时间序列基础【学习记录】
文章目录
- 1. 时间序列中的标签
- 2. 时间序列中的窗口分割器
- 2.1.概述
- 2.2.窗口分割器demo
- 3. 时间序列的数据加载器
- 3.1.概述
- 3.2.时间序列的dataset
- 3.3.Tensor类型
- 3.4.测试完整流程demo
1. 时间序列中的标签
在目标检测领域的数据集中的图像会有一个标签**(标记一个物体是猫还是狗或者是其它的物体),而对于时间序列,在预测的时候,实验者都会选择预测未来多少条数据。假设我们16条数据,选择其中的6条数据为窗口大小来预测未来的2条数据,那么我们的标签就是这2条数据(假设我们的特征数1即你是单元预测,那么我们这16条数据会送入到模型内部进行训练,模型会输出2条数据,输出的2条数据会和我们的标签求一个损失用于反向传播)**
在时间序列预测中,单元预测(Unit Prediction)通常指的是对时间序列中某个特定时间点的未来值进行预测。时间序列是一组按时间顺序排列的数据点,单元预测的目标是根据过去的数据点预测未来的单个数据点的值。
2. 时间序列中的窗口分割器
2.1.概述
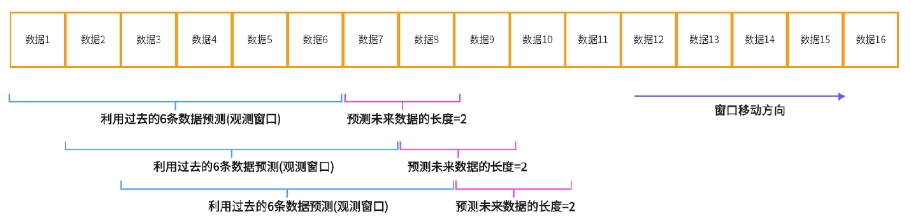
在时间序列中特有的就是窗口分割器,利用一个滑动的窗口(类似于卷积操作)沿着数据的方向进行滑动从而产生用于训练时间序列的数据和标签。如上图所示,我们的蓝色和粉色就是滑动的窗口,一个用于滑动训练数据一个用于滑动标签,最后滑动到数据的结尾。我们可以计算我们能够得到的训练数据的多少,其中数据为16条滑动窗口为6标签为2那么我们最后能够得到的训练加载器中的数据大小就为16 - ( 6 + 2 - 1) = 9,所以最后我们就能得到9个数据。
(样本数 = 数据总数 - (窗口大小 + 预测长度 - 1))
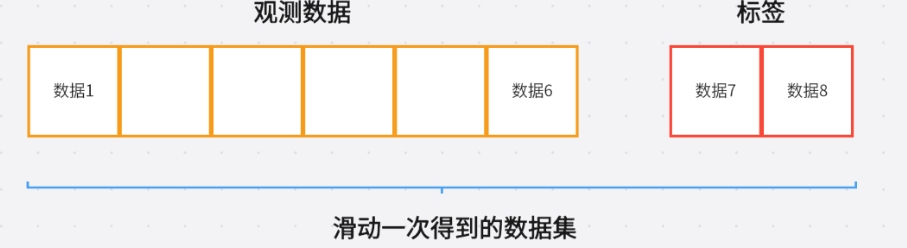
每个数据的内容如下图所示:
2.2.窗口分割器demo
"""
@Author: zhang_zhiyi
@Date: 2024/7/3_10:49
@FileName:1.时间序列中的窗口分割.py
@LastEditors: zhang_zhiyi
@version: 1.0
@lastEditTime:
@Description:
"""
import numpy as np# 分割数据集的函数
def create_data_sequence(input_data, ws, pl):# 存放分割后的数据seq_list = []# 数据集长度L = len(input_data)for i in range(L - ws):train_set = input_data[i:i + ws]if i + ws + pl > L:breaktrain_label = input_data[i + ws:i + ws + pl]seq_list.append((train_set, train_label))return seq_listdef main():# 定义参数total_data_points = 16 # 总数据点数window_size = 6 # 滑动窗口大小predict_length = 2 # 预测长度# 随机生成一个数据集data_set = np.random.rand(total_data_points)print(f"生成的数据集类型是{type(data_set)}, 数据集为{data_set}")# 分割数据集data_set_seq = create_data_sequence(data_set, window_size, predict_length)for i in range(len(data_set_seq)):print(f"分割的第{i}个数据为:{data_set_seq[i]}")if __name__ == '__main__':main()
3. 时间序列的数据加载器
3.1.概述
经过上面的数据分割器处理之后,我们得到了一个样本数为9的数据集,一般用list在外侧内部为tuple元组保存训练数据和标签,这样list就包含九个数据点,每个 数据点内包含一个大的元组,大的元组内包含两个小的元组一个是储存训练集一个储存标签。
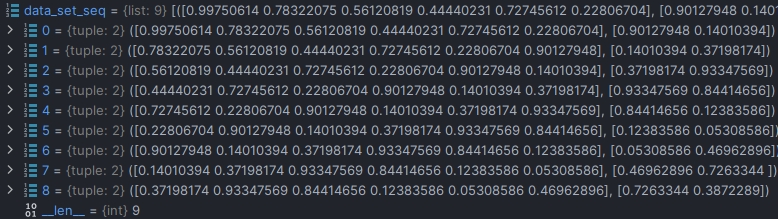
之后我们就要用这个list来生成数据加载器了,我们一般也用下面的加载器进行定义
from torch.utils.data import DataLoader
但是用它进行定义数据加载器之前需要输入的数据格式是dataset的格式,时间序列的dataset和其它领域的不太一样
3.2.时间序列的dataset
一般的数据的dataset需要两个数据的输入但是我们的数据只有一个,所以我们需要自己定义一个定义dataset的类来实现这个功能。
class TimeSeriesDataset(Dataset):def __init__(self, sequence):self.sequence = sequencedef __len__(self):return len(self.sequence)def __getitem__(self, index):sequence, label = self.sequence[index]return torch.Tensor(sequence), torch.Tensor(label)
上面这个就是一个基本的Dataset的定义, 通过这个类的定义我们将数据集输入到这个类里转化为Dataset格式,再将其输入到Dataloader里就形成了一个数据加载器
# 创建数据集train_dataset = TimeSeriesDataset(data_set_seq)# 创建数据加载器DataLoaderbatch_size = 2 # 根据需要调整批量大小# shuffle代表的含义是从我们定义的九条数据里随机的取# drop_last代表丢掉不满足条件的数据train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, drop_last=True)
**上面的代码就是定义一个数据加载器的方法,**其中我们设置了batch_size=2就是我们的批次大小, shuffle代表的含义是从我们定义的九条数据里随机的取,drop_last代表丢掉不满足条件的数据,类似于我们的数据大部分都是6条但是最后一条数据不足6,此时如果将其输入到模型里就会报错,所以这个参数就是将其丢弃掉。
3.3.Tensor类型
在PyTorch中,Tensor是一种多维数组结构,类似于NumPy的数组(ndarray),但Tensor提供了更强大的功能,特别是在GPU加速计算方面。Tensor是PyTorch中的基本数据结构,用于存储和操作数据。
关键特点:
- 多维数组:
Tensor可以是标量、向量、矩阵或高维数组。例如,0维的Tensor是标量,1维的Tensor是向量,2维的Tensor是矩阵。 - 支持GPU加速:
Tensor可以在GPU上进行计算,利用PyTorch的CUDA支持,大大加速深度学习模型的训练和推理过程。 - 自动微分:
Tensor支持自动微分,这是PyTorch的一个核心功能,使得梯度计算变得非常简单和高效,适用于深度学习中的反向传播算法。
创建Tensor:
"""
@Author: zhang_zhiyi
@Date: 2024/7/3_14:28
@FileName:3.Tensor.py
@LastEditors: zhang_zhiyi
@version: 1.0
@lastEditTime:
@Description:
"""
import torch# 创建Tensor# 从列表或数组创建Tensor
x = torch.tensor([1, 2, 3, 4, 5])
print(x)# 创建全零Tensor
zeros = torch.zeros((2, 3))
print(zeros)# 创建全一 Tensor
ones = torch.ones((2, 3))
print(ones)# 创建随机数 Tensor
random_tensor = torch.rand((2, 3))
print(random_tensor)# 创建单位矩阵
eye = torch.eye(3)
print(eye)# 创建指定数据类型的 Tensor
float_tensor = torch.tensor([1.0, 2.0, 3.0], dtype=torch.float32)
int_tensor = torch.tensor([1, 2, 3], dtype=torch.int32)# 检查是否有可用的GPU
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')# 在GPU上创建 Tensor
gpu_tensor = torch.tensor([1, 2, 3], device=device)
print(gpu_tensor) # tensor([1, 2, 3], device='cuda:0'# 或者将现有的 Tensor 移动到 GPU 上
cpu_tensor = torch.tensor([1, 2, 3])
gpu_tensor = cpu_tensor.to(device)
print(gpu_tensor) # tensor([1, 2, 3], device='cuda:0'# 示例
a = torch.tensor([1, 2, 3], dtype=torch.float32)
b = torch.tensor([4, 5, 6], dtype=torch.float32)c = a + b
d = a * bprint("a:", a)
print("b:", b)
print("c(a + b):", c)
print("d(a * b):", d)
3.4.测试完整流程demo
"""
@Author: zhang_zhiyi
@Date: 2024/7/3_14:36
@FileName:4.完整流程demo.py
@LastEditors: zhang_zhiyi
@version: 1.0
@lastEditTime:
@Description:
"""
import time
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
from matplotlib import pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from torch.utils.data import DataLoader
import torch
from torch.utils.data import Dataset# 随机数种子
np.random.seed(0)class TimeSeriesDataset(Dataset):def __init__(self, sequences):self.sequences = sequencesdef __len__(self):return len(self.sequences)def __getitem__(self, index):sequence, label = self.sequences[index]return torch.Tensor(sequence), torch.Tensor(label)def calculate_mae(y_true, y_pred):# 平均绝对误差mae = np.mean(np.abs(y_true - y_pred))return mae"""
数据定义部分
"""
true_data = pd.read_csv(r'E:\07-code\time_series_study\data\test.csv') # 填你自己的数据地址,自动选取你最后一列数据为特征列target = 'X' # 添加你想要预测的特征列
test_size = 0.15 # 训练集和测试集的尺寸划分
train_size = 0.85 # 训练集和测试集的尺寸划分
pre_len = 40 # 预测未来数据的长度
train_window = 320 # 观测窗口# 这里加一些数据的预处理, 最后需要的格式是pd.series
true_data = np.array(true_data[target])# 定义标准化优化器
scaler_train = MinMaxScaler(feature_range=(0, 1))
scaler_test = MinMaxScaler(feature_range=(0, 1))# 训练集和测试集划分
train_data = true_data[:int(train_size * len(true_data))]
test_data = true_data[-int(test_size * len(true_data)):]
print("训练集尺寸:", len(train_data))
print("测试集尺寸:", len(test_data))# 进行标准化处理
train_data_normalized = scaler_train.fit_transform(train_data.reshape(-1, 1))
test_data_normalized = scaler_test.fit_transform(test_data.reshape(-1, 1))# 转化为深度学习模型需要的类型Tensor
train_data_normalized = torch.FloatTensor(train_data_normalized)
test_data_normalized = torch.FloatTensor(test_data_normalized)def create_inout_sequences(input_data, tw, pre_len):# 创建时间序列数据专用的数据分割器inout_seq = []L = len(input_data)for i in range(L - tw):train_seq = input_data[i:i + tw]if (i + tw + 4) > len(input_data):breaktrain_label = input_data[i + tw:i + tw + pre_len]inout_seq.append((train_seq, train_label))return inout_seq# 定义训练器的的输入
train_inout_seq = create_inout_sequences(train_data_normalized, train_window, pre_len)
test_inout_seq = create_inout_sequences(test_data_normalized, train_window, pre_len)# 创建数据集
train_dataset = TimeSeriesDataset(train_inout_seq)
test_dataset = TimeSeriesDataset(test_inout_seq)# 创建 DataLoader
batch_size = 32 # 你可以根据需要调整批量大小
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, drop_last=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, drop_last=True)class GRU(nn.Module):def __init__(self, input_dim=1, hidden_dim=32, num_layers=1, output_dim=1, pre_len=4):super(GRU, self).__init__()self.pre_len = pre_lenself.num_layers = num_layersself.hidden_dim = hidden_dim# 替换 LSTM 为 GRUself.gru = nn.GRU(input_dim, hidden_dim, num_layers=num_layers, batch_first=True)self.fc = nn.Linear(hidden_dim, output_dim)self.relu = nn.ReLU()self.dropout = nn.Dropout(0.1)def forward(self, x):h0_gru = torch.zeros(self.num_layers, x.size(0), self.hidden_dim).to(x.device)out, _ = self.gru(x, h0_gru)out = self.dropout(out)# 取最后 pre_len 时间步的输出out = out[:, -self.pre_len:, :]out = self.fc(out)out = self.relu(out)return outlstm_model = GRU(input_dim=1, output_dim=1, num_layers=2, hidden_dim=train_window, pre_len=pre_len)
loss_function = nn.MSELoss()
optimizer = torch.optim.Adam(lstm_model.parameters(), lr=0.005)
epochs = 20
Train = True # 训练还是预测if Train:losss = []lstm_model.train() # 训练模式for i in range(epochs):start_time = time.time() # 计算起始时间for seq, labels in train_loader:lstm_model.train()optimizer.zero_grad()y_pred = lstm_model(seq)single_loss = loss_function(y_pred, labels)single_loss.backward()optimizer.step()print(f'epoch: {i:3} loss: {single_loss.item():10.8f}')losss.append(single_loss.detach().numpy())torch.save(lstm_model.state_dict(), 'save_model.pth')print(f"模型已保存,用时:{(time.time() - start_time) / 60:.4f} min")else:# 加载模型进行预测lstm_model.load_state_dict(torch.load('save_model.pth'))lstm_model.eval() # 评估模式results = []reals = []losss = []for seq, labels in test_loader:pred = lstm_model(seq)mae = calculate_mae(pred.detach().numpy(), np.array(labels)) # MAE误差计算绝对值(预测值 - 真实值)losss.append(mae)for j in range(batch_size):for i in range(pre_len):reals.append(labels[j][i][0].detach().numpy())results.append(pred[j][i][0].detach().numpy())reals = scaler_test.inverse_transform(np.array(reals).reshape(1, -1))[0]results = scaler_test.inverse_transform(np.array(results).reshape(1, -1))[0]print("模型预测结果:", results)print("预测误差MAE:", losss)plt.figure()plt.style.use('ggplot')# 创建折线图plt.plot(reals, label='real', color='blue') # 实际值plt.plot(results, label='forecast', color='red', linestyle='--') # 预测值# 增强视觉效果plt.grid(True)plt.title('real vs forecast')plt.xlabel('time')plt.ylabel('value')plt.legend()plt.savefig('test——results.png')
相关文章:

时间序列基础【学习记录】
文章目录 1. 时间序列中的标签2. 时间序列中的窗口分割器2.1.概述2.2.窗口分割器demo 3. 时间序列的数据加载器3.1.概述3.2.时间序列的dataset3.3.Tensor类型3.4.测试完整流程demo 1. 时间序列中的标签 在目标检测领域的数据集中的图像会有一个标签**(标记一个物体是猫还是狗或…...

Andorid之TabLayout+ViewPager
文章目录 前言一、效果图二、使用步骤1.主xml布局2.activity代码3.MyTaskFragment代码4.MyTaskFragment的xml布局5.Adapter代码6.item布局 总结 前言 TabLayoutViewPager功能需求已经是常见功能了,我就不多解释了,需要的自取。 一、效果图 二、使用步骤…...

光谱相机的光电信号转换
光谱相机的光电信号转换是将分光后的光学信息转化为可处理的数字信号的核心环节,具体分为以下关键步骤: 一、分光后光信号接收与光电转换 分光元件作用 光栅/棱镜/滤光片等分光元件将入射光分解为不同波长单色光,投射至探测器阵列表面…...

MySQL历史版本下载及安装配置教程
1、访问官网下载mysql https://dev.mysql.com/downloads/mysql/ 2、找到历史版本 我这里的版本是最新的mysql8.0.42 下载完成之后,将压缩包进行解压 3、环境变量 在系统变量中找到Path,点击进入编辑,然后依次点击确定退出即可 注意!!&am…...
)
【ArcGIS】根据shp范围生成系列等距点:范围外等距点+渔网点(Python全代码)
【ArcGIS】根据shp范围生成系列等距点 目标1:生成边界外一定范围、并且等间距分布的点📁 所需数据:操作步骤-ArcGIS代码处理-Python 目标2:生成等距渔网点📁 所需数据:代码处理-Python 参考 目标1ÿ…...
)
基于FPGA的视频接口之千兆网口(六GigE纯逻辑)
协议简介 相信大家只有对于GigE有所了解的读者,才能找到这篇文章,所谓的GigE协议包含两个方面分别是视频协议(GVSP)和控制协议(GVCP)。 在本文我们重点讲的是基于FPGA纯逻辑实现阉割版的GigE协议,也就是说在很多视频传输过中,只用到了视频流传输,并没有控制方面的要求…...

android 权限配置
在AOSP 14的ROM定制中,<exceptions>和<privapp-permissions>是用于管理特权应用权限的两种不同机制,主要区别在于作用范围、配置方式和权限授予逻辑。以下是具体分析: 1. <privapp-permissions> 标签 作用: 用…...

广告推荐算法入门 day1 --项目选型
文章目录 0 前言1 广告推荐的基本流程2 场景和baseline初步框定2.1召回场景2.2排场景2.3精排场景 3 一个入门小例子感受--淘宝用户购物行为数据可视化分析3.1 数据集介绍3.2 数据分析目标1.时间维度2.产品维度3.行为维度4.用户维度 4 基础项目选型4.1场景 推荐资料后记 0 前言 …...

【Qt】之音视频编程2:QtAV的使用篇
QtAV 基本播放控制功能实现(C & QML) QtAV 提供了完整的播放控制 API,支持 播放、暂停、停止、快进快退、截屏 等功能。以下是具体实现方法: 1. C 控制方式 基本播放控制 #include <QtAV> #include <QtAV/AVPlaye…...

技术视角下的TikTok店铺运营:从0到1的5个关键点
在当今数字化时代,TikTok Shop作为新兴的电商平台,为众多商家带来了新的机遇。从技术运营的角度来看,以下5个关键点是每个TikTok店铺运营者都需要注意的: 1、规则先行,技术助力合规开店 地区选择:技术分析显…...
)
机器学习 --- 特征工程(一)
机器学习 — 特征工程(一) 文章目录 机器学习 --- 特征工程(一)一,特征工程概念二,特征工程API三,DictVectorizer 字典列表特征提取四,CountVectorizer 文本特征提取4.1 API4.2 英文…...

cocos creator 3.8 下的 2D 改动
在B站找到的系统性cocos视频教程,纯2D开发入门,链接如下: zzehz黑马程序员6天实战游戏开发微信小程序(Cocos2d的升级版 CocosCreator JavaScript)_哔哩哔哩_bilibili黑马程序员6天实战游戏开发微信小程序(Cocos2d的升级版 CocosCreator Ja…...

2025-05-13 表征学习
表征学习 表征学习(Representation Learning),又称特征学习,是机器学习领域中的一类技术,旨在自动的从原始数据中学习处有效的特征表示,使得后续的机器学习任务(分类、聚类、预测)能…...

【WebApi】YiFeiWebApi接口安装说明
YiFeiWebApi接口安装说明 一、 数据库配置文件修改二、 IIS环境配置(建议IIS7.0)三、 安装.NET 8.0 运行时四、 IIS配置站点五、 发布系统六、 测试接口七、测试服务器站点接口八、其他问题查看日志解决九、ApiPost项目文档 一、 数据库配置文件修改 说明: DSCSYSSq…...

亚马逊云科技:开启数字化转型的无限可能
在数字技术蓬勃发展的今天,云计算早已突破单纯技术工具的范畴,成为驱动企业创新、引领行业变革的核心力量。亚马逊云科技凭借前瞻性的战略布局与持续的技术深耕,在全球云计算领域树立起行业标杆,为企业和个人用户提供全方位、高品…...

爬虫请求频率应控制在多少合适?
爬虫请求频率的控制是一个非常重要的问题,它不仅关系到爬虫的效率,还涉及到对目标网站服务器的影响以及避免被封禁的风险。合理的请求频率需要根据多个因素来综合考虑,以下是一些具体的指导原则和建议: 一、目标网站的政策 查看网…...

Rimworld Mod教程 武器Weapon篇 近战章 第二讲:生物可用的近战来源
本讲分析的是在原版(coreall dlc)环境下,一个Pawn可以用的Tools的所有来源。 重点要分析的是RimWorld.Pawn_MeleeVerbs下的方法GetUpdatedAvailableVerbsList,我把它贴在下面: public List<VerbEntry> GetUpdat…...

SAP汽配解决方案:无锡哲讯科技助力企业数字化转型
汽配行业面临的挑战与机遇 随着汽车行业的快速发展,汽配企业面临着激烈的市场竞争、供应链复杂化、成本压力增大等多重挑战。传统的管理模式已难以满足现代汽配企业对高效生产、精准库存、快速响应的需求。在此背景下,数字化转型成为汽配企业的必然选…...
(链表I))
day19-线性表(顺序表)(链表I)
一、补充 安装软件命令: sudo apt-get install (软件名) 安装格式化对齐:sudo apt-get install clang-format内存泄漏检测工具: sudo apt-get install valgrind 编译后,使用命令 valgrind ./a.out 即可看内存是…...

里氏替换原则:Java 面向对象设计的基石法则
一、原则起源与核心定义 20 世纪 80 年代,计算机科学家芭芭拉・里氏(Barbara Liskov)在一篇论文中首次提出了里氏替换原则(Liskov Substitution Principle,LSP),这成为面向对象设计的重要理论基…...
)
GBK与UTF-8编码问题(2)
1. 问题现象 在python代码中,用open函数打开文本文件并显示文本内容,中文显示乱码,代码如下。 from tkinter import * import tkinter.filedialogroot Tk() # 给窗口的可视化起名字 root.title(Open File Test)# 设定窗口的大小(长 * 宽) r…...

项目三 - 任务6:回文日期判断
本任务通过判断回文日期,深入学习了Java中日期和字符串处理的相关知识。通过输入年、月、日,生成8位日期字符串,利用StringBuffer的reverse()方法反转字符串,比较原字符串与反转后的字符串是否一致,从而判断是否为回文…...
移植到STM32)
从零开始掌握FreeRTOS(1)移植到STM32
目录 提前准备 源码文件移植 修改 stm32f10x_it.c 修改 FreeRTOS.h 本章思维导图。 提前准备 学习 FreeRTOS 的第一步就是有一份最工程能够跑在 STM32 上。本篇将记录本人从0搭建一个最基础的移植工程Demo。 要完成这份 Demo,首先我们需要预先准备以下东西&…...

esp32硬件支持AT指令
步骤1:下载AT固件 从乐鑫官网或Git鑫GitHub仓库(https://github.com/espressif/esp-at)获取对应ESP32型号的AT固件(如ESP32-AT.bin)。 步骤2:安装烧录工具 使用 esptool.py(命令行工具&#…...

【神经网络与深度学习】局部最小值和全局最小值
引言 在机器学习和优化问题中,目标函数的优化通常是核心任务。优化过程可能会产生局部最小值或全局最小值,而如何区分它们并选择合适的优化策略,将直接影响模型的性能和稳定性。 在深度学习等复杂优化问题中,寻找全局最小值往往…...

部署安装git-2.49.0.tar.xz
实验环境 git主机:8.10 所需软件 git-2.49.0.tar.xz 实验开始 实验目的:安装升级git2.49.0 编译安装 yum remove git -y --卸载旧版git cd /usr/local/src/ wget https://www.kernel.org/pub/software/scm/git/git-2.49.0.tar.xz …...

SpringBoot的单体和分布式的任务架构
在Spring Boot生态中,定时任务框架的选择需根据架构类型(单体或分布式)和功能需求进行权衡。以下从框架特性、适用场景及Spring Boot集成方式等角度,详细梳理主流的定时任务框架及其分类: 一、单体架构下的定时任务框架…...

第四章 部件篇之按钮矩阵部件
第四章 部件篇之按钮矩阵部件 在 LVGL中, 按钮矩阵部件相当于一系列伪按钮的集合,它按一定的序列来排布这些按钮。值得注意的是,这些伪按钮并不是真正的按钮部件(lv_btn) , 它们只是具有按钮外观的图形&…...

二分查找算法的思路
二分查找思路总结 明确目标与单调性特点: 核心目标:寻找满足某种条件的答案(如最小/最大值)。单调性要求:需要证明你的判断函数具有单调性——即如果某个答案 T 可行,那么大于 T 的答案通常也是可行的&…...

Shell脚本与Xshell的使用、知识点、区别及原理
Shell脚本与Xshell的使用、知识点、区别及原理 Shell脚本 基本概念 Shell脚本是一种为Shell编写的脚本程序,通常用于自动化执行一系列命令。它是在Unix/Linux系统下的命令行解释器与用户交互的接口。 主要知识点 脚本结构:以#!/bin/bash开头…...

【PmHub后端篇】PmHub中基于Redis加Lua脚本的计数器算法限流实现
1 限流的重要性 在高并发系统中,保护系统稳定运行的关键技术有缓存、降级和限流。 缓存通过在内存中存储常用数据,减少对数据库的访问,提升系统响应速度,如浏览器缓存、CDN缓存等多种应用层面。降级则是在系统压力过大或部分服务…...
)
【递归、搜索与回溯】专题一:递归(二)
📝前言说明: 本专栏主要记录本人递归,搜索与回溯算法的学习以及LeetCode刷题记录,按专题划分每题主要记录:(1)本人解法 本人屎山代码;(2)优质解法 优质代码…...

【Linux】操作系统入门:冯诺依曼体系结构
引言:从一次QQ聊天说起 你是否好奇,当你在键盘上敲下一行文字发送给好友时,计算机内部发生了什么?为什么鼠标点击后程序就能瞬间响应?这一切的答案,都藏在计算机的“心脏”——冯诺依曼体系结构中。 一、硬…...

量化感知训练与 PyTorch 的哪些事
大家好呀!今天咱们要来聊聊一个超厉害的技术——量化感知训练(Quantization-Aware Training,简称 QAT) 在神经网络的世界里,我们总是想方设法地让模型变得更准确、更高效,毕竟谁不想自己的模型在边缘设备上…...

【Mac 从 0 到 1 保姆级配置教程 15】- Python 环境一键安装与配置,就是这么的丝滑
文章目录 前言安装 Python 环境VSCode 配置Python 环境NeoVim 配置 Python 环境(选看)1. Python LSP 配置2. 打开 python 语言支持 最后参考资料系列教程 Mac 从 0 到 1 保姆级配置教程目录,点击即可跳转对应文章: 【Mac 从 0 到 …...
—— CSS实现热搜榜)
前端学习(3)—— CSS实现热搜榜
效果展示 具体的展示效果如下,可以直接在浏览器显示: 页面分为两部分,一部分是 body 标签里的 html 结构,一部分是 style 标签里的CSS代码(页面布局的部分数据直接在代码里显示了) 一,html结…...
)
大数据——解决Matplotlib 字体不足问题(Linux\mac\windows)
1、将下载好的字体文件放到文件夹中 谷歌官方字体 import matplotlib print(matplotlib.matplotlib_fname())cp NotoSansSC-Regular.ttf /data/home/miniconda3/envs/python3128/lib/python3.12/site-packages/matplotlib/mpl-data/fonts/ttf/cp wqy-zenhei.ttc /data/home/m…...
顺序表与单向链表)
嵌入式培训之数据结构学习(二)顺序表与单向链表
目录 一、顺序表 (一)顺序表的基本操作 1、创建顺序表 2、销毁顺序表 3、遍历顺序表 4、尾插,在顺序表的最后插入元素 5、判断表是否满 6、判断表是否空 7、按指定位置插入元素 8、查找元素,根据名字 9、根据名字修改指…...

PyInstaller 打包后 Excel 转 CSV 报错解决方案:“excel file format cannot be determined“
一、问题背景 在使用 Python 开发 Excel 转 CSV 工具时,直接运行脚本(python script.py)可以正常工作,但通过 PyInstaller 打包成可执行文件后,出现以下报错: excel file format cannot be determined, you must specify an engine manually 该问题通常发生在使用pandas…...

鸿蒙 PC 发布之后,想在技术上聊聊它的未来可能
最近鸿蒙 PC 刚发布完,但是发布会没公布太多技术细节,基本上一些细节都是通过自媒体渠道获取,首先可以确定的是,鸿蒙 PC 本身肯定是无法「直接」运行 win 原本的应用,但是可以支持手机上「原生鸿蒙」的应用,…...
)
HarmonyOS 【诗韵悠然】AI古诗词赏析APP开发实战从零到一系列(一、开篇,项目介绍)
诗词,作为中国传统文化的瑰宝,承载着中华民族几千年的思想智慧和审美情趣。然而,在现代社会快节奏的生活压力下,诗词文化却逐渐被忽视,更多的人感到诗词艰涩深奥,难以亲近。与此同时,虽然市场上…...
)
实物工厂零件画图案例(上)
文章目录 滑台气缸安装板旋转气缸安装板张紧调节块长度调节块双轴气缸安装板步进电机安装板梯形丝杆轴承座 简介:案例点击此处下载,这次的这几个案例并没有很大的难度,练习这几个案例最为重要的一点就是知道:当你拿到一个实物的时…...

js中的同步方法及异步方法
目录 1.代码说明 2.async修饰的方法和非async修饰的方法的区别 3.不使用await的场景 4.总结 1.代码说明 const saveTem () > {// 校验处理const res check()if (!res) {return}addTemplateRef.value.openModal() } 这段代码中,check方法返回的是true和fal…...

C 语言_基础语法全解析_深度细化版
一、C 语言基本结构 1.1 程序组成部分 一个完整的 C 程序由以下部分组成: 预处理指令:以#开头,在编译前处理 #include <stdio.h> // 引入标准库 #define PI 3.14159 // 定义常量全局变量声明:在所有函数外部定义的变量 int globalVar = 10; // 全局变量函数定义…...

【Linux系列】dd 命令的深度解析与应用实践
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

ETL背景介绍_1:数据孤岛仓库的介绍
1 ETL介绍 1.1 数据孤岛 随着企业内客户数据大量的涌现,单个数据库已不再足够。为了储存这些数据,公司通常会建立多个业务部门组织的数据库来保存数据。比如,随着数据量的增长,公司通常可能会构建数十个独立运行的业务数据库&am…...

【周输入】510周阅读推荐-1
本号一年了,有一定的成长,也有很多读者和点赞。自觉更新仍然远远不够,需要继续努力。 但是还是要坚持2点: 在当前这个时代,信息大爆炸,层次不齐,不追加多, 信息输入可以很多&#x…...

Games101作业四
作业0到作业3的代码 这次是实现 de Casteljau 算法,以及绘制 Bezier 曲线,比上次简单 核心思想就是递归,原理忘了就去看第十一节课,从15:00开始的 GAMES101-现代计算机图形学入门-闫令琪 代码 先实现贝塞尔曲线 cv::Point2f recursive_bezier(const std::…...

从Aurora 架构看数据库计算存储分离架构
单就公有云来说,现在云数据面临的挑战有以下 5 个: 跨 AZ 的可用性与数据安全性。 现在都提多 AZ 部署,亚马逊在全球有 40 多个 AZ, 16 个 Region,基本上每一个 Region 之内的那些关键服务都是跨 3 个 AZ。你要考虑整个…...
:分页)
ElasticSearch深入解析(十一):分页
在Elasticsearch中,常用的分页方案有from size、search_after和scroll三种,适用于不同场景。from size基于偏移量分页,是全局排序后的切片查询,适用于小数据量、浅分页场景,但深度分页性能差,且有默认上限…...