《Python星球日记》 第69天:生成式模型(GPT 系列)
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
目录
- 一、GPT简介:从架构到原理
- 1. GPT的架构与工作原理
- 2. Decoder-only结构与生成能力
- 二、GPT如何生成文本
- 1. 基于GPT的文本补全与生成
- 2. 生成策略与Sampling技术
- 三、使用Hugging Face的GPT模型实战
- 1. 环境准备与模型加载
- 2. 文本生成实战示例
- 3. 参数调优与最佳实践
- 总结与展望
👋 专栏介绍: Python星球日记专栏介绍(持续更新ing)
✅ 上一篇: 《Python星球日记》 第68天:BERT 与预训练模型
大家好,欢迎来到Python星球的第69天!🪐
一、GPT简介:从架构到原理
GPT(Generative Pre-trained Transformer)是近年来自然语言处理领域最具革命性的模型之一。它由OpenAI开发,通过大规模的预训练和创新的架构设计,实现了令人惊叹的文本生成能力。让我们来揭开GPT的神秘面纱!

1. GPT的架构与工作原理
GPT的核心是Transformer架构,但与我们之前学习的BERT不同,GPT专注于Decoder-only结构。回顾一下,Transformer最初包含 编码器(Encoder) 和 解码器(Decoder) 两部分,而GPT只保留并改进了解码器部分。
GPT的工作流程可以概括为:
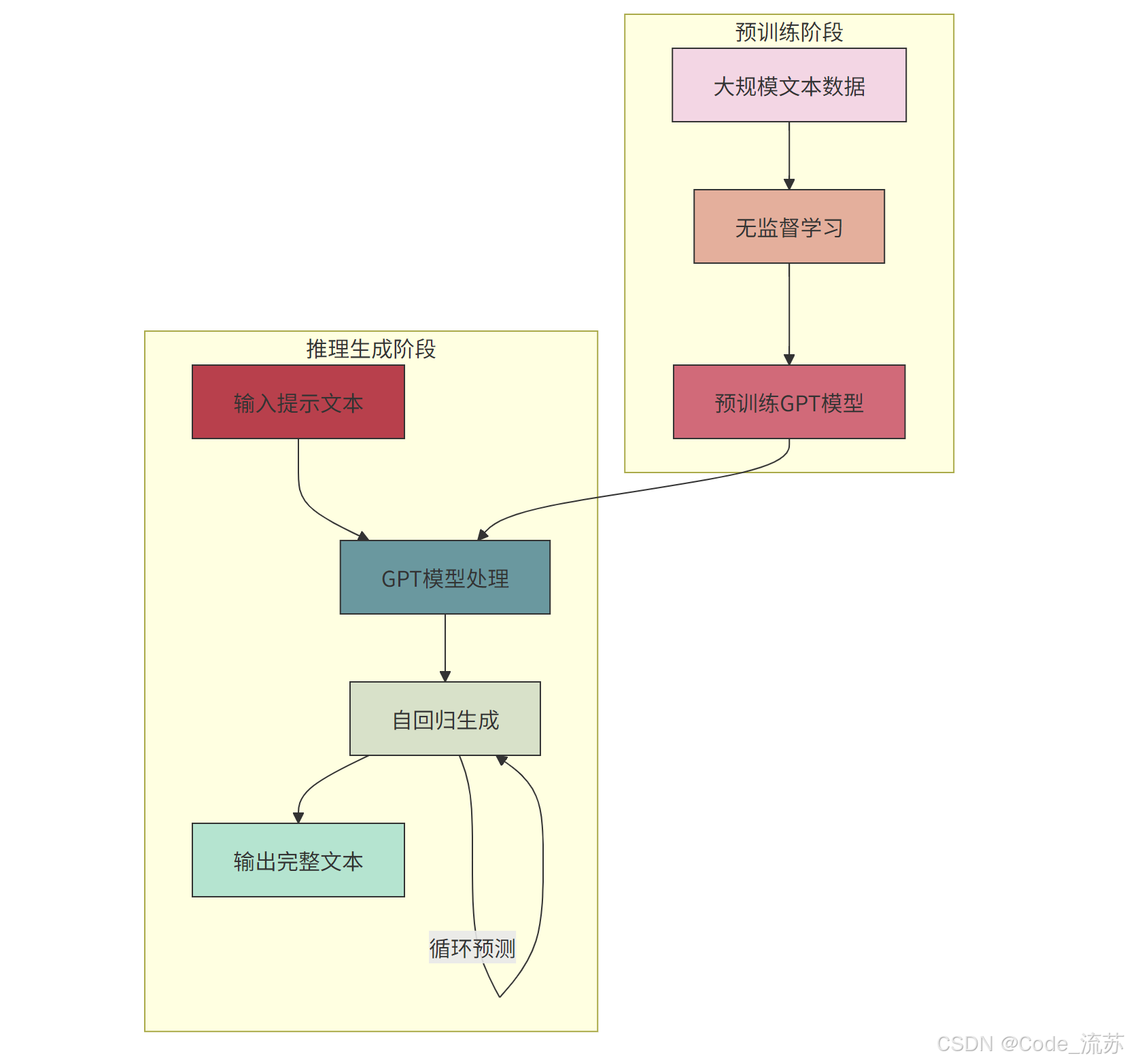
GPT的核心工作原理包括:
- 预训练阶段:模型在海量文本数据上进行无监督学习,学习语言的规律和知识
- 自注意力机制:通过
self-attention层,模型能够捕捉文本中各个部分之间的复杂关系 - 自回归生成:GPT一次预测一个token,并将预测结果作为下一步的输入,循环往复
2. Decoder-only结构与生成能力
GPT采用的Decoder-only架构是其强大生成能力的关键。与BERT的双向注意力不同,GPT使用单向注意力掩码(masked attention),确保每个位置只能看到之前的token,不能"偷看"未来的内容。
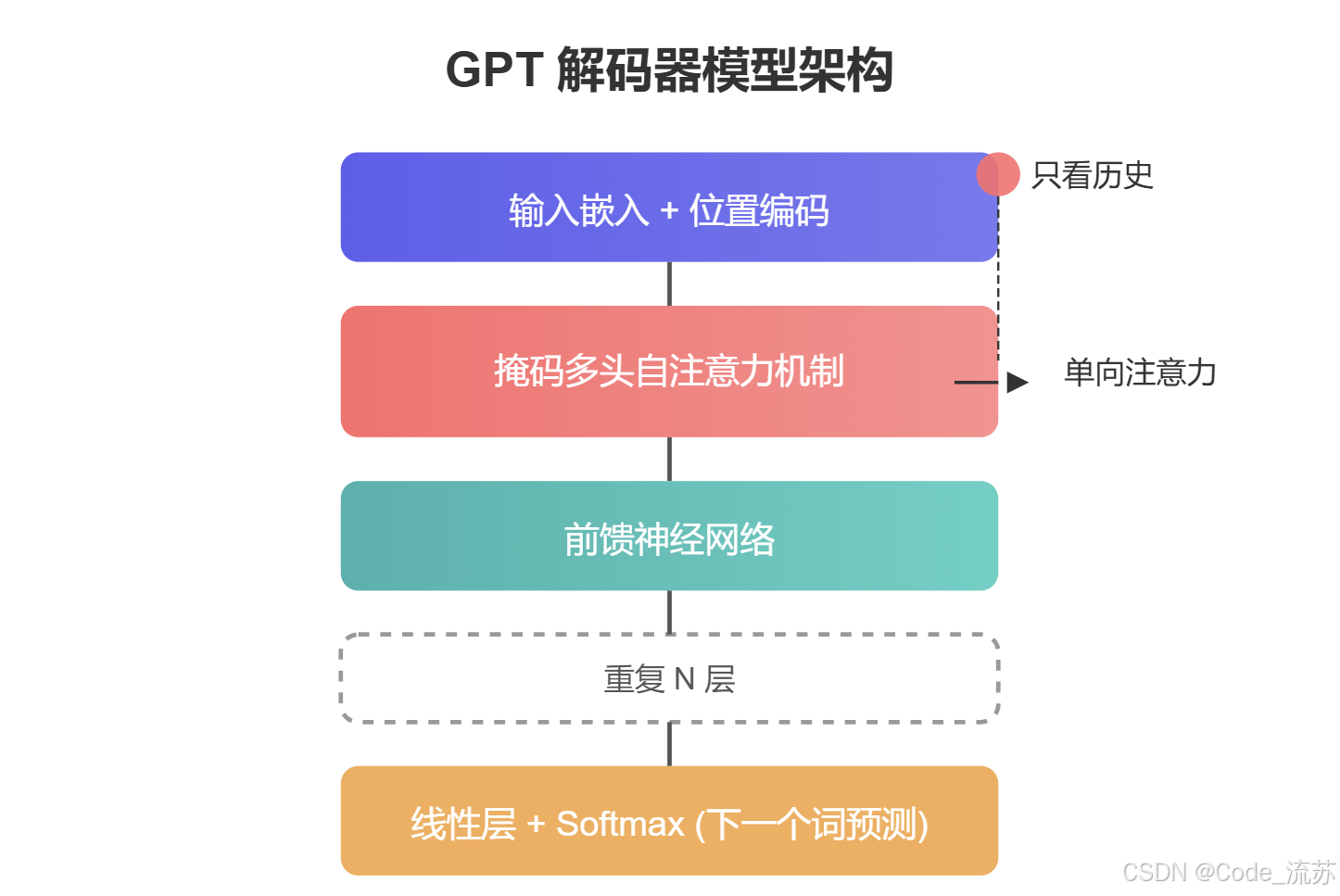
GPT的单向注意力机制很像我们人类写作的过程——我们一次写一个词,每次都是基于前面已经写过的内容来决定下一个词应该是什么。这种设计使得GPT特别适合文本生成任务,因为它模拟了人类自然的语言生成过程。
与此同时,这也是GPT与BERT最本质的区别之一。BERT可以同时看到一段文本的前后内容(双向注意力),这让它在理解任务上表现出色,但不适合生成任务。而GPT只能看到前面的内容(单向注意力),这让它特别适合生成连贯的文本序列。
二、GPT如何生成文本
1. 基于GPT的文本补全与生成
GPT的文本生成过程可以看作是一种条件概率计算。给定前面的词语序列,模型预测下一个最可能出现的词语。这种方式也被称为自回归生成(autoregressive generation)。
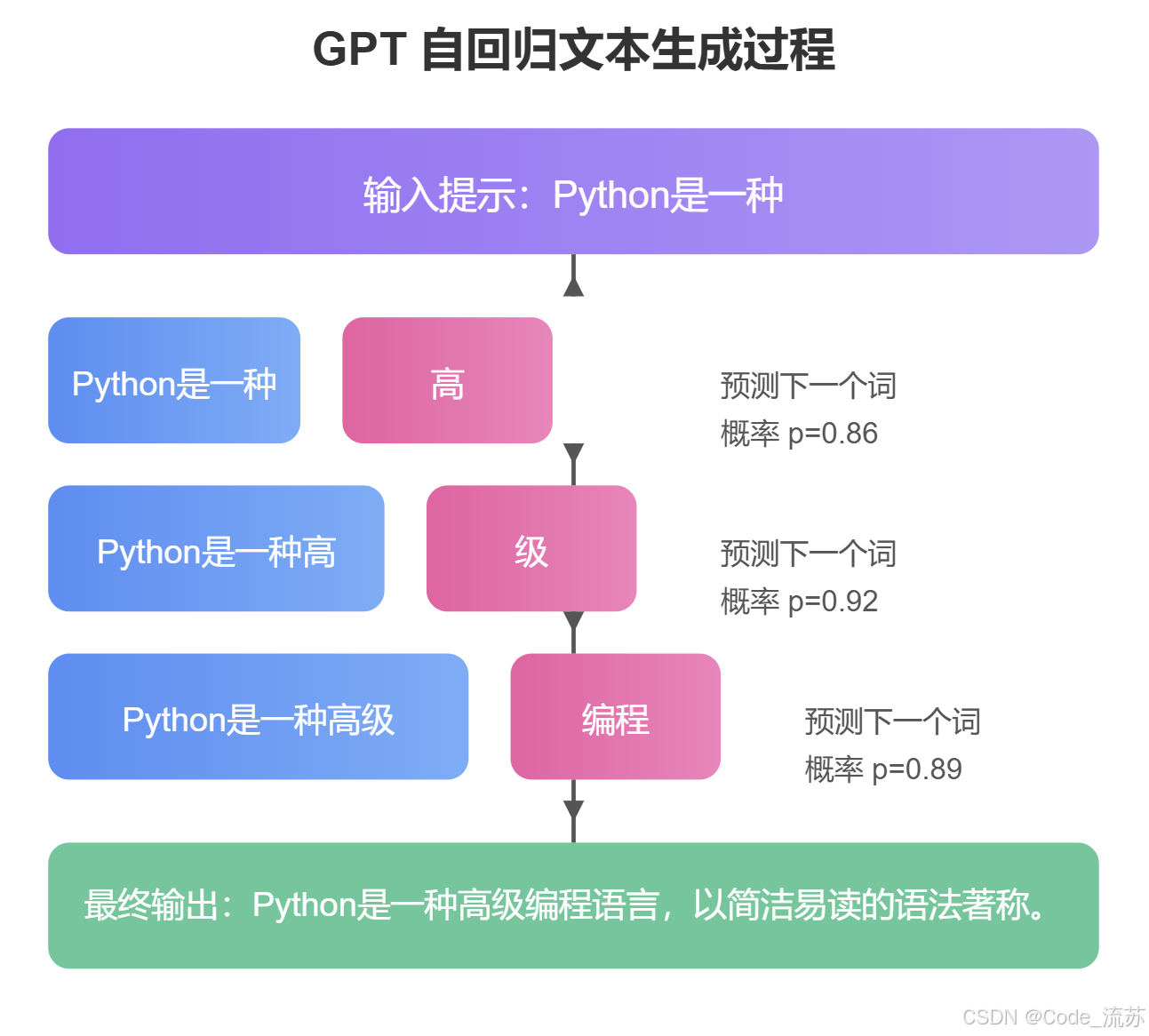
我们可以一起试着想象一下,GPT就像一个文字接龙的高手。当你给它一个开头"今天天气真",它会根据已经学到的语言模式,计算最有可能跟在这个短语后面的词是什么。
它可能会选择"好",形成"今天天气真好",然后再基于这个更长的短语预测下一个词,比如",",以此类推,直到形成一个完整的句子或段落。
这个过程中,每一步GPT都会考虑之前所有的词语,这也是为什么GPT生成的文本通常具有良好的上下文连贯性。GPT不仅仅是记住了单词之间的简单组合,而是学会了更深层次的语言结构和语义关系。
2. 生成策略与Sampling技术
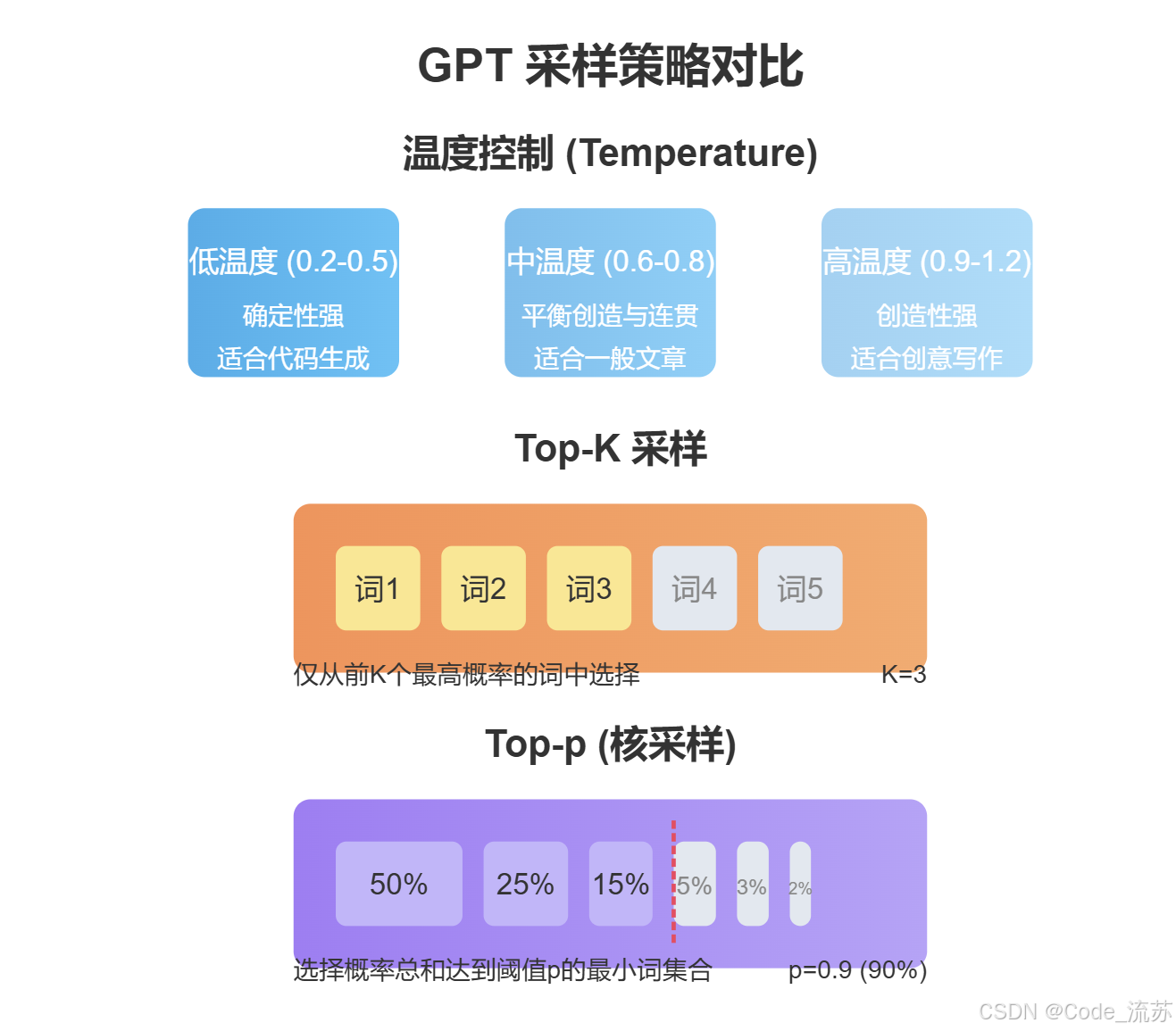
GPT生成文本时,并非总是选择概率最高的下一个词(贪婪解码),而是使用多种采样策略来提高文本的多样性和创造性:
-
温度控制(Temperature):通过调整
temperature参数,控制输出的随机性。较高的温度会产生更多样但可能不太连贯的文本,较低的温度则产生更保守但可预测的结果。 -
Top-K采样:不是从所有可能的词中选择,而是只从概率最高的K个词中进行选择,平衡了创造性和连贯性。
-
Top-p(核采样):选择概率总和达到阈值p的最小词集合,是一种更动态的选择机制。
# 简化的核采样示例代码
def top_p_sampling(logits, p=0.9):# 将logits转换为概率probs = softmax(logits)# 按概率降序排列sorted_probs, sorted_indices = torch.sort(probs, descending=True)# 计算累积概率cumulative_probs = torch.cumsum(sorted_probs, dim=-1)# 找到累积概率超过p的索引mask = cumulative_probs > p# 创建一个新的分布,只保留前面的tokensindices_to_remove = mask.scatter(1, sorted_indices, mask)filtered_logits = logits.masked_fill(indices_to_remove, float('-inf'))# 从过滤后的分布中采样return torch.multinomial(softmax(filtered_logits), 1)
这些采样策略有点像作家写作时的思考过程。代入你在写一个故事,每次选择下一个词该怎么选的时候:
- 温度控制就像你的创造性模式——设置为低温时,你会选择最安全、最常规的词汇;设置为高温时,你会冒险使用更独特、更出人意料的表达。
- Top-K采样相当于你限制自己只从几个最合理的选项中挑选,而不是考虑所有可能的词。
- Top-p采样则更灵活,有时候你会考虑很多选项(当没有特别明显的"最佳选择"时),有时候你只考虑几个(当某些词明显更合适时)。
这些策略的组合使得GPT能够生成既有创意又保持连贯性的文本,避免了纯随机或纯确定性文本的缺点。
三、使用Hugging Face的GPT模型实战
现在,让我们来实际操作,看看如何使用Hugging Face提供的GPT模型来生成文本。
1. 环境准备与模型加载
首先,我们需要安装必要的库,并加载一个GPT模型:
# 安装必要的库
!pip install transformers torch# 导入相关库
import torch
from transformers import GPT2LMHeadModel, GPT2Tokenizer# 加载预训练的GPT-2模型和分词器
model_name = "gpt2" # 可以选择不同大小的模型:gpt2, gpt2-medium, gpt2-large, gpt2-xl
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
model = GPT2LMHeadModel.from_pretrained(model_name)# 如果有GPU,将模型移到GPU上
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
在这段代码中,我们使用了Hugging Face的transformers库,这是一个强大的NLP工具集,它提供了许多预训练模型的便捷接口。我们选择加载GPT-2模型,这是OpenAI发布的GPT系列的一个版本。您可以根据自己的计算资源选择不同大小的模型变体。
需要注意的是,较大的模型(如gpt2-xl)需要更多的内存,但通常能产生更高质量的文本。如果您的设备内存有限,可以从较小的模型开始尝试。
2. 文本生成实战示例
让我们通过几个例子,演示如何使用GPT模型生成文本:
def generate_text(prompt, max_length=100, temperature=0.7, top_k=50, top_p=0.95):"""使用GPT模型生成文本参数:prompt (str): 起始提示文本max_length (int): 生成文本的最大长度temperature (float): 控制生成文本的随机性,较高的值使输出更多样top_k (int): 仅从概率最高的k个token中采样top_p (float): 核采样的概率阈值返回:str: 生成的文本"""# 对输入文本进行编码input_ids = tokenizer.encode(prompt, return_tensors="pt").to(device)# 生成文本output = model.generate(input_ids,max_length=max_length,temperature=temperature,top_k=top_k,top_p=top_p,do_sample=True,no_repeat_ngram_size=2,pad_token_id=tokenizer.eos_token_id)# 解码输出为文本generated_text = tokenizer.decode(output[0], skip_special_tokens=True)return generated_text# 示例1:文章生成
article_prompt = "Python是一种易学易用的编程语言,它具有以下特点:"
article = generate_text(article_prompt, max_length=200)
print("生成的文章:\n", article)# 示例2:对话生成
dialogue_prompt = "顾客:您好,我想了解一下Python能做什么?\n销售:您好!Python是一种非常强大的编程语言,"
dialogue = generate_text(dialogue_prompt, max_length=150, temperature=0.8)
print("\n生成的对话:\n", dialogue)
我们创建了一个generate_text函数,它封装了文本生成的过程,让我们可以方便地调整各种参数。这个函数的工作流程是:
- 首先,将提示文本(prompt)转换为模型能理解的token ID序列
- 然后,调用模型的
generate方法,设置各种参数控制生成过程 - 最后,将模型输出的token ID序列解码回普通文本
在实际应用中,我们可以通过调整参数来控制生成文本的特性:
- 增加
max_length可以生成更长的文本 - 调整
temperature可以控制文本的创造性与随机性 - 修改
top_k和top_p可以平衡文本的多样性与连贯性 - 设置
no_repeat_ngram_size可以减少重复内容
3. 参数调优与最佳实践
要获得高质量的生成结果,调整正确的参数非常重要:
在实践中,不同任务需要不同的参数配置。例如,当你需要GPT生成代码或技术文档时,应该使用较低的温度(0.2-0.5)来确保输出的准确性和一致性。而如果你希望GPT帮你创作故事或诗歌,则可以使用较高的温度(0.7-1.0)来鼓励更有创意的输出。
另外,对于不同长度的生成任务,你可能需要调整不同的参数组合:
- 短文本生成(如标题、简短回复):使用较低的温度和较小的top-k值,确保输出简洁明了
- 中等长度文本(如段落、短篇文章):平衡的温度和top-p采样,兼顾连贯性和创造性
- 长文本生成(如长篇故事、报告):考虑增加
no_repeat_ngram_size参数,避免长文本中的重复问题
最重要的是,不要害怕尝试不同的参数组合,因为找到最适合特定任务的配置往往需要一些实验和调整。通过反复测试,你会逐渐掌握如何控制GPT生成出你想要的文本风格和质量。
总结与展望
在本篇《Python星球日记》中,我们探索了GPT系列模型的核心特性、架构和实际应用。GPT作为一种强大的生成式预训练变换器模型,已经在文本生成、对话系统、内容创作等领域展现出令人惊叹的能力。
我们了解了GPT的Decoder-only架构如何通过单向注意力机制实现自然流畅的文本生成,以及各种采样策略如何帮助平衡输出文本的创造性和连贯性。通过Hugging Face提供的接口,我们可以轻松使用这些先进的模型进行各种文本生成任务。
随着GPT-4等更强大模型的出现,生成式AI正在迎来爆发式发展。
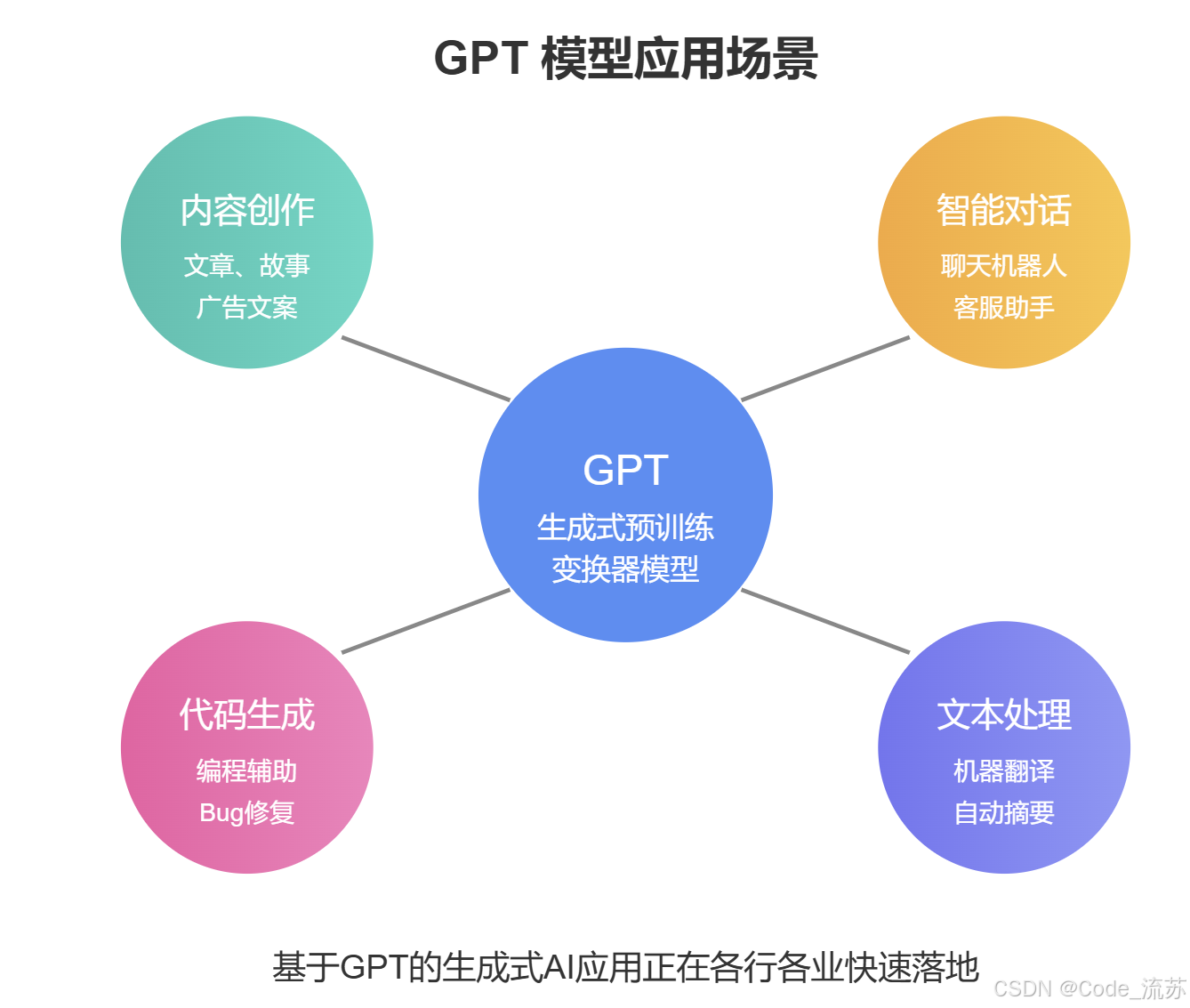
这些模型不仅能生成更长、更连贯、更有创意的文本,还能理解和执行复杂的指令,甚至展现出一定程度的推理能力。未来,我们可以期待这些技术在教育、创作、编程辅助等领域带来更多创新应用。
你对GPT模型有什么疑问?或者你有什么创意想法要用GPT实现?欢迎在评论区分享你的想法和经验!
祝你学习愉快,Python星球的探索者!👨🚀🌠
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
如果你对今天的内容有任何问题,或者想分享你的学习心得,欢迎在评论区留言讨论!
相关文章:
)
《Python星球日记》 第69天:生成式模型(GPT 系列)
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 一、GPT简介:从架构到原理1. GPT的架构与工作原理2. Decoder-only结…...

STM32 之网口资源
1 网口资源介绍 STM32F407 是 STMicroelectronics 推出的高性能 ARM Cortex-M4 微控制器,具备多种外设接口,其中包括一个 Ethernet MAC 控制器(带 IEEE 1588 支持)。这意味着你可以使用 STM32F407 实现网络通信功能(通…...

一分钟在Cherry Studio和VSCode集成火山引擎veimagex-mcp
MCP的出现打通了AI模型和外部数据库、网页API等资源,成倍提升工作效率。近期火山引擎团队推出了 MCP Server SDK: veimagex-mcp。本文介绍如何在Cherry Studio 和VSCode平台集成 veimagex-mcp。 什么是MCP MCP(Model Context Protocol&…...
)
业务中台-典型技术栈选型(微服务、容器编排、分布式数据库、消息队列、服务监控、低代码等)
在企业数字化中台建设中,业务中台是核心支撑平台,旨在通过技术手段将企业核心业务能力抽象、标准化和复用,以快速响应前端业务需求。其核心技术流涉及从业务抽象到服务化、治理和持续优化的全流程。以下是业务中台建设中的核心技术体系及关键…...

图像颜色理论与数据挖掘应用的全景解析
文章目录 一、图像颜色系统的理论基础1.1 图像数字化的本质逻辑1.2 颜色空间的数学框架1.3 量化过程的技术原理 二、主要颜色空间的深度解析2.1 RGB颜色空间的加法原理2.2 HSV颜色空间的感知模型2.3 CMYK颜色空间的减色原理 三、图像几何属性与高级特征3.1 分辨率与像素密度的关…...

从规则驱动到深度学习:自然语言生成的进化之路
自然语言生成技术正经历着人类文明史上最剧烈的认知革命。这项起源于图灵测试的技术,已经从简单的符号操作演变为具备语义理解能力的智能系统。当我们回溯其发展历程,看到的不仅是算法模型的迭代更新,更是一部人类认知自我突破的史诗。这场革…...

影刀RPA网页自动化总结
1. 影刀RPA网页自动化概述 1.1 定义与核心功能 影刀RPA网页自动化是一种通过软件机器人模拟人类操作网页行为的技术,旨在提高网页操作效率、减少人工干预。其核心功能包括: 网页数据抓取:能够高效抓取网页上的数据,如电商数据、…...

[:, :, 1]和[:, :, 0] 的区别; `prompt_vector` 和 `embedding_matrix`的作用
prompt_vector = torch.sum(prompt_embedding * attention_weights.unsqueeze(-1), dim=1) # [1, hidden_dim] prompt_vector = torch.sum(prompt_embedding * attention_weights.unsqueeze(-1), dim=1) 主要作用是通过将 prompt_embedding 与 attention_weights 相乘后再按指…...

LeetCode 题解 41. 缺失的第一个正数
41. 缺失的第一个正数 给你一个未排序的整数数组 nums ,请你找出其中没有出现的最小的正整数。 请你实现时间复杂度为 O(n) 并且只使用常数级别额外空间的解决方案。 示例 1: 输入:nums [1,2,0] 输出:3 解释:范围 [1,…...

3337. 字符串转换后的长度 II
3337. 字符串转换后的长度 II # 定义了一个大质数 MOD,用于取模运算,防止数值溢出。 MOD 1_000_000_007# 矩阵乘法 mul def mul(a:List[List[int]], b:List[List[int]]) -> List[List[int]]:# 输入两个矩阵 a 和 b,返回它们的矩阵乘积 a…...

基于 TensorFlow 框架的联邦学习可穿戴设备健康数据个性化健康管理平台研究
基于 TensorFlow 框架的联邦学习可穿戴设备健康数据个性化健康管理平台研究 摘要: 随着可穿戴设备的普及,人们对于自身健康管理的需求日益增长。然而,可穿戴设备所收集的健康数据往往分散在不同用户的设备中,且涉及用户隐私敏感信息。本研究旨在构建一个基于 TensorFlow 框…...

查看字节真实二进制形式示例解析1
查看字节的真实二进制形式? 若需要显式查看二进制0/1,可以通过以下方法转换: 方法1:逐字节转换为二进制字符串 def bytes_to_binary(data: bytes) -> str:return .join([bin(byte)[2:].zfill(8) for byte in data])# 示例 …...

hadoop中spark基本介绍
Spark是一个基于内存计算的快速、通用、可扩展的大数据处理引擎,可与Hadoop集成并在其生态系统中发挥重要作用。以下是其基本介绍: 特点 - 快速:基于内存计算,能将中间结果缓存在内存中,避免频繁读写磁盘,大…...

Apollo学习——键盘控制速度
# keyboard_control.py import time import keyboard # 键盘输入模块 pip install keyboard from getkey import getkey, keys from cyber.python.cyber_py3 import cyber_time from cyber.python.cyber_py3 import cyber from modules.common_msgs.control_msgs import contro…...

无人机数据处理与特征提取技术分析!
一、运行逻辑 1. 数据采集与预处理 多传感器融合:集成摄像头、LiDAR、IMU、GPS等传感器,通过硬件时间戳或PPS信号实现数据同步,确保时空一致性。 边缘预处理:在无人机端进行数据压缩(如JPEG、H.265)…...

Java内存马的检测与发现
【网络安全】Java内存马的检测与发现 一、Java内存马的现象二、检测思路三、重点关注类四、检测方法1. 检查方法(FindShell)2. 检查方法(sa-jdi)3. 检查方法(arthas-boot)4. 检查方法(cop.jar&a…...
详解)
基于策略的强化学习方法之策略梯度(Policy Gradient)详解
在前文中,我们已经深入探讨了Q-Learning、SARSA、DQN这三种基于值函数的强化学习方法。这些方法通过学习状态值函数或动作值函数来做出决策,从而实现智能体与环境的交互。 策略梯度是一种强化学习算法,它直接对策略进行建模和优化,…...

未来软件开发趋势与挑战
未来软件开发的方向将受到技术进步、市场需求和社会变革的多重影响。以下是可能主导行业发展的关键趋势: 1. AI与自动化深度整合 AI代码生成:GitHub Copilot等工具将进化成"AI开发伙伴",能理解业务逻辑并自动生成完整模块。自修复…...

【vue】生命周期钩子使用
一、详解 created:实例化完成还没有渲染 mounted:渲染完成 二、应用 在created之后获取网络请求,封装成函数,在需要的地方直接调用函数...

【CTFShow】Web入门-信息搜集
Web1 好长时间没刷题了,第一眼看到的时候有点儿手足无措 在信息搜集中最常用的手段就是直接查看源代码,所以直接F12大法吧,果不其然拿到了flag Web2 题目给了提示js前台拦截 无效操作 打开题看到界面还是一脸茫然 坏了,这波貌似…...

Go 语言 net/http 包使用:HTTP 服务器、客户端与中间件
Go 语言标准库中的net/http包十分的优秀,提供了非常完善的 HTTP 客户端与服务端的实现,仅通过几行代码就可以搭建一个非常简单的 HTTP 服务器。几乎所有的 go 语言中的 web 框架,都是对已有的 http 包做的封装与修改,因此…...

YOLO v2:目标检测领域的全面性进化
引言 在YOLO v1取得巨大成功之后,Joseph Redmon等人在2016年提出了YOLO v2(也称为YOLO9000),这是一个在准确率和速度上都取得显著提升的版本。YOLO v2不仅保持了v1的高速特性,还通过一系列创新技术大幅提高了检测精度…...

卓力达红外热成像靶标:革新军事训练与航空检测的关键技术
引言 红外热成像技术凭借其非接触、无辐射、全天候工作的特性,已成为现代军事和航空领域的重要工具。南通卓力达研发的**自发热红外热成像靶标**,通过创新设计与制造工艺,解决了传统训练器材的痛点,并在军事和航空应用中展现出显…...

【生产实践】Dolphinscheduler集群部署后Web控制台不能登录问题解决
太长不看版 问题描述: Dolphinscheduler按生产手册使用一键脚本集群部署后,控制台登录页面可以打开,但使用默认账户怎么都登录不进去,尝试在数据库中清理登录用户字段,发现数据库中并没有相关用户字段,而后…...

Shell和Bash介绍
Shell是硬件和软件之间的交互界面。Bash是一种shell,在Linux系统中比较常见。我目前使用的Mac用的Z shell(zsh). 可以在terminal里面通过zsh命令对系统进行操作。这是与Windows所见所得,用鼠标点相比,Mac和Linux都可以完全用命令操作。常用的…...

数据 分析
应用统计和计算方法,识别数据特征与规律. 1 分析方法 1.1 描述性分析 总结和呈现数据的基本特征;特点是简单直观. 1.1.1 集中趋势分析 ①均值:数据总和除以数据个数,反映数据的平均水平;特点是易受极端值影响;用于了解整体平均情况,例如计算班级学生平均成绩. ②中位数:将数…...

纯css实现蜂窝效果
<!DOCTYPE html><html lang"en"><head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>蜂窝效果</title><style>body {margin: 0…...

用PyTorch在超大规模下训练深度学习模型:并行策略全解析
我猜咱们每个人肯定都累坏了,天天追着 LLM 研究社区跑,感觉每天都冒出个新的最牛模型,把之前的基准都给打破了呢。要是你好奇为啥创新速度能这么快,那主要就是研究人员能够在超大规模下训练和验证模型啦,这全靠并行计算…...

linux-进程信号捕捉
1. 信号捕捉流程 操作系统会在合适的时候处理信号,那这个合适的时候是什么时候呢?进程从内核态返回到用户态的时候。 假如用户程序注册了 SIGQUIT 信号的处理函数 sighandler。当程序正在执行 main 函数时,如果发生中断、异常或系统调用&…...
shellcode加密)
【免杀】C2免杀技术(三)shellcode加密
前言 shellcode加密是shellcode混淆的一种手段。shellcode混淆手段有多种:加密(编码)、偏移量混淆、UUID混淆、IPv4混淆、MAC混淆等。 随着杀毒软件的不断进化,其检测方式早已超越传统的静态特征分析。现代杀软往往会在受控的虚…...

人工智能驱动的临床路径体系化解决方案与实施路径
引言 临床路径管理作为现代医疗质量管理的重要工具,其核心在于通过标准化诊疗流程来提升医疗服务的规范性、一致性和效率。然而,传统临床路径管理面临路径设计僵化、执行依从性低、变异管理滞后等诸多挑战,亟需借助人工智能技术实现转型升级。本研究旨在探讨如何通过构建系…...

旋变信号数据转换卡 旋变解码模块 汽车永磁同步电机维修工具
旋变信号数据转换卡,是一款专门针对与永磁同步电机的旋变编码器和 BRX 型旋转变压器编码器进行旋变信号解码转换串行总线协议的专用转换卡。此款转换卡结合了专用的旋变信号解码芯片解码逻辑处理,解码信号分辨率高、线性度高、响应速度快。板卡采用工业级…...

RPM 包制作备查 SRPM 包编译
🌈 个人主页:Zfox_ 目录 🔥 前言 一:🔥 准备 二:🔥 制作 rpm 1.设置目录结构(制作车间)2. 源码放置到规划好的目录当中3. 创建一个spec文件,指挥如何使用这些…...

[学习] RTKLib详解:rtcm2.c、rtcm3.c、rtcm3e与rtcmn.c
RTKLib详解:rtcm2.c、rtcm3.c、rtcm3e与rtcmn.c 本文是 RTKLlib详解 系列文章的一篇,目前该系列文章还在持续总结写作中,以发表的如下,有兴趣的可以翻阅。 [学习] RTKlib详解:功能、工具与源码结构解析 [学习]RTKLib详…...
:智能皮电手环(GSR智能手环)性能与存储的深度评测)
MCU ESP32-S3+SD NAND(贴片式T卡):智能皮电手环(GSR智能手环)性能与存储的深度评测
在智能皮电手环与数据存储领域,主控MCU ESP32-S3FH4R2 与 存储SD NAND MKDV2GIL-AST 的搭档堪称行业新典范。二者深度融合低功耗、高速读写、SMART 卓越稳定性等核心优势,以高容量、低成本的突出特性,为大规模生产场景带来理想的数据存储方案…...

股指期货套期保值怎么操作?
股指期货套期保值就是企业或投资者通过持有与其现货市场头寸相反的期货合约,来对冲价格风险的一种方式。换句话说,就是你在股票市场上买了股票(现货),担心股价下跌会亏钱,于是就在期货市场上卖出相应的股指…...

Pytorch的Dataloader使用详解
PyTorch 的 DataLoader 是数据加载的核心组件,它能高效地批量加载数据并进行预处理。 Pytorch DataLoader基础概念 DataLoader基础概念 DataLoader是PyTorch基础概念 DataLoader是PyTorch中用于加载数据的工具,它可以:批量加载数据…...
)
Ros2 - Moveit2 - DeepGrasp(深度抓握)
本教程演示了如何在 MoveIt 任务构造器中使用抓握姿势检测 (GPD)和 Dex-Net 。 GPD(左)和 Dex-Net(右)用于生成拾取圆柱体的抓取姿势。 https://moveit.picknik.ai/main/_images/mtc_gpd_panda.gif 入门 如果您还没有这样做&am…...

【DRAM存储器五十一】LPDDR5介绍--CK、WCK、RDQS单端模式、Thermal Offset、Temperature Sensor
👉个人主页:highman110 👉作者简介:一名硬件工程师,持续学习,不断记录,保持思考,输出干货内容 参考资料:《某LPDDR5数据手册》 、《JESD209-5C》 目录 CK、WCK、RDQS单端模式 Thermal Offset Temperature Sensor...
】Eureka 客户端服务注册(含源代码)(四))
【springcloud学习(dalston.sr1)】Eureka 客户端服务注册(含源代码)(四)
d该系列项目整体介绍及源代码请参照前面写的一篇文章【springcloud学习(dalston.sr1)】项目整体介绍(含源代码)(一) 这篇文章主要介绍Eureka客户端服务注册到eureka的server端。 上篇文章【springcloud学习(dalston.sr1)】Eurek…...

数据结构 栈和队列
文章目录 📕1.栈(Stack)✏️1.1 栈的基本操作✏️1.2 栈的模拟实现🔖1.2.1 构造方法🔖1.2.2 扩容方法🔖1.2.3 判断栈是否为空或是否满🔖1.2.4 存储元素🔖1.2.5 删除元素🔖1.2. 6 获取栈顶元素 ✏…...

[数据结构]5. 栈-Stack
栈-Stack 1. 介绍2. 栈的实现2.1 基于链表的实现2.2 基于数组的实现 3. 栈操作CreateInitilizateDestoryPushPopTopEmptySize 1. 介绍 栈(stack) 是一种遵循先入后出逻辑的线性数据结构。顶部称为“栈顶”,底部称为“栈底”。把元素添加到栈…...
)
Git的安装和配置(idea中配置Git)
一、Git的下载和安装 前提条件:IntelliJ IDEA 版本是2023.3 ,那么配置 Git 时推荐使用 Git 2.40.x 或更高版本 下载地址:CNPM Binaries Mirror 操作:打开链接 → 滚动到页面底部 → 选择2.40.x或更高版本的 .exe 文件…...

QT-1.信号与槽
一、信号与槽机制概述 四、信号与槽的连接 六、自定义信号与槽 思考 定义与作用 :信号与槽是Qt中的核心通信机制,用于实现对象间的数据交互和事件处理。当特定事件发生时,对象会发出信号,而与之相连的槽函数会被自动调用。 特点 …...

常用的应用层网络协议对比
概述 协议通信模式加密支持传输层主要特点典型应用场景WSS全双工是(TLS/SSL)TCP安全的实时双向通信实时聊天、在线游戏WebSocket (WS)全双工否TCP持久连接、低延迟协同编辑、实时通知HTTPS请求-响应是(TLS/SSL)TCP安全性强、兼容…...

数据结构与算法:状压dp
前言 状压dp在整个动态规划专题里特别重要,用位信息表示元素的思想更是重中之重。 一、状态压缩 1.内容 对于一些带路径的递归,通常来讲没法改记忆化搜索和严格位置依赖的动态规划。但如果这个路径的数据量在一定范围内,就可以考虑使用一个整数status的位信息0和1来存路…...

Spring Cloud Gateway 聚合 Swagger 文档:一站式API管理解决方案
前言 在微服务架构中,随着服务数量的增加,API文档管理变得越来越复杂。每个微服务都有自己的Swagger文档,开发人员需要记住每个服务的文档地址,这无疑增加了开发难度。本文将介绍如何使用Spring Cloud Gateway聚合所有微服务的Sw…...

Android 适配之——targetSdkVersion 30升级到31-34需要注意些什么?
在Android 16即将到来的之际。也就是targetSdkVersion即将出现36,而30已然会成为历史。那么我的项目已经停留在30很久了。是时候要适配一下适用市场的主流机型了。正常来查找资料的,无非就是已经升级和准备升级targetSdkVersion开发版本。所以你是哪一种…...

网络运维过程中的常用命令
一、通用网络命令 ping 作用:测试与目标 IP 或域名的连通性。 示例: ping www.baidu.com # 持续发送ICMP包 ping -c 4 8.8.8.8 # 发送4个包后停止 traceroute/tracert 功能:追踪数据包经过的路由节点。 示例: traceroute…...
)
[Java实战]Spring Boot 3整合JWT实现无状态身份认证(二十四)
[Java实战]Spring Boot 3整合JWT实现无状态身份认证(二十四) 一、JWT简介与核心概念 1. JWT是什么? JSON Web Token (JWT) 是一种开放标准(RFC 7519),用于在各方之间安全地传输信息。JWT由三部分组成&am…...