高速系统设计实例设计分析二
6.6 仿真约束的生成和实施
进行到这一步,我们已经完成了对实例进行仿真的所有条件的设置,包括对板子的设计要求分析和预布局处理。虽然从技术上讲,我们可以开始进行仿真分析并生成设计的约束,但是根据作者的工作经验,在进行关键网络仿真分析之前最好再做一步准备工作,那就是网络整理和仿真对象规划。进行了网络整理和仿真对象规划工作以后,再进行有针对性的仿真和约束实施,这样做不仅能够使设计流程更加规范,而且还能够提高工作效率,尤其是对规模较大的复杂系统而言。
6.6.1 网络整理和仿真对象规划
读者应该注意到,在第5章所介绍的Cadence高速设计流程中,并没有网络整理和仿真对象规划这个环节。之所以要在实际的流程实施过程中加入这个环节,这是作者基于多年的工作经验和体会,认为有必要把这个工作内容提升到流程的高度,使之成为流程中的一个环节。作者认为,这样做有两个好处。
● 从实际的工作角度上讲,通过对网络的整理和仿真对象的规划,可以让SI工程师对系统的总体设计有个更清楚的认识,使得仿真分析结果和定义的约束更加符合实际情况,从而提高约束实施的成功率,也会提高工作效率。
● 读者应该记得,我们在第5章的Cadence设计约束实施规则内容介绍中,要求大家记住一个表,那就是Constraint Manager中对象属性和约束实施的继承和覆盖关系。事实上,对网络整理和仿真对象规划的工作,就是这个约束的继承和覆盖关系表格在实际工作中的体现。从Cadence软件的角度上讲,把对网络整理和仿真对象规划提升到高速设计流程中的一个环节,也是符合Cadence工具的功能架构,是符合高速设计方法学的。
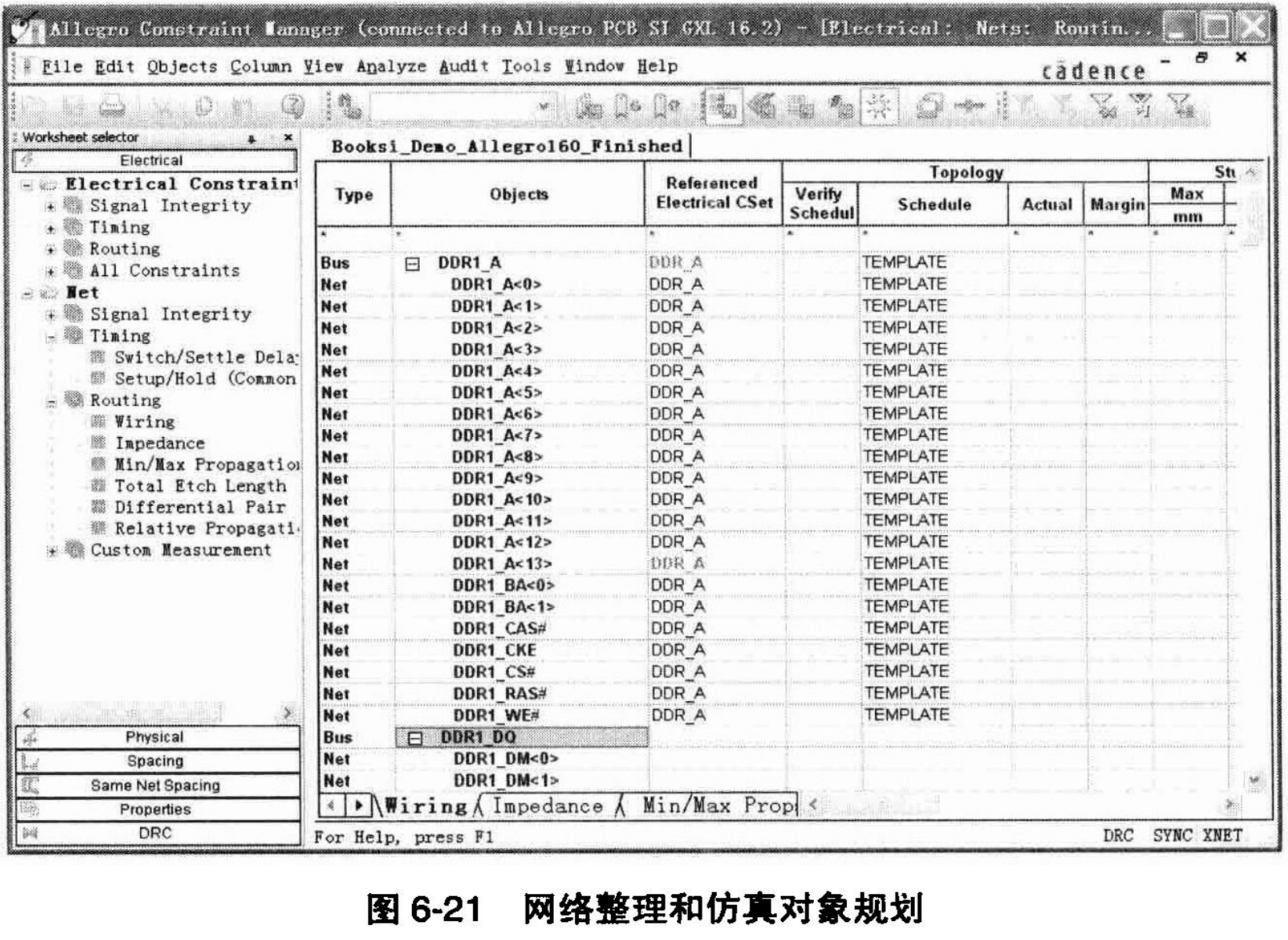
而对于网络整理和仿真对象规划的工作内容,有以下两个方面。对照图6-21所示,逐一讲解这两个方面的内容。
● 高速差分信号对的定义和生成;
● 总线的整理和规划。
1. 高速差分信号对的定义和生成
对于高速差分线,在布线上是有严格要求的,必须要让Constraint Manager知道哪些信号线之间可以构成差分线对。在CM的约束管理器中,有两种方式来生成差分线对。第一种是手动方式,在CM的约束管理器菜单中选择“Objects→Create→Differential Pair...”命令后,出现差分对设计界面,如图6-22所示。
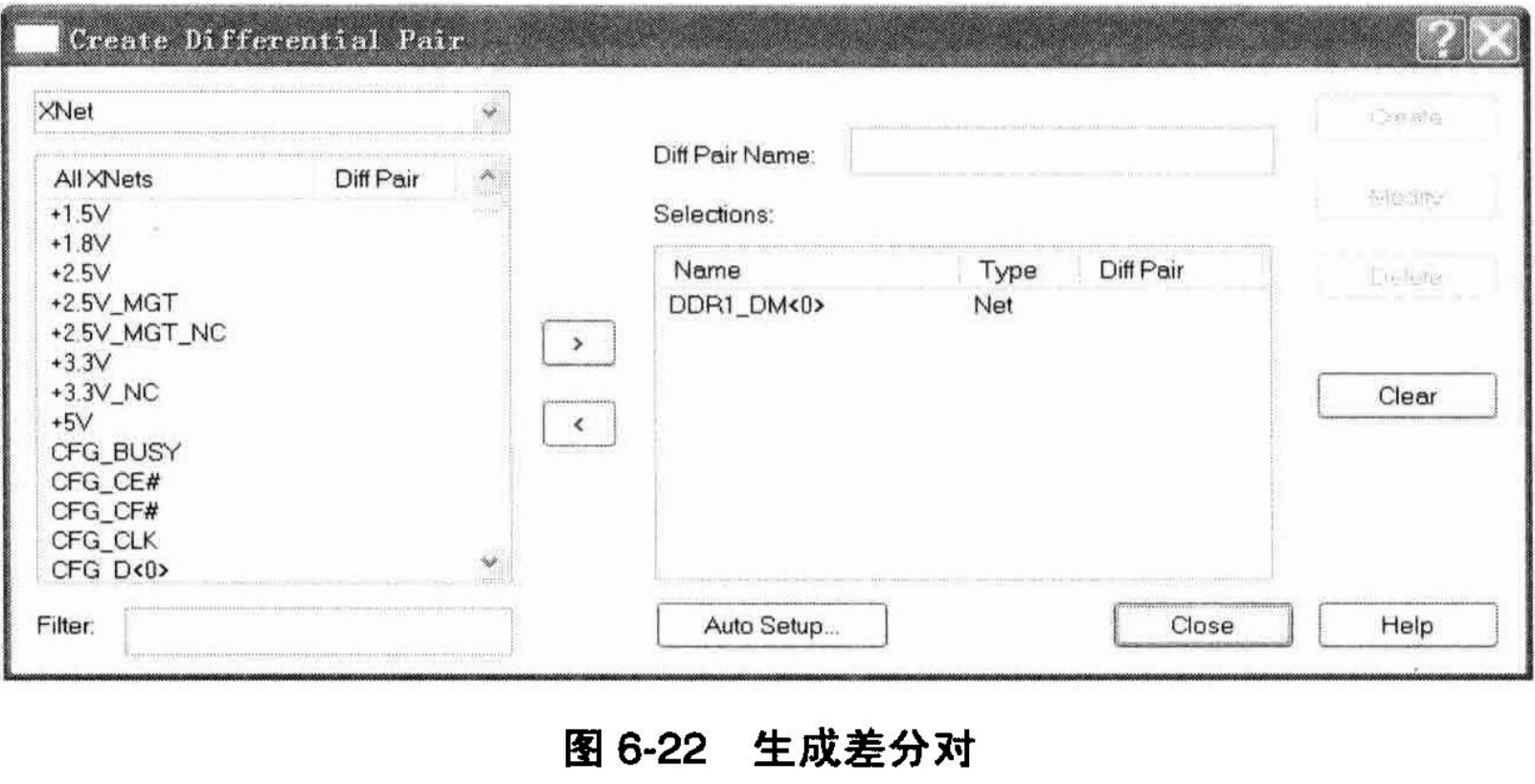
在这个界面中,用户可以通过选择左侧网络列表中的任意两个网络,再在“Diff Pair Name”文本框中输入想要创建的差分对的名称,单击“Create”按钮就可以了。用这种方式,用户可以指定任何两个网络构成差分对。但是这是很不严谨的做法,推荐读者采用下面的第二种方式来创建差分对。
一般来讲,原理图设计工程师在对网络命名的时候,会对差分对信号按照某种固定的模式来命名,比如对所有的差分线网络先以同样的网络名称命名,然后分别以“/+”或者“/NP”作为后缀,这样,在CM约束管理器中,通过适当的设置,CM约束管理器能够自动将这两个信号作为差分对来对待。例如,假如系统中有两个网络的名称分别为DDR1_CLKIN和DDR1_CLKIP,通过同样的方式打开图6-22所示的“Create Differential Pair”界面,单击其中的“Auto Setup”按钮,会打开如图6-23所示的“Differential Pair Automatic Setup”设置界面。
然后在“+Filter”文本框中输入“P”,在“-Filter”文本框中输入“N”,系统就会自动找到那些匹配的网络,再单击“Create”按钮就可以了。当然,如果在设计中,还有其他的差分对匹配模式,比如“+”和“-”,按照同样的方式做就可以了。

2. 总线的整理和规划
这里讲的总线有两个含义。首先是传统的总线含义,比如,如果原理图设计工程师在进行原理图设计时,有意识地将一组网络定义成总线,并使用标准的总线标识方法,比如DDR_A<13>,…DDR_A<12>,…DDR_A<0>,那么在CM约束管理器中就会自动将这组网络组合成DDR_A这个总线。而这里讲的总线的第二个含义是在继承传统总线的基础之上,认为功能上相近或类似、电气上一致的一组信号线也应该以总线的方式进行处理,例如本例中,除了地址总线外,DDR的控制信号线,还有DDR_CAS#,DDR_RAS#,DDR_CKE,DDR_CS#和DDR_WE,这些信号线在电气上和真正的地址总线完全一致,而在功能上和地址总线同属控制总线,因此,尽管它们不是传统意义上的总线,但是由于它们功能上的相似性和电气上的一致性,我们完全有理由将它们作为一组总线处理。
通过这种方式,我们可以更好地对设计的约束进行实施,对设计对象进行统一管理。如图6-21中所示的那样,把这些信号线归在同一个总线类别下,就可以一次性地对它们进行约束条件设置。不管是约束实施成功与否,在后续工作中我们对这些信号线都以同样的方式处理。否则的话,按照常规的方法,我们首先对DDR_A这个总线进行仿真和约束设置,成功以后,再逐一地对DDR_CAS#,DDR_RAS#,DDR_CKE,DDR_CS#和DDR_WE这些信号线加以约束实施和管理,这样做不仅工作效率低,而且一旦出错,也不容易对错误进行定位和分析。因此,基于作者多年的工作经验所总结出的对总线定义的扩充和使用,是符合Cadence高速设计流程的需求、提高工作效率的有效方法。
但是,读者需要注意的是,正如上面提到的,这里介绍的关于总线整理和规划的方法是作者基于多年的工作经验所总结出的符合Cadence高速设计流程需求、提高工作效率的方法,但这不是唯一的办法。Cadence在发展过程中,注意到了实际设计中的这种需求,因此,在对设计对象实施的约束管理时,Cadence提供了多种途径和方法对功能相似或者相关的总线进行约束。例如本例中,按照DDR规范严格地讲,我们应该将DDR数据总线分为四组,DDR_DQ<7..0>,DDR_DQ<15..8>,DDR_DQ<23..16>和DDR_DQ<31..24>,相应地将和数据总线密切相关的控制信号也分为四组DQS<0>,DQS<1>,DQS<2>,DQS<3>,以及DM<0>,DM<1>,DM<2>,DM<3>。这样才是最符合规范的分类方法。在对些和数据密切相关的信号进行约束时,既有共性的约束条件,又有控制线所独有的个性约束条件。比如,对于DQS信号要严格按照时钟信号要求布线,和其他信号线保持一定的间距。对于这样的一个复杂的系统进行约束时,可使用Cadence提供的约束范围,即Scope,用这个参数来控制每个约束所适用的信号范围。约束条件中的“Scope”参数能够从Local,Global,Bus和Class等几个层次上对信号网络实施约束,从而构成一个复杂的约束体系。
但基于本书的写作目的是通过一个设计实例把Cadence的高速设计流程和环境展现给读者,所以不可能对Cadence系统中各个参数介绍得非常详尽。为了让读者能够以最直接简明的方式了解和掌握使用Cadence工具进行高速设计的方法,本书中只能采取比较粗略的设计方法,以便带领读者在最短的时间内,以简洁有效的形式掌握Cadence设计的基本方法和要点,更多的工具使用技巧和复杂系统设计方法还需要读者在自身的实践工作过程中不断地发掘和掌握。
6.6.2 结构抽取与仿真分析
在上一步中,我们通过对网络进行整理,对进行仿真分析的对象在CM约束管理器中进行了规划,从仿真意义的角度考虑,扩充了传统意义上总线的概念,重新认识DDR_A和DDR_D总线集合。在这一节中,我们就针对这两组DDR的总线进行仿真分析。
在进行拓扑结构抽取之前,还有一个小技巧需要读者了解。对于拓扑结构的抽取,可以针对不同的对象。以DDR1_A总线为例,读者既可以直接对DDR1_A总线中的某一个具体网络,例如DDR1_A<11>,进行拓扑结构抽取,也可以从我们刚刚定义的DDR1_A总线这个层次上进行抽取。在总线上抽取和具体的线网上抽取,对于仿真过程和结果来说没有什么区别,但是当我们根据仿真结果生成设计的约束,并把这个约束返回到CM的约束管理器中的时候,这两种方式的区别就体现出来了。
对于总线的抽取、仿真分析后,它的约束结果是直接实施在总线中所有的网络上的,而对于单线进行抽取仿真后,它的约束结果只是实施被抽取仿真的这个网络上。如果需要将这个仿真约束的结果也实施到总线中的其他网络上,那就需要用户自己去手工定义了。软件功能的这种区别是很容易理解的,这也是Cadence设计对象的层次化管理和约束实施的体现。再一次了解了这种设计方法后,我们从DDR1_A的总线层次上开始对DDR地址类别的总线进行抽取和仿真分析。在图6-21所示的界面中,在DDR1_A总线的文本框中单击鼠标右键,然后选择“SigXplorer”命令,系统将自动对DDR_A总线的拓扑结构进行抽取,进入SigXplorer的工作界面。在SigXP中,读者会看到抽取到的DDR1_A的拓扑结构图,如图6-24所示。
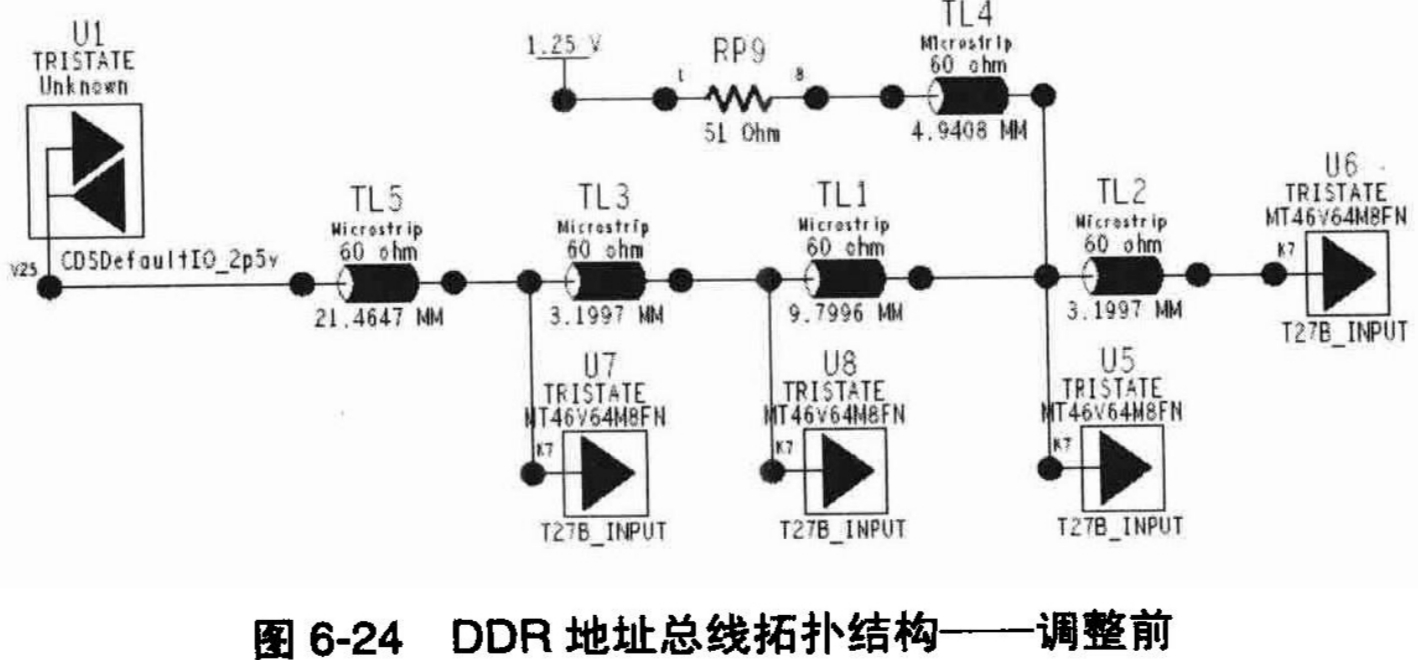
得到DDR1_A的拓扑结构图之后,首先需要对这个图进行解读,检查抽取出来的网络结构中是否包含了我们要仿真分析的网络元素,以及各元素的参数,比如器件的数量、连接关系和器件参数等是否正常?通过这些检查,可以检验我们在前面的步骤中对于仿真分析进行的各种设置,也可以加强对设计的理解。经过初步的检查之后,可以确认这个拓扑结构及各参数的设置都是正确的,下一步就可以开始进行仿真。
但是,在仿真之前,读者还应该思考一个问题:在我们抽取的信号拓扑结构中,由于驱动器和接收器的器件模型及匹配策略都已经确定的前提下,还有什么因素是影响信号性能最关键的因素?回顾一下我们在3.3.2节中的论述,这个关键因素就是网络的拓扑结构。如果一个网络的拓扑结构规划得不好,那么再做什么其他的优化也不会有明显的效果。在我们的这个设计实例中,是一个DDR控制器输出地址和控制信号,负载是各个DDR存储芯片,根据3.3.2节中对各种拓扑结构适用情况的论述,像这样一对多的单向网络,应该采用远端簇结构。
事实上,在实际工作中,如果读者想不到这一点,可以参照DDR设计的实例和文档,如果参考设计也同样能够确定合适的拓扑结构。例如,对于本书的设计实例而言,DDR内存条的设计应该是个很好的参考设计。我们找到DDR内存条设计的规范“PC1600/PC2100 DDR SDRAM Unbuffered DIMM Design Specification.pdf”,在这个文档的33页“DIMM Wiring Details”一节中,可以找到对于地址总线设计的具体要求,如图6-25所示。
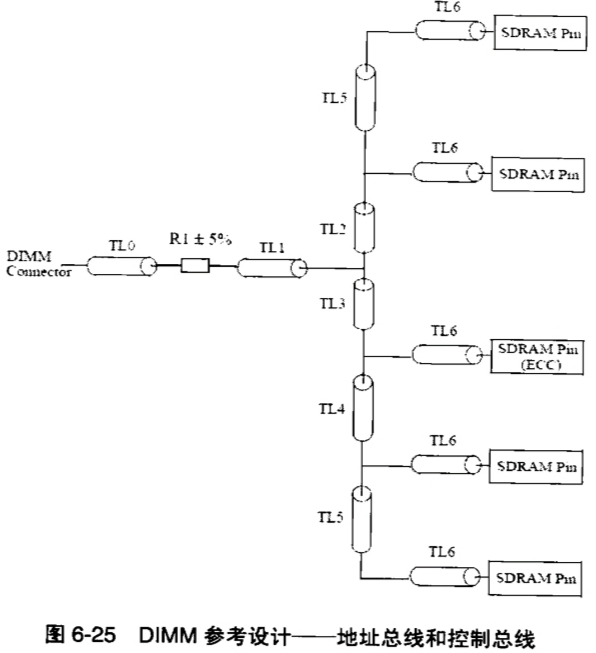
这个逻辑结构图描述的是在DIMM上对于地址总线及控制总线的布线要求。如果读者看得再仔细一些,能够从上面的DIMM设计规范文档中找到关于各段传输线的要求,通过比较后会发现,TL0+ TL1的长度要远远大于TL2和TL3的长度,并且从各个分支点到每个芯片的传输线长度是相等的,如图6-25所示每个芯片前面的传输线都是TL6。这是远端簇结构的一个典型特征,因此也再次印证了本书第3章中对于远端簇结构结构特征和适用情况的分析。对照本书的设计实例,我们可以模仿这种拓扑结构,来设计地址总线和控制总线。
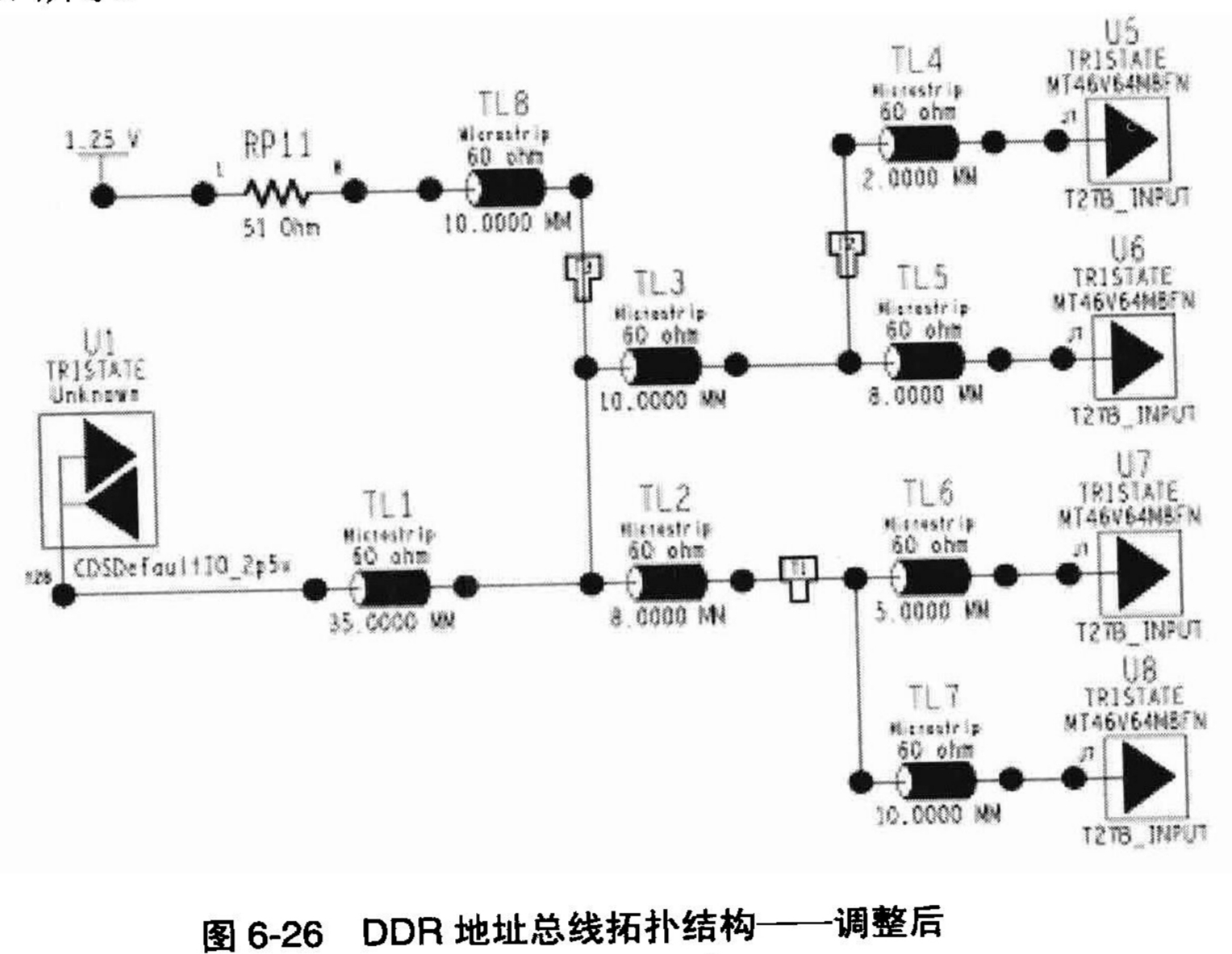
注意,为了描述方便,我们现在把各传输线的名称修改一下。读者每次对同一个网线抽取后,拓扑结构是相同的,但是传输线的名称可能会不一样。这里,我们把传输线的名称按照顺序进行排序,并将拓扑结构按照远端簇结构进行整理,整理之后的拓扑结构和传输线的名称,如图6-26所示。
现在,拓扑结构已经调整成我们需要的形式,那么是不是我们就可以开始做仿真了?答案还是不是。请读者仔细考虑一下在图6-26中U1这个器件的I/O模型。在6.4.3这一小节中,我们放弃了对U1的器件模型的指定,所以在系统对DDR1_A进行模型抽取的时候,由系统自动按照U1的Y28管脚属性,赋予了一个CDSDefaultIO_2p5V的I/O模型给它。但是,在我们的DDR Controller的设计中,我们需要的是SSTL2C2模型,所以,在SigXP的环境中进行仿真之前,我们需要手动把U1.Y28的I/O模型,修改为V2Pro_SSTL2C2模型。然后还需要把U1设定为Driver,并在“IO Cell Stimulus Edit”界面中,修改U1.Y28的数据激励模式,如图6-27所示。
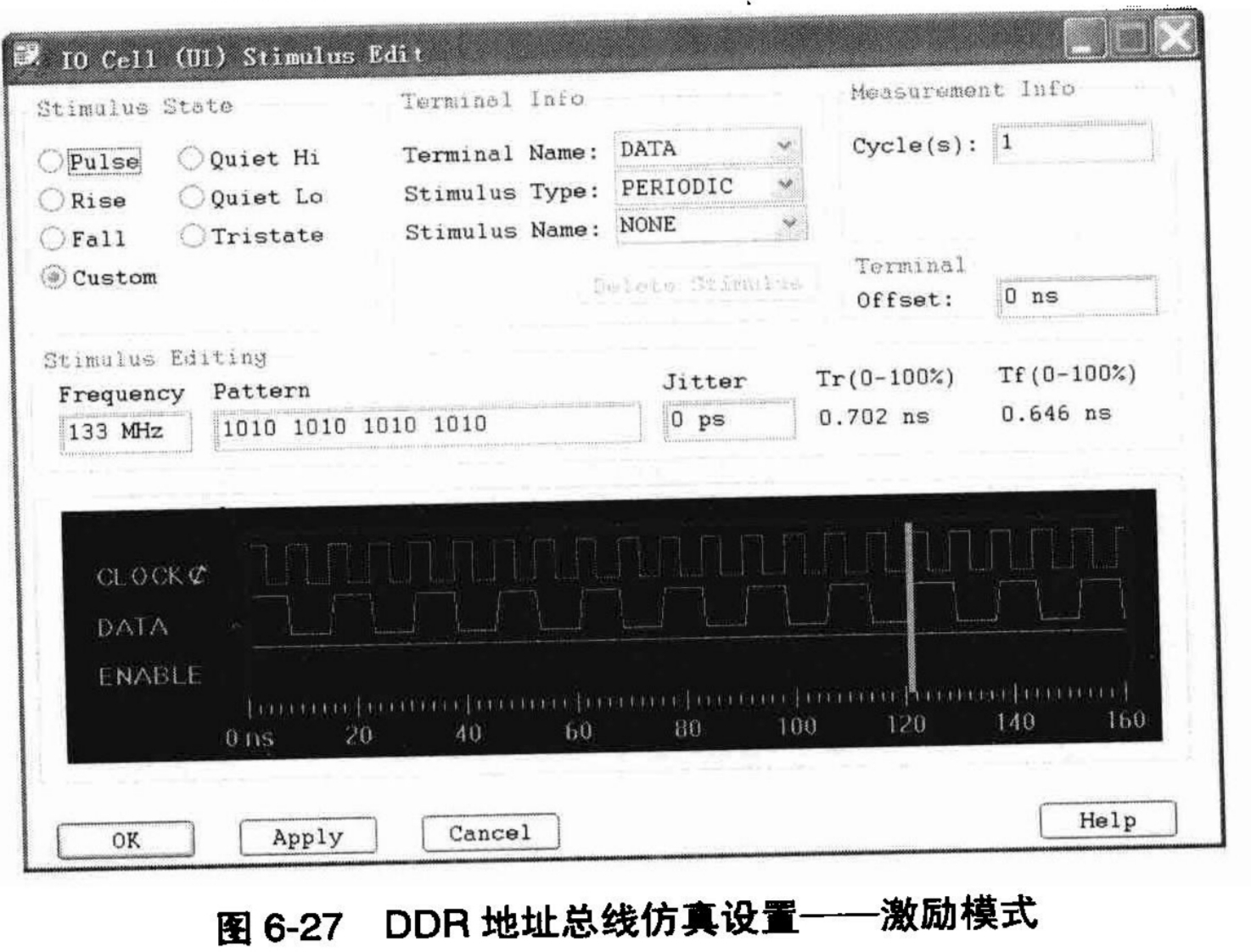 按照系统设计目标的DDR时钟频率,正确设置激励数据的频率。做好激励的设置之后,这时就可以进行仿真了,记得要在“Measurements”选项卡中要选中“Reflection”参数。单击工具栏上的内按钮,或者选择“Analyze→Simulate”命令开始仿真。仿真后SigXP自动调用SigWave对仿真结果进行显示。仿真波形如图6-28所示。
按照系统设计目标的DDR时钟频率,正确设置激励数据的频率。做好激励的设置之后,这时就可以进行仿真了,记得要在“Measurements”选项卡中要选中“Reflection”参数。单击工具栏上的内按钮,或者选择“Analyze→Simulate”命令开始仿真。仿真后SigXP自动调用SigWave对仿真结果进行显示。仿真波形如图6-28所示。
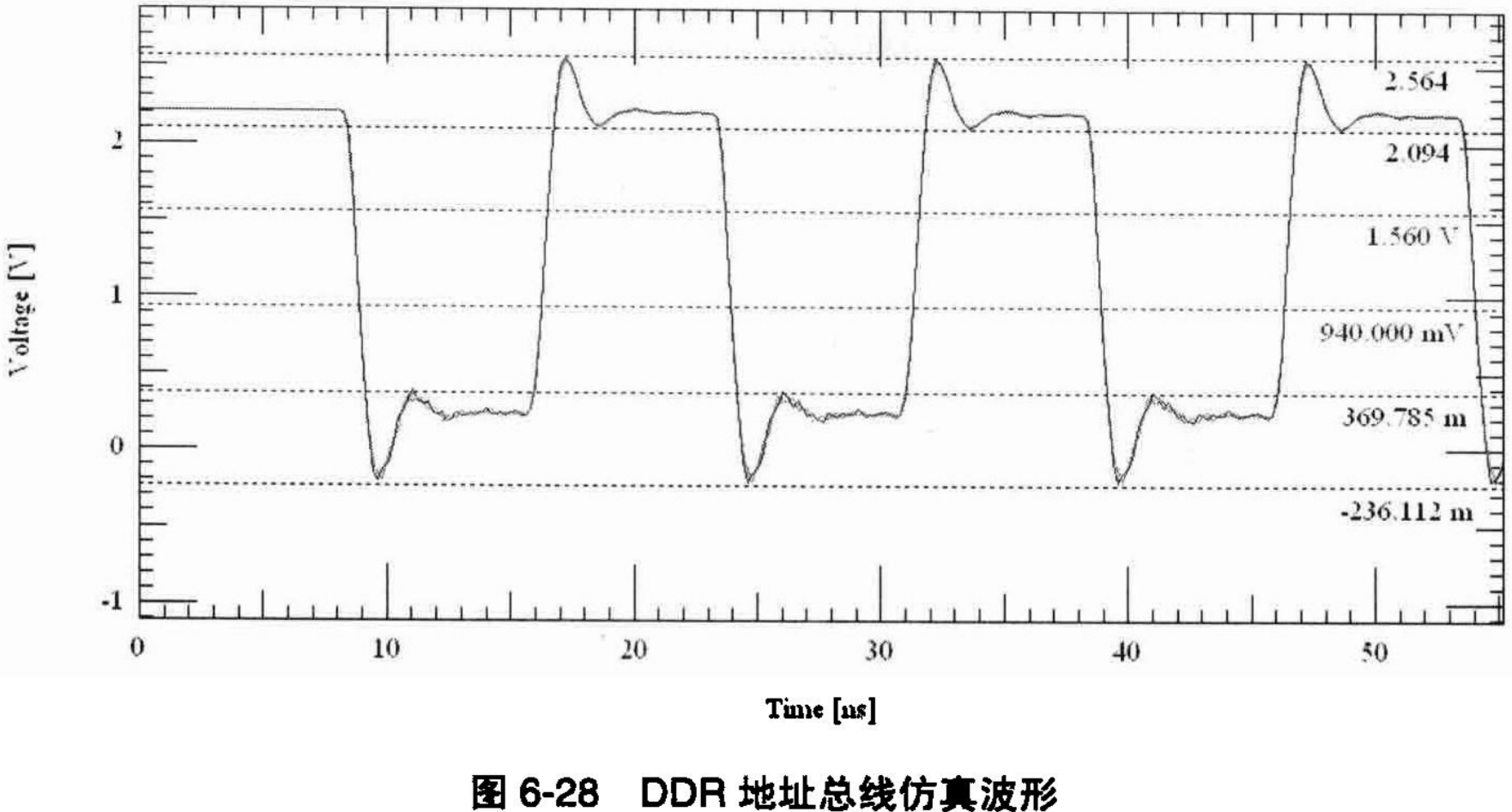
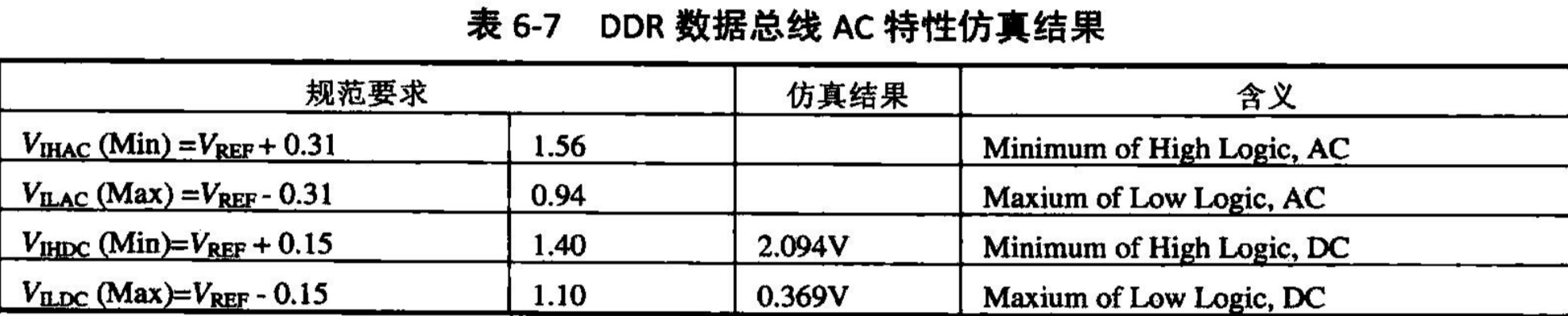
从这个波形的测量结果可以看出,各项数据都比较完美,没有幅度较高的过冲,各数据接收的波形也比较一致,没有明显的延时。初步看上去,仿真结果比较乐观。下面,我们从两个方面对DDR地址总线的仿真结果进行校验。首先,从时序上看,在这个仿真结果中,信号的单调性比较好,而且没有明显延时。通过对DDR设计规范的阅读和理解,DDR的数据和控制总线都是以时钟对齐的,因此从这个仿真结果我们可以明显地看出只要DDR的时钟线和DDR的数据、控制总线的长度保持一致,就不会有时序问题。其次,参照DDR芯片手册中的信号AC特性,根据仿真结果,信号的AC特性和规范对比如表6-7所示。虽然VDAC和VDAC没有具体实测数据,但从仿真结果上可以判断出,仿真结果明显能够满足规范要求。
6.6.3 DDR地址总线约束定义
通过以上的对DDR地址总线、控制总线的仿真分析和AC特性数据的测量,我们可以确定对DDR地址总线和控制总线的约束条件了,这些约束条件可以用表6-8中的项目概括。
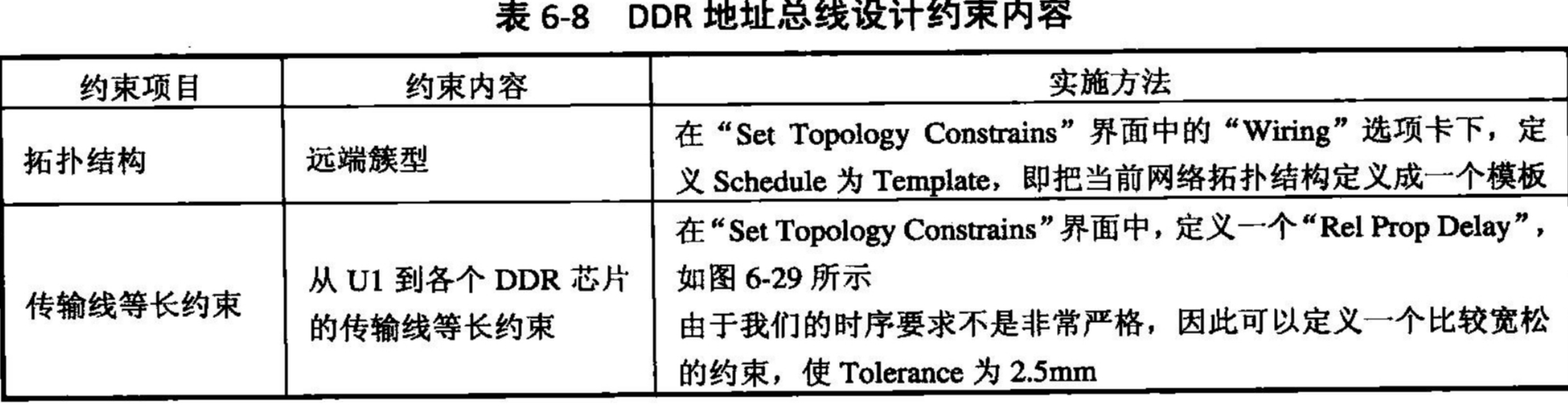
为方便读者进行同步操作,图6-29是在SigXP中对DDR地址总线进行约束定义的示范。读者对照约束设置界面和约束内容的表格,不难理解该规则所包含的含义。
在这个例子中,我们使用了相对传输延迟“Relative Propagation Delay”这个约束。顾名思义,这个约束是控制一组信号线之间的相对布线长度。但遗憾的是,有很多工程师对这个约束使用时常犯错误。在这里有必要和读者一起对这个约束及相关参数的设置再学习一遍。
首先,我们通过表6-9理解一下相关参数的含义。


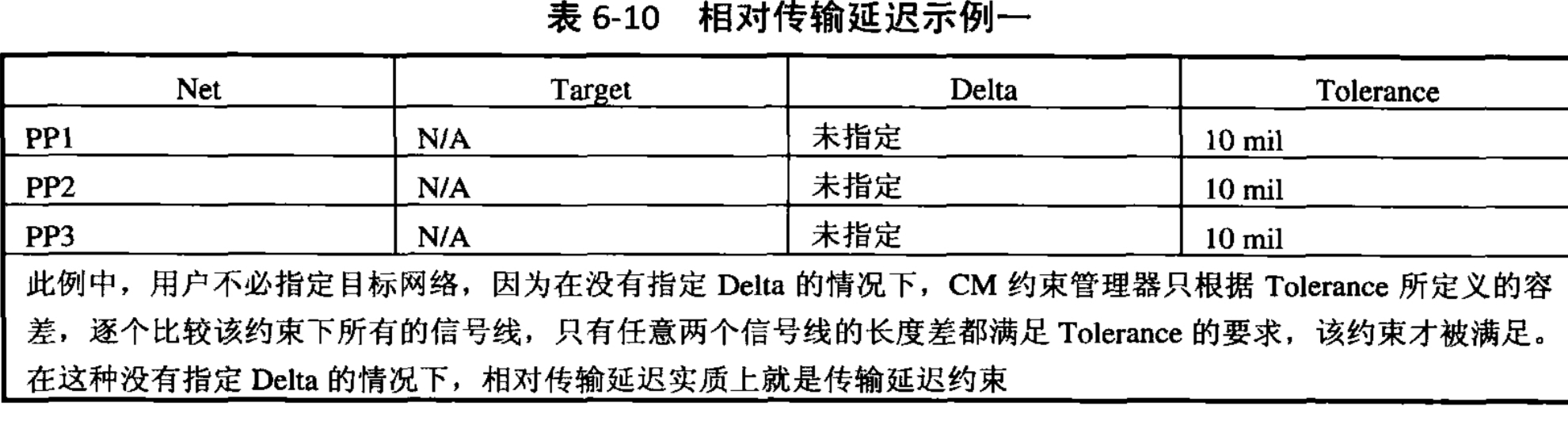
此例中,用户不必指定目标网络,因为在没有指定Delta的情况下,CM约束管理器只根据Tolerance所定义的容差,逐个比较该约束下所有的信号线,只有任意两个信号线的长度差都满足Tolerance的要求,该约束才被满足。在这种没有指定Delta的情况下,相对传输延迟实质上就是传输线等长约束。
相对传输延迟的约束示例二如表6-11所示。
此例中,PP3被指定为目标网络,其他信号线以PP3作为布线长度参考,并且长度差应该在Tolerance所定义的10mil范围内。如果PP1的长度为1000mil,那么PP1和PP2的长度应该在990mil和1010mil之间。
相对传输延迟的约束示例三如表6-12所示。
此例中,PP1被指定为目标网络,其他信号线以PP1作为布线长度参考,加上(或减去)Delta所定义的长度后,剩余的容差要在Tolerance所定义的范围内。此例中如果PP1的长度为1000mil,那么PP2的长度应该在990mil和1010mil之间,而PP3的长度应该在890mil和910mil之间。
在相对传输延迟约束中,目标网络的指定非常重要,读者要理解目标网络的生成原则。
● 用户可以在CM的约束管理器中自己指定目标网络;
● 如果用户明确了Delta值,那么Delta值最小的网络被CM的约束管理器自动指定为目标网络;如果Delta的值都一样,那么具有最长Manhattan距离的那个网络为目标网络。
至此,我们已经完成了对DDR1_A地址总线的仿真分析和约束定义。下一步就是将这个约束返回到CM的约束管理器中,从而实施对该设计的约束。这个步骤非常简单,单击一下菜单栏上的更新按钮,或者选择“File→Update Constraint Manager”命令对Constraint Manager进行更新即可。回到PCB的设计环境中,我们可以发现已经有了一个DDR1_A的CSet约束在了DDR1_A总线上,这时就可以在PCB的环境中进行约束驱动布线了。
6.6.4 DDR数据总线仿真分析和约束
在上一步中,我们完成了对DDR1_A地址总线、控制总线的仿真分析和约束生成,一个完整的DDR设计还需要对数据总线进行分析和约束。在这一节中,我们需要讲两个问题,一个是DDR_D数据总线本身的仿真分析,另外一个就是DDR数据总线和相应的数据锁存信号DQS的仿真分析。
6.6.4.1 DDR数据总线仿真分析
对于DDR数据总线本身的仿真分析,其过程和上节讲的对DDR1_A数据总线的抽取和仿真分析的过程都是一样的。
但是,在做DDR_D数据总线的仿真时,读者需要注意和DDR1_A总线的几点不同。
● DDR_D数据总线的拓扑结构比较简单,是一对一的连接;
● DDR_D数据总线是双向的;
● DDR_D数据总线是以DQS对齐,双倍速采样的。
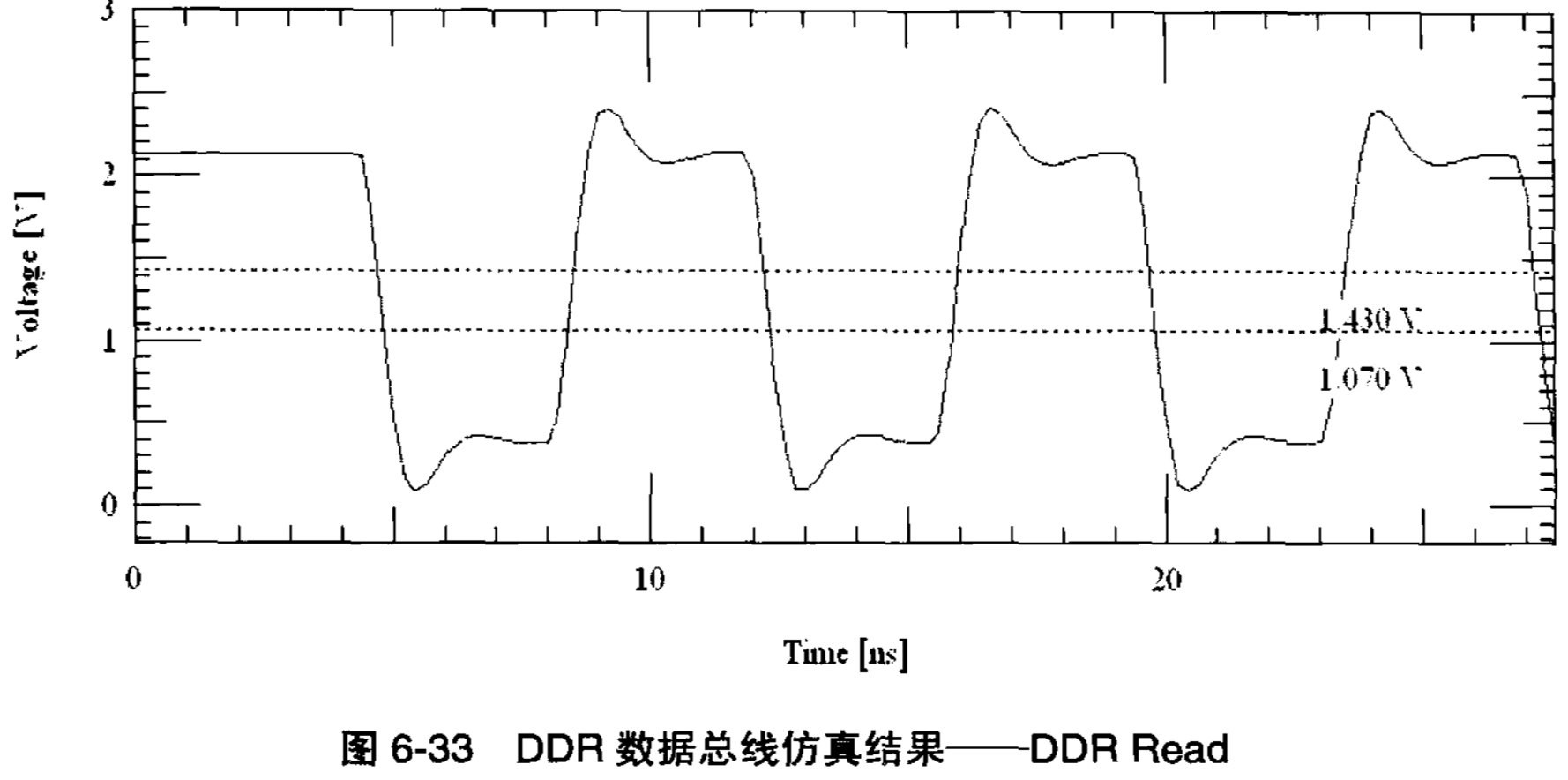
对于DDR数据总线的前两个不同点,我们在做仿真的时候注意一下就可以了,由于此类信号是双向的,因此需要做两个仿真波形,一个是从DDR芯片驱动信号到DDR Controller,如图6-30的仿真结构,对应图6-32中的仿真结果;另一个是从DDR Controller驱动信号到DDR芯片,如图6-31的仿真结构,对应图6-33的仿真结果。对于这两个波形,首先需要和DDR规范中的信号AC特性进行比较,从图中的标注可以看出,无论是从DDR芯片驱动信号,还是从DDR控制器驱动信号,这两种波形都能满足DDR规范对信号AC特性的要求。那么对于DDR数据信号,还有一个问题,那就是DDR数据信号的时序仿真分析,这个是我们对DDR数据信号进行分析的重点,需要详细讲解。
6.6.4.2 DDR数据总线时序仿真分析
正如我们以前提到的,DDR的数据是以DQS作为锁存控制信号的,而且DQS在DDR进行数据读写时的时序要求是不一样的(也就是由哪一端来驱动信号进行输出)。这就要求我们做DDR数据总线的仿真分析时需要区别对待。
首先,我们来分析当DDR芯片作为信号驱动端的情况,相当于DDR芯片的数据读出操作。在这种方式下,DQ和DQS信号从DDR芯片发出时,DQ和DQS是对齐的,参照图6-6的DDR芯片手册中的数据读出时序。因此,对这种情况的分析比较简单,只要保证DQ和DQS之间的相对延迟保持在一定的范围之内就可以了,也不需要做特别的仿真。
但是当DDR芯片进行写操作的时候,也就是DDR控制器作为信号驱动端对DDR芯片进行信号操作时,DQ和DQS信号之间要有一定的时序关系。为了仿真这种情况,我们需要对仿真环境进行特别的设置,使得DQ和DQS信号能够在一起进行仿真,并直接进行仿真波形的比较。下面,我们就介绍这个过程的实现过程。
第一步,要先对DQ信号进行抽取,抽取成功之后,要把这个网络拓扑保存起来,比如保存成“DDR1_D.top”文件,并记住存储路径。
第二步,对DQS信号进行抽取。抽取成功之后,可以先保存为“DDR1_DQS.top”文件,然后在菜单中选择“File→Append”命令,此时会弹出文件选择对话框,按照上一步中存储的路径,找到“DDR1_D.top”文件,将其打开。这样回到SigXP的界面中,读者会发现,此时有两个拓扑网络,一个是DDR1_D.top,一个是DDR1_DQS.top。
第三步,连接网络。在SigXP中,是不能有两个独立网络存在的,因此我们必须“欺骗”SigXP,使SigXP认为仿真环境中只有一个网络存在,因此我们在这两个网络的同一位置加一个大阻值电阻(或者很小的电容也可以,只要能造成电气上的连接关系就可以了,设定阻值为MΩ以上,比如我们在例子中设为5MΩ。电阻的两端分别连接在两个网络上,这时,我们的仿真网络就搭建成功了,如图6-34所示。图中的电阻R0就是我们加进去的连接电阻。之所以设置非常大的阻值,是为了保证两个网络之间干扰最小。
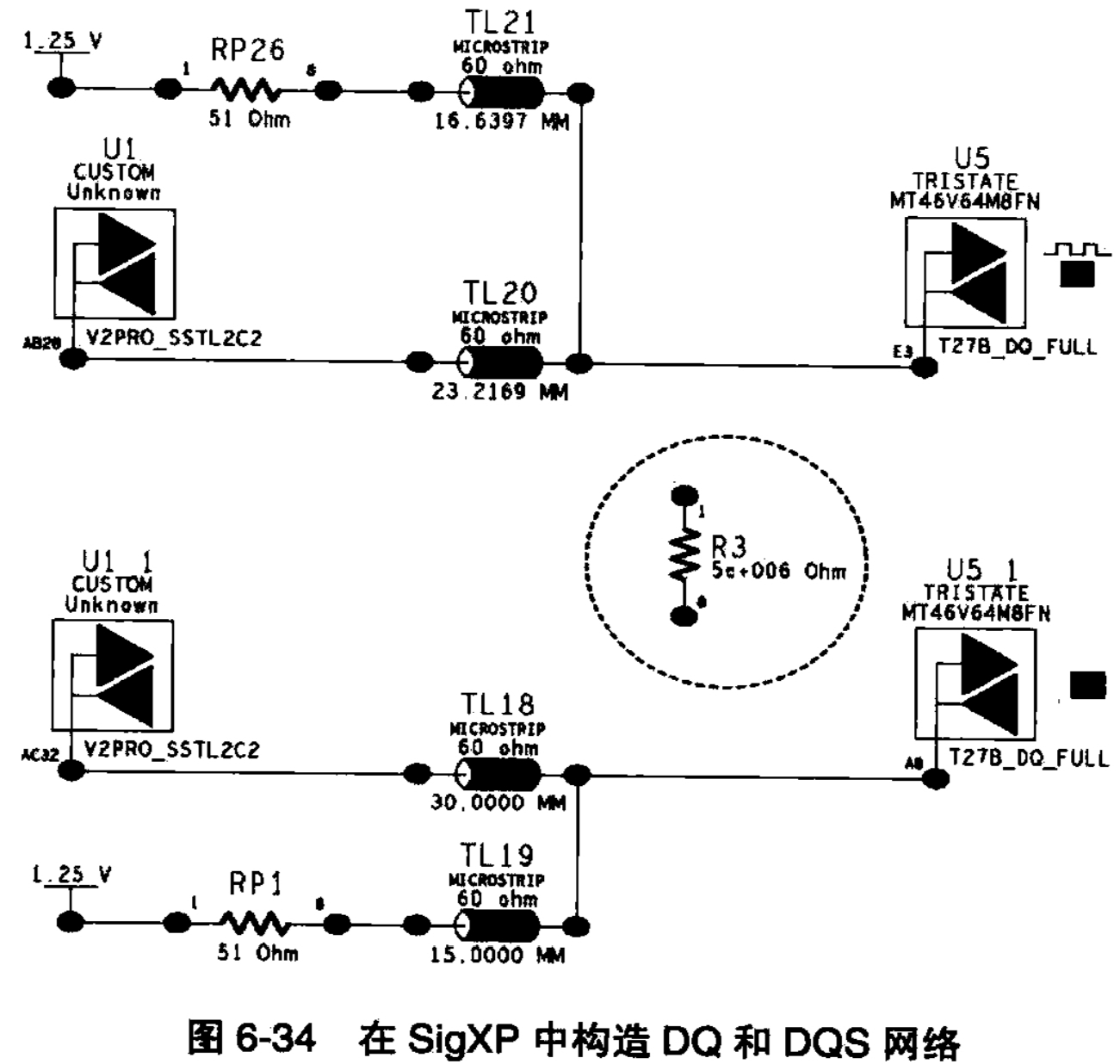
第四步,设置激励。分别对这两个拓扑网络的驱动端,比如我们选择U1,单推它的激励数据,记住,频率一定是一样的。但是对于DQS信号而言(当进行数据写入操作时),要对DQS信号设置半个周期的延迟,对于133MHz的DDR而言,就是1.875ns。如图6-35所示,是对DQS信号进行激励设置。
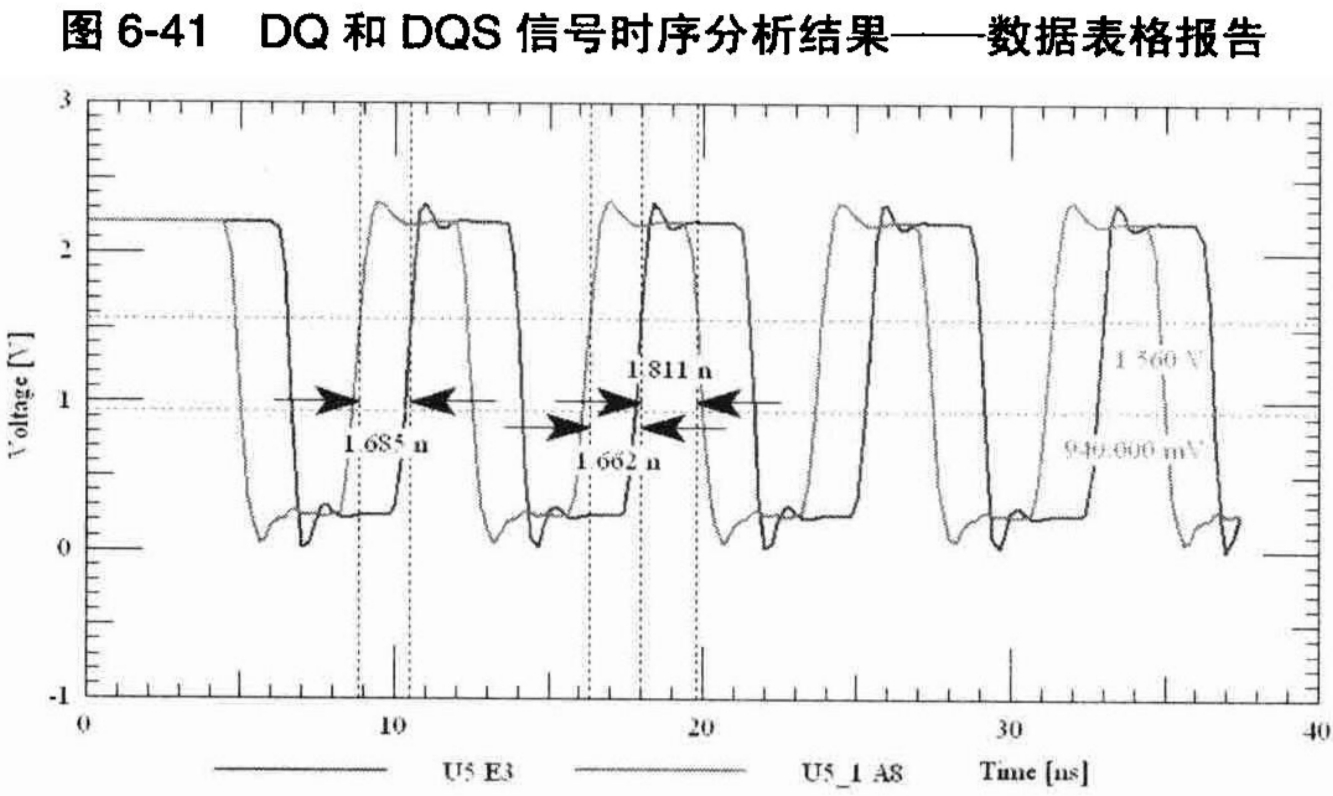
同样,对DQ信号也要设计类似的激励,只是DQ信号没有相对于时钟信号的延迟,它和时钟信号完全同步。设置完激励之后,如果不需要对仿真结果进行自动测量和计算的话,就可以进行仿真了,在本书的例子中,仿真后的波形如图6-42所示(为了使仿真结果清晰,作者删除了发送端信号的波形,只显示了DQ和DQS信号在DDR芯片接收端的波形)。从这个波形可以看出,在不考虑其他因素的情况下,如果DQ和DQS信号的传输线长度保持一致,建立和保持时间都分别为1.662ns和1.81ns,远远大于DDR芯片所要求的0.5ns的要求。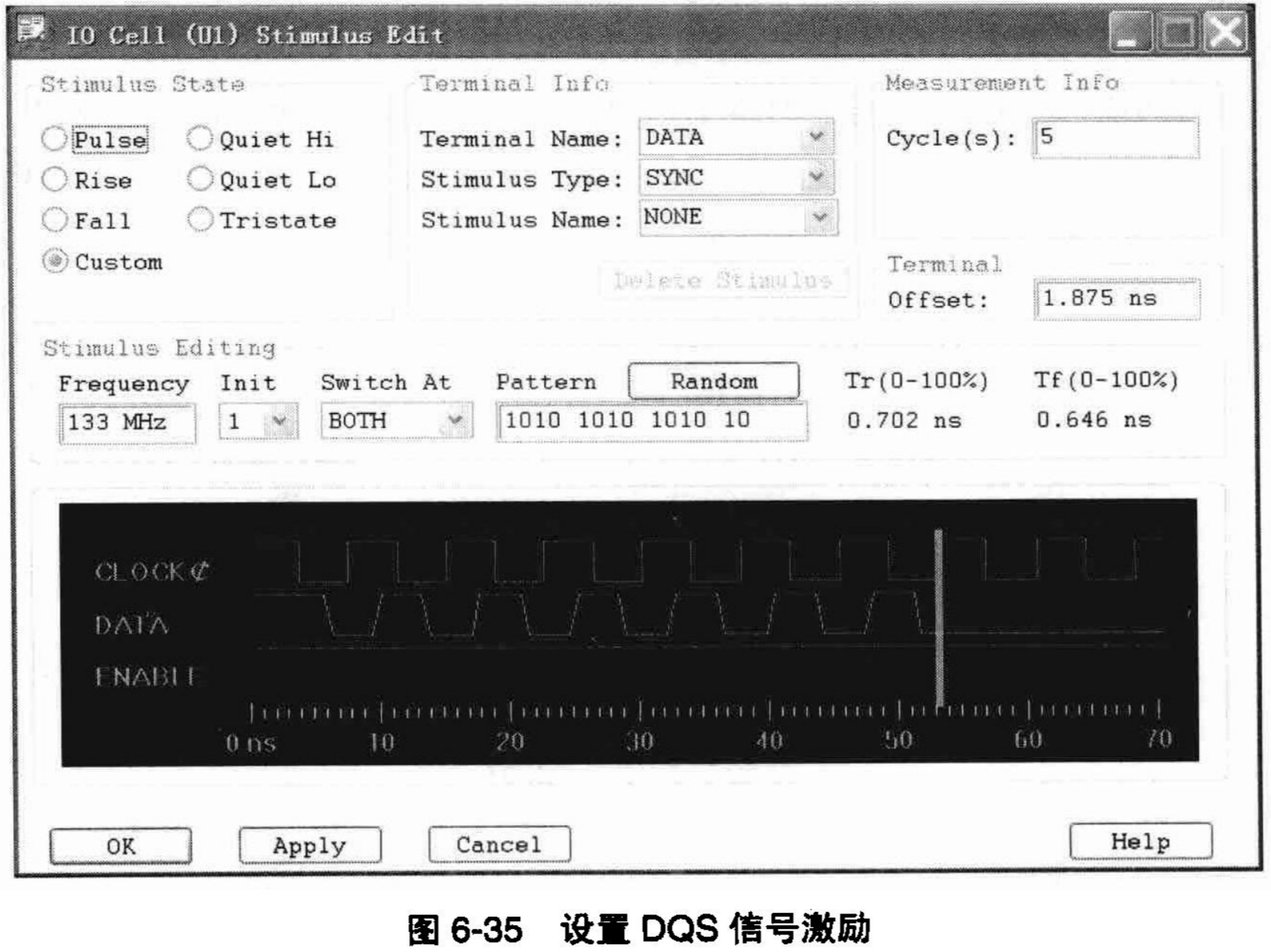
第五步(可选),在前一步中,我们讲过,如果不需要软件帮我们自动进行仿真结果的测量和计算,那么就可以直接仿真,然后用仿真波形中进行人工的测量。如果测量的数据量比较小的话,人工测量还可以接受,但是如果需要测量的数据量比较大,那么人工测量的效率和精度就会大大降低。因此,我们还需要学习如何让软件进行仿真结果的自动测量。
为了让软件能够进行自动测量,需要让软件知道如下一些信息。
● 有哪些对象需要测量,也即,在测量过程中,要涉及到哪些数据,包括数据从哪个仿真对象中来,以及对象的哪些数据需要参与测量计算;
● 测量结果是如何计算的,即在仿真结果获得所需的数据后,数据之间按照怎样的关系式运算之后,才是我们最终想要的结果。
这类信息都需要通过合理的设置,让软件工具知道设计者的测量意图,才能完成真正的测量工作。具体对我们这个DDR设计实例而言,我们的测量目的是以DQS信号作为采样信号的DQ信号的SetupTime和HoldTime。我们首先要让系统知道哪个信号是DQS,可以作为Strobe(系统不会按照拓扑中的信号名称进行判断),通过选择菜单中的“Set→Strobe Pins...”命令,将打开如图6-36所示的设置界面,在相应的列表框中选择合适的管脚,然后单击“Add”按钮,生成Strobe和Data信号关系。如图6-36所示,选择U5.E3为Strobe信号,并将Active Edge设置为Both,意为Strobe信号的上升沿和下降沿都是有效的采样触发机制,这也是DDR的本意。通过这样的设置,完成了对Strobe信号的定义,然后进入下一步,描述仿真对象之间的表达式,描述计算关系,从而自动计算仿真结果。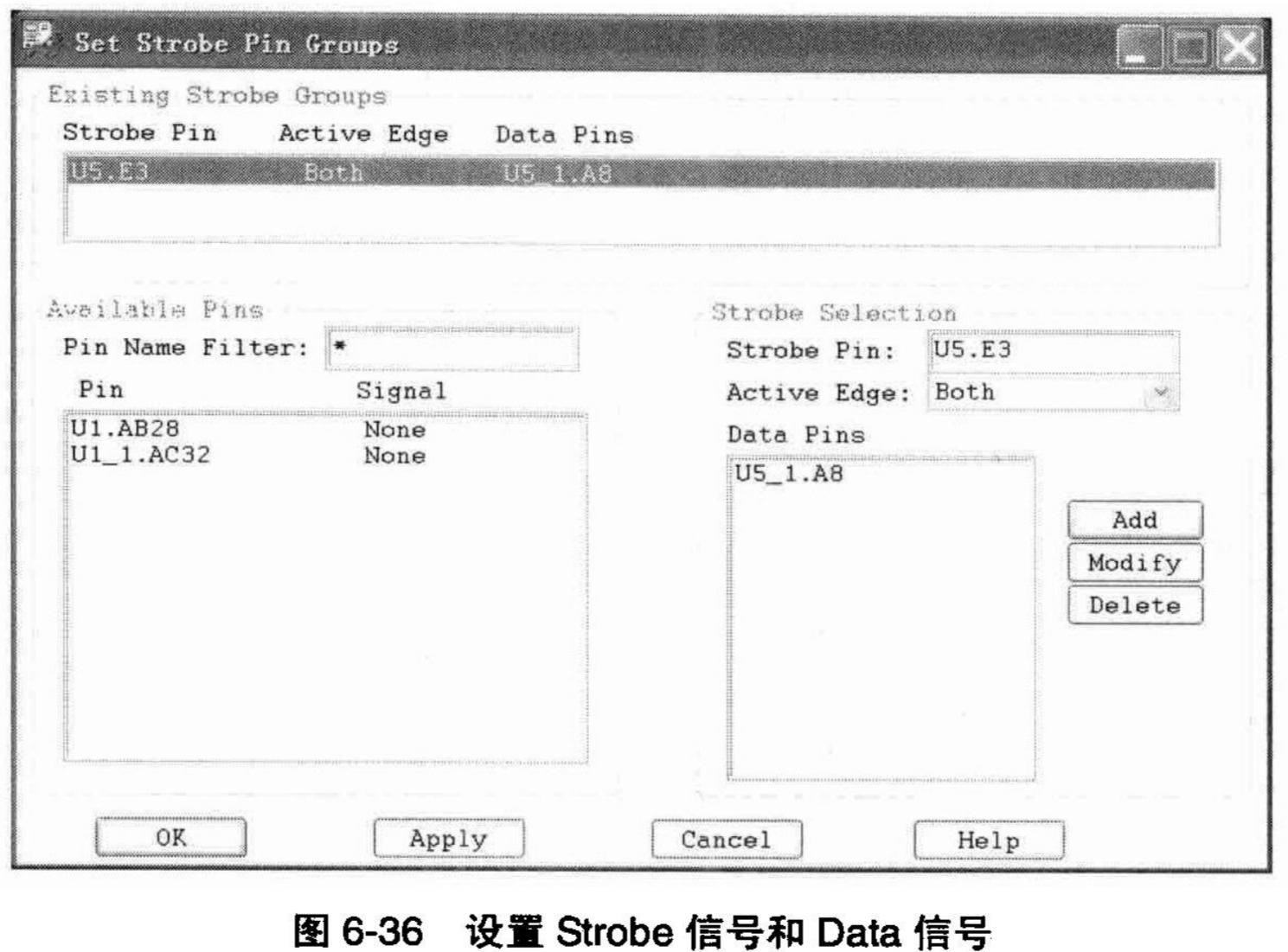
第六步,设置测量表达式。在上一步中,我们明确了要测量的目的并设置了Strobe信号,这里我们要完成测量表达式的设置。在设置测量表达式之前,首先要完成表达式中所使用的参数的设置。针对我们实例的测量目的,即DQ信号相对于DQS信号的SetupTime和HoldTime,我们需要如下一些数据被测量表达式所使用。
● DQS信号本身的上升沿和下降沿发生的时间点,知道了这个时间点,才能够去计算DQ信号的SetupTime和HoldTime,这个应该比较容易理解。为方便说明,我们把这个时间点记为StrobeTime。
● DQ信号有效的高电平和低电平转换点,也即DQ信号从比特1变成有效的比特0的时间点,以及从比特0变成有效的比特1的时间点。为方便说明,我们把这个时间点记为DQCrossingTime。
得到了上述两个时间点之后,剩下的事情就很简单了,我们就可以计算SetupTime和HoldTime了。如果DQCrossingTime发生在StrobeTime之前,那么StrobeTime减去DQCrossingTime的值就是SetupTime;如果DQCrossingTime发生在StrobeTime之后,那么DQCrossingTime减去StrobeTime的值就是HoldTime。
下面,我们就要在软件中完成这些数据及相应的表达式的设置。首先,我们来设置DQS信号的StrobeTime。因为这里所使用的测量方式和数据都不是SigXP中已提供的内容,因此我们必须在“Measurements”选项卡中,进行用户自定义参数的测量。在SigXP的操作界面下方,单击“Measurements”选项卡,首先清除对“EMI”、“Reflection”和“Crosstalk”等测量参数的选择,并选中“Custom”这个测量选项,然后展开这个选项,单击鼠标右键,选择“Add”命令来增加用户自定义的测量项目。系统将打开如图6-37所示的“Measurement Expression Editor: Strobe_Time”对话框,在对话框中的“Expression Name”和“Description”文本框中输入“Strobe_Time”,来命名用户自定义的测量项目名称及描述。然后在最下面的“Value TBD”上单击鼠标右键,选择“CrossingTime”命令,说明这个测量是要得到信号穿越某个电压阈值的时间点。对于右键菜单中出现的众多测量参数,这里就不一一介绍了,希望读者自行查找SigXP的用户使用手册进行学习。一定要认真学习测量参数,因为,只有对这些参数充分了解之后,才能灵活地使用它们进行各种各样的自定义测量。
读者要对自定义测量的参数进行详细了解,可以在SigXP的帮助系统中搜索“The Expression Editing Pull-Down Menu”一节的内容,该文档中详细对自定义测量的各种测量项目及所使用的参数进行了详细的描述。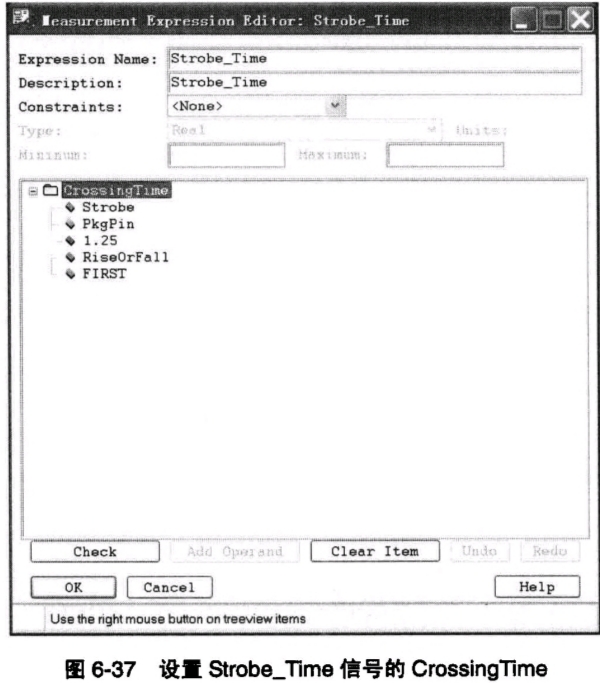
在上述的CrossingTime参数设置中,各参数设置含义如下:计算Strobe_Time信号(在前面已经定义过的)在位于芯片管脚PkgPin处的仿真波形中,无论是上升沿还是下降沿,其电压值第一次穿越1.25V电平的时间点。由于DDR的参考电源是1.25V,所以这里设置1.25V为电平转换阈值。
设置好Strobe_Time信号的CrossingTime之后,我们再来设置SetupTime和HoldTime的自定义测量表达式。同样,还是在“Measurements”选项卡中,选中“Custom”这个测量参数,单击鼠标右键,选择“Add”命令增加测量项目,这时我们选用“Difference”这个数学函数进行测量计算,将打开如图6-38所示的“Measurement Expression Editor: Setup_Time”对话框。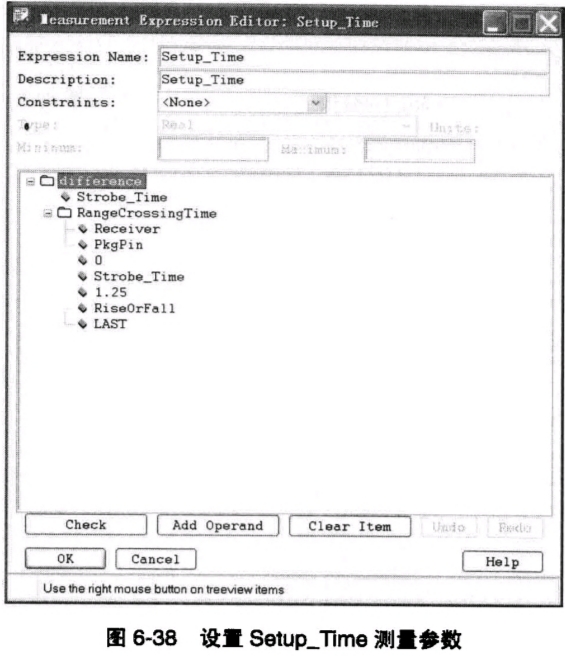
在对话框中的“Expression Name”和“Description”文本框中输入“Setup_Time”,来命名用户自定义的测量项目名称及描述。然后把“difference”下面的第一个时间参数改成“Strobe_Time”,也即我们刚刚做好的DQS信号的测量时间值。因为此时,我们要设置的是SetupTime的计算,那么应该是用Strobe_Time的值减去DQ信号电平转换时间点的值。所以,对于第二个时间参数,我们选择“RangeCrossingTime”命令,并设置相应的测量参数。这个参数的设置含义如下:计算Receiver在位于芯片管脚PkgPin处的仿真波形中,从时刻0到当前的Strobe_Time时刻的这段时间内,不论是上升沿还是下降沿,Receiver的信号电压最后一次穿越1.25V的时间。选用“LAST”参数的含义就是找到在Strobe_Time之前的,并且离当前Strobe_Time最近的那一次变化的时间。用当前的Strobe_Time减去这个RangeCrossingTime,即是对应于当前Strobe_Time的SetupTime。难以理解么?不要着急,对照下面Hold_Time的设置,我们通过两个参数的设置对比,应该能容易理解一些。
按照同样的方法,我们可以完成对Hold_Time测量的设置,如图6-39所示。对比前面关于Setup_Time的设置,这里有几点需要说明。
● 对于两个“difference”设置中,关于两个时间参数的位置正好相反。原因在前面已经讲清楚了,因为计算Setup_Time和Hold_Time时,DQ信号的CrossingTime和DQS信号的CrossingTime相对位置不一样,一个在前,一个在后,因此,反应到“difference”时间参数中,自然要调整减数和被减数的位置。
两个RangeCrossingTime的参数中,时间范围设置也不一样,一个是从0时刻到Strobe_time,另一个是从Strobe_time到5e-008(即50ns),这是个确定的仿真时间点,这个区别也是因为SetupTime和HoldTime的计算区别所致,对于SetupTime的计算,需要在当前Strobe_time的前面找到DQ信号的CrossingTime,所以从0时刻开始,到当前Strobe_time范围内寻找用于计算HoldTime的DQ信号的CrossingTime,则需要从当前Strobe_time开始向后寻找;并且,对于SetupTime寻找的是最后一个(LAST参数)DQ信号的变化时间,而对于HoldTime寻找的是第一个(FIRST参数)DQ信号的变化时间。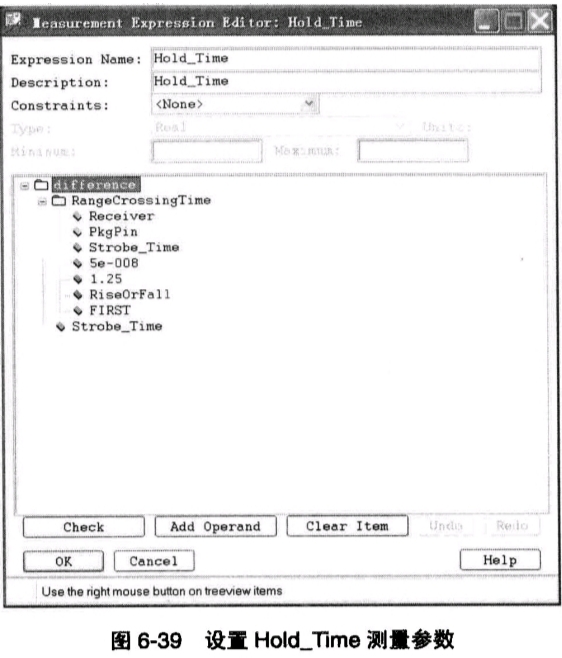
通过这样的对比解释,相信读者应该能理解参数设置的含义了。
第七步,测量并比较结果。至此,我们对软件自动测量所需要的(用户自定义)测量值都定义好了。在仿真之前,要记得选中相应的测量项目,如图6-40所示,Strobe_Time一定要选中,因为它被另外两个测量项所调用。
现在单击仿真按钮进行仿真,对于这个仿真,我们可以得到时域数据表格报告和波形报告。先看图6-41中的数据表格仿真报告。从这个仿真结果中我们可以清楚地看到Setup_Time和Hold_Time的数值。对照图6-42的波形仿真报告,在这个波形报告中,作者手工加入了对Setup_Time和Hold_Time的测量。从测量结果的对比中可以看出,还是比较接近的,但是自动测量结果更加全面而且准确。这是因为自动测量所依据的模型中的数据并自动运算,而手工测量的结果难免会有人为的偏差。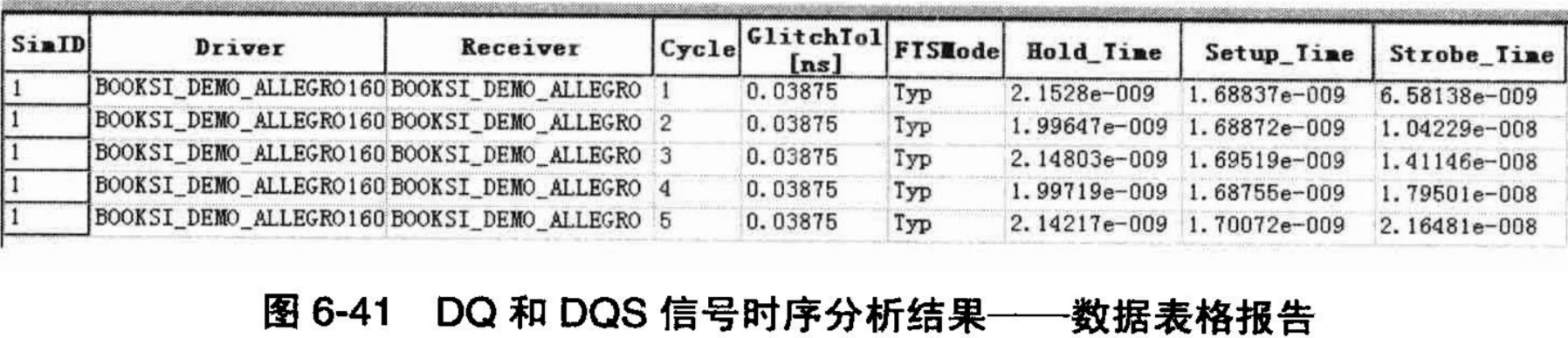
如果读者对于如何进行自定义测量的方法还不能透彻理解,那么可以通过打开网上下载的资料中的拓扑文件,位于“DemoBoard”目录下的“DDR1_DQ_DQS.top”文件,并结合本书的讲解,通过修改定义的表达式或者参数做几次练习,比较不同的仿真结果,这样做应该会有更深刻的认识。
至此,我们完成了对DQ和DQS信号完整性及相对时序的仿真分析,并介绍两种方式对仿真结果进行测量的方法,下面我们就根据这些测量结果,对设计进行约束定义和实施。
6.6.5 DDR数据总线约束定义
根据以上的对DDR数据总线的仿真分析、AC特性数据的测量,以及DQ和DQS信号之间的时序关系验证,我们可以确定对DDR数据、地址/控制总线的约束条件。由于数据总线本身的拓扑结构就比较简单,因此对于它的约束也相对简单一些,只需定义一个数据总线之间的相对延迟即可,这里先暂时定义相对延迟为2.5mm,时间上小于0.02ns。具体的约束设置过程和对地址/控制总线的约束设置方法一样,在此不再重复。
6.6.6 约束的时序验证
为了确保约束的可靠性,在所有的约束定义完成之后,要核对整个DDR系统时序,此时,必须把PCB的设计因素考虑进去。参照前一节中,我们对DDR芯片及DDR控制器的关键时序参数列表,这里把PCB上影响DDR时序的因素列举一下,如表6-13所示。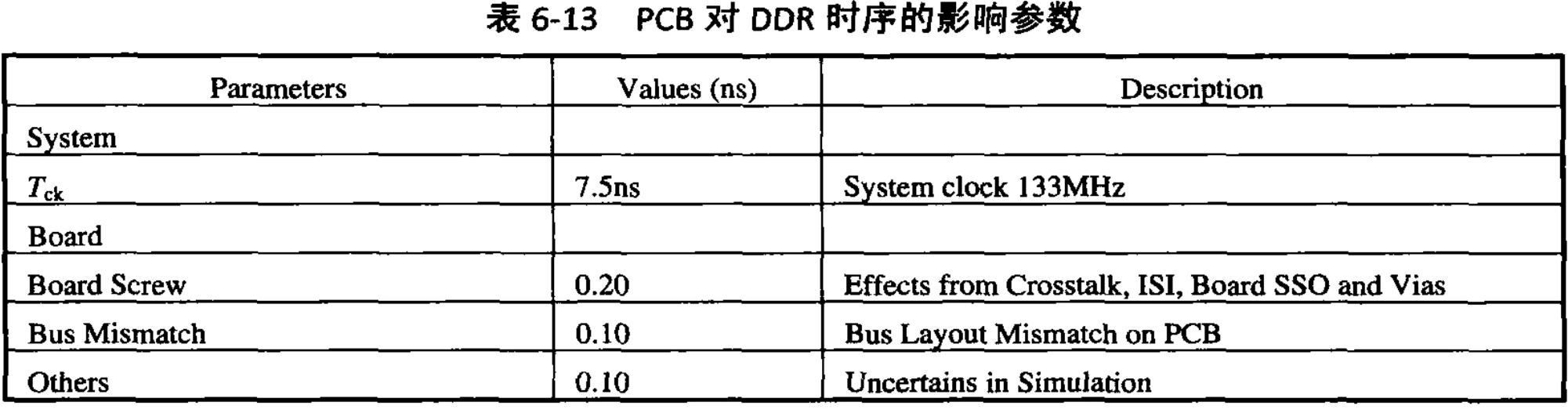
为了方便验证整个系统的时序,我们把能够影响DDR时序的所有参数汇总在一个表中来对设计中的时序关系进行计算分析,从而得出系统设计的时间余量,如表6-14所示。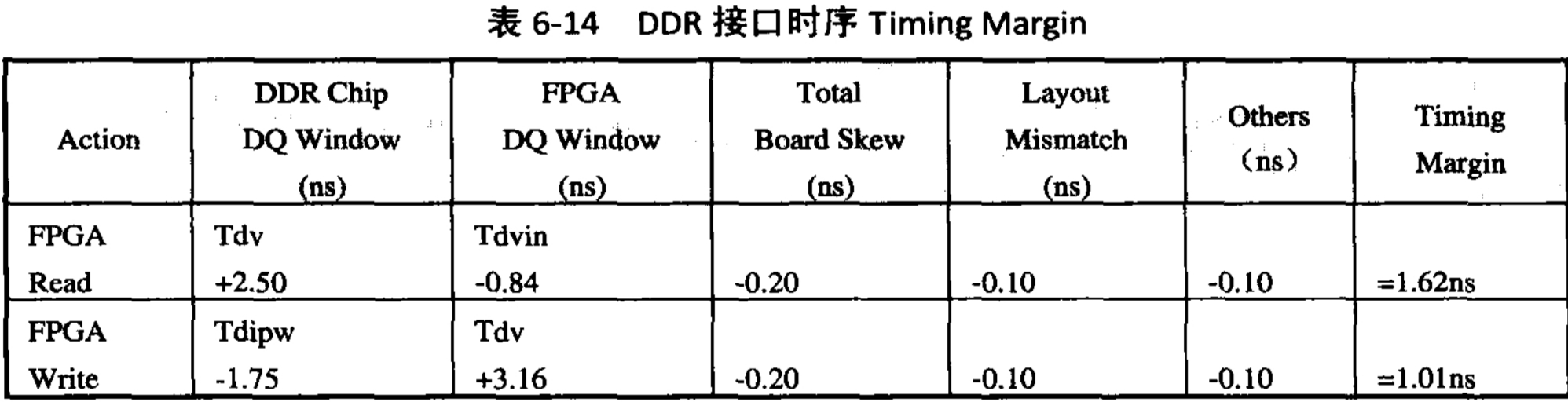
从表中的结果来看,本书的设计实例中所留的时间余量还是比较大的,分别为1.62ns和1.01ns,实际上对于大多数的DDR接口是不可能这么轻松实现的。之所以在本例中有这么大的时间余量,是因为这里以FPGA作为DDR的控制器,FPGA 的 I/O 特性和专用芯片相对差一些,FPGA 内部的 DDR 控制器逻辑都需要仔细调节才能达到一个比较好的性能。所以,作为 SI 工程师和 PCB 设计人员,如果能够从外部设计环节上留给 FPGA 更大的时间余量,对于减轻 FPGA 工程师的工作压力很有帮助,也是系统设计、团队合作的一个体现。
相关文章:

高速系统设计实例设计分析二
6.6 仿真约束的生成和实施 进行到这一步,我们已经完成了对实例进行仿真的所有条件的设置,包括对板子的设计要求分析和预布局处理。虽然从技术上讲,我们可以开始进行仿真分析并生成设计的约束,但是根据作者的工作经验,…...

AUTOSAR图解==>AUTOSAR_SWS_V2XGeoNetworking
AUTOSAR V2X GeoNetworking 模块分析 车联网地理网络协议解析与实现 目录 1. 概述2. 模块架构分析 2.1 AUTOSAR V2X GeoNetworking 在BSW架构中的位置 2.1.1 架构层次说明2.1.2 模块间关系 2.2 V2X GeoNetworking 模块内部组件结构 2.2.1 核心组件2.2.2 接口说明 3. 消息处理…...

在 Rocky Linux 上手动安装 zsh
目录 🧩 一、准备:检查是否已经安装Zsh 🛠️ 二、从源码安装 Zsh(推荐方式) 1. 下载 Zsh 源码 2. 解压源码 3. 配置安装路径(到你的 home 目录下) 4. 编译并安装 🧪 三、测试…...

Vector和list
一、Vector和list的区别——从“它们是什么”到“区别在哪儿” 1. 它们是什么? Vector:类似于一排排整齐的书架(数组),存放元素时,元素排成一条线,连续存储。可以很快通过编号(索引…...

人工智能外呼系统:重构智能交互的全维度进化
在数字化浪潮席卷全球的今天,人工智能外呼系统正以其颠覆性的技术革新,重新定义企业与客户的沟通范式。这一融合语音识别、自然语言处理与机器学习的智能系统,不仅实现了从 “机械应答” 到 “智慧交互” 的跨越,更在金融、医疗、…...
gdb调试)
嵌入式培训之数据结构学习(三)gdb调试
一、gdb调试 (一)一般调试步骤与命令 1、gcc -g (调试版本,内含调试信息与源码;eg:gcc -g main.c linklist.c) 2、gdb a.out(调试可执行文件,eg:gdb ./a.o…...

元宇宙赛道新势力:成都芯谷产业园创新业务如何重构产业格局
成都芯谷产业园在元宇宙有啥新搞头?看看它的创新业务怎么改变行业! 成都芯谷产业园在元宇宙赛道上的创新业务,核心在于系统性构建一个开放、协同、高效的元宇宙创新生态系统,以此重构产业格局。这并非简单的企业物理聚集…...

Java 日期解析与格式化:从标准格式到自然语言解析
使用 Java 搭配 Apache Commons Lang3 和 Natty 库,实现灵活高效的日期解析与格式化。 一、背景 将不同格式的日期统一成一个格式。日期格式可能有以下几种类型: 标准格式:2024-02-28、14/05/2022、2002年5月6日非英文月份缩写:…...

【windows server脚本每天从网络盘复制到本地】
windows server脚本每天从网络盘复制到本地 调试模板 echo off :: 显示详细操作 echo echo 执行批处理文件:文件复制任务 echo :: 配置参数 set sourcePath\\network_drive\shared_folder :: 网络盘路径 set destinationPathC:\LocalBackup :: 本地保…...

GraphPad Prism简介、安装与工作界面
GraphPad Prism图表可视化与统计数据分析(视频教学版) - 商品搜索 - 京东 1.1 GraphPad Prism简介 GraphPad Prism 将科学绘图、综合曲线拟合(包括非线性回归)、易于理解的统计分析以及数据管理功能集于一身,帮助用…...

尚硅谷阳哥JVM
文章目录 第01章 JVM快速入门1、什么是JVM2、主流虚拟机有哪些?3、结构图3、执行引擎Execution Engine4、本地方法接口Native Interface5、Native Method Stack6、PC寄存器(程序计数器) 第02章 类加载器ClassLoader1、 类的加载过程2、类加载器的作用3、类加载器分类…...

spark的Standalone模式介绍
Apache Spark 的 Standalone 模式是其自带的集群管理模式,无需依赖外部资源管理器(如 YARN 或 Mesos),可快速部署和运行 Spark 集群。以下是对 Standalone 模式的详细介绍: 1. 核心组件 Master 节点 集群的主控制器…...

自营交易考试中,怎么用“黄昏之星”形态做出漂亮反转单?
在自营交易考试中,如何在复杂的市场波动中抓住关键的趋势反转点,常常决定了一笔交易的成败。尤其是在规则清晰、交易明确的交易考试中,具备对K线形态的敏感度,是不少EagleTrader交易员在晋级过程中总结出的实用经验。今天…...

【算法】版本号排序
对版本号数组进行排序,比如:[0.1.2.3,1.2.1.0,4.2.1.0,0.1.2.0] 核心思路 将版本号拆分为数字数组,逐个比较每个子版本段。具体步骤: 拆分版本号:将每个版本字符串按 . 分割成数字数…...

wordcount程序
### 在 IntelliJ IDEA 中编写和运行 Spark WordCount 程序 要使用 IntelliJ IDEA 编写并运行 Spark 的 WordCount 程序,需按照以下流程逐步完成环境配置、代码编写以及任务提交。 --- #### 1. **安装与配置 IntelliJ IDEA** 确保已正确安装 IntelliJ IDEA&#x…...

MySQL Explain 中 Type 与 Extra 字段详解
引言 在数据库性能调优过程中,理解执行计划(EXPLAIN)的输出信息至关重要。MySQL 的 EXPLAIN 命令能够帮助开发者分析查询的执行路径和效率,其中 Type 和 Extra 字段提供了关键的执行细节。Type 字段表示访问类型,反映…...

代码随想录算法训练营第60期第三十六天打卡
大家好!今天我们就会正式进入动态规划的章节,以前我们相继学完了回溯算法,贪心算法,今天的动态规划应该是相当重要同时也是相当难的章节,那我们废话不多说直接进入我们今天的章节。 第一部分 动态规划理论基础 那究竟…...

Python操作MySQL 连接加入缓存层完整方案
更多内容请见: python3案例和总结-专栏介绍和目录 文章目录 1、整体架构设计2、MySQL 连接方案2.1 使用连接池 (推荐)2.2 使用 SQLAlchemy (ORM方案)3、缓存层实现方案3.1 Redis 缓存实现3.2 Memcached 缓存实现4、完整集成方案4.1 带缓存的数据库访问层4.2 使用装饰器实现缓存…...
)
PyTorch深度神经网络(前馈、卷积神经网络)
文章目录 神经网络概述神经元模型多层感知机前馈神经网络网络拓扑结构数学表示基本传播公式符号说明整体函数视角 卷积神经网络卷积神经网络发展简史第一代(1943-1980)第二代(1985-2006)第三代(2006-至今)快…...

现代垃圾收集器
大家好,我是你们的花姐。 话说java的长期支持版本已经发展到了JDK21,大部分同学对jvm中的垃圾收集器还停留在java8之前的CMS和G1。对java11之后引入的低延迟垃圾收集器shenandoah和zgc几乎是一无所知,甚至有同学是连这两个名字也没有听过呀,…...

Android学习总结之类LiveData与ViewModel关系篇
1. ViewModel 和 LiveData 的强依赖关系 ViewModel 和 LiveData 虽非强依赖,但在 Android 架构中常紧密协作,这基于它们的设计理念和优势互补: 数据与 UI 分离:ViewModel 的主要职责是存储和管理与 UI 相关的数据,而…...

GaussDB 实例 gsql 连接方式详解
GaussDB 实例 gsql 连接方式详解 GaussDB 是华为云推出的分布式关系型数据库服务,支持多种数据库引擎(如 MySQL、PostgreSQL、SQL Server 等)。gsql 是 GaussDB 提供的命令行客户端工具,用于连接和管理数据库实例。本文将详细介绍…...

智能体制作学习笔记2——情感客服
02 案例1-情感客服_哔哩哔哩_bilibili 目录 一、AI对视频内容总结 二、选择可代替视频总结的方案 三、豆包AI插件安装 四、通义 五、情感客服智能体制作 (一)注册 (二)进入工作空间 (三)创建智能体 (…...

部署GraphRAG配置Neo4j实现知识图谱可视化【踩坑经历】
文章目录 概要部署graphrag(一)使用conda创建虚拟环境(前提已经安装好anaconda)(二)部署graphrag 部署neo4jgraphrag生成的知识图谱导入neo4j踩坑经历1.graphrag执行graphrag index --root ./ragtest命令报错2.neo4j没有Relationship types 概要 在本地部署GraphRag࿰…...

跨域的几种方案
因为浏览器出于安全考虑,有同源策略。也就是说,如果协议、域名、端口有一个不同就是跨域,Ajax 请求会失败。 我们可以通过以下几种常用方法解决跨域的问题 JSONP JSONP 的原理很简单,就是利用 <script> 标签没有跨域限制…...

5 WPF中的application对象介绍
WPF Application 类提供了一系列生命周期事件,了解它们的触发顺序对于应用程序开发非常重要。以下是主要事件的触发顺序 1. 主要事件顺序 Startup - 应用程序启动时触发 这是第一个触发的事件 适合在此处初始化应用程序级资源 可以在此取消启动(通过设置e.Cancel = true) Act…...

Nexus首次亮相迪拜 TOKEN2049:以“手机 + 钱包 + 公链 + RWA”生态系统引领未来区块链基建
迪拜,2025年5月—— 全球 Web3 基础设施创新平台 Nexus,在本年度迪拜 TOKEN2049 全球峰会 上完成了其主网与全生态系统的首次国际公开亮相。此次参会不仅展示了 Nexus 的国际生态布局,更标志着其迈出了全球化战略关键一步。凭借对现实世界资产…...

C++ 套接字函数详细介绍
目录 头文件1. 套接字创建与配置2. 绑定地址与端口3. 连接建立4. 数据传输5. 套接字选项6. 地址转换7. 套接字关闭8. 其他实用函数 C 套接字函数详细介绍 套接字(Socket)是网络通信的基本端点,C中通常使用BSD套接字API进行网络编程。以下是主要的套接字相关函数及其…...

WordPress 和 GPL – 您需要了解的一切
如果您使用 WordPress,GPL 对您来说应该很重要,您也应该了解它。查看有关 WordPress 和 GPL 的最全面指南。 您可能听说过 GPL(通常被称为 WordPress 的权利法案),但很可能并不完全了解它。这是有道理的–这是一个复杂…...

机器人示教操作
机器人基础操作 **ES机器人试教操作知识** **1. 视角移动** **1.1 基础模式** - 关节轴控制:通过关节1至关节6实现单轴正反转移动 - 直线移动:通过X/Y/Z坐标轴沿指定方向直线移动 - 旋转移动:通过RX/RY/RZ坐标轴绕指定轴旋转 **1.2 步进模式…...

【python】UnicodeDecodeError: ‘gbk‘ codec can‘t decode byte 0xb2
报错 C:\Users\zhangbin\AppData\Local\Programs\Python\Python310\python.exe D:\XTRANS\cuda\03-graph-db\04-cmkg\pdf2zh-v1.9.9-with-assets-win64\pdf2zh\gui.py Traceback (most recent call last): File “D:\XTRANS\cuda\03-graph-db\04-cmkg\pdf2zh-v1.9.9-with-asset…...

[python] python静态方法,类方法,实例方法实现及其区别
一 静态方法 格式: 使用 staticmethmod 装饰器修饰 应用: 某个方法既不需要使用实例属性也不需要使用类属性时,就可以考虑使用静态方法 注意: 静态方法与类无关,可以被转换成函数使用,属于类本身 1.1 经典示例 创建一个与日期相关的辅助函数,这些函数不需要访问或修改类的…...

Kite AI 自动机器人部署教程
最近比较火的AI赛道,每日自动对话训练AI,赚积分 一个个用于 Kite AI 平台的自动交互机器人,支持多钱包和代理。 登记 注册链接 🌟 功能 多钱包支持(手动输入或基于文件) 代理支持(HTTP/HTTP…...
)
50. Pow(x, n)
50. Pow(x, n) 分治法的基本思想是将一个大问题分解成若干个相同或相似的小问题,递归地解决这些小问题,然后将这些小问题的解合并起来得到原问题的解。 class Solution:def myPow(self, x: float, n: int) -> float:# 内部定义了一个嵌套的辅助函数…...

Go 语言 sqlx 库使用:对 MySQL 增删改查
MySQL 作为目前最流行的开源关系型数据库,其 SQL 语法体系已形成行业标准,相关知识体系庞大且成熟,本文不再对 SQL 基础进行详细展开,建议尚未掌握的读者先行系统学习。本文聚焦于如何使用 Go 语言进行 MySQL 数据库操作ÿ…...

反射, 注解, 动态代理
文章目录 单元测试什么是单元测试咱们之前是如何进行单元测试的? 有啥问题 ?现在使用方法进行测试优点Junit单元测试的使用步骤删除不需要的jar包总结 反射认识反射、获取类什么是反射反射具体学什么?反射第一步:或者Class对象 获…...

继续预训练 LLM ——数据筛选的思路
GPT生成数据微调qwen-2.5多模态模型实战项目 作者:柠檬养乐多 原文地址:https://zhuanlan.zhihu.com/p/30645776656 qwen2.5-vl是阿里通义实验室推出的qwen系列最新多模态大模型,在许多指标上已经超过或接近了gpt-4o。更为方便的是࿰…...
的 SELECT 查询执行机制)
深入解析 PostgreSQL 外部数据封装器(FDW)的 SELECT 查询执行机制
引言 PostgreSQL 中的外部数据封装器(Foreign Data Wrapper, FDW)是一种扩展,允许您像访问 PostgreSQL 数据库中的表一样,访问和操作存储在外部数据源中的数据。FDW 使 PostgreSQL 能够与多种数据存储系统(包括关系型…...

数据库系统概论|第六章:关系数据理论—课程笔记2
前言 前文我们介绍了规划化的基本概念,同时引入了关于规范化的相关定义与基本概念,低一级范式的关系模式,通过模式分解,可以转换为若干个高一级范式的关系模式的集合,这种过程就叫规范化。本文将围绕范式展开讨论&…...

package-lock.json能否直接删除?
package-lock.json能否直接删除? package-lock.json 生成工具:由 npm 自动生成。 触发条件:当运行 npm install 时,如果不存在 package-lock.json,npm 会创建它;如果已存在,npm 会根据它精确安…...

Ubuntu磁盘空间分析:du命令及常用组合
1、du命令的作用 du(Disk Usage)是 Ubuntu 系统中用于查看目录或文件磁盘使用情况的命令,主要用于分析磁盘空间占用。 2、语法 du [选项] [目录/文件路径]常用选项 2.1、-h 以 KB、MB、GB 等人性化可读格式(Human-readable&am…...

《数据库原理》部分习题解析1
《数据库原理》部分习题解析1 1. 名词解释 (1)关系(2)属性(3)域(4)元组(5)码(6)分量(7)关系模式 ࿰…...
)
汇川Easy系列PLC数据值改变功能块(随动增益改变判断)
PLC值改变事件 值改变触发功能块 PLC值改变事件 值改变触发功能块(SCL ST完整源代码)-CSDN博客文章浏览阅读1.1k次。本文介绍了在PLC中处理值改变事件的方法,包括值改变触发功能块的实现,详细讲解了FB接口定义、ST代码,并提供了在博途平台上的实现。此外,还分享了如何利用…...

数据清洗的艺术:如何为AI模型准备高质量数据集?
数据清洗的艺术:如何为AI模型准备高质量数据集? 引言 在人工智能和机器学习领域,我们常常听到"垃圾进,垃圾出"(Garbage in, garbage out)这句格言。无论你的模型架构多么精妙,算法多么先进,如果…...

怎么查看当前vue项目,要求的node.js版本
怎么查看当前vue项目,要求的node.js版本 找到 package.json package-lock.json 搜索 node...

游戏引擎学习第278天:将实体存储移入世界区块
总结并为今天的内容做好铺垫 今天的内容是关于开发一个完整的实体系统,目标是让这个系统更加实际和有效。之前讨论了如何通过一个模拟区域来处理无限大的世界。最初,使用浮动点数而不是双精度浮点数来避免潜在的精度问题,因为一些平台&#…...
)
计算机组成与体系结构:缓存设计概述(Cache Design Overview)
目录 Block Placement(块放置) Block Identification(块识别) Block Replacement(块替换) Write Strategy(写策略) 总结: 高速缓存设计包括四个基础核心概念…...
,向进程发送发送信号)
在Linux中如何使用Kill(),向进程发送发送信号
kill()函数 #include <sys/types.h> #include <signal.h> int kill(pid_t pid, int sig); 函数参数和返回值含义如下: pid:参数 pid 为正数的情况下,用于指定接收此信号的进程 pid;除此之外,参数 pid 也可设置为 0 或-1 以及小于-1 等不同值,稍后给说明。 …...

ElasticSearch重启之后shard未分配问题的解决
以下是Elasticsearch重启后分片未分配问题的完整解决方案,结合典型故障场景与最新实践: 一、快速诊断定位 检查集群状态 GET /_cluster/health?pretty # status为red/yellow时需关注unassigned_shards字段值 2.查看未分配分片详情 …...
)
基于 Spring Boot 瑞吉外卖系统开发(十四)
基于 Spring Boot 瑞吉外卖系统开发(十四) 查询订单 在管理端的首页,单击左侧菜单栏中的“订单明细”,会在右侧打开订单明细页面。 请求路径:/order/page 请求方法:GET 参数:page pageSize …...