scikit-learn在无监督学习算法的应用
哈喽,我是我不是小upper~
前几天,写了一篇对scikit-learn在监督学习算法的应用详解,今天来说说关于sklearn在无监督算法方面的案例。
稍微接触过机器学习的朋友就知道,无监督学习是在没有标签的数据上进行训练的。其主要目的可能包括聚类、降维、生成模型等。
以下是 6 个重要的无监督学习算法,这些算法都可以通过使用sklearn(Scikit-learn)库在Python中很好地处理:
-
K-Means 聚类
-
层次聚类
-
DBSCAN
-
主成分分析
-
独立成分分析
-
高斯混合模型
K-Means 聚类
在数据挖掘和机器学习领域,K-Means 聚类是一种广泛使用的无监督学习算法,主要用于将数据集中的样本划分为多个不同的组(即聚类),使得同一组内的数据点具有较高的相似性,而不同组之间的数据点差异较大。下面我们将详细介绍 K-Means 聚类的实现过程。
首先,我们需要导入必要的 Python 库并准备好用于分析的数据集。这里我们将使用 sklearn 库中自带的鸢尾花数据集(Iris dataset)进行演示。该数据集包含了 150 个样本,每个样本有 4 个特征,分别是花萼长度(sepal length)、花萼宽度(sepal width)、花瓣长度(petal length)和花瓣宽度(petal width),这些特征可以帮助我们对鸢尾花的品种进行分类。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import load_iris
from time import time# 加载鸢尾花数据集
iris = load_iris()
# 将数据转换为 DataFrame 格式,方便后续处理
data = pd.DataFrame(data= np.c_[iris['data'], iris['target']],columns= iris['feature_names'] + ['target'])
# 查看数据集的基本信息
print("数据基本信息:")
data.info()
# 查看数据集行数和列数
rows, columns = data.shape# 提取用于聚类的特征,这里选择花萼长度、花萼宽度和花瓣长度这三个特征
X = data.iloc[:, [0, 1, 2]].values # 0: sepal length, 1: sepal width, 2: petal length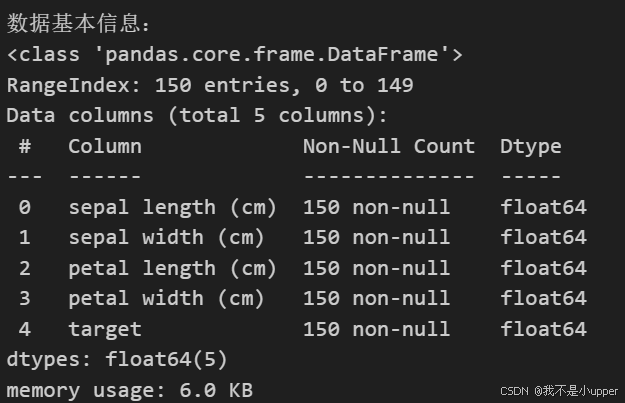
接下来,我们需要对数据进行标准化处理。由于 K-Means 聚类是基于距离计算的算法,如果各个特征的量纲不同,可能会导致某些特征对聚类结果的影响过大。例如,一个特征的取值范围在 0 到 1 之间,而另一个特征的取值范围在 0 到 1000 之间,那么后者在计算距离时的影响会远大于前者。为了避免这种情况,我们使用 StandardScaler 对数据进行标准化处理,将每个特征转换为均值为 0,标准差为 1 的标准正态分布。
# 数据标准化
scaler = StandardScaler()
scaled_data = scaler.fit_transform(X)在进行 K-Means 聚类之前,我们需要确定一个合适的聚类数量 K。这里我们使用轮廓系数(Silhouette Score)来帮助我们选择最优的 K 值。轮廓系数是衡量聚类质量的一个指标,它的取值范围在 -1 到 1 之间。对于每个样本,轮廓系数计算其与同一聚类内其他样本的平均距离(a)和与最近的另一个聚类中样本的平均距离(b),然后用公式:
计算得到。
一个高的轮廓系数表示样本点离自己所属的聚类较近,而离其他聚类较远,说明聚类效果较好。
# 确定最优的 K 值
k_values = range(2, 11) # 尝试 K 从 2 到 10
silhouette_scores = []# 计算不同 K 值下的轮廓系数
for k in k_values:kmeans = KMeans(n_clusters=k, random_state=42)cluster_labels = kmeans.fit_predict(scaled_data)silhouette_avg = silhouette_score(scaled_data, cluster_labels)silhouette_scores.append(silhouette_avg)print(f"For k={k}, the average silhouette_score is : {silhouette_avg}")# 绘制轮廓系数图
plt.plot(k_values, silhouette_scores, marker='o')
plt.title('Silhouette Score for Different k')
plt.xlabel('Number of clusters (k)')
plt.ylabel('Silhouette Score')
plt.grid(True)
plt.show()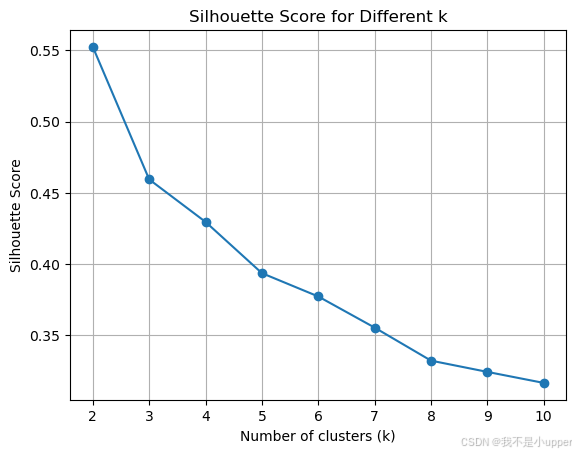
通过观察轮廓系数图,我们可以选择轮廓系数最高的 K 值作为最优的聚类数量。在这个例子中,我们假设选择 K=3 进行模型训练。
# 模型训练与聚类
k = 3 # 根据轮廓系数图选择合适的 K 值
kmeans = KMeans(n_clusters=k, random_state=42)
clusters = kmeans.fit_predict(scaled_data)# 可视化聚类结果(这里仅展示前两个特征的二维投影)
plt.figure(figsize=(10, 7))# 绘制每个聚类的散点图
for i in range(k):plt.scatter(scaled_data[clusters == i, 0], scaled_data[clusters == i, 1], s=50, label=f'Cluster {i+1}')# 绘制聚类中心
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], s=300, c='red', marker='*', label='Centroids')plt.title('K-Means Clustering Results')
plt.xlabel('Sepal Length (scaled)')
plt.ylabel('Sepal Width (scaled)')
plt.legend()
plt.grid(True)
plt.show()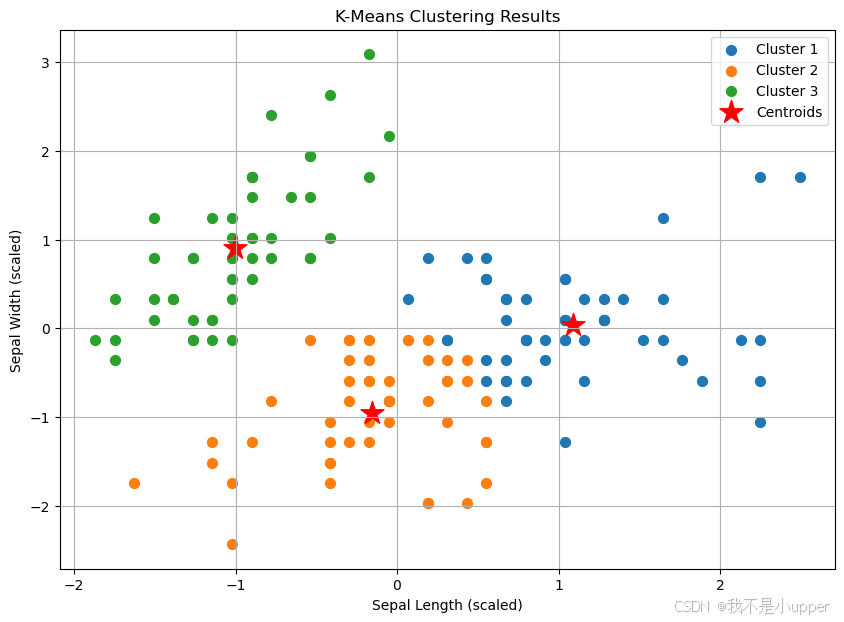
在得到聚类结果后,我们可以对各个聚类进行分析和解读。例如,在这个鸢尾花数据集的聚类结果中,我们可以根据每个聚类的中心点位置以及样本分布情况,推测出每个聚类可能代表的鸢尾花品种特征。
需要注意的是,在实际项目中,选择合适的 K 值不仅仅依赖于轮廓系数等数学指标,还需要结合业务背景和领域知识。同时,聚类结果的解读也需要深入理解数据的含义和业务目标,以便为决策提供有价值的信息。
此外,K-Means 算法虽然简单高效,但也存在一些局限性,例如对初始聚类中心的选择敏感,可能会陷入局部最优解;对异常值比较敏感;无法很好地处理非球形分布的数据等。在实际应用中,可以考虑使用一些改进的 K-Means 算法,如 K-Means++(改进初始中心的选择方法),或者尝试其他聚类算法,如 DBSCAN、高斯混合模型等,以获得更好的聚类效果。
层次聚类
在数据分析领域,层次聚类(Hierarchical Clustering)是一种通过构建数据点之间的层次结构来揭示数据内在群集结构的无监督学习方法。它不需要预先指定聚类数量,而是根据数据点之间的相似性或距离,自底向上(凝聚型)或自顶向下(分裂型)地逐步合并或拆分聚类,最终形成树状结构的聚类谱系图( dendrogram )。以下将使用 sklearn 库中自带的鸢尾花数据集( Iris dataset ),详细介绍层次聚类的实现过程。
数据准备与标准化
我们继续使用鸢尾花数据集,该数据集包含花萼长度、花萼宽度、花瓣长度和花瓣宽度 4 个特征。为了便于展示,这里选取前 3 个特征(花萼长度、花萼宽度、花瓣长度)进行分析:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from scipy.cluster.hierarchy import dendrogram, linkage
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import AgglomerativeClustering
from sklearn.datasets import load_iris# 加载鸢尾花数据集
iris = load_iris()
data = pd.DataFrame(data=iris.data, columns=iris.feature_names[:4]) # 选取前4个特征由于层次聚类基于距离计算(如欧几里得距离),为避免不同特征量纲对结果的影响,需对数据进行标准化处理:
scaler = StandardScaler()
scaled_data = scaler.fit_transform(data)构建层次聚类模型与树状图
层次聚类通过 链接方法(Linkage Methods) 定义聚类间的距离,常见方法包括:
- Ward 法:最小化合并后聚类内的方差,适用于正态分布数据。
- 单链接(Single Linkage):以两个聚类中距离最近的点作为聚类间距离,易形成链式结构。
- 全链接(Complete Linkage):以两个聚类中距离最远的点作为聚类间距离,倾向于形成紧凑聚类。
此处使用 Ward 法 构建层次聚类模型,并通过 dendrogram 函数绘制树状图:
# 使用 Ward 链接方法计算层次聚类
linked = linkage(scaled_data, method='ward', metric='euclidean') # metric 指定距离度量方式# 绘制树状图
plt.figure(figsize=(10, 7))
dendrogram(linked,orientation='top', # 树状图方向(从上到下)distance_sort='descending', # 按距离降序排列节点show_leaf_counts=True, # 显示叶子节点(数据点)数量leaf_rotation=90, # 旋转叶子节点标签防止重叠labels=data.index # 为叶子节点添加样本索引标签(可选)
)
plt.title('Hierarchical Clustering Dendrogram (Ward Method)')
plt.xlabel('Data Points')
plt.ylabel('Distance')
plt.show()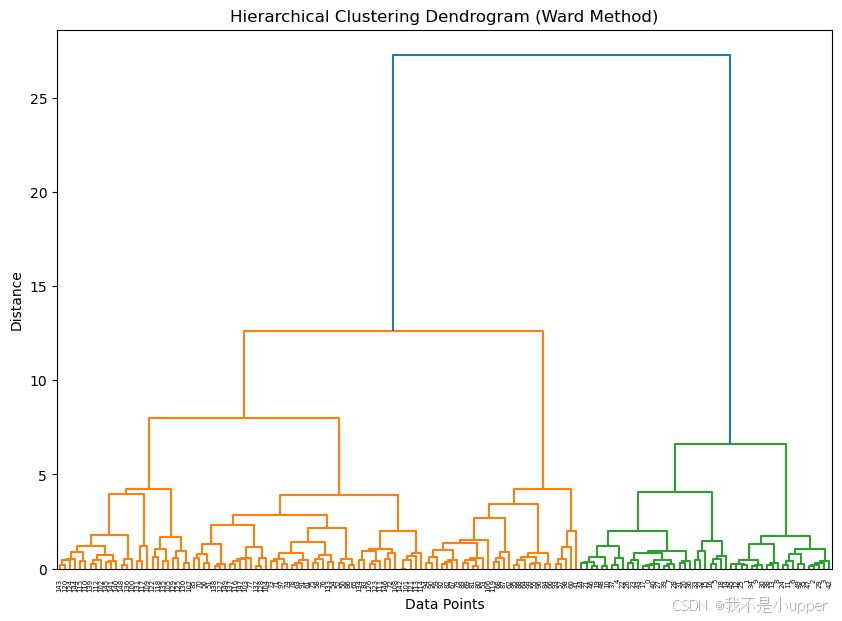
树状图解读:
- 横轴表示数据点(或聚类),纵轴表示聚类间的距离。
- 每个数据点初始为独立聚类,随着距离阈值降低,相邻聚类逐步合并。
- 树状图中的垂直线高度表示聚类合并时的距离,可通过观察 “肘部”(距离突然增大的位置)判断合适的聚类数量。
模型训练与结果可视化
根据树状图中聚类合并的趋势,选择合适的聚类数量(如 \(k=3\) ),使用 AgglomerativeClustering 类进行聚类:
# 定义层次聚类模型(凝聚型,自底向上合并)
cluster = AgglomerativeClustering(n_clusters=3, # 指定聚类数量linkage='ward', # 链接方法(Ward 法)metric='euclidean' # 距离度量方式(欧几里得距离)
)# 训练模型并获取聚类标签
cluster_labels = cluster.fit_predict(scaled_data)# 可视化聚类结果(仅展示前两个特征:花萼长度 vs. 花萼宽度)
plt.figure(figsize=(10, 7))
plt.scatter(scaled_data[:, 0], # 花萼长度(标准化后)scaled_data[:, 1], # 花萼宽度(标准化后)c=cluster_labels, # 颜色区分聚类cmap='rainbow',edgecolor='k',s=60
)
plt.title('Hierarchical Clustering Results (k=3)')
plt.xlabel('Sepal Length (Scaled)')
plt.ylabel('Sepal Width (Scaled)')
plt.legend(title='Cluster Labels')
plt.grid(True)
plt.show()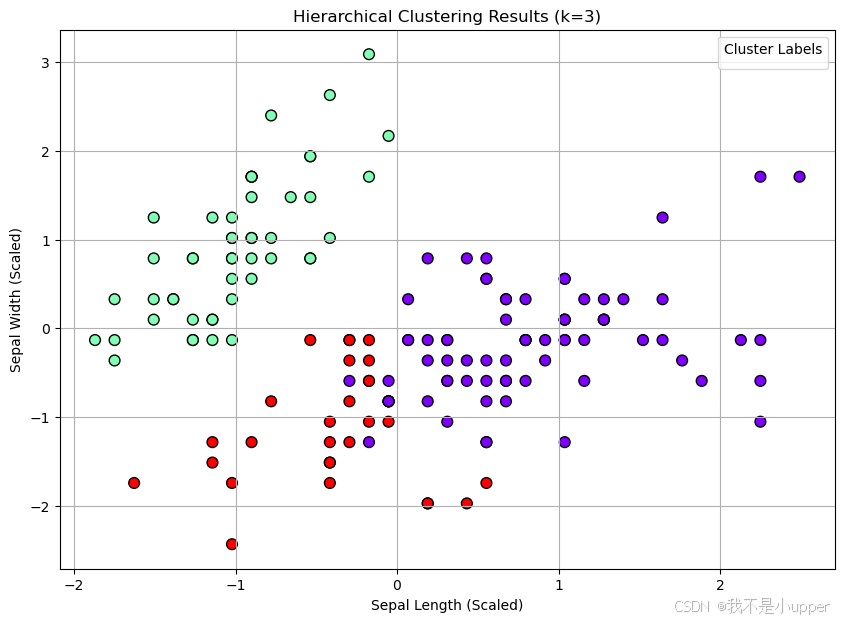
关键参数与注意事项
-
距离度量(Affinity):
affinity参数指定距离计算方式,常见选项包括:euclidean:欧几里得距离(默认),适用于连续型数据。manhattan:曼哈顿距离,对异常值鲁棒性更强。cosine:余弦相似度,适用于文本或高维数据。
-
链接方法(Linkage):
linkage参数决定聚类间距离的计算方式,除ward外,还可选择single(单链接)、complete(全链接)等,不同方法会影响聚类形状和紧凑性。
-
聚类数量选择:
- 树状图中 “肘部” 对应的距离阈值可作为聚类数量的参考(如某高度处合并距离显著增大,说明此时分割的聚类间差异较大)。
- 也可结合业务需求或轮廓系数(Silhouette Score)等指标辅助决策。
与 K-Means 聚类的对比
- 层次聚类:无需预设聚类数量,适合探索性分析,结果以树状图呈现,可直观展示数据层次结构,但计算复杂度较高(尤其对大规模数据)。
- K-Means:需预设聚类数量,计算效率高,适用于大规模数据,但对初始中心敏感,可能陷入局部最优。
在实际应用中,可结合两种方法:先用层次聚类探索数据结构、确定合理聚类数量,再用 K-Means 对大规模数据进行高效聚类。通过以上步骤,层次聚类能够帮助我们从数据中挖掘出隐含的层次化群集结构,可以为后续的数据分析和业务决策提供有力支持。
DBSCAN
在无监督学习领域,DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的聚类算法,能够有效识别数据集中的密集区域(聚类)和低密度区域(噪声点)。与 K-Means、层次聚类等算法不同,DBSCAN 无需预先指定聚类数量,且能够发现任意形状的聚类,尤其适合处理非球形分布的数据。以下将使用 sklearn 库中自带的鸢尾花数据集(Iris dataset),详细演示 DBSCAN 算法的实现流程。
数据准备与标准化
我们继续使用鸢尾花数据集,选取前两个特征(花萼长度、花萼宽度)进行分析,以便于二维可视化:
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import DBSCAN
from sklearn.metrics import silhouette_score
from sklearn.datasets import load_iris# 加载鸢尾花数据集
iris = load_iris()
data = pd.DataFrame(iris.data, columns=iris.feature_names[:4]) # 选取前4个特征:花萼长度、花萼宽度由于 DBSCAN 基于距离计算(默认使用欧几里得距离),为确保特征权重一致,需对数据进行标准化处理:
scaler = StandardScaler()
scaled_data = scaler.fit_transform(data)DBSCAN 模型构建与训练
DBSCAN 算法有两个核心参数:
eps(邻域半径):定义样本点的邻域范围,即某样本点的邻域是以该点为中心、半径为eps的区域。min_samples(最小样本数):定义一个核心点的条件,即邻域内至少包含min_samples个样本点(包括自身)。
算法逻辑:
- 核心点:若某样本点的邻域内包含至少
min_samples个样本,则该点为核心点。 - 密度直达:若样本点
B在核心点A的邻域内,则称B从A密度直达。 - 密度可达:若存在一系列核心点
A→C→B,使得C从A密度直达,B从C密度直达,则称B从A密度可达。 - 密度相连:若存在核心点
O,使得样本点A和B均从O密度可达,则称A和B密度相连。 - 聚类:由密度相连的样本点构成的最大集合称为一个聚类。
- 噪声点:不属于任何聚类的样本点(即无法从任何核心点密度可达的点)。
模型实现:
# 实例化DBSCAN模型(需调参确定合适的eps和min_samples)
dbscan = DBSCAN(eps=0.8, min_samples=5) # 示例参数,实际需调整# 训练模型并获取聚类标签(标签-1表示噪声点)
clusters = dbscan.fit_predict(scaled_data)# 计算轮廓系数(排除噪声点对评分的影响)
# 提取有效聚类标签(非-1的样本)
valid_labels = clusters != -1
if np.any(valid_labels):silhouette_avg = silhouette_score(scaled_data[valid_labels], clusters[valid_labels])print(f'Silhouette Score (excluding noise): {silhouette_avg:.2f}')
else:print('No valid clusters found.')结果可视化与分析
使用散点图可视化聚类结果,不同颜色代表不同聚类,黑色点表示噪声点:
# 可视化聚类结果
plt.figure(figsize=(10, 7))# 绘制聚类点
for cluster_label in np.unique(clusters):if cluster_label == -1:# 噪声点用黑色表示plt.scatter(scaled_data[clusters == cluster_label, 0], scaled_data[clusters == cluster_label, 1],c='black', label='Noise', s=60)else:# 聚类点用彩色表示plt.scatter(scaled_data[clusters == cluster_label, 0], scaled_data[clusters == cluster_label, 1],c=plt.cm.plasma(cluster_label / np.max(clusters)), label=f'Cluster {cluster_label}', s=60, edgecolor='k')plt.title('DBSCAN Clustering Results')
plt.xlabel('Sepal Length (Scaled)')
plt.ylabel('Sepal Width (Scaled)')
plt.legend()
plt.grid(True)
plt.show()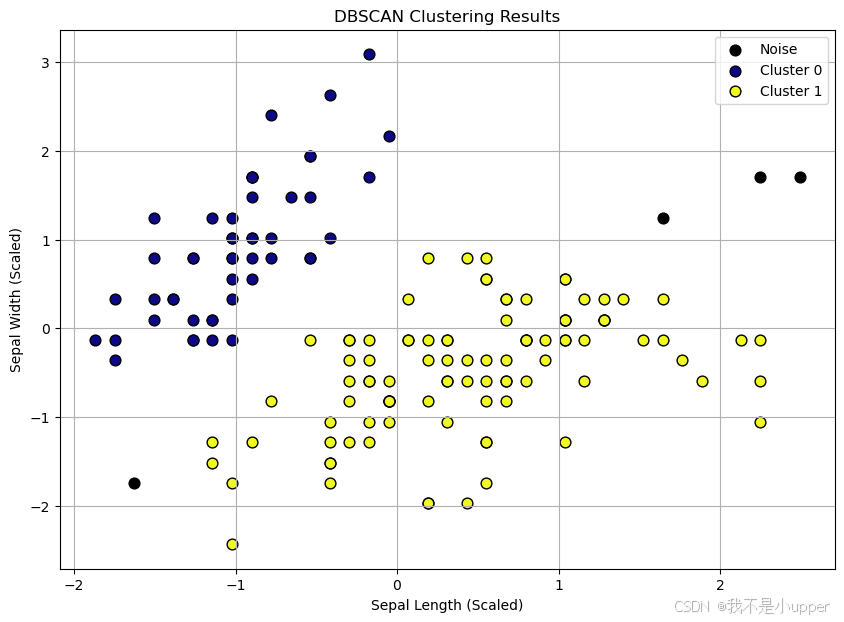
结果解读:
- 轮廓系数:取值范围为 [-1, 1],值越接近 1 表示聚类内样本越紧凑、聚类间分离度越好;值为负数表示样本可能被错误分类。由于 DBSCAN 允许噪声点存在,计算轮廓系数时需排除标签为 - 1 的样本,以避免噪声对评分的干扰。
- 聚类形状:DBSCAN 能识别非球形聚类(如带状、环形等),而 K-Means 等基于距离中心的算法难以处理此类结构。
- 噪声点:图中黑色点为 DBSCAN 识别出的噪声点,这些点通常位于低密度区域,不属于任何聚类。
关键参数调参与注意事项
-
参数选择方法:
- k - 距离图(k-Distance Graph):对于每个样本点,计算其到第
k近邻的距离(k通常取min_samples),绘制距离排序图。选择曲线中 “肘部”(距离突然增大的点)对应的距离作为eps的参考值。 - 网格搜索:通过交叉验证尝试不同的
eps和min_samples组合,结合轮廓系数或业务需求选择最优参数。
- k - 距离图(k-Distance Graph):对于每个样本点,计算其到第
-
标准化的必要性:
- DBSCAN 对特征量纲敏感,例如未标准化时,数值范围大的特征会主导距离计算。因此,标准化是 DBSCAN 预处理的必要步骤。
-
处理密度不均数据:
- 若数据中存在密度差异较大的区域,DBSCAN 可能无法同时识别所有聚类(低密度区域的聚类可能被误判为噪声)。此时可尝试:
- 调整参数
eps和min_samples(如对低密度区域降低min_samples)。 - 使用基于密度可达的改进算法(如 HDBSCAN)。
- 调整参数
- 若数据中存在密度差异较大的区域,DBSCAN 可能无法同时识别所有聚类(低密度区域的聚类可能被误判为噪声)。此时可尝试:
-
噪声点的处理:
- 噪声点的标签为 - 1,在业务分析中需结合领域知识判断其是否为真实噪声(如异常数据)或因参数设置不当导致的误判。
DBSCAN 的优缺点
- 优点:
- 无需预设聚类数量,自动识别噪声点。
- 适用于发现任意形状的聚类,对非球形数据效果优于 K-Means。
- 缺点:
- 对参数
eps和min_samples敏感,需反复调参。 - 对高维数据性能下降(距离度量在高维空间中意义减弱)。
- 密度均匀性要求较高,难以处理密度差异大的数据集。
- 对参数
通过以上步骤,DBSCAN 能够有效挖掘数据中基于密度的聚类结构,为复杂数据分布的分析提供了灵活的解决方案。在实际应用中,建议结合数据探索和多次参数调整,以充分发挥算法的优势。
主成分分析
主成分分析(Principal Component Analysis,PCA)是一种广泛应用于高维数据降维和可视化的无监督学习技术。其核心思想是通过线性变换将原始高维数据投影到一组正交的低维主轴(即主成分)上,使得投影后的数据尽可能保留原始数据的方差(信息),从而在减少维度的同时避免关键信息的丢失。以下将结合 sklearn 库中自带的鸢尾花数据集(Iris dataset),详细介绍 PCA 的实现过程。
数据准备与标准化
我们使用经典的鸢尾花数据集,该数据集包含 150 个样本,每个样本有 4 个特征:花萼长度(Sepal Length)、花萼宽度(Sepal Width)、花瓣长度(Petal Length)和花瓣宽度(Petal Width)。我们的目标是将这 4 维数据降维到 2 维,以便于可视化和分析。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler# 加载鸢尾花数据集
iris = load_iris()
X = iris.data # 特征矩阵,形状为 (150, 4)
y = iris.target # 类别标签,形状为 (150,)
feature_names = iris.feature_names # 特征名称列表由于 PCA 对数据的尺度敏感(例如,数值范围较大的特征可能主导方差计算),因此需要先对数据进行标准化处理,使每个特征的均值为 0,标准差为 1:
# 标准化数据
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)模型训练与主成分提取
使用 PCA 类对标准化后的数据进行降维。n_components=2 表示我们希望将数据投影到前两个主成分上,这两个主成分将构成新的 2 维特征空间:
# 初始化 PCA 模型,指定保留 2 个主成分
pca = PCA(n_components=2)
# 拟合模型并转换数据
X_pca = pca.fit_transform(X_scaled)关键原理:
- 主成分是原始特征的线性组合,彼此正交(即不相关)。
- 第一个主成分(PC1)捕获原始数据中最大的方差,第二个主成分(PC2)捕获剩余方差中最大的部分,以此类推。
- 降维后的维度 k 通常由 “累计解释方差比例” 决定,例如保留累计方差贡献率达 95% 的主成分。
数据可视化
将降维后的数据在 2 维空间中可视化,观察不同类别样本在主成分上的分布情况:
plt.figure(figsize=(8, 6))# 遍历不同类别,用不同颜色绘制散点图
for target in np.unique(y):mask = y == targetplt.scatter(X_pca[mask, 0], # 第一主成分X_pca[mask, 1], # 第二主成分label=iris.target_names[target],s=80,edgecolor='k')# 添加图例、坐标轴标签和标题
plt.legend(loc='upper right', fontsize='large')
plt.xlabel(f'Principal Component 1 (Variance Explained: {pca.explained_variance_ratio_[0]:.3f})')
plt.ylabel(f'Principal Component 2 (Variance Explained: {pca.explained_variance_ratio_[1]:.3f})')
plt.title('2D Projection of Iris Dataset via PCA')
plt.grid(True, linestyle='--', alpha=0.7)
plt.show()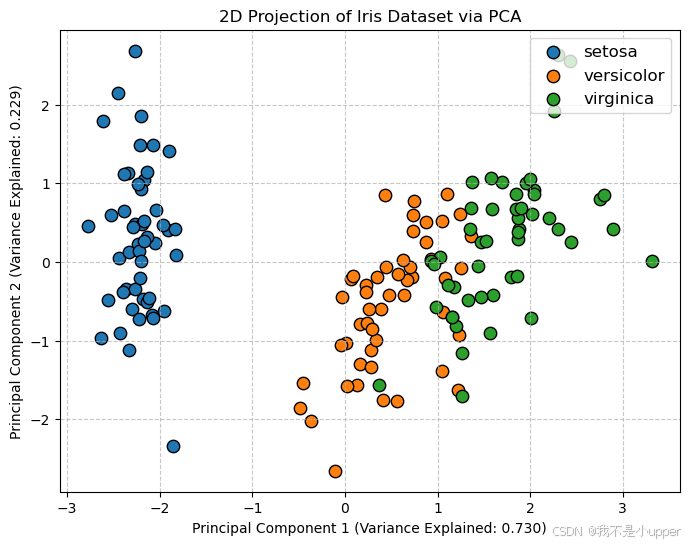
可视化解读:
- 第一主成分(PC1)和第二主成分(PC2)分别对应新的坐标轴,样本点在该空间中的位置反映了其在原始特征上的综合表现。
- 不同颜色的点代表鸢尾花的不同类别(山鸢尾、变色鸢尾、维吉尼亚鸢尾)。从图中可以看到,前两个主成分能够较好地将山鸢尾与其他两类区分开,但变色鸢尾和维吉尼亚鸢尾仍有部分重叠,说明这两类在原始特征上的差异可能需要更多主成分来区分。
解释方差分析
通过 explained_variance_ratio_ 属性可以查看每个主成分解释的方差比例,即该主成分捕获的原始数据方差占总方差的比例:
explained_variance = pca.explained_variance_ratio_
print(f"各主成分解释的方差比例: {np.round(explained_variance, 3)}")
print(f"累计解释方差比例: {np.round(np.sum(explained_variance), 3)}")
- 上述结果表明,第一主成分解释了原始数据 72.7% 的方差,第二主成分解释了 23% 的方差,两者累计保留了约 95.7% 的方差。这说明降维到 2 维后,数据的主要信息已被保留,适合用于可视化和后续分析。
关键注意事项
- 标准化的必要性:若原始特征量纲不同(如收入以 “元” 为单位,年龄以 “岁” 为单位),必须进行标准化,否则 PCA 结果会偏向数值范围大的特征。
- 主成分数量选择:
- 直接指定目标维度(如
n_components=2)。 - 通过累计方差贡献率确定(如
n_components=0.95表示保留累计方差达 95% 的主成分)。
- 直接指定目标维度(如
- 主成分的可解释性:主成分是原始特征的线性组合,可通过
pca.components_查看每个主成分中各原始特征的权重,从而分析其物理意义(例如,PC1 可能主要由花瓣长度和花瓣宽度主导)。
PCA 的应用场景
- 数据可视化:将高维数据降维到 2 维或 3 维,便于通过散点图、三维图观察数据分布。
- 去除噪声:过滤掉解释方差较低的主成分,保留主要信息,减少冗余。
- 机器学习预处理:降低数据维度,加速模型训练(如支持向量机、神经网络),避免 “维数灾难”。
通过以上步骤,PCA 能够高效地将高维数据映射到低维空间,在保留关键信息的同时简化数据结构,是数据分析和机器学习中不可或缺的工具。
独立成分分析
独立成分分析(Independent Component Analysis,ICA)是一种用于从混合信号中提取独立原始信号的无监督学习技术,其核心目标是在仅观测到混合信号的情况下,实现 “盲源分离”(Blind Source Separation),即恢复出相互独立的原始信号。以下将通过生成虚拟混合信号的示例,结合 Python 代码详细介绍 ICA 的原理与实现过程。
数据准备:生成混合信号
假设我们有两个相互独立的原始信号,通过一个未知的混合矩阵线性组合成观测到的混合信号。我们的任务是仅利用混合信号数据,通过 ICA 算法恢复出原始信号。
import numpy as np
from sklearn.decomposition import FastICA
import matplotlib.pyplot as plt# 生成两个独立的原始信号
np.random.seed(42) # 固定随机种子确保可复现性
n_samples = 1000 # 样本点数# 信号 1:服从均匀分布的随机噪声(非高斯分布)
signal_1 = np.random.rand(n_samples)
# 信号 2:正弦波信号(周期性信号,与信号 1 独立)
signal_2 = np.sin(np.linspace(0, 10 * np.pi, n_samples)) # 构建混合矩阵(未知的线性混合系数)
mixing_matrix = np.array([[2, 1], [1, 2]]) # 2x2 矩阵,每行对应一个混合信号的线性组合系数# 生成混合信号(每行是一个混合信号,每列是一个样本点)
original_signals = np.vstack((signal_1, signal_2)) # 原始信号矩阵,形状为 (2, 1000)
mixed_signals = np.dot(mixing_matrix, original_signals).T # 混合信号矩阵,形状为 (1000, 2)关键说明:
- 独立性假设:ICA 要求原始信号之间相互独立(如随机噪声与正弦波),这是算法能够分离信号的前提。
- 混合过程:混合信号是原始信号的线性组合,数学上可表示为:
- \(\mathbf{X} = \mathbf{A} \mathbf{S}\),其中 \(\mathbf{X}\) 是混合信号矩阵,\(\mathbf{A}\) 是混合矩阵,\(\mathbf{S}\) 是原始信号矩阵。
ICA 模型训练与信号分离
使用 sklearn 中的 FastICA 算法(基于快速定点法的 ICA 实现)来拟合混合信号数据,恢复原始信号:
# 初始化 ICA 模型,指定恢复的独立成分数量(等于原始信号数量)
ica = FastICA(n_components=2, random_state=42) # n_components 需与原始信号数一致# 训练模型并分离信号
recovered_signals = ica.fit_transform(mixed_signals) # 输出形状为 (1000, 2)- 通常选择使 AIC/BIC 最小的成分数量。
-
协方差类型:
covariance_type参数控制成分协方差矩阵的约束:'full':每个成分有独立的协方差矩阵(最灵活)。'tied':所有成分共享相同的协方差矩阵。'diag':每个成分有对角协方差矩阵(方差独立)。'spherical':每个成分有单一方差参数。
-
初始化与稳定性:
- GMM 对初始值敏感,可通过
n_init参数设置多次初始化并选择最优结果。 - 对于高维数据,可先使用 PCA 降维以提高稳定性。
- GMM 对初始值敏感,可通过
GMM 的应用场景
- 聚类:通过成分标签将数据点分配到不同簇(soft clustering)。
- 异常检测:低概率区域的样本可被视为异常。
- 密度估计:对复杂分布进行建模,用于生成新样本。
通过以上步骤,GMM 能够有效捕捉数据中的多峰分布特性,是数据建模和分析的强大工具。
最后
今天演示了关于scikit-learn在无监督学习方面的使用。后续会出scikit-learn在其他方面的使用,大家可以关注起来!
相关文章:

scikit-learn在无监督学习算法的应用
哈喽,我是我不是小upper~ 前几天,写了一篇对scikit-learn在监督学习算法的应用详解,今天来说说关于sklearn在无监督算法方面的案例。 稍微接触过机器学习的朋友就知道,无监督学习是在没有标签的数据上进行训练的。其主要目的可能…...

聊聊JetCache的缓存构建
序 本文主要研究一下JetCache的缓存构建 invokeWithCached com/alicp/jetcache/anno/method/CacheHandler.java private static Object invokeWithCached(CacheInvokeContext context)throws Throwable {CacheInvokeConfig cic context.getCacheInvokeConfig();CachedAnnoC…...

【ios越狱包安装失败?uniapp导出ipa文件如何安装到苹果手机】苹果IOS直接安装IPA文件
问题场景: 提示:ipa是用于苹果设备安装的软件包资源 设备:iphone 13(未越狱) 安装包类型:ipa包 调试工具:hbuilderx 问题描述 提要:ios包无法安装 uniapp导出ios包无法安装 相信有小伙伴跟我一样&…...

浅析 Golang 内存管理
文章目录 浅析 Golang 内存管理栈(Stack)堆(Heap)堆 vs. 栈内存逃逸分析内存逃逸产生的原因避免内存逃逸的手段 内存泄露常见的内存泄露场景如何避免内存泄露?总结 浅析 Golang 内存管理 在 Golang 当中,堆…...

仿射变换 与 透视变换
仿射变换 与 透视变换 几种变换之间的关系 1、缩放 Rescale 1)变换矩阵 缩放变换矩阵,形为 : , 其中: 、 为 x轴 和 y轴的缩放因子,即 宽高的缩放因子 图像中的每一个像素点 (x, y),经过矩阵…...

Vue.js---嵌套的effect与effect栈
4.3嵌套的effect与effect栈 1、嵌套的effect effect是可以发生嵌套的 01 effect(function effectFn1() { 02 effect(function effectFn2() { /* ... */ }) 03 /* ... */ 04 })有这么一段代码: 01 // 原始数据 02 const data { foo: true, bar: true } 03 /…...

jQuery知识框架
一、jQuery 基础 核心概念 $ 或 jQuery:全局函数,用于选择元素或创建DOM对象。 链式调用:多数方法返回jQuery对象,支持连续操作。 文档就绪事件: $(document).ready(function() { /* 代码 */ }); // 简写 $(function…...

【Java学习笔记】hashCode方法
hashCode方法 注意:C要大写 作用:返回对象的哈希码值(可以当作是地址,真实的地址在 Java 虚拟机上),支持此方法是为了提高哈希表的性能 底层实现:实际上,由Object类定义的hashCod…...

[思维模式-37]:什么是事?什么是物?什么事物?如何通过数学的方法阐述事物?
一、基本概念 1、事(Event) “事”通常指的是人类在社会生活中的各种活动、行为、事件或情况,具有动态性和过程性,强调的是一种变化、发展或相互作用的流程。 特点 动态性:“事”往往涉及一系列的动作、变化和发展过程。例如&a…...
)
STM32-USART串口通信(9)
一、通信接口介绍 通信的目的:将一个设备的数据传送到另一个设备,扩展硬件系统。 当STM32想要实现一些功能,但是需要外挂一些其他模块才能实现,这就需要在两个设备之间连接上一根或多跟通信线,通过通信线路发送或者接…...

【内网渗透】——NTML以及Hash Relay
【内网渗透】——NTLM以及Hash Relay 文章目录 【内网渗透】——NTLM以及Hash Relay[toc]前情提要1.NTML网络认证机制1.1NTML协议1.2NET NTMLv21.3NTML的认证方式1.4NTLM hash的生成方法: 2.PTH(pass the hash)2.1原理2.2漏洞原理2.3实验环境2.4攻击过程…...

速查 Linux 常用指令 II
目录 一、网络管理命令1. 查看和配置网络设备:ifconfig1)重启网络命令2)重启网卡命令 2. 查看与设置路由:route3. 追踪网络路由:traceroute4. 查看端口信息和使用情况1)netstat 命令2)lsof 命令…...

基于 GPUGEEK平台进行vLLM环境部署DeepSeek-R1-70B
选择 GPUGEEK 平台的原因 算力资源丰富:GPUGEEK 提供多样且高性能的 GPU 资源,像英伟达高端 GPU 。DeepSeek - R1 - 70B 模型推理计算量巨大,需要强大算力支持,该平台能满足其对计算资源的高要求,保障推理高效运行。便…...

深入理解ThingsBoard的Actor模型
1、ThingsBoard系统中定义了哪些Actor ✅ ThingsBoard Actor 创建机制与作用对照表: Actor 类型 何时创建 由谁创建 是否缓存 作用描述 SystemActor 系统启动时 DefaultActorService / ActorSystem ✅ 是 ★ ThingsBoard 平台服务级别管理器:负责创建所有的Actor AppActor...

虚幻引擎5-Unreal Engine笔记之Qt与UE中的Meta和Property
虚幻引擎5-Unreal Engine笔记之Qt与UE中的Meta和Property code review! 文章目录 虚幻引擎5-Unreal Engine笔记之Qt与UE中的Meta和Property1.Qt 中的 Meta(元对象系统)1.1 主要功能1.2 如何实现1.2.1 例子1.2.2 访问 meta 信息 2.UE5 中的 Metaÿ…...
)
技术中台-核心技术介绍(微服务、云原生、DevOps等)
在企业数字化中台建设中,技术中台是支撑业务中台、数据中台及其他上层应用的底层技术基础设施,其核心目标是提供标准化、可复用的技术能力,降低业务开发门槛,提升系统稳定性与扩展性。技术中台的技术栈需覆盖从开发、运维到治理的…...
:切片操作获取第二维度,第三维度)
attention_weights = torch.ones_like(prompt_embedding[:, :, 0]):切片操作获取第二维度,第三维度
attention_weights = torch.ones_like(prompt_embedding[:, :, 0]):切片操作获取第1 维度,第二维度 attention_weights = torch.ones_like(prompt_embedding[:, :, 0]) 这行代码的作用是创建一个与 prompt_embedding[:, :, 0] 形状相同且所有元素都为 1 的张量,它用于初始化…...

2025年中国DevOps工具选型指南:主流平台能力横向对比
在数字化转型纵深发展的2025年,中国企业的DevOps工具选型呈现多元化态势。本文从技术架构、合规适配、生态整合三个维度,对Gitee、阿里云效(云效DevOps)、GitLab CE(中国版)三大主流平台进行客观对比分析&a…...

国产ETL数据集成软件和Informatica 相比如何
数据集成领域Informatica名号可谓无人不知无人不晓。作为国际知名的ETL工具,凭借其强大的功能和多年的市场积累,赢得了众多企业的信赖。然而,随着国内企业数字化转型的加速以及对数据安全、成本控制和本地化服务的需求日益增长,国…...

FFMPEG 与 mp4
1. FFmpeg 中的 start_time 与 time_base start_time 流的起始时间戳(单位:time_base),表示第一帧的呈现时间(Presentation Time)。通常用于同步多个流(如音频和视频)。 time_base …...

在RAG中 如何提高向量搜索的准确性?
在RAG(Retrieval-Augmented Generation)系统中,提高向量搜索的准确性需要从数据预处理、模型选择、算法优化和后处理等多个维度进行综合改进。以下是具体策略的详细分析: 一、优化数据质量与预处理 1. 数据清洗与结构化 去噪与规范化:去除停用词、拼写纠错、统一大小写和…...

Python调用SQLite及pandas相关API详解
前言 SQLite是一个轻量级的嵌入式关系数据库,它不需要独立的服务器进程,将数据存储在单一的磁盘文件中。Python内置了sqlite3模块,使得我们可以非常方便地操作SQLite数据库。同时,pandas作为Python数据分析的重要工具,…...

【Java学习笔记】finalize方法
finalize 方法 说明:实际开发中很少或者几乎不会重写finalize方法,更多的是应对面试考点 说明 (1)当对象被回收时,系统会自动调用该对象的 finalize 方法。子类可以重写该方法,做一些额外的资源释放操作&…...

MySQL之基础索引
目录 引言 1、创建索引 2、索引的原理 2、索引的类型 3、索引的使用 1.添加索引 2.删除索引 3.删除主键索引 4.修改索引 5.查询索引 引言 当一个数据库里面的数据特别多,比如800万,光是创建插入数据就要十几分钟,我们查询一条信息也…...
ID 验证法 加密与解密)
MCU程序加密保护(二)ID 验证法 加密与解密
STM32 微控制器内部具有一个 96 位全球唯一的 CPU ID,不可更改。开发者可利用此 ID 实现芯片绑定和程序加密,增强软件安全性。 ID 验证法就是利用这个 UID,对每颗芯片的身份进行识别和绑定,从而防止程序被复制。 实现方式…...

SparkSQL的基本使用
SparkSQL 是 Apache Spark 的一个模块,用于处理结构化数据。它提供了一个高性能、分布式的 SQL 查询引擎,可以轻松处理各种数据源,包括结构化数据、半结构化数据和非结构化数据12。 SparkSQL 的特点 易整合:SparkSQL 无缝整合了…...

QListWedget控件使用指南
QListWedget公共函数 函数签名功能描述QListWidget(QWidget *parent nullptr)构造函数,创建一个QListWidget对象,可指定父部件(默认为nullptr)。virtual ~QListWidget()虚析构函数,释放QListWidget对象及其资源。voi…...

primitive创建图像物体
本节我们学习使用entity来创建物体 我们以矩形为例,在输入矩形的四个点后运行程序 //使用entity创建矩形var rectangle viewer.entities.add({rectangle: {coordinates:Cesium.Rectangle.fromDegrees(//西边的经度90,//南边维度20,//东边经度110,//北边维度30 ),material:Ces…...
)
MySQL 服务器配置和管理(上)
MySQL 服务器简介 通常所说的 MySQL 服务器指的是mysqld(daemon 守护进程)程序,当运⾏mysqld后对外提供MySQL 服务,这个专题的内容涵盖了以下关于MySQL 服务器以及相关配置的内容,包括: • 服务器⽀持的启动选项。可以在命令⾏和…...

跨区域智能电网负荷预测:基于 PaddleFL 的创新探索
跨区域智能电网负荷预测:基于 PaddleFL 的创新探索 摘要: 本文聚焦跨区域智能电网负荷预测,提出基于 PaddleFL 框架的联邦学习方法,整合多地区智能电网数据,实现数据隐私保护下的高精度预测,为电网调度优化提供依据,推动智能电网发展。 一、引言 在当今社会,电力作为经…...

Java 重试机制详解
文章目录 1. 重试机制基础1.1 什么是重试机制1.2 重试机制的关键要素1.3 适合重试的场景2. 基础重试实现2.1 简单循环重试2.2 带延迟的重试2.3 指数退避策略2.4 添加随机抖动2.5 使用递归实现重试2.6 可重试异常过滤3. 常用重试库介绍3.1 Spring Retry3.1.1 依赖配置3.1.2 编程…...

Spark缓存---cache方法
在Spark 中,cache() 是用于优化计算性能的核心方法之一,但它有许多细节需要深入理解。以下是关于 cache() 的详细技术解析: 1. cache() 的本质 简化的 persist():cache() 是 persist(StorageLevel.MEMORY_ONLY) 的快捷方式&#…...
)
一分钟了解大语言模型(LLMs)
一分钟了解大语言模型(LLMs) A Minute to Know about Large Language Models (LLMs) By JacksonML 自从ChatGPT上线发布以来,在短短的两年多时间里,全球ChatBot(聊天机器人)发展异常迅猛,更为…...

当数控编程“联姻”AI:制造工厂的“智能大脑”如何炼成?
随着DeepSeek乃至AI人工智能技术在企业中得到了广泛的关注和使用,多数企业开始了AI探索之旅,迅易科技也不例外,且在不断地实践中强化了AI智能应用创新的强大能力。许多制造企业面临着工艺知识传承困难、编程效率低下等诸多挑战, 今…...

鸿蒙OSUniApp 实现的二维码扫描与生成组件#三方框架 #Uniapp
UniApp 实现的二维码扫描与生成组件 前言 最近在做一个电商小程序时,遇到了需要扫描和生成二维码的需求。在移动应用开发中,二维码功能已经成为标配,特别是在电商、社交和支付等场景下。UniApp作为一个跨平台开发框架,为我们提供…...

【Python 内置函数】
Python 内置函数是语言核心功能的直接体现,无需导入即可使用。以下是精选的 10 大类、50 核心内置函数详解,涵盖日常开发高频场景: 一、数据类型转换 函数示例说明int()int("123") → 123字符串/浮点数转整数float()float("3…...

鸿蒙OSUniApp开发支持多语言的国际化组件#三方框架 #Uniapp
使用UniApp开发支持多语言的国际化组件 在全球化的今天,一个优秀的应用往往需要支持多种语言以满足不同地区用户的需求。本文将详细讲解如何在UniApp框架中实现一套完整的国际化解决方案,从而轻松实现多语言切换功能。 前言 去年接手了一个面向国际市场…...

MySQL之基础事务
目录 引言: 什么是事务? 事务和锁 mysql数据库控制台事务的几个重要操作指令(transaction.sql) 1、事物操作示意图: 2.事务的隔离级别 四种隔离级别: 总结一下隔离指令 1. 查看当前隔离级别 …...
)
OpenHarmony系统HDF驱动开发介绍(补充)
一、HDF驱动简介 HDF(Hardware Driver Foundation)驱动框架,为驱动开发者提供驱动框架能力,包括驱动加载、驱动服务管理、驱动消息机制和配置管理。 简单来说:HDF框架的驱动和Linux的驱动比较相似都是由配置文件和驱动…...

深度学习中的查全率与查准率:如何实现有效权衡
📌 友情提示: 本文内容由银河易创AI(https://ai.eaigx.com)创作平台的gpt-4-turbo模型辅助生成,旨在提供技术参考与灵感启发。文中观点或代码示例需结合实际情况验证,建议读者通过官方文档或实践进一步确认…...

文件名是 E:\20250512_191204.mp4, EV软件录屏,未保存直接关机损坏, 如何修复?
去github上下载untrunc 工具就能修复 https://github.com/anthwlock/untrunc/releases 如果访问不了 本机的 hosts文件设置 140.82.112.3 github.com 199.232.69.194 github.global.ssl.fastly.net 就能访问了 实在不行,从这里下载,传上去了 https://do…...

界面控件DevExpress WinForms v24.2 - 数据处理功能增强
DevExpress WinForms拥有180组件和UI库,能为Windows Forms平台创建具有影响力的业务解决方案。DevExpress WinForms能完美构建流畅、美观且易于使用的应用程序,无论是Office风格的界面,还是分析处理大批量的业务数据,它都能轻松胜…...

Web UI测试效率低?来试Parasoft Selenic的智能修复与分析!
如果你正在使用Selenium进行Web UI测试,但被测试维护的繁琐、测试不稳定以及测试执行缓慢等问题困扰,不妨试试Parasoft Selenic! Parasoft Selenic能够通过智能修复与分析功能,帮你自动检测并修复测试中的不稳定因素,…...

计算机视觉最不卷的方向:三维重建学习路线梳理
提到计算机视觉(CV),大多数人脑海中会立马浮现出一个字:“卷”。卷到什么程度呢?2022年秋招CV工程师岗位数下降了16%,但求职人数增加了23%,求职人数与招聘岗位的比例达到了恐怖的15:1࿰…...

国产 ETL 数据集成厂商推荐—谷云科技 RestCloud
数字化转型加速推进的商业环境中,数据已成为企业最为关键的资产之一。然而,随着企业信息化的建设不断深入,各个业务系统之间数据分散、格式不一、难以互通等问题日益凸显,严重制约了企业对数据价值的深度挖掘与高效利用。在此背景…...

vscode extention踩坑记
# npx vsce package --allow-missing-repository --no-dependencies #耗时且不稳定 npx vsce package --allow-missing-repository #用这行 code --install-extension $vsixFileName --force我问ai:为什么我的.vsix文件大了那么多 ai答:因为你没有用 --n…...

AI时代的弯道超车之第十二章:英语和编程重要性?
在这个AI重塑世界的时代,你还在原地观望吗?是时候弯道超车,抢占先机了! 李尚龙倾力打造——《AI时代的弯道超车:用人工智能逆袭人生》专栏,带你系统掌握AI知识,从入门到实战,全方位提升认知与竞争力! 内容亮点: AI基础 + 核心技术讲解 职场赋能 + 创业路径揭秘 打破…...

关于数据湖和数据仓的一些概念
一、前言 随着各行业数字化发展的深化,数据资产和数据价值已越来越被深入企业重要发展的战略重心,海量数据已成为多数企业生产实际面临的重要问题,无论存储容量还是成本,可靠性都成为考验企业数据治理的考验。本文来看下海量数据存储的数据湖和数据仓,数据仓库和数据湖,…...

hbase shell的常用命令
一、hbase shell的基础命令 # 客户端登录 [rootCloud-Hadoop-NN-02 hbase]$ ./bin/hbase shell# 查看所有表 hbase> list### 创建数据表student,包含Sname、Ssex、Sage、Sdept、course列族/列 ### 说明:列族不指定列名时,列族可以直接成为…...
:Page Cache结构设计)
高并发内存池(四):Page Cache结构设计
目录 一,项目整体框架回顾 Thread Cache结构 Central Cache结构 二,Page Cache大致框架 三,Page Cache申请内存实现 Central Cache向Page Cache申请内存接口 从Page Cache中获取span接口 Page Cache加锁问题 申请内存完整过程 源码&a…...