数据库系统概论(八)SQL单表查询语言超详细讲解(附带例题表格对比带你一步步掌握)
数据库系统概论(八)SQL单表查询语言超详细讲解(附带例题表格对比带你一步步掌握)
- 前言
- 一、创建表(了解一下就好,后面会详细讲)
- 二、数据查询的概念
- 2.1 什么是数据查询?
- 2.2 数据查询的语句样式:
- 1. 最基本的查询语句(查“某张表的某几列数据”)
- 2. 带条件的查询(加一个“筛选条件”,只查符合条件的数据)
- 3. 其他常用“小工具”
- 三、单表查询语言的种类
- 3.1 单表查询
- 3.1.1 查询表中的若干列
- 1. 查询指定的列(只选需要的信息)
- 2. 查询全部列(查所有信息)
- 3. 查询计算后的值(加工数据)
- 4. 去重查询
- 总结
- 3.1.2 选择表中的若干元组
- 1.基础:查询条件放在哪里?
- 2.常用查询条件分类
- 3. 简单比较(比大小、是否相等)
- 4. 范围查询(某个区间内/外)
- 5. 集合查询(是否在指定列表中)
- 6. 字符匹配(模糊查询,含通配符)
- 5. 空值判断(数据是否为空)
- 6. 多重条件组合(多个条件一起用)
- 总结:
- 3.1.3 ORDER BY子句
- 1. ORDER BY子句的作用
- 2. 基本语法
- 3.单字段排序:按一个列排序
- 4.多字段排序:按多个列排序
- 5.注意事项
- 6.总结:
- 3.1.4 聚集函数
- 1.什么是聚集函数?
- 2、5 个常用聚集函数
- 3. 统计个数:COUNT
- 4. 求和:SUM(只能用于数值列)
- 5. 求平均值:AVG(只能用于数值列)
- 6. 求最值:MAX和 MIN
- 7.关键细节
- 8.经典示例拆解(从简单到复杂)
- 9.练习
- 10.总结:
- 3.1.5 GROUP BY子句
- 1.什么是GROUP BY子句?
- 2.基本语法与核心逻辑
- 3.关键逻辑步骤:
- 4.核心用法示例(对比WHERE和HAVING)
- 1. 按单字段分组:统计每组的聚集结果
- 2. 错误示例:在WHERE中用聚集函数
- 3.WHERE vs HAVING:核心区别
- 4.多字段分组:按多个列分组
- 5 练习(附正确答案)
- 6.总结:
- 3.1.6 LIMIT子句
- 1.LIMIT子句的作用
- 2.基本语法与参数解析
- 3.常用场景与示例
- 3.1 取前N条数据(最常用)
- 3.2 分页查询(跳过前面的行,取中间部分)
- 3.3搭配分组和排序使用
- 4.关键细节
- 5.总结:
前言
- 之前我们已经简单认识了 SQL 语言(结构化查询语言),并了解了它的基本概念(比如表、元组、属性、数据库等)。
- 现在,我们正式进入 SQL 核心功能 的学习 —— SQL 查询语言,这是日常使用最频繁、也是掌握 SQL 的关键部分。
我的个人主页,欢迎来阅读我的其他文章
https://blog.csdn.net/2402_83322742?spm=1011.2415.3001.5343
我的数据库系统概论专栏
https://blog.csdn.net/2402_83322742/category_12911520.html?spm=1001.2014.3001.5482
一、创建表(了解一下就好,后面会详细讲)
- 在开始之前我们需要创建这三张表,以方便我们后续的查询
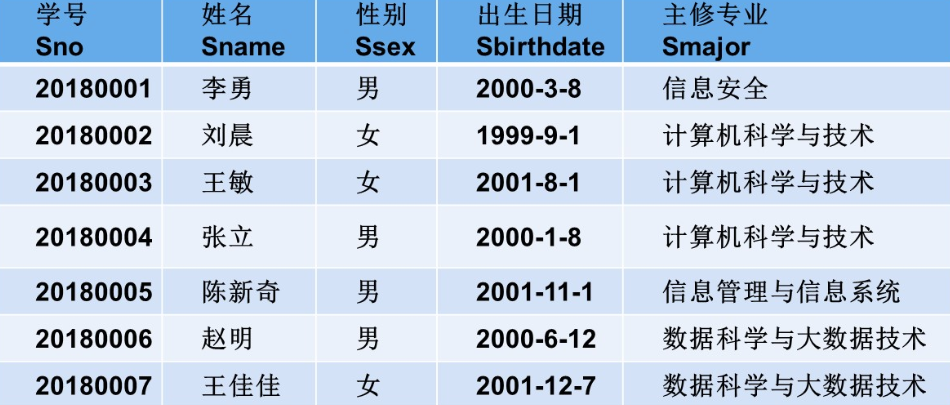
CREATE TABLE Student (Sno CHAR(7) PRIMARY KEY, -- 学号,主键,假设学号固定 7 位Sname VARCHAR(20) NOT NULL, -- 姓名,非空Ssex CHAR(2) CHECK (Ssex IN ('男', '女')), -- 性别,限制为男或女Sbirthdate DATE, -- 出生日期,日期类型Smajor VARCHAR(50) -- 主修专业
);
INSERT INTO Student (Sno, Sname, Ssex, Sbirthdate, Smajor) VALUES
('20180001', '李勇', '男', '2000-03-08', '信息安全'),
('20180002', '刘晨', '女', '1999-09-01', '计算机科学与技术'),
('20180003', '王敏', '女', '2001-08-01', '计算机科学与技术'),
('20180004', '张立', '男', '2000-01-08', '计算机科学与技术'),
('20180005', '陈新奇', '男', '2001-11-01', '信息管理与信息系统'),
('20180006', '赵明', '男', '2000-06-12', '数据科学与大数据技术'),
('20180007', '王佳佳', '女', '2001-12-07', '数据科学与大数据技术');
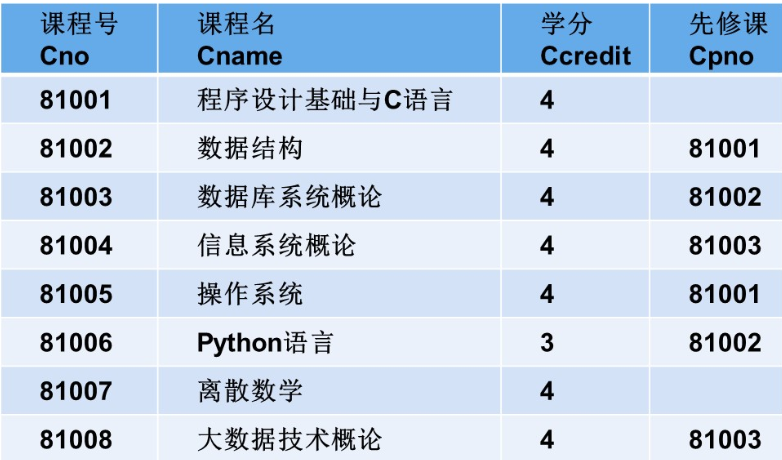
CREATE TABLE Course (Cno CHAR(5) PRIMARY KEY, -- 课程号,主键,假设课程号固定 5 位Cname VARCHAR(50) NOT NULL, -- 课程名,非空Ccredit INT, -- 学分,整数类型Cpno CHAR(5), -- 先修课课程号FOREIGN KEY (Cpno) REFERENCES Course(Cno) -- 外键,先修课引用自身课程号
);
INSERT INTO Course (Cno, Cname, Ccredit, Cpno) VALUES
('81001', '程序设计基础与C语言', 4, NULL),
('81002', '数据结构', 4, '81001'),
('81003', '数据库系统概论', 4, '81002'),
('81004', '信息系统概论', 4, '81003'),
('81005', '操作系统', 4, '81001'),
('81006', 'Python语言', 3, '81002'),
('81007', '离散数学', 4, NULL),
('81008', '大数据技术概论', 4, '81003');
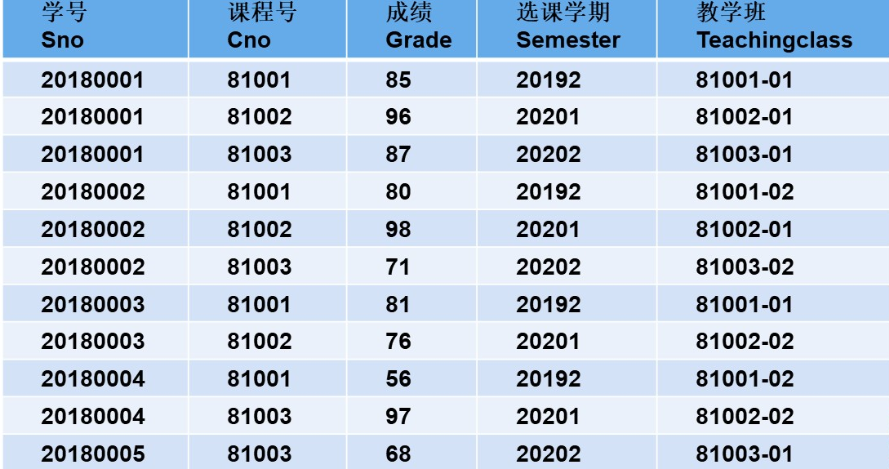
CREATE TABLE SC (Sno CHAR(7), -- 学号Cno CHAR(5), -- 课程号Grade INT, -- 成绩,整数类型Semester CHAR(4), -- 选课学期,如 "20192"Teachingclass VARCHAR(20), -- 教学班PRIMARY KEY (Sno, Cno), -- 联合主键(学号 + 课程号)FOREIGN KEY (Sno) REFERENCES Student(Sno), -- 外键,关联学生表FOREIGN KEY (Cno) REFERENCES Course(Cno) -- 外键,关联课程表
);
INSERT INTO SC (Sno, Cno, Grade, Semester, Teachingclass) VALUES
('20180001', '81001', 85, '20192', '81001-01'),
('20180001', '81002', 96, '20201', '81002-01'),
('20180001', '81003', 87, '20202', '81003-01'),
('20180002', '81001', 80, '20192', '81001-02'),
('20180002', '81002', 98, '20201', '81002-01'),
('20180002', '81003', 71, '20202', '81003-02'),
('20180003', '81001', 81, '20192', '81001-01'),
('20180003', '81002', 76, '20201', '81002-02'),
('20180004', '81001', 56, '20192', '81001-02'),
('20180004', '81003', 97, '20201', '81002-02'),
('20180005', '81003', 68, '20202', '81003-01');
二、数据查询的概念
2.1 什么是数据查询?
你可以把 数据库 想象成一个超级大的电子表格(比如Excel),里面存满了各种数据(比如学生信息、订单记录、商品列表等)。
数据查询 就是:从这个“超级表格”里快速找到你需要的信息。
比如:
- 你想知道“数学成绩超过80分的学生有哪些?”
- 或者“昨天销量超过100件的商品有哪些?”
这些“找信息”的过程,就是数据查询。
2.2 数据查询的语句样式:
大部分数据库(比如MySQL、SQL Server、Oracle)都用一种叫 SQL(结构化查询语言) 的语句来查询数据。
它的语法很像“人话”,比如:
1. 最基本的查询语句(查“某张表的某几列数据”)
SELECT 列1, 列2, 列3 -- 你想查的“表格中的列”(比如“姓名”“分数”)
FROM 表名; -- 数据所在的“表格名称”(比如“学生表”)
例子:查“学生表”中的所有学生的姓名和数学成绩:
SELECT 姓名, 数学成绩
FROM 学生表;
2. 带条件的查询(加一个“筛选条件”,只查符合条件的数据)
如果想只查“数学成绩大于80分”的学生,就加一个 WHERE 条件:
SELECT 列1, 列2 -- 想查的列
FROM 表名 -- 表格名
WHERE 条件; -- 筛选条件(比如“数学成绩 > 80”)
例子:
SELECT 姓名, 数学成绩
FROM 学生表
WHERE 数学成绩 > 80; -- 只查数学成绩超过80分的学生
3. 其他常用“小工具”
- 查所有列:如果想查表格里的所有列,不用一个个列名写出来,直接用
*:SELECT * -- * 代表“所有列” FROM 学生表; - 去重:如果想查“不重复”的数据,比如“有哪些不同的班级”,用
DISTINCT:SELECT DISTINCT 班级 -- 只显示不同的班级名称,重复的只留一个 FROM 学生表;
三、单表查询语言的种类
- 接着我们用上面刚刚所创建的表
3.1 单表查询
就是只从 一个表 里查数据,比如只查学生表(Student)、课程表(Course)或选课表(SC)中的数据。
3.1.1 查询表中的若干列
1. 查询指定的列(只选需要的信息)
- 作用:只查表中某几列的数据,比如只查学生的学号和姓名,不查其他信息(性别、年龄等)。
- 语法:
SELECT 列1, 列2, 列3 -- 想查的列,用逗号隔开 FROM 表名; -- 从哪个表查 - 例子:
- 查全体学生的学号和姓名:
SELECT Sno, Sname -- 只查这两列 FROM Student; -- 从学生表查 - 查姓名、学号、专业(列的顺序可以自己调):
SELECT Sname, Sno, Smajor -- 顺序和表中不一定一样,按需求排 FROM Student;
- 查全体学生的学号和姓名:
2. 查询全部列(查所有信息)
- 方法1:列出表的所有列(麻烦,表列多的时候不推荐):
SELECT 列1, 列2, 列3, ..., 列N -- 把所有列名写出来 FROM 表名; - 方法2(推荐):用
*代替所有列,一键查询所有信息:SELECT * -- * 表示“所有列” FROM 表名; - 例子:查学生的所有详细信息:
SELECT * FROM Student; -- 简单又快捷!
3. 查询计算后的值(加工数据)
- 作用:表中没有直接的数据,但可以通过 公式、函数 计算出来。
比如表中存的是出生日期(Sbirthdate),想算年龄,就用当前日期减出生日期。 - 语法:
SELECT 列1, 计算表达式 [AS 别名] -- AS 给结果起个名字(可选) FROM 表名; - 例子:查学生的学号、姓名和年龄(年龄用函数计算):
SELECT Sno, Sname, TIMESTAMPDIFF(YEAR, Sbirthdate, CURDATE()) AS Age -- 计算年龄,别名是Age FROM Student;TIMESTAMPDIFF(YEAR, 出生日期, 当前日期):算两个日期相差多少年(年龄)。CURDATE():获取当前日期(2025-05-12,例子中的今天)。
4. 去重查询
- 作用:如果某列有重复数据(比如选课表SC中同个学生选多门课,学号会重复),想只看唯一的学号,就用
DISTINCT。 - 语法:
SELECT DISTINCT 列名 -- 只保留该列的唯一值 FROM 表名; - 例子:查所有选过课的学生学号(不重复):
SELECT DISTINCT Sno -- 不管一个学生选了多少课,学号只出现一次 FROM SC;
总结
| 场景 | 语法示例 | 说明 |
|---|---|---|
| 指定列 | SELECT 列1, 列2 FROM 表名; | 只查需要的列,列名用逗号隔开。 |
| 所有列 | SELECT * FROM 表名; | * 代表所有列,简单方便。 |
| 计算值 | SELECT 列, 表达式 AS 别名 FROM 表名; | 用公式/函数加工数据,AS 起别名(可选)。 |
| 去重 | SELECT DISTINCT 列 FROM 表名; | 去掉重复的行,只保留唯一值。 |
3.1.2 选择表中的若干元组
1.基础:查询条件放在哪里?
所有筛选条件都写在 WHERE 子句里(如果是分组后的筛选,用 HAVING,这里先重点学 WHERE)。
格式:
SELECT 列名 FROM 表名 WHERE 条件;
2.常用查询条件分类
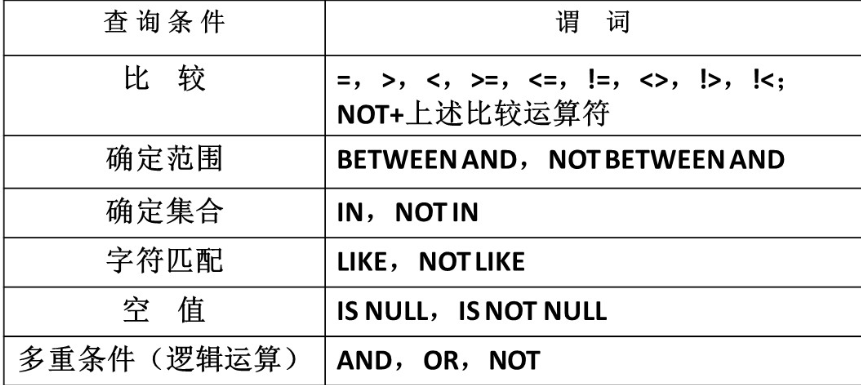
3. 简单比较(比大小、是否相等)
- 谓词:
=、>、<、>=、<=、!=(或<>),以及NOT+这些符号(取反)。 - 作用:直接对比数据是否符合某个值或范围。
- 例子:
- 查“计算机科学与技术”专业的学生姓名:
SELECT Sname FROM Student WHERE Smajor = '计算机科学与技术'; - 查成绩不及格(<60分)的学生学号(去重,避免重复):
SELECT DISTINCT Sno FROM SC WHERE Grade < 60; - 查2001年及以后出生的学生(用
year(日期列)提取年份):SELECT ... WHERE year(Sbirthdate) >= 2001;
- 查“计算机科学与技术”专业的学生姓名:
4. 范围查询(某个区间内/外)
- 谓词:
BETWEEN 最小值 AND 最大值:包含两端,比如20-23岁之间。NOT BETWEEN 最小值 AND 最大值:不在这个区间内。
- 作用:快速筛选连续区间的数据,比用
>= 最小值 AND <= 最大值更简洁。 - 例子:
- 查年龄20-23岁的学生(用
TIMESTAMPDIFF(year, 出生日期, 当前日期)计算年龄):SELECT ... WHERE TIMESTAMPDIFF(year, Sbirthdate, CURDATE()) BETWEEN 20 AND 23; - 查年龄不在20-23岁之间的学生,只需加
NOT:... WHERE ... NOT BETWEEN 20 AND 23;
- 查年龄20-23岁的学生(用
5. 集合查询(是否在指定列表中)
- 谓词:
IN (值1, 值2, ...):数据等于列表中的任意一个。NOT IN (值1, 值2, ...):数据不在列表中。
- 作用:快速筛选多个指定值,比用多个
OR更方便。 - 例子:
- 查“计算机科学与技术”或“信息安全”专业的学生:
SELECT ... WHERE Smajor IN ('计算机科学与技术', '信息安全'); - 等价于用
OR连接:... WHERE Smajor = '计算机科学与技术' OR Smajor = '信息安全'; - 查不在这两个专业的学生,加
NOT:... WHERE Smajor NOT IN (...);
- 查“计算机科学与技术”或“信息安全”专业的学生:
6. 字符匹配(模糊查询,含通配符)
- 谓词:
LIKE '匹配串':数据符合匹配规则(支持通配符)。NOT LIKE '匹配串':不符合匹配规则。
- 通配符:
%:代表任意长度的字符串(包括0个字符,即空)。_:代表任意单个字符。
- 例子:
- 固定字符串(精确匹配,等价于
=):WHERE Sno LIKE '20180003'; -- 等价于 Sno = '20180003' - 以某个字符开头(比如“刘”姓):
WHERE Sname LIKE '刘%'; -- 姓名以“刘”开头,后面任意字符 - 指定长度和位置(比如学号以2023开头,课程号第5位是6,总长度5位):
WHERE Sno LIKE '2023%'; -- 学号以2023开头(后面任意长度) WHERE Cno LIKE '81__6'; -- 课程号第1-2位是81,第3-4位任意单个字符,第5位是6(共5位) - 排除匹配(不姓刘的学生):
WHERE Sname NOT LIKE '刘%'; - 转义特殊字符(如果数据中包含
%或_,需要用ESCAPE声明转义符,比如\):-- 查名称为“DB_Design”的课程(下划线是普通字符,不是通配符) WHERE Cname LIKE 'DB\_Design' ESCAPE '\'; -- 用\转义下划线
- 固定字符串(精确匹配,等价于
5. 空值判断(数据是否为空)
- 谓词:
IS NULL:数据为空(比如没参加考试,成绩为空)。IS NOT NULL:数据不为空。
- 注意:不能用
=或!=判断空值,必须用IS! - 例子:
- 查缺少成绩的学生(成绩列为空):
SELECT Sno, Cno FROM SC WHERE Grade IS NULL; - 查有成绩的学生:
... WHERE Grade IS NOT NULL;
- 查缺少成绩的学生(成绩列为空):
6. 多重条件组合(多个条件一起用)
- 逻辑运算符:
AND:多个条件同时满足(“且”)。OR:至少满足一个条件(“或”)。NOT:对条件取反(“非”)。
- 优先级:
NOT > AND > OR,但建议用括号明确顺序,避免出错。 - 例子:
- 查“计算机科学与技术”专业,且2004年及以后出生的学生:
SELECT ... WHERE Smajor = '计算机科学与技术' AND year(Sbirthdate) >= 2004; - 查“计算机科学与技术”专业 或 成绩不及格的学生(用括号区分优先级):
SELECT ... WHERE (Smajor = '计算机科学与技术') OR (Grade < 60);
- 查“计算机科学与技术”专业,且2004年及以后出生的学生:
总结:
- 精确比较(等于、大于等):用
=、>、<等符号。 - 区间范围(20-23岁):用
BETWEEN AND或NOT BETWEEN AND。 - 多个指定值(两个专业):用
IN或NOT IN。 - 模糊匹配(姓刘、学号开头):用
LIKE,搭配%(任意长度)、_(单个字符),特殊字符用ESCAPE转义。 - 空值处理(有无成绩):用
IS NULL或IS NOT NULL。 - 多个条件组合:用
AND(同时满足)、OR(满足其一),必要时加括号。
3.1.3 ORDER BY子句
1. ORDER BY子句的作用
一句话:让查询结果按照你指定的列(或多列)排序,就像给数据“整理队形”!
2. 基本语法
SELECT 列1, 列2 FROM 表名 WHERE 条件 ORDER BY 排序列 [ASC/DESC];
ORDER BY必须放在WHERE子句之后(如果有WHERE的话)。ASC(Ascending):升序(从小到大,默认)。DESC(Descending):降序(从大到小)。
3.单字段排序:按一个列排序
例子1:查询选修了81003号课程的学生学号和成绩,按成绩降序排列(高分在前)。
SELECT Sno, Grade FROM SC WHERE Cno='81003' ORDER BY Grade DESC;
- 结果:成绩最高的学生排在最前面,最低的在最后。
例子2:查询所有学生的姓名,按姓名升序排列(默认升序,可省略ASC)。
SELECT Sname FROM Student ORDER BY Sname; -- 等价于 ORDER BY Sname ASC
- 结果:姓名按字母或拼音顺序排列(A-Z或拼音首字母)。
4.多字段排序:按多个列排序
规则:先按第一列排序,如果第一列值相同,则按第二列排序,以此类推。
例子:查询全体学生的选课情况,先按课程号升序,同一课程内按成绩降序。
SELECT * FROM SC ORDER BY Cno, Grade DESC;
- 结果:
- 课程号(Cno)从小到大排列。
- 若课程号相同(比如都是81003),则按成绩(Grade)从高到低排列。
5.注意事项
-
空值(NULL)的排序:
- 不同数据库系统处理不同,常见两种:
- NULL值排在最前(如MySQL)。
- NULL值排在最后(如SQL Server)。
- 若想控制NULL的位置,可结合
IS NULL或COALESCE函数处理。
- 不同数据库系统处理不同,常见两种:
-
排序性能:
- 对大量数据排序时,会消耗更多资源。
- 尽量在排序字段上创建索引,提高速度。
6.总结:
-
单字段排序:
ORDER BY 列名 ASC; -- 升序(默认) ORDER BY 列名 DESC; -- 降序 -
多字段排序:
ORDER BY 列1 [ASC/DESC], 列2 [ASC/DESC]; -- 先按列1,再按列2 -
常见场景:
- 成绩排名(降序)。
- 时间线(最新的在前,降序)。
- 字典序(姓名、商品名升序)。
3.1.4 聚集函数
1.什么是聚集函数?
一句话总结:聚集函数专门用来 “批量计算” 数据,比如统计有多少行、求和、求平均等。
举个生活例子:
- 想知道全班有多少人?用
COUNT。 - 想算全班数学平均分?用
AVG。 - 想找最高分、最低分?用
MAX和MIN。
2、5 个常用聚集函数

3. 统计个数:COUNT
- 功能:数“有多少个”。
- 两种用法:
COUNT(*):统计表格中 所有行的数量(包括有NULL的行)。
▶ 例:查学生总人数SELECT COUNT(*) FROM Student; -- 不管学生信息是否完整,只要有记录就数进去COUNT(列名):统计这一列中 非空值的数量(排除NULL)。
▶ 例:查选修了课程且有成绩的学生人数(Grade列非空)SELECT COUNT(Grade) FROM SC; -- 只数有成绩的行,忽略成绩为空的COUNT(DISTINCT 列名):先去重,再统计非空值的数量。
▶ 例:查选修了课程的学生人数(同一个学生选多门课,只算一次)SELECT COUNT(DISTINCT Sno) FROM SC; -- 不管选了多少门课,每个学生只算1次
4. 求和:SUM(只能用于数值列)
- 功能:把某一列的数值加起来。
- 用法:
SUM(列名),可选DISTINCT去重后求和(很少用,默认ALL算所有值)。
▶ 例:计算学号 20180003 的学生选修课程的总学分(需要连接SC和Course表,因为学分在Course表中)SELECT SUM(Credit) FROM SC, Course WHERE Sno='20180003' AND SC.Cno=Course.Cno; -- 通过课程号连接,把选的课的学分加起来
5. 求平均值:AVG(只能用于数值列)
- 功能:计算某一列数值的平均值(自动忽略
NULL)。
▶ 例:算选修 81001 号课程的学生平均成绩SELECT AVG(Grade) FROM SC WHERE Cno='81001';
6. 求最值:MAX和 MIN
- 功能:
MAX(列名):找某一列的最大值(数值、日期、字符串都能用,字符串按字典序)。MIN(列名):找某一列的最小值(同上)。
▶ 例:查 81001 号课程的最高分和最低分
SELECT MAX(Grade) AS 最高分, MIN(Grade) AS 最低分 FROM SC WHERE Cno='81001';
7.关键细节
-
NULL值的处理:COUNT(*):不管有没有NULL,只要有行就统计。COUNT(列名)、SUM、AVG、MAX、MIN:自动忽略NULL(当列值是NULL时,不参与计算)。
-
DISTINCT 和 ALL:- 默认为
ALL(计算所有值,包括重复的)。 DISTINCT表示去重后再计算,比如COUNT(DISTINCT Sno)只算不同的学生。
- 默认为
-
多表使用:
- 如果要统计的列在多个表中,需要先通过 表连接(比如
SC和Course用课程号连接),再用聚集函数。
- 如果要统计的列在多个表中,需要先通过 表连接(比如
8.经典示例拆解(从简单到复杂)
| 需求 | 代码示例 | 核心逻辑 |
|---|---|---|
| 学生总人数 | SELECT COUNT(*) FROM Student; | 数所有学生记录,不管信息是否完整。 |
| 有成绩的学生选课记录数 | SELECT COUNT(Grade) FROM SC; | 只数 Grade 列不为空的行(有成绩的选课记录)。 |
| 选修过课程的学生人数(去重) | SELECT COUNT(DISTINCT Sno) FROM SC; | 同一个学生选多门课,只算1次(去重)。 |
| 某课程平均成绩 | SELECT AVG(Grade) FROM SC WHERE Cno='81001'; | 先筛选课程,再算平均成绩(自动忽略成绩为空的行)。 |
| 跨表求总学分 | SELECT SUM(Credit) FROM SC, Course ... | 通过课程号连接两张表,把学生选的所有课的学分加起来。 |
9.练习
-
查询软件工程专业的女生总数:
- 条件:
Smajor='软件工程'且Ssex='女',统计人数用COUNT(*)。
SELECT COUNT(*) FROM Student WHERE Smajor='软件工程' AND Ssex='女'; - 条件:
-
2023年第2学期“81003”课程的不及格人数:
- 条件:
Semester='2023-2'(假设学期格式如此)、Cno='81003'、Grade<60,统计人数用COUNT(*)。
SELECT COUNT(*) FROM SC WHERE Semester='2023-2' AND Cno='81003' AND Grade<60; - 条件:
-
全部课程的总学分:
- 直接对
Course表的Credit列求和。
SELECT SUM(Credit) FROM Course; - 直接对
-
81002号课程的最高分、最低分、平均分:
- 用
MAX、MIN、AVG三个函数一起统计。
SELECT MAX(Grade) AS 最高分, MIN(Grade) AS 最低分, AVG(Grade) AS 平均分 FROM SC WHERE Cno='81002'; - 用
10.总结:
- 数数量:
- 所有行:
COUNT(*)。 - 某列非空值:
COUNT(列名)。 - 去重后数量:
COUNT(DISTINCT 列名)。
- 所有行:
- 算总和/平均(仅限数值列):
SUM(列名)、AVG(列名)。 - 找最值:
MAX(列名)(最大)、MIN(列名)(最小)。
3.1.5 GROUP BY子句
1.什么是GROUP BY子句?
一句话总结:把数据按某一列或多列「分组」,然后对每个组分别进行统计(比如算每组的平均分、人数等)。
举个生活例子:
- 想按「班级」统计每个班的平均分?用
GROUP BY 班级。 - 想按「课程号」统计每门课的及格人数?用
GROUP BY 课程号。
2.基本语法与核心逻辑
SELECT 分组列, 聚集函数(其他列) -- 分组列必须出现在GROUP BY中
FROM 表名
[WHERE 行级条件] -- 先筛选行,再分组
GROUP BY 分组列 [, 分组列2,...] -- 按一列或多列分组
[HAVING 组级条件] -- 对分组后的结果筛选(常用聚集函数)
[ORDER BY 排序列]; -- 最后排序
3.关键逻辑步骤:
- 先过滤行:用
WHERE筛选符合条件的行(还没分组时就过滤)。 - 再分组:按
GROUP BY的列把数据分成多个组(同组的分组列值相同)。 - 组内统计:对每个组用聚集函数(如
AVG(Grade)、COUNT(*))计算。 - 筛选组:用
HAVING筛选掉不符合条件的组(比如平均成绩<60分的组)。 - 最后排序:用
ORDER BY给结果排序。
4.核心用法示例(对比WHERE和HAVING)
1. 按单字段分组:统计每组的聚集结果
例:查询每个学生的平均成绩(只显示平均≥90分的学生)
SELECT Sno, AVG(Grade) AS 平均分 -- 分组列是Sno,对每个Sno的Grade求平均
FROM SC
GROUP BY Sno -- 按学号分组,每个学号一组
HAVING AVG(Grade) >= 90; -- 筛选出平均分≥90的组
- 为什么不用WHERE?:
WHERE只能筛选「行」(比如Grade>80的行),但「平均分≥90」是针对整个组的条件,必须用HAVING。
2. 错误示例:在WHERE中用聚集函数
下面的写法是 错误的:
SELECT Sno, AVG(Grade)
FROM SC
WHERE AVG(Grade)>=90 -- ❌ 错误!WHERE不能用聚集函数(AVG是分组后的统计结果)
GROUP BY Sno;
- 原因:
WHERE在分组 之前 执行,此时还没有分组结果,无法计算AVG(Grade)。 - 正确做法:用
HAVING在分组 之后 筛选组。
3.WHERE vs HAVING:核心区别
| 子句 | 作用对象 | 执行时机 | 能否用聚集函数 | 典型场景 |
|---|---|---|---|---|
| WHERE | 原始表中的行 | 分组 之前 | ❌ 不能 | 筛选单个行(如Grade<60的行) |
| HAVING | 分组后的组 | 分组 之后 | ✅ 能用 | 筛选组(如平均成绩<60的组) |
例子对比:
- 查「成绩<60分且属于2023学期的行」(行级筛选):
WHERE Semester='2023' AND Grade<60 - 查「2023学期中,平均成绩<60分的课程组」(组级筛选):
GROUP BY Cno HAVING AVG(Grade)<60
4.多字段分组:按多个列分组
例:按「课程号」和「学期」分组,统计每门课每学期的选课人数
SELECT Cno, Semester, COUNT(Sno) AS 选课人数 -- 分组列是Cno和Semester
FROM SC
GROUP BY Cno, Semester; -- 同时按两个列分组,组内这两个列的值都相同
- 结果:每个(课程号,学期)组合为一组,统计该组的选课人数。
5 练习(附正确答案)
练习1:查询平均分低于50分的课程的课程号及其平均分
需求分析:
- 按「课程号(Cno)」分组,计算每组的平均分。
- 筛选出平均分<50的组(组级条件,用HAVING)。
正确写法:
SELECT Cno, AVG(Grade) AS 平均分
FROM SC
GROUP BY Cno -- 按课程号分组
HAVING AVG(Grade) < 50; -- 筛选平均分<50的组
- 注意:如果写成
WHERE AVG(Grade)<50会报错,因为WHERE不能用聚集函数。
练习2:查询2019学年不及格课程总数≥3门的学生,显示学号和不及格门数,按学号升序排序
需求分析:
- 行级筛选:先筛选出「2019学年(Semester含2019)」且「成绩<60(不及格)」的行。
- 分组:按「学号(Sno)」分组(每个学生一组)。
- 组内统计:统计每组的不及格课程数(用COUNT(*))。
- 组级筛选:筛选出不及格门数≥3的组(用HAVING)。
- 排序:按学号升序排列。
正确写法:
SELECT Sno, COUNT(*) AS 不及格门数
FROM SC
WHERE Semester LIKE '2019%' AND Grade < 60 -- 行级筛选:2019学年且不及格
GROUP BY Sno -- 按学号分组
HAVING COUNT(*) >= 3 -- 组级筛选:不及格门数≥3
ORDER BY Sno ASC; -- 按学号升序排序(ASC可省略,默认升序)
- 关键点:
WHERE先排除无关的行(比如非2019学年、成绩≥60的行),再分组统计,效率更高。
6.总结:
- 确定分组列:数据按哪列/哪些列分组(如Sno、Cno)。
- 行级筛选(可选):用WHERE过滤掉不需要的行(分组前执行)。
- 分组+统计:用GROUP BY分组,对每组用聚集函数(COUNT、AVG等)。
- 组级筛选(可选):用HAVING筛选不符合条件的组(必须用聚集函数时)。
- 排序(可选):用ORDER BY对最终结果排序。
3.1.6 LIMIT子句
1.LIMIT子句的作用
一句话总结:让查询结果只显示 指定数量的行,比如只看前10条数据,或第3-5条数据。
举个生活例子:
- 成绩单太长,只想看前10名?用
LIMIT 10。 - 分页查看数据(比如第2页,每页5条)?用
LIMIT 5 OFFSET 5(跳过前5条,取接下来的5条)。
2.基本语法与参数解析
SELECT 列名 FROM 表名 [WHERE 条件] [ORDER BY 排序] LIMIT <数量> [OFFSET <跳过行数>];
- 核心参数:
LIMIT <n1>:必选,指定要显示的 最大行数(从第1行开始取n1行)。OFFSET <n2>:可选,指定 跳过前面的n2行,再取后面的n1行(默认OFFSET 0,即不跳过)。
- 执行顺序:先执行
SELECT和WHERE,再排序(ORDER BY),最后用LIMIT限制行数。
3.常用场景与示例
3.1 取前N条数据(最常用)
例:查询成绩前10名的学生学号(按成绩降序,取前10行)
SELECT Sno FROM SC, Course
WHERE Course.Cname = '数据库系统概论' AND SC.Cno = Course.Cno
ORDER BY Grade DESC -- 先按成绩从高到低排序
LIMIT 10; -- 只取前10行(第1-10名)
- 作用:快速获取“Top N”数据(如Top 5销量、Top 3分数)。
3.2 分页查询(跳过前面的行,取中间部分)
例:查询平均成绩排名3-5名的学生(第3、4、5名)
SELECT Sno, AVG(Grade) AS 平均分 FROM SC
GROUP BY Sno
ORDER BY 平均分 DESC -- 先按平均分从高到低排序
LIMIT 3 OFFSET 2; -- 跳过前2行(第1-2名),取接下来的3行(第3-5名)
- 公式:第n页,每页m条数据 →
LIMIT m OFFSET (n-1)*m。- 比如第2页,每页5条:
LIMIT 5 OFFSET 5(跳过前5条,取第6-10条)。
- 比如第2页,每页5条:
3.3搭配分组和排序使用
练习:查询选课人数最多的前5名课程
SELECT Cno, COUNT(*) AS 选课人数 FROM SC
GROUP BY Cno -- 按课程号分组,统计每组人数
ORDER BY 选课人数 DESC -- 按人数从多到少排序
LIMIT 5; -- 只取前5名课程
- 逻辑:先分组统计,再排序,最后用LIMIT限制结果为前5条。
4.关键细节
-
OFFSET的省略:- 若只写
LIMIT n1,等价于LIMIT n1 OFFSET 0(从第1行开始取n1行)。 - 例:
LIMIT 5→ 取前5行;LIMIT 5 OFFSET 0→ 同上。
- 若只写
-
排序的重要性:
- 如果不先排序(
ORDER BY),LIMIT取的是数据库默认的无序结果(可能每次运行结果不同)。 - 最佳实践:
LIMIT几乎总是和ORDER BY一起使用,确保取到正确顺序的数据。
- 如果不先排序(
-
性能优势:
- 当数据量很大时,用
LIMIT可以避免加载全部数据,提升查询速度(比如只需要前10条,不用查全部10万条)。
- 当数据量很大时,用
5.总结:
| 需求场景 | 语法示例 | 说明 |
|---|---|---|
| 取前N条数据 | LIMIT N | 从第1行开始,取N行(如N=10,取前10行)。 |
| 取第M到第N条数据 | LIMIT N-M OFFSET M | 跳过前M行,取接下来的N-M行(如M=2,N=5,取第3-5行,用LIMIT 3 OFFSET 2)。 |
| 分页(第n页,每页m条) | LIMIT m OFFSET (n-1)*m | 例:第2页,每页5条 → LIMIT 5 OFFSET 5(跳过前5条,取第6-10条)。 |
| 取Top N数据(排序后) | ORDER BY 列 DESC LIMIT N | 先降序排序,再取前N条(如Top 5高分)。 |
以上就是这篇博客的全部内容,下一篇我们将继续探索更多精彩内容。
我的个人主页,欢迎来阅读我的其他文章
https://blog.csdn.net/2402_83322742?spm=1011.2415.3001.5343
我的数据库系统概论专栏
https://blog.csdn.net/2402_83322742/category_12911520.html?spm=1001.2014.3001.5482
| 非常感谢您的阅读,喜欢的话记得三连哦 |

相关文章:
SQL单表查询语言超详细讲解(附带例题表格对比带你一步步掌握))
数据库系统概论(八)SQL单表查询语言超详细讲解(附带例题表格对比带你一步步掌握)
数据库系统概论(八)SQL单表查询语言超详细讲解(附带例题表格对比带你一步步掌握) 前言一、创建表(了解一下就好,后面会详细讲)二、数据查询的概念2.1 什么是数据查询?2.2 数据查询的…...

【IPMV】图像处理与机器视觉:Lec11 Keypoint Features and Corners
【IPMV】图像处理与机器视觉:Lec11 Keypoint Features and Corners 本系列为2025年同济大学自动化专业**图像处理与机器视觉**课程笔记 Lecturer: Rui Fan、Yanchao Dong Lec0 Course Description Lec3 Perspective Transformation Lec7 Image Filtering Lec8 I…...

C++23 中的 ranges::starts_with 与 ranges::ends_with
文章目录 功能介绍ranges::starts_withranges::ends_with 示例代码编译器支持总结 C23 标准引入了 ranges::starts_with 和 ranges::ends_with,这两个算法由提案 P1659R3 提出,旨在为任意范围提供检查前缀和后缀的功能。 功能介绍 ranges::starts_wit…...

2025 uniapp的请求封装工具类以及使用【拿来就用】
一、创建一个http请求封装的js文件,名字自定义:my_http.js /*** 基础API请求地址(常量,全大写命名规范)* type {string}* constant*/ let BASE_URL //通过环境来判断基础路径 if (process.env.NODE_ENV development…...

Axure设计之内联框架切换页面、子页面间跳转问题
在Axure中,你可以通过以下步骤实现主页面中的内联框架在点击按钮时切换页面内容,从A页面切换到B页面。(误区:子页面之间切换不要设置“框架中打开链接”然后选“父级框架”这个交互) 主框架页面(左侧导航展…...
及优化方法总结)
PyTorch 中神经网络相关要点(损失函数,学习率)及优化方法总结
笔记 1 神经网络搭建和参数计算 1.1 构建神经网络模型 import torch import torch.nn as nn # 线性模型和初始化方法 # todo:1-创建类继承 nn.module类 class ModelDemo(nn.Module):# todo:2-定义__init__构造方法, 构建神经网络def __init__(self):# todo:2-1 调用父…...

适用于 iOS 的 开源Ultralytics YOLO:应用程序和 Swift 软件包,用于在您自己的 iOS 应用程序中运行 YOLO
一、软件介绍 文末提供程序和源码下载 该项目利用 Ultralytics 最先进的 YOLO11 模型将您的 iOS 设备转变为用于对象检测的强大实时推理工具。直接从 App Store 下载该应用程序,或浏览我们的指南,将 YOLO 功能集成到您自己的 Swift 应用程序中。 二、…...

why FPGA喜欢FMC子卡?
FMC 即 FPGA Mezzanine Card ( FPGA中间层板卡),由子板模块、载卡两构成。 FMC 载卡:为子板模块提供插槽,使用母座FMC连接器。载卡连接器引脚与具有可配置IO资源的芯片例如FPGA引脚通过PCB设计连接在一起。。 盘古100…...

【优选算法 | 字符串】字符串模拟题精选:思维+实现解析
算法相关知识点可以通过点击以下链接进行学习一起加油!双指针滑动窗口二分查找前缀和位运算模拟链表哈希表 在众多字符串算法题中,有一类题目看起来没有太多算法技巧,却经常让人“翻车”——那就是字符串模拟题。这类题型往往不依赖复杂的数据…...

比亚迪固态电池突破:王传福的技术哲学与产业重构|创客匠人热点评述
合肥某车间凌晨两点依然灯火通明,工程师正在调试的银白色设备,即将颠覆整个电动车行业 —— 比亚迪全固态电池产线的曝光,标志着中国新能源汽车产业正式迈入 “技术定义市场” 的新纪元。 一、技术突破的底层逻辑 比亚迪全固态电池的核心竞…...

UUG杭州站 | 团结引擎1.5.0 OpenHarmony新Feature介绍
PPT下载地址:https://u3d.sharepoint.cn/:b:/s/UnityChinaResources/EaZmiWfAAdFFmuyd6c-7_3ABhvZoaM69g4Uo2RrSzT3tZQ?e2h7RaL 在2025年4月12日的Unity User Group杭州站中,Unity中国OpenHarmony技术负责人刘伟贤带来演讲《团结引擎1.5.0 OpenHarmony新…...

OpenHarmony轻量系统--BearPi-Nano开发板网络程序测试
本文介绍RISC-V架构海思Hi3861开发板,通过Linux开发环境运行OpenHarmony轻量化系统,下载测试网络例程的过程与步骤。 OpenHarmony操作系统分类 轻量系统(mini system) 面向MCU类处理器例如Arm Cortex-M、RISC-V 32位的设备&#x…...

k8s 中使用 Service 访问时NetworkPolicy不生效问题排查
背景 针对一个服务如下NetworkPolicy, 表示只有n9e命名空间的POD才能访问 k8s-man 服务 kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata:name: k8s-mannamespace: n9elabels:app: k8s-manversion: v1 spec:podSelector:matchLabels:app: k8s-manversion: v1…...

2025 AI如何重构网络安全产品
威胁检测与防御 利用机器学习算法提升威胁检测能力 :AI能够分析大量的网络数据和行为模式,通过机器学习算法自动识别出潜在的威胁和异常行为。例如,Darktrace的Cyber AI Analyst基于真实SOC数据训练,可推进威胁调查,提…...

ARM杂谈——临界段保护恢复的中断状态可靠吗
0 前言 在MCU中,临界段保护是指在多任务或多线程环境中,确保某段代码在执行时不会被其他任务或中断打断,从而避免数据竞争或不一致的问题。临界段保护通常用于共享资源的访问,如全局变量、硬件寄存器等。 我们有一些常用的临界段…...
)
数据库MySQL学习——day10()
文章目录 1. 什么是子查询(Subquery)?2. 创建样例表:商品表 products3. 插入示例数据4. 子查询的三种常用位置4.1 子查询在 WHERE 子句中(最常见)4.2 子查询在 FROM 子句中(可以当成临时表&…...

YashanDB V23.4 LTS 正式发布|两地三中心、库级闪回重磅特性上线,生产级可用性再升级
近日,YashanDB V23.4 LTS(Long-Term Support Release)版本正式发布,新版本深度契合关键行业数字化转型对数据库“业务永续、风险可控”的核心诉求,打造两地三中心秒级容灾、库级闪回秒级恢复、MySQL全面兼容等重磅特性…...

AI规则引擎:解锁SQL数据分析新姿势
一、AI 规则引擎与 SQL 的奇妙邂逅 在当今数字化时代,数据如同石油,是企业发展和创新的核心驱动力。而如何从海量的数据中提取有价值的信息,成为了企业面临的关键挑战。人工智能规则引擎和 SQL,作为数据分析领域的两大重要工具&a…...

Kotlin Multiplatform与Flutter、Compose共存:构建高效跨平台应用的完整指南
简介 在移动开发领域,跨平台技术正在重塑开发范式。Kotlin Multiplatform (KMP) 作为 JetBrains 推出的多平台开发框架,结合了 Kotlin 的简洁性与原生性能优势,使开发者能够高效共享业务逻辑。而 Flutter 凭借其高性能渲染引擎(Skia)和丰富的组件库,成为混合开发的首选方…...

FunASR:语音识别与合成一体化,企业级开发实战详解
简介 FunASR是由阿里巴巴达摩院开源的高性能语音识别工具包,它不仅提供语音识别(ASR)功能,还集成了语音端点检测(VAD)、标点恢复、说话人分离等工业级模块,形成了完整的语音处理解决方案。 FunASR支持离线和实时两种模式,能够高效处理多语言音频,并提供高精度的识别结果。…...

【Spark分析HBase数据】Spark读取并分析HBase数据
Spark读取并分析HBase数据 一、摘要二、实现过程三、小结 一、摘要 Apache Spark 是一个快速、通用的大数据处理引擎,提供了丰富的 API 用于数据处理和分析。HBase 是一个分布式、可扩展的 NoSQL 数据库,适合存储海量结构化和半结构化数据。Spark 与 HB…...

探索直播美颜SDK的核心算法:图像增强与AI美颜技术详解
一款优秀的直播美颜SDK不仅能让主播拥有完美的在线形象,还能帮助平台吸引更多用户。然而,这背后的关键在于其核心算法——从基本的图像增强到前沿的AI美颜技术,每一步都至关重要。今天,我们就来深入探讨这些技术背后的秘密。 一、…...

全新linux网络配置工具nmcli:
1.Linux全新网络管理工具nmcli的使用 ,网络管理命令行工具nmcli 在nmcli中有2个命令最为常用: (1)nmcli connection 表示连接,可理解为配置文件,相当于ifcfg-ethX。可以简写为nmcli c (2)nmcl…...

LeetCode100.5 盛最多水的容器
对于这题,首先明确的是:盛水的体积取决于两垂线间的距离与两垂线中最短的长度。 那么使用双指针,在每次移动时,只移动其中最短的那个,因为若移动最长的那个,体积不会变大。 class Solution { public:int …...
)
AI开发者的算力革命:GpuGeek平台全景实战指南(大模型训练/推理/微调全解析)
目录 背景一、AI工业化时代的算力困局与破局之道1.1 中小企业AI落地的三大障碍1.2 GpuGeek的破局创新1.3 核心价值 二、GpuGeek技术全景剖析2.1 核心架构设计 三、核心优势详解3.1 优势1:工业级显卡舰队3.2 优势2:开箱即用生态3.2.1 预置镜像库…...

Java元注解
Java 元注解(Meta-Annotations) 元注解是指用于注解其他注解的注解,Java 提供了5个内置的元注解: 1. Target 指定注解可以应用的目标元素类型。 Target(ElementType.TYPE) // 只能用于类、接口或枚举 public interface MyAnno…...

FPGA:Xilinx Kintex 7实现DDR3 SDRAM读写
在Xilinx Kintex 7系列FPGA上实现对DDR3 SDRAM的读写,主要依赖Xilinx提供的Memory Interface Generator (MIG) IP核,结合Vivado设计流程。以下是详细步骤和关键点: 1. 准备工作 硬件需求: Kintex-7 FPGA(如XC7K325T&…...

深度剖析 GpuGeek 实例:GpuGeek/Qwen3-32B 模型 API 调用实践与性能测试洞察
深度剖析 GpuGeek 实例:GpuGeek/Qwen3-32B 模型 API 调用实践与性能测试洞察 前言 GpuGeek专注于人工智能与高性能计算领域的云计算平台,致力于为开发者、科研机构及企业提供灵活、高效、低成本的GPU算力资源。平台通过整合全球分布式数据中心资源&#…...
)
散列表(1)
散列表概念 键通过散列函数后转换为数组的下标,在对应的下标位置上存储相应的信息 键------>散列函数-------->数组下标------->存储信息 散列函数 散列函数就是一个函数,能够将给定的key转换为特定散列值。hashValuehash(key&…...
】)
E. 23 Kingdom【Codeforces Round 1024 (Div. 2)】
E. 23 Kingdom 思路: 这道题的核心在于如何构造一个数组b,使得每个数的最远两个出现位置之差总和最大。通过分析,我们发现要最大化总美丽值,应尽可能让每个数的首次出现尽可能靠左、末次出现尽可能靠右。这样每个数的距离贡献j-i…...

TTS-Web-Vue系列:Vue3实现侧边栏与顶部导航的双向联动
🔄 本文是TTS-Web-Vue系列的最新文章,重点介绍如何在Vue3项目中实现侧边栏与顶部导航栏的双向联动功能。通过Vue3的响应式系统和组件通信机制,我们构建了一套高效、流畅的导航联动方案,让用户在不同入口都能获得一致的导航体验。 …...
)
【C++】模板(初阶)
一、模板与泛型编程 我们先来思考一下:如何实现一个通用的交换函数? void Swap(int& left, int& right) {int temp left;left right;right temp; }void Swap(double& left, double& right) {double temp left;left right;right te…...

大模型微调实战:基于GpuGeek平台的低成本高效训练方案
文章目录 引言一、GpuGeek平台使用入门1. 注册与账号设置2. 控制台功能概览3. 快速创建GPU实例3. 预置镜像与自定义环境 二、GpuGeek平台核心优势解析1. 显卡资源充足:多卡并行加速训练2. 镜像超多:开箱即用的开发环境3. 计费灵活:按需付费降…...
)
黑马k8s(六)
1.Deployment(Pod控制器) Selector runnginx 标签选择:会找pod打的标签 执行删除之后,pod也会删除,Terminating正在删除 如果想要访问其中的一个pod借助:IP地址端口号访问 假设在某一个瞬间,…...

WEB安全--Java安全--CC1利用链
一、梳理基本逻辑 WEB后端JVM通过readObject()的反序列化方式接收用户输入的数据 用户编写恶意代码并将其序列化为原始数据流 WEB后端JVM接收到序列化后恶意的原始数据并进行反序列化 当调用: ObjectInputStream.readObject() JVM 内部逻辑: → 反…...
)
16S18S_OTU分析(3)
OTU的定义 OTU:操作分类单元是在系统发生学研究或群体遗传学研究中,为了便于进行分析,人为给某一个分类单元(如品系、种、属、分组等)设置的同一标志。目的:OTU用于将相似的序列归为一类,以便于…...
Day20)
嵌入式开发学习日志(数据结构--单链表)Day20
一、gdb调试 (一)一般调试步骤与命令 1、gcc -g (调试版本,内含调试信息与源码;eg:gcc -g main.c linklist.c) 2、gdb a.out(调试可执行文件,eg:gdb …...
 failed in /etc/nginx/nginx.conf:2)
nginx报错-[emerg] getpwnam(“nginx“) failed in /etc/nginx/nginx.conf:2
报错 - nginx: [emerg] getpwnam(“nginx”) failed in /etc/nginx/nginx.conf:2 问题描述: nginx: [emerg] getpwnam(“nginx”) failed in /etc/nginx/nginx.conf:2 问题原因: 是因为配制文件中使用的启动账户在系统中并没有找到 解决方法&#x…...

Linux系统编程——fork函数的使用方法
在 Linux 系统编程 中,fork() 函数是创建新进程的关键系统调用。fork() 在当前进程(父进程)中创建一个几乎完全相同的子进程。子进程和父进程从调用 fork() 的位置继续执行,但它们是两个独立的进程,每个进程都有自己的…...
)
Linux进程信号处理(26)
文章目录 前言一、信号的处理时机处理情况“合适”的时机 二、用户态与内核态概念重谈进程地址空间信号的处理过程 三、信号的捕捉内核如何实现信号的捕捉?sigaction 四、信号部分小结五、可重入函数六、volatile七、SIGCHLD 信号总结 前言 这篇就是我们关于信号的最…...
)
黑马Java跟学.最新AI+若依框架项目开发(一)
黑马Java跟学.最新AI若依框架项目开发.一 前瞻为什么学习若依?AI局限性若依是什么?创新项目开发新方案课程安排前置知识 一、若依搭建若依版本官方非官方 RuoYi-Vue运行后端项目初始化项目Git下载Maven构建 MySQL相关导入sql配置信息 Redis相关启动配置信息 项目运…...

【自学30天掌握AI开发】第1天 - 人工智能与大语言模型基础
自学30天掌握AI开发 - 第1天 📆 日期和主题 日期:第1天 主题:人工智能与大语言模型基础 🎯 学习目标 了解人工智能的发展历史和基本概念掌握大语言模型的基本原理和工作机制区分不同类型的AI模型及其特点理解AI在当前社会中的…...
Java String类全面解析)
(十六)Java String类全面解析
一、String类概述 1.1 String的本质 在Java中,String类可能是使用最频繁的类之一,但它也是最容易被误解的类之一。从本质上讲,String代表的是一个不可变的Unicode字符序列。这种不可变性(immutability)是String类设计的核心特性。 java S…...

Android架构之自定义native进程
在Android五层架构中,native层基本上全是c的世界,这些c进程基本上靠android世界的第一个进程init进程创建,init通过rc配置文件,创建了众多的c子进程,也是这众多的c进程,构建了整个android世界的native层。 …...

#跟着若城学鸿蒙# HarmonyOS NEXT学习之AlphabetIndexer组件详解
一、组件介绍 AlphabetIndexer(字母索引条)是HarmonyOS NEXT中一个非常实用的UI组件,它主要用于在列表视图中提供快速的字母导航功能。当应用中有大量按字母顺序排列的数据(如联系人列表、城市列表等)时,A…...

React百日学习计划——Deepseek版
阶段一:基础巩固(1-20天) 目标:掌握HTML/CSS/JavaScript核心语法和开发环境搭建。 每日学习内容: HTML/CSS(1-10天) 标签语义化、盒模型、Flex布局、Grid布局、响应式设计(媒体查询…...

Room持久化库:从零到一的全面解析与实战
简介 在Android开发中,Room作为官方推荐的数据库持久化库,提供了对SQLite的抽象层,使得数据库操作更加安全、高效且易于维护。 Room通过注解处理器和编译时验证,显著降低了数据库操作的复杂度,同时支持响应式编程模式,使开发者能够轻松实现数据变化的实时监听。对于企业…...
)
Linux云计算训练营笔记day07(MySQL数据库)
数据库 DataBase 保存数据的仓库 数据库管理系统 DBMS 这是一个可以独立运行,用于维护磁盘上的数据的一套软件 特点: 维护性高,灵活度高,效率高,可扩展性强 常见的DBMS Mysql Mariadb Oracle DB2 SQLServer MySQL是一个关系型…...

C语言之旅5---分支与循环【2】
💫只有认知的突破💫才来带来真正的成长💫编程技术的学习💫没有捷径💫一起加油💫 🍁感谢各位的观看🍁欢迎大家留言🍁咱们一起加油🍁努力成为更好的自己&#x…...

K230 ISP:一种新的白平衡标定方法
第一次遇见需要利用光谱响应曲线进行白平衡标定的方法。很好奇是如何利用光谱响应曲线进行白平衡标定的。 参考资料参考:K230 ISP图像调优指南 K230 介绍 嘉楠科技 Kendryte 系列 AIoT 芯片中的最新一代 AIoT SoC K230 芯片采用全新的多核异构单元加速计算架构&a…...