习,我掌握了机器学习中的特征降维的概念以及用法,KNN算法的基本原理及用法,模型的保存和加载 一、特征降维…...

鸿蒙OSUniApp 制作简洁高效的标签云组件#三方框架 #Uniapp
UniApp 制作简洁高效的标签云组件 在移动端应用中,标签云(Tag Cloud)是一种常见的UI组件,它以视觉化的方式展示关键词或分类,帮助用户快速浏览和选择感兴趣的内容。本文将详细讲解如何在UniApp框架中实现一个简洁高效的…...

【测试】用例篇
目录 1、如何编写测试用例: 1.1、设计测试用例时:正向思维逆向思维发散思维 2.2、万能公式 2、设计测试用例的方法 2.1、基于需求设计方法 1)等价类: 2)边界类 3)场景法 4)正交表法 5)…...

力扣-46.全排列
题目描述 给定一个不含重复数字的数组 nums ,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案。 class Solution {List<List<Integer>> res new ArrayList<>();List<Integer> path new ArrayList<>();void backtracking(i…...

【氮化镓】HfO2钝化优化GaN 器件性能
2025年,南洋理工大学的Pradip Dalapati等人在《Applied Surface Science》期刊发表了题为《Role of ex-situ HfO2 passivation to improve device performance and suppress X-ray-induced degradation characteristics of in-situ Si3N4/AlN/GaN MIS-HEMTs》的文章。该研究基…...

STL?list!!!
一、引言 之前我们一起完成了STL库中的vector,本期我们将一起完成list这一容器,在本期学习中,我们会更加加深对于模板的认识,让我们更加能感受到模板的魅力! 二、list的介绍与相关接口 list是STL库中提供的一个链表容…...

2025.05.14华为机考笔试题-第一题-100分
📌 点击直达笔试专栏 👉《大厂笔试突围》 💻 春秋招笔试突围在线OJ 👉 笔试突围OJ 01. 优先级任务调度系统 问题描述 LYA公司的开发团队正在设计一个智能任务调度系统。该系统需要根据任务优先级动态调整执行顺序,以提高团队工作效率。系统需要支持以下三种操作:…...

紫外相机工作原理及可应用范围
紫外相机是一种利用紫外线(UV)波段进行成像的设备,紫外线可用于机器视觉应用中,以检测使用可见光无法检测到的特征,工业上使用最常见的紫外波长是365nm和395nm。紫外相机通常用于高分辨率视频显微镜、电晕检测、半导体…...

海外短剧H5/App开源系统搭建指南:多语言+国际支付+极速部署
在全球短视频与短剧内容消费热潮下,搭建一个支持多语言、集成国际支付且能快速部署的海外短剧平台,已成为内容创作者和运营者的核心需求。本文将结合行业前沿技术与开源方案,提供一套完整的系统搭建指南,助您高效实现全球化布局 …...
方案)
AWS EC2 微服务 金丝雀发布(Canary Release)方案
为什么需要实现金丝雀发布? 在当前项目的工程实践中, 已经有了充分的单元测试, 预发布环境测试, 但是还是会在线上环境出现非预期的情况, 导致线上事故, 因此, 为了提升服务质量, 需要线上能够有一个预验证的机制. 如何实现金丝雀发布? 使用AWS code deploy方案 AWS code…...

2025年5月华为H12-821新增题库带解析
IS-IS核心知识 四台路由器运行IS-IS且已经建立邻接关系,区域号和路由器的等级如图中标记,下列说法中正确的有? R2和R3都会产生ATT置位的Level-1的LSPR1没有R4产生的LSP,因此R1只通过缺省路由和R4通信R2和R3都会产生ATT置位的Leve1-2的LSPR2和…...

从单体架构到微服务:架构演进之路
引言:当“大货车”遇上“集装箱运输” 在软件开发领域,单体架构曾像一辆载满货物的大货车,将所有功能打包在一个应用中。但随着业务复杂度飙升,这辆“大货车”逐渐陷入泥潭:启动慢如蜗牛、故障波及全局、升级如履薄冰……...

从 Excel 到 Data.olllo:数据分析师的提效之路
背景:Excel 的能力边界 对许多数据分析师而言,Excel 是入门数据处理的第一工具。然而,随着业务数据量的增长,Excel 的一些固有限制逐渐显现: 操作容易出错,难以审计; 打开或操作百万行数据时&…...

Uniapp开发鸿蒙购物项目教程之样式选择器
大家好,今天依然为大家带来鸿蒙跨平台开发教程的分享,我们本系列的教程最终要做一个购物应用,通过这个项目为大家分享uniapp开发鸿蒙应用从配置开发环境到应用打包上架的完成过程。 昨天的文章实现了应用首页的轮播图,其中涉及到…...