MySQL 服务器配置和管理(上)
MySQL 服务器简介
通常所说的 MySQL 服务器指的是mysqld(daemon 守护进程)程序,当运⾏mysqld后对外提供MySQL 服务,这个专题的内容涵盖了以下关于MySQL 服务器以及相关配置的内容,包括:
• 服务器⽀持的启动选项。可以在命令⾏和配置⽂件中指定这些选项。(写[mysqld])
• 服务器系统变量。反映了启动选项的当前状态和值,其中⼀些变量可以在服务器运⾏时修改。(系统变量可以被修改, 比如修改编码集, 给mysql服务器分配多少内存)
• 服务器状态变量。这些变量包含了有关运⾏时操作的计数器和统计信息。(状态变量不能被修改, 只是代表了当前的状态而已, 是一个指示器, 描述当前有多少个客户端进行连接,服务器运行了多少时间)
• 服务器如何管理客⼾端连接。
• 配置和使⽤时区⽀持。
• 服务器端帮助功能。
服务器的配置和默认值
mysqld 有很多选项和系统变量可以在启动时进⾏配置,要查看服务器的默认选项和系统变量值,
可以执⾏以下命令:mysqld --verbose --help
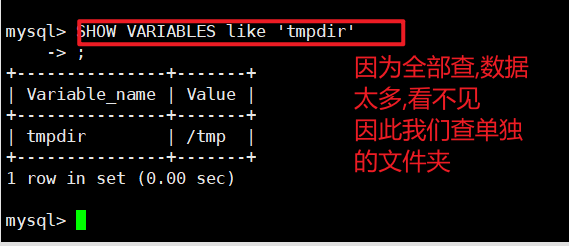
查看服务器在运行时的系统变量的值, 连接到MySQL并执行下面语句:
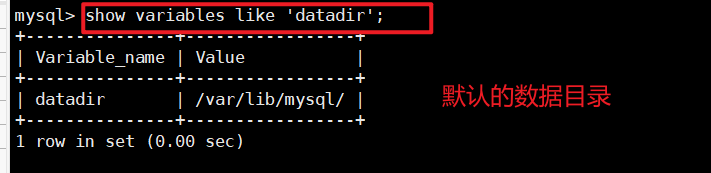
mysql> SHOW VARIABLES like ' xxxx'; 查看指定的某个变量
SHOW VARIABLES like ' %tmp%' 记不住全称就这么搜, 结合通配符来完成
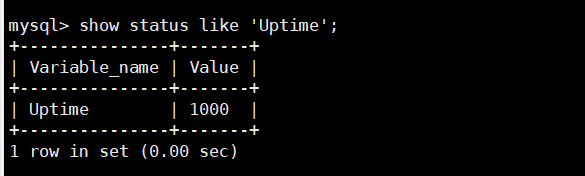
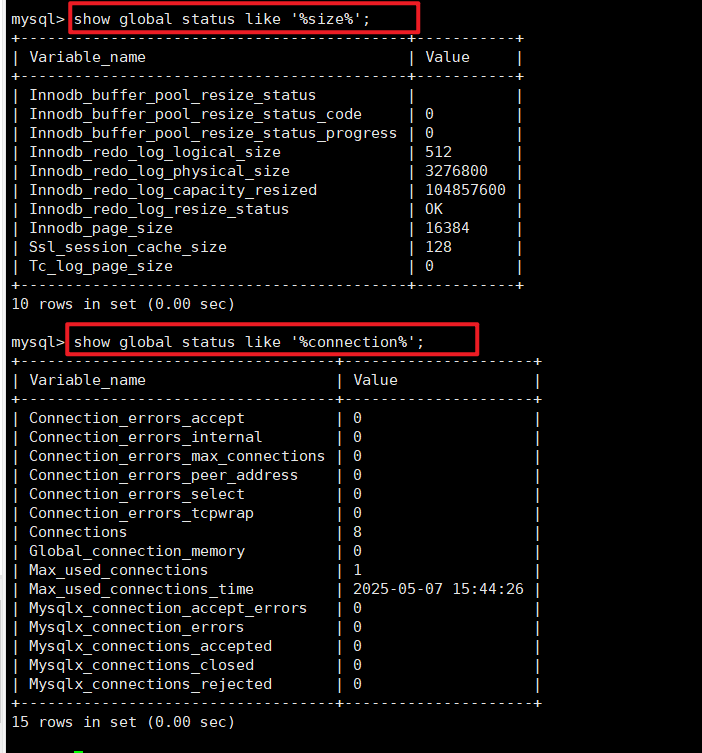
查看服务器在运⾏时的⼀些统计和状态指⽰器,连接到MySQL并执⾏以下语句:
mysql> show status like 'xx'; 也可以结合通配符, 同上
系统变量和状态信息也可以使⽤ mysqladmin命令来查看:
mysqladmin varibales -u root -p123456
mysqladmin extended-status -uroot -p123456
官方有更多的选项和配置: https://dev.mysql.com/doc/refman/8.0/en/server-option-variable-reference.html
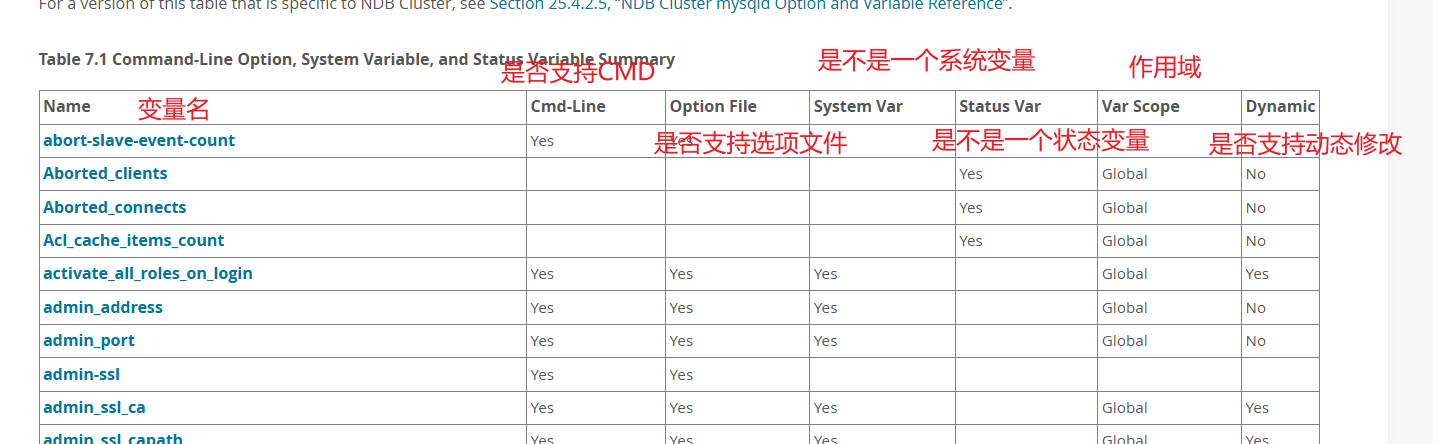
注意:系统变量、状态变量的作⽤域分为: Global (全局), Session (当前会话或连接), 或 两
者都⽀持.
全局作用域: 每个会话都会生效
会话作用域: 只针对当前的会话(连接)
系统变量和选项
简介:
• 当通过mysqld启动数据库服务器时,可以通过选项⽂件或命令⾏中提供选项,但是,在⼤多数情
况下,为确保服务器每次运⾏时都使⽤相同的选项,最好的⽅法是在选项⽂件中指定相应的选项。
• mysqld从选项⽂件中的 [mysqld] (再读这个)和 [server] (先读这个)组(节点)中读取选项内容
这俩个是服务器端的启动脚本

• mysqld接受的选项可以通过 mysqld --verbose --help 查看,列表中的有些项⽬是可以在服务器启动时设置的系统变量,系统变量可以在连接MySQL后使⽤ SHOW VARIABLES 语句查看,但有些内容只在 --help 中存在,使⽤ SHOW VARIABLES 时并没有显⽰,这是因为它们只是选项⽽不是系统变量。
mysql --verbose --help 显示选项(可以命令行和配置文件进行指定的)和系统变量(不能够进行指定)
show variables 只显示系统变量
常见选项
| 选项 | 系统变量 | 说明 |
| --character-set-server | character_set_ server | 服务器的默认字符集(客户端按照什么编码进行解析,服务器器里面按照什么编码进行存储),默认 utf8mb4 ,如果设置了这个变量,还应该设置 collation_server 来指定字符集的排序规则。MySQL8.0之前版本默认字符集是 latin1(不能保存中文) ,建议明确指定此选项为 utf8mb4 |
| --collation-server | collation_serv er | 服务器的默认排序,默认utf8mb4_0900_ai_ci( uft8mb4 编码集 0900: 表示unicode 的版本9 ai = accent insensitive 口音不敏感 ci = caze insensitice 忽略大小写
|
| --port | port | MySQL服务启动后监听的端⼝号 默认3306 |
| --datadir | datadir | MySQL服务器的数据⽬录
|
| --default-storage-engine | default_storag e_engine | 表的默认存储引擎(默认是 innodb) |
| --log-output | log_output | ⼀般查询⽇志和慢速查询⽇志输出的⽬的地,值可以是TABLE , FILE(可以使用表或文件来把日志记录下来) 和 NONE ,可以同时指定多个值, NONE的优先级最⾼ |
| --general-log | general_log | 是否启⽤⼀般查询⽇志。值为 0 (或 OFF )禁⽤⽇志,为1 (或 ON )来启⽤⽇志。⽇志输出⽬录由 log_output 系统变量控制 |
| --general-log-file | general_log_fil e | ⼀般查询⽇志⽂件的名称。默认值是host_name.log(一般指定的是绝对路径) |
| --slow-query-log | slow_query_lo g | 是否启⽤慢查询⽇志。值为 0 (或 OFF )禁⽤⽇志,为1 (或 ON )来启⽤⽇志。⽇志输出⽬录由 log_output 系统变量控制 |
| --slow-query-log-file | slow_query_lo g_file | 慢查询⽇志⽂件的名称(一般指定绝对路径)。默认值是host_name-slow.log(慢查询日志) |
| --long-query-time | long_query_ti me | 如果查询花费的时间超过这个数秒,服务器将增加Slow_queries状态变量,如果慢速查询⽇志开启,查询将被记录到慢速查询⽇志⽂件中,默认值为10,单位为秒(指定慢查询的时间阈值) |
| --log-error | log_error | 默认的错误⽇志⽬标。如果⽬标是控制台值为 stderr ,⽬标是⼀个⽂件,值为具体的⽂件名 |
| --log-bin | N/A | 指定⽤于⼆进制⽇志⽂件的基本名称
|

| -server-id | server_id | 该变量指定服务器ID,默认为 1 。(集群下使用,在集群环境下不同的server-id服务器id必须不同) |
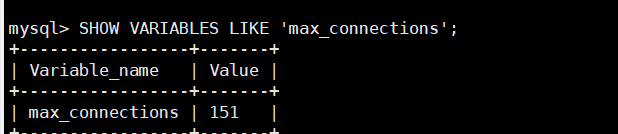
| --max-connections | max_connections | 允许客⼾端同时连接的最⼤数(mysql服务器支持的最大并发数)
|
| --table-open-cache | table_open_cache | 所有线程可以打开的表的数量 |
| --innodb-log-buffer-size | innodb_log_bu ffer_size | InnoDB向磁盘写⼊⽇志⽂件的缓冲区⼤⼩,默认16MB |
| --innodb-buffer-pool-size | innodb_buffer _pool_size | InnoDB缓存表和索引数据的缓冲区⼤⼩,默认128MB |
| --innodb-redo-logcapacity | innodb_redo_l og_capacity | 重做⽇志⽂件占⽤的磁盘空间 |
| --innodb-threadconcurrency | innodb_thread _concurrency | 定义InnoDB内部允许的最⼤线程数,默认值 0 ,多⽤于⾼性能机器上的调优 |
| --innodb-autoextendincrement | innodb_autoex tend_incremen t | ⾃动扩展InnoDB系统表空间⽂件的增量⼤⼩(以兆为单位)。默认值为64。 |
| --flush-time | flush_time | 如果将该值设置为⾮零值,则每flush_time秒关闭⼀次所有表,以释放资源并将未刷新的数据同步到磁盘。 |
| --join-buffer-size | join_buffer_siz e | ⽤于普通索引扫描、范围索引扫描和不使⽤索引从⽽执⾏全表扫描的连接的缓冲区的最⼩⼤⼩,默认256KB |
| --max-allowed-packet | max_allowed_ packet | ⼀个数据包的最⼤⼤⼩,默认值是64MB。 |
| --max-connect-errors | max_connect_ errors | 来⾃客⼾端主机连续连接请求失败数达到指定值后,服务器将阻⽌该客⼾端的连接。 |
| --open-files-limit | open_files_lim it | mysqld在操作系统中可⽤的⽂件描述符的数量 |
| --sort-buffer-size | sort_buffer_siz e | 每个必须执⾏排序的会话分配的缓冲区⼤⼩ |
| --binlog-row-event-maxsize | binlog_row_ev ent_max_size | 当记录基于⾏的⼆进制⽇志时,设置事件的最⼤值,必须是256的倍数,默认值8192字节,如果事件不能分割,则可能超过最值。 |
使用系统变量
为什么要使用系统变量?
系统变量很多的值都是默认的, 但是在开发条件下, 我们程序的负载比较大, 使用默认值是不够的, 因此我们需要提高我们mysqld服务器的配置, 当加内存,加cpu,加带宽...后, 我们需要修改mysqld的服务器配置来提高我们的性能. 比如我当前内存比较充裕, 我们就可以把当前的内存的系统变量改大一些...
使用系统变量
1. 以上我们介绍了通过选项⽂件和命令⾏设置相应系统变量的值,设置系统变量的语法与命令选项的语法相同,指定变量名称时,破折号和下划线可以互换使⽤。例如, --general_log=ON(建议使用这一种)和 - -general-log=ON 是等价的。
2. 当使⽤选项设置⼀个数值的变量时,可以带有后缀 K 、 M 或 G (⼤⼩写不限)表⽰ 1024 、1024^2 或 1024^3 ;从MySQL 8.0.14 开始,后缀也可以⽤ T 、 P 和 E 来表⽰ 1024^4 、1024^5 或 1024^6 。(用单位来代表一个很长的数字)
⽰例:为服务器指定 256 KB 的排序缓冲区⼤⼩和 1 GB 的最⼤数据包⼤⼩
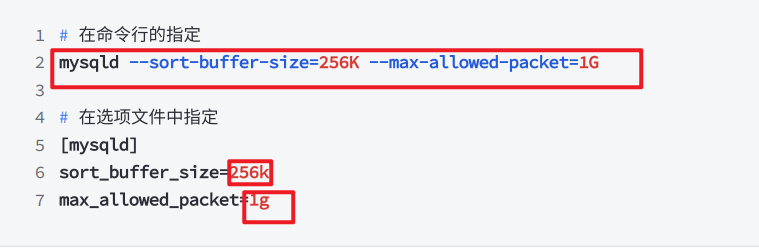
3. 系统变量有两个作⽤域,分别是 Global (全局) 和 Session (会话)(单独的连接), Global 全局变量影响服务器的整体操作, Session 会话变量影响各个客⼾端连接的操作。给定的系统变量可以同时具有全局值和会话值,它们的关系如下:
◦ 服务器启动时,会将每个全局变量初始化并设置默认值,具体的值可以通过命令⾏或选项⽂件更改。
◦ 服务器为每个客⼾端维护⼀组 Session 变量,在客⼾端连接时使⽤相应全局变量的当前值进⾏初始化。
Global变量的初始值
1> 默认值
2> 通过选项指定
Session作用域的初始值
1> 全局变量的值
2> 可以自己设置调整
4. ⼤部分系统变量是动态的,在服务器运⾏时可以通过 SET 语句动态更改,并且⽆需停⽌和重新启动服务器。在服务器运⾏时,使⽤ SET 语句设置系统变量,需要指定作⽤域(也可以在前⾯加上@@ 修饰符),然后指定系统变量的名称,名称必须使⽤下划线⽽不是破折号
主要这个set指定作用域是针对这个系统变量既是session又是global, 反正后续我们修改系统变量, 不管是不是both我们就根据这个表来指定就行

如下所⽰:
a. 设置全局系统变量最⼤连接数为1000. 下面是俩种写法, 建议第一种写法
mysql> SET GLOBAL max_connections = 1000; 其中mac_connection 是系统变量名
mysql> SET @@GLOBAL.max_connections = 1000;
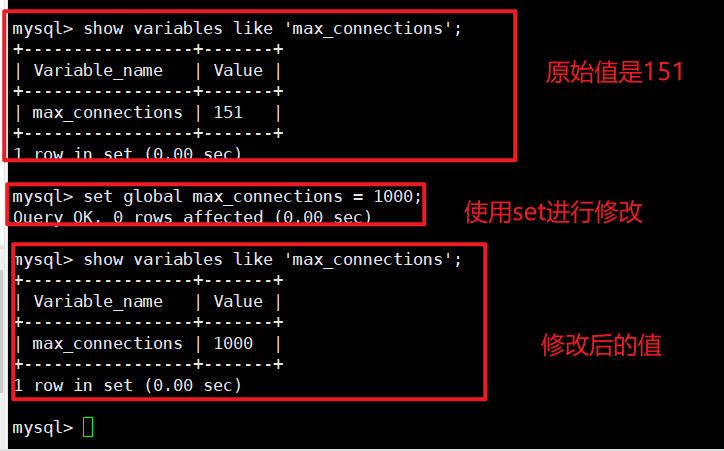
使用第二种方法来进行修改
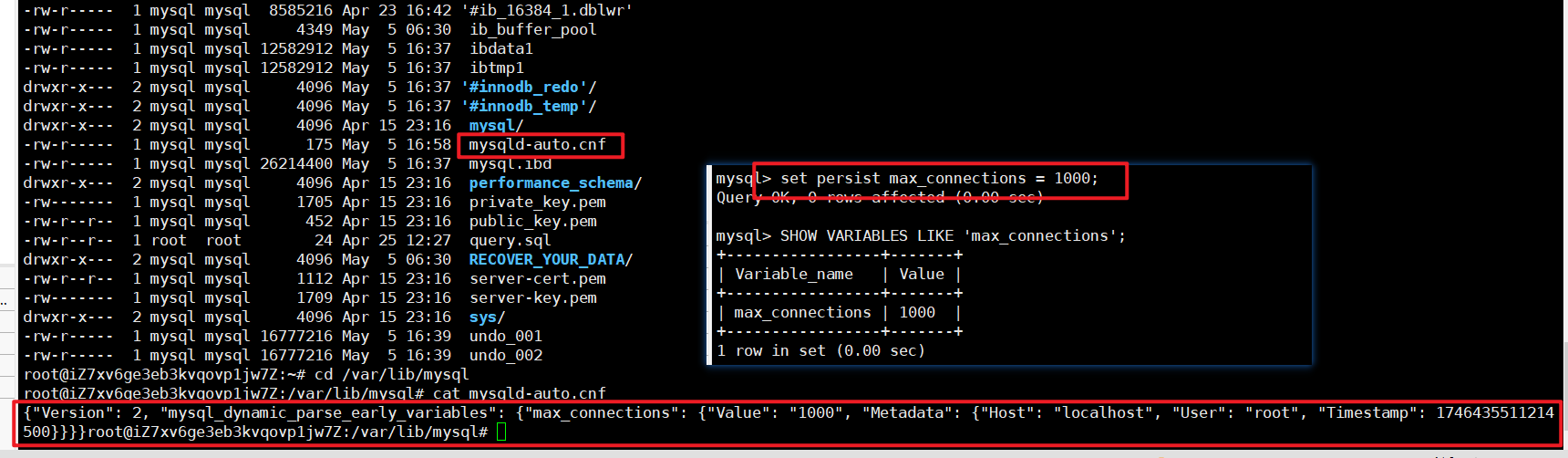
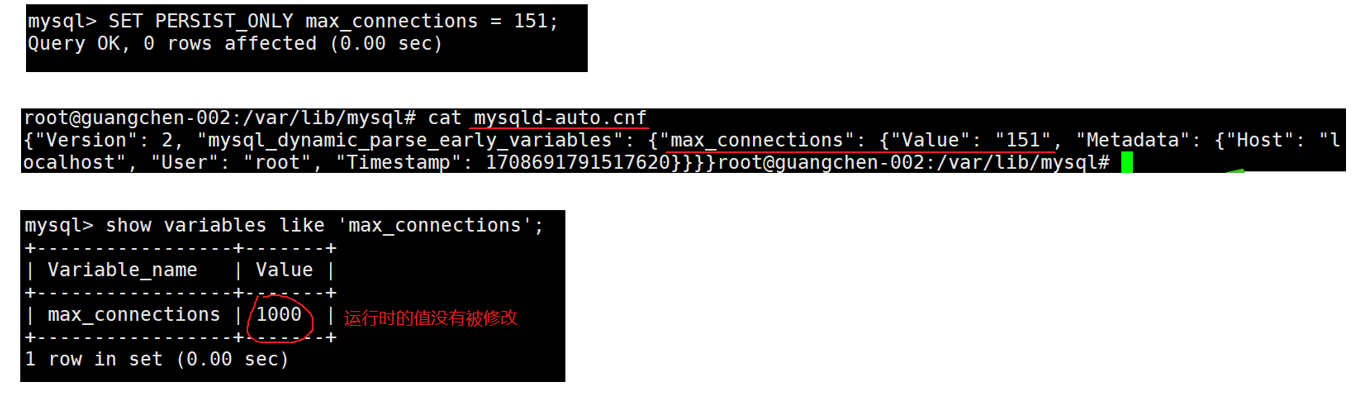
b. 将全局系统变量持久化到 mysqld-auto.cnf ⽂件(同时设置运⾏时值:
配置文件优先级
# PERSIST 表⽰持久化的同时设置全局变量的值mysql> SET PERSIST max_connections = 1000;
mysql> SET @@PERSIST.max_connections = 1000;

c. 将全局系统变量持久化到 mysqld-auto.cnf ⽂件(不设置运⾏时值):
# PERSIST 表⽰持久化的同时设置全局变量的值
mysql> SET PERSIST_ONLY max_connections = 1000; 这里注意要启动权限
mysql> SET @@PERSIST_ONLY.max_connections = 1000;
删除持久化的系统变量可以使⽤语句
RESET PERSIST IF EXISTS system_var_name;

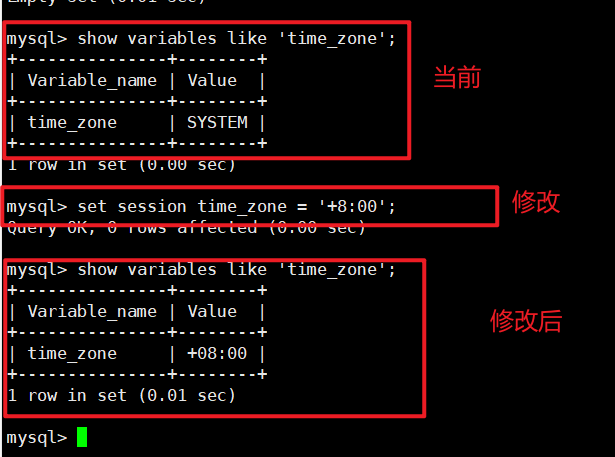
d. 设置 Session 系统变量,时区为"+8:00":session 只会针对当前的连接生效
mysql> SET SESSION time_zone='+8:00';
mysql> SET @@SESSION.time_zone='+8:00';
mysql> SET @@time_zone='+8:00';
这个只针对session
注意在选项文件中, 我们配置的是default-time-zone 而不是time_zone

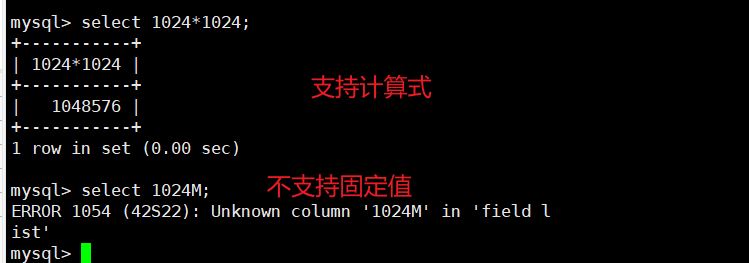
5. 对于数值型的系统变量,⽤带有后缀的值指定时,只适⽤于选项⽅式,⽽不能⽤在 SET ⽅式中;
SET ⽅式可以使⽤表达式为系统变量指定值,⽽在选项⽅式中不允许,如下所⽰:
# 选项形式
root@guangchen-vm:~# mysqld --max_allowed_packet=16M # 允许 解析单位
root@guangchen-vm:~# mysqld --max_allowed_packet=16*1024*1024 # 不允许, 不支持运算
# 运⾏时SET形式
mysql> SET GLOBAL max_allowed_packet=16M; # 不允许 不能解析单位
mysql> SET GLOBAL max_allowed_packet=16*1024*1024; # 允许 支持运算
为什么要指定global关键字
说明:在设置全局变量时需要指定GLOBAL关键字的原因是为了防⽌出现以下问题:
• 如果要删除的SESSION变量与GLOBAL变量名相同,那么具有修改全局变量权限的客⼾端可能会 意外地更改GLOBAL变量,⽽不仅仅是只修改SESSION变量。 • 如果已经有⼀个SESSION变量⽽且与GLOBAL变量同名,那么本意是要修改GLOBAL变量,可能 只是修改了SESSION变量的值所以没有明确指定 GLOBAL 和 SESSION 时,对于当前客⼾端来说 SESSION 的优先级更⾼
6. 要显⽰系统变量名称和值,请使⽤以下 SHOW VARIABLES 语句:一般还是搭配like来使用
mysql> SHOW VARIABLES;
7. 可以使⽤ LIKE ⼦句显⽰与指定内容匹配的变量,也可以使⽤通配符
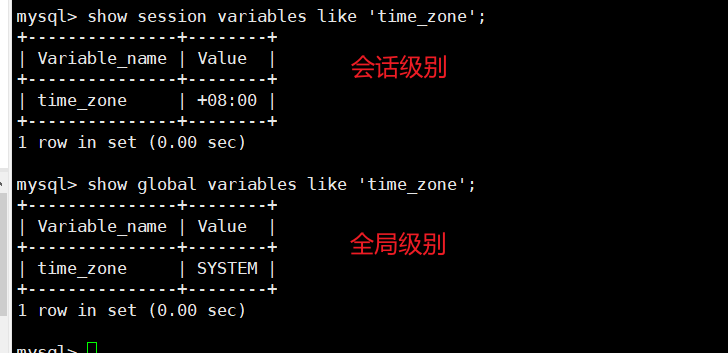
# 查看指定的系统变量
SHOW VARIABLES LIKE 'max_join_size';
# 查看指定系统变量SESSION作⽤域的值
SHOW SESSION VARIABLES LIKE 'max_join_size';
# 查看包含指定内容的系统变量
SHOW VARIABLES LIKE '%size%';
# 查看包含指定内容系统变量的GLOBAL作⽤域的值
SHOW GLOBAL VARIABLES LIKE '%size%';
8. ⼀部分系统变量是内置的,也有⼀些需要通过安装服务器插件或组件才可以使⽤
◦ ⽐如⽤于审计插件 audit_log 实现了名为 audit_log_policy 的系统变量
◦ 错误⽇志过滤组件 log_filter_dragnet 实现了名为 log_error_filter_rules 的系统变量
没下载就是空的

9. 可以动态设置的系统变量参考这个链接
https://dev.mysql.com/doc/refman/8.0/en/dynamic-system-variables.html
示例: 服务器常用配置的练习
• Linux系统下编辑 /etc/mysql/my.cnf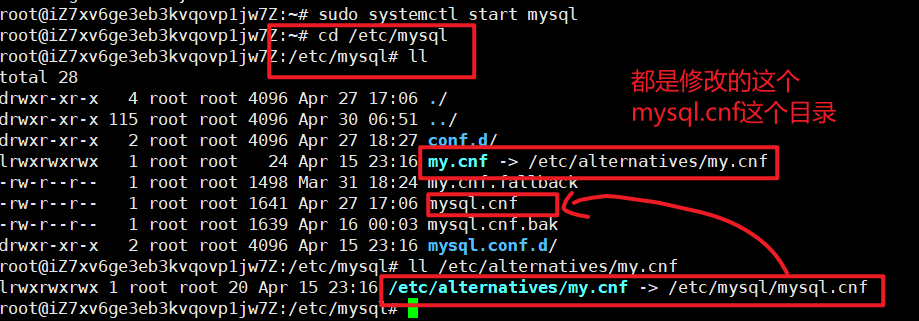
查看配置文件my.cnf
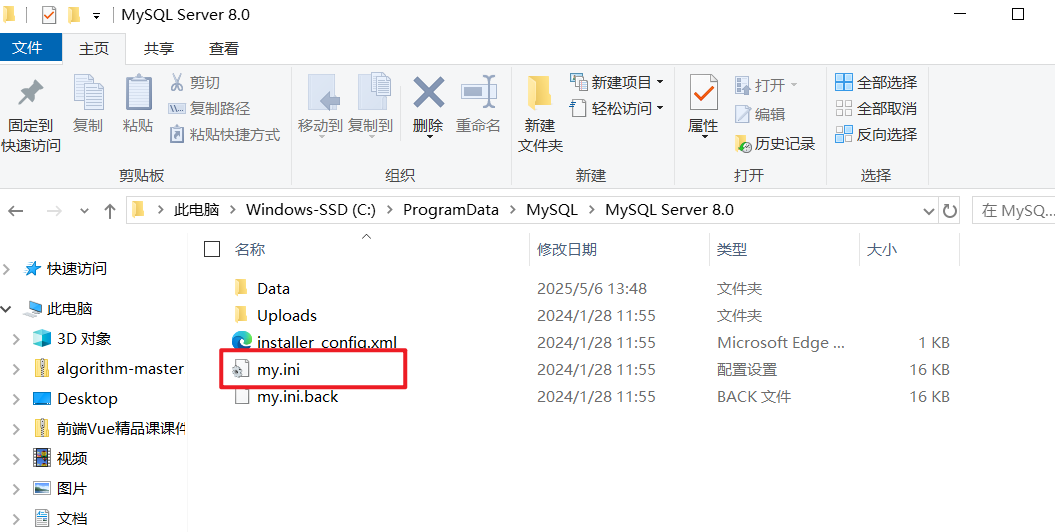
• Windows系统下打开C:/ProgramData/MySQL/MySQL Server 8.0/my.ini
注意:
• 编辑前先备份原始⽂件
• 如果要修改数据⽬录选项建议先停⽌MySQL服务,并把原data⽬录整体复制到新路径,配置完成后重启服务
• 在 [mysqld] 节点下添加以下内容, 服务器可以使用[mysqld]和[server]

除了上面的配置, 我们还可以配置时区: 东8时区
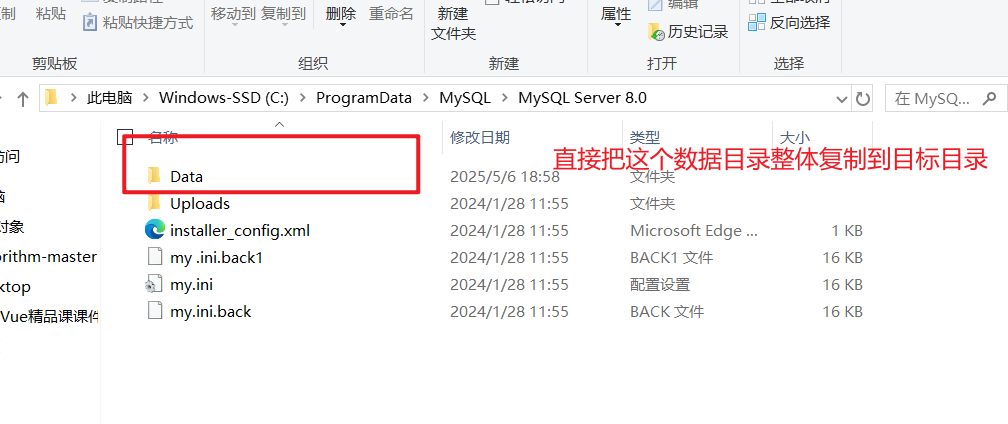
mysql默认的数据目录(建议进行修改), 把指定到其他盘,别在c盘
 Windows进行移动
Windows进行移动
我们如果移动就要把这个Data目录整体进行移动, 而不是新建一个文件夹, 因为在安装Mysql的过程中会设置一些用户自定义的值,比如用户的密码...这些值在Mysql启动的时候会从系统中进行读取
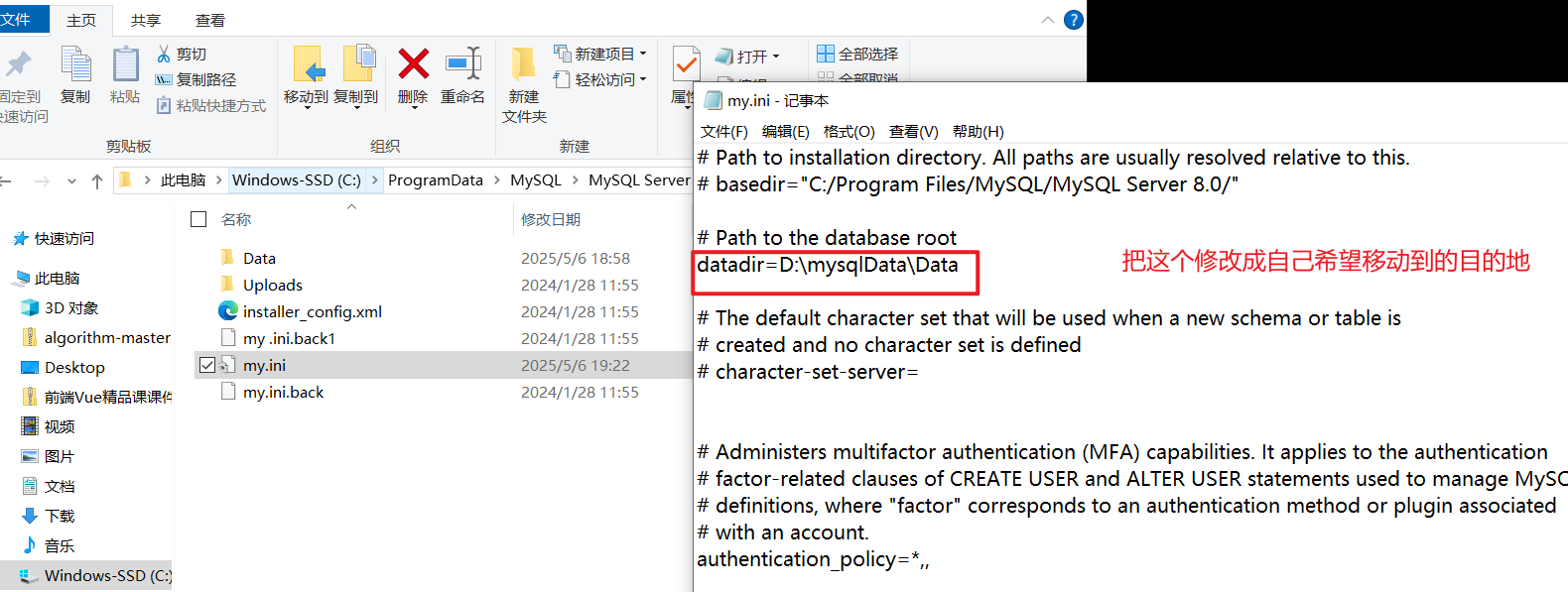
然后点击my.ini 进行复制
Linux进行移动, 也是一样的操作, 下面是为什么要移动的原因. 磁盘阵列相当于一个硬盘
在修改datadir的时候, 可能会遇到权限问题, 那么需要把目标数据目录的权限修改成mysql

现在对我们的 ini 进行配置
1> 编写ini文件

2> 注意每次修改配置文件都需要把我们的mysql服务器停掉
root@iZ7xv6ge3eb3kvqovp1jw7Z:~# systemctl stop mysql 停止服务器
root@iZ7xv6ge3eb3kvqovp1jw7Z:~# systemctl status mysql 查看服务器状态
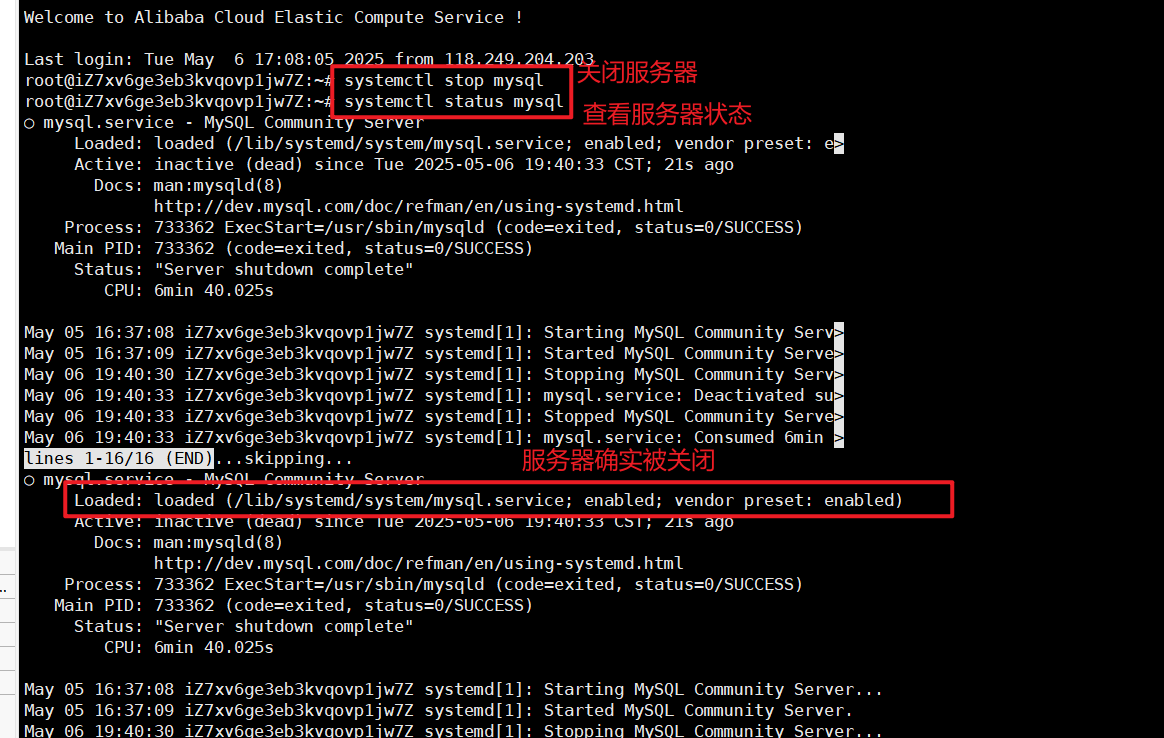
3> 修改我们的文件
vim /etc/mysql/my.cnf 注意, 我们的最后一行必须换行!
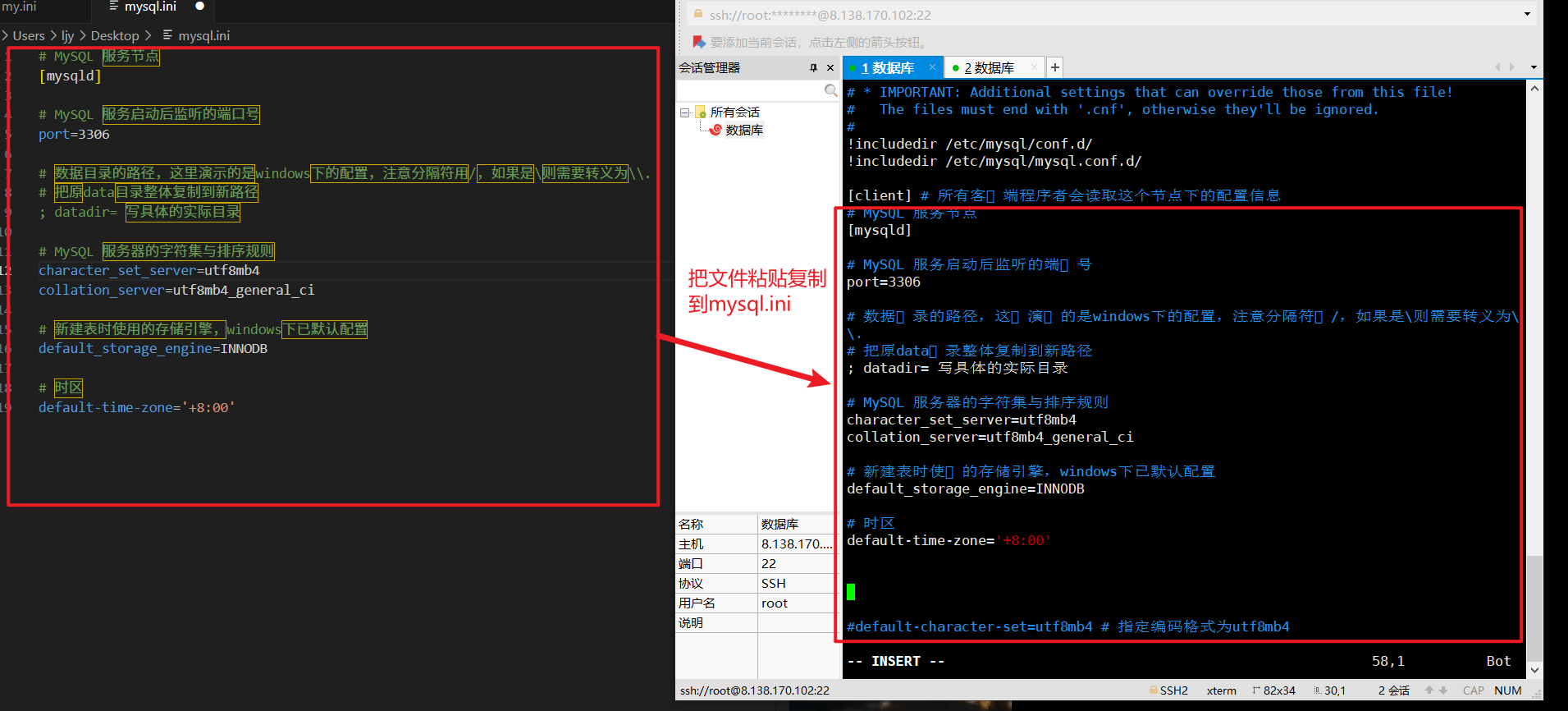
4> 重新启动服务器, 来使用我们刚刚配置好的文件
systemctl start mysql 重新启动服务器
systemctl status mysql 查看状态
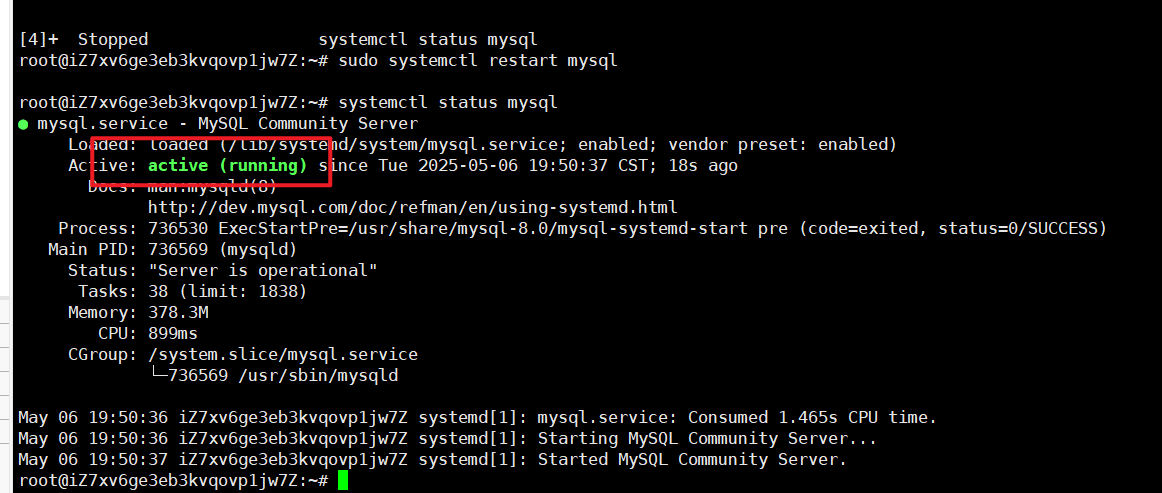
5> 检验配置
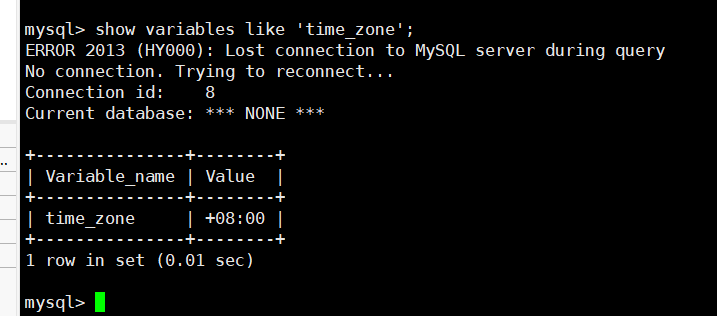
查看状态变量
MySQL服务器维护着当前系统信息的状态变量(这个变量时指示类型的变量, 不能进行人为修改)
可以使⽤ SHOW [GLOBAL | SESSION] STATUS [like status_name]; (可以使用通配符)语句查看这些变量
和对应的值。
GLOBAL显⽰所有连接的值,SESSION显⽰当前连接的值。
官方关于状态变量的介绍: https://dev.mysql.com/doc/refman/8.0/en/server-status-variables.html
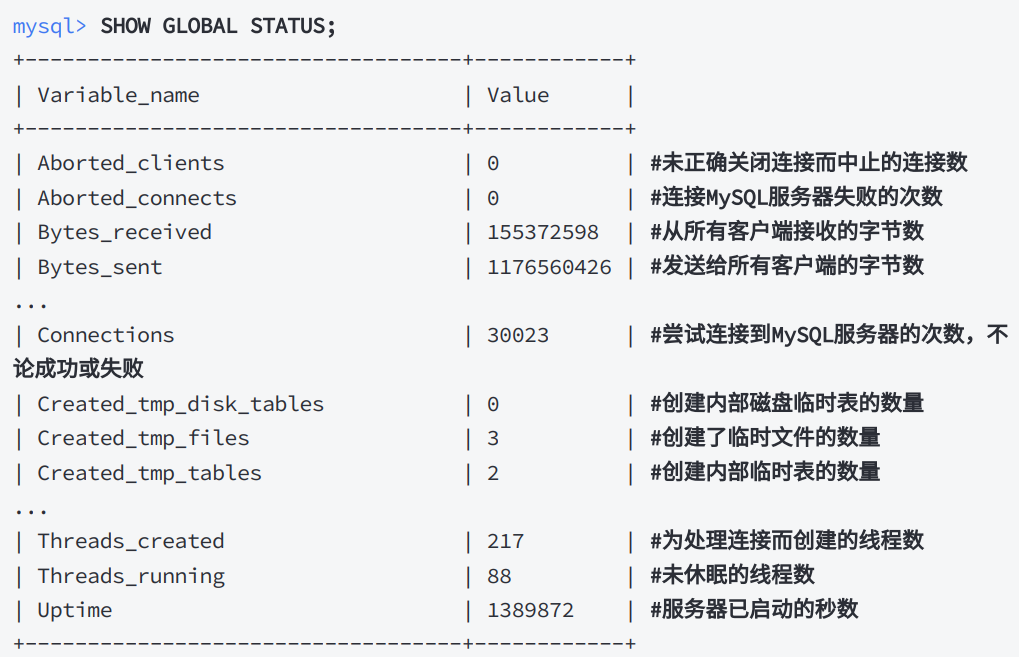
下面时例子:
MySQL 数据目录
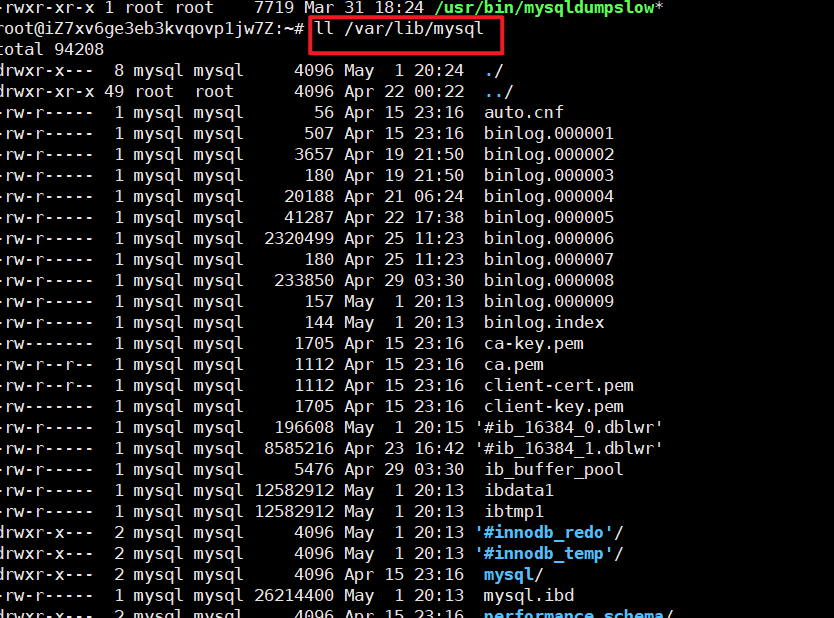
MySQL 服务器的管理信息、业务数据、日志⽂件、磁盘缓冲⽂件默认存储在数据目录(mysql工作的时候最主要操作的目录, 十分重要的一个目录)下
管理信息: 自身的一些数据, 比如: 1> 用户名和密码 2> 用户的授权 3> 系统变量的默认值 4> 用户创建库和表都要进行维护...
业务数据: 用户创建的库和表以及表中的数据
日志文件: 慢查询日志,通用日志,错误日志,回滚日志...
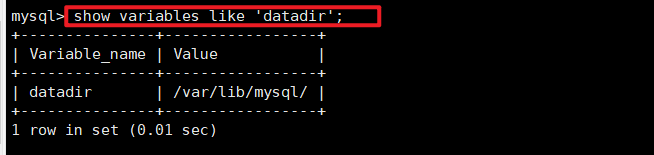
数据目录可以通过选项datadir 进行修改
数据目录一般包含下面内容
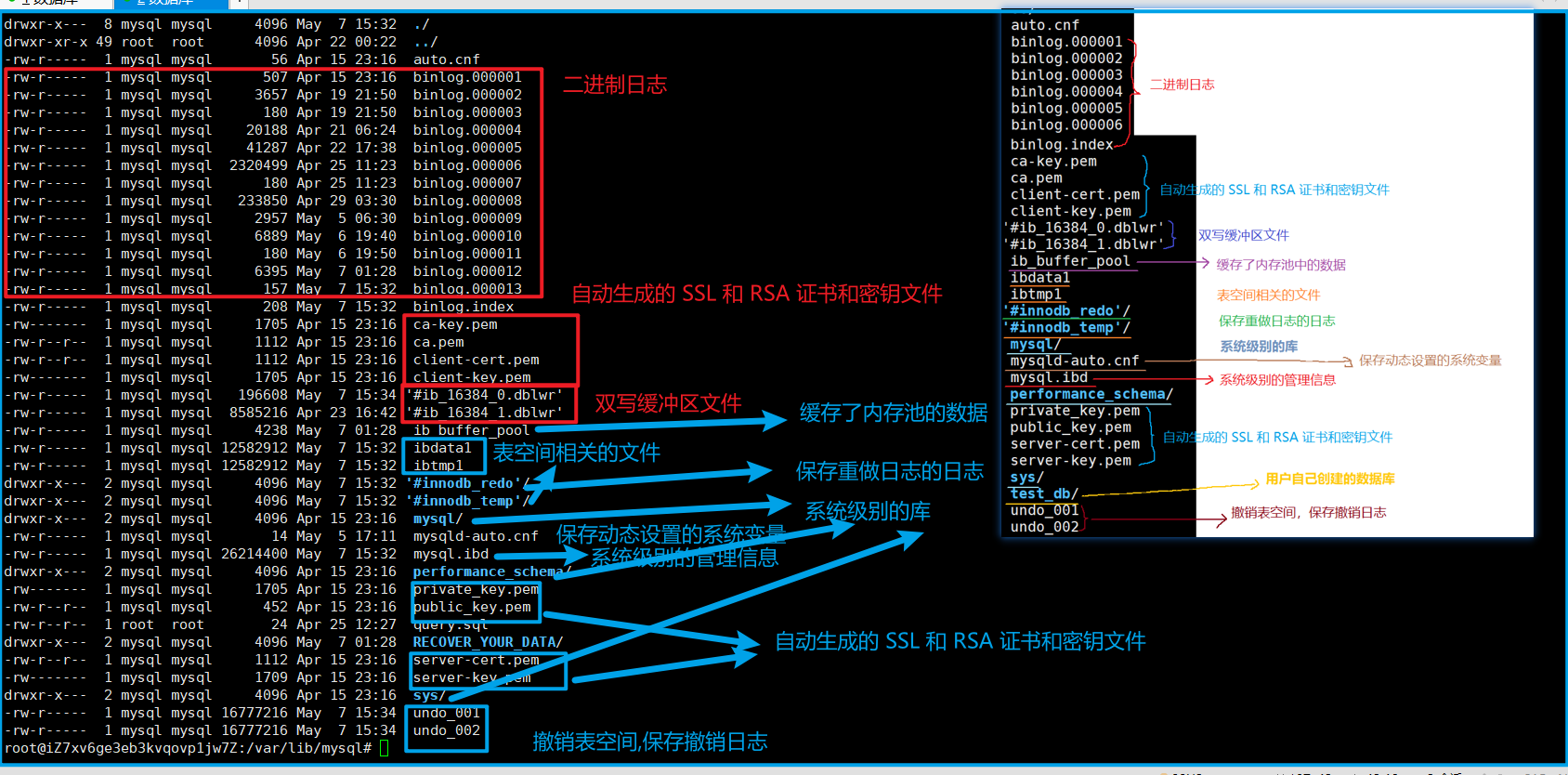
1. 数据⽬录下的每个⼦⽬录都是⼀个数据库⽬录,对应服务器管理的⼀个数据库,包括MySQL 安装成功后创建的标准数据库:
a. mysql⽬录对应于mysql系统库,包含mysql服务器运⾏时所需的信息,该数据库包含数据字典
表和系统表;
b. performance_schema⽬录对应于Performance Schema,提供了在运⾏时⽤于检查服务器内
部执⾏的信息;
c. sys⽬录对应于sys系统库,提供⼀组对象来帮助解释性能模式相关信息;
d. 其他⼦⽬录对应于⽤⼾或应⽤程序创建的数据库,也就是说我们每创建⼀个数据库,就会在数
据⽬录⽣成⼀个同名的⽬录来保存对应的数据。
2. 服务器写⼊的⽇志⽂件
3. InnoDB 表空间和⽇志⽂件
4. 默认或⾃动⽣成的 SSL 和 RSA 证书和密钥⽂件
5. 服务器进程 ID ⽂件(当服务器运⾏时)
6. mysqld-auto.cnf ⽂件⽤来存储持久化全局系统变量设置
通过选项重新配置服务器,可以将上述某些项⽬重新定位到指定⽬录。
使⽤ --datadir 选项允许更改数据⽬录本⾝的位置。
以上涉及到的系统库,和 InnoDB 相关内容,在后⾯的相关专题会详细介绍
日志简介(日志类型记一下)
日志类型简洁(有几种日志,面试题)
MySQL Server 有以下⼏种⽇志(面试题),可以记录服务器正在发⽣的活动。
| ⽇志类型 | ⽇志信息 |
| 错误⽇志 (Error log) | mysqld在启动、运⾏或停⽌时遇到的问题(比如启动失败, 运行崩溃) |
| ⼀般查询⽇志 (General query log) | 已建⽴的客⼾端连接和从客⼾端接收到的语句 |
| 慢查询⽇志 (Slow query log) | 执⾏时间超过 long_query_time 指定秒数的查询(优化的场景) |
| ⼆进制⽇志 (Binary log) | 更改(update,delete..)数据的语句(也⽤于主从复制) |
| 中继⽇志 (Relay log) | 从源服务器接收到的数据更改(来源于集群中的主服务器) |
| DDL⽇志(metadata log) | DDL 语句执⾏的操作 (定义语句 |
| 回滚⽇志/撤销⽇志(undo log) | ⽤于事务的回滚操作 |
| 重做⽇志(redo log) | ⽤于服务器崩溃恢复 |
我们这个章节主要介绍: 错误日志, 一般查询日志, 慢查询日志. 后面章节继续学习后面的日志
基础常识
• 默认情况下,除 Windows 上的错误⽇志外,不启⽤任何⽇志,Linux下默认开启错误⽇志和⼆进制⽇志
• 在服务器运⾏期间可以控制⼀般查询和慢查询⽇志的禁⽤与开启(有错误就可以开启来看看),也可以更改⽇志⽂件名
• ⼀般查询⽇志和慢查询⽇志记录可以写⼊⽇志表、⽇志⽂件(FILE TABLE)或两者同时写⼊
• 默认情况下,所有启⽤的⽇志将写⼊数据⽬录,可以通过刷新⽇志强制服务器关闭并重新打开⽇志⽂件
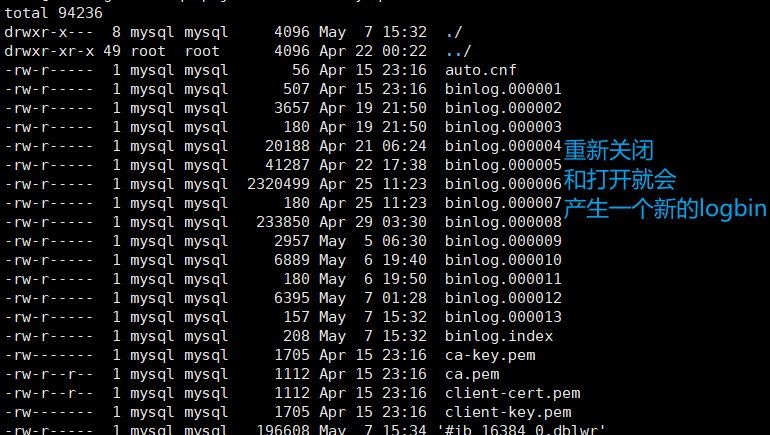
• 通过 FLUSH LOGS 语句刷新⽇志来强制服务器关闭并重新打开⽇志⽂件,也可以使⽤
mysqladmin 的 flush-logs 或 refresh 参数,或mysqldump 的 --flush-logs 或 --master-data 选项
• 中继⽇志仅⽤于主从复制过程中的从服务器。有关中继⽇志内容和配置的讨论在主从复制的章节
讨论
一般查询日志和慢查询日志的输出形式
如果启⽤⼀般查询⽇志和慢查询⽇志,⽇志的输出⽅式(记录日志的方式)可以指定为⽇志⽂件或 mysql 系统库中的 general_log 和 slow_log 表,也可以两者同时指定
启动时的日志控制
• log_output 系统变量指定⽇志输出的形式,但并不会真正的启⽤⽇志。 log_output 可以有三个值,分别是: TABLE (表)、 FILE (⽂件)(默认值)(这里是指定保存在表里面还是保存在在文件里面)、 NONE (不输出),可以同时指定多个值,并⽤逗号隔开,未指定值时默认是 FILE ,如果列表中存在 NONE 则其他的不⽣效,也就是说 NONE 的优先级最⾼。
TABLE,NONE 不生效
FILE,NONE 不生效
TABLE,FILE 生效
• 通过设置 general_log 系统变量的值来控制⼀般查询⽇志的 开启 1 与 禁⽤ 0 ,如果要为⽇志指定⾃定义的路径或⽂件名可以使⽤ general_log_file 系统变量
默认的一般日志路径
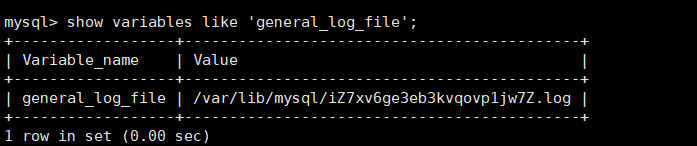
• 通过设置 slow_query_log 系统变量的值来控制慢查询⽇志的 开启 1 与 禁⽤ 0 ,如果要为⽇志指定⾃定义的路径或⽂件名可以使⽤ slow_query_log_file 系统变量
默认的慢查询日志路径
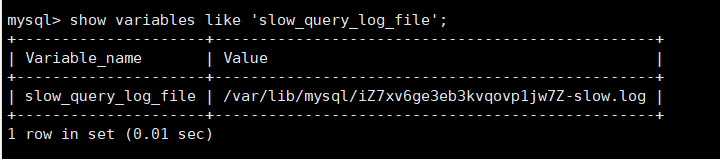
一般查询日志和慢查询日志的区别: 一般查询日志记录了所有的查询语句. 慢查询日志记录了超过查询阈值的查询语句是一般查询日志的子集
• ⽰例,以选项⽂件中的配置为例:
◦ 将⼀般查询⽇志写⼊⽇志表和⽇志⽂件
[mysqld]
#⽇志写⼊表和⽂件
log_output=TABLE,FILE
#开启⼀般查询⽇志
general_log=1
◦ 仅将⼀般查询⽇志和慢查询⽇志写⼊⽇志表
[mysqld]
log_output=TABLE #⽇志写⼊表
general_log=1 #开启⼀般查询⽇志
slow_query_log=1 #开启慢查询⽇志
◦ 仅将慢查询⽇志写⼊⽇志⽂件
[mysqld]
log_output=FILE #⽇志⽂件slow_query_log=1 #开启慢查询⽇志
◦ 将⼀般查询⽇志和慢查询⽇志写⼊⽇志⽂件,并指定⾃定义的⽇志路径
[mysqld]
#⽇志⽂件
log_output=FILE
#开启⼀般查询⽇志
general_log=1
#指定⾃定义的⽂件名
general_log_file=/var/lib/mysql/general.log
#开启慢查询⽇志
slow_query_log=1
#指定⾃定义的⽂件名slow_query_log_file=/var/lib/mysql/slow_query.log
在自己的Linux系统下进行配置:
将⼀般查询⽇志和慢查询⽇志写⼊⽇志⽂件同时也写入表,并指定⾃定义的⽇志文件名
log_output = FILE,TABLE 日志的输出方式
/var/lib/mysql/general.log 一般查询日志文件名
/var/lib/mysql/show_query.log 慢查询日志文件名
1> 编辑文件
############### 日志相关 ################
#配置项记得去官方文档查, 要验证确实是在
#⽇志⽂件
log_output=FILE,TABLE
#开启⼀般查询⽇志
general_log=1
#指定⾃定义的⽂件名
general_log_file=/var/lib/mysql/general.log
#开启慢查询⽇志
slow_query_log=1
#指定⾃定义的⽂件名
slow_query_log_file=/var/lib/mysql/slow_query.log
2> 修改配置, 编辑选项文件
vim /etc/mysql/my.cnf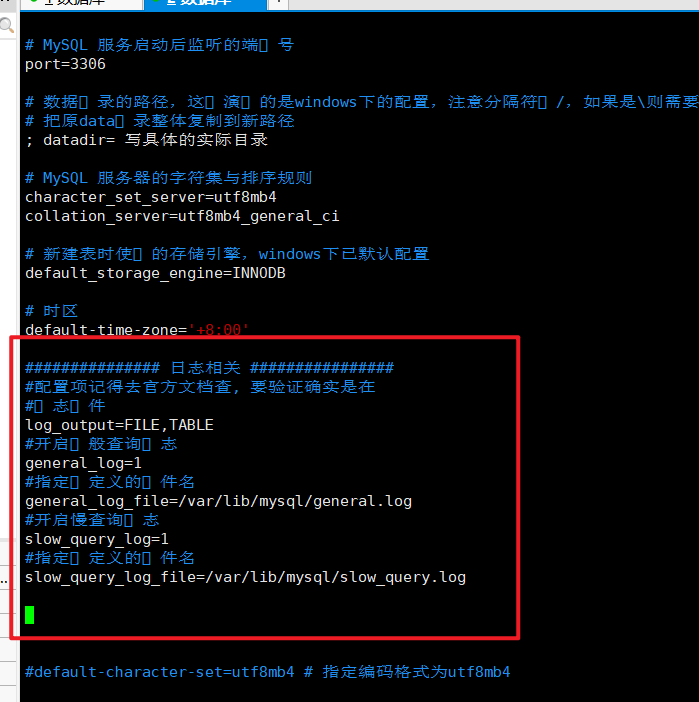
3> 重启一下mysql: systemctl restart mysql 并查看当前状态
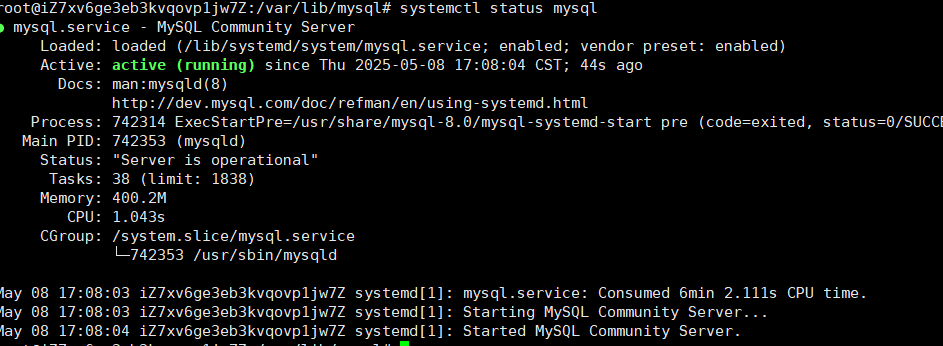
4> 用客户端连接到MYSQL服务器, 查看相应的系统变量是否生效
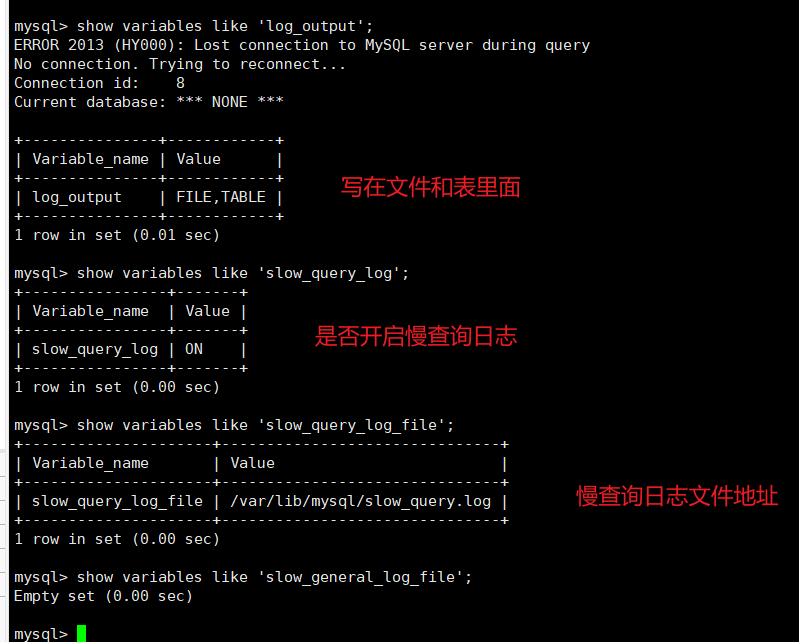
运行时的日志控制
动态的收集日志, 出现问题不需要停掉服务器, 然后配置开启一般查询日志和慢查询日志.而是保证mysql服务器在运行的状态下进行设置开启一般查询日志和慢查询日志
• 在运⾏时修改 log_output 的值,以更改⽇志的输出形式,通过语句控制
• 语法:SET [GLOBAL|SESSION] variable_name=value
SET GLOBAL log_output=[FILE, TABLE, NONE]
• general_log[={0|1}] 和 slow_query_log[={0|1}] 可以表⽰启⽤和禁⽤⼀般查询⽇志和慢查询⽇志
• general_log_file 和 slow_query_log_file 表⽰通⽤查询⽇志和慢查询⽇志⽂件名称
上面是globel
• 只对当前会话禁⽤或启⽤⼀般查询⽇志记录,将 SESSION 作⽤域的 sql_log_off 变量设置为 ON 或 OFF( SET SESSION sql_log_off = ON|OFF)
使用日志表的优点
• 可以通过 SQL 语句的条件查询过滤⽇志内容(使用where 条件),从⽽选择满⾜特定条件的⽇志记录。⽐如,某个客⼾端的⽇志;
• 可以通过客⼾端程序连接到服务器并查询表中的⽇志信息(使用客户端用SQL语句进行查询 应用程序级别),⽆需登录服务器主机访问⽂件系统(需要有一个系统用户, 并且有相应的权限 系统级别)。
• ⽇志记录具有标准格式,可看⽇志表的结构,可以使⽤以下语句:
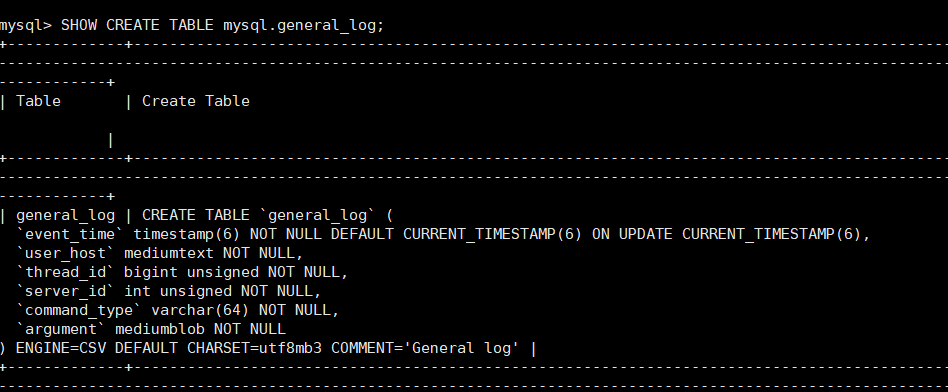
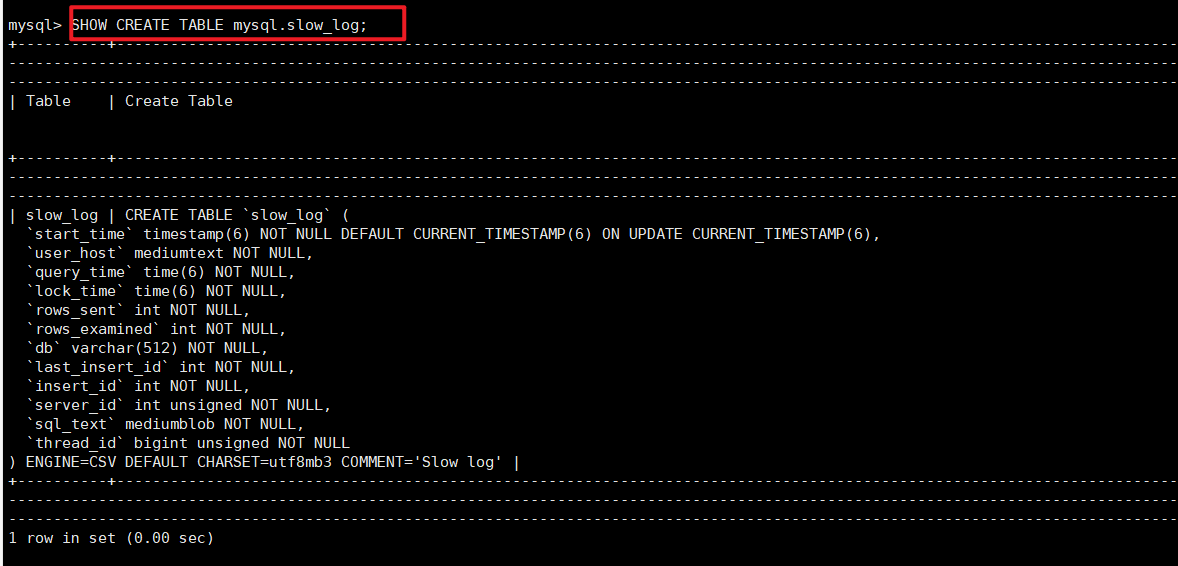
SHOW CREATE TABLE mysql.general_log; # ⼀般查询⽇志
SHOW CREATE TABLE mysql.slow_log; # 慢查询⽇志
一般查询日志
• General query log - ⼀般查询⽇志,记录客⼾端连接或断开连接的信息,也会记录从客⼾端接收的每个SQL语句。如果开启将会产⽣⼤量的内容,⾮常耗费服务器资源,所以默认为关闭(不开启,阶段性开启排错),要启⽤⼀般查询⽇志可以使⽤:请使⽤ --general_log[={0|1}]
• 默认⽇志⽂件名为 host_name.log ,可以使⽤ general_log_file=file_name 修改;
• 记当客⼾端连接的⽇志⾏,使⽤ connection_type 来指⽰⽤于建⽴连接的协议。 TCP/IP 表⽰不使⽤SSL建⽴的TCP/IP连接、 SSL/TLS 表⽰使⽤SSL建⽴的TCP/IP连接、 Socket 表⽰Unix套接字⽂件连接、 Named Pipe 表⽰Windows命名管道连接、 Shared Memory 表⽰Windows共享内存连接。
• Mysqld按照接收到SQL语句的顺序将语句写⼊查询⽇志,这个顺序可能与语句执⾏的顺序不同(和系统调度有关系)。
• 表结构如下:
SHOW CREATE TABLE mysql.general_log
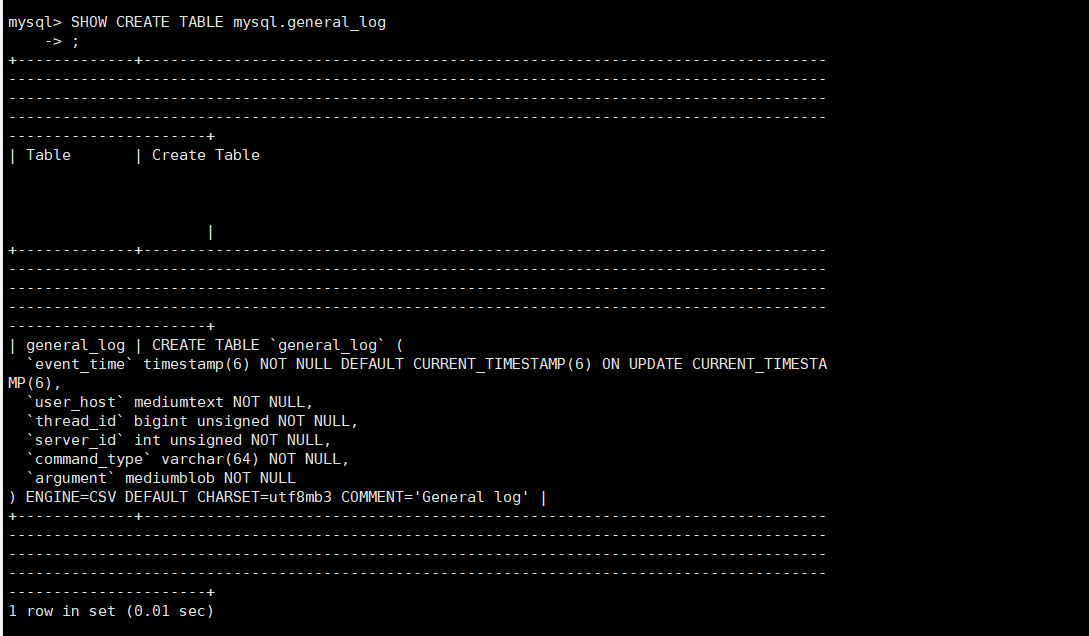
具体解释
CREATE TABLE `general_log` (
# 发⽣时间
`event_time` timestamp(6) NOT NULL DEFAULT CURRENT_TIMESTAMP(6) ON UPDATE
CURRENT_TIMESTAMP(6), 发生的时间
`user_host` mediumtext NOT NULL, 用户主机
`thread_id` bigint unsigned NOT NULL, 执行当前SQL语句的系统线程ID
`server_id` int unsigned NOT NULL, 选项文件中配置的server-id(应用于集群环境)
`command_type` varchar(64) NOT NULL, 日志的类型
`argument` mediumblob NOT NULL 具体的SQL
) ENGINE=CSV DEFAULT CHARSET=utf8mb3 COMMENT='General log'
确保一般查询目录是开启的

通过正常的SQL语句查询日志: select*from mysql.general_log\G
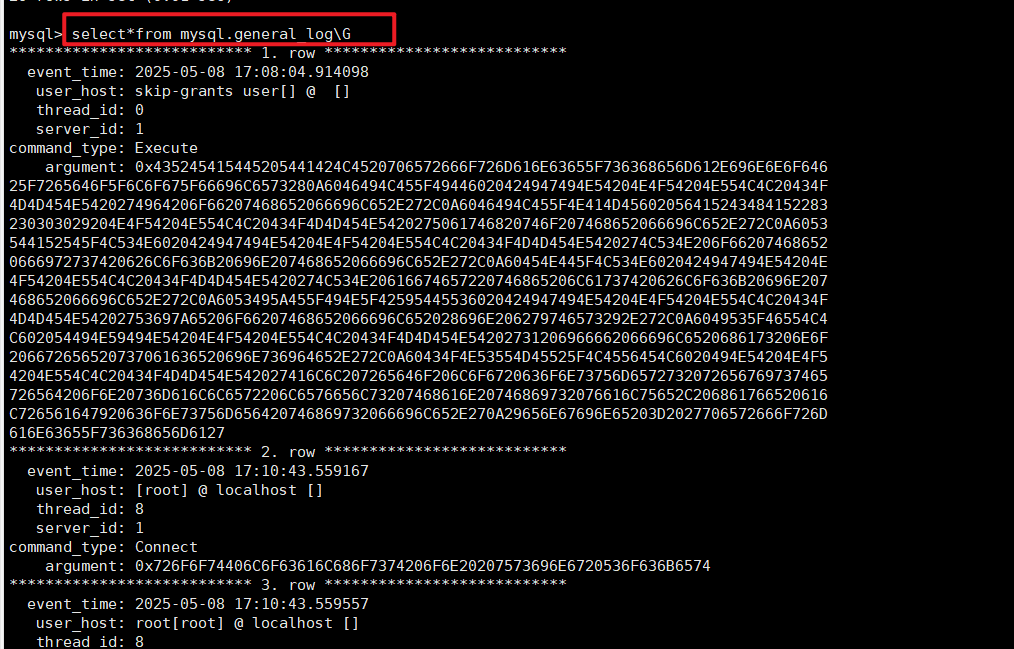
通过 CAST() 函数 把编码后的内如转化为可读的字符类型
CAST(要转换的内容 AS 目标数据类型)
通过例子来显示一般查询日志
查询表中的日志内容
# 查看⽇志
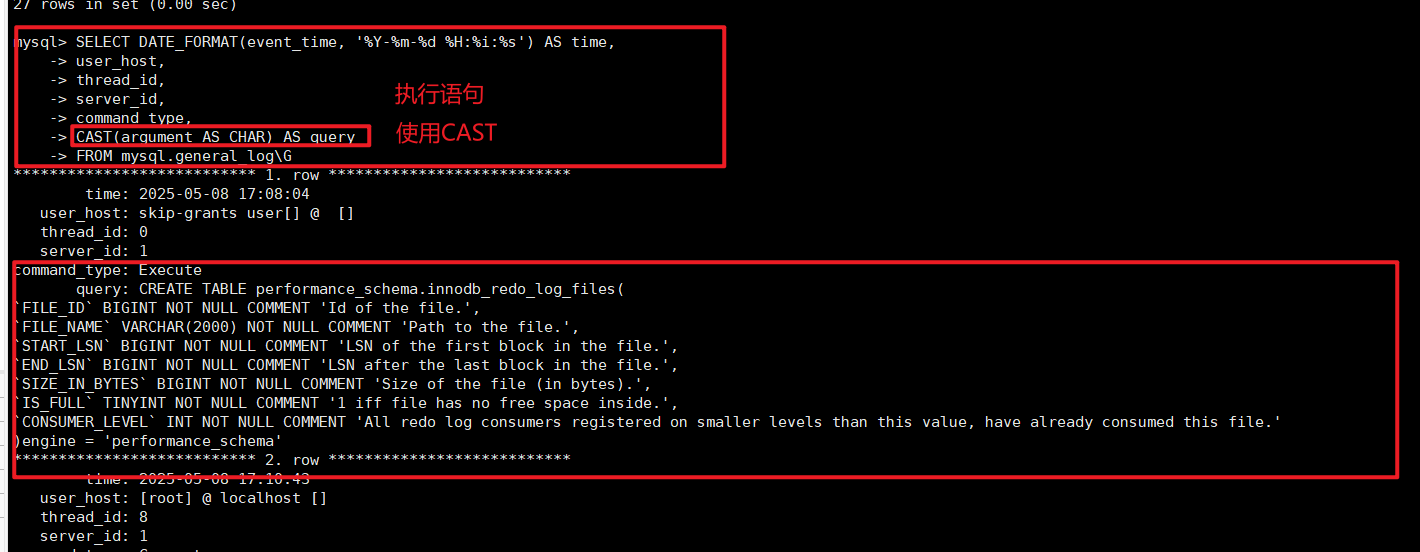
SELECT DATE_FORMAT(event_time, '%Y-%m-%d %H:%i:%s') AS time, user_host,
thread_id, server_id,
command_type,
CAST(argument AS CHAR) AS queryFROM mysql.general_log;

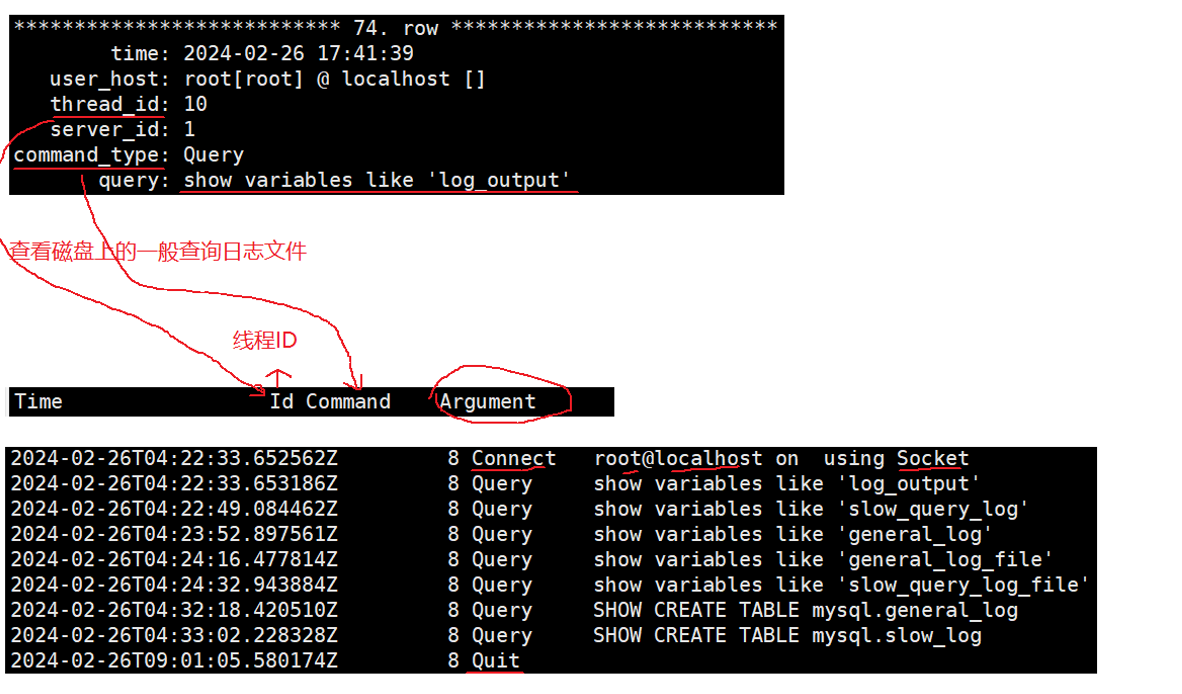
查看磁盘上的一般查询日志文件
root@iZ7xv6ge3eb3kvqovp1jw7Z:/var/lib/mysql# cat general.log
慢查询日志
概念
• 慢查询⽇志由执⾏时间超过系统变量 long_query_time(默认是10s)这样的查询语句就是慢查询 指定的秒数的 SQL 语句组成,并且检查的⾏数⼤于系统变量 min_examined_row_limit(查询语句返回的结果集中所包含的行数, 比如10)指定值。被记录的慢查询需要进⾏优化,可以使⽤ mysqldumpslow客⼾端程序对慢⽇志进⾏分析汇总。(同时满足上述俩个条件才会被判定为慢查询日志)
• 获取初始锁的时间不计⼊执⾏时间,mysqld在执⾏完SQL语句并释放所有锁后才将符合条件的语句写⼊慢速查询⽇志,因此⽇志顺序可能与执⾏顺序不同。
一个SQL语句的执行经历的几个阶段
1> 执行线程要获取到锁 如果线程没有获取到锁就会阻塞等待(这个不是执行时间, 因此第一步不在慢查询记录的时间内)
2> 执行SQL语句并返回结果
3> 释放锁
第二步和第三步才是慢查询记录的真正执行时间
慢查询日志参数
• long_query_time 的默认值是10,最⼩值是0;
• 默认情况下,不记录管理语句(创建表,修改表...),也不记录不使⽤索引的查询
• 默认为关闭(不开启),要启⽤慢查询⽇志可以使⽤:请使⽤ --slow_query_log[={0|1}] .
• 默认日志文件为 host_name-slow.log, 可以使用slow_query_log_file = file_name 修改
• 使⽤ --log-short-format 选项,以简要格式记录慢查询⽇志
• 要记录管理语句,启⽤ log_slow_admin_statements 系统变量。管理语句包括 ALTER、TABLE 、 ANALYZE TABLE 、 CHECK TABLE 、 CREATE INDEX 、 DROP INDEX 、OPTIMIZE TABLE 和 REPAIR TABLE 。
• 要记录不使⽤索引的查询,启⽤ log_queries_not_using_indexes 系统变量。当记录不使⽤索引的查询时,⽇志会快速增⻓,通过设置系统变量.
log_throttle_queries_not_using_indexes 限制每分钟写⼊慢查询⽇志同类查询的数量,默认值是0,表⽰⽆限制(可以设置这个每次重复慢查询的次数)。当我们开启了记录不使用索引的查询的时候, 一定要记得配置一下每分钟记录的日志数.
慢查询日志内容
1> FILE格式(建议使用这种方式记录慢查询日志)
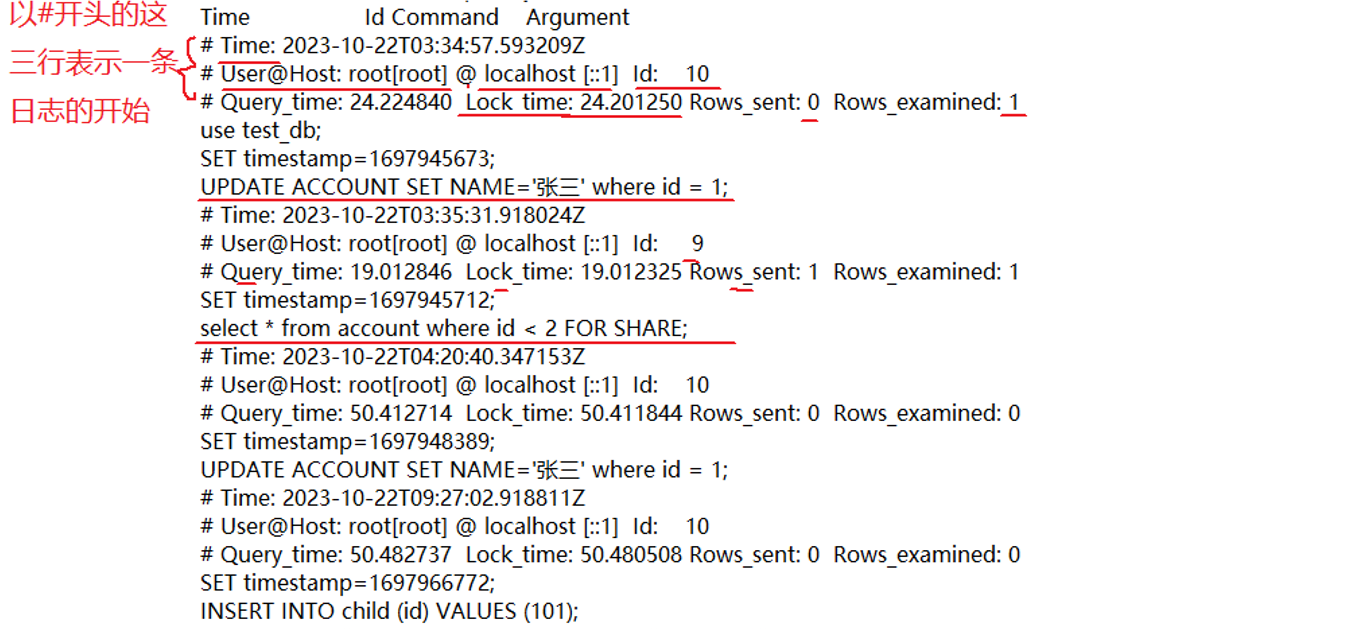
• 如果启⽤慢查询⽇志并将 FILE 作为输出⽬标,每条语句前⾯都⽤⼀⾏来表⽰⽇志的字段,该⾏以 # 字符开头并包含以下内容:
◦ Query_time: :SQL语句的执⾏时间,单位秒
◦ Lock_time: 获取锁的时间,单位秒
◦ Rows_sent: 发送到客⼾端的⾏数 返回的查询结果集的行数
◦ Rows_examined: 服务器检查的⾏数 服务器扫描数据表中具体数据行的数量
• 启⽤--log-slow-extra[={OFF|ON}]系统变量会将以下额外字段写⼊到FILE中,TABLE形式不受响
◦Thread_id: 线程标识符
◦ Errno: 错误码,没有发⽣错误则为 0
◦ Killed: 如果语句被终⽌,⽤错误码表⽰原因,如果语句正常终⽌则为 0。
◦ Bytes_received: 接收到SQL语句的Bytes值。
◦ Bytes_sent: 返回给客⼾端的Byte值。
◦ Read_first: 索引中第⼀个条⽬被读取的次数,如果这个值很⾼,表明服务器正在执⾏⼤量完整索引扫描
◦ Read_last: 读取索引中最后⼀个键的请求数,使⽤ ORDER BY 时关注
◦ Read_key: 基于索引读取⼀⾏数据的请求数。如果这个值很⾼,表明表为当前查询建⽴了正确的索引
◦ Read_next: 按索引排序读取下⼀⾏的请求数,查询具有范围约束的索引列,或者进⾏索引扫描,此值将递增。
◦ Read_prev: 按索引排序读取前⼀⾏的请求数。主要⽤于优化ORDER BYRDESC。
◦ Read_rnd: 基于固定位置读取⼀⾏的请求数。这个值很⾼表⽰,正在执⾏⼤量需要对结果进⾏排序的查询,可能有很多查询进⾏了全表扫描整,或者没有正确使⽤索引的连接。
◦ Read_rnd_next: 读取数据⽂件中下⼀⾏的请求数。如果进⾏⼤量的表扫描,这个值会很⾼。通常,表⽰表没有建⽴正确地索引,或者查询没有利⽤索引。
◦ Sort_merge_passes: 排序算法完成的归并次数,如果这个值很⼤,考虑增加sort_buffer_size 系统变量的值。
◦ Sort_range_count: 使⽤范围进⾏排序的次数。
◦ Sort_rows: 排序的⾏数。
◦ Sort_scan_count: 通过扫描表完成的排序数。
◦ Created_tmp_disk_tables: 服务器在执⾏语句时创建内部磁盘临时表的数量。
◦ Created_tmp_tables: 服务器在执⾏语句时创建的内部临时表的数量。
◦ Start: 执⾏SQL语句开始时间
◦ End: 执⾏SQL语句结束时间• 如果启⽤慢查询⽇志并将 FILE 作为输出⽬标,每条语句前⾯都⽤⼀⾏来表⽰⽇志的字段,该⾏
2> TABLE 格式
慢查询⽇志表的表结构如下:
mysql> SHOW CREATE TABLE mysql.slow_log;
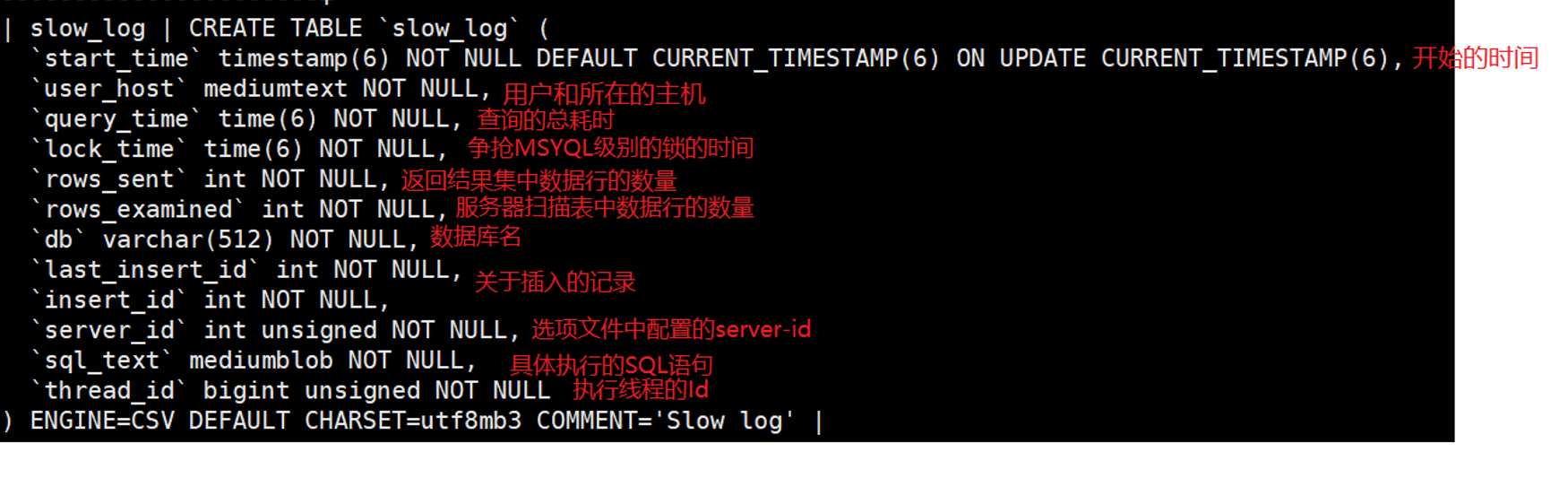
字段说明:start_time:记录查询开始的时间,精确到微秒。
user_host:执行查询的用户和主机信息。
query_time:查询执行的总时间,精确到微秒。
lock_time:查询等待锁的时间,精确到微秒。
rows_sent:查询返回的行数。
rows_examined:查询扫描的行数。
db:查询所针对的数据库名称。
last_insert_id:最后一次插入操作的 ID。
insert_id:插入操作的 ID。
server_id:服务器 ID,用于区分多服务器环境。
sql_text:执行的 SQL 语句文本。
thread_id:执行查询的线程 ID。
相关文章:
)
MySQL 服务器配置和管理(上)
MySQL 服务器简介 通常所说的 MySQL 服务器指的是mysqld(daemon 守护进程)程序,当运⾏mysqld后对外提供MySQL 服务,这个专题的内容涵盖了以下关于MySQL 服务器以及相关配置的内容,包括: • 服务器⽀持的启动选项。可以在命令⾏和…...

跨区域智能电网负荷预测:基于 PaddleFL 的创新探索
跨区域智能电网负荷预测:基于 PaddleFL 的创新探索 摘要: 本文聚焦跨区域智能电网负荷预测,提出基于 PaddleFL 框架的联邦学习方法,整合多地区智能电网数据,实现数据隐私保护下的高精度预测,为电网调度优化提供依据,推动智能电网发展。 一、引言 在当今社会,电力作为经…...

Java 重试机制详解
文章目录 1. 重试机制基础1.1 什么是重试机制1.2 重试机制的关键要素1.3 适合重试的场景2. 基础重试实现2.1 简单循环重试2.2 带延迟的重试2.3 指数退避策略2.4 添加随机抖动2.5 使用递归实现重试2.6 可重试异常过滤3. 常用重试库介绍3.1 Spring Retry3.1.1 依赖配置3.1.2 编程…...

Spark缓存---cache方法
在Spark 中,cache() 是用于优化计算性能的核心方法之一,但它有许多细节需要深入理解。以下是关于 cache() 的详细技术解析: 1. cache() 的本质 简化的 persist():cache() 是 persist(StorageLevel.MEMORY_ONLY) 的快捷方式&#…...
)
一分钟了解大语言模型(LLMs)
一分钟了解大语言模型(LLMs) A Minute to Know about Large Language Models (LLMs) By JacksonML 自从ChatGPT上线发布以来,在短短的两年多时间里,全球ChatBot(聊天机器人)发展异常迅猛,更为…...

当数控编程“联姻”AI:制造工厂的“智能大脑”如何炼成?
随着DeepSeek乃至AI人工智能技术在企业中得到了广泛的关注和使用,多数企业开始了AI探索之旅,迅易科技也不例外,且在不断地实践中强化了AI智能应用创新的强大能力。许多制造企业面临着工艺知识传承困难、编程效率低下等诸多挑战, 今…...

鸿蒙OSUniApp 实现的二维码扫描与生成组件#三方框架 #Uniapp
UniApp 实现的二维码扫描与生成组件 前言 最近在做一个电商小程序时,遇到了需要扫描和生成二维码的需求。在移动应用开发中,二维码功能已经成为标配,特别是在电商、社交和支付等场景下。UniApp作为一个跨平台开发框架,为我们提供…...

【Python 内置函数】
Python 内置函数是语言核心功能的直接体现,无需导入即可使用。以下是精选的 10 大类、50 核心内置函数详解,涵盖日常开发高频场景: 一、数据类型转换 函数示例说明int()int("123") → 123字符串/浮点数转整数float()float("3…...

鸿蒙OSUniApp开发支持多语言的国际化组件#三方框架 #Uniapp
使用UniApp开发支持多语言的国际化组件 在全球化的今天,一个优秀的应用往往需要支持多种语言以满足不同地区用户的需求。本文将详细讲解如何在UniApp框架中实现一套完整的国际化解决方案,从而轻松实现多语言切换功能。 前言 去年接手了一个面向国际市场…...

MySQL之基础事务
目录 引言: 什么是事务? 事务和锁 mysql数据库控制台事务的几个重要操作指令(transaction.sql) 1、事物操作示意图: 2.事务的隔离级别 四种隔离级别: 总结一下隔离指令 1. 查看当前隔离级别 …...
)
OpenHarmony系统HDF驱动开发介绍(补充)
一、HDF驱动简介 HDF(Hardware Driver Foundation)驱动框架,为驱动开发者提供驱动框架能力,包括驱动加载、驱动服务管理、驱动消息机制和配置管理。 简单来说:HDF框架的驱动和Linux的驱动比较相似都是由配置文件和驱动…...

深度学习中的查全率与查准率:如何实现有效权衡
📌 友情提示: 本文内容由银河易创AI(https://ai.eaigx.com)创作平台的gpt-4-turbo模型辅助生成,旨在提供技术参考与灵感启发。文中观点或代码示例需结合实际情况验证,建议读者通过官方文档或实践进一步确认…...

文件名是 E:\20250512_191204.mp4, EV软件录屏,未保存直接关机损坏, 如何修复?
去github上下载untrunc 工具就能修复 https://github.com/anthwlock/untrunc/releases 如果访问不了 本机的 hosts文件设置 140.82.112.3 github.com 199.232.69.194 github.global.ssl.fastly.net 就能访问了 实在不行,从这里下载,传上去了 https://do…...

界面控件DevExpress WinForms v24.2 - 数据处理功能增强
DevExpress WinForms拥有180组件和UI库,能为Windows Forms平台创建具有影响力的业务解决方案。DevExpress WinForms能完美构建流畅、美观且易于使用的应用程序,无论是Office风格的界面,还是分析处理大批量的业务数据,它都能轻松胜…...

Web UI测试效率低?来试Parasoft Selenic的智能修复与分析!
如果你正在使用Selenium进行Web UI测试,但被测试维护的繁琐、测试不稳定以及测试执行缓慢等问题困扰,不妨试试Parasoft Selenic! Parasoft Selenic能够通过智能修复与分析功能,帮你自动检测并修复测试中的不稳定因素,…...

计算机视觉最不卷的方向:三维重建学习路线梳理
提到计算机视觉(CV),大多数人脑海中会立马浮现出一个字:“卷”。卷到什么程度呢?2022年秋招CV工程师岗位数下降了16%,但求职人数增加了23%,求职人数与招聘岗位的比例达到了恐怖的15:1࿰…...

国产 ETL 数据集成厂商推荐—谷云科技 RestCloud
数字化转型加速推进的商业环境中,数据已成为企业最为关键的资产之一。然而,随着企业信息化的建设不断深入,各个业务系统之间数据分散、格式不一、难以互通等问题日益凸显,严重制约了企业对数据价值的深度挖掘与高效利用。在此背景…...

vscode extention踩坑记
# npx vsce package --allow-missing-repository --no-dependencies #耗时且不稳定 npx vsce package --allow-missing-repository #用这行 code --install-extension $vsixFileName --force我问ai:为什么我的.vsix文件大了那么多 ai答:因为你没有用 --n…...

AI时代的弯道超车之第十二章:英语和编程重要性?
在这个AI重塑世界的时代,你还在原地观望吗?是时候弯道超车,抢占先机了! 李尚龙倾力打造——《AI时代的弯道超车:用人工智能逆袭人生》专栏,带你系统掌握AI知识,从入门到实战,全方位提升认知与竞争力! 内容亮点: AI基础 + 核心技术讲解 职场赋能 + 创业路径揭秘 打破…...

关于数据湖和数据仓的一些概念
一、前言 随着各行业数字化发展的深化,数据资产和数据价值已越来越被深入企业重要发展的战略重心,海量数据已成为多数企业生产实际面临的重要问题,无论存储容量还是成本,可靠性都成为考验企业数据治理的考验。本文来看下海量数据存储的数据湖和数据仓,数据仓库和数据湖,…...

hbase shell的常用命令
一、hbase shell的基础命令 # 客户端登录 [rootCloud-Hadoop-NN-02 hbase]$ ./bin/hbase shell# 查看所有表 hbase> list### 创建数据表student,包含Sname、Ssex、Sage、Sdept、course列族/列 ### 说明:列族不指定列名时,列族可以直接成为…...
:Page Cache结构设计)
高并发内存池(四):Page Cache结构设计
目录 一,项目整体框架回顾 Thread Cache结构 Central Cache结构 二,Page Cache大致框架 三,Page Cache申请内存实现 Central Cache向Page Cache申请内存接口 从Page Cache中获取span接口 Page Cache加锁问题 申请内存完整过程 源码&a…...
)
易学探索助手-项目记录(九)
本文介绍本地大模型推理数据集构成 (一)古籍数据获取 以44种竖向从右至左排列的繁体古文为研究对象,通过OCR识别、XML结构化处理,最终生成符合大模型训练要求的数据集。 1.技术路线设计 图像处理层:PaddleOCR识别竖…...

Idea 设置编码UTF-8 Idea中 .properties 配置文件中文乱码
Idea 设置编码UTF-8 Idea中 .properties 配置文件中文乱码 一、设置编码 1、步骤: File -> Setting -> Editor -> File encodings --> 设置编码二、配置文件中文乱码 1、步骤: File -> Setting -> Editor -> File encodings ->…...

Redis缓存穿透、雪崩、击穿的解决方案?
Redis 缓存问题解决方案及Java实现 一、缓存穿透解决方案 (缓存穿透指查询不存在数据,绕过缓存直接访问数据库) 1. 布隆过滤器 空值缓存 注意点: 1.布隆过滤器是需要预热数据的,就是需要输入当前数据库已经存在的…...

第29节:现代CNN架构-Inception系列模型
引言 Inception系列模型是卷积神经网络(CNN)发展历程中的重要里程碑,由Google研究人员提出并不断演进。这一系列模型通过创新的架构设计,在保持计算效率的同时显著提升了图像识别任务的性能。从最初的Inception v1到最新的Inception-ResNet,每一代Inception模型都引入了突破…...
)
初识C++:类和对象(上)
概述:本篇博客主要讲解类和对象的学习。 目录 1. 类的定义 1.1 类定义格式 1.2 访问限定符 1.3 类域 2.实例化 2.1 实例化概念 2.2 this指针 3. 小结 1. 类的定义 1.1 类定义格式 class为定义类的关键字,Stack为类的名字,{} 中为类的…...

腾讯 IMA 工作台升级:新增知识库广场与 @提问功能
目录 一、引言 二、知识库广场功能 2.1 功能架构解析 2.2 技术实现突破 三、知识库提问功能 3.1 交互模式革新 3.2 技术底层逻辑 四、实战价值 4.1 知识管理方面 4.2 工作效率提升方面 4.3 团队协作方面 4.4 知识变现方面 五、未来展望 5.1 技术演进方向 5.2 商业…...

[目标检测] YOLO系列算法讲解
前言 目标检测就是做到给模型输入一张图片或者视频,模型可以迅速判断出视频和图片里面感兴趣的目标所有的位置和它 的类别,而当前最热门的目标检测的模型也就是YOLO系列了。 YOLO系列的模型的提出,是为了解决当时目标检测的模型帧率太低而提…...

Python 之 selenium 打开浏览器指定端口进行接续操作
一般使用 selenium 进行数据爬取时,常用处理流程是让 selenium 从打开浏览器开始,完成全流程的所有操作。但是有时候,我们希望用户先自己打开浏览器进入指定网页,完成登录认证等一系列操作之后(比如用户、密码、短信验…...

GPUGeek携手ComfyUI :低成本文生图的高效解决方案
一、文生图领域的困境与ComfyUI的优势 在当今数字化创意表达的时代,文生图技术日益受到关注。像豆包这类以语言交互为主的大模型,虽然在文本处理上表现出色,但在文生图方面,其生成效果难以达到专业图像创作的要求。而Midjourney&…...

OpenCV CUDA 模块中用于在 GPU 上计算两个数组对应元素差值的绝对值函数absdiff(
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 void cv::cuda::absdiff 是 OpenCV CUDA 模块中的一个函数,用于在 GPU 上计算两个数组对应元素差值的绝对值。 该函数会逐元素计算两…...

互联网大厂Java面试题:深入解析SpringCloud微服务架构中的服务注册与发现机制
互联网大厂Java面试题:深入解析SpringCloud微服务架构中的服务注册与发现机制 面试题 问题: 在SpringCloud微服务架构中,服务注册与发现是核心功能之一。请详细说明Nacos作为服务注册中心的实现原理,并对比其与Eureka的异同点。…...

东芝新四款产品“TB67Z830SFTG、TB67Z830HFTG、TB67Z850SFTG、TB67Z850HFTG系列三相栅极驱动器ic三相栅极驱动器IC
支持用于电动工具、吸尘器、工业机器人等的三相无刷DC电机 东芝电子设备与存储公司(简称“东芝”)推出了TB67Z83xxFTG系列三相栅极驱动器ic的四个产品和TB67Z85xxFTG系列三相栅极驱动器IC的四个产品,用于消费和工业设备的三相无刷DC电机。通过将新产品与作为电机控制…...

react+html-docx-js将页面导出为docx
1.主要使用:html-docx-js进行前端导出 2.只兼容到word,wps兼容不太好 3.处理分页换行 4.处理页眉 index.tsx import { saveAs } from file-saver; import htmlToDocxGenerate from ./HtmlToDocx;const handleExportByHtml async () > {const expor…...

Linux基础 -- SSH 流式烧录与压缩传输笔记
Linux SSH 流式烧录与压缩传输指南 一、背景介绍 在嵌入式开发和维护中,常常需要通过 SSH 从 PC 向设备端传输大文件(如系统镜像、固件)并将其直接烧录到指定磁盘(如 /dev/mmcblk2)。然而,设备端存储空间…...
避免推荐域外物品:基于LLM的受限生成式推荐)
<论文>(微软)避免推荐域外物品:基于LLM的受限生成式推荐
一、摘要 本文介绍微软和深圳大学合作发表于2025年5月的论文《Avoid Recommending Out-of-Domain Items: Constrained Generative Recommendation with LLMs》。论文主要研究如何解决大语言模型(LLMs)在推荐系统中推荐域外物品的问题,提出了 …...
)
2025年渗透测试面试题总结-360[实习]安全工程师(题目+回答)
网络安全领域各种资源,学习文档,以及工具分享、前沿信息分享、POC、EXP分享。不定期分享各种好玩的项目及好用的工具,欢迎关注。 目录 1. 自我介绍 2. WAF及其绕过方式 3. IPS/IDS/HIDS 4. 云安全 5. 绕过安骑士/安全狗 6. Gopher扩展…...
从入门到实战:原理、实现与优化指南)
【机器学习】支持向量回归(SVR)从入门到实战:原理、实现与优化指南
前言 在机器学习的广阔领域中,回归分析作为预测连续型变量的重要手段,被广泛应用于金融预测、工业生产、科学研究等诸多场景。支持向量回归(SVR)作为回归算法家族中的佼佼者,凭借独特的理论优势与强大的实践能力脱颖而…...

右值引用的学习
传统的C语法中就有引用的语法,而C11中新增了的右值引用语法特性,所以从现在开始我们之前学习的引用就叫做左值引用。无论左值引用还是右值引用,都是给对象取别名。 左值引用和右值引用 在讲之前,我们先来看一下什么是左值和右值…...
)
碎片笔记|AI生成图像溯源方法源码复现经验(持续更新中……)
前言:本篇博客分享一些溯源方法的复现经验,希望能帮助到大家🎉。 目录 1. Close-set AttributionRepmixDe-FakeDNA-Net 2. Open-set AttributionPOSE 3. Single-Model AttributionOCC-CLIPLatentTracer 1. Close-set Attribution Repmix 论…...

elementplus el-tree 二次封装支持配置删除后展示展开或折叠编辑复选框懒加载功能
本文介绍了基于 ElementPlus 的 el-tree 组件进行二次封装的 TreeView 组件,使用 Vue3 和 JavaScript 实现。TreeView 组件通过 props 接收树形数据、配置项等,支持懒加载、节点展开/收起、节点点击、删除、编辑等操作。组件内部通过 ref 管理树实例&…...

【C/C++】深度探索c++对象模型_笔记
1. 对象内存布局 (1) 普通类(无虚函数) 成员变量排列:按声明顺序存储,但编译器会根据内存对齐规则插入填充字节(padding)。class Simple {char a; // 1字节(偏移0)int b; …...

Spring MVC数据绑定和响应 你了解多少?
数据绑定的概念 在程序运行时,Spring MVC接收到客户端的请求后,会根据客户端请求的参数和请求头等数据信息,将参数以特定的方式转换并绑定到处理器的形参中。Spring MVC中将请求消息数据与处理器的形参建立连接的过程就是Spring MVC的数据绑…...

外贸礼品禁忌
一、亚洲 1.印度 牛是神圣动物,别送牛皮制品。另外,左手不洁,送礼得用右手或双手。 2.日本 “梳” 和 “苦” 谐音,不送梳子。日本男性不咋佩戴首饰,除结婚戒指。礼物得装盒、纸包、绳饰,白色包装得有…...

【MySQL 基础篇】深入解析MySQL逻辑架构与查询执行流程
1 MySQL逻辑架构概述 MySQL 的逻辑架构主要分为 Server 层和存储引擎层两部分。 Server 层:包含连接器、查询缓存、分析器、优化器、执行器等组件。同时,所有的内置函数(如日期、时间、数学和加密函数等)也在这一层实现。此外&a…...

基于C#实现中央定位服务器的 P2P 网络聊天系统
基于中央定位服务器的 P2P 网络聊天系统 1 需求分析与实现功能 本次作业旨在实现一个基于中央定位服务器的 P2P 网络聊天系统,也即通过中央定位服务器实现登入,登出与好友的 IP 查询等操作,在好友间的通信使用 P2P 来完成,具体见…...

【C++】map和set的模拟实现
1.底层红黑树节点的定义 enum Colur {RED,BLACK }; template<class T> struct RBTreeNode {RBTreeNode<T>* _left;RBTreeNode<T>* _right;RBTreeNode<T>* _parent;T _data;Colur _col;RBTreeNode(const T& data):_left(nullptr), _right(nullptr…...

数据结构·字典树
字典树trie 顾名思义,在一个字符串的集合里查询某个字符串是否存在树形结构。 树存储方式上用的是结构体数组,类似满二叉树的形式。 模板 定义结构体和trie 结构体必须的内容:当前结点的字符,孩子数组可选:end用于查…...

centos服务器,疑似感染phishing家族钓鱼软件的检查
如果怀疑 CentOS 服务器感染了 Phishing 家族钓鱼软件,需要立即进行全面检查并采取相应措施。以下是详细的检查和处理步骤: 1. 立即隔离服务器 如果可能,将服务器从网络中隔离,以防止进一步传播或数据泄露。如果无法完全隔离&…...